
AI Research Archive
KOINEU is a research analysis platform that summarizes and explains AI and machine learning papers in an accessible format.
Latest Research

An Online Optimization-Based Trajectory Planning Approach for Cooperative Landing Tasks

Triangular lattice models of the Kalmeyer-Laughlin spin liquid from coupled wires

Unravelling magnetic vortex-like excitations through rapid thermal quenching in low-carbon steel

Analysis of the Security Design, Engineering, and Implementation of the SecureDNA System

B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability
Editorial by 일리케
Science through a curator's lens — personal analysis by 일리케
EDITORIAL
6G is Coming: What Researchers Really Say About Human-Machine Collaboration
23 Mar, 2026
일리케
EDITORIAL
AI Models Are Learning to Disagree with Each Other
23 Mar, 2026
일리케
EDITORIAL
AI Reads X-rays Better Than Most Doctors. What's Next?
23 Mar, 2026
일리케
EDITORIAL
Escaping the Prison of the Solar System: How Stars and Planetary Systems Are Born?
23 Mar, 2026
Woojoo Meonji
EDITORIAL
How LLMs Are Changing Scientists' Research Methods
23 Mar, 2026
일리케
EDITORIAL
NASA's Headache? Behind the Scenes of the SLS Rocket and Artemis Mission
23 Mar, 2026
Woojoo Meonji
EDITORIAL
Quantum Leap: The Future of Computing as Told by 2026 Research
23 Mar, 2026
일리케
EDITORIAL
Real-Time Brain Mapping: EEG, Graph Networks, and What Neuroscience is Learning from AI
23 Mar, 2026
일리케
EDITORIAL
Robots Signing and Assembling: Robotics at the Forefront
23 Mar, 2026
일리케
Editor's Pick

ESPADA: Execution Speedup via Semantics Aware Demonstration Data Downsampling for Imitation Learning

TICL+: A Case Study On Speech In-Context Learning for Children's Speech Recognition
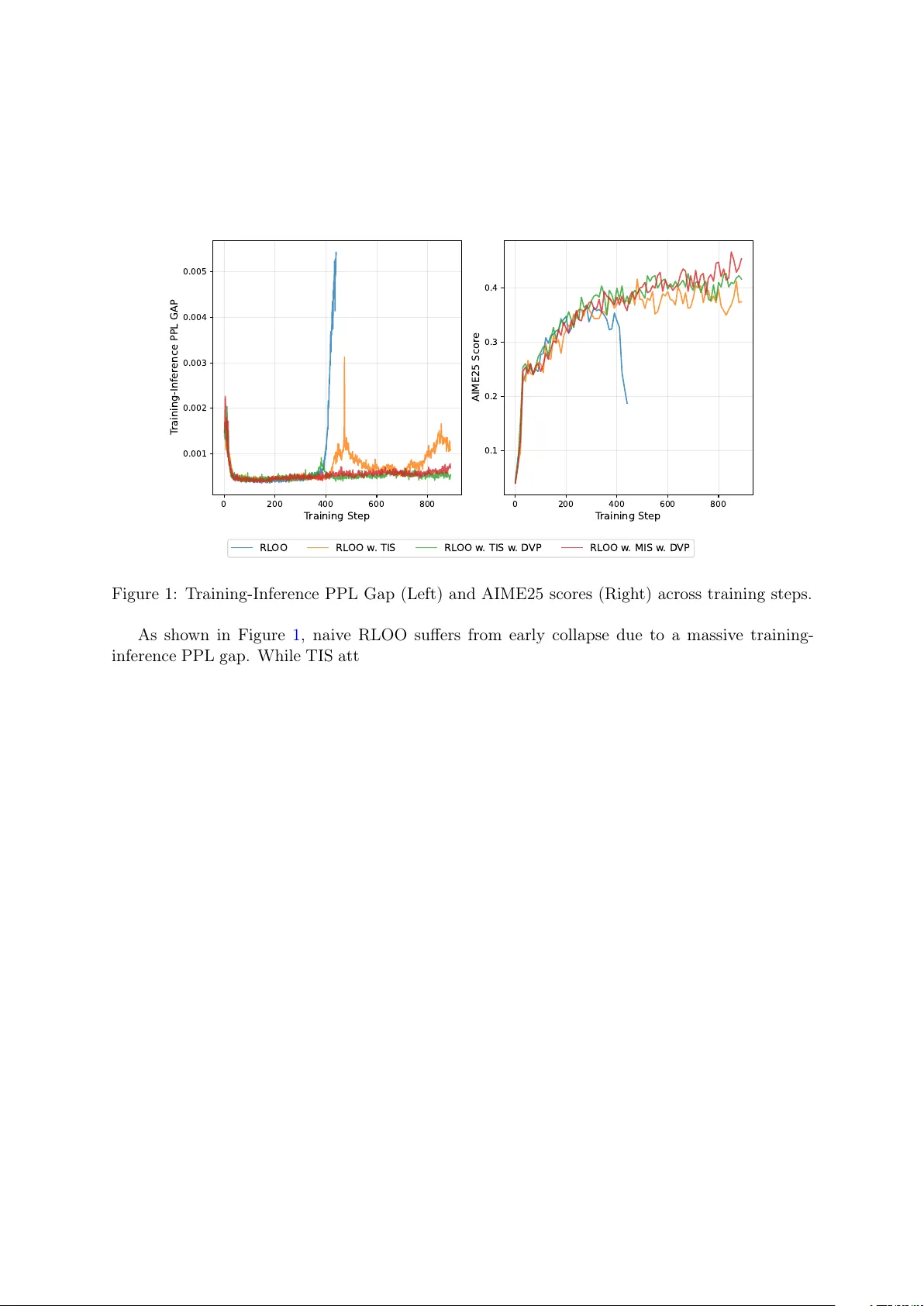
Taming the Tail: Stable LLM Reinforcement Learning via Dynamic Vocabulary Pruning
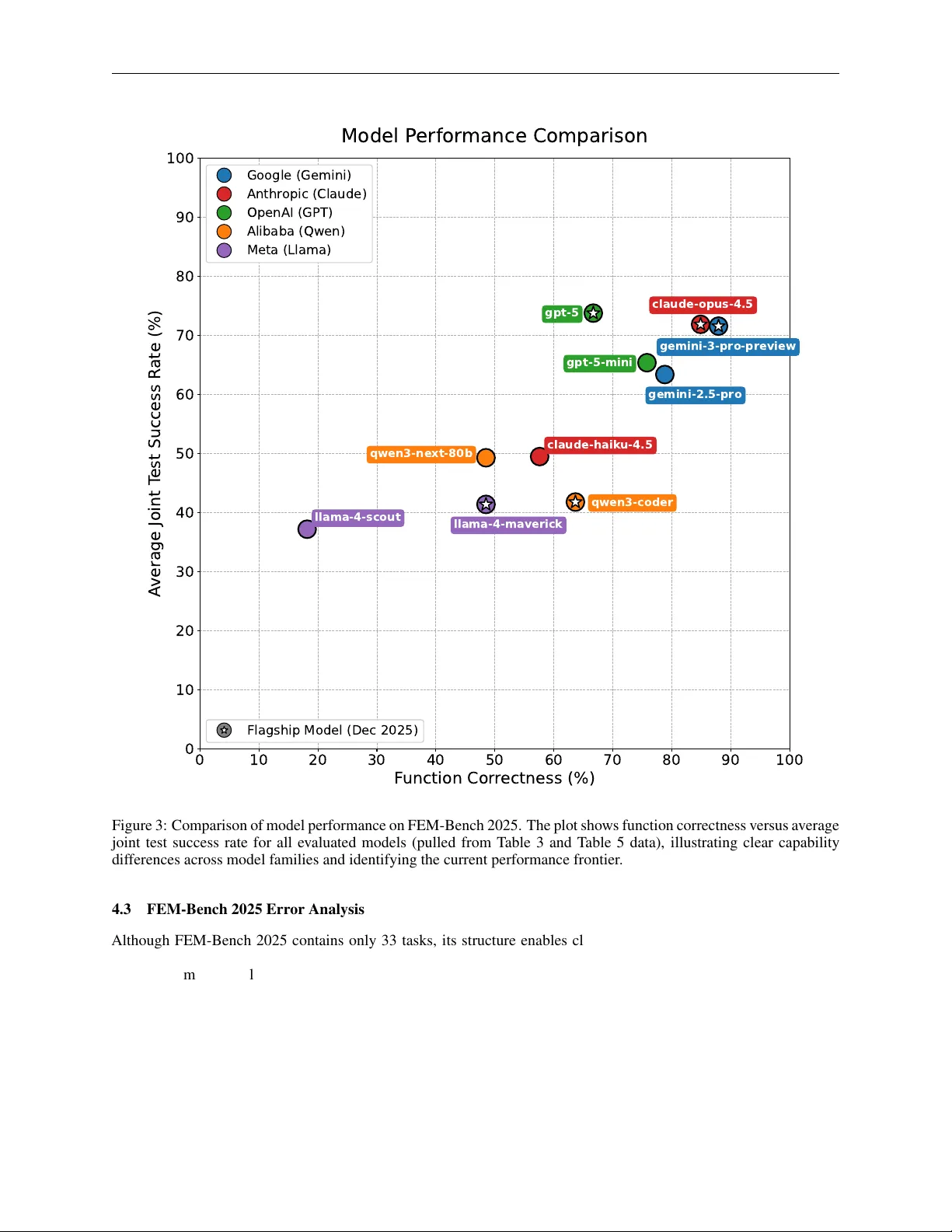
FEM-Bench: A Structured Scientific Reasoning Benchmark for Evaluating Code-Generating LLMs

Chat with UAV -- Human-UAV Interaction Based on Large Language Models

경험 재생에서 깊은 망각과 얕은 망각의 비대칭: 작은 버퍼는 특징 공간을 유지하지만 분류 경계는 왜곡한다
Information Theory
1,601 Papers
Artificial Intelligence
1,580 Papers
Cryptography and Security
1,290 Papers
Data Structures and Algorithms
1,258 Papers
Networking
1,126 Papers
Discrete Mathematics
1,039 Papers
Distributed Computing
981 Papers
Logic in Computer Science
972 Papers
Software Engineering
935 Papers
Machine Learning
932 Papers
Computers and Society
915 Papers
Computational Complexity
861 Papers
Latest in Computer Science
VIEW ALL →
Early Detection of Forest Calamities in Homogeneous Stands -- Deep Learning Applied to Bark-Beetle Outbreaks
Analysis of the Security Design, Engineering, and Implementation of the SecureDNA System
B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability

Proper Learnability and the Role of Unlabeled Data

Federated Distillation Assisted Vehicle Edge Caching Scheme Based on Lightweight DDPM

Rates and architectures for learning geometrically non-trivial operators

Refining Diffusion Models for Motion Synthesis with an Acceleration Loss to Generate Realistic IMU Data

Eunomia: A Multicontroller Domain Partitioning Framework in Hierarchical Satellite Network

Passing the Baton: High Throughput Distributed Disk-Based Vector Search with BatANN

Improved Physics-Driven Neural Network to Solve Inverse Scattering Problems

CREME: Robustness Enhancement of Code LLMs via Layer-Aware Model Editing

A Distributed Framework for Privacy-Enhanced Vision Transformers on the Edge
High Energy Astrophysics
4,296 Papers
Cosmology
1,434 Papers
Computational Physics
1,379 Papers
Physics and Society
1,070 Papers
Solar and Stellar Astrophysics
988 Papers
Astrophysics of Galaxies
980 Papers
Data Analysis (Physics)
976 Papers
Instrumentation and Methods for Astrophysics
834 Papers
Nonlinear Systems
771 Papers
Statistical Mechanics
730 Papers
Planetary Astrophysics
689 Papers
Geophysics
684 Papers
Latest in Physics
VIEW ALL →
Investigating the interaction of a Cosmic String with an Accreting Black Hole

The Most Probable Behaviour of the Dark Energy Equation of State Indicates a Thawing Quintessence Field: Tomographic Alcock-Paczyński Test with Redshift-Space Correlation Function II

On the Exoplanet Yield of Gaia Astrometry

Predicting tunable nonreciprocal spin wave generation mediated by interfacial Dzyaloshinskii-Moriya interaction in magnonic heterostructures

Tracing a Multi-Temperature Quiescent Prominence's Thermodynamic Evolution from Sun to Earth

A Propagator-based Multi-level Monte Carlo Method for Kinetic Neutral Species in Edge Plasmas

Discovery of the redback millisecond pulsar PSR J1728-4608 with ASKAP

The stellar and dark matter distributions in elliptical galaxies measured by stacked weak gravitational lensing

Four Giant Planets from 2024 KMTNet Microlensing Campaign

The ONs and OFFs of Pulsar Radio Emission: Characterizing the Nulling Phenomenon

Baryonification: An alternative to hydrodynamical simulations for cosmological studies

Source Wavefront Generation for a Non-Interferometric Reconfigurable Null Test using a Photonic Lantern
Information Theory
1,599 Papers
Mathematical Physics
611 Papers
Mathematical Physics
610 Papers
Combinatorics
593 Papers
Category Theory
538 Papers
K-Theory and Homology
428 Papers
General Topology
365 Papers
Optimization and Control
345 Papers
Algebraic Topology
326 Papers
Mathematical Statistics
309 Papers
Probability
302 Papers
Metric Geometry
288 Papers
Latest in Mathematics
VIEW ALL →
Szekeres Universes with GUP corrections

The Dirac and Rarita-Schwinger equations on scalar flat metrics of Taub-NUT type

Oriented Hamiltonian Paths in Tournaments: Stability under Arc Deletion

A Benamou-Brenier Proximal Splitting Method for Constrained Unbalanced Optimal Transport

On asymptotic behavior of solutions to random fractional Riesz-Bessel equations with cyclic long memory initial conditions

Estimating order scale parameters of two scale mixture of exponential distributions

Infinitesimal containment and sparse factors of iid

Anderson-type acceleration method for Deep Neural Network optimization

Debiased Bayesian Inference for High-dimensional Regression Models

MoDaH achieves rate optimal batch correction

Random time-shift approximation enables hierarchical Bayesian inference of mechanistic within-host viral dynamics models on large datasets

The Gauss-Markov Adjunction Provides Categorical Semantics of Residuals in Supervised Learning
Quantitative Methods
536 Papers
Biomolecules
482 Papers
Molecular Networks
444 Papers
Populations and Evolution
351 Papers
Neuroscience
336 Papers
Genomics
288 Papers
Cell Behavior
240 Papers
Subcellular Processes
235 Papers
Tissues and Organs
207 Papers
Other Quantitative Biology
178 Papers
Latest in Medical & Biology
VIEW ALL →
The Third Visual Pathway for Social Perception
MoDaH achieves rate optimal batch correction

Exact identifiability analysis for a class of partially observed near-linear stochastic differential equation models

Food, Affection and Gaze: Which Cues do Free-Ranging Dogs Consider for Engaging with Humans?

BeeTLe: An Imbalance-Aware Deep Sequence Model for Linear B-Cell Epitope Prediction and Classification with Logit-Adjusted Losses

Coupling opinion dynamics and epidemiology

Why a chloroplast needs its own genome tethered to the thylakoid membrane -- Co-location for Redox Regulation

Ultra-large library screening with an evolutionary algorithm in Rosetta (REvoLd)

Scalable Construction of Spiking Neural Networks using up to thousands of GPUs

How Conflict Aversion Can Enable Authoritarianism: An Evolutionary Dynamics Approach

Stabilization of Microbial Communities by Responsive Phenotypic Switching

Detecting Discontinuities in the Topology of Alzheimers gene Co-expression
Methodology (Stats)
578 Papers
Applications
537 Papers
Machine Learning (Stats)
514 Papers
Statistical Computing
311 Papers
Statistical Theory
304 Papers
Other Statistics
61 Papers
Latest in Statistics
VIEW ALL →
Proper Learnability and the Role of Unlabeled Data

Minimization of Functions on Dually Flat Spaces Using Geodesic Descent Based on Dual Connections

Balancing Weights for Causal Mediation Analysis

Self-Supervised Learning with Gaussian Processes
On asymptotic behavior of solutions to random fractional Riesz-Bessel equations with cyclic long memory initial conditions
Estimating order scale parameters of two scale mixture of exponential distributions
Debiased Bayesian Inference for High-dimensional Regression Models
MoDaH achieves rate optimal batch correction
Random time-shift approximation enables hierarchical Bayesian inference of mechanistic within-host viral dynamics models on large datasets
The Gauss-Markov Adjunction Provides Categorical Semantics of Residuals in Supervised Learning

Automatic Inference for Value-Added Regressions

Efficient $Q$-Learning and Actor-Critic Methods for Robust Average Reward Reinforcement Learning
Latest in Engineering
VIEW ALL →
Rates and architectures for learning geometrically non-trivial operators

Intelligent Resilience Testing for Decision-Making Agents with Dual-Mode Surrogate Adaptation

133-Tbps 1040-km (13$ imes$80 km) Lumped-Amplified Transmission Over 22 THz in S-to-U-Band Using Hybrid Multiband Repeater with PPLN-Based Optical Parametric Amplifiers and EDFAs

389.3-Tb/s 1017-km C-band Transmission over Field-Installed 12-Coupled-Core Fiber Cable with >12-Tb/s Spatial MIMO Channels

Analysis of Frequency and Voltage Strength in Power Electronics-Dominated Power Systems Based on Eigen-subsystems

Electric Arc Furnaces Scheduling under Electricity Price Volatility with Reinforcement Learning

SITP: A High-Reliability Semantic Information Transport Protocol Without Retransmission for Semantic Communication

Hybrid Learning for Cold-Start-Aware Microservice Scheduling in Dynamic Edge Environments

Data-driven Pressure Recovery in Diffusers

POLO: Phase-Only Localization in Uplink Distributed MIMO Systems

System Identification Under Multi-rate Sensing Environment
