Semi-Automated Data Annotation in Multisensor Datasets for Autonomous Vehicle Testing
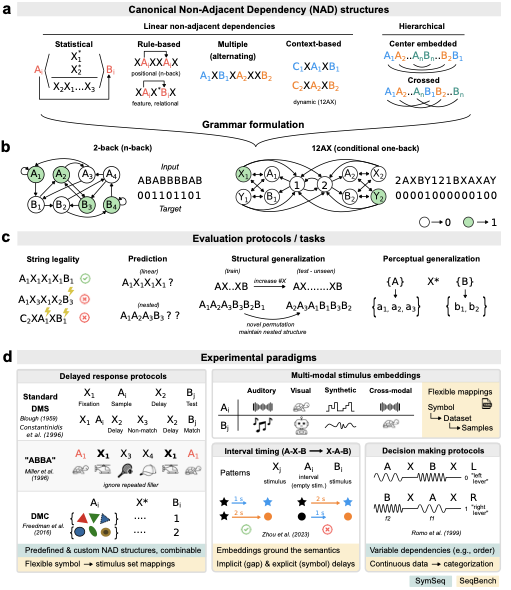
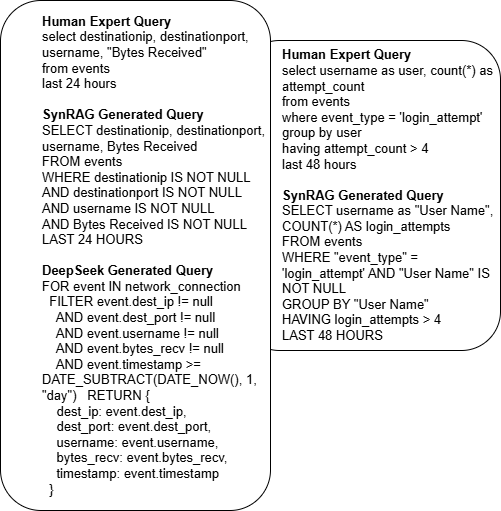
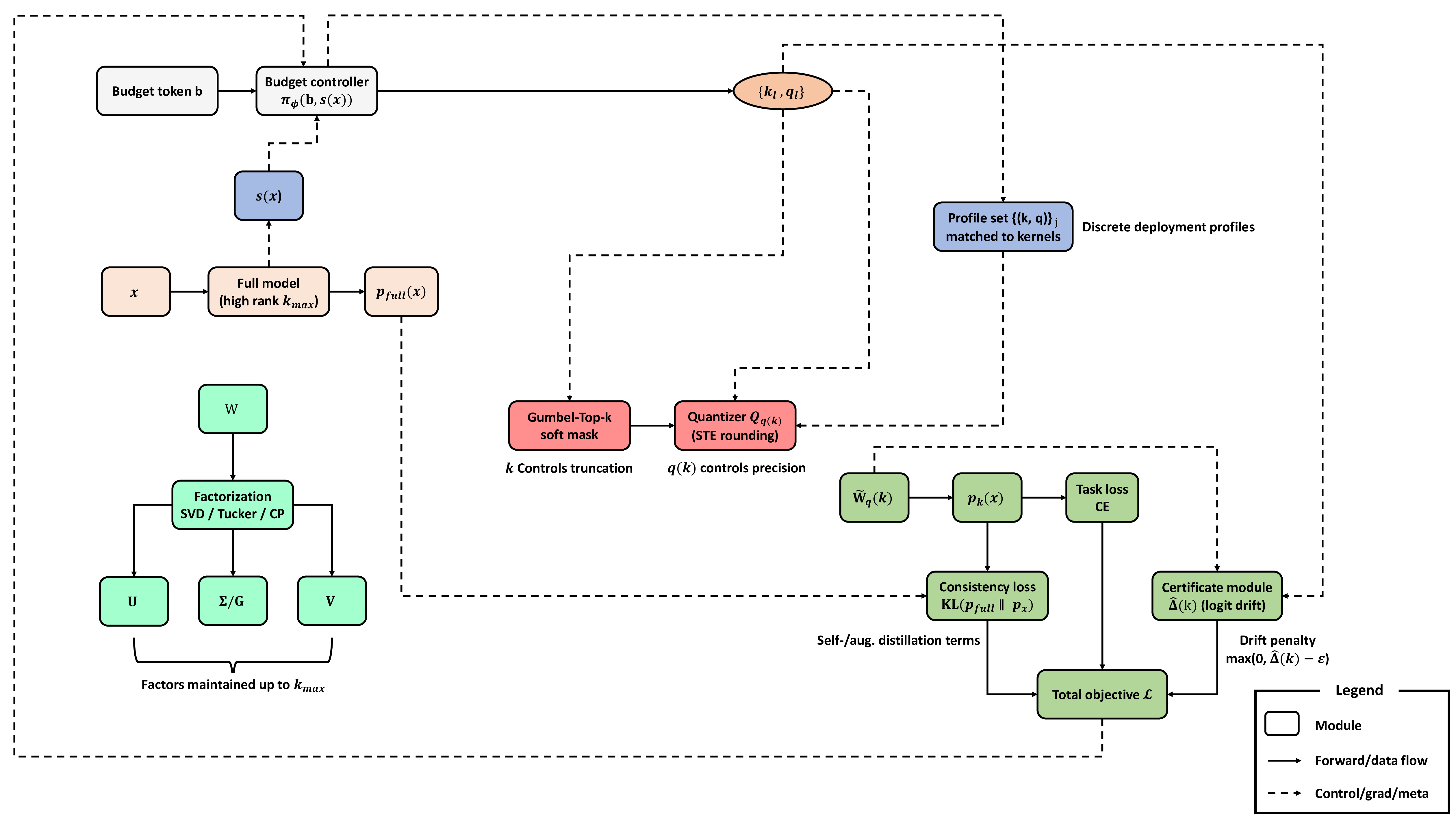
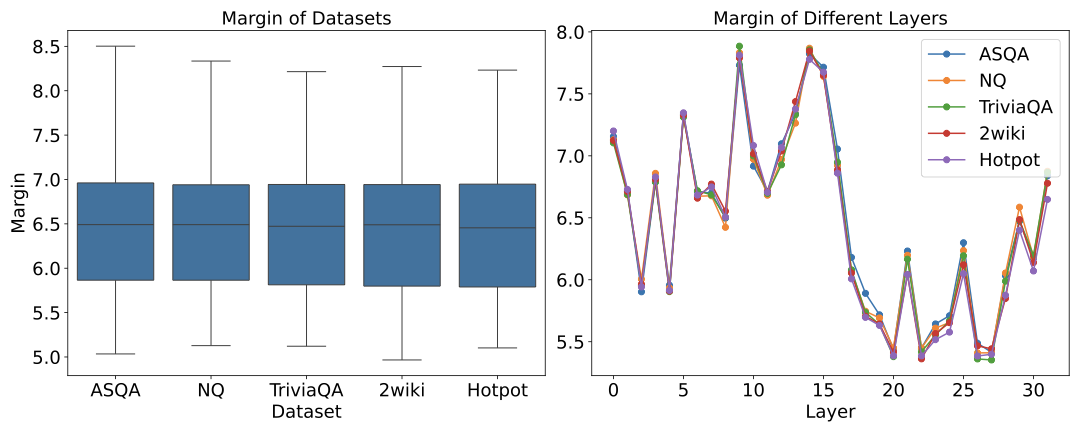
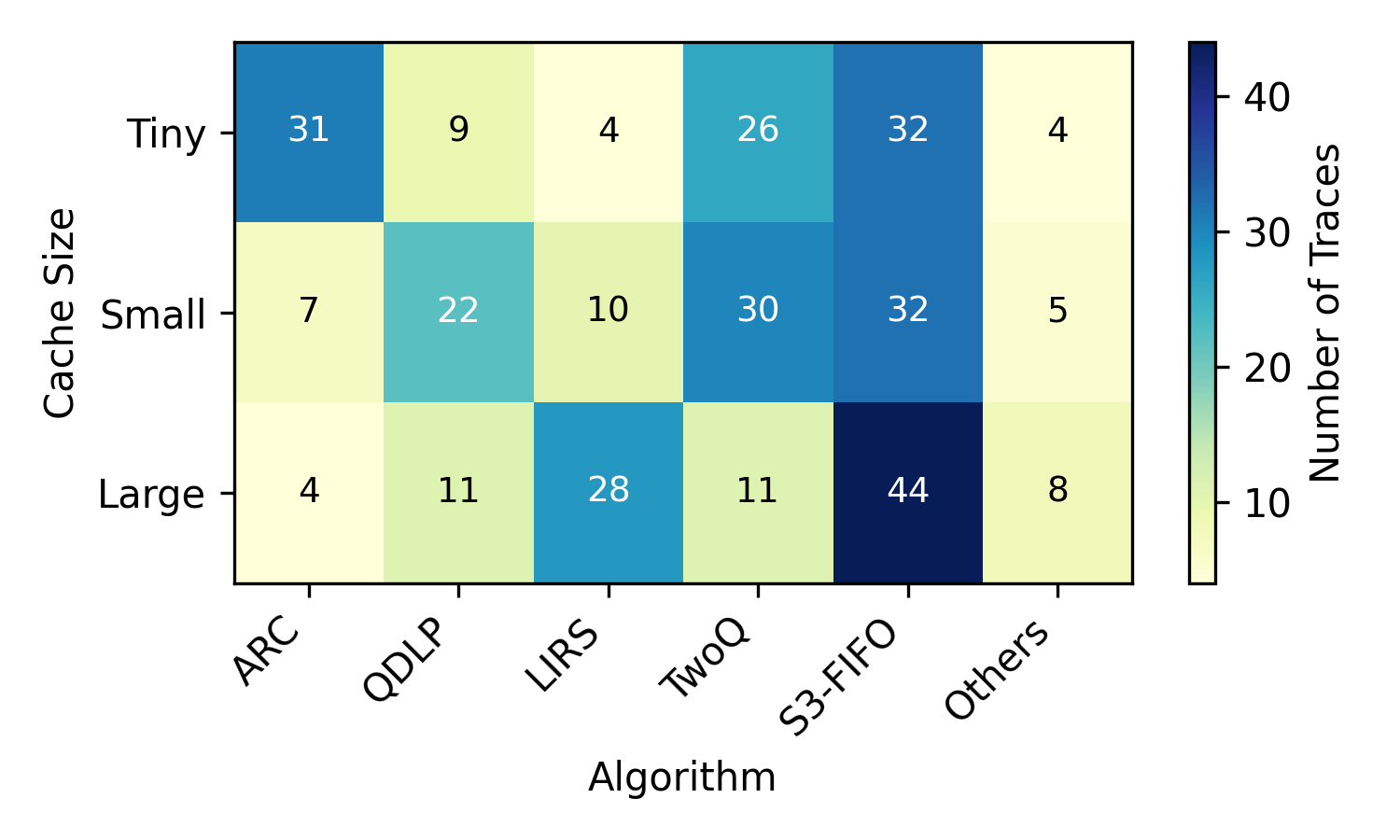
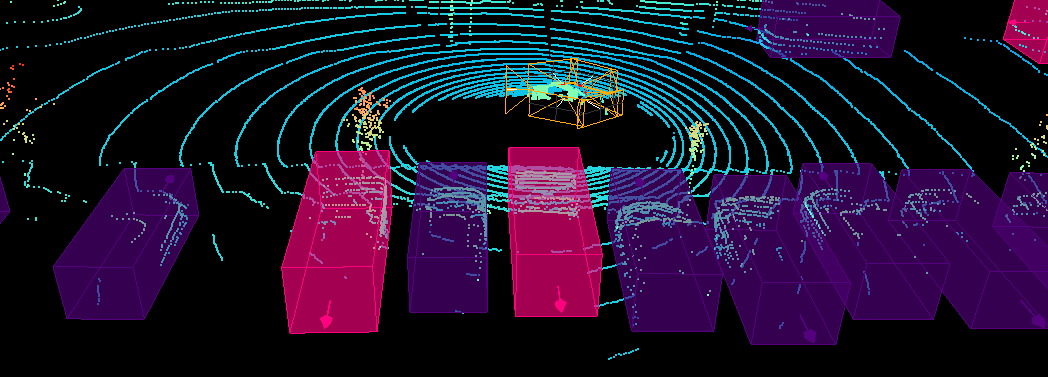
This report presents the design and implementation of a semi-automated data annotation pipeline developed within the DARTS project, whose goal is to create a large-scale, multimodal dataset of driving scenarios recorded in Polish conditions. Manual annotation of such heterogeneous data is both costly and time-consuming. To address this challenge, the proposed solution adopts a human-in-the-loop approach that combines artificial intelligence with human expertise to reduce annotation cost and duration. The system automatically generates initial annotations, enables iterative model retraining, and incorporates data anonymization and domain adaptation techniques. At its core, the tool relies on 3D object detection algorithms to produce preliminary annotations. Overall, the developed tools and methodology result in substantial time savings while ensuring consistent, high-quality annotations across different sensor modalities. The solution directly supports the DARTS project by accelerating the preparation of large annotated dataset in the project s standardized format, strengthening the technological base for autonomous vehicle research in Poland.