Can Semantic Methods Enhance Team Sports Tactics? A Methodology for Football with Broader Applications
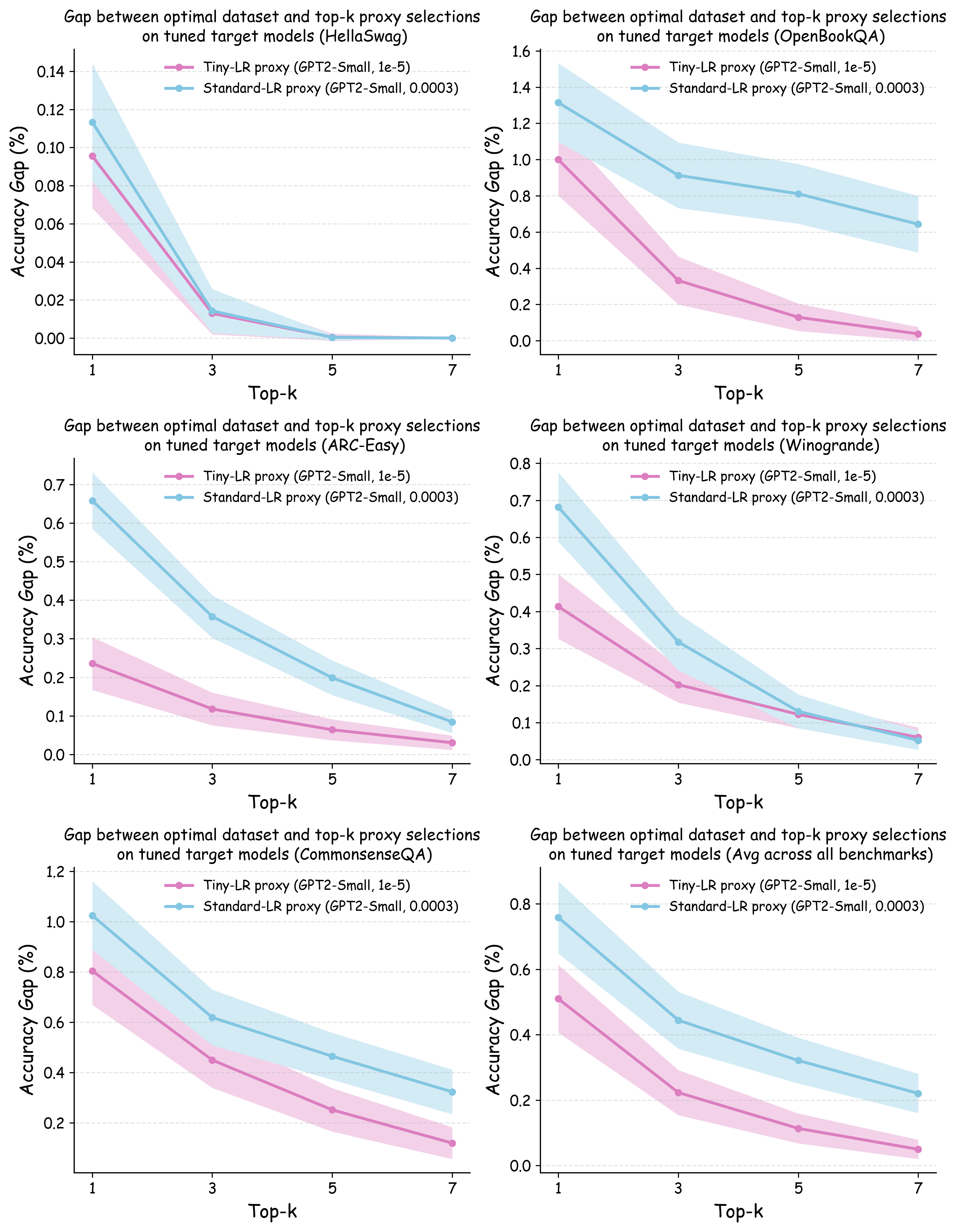
This paper explores how semantic-space reasoning, traditionally used in computational linguistics, can be extended to tactical decision-making in team sports. Building on the analogy between texts and teams -- where players act as words and collective play conveys meaning -- the proposed methodology models tactical configurations as compositional semantic structures. Each player is represented as a multidimensional vector integrating technical, physical, and psychological attributes; team profiles are aggregated through contextual weighting into a higher-level semantic representation. Within this shared vector space, tactical templates such as high press, counterattack, or possession build-up are encoded analogously to linguistic concepts. Their alignment with team profiles is evaluated using vector-distance metrics, enabling the computation of tactical ``fit and opponent-exploitation potential. A Python-based prototype demonstrates how these methods can generate interpretable, dynamically adaptive strategy recommendations, accompanied by fine-grained diagnostic insights at the attribute level. Beyond football, the approach offers a generalizable framework for collective decision-making and performance optimization in team-based domains -- ranging from basketball and hockey to cooperative robotics and human-AI coordination systems. The paper concludes by outlining future directions toward real-world data integration, predictive simulation, and hybrid human-machine tactical intelligence.