This paper addresses low-light video super-resolution (LVSR), aiming to restore high-resolution videos from lowlight, low-resolution (LR) inputs. Existing LVSR methods often struggle to recover fine details due to limited contrast and insufficient high-frequency information. To overcome these challenges, we present RetinexEVSR, the first event-driven LVSR framework that leverages high-contrast event signals and Retinex-inspired priors to enhance video quality under low-light scenarios. Unlike previous approaches that directly fuse degraded signals, RetinexEVSR introduces a novel bidirectional cross-modal fusion strategy to extract and integrate meaningful cues from noisy event data and degraded RGB frames. Specifically, an illumination-guided event enhancement module is designed to progressively refine event features using illumination maps derived from the Retinex model, thereby suppressing low-light artifacts while preserving high-contrast details. Furthermore, we propose an eventguided reflectance enhancement module that utilizes the enhanced event features to dynamically recover reflectance details via a multi-scale fusion mechanism. Experimental results show that our RetinexEVSR achieves state-of-the-art performance on three datasets. Notably, on the SDSD benchmark, our method can get up to 2.95 dB gain while reducing runtime by 65% compared to prior event-based methods.
Video super-resolution (VSR) aims to restore highresolution (HR) videos from low-resolution (LR) inputs. While existing methods (Zhou et al. 2024) get good results on general videos, they often fail under low-light conditions. However, such conditions are common in real-world applications, such as video surveillance, where zooming in on distant license plates or human faces at night is often required. Other important scenarios include remote sensing (Xiao et al. 2025) and night videography (Yue, Gao, and Su 2024;Li et al. 2025a). Therefore, it is essential to develop VSR algorithms specifically designed for low-light videos.
To achieve VSR from low-light videos, i.e., low-light VSR (LVSR), a straightforward approach is to first apply Figure 1: An example (a) from an extremely low-light (-6.7 EV) LR sample, enhanced by (b) SOTA LVE (Li et al. 2023) + VSR (Xu et al. 2024) methods; (c) SOTA one-stage LVSR method (Lu et al. 2023); and (e) our event-based approach. It can be observed that only our method produces well-lit, high-quality results with clearly recognizable text. low-light video enhancement (LVE) (Li et al. 2023), followed by VSR methods, which we refer to as the cascade strategy. However, this approach has a major drawback in that the pixel errors introduced during the LVE stage are propagated and amplified in the VSR step, thus degrading the overall performance. An alternative strategy is to perform VSR first and then apply LVE. However, the quality deteriorates because the super-resolved frames suffer from weakened textures, amplified noise, and low contrast. To address these issues, Xu et al. (2023b) proposed the first onestage LVSR model that directly learns a mapping from lowlight LR inputs to well-lit HR outputs. However, as shown in Fig. 1, these methods still suffer from severe artifacts, structural distortions, and inaccurate illumination.
LVSR is a very challenging problem. It is difficult to rely solely on low-light LR frames to restore high-quality HR videos due to the inherent lack of sufficient contrast to distinguish fine textures, as well as the lack of high-frequency details in LR frames. In addition, sudden lighting changes at night, such as flashes from streetlights or car headlights, further exacerbate the problem. Recently, event signals captured by event cameras have been used for low-light enhancement (Liang et al. 2023), super-resolution (Kai, Zhang, and Sun 2023), and high dynamic range imaging (Han et al. 2023). Compared with standard cameras, event cameras offer a very high dynamic range (120 dB), high temporal resolution (about 1 µs), and rich “moving edge” information (Gallego et al. 2020). These characteristics enable event signals to provide complementary cues, such as sharp edges and motion details, even at night, for LVSR. Motivated by these advantages, we propose including event signals as auxiliary information to improve LVSR performance.
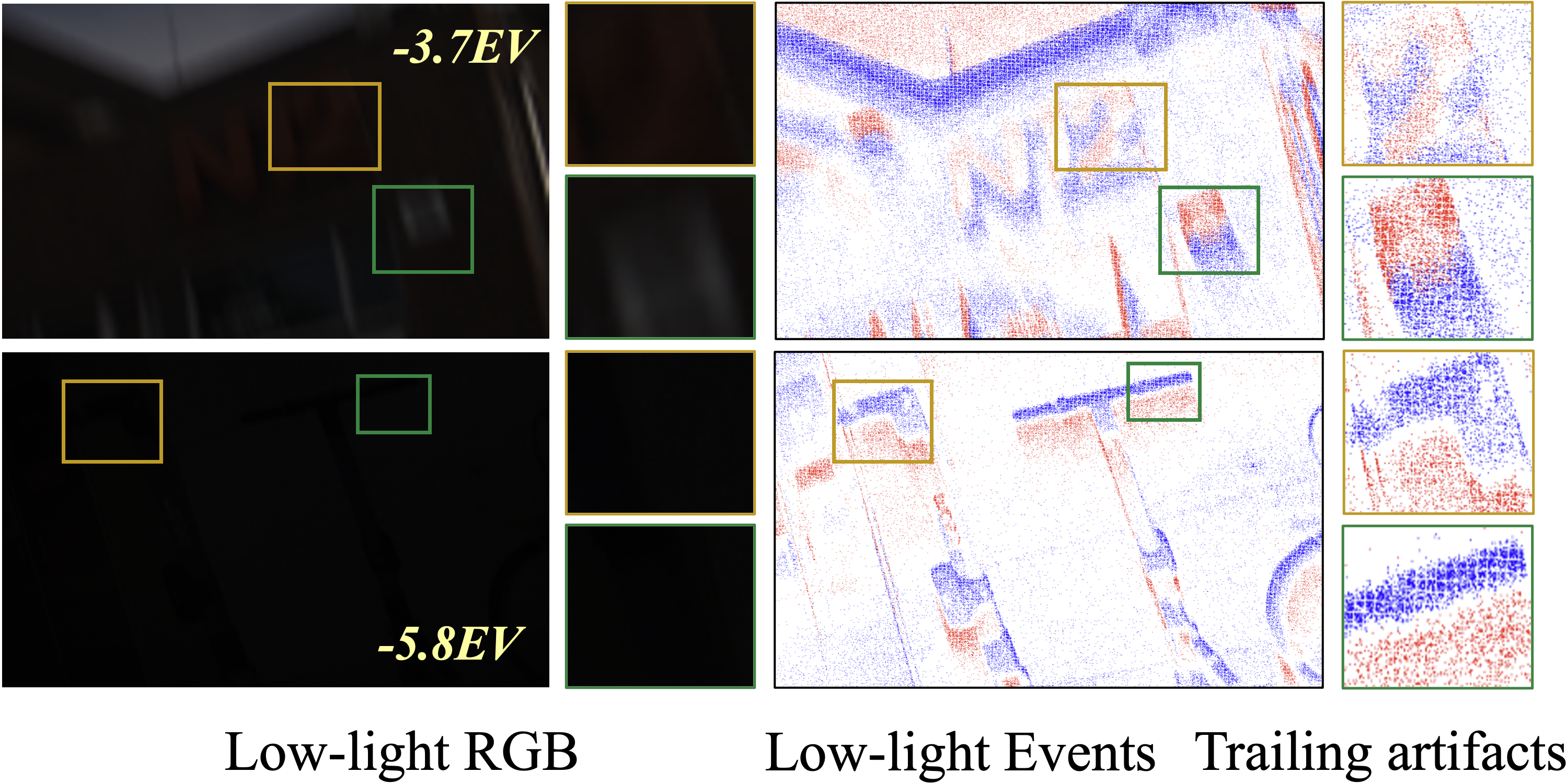
However, while event signals offer valuable information, effectively integrating them into LVSR remains challenging. As shown in Fig. 2, not only are RGB frames heavily degraded under low-light conditions, but event data also suffers from noise, temporal trailing effects, and spatially nonstationary distributions (Liu et al. 2025b). Directly fusing such degraded event signals with low-quality RGB frames inevitably introduces noise and artifacts into the reconstructed results. Therefore, how to effectively extract and fuse meaningful information from both degraded signals is of paramount importance for event-based LVSR.
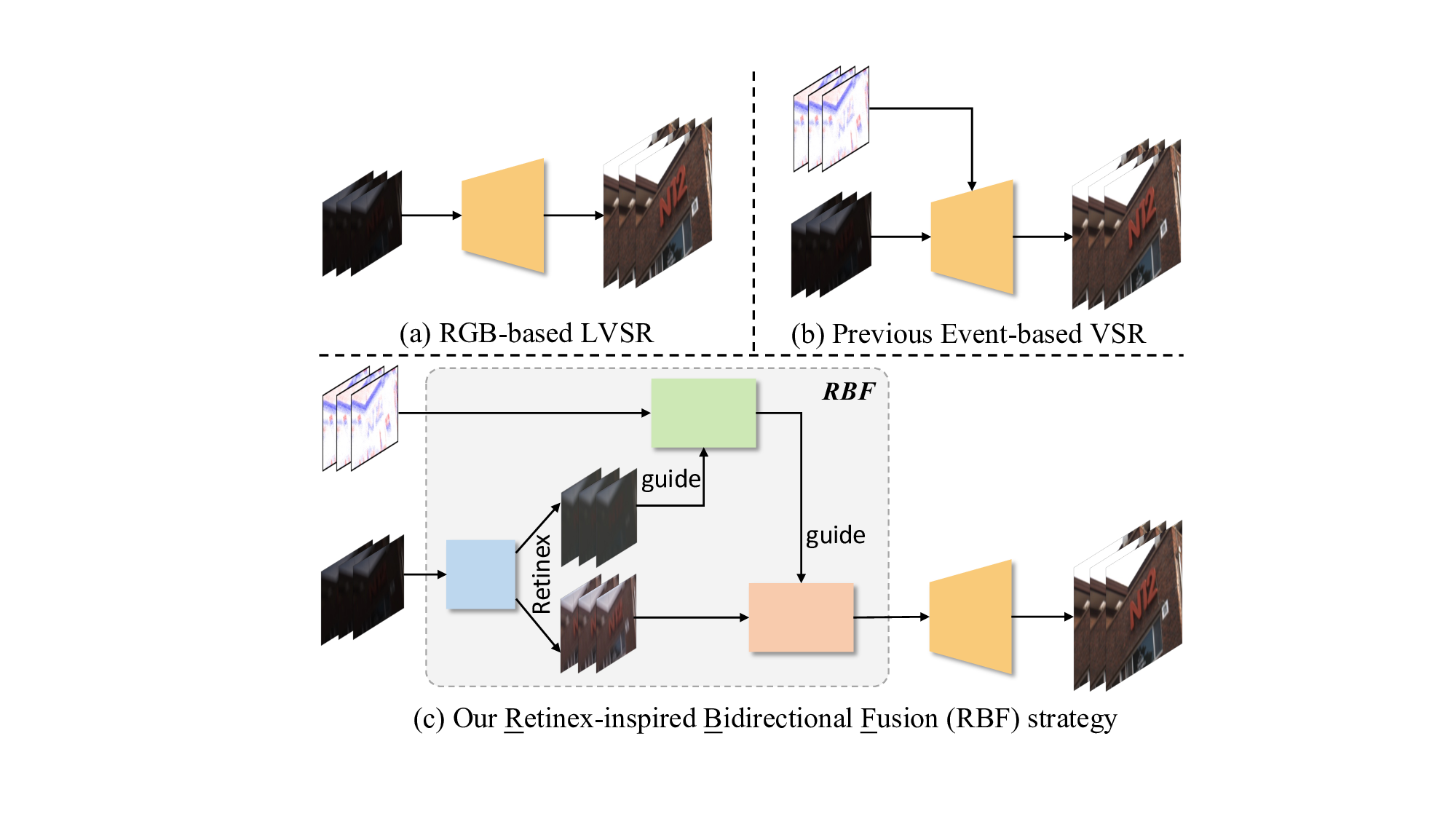
To achieve this, we first argue that the degradation in both modalities mainly arises from insufficient lighting, and that relying solely on event data is inadequate to address these issues without additional low-light priors. To address this, we draw inspiration from Retinex decomposition (Wei et al. 2018), which separates a low-light image into illumination and reflectance. Illumination provides smooth, lownoise global lighting cues, while reflectance preserves intrinsic scene content but lacks fine details in LR settings. Based on this insight, we propose a Retinex-inspired Bidirectional Fusion (RBF) strategy: illumination guides the refinement of noisy events, and enhanced events are then used to recover reflectance details, as illustrated in Fig. 3(c). This bidirectional process enables effective mutual guidance between RGB and event modalities.
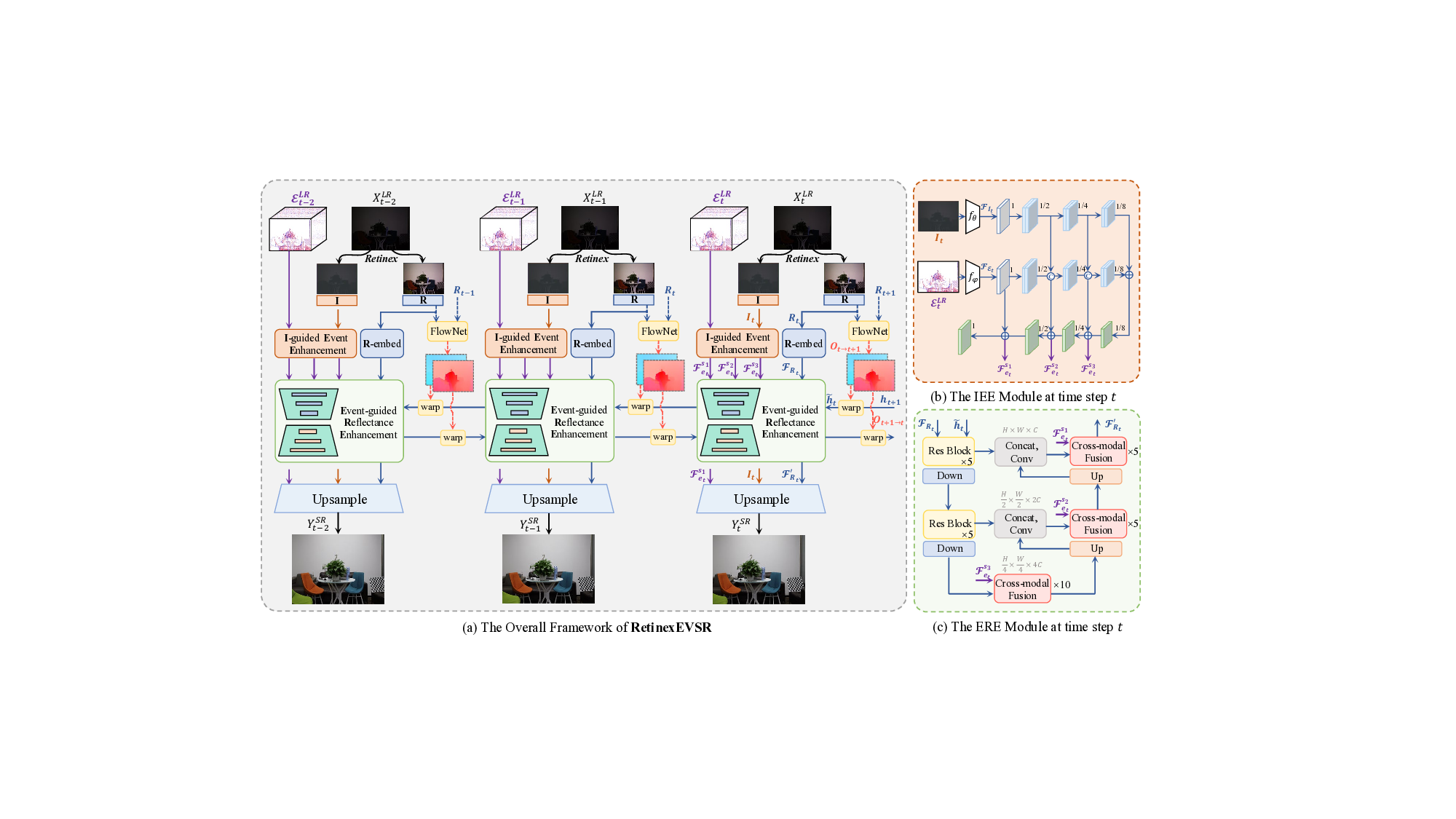
To this end, we present RetinexEVSR, an innovative LVSR network that integrates high-contrast event signals with Retinex-inspired priors to enhance video quality under low-light conditions. In our RetinexEVSR, the input frames are first decomposed into illumination and reflectance components. Guided by the proposed RBF strategy, we introduce an Illumination-guided Event Enhancement (IEE) module, which progressively refines event features through multiscale fusion with illumination, enabling hierarchical guid- ance from coarse to fine levels. The refined events are then passed to the Event-guided Reflectance Enhancement (ERE) module to recover reflectance details. This module adopts a dynamic attention mechanism to inject high-frequency information from events into the reflectance stream via multi-scale fusion. Finally, the illumination, enhanced reflectance, and refined event features are jointly used to guide the upsampling process, reducing information loss and improving reconstruction quality. Experimental results on three datasets demonstrate the effectiveness of our proposed RetinexEVSR, which remains robust even under extreme darkness and severe motion blur. To summarize, our main contributions are:
• We present RetinexEVSR, the first event-driven scheme for LVSR. Our RetinexEVSR leverages event signals and Retinex-inspired priors to restore severely degraded RGB inputs under low-light conditions. • We introduce a novel RBF strategy to enable effective cross-modal fusion between RGB and event signals, addressing the challenge of combining degraded inputs. • We propose the IEE and ERE modules to progressively enhance event and reflectance features, enabling coarseto-fine guidance and detailed texture restoration. • RetinexEVSR achieves state-of-the-art performance on three datasets, including synthetic and real-world data.
Video Super-Resolution. As a fundamental computer vision task, VSR technology has made remarkable progress in recent years (Li et al. 2025b;Wei et al. 2025;Xie et al. 2025). The essential challenge in VSR is to predict the missing details of the current HR frame from other unaligned Low-Light Video Enhancement. To achieve LVE, a common strategy is to apply low-light image enhancement (LIE) methods to each frame independently. In recent years, a large number of CNN-based (Wu et al. 2025a,b;Ju et al. 2025) and Transformer-based (Wang et al. 2023a;Cai et al. 2023) LIE methods have emerged. Among them, the Retinex model (Wei et al. 2018) is a popular tool for LIE, where an observed image X can be expressed as X = R ⊙ I. Here, R and I represent reflectance and illumination maps, respectively, and ⊙ denotes element-wise multiplication. Cai et al. (2023) introduced Retinexformer, the first Transformer-based method that uses illumination derived from Retinex theory to guide the modeling of long-range dependencies in the self-attention mechanism. However, frame-by-frame LIE often causes temporal flickering and jitter effects due to dynamic illumination changes in low-light videos. To address these, many onestage LVE methods (Zhu et al. 2024a,b) have been proposed. Li et al. (2023) proposed an efficient pipeline named FastLLVE, which leverages the look-up table technique to effectively maintain inter-frame brightness consistency. However, they still face limitations in using temporal redundancy in low-light videos due to difficulties in extracting distinct features for motion estimation.
Event-based Vision. Event cameras are bio-inspired sensors that offer several advantages over standard RGB cameras, including ultra-high temporal resolution (about 1µs) (Xiao et al. 2024a), high dynamic range (120 dB), and low power (5 mW). They have been widely used for tasks like frame interpolation (Liu et al. 2025a;Sun et al. 2025;Liu et al. 2025c), deblurring (Yang et al. 2024(Yang et al. , 2025)), and low-light enhancement (Zhang et al. 2024;Kim et al. 2024).
More closely related to our work, recent studies (Xiao et al. 2024c,b;Yan et al. 2025;Kai et al. 2025;Xiao and Wang 2025) have introduced event signals for VSR. For instance, Jing et al. (2021) proposed the first event-based VSR method, named E-VSR, which uses events for frame interpolation followed by VSR, enhancing overall performance. Kai et al. (2024) introduced EvTexture, utilizing high-frequency information from events to improve texture restoration. While these methods perform well under normal-light conditions, they struggle in low-light scenarios. The challenge of training with event data for VSR under low-light conditions remains largely unexplored. (Ma et al. 2022(Ma et al. , 2025)). The illumination I t is used to guide event feature extraction within the IEE module, producing multi-scale event features. In our implementation, we use three scales: {F s1 et , F s2 et , F s3 et }, where s 1 corresponds to the largest spatial scale. The reflectance R t is fed into the R-embed layer, which consists of five Residual Blocks adopted from (Wang et al. 2018), to ex-tract the feature representation F Rt . This feature is then enhanced by events in the ERE module, yielding the enhanced reflectance feature F ′ Rt . Finally, features from events, illumination, and reflectance are fused to guide upsampling, producing the final output Y SR t .
From a temporal perspective, RetinexEVSR employs a bidirectional recurrent framework (Chan et al. 2021), where inter-frame optical flow serves as a bridge for temporal alignment and feature propagation. Unlike prior methods (Xu et al. 2023b), we compute flow from reflectance maps instead of raw inputs, as they offer higher contrast and enable more accurate alignment under low-light conditions. For example, between timestamps t and t + 1, flows O t+1→t and O t→t+1 are computed between R t and R t+1 . In backward propagation, the feature h t+1 is warped to time t using O t→t+1 via a backward warping operation, producing the aligned feature ht , which is then fed into the ERE module for reflectance enhancement. t , the IEE module first extracts shallow features using two symmetric branches: f θ for illumination and f φ for events. Both branches adopt lightweight residual blocks:
where F It and F Et denote the initial features from illumination and events. However, F Et still suffers from trailing artifacts and noise. To refine event features, we adopt a multi-scale fusion strategy inspired by (Wang et al. 2023b).
Convolutions with varying kernel sizes are used to extract features at four spatial scales: full, half, quarter, and oneeighth resolution (i.e., 1, 1/2, 1/4, and 1/8), enabling the network to perceive illumination-aware cues across multiple receptive fields. At each scale, illumination features guide the fusion process via channel-wise concatenation and convolution, allowing the network to recalibrate event representations based on lighting priors. The fused features are then progressively upsampled from coarse to fine in a top-down refinement pathway. At each stage, they are combined with finer-scale event features to recover spatial details while maintaining illumination consistency. We retain the top three scales after fusion as the final enhanced event features: {F s1 et , F s2 et , F s3 et }, where s 1 corresponds to the largest spatial scale. This hierarchical strategy effectively enhances event representations under low-light conditions, providing reliable guidance for subsequent reconstruction.
Event-guided Reflectance Enhancement. In Retinexbased LIE, reflectance is commonly used as the target since it carries well-lit content and structural information. However, in the LVSR setting, it often lacks high-frequency details. To compensate for this, we propose the ERE module, which utilizes refined event features-enhanced by the IEE module-to supplement reflectance features with highfrequency cues. As illustrated in Fig. 4(c), the ERE module adopts an ’encoder-bottleneck-decoder’ architecture. To incorporate temporal information, we introduce the temporally propagated feature h t into the input. Additionally, event and reflectance features are dynamically fused in both the bottleneck and decoder stages through an attention-based cross-modal fusion (Li et al. 2024) block. This design enables the network to selectively inject informative structures from events into the reflectance stream while suppressing noise specific to either modality. After processing through the ERE module, the original reflectance feature F Rt is en- riched with detailed textures and contrast information from the event features. The output, denoted as F ′ Rt , also serves as the updated temporal feature h t for the next frame, enabling continuous refinement. This enhancement not only improves the perceptual quality of the reconstructed frames but also provides stronger guidance for the final restoration. Further details about the fusion block are provided in the appendix.
Loss Function. We follow the previous study (Kai et al. 2024) and adopt the Charbonnier loss (Lai et al. 2017) as the training loss function, which is defined as:
where ε = 1 × 10 -12 is set for numerical stability.
Datasets. We first follow the previous LVSR method DP3DF (Xu et al. 2023b) and use the SDSD dataset (Wang et al. 2021), which provides paired low-light and normallight videos. Since SDSD does not include event signals, we simulate events using the vid2e event simulator (Gehrig et al. 2020) with a noise model based on ESIM (Rebecq, Gehrig, and Scaramuzza 2018). We further train and evaluate our method on two real-world event datasets: SDE (Liang et al. 2024) and RELED (Kim et al. 2024). SDE contains over 30K image-event pairs captured under varying lighting conditions in indoor and outdoor scenes. RELED introduces
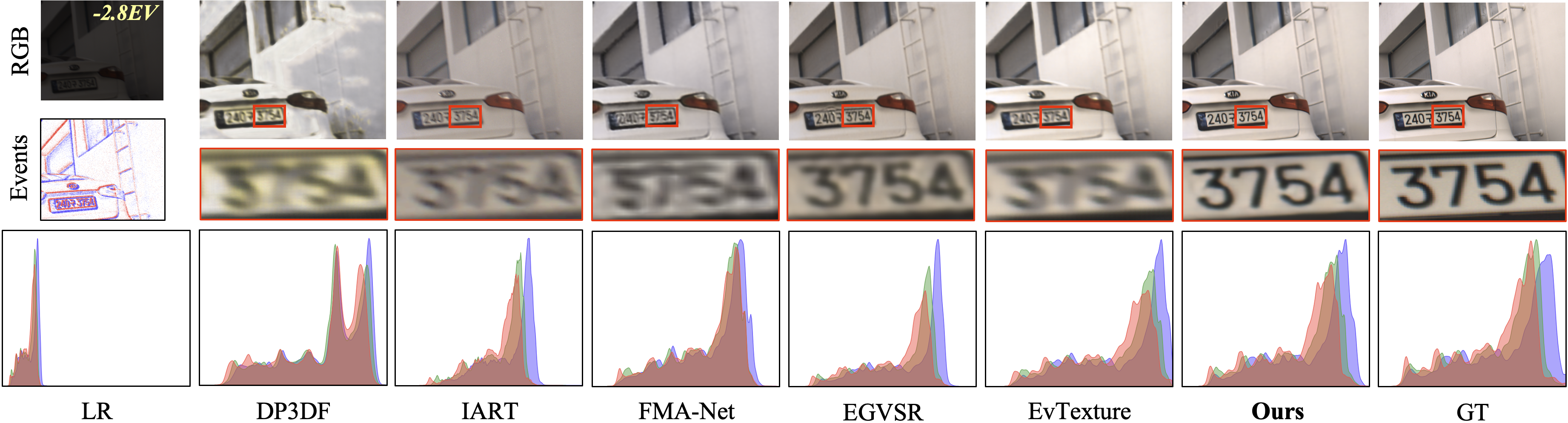
Baselines. We compare our method with both RGB-based and event-based SOTA methods, covering two strategies: cascade and one-stage LVSR. For RGB-based VSR, we include BasicVSR++ (Chan et al. 2022), DP3DF (Xu et al. 2023b), MIA-VSR (Zhou et al. 2024), IART (Xu et al. 2024), and FMA-Net (Youk, Oh, and Kim 2024). For eventbased VSR, we compare with EGVSR (Lu et al. 2023) and EvTexture (Kai et al. 2024). We also include RGB-based low-light enhancement methods: Retinexformer (Cai et al. 2023), FastLLVE (Li et al. 2023), CoLIE (Chobola et al.
We conduct comprehensive ablation studies on the SDSDindoor dataset due to its good convergence and stable per-
In this paper, we present RetinexEVSR, the first eventdriven framework for LVSR. Our method leverages Retinexinspired priors, coupled with a novel RBF strategy, to effectively fuse degraded RGB and event signals under lowlight conditions. Specifically, it includes an IEE module that treats the illumination component, decomposed from the input frames, as a global lighting prior to enhance event features. The refined events are then utilized in the ERE module to enhance reflectance details by injecting high-frequency information. Extensive experiments demonstrate that RetinexEVSR achieves state-of-the-art performance on three datasets, including both synthetic and realworld datasets, and generalizes well to unseen degradations, highlighting its potential for low-light video applications. Unlike standard self-attention mechanisms, our crossmodal attention dynamically integrates information across the event and reflectance modalities. The query Q r is derived from the reflectance feature map, while the key K e and value V e are generated from the event signals. Specifically, given the input features F r , F e ∈ R H×W ×C from the reflectance and event branches, respectively, the query, key, and value are computed as:
where W Q , W K , and W V represent learnable projection matrices, implemented as a stack of 1 × 1 and 3 × 3 depthwise convolutions. While vanilla attention computes querykey correlations individually-resulting in a static attention map-it often fails to capture the intricate temporal dynamics of event features F e . To address this limitation, we propose a dynamic attention mechanism formulation:
Here, the dynamic keys and values, denoted as ⃗ K e and ⃗ V e ∈ R D×C×N , are computed via a Dynamic Contrast Extractor (DCE) employing depth-wise convolutions. The parameter D = 4 represents the projected temporal dimension within our model. This design empowers the attention mechanism to adaptively capture temporal variations inherent in the event data. The output of the cross-modal attention is computed as shown in Eq. 4, where F ′ r ∈ R H×W ×C By adaptively focusing on the temporal dynamics of event data, this approach significantly enhances the fusion of event and reflectance features. By leveraging both spatial and temporal contexts, the ERE module improves the robustness and fidelity of reflectance reconstruction, particularly under challenging low-light conditions.
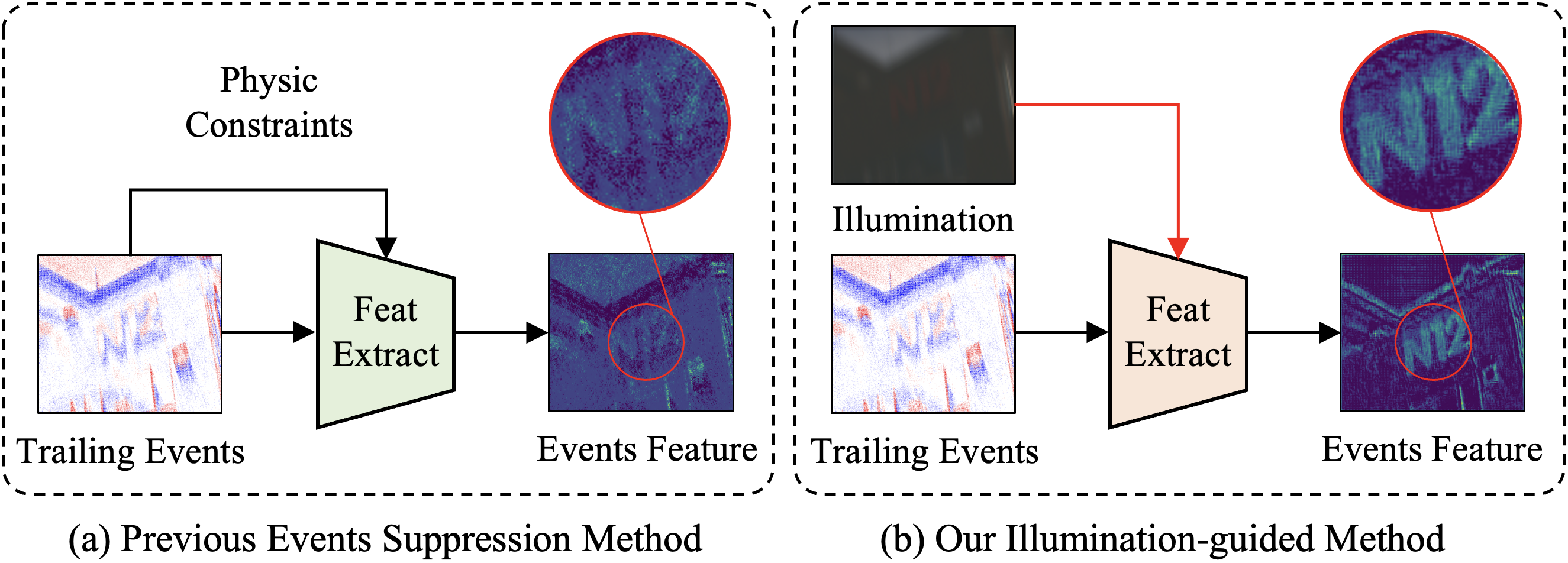
Mitigating trailing effects is paramount when leveraging event data for low-light VSR, particularly in scenes containing fast-moving objects. Failure to effectively handle these trailing artifacts can blur critical details and degrade the quality of the final reconstruction. Similar challenges have been documented in prior works (Liu et al. 2024(Liu et al. , 2025b)).
In Fig. 12, we compare the trailing suppression strategy used in these previous methods with our proposed illumination-guided approach. While existing methods rely exclusively on the intrinsic properties of event data, our method introduces illumination information as a global lighting prior to guide the enhancement process. Consequently, our approach more effectively suppresses trailing artifacts induced by low-light conditions, producing more distinct and sharper event features.
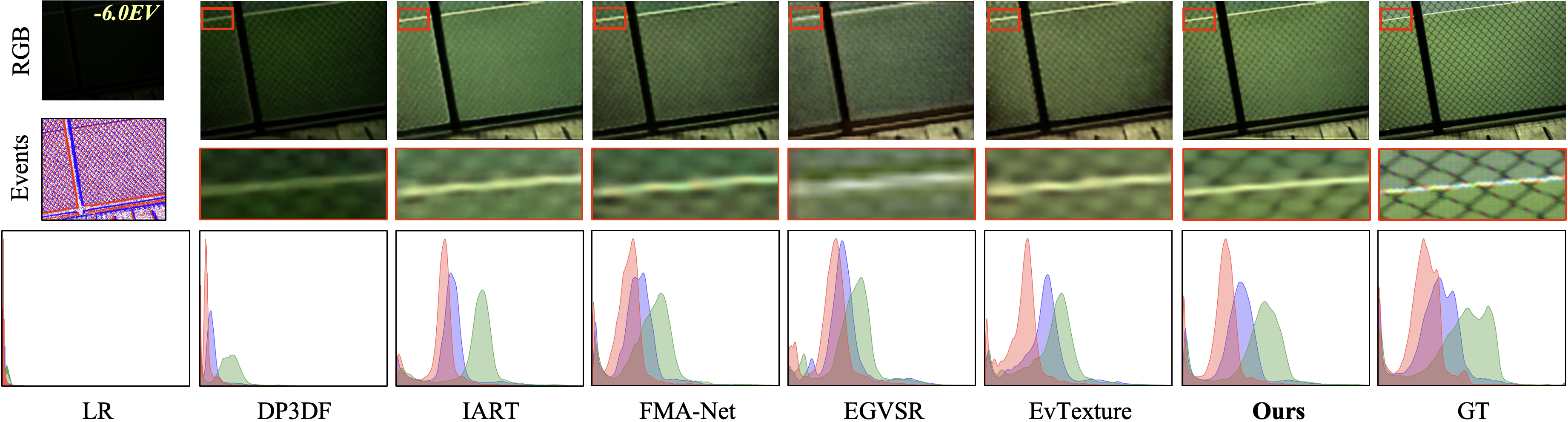
To further validate the performance of RetinexEVSR, we provide additional visual comparisons on the SDSD (Wang et al. 2021), SDE (Liang et al. 2024), and RELED (Kim et al. 2024) datasets. The results, presented in Figs. 13 through 16, demonstrate that RetinexEVSR successfully restores complex scenes under low-light conditions, effectively enhancing the visibility of fine details and textures. These compelling results underscore the framework’s potential for real-world applications in computational photography and surveillance systems, where low-light video enhancement is critical.
(c) The ERE Module at time step 𝑡𝑡
Ablation study of model components on SDSDindoor. * indicates the setting used in our final model.
This content is AI-processed based on open access ArXiv data.