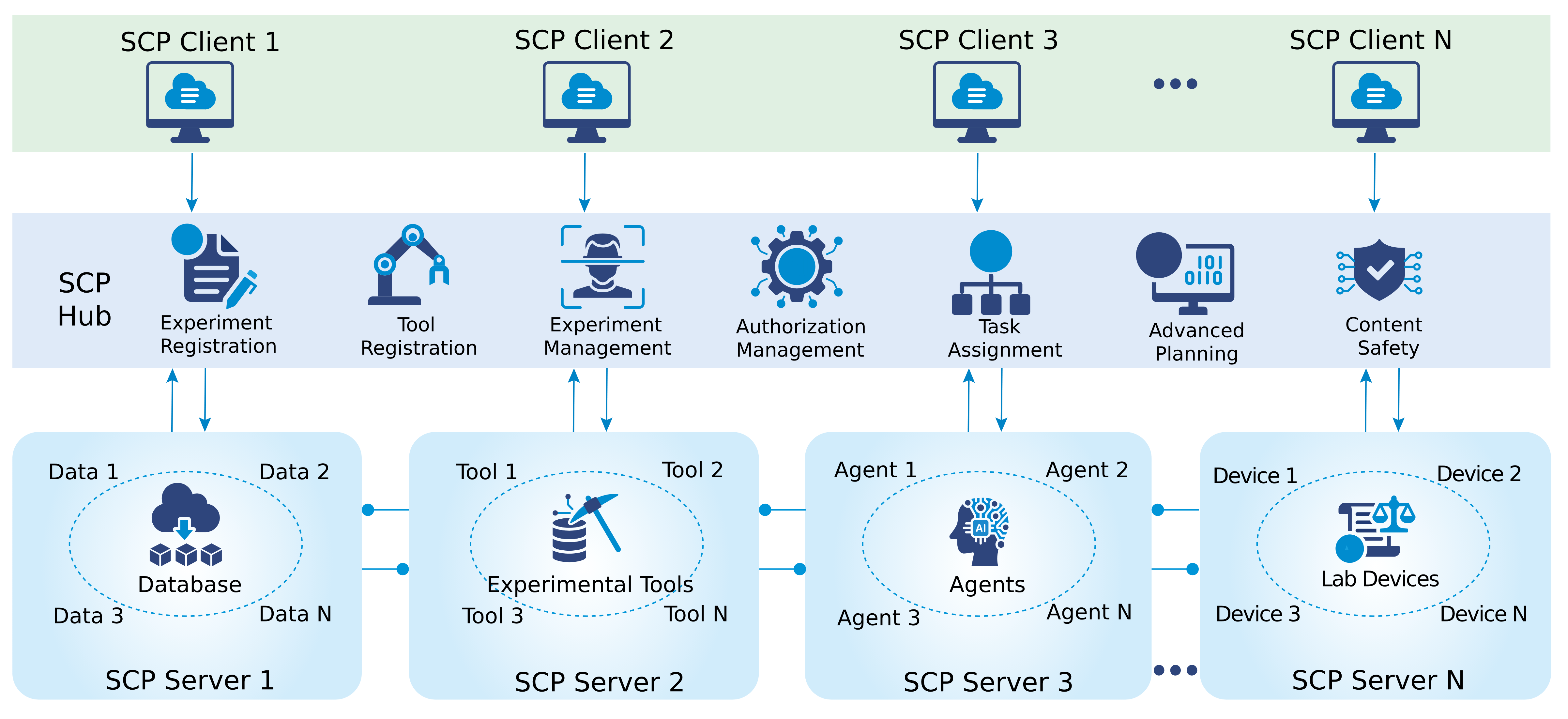
OmniNeuro A Multimodal HCI Framework for Explainable BCI Feedback Generation
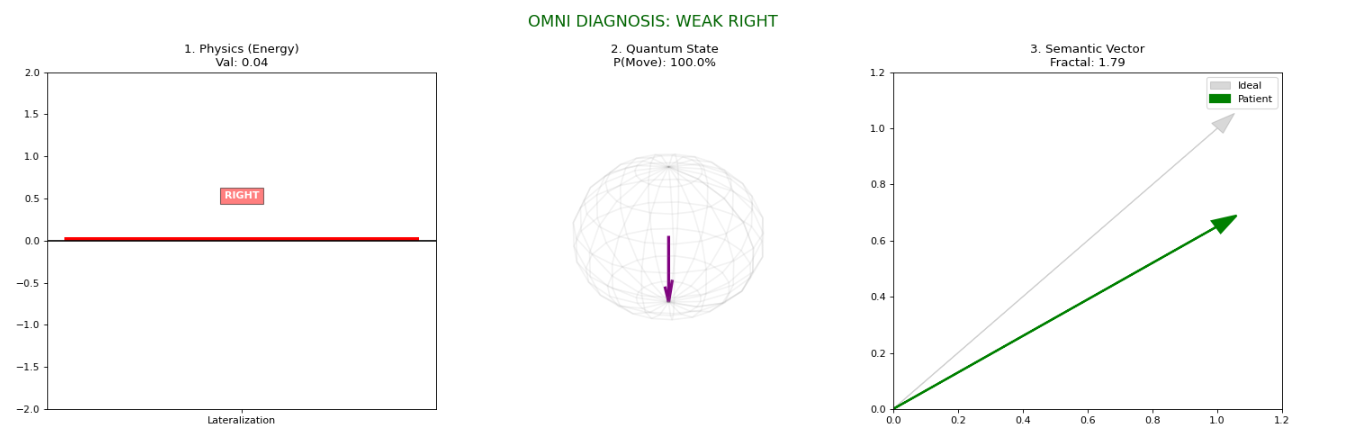
While Deep Learning has improved Brain-Computer Interface (BCI) decoding accuracy, clinical adoption is hindered by the Black Box nature of these algorithms, leading to user frustration and poor neuroplasticity outcomes. We propose OmniNeuro, a novel HCI framework that transforms the BCI from a silent decoder into a transparent feedback partner. OmniNeuro integrates three interpretability engines (1) Physics (Energy), (2) Chaos (Fractal Complexity), and (3) Quantum-Inspired uncertainty modeling. These metrics drive real-time Neuro-Sonification and Generative AI Clinical Reports. Evaluated on the PhysioNet dataset ($N=109$), the system achieved a mean accuracy of 58.52%, with qualitative pilot studies ($N=3$) confirming that explainable feedback helps users regulate mental effort and reduces the trial-and-error phase. OmniNeuro is decoder-agnostic, acting as an essential interpretability layer for any state-of-the-art architecture.