RelayGR Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
📝 Original Paper Info
- Title: RelayGR Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference- ArXiv ID: 2601.01712
- Date: 2026-01-05
- Authors: Jiarui Wang, Huichao Chai, Yuanhang Zhang, Zongjin Zhou, Wei Guo, Xingkun Yang, Qiang Tang, Bo Pan, Jiawei Zhu, Ke Cheng, Yuting Yan, Shulan Wang, Yingjie Zhu, Zhengfan Yuan, Jiaqi Huang, Yuhan Zhang, Xiaosong Sun, Zhinan Zhang, Hong Zhu, Yongsheng Zhang, Tiantian Dong, Zhong Xiao, Deliang Liu, Chengzhou Lu, Yuan Sun, Zhiyuan Chen, Xinming Han, Zaizhu Liu, Yaoyuan Wang, Ziyang Zhang, Yong Liu, Jinxin Xu, Yajing Sun, Zhoujun Yu, Wenting Zhou, Qidong Zhang, Zhengyong Zhang, Zhonghai Gu, Yibo Jin, Yongxiang Feng, Pengfei Zuo
📝 Abstract
Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.💡 Summary & Analysis
1. **Problem and Insight:** Identifies that the fine-grained ranking stage's P99 latency is a primary barrier to deploying long-sequence GR models online. Most of the computation in GR lies within an item-independent user-behavior prefix.Explanation: This section highlights how strict tail-latency requirements for fine-grained ranking stages limit the deployment of GR models with longer sequences, as most of their computational load is tied to user behavior data.
-
System Design: Proposes RelayGR, a system that optimizes when to pre-infer long-term user-behavior prefixes, where to store caches, and how to extend safe reuse.
Explanation: RelayGR aims to optimize the performance of GR models by caching the results of long-term behavior computation during the retrieval phase, which can then be reused in ranking without causing significant latency issues.
-
Production Implementation and Evaluation: Evaluates RelayGR on Ascend NPUs, showing it supports up to 1.5x longer sequences and increases system throughput up to 3.6x under fixed P99 SLOs.
Explanation: The evaluation demonstrates that RelayGR successfully addresses the latency issues while allowing for more extensive use of GR models in real-time recommendation systems.
📄 Full Paper Content (ArXiv Source)
Introduction
Modern industrial recommender systems serve tens of billions of requests per day through a multi-stage cascade—retrieval, pre-processing (also known as coarse ranking), and fine-grained ranking. Because user engagement is highly sensitive to latency, the entire pipeline must complete within a few hundred milliseconds; otherwise, timeouts translate directly into revenue loss. The fine-grained ranking stage is the bottleneck: it typically has only tens of milliseconds at the 99th percentile (P99) to score hundreds of candidate items with a high-capacity model.
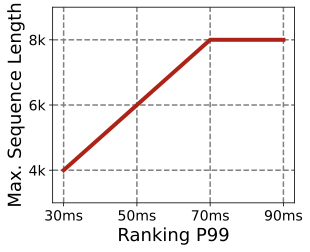
Generative recommendation (GR) models are increasingly adopted as the next generation of ranking models. Compared with traditional deep learning recommenders (DLRMs) , GR models better capture long sequential behaviors and often exhibit favorable scaling with longer sequences and larger capacity. Offline training and evaluation routinely use thousands of behavior tokens per user; in online serving, however, increasing sequence length (or feature dimension) quickly inflates inference latency and violates the ranking-stage P99 SLO. Prior efforts either pursue end-to-end GR that unifies retrieval and ranking but may need to weaken or remove the candidate-specific cross features , or deploy GR within retrieval/ranking and treat cross features as compensation. In all cases, production deployments remain bounded by the same first-order barrier: ranking-stage P99 caps the usable sequence length and thus limits GR’s online scaling benefits (Figure 3).
Our key observation is that GR inputs have a key structure property, i..e, most tokens encode user behaviors rather than candidate items. Long-term behaviors (e.g., weeks/months of clicks and views) naturally form a prefix and evolve more slowly than short-term signals and candidate-dependent cross features injected later. This suggests a simple opportunity: pre-infer the long-term user prefix, cache its intermediate states (per-layer KV), and reuse them when scoring candidate items in fine-grained ranking. This resembles prefix caching in LLM serving , but the recommender setting is fundamentally harder: prefixes are user-specific (not shared across queries), and the cache must survive across multiple pipeline stages before ranking executes.
Turning the above idea into a production optimization requires solving three systems challenges.
(1) Bridging caches across the pipeline under late binding. A prefix cache may be produced during retrieval, but can only be consumed during ranking after pre-processing completes. At cache creation time, the eventual ranking instance may not yet be determined; if production and consumption land on different instances, the cache must be fetched remotely—often too expensive for a tens-of-milliseconds ranking. Even within a server, overflowing device memory forces a flush/reload that competes with the ranking SLO.
(2) The user population makes “cache everything” infeasible. Industrial recommenders serve billions of users . Even modest GR backbones can generate megabytes of KV states per user when consuming thousands of tokens, yielding petabyte-scale aggregates (megabytes multiplying all users). A naïve distributed cache pool would frequently trigger remote fetches whose latency can rival or exceed the ranking budget, undermining the entire approach.
(3) High QPS makes unconditional pre-inference unsafe. At production scale, each accelerator instance may serve hundreds of queries per second . After feature processing and embedding lookup, each query can carry tens of megabytes of embeddings . Under concurrency, host-to-device transfers and accelerator execution contend for shared CPU/PCIe/NPU resources . If we pre-infer prefixes for every request, we risk overloading the very resources needed to keep ranking within P99. Therefore, pre-inference must be selective and load-aware.
 style="width:85.0%" />
style="width:85.0%" />
 style="width:85.0%" />
style="width:85.0%" />
To address these challenges, we present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR pre-infers long-term user prefixes only when beneficial, keeps the resulting per-layer KV cache resident in device memory over the request lifecycle, and ensures the subsequent ranking stage consumes the cache locally without remote fetches. More broadly, RelayGR addresses a distinct systems problem: lifecycle caching under late-binding placement, where cache production and consumption are separated by multiple pipeline stages and the consumer is determined only after intermediate filtering.
RelayGR is built around three techniques that co-design when to pre-infer, where to place the cache, and how to extend reuse safely, for the real-time recommender:
Sequence-aware Trigger. During retrieval, RelayGR inspects lightweight user-behavior metadata (e.g., prefix length and/or dimension) and estimates whether the request is at risk of violating the ranking-stage P99 under full inference. Only at-risk requests are admitted for prefix pre-inference, bounding the overhead and preventing it from becoming a new bottleneck.
Affinity-aware Router. For admitted requests, RelayGR enforces a routing contract: the subsequent ranking request must arrive at the same instance that produced the cache. The design leverages the fact that a request lifecycle lasts only a few hundred milliseconds, allowing HBM to act as a sliding-window cache that retains per-user prefixes long enough for consumption (e.g., to enable the relay-race), while eliminating cross-server fetches on the ranking critical path.
Memory-aware Expander. RelayGR further exploits server-local DRAM to capture short-term reuse across repeated requests from the same user (e.g., rapid refresh) without introducing remote traffic. HBM guarantees cache availability within a single lifecycle, while DRAM acts as a controlled compensation tier that extends reuse beyond the HBM window at bounded H2D cost.
We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries under production constraints. Under a fixed ranking-stage P99 SLO (also the entire recommender SLO), RelayGR supports up to 1.5$`\times`$ longer input sequences while improving the system throughput by up to 3.6$`\times`$.
In summary, this paper makes three contributions:
-
Problem and insight. We identify ranking-stage P99 as a first-order barrier to deploying long-sequence GR online and observe that most GR computation lies in an item-independent user-behavior prefix.
-
System design. We present RelayGR, a production system that realizes in-HBM relay-race inference as lifecycle caching under late-binding placement via the sequence-aware trigger, the affinity-aware routing, and the DRAM-backed expander.
-
Production implementation and evaluation. We implement RelayGR on Ascend NPUs and demonstrate up to 1.5$`\times`$ longer supported sequences and up to 3.6$`\times`$ higher SLO-compliant throughput under fixed P99 SLOs.
 style="width:80.0%" />
style="width:80.0%" />
Background and Motivation
Real-time recommender systems actually execute a multi-stage cascade—retrieval, pre-processing, and fine-grained ranking—under strict tail-latency SLOs. Meanwhile, generative recommendation (GR) models benefit from long user-behavior sequences, but production deployments cap online sequence length (and also the feature dimension) to meet the ranking-stage P99 budget. This section first reviews the real-time pipeline (§2.1) and the structure of GR inference (§2.2). We then motivate an opportunity to pre-infer user-behavior prefixes (§2.3) and explain why turning that opportunity into an industrial-scale optimization is non-trivial (§2.4).
Real-time Recommender Pipeline
Latency budgets and tail amplification.
Industrial recommenders process massive traffic volumes and must keep end-to-end latency within a few hundred milliseconds at P99 to avoid timeout-induced failures and revenue loss . Crucially, the budget is partitioned across pipeline stages, leaving only tens of milliseconds for fine-grained ranking. Because ranking runs at high concurrency, production deployments also avoid operating near peak utilization: saturating CPU, PCIe, or accelerators amplifies queuing delay and worsens tails, making P99 compliance brittle.
Three-stage cascade.
A typical pipeline comprises: (i) retrieval, which selects a large candidate pool; (ii) pre-processing/coarse ranking, which performs feature transformation and prunes candidates; and (iii) fine-grained ranking, which scores the remaining candidates with heavyweight models . Figure 4 illustrates this cascade. Candidate set size shrinks stage by stage, but ranking remains latency-critical because it must score hundreds of items within a rigid P99 window while competing for shared CPU/PCIe/accelerator resources with other pipeline work.
Generative Recommendation Under Tight P99
Why GR is attractive.
GR models improve recommendation quality by modeling long sequential user behaviors and exhibiting favorable scaling with longer sequences and larger model capacity . In offline training and evaluation, GR models can consume thousands of behavior tokens per user, learning rich dependencies across a user’s behavior trajectory and the contents presented over time.
GR can be deployed in two common modes. In a discriminative mode, the model outputs scores/logits for candidate ranking, effectively learning decision boundaries between items . In a generative mode, the model produces targets token by token or generates representations that are consumed by downstream towers for retrieval or ranking . While recent end-to-end GR proposals aim to unify retrieval and ranking , in practice, candidate-dependent cross features remain an important source of quality gain . Many deployments therefore still rely on them (explicitly or implicitly) even when adopting GR backbones.
Why GR is constrained online.
Online fine-grained ranking operates under a tens-of-milliseconds P99 budget. Increasing GR sequence length or feature dimension directly increases inference cost and makes tail latency hard to sustain. As a result, production systems cap the online sequence length, creating a gap between offline training (thousands of behaviors) and online inference (typically far fewer) . Existing responses largely shrink compute to fit the fixed budget—for example, compressing tokens or representations (Figure 5). For industrial deployments, however, realizing GR’s scaling benefits requires the complementary capability: raising the online sequence-length ceiling while still meeting the same tail-latency SLO.
 style="width:70.0%" />
style="width:70.0%" />
Opportunity: Pre-infer User-behavior Prefix
Long-term behaviors form a large, stable prefix.
GR inputs interleave user-side context and item-side targets. In practice, user behaviors are time-ordered; long-term behaviors (months/years to days ago) appear early and constitute a large prefix . The remaining tokens typically include short-term behaviors (hours/days) and cross features, followed by the candidate items to be scored. Importantly, long-term behaviors dominate the token count (often thousands) and evolve slowly, whereas short-term signals and embeddings are refreshed frequently and are tied to tight update pipelines (e.g., hourly refresh). This paper therefore focuses on pre-inferring only the long-term prefix: it captures the dominant compute while avoiding strong coupling with fast model/embedding refresh and preserving production robustness .
 style="width:70.0%" />
style="width:70.0%" />
Prefix reuse: analogous to LLMs, but with different reuse semantics.
Prefix caching is widely used in LLM inference to reuse computation across requests . In LLMs, prefixes are often shared (common prompts/templates), so reuse is cross-request and cross-user. In GR, prefixes are predominantly user-specific: two users rarely share the same behavior history. Thus, the most reliable reuse opportunity is within-user reuse across stages of the same request lifecycle (and, opportunistically, across repeated requests from the same user), not broad cross-user caching.
Pre-infer before ranking.
The long-term prefix is available at the beginning of retrieval and is largely decoupled from candidate filtering. This enables a “race-ahead” execution: compute the prefix during retrieval, cache its intermediate states, and reuse them when ranking later scores candidate items (Figure 6). If the expensive long-prefix computation is removed from the ranking critical path, ranking latency becomes much less sensitive to total sequence length; it primarily depends on the incremental tokens (short-term/cross features) and the item batch. We formalize this idea as
\begin{equation}
\psi \leftarrow f([\mathcal{U}, \mathcal{S}_{l}, \emptyset, \emptyset], \emptyset),\;\;\;
\left|f([\mathcal{U}, \mathcal{S}_{l}, \widetilde{\mathcal{S}_{l}}, \mathcal{I}], \emptyset) -
f([\emptyset, \emptyset, \widetilde{\mathcal{S}_{l}}, \mathcal{I}], \psi)\right| \le \varepsilon,
\nonumber
\end{equation}where $`f`$ is the GR ranking model (a generative backbone plus downstream task towers). The input sequence contains user info $`\mathcal{U}`$, long-term behaviors $`\mathcal{S}_{l}`$, non-long-term tokens $`\widetilde{\mathcal{S}_{l}}`$ (short-term behaviors $`\mathcal{S}_{s}`$ and cross features $`\mathcal{C}`$; either may be $`\emptyset`$), and candidate items $`\mathcal{I}`$. $`\psi`$ is the cached per-layer KV state produced by pre-inferring the long-term prefix. The bound $`\varepsilon`$ indicates that using $`\psi`$ preserves ranking scores (up to a small deviation) relative to full inference.
Challenges: Making Prefix Caching Work at Industrial Scale
Pre-inferring long-term prefixes is appealing, but making it effective online requires solving three systems challenges.
(1) Cross-stage cache survivability under late-binding placement.
In LLM serving, the cache produced by prefill is consumed immediately by decode, and the system can hand it off at a clear phase boundary . In a recommender pipeline, a GR prefix cache may finish during retrieval or pre-processing but is only consumed when fine-grained ranking begins. At production time, the final ranking instance is often chosen after pre-processing, so cache producer and consumer are separated by both time and routing. If the consumer differs from the producer, a remote fetch is required; if the cache is spilled to host memory, D2H/H2D adds latency and contention. Either path can consume a material fraction of a tens-of-milliseconds ranking budget. An effective solution must therefore ensure the cache survives across stages and is consumed locally.
(2) Footprint at billion-user scale makes “cache everything” impossible.
Accelerator HBM provides only tens of GBs. Even for relatively small GR models, a per-user prefix cache can be MB-scale at a few-thousand-token input; at billion-user scale, the aggregate is inevitably TB–PB. This eliminates any design that assumes persistent per-user residency in device memory and makes naïve distributed KV pools problematic: remote fetch latency can match or exceed ranking-stage P99. Therefore, an online solution must avoid remote cache fetches on the ranking critical path and treat caching as a lifecycle mechanism rather than a global persistent store.
(3) Operational safety under high QPS and shared-resource contention.
Production traffic reaches tens of billions of requests per day, and each instance commonly sustains hundreds of QPS. Under such concurrency, CPU feature processing, H2D transfers (tens of MBs of embeddings per request), and accelerator execution compete for shared resources. Unconditionally pre-inferring every request is infeasible: it increases PCIe/NPU pressure and can worsen ranking tail latency. Instead, the system must (i) admit only at-risk requests that would otherwise violate ranking-stage P99, and (ii) bound the admitted pre-inference rate and live-cache footprint in a service-specific way, trading available slack in retrieval against added load near ranking.
Implication.
An effective design must selectively pre-infer long-term prefixes, enforce affinity between cache production and consumption to eliminate remote fetch, and tightly control the additional compute and memory pressure under high QPS. This motivates the RelayGR design in §3.
The RelayGR Design
System Overview
RelayGR addresses the industrial barrier for long-sequence GR serving: ranking must satisfy a tens-of-milliseconds P99 budget, yet most GR compute lies in a user-behavior prefix that is available early and is independent of candidate items. RelayGR introduces a relay-race side path that computes and reuses prefix states across the recommender pipeline (retrieval $`\rightarrow`$ pre-processing $`\rightarrow`$ ranking), without adding remote cache fetches to the ranking critical path.
Abstraction: lifecycle caching under late-binding placement.
We model prefix reuse as lifecycle caching. For a request associated with user key $`u`$, the system may produce a prefix cache $`\psi(u)`$ early and consume it later:
-
Cache object. $`\psi(u)`$ is the per-layer KV cache of the GR backbone computed on the long-term behavior prefix of $`u`$. Importantly, $`\psi(u)`$ is a deterministic function of the prefix tokens and model weights, and does not depend on candidate items.
-
Lifecycle window. Let $`T_{\text{life}}(u)`$ denote the time from when the auxiliary
pre-inferis issued to when the corresponding ranking consumes $`\psi(u)`$. In production, $`T_{\text{life}}`$ is bounded by the pipeline tail (retrieval + pre-processing + ranking), and is typically a few hundred milliseconds. -
Late-binding placement. The eventual ranking instance is chosen after pre-processing. Thus, at the time $`\psi(u)`$ is produced, the consumer location is not yet fixed unless the system enforces a placement contract.
The system’s objective is to make $`\psi(u)`$ available throughout $`T_{\text{life}}(u)`$ and locally consumable at ranking time, under high QPS and bounded device memory.
 style="width:80.0%" />
style="width:80.0%" />
System invariants.
RelayGR is designed to enforce two invariants for every admitted long-sequence request:
-
(I1) No remote fetch on ranking critical path. Ranking either consumes $`\psi(u)`$ locally (HBM or server-local DRAM) or safely falls back to baseline inference; it never blocks on cross-server cache fetching.
-
(I2) Survivability under bounded footprint and load. The system caps (a) the live-cache footprint in HBM and (b) the admitted pre-inference rate so that the caches survive for at least $`T_{\text{life}}`$ while preserving P99 SLOs.
Decomposition: admission, placement, and local capacity extension.
As shown in Figure 7, RelayGR decomposes lifecycle caching into three responsibilities:
-
Admission (sequence-aware trigger). Decide which requests should create $`\psi(u)`$ (only “at-risk” long-sequence requests) and how many can be admitted so their caches survive $`T_{\text{life}}`$ under HBM and rate budgets (enforcing I2).
-
Placement (affinity-aware router). Convert late-binding routing into an early-binding placement contract: ensure the auxiliary
pre-inferand later ranking request for the same $`u`$ land on the same special instance, so ranking can reuse $`\psi(u)`$ without remote fetch (enforcing I1). -
Local capacity extension (memory-aware expander). Opportunistically extend reuse across repeated requests from the same user using server-local DRAM, while bounding DRAM$`\rightarrow`$HBM reload overhead and avoiding redundant reloads under concurrency (preserving I1 and stabilizing tail latency).
End-to-end flow.
If the trigger admits user $`u`$, it issues a response-free pre-infer
signal to a special ranking service, causing the selected instance to
compute $`\psi(u)`$ and keep it resident in HBM for
$`T_{\text{life}}(u)`$. The router then guarantees that the subsequent
ranking request for $`u`$ is routed to the same instance, allowing
ranking to reuse $`\psi(u)`$ locally. After consumption, the expander
may spill $`\psi(u)`$ to server-local DRAM to accelerate short-term
repeated requests (e.g., rapid refresh), with bounded reload concurrency
and correctness-preserving ordering control.
In summary, the design goal of this paper is to provide a systems contract for GR prefix reuse: admitted caches survive across pipeline stages and are consumed locally at ranking time under strict constraints. By separating what to compute (admission) from where to consume (placement) and how to extend reuse locally (DRAM tier), RelayGR turns prefix caching into a controlled mechanism that preserves correctness while avoiding remote fetches and tail-latency blowups.
 style="width:75.0%" />
style="width:75.0%" />
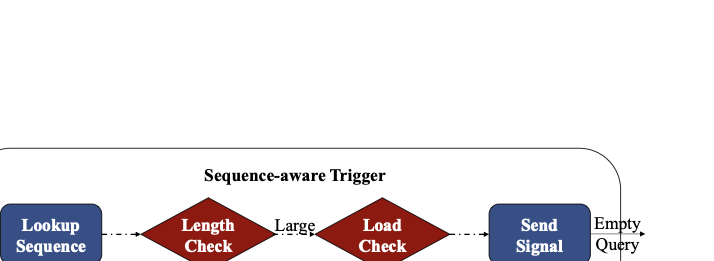
Sequence-aware Trigger
Design goal.
Admit only at-risk long-sequence requests for prefix pre-inference and ensure their caches $`\psi`$ can survive until ranking consumption, subject to bounded HBM footprint and bounded additional pre-inference load.
Side-path risk test using metadata.
Figure 8 illustrates the trigger workflow. The trigger runs in parallel with retrieval and only fetches lightweight behavior metadata (e.g., prefix length and/or feature dimension). This avoids transferring full behavior sequences and keeps the trigger fast. If metadata indicates that full ranking inference is unlikely to violate the ranking-stage P99, the trigger terminates immediately and introduces zero additional work. Only requests deemed at risk (e.g., long prefixes or high-dimensional features) are candidates for admission.
Admission control via lifecycle-window survivability.
Pre-inference is beneficial only if $`\psi`$ remains available when
ranking arrives. Let $`Q_{\text{admit}}`$ be the admitted pre-infer
rate (queries/s) for a given special instance. Over a lifecycle window
of length $`T_{\text{life}}`$, the number of simultaneously live
caches per special instance is upper-bounded by
\begin{equation}
L \;\triangleq\; Q_{\text{admit}} \cdot T_{\text{life}}.
\label{eq:livecache}
\end{equation}Using $`kv_{p99}`$ as the P99 footprint of $`\psi`$ (per admitted user) and reserving a fraction $`r_1`$ of HBM for live caches, survivability requires the following inequality per special instance:
\begin{equation}
L \cdot kv_{p99} \;\le\; r_1 \cdot HBM.
\label{eq:hbm_budget}
\end{equation}Bounding pre-inference load.
Let $`Q_m`$ be the sustainable pre-infer throughput per model slot
(queries/s) on a special instance and $`M`$ the number of concurrent
model slots. The trigger caps admission by
\begin{equation}
Q_{\text{admit}} \;\le\; Q_m \cdot M,\qquad
Q_{\text{max}} \;\le\; (Q_m \cdot M)\cdot (r_2 \cdot N),
\label{eq:qps_budget}
\end{equation}where $`N`$ is the total number of ranking instances and $`r_2N`$ are designated as special. The first inequality prevents per-instance overload; the second bounds system-wide admitted long-sequence traffic by the aggregate capacity of the special-instance pool (i.e., $`r_{2}`$ is a control variable).
 style="width:75.0%" />
style="width:75.0%" />
Example (sanity check).
If pre-inference takes 35 ms, then $`Q_m \approx \lfloor 1000/35 \rfloor \approx 30`$ queries/s per model slot. With $`M{=}5`$, $`kv_{p99}{\approx}0.1`$ GB, $`HBM{=}32`$ GB, and $`r_1{=}0.5`$, Eq. [eq:hbm_budget] allows up to $`L \le 16/0.1 = 160`$ live caches per special instance, corresponding to $`Q_{\text{admit}} \le 160/T_{\text{life}}`$ via Eq. [eq:livecache]. Meanwhile Eq. [eq:qps_budget] caps compute: $`Q_{\text{admit}} \le 30 \cdot 5 = 150`$ QPS per special instance. With $`N{=}100`$ and $`r_2{=}0.1`$, the pool supports $`Q_{\text{max}}\le 1500`$ QPS of admitted long-sequence traffic.
Auxiliary pre-infer request as a control signal.
For an admitted request, the trigger sends a response-free pre-infer
signal carrying the user-keyed consistency hash:
header { consistency-hash-key: userID, ... }
body { user_id: userID, stage: pre-infer }
This signal asks the special instance to fetch the user’s long-term behaviors, run pre-inference, and populate $`\psi`$ in HBM. Because it is issued during retrieval, it contains no candidate items (obey the same format of ranking queries).
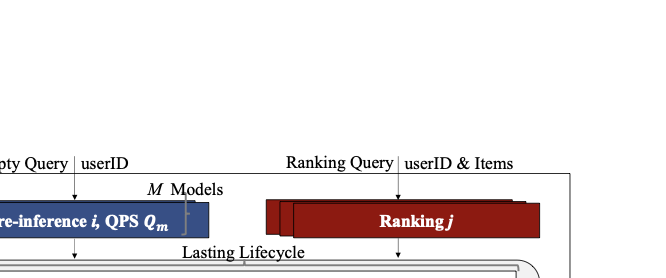
Concurrency inside a special instance.
A special instance processes a mix of auxiliary pre-infer requests and
ranking requests for different users
(Figure 9). Increasing $`M`$ improves overlap
but also increases contention on compute and memory-transfer engines;
thus, $`M`$ is a tunable knob jointly configured with $`r_2`$ and
admission thresholds. Upon request arrival, the instance checks stage:
if pre-infer, it computes and stores $`\psi`$; otherwise, it looks up
$`\psi`$ by user ID and performs ranking using the cached prefix when
present.
Why it works.
The trigger converts an unbounded optimization into a bounded one: only requests that would otherwise violate ranking-stage P99 are admitted, and Eqs. [eq:livecache]–[eq:qps_budget] ensure admitted caches survive for $`T_{\text{life}}`$ without overloading HBM or pre-inference capacity (invariant I2).
 style="width:75.0%" />
style="width:75.0%" />
Affinity-aware Router
Design goal.
Guarantee placement: for every admitted user, the auxiliary
pre-infer request and the subsequent ranking request are routed to the
same special instance, so ranking can reuse $`\psi`$ without
cross-server fetching (invariant I1).
Special-instance pool and interference control.
As illustrated in Figure 10, RelayGR deploys both normal and special ranking instances across servers, distinguished by the service names. To bound interference on shared server resources, we cap the number of special instances per server (typically one or two). This matters because pre-inference stresses (i) CPU (behavior processing to construct model inputs) and (ii) PCIe/H2D bandwidth (transferring embeddings from host DRAM to device HBM). Even when a server is partitioned into multiple instances, PCIe remains a shared bottleneck; thus, bounding special-instance density per server limits worst-case contention.
Balancing independent requests vs. coupling related requests.
Long-sequence traffic is distributed across special instances by the
existing load balancer and gateway
(Figure 11). Standard policies (round-robin,
least-connections) balance independent requests. However, RelayGR
introduces coupled requests for the same user: an auxiliary
pre-infer and a later ranking request. To reuse $`\psi`$, these two
must rendezvous at the same cache-holding instance.
Affinity routing to exact the cache-holding instance.
For long-sequence users, the ranking request carries a
consistency-hash-key derived from the ID in its header:
header { consistency-hash-key: userID, ... }
body { user_id: userID, items: ... }
The body includes both the user ID and the filtered items required for ranking. During pre-processing, the system determines whether a request should be served by normal or special instances: short-sequence requests follow the normal service, while long-sequence requests are sent to the special service. For special instances, the user ID also serves as the lookup key for the HBM-resident prefix cache; including it in both header and body improves robustness (e.g., for cache-miss fallback paths that require additional processing).
Both the auxiliary pre-infer request and the long-sequence ranking
request carry the same key in the header consistency-hash-key. The
load balancer and gateway apply consistent hashing on this key when
selecting the gateway and the final instance, respectively, ensuring
that the two related requests are routed to the same recipient. If
affinity is disrupted (e.g., deployment churn or network changes) and
the ranking request lands on a different instance, that instance simply
falls back to inference without cache, preserving correctness at the
cost of losing the optimization. For normal ranking requests that do not
include the key, the system continues to use standard load-balancing
policies (e.g., round-robin and least-connections).
 style="width:75.0%" />
style="width:75.0%" />
HBM as a lifecycle window.
As enforced by the trigger, the total HBM footprint consumed by prefix caches is bounded. Consequently, HBM functions as a sliding-window cache (Figure 12): per-user prefix caches are inserted by pre-inference, consumed by ranking, and then evicted as new admitted users arrive. Although HBM cannot hold caches for all users, admission control ensures it can hold the caches that must survive for a single recommendation lifecycle—typically a few hundred milliseconds. Since the cache lifetime is short, HBM capacity is sufficient to cover the required window even with model concurrency.
Finally, the ratio of special instances to all ranking instances determines how long-sequence load is distributed: increasing the ratio reduces per-instance pressure (CPU/PCIe/HBM) and enlarges the effective window, while decreasing it concentrates long-sequence traffic onto fewer instances. In practice, we set this ratio to be small (often $`<10\%`$), roughly matching the fraction of long-sequence users, and rely on autoscaling to keep per-instance load stable as traffic grows.
Why it works.
Consistent hashing turns late-binding placement into a stable affinity contract: producer and consumer rendezvous at the same instance without coordination, eliminating remote fetch on the ranking critical path (invariant I1). If affinity is disrupted (e.g., churn), the system safely falls back to baseline inference, preserving correctness.
Memory-aware Expander
Design goal.
Extend reuse of $`\psi`$ across repeated requests from the same user uses server-local DRAM, while bounding DRAM$`\rightarrow`$HBM reload overhead and preventing redundant reloads under concurrent and out-of-order arrivals.
 style="width:75.0%" />
style="width:75.0%" />
DRAM as a server-local reuse tier.
HBM residency is sufficient to bridge caches within a single recommendation lifecycle: once admitted, the prefix cache remains available until the corresponding ranking consumes it. However, the same user may trigger multiple recommendation trials in a short period (e.g., rapid refresh), and HBM alone cannot retain caches across these trials while simultaneously serving many other users. In contrast, host DRAM provides hundreds of GBs of capacity per server. RelayGR therefore uses DRAM as a server-local reuse tier: after a cache is consumed, it can be spilled to DRAM and reloaded later to accelerate subsequent requests, without incurring cross-server fetches.
Upon receiving a ranking request at a special instance, RelayGR performs a two-level lookup using the user ID as the key: it first checks HBM, and on a miss it queries the local expander for a DRAM hit. If the cache exists in DRAM, the instance reloads it into HBM (incurring H2D) and proceeds to ranking. To prevent the expander from becoming a new bottleneck, DRAM-to-HBM reloads are rate-limited and scheduled with bounded concurrency.
Concurrent requests for the same user can otherwise trigger repeated DRAM-to-HBM reloads and repeated cache state transitions (spill/reload). The expander enforces per-user serialization: it maintains a per-user queue (or lock) and ensures that at most one cache-affecting action is in-flight per user at any time. Subsequent requests for the same user wait for the first operation to complete, then reuse the cache in HBM.
Handling out-of-order arrivals.
In practice, auxiliary pre-inference and ranking for the same user may
arrive out of order
(Figure [fig:design_7]). For example, if
behavior processing is slow, the pre-infer request may be delayed
while one or more ranking requests (with different candidate sets)
arrive earlier. A naïve design would cause each ranking request to
reload the cache from DRAM independently, leading to redundant H2D
transfers and increased tail latency.
To handle out-of-order arrivals and eliminate redundant reloads, RelayGR
inserts a lightweight pseudo pre-inference step in front of each
ranking request. Conceptually, the per-user queue becomes:
pseudo-pre-infer $`\rightarrow`$ rank $`\rightarrow`$ pseudo-pre-infer
$`\rightarrow`$ rank $`\rightarrow \dots`$ The pseudo step performs the
same cache checks as real pre-inference: it first probes HBM, then DRAM
on a miss. If the cache is in DRAM, only the first pseudo step
triggers a DRAM-to-HBM reload; all subsequent pseudo steps hit in HBM
and proceed directly to ranking. This guarantees that, even when the
real pre-infer request arrives late (e.g., after several ranking
requests), the system performs at most one reload per user and avoids
redundant transfers while preserving correctness.
Why it works.
Server-local DRAM increases effective cache capacity without violating the no-remote-fetch invariant (I1). The per-user single-flight serialization and idempotent pseudo-pre-inference ensure at-most-once DRAM$`\rightarrow`$HBM reload per user per burst, eliminating redundant transfers and stabilizing tail latency under concurrency.
Performance Evaluation
We evaluate RelayGR in a production-mirror recommender environment to answer three questions:
-
Q1 (Effectiveness). Does in-HBM relay-race inference improve tail-latency compliant capacity, i.e., the maximum supported sequence length and the SLO-compliant throughput?
-
Q2 (Scaling). As sequence length grows, does RelayGR degrade gracefully and continue to provide non-trivial throughput under the same P99 constraints?
-
Q3 (Extensibility). Does RelayGR remain effective when extending GR models (e.g., larger embedding dimensions and deeper backbones), and when varying deployment knobs (e.g., candidate set size and concurrency)?
Prototype and Experimental Setup
Prototype in a production-mirror environment.
We deploy RelayGR as a set of production-compatible services in a mirror environment and evaluate it with real queries. The recommender pipeline follows the standard cascade: retrieval $`\rightarrow`$ pre-processing (coarse ranking) $`\rightarrow`$ fine-grained ranking. Each phase typically consumes tens of milliseconds; the pipeline-level tail-latency SLO is P99 $`\le 135`$ ms, and fine-grained ranking is the tightest stage (e.g., $`\sim`$50 ms budget at P99). Fine-grained ranking consists of (i) feature processing, (ii) embedding lookup via external embedding service, and (iii) GR inference on NPUs.
Deployment and routing substrate.
Requests are forwarded through the same load balancers and message
gateways as in production, which we extend to support affinity-aware
routing via a user-keyed consistency-hash-key. The network is
tenant-isolated, while the load balancers and gateways are shared among
multiple services. We deploy multiple instances of both load balancers
and gateways to match production fan-out and contention patterns.
Ranking instances and “special” instances.
Fine-grained ranking uses two service names: normal instances and special instances (for over-long sequences, e.g., length larger than a configured threshold such as 4K). Each ranking instance (normal or special) is mapped to one Ascend 910C NPU with tens-of-GB HBM. Instances process multiple requests concurrently by combining CPU-side parallelism (feature/sequence processing) and NPU-side model concurrency (multiple model slots). The sequence-aware trigger controls the admitted pre-inference load and thus the effective QPS delivered to special instances.
Models and workloads.
We evaluate multiple GR architectures used in practice and their variants (e.g., HSTU and its revised version, and our internal GR blocks). Across experiments, sequence lengths range from 1K to tens of thousands of tokens; embedding dimensions range from 128 to 1024; and the generative backbone contains several to tens of layers. These settings stress the ranking critical path due to high FLOP and memory costs under long sequences. The distribution of the user-behavior length shows that most users have short histories and fewer than 6% have long sequences exceeding 2K tokens. Even caching only these long-sequence users would require tens of terabytes of storage, far beyond the capacity of any single device.
Cache semantics.
The cached object $`\psi`$ is the per-layer KV cache of the generative backbone computed from long-term behavior prefix (e.g., $`\sim`$32 MB for a 2K-token request in HSTU with 8 layers, 256-dimensional embeddings, and fp32 format). RelayGR keeps $`\psi`$ in HBM over the request lifecycle window, and optionally spills it to server-local DRAM for short-term cross-request reuse.
Metrics and measurement protocol.
We report: (1) Maximum supported sequence length, defined as the
largest sequence length that meets the pipeline SLO (P99 $`\le 135`$ ms)
with a success rate $`\ge 99.9\%`$ across all evaluated queries; (2)
SLO-compliant throughput (QPS) per special instance and at the system
level, measured under the same P99 constraints; and (3) Component
latencies (P99) for pre (pre-inference), load
(DRAM$`\rightarrow`$HBM cache loading), and rank (ranking with cache).
We distinguish QPS (completed queries per second) from concurrency
(simultaneously in-flight queries), since the latter is the key driver
of resource contention and tail latency.
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
Baselines and variants.
Baseline is the production configuration without relay-race: fine-grained ranking performs full GR inference inline under the ranking-stage P99. RelayGR denotes in-HBM relay-race inference with no DRAM reuse (0% DRAM hit). RelayGR+$`x`$% denotes RelayGR augmented with server-local DRAM reuse where $`x\%`$ is the measured DRAM hit rate (controlled by available DRAM budget for spilling, typically 500GB and maximum 4TB).
Q1: Effectiveness of RelayGR
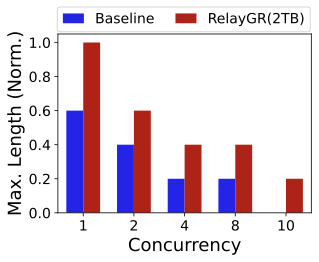
Maximum supported sequence length.
Figure 13 shows that RelayGR increases the maximum sequence length that satisfies the P99 SLO compared to the baseline. Adding server-local DRAM reuse further extends the maximum supported length by avoiding repeated pre-inference across bursts of requests from the same users. In our setup, using all available DRAM ($`\sim`$500GB) yields a DRAM hit rate of about 10% and increases the maximum supported sequence length by up to 1.5$`\times`$ over the baseline. (We discuss higher hit rates enabled by additional tiers, e.g., SSD, as an extension point; the core results in this paper focus on HBM/DRAM, i.e., 2TB and 4TB yielding $`\sim`$50% and $`\sim`$100% hit rates, respectively.)
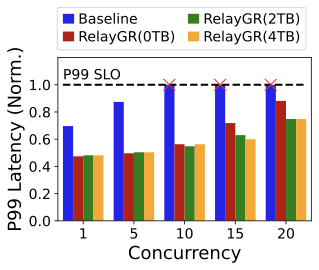
Tail latency under concurrency.
Figure 14 reports end-to-end P99 under different concurrency levels at fixed sequence length. The baseline quickly violates the pipeline SLO as concurrency increases because full GR inference remains on the ranking critical path. RelayGR shifts the expensive long-prefix computation to the relay-race path, enabling roughly 2$`\times`$ more concurrent in-flight requests without exceeding the P99 SLO in our experiments (also confirmed in our production environment). Increasing DRAM hit rate further reduces compute on the special instances, improving tail latency headroom at the same concurrency.
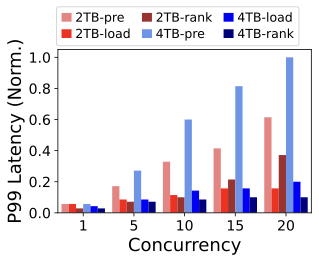
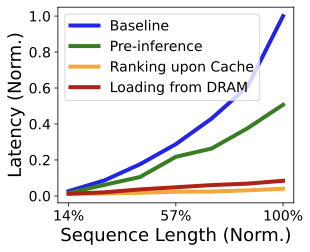
Where the savings come from.
Figure 15 breaks down P99 latency into pre,
load, and rank. Pre-inference cost grows rapidly with sequence
length because it processes the long-term prefix; this is precisely why
removing it from the ranking critical path is essential. In contrast,
load and rank grow much more slowly: cache loading is linear in
cache size, and ranking-on-cache only processes the incremental tokens
and candidate items. Consequently, even as concurrency increases,
RelayGR keeps the ranking tail latency below the baseline by confining
the expensive component to the relay-race path. The rank further
decreases using half precision (i.e., fp16 format) or the NPU type with
higher computing power.
 />
/>
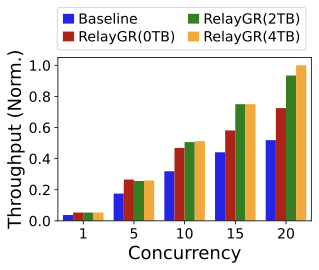
SLO-compliant throughput.
Figure 17 shows that RelayGR improves throughput (QPS) under the P99 constraint. With DRAM reuse, more requests skip pre-inference and directly reuse cached $`\psi`$, yielding further gains. Using all available DRAM improves throughput by up to 3.6$`\times`$ over the baseline in our setup. These results indicate that relay-race inference is a practical path to making long-sequence GR cost-effective in production while maintaining strict P99 SLOs.
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
 style="width:90.0%" />
style="width:90.0%" />
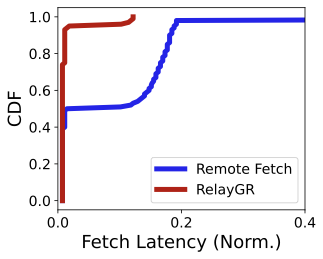
Affinity is necessary.
If prefix caches are placed in a distributed pool without affinity (i.e., without RelayGR), ranking may require remote cache fetches across servers. As shown in Figure 18, remote fetch latency (blue line) can be hundreds of times higher than local-cache access (red line, RelayGR) and can easily exceed the request lifecycle window.. These results motivate RelayGR’s key invariant: no remote fetch on the ranking critical path.
Q2: RelayGR for Scaled Sequences
Throughput degrades gracefully with longer sequences.
Figure 19 shows that throughput decreases as sequence length grows for all approaches, but RelayGR degrades much more slowly than the baseline. The baseline throughput collapses to only a few QPS beyond $`\sim`$6K tokens under the same SLO (far from the throughput demands), while RelayGR maintains tens of QPS even with 0% DRAM hit (pure in-HBM relay-race) beyond 6K tokens (the throughput per instance in production is about tens or a few hundred of QPS). With higher hit rates (e.g., 100% DRAM hit), RelayGR sustains hundreds of QPS even for sequences beyond 8K. Overall, RelayGR expands the feasible operating region where long-sequence GR can be served under strict tail latency.
Latency composition under longer sequences.
Figure 20 reports the component latencies as
sequence length increases. Pre-inference latency increases with sequence
length, but it is smaller than baseline full inference because it only
processes long-term behaviors (excluding candidate-item tokens). Both
load and rank remain within tens of milliseconds even at large
sequences, making them suitable for the ranking-stage P99 budget. In our
setup, RelayGR supports sequences up to $`\sim`$15K tokens with
load (no concurrency) below 20 ms and rank below 10 ms (under the
ranking-stage P99 SLO).
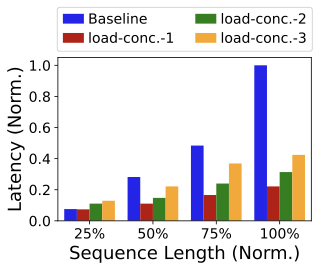
Cache loading under sequence growth and concurrency.
Figure 21 shows that DRAM$`\rightarrow`$HBM loading latency increases with both sequence length and concurrency, but remains far below baseline full inference. This aligns with the cost model: attention computation grows super-linearly with sequence length, whereas cache loading scales approximately linearly with cache size (about tens of megabytes per user). Thus, for long sequences, using stored $`\psi`$ to avoid recomputation is increasingly advantageous, especially at moderate concurrency and under tight SLO constraint.
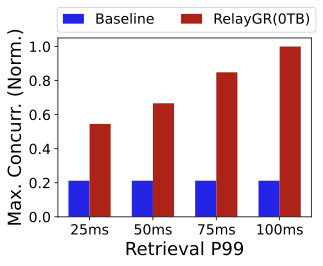
Effect of retrieval slack.
Figure 23 studies how the retrieval-stage tail latency budget impacts the maximum supported concurrency. The baseline is unaffected because all computation happens in fine-grained ranking. In contrast, RelayGR can exploit additional retrieval slack to perform more relay-race pre-inference, increasing the number of simultaneously supported queries. When retrieval P99 is 100 ms, the maximum supported concurrency is about 5$`\times`$ that of the baseline in our experiments (more pre-inference are triggered during the retrieval). This suggests RelayGR can trade retrieval slack for ranking tail-latency headroom in bursty scenarios.
Q3: Extension of RelayGR
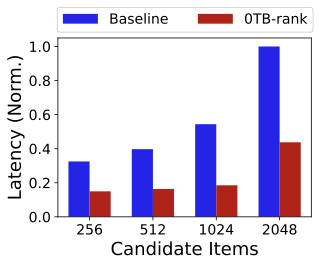
Sensitivity to candidate set size.
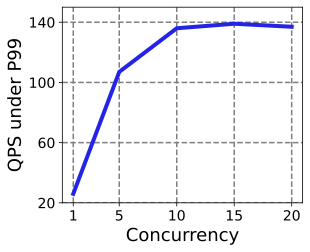
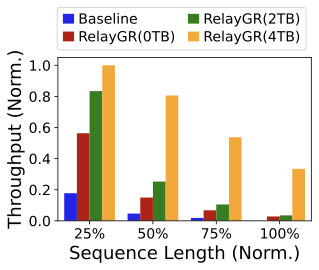
Figure 24 shows that RelayGR’s ranking latency is primarily driven by the incremental input (short-term tokens and candidate items), and is substantially smaller than the baseline where long-prefix computation remains on the critical path. In production, candidate set size is typically around 512 per query; RelayGR keeps ranking-on-cache latency well controlled (e.g., below 10 ms even at 2048 items per ranking inference in our setup). This indicates the relay-race design decouples long-prefix cost from the per-query item scoring workload.
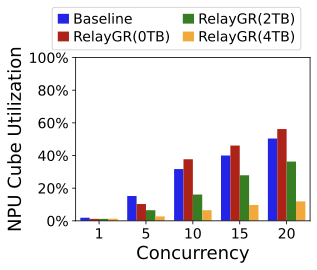
Utilization under concurrency.
Figure 25 reports NPU (cube) utilization under different concurrency levels. GR inference is compute-intensive; utilization increases with concurrency but also increases tail latency due to contention. RelayGR with 0% DRAM hit can increase utilization because it introduces additional pre-inference work; higher DRAM hit rates reduce this extra work and thus reduce utilization. Importantly, RelayGR allows this utilization–latency trade-off to be tuned while keeping ranking-stage P99 intact.
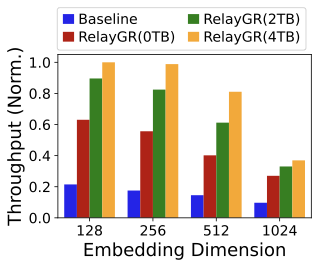
Scaling to larger embedding dimensions.
Figure 26 shows that throughput decreases as embedding dimension increases for both baseline and RelayGR, reflecting increased FLOPs. However, RelayGR consistently provides higher SLO-compliant throughput: at 1024-dim (whose parameters are several times larger than that of the original HSTU), the baseline drops below 50 QPS in our setup, while RelayGR achieves $`\ge 2\times`$ throughput, and RelayGR with 100% DRAM hit reaches $`\sim 3\times`$. This demonstrates that RelayGR generalizes beyond sequence scaling to “width” scaling.
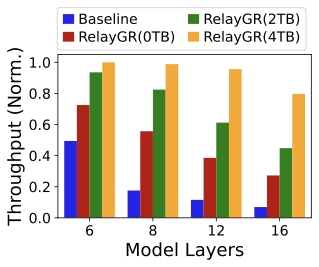
Scaling to deeper models.
Figure 28 shows that throughput decreases as model depth increases. When doubling the layers, baseline throughput drops by about 50%, whereas RelayGR exhibits a smoother degradation due to cached-prefix reuse; with 100% hit, doubling layers reduces throughput by only about 14%. When the backbone has 16 layers, RelayGR achieves $`\ge 4\times`$ throughput over baseline, indicating relay-race inference remains beneficial for deeper GR blocks.
 style="width:80.0%" />
style="width:80.0%" />
 style="width:80.0%" />
style="width:80.0%" />
| Model | Seq. | Layer | Format | Dim. | Size |
|---|---|---|---|---|---|
| Type 1/2/3 | 2K | 8 | fp32 | 256 | 32MB |
KV caches under default settings.
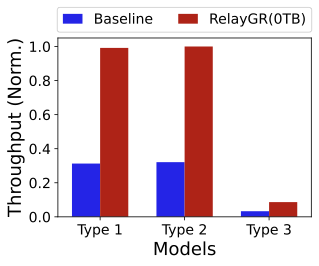
Generality across models and NPUs.
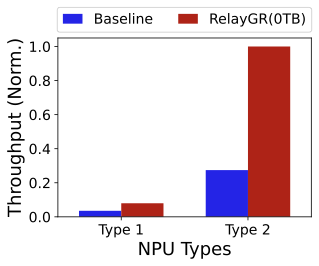
Finally, we evaluate RelayGR across multiple GR models (Figure 29) and Ascend NPU types (e.g., Ascend 310 (Type 1) and 910C (Type 2), Figure 30). Although the absolute latency and throughput vary substantially across models—sometimes by nearly an order of magnitude under default settings—the relative trends are consistent: RelayGR extends the maximum sequence length that can be served and increases SLO-compliant throughput under strict tail-latency constraints. Model sizes also differ markedly. The combined Longer + RankMixer model (Type 3) is significantly larger than HSTU (Type 1) and its variant (Type 2). Under default settings, Table 1 reports a per-request KV cache footprint of 32,MB. Note that Type 2 differs from Type 1 only in its attention computation, while for Type 3 we cache only the Longer component; RankMixer is implemented as a downstream DLRM in the fine-grained ranking stage. Finally, even with a 2K-token input, the Type 1 baseline can exceed the P99 latency budget, making long-sequence GR infeasible without caching—further highlighting the practical value of RelayGR.
Related Work
We discuss three lines of work most relevant to RelayGR: (i) LLM serving architectures that manage KV caches across phases, (ii) generative recommendation (GR) models that motivate long-sequence inference, and (iii) production recommender optimizations.
LLM Serving: Prefill–Decode Placement and KVCache Management.
A large body of LLM serving work studies how to place prefill and decode and how to manage KVCache to maximize goodput under SLOs. Representative systems disaggregate and coordinate prefill and decode (e.g., Splitwise , DistServe , TetriInfer , P/D-Serve ), scale deployment across GPU/NPU clusters (e.g., Mooncake and related production-scale deployments), dynamically balance resources between prefill and decode (e.g., DynaServe , Adrenaline ), and use distributed KVCache pools or cache-centric designs (e.g., MemServe , CachedAttention , TaiChi ).
Most of these systems operate on a two-stage inference graph: prefill produces a KVCache that decode consumes immediately. The producer therefore knows (or can decide) the consumer at handoff time, and cache movement is a direct phase-boundary operation. RelayGR targets a different regime: GR caching is a lifecycle problem across a multi-stage recommender pipeline. The prefix cache is produced early (during retrieval) and consumed later (during ranking) after pre-processing, while the eventual ranking instance is only determined after intermediate filtering. This setting introduces (i) a non-trivial survivability window, (ii) a placement problem under late-binding routing, and (iii) stringent P99 constraints under high QPS. RelayGR addresses these challenges by jointly enforcing admission control (bounded live-cache footprint) and an affinity routing contract (no remote fetch on the ranking critical path). We thus study a distinct systems problem: lifecycle caching under late-binding placement.
Generative Recommendation and Long-Sequence Modeling.
Traditional recommender models (e.g., DLRMs and variants ) have motivated extensive systems work on efficient embedding and ranking. More recently, GR models improve recommendation quality by modeling long sequential behaviors and exhibiting favorable scaling with longer sequences and larger capacity. Representative GR models include HSTU , LONGER , MTGR , HLLM , TIGER , LUM , Climber , GenRank , OneRec , OneRec-v2 , OneRec-Think , and OneTrans . These works span discriminative usage for scoring/ranking (e.g., LONGER/MTGR/HLLM) and generative usage (e.g., producing embeddings or token-by-token targets, often with additional task towers).
Our work is complementary: we do not propose a new GR model. Instead, we address the online systems barrier that prevents GR from realizing its offline scaling potential. Production ranking must satisfy tens-of-milliseconds tail latency; increasing sequence length or feature dimension inflates inference cost and quickly violates P99, forcing systems to cap online sequences. RelayGR enables long-prefix reuse by pre-inferring the user’s long-term behavior prefix and caching the per-layer KV, thereby removing expensive long-prefix computation from the ranking critical path. Compared with model-side compression (e.g., token compression), RelayGR preserves long-sequence semantics while enforcing tail-latency constraints through admission control and placement.
Production Recommender Optimization.
Industrial recommender stacks optimize end-to-end pipelines via kernel fusion, mixed precision, embedding caching, and efficient feature/embedding services. Tooling such as NVIDIA Merlin and RecSys-oriented GR stacks exemplify best practices for efficient training and inference. Other production efforts emphasize holistic pipeline optimization (e.g., co-design over the entire recommender) .
These systems primarily optimize within-stage execution (e.g., faster embedding lookup, fused operators, or more efficient model kernels). Such optimizations improve constant factors but do not fundamentally address the cross-stage nature of long-sequence GR inference, where expensive prefix computation is separated from ranking by intermediate pipeline stages. RelayGR is orthogonal: it introduces a cross-stage execution path that shifts long-prefix computation earlier and makes it reusable later under a lifecycle window and strict constraints. In particular, RelayGR explicitly handles (i) survivability of prefix KV caches across pipeline stages, (ii) late-binding routing to the eventual ranking instance, and (iii) high-QPS contention, which are not the primary focus of within-stage kernel and embedding optimizations.
Conclusion
Long-sequence generative recommendation is currently bottlenecked by the ranking-stage P99: as sequence length grows, full GR inference quickly becomes infeasible on the online critical path, preventing production systems from realizing the scaling gains observed offline. This paper shows that the key opportunity is to pre-infer the user’s long-term behavior prefix and reuse its per-layer KV cache across the multi-stage recommender pipeline.
We presented RelayGR, a production system that enables in-HBM relay-race inference—a form of lifecycle caching under late-binding placement—where prefix caches are produced early, survive through intermediate stages, and are consumed by ranking without remote fetches. RelayGR combines (i) a sequence-aware trigger that admits only at-risk requests under bounded cache footprint and load, (ii) an affinity-aware router that co-locates cache production and consumption despite late-binding routing decisions, and (iii) a memory-aware expander that leverages server-local DRAM to extend reuse across repeated requests while avoiding redundant reloads.
We implemented RelayGR on Ascend NPUs and evaluated it with real queries in a production-mirror environment. Under industrial P99 constraints, RelayGR increases the maximum supported input sequence length by up to 1.5$`\times`$ and improves SLO-compliant throughput by up to 3.6$`\times`$, demonstrating that relay-race inference is an effective systems path to bringing long-sequence GR to real-time recommenders.
📊 논문 시각자료 (Figures)

A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
*Equal contribution. ↩︎
-
Work done during their internships at Huawei. ↩︎
-
Corresponding authors: {jinyibo1, fengyongxiang1, pengfei.zuo}@huawei.com. ↩︎