Implementation details We implemented Cadence using PyTorch and trained it with the Adam optimizer, setting the learning rate to 0.001. The batch size was fixed at 2048, and the embedding dimension was set to 32. For the UACR-driven item-item aggregation layer, we set L II = 2. The number of propagation layers in LightGCN was set to L = 3. For the two-stage candidate selection in the CSCE module, the global selection number K g was set to 4 for Beauty, 12 for TaoBao, and 6 for Toy, while the category-specific selection number K c was set to 1 across all three datasets. The scaling factor α was set to 1.15 for Beauty, 1.05 for TaoBao, and 1.15 for Toy. We employ the Bayesian Personalized Ranking (BPR) (Rendle et al. 2012) loss with negative sampling for training. The BPR loss is defined as: where D S is the set of training triplets, σ is the sigmoid function, r u,i and r u,j are predicted scores for positive item i and negative item j, λ is the regularization coefficient, and θ represents the model parameters.
Computing Infrastructure All experiments were conducted using NVIDIA A100 80GB PCIe GPUs on an Ubuntu 22.04 system, with Python 3.9 and PyTorch version 2.4.
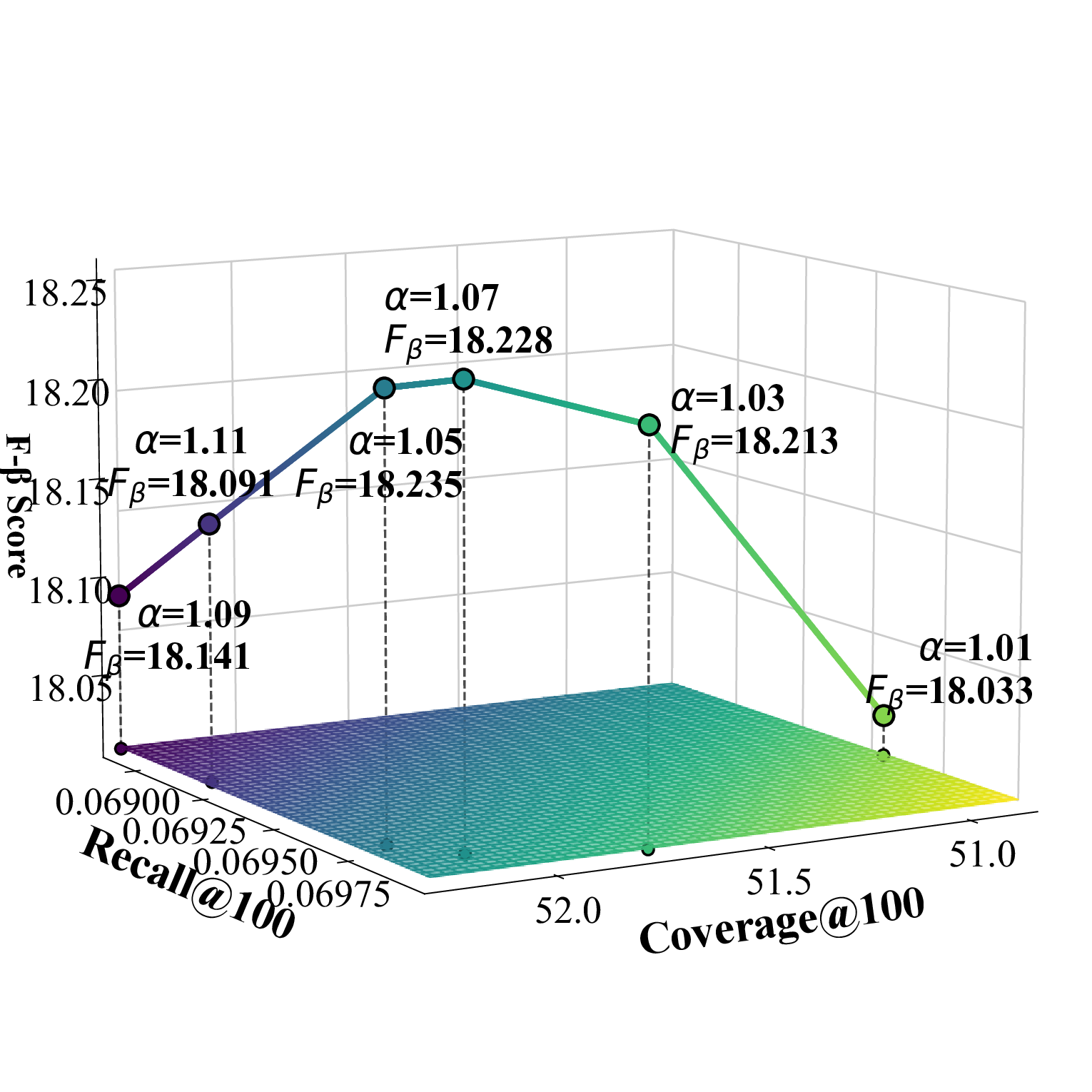
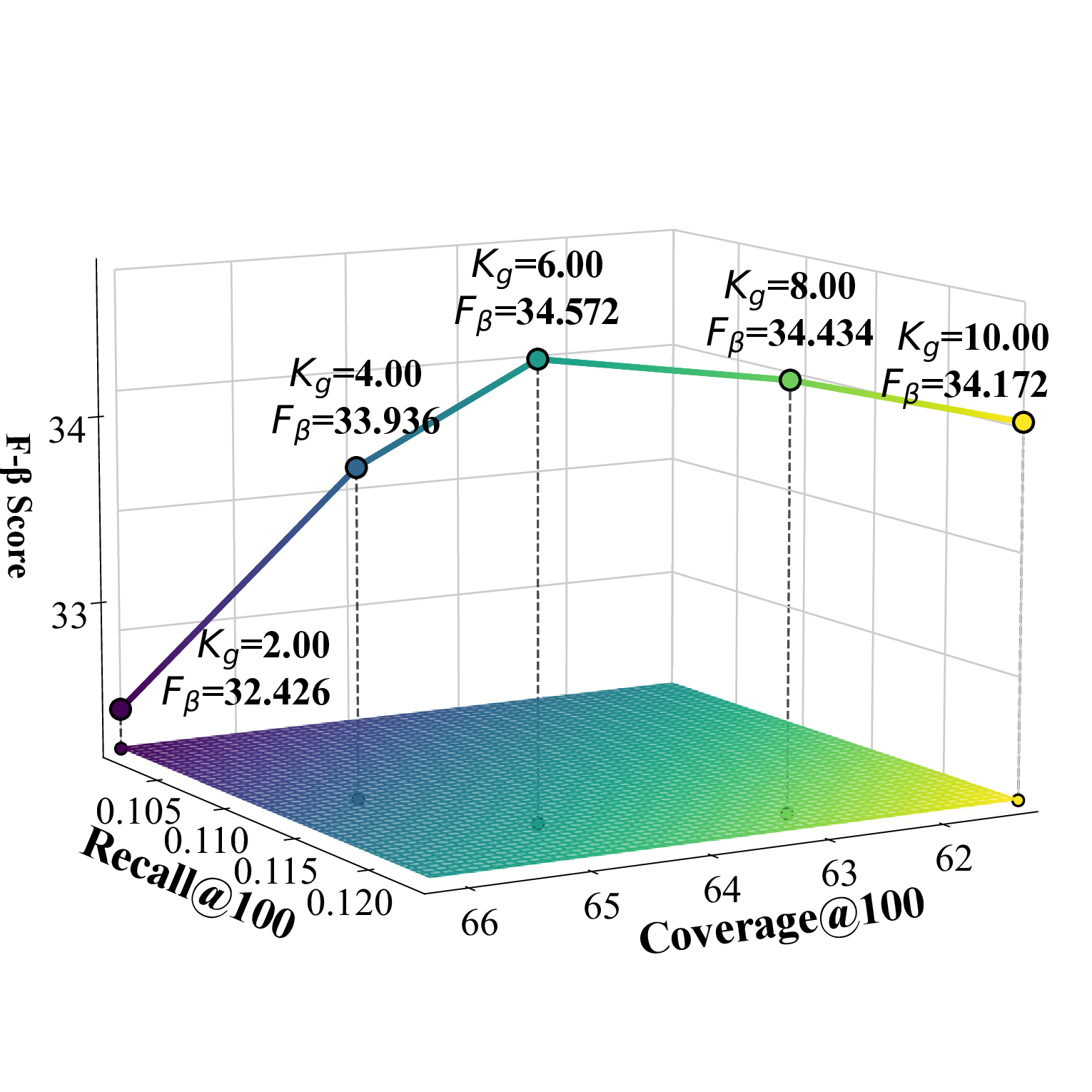
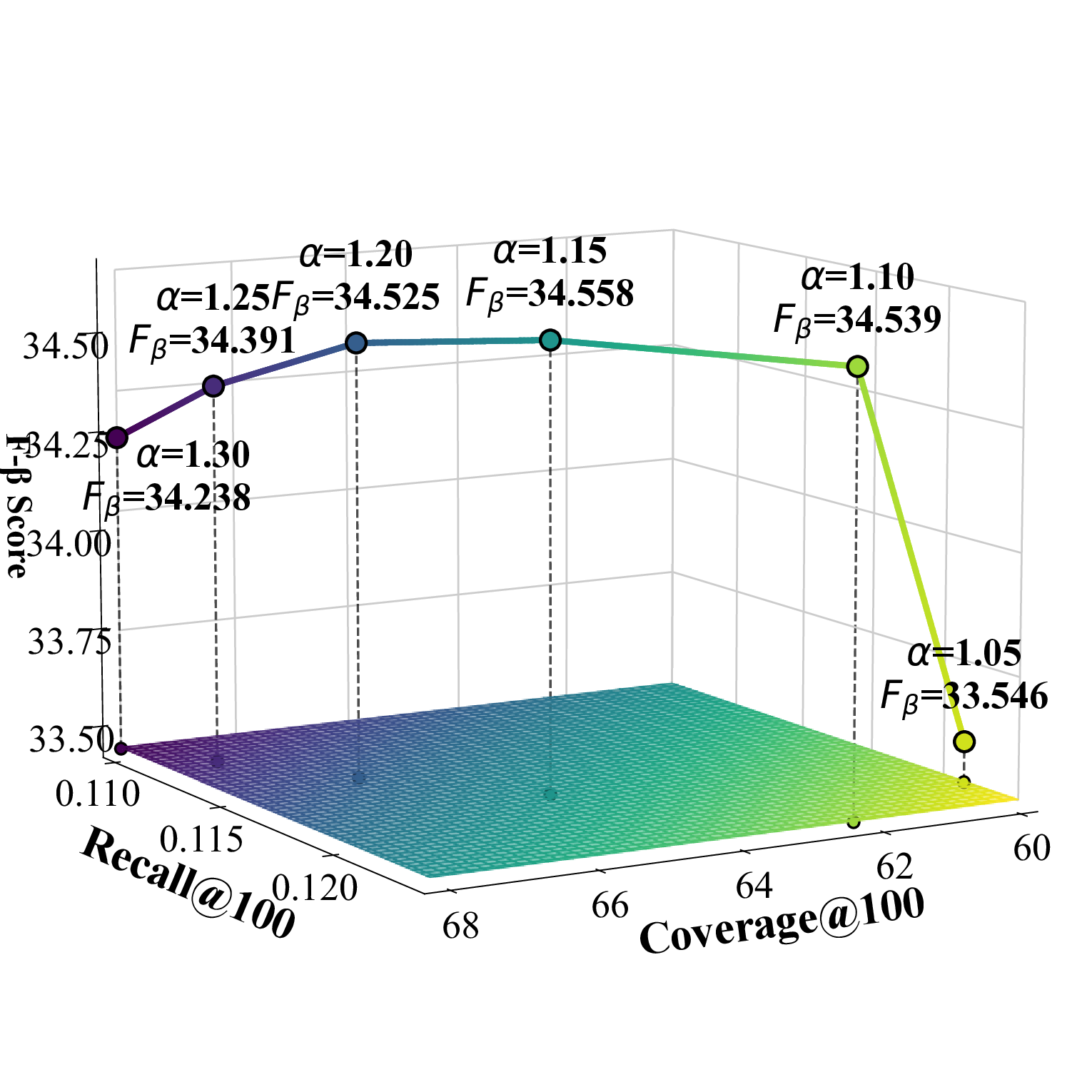
Parameter analysis In this subsection, we conduct experiments to study the impact of the scaling factor α and the global filtering coeffi-* These authors contributed equally.
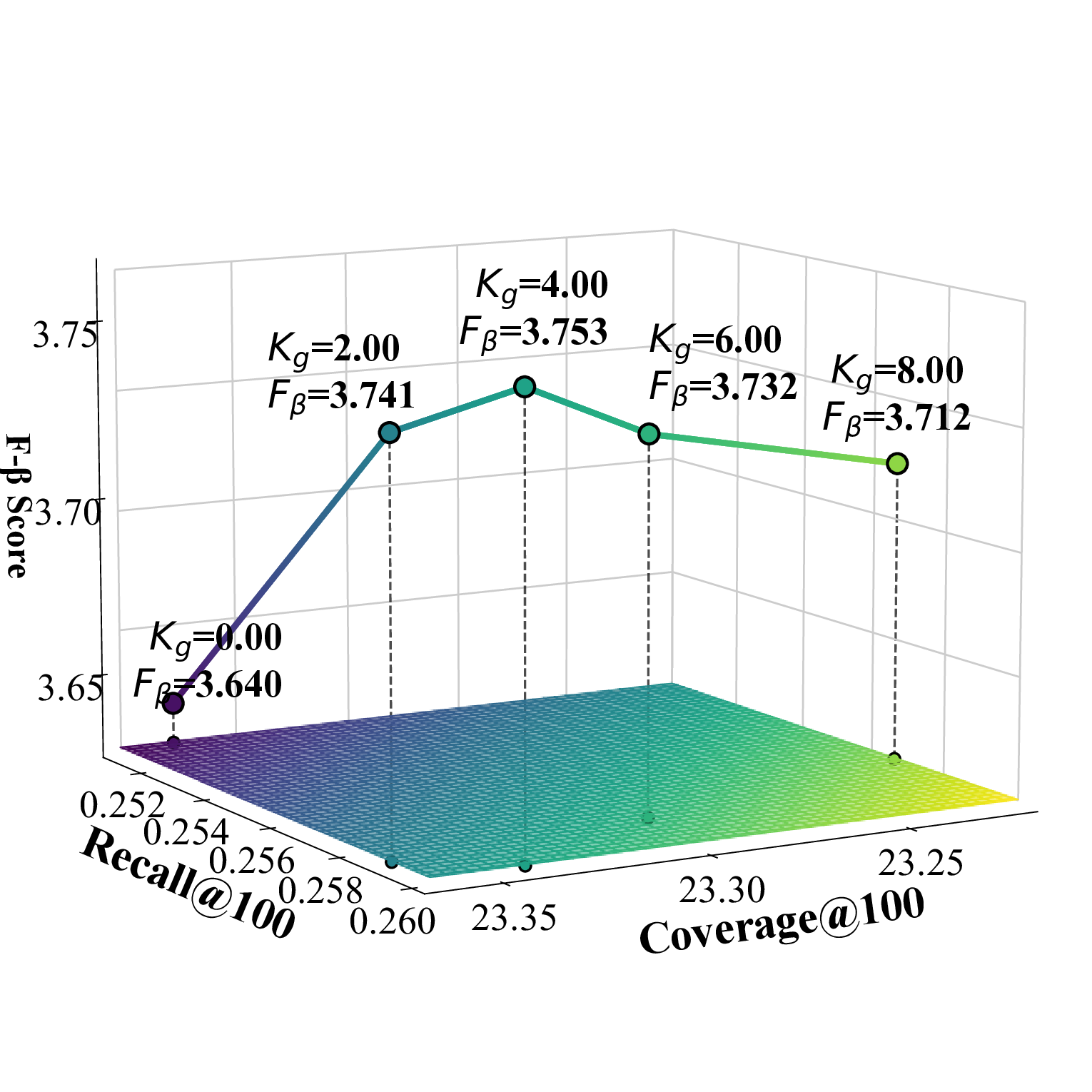
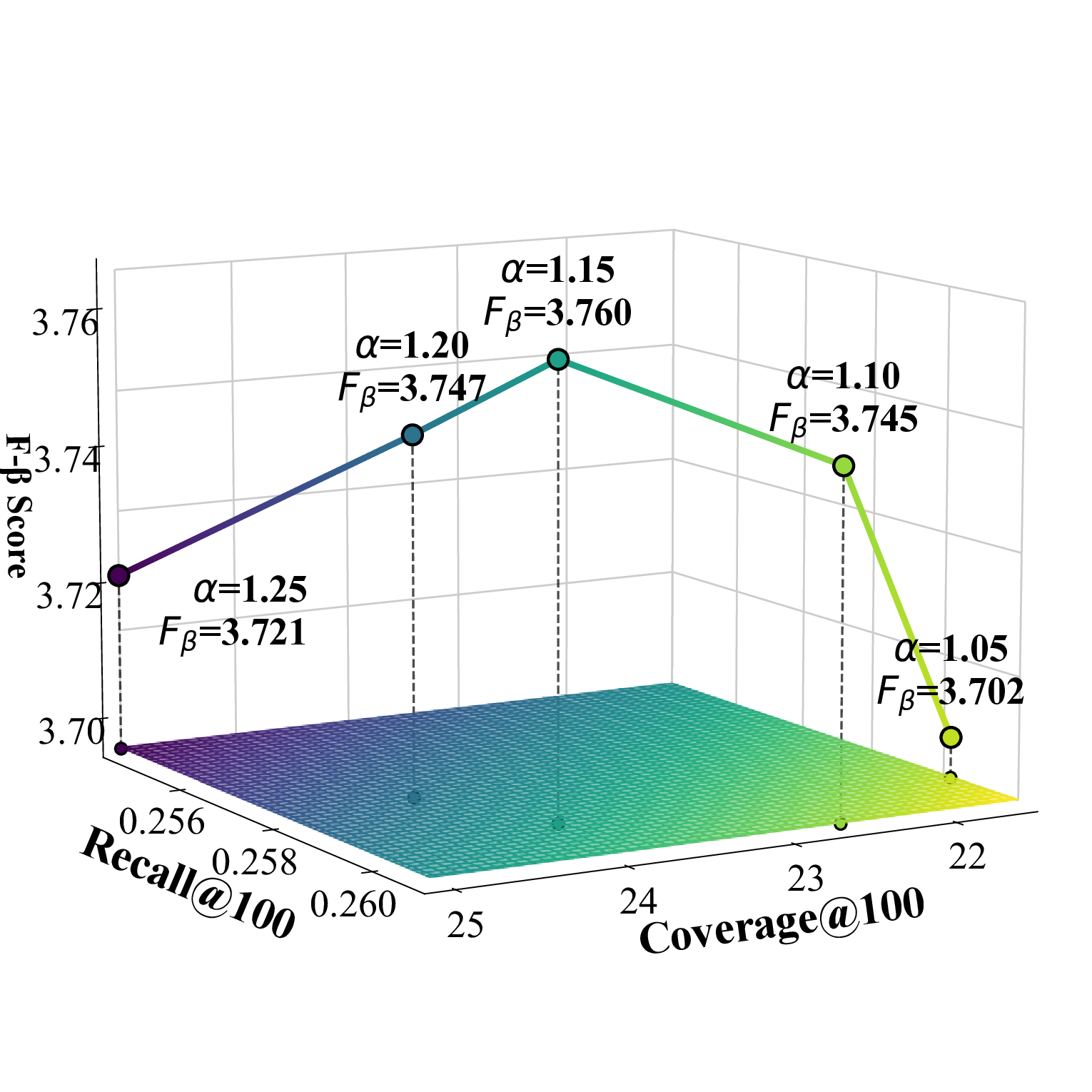
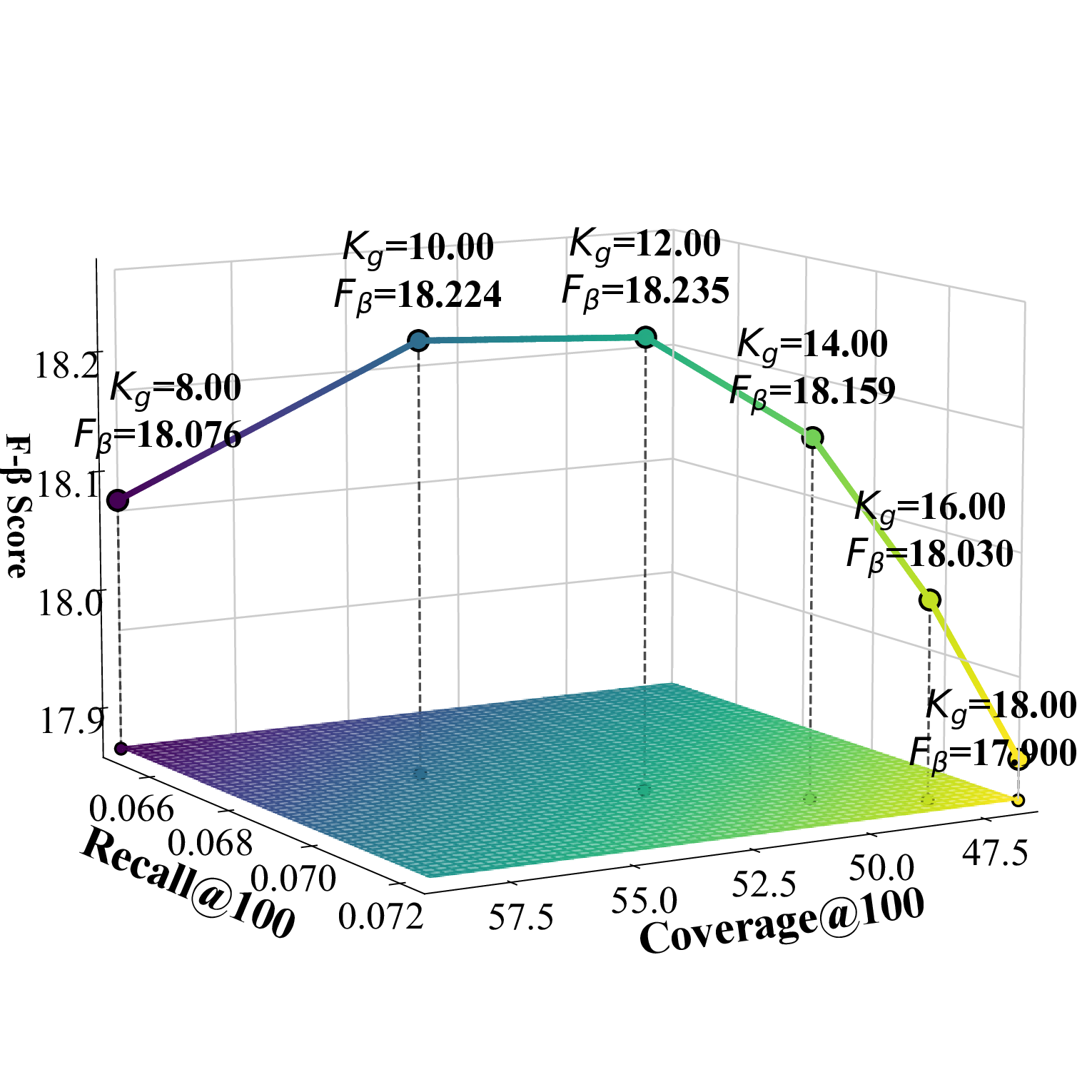
cient K g , as illustrated in Figure 1. Under the recommendation list length setting of {100, 300}, the category-specific selection number K c achieves the best performance when set to 1 for all datasets. To simultaneously consider accuracy and diversity performance, we adopt the F β -score as the evaluation metric, where the β value can be adjusted according to specific requirements and application scenarios.
The F β -score is defined as:
Here, the β values for the Beauty, TaoBao, and Toy datasets are set to 4, 20, and 15, respectively.
Effect of α α represents the intensity of counterfactual popularity enhancement. As α increases, potential interest items selected based on UACR are more likely to be successfully recommended, leading to a continuous rise in diversity metrics. This is because the two-stage filtering and aggregation strategy introduces more diversified candidate items. The accuracy metrics show a trend of first increasing and then decreasing, indicating that moderate α values can discover relevant potential interest items. However, when α becomes too large, it leads to recommending too many items that users are not interested in, thereby compromising recommendation quality. This phenomenon demonstrates the need to find an optimal balance between discovering potential diversified interests and maintaining recommendation relevance.
Effect of K g K g represents the number of candidate items in the global filtering process of the two-stage screening. As K g increases, the accuracy of the Beauty dataset shows a trend of first increasing and then decreasing, indicating that in small-scale dense datasets, moderately increasing the number of candidates helps discover relevant items, but too many candidates introduce noise and reduce accuracy. In contrast, the accuracy of TaoBao and Toy datasets continues to rise, showing that in large-scale sparse data environments, more candidate items can effectively alleviate data sparsity issues and significantly improve recommendation hit rates. However, the diversity metrics of all three datasets show a declining trend, because as the number of global candidates increases, mainstream items with high UACR scores occupy more recommendation positions, squeezing out the space for diverse candidates, thus sacrificing the diversity of recommendation results to some extent.
Our framework is built on the lightweight LightGCN backbone, with the insertion of two modules: UACR-Guided Causal Inference and Graph Refinement (CIGR) and UACR-Guided Candidate Selection and Counterfactual Exposure (CSCE). In LightGCN, user-item interactions are modeled through L-layer graph convolutions. Let E denote the number of user-item edges, d the embedding dimension, and b the batch size. The time complexity of one forward pass is In the CIGR module, we compute UACR values only for item pairs with co-purchase relations. Let γ denote the number of such co-purchase edges; the computation complexity is O(γ), as these edges are typically sparse. As this process is executed once offline, the overhead is negligible. Afterward, we apply geometric truncation to prune the co-purchase graph to β edges and perform L II -layer graph convolution over this sparse graph. The time complexity is O(L II × β × d). The CSCE module is executed only once after training for offline inference, with a complexity of O(U ), which is negligible. The overall training complex-
Therefore, the overall training complexity remains at the same level as LightGCN, since β ≪ γ and β ≪ E.
To validate the training efficiency, we record the total time to convergence (measured in seconds) for each model. To ensure a fair comparison, we adopt an early stopping strategy based on Recall@100, where training is terminated if no improvement is observed for 10 consecutive epochs. Experimental results show that our method consistently outperforms all baselines, while achieving training efficiency comparable to LightGCN, as shown in Table 1, demonstrating both its effectiveness and practicality.
To validate the robustness of Cadence, we conduct five independent runs for each experiment using different random seeds [2021,2022,2023,2024,2025], reporting the mean and standard deviation for each evaluation metric. As illustrated in Figure 2, Cadence consistently demonstrates superior performance with low variance across multiple independent executions, confirming its stability under various random initialization conditions.
To further establish the statistical significance of the performance improvements, we employ the Wilcoxon signedrank test to compare Cadence against the top-performing (Tang et al. 2025), counterfactual explanation generation for interpretable recommendation (Li et al. 2024), and mitigation of unfair exposure caused by user attributes or system biases in fair recommendation (Shao et al. 2024). Discussion. UCRS (Wang et al. 2022) uses user-issued controls and counterfactual inference to adjust recommendations by simulating changes in user features, aiming at controllable recommendation rather than explicit diversity optimization or causal item modeling. In contrast, our method enhances diversity from a causal perspective by constructing a deconfounded causal item graph and applying counterfactual exposure interventions to uncover under-exposed yet relevant items.
Diversity-aware recommendation aims to alleviate the issue of homogeneity in recommendation results and enhance overall user satisfaction (Ziegler et al. 2005). Early approaches primarily relied on re-ranking strategies, such as Maximum Marginal Relevance (MMR) (Abdool et al. 2020;Carbonell and Goldstein 1998;Lin et al. 2022;Peska and Dokoupil 2022) and Determinantal Point Process (DPP) (Chen, Zhang, and Zhou 2018;Gan et al. 2020;Huang et al. 2021), which optimize the recommendation list to promote item dissimilarity. With the advancement of graph neural networks (Tian et al. 2022), more recent methods leverage high-order graph structures to capture complex user-item relationships for improved diversity, including category-aware sampling (Zheng et al. 2021), submodular neighbor selection (Yang et al. 2023), clustering-based candidate generation (Liu et al. 2024), and dynamic graph updates (Ye et al. 2021). Moreover, the emergence of large language models (LLMs) has introduced new opportunities for diversity modeling, where controllable generation frameworks (Chen et al. 2025a) are developed to regulate category coverage and further enrich the diversity of recommendations.
Discussion. Most existing approaches lack principled theoretical grounding and a causal perspective, limiting their capacity to generate genuinely diverse recommendations. Traditional co-occurrence-based methods are prone to confounding from item popularity and user attributes, leading systems to favor popular but homogeneous items while neglecting underexposed yet causally relevant ones. In our work, we employ causal inference to remove these spurious associations, recover true item dependencies, uncover latent user interests, and enhance diversity without compromising relevance.
This section provides the complete mathematical proof of the norm-popularity correlation theorem.
• U, I: user set and item set;
• A: the random-walk normalised adjacency matrix with ∥A∥ 2 ≤ 1;
• n i : number of positive interactions for item i (“popularity”), and |D| = i n i ;
• η, λ: SGD step size η and ℓ 2 regularisation coefficient λ;
• e (ℓ)
x : embedding of node x at layer ℓ; the final embedding is defined as e x = K k=0
α k e (k) x ;
• ∆ = ⟨e u , e i ⟩ -⟨e u , e j ⟩;
• σ(•): sigmoid function.
Default sampling strategy. At each training step we randomly draw one positive interaction (u, i) and then uniformly sample a negative item j from the set of items not interacted by u; hence
A.2 Full Chain-Rule Derivation of ∂ℓ/∂e (0) i
The BPR loss is
Gradient with respect to the final embeddings.
Backpropagation to e (0) i
Since e = M e (0) (LightGCN only performs linear propagation), we have
Therefore ∂ℓ ∂e
Component along ê(0) i direction Let θ ui be the angle between e u and e
A.3 Single-step Norm Increment SGD update with small learning rate for stability,
Substituting ( 12) and taking the conditional expectation over (u, i, j), in large-scale datasets κ and β vary minimally across items, so we approximate them as constants
Since user embedding norms have no significant correlation with individual item popularity, in the statistical sense of large datasets we can treat (κ -βµ i )
Solving yields
Because the dependence of κ and β on i is extremely weak, µ i grows linearly with n i and the proportionality constant is essentially item-independent. The parameters κ and C vary little across items, so the bounded-difference condition holds uniformly for all i.
A.6 Theorem Statement (Uniform Negative Sampling)
Combining (3), (19) and the above bound, we obtain ∥e i ∥ 2 = Θ(n i ) and Pr ∥e i ∥ 2 > ∥e j ∥ 2 ≥ 1 -e -Ω(1) .
(21) This completes the proof.
This content is AI-processed based on open access ArXiv data.