Theoretical Convergence of SMOTE-Generated Samples
📝 Original Paper Info
- Title: Theoretical Convergence of SMOTE-Generated Samples- ArXiv ID: 2601.01927
- Date: 2026-01-05
- Authors: Firuz Kamalov, Hana Sulieman, Witold Pedrycz
📝 Abstract
Imbalanced data affects a wide range of machine learning applications, from healthcare to network security. As SMOTE is one of the most popular approaches to addressing this issue, it is imperative to validate it not only empirically but also theoretically. In this paper, we provide a rigorous theoretical analysis of SMOTE's convergence properties. Concretely, we prove that the synthetic random variable Z converges in probability to the underlying random variable X. We further prove a stronger convergence in mean when X is compact. Finally, we show that lower values of the nearest neighbor rank lead to faster convergence offering actionable guidance to practitioners. The theoretical results are supported by numerical experiments using both real-life and synthetic data. Our work provides a foundational understanding that enhances data augmentation techniques beyond imbalanced data scenarios.💡 Summary & Analysis
#### 1. Simple Explanation (Elementary Level) SMOTE is a method that creates more samples for the minority class to balance out imbalanced data. We checked if SMOTE makes new samples similar to the original ones.2. Medium Explanation (High School Level)
To improve performance on the minority class in imbalanced datasets, we use the SMOTE algorithm. This paper analyzes how closely synthetic samples generated by SMOTE resemble the original data distribution. Specifically, it was found that lower values of $`k`$ (the number of nearest neighbors) lead to faster convergence.
3. Advanced Explanation (College Level)
This research provides a theoretical analysis of the convergence of synthetic samples created by the SMOTE algorithm back to the original data distribution. Key findings include proving that with larger sample sizes, these synthetic samples converge in probability and mean to the original distribution, particularly when $`k`$ is small.
📄 Full Paper Content (ArXiv Source)
Introduction
Imbalanced datasets are a pervasive challenge in machine learning and statistical analysis, where one class (the minority class) is significantly underrepresented compared to others (the majority class). The imbalance often leads to biased predictive models that perform poorly on the minority class , which may represent critical cases such as fault detection , medical diagnoses , network security , or computer vision . To mitigate this issue, various data augmentation techniques have been developed to generate synthetic samples of the minority class, thereby balancing the dataset and improving model performance.
One of the most widely used augmentation methods is the Synthetic Minority Over-sampling Technique (SMOTE), introduced by Chawla et al. . SMOTE generates new synthetic samples by interpolating between existing minority class instances and their nearest neighbors. Specifically, for a given minority class sample, synthetic points are created along the line segments joining it with its $`k`$-nearest neighbors. This approach has been empirically successful and has been integrated into numerous applications and extended in various ways .
Despite its widespread adoption and a plethora of empirical studies that analyze its properties, the theoretical aspects of SMOTE remain relatively unexplored. In particular, there is limited understanding of how the synthetic samples generated by SMOTE relate to the original data distribution as the sample size increases. The question of convergence is central to understanding the effectiveness of the SMOTE algorithm. The gap in the literature is significant because a theoretical foundation would provide insights into the algorithm’s effectiveness, inform parameter selection, and guide the development of improved augmentation methods.
In this paper, we fill the gap in analytical framework by providing a theoretical analysis of the convergence of SMOTE-generated samples to the original data distribution. Our study considers a continuous random variable $`X`$ and examines the behavior of the synthetic random variable $`Z`$, which is generated from an independent and identically distributed (i.i.d.) sample of $`X`$.
Our main contributions are as follows:
-
Convergence in Probability: We prove that the synthetic random variable $`Z`$ converges in probability to the original random variable $`X`$ as the sample size $`n`$ approaches infinity (Theorem 1). This result establishes that, with sufficiently large samples, the distribution of SMOTE-generated samples approximates the original data distribution.
-
Impact of Nearest Neighbor Rank $`k`$: We analyze the effect of the choice of $`k`$ on the convergence rate of $`Z`$ to $`X`$. Our analysis reveals that selecting lower values of $`k`$ leads to faster convergence. Specifically, we demonstrate through Equation [compk] that the expected distance between a sample point and its $`k`$-th nearest neighbor increases with $`k`$. Consequently, synthetic samples generated using higher values of $`k`$ are more likely to be farther from the original data points, potentially slowing down convergence.
-
Empirical Validation: We support our theoretical findings with simulation studies using uniform, Gaussian, and exponential distributions. The simulations illustrate the convergence behavior of $`Z`$ for different values of $`k`$ and sample sizes $`n`$ (Figures 5–8). We observe that lower values of $`k`$ result in faster convergence of $`Z`$ to the distribution of $`X`$, as measured by the Kullback-Leibler (KL) divergence (Figure 12).
-
Convergence in Mean: Under the additional assumption that $`X`$ has compact support, we establish that $`Z`$ converges to $`X`$ in mean as $`n \rightarrow \infty`$ (Theorem 3). This stronger form of convergence provides a deeper understanding of the relationship between the synthetic and original data distributions.
Our results have practical implications for the application of SMOTE in data augmentation. They suggest that using the nearest neighbor ($`k = 1`$) in the SMOTE algorithm is preferable for achieving faster convergence to the original distribution. This insight can guide practitioners in selecting appropriate parameters for SMOTE and potentially improve the performance of models trained on augmented data.
The remainder of the paper is organized as follows. In Section 3, we present the main theoretical results, including proofs of convergence in probability and mean. Section 4 details the simulation studies that corroborate our theoretical findings and explore the effects of different choices of $`k`$ and sample sizes $`n`$. Finally, in Section 5, we discuss the implications of our work and suggest directions for future research.
We believe that this work contributes significantly to the theoretical understanding of SMOTE and opens avenues for further exploration of data augmentation techniques in machine learning.
$$\begin{equation} \label{eq:elreedy} \begin{split} f_Z(z)&= (N-K) \binom{N-1}{K} \int_x f_X(x) \int_{r=|| z-x||}^\infty f_X \left(x+ \frac{(z-x)r}{||z-x||}\right) \left( \frac{r^{d-2}}{||z-x||^{d-1}} \right) \\ &\times B\left(1-I_{B(x,r);N-K-1,K} \right)dr dx. \end{split} \end{equation}$$
Background
Handling imbalanced data remains a dynamic area of research. Although numerous sampling algorithms have been developed , the SMOTE algorithm is arguably the most widely recognized method in the literature. Initially introduced by Chawla et al. in 2002 , SMOTE has been successfully applied across a variety of applications. There are numerous extensions of SMOTE that aim to enhance the original algorithm’s sampling performance. For example, the Adaptive Synthetic (ADASYN) algorithm is similar to SMOTE but varies the number of generated samples based on the estimated local distribution of the class being oversampled. Another widely used variant, Borderline SMOTE , identifies borderline samples and utilizes them to create new synthetic instances. Additionally, SVM-SMOTE was developed in by incorporating support vector machines into the SMOTE framework. More recently, several other extensions have been proposed, including Center Point SMOTE, Inner and Outer SMOTE , DeepSMOTE , and Deep Attention SMOTE , among others, further expanding the applicability and effectiveness of SMOTE in various contexts.
Despite its popularity and wide-spread use, there exist very few studies that analyze theoretical properties of SMOTE. In early attempt to understand theoretical aspects of sampling strategies, King and Zeng studied the random undersampling strategy in the context of the logistic regression. In , Elreedy and Atiya derived the expectation and covariance matrix of the SMOTE generated patterns. More recently, Elreedy et al. developed the theoretical distribution of $`Z`$ described in Equation [eq:elreedy]. While enlightening, the expression in Equation [eq:elreedy] is not practical as it is expressed in the form of a double integral. In , Sakho et al. proposed an alternative derivation of Equation [eq:elreedy] using random variables instead of geometrical arguments. Sakho et al. also studied the convergence of $`Z`$ to $`X`$ and showed that if $`X`$ has a bounded support, then $`Z_{K,n}\mid X_c = x_c\to x_c`$ in probability (Theorem 3.3 ). In , the authors improve the convergence result of by showing that $`Z`$ converges to $`X`$ conditionally in mean, when $`X`$ is left-bounded.
Our research advances existing literature in two significant ways. First, we demonstrate that $`Z`$ converges to $`X`$ in probability without requiring any assumptions about the boundedness of the support. Second, we show that when the support is bounded, $`Z`$ converges to $`X`$ in mean, which is a stronger form of convergence than convergence in probability.
Main Results
Let $`X`$ be a real-valued random variable with cumulative distribution function $`F`$ and probability density function $`f`$. Consider an independent and identically distributed (i.i.d.) sample $`X_1, X_2, \dots, X_n`$ drawn from $`X`$. Let $`Z`$ be the random variable generated via the SMOTE-$`k`$ procedure, as described in Algorithm 1. We will show that $`Z`$ converges to $`X`$ in probability as $`n\rightarrow \infty`$.
Input: A sample $`(X_1, X_2, \dots, X_n)`$ and neighbor rank $`1\leq k\leq n-1`$ Output: A synthetic sample $`Z`$ Randomly choose an instance $`X_i`$ from the sample Find the $`k`$-th nearest neighbor of $`X_i`$, denoted $`X_{i,(k)}`$ Generate a random number $`\lambda \sim U(0, 1)`$ Create a synthetic point $`Z= X_i + \lambda (X_{i,(k)} - X_i)`$ Return $`Z`$
We note that there exists a more general version of the SMOTE-$`k`$ algorithm which will be discussed in Section 3.1. Specifically, all the results established for the SMOTE-$`k`$ algorithm are also applicable to this broader algorithm.
Theorem 1. Let $`X`$ be a continuous random variable. Let $`Z`$ be the random variable generated via the SMOTE-k procedure from an i.i.d. sample $`X_1, X_2, \dots, X_n`$ drawn from $`X`$. Then, $`Z`$ converges to $`X`$ in probability as $`n\rightarrow \infty`$.
Proof. Let $`F`$ be the continuous cumulative distribution function and $`f`$ be the corresponding probability density function of $`X`$. Since $`X_1, X_2, \dots, X_n`$ is an i.i.d. sample, we can assume without the loss of generality that $`Z`$ is generated between $`X_1`$ and its $`k`$-th nearest neighbor $`X_{1,(k)}`$. We will show that $`Z`$ converges to $`X_1`$ in probability, i.e.,
\quad \lim_{n \to \infty} P\left( \left| Z - X_1 \right| > \epsilon \right) = 0, \,\forall \epsilon > 0.Since $`|Z - X_1| \leq |X_{1,(k)} - X_1|`$ then
P\left( \left| Z - X_1 \right| > \epsilon \right) \leq P\left( \left| X_{1,(k)} - X_1 \right| > \epsilon \right).Thus, it suffices to show that
\quad \lim_{n \to \infty} P\left( \left| X_{1,(k)} - X_1 \right| > \epsilon \right) = 0, \,\forall \epsilon > 0.For each $`i \neq 1`$, define the distance:
D_i = |X_i - X_1|.Arrange these distances in ascending order:
D_{(1)} \leq D_{(2)} \leq \dots \leq D_{(n - 1)},so that $`D_{(k)} = |X_{1,(k)} - X_1|`$ is the $`k`$-th smallest distance from $`X_1`$ to the other sample points. Our objective is to estimate $`P(D_{(k)} \geq \varepsilon)`$.
Let $`Y`$ denote the number of sample points among $`X_2, X_3, \dots, X_n`$ that are within $`\varepsilon`$ of $`X_1`$:
Y = \sum_{i=2}^{n} \mathbf{1}_{\{ D_i \leq \varepsilon \}},where $`\mathbf{1}_{\{ D_i \leq \varepsilon \}}`$ is the indicator function that equals 1 if $`D_i \leq \varepsilon`$ and 0 otherwise. Given $`X_1 = x_1`$, each $`D_i`$ is independent of the others, and the events $`\{ D_i \leq \varepsilon \}`$ are independent Bernoulli trials with success probability:
p(x_1) = P(D_i \leq \varepsilon \mid X_1 = x_1) = \int_{x_1 - \varepsilon}^{x_1 + \varepsilon} f(x) \, dx.Thus, conditional on $`X_1 = x_1`$, $`Y`$ follows a binomial distribution:
Y \mid X_1 = x_1 \sim \text{Binomial}(n - 1, p(x_1)).We can express the conditional probability $`P(D_{(k)} \geq \varepsilon \mid X_1)`$ as:
\begin{equation}
\label{distk}
P(D_{(k)} \geq \varepsilon \mid X_1) = P(Y \leq k - 1 \mid X_1).
\end{equation}To find the unconditional probability, we take the expectation over $`X_1`$:
\begin{equation}
\label{uncond}
P(D_{(k)} \geq \varepsilon) = E_{X_1}\left[ P(Y \leq k - 1 \mid X_1) \right].
\end{equation}Our goal is to show that this expectation tends to zero as $`n \to \infty`$. To this end, note that for any $`\delta > 0`$, since $`f`$ is integrable, there exists a compact set $`S \subset \mathbb{R}`$ such that:
\begin{equation}
\label{bound}
\int_{S^c} f(x_1) \, dx_1 < \delta.
\end{equation}Since $`S`$ is compact and $`p(x_1)`$ is strictly positive, there exist $`p_{\min} \gneq 0`$ such that
\begin{equation}
\label{comp}
p(x_1) \geq p_{\min}, \,\forall x_1 \in S.
\end{equation}We use $`S`$ to split $`P(D_{(k)} \geq \varepsilon)`$ into two parts to be handled separately:
\begin{equation}
\label{break}
P(D_{(k)} \geq \varepsilon) = P(D_{(k)} \geq \varepsilon, X_1 \in S) + P(D_{(k)} \geq \varepsilon, X_1 \in S^c).
\end{equation}Case 1: $`P(D_{(k)} \geq \varepsilon, X_1 \in S)`$
Using Equation [uncond] and [comp], we get:
\begin{aligned}
&P(D_{(k)} \geq \varepsilon, X_1 \in S) = E_{X_1}\left[ P(Y \leq k - 1 \mid X_1 \in S) \right]\\
&= \int_{S} P(Y \leq k - 1) f(x_1) \, dx_1\\
&=\sum_{j=0}^{k-1} \int_{S} \binom{n-1}{j} [p(x_1)]^j [1 - p(x_1)]^{n-1-j} f(x_1) \, dx_1\\
&\leq\sum_{j=0}^{k-1} (n-1)^{j} [1 - p_{\min}]^{n-1-j} \cdot \int_{S} [p(x_1)]^j f(x_1) \, dx_1\\
&\leq \sum_{j=0}^{k-1} (n-1)^{j} [1 - p_{\min}]^{n-1-j}
\end{aligned}Since $`(1 - p_{\min} )<1`$, then $`(1 - p_{\min})^{n-1-j}`$ decreases exponentially, as $`n\to \infty`$. On the other hand, $`(n-1)^{j}`$ increases in polynomial order. It follows that
\lim_{n\to \infty} \sum_{j=0}^{k-1} (n-1)^{j} [1 - f_{\min}]^{n-1-j}=0.Hence, $`\lim_{n\to \infty}P(D_{(k)} \geq \varepsilon, X_1 \in S)=0.`$
Case 2: $`P(D_{(k)} \geq \varepsilon, X_1 \in S^c)`$
Using Equation [bound], we have:
\begin{align*}
P(D_{(k)} \geq \varepsilon, X_1 \in S^c) &\leq P(X_1 \in S^c)\\
&= \int_{S^c} f(x_1) \, dx_1 < \delta.
\end{align*}It follows from Equation [break] that $`\lim_{n\to \infty}P(D_{(k)} \geq \varepsilon) < \delta.`$ Since $`\delta > 0`$ is arbitrary we have:
\lim_{n \to \infty} P(D_{(k)} \geq \varepsilon) = 0.Since $`|Z - X_1| \leq D_{(k)}`$, then:
P(|Z - X_1| > \varepsilon) \leq P(D_{(k)} \geq \varepsilon) \to 0 \quad \text{as} \quad n \to \infty.Therefore, $`Z`$ converges in probability to $`X_1`$. Given that $`X_1`$ is distributed as $`X`$, and convergence in probability is preserved under convergence to a random variable, we conclude that:
\lim_{n \to \infty} P(|Z - X| > \varepsilon) = 0.◻
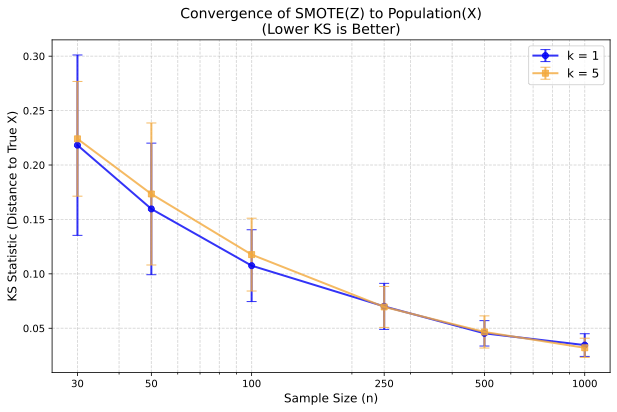
To validate Theorem 1 on real-world data, we analyzed carbon monoxide readings from the UCI Air Quality dataset , treating the full series as the ground truth $`X`$. We generated synthetic samples $`Z`$ from subsets of varying sizes $`n`$ using neighbor ranks $`k=1`$ and $`k=5`$, measuring the Kolmogorov-Smirnov (KS) distance to $`X`$. As shown in Figure 1, the error decreases monotonically as $`n`$ increases, confirming convergence in probability. Moreover, $`k=1`$ yields consistently lower KS statistics than $`k=5`$ at smaller sample sizes, empirically supporting our theoretical conclusion that lower neighbor ranks lead to faster convergence.
In the next theorem, we consider a continuous random variable with compact support. We show that the expected difference between any two consecutive order statistics tends to zero uniformly as the sample size increases. As a consequence (Theorem 3), we will obtain that $`Z`$ converges to $`X`$ in mean. Before proceeding further, we need the following auxiliary lemma whose proof is trivial.
Lemma 1. *Let $`X`$ and $`Y`$ be random variables. The expectation of $`X`$ can be expressed in terms of conditional expectations as
E[X] = \sum_y E[X \mid Y = y] \cdot f_Y(y).
```*
</div>
<div id="meanConverge" class="theorem">
**Theorem 2**. *Let $`X`$ be a continuous random variable with finite
support $`[a, b]`$. Let $`X_1, X_2, \dots, X_n`$ be independent and
identically distributed (i.i.d.) samples from $`X`$, and let
$`X_{(1)} \leq X_{(2)} \leq \dots \leq X_{(n)}`$ denote their order
statistics. Then $`\lim_{n\to\infty}E[X_{(k+1)} - X_{(k)}] =0`$
uniformly.*
</div>
<div class="proof">
*Proof.* Assume without the loss of generality that the cumulative
distribution function $`F`$ is continuous and strictly increasing on
$`[a, b]`$. Our goal is to show that for any $`\varepsilon > 0`$, there
exists an $`N \in \mathbb{N}`$ such that for all $`n > N`$ and all
$`1 \leq k \leq n - 1`$,
``` math
E[X_{(k+1)} - X_{(k)}] < \varepsilon.Since $`X`$ has support $`[a, b]`$, then $`F`$ is a bijection from $`[a, b]`$ to $`[0, 1]`$ and its inverse function $`F^{-1}`$ exists and is continuous and strictly increasing on $`[0, 1]`$. Moreover, both $`F`$ and $`F^{-1}`$ are uniformly continuous as they are continuous functions on compact intervals. Define
U_i = F(X_i), \quad \text{for } i = 1, 2, \dots, n.Since $`X_i`$ are i.i.d. samples from $`X`$, the $`U_i`$ are i.i.d. samples from the uniform distribution on $`[0, 1]`$. Let $`U_{(1)} \leq U_{(2)} \leq \dots \leq U_{(n)}`$ denote the order statistics of the $`U_i`$. The expected difference between consecutive order statistics for the uniform distribution on $`[0, 1]`$ is known :
\begin{equation}
\label{expectedDiff}
E[U_{(k+1)} - U_{(k)}] = \frac{1}{n + 1}, \quad \text{for } k = 1, 2, \dots, n - 1.
\end{equation}Since $`F^{-1}`$ is uniformly continuous, for any $`\varepsilon > 0`$, there exists a $`\delta > 0`$ such that for all $`u, v \in [0, 1]`$,
|u - v| < \delta \implies |F^{-1}(u) - F^{-1}(v)| < \varepsilon.We use Lemma 1 to decompose $`E[X_{(k+1)} - X_{(k)}]`$ based on whether $`U_{(k+1)} - U_{(k)}`$ is less than $`\delta`$:
\begin{align*}
E[X_{(k+1)} - X_{(k)}] &= E\left[ (X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} < \delta \right) \right] \\
&\quad + E\left[ (X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} \geq \delta \right) \right],
\end{align*}where $`\mathbb{I}(\cdot)`$ is the indicator function.
Case $`U_{(k+1)} - U_{(k)} < \delta`$:
When $`U_{(k+1)} - U_{(k)} < \delta`$, the uniform continuity of $`F^{-1}`$ implies
|X_{(k+1)} - X_{(k)}| = |F^{-1}(U_{(k+1)}) - F^{-1}(U_{(k)})| < \varepsilon.Therefore,
(X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} < \delta \right) \leq \varepsilon \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} < \delta \right).Taking expectations,
\begin{align*}
&E\left[ (X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} < \delta \right) \right]\\
&\leq \varepsilon \cdot P\left( U_{(k+1)} - U_{(k)} < \delta \right)\\
&\leq \varepsilon.
\end{align*}Case $`U_{(k+1)} - U_{(k)} \geq \delta`$:
Since $`X_{(k)}`$ and $`X_{(k+1)}`$ are in $`[a, b]`$, the maximum possible difference is
0 \leq X_{(k+1)} - X_{(k)} \leq b - a.Thus,
\begin{align*}
&E\left[ (X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} \geq \delta \right) \right]\\
&\leq (b - a) \cdot P\left( U_{(k+1)} - U_{(k)} \geq \delta \right).
\end{align*}To bound $`P\left( U_{(k+1)} - U_{(k)} \geq \delta \right)`$, we apply Markov’s inequality to the random variable $`U_{(k+1)} - U_{(k)}`$. Recall that Markov’s inequality states that for any non-negative random variable $`X`$ and any $`t > 0`$,
P(X \geq t) \leq \frac{E[X]}{t}.Applying this to $`U_{(k+1)} - U_{(k)}`$ with $`t = \delta`$,
P\left( U_{(k+1)} - U_{(k)} \geq \delta \right) \leq \frac{E[U_{(k+1)} - U_{(k)}]}{\delta}.It follows from Equation [expectedDiff] that
P\left( U_{(k+1)} - U_{(k)} \geq \delta \right) \leq \frac{1}{n \delta}.Let $`n`$ be large enough such that
\frac{1}{n \delta} \leq \frac{\varepsilon}{2(b - a)}.Then
(b - a) \cdot P\left( U_{(k+1)} - U_{(k)} \geq \delta \right) \leq \frac{\varepsilon}{2}.It follows that
\begin{align*}
&E[X_{(k+1)} - X_{(k)}]\\
&= E\left[ (X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} -
U_{(k)} < \delta \right) \right] \\
&\quad + E\left[ (X_{(k+1)} - X_{(k)}) \cdot \mathbb{I}\left( U_{(k+1)} - U_{(k)} \geq \delta \right) \right] \\
&\leq \varepsilon + (b - a) \cdot \frac{\varepsilon}{2(b - a)} = \varepsilon + \frac{\varepsilon}{2} = \frac{3\varepsilon}{2},
\end{align*}for all $`n > N`$ and all $`1 \leq k \leq n - 1`$, as desired. ◻
We can generalize Theorem 2 to the expected difference between any order statistics.
Corollary 1. In the same scenario as in Theorem 2, let $`1\leq m \leq n-1`$. Then $`\lim_{n\to\infty}E[X_{(k+m)} - X_{(k)}] =0`$ uniformly, for all $`1\leq k \leq n-m`$.
Proof. Let $`\varepsilon >0`$ be given. By Theorem 2, there exists an $`N \in \mathbb{N}`$ such that for all $`n > N`$ and all $`1 \leq k \leq n - 1`$,
E[X_{(k+1)} - X_{(k)}] < \frac{\varepsilon}{m}.It follows that
\begin{align*}
E[X_{(k+m)} - X_{(k)}] &=\sum_{i=k}^{m-1} E[X_{(i+1)} - X_{(i)}]\\
&\leq m\cdot \frac{\varepsilon}{m} = \varepsilon.
\end{align*}◻
In Theorem 1, we showed that $`X`$ converges to $`Z`$ in probability. Now, under additional condition of bounded support of $`X`$, we obtain a stronger result that $`X`$ converges to $`Z`$ in mean.
Theorem 3. Let $`X`$ be a continuous random variable with compact support. Let $`Z`$ be the random variable generated via the SMOTE-k procedure from an i.i.d. sample $`X_1, X_2, \dots, X_n`$ drawn from $`X`$. Then, $`Z`$ converges to $`X`$ in mean as $`n\rightarrow \infty`$.
Proof. Since $`X_1, X_2, \dots, X_n`$ is an i.i.d. sample, we can assume without the loss of generality that $`Z`$ is generated between $`X_1`$ and its $`m`$-th nearest neighbor $`X_{1,(m)}`$. We will show that $`Z`$ converges to $`X_1`$ in mean, i.e.,
\lim_{n\to\infty}E\left[ \left|Z - X_{1}\right| \right] =0.Let $`\varepsilon >0`$ be given. By Corollary 1, there exists an $`N \in \mathbb{N}`$ such that for all $`n > N`$ and all $`1\leq k \leq n-m`$,
E[X_{(k+m)} - X_{(k)}] < \varepsilon.Then,
\begin{align*}
E[|Z - X_{1}|] &\leq E[|X_{1,(m)} - X_{1}|]\\
&\leq \sup_{1\leq k \leq n-m} E[X_{(k+m)} - X_{(k)}] \\
&\leq \varepsilon
\end{align*}which completes the proof. ◻
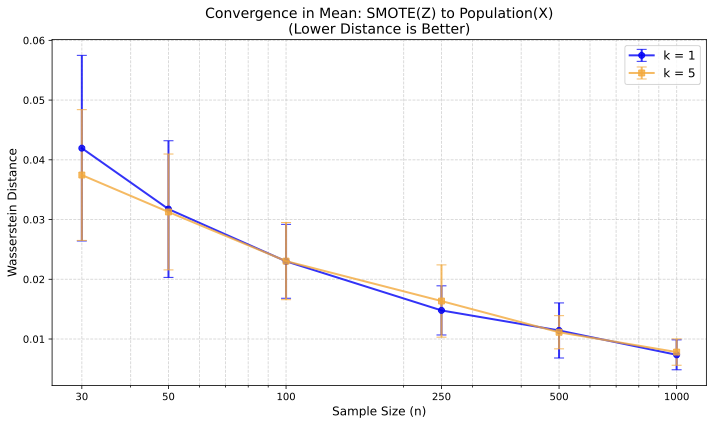
To verify Theorem 3, we analyzed the “median income” feature from the California Housing dataset . The data is normalized to $`[0, 1]`$ to satisfy the assumption of compact support. We calculated the Wasserstein distance as suitable proxy for convergence in mean between the synthetic samples $`Z`$ and the true population $`X`$. As illustrated in Figure 2, the distance decreases monotonically as the sample size $`n`$ increases. It empirically confirms that the synthetic distribution approaches the original distribution in mean.
General SMOTE
In this section, we broaden our main results related to converegence to a more general version of SMOTE. The general SMOTE algorithm is an extension of Algorithm [alg:smote1]. The details of the general procedure are presented in Algorithm [alg:smotek]:
Input: A sample $`(X_1, X_2, \dots, X_n)`$ and rank $`1\leq K\leq n-1`$ Output: A synthetic sample $`Z`$ Randomly choose an instance $`X_i`$ from the sample Find the $`K`$ nearest neighbors of $`X_i`$, denoted $`(X_{i,(1)}, X_{i,(2)},... X_{i,(K)})`$ Randomly choose a nearest neighbor $`X_{i,(k)}`$ from the previous step. Generate a random number $`\lambda \sim U(0, 1)`$ Create a synthetic point $`Z= X_i + \lambda (X_{i,(k)} - X_i)`$ Return $`Z`$
Let $`Z_k`$ and $`Z_K`$ denote the SMOTE variables generated via SMOTE-$`k`$ and SMOTE-$`K`$ procedures, respectively. Then,
Z_K = \frac{1}{K}\sum_{k=1}^K Z_k.First, we extend the result about the convergence in probability from $`Z_k`$ to $`Z_K`$.
Corollary 2. Let $`X`$ be a continuous random variable. Let $`Z`$ be the random variable generated via the SMOTE-K procedure from an i.i.d. sample $`X_1, X_2, \dots, X_n`$ drawn from $`X`$. Then, $`Z`$ converges to $`X`$ in probability as $`n\rightarrow \infty`$.
Proof. Let $`\varepsilon`$ and $`\delta`$ be given. We know from Theorem 1 that for each $`1\leq k \leq K`$, there exists $`N_k`$ such that $`P\left( \left| Z_k - X_1 \right| > \delta \right) <\varepsilon, \,\forall n > N_k`$. Let $`N=\sup_{N_1, N_2, ..., N_K}`$. Then, by the triangle inequality
\begin{align*}
P\left( \left| Z_K - X_1 \right| > \delta \right)
&=P\left( \left| \left(\frac{1}{K}\sum_{k=1}^K Z_k\right) - X_1 \right| > \delta \right)\\
&\leq P\left( \frac{1}{K}\sum_{k=1}^K \left| Z_k - X_1 \right| > \delta \right)\\
&= \frac{1}{K}\sum_{k=1}^K P\left( \left| Z_k - X_1 \right| > \delta \right)\\
&\leq\varepsilon,
\end{align*}for all $`n\geq N`$. ◻
Next, we extend the result about the convergence in mean from $`Z_k`$ to $`Z_K`$.
Corollary 3. Let $`X`$ be a continuous random variable with compact support. Let $`Z`$ be the random variable generated via the SMOTE-K procedure from an i.i.d. sample $`X_1, X_2, \dots, X_n`$ drawn from $`X`$. Then, $`Z`$ converges to $`X`$ in mean as $`n\rightarrow \infty`$.
Proof. Let $`\varepsilon`$ be given. We know from Theorem 3 that for each $`1\leq k \leq K`$, there exists $`N_k`$ such that $`E\left[ \left|Z_k - X_{1}\right| \right] \leq \varepsilon , \,\forall n > N_k.`$ Let $`N=\sup_{N_1, N_2, ..., N_K}`$. Then, by the triangle inequality
\begin{align*}
E\left[ \left|Z_K - X_{1}\right| \right]
&=E\left[ \left| \left(\frac{1}{K}\sum_{k=1}^K Z_k\right) - X_{1}\right| \right]\\
&\leq \frac{1}{K}\sum_{k=1}^K E\left[ \left|Z_k - X_{1}\right| \right] \\
&\leq\varepsilon,
\end{align*}for all $`n\geq N`$. ◻
Optimal rank $`k`$
In the standard SMOTE algorithm, the rank $`k`$ of the nearest neighbor is typically set to $`k=5`$ . However, Equation [distk] demonstrates that selecting lower values of $`k`$ is preferable. Concretely, since $`P(Y \leq k - 1 \mid X_1) \leq P(Y \leq k \mid X_1)`$, it follows that
\begin{equation}
\label{compk}
P(D_{(k)} \geq \varepsilon \mid X_1) \leq P(D_{(k+1)} \geq \varepsilon \mid X_1).
\end{equation}The above inequality implies that the expected distance between $`X_1`$ and its $`k`$-th nearest neighbor $`X_{1,(k)}`$ increases with $`k`$. Since the synthetic sample $`Z`$ is generated between $`X_1`$ and $`X_{1,(k)}`$, a larger $`k`$ results in $`Z`$ being farther from $`X_1`$. To illustrate this effect, we compare the distribution of $`Z`$ to that of $`X`$ for various values of $`k`$.
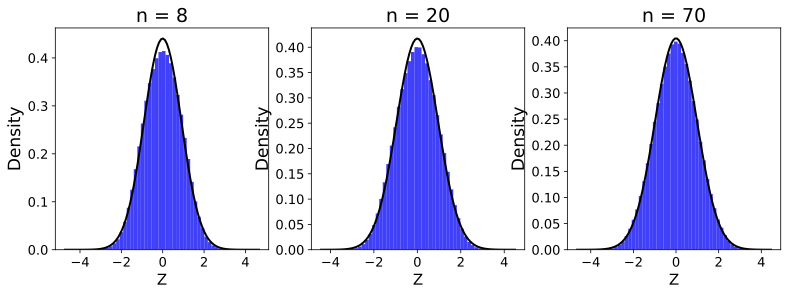
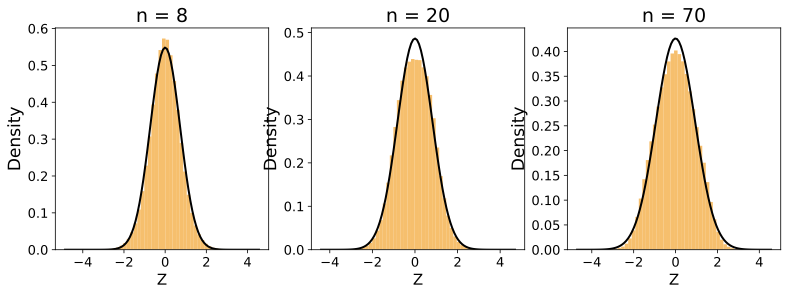
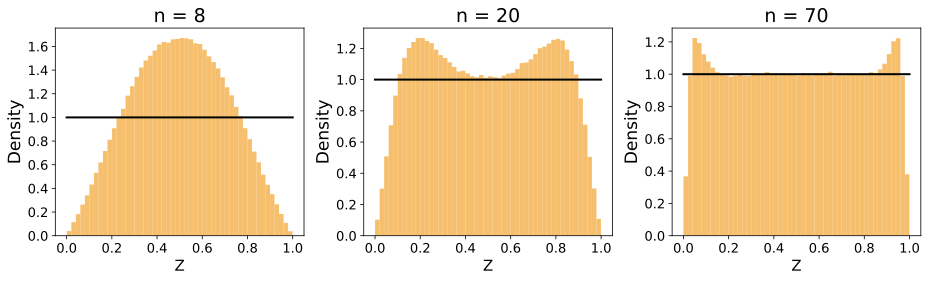
Figure 5 displays the distribution of $`Z`$ simulated for sample sizes $`n = 8, 20, 70`$ based on the uniform random variable $`X \sim U(0,1)`$. In Figure 3, we used the nearest neighbor of rank $`k=1`$, whereas in Figure 4, we used $`k=5`$. As shown in the figures, for both $`k=1`$ and $`k=5`$, the distribution of $`Z`$ converges to that of $`X`$ as $`n`$ increases. However, the convergence is significantly faster in the case of $`k=1`$ compared to $`k=5`$, especially for lower values of $`n`$.
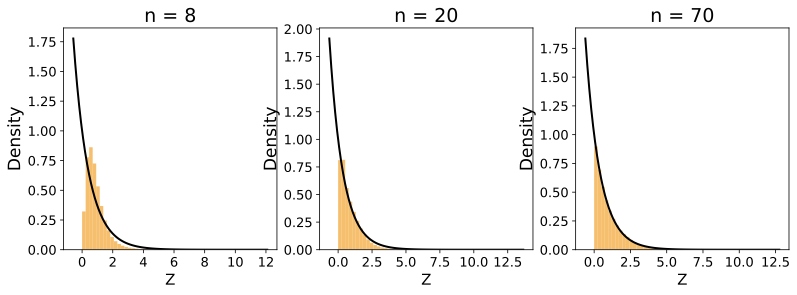
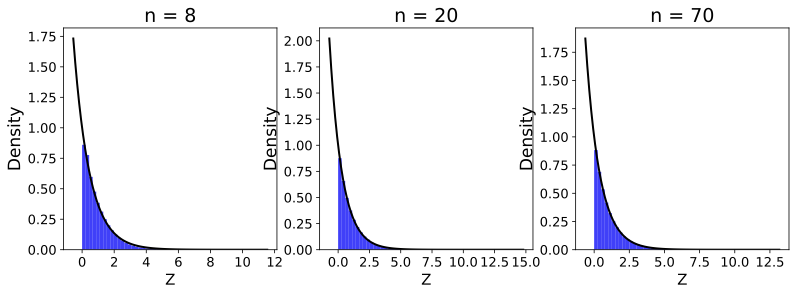
Similarly, we have conducted simulations using Gaussian ($`X \sim \mathcal{N}(0,1)`$) and exponential ($`X \sim \mathrm{Exp}(1)`$) random variables. The results, presented in Figure 8, show that the distribution of $`Z`$ approaches to the original distribution $`X`$ faster for $`k=1`$ than for $`k=5`$.
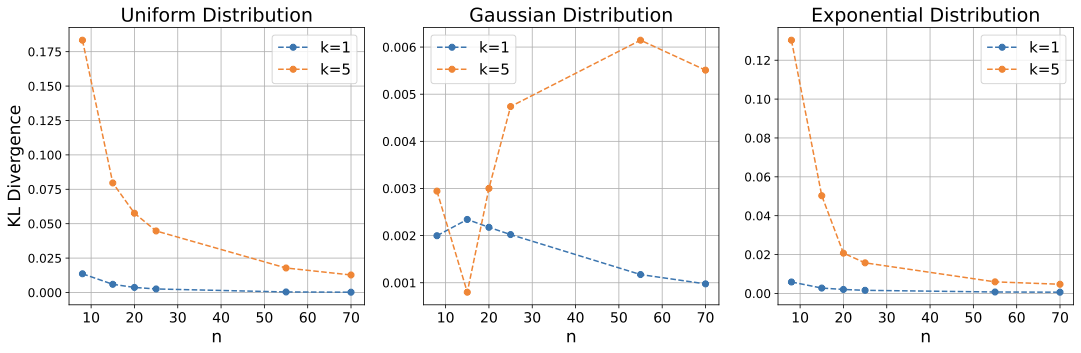
To further assess the rate of convergence of the synthetic sample $`Z`$ to the original distribution $`X`$, we calculated the Kullback-Leibler (KL) divergence between the simulated distribution of $`Z`$ and the theoretical distribution of $`X`$ for nearest neighbor ranks $`k = 1`$ and $`k = 5`$ over a range of sample sizes $`n`$. As illustrated in Figure 12, the KL divergence for both the uniform and Gaussian random variables decreases to zero as the sample size $`n`$ increases. Notably, the KL divergence is consistently smaller for $`k = 1`$ than for $`k = 5`$ across all values of $`n`$, particularly for smaller sample sizes. In the case of the exponential random variable, the KL divergence for $`k = 1`$ approaches zero, whereas for $`k = 5`$, it initially increases before starting to decrease around $`n = 55`$.
Conclusion
In this study, we conducted a thorough theoretical examination of the convergence behavior of the SMOTE algorithm. Our analysis demonstrated that the synthetic samples $`Z`$ generated by SMOTE converge in probability to the original data distribution $`X`$. In addition, under the assumption of compact support for $`X`$, we established that $`Z`$ also converges to $`X`$ in mean, providing a stronger form of convergence. Thus, our results offer a theoretical validation that the SMOTE algorithm accurately approximates the original data distribution for large sample sizes.
The practical implications of our findings are significant for those applying SMOTE to address imbalanced data challenges. Our main results provide theoretical support to the validity of SMOTE, allowing researchers and practitioners to use the SMOTE algorithm with confidence. By recommending smaller $`k`$ values, our work provides actionable guidance that can lead to more accurate and representative synthetic samples, thereby improving the performance and fairness of machine learning models in critical applications such as healthcare, finance, and security. Additionally, similar techniques can be applied to analyze convergence in higher dimensions. Future research could extend the theoretical framework to other data augmentation techniques, further enhancing our understanding and application of methods for handling imbalanced data.
34
Thabtah, F., Hammoud, S., Kamalov, F., & Gonsalves, A. (2020). Data imbalance in classification: Experimental evaluation. Information Sciences, 513, 429-441. https://doi.org/10.1016/j.ins.2019.11.004
Khushi, M., Shaukat, K., Alam, T. M., Hameed, I. A., Uddin, S., Luo, S., … & Reyes, M. C. (2021). A comparative performance analysis of data resampling methods on imbalance medical data. IEEE Access, 9, 109960-109975. https://doi.org/10.1109/ACCESS.2021.3102399
Kuang, J., Xu, G., Tao, T., & Wu, Q. (2021). Class-imbalance adversarial transfer learning network for cross-domain fault diagnosis with imbalanced data. IEEE Transactions on Instrumentation and Measurement, 71, 1-11. https://doi.org/10.1109/TIM.2021.3136175
Ding, H., Sun, Y., Huang, N., Shen, Z., & Cui, X. (2023). TMG-GAN: Generative adversarial networks-based imbalanced learning for network intrusion detection. IEEE Transactions on Information Forensics and Security, 19, 1156-1167. https://doi.org/10.1109/TIFS.2023.3331240
Li, X., Li, X., Li, Z., Xiong, X., Khyam, M. O., & Sun, C. (2021). Robust vehicle detection in high-resolution aerial images with imbalanced data. IEEE Transactions on Artificial Intelligence, 2(3), 238-250. https://doi.org/10.1109/TAI.2021.3081057
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321–357. https://doi.org/10.1613/jair.953
Dablain, D., Krawczyk, B., & Chawla, N. V. (2022). DeepSMOTE: Fusing deep learning and SMOTE for imbalanced data. IEEE Transactions on Neural Networks and Learning Systems, 34(9), 6390-6404. https://doi.org/10.1109/TNNLS.2021.3136503
Wang, L., Han, M., Li, X., Zhang, N., & Cheng, H. (2021). Review of classification methods on unbalanced data sets. IEEE Access, 9, 64606-64628. https://doi.org/10.1109/ACCESS.2021.3074243
Xie, Y., Qiu, M., Zhang, H., Peng, L., & Chen, Z. (2020). Gaussian distribution based oversampling for imbalanced data classification. IEEE Transactions on Knowledge and Data Engineering, 34(2), 667-679. https://doi.org/10.1109/TKDE.2020.2985965
Liu, Y., Liu, Y., Bruce, X. B., Zhong, S., & Hu, Z. (2023). Noise-robust oversampling for imbalanced data classification. Pattern Recognition, 133, 109008. https://doi.org/10.1016/j.patcog.2022.109008
He, H., Bai, Y., Garcia, E. A., & Li, S. (2008, June). ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence) (pp. 1322-1328). IEEE. https://doi.org/10.1109/IJCNN.2008.4633969
Han, H., Wang, W. Y., & Mao, B. H. (2005, August). Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing (pp. 878-887). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/11538059_91
Nguyen, H. M., Cooper, E. W., & Kamei, K. (2011). Borderline over-sampling for imbalanced data classification. International Journal of Knowledge Engineering and Soft Data Paradigms, 3(1), 4-21. https://doi.org/10.1504/IJKESDP.2011.039875
Bao, Y., & Yang, S. (2023). Two novel SMOTE methods for solving imbalanced classification problems. IEEE Access, 11, 5816-5823. https://doi.org/10.1109/ACCESS.2023.3236794
Liu, D., Zhong, S., Lin, L., Zhao, M., Fu, X., & Liu, X. (2023). Deep attention SMOTE: Data augmentation with a learnable interpolation factor for imbalanced anomaly detection of gas turbines. Computers in Industry, 151, 103972. https://doi.org/10.1016/j.compind.2023.103972
King, G., & Zeng, L. (2001). Logistic regression in rare events data. Political Analysis, 9(2), 137-163. https://doi.org/10.1093/oxfordjournals.pan.a004868
Elreedy, D., & Atiya, A. F. (2019). A comprehensive analysis of synthetic minority oversampling technique (SMOTE) for handling class imbalance. Information Sciences, 505, 32-64. https://doi.org/10.1016/j.ins.2019.07.070
Elreedy, D., Atiya, A. F., & Kamalov, F. (2024). A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Machine Learning, 113(7), 4903-4923. https://doi.org/10.1007/s10994-022-06296-4
Sakho, A., Scornet, E., & Malherbe, E. (2024). Theoretical and experimental study of SMOTE: limitations and comparisons of rebalancing strategies. https://doi.org/10.48550/arXiv.2402.03819
Kamalov, F. (2024). Asymptotic behavior of SMOTE-generated samples using order statistics. Gulf Journal of Mathematics, 17(2), 327-336. https://doi.org/10.56947/gjom.v17i2.2343
Vito, S. (2008). Air Quality [Dataset]. UCI Machine Learning Repository. https://doi.org/10.24432/C59K5F
Pace, R. K., & Barry, R. (1997). Sparse spatial autoregressions. Statistics & Probability Letters, 33(3), 291–297. https://doi.org/10.1016/S0167-7152(96)00140-X
📊 논문 시각자료 (Figures)