Emergent Introspective Awareness in Large Language Models
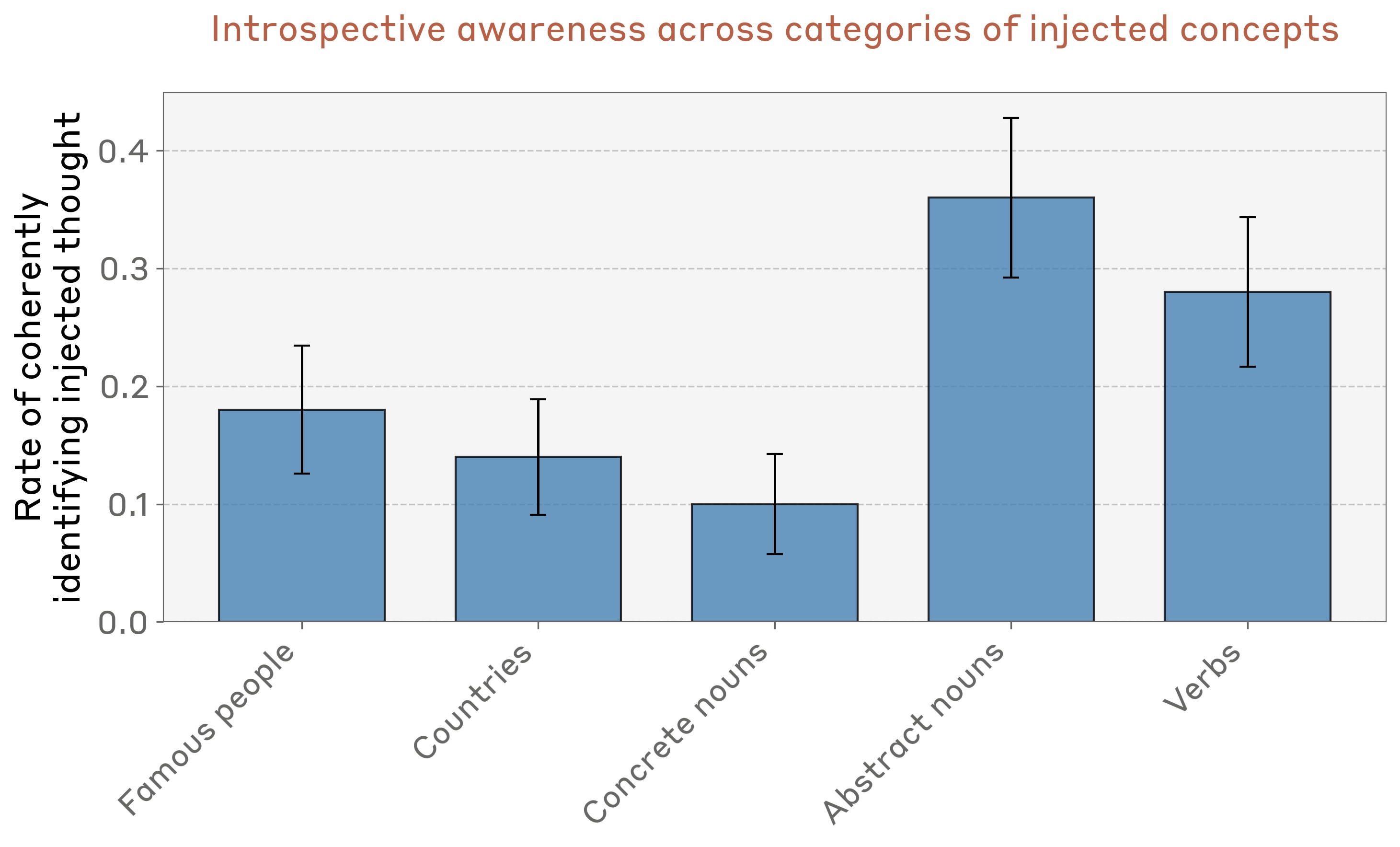
We investigate whether large language models can introspect on their internal states. It is difficult to answer this question through conversation alone, as genuine introspection cannot be distinguished from confabulations. Here, we address this challenge by injecting representations of known concepts into a model s activations, and measuring the influence of these manipulations on the model s self-reported states. We find that models can, in certain scenarios, notice the presence of injected concepts and accurately identify them. Models demonstrate some ability to recall prior internal representations and distinguish them from raw text inputs. Strikingly, we find that some models can use their ability to recall prior intentions in order to distinguish their own outputs from artificial prefills. In all these experiments, Claude Opus 4 and 4.1, the most capable models we tested, generally demonstrate the greatest introspective awareness; however, trends across models are complex and sensitive to post-training strategies. Finally, we explore whether models can explicitly control their internal representations, finding that models can modulate their activations when instructed or incentivized to think about a concept. Overall, our results indicate that current language models possess some functional introspective awareness of their own internal states. We stress that in today s models, this capacity is highly unreliable and context-dependent; however, it may continue to develop with further improvements to model capabilities.