CogFlow Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
📝 Original Paper Info
- Title: CogFlow Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving- ArXiv ID: 2601.01874
- Date: 2026-01-05
- Authors: Shuhang Chen, Yunqiu Xu, Junjie Xie, Aojun Lu, Tao Feng, Zeying Huang, Ning Zhang, Yi Sun, Yi Yang, Hangjie Yuan
📝 Abstract
Despite significant progress, multimodal large language models continue to struggle with visual mathematical problem solving. Some recent works recognize that visual perception is a bottleneck in visual mathematical reasoning, but their solutions are limited to improving the extraction and interpretation of visual inputs. Notably, they all ignore the key issue of whether the extracted visual cues are faithfully integrated and properly utilized in subsequent reasoning. Motivated by this, we present CogFlow, a novel cognitive-inspired three-stage framework that incorporates a knowledge internalization stage, explicitly simulating the hierarchical flow of human reasoning: perception$\Rightarrow$internalization$\Rightarrow$reasoning. Inline with this hierarchical flow, we holistically enhance all its stages. We devise Synergistic Visual Rewards to boost perception capabilities in parametric and semantic spaces, jointly improving visual information extraction from symbols and diagrams. To guarantee faithful integration of extracted visual cues into subsequent reasoning, we introduce a Knowledge Internalization Reward model in the internalization stage, bridging perception and reasoning. Moreover, we design a Visual-Gated Policy Optimization algorithm to further enforce the reasoning is grounded with the visual knowledge, preventing models seeking shortcuts that appear coherent but are visually ungrounded reasoning chains. Moreover, we contribute a new dataset MathCog for model training, which contains samples with over 120K high-quality perception-reasoning aligned annotations. Comprehensive experiments and analysis on commonly used visual mathematical reasoning benchmarks validate the superiority of the proposed CogFlow.💡 Summary & Analysis
1. **Key Contribution 1: A New Approach Inspired by Cognitive Science** This paper introduces a new approach called CogFlow that is inspired by cognitive science findings and aims to mimic the typical human reasoning process more closely than previous models. Unlike earlier attempts, which focused solely on extracting visual information accurately, this model also addresses how extracted cues are integrated into subsequent reasoning processes.-
Key Contribution 2: Enhanced Visual Element Recognition Through Reinforcement Learning
CogFlow employs Synergistic Visual Rewards (SynVRs) to improve the interaction between perception and inference, measuring perceptual accuracy in both parameter and semantic spaces. This approach ensures more precise visual recognition by integrating feedback into reinforcement learning loops. -
Key Contribution 3: Improved Stability During Training Through VGPO
CogFlow uses Visual-Gated Policy Optimization (VGPO) to ensure that the reasoning process remains firmly grounded in perceptual accuracy, thereby improving stability during multi-step reasoning processes.
📄 Full Paper Content (ArXiv Source)
Introduction
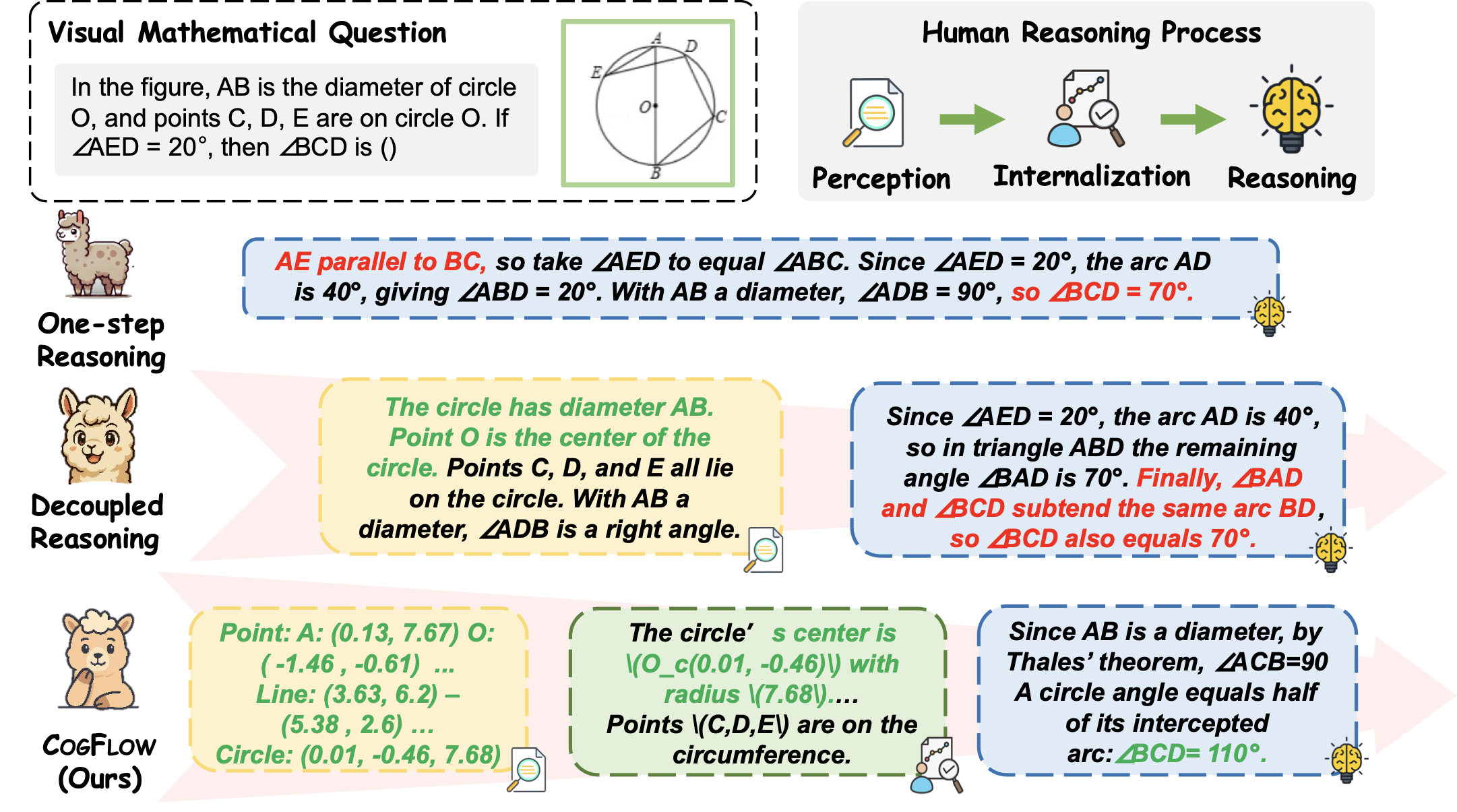
Multimodal large language models (MLLMs) are rapidly advancing and have been applied across various vision–language applications . However, existing MLLMs continue to struggle with challenging visual mathematical problems, resulting in low answer accuracy and inconsistent reasoning chains. Some early attempts adopt a one-step reasoning framework that directly interleaves visual perception with reasoning in an unstructured manner, often resulting in both perceptual and reasoning errors. Another line of work follows a decoupled reasoning pipeline that explicitly separates the perception and reasoning parts, with the former focusing on visual recognition and the latter responsible for subsequent inference. Yet in practice, we observe that such a pipeline often suffers from the reasoning drift issue, i.e., it tends to yield illogical or unwarranted reasoning steps that disregard perceptual evidence (see Figure 3). These observations motivate the development of a new approach that not only achieves robust fine-grained recognition of mathematical visual elements (e.g., diagrammatic primitives and symbols) but also faithfully incorporates extracted visual cues into subsequent reasoning.
 />
/>
 />
/>
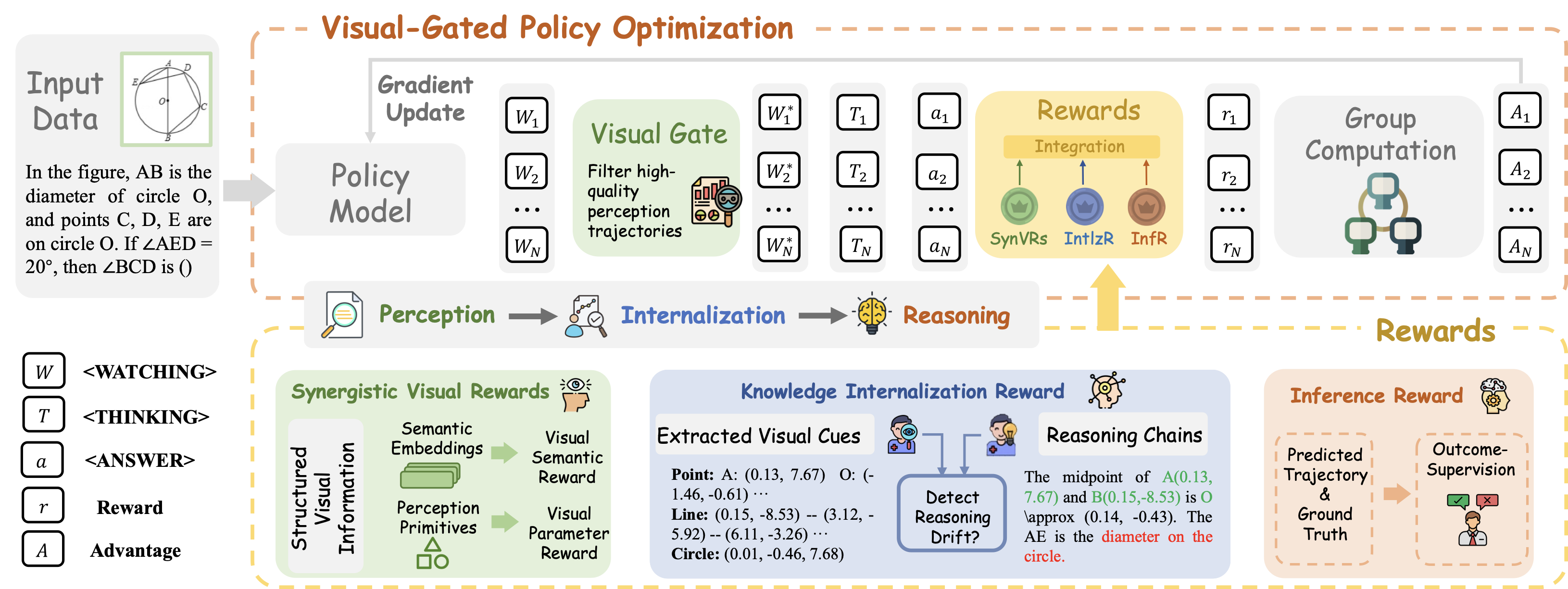
Inspired by cognitive science findings on knowledge internalization , this paper introduces CogFlow, a novel three-stage visual mathematical reasoning framework that better mirrors the typical hierarchical structure of the human reasoning process. Concretely, after perception captures raw sensory input, an intermediate knowledge internalization stage transforms low-level perceptual signals into structured and semantically grounded knowledge representations (e.g., humans internalize the perceptual facts that the line segment $`AB`$ is a diameter and the point $`C`$ lies on the circle into the knowledge that $`\angle ACB = 90^\circ`$) before high-level reasoning begins. As illustrated in Figure 1, to ensure both accurate extraction of visual information and its faithful use in reasoning, CogFlow explicitly models the hierarchical sequence of the human reasoning flow (i.e., perception$`\Rightarrow`$internalization$`\Rightarrow`$reasoning) and holistically enhances all three stages in synchrony with it, where each improvement is tailored to the functional role of the corresponding stage in the human reasoning process.
Unlike prior approaches that decouple perception from reasoning trajectories and enhance it with tailored tasks, CogFlow first integrates perception enhancement into a unified reinforcement learning (RL) framework through Synergistic Visual Rewards (SynVRs), enabling dynamic perception–reasoning interaction and improving generalization. Specifically, SynVRs complementarily optimize the model from two distinct perspectives: (1) a Visual Parameterized Reward (VPR) encoding normalized primitives (i.e., points, lines, and circles) and calculating the Euclidean distance in a parameter space for precise and interpretable measurement; (2) a Visual Semantic Reward (VSR) that extracts semantic embeddings from re-rendered images (derived from textual perception outputs) and measures the cosine distance in a semantic space to capture holistic style and layout consistency. Together, SynVRs ensure both local geometric fidelity and global perceptual coherence, forming trustworthy visual cues that serve as the foundation for effective visual mathematical reasoning.
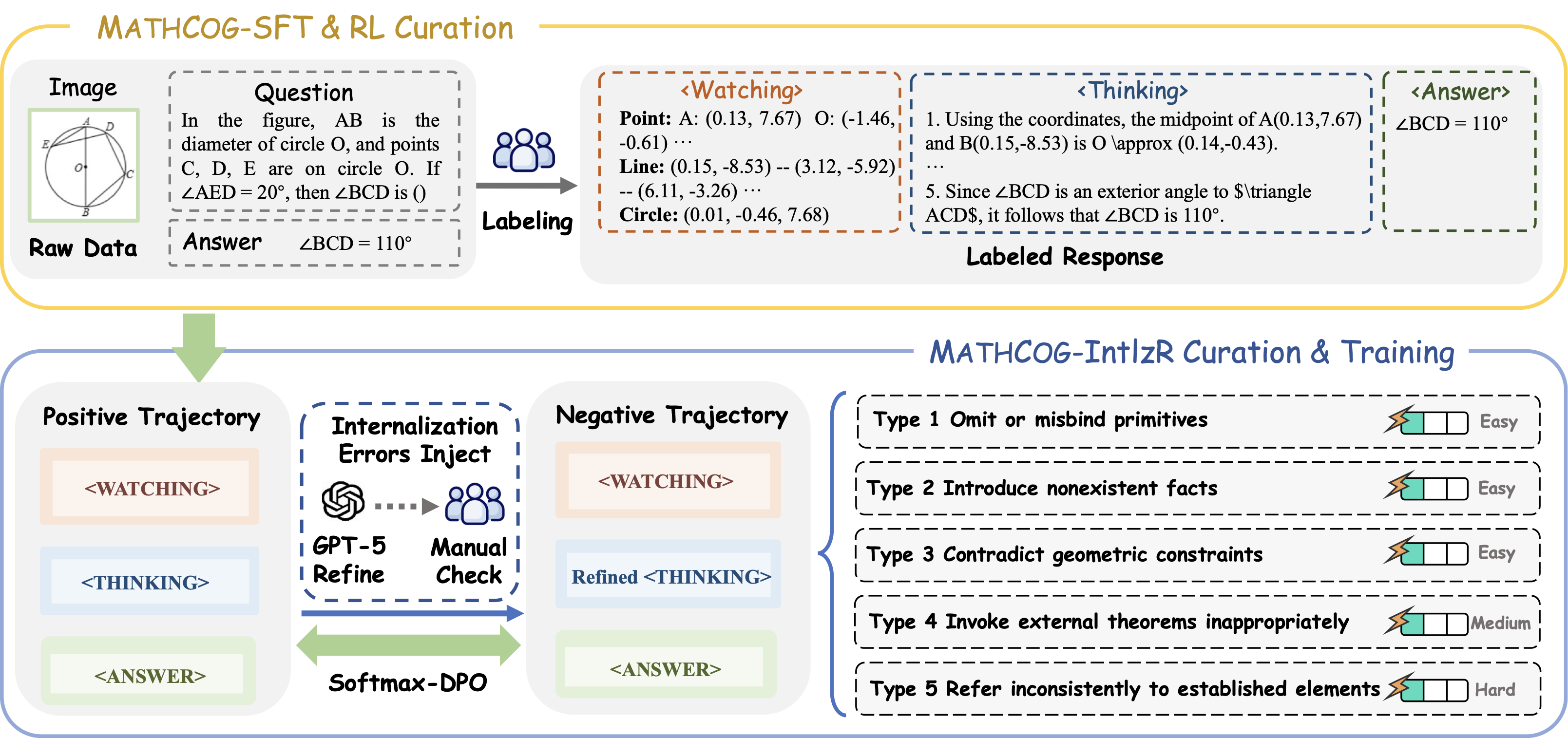
Notably, despite progress in perception enhancement, all prior efforts remain confined to accurate extraction of mathematical information from diagrams, while ignoring a key question: are the extracted visual cues properly and faithfully integrated into subsequent reasoning? As illustrated in Figure 2, our empirical findings reveal a typical reasoning drift issue (i.e., the reasoning stage in existing methods often deviates from perceptual results), leading to reasoning chains that appear coherent yet conflict with the underlying visual evidence. To prevent such drift and improve interpretability, CogFlow utilizes a Knowledge Internalization Reward (IntlzR) that bridges the perception and reasoning stages by encouraging the model to generate structured and reasoning-ready outputs (i.e., knowledge-internalized representations ) as a more reliable foundation for subsequent reasoning. Specifically, we curate positive trajectories integrating perception and reasoning processes with explicit internalization of perception primitives, and further derive five typical negative trajectories. Training with these trajectories enables the reward model to evaluate each response according to its fidelity to the internalized representation. IntlzR effectively improves the knowledge internalization stage, thereby reducing hallucinations and improving interpretability and robustness.
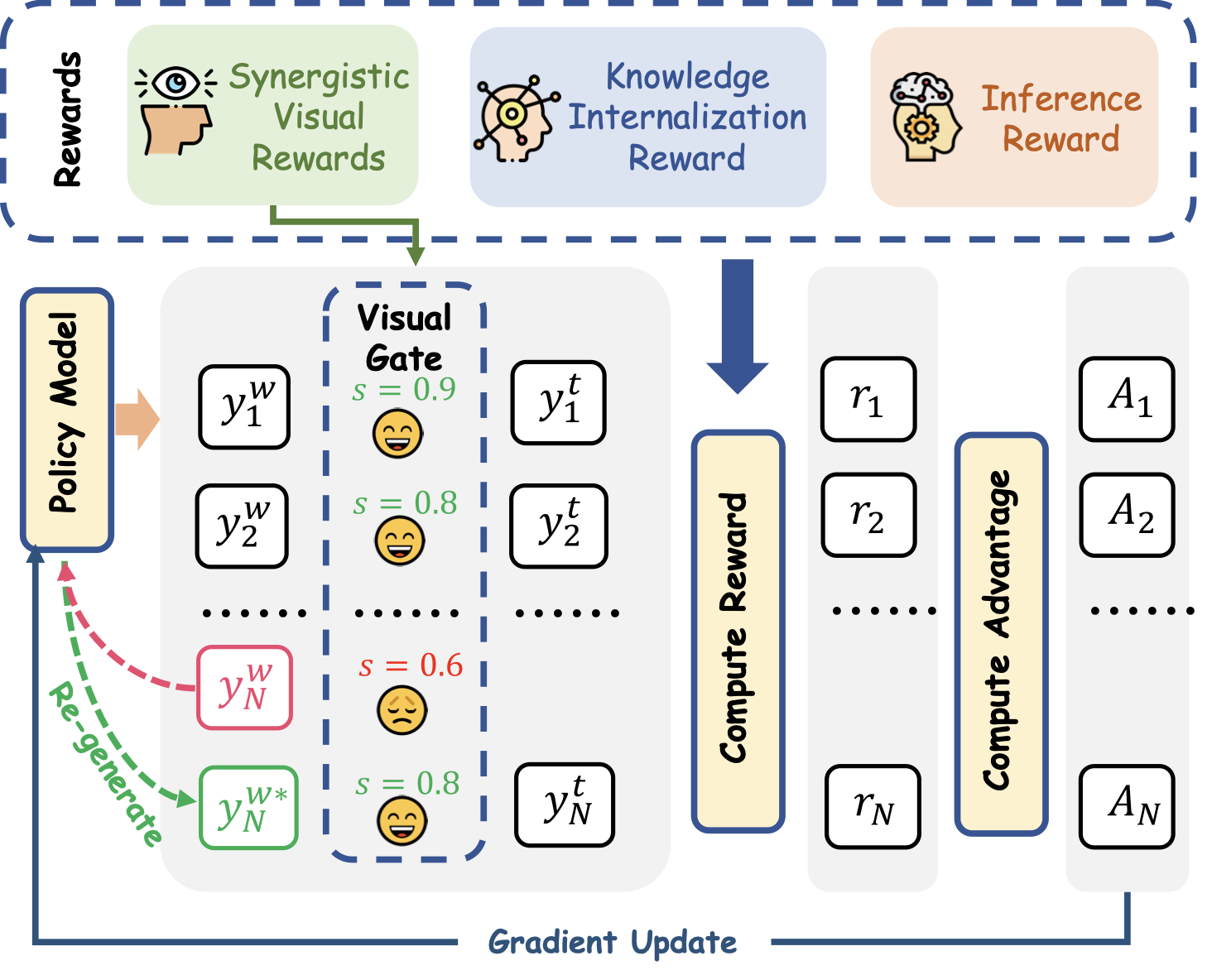
In accordance with the hierarchical flow of human reasoning, we further improve multi-step visual reasoning beyond enhanced perception and knowledge internalization. Existing approaches either follow a text-centric RL paradigm that is free from perceptual objectives , or overlook the structured dependency between perception and reasoning . To ensure more stable reasoning in the presence of perceptual errors, CogFlow introduces Visual-Gated Policy Optimization (VGPO) strategy that explicitly anchors the reasoning process in perceptual accuracy. In VGPO, a visual gate is designed to adaptively filter perceptual trajectories through perceptual quality assessment, retaining only high-quality ones before subsequent reasoning trajectory generation. If a low-quality perceptual trajectory is filtered out, the model regenerates alternative trajectories to obtain a higher-quality response. Along with the proposed visual gate, VGPO integrates an outcome-supervised Inference Reward for optimization, further strengthening multi-step visual reasoning.
To facilitate research, we curate a new MathCog dataset for model training, which contains three subsets and over 120K samples with high-quality perception-reasoning aligned annotations. We conduct extensive experiments on commonly used visual math problem-solving benchmarks to comprehensively evaluate CogFlow. The results show that CogFlow consistently outperforms state-of-the-art MLLMs with comparable model sizes. Notably, it achieves on-par or even better results compared to advanced closed-source MLLMs with much larger model sizes. The main contributions of this paper can be summarized as follows:
-
All prior works neglect whether extracted visual cues are faithfully used in reasoning. To address this issue, we present CogFlow, a novel cognitive-inspired three-stage framework that faithfully simulates the hierarchical human reasoning flow: perception$`\Rightarrow`$internalization$`\Rightarrow`$reasoning.
-
In line with human reasoning hierarchy, CogFlow holistically enhances all three stages: SynVRs complementarily enhance accurate and complete diagram perception in parametric and semantic spaces; IntlzR improves the knowledge internalization ability for promoting faithful conversion of perceptual outputs into a canonical context used for subsequent inference; VGPO employs a visual gate to filter high-quality perception trajectories and enhances the stability of reasoning.
-
To support model training, we curate a new dataset MathCog with disentangled perception and reasoning annotations. Comprehensive experiments on multiple visual mathematical benchmarks validate that CogFlow achieves substantial gains in both answer accuracy and reasoning quality.
Related Work
Visual Mathematical Reasoning with MLLMs. Solving visual mathematical problems (e.g., geometry diagrams, algebraic plots, and etc) requires both strong reasoning ability and accurate interpretation of visual primitives and symbolic content . Most previous works are dedicated to improving the reasoning process, including chain-of-thought strategies , tool-aided reasoning , test time scaling , and reinforcement learning . Several recent works suggest that one of the major bottlenecks in visual mathematical reasoning is inaccurate visual comprehension. They typically decouple perception from reasoning, and strengthen perception either by designing specialized visual encoders or by introducing auxiliary visual tasks . However, prior works ignore a key issue of whether correctly extracted visual cues are indeed faithfully incorporated into subsequent reasoning.
Reinforcement Learning for Multimodal Reasoning. Traditional actor–critic methods, such as proximal policy optimization , are computationally expensive. A lightweight alternative is group relative policy optimization (GRPO) , which stabilizes advantage estimation using group baselines. While its variants have been widely explored, GRPO has also been extended to multimodal reasoning . Some extensions introduce hybrid reward formulations augmented with preference signals during training , whereas others propose two-stage multimodal reinforcement learning paradigms, e.g., OVR . However, existing methods typically lack explicit mechanisms to strengthen the alignment between perception and reasoning, often leading to reasoning that is not firmly grounded in visual content.
CogFlow: A Cognitive-Inspired Hierarchical Framework
 style="width:100.0%" />
style="width:100.0%" />
Inspired by the typical cognitive process of human reasoning (i.e., perception$`\Rightarrow`$internalization $`\Rightarrow`$reasoning), CogFlow serves as a visual mathematical reinforcement learning framework that explicitly implements the internalization stage (see Figure 4). Before training, we first curate MathCog to support the subsequent training (see Figure 13). Specifically, the training pipeline of CogFlow consists of two sequential phases: a supervised fine-tuning (SFT) phase and a reinforcement learning (RL) phase. The SFT phase endows the base model with initial visual perception and basic reasoning skills based on the MathCog-SFT dataset. During the RL phase, we optimize the policy based on the MathCog-RL dataset under the Visual-Gated Policy Optimization (VGPO) framework to explicitly anchor the reasoning process in perceptual accuracy. Concretely, VGPO introduces a visual gate to adaptively filter perceptual trajectories before reasoning trajectory generation. Furthermore, the rewards in VGPO are composed of three components: Synergistic Visual Rewards (SynVRs) for forming trustworthy perception, Knowledge Internalization Reward (IntlzR) for detecting reasoning drift and Inference Reward (InfR) for providing outcome-supervision.
Forming Trustworthy Perception with Synergistic Visual Rewards
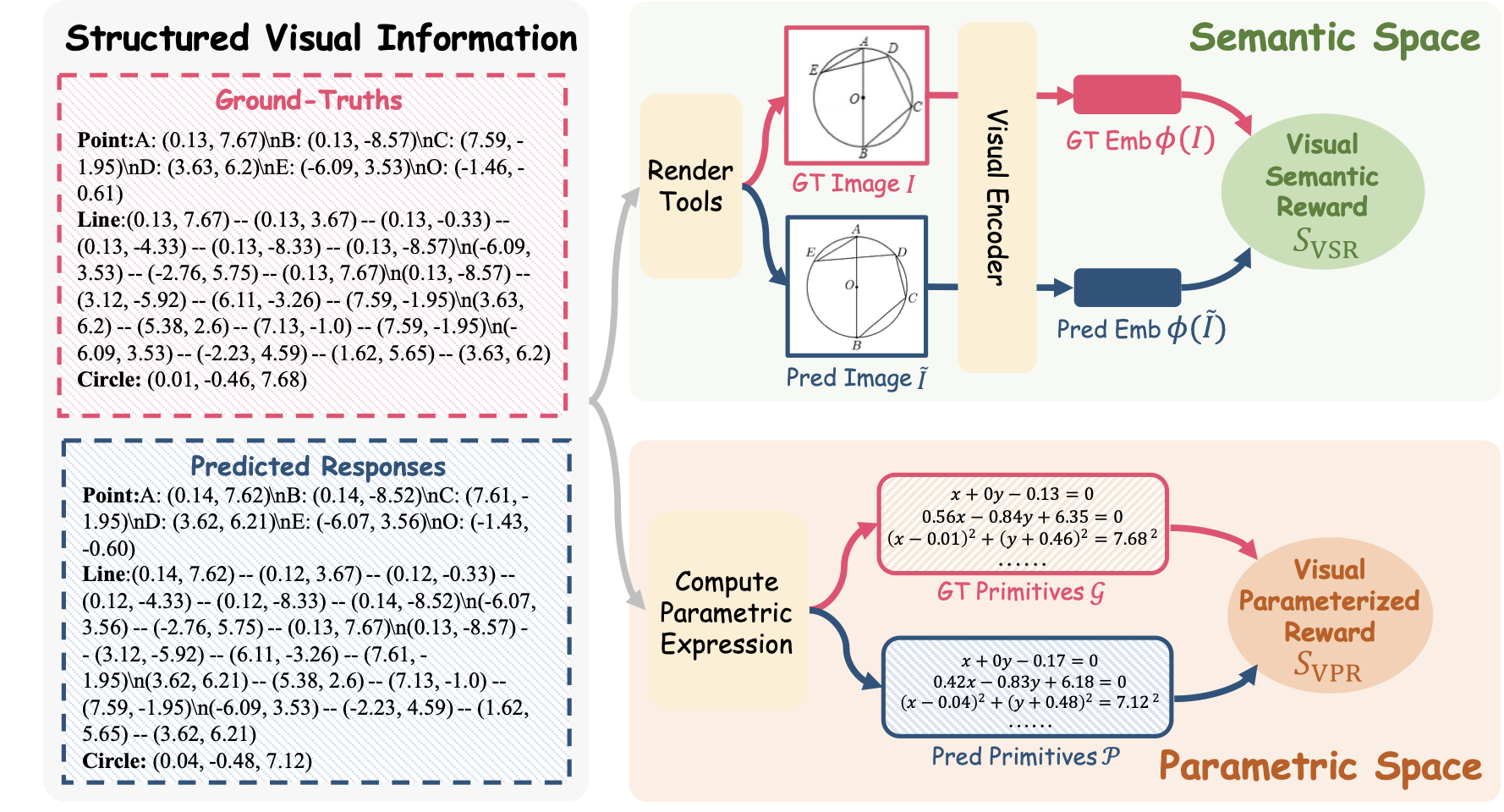
CogFlow first constructs Synergistic Visual Rewards (SynVRs), enabling dynamic perception-reasoning interaction and improving generalization. Specifically, the proposed SynVRs combine two complementary components: the Visual Parameterized Reward (VPR) and the Visual Semantic Reward (VSR), which respectively evaluate perceptual quality in the parametric and semantic spaces, thereby providing a synergistic perception feedback integrated into RL training loops.
 />
/>
 />
/>
Measuring Perceptual Accuracy in Parameter Space. As shown in Figure [fig:vr], VPR first converts structured visual information into parametric expressions. For example, the primitive Circle $`(0.01, -0.46, 7.68)`$ is transformed into the Equation $`(x-0.01)^2+(y+0.46)^2=7.68^2`$.
We then compute the cost matrix $`\mathcal C`$ between GT Primitives $`\mathcal{G}`$ and predicted Primitives $`\mathcal{P}`$ and apply the Hungarian matching algorithm to obtain the optimal one-to-one matching $`\mathcal{H}`$ that minimizes the total cost $`\mathcal{S}_{\text{VPR}}`$. The VPR offers interpretable, geometry-aware semantic supervision that avoids the pitfalls of pixel-level noise or black-box embedding similarity. More details are provided in §8.2.
Capturing Holistic Layout and Style Consistency in Semantic Space. We render the predicted response into an image $`\tilde{I}`$ and compare it against the ground-truth rendering $`I`$, using a frozen FG-CLIP encoder $`\phi(\cdot)`$ with higher sensitivity to spatial features. The VSR score $`\mathcal{S}_{\mathrm{VSR}}`$ is the normalized cosine similarity. The higher values indicate closer agreement in global layout and style while preserving fine-grained geometric fidelity.
Synergy of Complementary Visual Rewards. Finally, the SynVRs score can be formulated as
\begin{equation}
\small
\mathcal{S}_{\mathrm{SynVRs}}
=
\alpha\,\underbrace{\exp\!\left(-\,\frac{1}{|\mathcal H|}\sum\nolimits_{(i,j)\in\mathcal H} \mathcal C({\mathcal{P}_i,\mathcal{G}_j)}\right)}_{\mathcal{S}_{\mathrm{VPR}}}
\;+\;
(1-\alpha)\,\underbrace{\frac{1+\cos\!\big(\phi(\tilde I),\,\phi(I)\big)}{2}}_{\mathcal{S}_{\mathrm{VSR}}},
\label{eq:svr}
\end{equation}where $`\alpha\in[0,1]`$ balances local geometric precision ($`\mathcal{S}_{\mathrm{VPR}}`$) and global visual consistency ($`\mathcal{S}_{\mathrm{VSR}}`$). $`\mathcal{S}_{\mathrm{SynVRs}}`$ has two roles: (1) it acts as a gate to prevent low-quality perceptions from propagating during policy generation, and (2) as a training reward during RL to encourage accurate perception.
Alleviating Reasoning Drift with Knowledge Internalization Reward
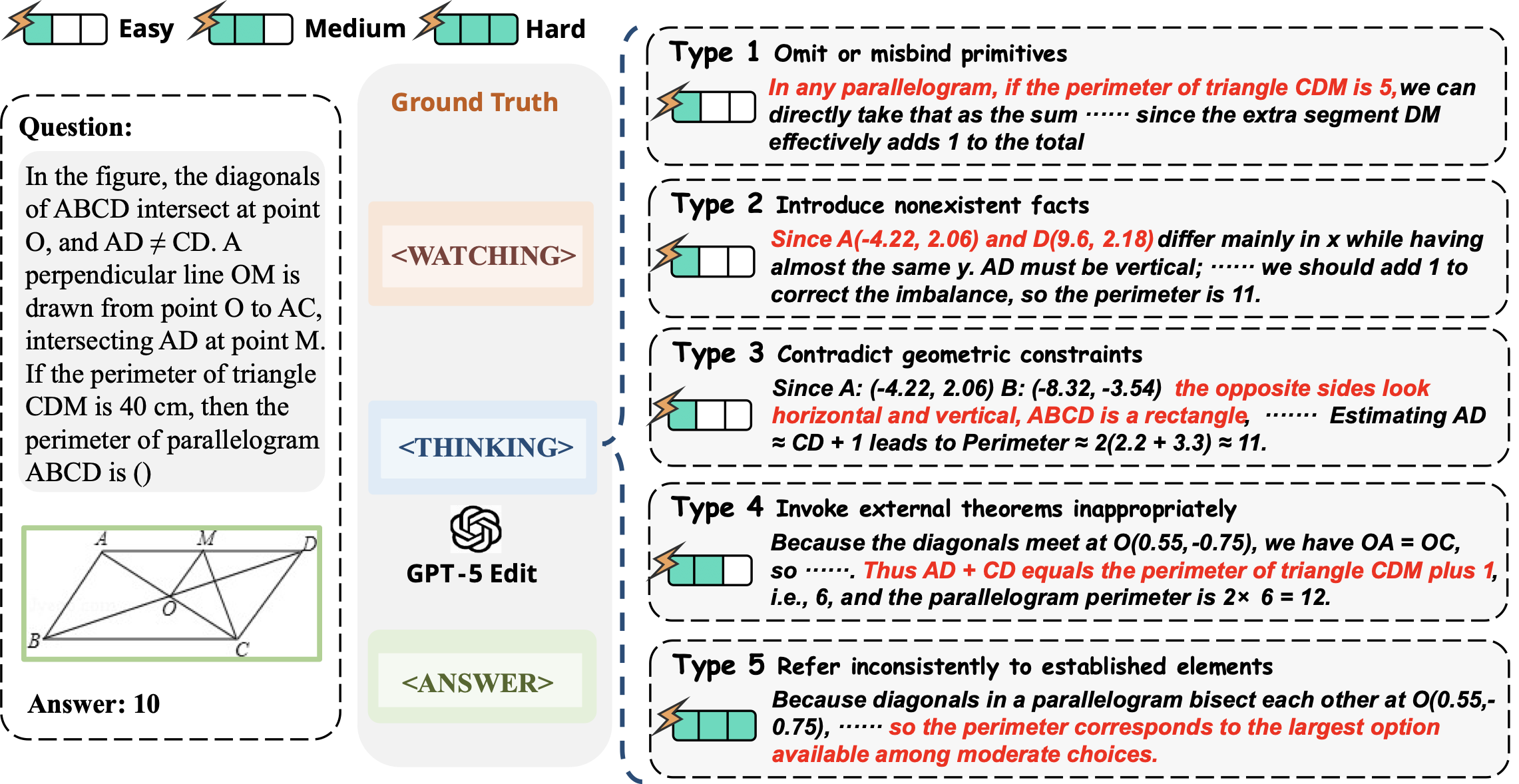
Failure Modes in Knowledge Internalization. Even with accurate perception, models often struggle to reliably internalize what they see. The empirical evidence suggests that such failures typically manifest in five forms: (1) omit or misbind primitives, losing essential elements or confusing their identifiers; (2) introduce nonexistent facts, fabricating geometric relations that are not present in the perceptual output; (3) invoke external theorems inappropriately, applying mathematical results that were never justified by the internalized structure; (4) contradict geometric constraints, producing inference steps that violate fundamental properties of the canonical representation; and (5) refer inconsistently to established elements, assigning shifting roles or properties to the same primitive across different reasoning steps. Therefore, to enhance knowledge internalization, it is crucial to mitigate these systematic failures.
Rewarding Faithful Knowledge Internalization. To address these systematic weaknesses, we introduce the Knowledge Internalization Reward (IntlzR), a trained reward model that evaluates whether each reasoning chain remains faithful to the internalized visual representation, thereby enforcing raw perception as the primary substrate of inference (e.g., reasoning drift). Within CogFlow, we train the IntlzR to enhance internalization explicitly, supported by the curated MathCog-IntlzR (see §8.3 for more details). This dataset is constructed from positive–negative pairs, with each positive matched to five corresponding negatives; positives are sampled from MathCog-SFT, and negatives are synthesized by injecting the five error types described above, providing fine-grained supervision for distinguishing grounded from unanchored reasoning. To better leverage diverse negative signals in IntlzR and adaptively emphasize the most challenging trajectories while improving gradient efficiency and training stability, we adopt Softmax-DPO for optimization:
\begin{equation}
\mathcal{L}_{\text{Softmax-DPO}}
= - \log \sigma\!\left(
- \log \sum_{j=1}^{m}
\exp\big( s_j^{-} - s^{+} \big)
\right),
\quad
s = \beta \big[ \log \pi_\theta(y \mid x) - \log \pi_{\text{ref}}(y \mid x) \big],
\label{eq:softmax-dpo}
\end{equation}where $`s^{+}`$ denotes the score of the preferred trajectory, $`\{s_j^{-}\}_{j=1}^m`$ represent the corresponding scores of the dispreferred trajectories, $`\beta`$ is the KL penalty coefficient and $`\sigma(\cdot)`$ denotes the sigmoid function. This formulation contrasts one positive trajectory against multiple negatives simultaneously, thereby providing denser and more informative supervision, implicitly emphasizing hard negatives through softmax weighting, and yielding more stable optimization with stronger robustness to unseen misalignment patterns. During RL, IntlzR is evaluated stepwise and aggregated across the chain, rewarding trajectories in which the extracted visual cues are faithfully and adequately integrated into subsequent reasoning.
Strengthening Multi-Step Visual Reasoning with VGPO
Accurate perception and faithful internalization are necessary but not sufficient: the model must also produce long reasoning chains that are coherent, interpretable, and verifiably grounded. Hence, we introduce Visual-Gated Policy Optimization (VGPO), which integrates a visual gate with group-level optimization to regularize the reasoning process. Concretely, as shown in Figure 5, for an input question $`x`$ we sample $`M`$ candidate trajectories $`y_i(x)=\big(y_i^{\mathrm{w}}(x),\,y_i^{\mathrm{t}}(x,\,y_i^{\mathrm{w}}(x))\big)`$. Here $`y_i^{\mathrm{w}}(x)`$ denotes the perception trajectories, i.e., structured parse of perceptual primitives and relations from the diagram, and $`y_i^{\mathrm{t}}(x,\,y_i^{\mathrm{w}}(x))`$ denotes the reasoning trajectories conditioned on $`x`$ and $`y_i^{\mathrm{w}}(x)`$.
Visual Gate for Reliable Visually Grounded Reasoning. We introduce a visual gate that scores each perception against the visual evidence and forwards only the most faithful parse to reasoning. Specifically, given a perception candidate $`y_i^{\mathrm{w}}(x)`$ and the ground-truth $`\hat{y}^{\mathrm{w}}(x)`$, while $`\tilde I_i`$ and $`I`$ denote their respective renderings, we define the perceptual accuracy score as:
\begin{equation}
S_{\mathrm{vis}}\big(y_i^{\mathrm{w}}(x)\big)=
\begin{cases}
\mathcal{S}_{\mathrm{VPR}}\big(y_i^{\mathrm{w}}(x),\,\hat{y}^{\mathrm{w}}(x)\big) + \mathcal{S}_{\mathrm{VSR}}\big(\tilde I_i,\, I\big), & \text{training,}\\[4pt]
\mathcal{S}_{\mathrm{VSR}}\big(\tilde I_i,\, I\big), & \text{inference.}
\end{cases}
\end{equation}Subsequently, the visual gate $`\Gamma(\cdot)`$ enforces perception quality by scoring each perception trajectory and accepting the first attempt whose score exceeds a preset threshold. If no attempt passes within $`M`$ trials, the gate returns the attempt with the highest $`S_{\mathrm{vis}}`$:
\begin{equation}
\kappa =
\begin{cases}
\min\{\,k\in\{1,\dots,M\}:\ S_{\mathrm{vis}}(y_{i,k}^{\mathrm{w}}(x)) \ge \tau\,\}, & \{k:\, S_{\mathrm{vis}}(y_{i,k}^{\mathrm{w}}(x)) \ge \tau\} \neq \varnothing,\\
M, & \{k:\, S_{\mathrm{vis}}(y_{i,k}^{\mathrm{w}}(x)) \ge \tau\} = \varnothing,
\end{cases}
\end{equation}\begin{equation}
y_i^{\mathrm{w}*}(x) = \Gamma\!\big(\{y_{i,k}^{\mathrm{w}}(x)\}_{k=1}^{\kappa}\big)
= \operatorname*{arg\,max}_{1\le k\le \kappa} S_{\mathrm{vis}}\!\big(y_{i,k}^{\mathrm{w}}(x)\big),
\end{equation}where $`\kappa`$ is the stopping index, defined as the smallest $`k`$ whose score reaches acceptance threshold $`\tau`$, $`y_i^{\mathrm{w}*}(x)`$ is the perception trajectory selected by the visual gate; and $`y_{i,k}^{\mathrm{w}}(x)`$ is the $`k`$-th perception trajectory for input $`x`$.
Stabilizing Multi-Step Reasoning via Visual-Gated Policy Optimization. For each problem, we collect multiple candidate trajectories $`y_i(x)`$ and evaluate them under a group-level reward $`r`$ that integrates (1) the Synergistic Visual Rewards $`R_{\text{SynVRs}}`$ for perceptual fidelity, (2) the Knowledge Internalization Reward $`R_{\text{IntlzR}}`$ for internalization faithfulness, and (3) an Inference Reward $`R_{\text{InfR}}`$ capturing answer correctness and output format, given by:
\begin{equation}
r \;=\; \lambda_{\text{SynVRs}}\,R_{\text{SynVRs}} + \lambda_{\text{IntlzR}}\,R_{\text{IntlzR}} + \lambda_{\text{InfR}}\,R_{\text{InfR}}.
\label{eq:total-reward}
\end{equation}Then the training optimization objective $`\mathcal{L}`$ is formulated as:
\begin{equation}
\mathcal L = -\,\mathbb E_i\!\left[
\min\!\Big(\eta_i(\theta) A_i,\; \operatorname{clip}\!\big(\eta_i(\theta),\,1-\epsilon,\,1+\epsilon\big) A_i\Big)
\right]
+ \beta_{\mathrm{KL}}\;\mathbb{D}_{\mathrm{KL}}\!\big(\pi_\theta \,\|\, \pi_{\mathrm{ref}}\big),
\end{equation}\begin{equation}
y_i(x)\;=\;\big(y_i^{\mathrm{w}}(x),\,y_i^{\mathrm{t}}(x,\,\Gamma(y_i^{\mathrm{w}}(x)))\big),\quad
\eta_i(\theta)\;=\;\frac{\pi_\theta\!\big(y_i(x)\mid x\big)}{\pi_{\theta_{\text{old}}}\!\big(y_i(x)\mid x\big)},\quad
A_i\;=\;\frac{r_i-\mu_{\text{group}}(r)}{\sigma_{\text{group}}(r)+\varepsilon},
\end{equation}where the $`\mathbb{E}_i[\cdot]`$ is the empirical average over candidates in the group; the $`A_i`$ is the group-normalized advantage; $`\eta_i(\theta)`$ is the likelihood ratio w.r.t. the behavior policy $`\pi_{\theta_{\text{old}}}`$; $`\operatorname{clip}(\cdot)`$ uses the PPO-style hyperparameter $`\epsilon`$; $`\mu_{\text{group}}`$ and $`\sigma_{\text{group}}`$ are the group mean and standard deviation of $`r_i`$ (with a small stabilizer $`\varepsilon`$ in the denominator); $`\beta_{KL}`$ is the KL penalty coefficient and $`\mathbb{D}_{\mathrm{KL}}(\pi_\theta\|\pi_{\mathrm{ref}})`$ denotes the forward KL to a frozen reference policy (e.g., the SFT model), implemented as the token/state-averaged KL in practice.
By combining visual gate with group-level optimization, VGPO stabilizes long-horizon training and encourages the emergence of interpretable chain-of-thoughts. This mechanism ensures that CogFlow converges toward the desired paradigm: first perceive correctly, then reason correctly.
width=
l|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm
* & & & & & & &
& CoT-E & Acc & CoT-E & Acc & CoT-E & Acc & CoT-E & Acc & CoT-E & Acc
& CoT-E & Acc & CoT-E & Acc
Claude-3.5-Sonnet & 55.5 & 45.1 & 60.8 & 52.6 & 58.7 & 50.3 & 64.0 &
58.3 & 45.0 & 25.4 & 56.5 & 48.0 & 48.1 & 45.2
GPT-4o & 56.9 & 49.7 & 61.0 & 56.8 & 58.7 & 54.4 & 62.2 & 58.2 & 45.2 &
30.0 & 58.6 & 52.6 & 54.1 & 51.0
GPT-4V & 64.2 & 58.7 & 69.1 & 57.1 & 65.0 & 55.0 & 72.0 & 61.4 & 48.1 &
30.3 & 61.8 & 46.3 & 42.0 & 36.7
MathFlow$`^{\star}`$$`_{\mathrm{GPT-4V}}`$ & 64.2 & 59.5 & 69.5 & 58.2 &
67.2 & 57.4 & 71.1 & 64.1 & 52.7 & 47.5 & 62.1 & 57.1 & 60.4 &
57.0
Gemini-2.5-pro & 64.5 & 56.2 & 68.3 & 61.9 & 66.1 & 60.8 & 68.9 & 64.1 &
52.1 & 37.1 & 65.7 & 57.9 & 57.0 & 54.6
GPT-5 & 68.2 & 59.3 & 74.3 & 68.1 & 73.5 & 66.7
& 77.0 & 69.2 & 53.8 & 44.7 & 67.1 & 61.7 & 60.3 &
57.5
InfiMM-Math-7B & 37.8 & 29.5 & 43.8 & 38.1 & 40.6 & 36.7 & 46.1 & 40.1 &
28.8 & 15.4 & 39.6 & 30.3 & 26.1 & 23.2
InternVL2.5-8B & 46.3 & 40.1 & 49.2 & 41.3 & 40.5 & 38.4 & 49.6 & 42.7 &
38.4 & 20.2 & 41.0 & 35.9 & 35.8 & 33.9
Math-LLaVA-13B & 39.3 & 30.8 & 45.1 & 39.3 & 44.4 & 37.4 & - & - & 36.2
& 18.6 & 41.7 & 35.9 & 37.0 & 34.2
MultiMath-7B & 45.2 & 35.3 & 50.6 & 44.8 & 49.9 & 42.9 & - & - & 41.7 &
22.1 & 47.2 & 40.4 & 39.7 & 38.8
SVE-Math-Qwen2.5-7B & 47.9 & 38.7 & 53.1 & 47.3 & 53.4 & 45.8 & - & - &
44.2 & 28.6 & 48.9 & 44.2 & 45.8 & 42.0
VLM-R1-7B & 50.7 & 41.2 & 59.0 & 54.2 & 57.9 & 49.8 & 65.5 & 58.9 & 36.2
& 24.5 & 46.1 & 37.8 & 30.6 & 26.1
CogFlow-7B &
66.0 &
56.2 &
67.9 &
58.6 &
67.3 &
58.3 &
68.1 &
60.9 &
57.8 &
42.7 &
68.2 &
61.1 &
66.7 &
63.5
width=
l|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm|C0.9cmC0.9cm
* & & & & & & &
& CoT-E & Acc & CoT-E & Acc & CoT-E & Acc & CoT-E & Acc & CoT-E & Acc
& CoT-E & Acc & CoT-E & Acc
Qwen-VL-Plus & 21.3 & 11.8 & 26.0 & 15.7 & 21.2 & 11.1 & 25.2 & 14.5 &
18.5 & 9.0 & 19.1 & 13.0 & 21.8 & 10.0
Gemini-Pro & 35.3 & 23.5 & 39.8 & 26.3 & 34.7 & 23.5 & 44.5 & 27.3 &
32.0 & 23.0 & 36.8 & 22.3 & 33.3 & 22.2
Qwen-VL-Max & 37.2 & 25.3 & 42.8 & 30.7 & 37.7 & 26.1 & 47.9 & 28.9 &
33.6 & 24.1 & 35.9 & 24.1 & 35.9 & 21.4
GPT-4V & 54.4 & 39.4 & 63.1 & 54.7 & 56.6 & 41.4 & 60.3 & 48.7 &
51.4 & 34.9 & 50.8 & 34.4 & 50.3 & 31.6
MathFlow$`^{\star}`$$`_{\mathrm{GPT-4V}}`$ & 56.7 & 43.8 &
65.2 & 51.1 & 58.9 & 46.4 & 62.1 & 48.5 & 53.7 &
40.3 & 52.1 & 37.4 & 52.5 & 39.0
SPHINX-MoE-56B & 25.8 & 15.6 & 33.3 & 22.2 & 21.9 & 16.4 & 40.7 & 18.3 &
21.1 & 14.8 & 19.6 & 12.6 & 18.3 & 9.1
InternLM-XC2-7B & 25.9 & 16.5 & 36.9 & 22.3 & 28.3 & 17.0 & 42.5 & 16.5
& 20.1 & 15.7 & 24.4 & 16.4 & 19.8 & 11.0
Math-LLaVA-13B & - & 20.1 & - & 22.8 & - & 21.8 & - & - & - & 21.1 & - &
19.2 & - & 15.4
MultiMath-7B & - & 26.9 & - & 34.8 & - & 30.8 & - & - & - & 28.1 & - &
25.9 & - & 15.0
SVE-Math-Qwen2.5-7B & - & 31.4 & - & 37.6 & - & 36.8 & - & - & - & 34.9
& - & 31.5 & - & 16.0
DVLR-14B & 48.1 & - & 54.3 & - & 49.0 & - & - & - & 46.3 & - & 47.2 & -
& 43.8 & -
SophiaVL-R1-7B & 48.8 & - & 45.4 & - & 43.9 & - & - & - & 45.1 & - &
58.5 & - & 51.3 & -
CogFlow-7B &
53.9 &
39.5 &
60.7 &
41.9 &
51.2 &
37.0 &
52.3 &
40.1 &
55.0 &
42.4 &
58.7 &
44.8 &
44.2 &
26.3
Experiments
Experimental Setup
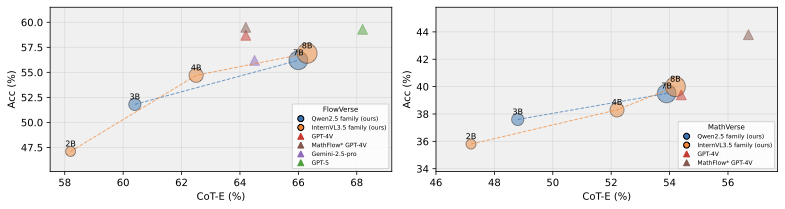
Evaluation Benchmarks and Metrics. We conduct experiments on widely used benchmarks (i.e., FlowVerse , MathVerse , MathVista , WeMath , LogicVista , and DynaMath ) with various visual mathematical reasoning tasks and different visual and textual complexity. Following common practice, we measure the accuracy (Acc) of the final answer and assess the reasoning ability from the intermediate reasoning process using the chain-of-thought evaluation (CoT-E).
Baselines. We compare our method with a wide range of closed-source MLLMs, such as GPT series , Gemini series , DouBao-1.5-pro , GLM-4.5V , Claude and Qwen-VL-Plus , as well as open-source MLLMs, including InfiMM-Math , InternVL2.5 , InternLM-XC2 , Math-LLaVA , MultiMath-7B , SVE-Math , VLM-R1 , MathFlow , DVLR , VCAR , VL-Rethinker , ThinkLite-VL and SPHINX-MoE . Since some concurrent works have yet to release their models, we report the results provided in their original papers, some of which do not include category-wise performance.
Implementation Details. We initialize CogFlow with Qwen2.5-VL-7B and train it on our curated MathCog dataset. For cold start, we first train CogFlow on MathCog-SFT subset for 2 epochs with a learning rate of $`1\times10^{-5}`$ and a batch size of 64. Subsequently, CogFlow is optimized using VGPO on MathCog-RL subset for 1 epoch with a learning rate of $`1\times10^{-6}`$ and a batch size of 16. The IntlzR reward model is based on Qwen2.5-VL-3B and trained on MathCog-IntlzR subset for 3 epochs with a learning rate of $`7\times10^{-6}`$ and a batch size 64. All our models are trained on 16 NVIDIA A100 GPUs. Please refer to §[more implementation details] for more detailed configures.
Main Results
As shown in Tables [tab:flowverse_benchmark]–6, CogFlow achieves 66.0% accuracy on FlowVerse, 53.9% on MathVerse, 76.8% on Mathvista, 64.1% accuracy on WeMath and 46.2% on DynaMath, surpassing all open-source baselines by large margins. In terms of LogicVista, it delivers competitive performance, trailing only GLM-4.IV-9B. CogFlow’s improvements in visual perception are particularly significant, as evidenced by its superior performance on subsets where visual information dominates. For example, on FlowVerse it reaches 42.7% on Vision Dense, 55.6% on Vision Primary, and 61.1% on Vision Centric. On MathVerse, the gains are consistent across Vision Intensive (44.8%), Vision Dominant (42.1%), and Vision Only (25.7%). These results demonstrate that CogFlow yields more accurate parsing of geometric primitives and relations, leading to stronger perception–reasoning integration. CogFlow also delivers higher-end-to-end problem-solving accuracy across all settings. The largest absolute gains appear in visually demanding subsets, where perception-anchored reasoning is essential. This demonstrates that CogFlow not only perceives diagrams more accurately but also reasons over them more effectively. Figure 22 further shows that CogFlow produces more structurally accurate and semantically consistent predictions compared to strong baselines. Please refer to §9.12 for more detailed configurations.
Accuracy (%) results on MathVista. CogFlow demonstrates consistent superiority.
| Model | All | FQA | GPS | MWP | TQA | VQA |
|---|---|---|---|---|---|---|
| GPT-4V | 49.9 | 43.1 | 50.5 | 57.5 | 65.2 | 38.0 |
| Claude-3.5-Sonnet | 67.7 | - | - | - | - | - |
| Doubao-pro-1.5 | 79.5 | 77.7 | 88.9 | 86.0 | 82.3 | 62.0 |
| G-LLaVA-7B | 25.1 | 19.1 | 48.7 | 3.6 | 25.0 | 28.7 |
| VCAR-7B | 33.7 | 30.9 | 34.6 | 38.7 | 37.3 | 28.5 |
| SPHINX-Plus-56B | 36.7 | 54.6 | 16.4 | 23.1 | 41.8 | 43.0 |
| SVE-Math-7B | 37.4 | 31.9 | 53.9 | 29.0 | 41.4 | 30.8 |
| MultiMath-7B | 50.0 | 40.1 | 66.8 | 61.8 | 50.0 | 33.0 |
| SophiaVL-R1-7B | 71.3 | - | - | - | 73.4 | - |
| ThinkLite-VL-7B | 71.6 | - | - | - | - | - |
| VL-Rethinker-7B | 73.7 | - | - | - | - | - |
| CogFlow-7B | 76.8 | 70.4 | 93.1 | 73.7 | 86.9 | 59.3 |
| Models | WeMath | LogicVista | DynaMath |
|---|---|---|---|
| Claude-3.7-Sonnet | 49.3 | 58.2 | 39.7 |
| GLM-4.5V | 68.8 | 62.4 | 53.9 |
| Doubao-1.5-Pro | 65.7 | 64.2 | 44.9 |
| GPT-5 | 71.1 | 70.0 | 60.9 |
| Gemini-2.5-Pro | 78.0 | 73.8 | 56.3 |
| Ovis-8B | 27.2 | 39.4 | 20.4 |
| Qwen2.5-VL-8B | 35.2 | 44.1 | 21.0 |
| InternVL3-8B | 37.1 | 44.1 | 25.5 |
| Keye-VL-8B | 60.7 | 54.8 | 37.3 |
| InternVL3.5-8B | 57.0 | 57.3 | 37.7 |
| GLM-4.1V-9B | 63.8 | 60.4 | 42.5 |
| CogFlow-7B | 64.1 | 58.1 | 46.2 |
Ablation Studies
Component Ablation. Table [tab:ablation_horizontal] reports the ablation results of CogFlow. We observe that every component in our framework contributes positively to overall performance, which confirms the necessity of jointly addressing perception, internalization, and reasoning. Among all modules, VGPO emerges as the most influential, as it directly stabilizes long-horizon reasoning through visual gate and group-level optimization, thereby yielding the largest single-module gain.
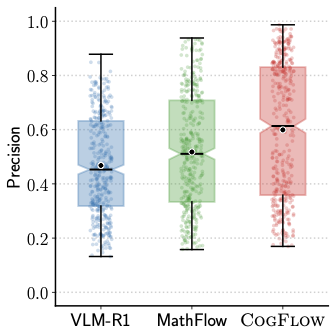
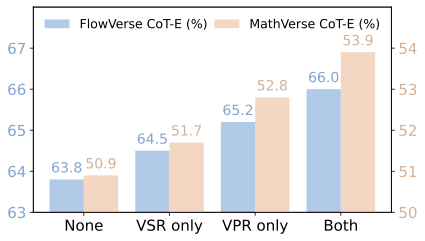
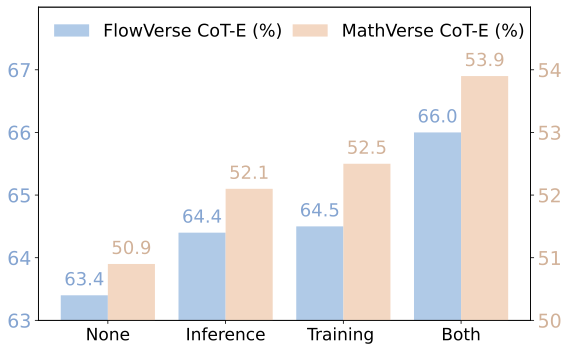
Analysis on Synergistic Visual Rewards. As shown in Figure 7, the model without any visual reward demonstrates reasonable performance. However, adding either VSR or VPR consistently improves both CoT-E and final accuracy across MathVerse and FlowVerse. The best results come from combining VSR and VPR, improving CoT-E by up to +3.0% and accuracy by +1.7% on MathVerse, and CoT-E by +2.2% and accuracy by +2.1% on FlowVerse over the baseline. These results confirm that VPR ensures geometric precision while VSR stabilizes the global layout, and their combination provides the most reliable perceptual supervision.
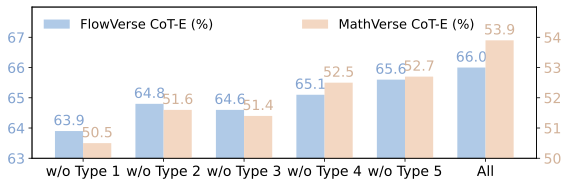
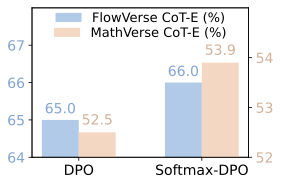
Analysis on Knowledge Internalization Reward. As shown in Figure 10, removing any single Error type consistently degrades performance, indicating that each contributes complementary supervision for internalization. The largest drops arise when excluding omission/misbinding primitives or contradicting geometric constraints, highlighting that correctly binding primitives and respecting core geometric constraints are most critical for keeping reasoning tied to perception. Figure 10 compares different training strategies during training. Vanilla DPO with all categories offers moderate gains, whereas Softmax-DPO achieves the best results, reaching 66.0% / 56.2% on FlowVerse. This suggests that fine-grained, within-problem preference modeling better captures the nuances of perception-grounded reasoning.
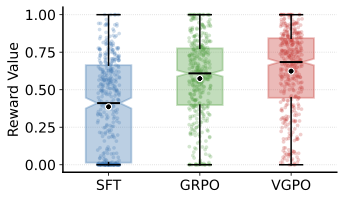
Analysis on Visual-Gated Policy Optimization. As shown in Figure [fig:vgpo_dis], the distribution of visual reward values shifts steadily upward among different post-training methods, with VGPO producing both higher medians and more concentrated high-reward samples. This indicates that VGPO further enhances stability and fidelity by explicitly introducing a visual-gated mechanism. To disentangle the effect of VGPO from the effect of the gate itself, we conducted an additional ablation of the visual gate, as shown in Figure 11. These results indicate that visual gate is also beneficial during inference, yielding a consistent absolute gain of around 0.6-1% accuracy even when the model is trained without VGPO. Moreover, VGPO provides an additional and more substantial improvement, because it uses the visual gate during training to shape the policy itself, rather than only filtering outputs at test time.
| SynVRs | IntlzR | VGPO | FlowVerse | MathVerse | ||
| CoT-E | Acc | CoT-E | Acc | |||
| 57.4 | 48.7 | 48.2 | 35.6 | |||
| 63.2 | 54.7 | 50.5 | 36.9 | |||
| 62.7 | 53.5 | 49.9 | 36.2 | |||
| 63.4 | 54.8 | 50.8 | 37.3 | |||
| 64.4 | 55.1 | 52.1 | 38.0 | |||
| 66.0 | 56.2 | 53.9 | 39.5 | |||
 style="width:98.0%" />
style="width:98.0%" />
 />
/>
 />
/>
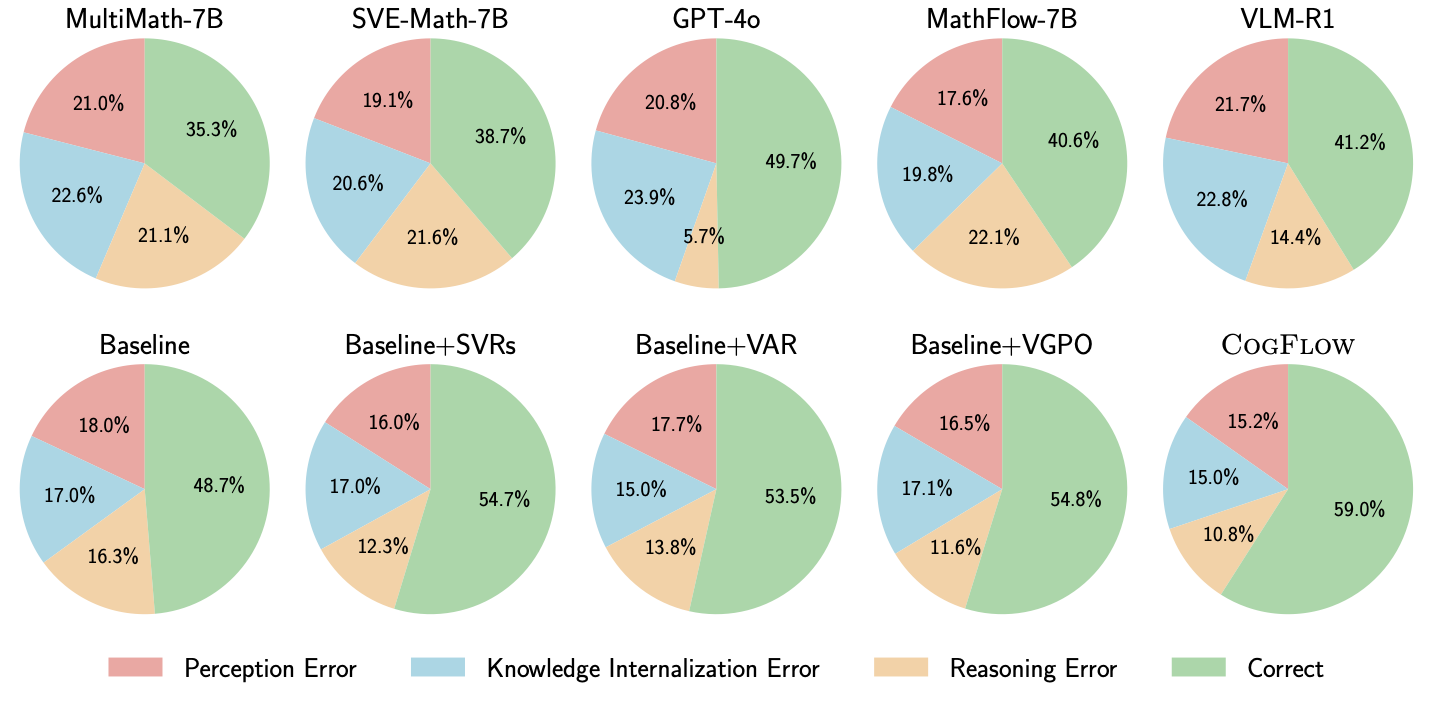
Error Type Analysis. As shown in Figure 12, we employ GPT-5 to classify each response on the FlowVerse benchmark into one of four categories: Perception Error, Knowledge Internalization Error, Reasoning Error, and Correct. The first row covers specialized visual-math MLLMs (MultiMath-7B , SVE-Math-7B ), an GRPO-style model (VLM-R1 ), the decoupled method (MathFlow-7B ), and GPT-4o ; the second row traces our variants from the SFT+GRPO baseline through +SynVRs, +IntlzR, and +VGPO to CogFlow. We observe: (1) GPT-4o’s strong overall performance is driven by superior reasoning, yet its diagram perception lags behind specialized 7B models, indicating that strengthening perception and internalization remains essential; (2) Although methods such as MathFlow-7B and VLM-R1 reduce Perception Error and Reasoning Error to some extent, these methods do not meaningfully alleviate Knowledge Internalization Error; (3) +SynVRs chiefly reduces Perception Errors ($`-2\%`$), confirming that geometry-aware and semantic visual rewards improve perceptual fidelity; (4) +IntlzR primarily mitigates reasoning drift, reducing Knowledge-Internalization Error by $`-2\%`$ relative to the baseline; and (5) when all components are combined, CogFlow minimizes every error type while maximizing the proportion of correct predictions. Furthermore, we conduct a systematic case study (see §9.13) to analyze the error compensation mechanism.
 />
/>
 />
/>
 />
/>
Conclusion
Faithful integration of visual perception into reasoning remains a critical yet overlooked challenge in visual mathematical problem solving. In this paper, we observe a prevalent reasoning drift issue and propose a cognitive-inspired three-stage framework CogFlow that explicitly models the hierarchical human reasoning flow from perception to knowledge internalization and finally to reasoning. By jointly enhancing perceptual fidelity, enforcing structured knowledge internalization, and anchoring multi-step reasoning to visual evidence, CogFlow effectively mitigates reasoning drift and improves both reasoning accuracy and interpretability. Extensive experiments on commonly used visual mathematical benchmarks validate its consistent advantages over existing MLLMs.
Appendix
Table of Contents
[2]
General Discussions
Ethics Statement
Our study focuses on visual mathematical reasoning and does not involve human-subjects experiments, personally identifiable information, or biometric data. All benchmarks used are publicly available under their original licenses. We introduce MathCog (SFT/IntlzR/RL subsets) to support training. MathCog contains diagrammatic math items and corresponding solutions (including synthetic negatives generated by controlled perturbations of reasoning), and—to the best of our knowledge—contains no sensitive or personal data. When reusing third-party content, we preserve original attribution, respect redistribution constraints, and release only the metadata/derivatives permitted by the source licenses. We do not identify any foreseeable ethical risks associated with this work. We disclose computing resources and carbon-related considerations in the appendix and follow common practices to reduce the footprint (mixed precision, batching, and early stopping). The authors declare no conflicts of interest beyond those listed on the title page.
Reproducibility Statement
To facilitate reproducibility, we have released the full training and evaluation package for CogFlow, including code, configuration files, and training dataset.
-
Data. We have released our constructed MathCog dataset (including MathCog-SFT, MathCog-IntlzR, and MathCog-RL subsets). We have also provided the construction scripts for MathCog-IntlzR, including the positive–negative pairing procedure and the five error-type perturbations used to synthesize negative trajectories.
-
Training and Implementation. We have provided runnable training recipes for the two-stage pipeline (SFT followed by VGPO-based RL), including the base model initialization, optimizer settings, batch sizes, learning rates, training epochs, and hardware requirements. We have released the exact reward formulation and hyperparameters used by VGPO, including the reward weights $`(\lambda_{\mathrm{SynVRs}}, \lambda_{\mathrm{IntlzR}}, \lambda_{\mathrm{InfR}})`$, the SynVRs mixing coefficient $`\alpha`$, and the visual gate parameters.
-
Evaluation Protocol. We have released evaluation scripts for all benchmarks used in the paper and report metrics consistent with the main text (answer accuracy and CoT-based evaluation). For baselines whose models or code are not publicly available, we have clearly indicated which numbers are taken from the original papers.
-
Ablations and Diagnostics. We provide detailed ablation studies in §4.3, covering the contributions of SynVRs, IntlzR, VGPO, and the visual gate. We further report extended analyses of VGPO and the visual gate in §8.6. All key training hyperparameters and configurations are specified in §[more implementation details], and the visual gate parameters are defined in §3.3.
The Use of Large Language Models
A large language model (i.e., ChatGPT-5) was used in two ways during the preparation of this paper:
-
To aid in polishing the writing, including improvements to grammar, clarity, and readability.
-
For retrieval and discovery, such as identifying and organizing related prior work.
The model did not contribute to research ideation, experiment design, data analysis, or interpretation of results. Its use was limited to non-scientific assistance (e.g., language polishing, rephrasing, and formatting) under direct author supervision. All scientific content, methodological decisions, and conclusions are the sole responsibility of the authors.
Limitations and Future Works
While our approach demonstrates strong performance, it has certain limitations. Most notably, the training procedure is computationally demanding, requiring substantial resources to achieve stable improvements. This dependence on large-scale computation may hinder broader adoption, especially in resource-constrained settings.
For future work, we would like to expand our method (especially the method of obtaining visual primitives) to general scenes. While this paper is primarily focused on visual mathematical problems, the procedure for obtaining these primitives is domain-agnostic. The notion of primitives, as a structured representation of visual information, naturally extends to natural scenes beyond the domain of shapes. Concretely, for natural images we could first leverage detection or segmentation models to obtain instance-level regions and their spatial extents. With the assistance of an LLM and lightweight human verification, these outputs can be normalized into a unified primitive schema that encodes structured semantic features for each instance and their relationships. Such a representation enables a consistent knowledge-internalization step that transforms raw perceptual outputs into a compact, reasoning-ready state, allowing downstream modules to operate over explicit and verifiable visual evidence.
CogFlow’s strong performance on visual mathematical reasoning suggests that the pipeline generalizes beyond visual math problems. By explicitly decomposing the process into perception, knowledge internalization, and reasoning—and training these stages to remain mutually consistent—we obtain a broadly effective framework for visually grounded multimodal reasoning, with the potential to achieve strong performance when transferred to other vision–language domains.
Additional Details of MathCog Dataset
Existing multimodal reasoning corpora provide abundant natural language annotations but rarely disentangle perception from reasoning . This gap makes it difficult to supervise models in a way that enforces accurate perception and strengthens their ability to internalize visual content. To address this, we construct the MathCog dataset, which explicitly separates the watching (perception) and thinking (reasoning) stages. Furthermore, to support the different training phases of CogFlow, we curate three tailored subsets: MathCog-SFT, MathCog-IntlzR, and MathCog-RL.
Dataset License and Intended Use
The MathCog dataset will be released
under the CC-BY-4.0 license, which permits redistribution and
adaptation for both academic research and commercial use, provided that
appropriate credit is given.
The dataset is intended primarily for research on multimodal reasoning, visual perception, and mathematical problem solving. It is designed to facilitate studies on perception–reasoning alignment in multimodal large language models. The dataset should not be used for purposes unrelated to research or education, including surveillance, profiling, or decision-making in sensitive domains such as healthcare or law enforcement. We encourage responsible use and proper citation in all derivative works.
Data Curation
Data Collection
To construct MathCog, we first collect a large pool of geometry-related visual math problems from existing corpora, including MAVIS , Geo170K , and LLaVA-CoT . We then perform a careful filtering process to obtain a high-quality subset of 111,752 problems. Specifically, we remove (1) problems dominated by weak geometric relevance charts (e.g., histograms, pie charts) or artistic illustrations that deviate from geometric reasoning, and (2) diagrams with either excessively low resolution ($`<`$ 64) or overly high resolution ($`>`$ 2048), which would otherwise compromise model training consistency.
 style="width:100.0%" />
style="width:100.0%" />
MathCog-SFT and MathCog-RL Curation
To construct a perception-enhanced dataset, we developed a preprocessing pipeline as illustrated in Figure 13. Since the raw dataset lacks sufficient perceptual information, we first curate additional geometric details from the original data. Formally, let $`I`$ denote the raw image. We apply OpenCV-based operators to extract a set of primitive geometric elements:
\begin{equation}
E = \text{Extract}(I;\theta_{\text{cv}}),
\end{equation}where $`\theta_{\text{cv}}`$ represents the parameters of the extraction process.
We utilize the OpenCV library to detect pixel-coordinate-based visual primitives in the images from the collected data, including endpoints and intersections of line segments, as well as circular features. For circles, we directly extract center coordinates $`(x, y)`$ and radius $`r`$ in pixel space. For points (e.g., vertices and character annotations), we similarly obtain precise pixel coordinates and establish optimal correspondences between detected visual elements and character labels via the Hungarian algorithm, thereby obtaining final mappings such as $`A:(x_1,y_1)`$ and $`B:(x_2,y_2)`$.
To unify the representation, the extracted elements are normalized and remapped to a fixed coordinate system, following the normalization scheme in prior work :
\begin{equation}
\hat{E} = \text{Normalize}(E) \times 20 - 10,
\end{equation}where normalization is performed by dividing coordinates by the image width and height, and the subsequent linear transformation maps the results into the range $`[-10, 10]`$.
The complete pipeline can thus be summarized as:
\begin{equation}
\tilde{E} = \text{Annotate}\!\left(\text{Normalize}\!\left(\text{Extract}(I;\theta_{\text{cv}})\right)\times 20-10;\,\mathcal{H}\right).
\end{equation}This ensures that the final dataset not only captures essential geometric primitives but also provides high-quality, standardized representations suitable for subsequent training and evaluation, thus forming the perception part.
System:
*# Your Role: expert math geometry teacher
## Objective
You will be provided with a visual mathematics problem, along with its
perception output (<WATCHING>) and a raw solution (<THINKING>).
Your task is to refine the solution such that the reasoning process
explicitly internalizes the perceptual information before carrying out
logical inference.
## Output Format
The output format should strictly follow the example following:
– Question: XXX
– <WATCHING>: XXX
– <THINKING>: XXX
– Refined <THINKING>: XXX
Now, here is the data you need to refine:
– Question: {question}
– <WATCHING>: {watching}
– <THINKING> (raw): {solution}
– Refined <THINKING>:*
Based on these visual primitives, we further construct reasoning trajectories from the solution rationales in the collected data. The goal is to (i) explicitly internalize the structured primitives into a symbolic representation, and (ii) perform step-by-step logical inference over this internalized state to answer the question. These trajectories are first generated with the assistance of GPT-5 and are subsequently verified and refined by human annotators. The prompt is shown in Table [supp-t2]. Finally, MathCog-RL is created by sampling 10,000 examples from this dataset, while MathCog-SFT is generated by sampling 100,000 examples.
A dedicated team of 31 professional annotators carried out this quality-assurance protocol over a one-month period, ensuring high-fidelity and consistent ground-truth annotations.
MathCog-IntlzR Curation
Building on MathCog-SFT, we construct MathCog-IntlzR as a set of contrastive reasoning trajectories with explicit perturbations:
We first sample 10,000 examples as positive samples from MathCog-SFT for MathCog-IntlzR. As mentioned earlier, we categorize the errors into five types: (1) omitting or misbinding primitives, (2) introducing nonexistent facts, (3) contradicting geometric constraints, (4) invoking external theorems inappropriately, and (5) referring inconsistently to established elements. The negative data for MathCog-IntlzR is constructed based on these five error types. The curation of MathCog-IntlzR is illustrated at the bottom of the Figure 13. We first use an LLM, such as GPT-5 , to generate negative trajectories conditioned on each positive trajectory by explicitly instructing it to modify the corresponding “Thinking” part, as specified in the prompt shown in Table [supp-t3]. The generated candidates are then manually checked. For example, for the Type 1 error: Omit or misbind primitives in Figure 14, we input the designed prompt into the LLM and obtain the variant “In any parallelogram, if the perimeter of triangle CDM is 5, …”, which deliberately alters the relevant content in the “Thinking” part of the original positive example. Specifically, for every positive trajectory we generate five distinct negative counterparts, resulting in 10,000 positive and 50,000 negative trajectories for Softmax-DPO training.
The easy/medium/hard labels characterize the relative difficulty for the model to detect and correct different types of reasoning drift errors, rather than the difficulty of constructing these cases. Easy errors are typically local and isolated (e.g., a minor mistake in a single visual primitive or reasoning step) and can often be corrected using limited contextual information. Medium errors involve multiple interacting primitives or steps and require the model to integrate information across a broader context. Hard errors are globally entangled with the full reasoning chain, where correcting them demands a coherent understanding of both the visual configuration and the multi-step logical structure of the solution.
 />
/>
Omit or Misbind Primitives:
Starting from the correct reasoning, deliberately omit or misbind at
least one basic geometric primitive (points, lines, circles, etc.),
while keeping the overall reasoning fluent and locally plausible.
– Positive Data: {positive data}
Introduce Nonexistent Facts:
Starting from the correct reasoning, introduce at least one geometric
or numerical fact that is not supported by the given figure or problem
statement, but make the reasoning appear locally coherent and
natural.
– Positive Data: {positive data}
Contradict Geometric Constraints:
Starting from the correct reasoning, modify the chain of thought so
that at least one step violates the true geometric constraints (e.g.,
equal lengths, parallelism, angle measures), while preserving a
seemingly reasonable narrative.
– Positive Data: {positive data}
Invoke External Theorems Inappropriately:
Starting from the correct reasoning, inappropriately invoke at least
one external theorem or formula whose preconditions are not satisfied,
or whose use is not justified by the internalized structure, while
keeping the explanation linguistically smooth.
– Positive Data: {positive data}
Refer Inconsistently to Established Elements:
Starting from the correct reasoning, alter the chain of thought so that
references to previously established elements (points, lines,
relationships) become inconsistent, such as swapping labels or changing
properties across steps, but without breaking the overall fluency of the
text.
– Positive Data: {positive data}
| Statistic | Number |
|---|---|
| Total Problem | 121,730 |
| - Number of MathCog-SFT | 100,000 |
| - Number of MathCog-RL | 10,000 |
| - Number of positive data of MathCog-IntlzR | 10,000 |
| - Number of negative data of MathCog-IntlzR | 50,000 |
| - Number of data for validation | 1730 |
| Maximum question length | 780 |
| Maximum watching length | 1,322 |
| Maximum thinking length | 1,288 |
| Average question length | 186 |
| Average watching length | 463.03 |
| Average thinking length | 527.79 |
Statistics of MathCog.
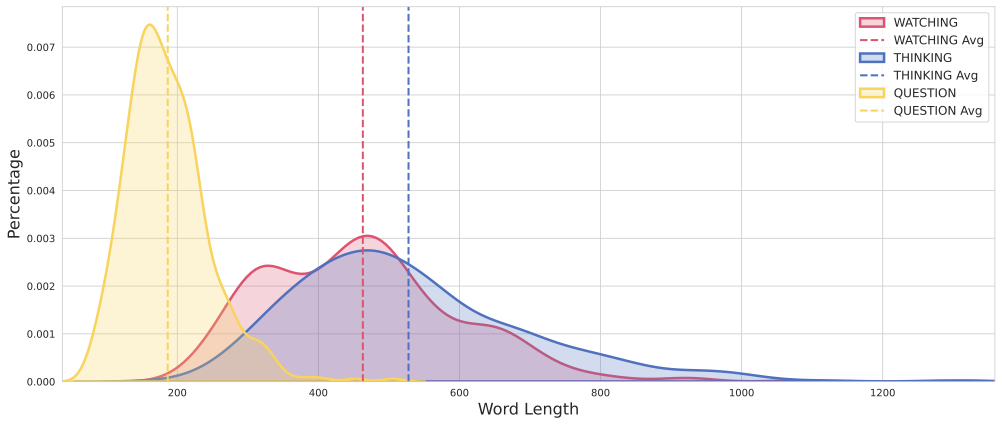
Dataset Statistics
 />
/>
Table 1 provides the statistics for the MathCog dataset, detailing the number of problems and the distribution of data across different categories. The dataset consists of a total of 121,730 problems, with 100,000 labeled for supervised fine-tuning (MathCog-SFT) and 10,000 labeled for reinforcement learning (MathCog-RL). Additionally, there are 10,000 positive samples and 50,000 negative samples used in the MathCog-IntlzR (Visual-Augmented Reward) subset. A validation set contains 1,730 examples.
Figure 15 shows the length of the various components. The maximum question length is 780, while the maximum lengths for the watching and thinking components are 1,322 and 1,288, respectively. On average, the question length is 186, with the watching and thinking components averaging 463.03 and 527.79, respectively.
 style="width:100.0%" />
style="width:100.0%" />
Dataset Examples
Figure 16 illustrates three representative
samples from the MathCog dataset
(covering both SFT and RL subsets), explicitly demonstrating our unique
data structure that disentangles perception from reasoning. Each sample
is organized into four distinct components: the raw visual input
(<IMAGE>), the problem statement (<PROBLEM>), the perception
trajectory (<WATCHING>), the reasoning trajectory (<THINKING>), and
the final answer (<ANSWER>).
Specifically, the perception trajectory translates raw diagrammatic pixels into structured geometric primitives (Points, Lines, and Circles) with precise coordinates in a visual parameterized space. For instance, in the leftmost example involving a rectangle, the model identifies specific coordinates for vertices $`A`$ and $`B`$ (e.g., $`A: (-7.56, 3.5)`$) and the intersection point $`O`$. Similarly, in the center and right examples, the model explicitly parameterizes circles by identifying center coordinates and radii (e.g., Circle: $`(2.52, -0.48, 7.84)`$).
The reasoning trajectory section then performs logical inference
anchored in these extracted visual cues. For example, in the rightmost
case, the reasoning process explicitly links the perceived fact that “AB
is the diameter” (derived from the coordinates in <WATCHING>) to the
geometric theorem that the angle subtended by a diameter is
$`90^{\circ}`$, leading to the correct deduction that
$`\angle ACB = 90^{\circ}`$5. This structured format ensures
that the final <ANSWER> is derived from a cognitive flow of perception
$`\Rightarrow`$ internalization $`\Rightarrow`$ reasoning.
Additional Implementation Details
Model Initialization
As shown in Table [tab:sft_config], we initialize CogFlow with a 7B-scale pretrained MLLM backbone, Qwen2.5-VL-7B . All parameters of the vision encoder, perception modules, and language decoder are updated during training without freezing any component.
| Config | Setting |
|---|---|
| epochs | 1 |
| batch size | 64 |
| base learning rate | $`1\times10^{-5}`$ |
| optimizer | AdamW |
| LR scheduler | Cosine |
| weight decay | 0.01 |
| gradient clipping | 1.0 |
| memory optimization | ZeRO-2 |
RL configurations.
| Config | Setting |
|---|---|
| epochs | 3 |
| batch size | 64 |
| Base learning rate | $`7\times10^{-6}`$ |
| optimizer | AdamW |
| $`\beta`$ | 1 |
| memory optimization | ZeRO-2 |
RL configurations.
| Config | Setting |
|---|---|
| epochs | 1 |
| batch size | 16 |
| base learning rate | $`1\times10^{-6}`$ |
| trajectory sampling | 8 |
| rollout generation | vLLM |
| precision | bfloat16 |
| gradient accumulation | enabled |
| KL penalty coefficient | 0.001 |
| memory optimization | ZeRO-2 |
RL configurations.
The Details of VPR
The Visual Parameterized Reward (VPR) metric quantifies perceptual accuracy within the parameter space of geometric primitives. As depicted in Figure [fig:vr], VPR first translates structured visual information into parametric representations. Critically, such structured inputs are constrained to three primitive types: points, lines, and circles, which constitute the foundational elements of geometric constructions . For lines, parametric representations are derived by fitting straight-line models to the input data; for circles, parameters are extracted directly as center coordinates and radii. Subsequently, an optimal one-to-one correspondence $`\mathcal{H}`$ between predicted and ground-truth primitives is established via a multi-class Hungarian algorithm. This matching minimizes the total assignment cost $`\mathcal{S}_{\mathrm{VPR}}`$. The complete computational procedure is formalized in Algorithm [alg:vpr_matching].
$`\mathcal{H} \gets \emptyset`$; $`\mathcal{S}_{\mathrm{VPR}} \gets 0`$ $`\mathcal{K} \gets \{\text{point}, \text{line}, \text{circle}\}`$
The Details of IntlzR Training
As shown in Table [tab:var_config], the Knowledge Internalization Reward (IntlzR) model is trained on the MathCog-IntlzR subset containing 10k pairs (one positive and five negatives per pair). We initialize the reward model with Qwen2.5-VL-3B using the HuggingFace Transformers library, and train it for 3 epochs with a batch size of 64 and a learning rate of $`7\times10^{-6}`$. It is worth noting that we adopt Softmax-DPO for training, with the objective function defined in Eq. [eq:softmax-dpo], where the temperature parameter $`\beta`$ is fixed to 1.
IntlzR is implemented as a reward model trained using Softmax-DPO on contrastive trajectory pairs generated in the MathCog-IntlzR subset. For each positive trajectory, we use an LLM to generate five negative trajectories by injecting one of the five structured reasoning-error types into the “Thinking” part, and all synthetic negatives are manually verified. Each trajectory is encoded into a hidden representation $`h`$, and IntlzR learns a scalar score $`R_{\text{IntlzR}}(h) \in [0,1]`$ that reflects its consistency with the visual evidence. During training, IntlzR is optimized with the Softmax-DPO objective so that positive trajectories receive higher scores than their corresponding negative trajectories.
The Details of InfR
Accuracy Reward. The accuracy reward evaluates whether the response
is correct. Following , we assess correctness solely based on the
answer field: the reward is 1 if the answer is correct and 0
otherwise.
Format Reward. The format reward verifies whether the response
adheres to the required output schema: the model must produce a
JSON-style response, i.e., <WATCHING> … </WATCHING> <THINKING>
… </THINKING> <ANSWER> … </ANSWER>. It returns 1 if the
response is compliant and 0 otherwise.
Finally, we have the Inference Reward $`R_{InfR}`$:
\begin{equation}
R_{InfR} \;=\; R_{Acc} + R_{Fmt}.
\end{equation}Details of SFT and RL Training
For supervised fine-tuning (SFT), we utilize the
MathCog-SFT subset, which consists of
100,000 curated samples. Both the
MathCog-SFT and
MathCog-RL splits are organized into
three components—<WATCHING>, <THINKING> and <ANSWER>. In our
training pipeline, we first perform supervised fine-tuning (SFT) on the
MathCog-SFT, where the model is trained
on the “Watching” sequences together with the corresponding <THINKING>
and<ANSWER> to strengthen its basic perceptual and reasoning
abilities. The model is optimized for 1 epoch with a batch size of 64
and a learning rate of $`1\times10^{-5}`$. We adopt AdamW as the
optimizer, using a cosine learning rate scheduler, a weight decay of
0.01, and gradient clipping at 1.0 to ensure stable updates.
For RL, the training is conducted on the
MathCog-RL subset (10k samples) for 1
epoch, with a learning rate of $`1\times10^{-6}`$ and batch size of 16.
For each input, we sample 8 candidate trajectories using
temperature-controlled decoding. The rewards are computed by combining
Synergistic Visual Rewards (SynVRs), Knowledge Internalization Reward
(IntlzR), and Inference Reward (InfR), with their weights fixed to
$`(1,1,1)`$. We implement reinforcement learning under the
Verl framework on 16 NVIDIA A100 GPUs,
with distributed acceleration provided by vLLM. Mixed-precision training
is conducted in bfloat16, and gradient accumulation is employed to
simulate larger effective batch sizes. We adopt DeepSpeed ZeRO-2 for
memory-efficient optimization, and the KL penalty coefficient is set to
$`0.001`$ to stabilize policy updates.
Details of the Reasoning Drift Precision Metric
As illustrated in Figure 3, we assess the precision of reasoning drift: whether each reasoning step is faithfully grounded in the perceived structure. Concretely, a generated solution is decomposed into steps $`\{s_t\}_{t=1}^{T}`$. From each step, we extract the referenced visual cues (primitives and relations) $`\mathcal{R}_t`$ by GPT-5 , and from the perception parse $`y^{\mathrm{w}*}`$ we obtain the set of perceived elements $`\mathcal{P}`$. A step is deemed grounded if its visual claims are entailed by the perception, formalized by a consistency predicate, i.e., $`D(s_t)=1`$. The precision of reasoning drift detection for a response is given by
\begin{equation}
\mathrm{Prec}\;=\;
\frac{1}{T}\sum_{t=1}^{T}\mathbf{1}(D(s_t)=1),
\end{equation}which measures the fraction of flagged steps that are truly ungrounded; higher values indicate fewer false positives and better alignment between perception and reasoning.
Additional Analysis
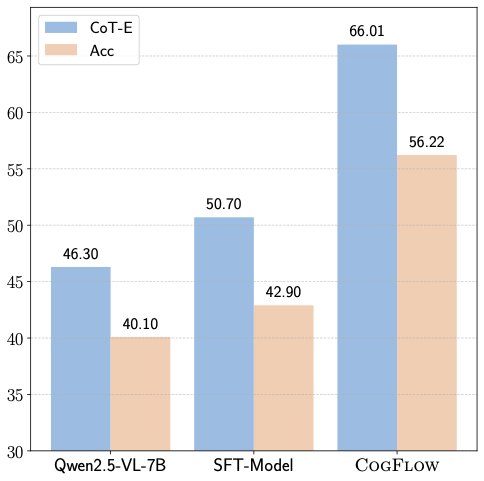
Analysis on the Overall Effectiveness of CogFlow
Figure [fig:performance] compares the performance of the base model (Qwen2.5-VL-7B), the model after SFT, and our full framework (CogFlow). The base model achieves 46.30/40.10 on CoT-E/Acc, while SFT brings moderate improvements to 50.70/42.90 (+4.40/+2.80; approximately +9.5%/+7.0%). Building upon this, CogFlow, trained with visual rewards and reinforcement learning, achieves substantial gains of 66.01/56.22, outperforming SFT by +15.31/+13.32 (around +30.2%/+31.0%) and the base model by +42.6%/+40.2%. Notably, CoT-E consistently surpasses Acc across all settings, with the largest margin observed in CogFlow (9.79 points), indicating that our approach not only improves final answer accuracy but also significantly enhances the reliability and coherence of intermediate reasoning chains.
Finally, as shown in Table [tab:mathvista_full], CogFlow attains an overall score of 76.8 (ALL), exceeding recent 7B-class multimodal reasoners and surpassing several general-purpose systems reported here (e.g., GPT-4o 63.8, Claude-3.5-Sonnet 67.7, Gemini-2.0-Flash 73.4). While Doubao-pro-1.5 reaches a higher ALL (79.5), CogFlow delivers the strongest category scores. The pronounced gains on geometry-centric GPS and text-heavy TQA align with our design: SynVRs stabilize fine-grained perceptual parsing, IntlzR enforces faithful internalization of visual cues, and VGPO optimizes reasoning under multi-signal feedback. Collectively, these components improve not only answer accuracy but also the consistency of “see correctly $`\Rightarrow`$ internalize faithfully $`\Rightarrow`$ reason coherently” across MathVista’s diverse task types.
More Analysis on Synergistic Visual Rewards
We assess perception fidelity by comparing the model’s structured output with the ground-truth primitives. Let $`\mathcal{E}^{\text{pred}}`$ and $`\mathcal{E}^{\text{gt}}`$ denote the predicted and gold sets of primitives (points/lines/circles). An LLM-based matcher sequentially aligns predicted elements to $`\mathcal{E}^{\text{gt}}`$ (type- and parameter-consistent), yielding a match set $`\mathcal{M}`$. We compute
\begin{equation}
\mathrm{Precision}=\frac{|\mathcal{M}|}{|\mathcal{E}^{\text{pred}}|},\qquad
\mathrm{Recall}=\frac{|\mathcal{M}|}{|\mathcal{E}^{\text{gt}}|},\qquad
\mathrm{F1}=\frac{2\,\mathrm{Precision}\cdot\mathrm{Recall}}{\mathrm{Precision}+\mathrm{Recall}}.
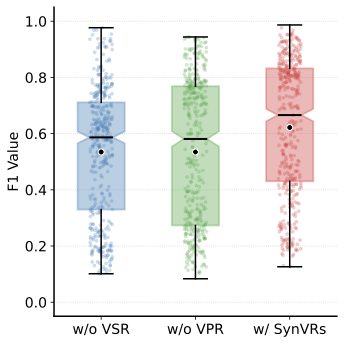
\end{equation}Figure 17 shows the F1 distribution under three settings (w/o VSR, w/o VPR, w/ VSR): removing either reward lowers perception fidelity, while enabling VSR produces the right-most, highest-centered distribution, indicating more primitives are correctly grounded; VPR provides complementary but weaker regularization.
 style="width:80.0%" />
style="width:80.0%" />
 style="width:80.0%" />
style="width:80.0%" />
| Method | All | FQA | GPS | MWP | TQA | VQA |
|---|---|---|---|---|---|---|
| Gemini-1.0-Pro | 47.7 | 48.3 | 35.1 | 50.5 | 65.8 | 42.5 |
| GPT-4V | 49.9 | 43.1 | 50.5 | 57.5 | 65.2 | 38.0 |
| GPT-4o | 63.8 | - | - | - | - | - |
| Claude 3.5 Sonnet | 67.7 | - | - | - | - | - |
| Gemini-2.0-Flash | 73.4 | - | - | - | - | - |
| Doubao-pro-1.5 | 79.5 | 77.7 | 88.9 | 86.0 | 82.3 | 62.0 |
| LLaVA-1.5-7B | 20.0 | 22.7 | 7.7 | 11.8 | 26.6 | 33.0 |
| LLaMA-Adapter-V2-7B | 23.9 | 21.2 | 25.5 | 11.3 | 32.3 | 31.8 |
| TinyLLaVA-3B | 26.7 | 20.4 | 19.7 | 23.1 | 44.9 | 31.8 |
| LLaVA-1.5-13B | 26.8 | 19.7 | 20.2 | 18.8 | 45.6 | 36.9 |
| mPLUG-Owl2-7B | 22.2 | 22.7 | 23.6 | 10.2 | 27.2 | 27.9 |
| MiniGPT-v2-7B | 23.1 | 18.6 | 26.0 | 13.4 | 30.4 | 30.2 |
| G-LLaVA-7B | 25.1 | 19.1 | 48.7 | 3.6 | 25.0 | 28.7 |
| VCAR | 33.7 | 30.9 | 34.6 | 38.7 | 37.3 | 28.5 |
| SPHINX-Plus | 36.7 | 54.6 | 16.4 | 23.1 | 41.8 | 43.0 |
| SVE-Math-7B | 37.4 | 31.9 | 53.9 | 29.0 | 41.4 | 30.8 |
| MultiMath-7B | 50.0 | 40.1 | 66.8 | 61.8 | 50.0 | 33.0 |
| X-REASONER | 69.0 | - | - | - | - | - |
| VL-Rethinker-7B | 73.7 | - | - | - | - | - |
| ReVisual-R1 | 73.1 | - | - | - | - | - |
| WeThink | 70.9 | - | - | - | - | - |
| Skywork-R1V-38B | 60.6 | - | - | - | - | - |
| CogFlow-7B | 76.8 | 70.4 | 93.1 | 73.7 | 86.9 | 59.3 |
l|l|c c |c Method & Configuration & FlowVerse CoT-E(%) &
FlowVerse Acc (%) &
*DAPO & w/o SynVRs, w/o IntlzR & 56.1 & 45.8 & 4.1
& w SynVRs, w/o IntlzR & 59.7 & 50.7 & 4.6
& w SynVRs, w IntlzR & 62.8 & 54.1 & 4.6
*PPO & w/o SynVRs, w/o IntlzR & 55.9 & 44.6 & 3.2
& w SynVRs, w/o IntlzR & 58.2 & 48.3 & 3.7
& w SynVRs, w IntlzR& 61.5 & 53.9 & 3.7
*GRPO & w/o SynVRs, w/o IntlzR & 56.7 & 47.6 & 4.2
& w SynVRs, w/o IntlzR & 61.4 & 52.9 & 4.7
& w SynVRs, w IntlzR & 64.4 & 55.1 & 4.8
*VGPO (ours) & w/o SynVRs, w/o IntlzR & 57.4 & 48.7 & 4.6
& w SynVRs, w/o IntlzR & 63.2 & 54.7 & 5.3
& w SynVRs, w IntlzR & 66.0 & 56.2 & 6.1
l|cc|c & &
& CoT-E & Acc &
VLM-R1-7B (single-pass) & 56.17 & 47.63 & 2.77
VLM-R1-7B (best-of-3 full) & 59.45 & 49.59 & 5.54
CogFlow-7B (single-pass) & 64.51
& 55.22 & 2.72
CogFlow-7B (best-of-3 full) & 66.04
& 56.17 & 5.52
CogFlow-7B (visual gate)
& 66.03 & 56.24 &
3.06
 style="width:93.0%" />
style="width:93.0%" />
The Impact and Efficiency of The Vision Gate
The Impact of the Visual Gate in the Training Phase.
To assess how the visual gate improves perceptual quality during VGPO training, we analyze the visual-reward scores produced by its conditional re-generation procedure. Figure 18 reports three visual rewards score distributions, each computed over the full training set but corresponding to different re-generation under visual gate with the threshold $`\tau`$: (i) the first-attempt scores for all instances; (ii) the post-gating scores after one re-generation round, where only instances with $`S_{\mathrm{vis}}<\tau`$ are re-generated and use their second-attempt scores while the rest keep their first-attempt scores; and (iii) the post-gating scores after a second re-generation round, where instances still below $`\tau`$ after the second attempt are re-generated again and use their third-attempt scores, while all others keep the earliest score at which they pass the gate. We visualize these distributions together with the threshold $`\tau`$ and compute the corresponding pass rates as the fraction of examples whose score exceeds $`\tau`$ at each stage. The results show that the score mass shifts upward and becomes increasingly concentrated above $`\tau`$, indicating that the visual gate acts as an effective perceptual quality-control mechanism that improves perceptual grounding rather than arbitrarily resampling trajectories.
Meanwhile, as evidenced by Table [tab:ablation_vgpo], enabling VGPO with the visual gate incurs only a modest overhead of $`+1.3`$ training hours, which is acceptable for standard MLLM post-training.
The Impact of the Visual Gate in the Inference Phase.
Moreover, we add additional experiments to further analyze the impact of the visual gate at inference. Specifically, we compare three inference schemes:
-
Single-pass: The model generates a full trajectory (
<WATCHING>,<THINKING>,<ANSWER>), which is identical to standard MLLM inference. -
Best-of-$`k`$ full: The model generates $`k`$ full trajectories and selects the one whose final answer matches the ground truth. We note that this is not a realistic inference strategy, as it relies on access to ground-truth answers.
-
Visual gate (best-of-$`k`$ perception): CogFlow samples $`k`$ alternative perception trajectories, selects the one with the highest visual score, and then performs a single reasoning pass conditioned on the selected perception.
As shown in Table [tab:Baseline_Comparison], to enable a fair and controlled comparison, we evaluate CogFlow and an open-source R1-style baseline (VLM-R1) under all three inference schemes with a fixed $`k=3`$. We additionally report the average time required to process 1,000 examples (computed by selecting 1,000 samples and averaging the end-to-end inference time) for each setting.
The results show that CogFlow outperforms VLM-R1 under both the single-pass and best-of-$`3`$ full settings, indicating that the observed gains are not attributable to more aggressive sampling. Moreover, the visual gate (best-of-$`3`$ perception) achieves nearly the same accuracy as best-of-$`3`$ full responses while requiring substantially less inference time (2.72 h vs. 3.06 h vs. 5.52 h). Overall, these results support that our comparison is fair, and that CogFlow’s visual-gated inference provides a more favorable computation–performance trade-off than naive best-of-$`k`$ sampling over full responses.
The Impact of $`k`$ in Visual Gate
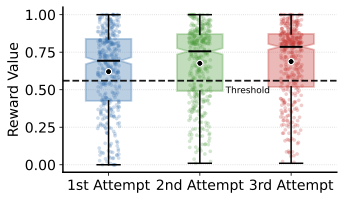
Finally, we ablate the perception sampling number $`k`$ used by the visual gate at both training time and inference time. Table [tab:k_ablation_train] varies the training-time $`k`$ while keeping the inference-time gate fixed to $`k=3`$, whereas Table 19 varies the inference-time $`k`$ with the training-time gate fixed to $`k=3`$. Across both ablations, $`k=3`$ consistently yields a favorable performance–computation trade-off, achieving most of the attainable accuracy gains without incurring excessive additional cost. Accordingly, we adopt $`k=3`$ as the default setting for both stages.
| k | FlowVerse | ||
| CoT-E | Acc | ||
| 1 | 64.40 | 55.13 | 4.85 |
| 3 | 66.03 | 56.24 | 6.17 |
| 5 | 66.60 | 56.52 | 7.91 |
c|c c|c & &
& CoT-E & Acc &
& 64.51 & 55.22 & 2.72
3 & 66.03 & 56.24 & 3.06
5 & 66.36 & 56.55 & 3.71
Analysis on Visual-Gated Policy Optimization
Table [tab:time] presents an ablation analysis across different reinforcement learning algorithms (DAPO , PPO , GRPO , and our VGPO) under consistent reward configurations based on the MathCog. Several clear trends emerge. First, the inclusion of visual perceptual reward (VPR) and Knowledge Internalization Reward (IntlzR) consistently improves performance across all methods, confirming their complementary roles in strengthening visual grounding. Second, GRPO outperforms both PPO and DAPO in all settings, highlighting its stability and effectiveness in geometry-oriented reasoning tasks. Most importantly, our proposed VGPO substantially surpasses all baselines, achieving 66.0%/56.2% accuracy on FlowVerse and MathVerse, respectively. This represents an improvement of over +6 points compared to GRPO with VPR and IntlzR, demonstrating the advantage of explicitly disentangling perception and reasoning optimization. Although VGPO incurs slightly higher training costs, the performance gain justifies the trade-off.
 style="width:100.0%" />
style="width:100.0%" />
Clarifying the Cognitive-Science Analogy
First, the “watching” stage in CogFlow is not intended to correspond to internalization. Its function is limited to extracting low-level structured visual information from an image—such as points, lines, circles, spatial groupings, and relative configurations. These representations are still purely perceptual: they serve as a normalized, noise-reduced description of the raw visual scene, but they do not yet constitute conceptual understanding or task-oriented reasoning.
The subsequent internalization stage is distinct and is designed precisely to bridge perception and reasoning. It transforms the structured primitives produced in the watching stage into a conceptually meaningful representation, integrating visual evidence with symbolic relations and problem-specific abstractions. Internalization therefore plays the role of aligning perceptual inputs with the evolving reasoning state. For instance: Type 1 (Omit or misbind primitives) errors stem from incorrect or incomplete internalization of otherwise correctly perceived primitives. They reflect failures in mapping the structured perceptual tokens into a coherent conceptual state—hence they lie at the interface between perception and reasoning. Type 4 (Invoke external theorems inappropriately) and Type 5 (Refer inconsistently to established elements) arise when the internalized conceptual representation is misinterpreted, misapplied, or inconsistently used within multi-step reasoning. These error types are characteristic of reasoning drift under an inadequately grounded internal state.
Deeper insights into the mechanism of multi-stage reward structure
On the one hand, each reward is designed to target a distinct failure mode in visual mathematical reasoning: Firstly, the Synergistic Visual Rewards (SynVRs), which comprise VPR and VSR, are designed to address perceptual failures. Figure 7 presents an ablation of the SynVRs components. The results show that adding either VPR or VSR alone consistently improves performance, and the best results are obtained when both are enabled. Figure 17 further reports the perception F1 scores for different SynVRs variants, indicating that removing either reward degrades perception fidelity. Finally, the error-type analysis in Figure 12 demonstrates that SynVRs effectively reduce perception-related errors, thereby validating their effectiveness. Taken together, these results show that VPR and VSR provide complementary supervision signals: VPR enforces local geometric fidelity, while VSR encourages global perceptual coherence in terms of overall style and layout, and together they form trustworthy visual cues that serve as a robust foundation for effective visual mathematical reasoning, which is consistent with the conclusions reported in prior studies . Secondly, the Knowledge Internalization Reward (IntlzR) is designed to alleviate reasoning drift by bridging the perception and reasoning stages, encouraging the model to produce structured, reasoning-ready outputs (i.e., knowledge-internalized representations ) that provide a more reliable foundation for subsequent reasoning. The ablation study on IntlzR (Figure 10) shows that removing any single error type consistently degrades performance, indicating that each error type provides complementary supervision. The largest drops occur when excluding the omission/misbinding primitives or contradicting geometric constraints error types, highlighting that correctly binding primitives and respecting core geometric constraints are most critical for keeping reasoning tied to perception. In addition, the error-type analysis in Figure 12 further demonstrates that IntlzR effectively reduces Knowledge Internalization Errors, which in turn leads to improved overall performance. Thirdly, the Inference Reward (InfR) ensures task-level correctness and proper output structure at the final reasoning stage .
On the other hand, this multi-stage reward structure provides a principled solution to the credit-assignment problem: instead of relying on a single sparse task-level reward, the stage-wise signals supply informative gradients at different points of the perception–internalization–reasoning pipeline. The ablation on CogFlow’s components (Table [tab:ablation_horizontal]) shows that both SynVRs and IntlzR are essential for achieving strong performance, and that the best results are obtained when all rewards are enabled. In addition, the reasoning drift analysis across three representative pipelines (Figure 2) demonstrates that CogFlow’s reasoning trajectories are more stable and better aligned with the visual information, which is consistent with the observed performance gains. Moreover, the error-type analysis in Figure 12 shows that, compared with the Baseline+VGPO setting, CogFlow substantially reduces Perception Errors, knowledge-internalization errors, and Reasoning Errors. This indicates that the three rewards together form a coherent cognitive paradigm: improved perception supports more reliable internalization, and IntlzR further aligns the reasoning trajectory with the visual evidence
Sizes and Architectures Ablation.
To demonstrate the scalability and broader applicability of CogFlow, we now explicitly evaluate CogFlow across multiple backbone architectures and parameter scales, rather than only on Qwen2.5-VL-7B (see Figure 20). Specifically, we report results for Qwen2.5-VL (3B and 7B) and InternVL3.5 (2B, 4B, and 8B). The results show that: (1) CogFlow consistently outperforms models of comparable size, and even with only 2B or 4B parameters it achieves competitive performance; (2) the performance gains are maintained or even amplified as model capacity increases; (3) the improvements hold for both the Qwen and InternVL families, indicating that the framework is not tied to a specific architecture. These findings provide empirical evidence that CogFlow is scalable and broadly applicable beyond a single model configuration.
Source of Performance Improvement
Since MathCog is explicitly designed to support the training of CogFlow, the method and the dataset are inherently coupled and cannot be treated as fully independent components. Nevertheless, for completeness, we conduct a controlled analysis to further investigate to what extent the observed performance gains arise from the dataset itself versus from the proposed training framework. We conducted an ablation study in the Table [tab:ablation_vgpo] where we fix the training data to MathCog and vary only the post-training algorithm. Starting from the same base model, we compare standard PPO, DAPO and our proposed VGPO. The results show that all methods benefit from training on MathCog, indicating that VGPO consistently achieves the best performance among all post-training methods under the same data. This suggests that the performance improvements cannot be attributed to the dataset alone, and that the CogFlow framework and its multi-stage optimization play a central role in the observed gain.
Ablations on Individual SynVRs Components
We note that the Figure 7 already included ablations of each SynVRs component. However, we did not previously investigate how different mixing ratios between VPR and VSR affect performance.
We therefore conduct an ablation study on the FlowVerse dataset (see Figure 21) by varying the weighting coefficient $`\alpha`$ while keeping IntlzR and the visual gate enabled. The results show that performance peaks at $`\alpha=0.6`$, indicating that balancing VPR and VSR yields the most effective supervisory signal. Moreover, the fact that $`\alpha=0`$ underperforms $`\alpha=1`$ suggests that parameter-level supervision (VPR) contributes more substantially to perceptual fidelity than semantic similarity alone (VSR).
| MetaCLIP2 | FG-CLIP | ||||||
| ViT-B-16 | ViT-L-14 | ViT-B-16 | ViT-L-14 | ||||
| CoT-E | Acc | CoT-E | Acc | CoT-E | Acc | CoT-E | Acc |
| 62.5 | 53.9 | 63.2 | 54.5 | 63.3 | 54.6 | 63.8 | 55.3 |
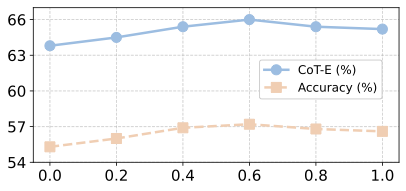 />
/>
Evaluating FG-CLIP for Similarity Reward
We further evaluate the FG-CLIP similarity module by replacing it with several alternative pre-trained models (e.g., MetaCLIP2 ) of comparable capacity. Across these variants, the FG-CLIP (ViT-L-14) configuration consistently achieves the best overall performance on FlowVerse, indicating that FG-CLIP provides a stronger and more discriminative supervision signal for our VSR component than the alternative encoders
Further Analysis of Error Types
From Figure 12, we observe that the Baseline+SynVRs setting leads to only a modest reduction in perception-related errors, but a more substantial reduction in reasoning-related errors (see also Figure 12 in the original submission). We explain this phenomenon as follows.
First, we view this as a natural consequence of the fact that perception, internalization, and reasoning are not independent modules: improvements in perception inevitably propagate to, and influence, the subsequent reasoning process. We conduct a systematic case study to analyze the error compensation mechanism. In the illustrated example, the perception stage exhibits partial errors: the coordinates of point $`A`$ are misidentified, which in turn corrupts lines $`AB`$ and $`AD`$. Nevertheless, during the subsequent reasoning stage, the model still produces the correct answer by accurately perceiving other visual primitives (e.g., points $`B`$ and $`C`$) and performing precise internalization. This analysis reveals a cognitive processing pattern in which response generation proceeds sequentially through perception $`\Rightarrow`$ internalization $`\Rightarrow`$ reasoning, and suggests that strengthened perception and internalization capabilities can mitigate Reasoning Errors even in the presence of localized perception failures.
In addition, among the Baseline+SynVRs, Baseline+IntlzR, and Baseline+VGPO configurations, Baseline+SynVRs already yields the largest reduction in Perception Errors, further demonstrating that SynVRs provide effective improvements to the perceptual component.
 style="width:100.0%" />
style="width:100.0%" />
 style="width:100.0%" />
style="width:100.0%" />
Case Studies
As shown in Figure 22, consider a circle with center $`O`$ and points $`A,B,C`$ on the circle, where $`\angle ABO = 50^\circ`$. A typical failure mode is primitive misbinding: one baseline incorrectly treats the given condition as $`\angle AOB = 50^\circ`$ and then applies the inscribed-angle theorem to obtain $`\angle ACB = 25^\circ`$. Another baseline perceives the condition correctly but makes an invalid geometric inference by asserting $`\angle AOB = 2\angle ABO`$, which yields $`\angle ACB = 50^\circ`$. In contrast, with internalized primitives and visual rewards (VPR/IntlzR), our model preserves consistent grounding. Since $`OA=OB`$, $`\triangle OAB`$ is isosceles, so $`\angle OAB=\angle ABO=50^\circ`$. It follows that $`\angle AOB = 180^\circ - 2\angle OAB = 80^\circ`$, and by the inscribed-angle theorem $`\angle ACB = \tfrac{1}{2}\angle AOB = 40^\circ`$, which is correct. This example illustrates that disentangling perception from reasoning and supervising both stages with VPR/IntlzR mitigates primitive misbinding and discourages spurious theorem application.
Analysis of Error Compensation Mechanism
As shown in Figure 23, we conduct a systematic case study to analyze the error compensation mechanism. In this instance, perception contains partial errors: the coordinates of point $`A`$ are misidentified, consequently corrupting lines $`AB`$ and $`AD`$. Crucially, during subsequent reasoning, the model produces correct answers by accurately perceiving other visual primitives (e.g., points $`B`$ and $`C`$) and performing precise knowledge internalization. Our analysis reveals a cognitive paradigm where response generation progresses sequentially through perception$`\Rightarrow`$internalization$`\Rightarrow`$reasoning. This demonstrates that enhanced perception and internalization capabilities can mitigate Reasoning Errors even when partial perception failures occur.
📊 논문 시각자료 (Figures)