Title: Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
ArXiv ID: 2601.02346
Date: 2026-01-05
Authors: Falcon LLM Team, Iheb Chaabane, Puneesh Khanna, Suhail Mohmad, Slim Frikha, Shi Hu, Abdalgader Abubaker, Reda Alami, Mikhail Lubinets, Mohamed El Amine Seddik, Hakim Hacid
📝 Abstract
This work introduces Falcon-H1R, a 7B-parameter reasoning-optimized model that establishes the feasibility of achieving competitive reasoning performance with small language models (SLMs). Falcon-H1R stands out for its parameter efficiency, consistently matching or outperforming SOTA reasoning models that are 2× to 7× larger across a variety of reasoning-intensive benchmarks. These results underscore the importance of careful data curation and targeted training strategies (via both efficient SFT and RL scaling) in delivering significant performance gains without increasing model size. Furthermore, Falcon-H1R advances the 3D limits of reasoning efficiency by combining faster inference (through its hybrid-parallel architecture design), token efficiency, and higher accuracy. This unique blend makes Falcon-H1R-7B a practical backbone for scaling advanced reasoning systems, particularly in scenarios requiring extensive chain-of-thoughts generation and parallel test-time scaling. Leveraging the recently introduced DeepConf approach, Falcon-H1R achieves state-of-the-art test-time scaling efficiency, offering substantial improvements in both accuracy and computational cost. As a result, Falcon-H1R demonstrates that compact models, through targeted model training and architectural choices, can deliver robust and scalable reasoning performance.
📄 Full Content
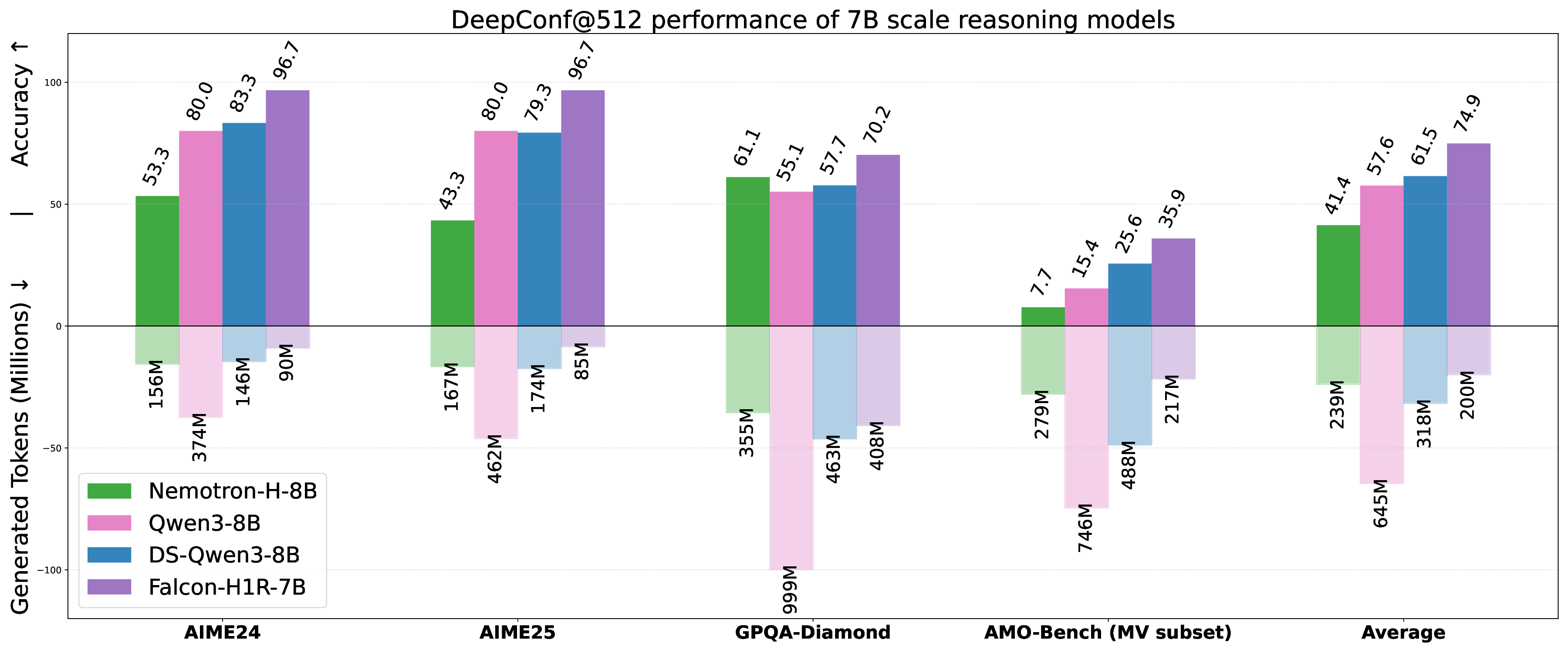
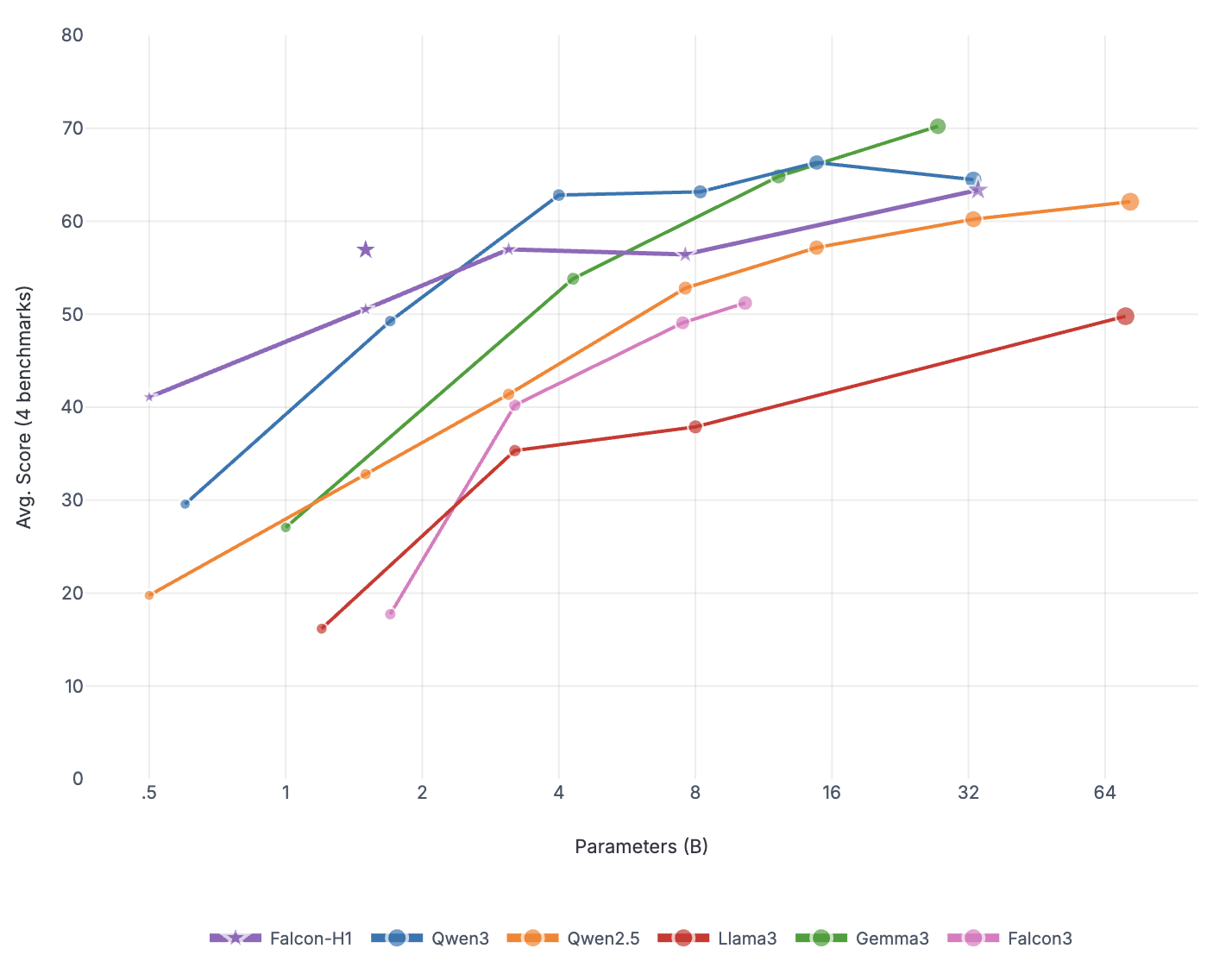
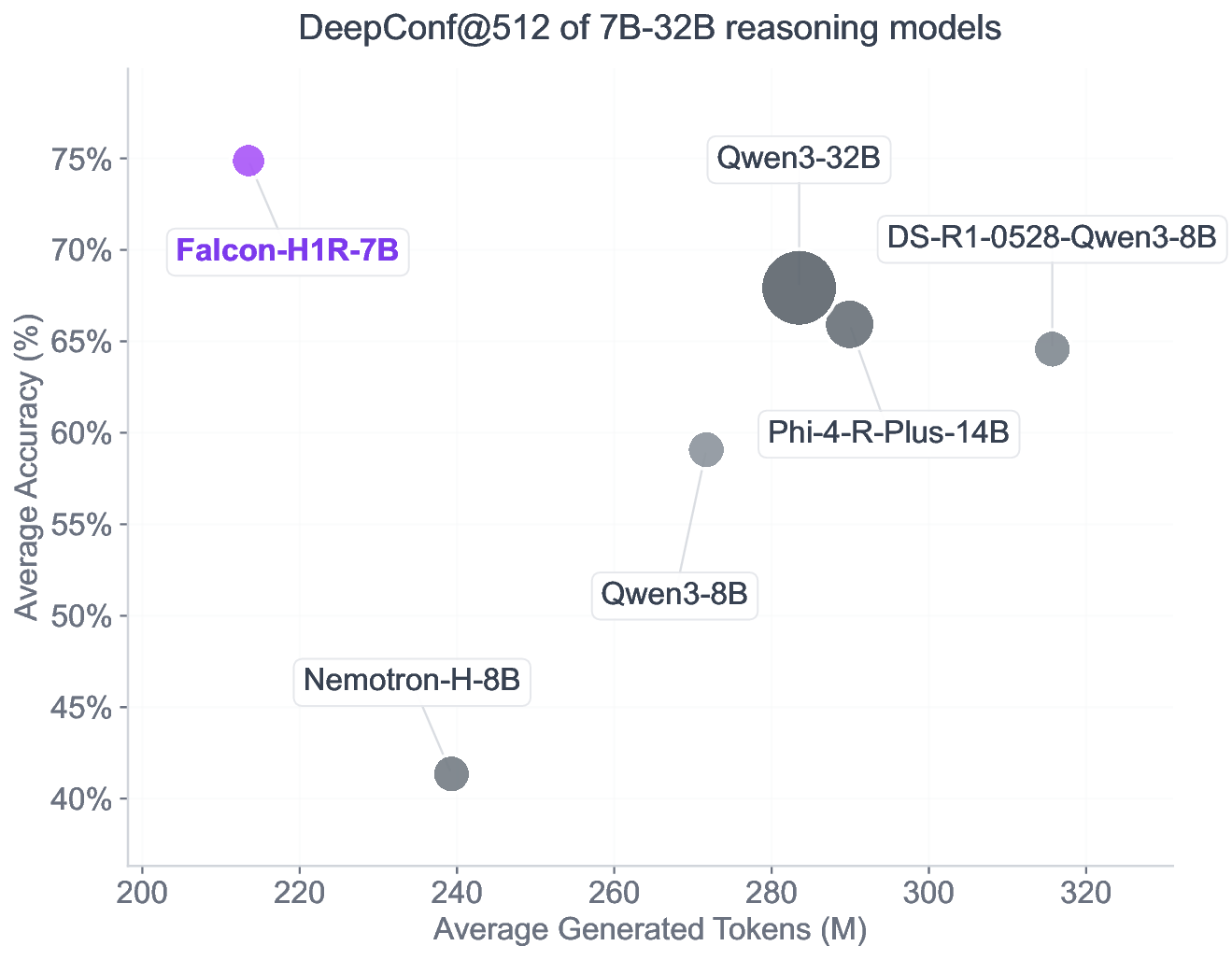
Figure 1: DeepConf@512 (Fu et al., 2025a) average results over AIME24, AIME25, AMO-Bench, and GPQA-Diamond (Detailed results in Table 7). Falcon-H1R-7B achieves exceptional performance by pushing the reasoning frontiers in 3 dimensions: higher accuracy, token efficiency and fast inference in the parallel thinking setting.
Large language models (LLMs) have rapidly advanced the state of complex reasoning tasks, achieving impressive results by scaling compute in two independent directions:
• Scaling Training: Improving model capabilities through comprehensive training (Kaplan et al., 2020;Hoffmann et al., 2022) that typically involves Supervised Fine-Tuning (SFT) on high-quality instruction data (Guha et al., 2025;Yue et al., 2025) followed by Reinforcement Learning (RL) (e.g., RLVR) for fine-grained alignment and performance maximization (Guo et al., 2025;OpenAI, 2024;Yu et al., 2025).
• Scaling Inference: Proposing parallel thinking methods that generate and aggregate multiple solution chains, such as through self-consistency or majority voting (Fu et al., 2025b;Lightman et al., 2023a;Stiennon et al., 2020;Nakano et al., 2021;Uesato et al., 2022).
Scaling training strategies have enabled LLMs to tackle increasingly complex reasoning tasks. However, as recent work notes (Wang et al., 2023;Snell et al., 2024;Yao et al., 2023;Dziri et al., 2025), pure pretraining progress is slowing due to extreme compute requirements and limited high-quality human data. This has motivated an emerging paradigm: Test-Time Scaling (TTS) (Zhang et al., 2025), which allocates additional inference-time compute to unlock latent reasoning capabilities.
The notable successes of reasoning models (Guo et al., 2025;OpenAI, 2024;Google DeepMind, 2025) have further fueled interest in TTS, highlighting its importance for both LLM reasoning and practical utility. TTS has shown significant gains across reasoning-intensive domains. In mathematics, sampling multiple reasoning chains and selecting consistent solutions improves accuracy (Wang et al., 2023). In code generation, generating diverse candidates and verifying them via execution enhances functional correctness (Chen et al., 2024;Dziri et al., 2025). For multi-hop and scientific reasoning, search-based inference approaches like Tree-of-Thoughts boost compositional reasoning (Yao et al., 2023), while agentic and evolutionary methods (Novikov et al., 2025) extend these ideas to openended scientific discovery. More generally, scaling inference-time compute improves reliability and calibration through confidence-based pruning (Snell et al., 2024;Fu et al., 2025b).
Despite these benefits, TTS incurs high inference costs, as generating and evaluating many candidate solutions per query is compute-intensive (Muennighoff et al., 2025). Balancing efficiency with strong baseline accuracy is therefore critical, particularly for models handling large parallel batches and long sequences. With this in mind, we build on the Falcon-H1 series (Falcon-LLM Team, 2025), a family of hybrid Transformer-Mamba architectures (Gu and Dao, 2024;Glorioso et al., 2024;Lieber et al., 2024;Dong et al., 2024;Li et al., 2025;Blakeman et al., 2025;Ostapenko et al., 2025;Team et al., 2025b) optimized for high throughput and low memory usage at long sequence lengths and high batch sizes. We construct Falcon-H1R-7B via further SFT and RL scaling of Falcon-H1-7B, to achieve a compact model that remains competitive with 8B-32B systems while substantially reducing inference overhead. We further incorporate a state-of-the-art TTS method that dynamically prunes weak reasoning chains during generation (Fu et al., 2025b), and demonstrate that Falcon-H1R enhances TTS efficiency by accommodating more parallel chains within the same compute budget and enabling effective early stopping. Collectively, these properties make Falcon-H1R a highly effective backbone for reasoning workloads demanding both accuracy and scalability.
We introduce Falcon-H1R, a 7B reasoning-optimized model leveraging a hybrid Transformer-SSM architecture for superior inference efficiency, designed to maximize the efficacy and efficiency of test-time scaling methods. The key contributions of this work are as follows:
Hybrid Architecture for Efficient Reasoning via TTS: We leverage the Falcon-H1 architecture (Falcon-LLM Team, 2025, Section 2), a parallel hybrid Transformer-Mamba (statespace) architecture known for its superior inference speed and memory efficiency (Falcon-LLM Team, 2025, Section 5.3) making it an ideal backbone for reasoning tasks that require high throughput under large batch sizes, which is typical of parallel test-time scaling techniques.
We train our model via cold-start supervised fine-tuning on datasets with long reasoning traces, with capabilities further enhanced through reinforcement learning using the GRPO approach. The SFT stage leverages rigorously curated data spanning mathematics, code, and science domains, with difficulty-aware filtering to emphasize challenging problems. GRPO training builds on the SFT model and addresses distinctive challenges, including training with exceptionally large response lengths (up to 48K tokens) and balancing exploration to improve output quality. The final model achieves strong performance on popular reasoning benchmarks, including 88.1% on AIME24, 83.1% on AIME25, 64.9% on HMMT25, 36.3% on AMO-Bench, and 68.6% on LiveCodeBenchv6 (Tables 4-5-6), competing with even larger and recent SOTA reasoning models such as GPT-OSS-20B, Qwen3-32B, Phi-4-Reasoning-Plus-14B, and DeepSeek-R1-0528-Qwen3-8B.
Superior Efficiency and Accuracy via TTS: By shifting the accuracy-cost frontier, Falcon-H1R delivers state-of-the-art reasoning performance with substantially lower inference overhead, demonstrating the impact of targeted training and architectural choices in realizing the full benefits of TTS. We evaluate Falcon-H1R using the DeepConf method (Fu et al., 2025b), which dynamically filters and aggregates parallel reasoning chains based on model confidence. Our results (Table 7) demonstrate that Falcon-H1R consistently improves both accuracy and cost-efficiency in test-time scaling scenarios. On AIME25, for example, Falcon-H1R-7B attains 96.7% accuracy while reducing token usage by 38% relative to DeepSeek-R1-0528-Qwen3-8B. These gains stem from strong reasoning performances of the base Falcon-H1R-7B model, as well as well-calibrated confidence estimates that support aggressive early stopping without sacrificing accuracy.
The remainder of this technical report is organized to provide a clear and comprehensive overview of the steps taken to achieve our results. We begin with Section 2, which details the supervised fine-tuning (SFT) stage, including data processing, filtering, ablation findings, key hyperparameters, and training specifics. Section 3 covers the reinforcement learning (RL) stage, describing data preparation, the training framework, experimental ablations, and the overall setup. Both sections conclude with key training insights. In Section 4, we present our evaluation methodology and results across a wide range of reasoning benchmarks. Finally, Section 5 provides an in-depth discussion of the test-time scaling experiments and outcomes.
To further expand the base model reasoning capabilities, the current paradigm relies first on coldstart supervised fine-tuning stage. This is particularly motivated by (Yue et al., 2025), which shows that while RLVR-training does indeed improve average accuracy (e.g., at pass@1), a deeper analysis reveals that the coverage of solvable problems (measured by pass@k for large k) is narrower than or equal to the base model’s, essentially all reasoning paths discovered by the RL-training are already present in the base model’s distribution. This section provides details on our SFT stage, which proved critical to performance improvements in our model, accounting for the majority of reasoning capability gains in our training pipeline.
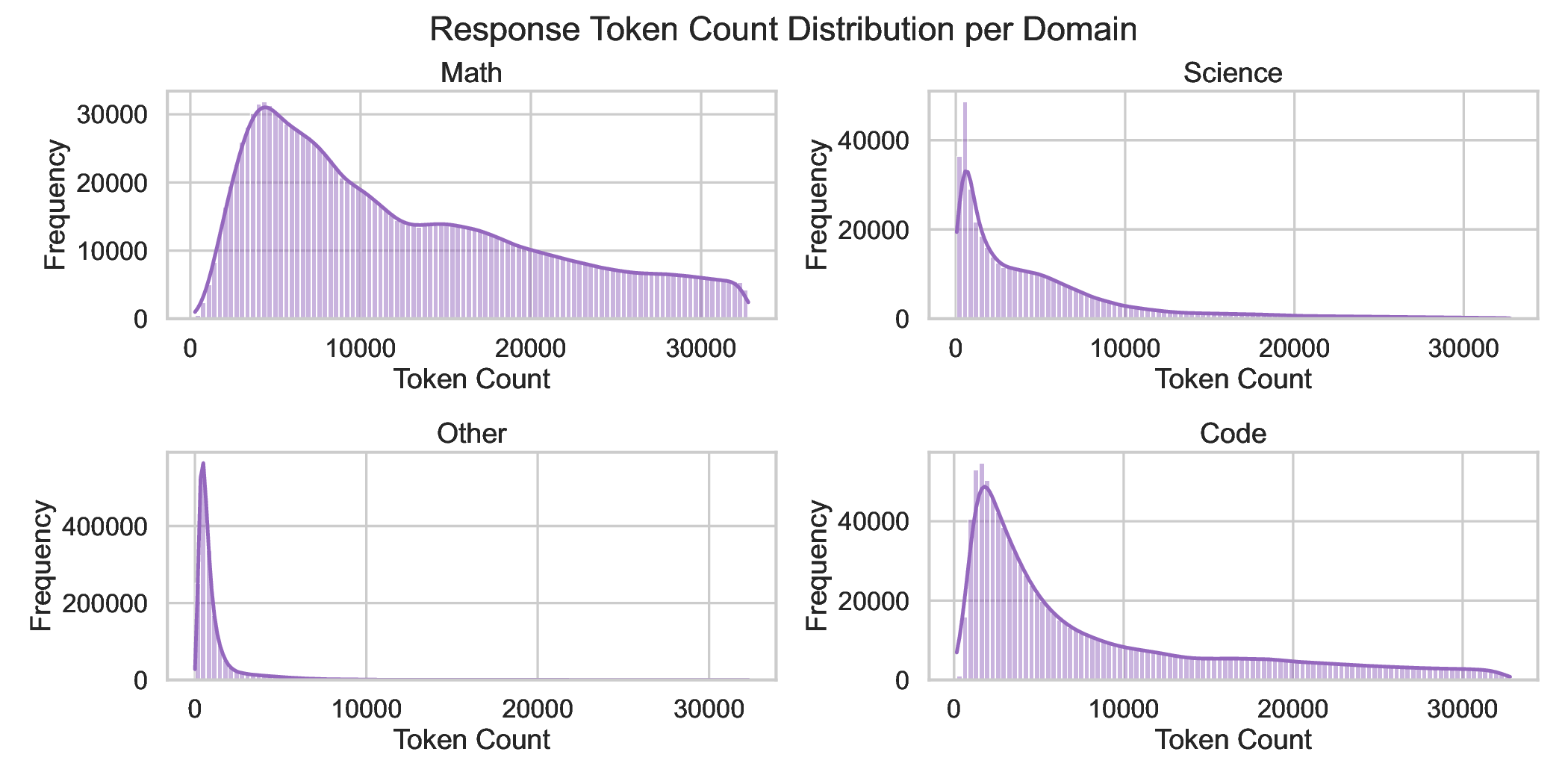
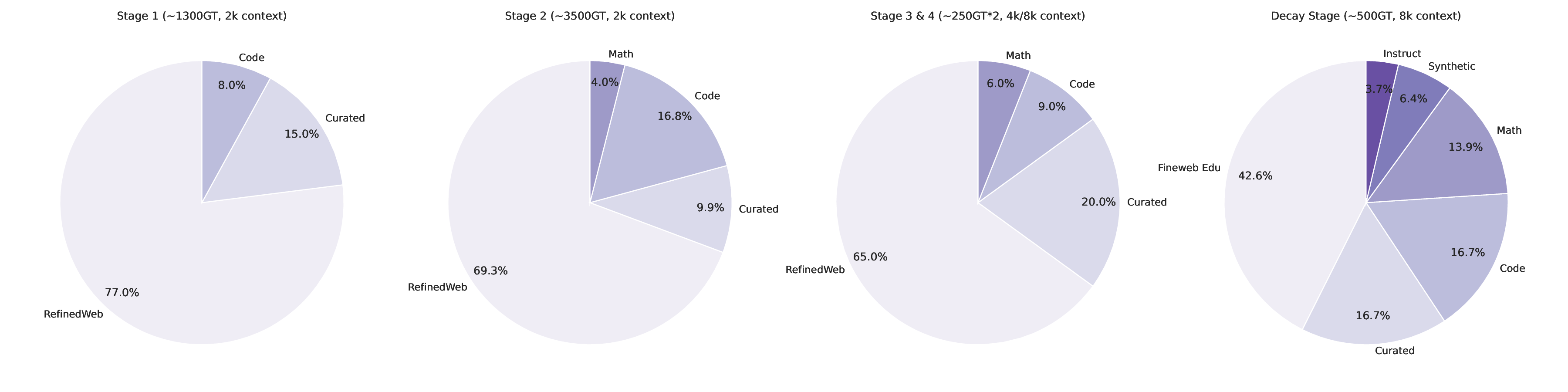
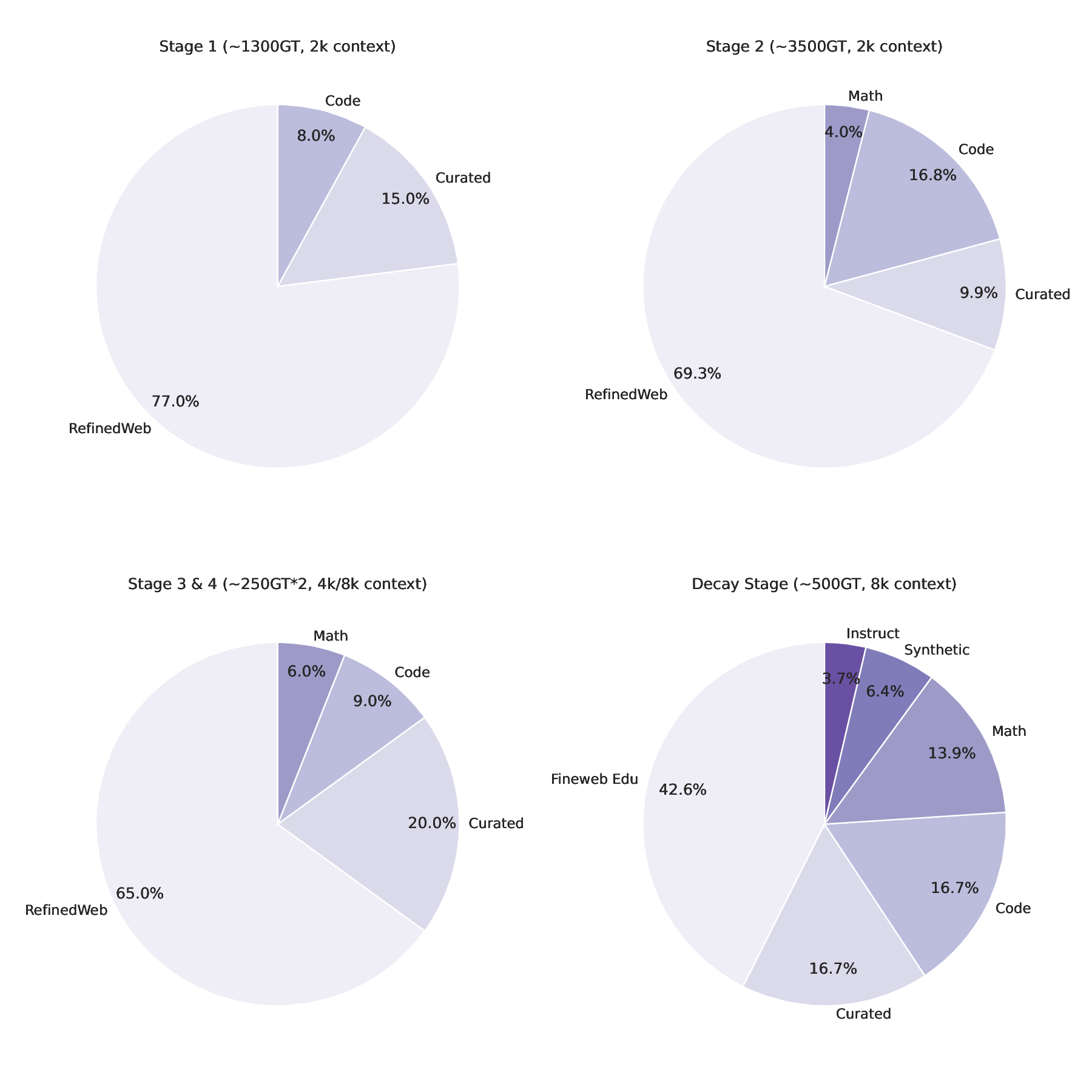
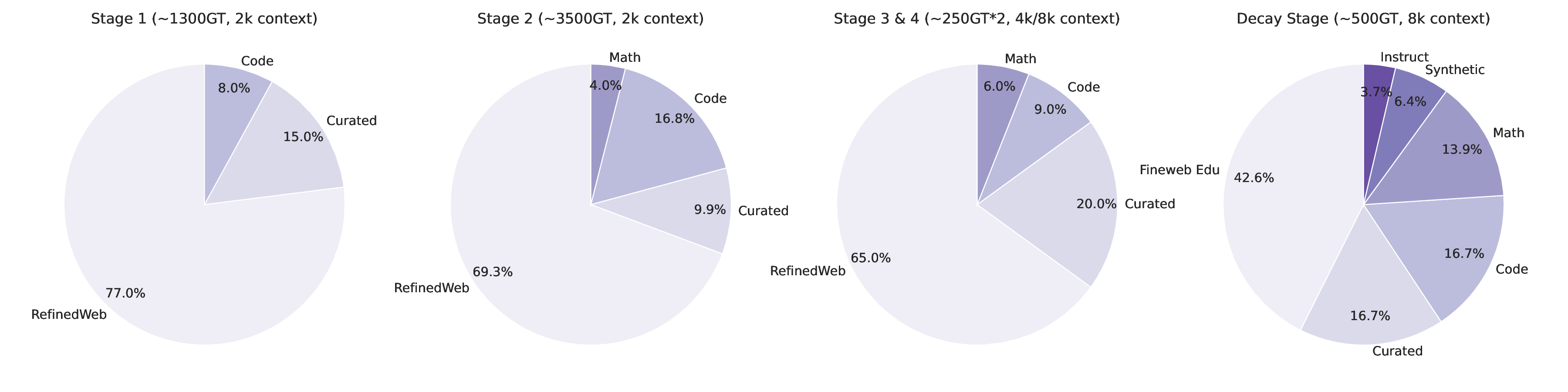
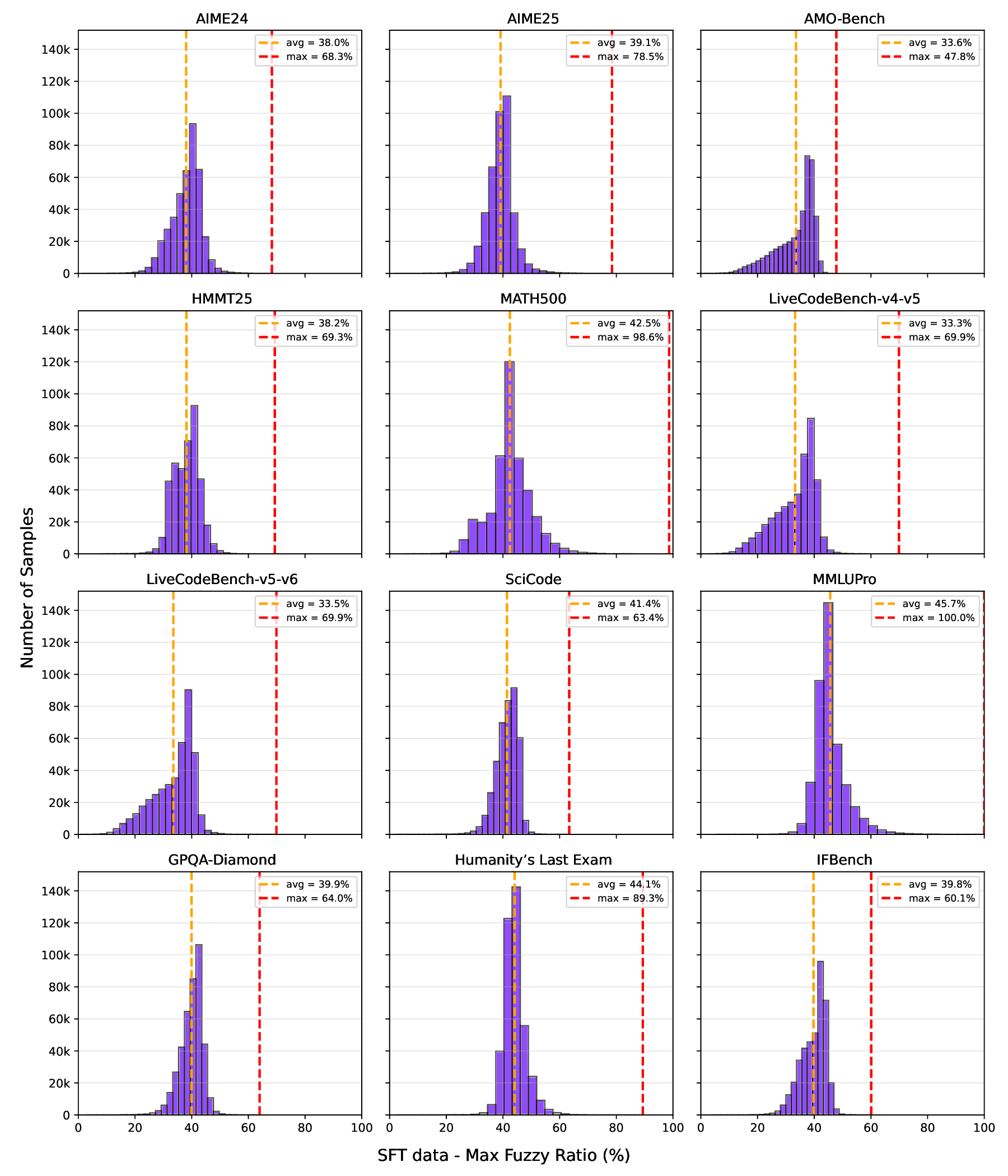
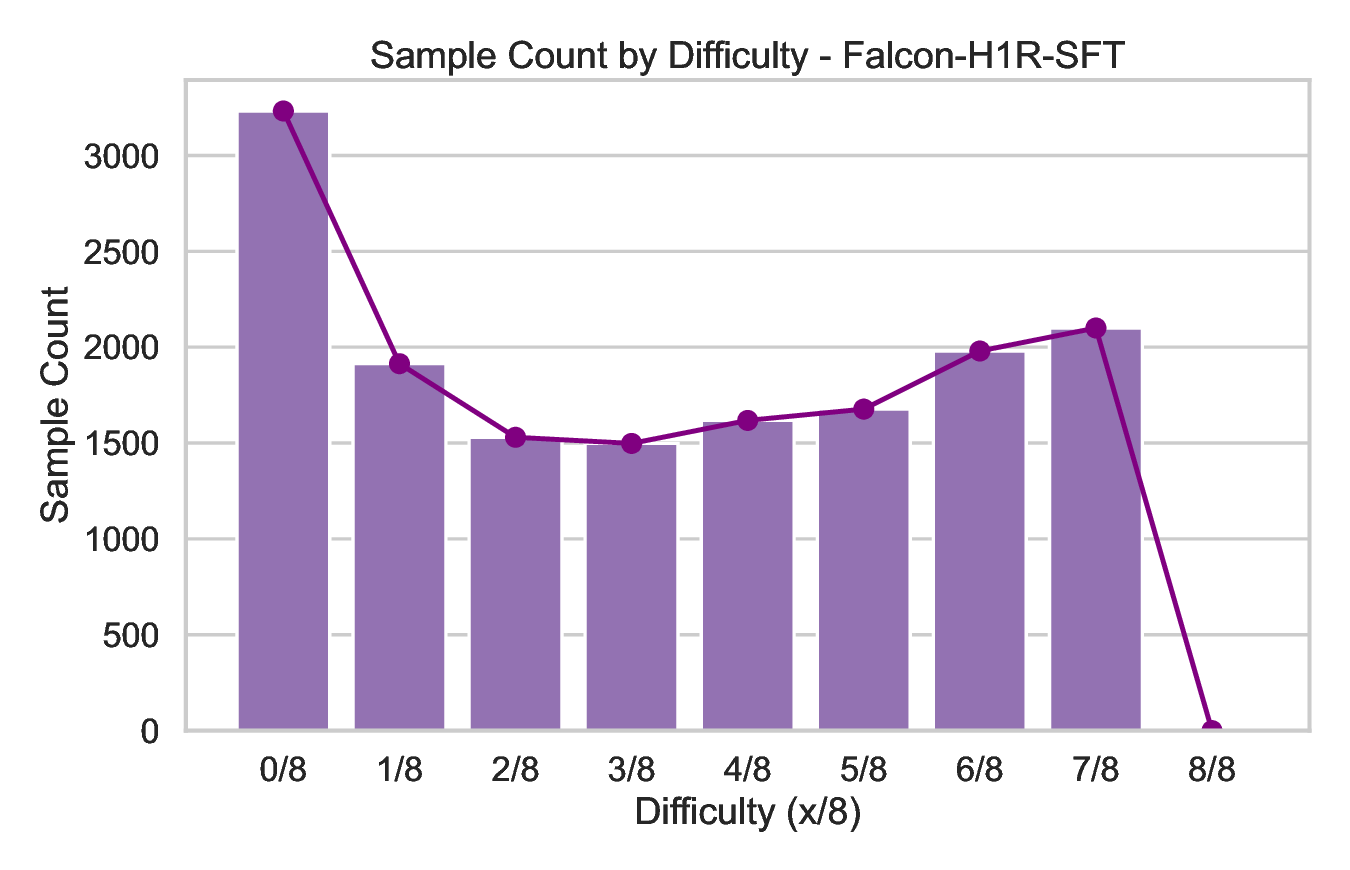
We curated a diverse set of datasets spanning different domains, including mathematics, coding, STEM, instruction-following, tool calling, and general chat, from which long chain-of-thoughts have been generated. Datasets were then organized into four primary domains as depicted in Fig. 3: mathematics, coding (with an emphasis on Python and C++), science, and other, comprising the remaining domains. For coding data, we emphasized algorithmic reasoning and functional correctness. In contrast, for mathematics and science tasks, we prioritized problems with verified ground-truth answers, resorting to an LLM-based judge only when such labels were unavailable. We implemented rigorous data verification, including selecting mathematical and science solutions based on correctness and cross-validating factual questions using official web sources when applicable. For mathematics, we relied on both math-verify2 and LLM-based verification for greater flexibility. Only correct solutions were kept, except for particularly difficult incorrect solutions or hardly verifiable problems such as theorems, which were retained to expose the models to complex reasoning traces as shown to be effective in (Guha et al., 2025). Quality filtering was also applied using several criteria: removing instances with empty reasoning content or final answer, mathematics solutions lacking a final \boxed{} answer, code with syntax errors or incorrect coding language, and tool-calling data that failed to produce reliable outputs. After filtering, the response token count distribution for each domain followed an approximately log-normal shape as shown in Fig. 2, reflecting long-tail problems’ difficulties.
For multi-turn conversational datasets, we exclude the reasoning () content from all previous turns and retain only the reasoning content from the final turn, applying supervision solely on the last-turn output. This mirrors inference-time behavior, where earlier reasoning traces are never injected into subsequent turns and prevents uncontrolled context growth. In contrast, toolcalling datasets may require tool invocation at any turn, and thus include reasoning annotations for all turns. To ensure the model learns multi-step tool-use behavior correctly, loss is applied across every turn during training, even though inference-time tool executions similarly avoid propagating prior reasoning traces between turns.
To optimize our SFT stage, we conducted several ablations across the following axes: learning rate tuning, rollout multiplicity per input prompt, incorporation of incorrect rollouts, teacher model mixing, domain-specific data mixtures, and data weighting strategies. Below, we provide a detailed description of the conducted ablations and corresponding key findings:
• Learning rate tuning: We selected the optimal learning rate through grid-searching the best validation performance on key reasoning benchmarks using a 10% representative subset of our training corpus. We also leveraged µP ((Falcon-LLM Team, 2025), Section 3.2.3) which notably ensures the transferability of the training hyper-parameters to the different model sizes of the Falcon-H1 series.
Larger learning rates consistently yielded superior model performance in our ablation runs (optimal selected LR was 1024 • 10 -6 ), outperforming smaller values typically recommended in standard SFT settings (e.g., for building instruct models). The selected LR has led to faster convergence as well as higher performance on downstream tasks.
• Rollout multiplicity and correctness analysis: We investigated the effect of varying the number of solution rollouts per problem instance, comparing n ∈ {4, 8, 12}. Ablation runs assessed whether increasing the number of diverse reasoning traces exposed the model to richer problem-solving strategies, particularly for complex problems. Additionally, we analyzed the impact of incorporating incorrect rollouts into the training set, evaluating in which conditions such traces would be beneficial.
Higher rollout counts (n = 12) were most effective, especially for difficult problem queries. The performance gain scaled with problem difficulty: harder problems showed greater boosts from increased rollout diversity, suggesting that exposure to multiple valid reasoning traces is crucial for the model to acquire robust and generalizable problem-solving skills. On the other hand, including incorrect rollouts resulted only marginal gains on the hardest problems (i.e., with low baseline pass rates). For easier or intermediate problem difficulties, the inclusion of incorrect rollouts showed almost negligible gains and, in some cases, led to slightly noiser training signals, suggesting that their benefit is highly problem-dependent.
• Teacher model mixing: We studied the impact of mixing reasoning traces generated from different teacher models, using in-domain (e.g., math only) or cross-domains (e.g., math and code) seeds. Our initial hypothesis was that mixing outputs from different teachers would increase data diversity and potentially improve generalization.
Cross-domain teacher mixing was found to be counterproductive: training the model on data from multiple teacher reasoning traces exhibited higher output entropy and lower evaluation scores compared to the optimal single-teacher baseline. We hypothesize that conflicting reasoning styles across different teachers introduced distribution shifts and inconsistencies, yielding diminishing returns in model generalization.
• Domain-Specific Ablations and Difficulty-Aware Weighting: To maximize performance within distinct reasoning domains (e.g., math, code, science), we conducted targeted ablations for each domain, by maximizing downstream performance on domain-specific data with corresponding key benchmarks. For designing the final mixture, we introduced a difficulty-aware weighting scheme: hard problems (as determined by pass rates or traces length) were treated as high-quality and up-weighted by factors between 1.25× and 1.75× to ensure sufficient model exposure, medium-difficulty samples retained standard weighting of 1, and easy problems were progressively down-weighted 0.5× or even removed in case of diminishing returns. This strategy focused training with harder problems yielding notable performance boosts, while minimizing overfitting to trivial samples.
• Full Training Mixture Ablations: Building on our domain-specific findings, we experimented with multiple data-mixture configurations. An initial mixture emphasized mathematics as the dominant component, with smaller contributions from code, science, and general reasoning. A refined mixture-used for the final model-increased the proportions of code and non-math reasoning data while slightly reducing the mathematical share. This produced a still math-dominant mixture but with broader cross-domain reasoning coverage and improved overall balance.
The most effective training mixture was math-dominant with moderate inclusion of code and science data. This configuration outperformed more balanced or code-centric mixtures, suggesting that mathematical reasoning skills transfer more effectively to other domains than vice versa.
These ablation experiments provided empirical guidance for selecting the final set of SFT hyperparameters and data-mixture composition. The final hyper-parameters and data-mixture configurations-selected based on the full set of studies, ablations, and downstream evaluations-are summarized in Table 1 andFigure 3.
The SFT stage for Falcon-H1R-7B training was performed using Fully Sharded Data Parallelism (FSDP) and context parallelism with CP = 2, allowing efficient scaling to 256 H100 GPUs of longcontext finetuning. To enable Ulysses sequence parallelism (Jacobs et al., 2023), the Falcon-H1 hybrid Transformer-Mamba block was monkey-patched with explicit gather and scatter operations. These modifications ensure that the block’s mixed attention and state-space computations execute correctly under sequence-partitioned parallelism. The default context length was set to 36K tokens, with some few extended samples (up to 48K tokens) right-trimmed to fit. The effective batch size was set to 512, and we used a 4% warmup phase of the total number of training steps. Training was performed over three epochs on a total of 3.1M samples. Table 1 summarizes the main SFT hyperparameters.
To support scalable training, we enhanced the codebase with a streaming-dataset implementation and weighted data-mixture support. The streaming pipeline minimizes CPU memory usage and ensures that effective batch composition accurately reflects the intended mixture proportions. We further observed that introducing a periodic call to torch.cuda.empty_cache() effectively mitigates memory fragmentation, preventing sporadic latency spikes and helping maintain consistent per-step training times during prolonged runs. To improve computational efficiency, we leverage Liger Kernels, which provide fused and memory-optimized implementations for Rotary Position Embedding (RoPE), RMSNorm, and Cross-Entropy operations. These kernels enable significant memory savings and throughput improvements during training by reducing redundant memory reads and kernel launch overheads (details in Section A).
Data-parallel Balance Tokens: Supervised fine-tuning with long reasoning traces combined with short instruction-response pairs (as depicted in Figure 2) induces a bias when training with data parallelism (DP). In standard DP, each rank may process batches with widely varying numbers of valid tokens. When the loss is averaged locally on each rank, every rank contributes an equally weighted loss to the global optimization step, irrespective of the actual number of valid tokens processed, which can yield large or noisy gradients from ranks processing short sequences. To overcome these imbalances, we employ a balanced data-parallel token normalization strategy which has been proved to be effective in our ablations. Essentially, for each DP rank r, let ℓ The data-parallel balanced loss across each DP rank r expresses as
where ε stands for some small value for numerical stability. Notably, this balanced data-parallel token normalization ensures that each token in the global batch contributes equally to the optimization step, regardless of sequence length. This is especially important for reasoning SFT, where training samples range from ultra-long chain-of-thought annotations and multi-step reasoning traces to short instruction-following examples. The procedure reduces gradient variance, stabilizes training, and prevents certain sequence lengths from being over-or under-weighted, resulting in more consistent and balanced training updates.
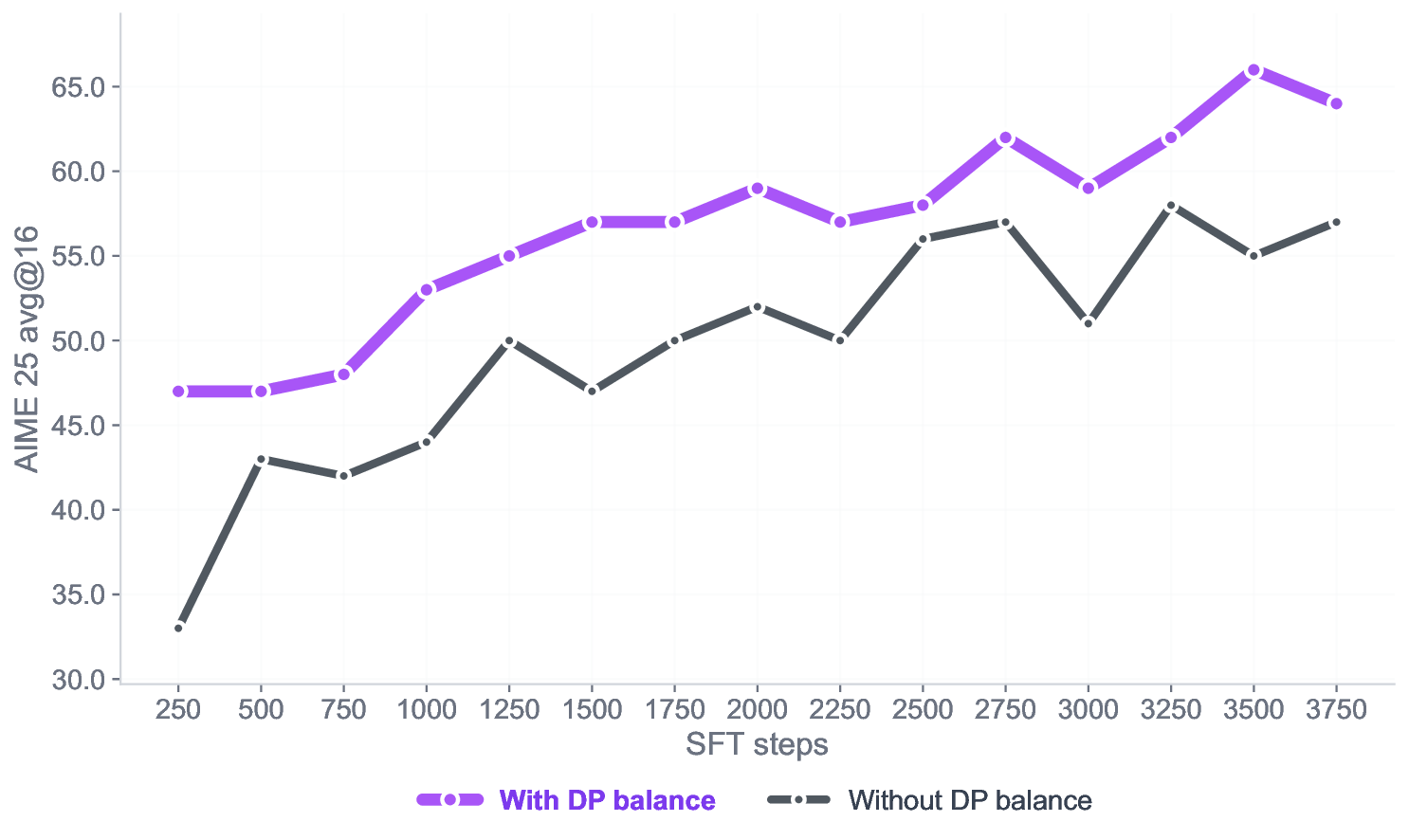
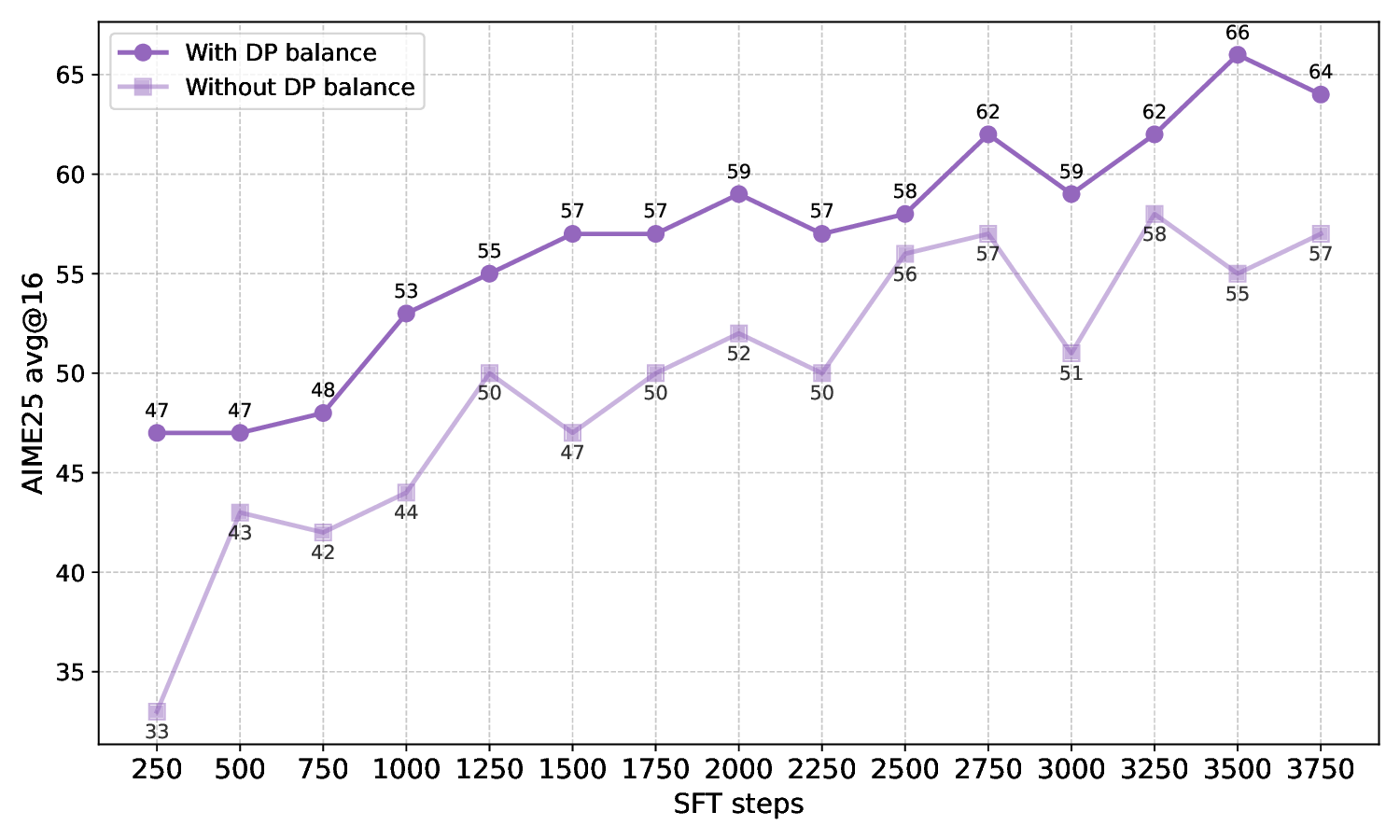
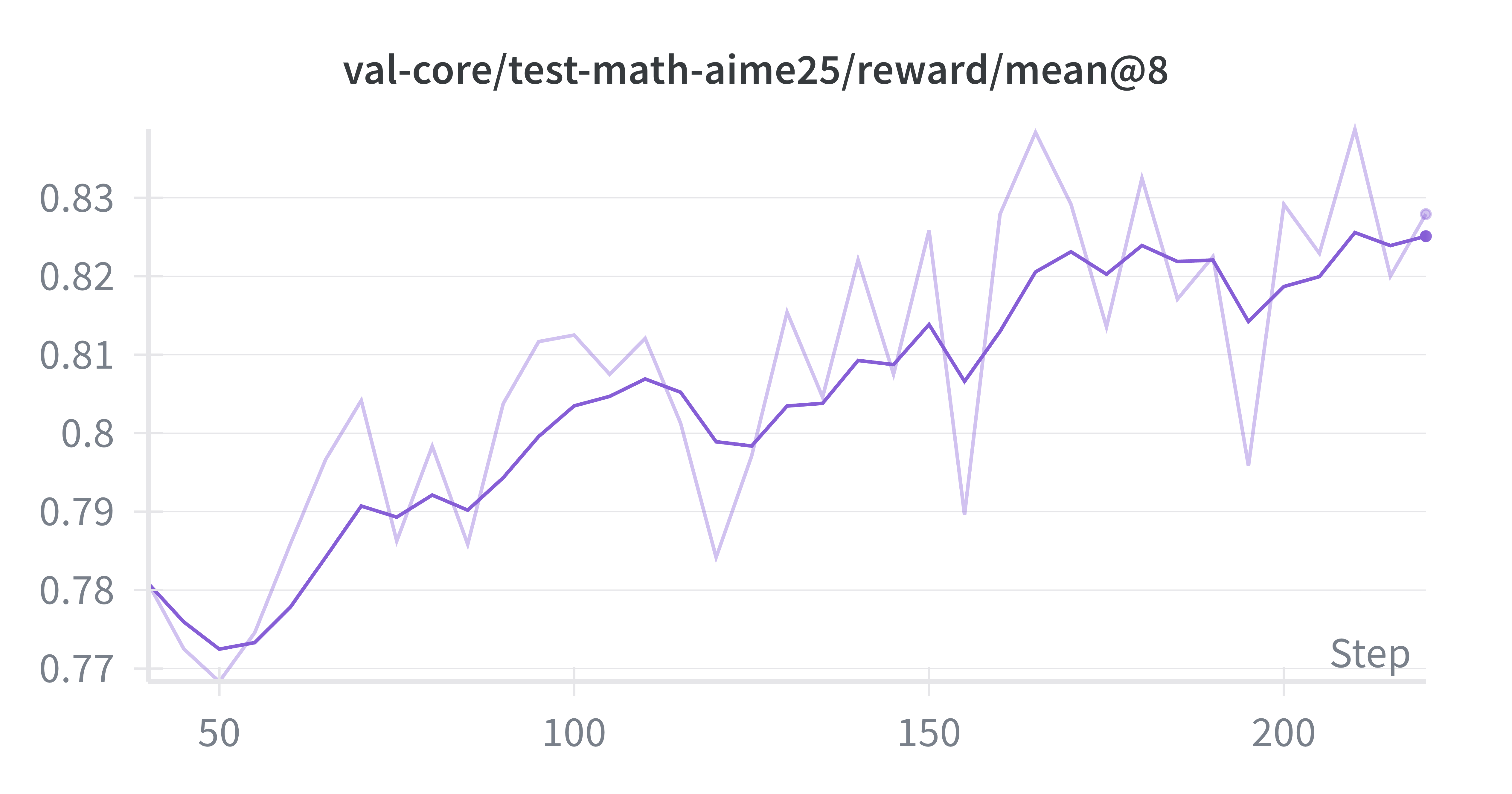
Figure 4 shows the performance gap on the AIME-25 benchmark during the first 3,750 SFT training steps of the Falcon-H1R-7B model, comparing models trained with and without Balanced Data-Parallel (DP) Token Normalization using our final data mixtures. This improvement is made possible by the verl (Sheng et al., 2024) update introduced in PR3 , which enables correct aggregation of global token counts across data-parallel ranks. The impact is both substantial and consistent: models using Balanced DP Token Normalization achieve 4-10% higher accuracy throughout training. These results demonstrate that equalizing per-token gradient contributions across heterogeneous batches, particularly when handling both long and short reasoning sequences, reduces gradient noise and stabilizes learning, leading directly to improved reasoning performance during SFT.
After completing the supervised fine-tuning (SFT) stage, we performed Reinforcement Learning with Verifiable Rewards (RLVR) to further enhance the reasoning capabilities of the model, i.e., improve pass@14 . Although the SFT model performed already well on reasoning benchmarks, the RLVR-stage further showed some extra boost in model’s reasoning performance while simultaneously improving output quality, for example, by controlling response length. To achieve these goals, we developed a custom RL framework on top of the verl5 library to perform GRPO-based RLVR. In the following subsections, we describe in detail our RL methodology, including data sources and curation techniques, training setup, and ablation studies conducted to produce the final model.
For the RL stage, we curated high-quality datasets focused on mathematics and coding. Each dataset was rigorously verified and filtered by difficulty to ensure effective learning of the model and control the distribution of problems’ difficulties. To prevent memorization, the RL datasets are entirely disjoint from the SFT data, ensuring that improvements result solely from reward-based optimization rather than exposure to previously seen examples.
Data Curation: To ensure consistent and reliable reward signals, ground-truth solutions were thoroughly verified across all domains before inclusion. For math, we excluded problems with answers that cannot be reliably verified by our rule-based checker. For coding, both curated and generated test cases were used to assess functional correctness and generalization across diverse programming tasks. We then filtered the training data based on problem difficulty estimated using different methods, based on data availability: (i) Publicly available difficulty metadata when provided. (ii) Pass-rate statistics when ground-truth solutions are available. (iii) Predicted difficulty from an LLM-based classifier otherwise. Data Processing: As illustrated in Figure 9, the data processing stage for RL consisted of the following steps:
Deduplication: We first de-duped all the math and code data against the original SFT data to ensure no overlap between training stages.
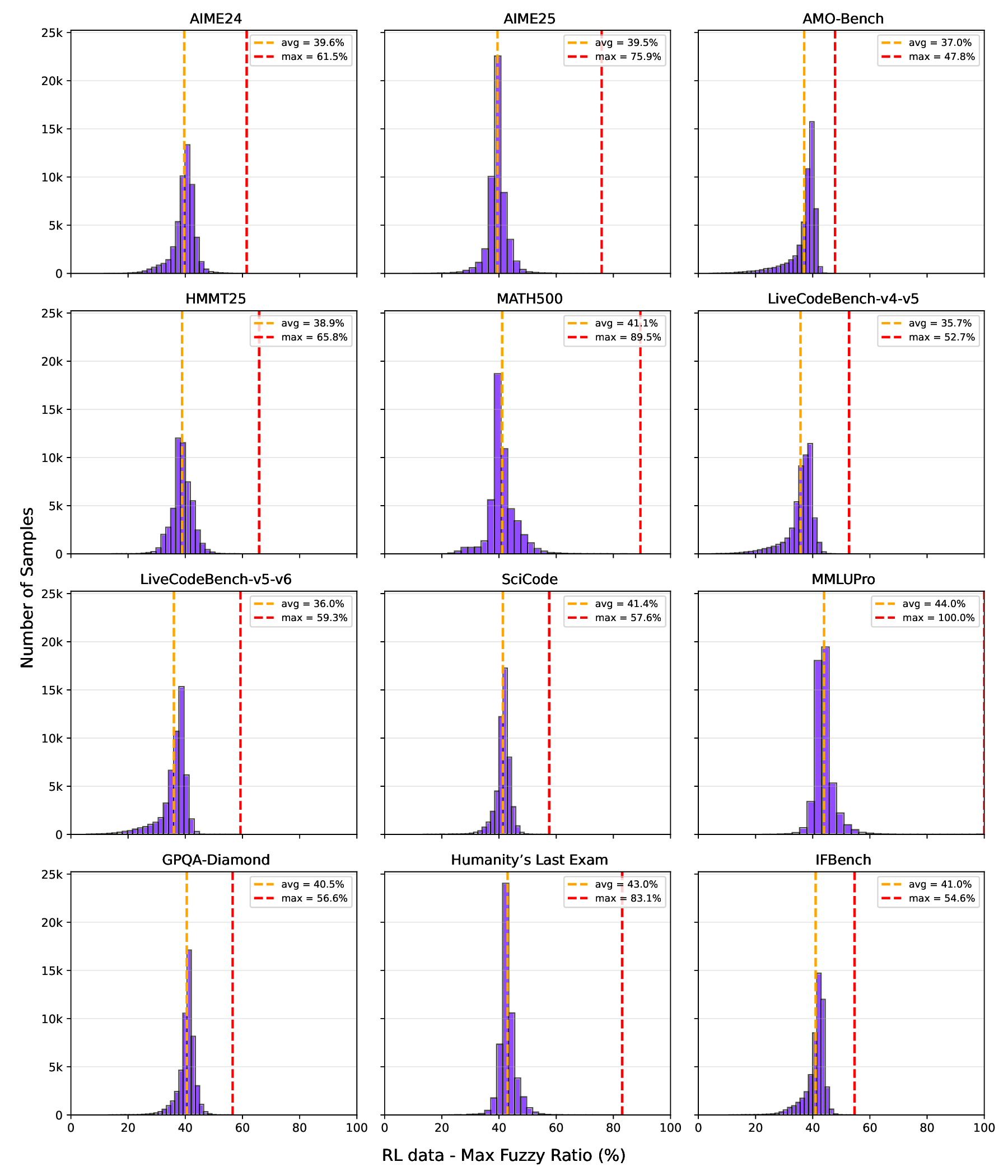
To evaluate the difficulty of the curated dataset relative to the SFT model and filter it accordingly, we generated 8 solution rollouts for each problem using the sampling parameters (τ = 0.6, p = 0.95, max-tokens = 32K). The percentage of correct solutions served as a proxy for difficulty. The filtering process was performed as follows:
(a) Easy problems were removed: Problems with 100% success rate were discarded.
(b) Hard problems were undersampled: For problems with 0% success rate:
(i) Problems where all solutions exceeded the token limit were majorly filtered out, and a small subset of truncated-solutions was retained through random sampling. (ii) For the remaining problems, the majority vote and its frequency were computed. (iii) Problems where the majority vote frequency ≥ 4 were removed.
The final math dataset after the above filtering exhibited a mirrored J-shaped distribution similar to (An et al., 2025a) as depicted in Figure 5.
Algorithm: Starting from the standard GRPO approach (Guo et al., 2025), which corresponds to the following objective:
where the group-relative advantage, A i,t is defined as
and D KL is the KL-penalty term defined as:
We incorporated additional techniques, proven effective in the literature, to avoid training instability due to slow convergence, policy collapse, or training-inference mismatches. These adjustments targeted sampling strategies, loss functions, and computation efficiency for improved stability and convergence. The incorporated GRPO changes are detailed as follows:
• Clip high, no KL-penaly and Entropy terms (Yu et al., 2025;Liu et al., 2025): Following (Yu et al., 2025, Section 3.1), we modify the upper importance sampling threshold. This adjustment encourages more exploratory token generation by preventing the policy from becoming overly conservative during training. Both the KL-penalty and entropy regularization terms β D KL (π θ ∥ π θ old ) and γ Entropy(π θ ) are removed entirely by setting β = 0 and γ = 0. This allows deviations from the old policy thereby allowing more exploration. In our setting, keeping the exploration bonus γ strictly positive was not necessary as the training with γ = 0 was relatively stable.
• Truncated Importance Sampling (TIS) (Yao et al., 2025): To reduce mismatch between sampling-time and training-time behavior, we incorporate the TIS correction, ensuring closer alignment between the model’s inference dynamics and its optimization updates.
• Cross Entropy Loss (Seed et al., 2025): We add a cross-entropy loss term computed exclusively on positive (correct) samples. This auxiliary objective accelerates convergence by providing additional direct supervision signal while maintaining the benefits of the policy gradient approach.
• Online Sampling (Yu et al., 2025): A challenge in GPRO training arises when entire batches contain zero-advantage samples-cases where all rollouts are uniformly correct or uniformly incorrect. Although these samples provide no policy-gradient signal, they still influence auxiliary losses such as the entropy bonus or supervised loss, which can destabilize training. To mitigate this, we evaluated three strategies:
Backfill: Discard zero-advantage prompts and iteratively draw additional samples from later batches until the target batch size is met.
Reject: Perform strict rejection sampling, allowing the batch size to vary depending on the number of valid samples.
Duplicate: Randomly duplicate positive-advantage samples to restore the batch size after filtering.
In our ablations, we found that the backfill approach provided the most stable performance, which we then adopted for our final setup. To improve the efficiency of the backfill strategy, we introduced a generation caching system with a bounded buffer in the same spirit as (Team et al., 2025a). This mechanism addresses a key inefficiency: when additional samples are needed to complete a batch, standard backfill often generates excess rollouts that are discarded, wasting computation. Our cache stores these surplus prompts for future use, with a fixed size to prevent staleness and optional periodic refreshes to ensure samples remain relatively on-policy. This approach reduces generation calls by approximately 30% while maintaining the freshness of training data through careful cache size limits and periodic refreshing.
We employ different reward schema for each domain: math reasoning, code generation and science reasoning. The reward orchestration layer dynamically selects the appropriate reward schema based on the task domain. Reward computation is executed in a distributed manner using Ray with AsyncIO coordination, while ThreadPoolExecutor accelerates I/O CPU-bound workloads.
• Math Reward: For mathematical tasks we use a binary reward system based on the correctness of the final extractable answer within the response. We employ a two-tier verification system wherein the first tier extracts and validates answers using LaTeX string matching and symbolic equivalence checks for fast heuristics. If tier one marks a response as incorrect, a semantic verification fallback using math-verify6 is triggered to handle more complex ground truths and provide additional validation.
• Code Reward: The execution backend for the code reward system is based on Sandbox-Fusion7 . To maximize concurrency and reduce reward evaluation latency, we deploy multiple instances of the Sandbox-Fusion execution engine using Docker containers. The main execution flow of the reward design is as follows:
Code extraction and language detection: Locate fenced code blocks using regex and detect programming language (Python, Java, C++, C, JS, Bash, Go, etc.).
To ensure efficient and scalable evaluation across the different sandboxes, we randomly select up to a configurable number of test cases from each data sample.
The payload is submitted via an HTTP request to the sandbox API in a round-robin dispatch across distributed sandbox instances. Just as for math, we use Boolean pass or fail reward with reward 1.0 assigned only in the event all tests pass.
• Science Reward: We also implemented a reward system using an LLM served through parallel vLLM instances to evaluate output correctness, especially in cases where traditional mathbased reward functions struggle with complex ground truths, such as in science problems.
The LLM judge takes the prompt, extracted answer, and ground-truth solution as input and produces a single scalar value that indicates whether the response is correct.
• Format Reward: Additionally, we penalize incoherent outputs and the use of mixed languages by applying a format-specific penalty for responses that do not adhere to the CoT Answer structure.
We conducted two forms of ablation studies. First, we explored various GRPO hyperparameters-including rollout sampling strategy, generation length, reward model configuration, and other optimization settings-to identify the optimal configuration for our training framework. Second, we investigated the best training strategy for mixing multiple data domains by experimenting with a range of RL setups, e.g., feeding data domains sequentially in multiple RL stages versus a combined RL stage with mixing data domains. Below, we summarize the selected hyperparameters (see Table 2) and present the results for each training setup.
The RL training hyperparameters were selected to ensure maximum diversity among rollouts and to manage the model’s response length. We summarize below the key choices.
• Group Size (G): We experimented with different group sizes, G ∈ {4, 8, 16, 32}. Increasing the number of rollouts from G = 4 to G = 16 improved response diversity and led to better performance on our downstream evaluations. However, further increasing to G = 32 did not yield significant gains and substantially increased generation time.
• Max Response Length (L max ): Given the large response lengths generated by the SFT model, L max proved to be an important parameter for maximizing RL performance. We experimented with both relatively shorter maximum lengths, L max = 24k tokens, and much longer lengths, L max = 48k tokens. Ultimately, we found that, similar to the conservative approach adopted by (An et al., 2025a), gradually allowing the model to think longer from the beginning by setting L max = 48k was best suited for our SFT model and led to the highest performance.
• Sampling Temperature (τ ):
The training temperature was selected to balance two competing objectives: maintaining sufficient diversity in generated rollouts to encourage exploration, while preserving strong model performance. Following the methodology in (An et al., 2025a), we conducted a systematic evaluation of the SFT model’s accuracy across different sampling temperatures on the AIME24 benchmark. For training, we selected a temperature within the Controlled Exploration Zone as described in (An et al., 2025a) to be a transitional region where accuracy begins to decline moderately while diversity increases substantially. • Entropy Control (γ): After tuning G and τ to achieve sufficient rollout diversity, we observed that the policy entropy remained stable without explicit entropy regularization. Therefore, we set γ = 0.
• KL coefficient (β): In line with the findings in (Yu et al., 2025), we removed the KL divergence term to allow the model to explore more freely beyond the limits of the original SFT model.
To determine the optimal training setup and data for our RL experiments, we conducted a series of ablation studies to assess how different task-domain sampling strategies influence model performance. We evaluated mathematical reasoning using the AIME25 benchmark, code generation using LCB v6, and scientific reasoning using GPQA-Diamond. All experiments were run until performance gains plateaued, and we report the best observed results in Table 3. Our analysis focused on the following experimental strategies:
• Math-Only: This ablation was conducted exclusively on math-reasoning problems, with rewards computed using the math reward function. It served as our primary setting for understanding model behavior under RL and for tuning core hyperparameters.
Consistent with our SFT findings, incorporating math-focused data during RL was essential for achieving strong accuracy gains across reasoning-heavy benchmarks. Math remained the dominant contributor to downstream performance for our training setup.
• Code-Only: To isolate performance improvements relevant to code generation, we trained solely on code-reasoning tasks using the code-sandbox reward model. This experiment aimed to assess the upper bound of code-centric performance achievable under our RL setup. Table 3: RL ablation results across different task domains.
• Science-Only: To evaluate whether science-oriented training improved scientific reasoning for our setup, we trained exclusively on science tasks scored by an LLM-based evaluator.
RL using an LLM-as-a-judge reward model for science tasks did not yield meaningful improvements on GPQA-Diamond, suggesting either limited coverage of science capabilities or insufficient signal quality from the LLM evaluator.
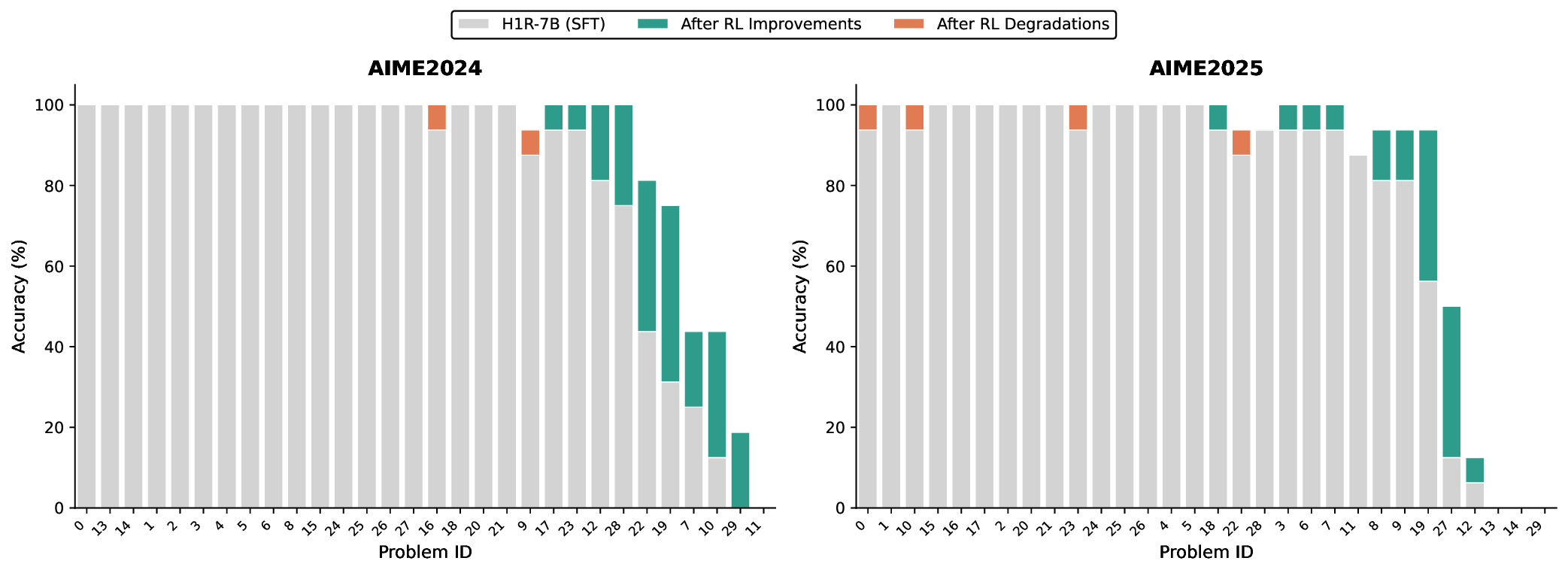
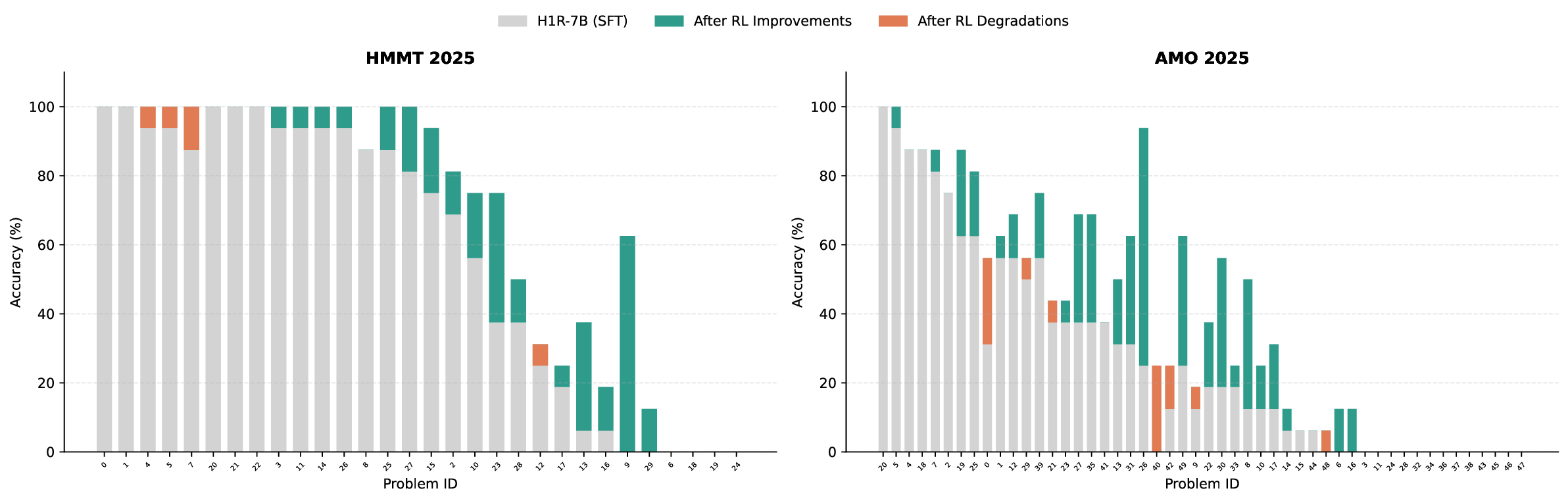
• Code Followed by Math: The two-stage curriculum took the checkpoint from Math-Only training and added a Code-Only stage on top. The goal was to assess whether gains from code training compound when followed by math-focused refinement. Prior to training, we re-evaluated the difficulty distribution of our code dataset relative to the Stage 2 checkpoint. This analysis revealed a significant shift in distribution compared to the SFT baseline: many problems that were previously unsolvable by the SFT model became solvable after the two stages of math-focused RL training.
Across the main math and code reasoning benchmarks, the sequential curriculum-math training followed by code training-achieved the best average performance across the benchmarks in Table 3, although the gains were more modest.
• Math and Code Combined: In this mixed-domain setting, each batch contained a blend of math and code problems. The ablation was done to test whether joint training offered complementary benefits compared to sequential or single-domain approaches. In our training setup, this strategy did not outperform the alternatives, suggesting that domain interleaving offers only a limited advantage over domain-focused training.
Our final Falcon-H1R-7B RL training was performed using the hyperparameters in Table 2. The training was conducted on 256 H100 GPUs using our custom GRPO framework built on verl.
The curriculum consisted of a single Math-Only stage aimed at progressively enhancing reasoning capabilities while carefully managing sequence length, domain specialization, and exploration efficiency. We chose this single-stage design because, according to our ablation studies (see Table 3), although adding a separate code stage yielded marginal improvements on the main benchmarks, it led to a decrease in average performance across the broader benchmarks we report in Section 4.
Prior to training, as illustrated in Figure 5, we filtered the mathematics dataset by difficulty using the pass rate from the SFT checkpoint. Training was then initialized with this curated set of mathematics-only data. We set the maximum response length to 48K tokens and used a sampling temperature of τ = 0.85. This higher temperature encouraged more diverse reasoning during rollouts, allowing the model to explore a broader range of solutions. Additionally, the following system prompt was applied during training.
You are Falcon, a helpful AI assistant created by Technology Innovation Institute (TII). To answer the user’s question, you first think about the reasoning process and then provide the user with the answer. The reasoning process is enclosed within tags, i.e., reasoning process here answer here.
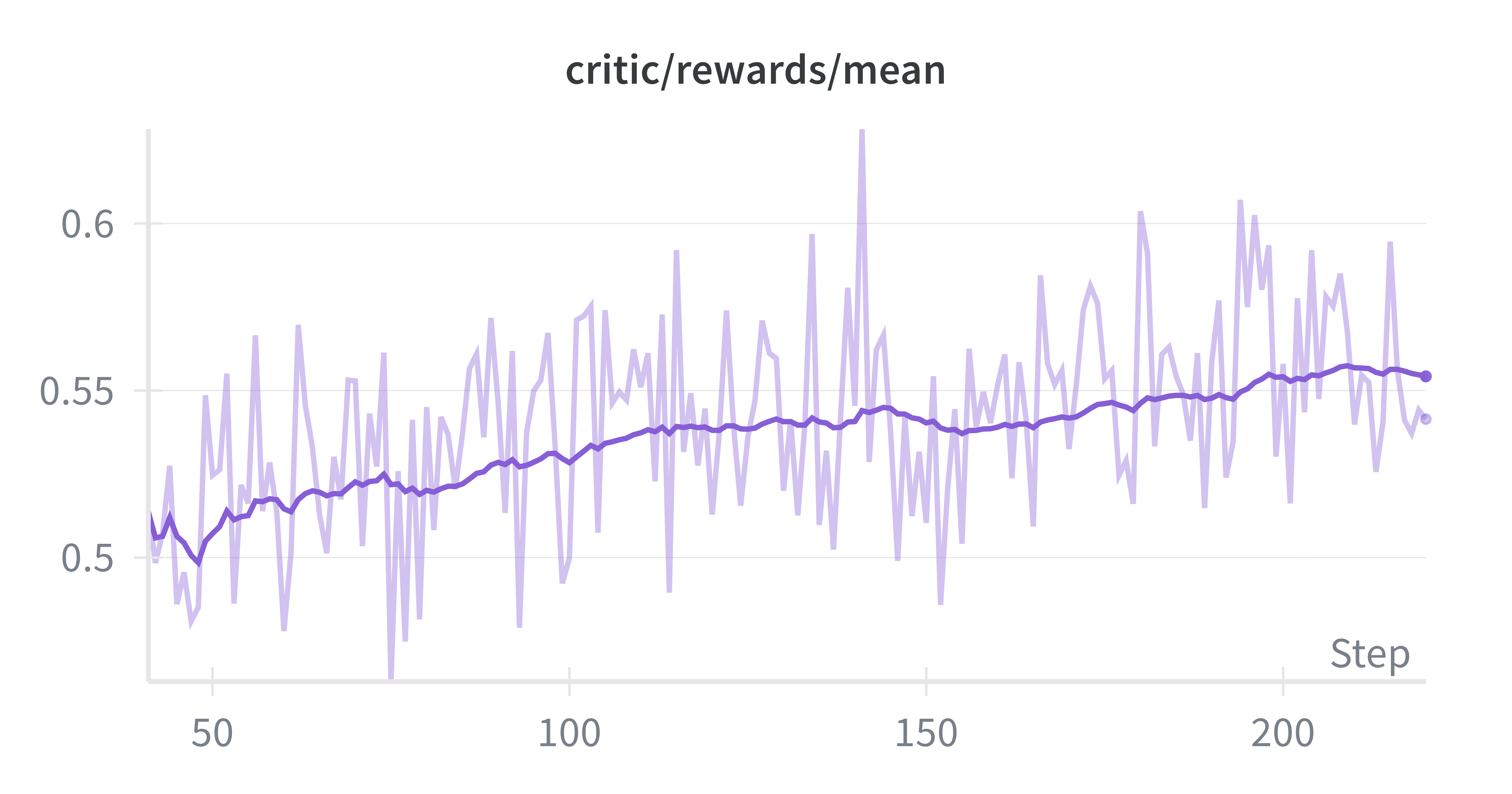
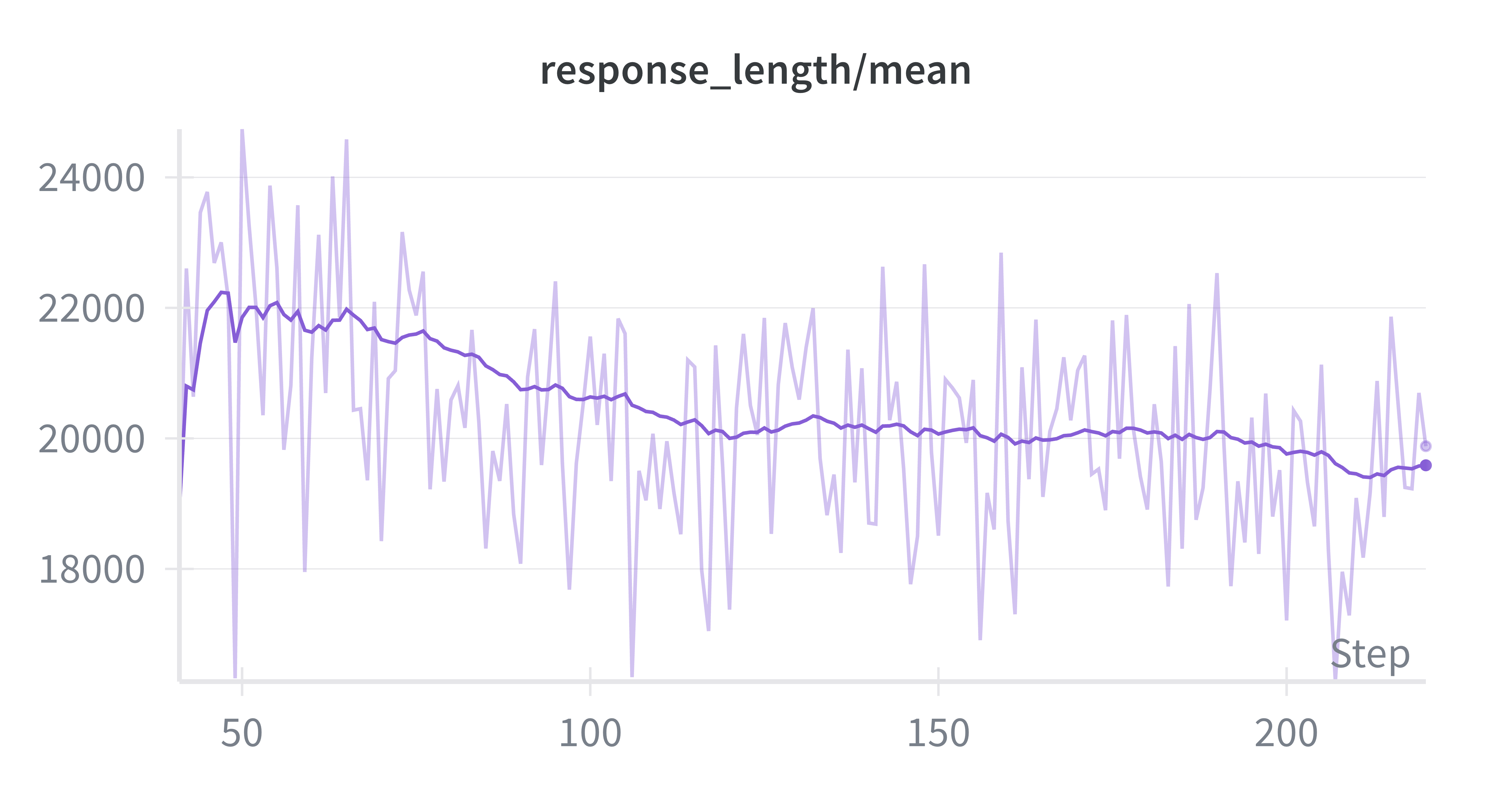
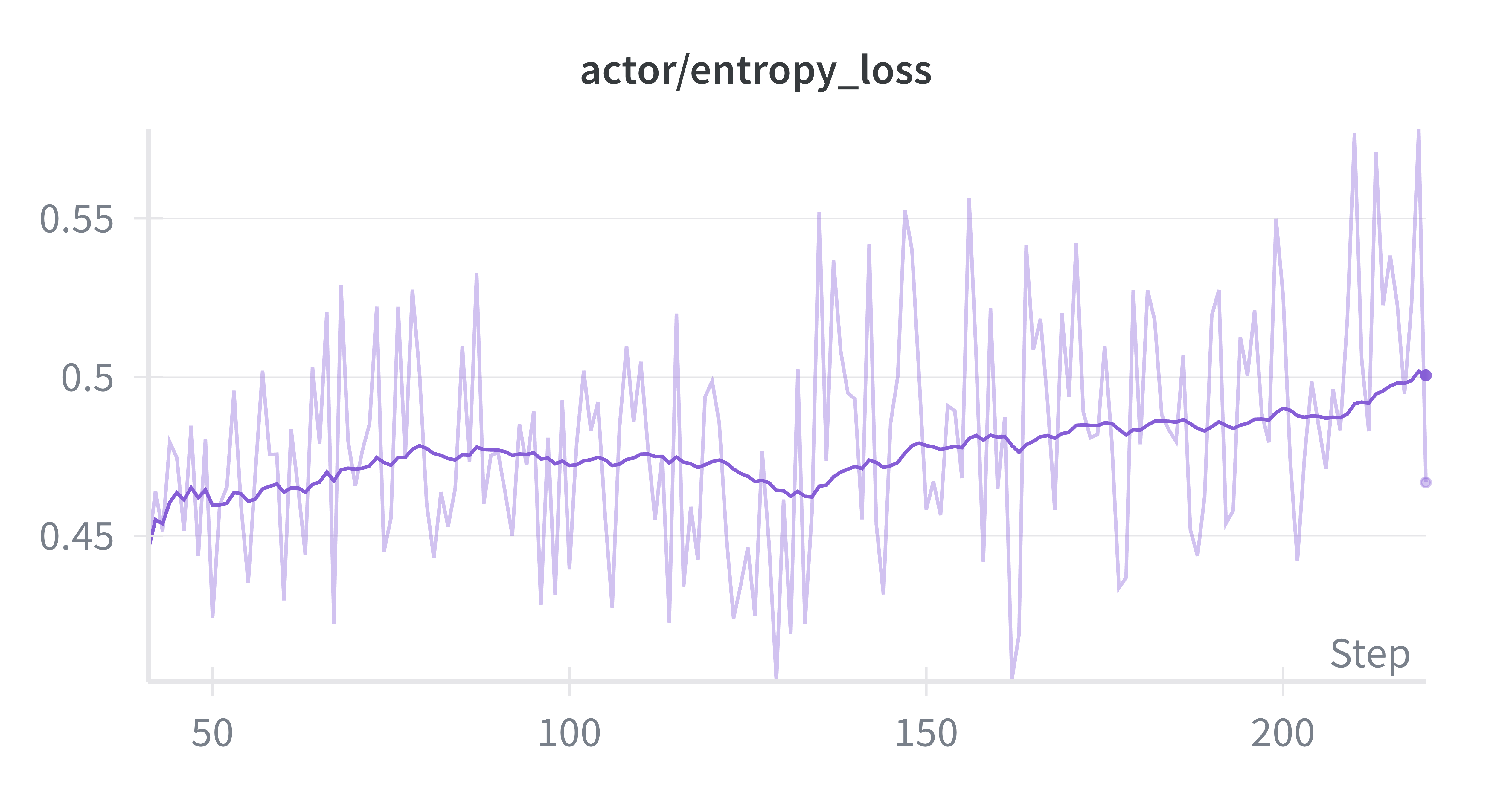
Training Dynamics and Monitoring: Throughout the training run, we monitored several key metrics to ensure stable optimization. The mean reward showed consistent improvement (Figure 6a), while average response length stabilized at 20k as the model learned to refined its reasoning (Figure 6b) across Stage 1. The entropy loss remained stable across training (Figure 6d), suggesting healthy exploration without collapse. The actor’s policy-gradient clipping fraction remained below 1%, indicating that updates were rarely clipped and optimization dynamics remained smooth.
This section introduces the reasoning benchmarks and the evaluation methodology and results to assess the performance of Falcon-H1R-7B. Additional safety evaluations of our model are presented in Appendix E.
We evaluated our model using a diverse set of challenging reasoning benchmarks, organized into three categories: Math (AIME24, AIME25, HMMT25, AMO-Bench, MATH500), Code (Live-CodeBench v6, SciCode, τ 2 -Telecom, Terminal Bench Hard), and General (GPQA-Diamond, MMLU-Pro, Humanity Last Exam, IFBench). For convenience, brief descriptions of each benchmark are presented in Table 9. In our evaluations, we report pass@1 with the following settings: For our model’s evaluation, we used the system prompt described in the previous section and set the sampling parameters to a temperature of 0.6 and a Top-p value of 0.95. In particular,
• For MMLU-Pro, Humanity’s Last Exam (HLE), and GPQA-Diamond, we adopt the prompts and answer extraction regular expressions provided by Artificial Analysis (AA)8 . Consistent with AA’s methodology, we use OpenAI’s GPT-4o as the equality checker for HLE.
• Terminal-Bench (TB) Hard evaluates 47 ‘hard’ tasks from the terminal-bench-core dataset (commit 74221fb) using the Terminus 2 agent. Each task is capped at 100 episodes and a 24-hour timeout, with model configurations set to the framework’s default values.
• For τ 2 -Bench Telecom, each task is limited to 100 steps, and the Qwen3 235B A22B 2507 (Non-reasoning) model acts as the user agent simulator.
• SciCode is evaluated using InspectAI9 as recommended by the SciCode repository10 , and correctness is measured at both sub-problem and full-problem levels.
• For HLE, we evaluate 2,158 text-only problems. For TB Hard, τ 2 -Bench Telecom, and Sci-Code, we repeat each evaluation three times and report the average result.
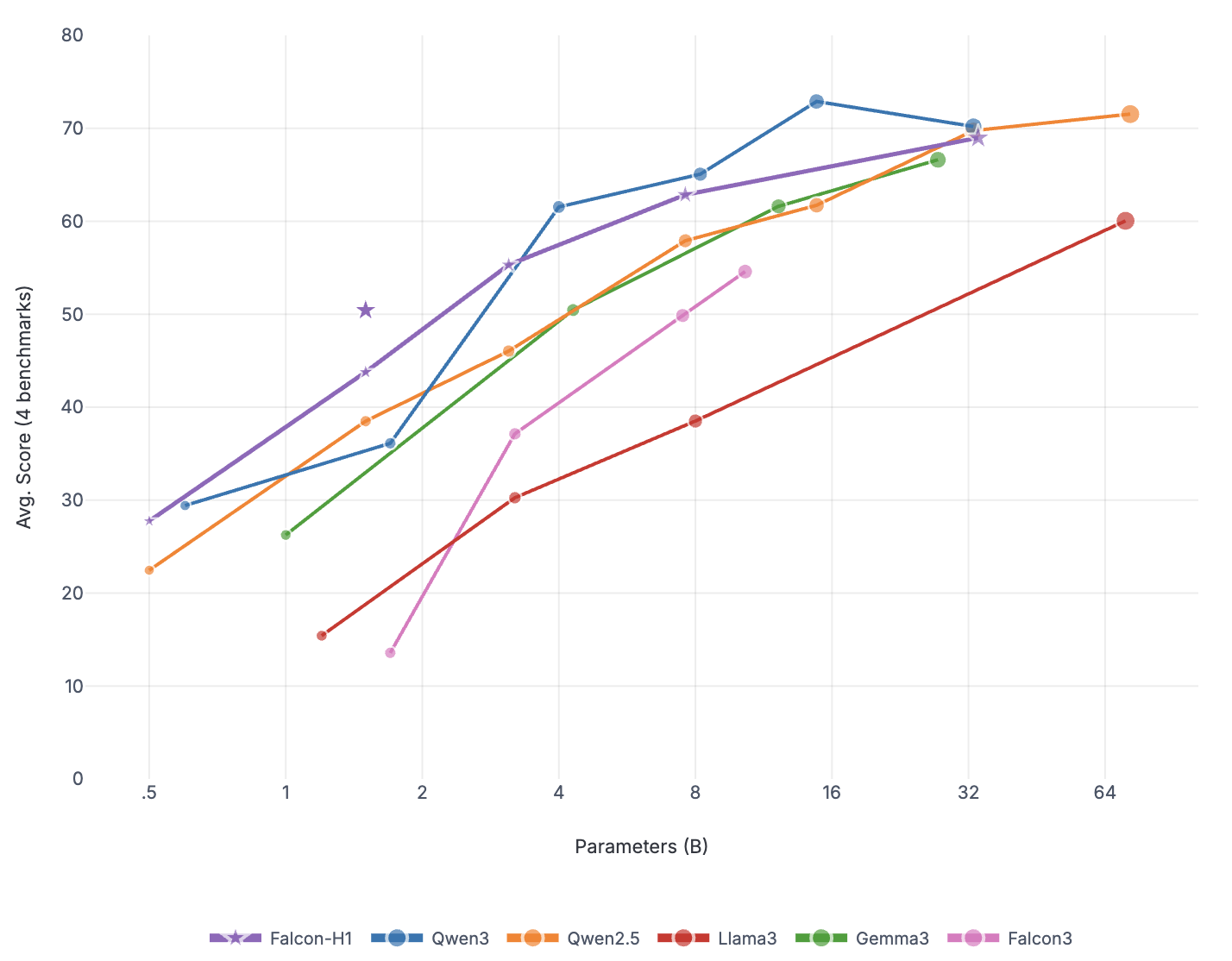
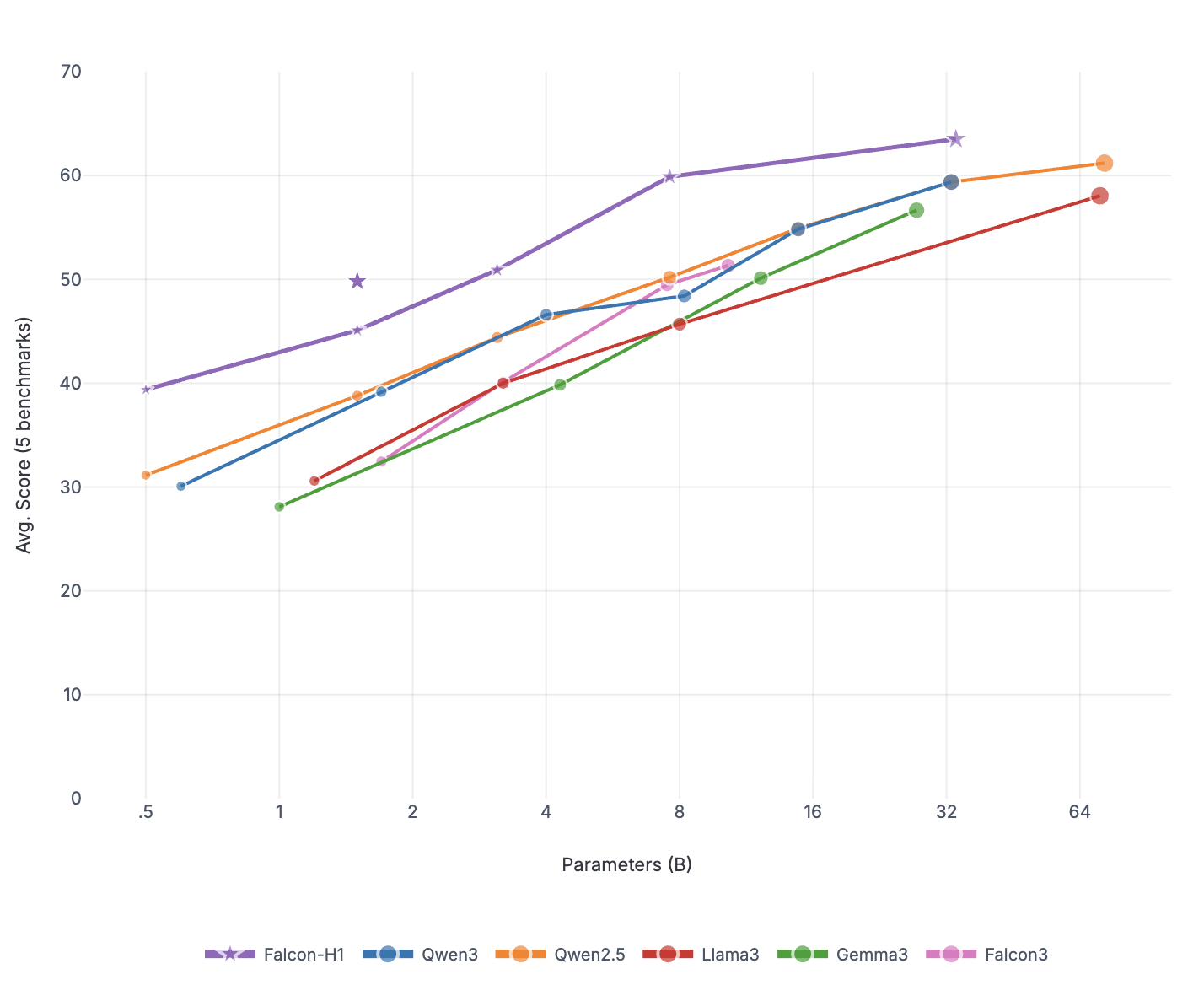
To compare performance, we evaluated a range of state-of-the-art (SOTA) models across 7B-32B parameter ranges, using each baseline’s recommended evaluation configurations. For the 7B category, we included leading models such as Qwen3-8B (Qwen Team, 2025) and DeepSeek-R1-0528-Qwen3-8B (Guo et al., 2025). In the mid-size range, we evaluated Phi-4-Reasoning-Plus-14B (Abdin et al., 2025), Apriel-1.5-15b-Thinker (Radhakrishna et al., 2025), GPT-OSS-20B (OpenAI, 2025), and Qwen3-32B (Qwen Team, 2025). We also included Nemotron-H-47B-Reasoning (Blakeman et al., 2025), which represents the current leading hybrid reasoning model.
To ensure the integrity of our evaluations, we thoroughly analyzed our training datasets for contamination across all considered benchmarks. Our results revealed extremely low contamination levels. Specifically, exact string matching indicated 0% contamination for all benchmarks except MMLU-Pro, which showed near-zero levels: 0.0005% for our SFT mixture and 0.035% for the RL data.
Evaluation results for Math, Code, and General benchmarks are shown in Tables 4,5, and 6, respectively. Falcon-H1R demonstrates competitive performance across all tasks, matching or exceeding state-of-the-art reasoning models, despite having a significantly smaller parameter count.
Mathematical Reasoning: Falcon-H1R demonstrates exceptional mathematical reasoning capabilities, achieving the highest scores on AIME24 (88.1%), HMMT25 (64.9%), AMO-Bench (36.3%), and MATH500 (97.4%), and second place on AIME25 (83.1%). Notably, our model surpasses much larger models, including Qwen3-32B, Nemotron-H-47B-Reasoning, and GPT-OSS-20B. On the AMO-Bench, which features advanced mathematical olympiad problems, Falcon-H1R scores 36.3%, exceeding the next best model (GPT-OSS-20B) by over 10 percentage points. These results indicate that our training methodology enables strong generalization on complex, multi-step mathematical reasoning tasks.
Falcon-H1R stands out for its parameter efficiency. With just 7B parameters, it consistently matches or outperforms models that are two to seven times larger-including Phi-4-Reasoning-Plus-14B, Apriel-1.5-15B-Thinker, GPT-OSS-20B, Qwen3-32B, and Nemotron-H-47B-Reasoning-on reasoning-intensive benchmarks. These results highlight how careful data curation and training strategies can deliver significant performance gains without scaling model size.
The parallel-hybrid design of the Falcon-H1R architecture enables efficient inference even under high batch-size settings (see Appendix B for details). This capability is especially important for test-time scaling techniques that rely on parallel reasoning. To showcase Falcon-H1R’s performance in such scenarios, we evaluate the model using the recent Deep Think with Confidence (DeepConf) method (Fu et al., 2025b). DeepConf is an efficient test-time scaling approach that dynamically filters parallel reasoning chains based on confidence scores derived from the model itself. By terminating low-confidence reasoning paths early and allowing only high-potential chains to continue, DeepConf further reduces computational overhead.
The settings of our TTS evaluations are detailed as follows:
• Adaptive Sampling Configuration: We use the online algorithm (Fu et al., 2025b, Algorithm 2) with a fixed trace budget of K = 512, where the total cost includes all generated tokens, even those from traces stopped early. The process begins with a warm-up phase that generates N init = 16 traces to determine the stopping threshold s, calculated by applying the Lowest Group Confidence criterion over a sliding window of 2,048 tokens. After the warm-up, we set s at the η-th percentile of the minimum confidence scores from these initial traces, with η = 10% for aggressive filtering. In the final phase, the remaining K -N init = 496 traces are generated with early stopping: each trace is terminated once its current group confidence (computed over the most recent 2,048 tokens) falls below s.
• Generation Parameters: All models are evaluated using their recommended decoding settings, including model-specific temperature T and top-p values as suggested in their official inference guidelines. We set the maximum generation length to 64K tokens per trace, and perform inference using vLLM with tensor parallelism configured based on each model’s parameter size. Each model is conditioned with its recommended system prompt for optimal instruction-following behavior. For Phi-4-Reasoning-Plus-14B and Qwen3-8B/Qwen3-32B, we use reduced context lengths of 32K and 40K tokens, respectively, to accommodate their maximum supported window sizes.
• Answer Extraction: To evaluate model output correctness, we extract final answers using the math_verify parsing framework rather than relying solely on the simple boxed{…} extraction used in the original DeepConf implementation11 . The reference DeepConf repository identifies answers by locating the last boxed{…} expression in the model output. For more robust parsing, we have consider an alternative approach: the math_verify parser first tries to interpret the final mathematical expression as the ground-truth answer, enabling consistent handling of algebraic forms, numerical expressions, and non-LaTeX formatting. If parsing fails, we revert to the boxed-expression extractor.
• Voting Methods: We evaluate below aggregation strategies for determining the final answer from the filtered traces:
Majority Voting: selection the most frequent answer.
: weighting each answer by its mean group confidence.
Tail Confidence-weighted Voting: weighting answers by their minimum confidence scores.
Bottom Window-weighted Voting: uses the confidence of the lowest-scoring window.
Note that across all evaluated models, we find that these voting strategies converge to very equivalent accuracies, indicating that DeepConf filtering produces a high-quality candidate trace set that is robust and flexible to the choice of the aggregation method.
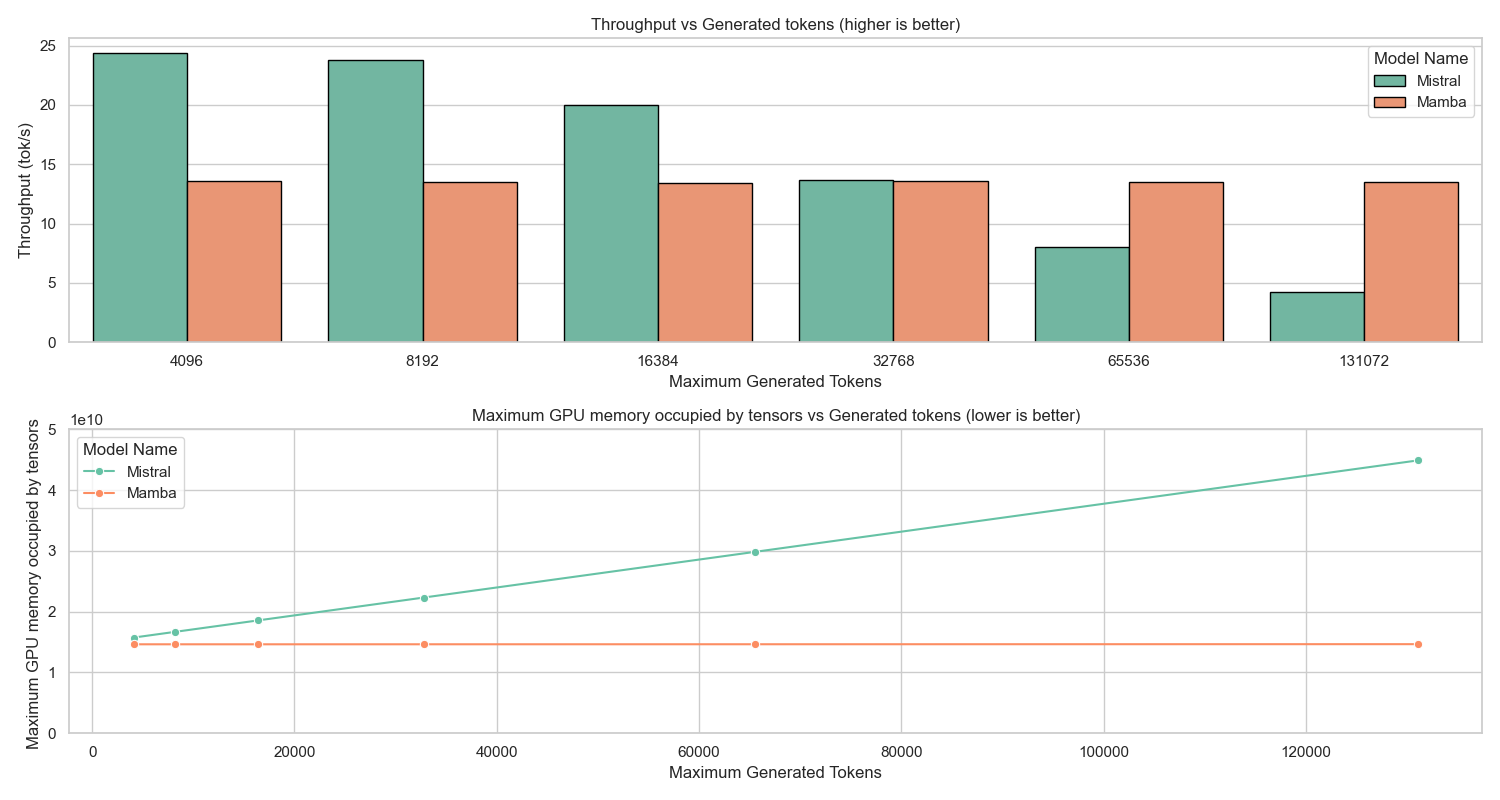
Using the DeepConf approach with the settings describe above, we evaluate our model and competitive baselines on a selected subset of the primary mathematical and scientific reasoning benchmarks, specifically AIME-2024, AIME-2025, GPQA-D, and AMO-Bench. For AMO-Bench, we focus on the parser-verifiable subset, which comprises 39 problems with deterministic correctness verification using automated parsers. Our TTS results are summarized in the table below: Falcon-H1R exhibits superior performance along two key dimensions: solution quality and amount of generated tokens, in addition to the computational efficiency highlighted in Appendix B. It consistently generates substantially fewer tokens while maintaining high accuracy across all benchmarks, reflecting stable confidence calibration and coherent reasoning traces. These results highlight the effectiveness of our training pipeline in producing reasoning models that are both cost-efficient and highly accurate.
The combination of faster inference, token efficiency and higher accuracy makes Falcon-H1R-7B a practical choice for scaling advanced reasoning systems, especially in settings that require substantial parallel chain-of-thoughts generation.
In summary, this report presented Falcon-H1R, a 7B-parameter, reasoning-optimized language model that demonstrates small language models (SLMs) can achieve state-of-the-art reasoning performance typically associated with much larger systems. Through a hybrid Transformer-Mamba architecture and a robust training strategy combining supervised fine-tuning and reinforcement learning, Falcon-H1R delivers competitive accuracy, superior inference efficiency, and substantial reductions in computational cost. The model consistently matches or surpasses larger state-of-theart models on a range of challenging reasoning benchmarks, validating the impact of careful data curation and targeted training via effective SFT and RL scaling. Its efficient architecture enables faster inference, greater token efficiency, and effective parallelization-features that make it wellsuited for advanced reasoning tasks, especially those leveraging test-time scaling (TTS) methods. Falcon-H1R’s integration with the DeepConf approach (Fu et al., 2025a) further enhances its scalability and cost-effectiveness in TTS scenarios, achieving high accuracy while reducing resource consumption. These results highlight the model’s potential as a practical backbone for scalable reasoning systems in real-world applications. Looking forward, this work opens new directions for pushing the limits of SLMs, such as training even smaller models for reasoning, and investigating architectural innovations to maximize efficiency and reliability in test-time scaling.
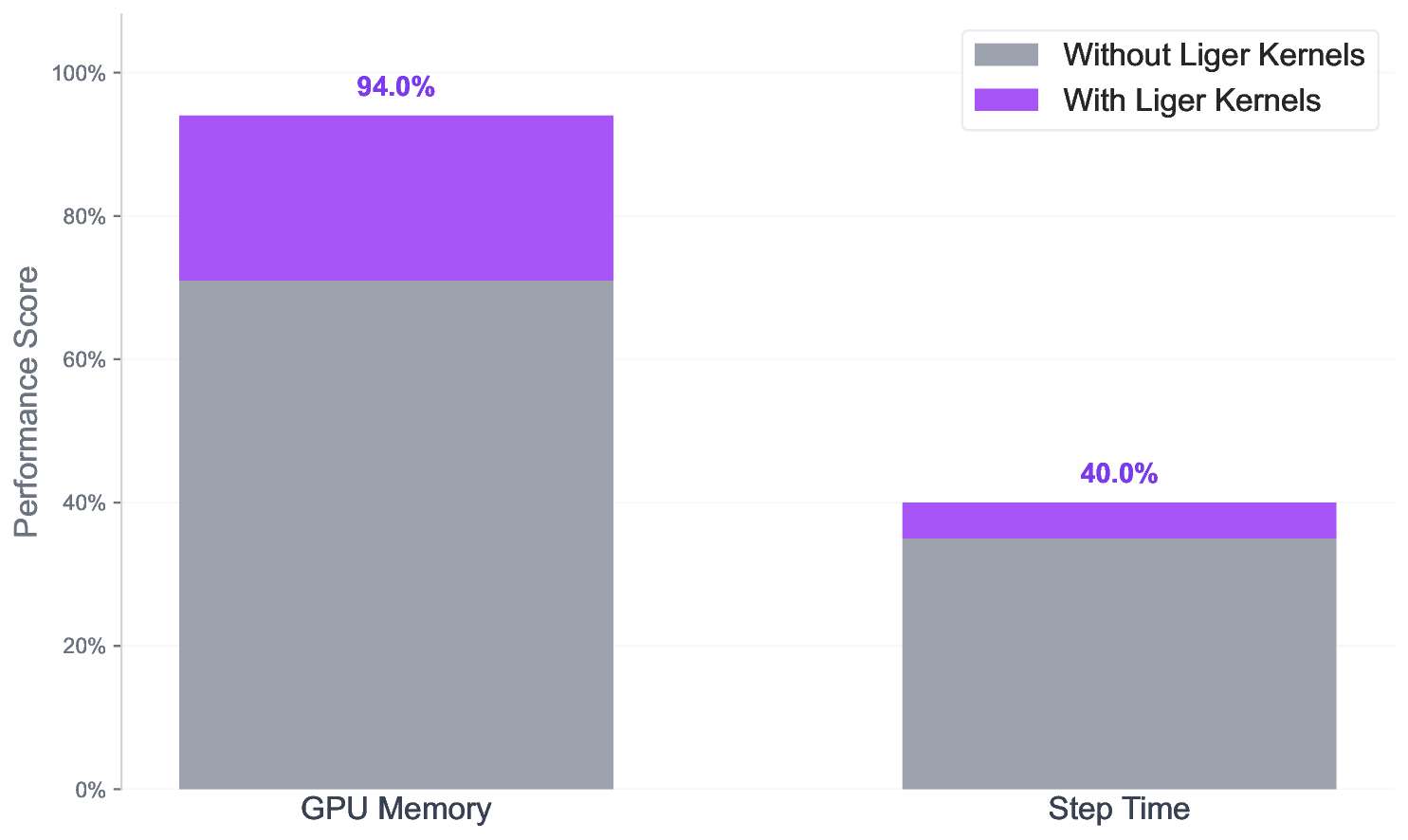
Figure 7 compares GPU memory utilization and per-step training time with and without Liger Kernels enabled. The results demonstrate consistent speedups and a reduced memory footprint for the Falcon-H1-7B model. Falcon-H1 models are now officially supported in the Liger Kernels framework (Hsu et al., 2025) through the following upstream integrations:
In addition to these kernel-level optimizations, we enabled fused AdamW and efficient gradient accumulation support within the verl framework, integrated through:
• https://github.com/volcengine/verl/pull/3692
Together, these improvements reduce optimizer overhead and provide smoother gradient-accumulation behavior for long-context workloads.
Step Time Table 8: Architectural specifications of Falcon-H1R-7B (Falcon- LLM Team, 2025).
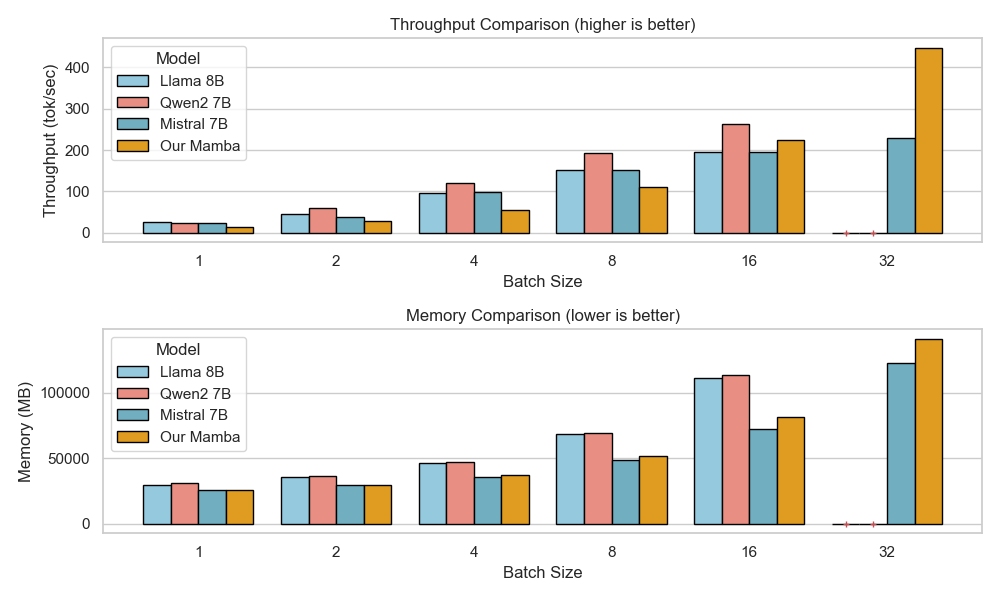
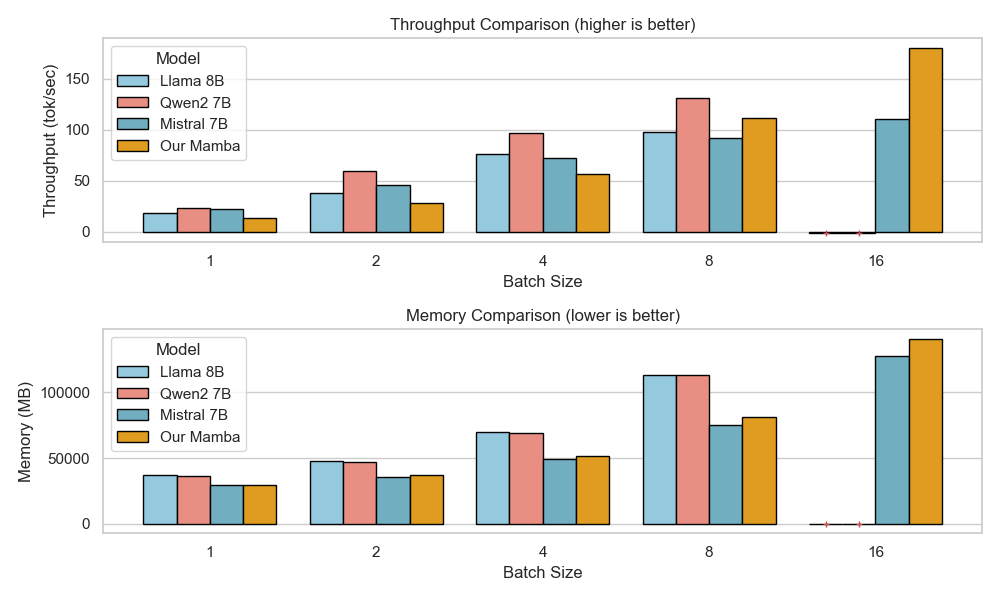
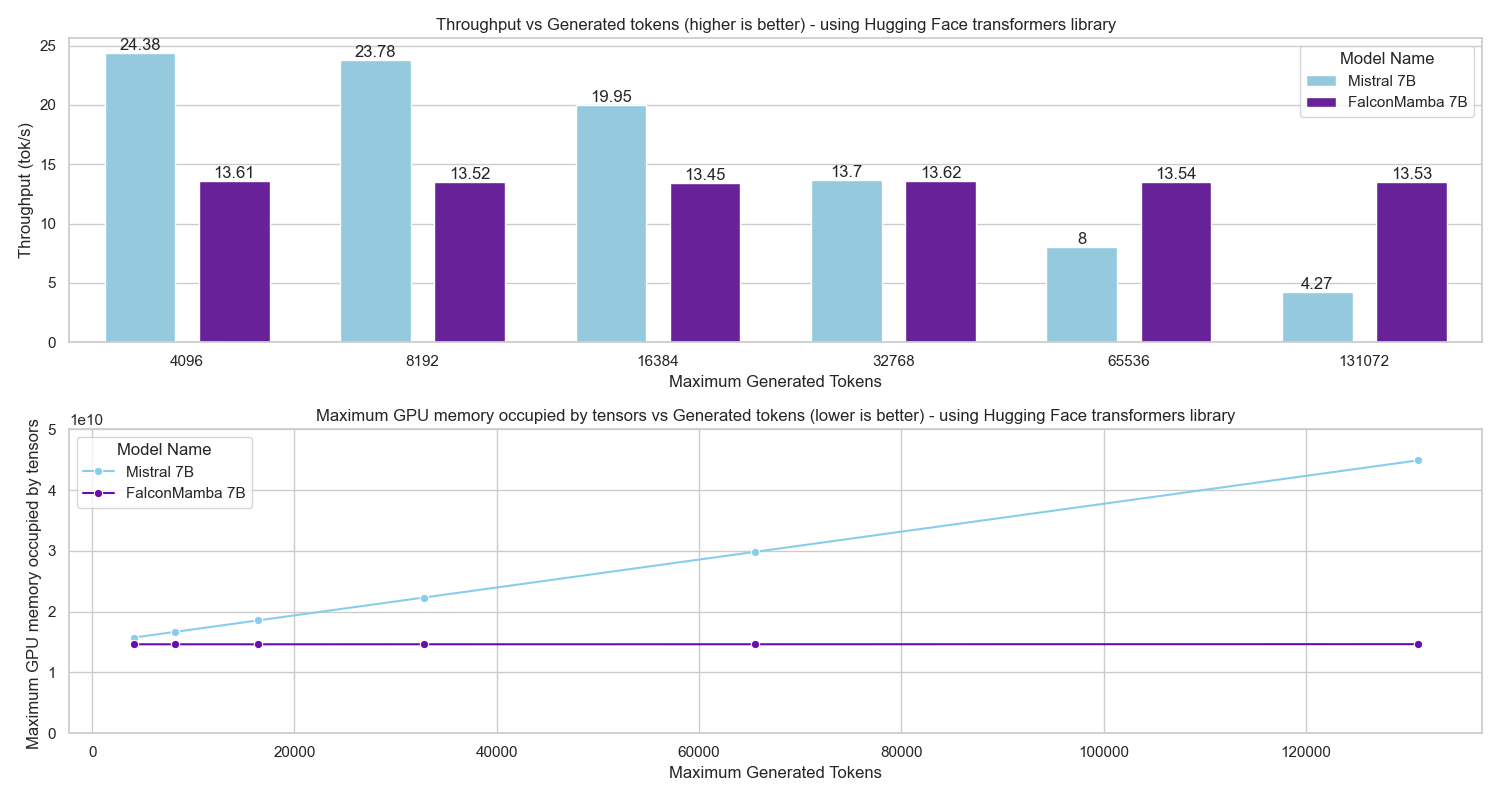
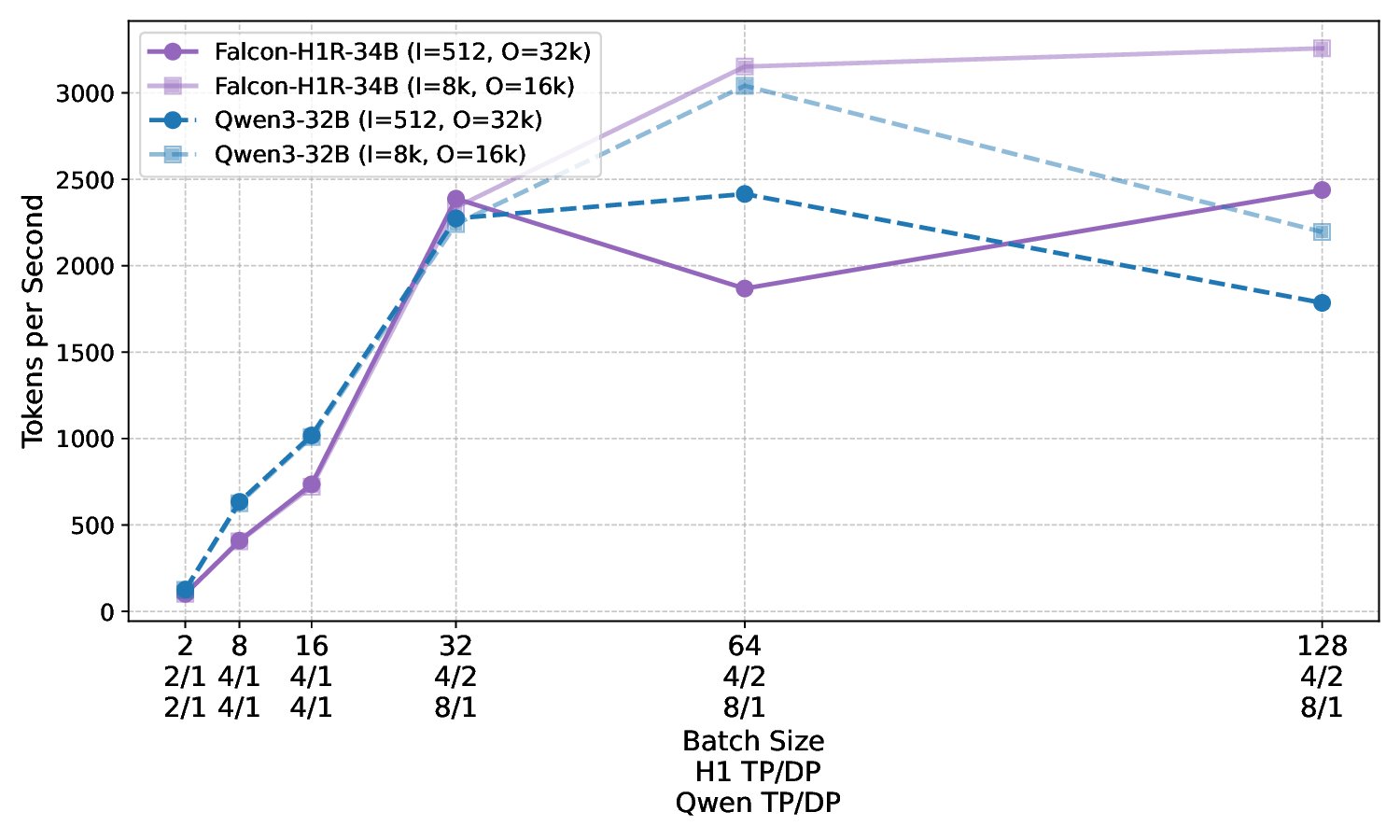
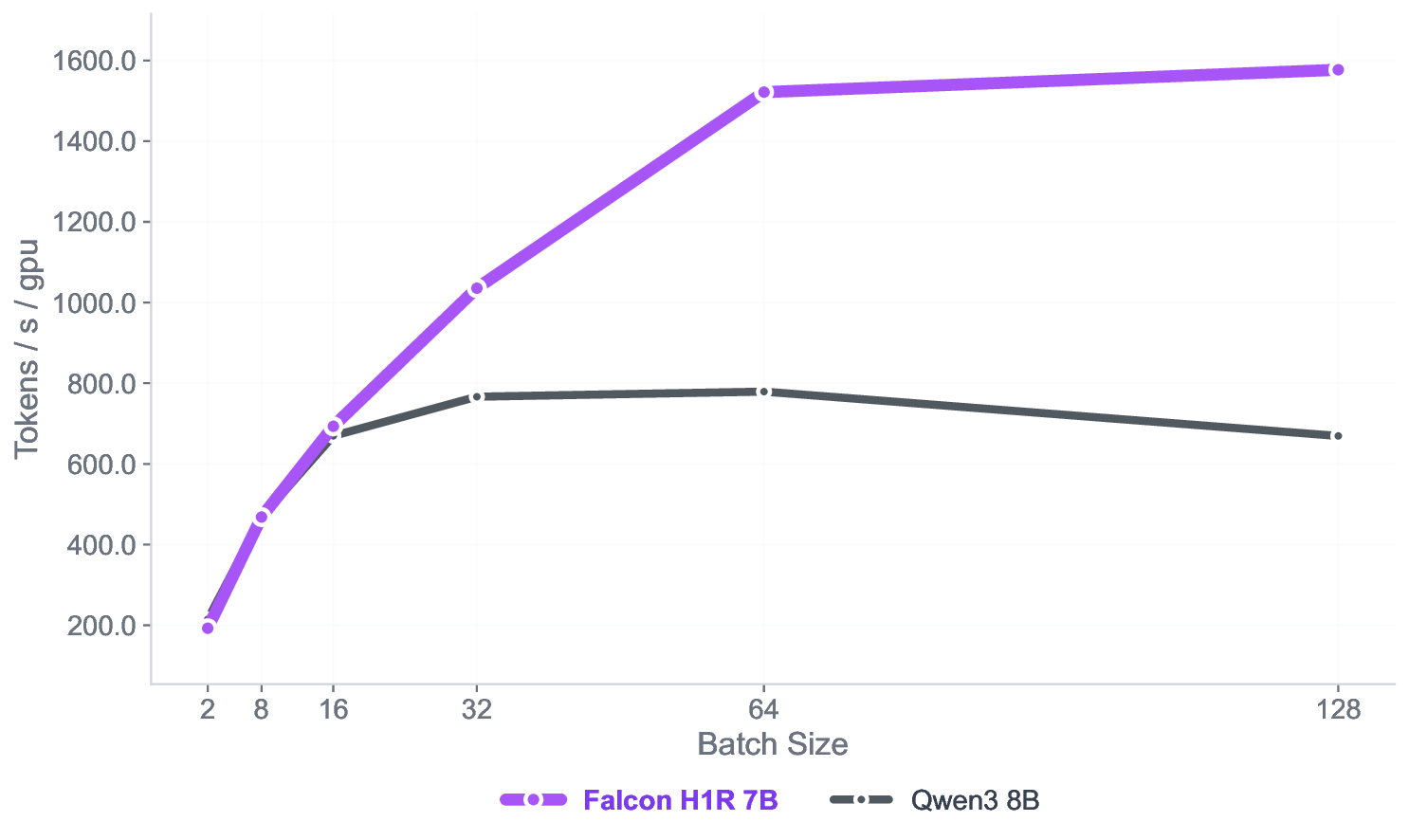
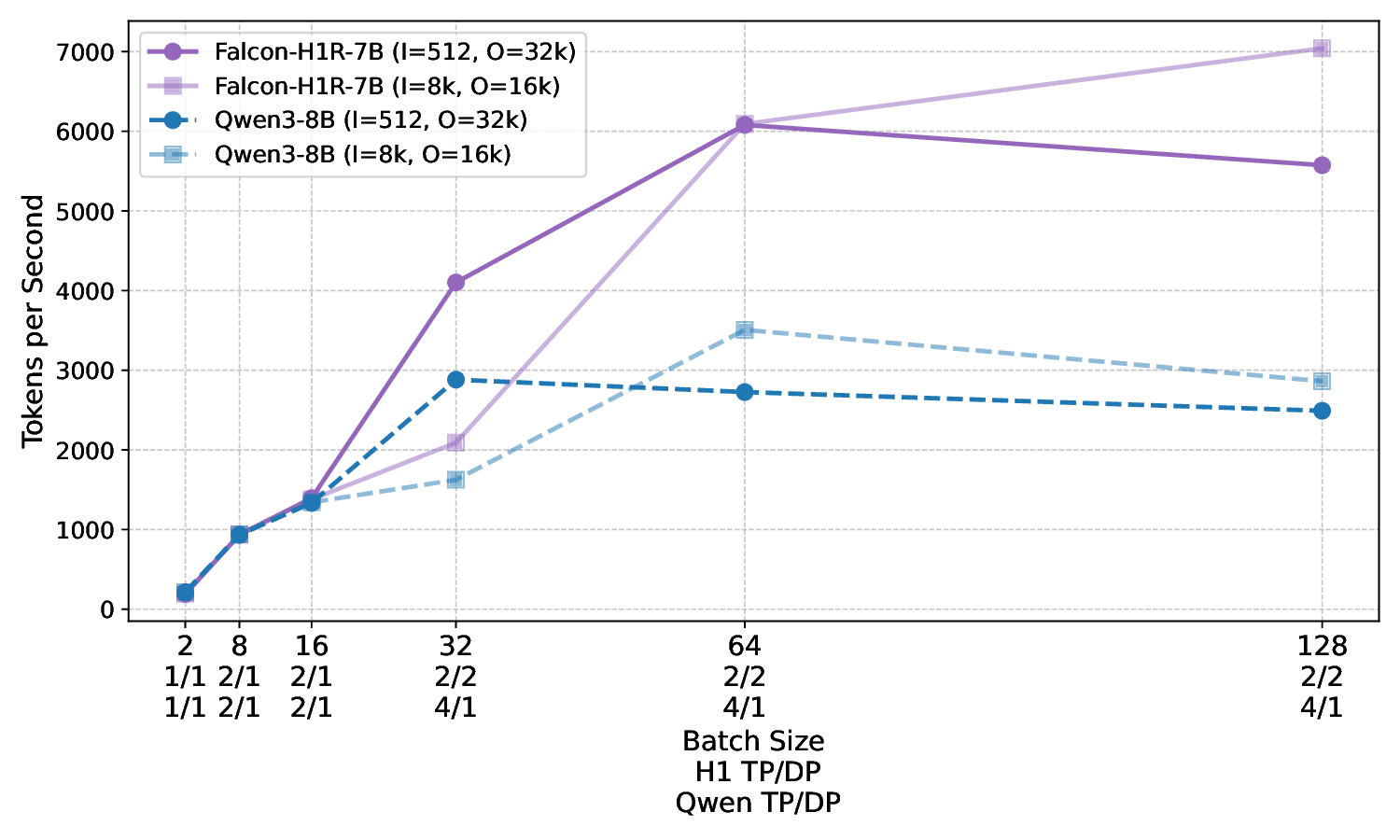
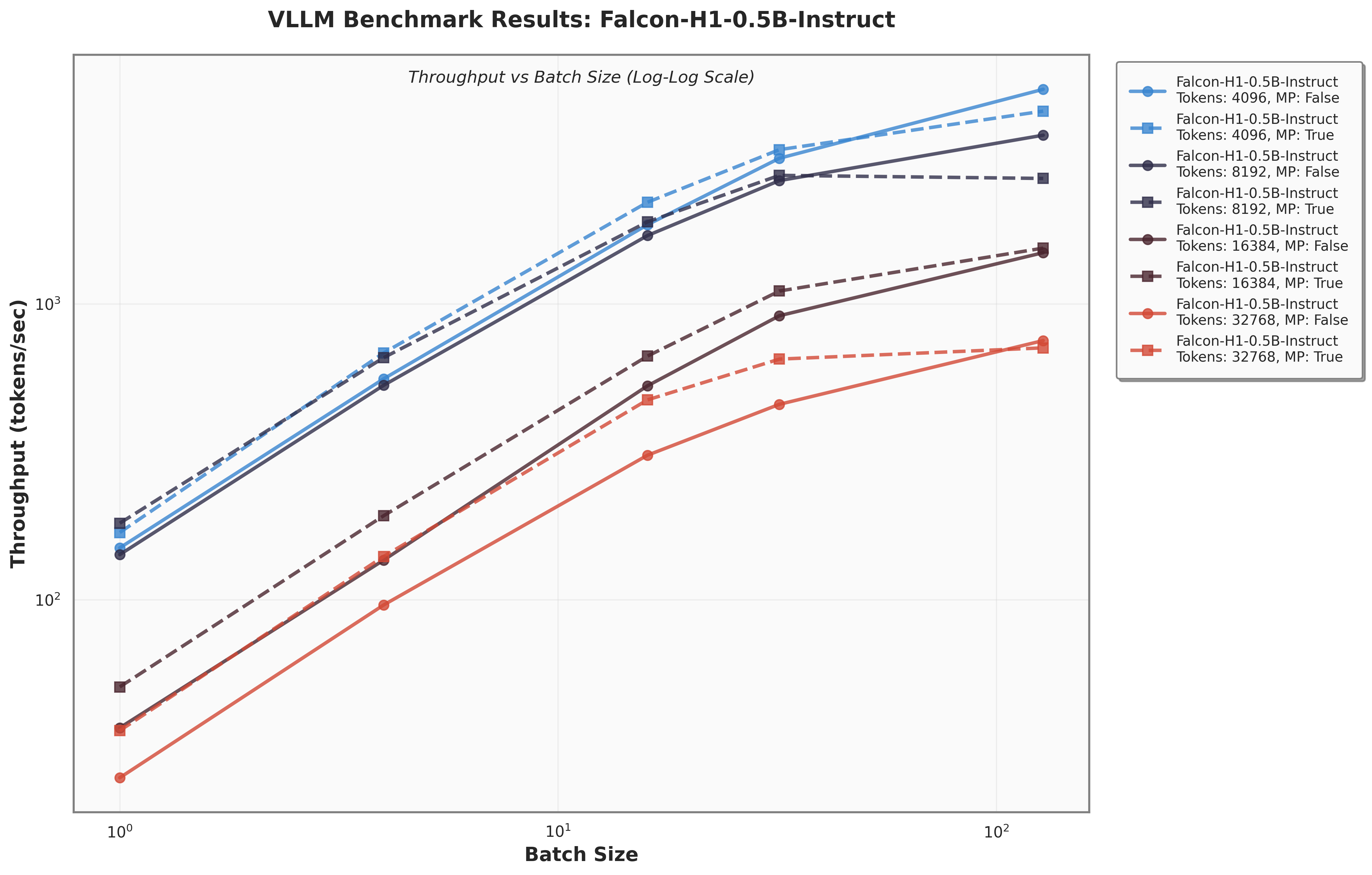
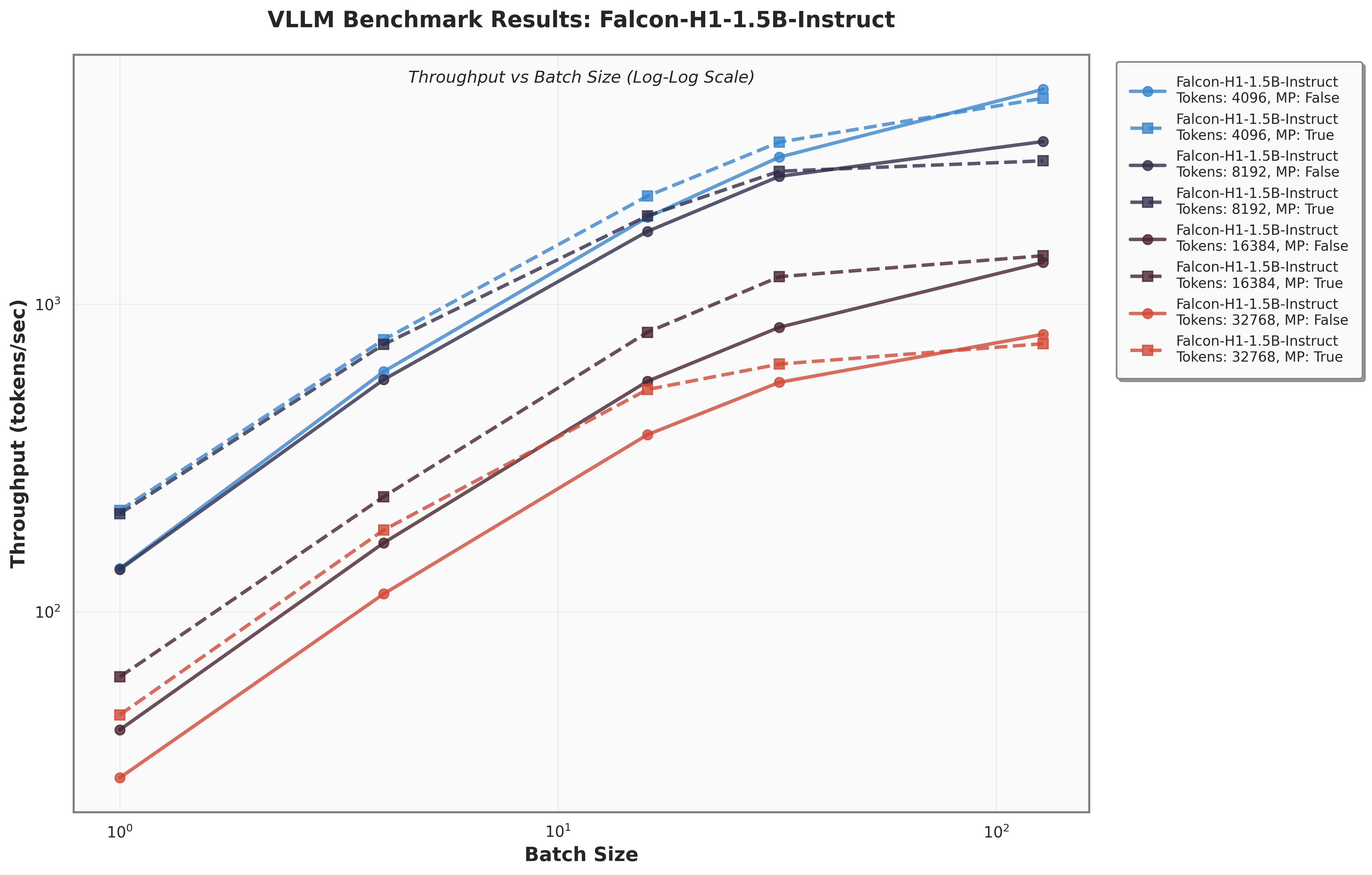
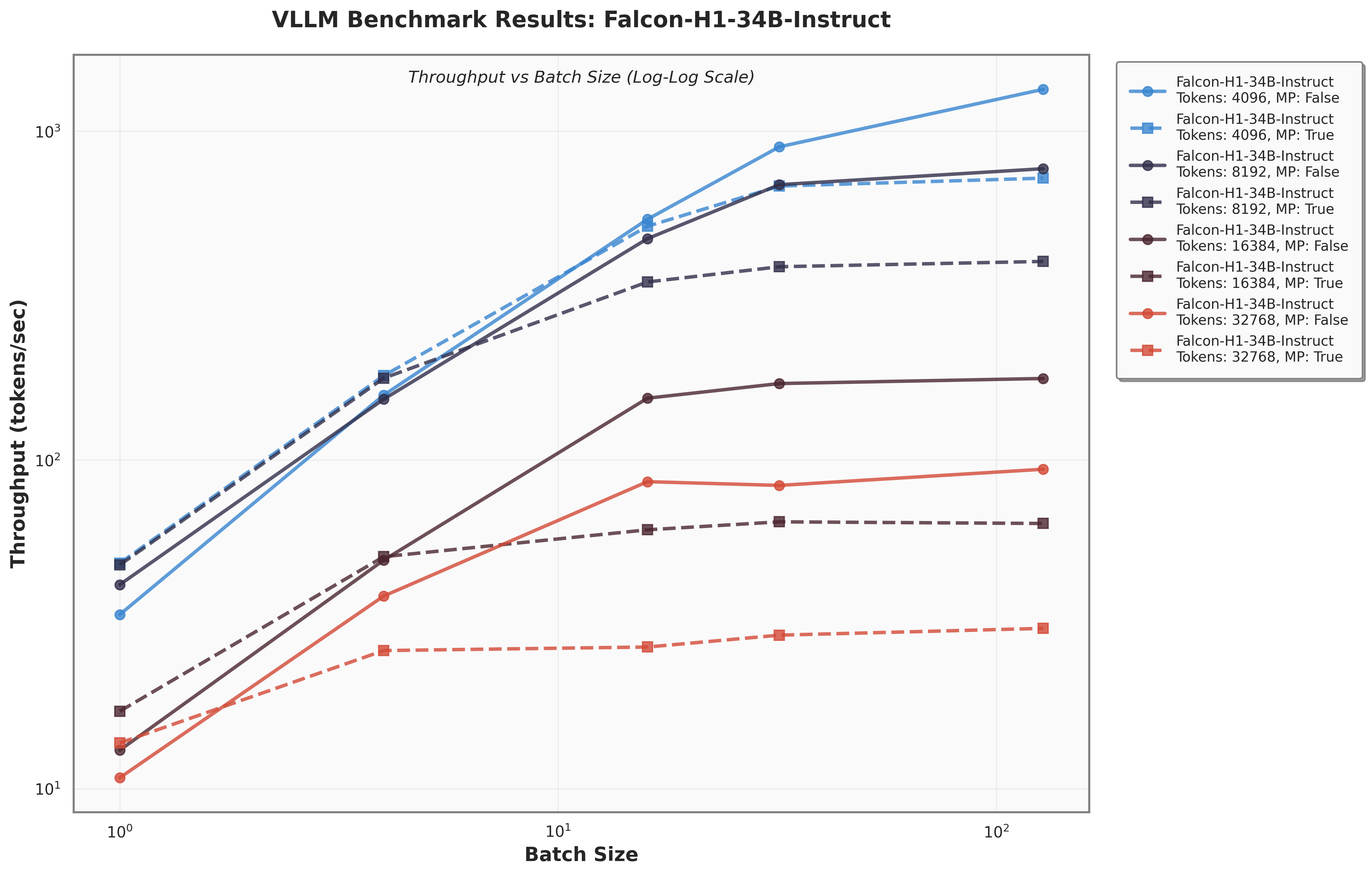
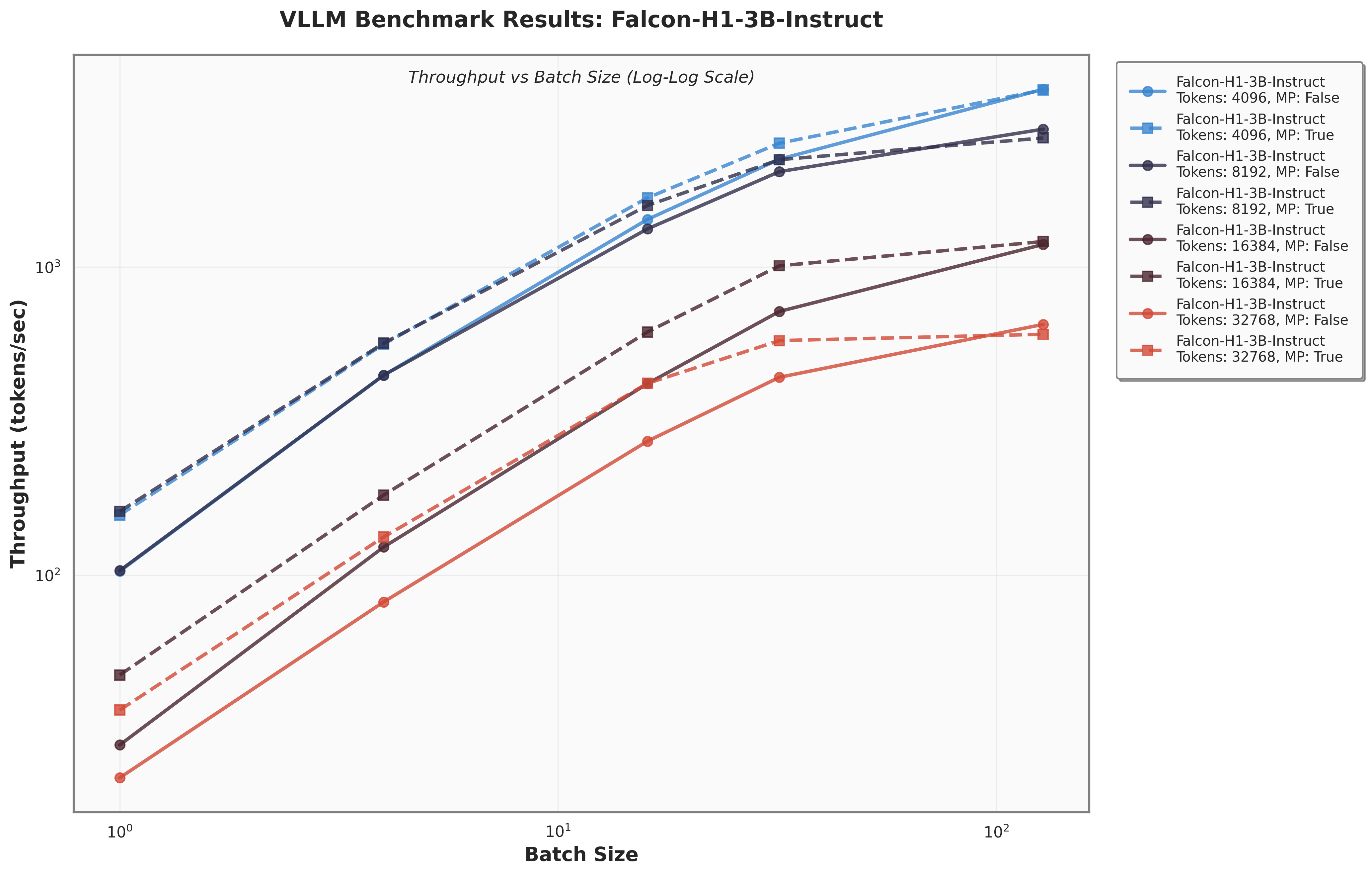
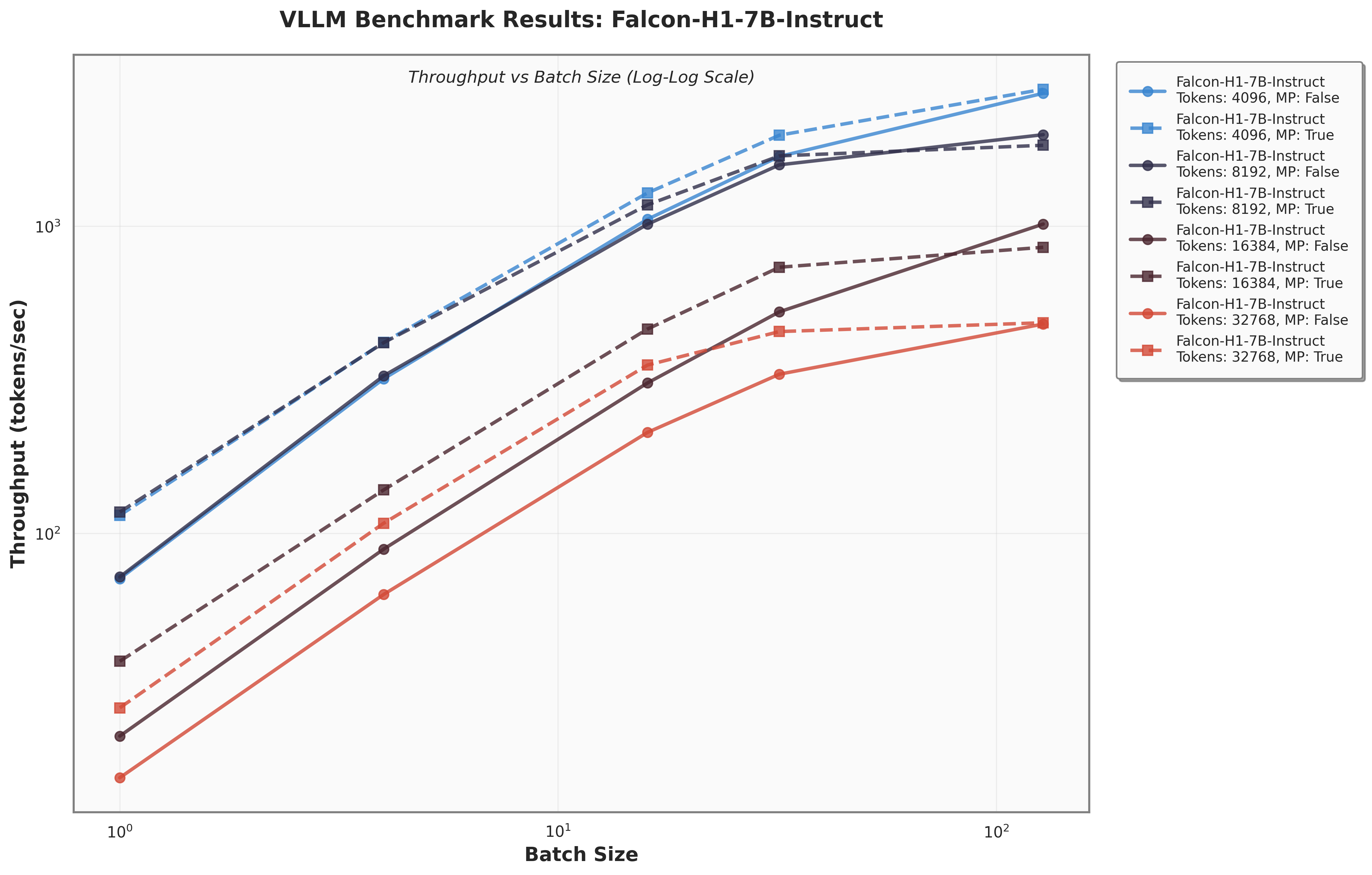
Figure 8 presents a comparison of inference throughput using vLLM (Kwon et al., 2023) between the transformer-based Qwen3-8B model (Qwen Team, 2025) and the hybrid Falcon-H1R-7B architecture (Table 8). Evaluations spanned batch sizes from 2 to 128 and averaged two input-output token configurations: (i) 512 input tokens with 32K output tokens, and (ii) 8K input tokens with 16K output tokens. To ensure fair and representative comparisons, we selected the optimal parallelism configuration for each regime: small batches (BS = 2) used TP1; medium batches (BS = 8 and BS = 16) used TP2; and the largest batches (BS = 32, 64, 128) used TP4 for Qwen3-8B and DP2 with TP2 for Falcon-H1R-7B, maximizing throughput for each architecture. All measurements were taken on NVIDIA H100 GPUs. Falcon-H1R-7B shows clear advantages at medium to large output reasoning lengths (16K-32K) and higher batch sizes, consistently surpassing Qwen3-8B with throughput improvements of +20% to +100%.
We assess the safety performance of the Falcon-H1R-7B model using a comprehensive set of benchmarks that cover jailbreak attempts, adversarial prompts, and harmful content detection. To gain a thorough understanding of model safety across different output configurations, we use three evaluation modes: (1) CoT Only, which evaluates only the chain-of-thought reasoning for safety violations while ignoring the final answer;
(2) Answer Only, which assesses only the final answer, excluding the reasoning process; and (3) CoT+Answer, which jointly evaluates both the reasoning trace and the final answer for safety. This multi-pronged strategy reveals whether safety issues arise mainly during the model’s reasoning, its final outputs, or both, offering insights into where interventions are most effective. As summarized in Table 10, we tested the Falcon-H1R-7B model on 81, 970 prompts drawn from diverse safety benchmarks, including JailbreakBench (Chao et al., 2024), ALERT (Tedeschi et al., 2024), AllenAI (Han et al., 2024), WalledEval (Gupta et al., 2024), and SALAD Bench (Li et al., 2024). Safety scores were assigned using the meta-llama/Llama-Guard-3-8B safety classifier (Grattafiori et al., 2024).
a Models Acc. ↑ Tok. ↓ Acc. ↑ Tok. ↓ Acc. ↑ Tok. ↓ Acc. ↑ Tok. ↓ a
(Mroueh, 2025) showed theoretically under a non-clipping GRPO objective that GRPO amplifies the policy’s probability of success, in line with the empirical findings of(Yue et al., 2025).