Inferring Network Evolutionary History via Structure-State Coupled Learning
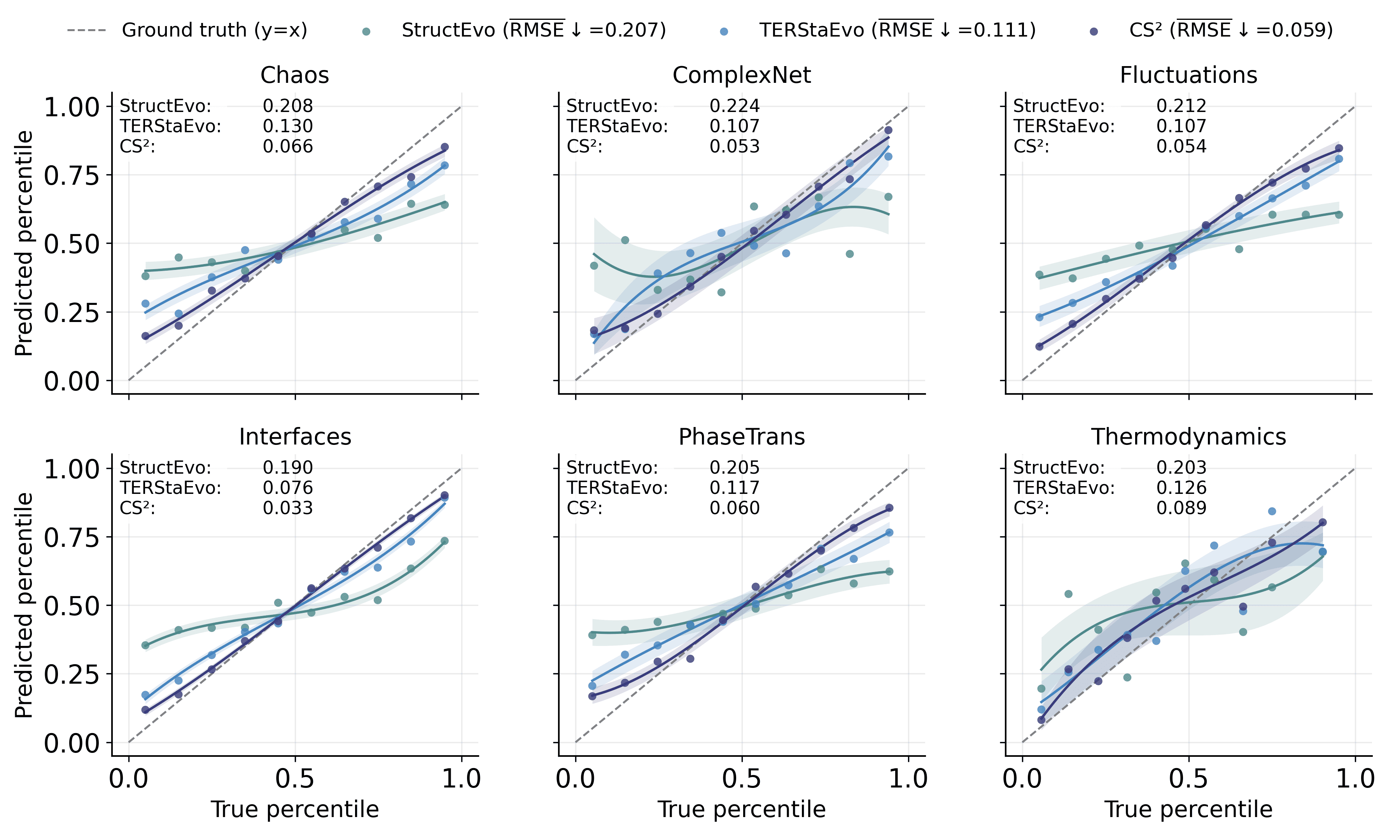
Inferring a network s evolutionary history from a single final snapshot with limited temporal annotations is fundamental yet challenging. Existing approaches predominantly rely on topology alone, which often provides insufficient and noisy cues. This paper leverages network steady-state dynamics -- converged node states under a given dynamical process -- as an additional and widely accessible observation for network evolution history inference. We propose CS$^2$, which explicitly models structure-state coupling to capture how topology modulates steady states and how the two signals jointly improve edge discrimination for formation-order recovery. Experiments on six real temporal networks, evaluated under multiple dynamical processes, show that CS$^2$ consistently outperforms strong baselines, improving pairwise edge precedence accuracy by 4.0% on average and global ordering consistency (Spearman-$ρ$) by 7.7% on average. CS$^2$ also more faithfully recovers macroscopic evolution trajectories such as clustering formation, degree heterogeneity, and hub growth. Moreover, a steady-state-only variant remains competitive when reliable topology is limited, highlighting steady states as an independent signal for evolution inference.