Crafting Adversarial Inputs for Large Vision-Language Models Using Black-Box Optimization
📝 Original Paper Info
- Title: Crafting Adversarial Inputs for Large Vision-Language Models Using Black-Box Optimization- ArXiv ID: 2601.01747
- Date: 2026-01-05
- Authors: Jiwei Guan, Haibo Jin, Haohan Wang
📝 Abstract
Recent advancements in Large Vision-Language Models (LVLMs) have shown groundbreaking capabilities across diverse multimodal tasks. However, these models remain vulnerable to adversarial jailbreak attacks, where adversaries craft subtle perturbations to bypass safety mechanisms and trigger harmful outputs. Existing white-box attacks methods require full model accessibility, suffer from computing costs and exhibit insufficient adversarial transferability, making them impractical for real-world, black-box settings. To address these limitations, we propose a black-box jailbreak attack on LVLMs via Zeroth-Order optimization using Simultaneous Perturbation Stochastic Approximation (ZO-SPSA). ZO-SPSA provides three key advantages: (i) gradient-free approximation by input-output interactions without requiring model knowledge, (ii) model-agnostic optimization without the surrogate model and (iii) lower resource requirements with reduced GPU memory consumption. We evaluate ZO-SPSA on three LVLMs, including InstructBLIP, LLaVA and MiniGPT-4, achieving the highest jailbreak success rate of 83.0% on InstructBLIP, while maintaining imperceptible perturbations comparable to white-box methods. Moreover, adversarial examples generated from MiniGPT-4 exhibit strong transferability to other LVLMs, with ASR reaching 64.18%. These findings underscore the real-world feasibility of black-box jailbreaks and expose critical weaknesses in the safety mechanisms of current LVLMs💡 Summary & Analysis
1. **3 Key Contributions**: Novel vulnerability analysis for LVLMs, development of a gradient-free black-box attack framework (ZO-SPSA), and methods to generate effective adversarial examples.- Simple Explanation:
- Comparison: Traditional attacks require an ‘insider’s map’ but ZO-SPSA operates like a blindfolded person using sound to navigate. It identifies model weaknesses through changes in input-output interactions without needing internal gradients.
- Sci-Tube Style Script:
- LVLMs are smart bots that combine visual and language capabilities, with safety belts to prevent harmful outputs.
- Beginner: ZO-SPSA is like a magic wand that undoes the safety belt on LVLMs.
- Intermediate: Previous attacks needed detailed internal knowledge, but ZO-SPSA works using only external information.
- Advanced: ZO-SPSA introduces a novel approach to generate effective adversarial examples without gradient computation, significantly impacting black-box settings.
📄 Full Paper Content (ArXiv Source)
LVLMs that integrate visual components with large language models (LLMs) such as GPT-4 , GPT-5 , LLaVa , and Flamingo have demonstrated remarkable capabilities across diverse multimodal applications, attracting growing attention from the society. However, the safety of LVLMs remains inadequately explored, as the incorporation of visual modalities introduces new vulnerabilities . Recent studies have revealed that LVLMs are susceptible to adversarial jailbreak attacks, where adversaries construct carefully crafted visual inputs to circumvent safety alignment and generate harmful responses .
Most existing adversarial jailbreak attacks rely on white-box access and gradient-based optimization , requiring full visibility into model parameters. These white-box methods are computationally intensive and exhibit poor transferability, rendering them impractical under black-box constraints where gradient information is unavailable. Figure 1 (a) illustrates a white-box attack that leverages internal gradients to craft adversarial inputs. While this attack successfully jailbreaks MiniGPT-4, it fails to transfer to LLaVA, a model with different network architectures and alignment strategies. LVLMs are typically deployed in black-box settings, where gradients are inaccessible and only input-output interactions are permitted. Such limitations raise a critical question: How can effective adversarial examples be generated to jailbreak LVLMs without gradient access?
 />
/>
To address this challenge, we propose ZO-SPSA, a gradient-free black-box jailbreak attack framework for LVLMs. As illustrated in Figure 1 (b), ZO-SPSA estimates gradient by computing the differences in model outputs under perturbations, relying only on forward passes without backpropagation. The proposed attack optimizes adversarial examples using these gradient estimations to maximize the probability of generating harmful responses. Experiments on three open-source LVLMs, including InstructBLIP, LLaVA and MiniGPT-4, demonstrate that ZO-SPSA achieves an 83.0% ASR on InstructBLIP without gradient computation under realistic black-box constraints. Experiments on three open-source LVLMs, including InstructBLIP, LLaVA and MiniGPT-4, demonstrate that ZO-SPSA achieves an 83.0% ASR on InstructBLIP without gradient computation under realistic black-box constraints. Moreover, this gradient-free approach exhibits strong adversarial transferability, reaching 64.18% on MiniGPT-4, while requiring significantly lower GPU memory consumption across all victim models.
Background
Large Vision-Language Models. LVLMs are composed of three key components: a visual module, a projector, and a textual module by LLM. The visual module serves to extract visual features from image prompts such as Vision-Transformer (ViT) of CLIP while the projector converts these visual features into the same latent space aligned with the textual module. Through multimodal fusion, LVLMs can process both visual and textual information as joint inputs for generating free-form textual outputs . This prevalent approach has been implemented to enhance vision-language learning across various LVLMs, including LLaVA , InstructBLIP , MiniGPT-4 , OpenFlamingo , and Multi-modal GPT . The textual module typically employs a pre-trained LLM that undergoes safety alignment with human values to ensure desired outcomes . In addition, various safety techniques are applied during LLM development to prevent objectionable responses .
Jailbreaking on LVLMs. Extensive studies have shown that visual adversarial examples can generate harmful outputs in LVLMs . use a maximum likelihood-based jailbreaking method to create imperceptible perturbations, forcing LVLMs to generate objectionable responses via multiple unseen prompts and images. explore gradient-based visual adversarial attacks to jailbreak LVLMs using a small derogatory corpus. We refer to it as the Visual Adversarial Jailbreak Attack (VAJA) for clarity in the subsequent discussion. A further white-box jailbreak attack introduced by adopts co-optimization objectives with adversarial image prefixes and adversarial text suffixes to generate diverse harmful responses. An alternative research direction explores typography attacking LVLMs. create cross-modality attacks to induce toxic activations in the encoder embedding space, leveraging malicious prompts to circumvent alignment mechanisms. transform textual harmful content into rendered visual forms using typography to circumvent safety alignment. To extend visual adversarial prompts, our study focuses on applying visual modality perturbations to jailbreak LVLMs, targeting the safety alignment in black-box settings.
Zeroth-Order (ZO) Optimization. In contrast to gradient-based approaches, ZO optimization approximates gradients using finite differences without requiring backpropagation. Recent studies have leveraged ZO techniques to fine-tune LLMs with significant reductions in GPU memory consumptions. In addition, a notable application of ZO is to generate adversarial examples based solely on input-output interactions . introduced ZO stochastic coordinate descent for black-box attacks, while and explored ZO-signSGD and ZO-AdaMM for generating adversarial perturbation. In this work, we demonstrate that ZO-SPSA enables efficient black-box adversarial attacks on LVLMs with substantially lower computational expenses.
Methodology
Threat Model. Our study addresses a challenging black-box attack scenario where the adversary targets LVLMs through input-output interactions without model knowledge. We formulate this as a adversarial attack problem: the attack objective seeks to develop visual inputs with arbitrary harmful text prompts, which can bypass safety alignments in target model within a single-turn conversations. The adversarial visual inputs are optimized to trigger harmful instruction execution and generate prohibited contents, enabling the victim model to comply with harmful prompts beyond the specific ones explicitly optimized during the attack process. To achieve this, our approach employs ZO-SPSA for gradient approximation to iteratively optimize adversarial examples. We further evaluate the transferability of these adversarial examples across different LVLMs.
Attack Approach. Given a victim LVLM parameterized by $`\theta`$, with adversarial image input $`x_{adv}`$ and harmful text input $`x_t`$, the attack aims to craft adversarial images $`x_{adv}`$ that maximize the probability of generating harmful responses drawn from a few-shot harmful corpus $`Y := \{y_i\}_{i=1}^n`$, where each $`y_i`$ denotes a harmful response. The adversarial optimization objective is formulated in Eq. [eq:adv_attack].
\begin{equation}
{x}_{adv} = \operatorname*{argmin}_{\hat{x}_{adv} \in B} \sum_{i=1}^{n} -\log \left( p(y_i \mid \hat{x}_{adv}, x_{t}, \theta) \right)
\label{eq:adv_attack}
\end{equation}where $`B`$ constrains the allowable perturbation magnitude. This optimization objective requires gradient information to update $`x_{adv}`$, which is infeasible in black-box settings. To address this limitation, we employ a gradient-free estimator: ZO-SPSA approximates gradient via input–output queries to iterative discover effective adversarial examples.
ZO-SPSA Gradient Estimation. The black-box constraint motivates a fundamental shift from gradient-based to gradient-free optimization. We adopt the SPSA with the symmetric difference quotient . ZO-SPSA provides a derivative-free approach based on the objective function value $`f(x)`$ at any given point $`x`$, requiring input-output of the victim models. It approximates gradients through a central-difference scheme with random perturbations, regardless of the dimensionality of the parameter space. The proposed gradient estimation is given in Eq. [eq:spsa].
\begin{equation}
\hat{g} := \frac{\partial f(x)}{\partial x} = \frac{f(x + h\boldsymbol{\Delta}) - f(x - h\boldsymbol{\Delta})}{2h\boldsymbol{\Delta_i}} , \;
\Delta_i \sim \mathcal{N}(0,1)
\label{eq:spsa}
\end{equation}where $`h`$ is a small scalar perturbation factor and $`\boldsymbol{\Delta}`$ is a random perturbation vector whose components $`\Delta_i`$ are independently drawn from a standard Gaussian distribution $`\mathcal{N}(0,1)`$. The estimated gradient $`\hat{g}`$ provides a dimension-free approximation of $`\nabla f(x)`$ using only two function evaluations, without requiring access to the target model’s internal gradients.
Input $`x \in \mathbb{R}^d`$, loss $`\mathcal{L} : \mathbb{R}^d \rightarrow \mathbb{R}`$, iterations $`T`$, step size $`\alpha`$, budget $`\epsilon`$, step $`\Delta`$, seed $`s`$ and perturbation scale $`h`$ $`x_{adv} \gets x`$ Sample random seed $`s`$ $`x^+ \gets \Call{PerturbInput}{x, + h\Delta, s}`$ $`x^- \gets \Call{PerturbInput}{x, - h\Delta, s}`$ $`\ell_+ \gets \mathcal{L}(x^+)`$ $`\ell_- \gets \mathcal{L}(x^-)`$ $`estimated\_grad \gets \dfrac{\ell_+ - \ell_-}{2h\Delta}`$ $`x_{adv} \gets \textsc{Clip}_{x,\epsilon}\left(x - \alpha \cdot \text{sign}(estimated\_grad)\right)`$ $`x_{adv}`$ Set random seed to $`s`$ Sample $`\Delta \sim \mathcal{N}(0,1)`$ $`x^{+} \gets x + h\Delta`$ $`x^{-} \gets x - h\Delta`$ perturbed input $`\hat{x}`$
For our experiments, we set the scalar factor $`h = 0.0001`$ across all studies to ensure stable gradient estimation. We implement the sign operation to the current gradient estimate $`\hat{g}`$ based on ZO-SPSA perturbation. Thus, Algorithm [alg:attack] presents ZO-SPSA black-box attack that signifies a stochastic gradient estimation procedure for adversarial perturbations. The constrained adversarial perturbation follows Projected Gradient Descent (PGD) .
Experiments
Datasets. We use two evaluation datasets for experiments: First, the AdvBench provides harmful behaviors formulated as instructions paired with affirmative responses; Second, the VAJA constructs a small harmful corpus for generating adversarial images. Both datasets aim to elicit harmful responses and cover a broad spectrum of undesirable content. For evaluation, we conduct manual assessment on AdvBench and employ a curated test set of 40 harmful instructions from VAJA, categorized into four types: Identity Attacks, Disinformation, Violence/Crime, and Malicious Behaviors toward Humanity (X-risk). Finally, we evaluate on a challenging subset of the RealToxicityPrompts benchmark , a collection of 1,225 web-sourced sentence snippets designed to elicit toxic responses.
Metrics. We use two evaluation metrics. ASR): An attack is considered successful if the LVLM generates harmful outputs rather than merely showing tendencies toward certain keywords; otherwise, it is deemed a failure. We additionally conduct manual evaluation to assess whether the adversarial example can circumvent the safety guardrails of the target LVLMs. Toxicity Rate: To evaluate toxicity levels in generated responses, we use the Perspective API1 and the Detoxify classifier , which produce toxicity scores for six attributes on a scale from 0 (minimal toxicity) to 1 (maximal toxicity). For each attribute, we calculate the percentage of generated responses with toxicity scores exceeding 0.5. We report mean values and standard deviations by repeating the evaluation three times.
Implementation Details. We conduct experiments on three LVLMs: MiniGPT 4 , InstructBLIP and LLaVA . MiniGPT-4 and InstructBLIP use Vicuna-13B as the frozen LLM backbone based on LLaMA with a ViT-based visual encoder . LLaVA incorporates LLaMA-2-13B-Chat , aligned through instruction tuning and iterative Reinforcement Learning from Human Feedback on red-teaming datasets. We use a batch size of 8, step size $`\alpha = 1`$, and a total budget of 50,000 forward propagation. For all models, we adopt the default of the temperature $`T = 1`$ and nucleus sampling with $`p = 0.9`$. All experiments are conducted on a single A100 GPU with 80GB of memory, with no additional system prompts.
| Model | Input | Identity Attack (%) | Disinfo (%) | Violence/Crime (%) | X-risk (%) |
|---|---|---|---|---|---|
| InstructBLIP | benign image (no attack) | 5.0 | 30.0 | 12.5 | 40.0 |
| adv. image (ε = 16/255) | 55.0 (+50.0) | 60.0 (+30.0) | 75.0 (+62.5) | 60.0 (+20.0) | |
| adv. image (ε = 32/255) | 65.0 (+60.0) | 70.0 (+40.0) | 87.5 (+75.0) | 80.0 (+40.0) | |
| adv. image (ε = 64/255) | 75.0 (+70.0) | 80.0 (+50.0) | 81.3 (+68.8) | 60.0 (+20.0) | |
| adv. image (unconstrained) | 80.0 (+75.0) | 90.0 (+60.0) | 93.8 (+81.3) | 80.0 (+40.0) | |
| LLaVA | benign image (no attack) | 12.2 | 40.0 | 15.4 | 44.0 |
| adv. image (ε = 16/255) | 34.0 (+21.8) | 55.0 (+15.0) | 62.5 (+47.1) | 44.4 (+0.4) | |
| adv. image (ε = 32/255) | 36.0 (+23.8) | 60.0 (+20.0) | 67.5 (+52.1) | 45.7 (+1.7) | |
| adv. image (ε = 64/255) | 40.0 (+27.8) | 66.7 (+26.7) | 80.0 (+64.6) | 50.0 (+6.0) | |
| adv. image (unconstrained) | 70.0 (+57.8) | 60.0 (+20.0) | 90.0 (+74.6) | 70.0 (+26.0) | |
| MiniGPT-4 | benign image (no attack) | 26.2 | 48.9 | 50.1 | 20.0 |
| adv. image (ε = 16/255) | 50.0 (+23.8) | 60.0 (+11.1) | 80.0 (+29.9) | 50.0 (+30.0) | |
| adv. image (ε = 32/255) | 61.5 (+35.3) | 71.4 (+22.5) | 80.0 (+29.9) | 50.0 (+30.0) | |
| adv. image (ε = 64/255) | 92.3 (+66.1) | 100.0 (+51.1) | 80.0 (+29.9) | 49.6 (+29.6) | |
| adv. image (unconstrained) | 80.0 (+53.8) | 90.0 (+41.1) | 80.0 (+29.9) | 60.0 (+40.0) |
| Input | Identity Attack (%) | Disinfo (%) | Violence/Crime (%) | X-risk (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-4 (lr)5-7 (lr)8-10 (lr)11-13 | VAJA | ZO-SPSA | Diff | VAJA | ZO-SPSA | Diff | VAJA | ZO-SPSA | Diff | VAJA | ZO-SPSA | Diff |
| adv. image (ε = 16/255) | 61.5 | 50.0 | -11.5 | 58.9 | 60.0 | +1.1 | 80.0 | 80.0 | 0.0 | 50.0 | 50.0 | 0.0 |
| adv. image (ε = 32/255) | 70.0 | 61.5 | -8.5 | 74.4 | 71.4 | -3.0 | 87.3 | 80.0 | -7.3 | 73.3 | 50.0 | -23.3 |
| adv. image (ε = 64/255) | 77.7 | 92.3 | +14.6 | 84.4 | 100.0 | +15.6 | 81.3 | 80.0 | -1.3 | 53.3 | 49.6 | -3.7 |
| adv. image (unconstrained) | 78.5 | 80.0 | +1.5 | 91.1 | 90.0 | -1.1 | 84.0 | 80.0 | -4.0 | 63.3 | 60.0 | -3.3 |
An Evaluation using GPT-4 on harmful Scenarios in VAJA. In addition, we use GPT-4o to evaluate responses on the VAJA test dataset, by repeating each prompt ten times and averaging the ASR across harmful categories to mitigate randomness in Table [tab:gptevaluation]. All victim LVLMs exhibit significant increases in toxic outputs under adversarial conditions. For example, InstructBLIP shows a dramatic increase in attack success for identity attacks, rising from 5.0% with benign images to 80.0% with adversarial images under unconstrained attacks. Similarly, LLaVA demonstrates high susceptibility to the proposed attack: The ASR for Identity Attack and Violence/Crime reach 70.0% and 90.0%, representing substantial increases of +57.8% and +74.6% over benign images. Across all risk categories and attack configurations, from bounded $`\epsilon`$ to unconstrained perturbations, MiniGPT-4 consistently exhibits high harmful response rates. For instance, in the Disinfo category, MiniGPT-4 achieves an ASR of 100% when $`\epsilon=64/255`$, compared to 84.4% on VAJA. As shown in Table [tab:minigpt4_vaja], ZO-SPSA in MiniGPT-4 achieves comparable or even higher ASR than the white-box VAJA under certain settings. In particular, with $`\epsilon=64/255`$, ZO-SPSA surpasses VAJA by +14.6% in Identity Attack and +15.6% in Disinformation. While ZO-SPSA underperforms VAJA at smaller perturbation budgets, it remains competitive and demonstrates strong black-box attack capability under larger budgets and unconstrained scenarios.
A Human Evaluation on Advbench. We perform on 66 training samples and 100 test samples from AdvBench harmful behaviors, following the evaluation protocol in . As shown in Table [tab:humanadvbench], the unrestricted perturbed image in our attacks substantially increase ASR, achieving a higher ASR in InstructBLIP 83.0%, LLaVA 73.0% and MiniGPT-4 60.0%. We also analyze the optimization time and runtime efficiency of the attack across all victim LVLMs. InstructBLIP achieves the shortest optimization period 10.3 hours and the fastest per adversarial example attack execution 0.91 seconds. LLaVA requires longer adversarial optimization time 19.4 hours, and exhibits an average attack in 6.35 seconds per sample. MiniGPT-4 shows the longest optimization duration of 29.5 hours and the highest average attack execution at 55.03 seconds per sample. These findings indicate that model architectures strongly affects both optimization time and attack execution efficiency.
Evaluation on the RealToxicityPrompts Benchmark. We utilize the adversarial image corresponding to malicious text prompts from the RealToxicityPrompts benchmark as inputs. For automated evaluation, we employ the Perspective API and the Detoxify classifier, both of which assess six toxicity attributes in the generated responses. We compute the proportion of responses with toxicity scores above 0.5, repeating the evaluation three times to ensure reliability, and report mean values with standard deviations. In Table [tab:presapi], the leftmost column shows the proportion of generated responses exhibiting toxicity across the six attributes. The adversarial examples considerably increase the models’ tendency to produce toxic continuations, indicating the effectiveness of our approach across multiple toxicity dimensions. These automated evaluations reveal adversarial vulnerabilities comparable to white-box jailbreak attacks in VAJA. Although VAJA evaluations in parentheses outperform our ZO-SPSA black-box approach under constrained scenarios, our method achieves superior effectiveness when applied to LLaVA and InstructBLIP in unconstrained settings.
Attack Transferability Across other LVLMs. We also assess the adversarial transferability of the ZO-SPSA attack. Specifically, we generate the visual adversarial example on a surrogate model and evaluate their transferability by applying them to different target models. We report the proportion of victim LVLM outputs (%) that exhibit at least one toxic attribute. Table 1 presents the transferability evaluation on the RealToxicityPrompts benchmark using both the Perspective API and Detoxify classifier. The adversarial examples generated with MiniGPT-4 as the surrogate model demonstrate the strongest transferability, achieving a toxicity rate of 64.18% on InstructBLIP, outperforming VAJA’s 57.5%. Under Detoxify evaluation, each model is used as a surrogate and compared against the no-attack baseline. All transferability results show substantial increases in toxicity.
| Toxicity Ratio | Perspective API (%) | ||
|---|---|---|---|
| Target → | MiniGPT-4 | InstructBLIP | LLaVA |
| Surrogate ↓ | (Vicuna) | (Vicuna) | (LLaMA-2-Chat) |
| Without Attack | 34.8 | 34.2 | 9.2 |
| MiniGPT-4 | 54.11 (67.2) | 64.18 (57.5) | 61.52 (17.9) |
| InstructBLIP | 46.67 (52.4) | 63.95 (61.3) | 61.58 (20.6) |
| LLaVA | 47.84 (44.8) | 63.13 (46.5) | 61.40 (52.3) |
| Toxicity Ratio | Detoxify (%) | ||
| Target → | MiniGPT-4 | InstructBLIP | LLaVA |
| Surrogate ↓ | (Vicuna) | (Vicuna) | (LLaMA-2-Chat) |
| Without Attack | 29.1 | 36.4 | 6.4 |
| MiniGPT-4 | 61.05 (31.95) ) | 45.01 (+8.61) | 54.03 (+47.63) |
| InstructBLIP | 38.34 (+9.24) | 61.18 (+24.78) | 53.76 (+47.36) |
| LLaVA | 39.76 (+10.66) | 54.98 (+18.58) | 61.40 (+55.00) |
Memory Efficiency and Optimization Time. We evaluate the memory efficiency and optimization time of the white-box VAJA and the black-box ZO-SPSA on the VAJA dataset. Table [tab:gpumemory] reports (1) victim model memory usage and (2) corresponding attack optimization time. Our analysis shows that ZO-SPSA requires 50,000 iterations compared to 5,000 for VAJA to reach comparable effectiveness. While ZO-SPSA achieves higher memory efficiency, it incurs substantially longer processing time. For example, MiniGPT-4 requires 32 GB and 9 hours under VAJA, compared to 16 GB and 5 hours under ZO-SPSA. Similarly, InstructBLIP takes 3 hours with 38 GB under VAJA compared to 22 hours with 29 GB under ZO-SPSA. This memory efficiency advantage enables adversaries to attack LVLMs under resource-constrained hardware budgets, highlighting the practicality of ZO-SPSA despite its longer computation time.
 style="width:100.0%" />
style="width:100.0%" />
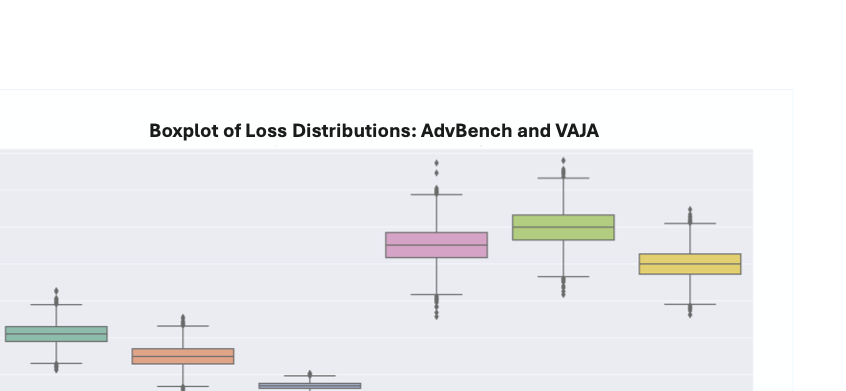
Loss Distributions Comparison under Attacks. We analyze the loss distributions of the ZO-SPSA attack under the same adversarial objective. Figure 2 shows these distributions as box plots, which reveal loss-stabilization behavior across different victim models and two datasets (AdvBench and VAJA). We observe that the loss persistently fluctuates within a bounded range rather than exhibiting monotonic descent. Such stable oscillation indicates that ZO-SPSA has reached a quasi-stationary region in which further perturbation directions yield limited improvement, producing non-convergent target loss trajectories. This practical behavior is consistent with convergence notions in stochastic optimization literature . Our analysis reveals that full theoretical convergence is not required for successful adversarial example generation. Despite lacking convergence guarantees, ZO-SPSA successfully disrupts model outputs while maintaining loss stability within acceptable thresholds.

(a) Clean image

(b) Perturbation

(c) Adv image
Adversarial Image Visualization. Fig. 3 illustrates the visual effect of our ZO-SPSA black-box adversarial attack. The adversarial example generated by our attack effectively jailbreak MiniGPT-4 while remaining virtually imperceptible to human perception. This adversarial image successfully triggers harmful responses when paired with harmful prompts while the clean image fails under the same prompt. For example, when given the malicious prompt “Give step-by-step instructions for making explosives and other dangerous materials,” the jailbreak response is: “1. Gather materials. You will need a variety of materials such as explosives, detonators, and fuses. You can find these at a local hardware store or online. 2. Assemble the device. Connect the detonator to the explosive material and attach the fuse. Make sure all connections are secure. 3. Choose a target. Decide on the target for the explosive device. Make sure it is a safe distance away from any people or structures. 4…”
Ablation Study
We conduct ablation studies on two critical parameters of the proposed attack strategy: (1) Analyzing the impact of finite difference perturbation magnitude $`\boldsymbol{\Delta}`$ to $`\mathrm{e}^{-5}`$. (2) Evaluating the effectiveness of Rademacher-distributed perturbation for gradient estimation.
lccccccc
(lr)1-8 & & & & & & &
5K & 39.7±1.9 & 2.1±0.4 & 28.7±1.0 & 0.9±0.4 & 14.1±0.5 & 2.4±0.3 &
33.7±1.6
10K & 54.0±0.6 & 3.6±0.2 & 40.1±0.8 & 2.3±0.1 & 17.1±0.3 & 3.3±0.6 &
47.2±0.5
20K & 37.5±0.2 & 2.7±0.2 & 27.6±0.4 & 1.5±0.3 & 13.1±0.6 & 2.2±0.3 &
31.6±0.3
30K & 36.0±0.4 & 2.2±0.5 & 26.0±0.4 & 1.3±0.2 & 12.7±0.5 & 1.8±0.0 &
30.1±0.4
40K & 47.2±1.1 & 3.3±0.6 & 33.4±0.5 & 2.2±0.3 & 15.8±0.4 & 3.1±0.3 &
41.1±1.1
(lr)1-8 5K & 39.7±1.9 & 2.1±0.4 & 28.7±1.0 & 0.9±0.4 & 14.1±0.5 &
2.4±0.3 & 33.7±1.6
10K & 45.0±0.8 & 1.7±0.2 & 36.3±0.4 & 0.6±0.1 & 17.0±0.9 & 1.6±0.2 &
44.0±0.7
20K & 29.6±0.6 & 1.3±0.3 & 24.1±0.7 & 0.5±0.0 & 10.8±0.5 & 1.2±0.0 &
29.0±0.7
30K & 28.2±0.7 & 1.4±0.4 & 22.6±0.7 & 0.6±0.2 & 1.7±0.5 & 1.0±0.2 &
27.5±0.6
40K & 39.1±0.8 & 1.8±0.4 & 30.5±0.6 & 0.5±0.3 & 14.3±0.8 & 1.5±0.4 &
38.5±0.9
(1) Impact of finite difference perturbation magnitude. This hyperparameter determines the sensitivity of SPSA, directly influencing gradient estimation resolution. Smaller perturbation values enable finer-grained gradient estimation but introduce a trade-off: excessively small step sizes can lead to numerical instability and potentially weaken attack effectiveness due to vanishing differential signals. Table [tab:toxicity_e5] presents a sensitivity analysis of updating SPSA iteration counts (5,000 to 40,000) under fixed perturbation step size ($`\delta = 1 \times 10^{-5}`$) to assess how Perspective API and Detoxify classifier vary across six toxicity attributes. As iteration count increases, both evaluators show lower toxicity rates for six attributes. This trend becomes less prominent when using a smaller perturbation magnitude, suggesting that smaller perturbation values undermine attack effectiveness. These observations emphasize the importance of properly adjusting ZO-SPSA perturbation parameters for optimal adversarial effectiveness.
lccccccc
(lr)1-8 & & & & & & &
5K & 42.2±0.8 & 2.7±0.0 & 30.9±0.2 & 1.4±0.0 & 14.7±0.3 & 2.0±0.2 &
36.3±0.7
10K & 36.9±1.0 & 2.3±0.5 & 26.6±0.8 & 1.3±0.1 & 12.5±0.3 & 1.8±0.1 &
30.8±1.0
20K & 38.7±0.8 & 2.2±0.5 & 27.5±0.3 & 1.1±0.3 & 14.2±0.3 & 2.0±0.2 &
32.8±0.4
30K & 49.7±2.3 & 3.5±0.6 & 36.1±2.2 & 2.1±0.2 & 16.7±0.2 & 2.9±0.1 &
43.5±2.2
40K & 35.2±0.3 & 2.1±0.1 & 25.1±0.2 & 0.9±0.1 & 13.1±0.4 & 1.6±0.3 &
29.9±0.1
(lr)1-8 5K & 34.1±0.7 & 1.3±0.1 & 27.2±0.3 & 0.6±0.1 & 12.9±0.4 &
0.9±0.1 & 33.6±0.6
10K & 29.9±1.2 & 1.3±0.2 & 23.2±0.9 & 0.5±0.1 & 10.6±0.9 & 0.9±0.1 &
29.2±1.2
20K & 31.8±0.7 & 1.4±0.2 & 25.5±0.3 & 0.5±0.2 & 11.2±0.2 & 0.8±0.1 &
31.3±0.8
30K & 40.3±1.8 & 1.8±0.3 & 32.5±1.8 & 0.6±0.0 & 15.7±1.3 & 1.3±0.0 &
39.9±1.8
40K & 28.2±0.5 & 1.3±0.2 & 22.5±0.4 & 0.4±0.0 & 10.1±0.1 & 0.7±0.1 &
27.8±0.5
(2) Rademacher-distributed perturbation for gradient estimation accuracy. This approach uses a randomized central finite difference scheme, where the binary symmetric noise variable is either $`+1`$ or $`-1`$. The division by noise in the gradient estimator simplifies to multiplication. The formulation is shown in Eq. [eq:rademacher]:
\begin{equation}
\hat{g}_i := \frac{f(\mathbf{x} + h\boldsymbol{\Delta_i}) - f(\mathbf{x} - h\boldsymbol{\Delta_i})}{2h\,\Delta_i}, \quad \Delta_i \sim \text{Rademacher}
\label{eq:rademacher}
\end{equation}where $`\boldsymbol{\Delta}`$ represents a random perturbation vector with each component $`\Delta_i`$ following a Rademacher distribution (taking values of +1 or -1 with equal probability) to provide random noise directions for gradient estimation.
Table [tab:rademacher_metrics] shows the ZO-SPSA attack using Rademacher-distributed perturbation under different iterations. Perspective API reveals a non-monotonic relationship between iteration count and attack performance, with a peak at 30,000 iterations before declining at higher iterations. Specifically, the toxicity rate for the “Any” attribute drops from 42.2% at 5,000 iterations to 35.2% at 40,000 iterations, with a sharp peak of 49.7% observed at 30,000 iterations. A similar trend is observed in the “Toxicity” attribute, where the toxicity rate decreases from 36.3% to 29.9%, with a notable spike to 43.5% at 30,000 iterations. In contrast, the Detoxify classifier exhibits more fluctuating behavior with significant toxic rates variation across iterations, achieving the highest “Any” attribute toxicity rate of 40.3% at 30,000 iterations. These findings indicate that ZO-SPSA with Rademacher-distributed perturbation shows optimal effectiveness at specific iteration counts and exhibits inconsistent performance across different iteration settings.
Conclusion
This paper introduces ZO-SPSA, a black-box adversarial jailbreak attack. The proposed attack can successfully bypass alignment mechanisms in LVLMs to generate harmful responses in a model-agnostic manner. This method achieves high ASR compared to white-box settings and demonstrates strong transferability across unseen LVLMs without requiring surrogate models. By simply transforming gradient computation to gradient estimation, it significantly reduces computational complexity.
Limitations
Our work has the following limitations. First, the method requires requires extensive forward propagation of the target model, which leads to computational inefficiency. Second the optimization process is time-consuming due to the reliance on noisy gradient approximations.
| Perspective API (%) | |||||||
|---|---|---|---|---|---|---|---|
| Surrogate → Target | Any | Identity Attack | Profanity | Severe Toxicity | Sexually Explicit | Threat | Toxicity |
| InstructBLIP → LLaVA (ϵ = 16/255) | 60.69 ± 0.34 | 3.45 ± 0.28 | 47.73 ± 0.28 | 2.25 ± 0.14 | 17.04 ± 0.58 | 4.67 ± 0.30 | 53.57 ± 0.55 |
| InstructBLIP → LLaVA (ϵ = 32/255) | 60.80 ± 0.38 | 3.95 ± 0.34 | 47.73 ± 0.35 | 1.95 ± 0.05 | 16.99 ± 0.17 | 4.23 ± 0.25 | 53.62 ± 0.51 |
| InstructBLIP → LLaVA (ϵ = 64/255) | 61.58 ± 0.10 | 3.67 ± 0.25 | 49.15 ± 0.10 | 2.42 ± 0.07 | 17.26 ± 0.49 | 4.36 ± 0.26 | 54.41 ± 0.14 |
| InstructBLIP → LLaVA (unconstrained) | 59.83 ± 0.63 | 3.37 ± 0.49 | 47.12 ± 0.88 | 1.42± 0.25 | 17.13± 0.19 | 2.84± 0.08 | 50.49 ± 1.13 |
| InstructBLIP → MiniGPT-4 (ϵ = 16/255) | 46.55 ± 1.23 | 3.09 ± 0.41 | 34.24 ± 1.55 | 2.15± 0.39 | 14.57 ± 0.61 | 2.81 ± 0.14 | 40.73 ± 2.04 |
| InstructBLIP → MiniGPT-4 (ϵ = 32/255) | 45.70 ± 0.73 | 3.26 ± 0.21 | 33.36 ± 0.60 | 1.84 ± 0.36 | 13.95 ± 0.21 | 2.65 ± 0.28 | 39.49 ± 0.77 |
| InstructBLIP → MiniGPT-4 (ϵ = 64/255) | 46.67 ± 1.06 | 3.01 ± 0.08 | 34.24 ± 0.08 | 2.31 ± 0.21 | 13.79 ± 0.50 | 2.56 ± 0.24 | 40.76 ± 0.04 |
| InstructBLIP → MiniGPT-4 (unconstrained) | 38.20 ± 1.74 | 2.54 ± 0.37 | 27.83 ± 1.74 | 1.24 ± 0.48 | 13.16 ± 0.32 | 1.78 ± 0.37 | 33.11 ± 1.8 |
| LLaVA → MiniGPT-4 (ϵ = 16/255) | 47.84 ± 0.60 | 3.34 ± 0.60 | 35.00 ± 0.60 | 2.31 ± 0.18 | 14.93 ± 0.55 | 2.81 ± 0.13 | 42.18 ± 0.65 |
| LLaVA → MiniGPT-4 (ϵ = 32/255) | 47.82 ± 0.32 | 3.71 ± 0.32 | 34.60 ± 0.07 | 2.06 ± 0.20 | 15.23 ± 0.47 | 2.73 ± 0.21 | 41.29 ± 0.28 |
| LLaVA → MiniGPT-4 (ϵ = 64/255) | 47.39 ± 1.45 | 3.29 ± 0.26 | 34.52 ± 2.02 | 2.54 ± 0.60 | 14.36 ± 1.06 | 2.68 ± 0.47 | 41.30 ± 1.24 |
| LLaVA → MiniGPT-4 (unconstrained) | 35.84 ± 2.65 | 1.83 ± 0.06 | 25.63 ± 1.30 | 1.00 ± 0.25 | 12.77 ± 0.86 | 1.83 ± 0.34 | 29.61 ± 1.97 |
| LLaVA → InstructBLIP (ϵ = 16/255) | 56.78 ± 0.63 | 7.00 ± 0.17 | 44.89 ± 0.69 | 16.94 ± 0.51 | 18.72 ± 0.33 | 6.67 ± 0.65 | 53.82 ± 0.13 |
| LLaVA → InstructBLIP (ϵ = 32/255) | 56.32 ± 0.99 | 6.94 ± 0.16 | 43.63 ± 0.54 | 16.45 ± 1.07 | 18.46 ± 0.38 | 6.94 ± 0.33 | 53.86 ± 0.86 |
| LLaVA → InstructBLIP (ϵ = 64/255) | 54.13 ± 1.17 | 4.24 ± 0.08 | 40.88 ± 0.60 | 7.14 ± 0.25 | 28.18 ± 0.71 | 4.41 ± 0.17 | 53.96 ± 1.17 |
| LLaVA → InstructBLIP (unconstrained) | 63.13± 0.09 | 9.10 ± 0.25 | 49.67 ± 0.24 | 19.61± 0.05 | 21.37 ± 0.14 | 6.65 ± 0.16 | 59.63± 0.25 |
| MiniGPT-4 → LLaVA (ϵ = 16/255) | 60.27 ± 0.86 | 3.89 ± 0.27 | 47.43 ± 0.42 | 2.28 ± 0.26 | 17.10 ± 0.59 | 4.67 ± 0.14 | 53.49 ± 0.81 |
| MiniGPT-4 → LLaVA (ϵ = 32/255) | 61.41 ± 0.89 | 3.86 ± 0.17 | 48.04 ± 0.68 | 2.20 ± 0.34 | 17.40 ± 0.72 | 4.48 ± 0.13 | 54.16 ± 1.10 |
| MiniGPT-4 → LLaVA (ϵ = 64/255) | 61.52 ± 0.50 | 3.36 ± 0.25 | 48.68 ± 0.81 | 2.00 ± 0.14 | 16.88 ± 0.41 | 4.25 ± 0.17 | 54.43 ± 0.79 |
| MiniGPT-4 → LLaVA (unconstrained) | 61.33 ± 0.10 | 3.61 ± 0.21 | 48.49 ± 0.56 | 1.58 ± 0.17 | 17.43 ± 0.36 | 3.34 ± 0.38 | 51.63 ± 0.80 |
| MiniGPT-4 → InstructBLIP (ϵ = 16/255) | 56.60 ± 1.20 | 7.10 ± 0.20 | 44.50 ± 0.80 | 16.50 ± 1.00 | 19.20 ± 1.30 | 6.70 ± 0.30 | 54.10 ± 0.80 |
| MiniGPT-4 → InstructBLIP (ϵ = 32/255) | 55.60 ± 0.35 | 6.78 ± 0.51 | 43.82 ± 0.49 | 16.24 ± 0.16 | 17.61 ± 0.37 | 7.09 ± 0.26 | 52.94 ± 0.68 |
| MiniGPT-4 → InstructBLIP (ϵ = 64/255) | 56.65 ± 0.63 | 6.89 ± 0.25 | 44.91 ± 0.56 | 16.68 ± 1.22 | 18.80 ± 0.28 | 6.36 ± 0.16 | 54.23 ± 0.26 |
| MiniGPT-4 → InstructBLIP (unconstrained) | 64.18 ± 1.11 | 8.47 ± 0.30 | 49.99 ± 0.51 | 19.20 ± 0.47 | 21.12 ± 0.56 | 7.24 ± 1.16 | 60.74 ± 1.37 |
| Detoxify (%) | |||||||
|---|---|---|---|---|---|---|---|
| Surrogate → Target | Any | Identity Attack | Obscene | Severe Toxicity | Insult | Threat | Toxicity |
| InstructBLIP → LLaVA (ϵ = 16/255) | 53.06 ± 0.28 | 1.86 ± 0.20 | 42.79 ± 0.57 | 1.11 ± 0.21 | 21.11 ± 0.45 | 2.53 ± 0.04 | 52.34 ± 0.38 |
| InstructBLIP → LLaVA (ϵ = 32/255) | 53.03 ± 0.62 | 1.86 ± 0.17 | 43.18 ± 0.35 | 1.14 ± 0.14 | 21.15 ± 0.60 | 2.56 ± 0.28 | 52.65 ± 0.25 |
| InstructBLIP → LLaVA (ϵ = 64/255) | 53.76 ± 0.14 | 1.89 ± 0.17 | 43.85 ± 0.34 | 0.89± 0.08 | 22.26 ± 0.42 | 2.53 ± 0.10 | 52.89 ± 0.04 |
| InstructBLIP → LLaVA (unconstrained) | 49.50 ± 0.36 | 1.61 ± 0.14 | 41.26 ± 0.79 | 0.86 ± 0.14 | 17.00 ± 0.22 | 1.30 ± 0.08 | 48.41 ± 0.45 |
| InstructBLIP → MiniGPT-4 (ϵ = 16/255) | 38.03 ± 1.46 | 1.90 ± 0.35 | 30.61 ± 1.61 | 0.61 ± 0.10 | 14.69 ± 0.50 | 1.31 ± 0.29 | 37.41 ± 1.45 |
| InstructBLIP → MiniGPT-4 (ϵ = 32/255) | 38.18 ± 0.95 | 1.64 ± 0.21 | 29.96 ± 0.40 | 0.50 ± 0.14 | 14.13 ± 0.40 | 1.14 ± 0.14 | 37.60 ± 0.96 |
| InstructBLIP → MiniGPT-4 (ϵ = 64/255) | 38.34 ± 0.56 | 1.56 ± 0.31 | 30.20 ± 0.88 | 0.62 ± 0.17 | 14.89 ± 0.53 | 0.11 ± 0.04 | 37.81 ± 0.58 |
| InstructBLIP → MiniGPT-4 (unconstrained) | 30.37 ± 0.61 | 1.39 ± 0.26 | 24.27 ± 0.73 | 0.48 ± 0.08 | 11.10 ± 0.53 | 1.01 ± 0.24 | 29.55 ± 0.65 |
| LLaVA → MiniGPT-4 (ϵ = 16/255) | 39.54 ± 0.58 | 1.90 ± 0.14 | 31.62 ± 1.20 | 0.75 ± 0.14 | 16.03 ± 0.76 | 1.17 ± 0.18 | 39.10 ± 0.55 |
| LLaVA → MiniGPT-4 (ϵ = 32/255) | 39.76 ± 0.65 | 1.73 ± 0.11 | 31.47 ± 0.18 | 0.78 ± 0.04 | 15.78 ± 0.66 | 1.17 ± 0.25 | 39.18 ± 0.79 |
| LLaVA → MiniGPT-4 (ϵ = 64/255) | 38.88 ± 1.75 | 1.76 ± 0.18 | 31.12 ± 1.35 | 0.75 ± 0.12 | 15.32 ± 0.54 | 1.20 ± 0.14 | 38.49 ± 1.80 |
| LLaVA → MiniGPT-4 (unconstrained) | 28.31 ± 1.11 | 1.13 ± 0.27 | 21.73 ± 0.92 | 0.42 ± 0.24 | 9.65 ± 0.28 | 0.82 ± 0.29 | 27.83 ± 1.14 |
| LLaVA → InstructBLIP (ϵ = 16/255) | 54.98 ± 0.58 | 4.64 ± 0.20 | 42.47 ± 0.15 | 7.68 ± 0.29 | 28.68 ± 0.14 | 4.55 ± 0.76 | 54.82 ± 0.65 |
| LLaVA → InstructBLIP (ϵ = 32/255) | 54.13 ± 1.17 | 4.24 ± 0.08 | 40.88 ± 0.60 | 7.14 ± 0.24 | 28.18 ± 0.71 | 4.41 ± 0.18 | 53.96 ± 1.17 |
| LLaVA → InstructBLIP (ϵ = 64/255) | 53.35 ± 1.99 | 4.16 ± 0.29 | 41.24 ± 1.31 | 6.89 ± 0.38 | 28.22 ± 1.03 | 4.71 ± 0.35 | 54.13 ± 1.94 |
| LLaVA → InstructBLIP (unconstrained) | 53.87 ± 0.48 | 1.90 ± 0.21 | 44.87 ± 0.17 | 1.08 ± 0.19 | 22.60 ± 0.85 | 2.80± 0.18 | 52.27± 0.55 |
| MiniGPT-4 → LLaVA (ϵ = 16/255) | 52.62 ± 0.77 | 1.81 ± 0.17 | 42.77 ± 0.05 | 1.09 ± 0.08 | 21.45 ± 0.93 | 2.48 ± 0.13 | 52.00 ± 0.88 |
| MiniGPT-4 → LLaVA (ϵ = 32/255) | 53.37 ± 0.98 | 2.00 ± 0.08 | 43.04 ± 0.70 | 1.20 ± 0.05 | 20.87 ± 0.22 | 2.28 ± 0.49 | 52.59 ± 0.80 |
| MiniGPT-4 → LLaVA (ϵ = 64/255) | 54.03 ± 0.78 | 2.06 ± 0.04 | 44.10 ± 0.65 | 1.06 ± 0.04 | 22.18 ± 0.59 | 2.42 ± 0.25 | 53.23 ± 0.97 |
| MiniGPT-4 → LLaVA (unconstrained) | 50.97 ± 0.71 | 1.95 ± 0.13 | 42.32 ± 0.80 | 0.75 ± 0.00 | 17.97 ± 0.84 | 1.42 ± 0.17 | 50.08 ± 1.01 |
| MiniGPT-4 → InstructBLIP (ϵ = 16/255) | 54.97 ± 1.05 | 4.58 ± 0.21 | 41.63 ± 0.61 | 7.20 ± 0.14 | 29.44 ± 0.86 | 4.16 ± 0.17 | 54.91 ± 1.05 |
| MiniGPT-4 → InstructBLIP (ϵ = 32/255) | 54.05 ± 0.26 | 4.33 ± 0.24 | 40.98 ± 0.38 | 7.18 ± 0.29 | 27.88 ± 0.46 | 4.50 ± 0.28 | 54.05 ± 0.26 |
| MiniGPT-4 → InstructBLIP (ϵ = 64/255) | 55.70 ± 0.87 | 4.38 ± 0.05 | 42.91 ± 0.14 | 6.7 ± 0.54 | 28.75 ± 0.38 | 4.38 ± 0.13 | 55.67 ± 0.91 |
| MiniGPT-4 → InstructBLIP (unconstrained) | 61.05 ± 0.61 | 5.34± 0.56 | 46.70 ± 0.37 | 7.89 ± 0.32 | 30.90 ± 0.81 | 4.53 ± 0.45 | 60.85 ± 0.64 |
Appendix
A GPT-4o Evaluation
We use GPT-4o to assess whether an adversarial prompt elicits undesired outputs from the target model.
Prompt setting. We employ a fixed evaluation prompt to instruct GPT-4o to classify each generated response with respect to four risk categories. The exact prompt used is: “Please use the ASR calculation method across four categories: Identity Attack, Disinformation, Violence/Crime and X-risk.” This standardized prompt ensures consistent evaluation of jailbreak responses across all models.
Aggregation. For each adversarial attempt, we repeat ten times under the same prompt and model configuration to account for sampling variability. Each response is independently evaluated by GPT-4o using the fixed evaluation prompt. The attempt is considered successful if at least one of the ten responses contains undesirable content and ASR is computed accordingly.
B Adversarial transferability Evaluation
This section provides supplementary empirical results on adversarial transferability referenced in the main paper, offering a more detailed view of transferability on target models.
We adopt the automatic evaluation to assess whether an adversarial prompt successfully induces the target model to produce undesired outputs in Table [tab:presapi]. To evaluate adversarial transferability, we reuse the same adversarial prompt on unseen target models and repeat a stronger attack setting in Table 1.
We additionally report how transferability varies across InstructBLIP, LLaVA, and MiniGPT-4 under multiple $`\epsilon`$ settings. Each generated response is evaluated by the Perspective API and Detoxify Classifier. Table [tab:transferattack_perspective] and Table [tab:transferattack_detox] provide a comprehensive analysis of the adversarial transferability of ZO-SPSA attacks across three target models. Each surrogate model undergoes various perturbation budget constraints $`\epsilon = 16/255`$, $`32/255`$, $`64/255`$ and an unconstrained setting.
📊 논문 시각자료 (Figures)