낮은 누수와 강한 인과력: LLM 인과 추론 파라미터의 새로운 통찰
Reading time: 3 minute
...
📝 Original Info
- Title: 낮은 누수와 강한 인과력: LLM 인과 추론 파라미터의 새로운 통찰
- ArXiv ID: 2512.11909
- Date:
- Authors: Unknown
📝 Abstract
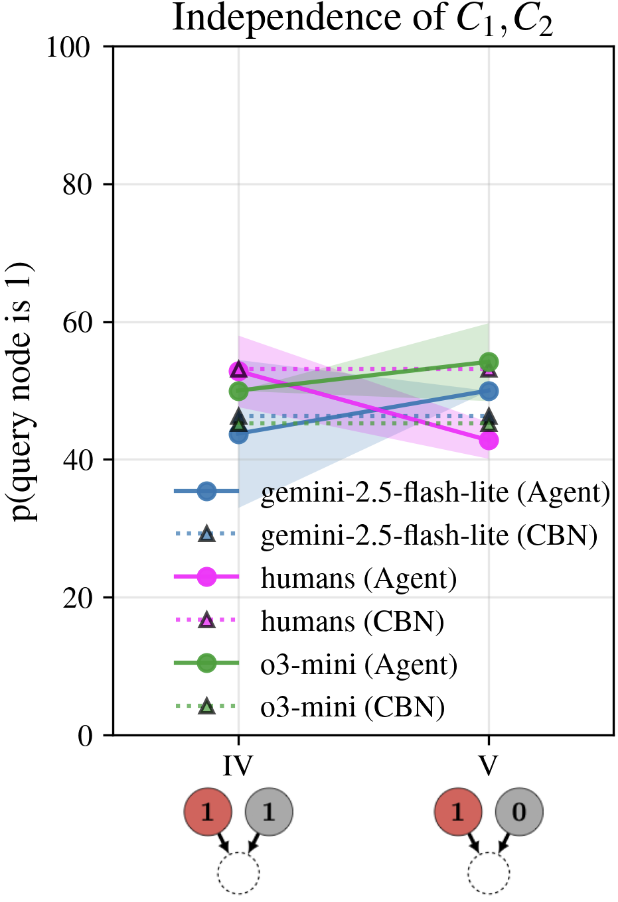
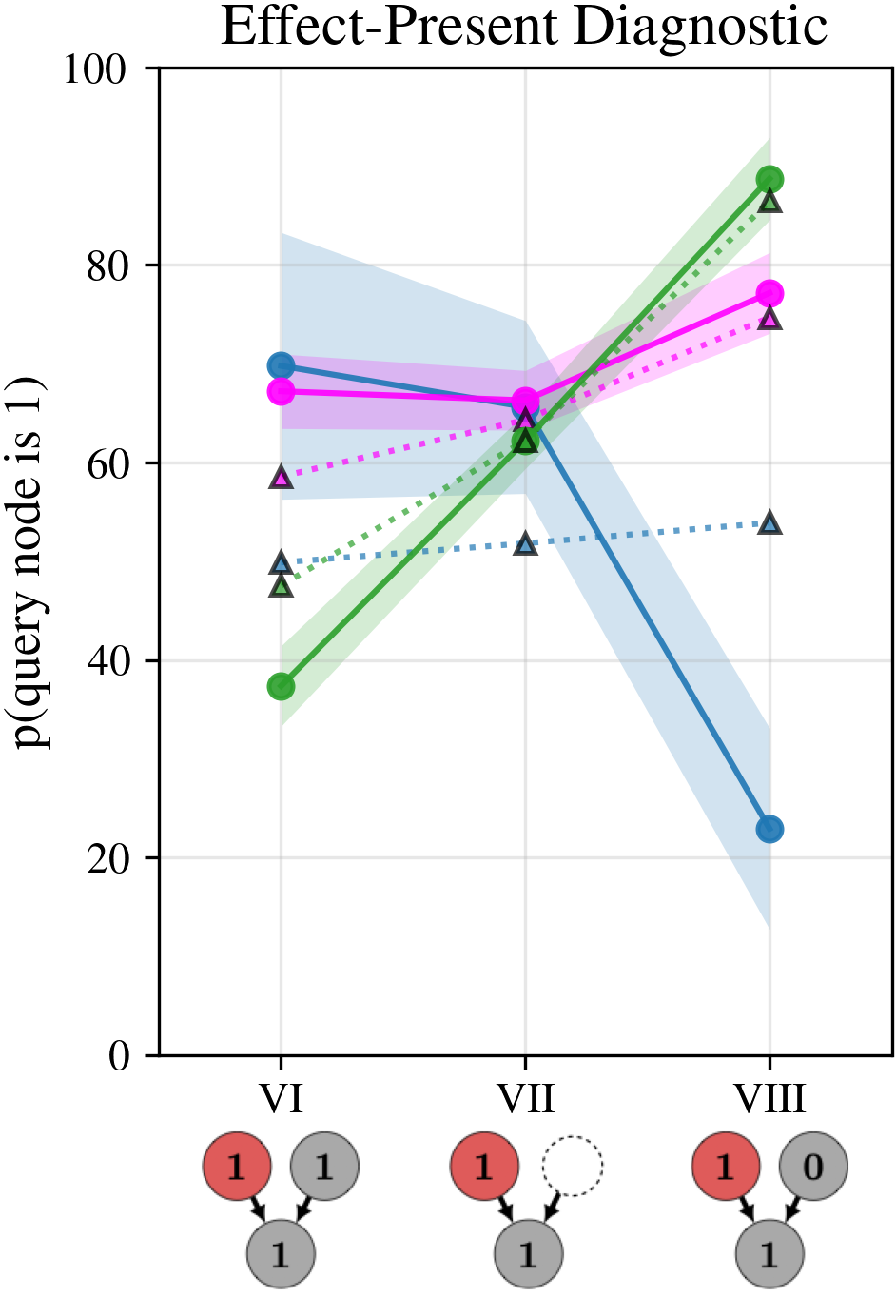
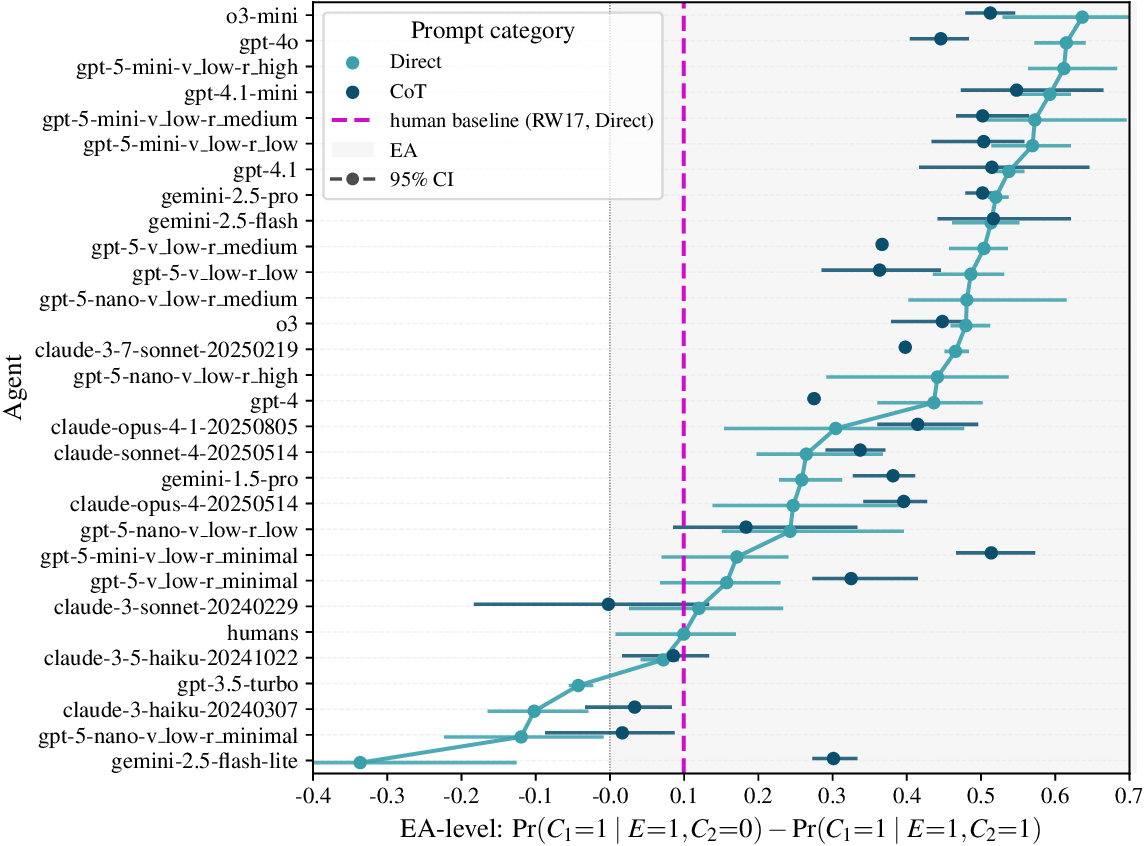
no-MV agents have low leakage b (0-0.1), strong causal strength m 1 , m 2 (0.75-0.99), and midrange priors, while agents with MV or weak EA show higher b (0.15-0.62) and weaker m i (0.25-0.82). Outlook. Next steps include extending this framework to semantically meaningless tasks and other causal structures beyond colliders to probe reasoning robustness. It should be noted that "normative" parameter regimes (low leak, strong causes) are not universally optimal and ultimately depend on the user-setting: tasks that legitimately require uncertainty about unobserved causes may warrant nonzero leak. Our prompts do not control this dimension -we neither instruct models to ignore nor to include unmentioned causes. A targeted analysis of the explanations received through CoT could provide first insights into whether and how LLMs represent and regulate them.📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.