Physics-informed neural networks (PINNs) have recently emerged as a prominent paradigm for solving partial differential equations (PDEs), yet their training strategies remain underexplored. While hard prioritization methods inspired by finite element methods are widely adopted, recent research suggests that easy prioritization can also be effective. Nevertheless, we find that both approaches exhibit notable trade-offs and inconsistent performance across PDE types. To address this issue, we develop a hybrid strategy that combines the strengths of hard and easy prioritization through an alternating training algorithm. On PDEs with steep gradients, nonlinearity, and high dimensionality, the proposed method achieves consistently high accuracy, with relative L 2 errors mostly in the range of O(10 -5 ) to O(10 -6 ), significantly surpassing baseline methods. Moreover, it offers greater reliability across diverse problems, whereas compared approaches often suffer from variable accuracy depending on the PDE. This work provides new insights into designing hybrid training strategies to enhance the performance and robustness of PINNs.
📄 Full Content
The rapid development of deep learning has revolutionized scientific computing, offering novel solutions to longstanding challenges in modeling complex physical systems [3,8,21,24,39]. Among these advances, physics-informed neural networks (PINNs), seamlessly integrating partial differential equations into neural network training through residual-based loss functions, have emerged as an vital framework [9,16,18,38,41]. By bridging data-driven flexibility with physical consistency, PINNs circumvent the need for computationally expensive mesh generation and demonstrate remarkable capabilities in solving parametrized and high-dimensional partial differential equations (PDEs) [4,10,27,30,40]. However, their effectiveness is frequently compromised by a critical challenge: the heterogeneous contributions of loss components, which lead to unstable solution accuracy [2,6,12,32,33].
To improve the accuracy and stability of PINNs, two seemingly distinct training strategies have been extensively studied. The first strategy, hard prioritization, identifies and emphasizes high-loss sample points during PINN training through resampling or adaptive weighting techniques [7,20,23,26,35]. This strategy forces the model to focus on the more challenging regions of the PDE domain, thereby helping it capture more essential physical characteristics. For instance, residual-based adaptive sampling automatically adds more sample points in computational regions with larger residual loss [35]. Luo et al. [23] introduce Residual-based Smote (RSmote), an innovative local adaptive sampling technique tailored to improve the performance of PINNs through imbalanced learning strategies. Gu et al. [7] proposed SelectNet, a self-paced learning framework that emphasizes higher-loss sample points during training. Liu and Wang [20] developed a Physics-Constrained Neural Network with the Mini-Max architecture (PCNN-MM) to simultaneously update network weights (via gradient descent) and loss weights (via gradient ascent), targeting a saddle point in the weight space. McClenny and Braga-Neto [26] advanced this approach by proposing Self-Adaptive PINN (SAPINN), which adaptively assigns heavier weights to larger individual sample losses.
The second strategy, easy prioritization, draws inspiration from human curriculum learning [1,17,31] by initially focusing on simpler samples or tasks and gradually increasing the level of difficulty [15,22,25,33]. This approach can reduce training instability, especially in the early stages, and promote faster convergence. Krishnapriyan et al. [15] applied curriculum learning approach in PINNs by progressively introducing highfrequency components or refining the spatiotemporal domains. Monaco and Apiletti [25] proposed a new curriculum regularization strategy to enable smooth transitions in parameter values as task difficulty increases. Wang et al. [33] addressed convection-dominated diffusion equations by assigning reduced weights to challenging regions such as boundary or interior layers to improve solution accuracy. More recently, Li et al. [22] introduced an Anomaly-Aware PINN (AAPINN), which enhances robustness and accuracy by identifying and excluding difficult, high-loss samples.
While both training strategies have achieved empirical success in enhancing the performance of PINNs, their relative merits and inherent trade-offs for solving PDEs remain unclear due to the lack of systematic comparative analysis. To bridge this gap, this study first conducts a comparison of these two types of training approaches based on a toy example. Our experiments reveal that the easy-prioritization method tends to emphasize the global structure of the solution -capturing smooth, low-frequency components that dominate the overall behavior of the PDE across the entire domain [36]. In contrast, hard-prioritization strategies are more inclined to focus on localized regions with higher complexity, such as areas with sharp gradients, singularities, or rapidly varying solution features, which are often more difficult to learn. Another important observation is that there is no consistent winner between the two strategies. In some cases, the hard sample prioritization method yields better results, whereas in others, the easy sample prioritization strategy is more effective. Notably, even for the same PDE, variations in the equation coefficients can shift the advantage between the two strategies. These findings suggest that real-world PDEs, which are often complex, may not be well-suited to a one-size-fits-all training strategy.
To address this challenge, we propose a hybrid training framework that combines the strengths of both easy and hard sample prioritization. Specifically, the proposed method alternates between two training phases, each guided by a distinct optimization objective. The first phase adopts a hard prioritization strategy, employing a min-max framework to optimize a weighted PINN loss function. The second phase switches to an easy prioritization strategy, using an anomaly-aware mechanism to progressively focus hard samples and minimize a standard (non-weighted) PINN loss. In each training epoch, these two phases are executed alternately. The alternating structure ensures a dynamic balance between easy and hard sample learning, thereby improving the robustness and generalization ability of PINNs. Given its alternating nature between easy and hard phases, we name the method Alternating Easy-Hard PINN (AEH-PINN). Experimental results demonstrate that the proposed AEH-PINN consistently surpasses existing training strategies by overcoming their accuracy trade-offs, achieving superior relative L 2 errors on the order of O (10 -5 ) to O (10 -6 ) across most challenging PDEs. The code is provided at https://github.com/Gao-ST/PINN-Alternating-Easy-Hard
to facilitate reproducibility and comparison.
The remainder of this paper is organized as follows. Section 2 provides a brief overview of PINN and introduces a toy example to compare hard and easy prioritization strategies, which motivates our proposed approach. Section 3 presents the proposed hybrid training method. Section 4 reports the experimental results on various PDEs and compares the performance of our approach with several benchmark PINN methods. Section 5 concludes the paper.
We begin with a brief overview of PINN [29]. Consider a general PDE with initial and boundary conditions:
where u(x, t) denotes the solution of the PDE, N [•] is a (possibly nonlinear) differential operator, and B[•] represents a boundary operator that can encode various types of boundary conditions, including Dirichlet, Neumann, Robin, and periodic conditions. The core idea of PINN is to utilize a neural network u θ (x, t), where θ denotes trainable parameters of the network, to approximate the solutions of PDEs u(x, t). The neural networks’ output u θ provides a continuous representation that can be evaluated at any point (x, t). The network is trained by minimizing the following objective function:
where
These loss terms enforce the neural network to satisfy the governing PDE as well as the initial and boundary conditions. The solution procedure for ( 2) is generally based on stochastic gradient descent (SGD) algorithms [28]. Owing to the non-convex nature of the optimization landscape, training is prone to convergence to local minima, which can limit the achievable accuracy. Furthermore, the loss function incorporates contributions from multiple sample points, whose loss magnitudes may vary significantly. Although the objective is to minimize the average loss, individual sample points can still exhibit large residuals even when the overall loss is small. This imbalance undermines the reliability of the learned solution, particularly in multiscale scenarios.
As outlined in Section 1, two distinct strategies have been developed to mitigate this problem: (1) hard prioritization and (2) easy prioritization. In the following subsection, we are to introduce a toy example to conduct a comparative analysis of these strategies.
Consider the following heat conduction problem with steep gradients, adapted from [34]:
where the exact solution is set as u(x, t) = (1 -x 2 )e 1 (2t-1) 2 +α . The source term f (x, t), visualized in Figure 1, exhibits sharp localized peaks and steep gradients. As α decreases, the solution becomes increasingly sharp, presenting a challenging test case for numerical methods. For comparison, we consider two baseline methods. The first is SAPINN [26], a hardsample-prioritization method that introduces an adversarial min-max optimization frame-work. The overall objective is formulated as:
where the three components correspond to the residual loss, initial condition loss and boundary condition loss, respectively:
Here w R , w I , w B are trainable weights, and m(•) is a non-negative self-adaptation mask function defined on [0, ∞). SAPINN simultaneously updates the network parameters θ via gradient descent and the sample weights w via gradient ascent:
This adversarial learning scheme adaptively reallocates attention toward regions with higher residuals and aims to improve the network’s ability to capture sharp transitions in the solution.
The second method is AAPINN [22], which introduces a dynamic anomaly exclusion mechanism during training. It builds upon the standard PINN loss function (2) and computes the mean and standard deviation of the sample-wise feedforward losses:
where L i (θ) is the feedforward loss of the i-th sample. Based on these statistics, AAP-INN periodically detects outliers with exceptionally high losses. If no such samples are identified, the model is trained on the full dataset. Otherwise, the training focuses only on a subset of easy and moderate samples, excluding the identified anomalies.
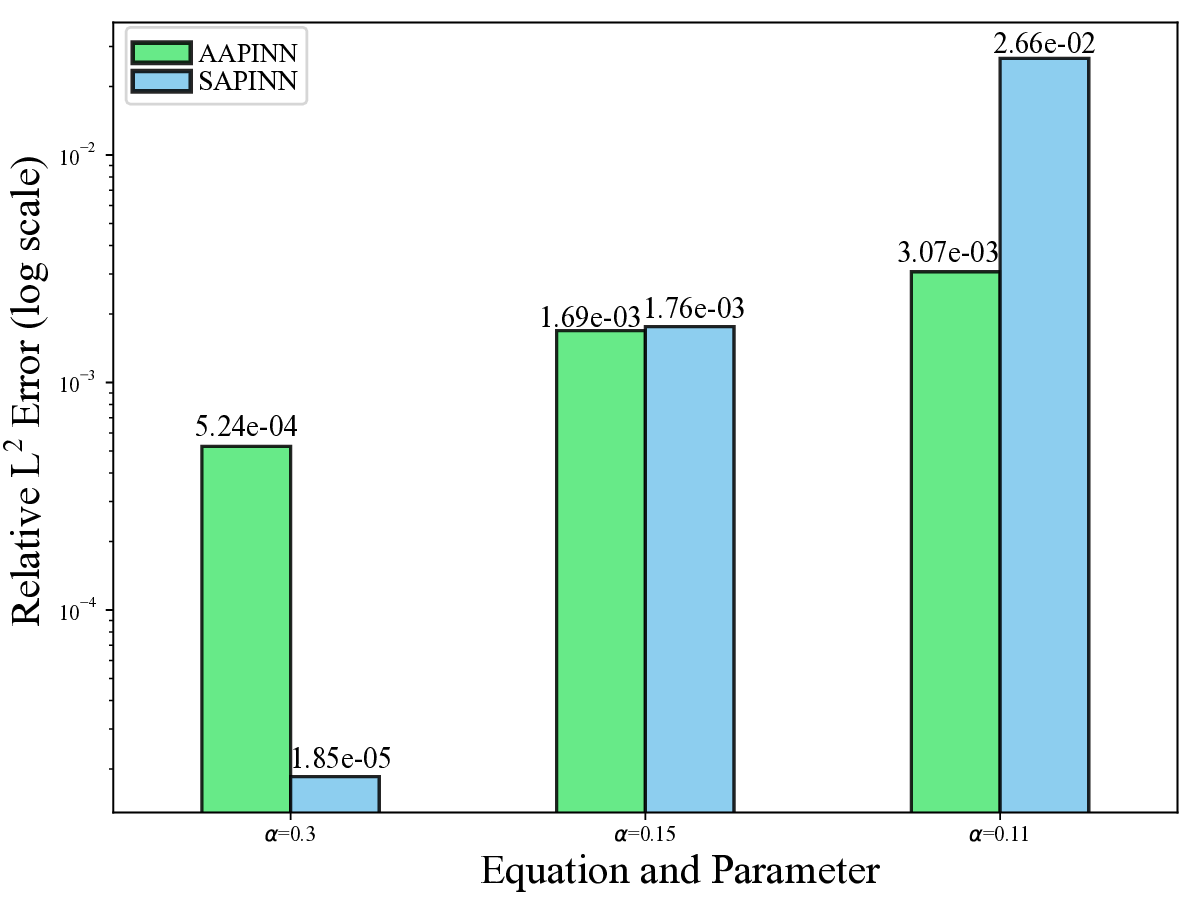
We apply SAPINN and AAPINN to solve the equation ( 5) under varying levels of difficulty, controlled by the parameter α = 0.3, 0.15, 0.11. Both models employ the same architecture: a fully connected neural network with four hidden layers, each containing 50 neurons and activated by the Tanh function. Training is performed using the Adam optimizer [14]. As shown in Figure 2, neither method consistently outperforms the other across all difficulty levels. For moderate difficulties (α = 0.3), SAPINN achieves notably higher accuracy, reaching a relative L 2 error of 1.85 × 10 -5 compared to AAPINN’s 5.24 × 10 -4 , a reduction by a factor of approximately 28.3. However, this advantage reverses at α = 0.11, where AAPINN attains a relative error of 3.07 × 10 -3 , outperforming SAPINN’s 2.66 × 10 -2 by a factor of 8.7. These results suggest that, even for the same type of PDE, neither hard prioritization nor easy prioritization strategy can maintain universally superior performance.
We note that as two fundamentally different learning mechanisms, AAPINN mitigates the impact of extreme outliers by eliminating highly difficult samples and focusing on easier ones. Over time, it gradually shifts attention toward more challenging regions. This strategy avoids overemphasis on problematic samples and promotes training stability, especially during the early stages (as will be further illustrated in the training curves in Section 4.9). In contrast, SAPINN emphasizes learning from difficult samples. As shown in Figure 3, the relative L 2 error and weight distributions at different training stages reveal that SAPINN assigns significantly larger weights to a small subset of samples with high residuals. While this boosts the approximation accuracy in those specific regions, the overall prediction performance remains suboptimal: some low-weighted regions experience increased approximation errors.
Given that computationally difficult regions are usually limited in proportion, hard prioritization strategies tend to act as “local” methods. In contrast, easy-sample prioritization can be viewed as a more “global” approach that better accounts for general sample behavior. However, both strategies involve inherent trade-offs: hard prioritization may hinder convergence due to overemphasis on difficult samples, whereas easy prioritization may fail to adequately resolve complex regions of the solution space. We argue that a hybrid of these two approaches may yield more consistent and robust performance for PINNs. In the next section, we will introduce our proposed method based on this idea.
In order to balance the inherent trade-offs between easy and hard prioritization strategies in training PINNs, we propose a hybrid framework that integrates both paradigms. This framework consists of two key phases. The first is a weighted adversarial phase, inspired by SAPINN [26], which prioritizes difficult regions by dynamically adjusting sample weights through a min-max optimization process. The second is an easy-prioritization phase, drawing from the ideas in AAPINN [22], which excludes extreme difficult samples to stabilize training.
To effectively combine these two phases, we design an alternating training scheme that iteratively switches between the hard-and easy-prioritization stages. Rather than simply connecting the two phases in a fixed sequential or parallel fashion, this alternating strategy promotes continual interaction between local refinement and global stability throughout the training process.
While the specific implementation is novel in the context of PINNs, the underlying intuition echoes broader insights from curriculum learning and self-paced learning in computer vision and natural language processing [5,13]. Jiang et al. [13] discover the missing link between CL and SPL, and propose a unified framework named self-paced curriculum leaning, which takes into account both prior knowledge known before training and the learning progress during training. Graves et al. [5] introduce a method for automatically selecting the path, or syllabus, that a neural network follows through a curriculum so as to maximise learning efficiency. These studies suggest that dynamically balancing sample difficulty over time, rather than committing to a single difficulty regime, can lead to more robust and generalizable models. To the best of our knowledge, this is the first work to introduce such a structured alternating training mechanism into PINNs.
Specifically, in the first phase, we emphasize difficult samples by employing a min-max optimization scheme. Penalty weights are assigned to each training sample {(x i , t i )} N i=1 and iteratively updated to focus on high-loss regions. The objective is formulated as:
where w i denotes the sample-wise weights. Unlike the original SAPINN formulation (6), our implementation omits the use of the mask function, resulting in a simplified objective. The penalty weight updates are performed via gradient ascent:
where η is the learning rate for the weight update. This encourages the network to place more emphasis on samples associated with larger residuals. The network parameters and weights are jointly updated in parallel using the gradients of the weighted loss.:
In the second phase, the lack of batch training in SGD poses a challenge, often leading to unstable updates and poor model generalization. Inspired by [22], we address this issue by dynamically prioritizing easy samples through a easy-to-hard sampling strategy. Besides, instead of using the weighted loss function as in (8), we adopt the standard PINN loss (2) without any sample weighting.
Different from the sample selection mechanism in (7), we do not rely on statistical heuristics to select samples. Instead, we sort all samples based on their feedforward loss values and retain only the top r fraction with the lowest losses. These selected samples form a subset X sub , which is used for updating the network parameters via:
The selection ratio r is determined as follows. Let cycle denote the current position within a training cycle, defined as the current epoch index modulo the update period P . The sample selection ratio r is then dynamically adjusted according to: r = min{0.5 + 0.99 • cycle P , 1}, where cycle = 1, 2, . . . , P. (12) Clearly, the value of r increases progressively from 50% to 100%, allowing more samples to participate in training as the cycle progresses. By using the period P to reset r periodically, the model restarts with 50% of the easy samples every P epochs and gradually increases the sample ratio. This way may explore the solution space more randomly and helps avoid potential local minima. Morevoer, it is worth noting that a key difference between our second phase and AAPINN [22] lies in the treatment of difficult samples. AAPINN operates under an outlier assumption and permanently excludes a small subset of extremely difficult samples throughout training, which may result in information loss. In contrast, our approach ensures that all training samples are eventually incorporated as r reaches 1. This fullsample utilization mitigates the risk of discarding potentially informative sample points.
The entire training procedure alternates between two phases in a repeated manner: Phase 1 runs for S 1 steps, followed by Phase 2 for S 2 steps. This alternating cycle continues until convergence or until the maximum number of epochs is reached. The complete pseudo-code is presented in Algorithm 1. X sub ← top-r% of samples sorted by L i (θ) (ascending)
We evaluate the proposed method in this section. The PINN architecture consists of four hidden layers with 50 neurons each, initialized using He initialization [11]. The Tanh activation function is used throughout the network. For comparison, we consider several PINN baselines:
RAD [35]: Dynamically allocates more sampling points to regions with higher residual losses, enabling the model to focus on areas where it performs poorly. 2. SelectNet [7]: A learning framework that emphasizes harder samples by adaptively adjusting sample weights. It updates weights and network parameters in an alternating manner. 3. CL-Reg [25]: Decomposes the training of a complex PDE into a sequence of related PDEs with incrementally increasing difficulty. Unlike other compared methods, it is a task-based approach rather than a sample-based PINN training method. 4. SAPINN [26]: Assigns adaptive weights to each sample point and updates both weights and network parameters simultaneously, in contrast to SelectNet’s alternating scheme.
AAPINN [22]: Introduces anomaly-aware progressive learning by dynamically filtering out high-loss samples during training, allowing the model to focus on more reliable sample points.
We evaluate our method on three challenging linear PDEs, each presenting distinct numerical difficulties: (1) a heat conduction equation with steep gradients, (2) the Helmholtz equation exhibiting oscillatory behavior, and (3) a singularly perturbed convection-diffusion equation. Beyond these, we consider two nonlinear PDEs known for their complexity: (1) the Allen-Cahn equation and (2) the Sine-Gordon equation. To further test scalability and robustness, we also apply our method to a four-dimensional multiscale PDE that combines high dimensionality with complex multiscale features.
The configuration of sampling points for each problem is summarized in Table 1. For our method, we set the number of inner-loop iterations to S 1 = 10 and S 2 = 1 for Phase 1 and Phase 2, respectively. In Phase 2, the sample selection ratio is updated with a cycle period of P = 300. The network is trained using the Adam optimizer [14] in float32 precision with a initial learning rate of 10 -3 . All baseline methods are implemented with their original default hyperparameters unless otherwise specified. The maximum number of training epochs is fixed at 100,000 to ensure convergence for all tested PDEs, especially those with sharp gradients or multiscale behavior.
We evaluate all methods using the relative L 2 error:
where u θ (x) denotes the predicted solution, u(x) represents the ground truth, and N is the number of uniformly sampled test points. To ensure statistical reliability, each experiment is repeated 10 times, and the average performance is reported.
Consider the following heat conduction problem with steep gradients [34]:
where u(x, t) is the unknown solution, f (x, t) is a given source term, and Dirichlet boundary conditions are imposed at the spatial boundaries. Following [34], the exact solution is defined as u(x, t) = (1-x 2 )e 1 (2t-1) 2 +α with α = 0.11. This solution exhibits extremely steep gradients near the interior of the domain Ω, where the function values rise sharply from near zero to over 8000. Such behavior creates a highly stiff and localized profile, presenting a serious challenge for both traditional numerical solvers and PINN-based methods.
Figure 4 demonstrates that hard prioritization strategies, such as RAD, SelectNet, and SAPINN, tend to yield relatively poor accuracy on this problem. In contrast, easy prioritization approaches like CL-Reg and AAPINN exhibit significantly improved performance, benefiting from their progressive or anomaly-aware learning schemes. Table 2 quantitatively compares the relative L 2 errors achieved by different methods. hard prioritization methods generally produce errors on the order of 10 -1 to 10 -2 , indicating difficulty in resolving this steep gradients problem. In comparison, CL-Reg and AAPINN achieve substantially lower errors of 9.17 × 10 -4 and 2.59 × 10 -3 , respectively. Notably, the proposed AEH-PINN outperforms all baselines, achieving a relative L 2 error Method RAD [35] SelectNet [7] CL-Reg [25] SAPINN [26] AAPINN [22] Ours ReL2 9.94e-01 5.79e-01 9.17e-04 2.66e-02 2.59e-03 1.05e-5 of 1.05 × 10 -5 and successfully capturing the solution’s sharp internal transitions with a significant advantage.
Consider the following Helmholtz equation, which models wave propagation and acoustics:
-∆u -
where u denotes the wave field, k is the wave number controlling the oscillatory nature of the solution, and f is a known source term. The problem is defined on the unit square Ω = (0, 1) 2 with homogeneous Dirichlet boundary conditions imposed on ∂Ω.
The Helmholtz equation poses significant challenges for numerical methods, especially as the wave number k increases. This is primarily due to the so-called pollution effect, where standard discretization methods require increasingly fine meshes to resolve the oscillations accurately, resulting in high computational cost. In our setup, following [19], we use the exact solution u(x, y) = sin(kx) sin(ky) with k = 4π, which corresponds to a moderately high-frequency regime and serves as a stringent test for the accuracy and resolution capability of the proposed method. Compared to the heat conduction problem (14), the solution of the Helmholtz equation varies within a much narrower range, between 0 and 1, making it relatively less challenging. As shown in Figure 5, most methods, including both hard prioritization and easy prioritization approaches, yield comparable levels of accuracy. The only notable exception is CL-Reg, which, despite being the second-best performer in the heat conduction task, exhibits substantially inferior accuracy in this case. This observation suggests that current PINN methods may exhibit problem-dependent behavior, performing well in some cases but less effectively in others. Method RAD [35] SelectNet [7] CL-Reg [25] SAPINN [26] AAPINN [22] Ours ReL2 3.06e-03 4.97e-04 1.47e-02 1.66e-03 4.54e-04
Furthermore, Table 3 reveals that our proposed AEH-PINN method still achieves a clear advantage in accuracy. It attains a relative L 2 error of 6.01 × 10 -5 , which is significantly better than the second-best result from AAPINN (4.54 × 10 -4 ) and has an improvement of 7 times. This performance is also consistent with the previous experiment, where the errors maintain an order of 10 -5 .
Consider the following convection-diffusion problem [33]:
where u denotes the solution and f is the source term. Dirichlet boundary conditions are imposed. This problem is a classical example of a singularly perturbed equation, where the small diffusion parameter ϵ ≪ 1 leads to a sharp boundary layer near x = 0. As ϵ decreases, the solution becomes increasingly steep in this region, with gradients on the order of O(1/ϵ). Such behavior poses significant challenges:
• Standard discretization methods (e.g., uniform grids with finite differences or finite elements) may fail to resolve the steep boundary layer unless extremely fine meshes are used near x = 0, resulting in high computational cost.
• Moreover, common PINNs tend to struggle with such layer behavior [2,15], especially when the gradient scale is far beyond the global resolution captured by the neural network.
Thus, the problem is a demanding test case for assessing the robustness of PINN-based methods. We set ϵ = 10 -6 and take the exact solution as
) . The hard prioritization method outperforms the easy prioritization strategy in capturing the locally challenging region.
Figure 6 provides a visual comparison of the approximated solutions produced by various methods. hard prioritization approaches such as RAD and SelectNet struggle to resolve sharp-gradient regions, while the easy prioritization method AAPINN accurately captures the global trend but lacks local precision. The task-based method CL-Reg, on the other hand, fails to deliver an adequate approximation across both global and local features.
Table 4: Relative L 2 errors of various methods for the convection-dominated equation (16).
Quantitative results presented in Table 4 show that both SAPINN and our proposed method significantly outperform the other baselines, achieving relative errors on the order of 10 -6 -about three orders of magnitude lower than competing methods. Among the two, our method yields slightly better accuracy, consistently attaining the lowest errors.
To evaluate the performance of our proposed method on nonlinear PDEs, we consider the Allen-Cahn equation [19]:
where u is the scalar field of interest, and d > 0 is the diffusion coefficient, controlling the strength of spatial diffusion relative to the nonlinear reaction term. The initial condition is defined as:
and the Dirichlet boundary conditions are specified as:
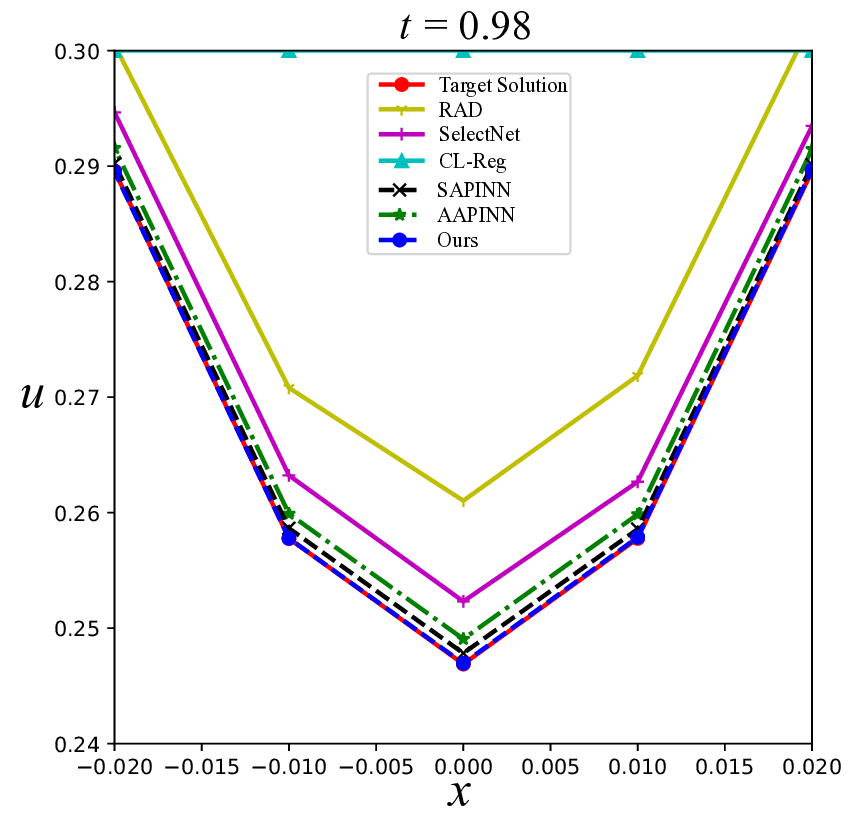
The Allen-Cahn equation is widely studied in the PINN literature due to its pronounced nonlinear behavior, particularly the emergence of sharp internal transition layers and high sensitivity to time discretization in classical numerical schemes [22,26]. In our experiments, we set the diffusion coefficient d = 0.001, which leads to narrow interfaces and poses significant challenges for accurate approximation. a zoomed-in comparison at t = 0.98, where our method attains the best fitting, whereas the baseline methods exhibit notable deviation.
We summarize the relative L 2 errors of all methods in Table 5. The results show that our hybrid method achieves the lowest prediction error (8.12 × 10 -5 ) among all compared approaches. While RAD, AAPINN, and CL-Reg show some ability to approximate the solution, they struggle to capture the sharp interface as effectively as our model. The hardprioritization strategy SAPINN(2.11×10 -4 ) demonstrates superior capability in resolving the challenging regions, outperforming the easy-prioritization strategy AAPINN(2.76 × 10 -4 ) in terms of accuracy. Method RAD [35] SelectNet [7] CL-Reg [25] SAPINN [26] AAPINN [22] Ours ReL2 1.32e-03 6.58e-04 3.87e-02 2.11e-04 2.76e-04 8.12e-05
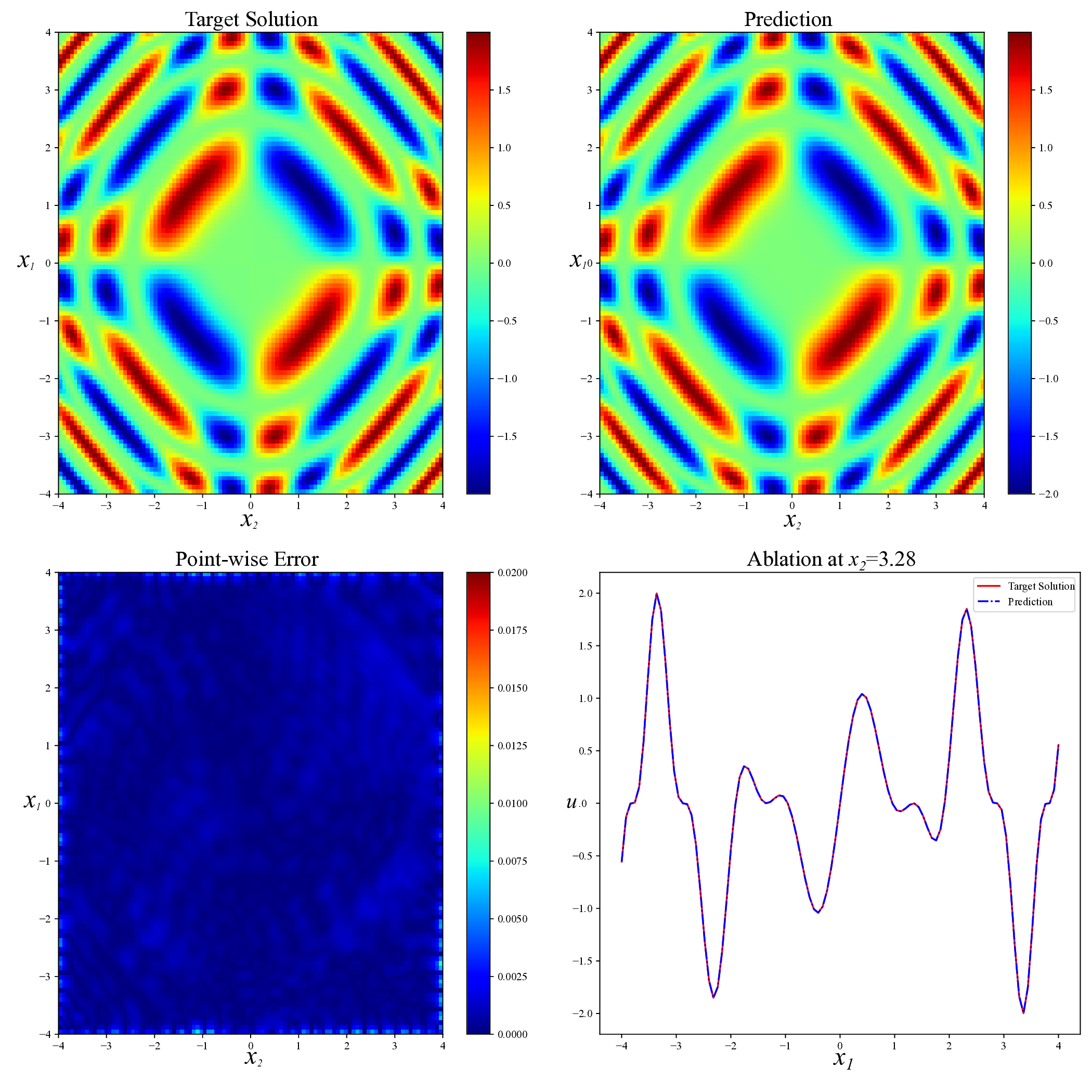
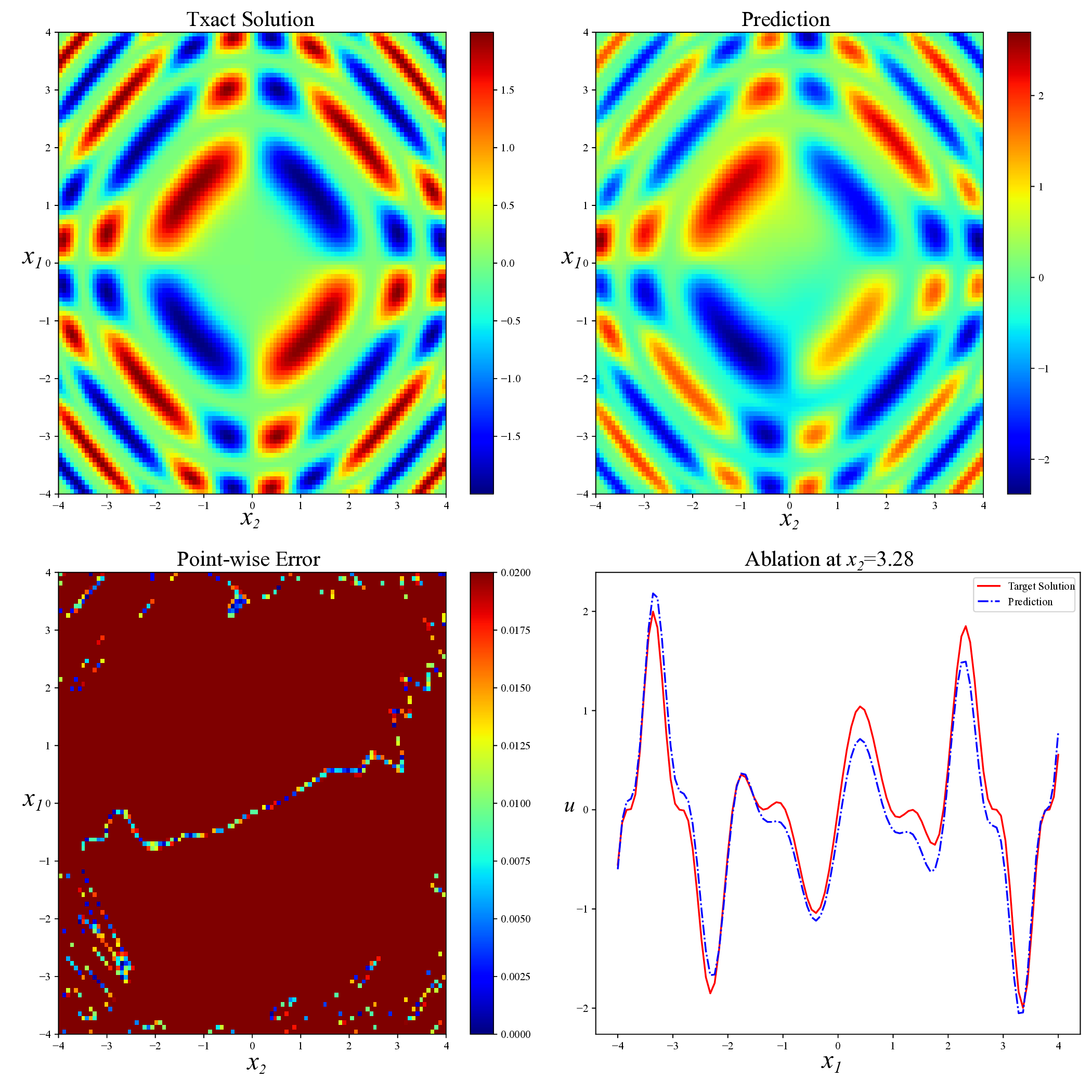
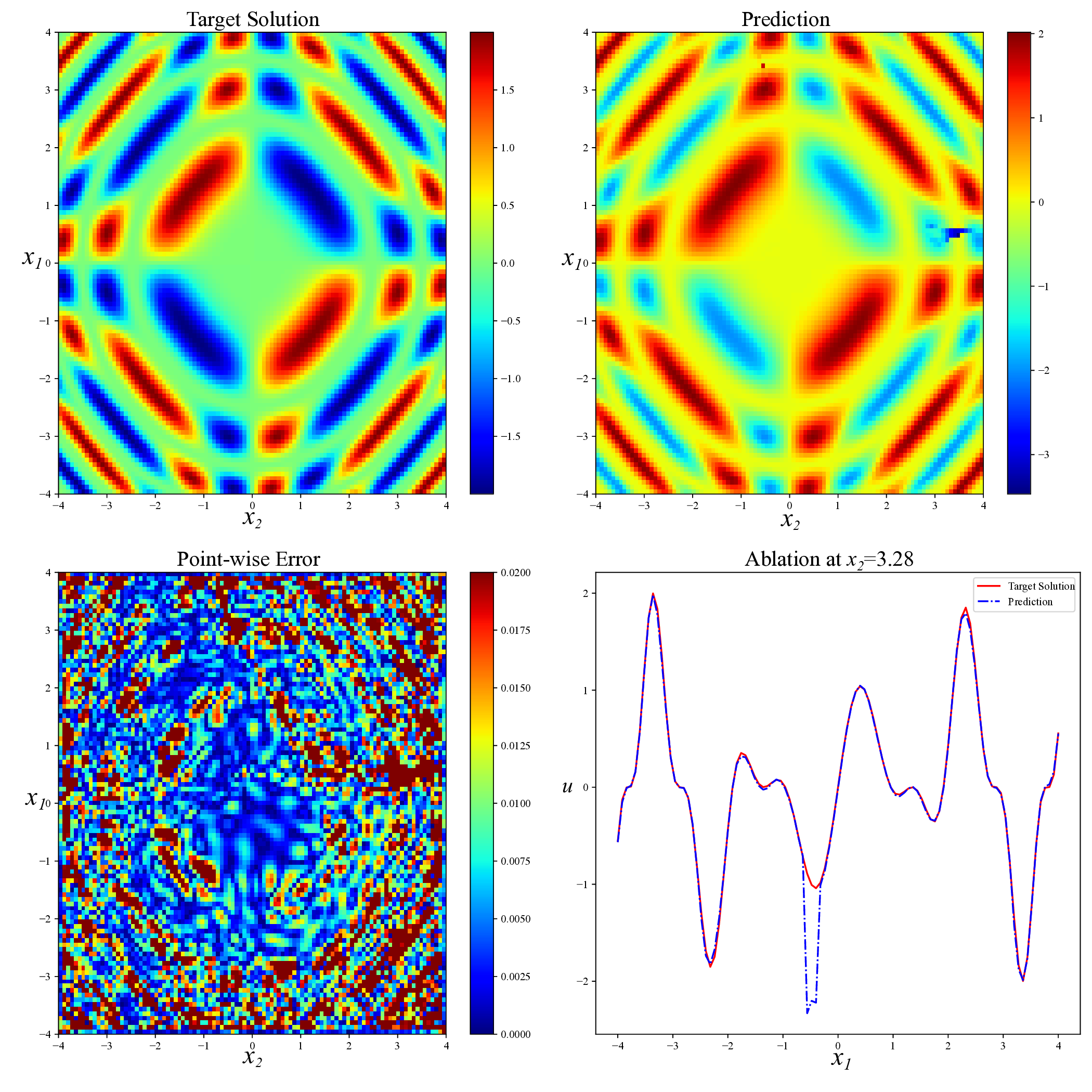
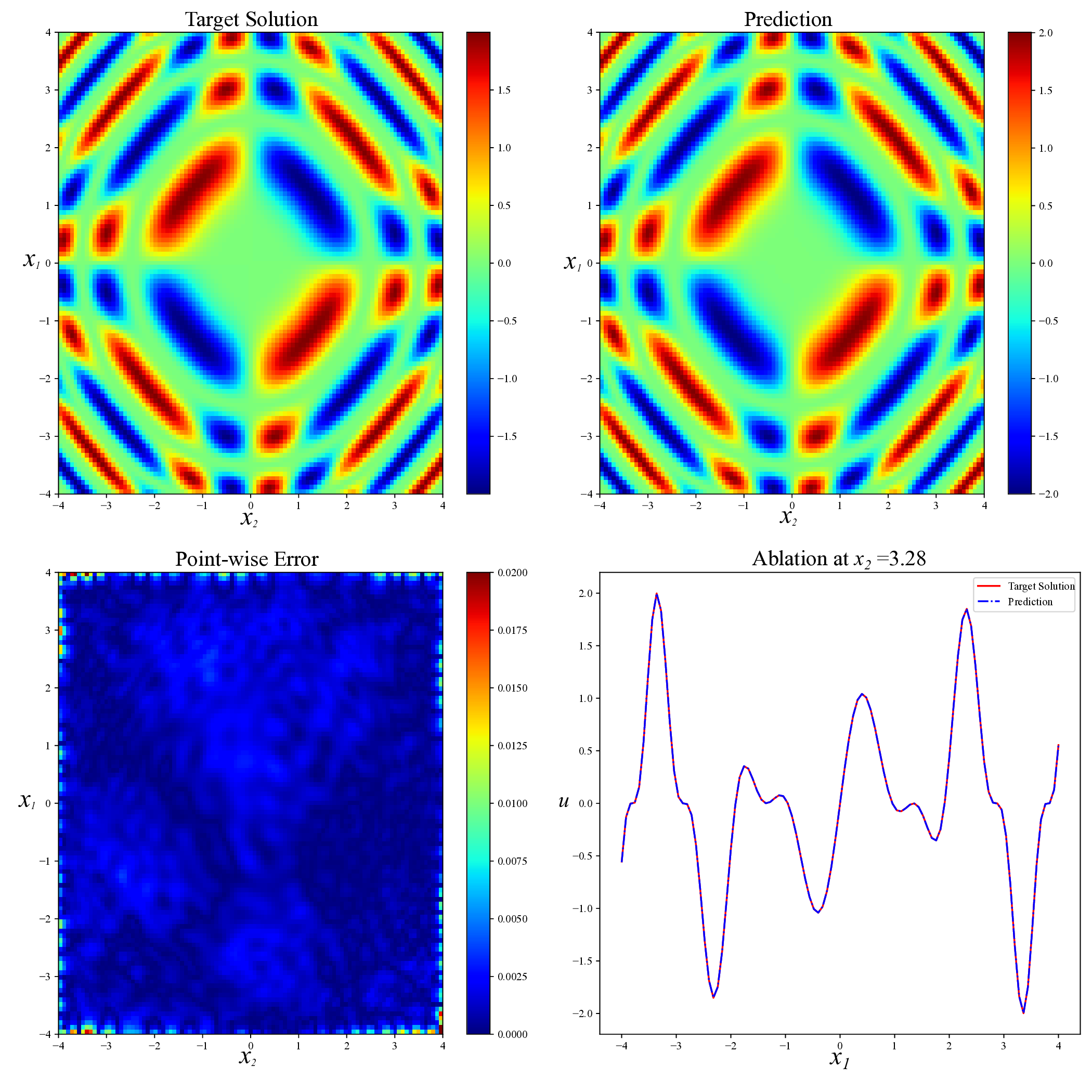
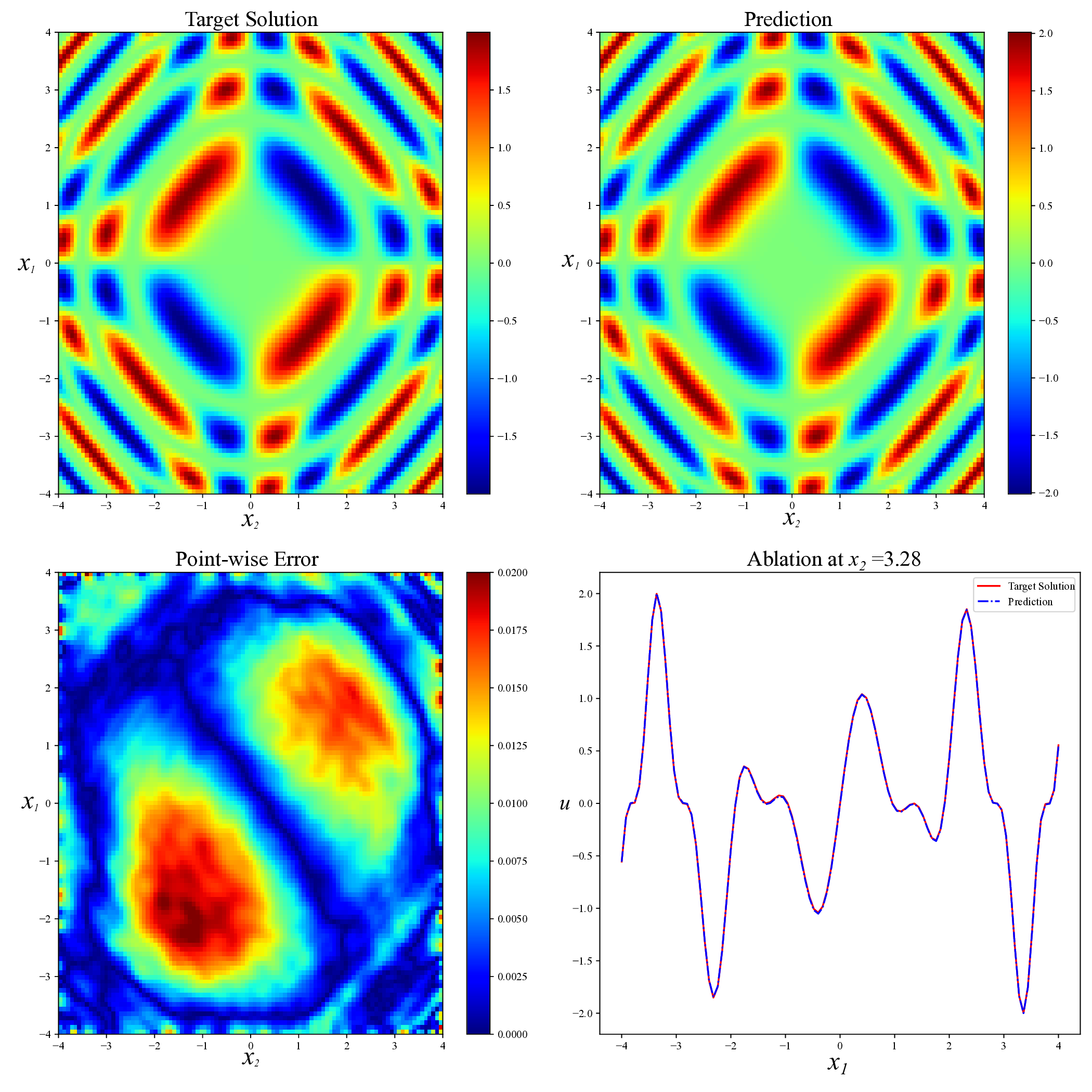
Another type of nonlinear PDE we consider is the two-dimensional Sine-Gordon equation [10]:
with the boundary condition
This Sine-Gordon equation poses considerable challenges throughout most regions of the domain. The key difficulty stems from the strong nonlinearity of the sin(u) term and the tight coupling among variables, which often leads to complex, spatially varying solution structures. Traditional numerical solvers may suffer from instability or require dense meshes to maintain accuracy, while standard PINN training strategies frequently fail to converge or do so at a prohibitively slow rate.
To evaluate model robustness in such settings, we adopt the exact solution
which is highly nonlinear, non-separable, and strongly coupled across both variables.
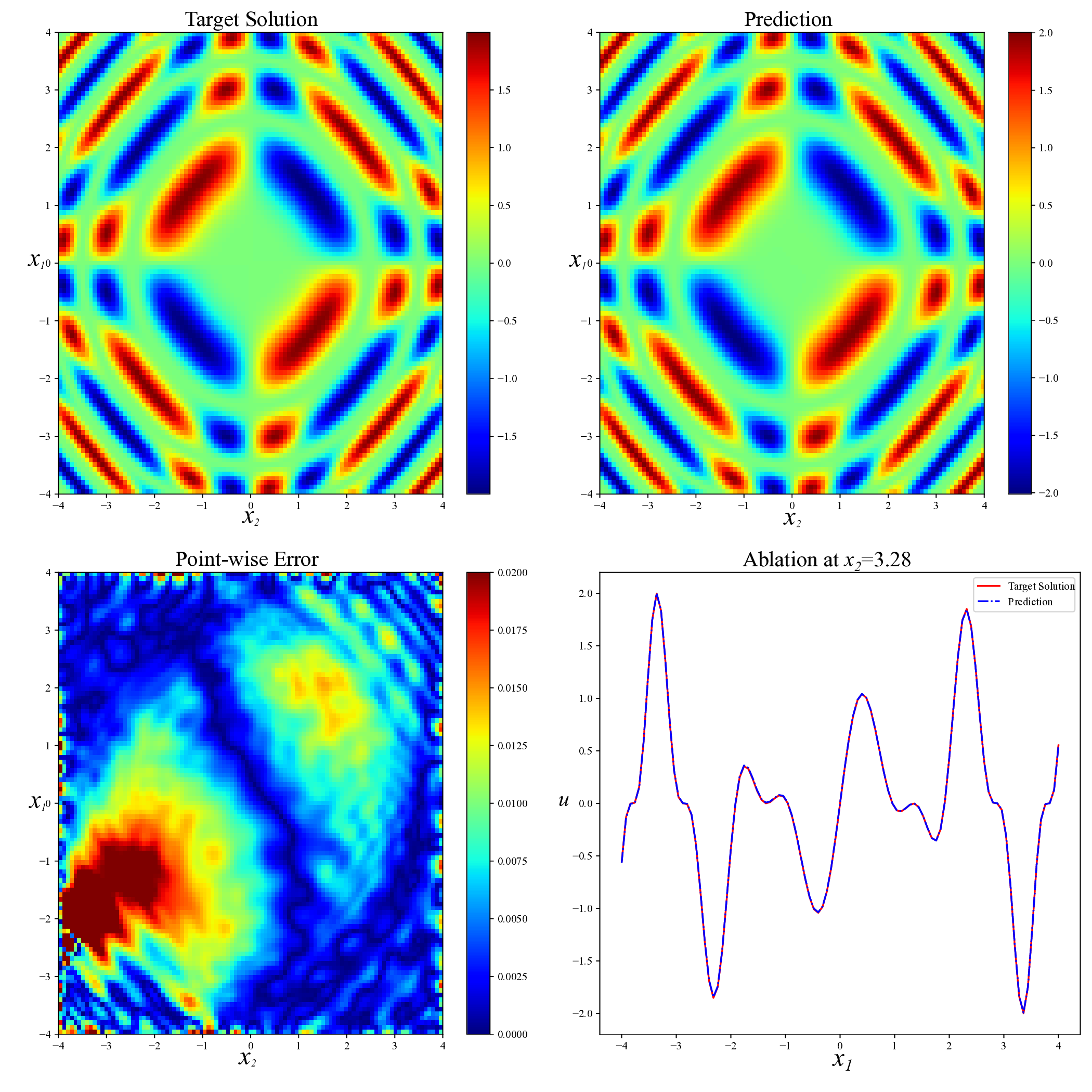
Unlike simpler expressions such as u(x 1 , 2 ) = f (x 1 + x 2 ), which can be reduced to a one-dimensional problem via coordinate transformation, the solution does not admit such simplification. Instead, it involves complex pairwise interactions between x 1 and x 2 that give rise to rich local structures and intricate spatial patterns. These features make the problem difficult and highlight the need for training methods that are reliable and flexible. Figure 9 presents a visual comparison of predicted solutions for the Sine-Gordon equation across various methods. The proposed AEH method (bottom right) yields remarkably accurate predictions, with visibly lower point-wise error and excellent agreement with the exact solution. Compared to existing baselines, including RAD, SelectNet, CL-Reg, SAPINN, and AAPINN, our method exhibits superior stability and resolution of fine-scale structures. The quantitative accuracy results are summarized in Table 6. Compared with other methods, our strategy achieves the lower relative L 2 error(8.42 × 10 -4 ). This result validate the capacity of our approach to serve as a reliable and generalizable solver in high-nonlinear, oscillatory PDE scenarios. Method RAD [35] SelectNet [7] CL-Reg [25] SAPINN [26] AAPINN [22] Ours
Finally, we consider a periodic high-dimensional partial differential equation with multiscale features. Specifically, we study the following equation:
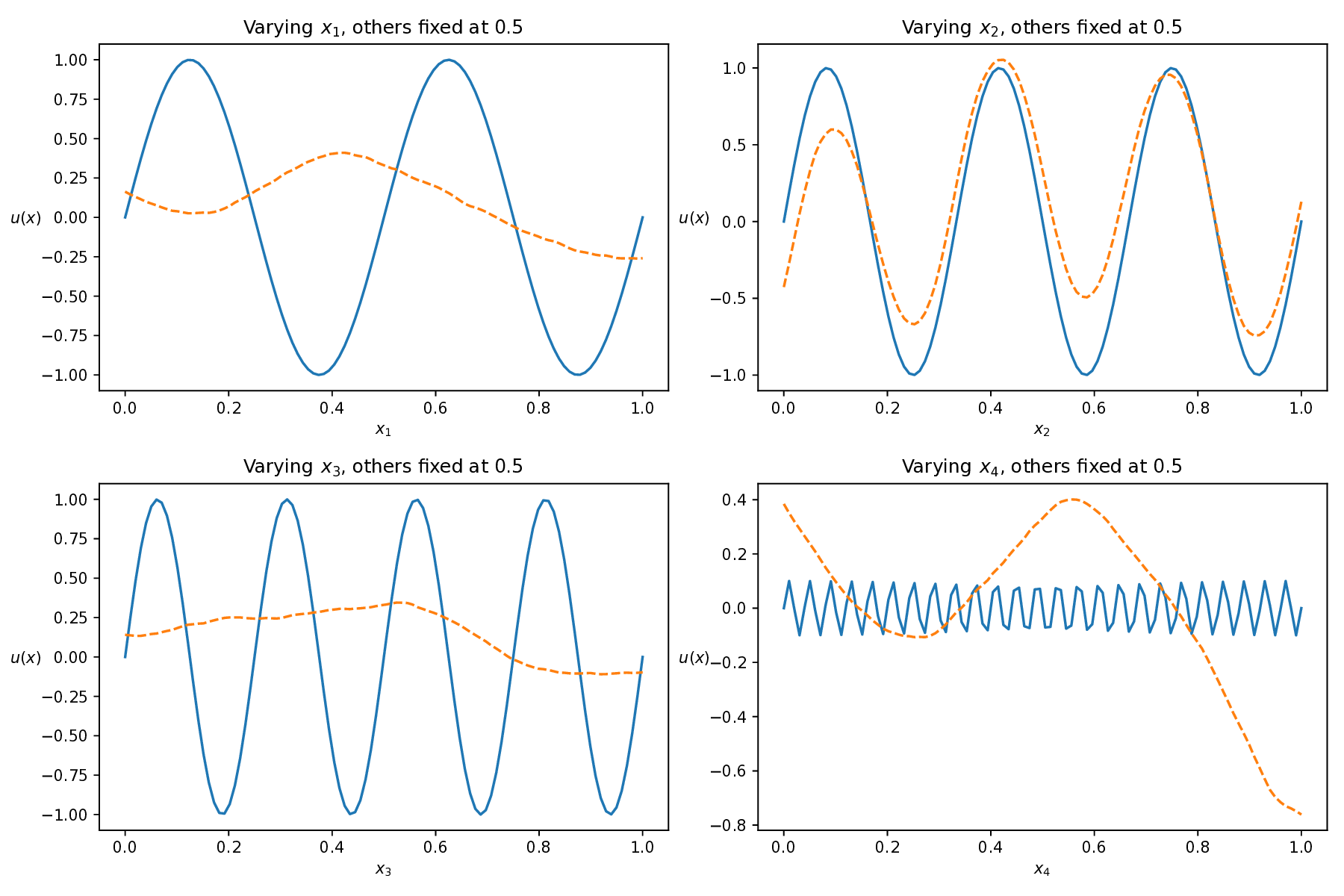
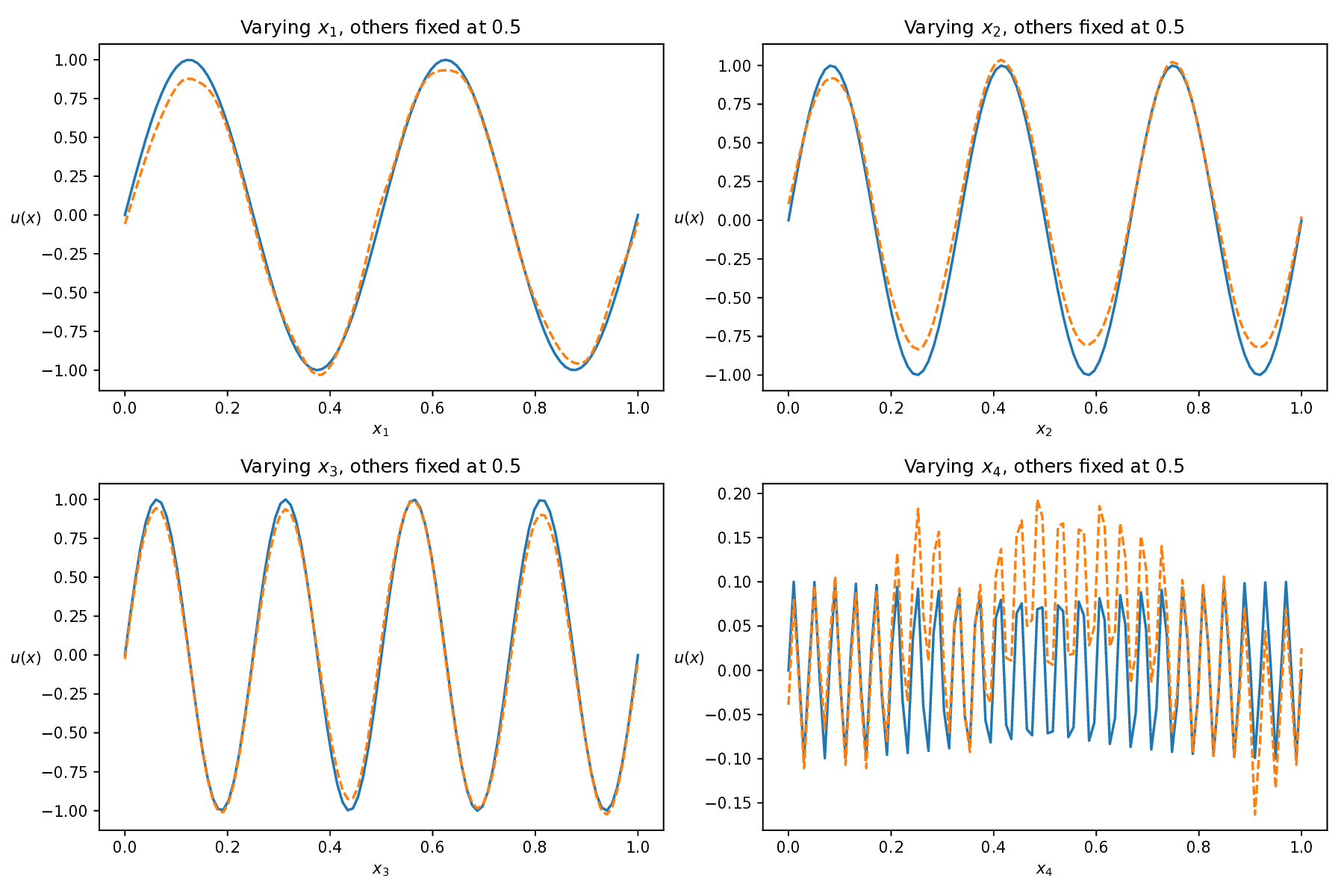
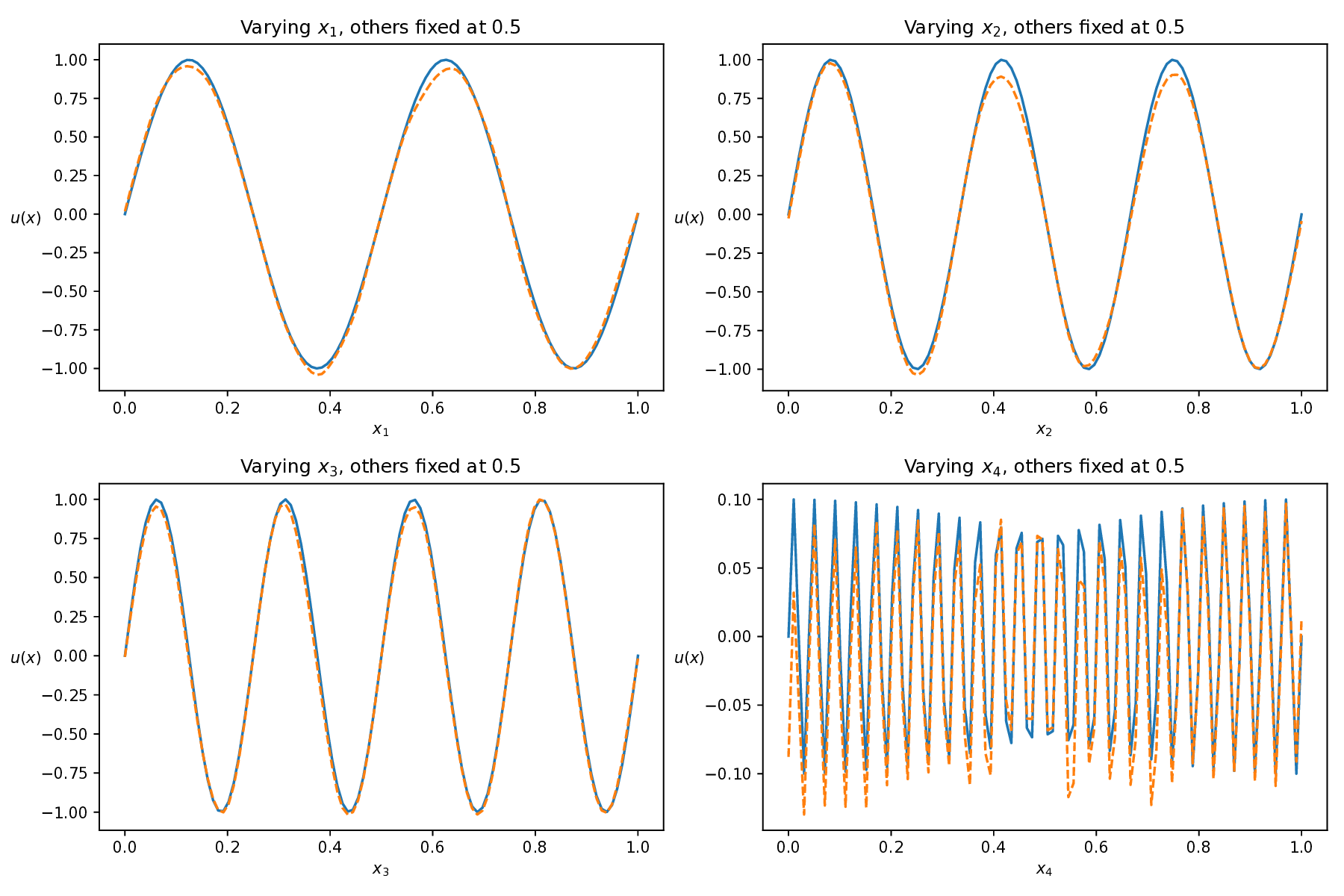
where the exact solution is given by u(x) = sin(4πx 1 ) + sin(6πx 2 ) + sin(8πx 3 ) + 0.1 sin(50πx 4 ).
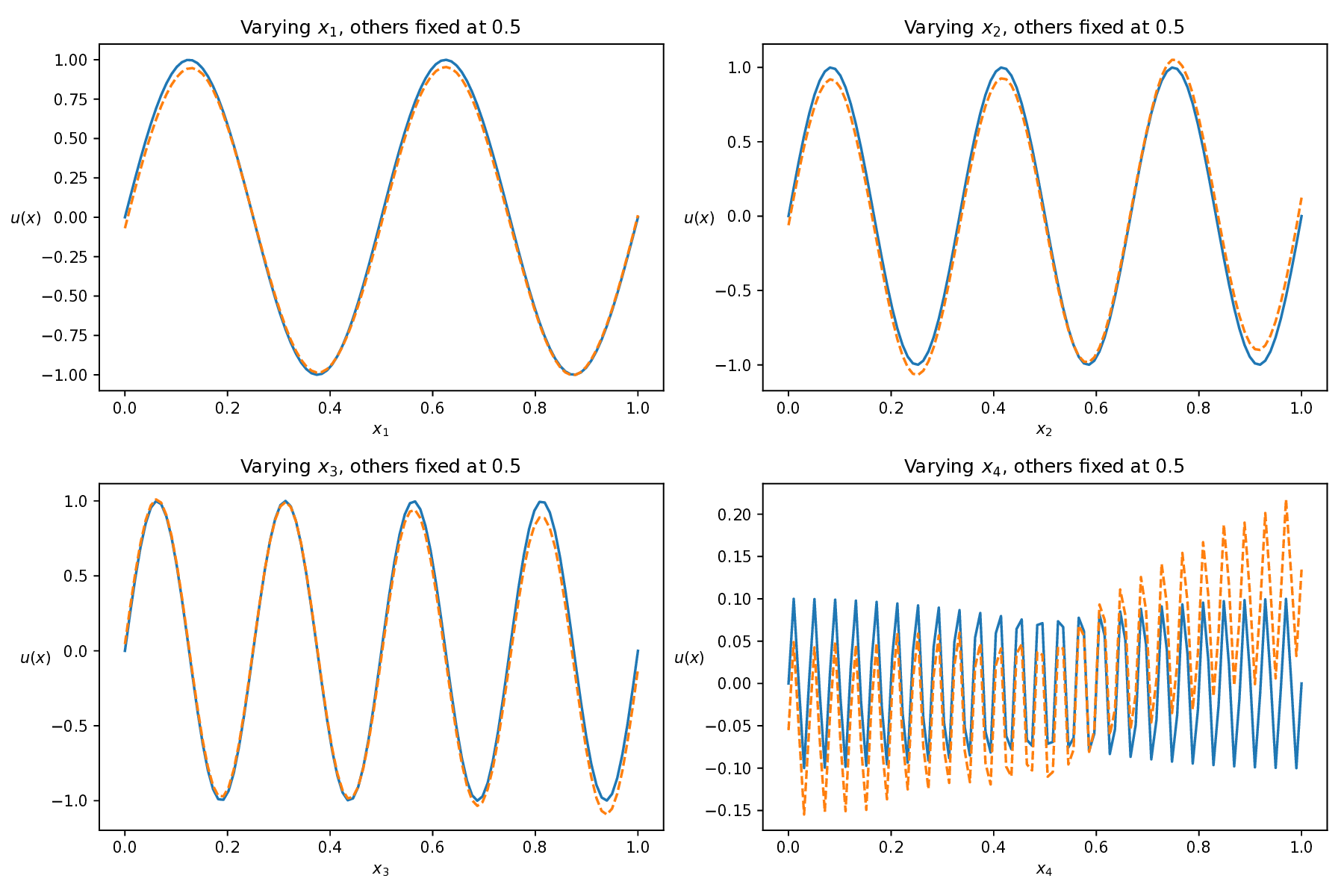
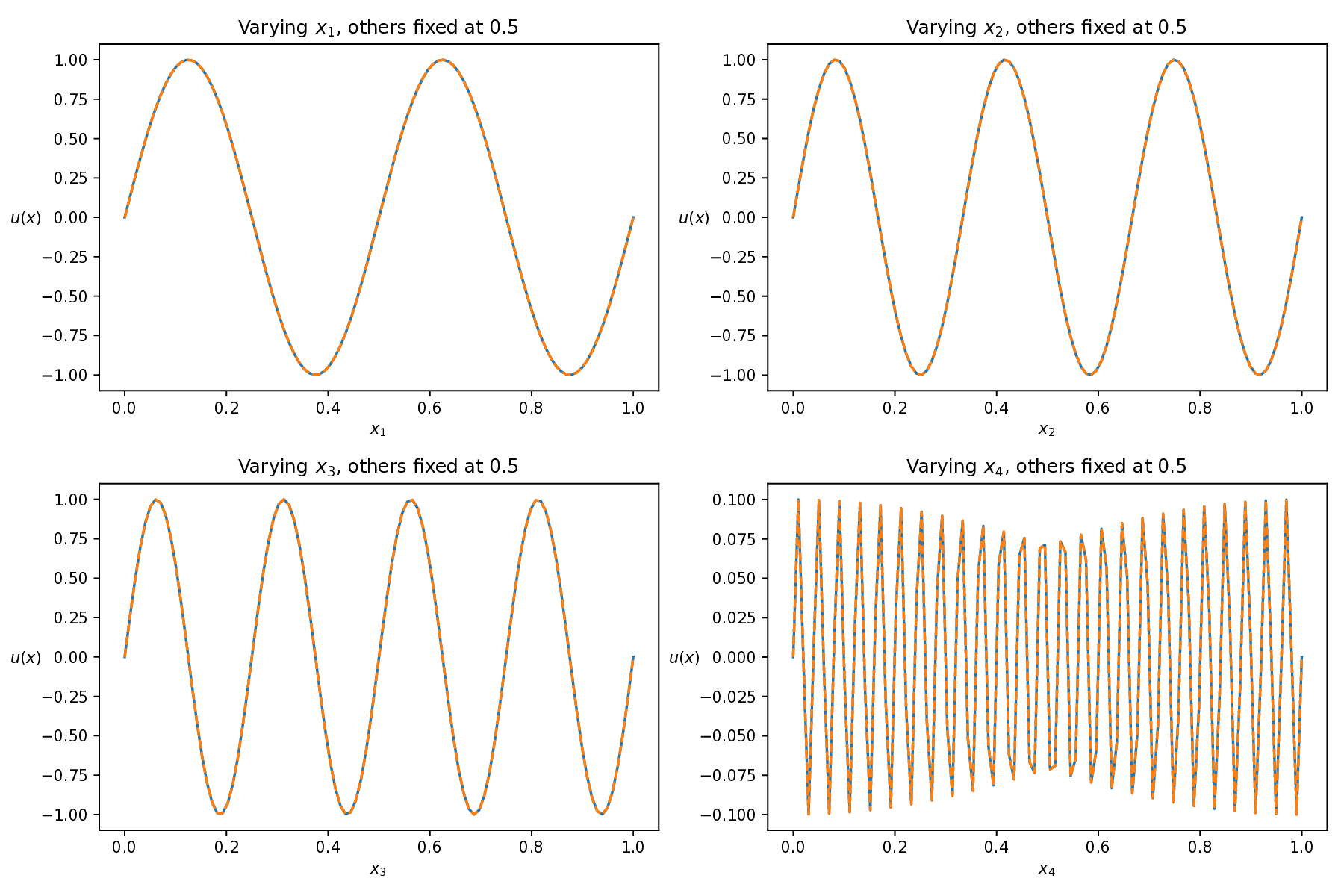
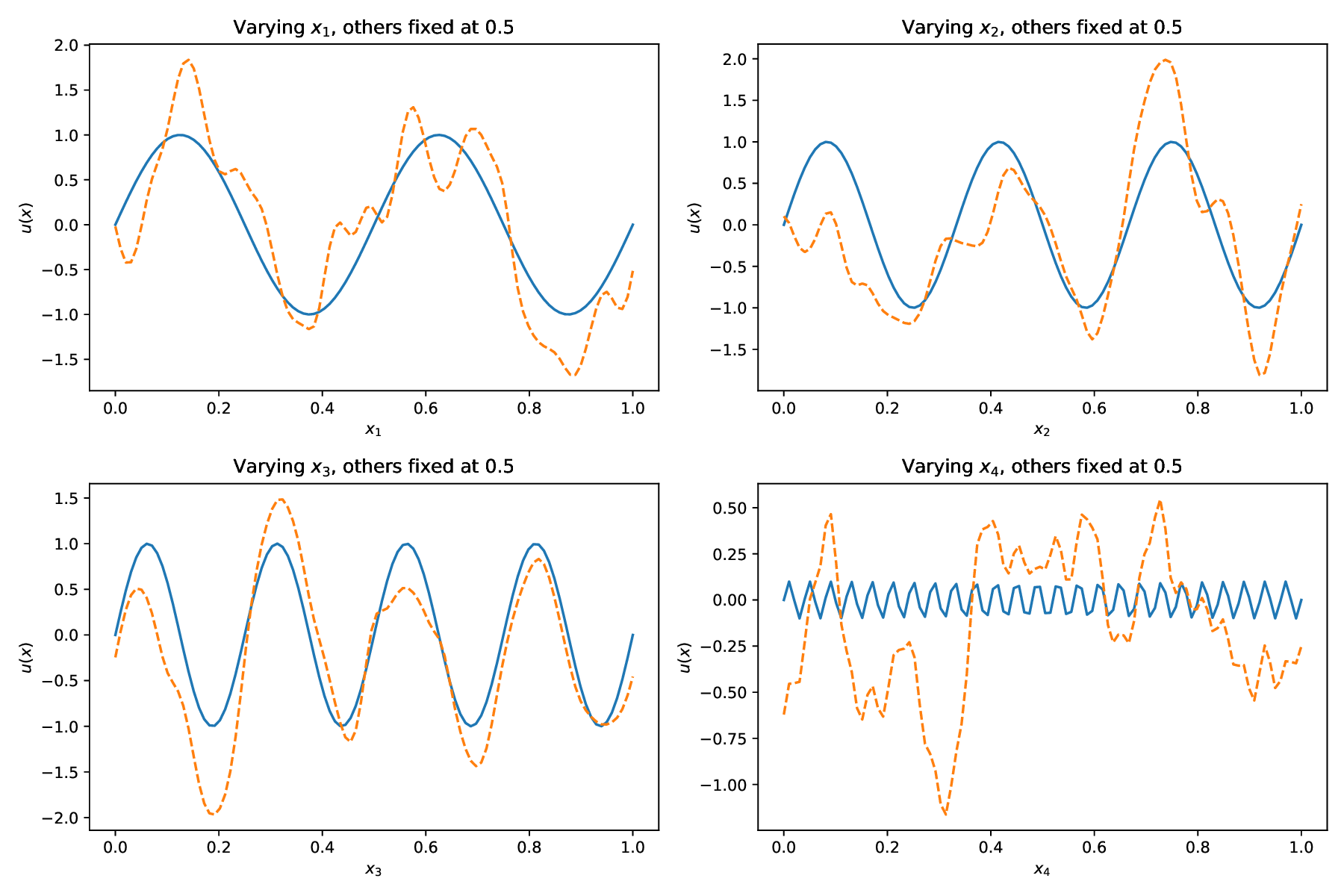
This equation poses a significant challenge due to the interplay of high dimensionality and multiscale features, where complex interactions across dimensions and the presence of high-frequency components-especially in x 4 -make the solution landscape highly intricate. This combination greatly increases the difficulty for numerical and learning-based solvers Figure 10 shows the predicted solutions of different methods along each individual dimension, with the remaining three dimensions fixed at 0.5. This visualization evaluates how accurately each method captures the solution’s behavior along each coordinate axis. Among these baseline methods, our AEH framework achieves the best performance, especially along the x 4 axis, where the high-frequency multiscale feature is most prominent, while other methods struggle to capture these challenging details.
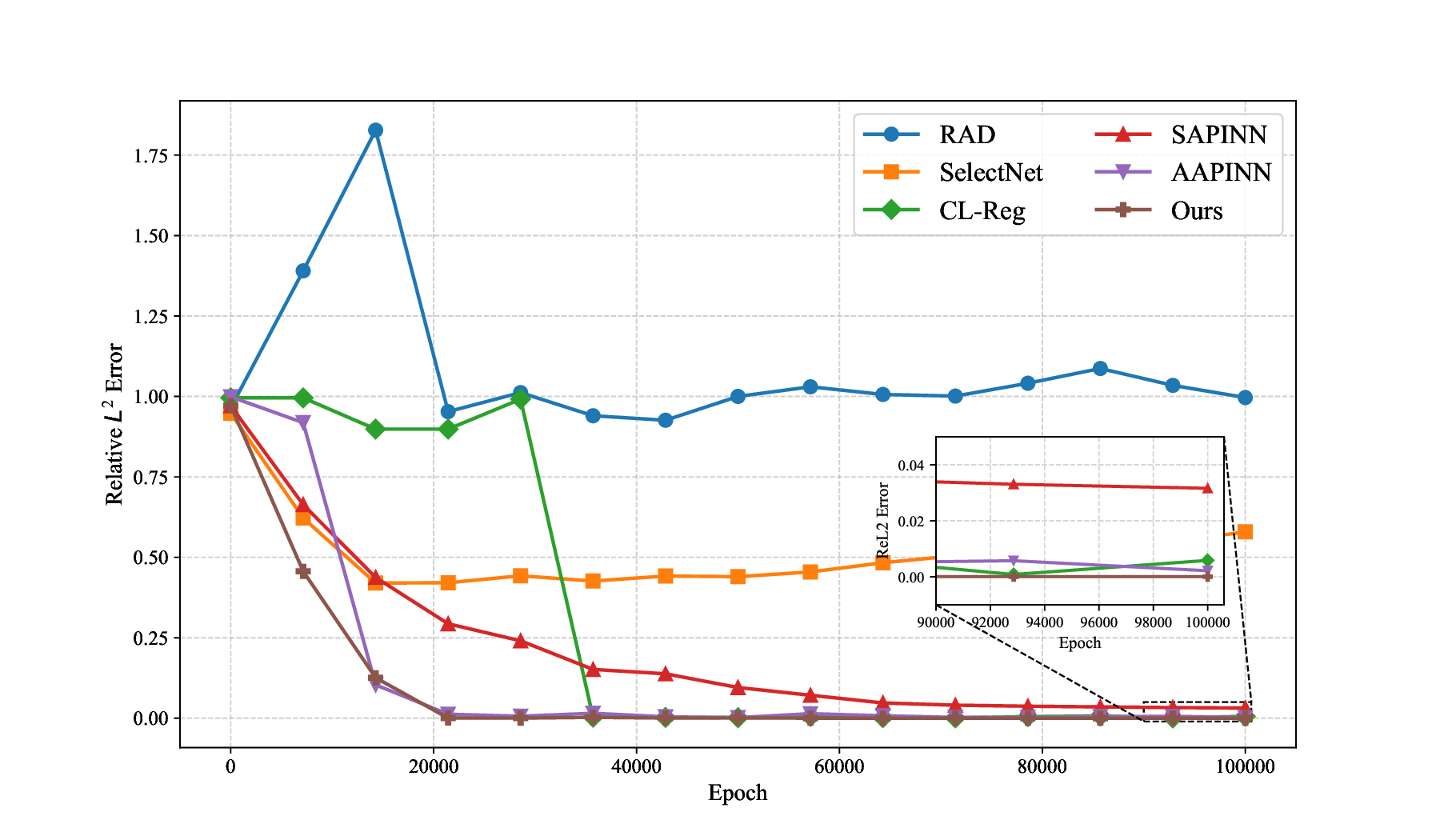
Table 7 presents the relative L 2 errors for all methods. While other baseline methods achieve relative errors on the order of 10 -1 to 10 -2 , our method reaches an error as low as 5.59 × 10 -5 , demonstrating an improvement of three to four orders of magnitude in accuracy. This significant reduction clearly demonstrates the superior accuracy and robustness of our framework in handling high-dimensional, multiscale PDEs. Method RAD [35] SelectNet [7] CL-Reg [25] SAPINN [26] AAPINN [22] Ours ReL2 8.40e-01 2.16e-02 2.72e-01 3.93e-02 5.54e-02 5.59e-05
Previous experiments show that most baseline methods lack consistent accuracy across different PDEs. In contrast, our method employs a hybrid alternating strategy between a hard prioritization phase (Phase 1) and an easy prioritization phase (Phase 2), leading to more reliable performance. In this subsection, we examine the impact of the alternating mechanism on model performance. (20). The blue solid line represents the exact solution, while the orange dashed line denotes the predicted result. To illustrate the solution behavior in each dimension, one variable is varied while the others are fixed at 0.5. Top left: solution profile along x 1 ; top right: along x 2 ; bottom left: along x 3 ; bottom right: along x 4 . The proposed AEH method accurately captures the complex behavior along the most challenging dimension, x 4 .
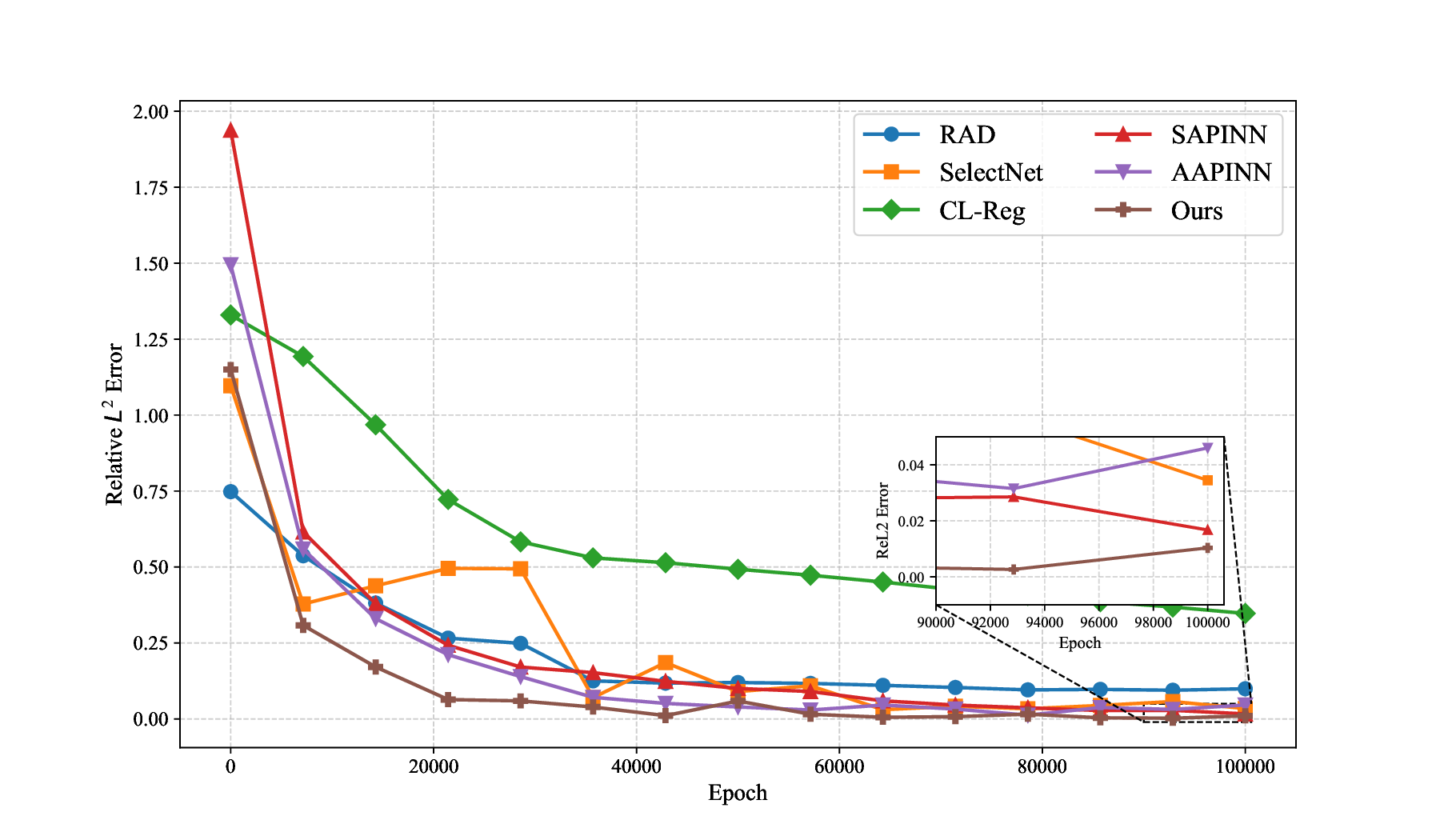
We first conduct an ablation study on three variants: (1) the full alternating model, (2) hard prioritization-only (Phase 1), and (3) easy prioritization-only (Phase 2). As evidenced by Table 8, neither single-phase variant achieves consistent dominance, even when one phase outperforms the other on a specific PDE (e.g., Phase 2 excels on Helmholtz, while Phase 1 is competitive for 1D convection-dominated cases). Crucially, the full model not only integrates both phases but also surpasses them individually, reducing errors by 1-3 orders of magnitude across all benchmarks. This indicates that the alternating mechanism is not a simple compromise, but rather a synergistic strategy that achieves superior performance beyond either phase alone. Second, in our alternating algorithm, each phase is controlled by inner-loop iteration counts (S 1 , S 2 ), with a default setting of S 1 = 10 (Phase 1) and S 2 = 1 (Phase 2). To examine the influence of iteration counts, we evaluate five configurations: (1, 1), (1, 10), (5, 1), (10, 1), and (50, 5). For fairness, we test on two representative PDEs: the heat conduction equation ( 14) and the Allen-Cahn equation (17), where the former favors easy prioritization learning, while the latter benefits more from hard prioritization learning. The results in Table 9 yield two observations. First, the easy prioritization iterations (S 2 ) should not dominate the hard prioritization iterations (S 1 ); doing so, as in the case of (1, 10), leads to significant error increases. Second, configurations with S 1 > S 2 , such as (5, 1), (10,1), and (50, 5), produce similar and stable results. These findings suggest that the hard prioritization phase may play a fundamental role in structuring the solution space, while the easy prioritization phase acts more like a local refinement step. As such, emphasizing hard prioritization iterations (S 1 > S 2 ) can ensure stable convergence and prevent overfitting to simpler patterns. To further analyze training dynamics, we track the evolution of relative L 2 errors during training, as shown in Figure 11. Two representative PDEs are considered: (a) the heat conduction equation with steep gradients (14), and (b) the Sine-Gordon equation (18).
For the heat problem, AAPINN (easy prioritization) achieves a rapid initial drop in error but quickly plateaus, while SAPINN (hard prioritization) improves more gradually yet steadily. In the Sine-Gordon case, AAPINN again converges quickly but stagnates, whereas SelectNet and CL-Reg show significant fluctuations. In contrast, our method achieves faster and more consistent convergence, significantly outperforming all baselines. These observations demonstrate that the alternating strategy not only accelerates early convergence similar to easy prioritization training but also sustains accuracy improvements throughout the entire training process.
Our method incorporates an alternating training mechanism with two phases, which naturally increases training time. As shown in Table 10, on the Helmholtz equation ( 5), Time per epoch/s Params/M Flops/KFlops RAD [35] 0.0114 0.0078 7.6 SelectNet [7] 0.0324 0.0078 7.6 CL-Reg [25] 0.0139 0.0078 7.75 SAPINN [26] 0.4399 0.0078 7.6 AAPINN [22] 0.4718 0.0078 7.6 Ours 0.8799 0.0078 7.6
our approach needs about twice training time compared to SAPINN and AAPINN methods. However, the number of parameters and per-pass computational cost (Flops) remain nearly identical across all models, around 7.6 KFlops, which indicates similar architectural complexity and inference-time efficiency.
Many existing training strategies for PINNs draw inspiration from adaptive algorithms in traditional finite element methods, which often emphasize refining or reweighting samples in regions with large residuals-an approach referred to as hard prioritization. However, deep learning differs fundamentally from classical numerical methods. As a learning-based paradigm, both hard prioritization and easy prioritization strategies can be effective, depending on the problem. In the broader machine learning literature, particularly in computer vision and natural language processing, it is widely recognized that easy prioritization training can outperform hard prioritization training when dealing with highly complex tasks, and vice versa [5,13,31,37]. However, unlike vision or language tasks where difficulty can often be intuitively assessed (e.g., image complexity or sentence length), determining the hardness of PDE solutions is non-trivial in scientific computing, it may depend on hidden factors that are not directly observable from the PDE formulation.
Recent works have introduced easy prioritization strategies to PINNs. Curriculumbased approaches, for example, decompose complex PDEs into a sequence of progressively harder sub-problems [15,25], enabling more stable training. Some studies have proposed down-weighting hard samples to mitigate training instability in PDEs with sharp layers or discontinuities [22,33]. Nevertheless, despite these advances, as noted in [25], there is no one rule for PINN. Our analysis confirms this: both hard prioritization and easy prioritization methods exhibit inherent trade-offs and inconsistent performance across different PDEs.
To overcome this, we propose a hybrid alternating training framework that dynamically combines hard and easy prioritization without requiring prior knowledge of sample difficulty. Our approach consistently achieves state-of-the-art accuracy across various challenging PDE benchmarks, reducing relative L 2 errors to the order of 10 -5 to 10 -6improving by several orders of magnitude over existing methods under the same conditions. Importantly, this improvement comes from an effective sample scheduling mechanism without altering the underlying network architecture, making our method widely applicable and easy to integrate.
The current alternating scheme represents one instantiation of hybrid training; exploring other variants may yield further benefits. Additionally, since performance depends on inner-loop hyperparameters, developing adaptive tuning strategies presents a promising avenue for future research.