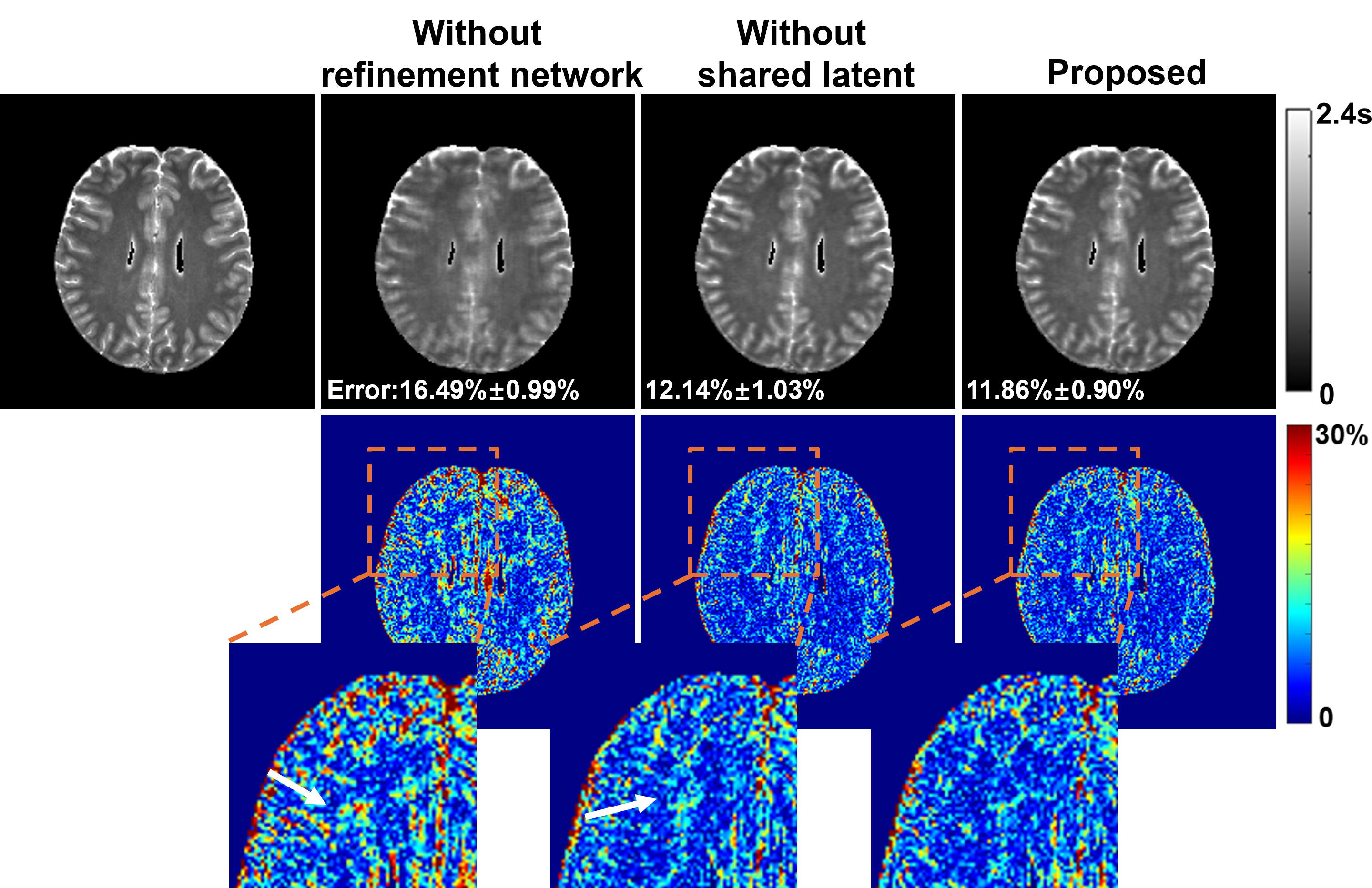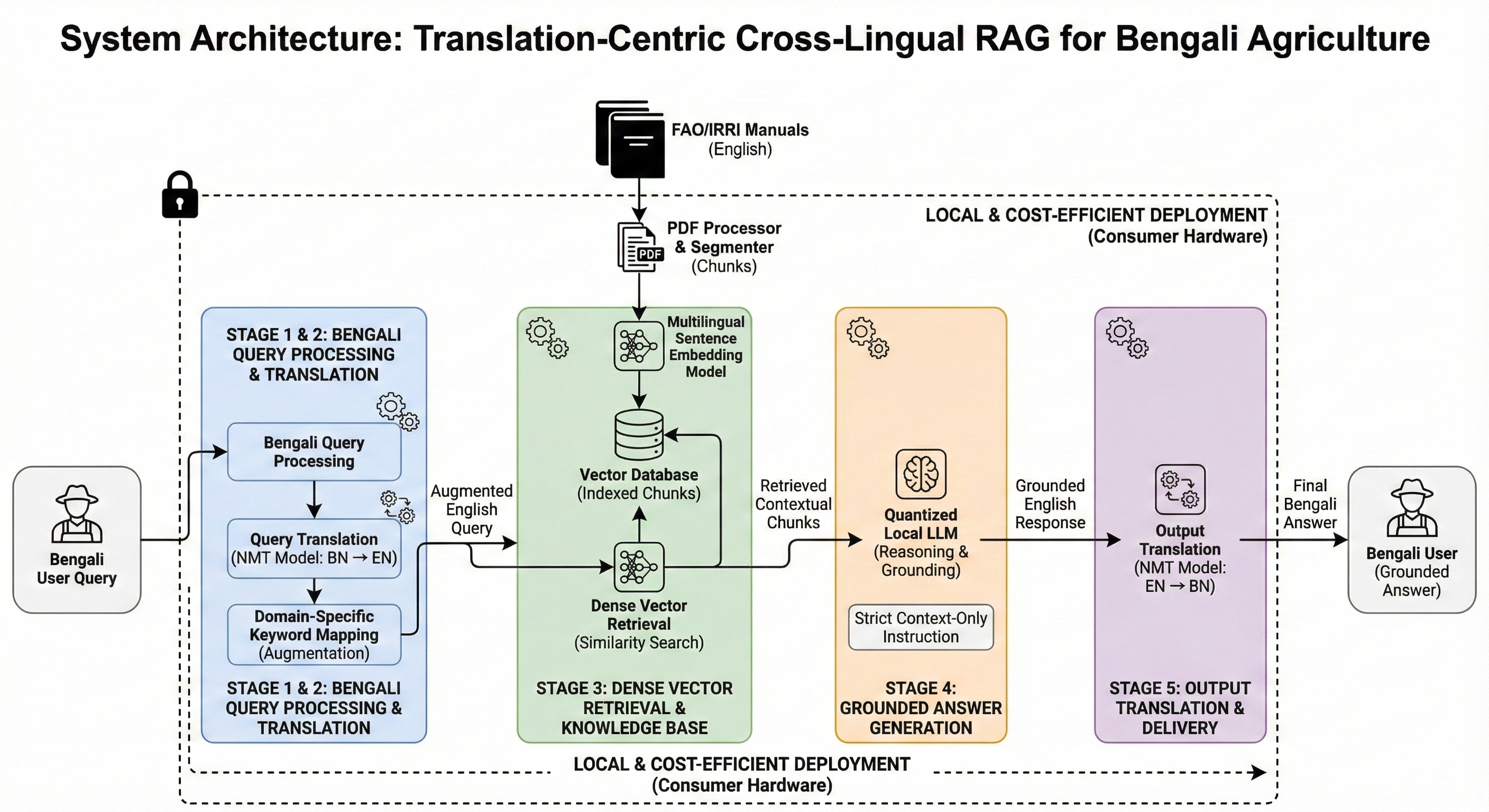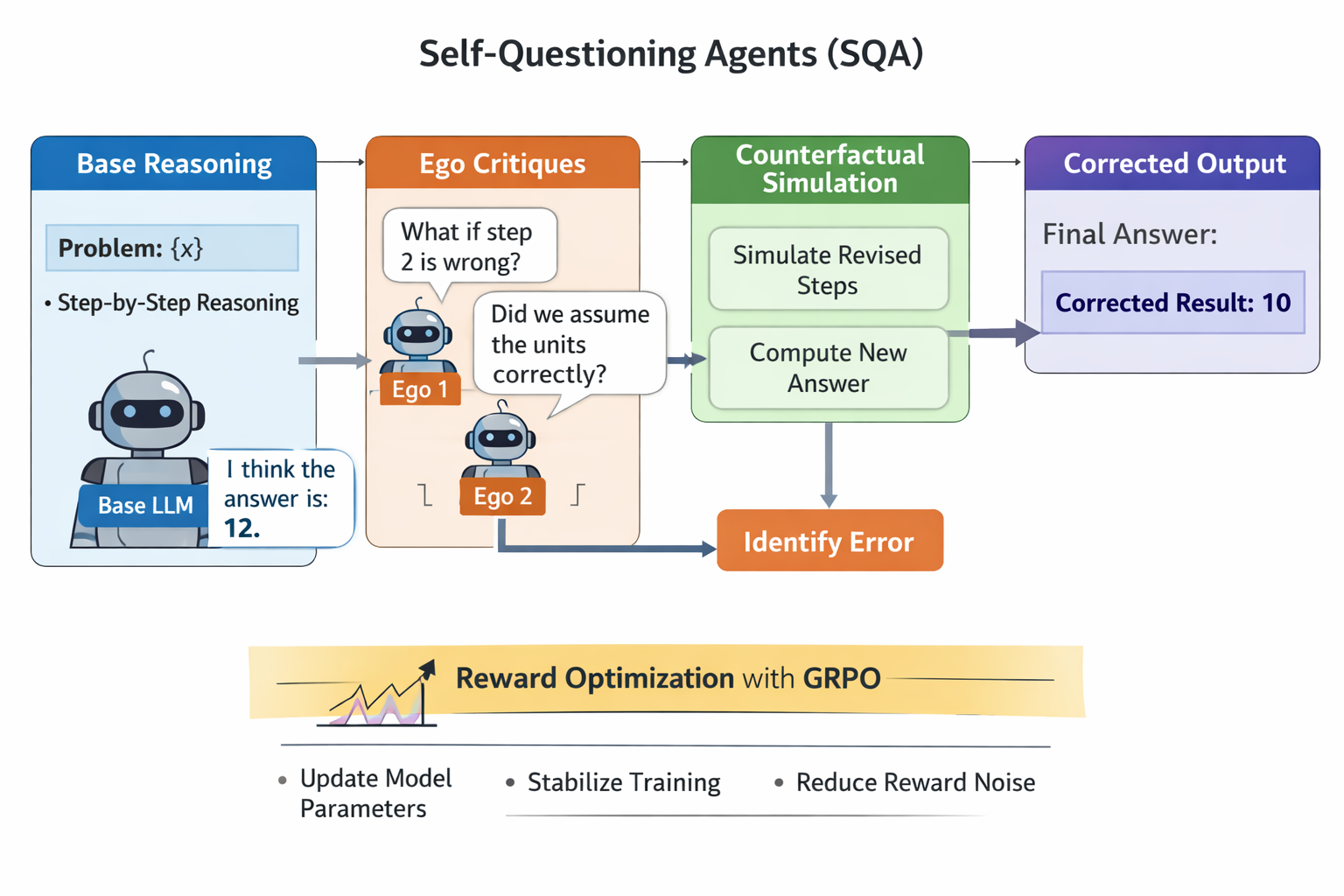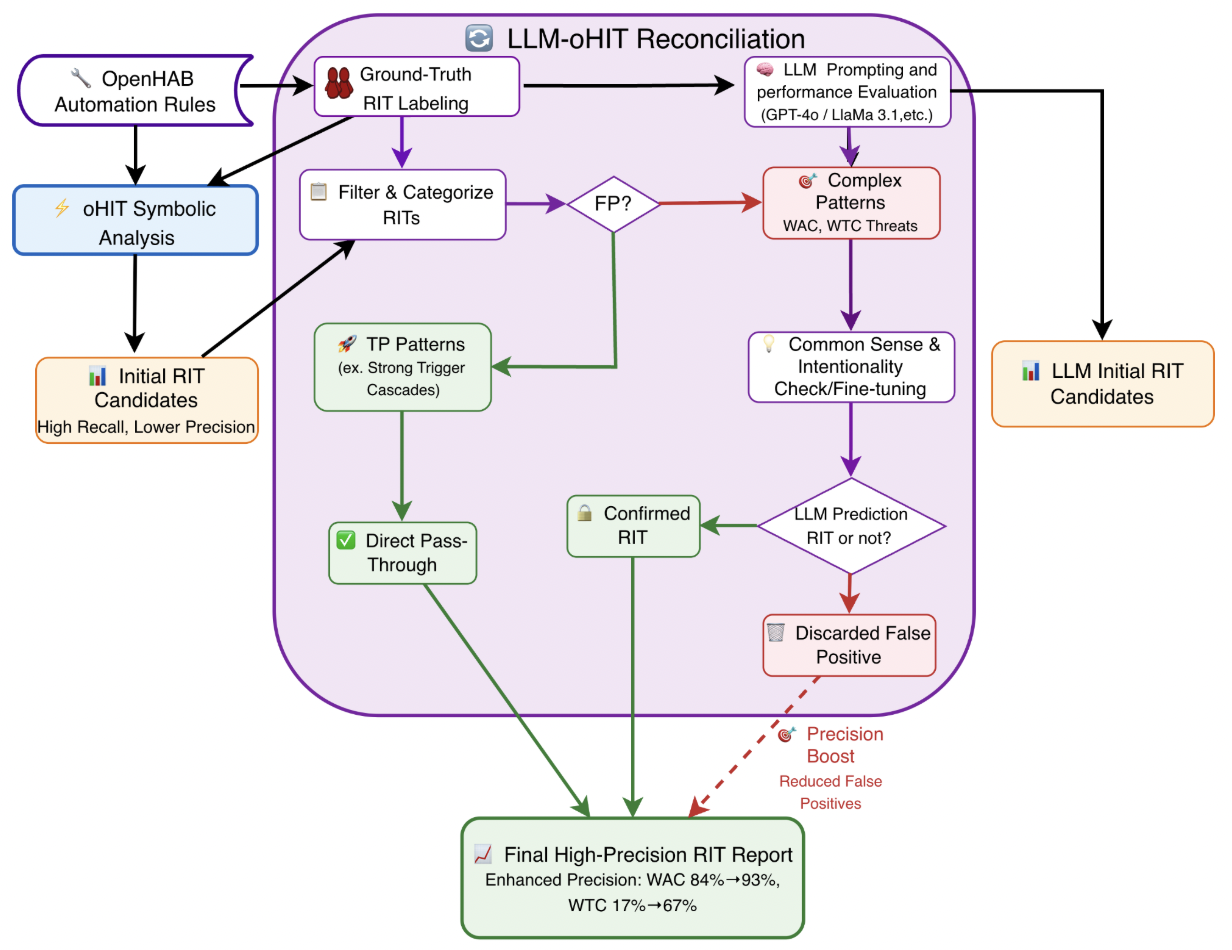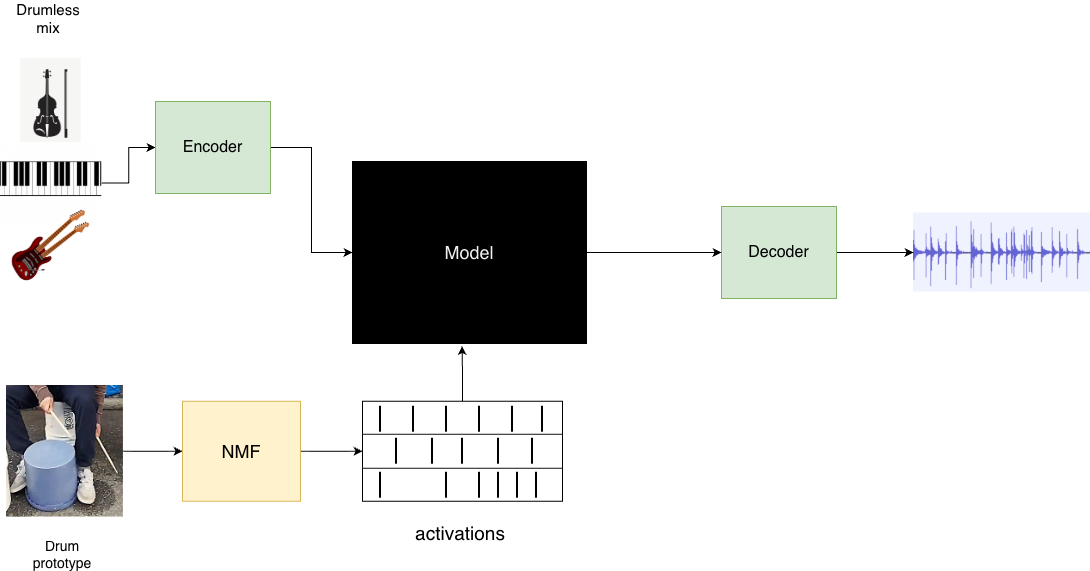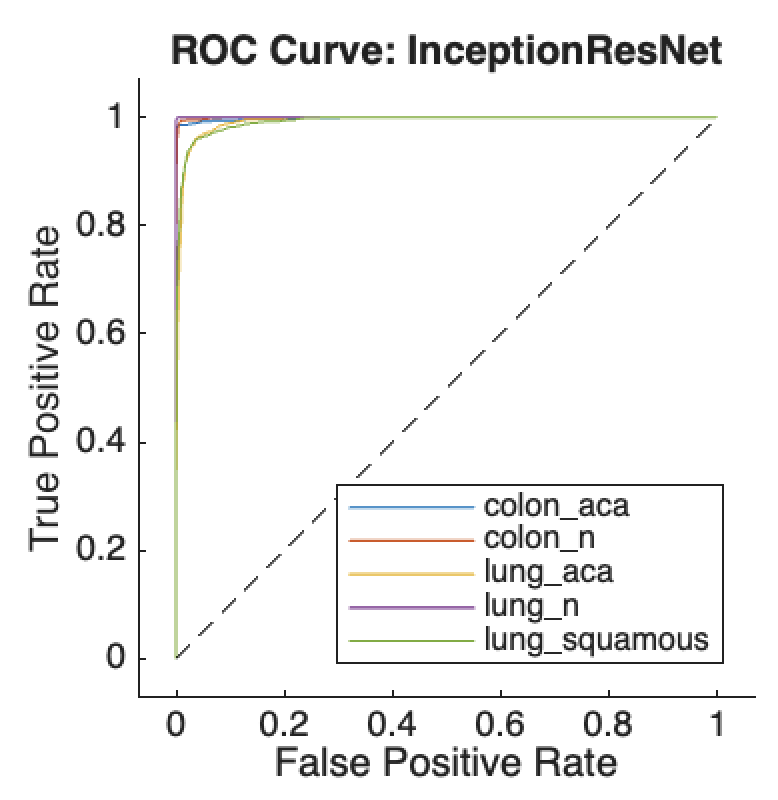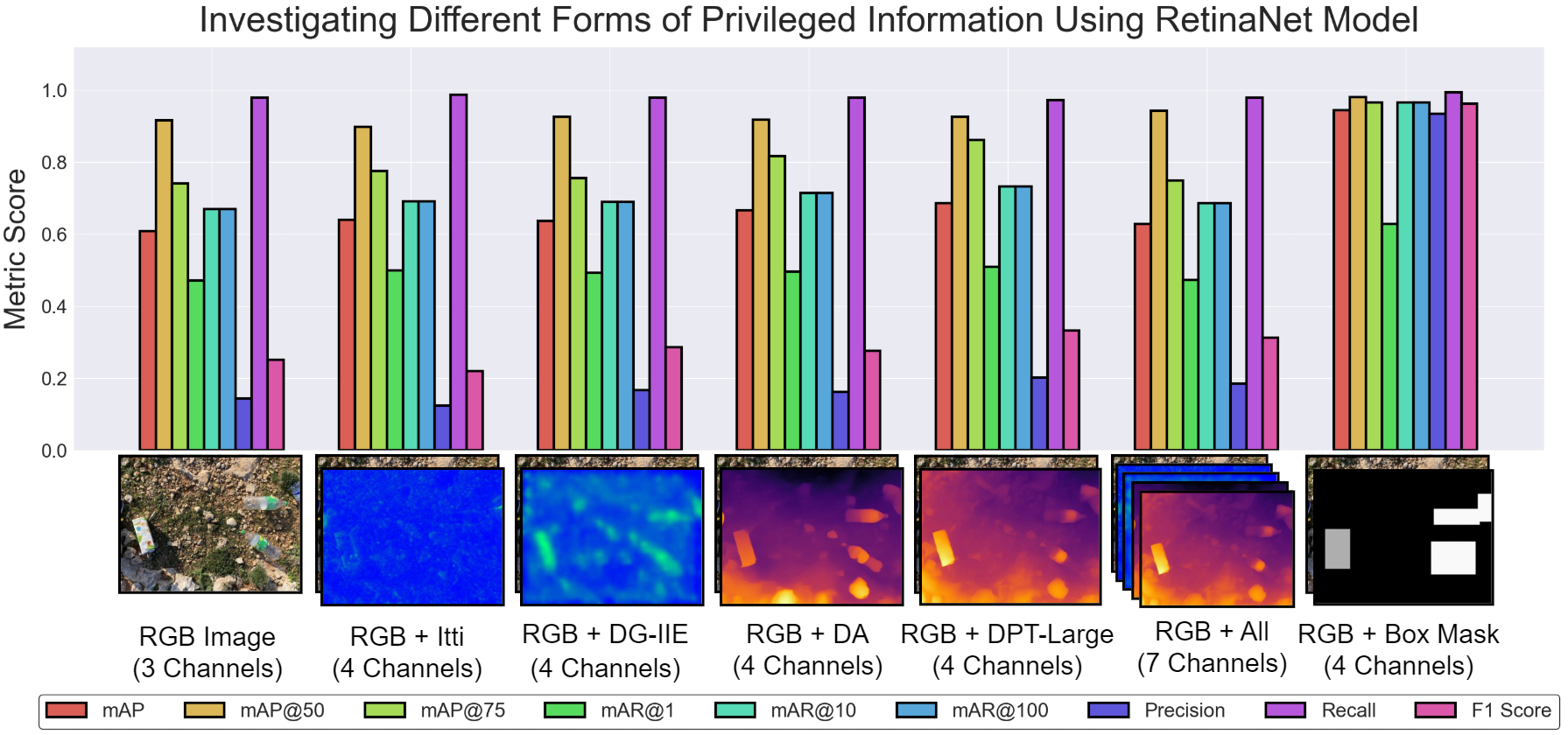
A Comparative Study of Custom CNNs, Pre-trained Models, and Transfer Learning Across Multiple Visual Datasets
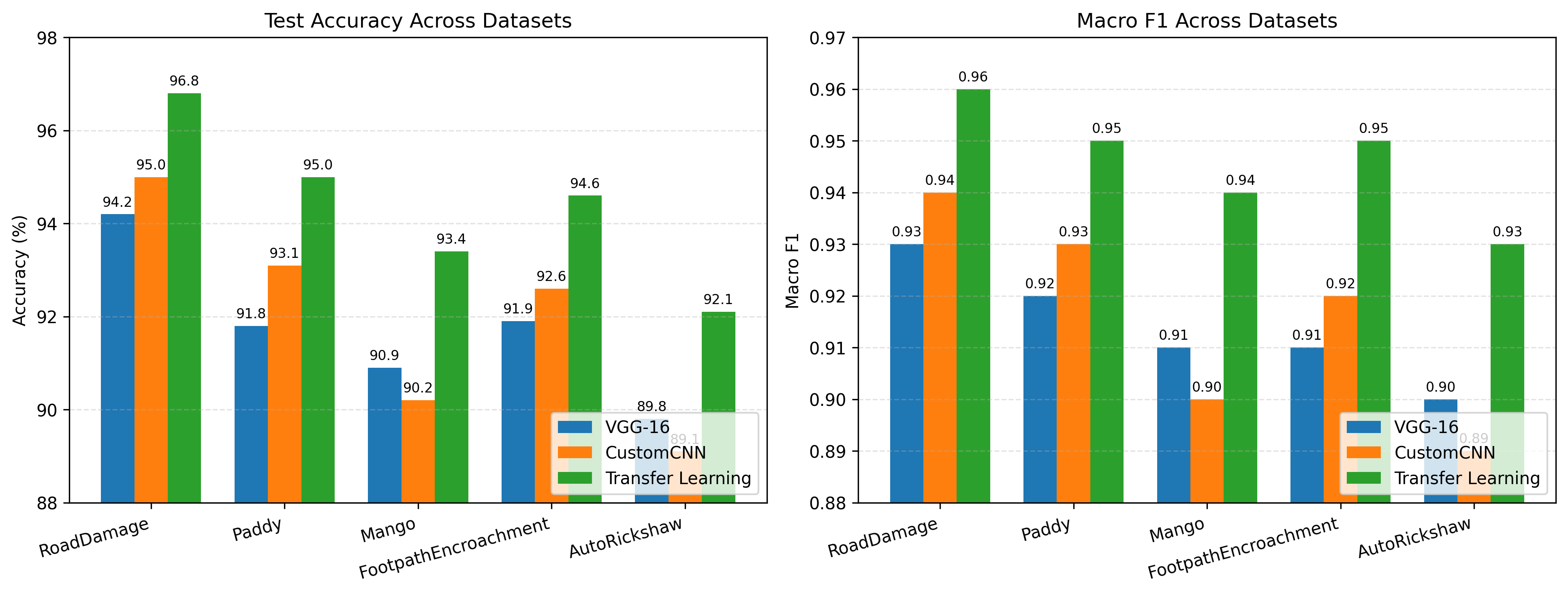
Convolutional Neural Networks (CNNs) are a standard approach for visual recognition due to their capacity to learn hierarchical representations from raw pixels. In practice, practitioners often choose among (i) training a compact custom CNN from scratch, (ii) using a large pre-trained CNN as a fixed feature extractor, and (iii) performing transfer learning via partial or full fine-tuning of a pre-trained backbone. This report presents a controlled comparison of these three paradigms across five real-world image classification datasets spanning road-surface defect recognition, agricultural variety identification, fruit/leaf disease recognition, pedestrian walkway encroachment recognition, and unauthorized vehicle recognition. Models are evaluated using accuracy and macro F1-score, complemented by efficiency metrics including training time per epoch and parameter counts. The results show that transfer learning consistently yields the strongest predictive performance, while the custom CNN provides an attractive efficiency--accuracy trade-off, especially when compute and memory budgets are constrained.