CNC-TP Classifier Nominal Concept Based on Top-Relevant Attributes
📝 Original Paper Info
- Title: CNC-TP Classifier Nominal Concept Based on Top-Pertinent Attributes- ArXiv ID: 2601.01976
- Date: 2026-01-05
- Authors: Yasmine Souissi, Fabrice Boissier, Nida Meddouri
📝 Abstract
Knowledge Discovery in Databases (KDD) aims to exploit the vast amounts of data generated daily across various domains of computer applications. Its objective is to extract hidden and meaningful knowledge from datasets through a structured process comprising several key steps: data selection, preprocessing, transformation, data mining, and visualization. Among the core data mining techniques are classification and clustering. Classification involves predicting the class of new instances using a classifier trained on labeled data. Several approaches have been proposed in the literature, including Decision Tree Induction, Bayesian classifiers, Nearest Neighbor search, Neural Networks, Support Vector Machines, and Formal Concept Analysis (FCA). The last one is recognized as an effective approach for interpretable and explainable learning. It is grounded in the mathematical structure of the concept lattice, which enables the generation of formal concepts and the discovery of hidden relationships among them. In this paper, we present a state-of-theart review of FCA-based classifiers. We explore various methods for computing closure operators from nominal data and introduce a novel approach for constructing a partial concept lattice that focuses on the most relevant concepts. Experimental results are provided to demonstrate the efficiency of the proposed method.💡 Summary & Analysis
1. **New Attribute Selection Strategy**: CNC-TP uses the Gain Ratio to select the most important attributes, reducing noise and improving classification accuracy. This is like fishing in a pool where you only target the most active fish for more effective catches. 2. **Balancing Complexity and Performance**: By offering fast learning times and concise models even with complex datasets, CNC-TP enhances both classification accuracy and computational efficiency. It’s akin to optimizing a car for maximum fuel efficiency and speed simultaneously, achieving balance between complexity and performance. 3. **Maintaining Interpretability**: Selecting the most relevant attributes ensures that the model remains interpretable, making the decision-making process transparent for users. This is similar to simplifying a recipe by highlighting only key ingredients and steps, ensuring ease of understanding.📄 Full Paper Content (ArXiv Source)
Artificial Intelligence, Data Mining, Machine Learning, Formal Concept Analysis, Classification.
Introduction
Classification based on Formal Concept Analysis (FCA) is a machine learning approach that leverages rule induction to construct classifiers. It is grounded in the mathematical framework of formal contexts, Galois connections, and concept lattices, which are used to derive classification rules from data.
Several FCA-based classification methods have been proposed recently, including CNC (Classifier Nominal Concept) , CpNC_CORV (Classifier pertinent Nominal Concept based on Closure Operator for Relevant-Values) , DFC (Dagging Formal Concept) , NextPriorityConcept , and Adapted SAMME Boosting . Despite their contributions, these methods face several challenges, such as high error and rejection rates, as well as overfitting.
Furthermore, the exhaustive construction of all formal concepts can be computationally intensive and often lacks contextual relevance. There is also a notable absence of adaptive strategies for selecting the most pertinent concepts . To address these limitations, various enhancements have been explored, including ensemble learning techniques and pattern structures . However, the quality of the generated concepts used for classification remains an under-explored aspect.
In this work, we propose an enhancement of the CNC method by introducing a novel strategy for selecting relevant attributes and constructing classifiers based on formal concepts. Section 2 introduces the fundamentals of Formal Concept Analysis. Section 3 reviews recent FCA-based classification methods. Section 4 presents our proposed method, CNC-TP. Section 5 details the experimental evaluation of our approach. Finally, Section 6 concludes the paper with a summary and perspectives for future work.
Formal Concept Analysis
Formal Concept Analysis (FCA) is a mathematical framework rooted in lattice theory and propositional logic. It is used to extract conceptual structures from data by identifying and organizing formal concepts into a concept lattice. FCA operates on a formal context, which represents the relationships between a set of objects (instances) and a set of attributes. To illustrate this, we draw inspiration from the well-known weather.symbolic dataset, which describes meteorological conditions and the decision of whether to play outside. Table 1 presents an example of a formal and nominal context, containing the first seven instances of the weather.symbolic dataset.
| ID | Outlook | Temperature | Humidity | Windy | Play |
|---|---|---|---|---|---|
| 1 | sunny | hot | high | FALSE | no |
| 2 | sunny | hot | high | TRUE | no |
| 3 | overcast | hot | high | FALSE | yes |
| 4 | rainy | mild | high | FALSE | yes |
| 5 | rainy | cool | normal | FALSE | yes |
| 6 | rainy | cool | normal | TRUE | no |
| 7 | overcast | cool | normal | TRUE | yes |
Subset of the weather.symbolic data-set (7 first instances)
The symbolic (nominal) dataset is transformed into a binary formal context, where each attribute–value pair is represented as a distinct binary feature. The resulting binary context is presented in Table 2. Table 3 provides the mapping between each binary attribute $`a_i`$ and its corresponding attribute–value pair from the original symbolic dataset.
| ID | $`a_1`$ | $`a_2`$ | $`a_3`$ | $`a_4`$ | $`a_5`$ | $`a_6`$ | $`a_7`$ | $`a_8`$ | $`a_9`$ |
|---|---|---|---|---|---|---|---|---|---|
| $`i_1`$ | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| $`i_2`$ | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| $`i_3`$ | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| $`i_4`$ | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| $`i_5`$ | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| $`i_6`$ | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
| $`i_7`$ | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
Example of formal and binary context from Table 1 .
| Binary Attribute | Description |
|---|---|
| $`a_1`$ | Outlook = sunny |
| $`a_2`$ | Outlook = overcast |
| $`a_3`$ | Outlook = rainy |
| $`a_4`$ | Temperature = hot |
| $`a_5`$ | Temperature = mild |
| $`a_6`$ | Temperature = cool |
| $`a_7`$ | Humidity = high |
| $`a_8`$ | Humidity = normal |
| $`a_9`$ | Windy = TRUE |
Signification of binary attributes from previous binary context
We define the formal context as a triplet $`\langle I, A, R \rangle`$, where:
-
$`I = \{i_1, i_2, \dots, i_7\}`$ is the set of objects (instances),
-
$`A = \{a_1, a_2, \dots, a_9\}`$ is the set of binary attributes (e.g., $`a_1`$: outlook = sunny, $`a_4`$: temperature = hot, …),
-
$`R \subseteq I \times A`$ is the binary relation such that $`R(i_k, a_l) = 1`$ if instance $`i_k`$ possesses attribute $`a_l`$.
Two operators define the Galois connection:
-
$`\varphi(X) = \{ a \in A \mid \forall i \in X, (i, a) \in R \}`$: attributes common to all objects in $`X`$,
-
$`\delta(Y) = \{ i \in I \mid \forall a \in Y, (i, a) \in R \}`$: objects sharing all attributes in $`Y`$.
These operators allow us to compute the closures:
X" = \delta(\varphi(X)), \quad Y" = \varphi(\delta(Y))A formal concept is a pair $`(X, Y)`$ such that $`\varphi(X) = Y`$ and $`\delta(Y) = X`$.
For example, if $`X = \{i_1, i_2\}`$ then:
\varphi(X) = \{a_1, a_4, a_7\}, \quad \delta(\{a_1, a_4, a_7\}) = \{i_1, i_2\}So, $`(\{i_1, i_2\}, \{a_1, a_4, a_7\})`$ is a formal concept.
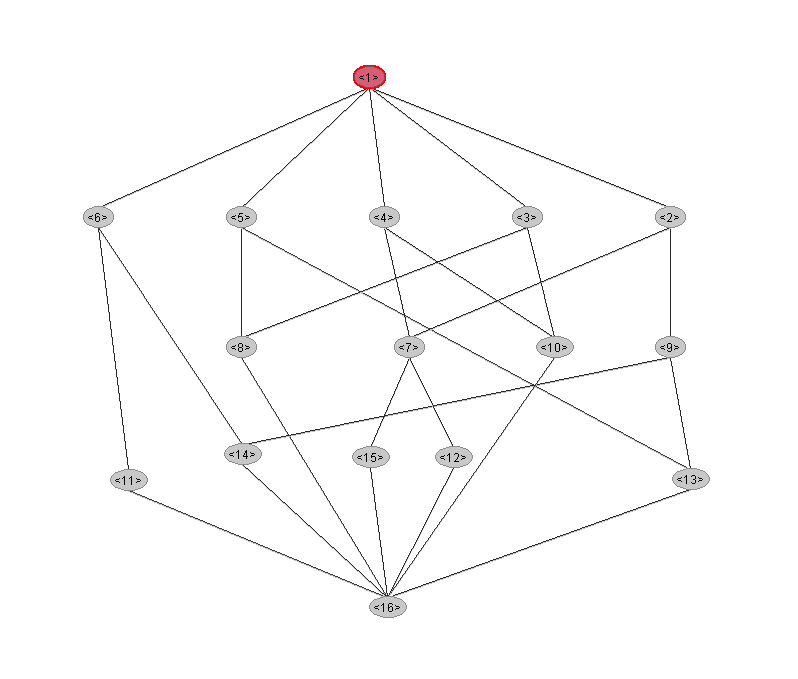
These concepts can be organized into a lattice structure, where each node represents a concept and edges define the partial order based on set inclusion. This hierarchical structure reveals how concepts are related through shared attributes and objects, and highlights generalization–specialization relationships. Figure 1 shows the concept lattice derived from the weather.symbolic formal context using the Galicia tool1 . This lattice serves as a foundation for many FCA-based applications, including rule extraction and classification.
State of the Art for Classification Based on Formal Concept Analysis
Formal Concept Analysis (FCA) has attracted growing interest across various domains due to its ability to extract structured knowledge from binary and nominal data. This section reviews significant contributions that demonstrate how FCA has been applied to real-world classification problems. We focus particularly on FCA-based classifiers designed to handle nominal data, highlighting their strengths, limitations, and recent improvements. These works underscore both the versatility of FCA in data analysis and the ongoing efforts to enhance its scalability and interpretability for complex datasets.
In , the authors propose a method for generating formal concepts from empirical data by combining classical (a posteriori) approaches, such as traditional FCA, with non-classical (a priori) methodologies like the System of Measured Properties (SMP). The study also addresses the challenge of incomplete and inconsistent data using multi-valued logic. The authors conclude that both methodologies are essential for deriving meaningful formal concepts, and emphasize the importance of normalizing the formal context when dealing with multi-valued logic.
The work in introduces a novel approach for extracting pertinent concepts from nominal data using closure operators derived from Galois connections. The authors propose and evaluate four classification methods: CpNC_COMV (Closure Operator for Multi-Values), CpNC_CORV (Closure Operator for Relevant-Values), CaNC_COMV, and CaNC_CORV. Experimental results demonstrate that CpNC_CORV outperforms the others in terms of classification accuracy.
In , the authors propose a method for constructing only a subset of the concept lattice, focusing on the most relevant concepts. They introduce the DNC (Dagging Nominal Concept) classifier, which leverages the Dagging technique to create ensembles of FCA-based classifiers. The study shows that parallel learning significantly improves performance compared to single classifiers. While this approach reduces computational complexity, it may also lead to information loss by omitting less prominent concepts, potentially affecting classification precision.
The NextPriorityConcept algorithm, introduced in , uses priority queues and filtering strategies to compute concepts efficiently. It treats all data uniformly by converting them into logical predicates, making it format-independent. However, the algorithm may face scalability issues when applied to large or highly complex datasets due to exponential growth in computational complexity.
In another contribution from , the authors explore ensemble methods to enhance lazy classification using pattern structures. While pattern structures offer interpretable models, they often underperform compared to traditional ensemble techniques. To address this, the authors adapt the SAMME boosting algorithm to pattern structures and investigate various aggregation functions and weighting schemes. Their work demonstrates that it is possible to improve predictive accuracy without compromising interpretability.
Finally, in , FCA is applied to corpus visualization as an alternative to traditional topic modeling techniques. The study shows that FCA can effectively visualize keywords and document relevance, offering a promising alternative to Latent Dirichlet Allocation (LDA) for topic modeling and relevance analysis.
Despite the diversity and progress of FCA-based classification methods, several common limitations persist across the literature. First, many approaches suffer from high computational complexity due to the exhaustive generation of formal concepts, which becomes impractical for large or complex datasets. While some methods attempt to reduce this burden by constructing only a subset of the concept lattice, this often leads to a loss of potentially useful information, thereby affecting classification accuracy. Second, most existing techniques lack contextual adaptability, as they do not dynamically select the most relevant concepts based on the classification task. Third, handling nominal and multi-valued data remains a challenge, particularly during the transformation into binary contexts, which can introduce redundancy or information loss. Additionally, several methods exhibit high error or rejection rates, especially when the generated concepts are overly specific or insufficiently discriminative. Overfitting is another recurring issue, particularly in models that generate a large number of rules or concepts. Furthermore, few studies explicitly evaluate the quality or discriminative power of the concepts used for classification. Finally, although ensemble methods such as Dagging and SAMME Boosting have improved performance, they can compromise model interpretability—one of the core advantages of FCA.
Proposed Approach: CNC-TP
The previously reviewed studies demonstrate the adaptability and effectiveness of FCA in addressing various data types and classification challenges. From optimizing concept extraction to enhancing classifier performance through ensemble techniques and specialized measures, FCA continues to evolve as a powerful analytical framework. However, challenges remain—particularly in balancing computational complexity and classification precision when dealing with large-scale or multi-valued datasets. These insights motivate the development of more refined FCA-based classification methods, as proposed in this work.
Our proposed approach builds upon the Classifier Nominal Concept (CNC) , a classification method that leverages nominal attributes to induce decision rules. Starting from a nominal (multi-valued) context, CNC extracts the most pertinent nominal concepts by computing Galois connections (closure operators) on attributes that maximize Information Gain, thereby improving data separability. The primary objective of CNC is to reduce training time and complexity while ensuring the interpretability and explainability of the resulting model.
In this work, we introduce CNC-TP (CNC based on Top Pertinent attributes), a classification approach that enhances CNC by selecting the most informative attributes using the Gain Ratio measure. Unlike traditional FCA-based classifiers that consider all attributes or rely on fixed thresholds, CNC-TP dynamically selects a top-ranked subset of attributes based on their relevance. This strategy improves both the interpretability and performance of the classifier by reducing noise and focusing on the most discriminative patterns. The approach follows a structured pipeline: attribute ranking, formal concept extraction, and rule-based classification.
The core steps of CNC-TP involve selecting the most relevant attributes according to the Gain Ratio pertinence measure, followed by computing the Galois Connection to generate only the formal concepts derived from these attributes. Rather than retaining all attributes above a fixed threshold, CNC-TP selects the top-$`p\%`$ of attributes ranked by Gain Ratio, where $`p`$ is either user-defined or automatically determined by the classifier.
Classifier Construction
Algorithm [Algo_CNC_TP] outlines the construction process of the CNC-TP classifier. It begins by selecting the most relevant attributes using the Gain Ratio measure, then derives formal concepts based on these attributes, generates classification rules, and assigns a weight to each rule based on its coverage. Finally, the classifier uses a voting mechanism to predict the class of new instances.
Concept Extraction Strategies
CNC-TP supports two strategies for concept extraction:
-
Top-$`p\%`$ Attributes with All Values: Galois connections are computed for all values of the top-ranked attributes.
-
Top-$`p\%`$ Attributes with Relevant Values: Only the majority value of each selected attribute is considered for concept generation.
To identify the most informative attributes, we employ the Ratio Gain measure. As introduced in , the Ratio Gain is designed to mitigate the bias of the traditional Information Gain, which tends to favor attributes with a large number of distinct values. The Ratio Gain evaluates the usefulness of an attribute by considering both its information gain and the intrinsic information of its value distribution. It favors attributes that provide a balanced and meaningful partitioning of the data, penalizing overly specific or fragmented splits. This makes it particularly suitable for selecting attributes in FCA-based classification, where interpretability and generalization are key objectives.
First, the attributes are sorted in descending order according to their Gain Ratio (GR) values.
Concepts and Rules Generation
After selecting the most relevant attributes, the next step is to compute the Galois connection by identifying the set of instances associated with each attribute value. Then, the closure operator is applied to determine additional attributes that are common to all selected instances.
In our example, we extract concepts based on the values of the selected attribute outlook. For each value:
-
sunny: covers instances $`o_1`$ and $`o_2`$, both labeled no
$`\Rightarrow`$ Concept: $`[\{\textit{Outlook = sunny}\}, \{o_1, o_2\}]`$ -
overcast: covers instances $`o_3`$ and $`o_7`$, both labeled yes
$`\Rightarrow`$ Concept: $`[\{\textit{Outlook = overcast}\}, \{o_3, o_7\}]`$ -
rainy: covers instances $`o_4`$, $`o_5`$, and $`o_6`$; two labeled yes, one labeled no
$`\Rightarrow`$ Concept: $`[\{\textit{Outlook = rainy}\}, \{o_4, o_5, o_6\}]`$ (majority class: yes)
At the end of this step, we obtain a set of formal (nominal) concepts, each of which is used to generate a classification rule. Each rule consists of:
-
Premises: derived from the attribute–value pair(s) defining the concept.
-
Conclusion: the majority class among the instances covered by the concept.
-
Weight: the proportion of instances covered by the rule relative to the total dataset.
The resulting rules from our example are:
-
If Outlook = sunny then play = no (coverage: $`2/7`$)
-
If Outlook = overcast then play = yes (coverage: $`2/7`$)
-
If Outlook = rainy then play = yes (coverage: $`2/7`$)
Classification by CNC-TP
To classify a new instance, all applicable rules generated during the training phase are identified and evaluated. A weighted majority voting strategy is employed, where each rule contributes to the final decision proportionally to its coverage ratio. This ensures that rules covering a larger portion of the dataset have a stronger influence on the classification outcome.
A distinctive feature of the CNC-TP approach is its ability to reject classification for instances that are not covered by any rule. This mechanism prevents unreliable predictions and ensures that only confidently supported decisions are made, thereby enhancing the robustness of the classifier.
Experimentation
To evaluate the effectiveness of the proposed CNC-TP method, we conducted a series of experiments comparing its performance with other FCA-based and classical classification approaches across multiple benchmark datasets. The goal is to assess its accuracy, interpretability, and robustness under various data conditions. The CNC-TP method was implemented within the WEKA framework , and the source code is publicly available2 for reproducibility and further experimentation.
Experimental Protocol
In our experimental study, we adopted a 10-fold cross-validation strategy to evaluate the performance and generalization ability of the proposed CNC-TP classifier. According to , cross-validation is a widely used resampling technique that helps assess the robustness of predictive models and mitigate overfitting. In $`k`$-fold cross-validation, the dataset is partitioned into $`k`$ disjoint subsets (folds) of approximately equal size. The model is trained on $`k-1`$ folds and tested on the remaining fold. This process is repeated $`k`$ times, ensuring that each instance is used exactly once for validation. The final performance is computed as the average across all $`k`$ iterations.
In our case, we used $`k = 10`$, meaning that the dataset was divided into 10 folds. For each iteration, the model was trained on 9 folds and evaluated on the remaining one. This setup ensures a reliable and unbiased estimation of the classifier’s predictive performance.
To assess the effectiveness of CNC-TP, we employed a comprehensive set of evaluation metrics, covering both classification accuracy and error analysis, as well as probabilistic and ranking-based measures: Accuracy, Percent Incorrect, Percent Unclassified, Precision, Recall, F-Measure, Kappa, AUC-ROC, AUC-PRC, RMSE, MAE.
These metrics provide a multidimensional evaluation of the classifier’s performance, capturing not only its accuracy but also its reliability, robustness, and ability to handle uncertainty and class imbalance.
Data Sets
For our experimental evaluation, we selected 16 datasets from the UCI Machine Learning Repository, covering a wide range of domains and data characteristics. These datasets include both binary and multi-class classification tasks, and feature a mix of nominal, numeric, and symbolic attributes. Table [table:experimental_Datasets_extended] summarizes the key properties of each dataset, including the number of attributes and instances, class distribution, percentage of missing values, entropy, Gini index, and Palma ratio.
| Dataset | Attributes | Instances | Classes | % Missing | Entropy | Gini Index | Palma Ratio |
|---|---|---|---|---|---|---|---|
| Balance-scale | 5 | 625 | 3 | 0 | 1.318 | 0.5692 | 0.855 |
| Breast-cancer | 10 | 277 | 2 | 9 | 0.878 | 0.9412 | 3.519 |
| Contact-lenses | 5 | 24 | 3 | 0 | 1.326 | 0.9082 | 1.667 |
| Credit-rating | 16 | 653 | 2 | 67 | 0.991 | 0.9038 | 1.206 |
| Glass | 10 | 214 | 6 | 0 | 2.177 | 0.7367 | 0.55 |
| Heart-statlog | 14 | 270 | 2 | 0 | 0.991 | 0.4938 | 1.25 |
| Iris | 5 | 150 | 3 | 0 | 1.585 | 0.6667 | 0.5 |
| Iris-2D | 5 | 150 | 3 | 0 | 1.585 | 0.6667 | 0.5 |
| Labor-neg-data | 17 | 57 | 2 | 326 | 0.935 | 0.8642 | inf |
| Lupus | 4 | 87 | 2 | 0 | 0.972 | 0.4809 | 1.486 |
| Pima_diabetes | 9 | 768 | 2 | 24 | 0.933 | 0.4544 | 1.865 |
| Vowel | 14 | 990 | 11 | 0 | 3.459 | 0.9274 | 0.1 |
| Weather.numeric | 5 | 14 | 2 | 0 | 0.94 | 0.9106 | 1.8 |
| Weather.symbolic | 5 | 14 | 2 | 0 | 0.94 | 0.9106 | 1.8 |
| Wisconsin-breast-cancer | 10 | 683 | 2 | 16 | 0.929 | 0.455 | 1.857 |
| Zoo | 18 | 101 | 7 | 0 | 2.391 | 0.6034 | 0.683 |
The diversity of these datasets allows for a robust assessment of the proposed CNC-TP method under various conditions. For instance, datasets such as vowel, zoo, and glass present multi-class challenges, while others like lupus, heart-statlog, and pima_diabetes focus on binary classification. The presence of missing values in datasets such as labor-neg-data, credit-rating, and wisconsin-breast-cancer tests the classifier’s resilience to incomplete data.
The entropy and Gini index values provide insight into the class distribution and impurity of each dataset. Higher entropy (e.g., vowel: 3.459) indicates more evenly distributed classes, while lower values (e.g., lupus: 0.972) suggest class imbalance. Similarly, the Gini index reflects the heterogeneity of the data; values close to 1 (e.g., breast-cancer: 0.9412) indicate high impurity, which can complicate classification.
The Palma ratio, a measure of inequality adapted from economics, is used here to quantify the imbalance in attribute distributions. A low Palma ratio (e.g., vowel: 0.1) suggests uniform attribute distribution, while high values (e.g., breast-cancer: 3.519) indicate strong skewness, which may affect rule generation and classifier performance.
Overall, the selected datasets offer a comprehensive testbed for evaluating the adaptability, interpretability, and robustness of the CNC-TP classifier across diverse data scenarios.
CNC-TP-AV: Top Pertinent Attributes with All Values
In this experiment, we evaluate the performance of the CNC-TP classifier using the first concept extraction strategy described in Section 4.2, which selects the top-ranked attributes and considers all their values. The threshold for attribute selection is varied from 0.025 (2.5%) to 1.000 (100%) to identify the optimal value that yields the best classification performance.

As shown in Figure 2, the percentage of correctly classified instances increases steadily with the threshold, reaching a peak of 73.642% at a threshold of 0.775.
In contrast, the rates of incorrectly classified and unclassified instances both decrease as the threshold increases, reaching their minimum values at the same threshold. This indicates that a threshold of 0.775 offers an optimal trade-off between classification accuracy and rejection rate, maximizing the classifier’s effectiveness while minimizing uncertainty.

Figure 3 illustrates the performance of the CNC-TP classifier (variant CNC-TP-AV) using several evaluation metrics as the attribute selection threshold varies. The evolution of the F1-score is nearly linear and peaks around a threshold of 0.775, indicating a strong balance between precision and recall. This suggests that the classifier is not only accurate but also consistent in identifying both positive and negative instances. The Area Under the ROC Curve (AUC-ROC) value reaches 0.735 and the Area Under the Precision-Recall Curve (AUC-PRC) 0.745. These values confirm that CNC-TP-AV is a reliable learning model capable of effectively distinguishing between classes, including minority ones. Regarding error metrics, the Root Mean Squared Error (RMSE) reaches a value of 0.397, while the Mean Absolute Error (MAE) reaches 0.211. These results indicate that the model tends to minimize large prediction errors (RMSE) and maintains a low average error (MAE), reflecting both robustness and stability.
When comparing Figures 2 and 3, a notable performance shift is observed around the threshold value of 0.775. This threshold corresponds to the highest classification accuracy and the best trade-off between precision and recall, making it a strong candidate for the optimal configuration of the CNC-TP classifier.
CNC-TP-RV: Top Pertinent Attributes with Relevant Values
As a reminder, an alternative variant of the CNC-TP method is also possible. In this configuration, instead of computing the closure for all nominal values of a selected attribute, we focus only on the most relevant/frequent value. This strategy aims to reduce computational complexity while preserving classification effectiveness. In line with the previous experiment, we vary the attribute selection threshold from 0.025 (2.5%) to 1.000 (100%) to identify the optimal value that yields the best performance.
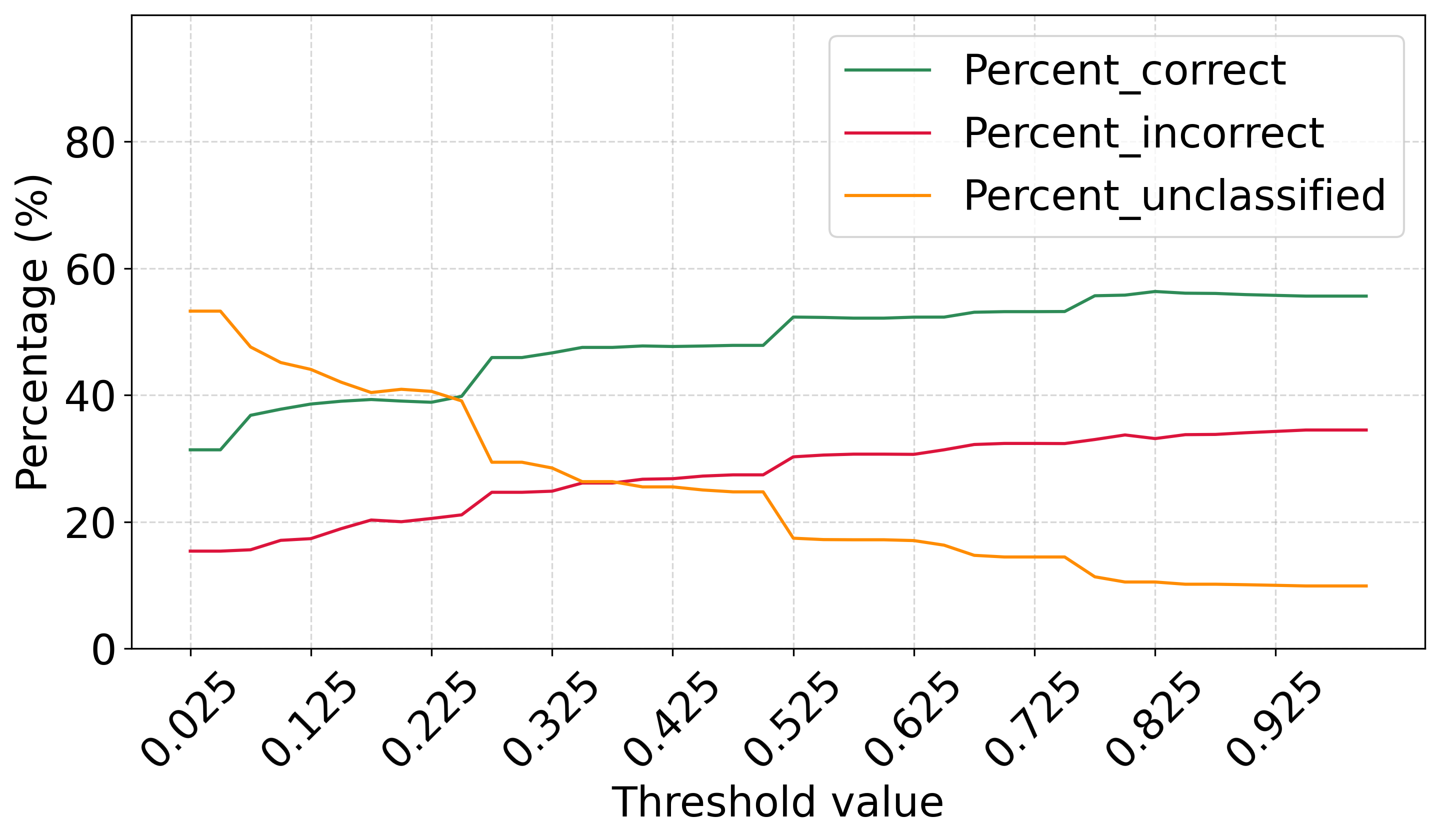
Figure 4 shows the evolution of classification performance for the CNC-TP-RV variant using the second strategy described in Section 4.2. As the threshold increases, the percentage of correctly classified instances rises, reaching a maximum of 55.684% at a threshold of 0.775. Similarly, the rate of incorrectly classified instances peaks at 32.993% at the same threshold. Notably, this variant achieves the lowest rejection rate (unclassified instances) at the threshold of 0.775, indicating that most instances are covered by at least one rule. However, the overall performance of CNC-TP-RV remains significantly lower than that of the previous variant (CNC-TP-AV), both in terms of accuracy and balance between precision and recall. These results suggest that while CNC-TP-RV offers computational advantages by simplifying concept generation, it may sacrifice classification quality. Therefore, its use should be considered in contexts where interpretability and efficiency are prioritized over predictive accuracy.

Figure 5 presents the evolution of various performance metrics for the CNC-TP-RV variant, as the attribute selection threshold increases. The F1-score shows a decreasing trend, dropping from 0.823 to 0.720. This indicates that the model struggles to maintain a good balance between precision and recall as the threshold increases, suggesting a degradation in classification quality. Similarly, both the Area Under the ROC Curve (AUC-ROC) and the Area Under the Precision-Recall Curve (AUC-PRC) decline, ranging between 0.560 and 0.603. These values are relatively low, and the proximity of AUC-ROC to 0.5 suggests that the model performs only marginally better than random guessing in some configurations. The Root Mean Squared Error (RMSE) varies between 0.40 and 0.487, while the Mean Absolute Error (MAE) ranges from 0.209 to 0.279. These results indicate that although the model maintains a moderate level of error control, it does not compensate for the overall drop in classification performance.
Comparing Figures 2 and 3, we observe that performance metrics tend to stabilize once the threshold exceeds 0.775. However, the overall performance of this variant remains inferior to the one presented in the previous section. Based on these findings, we choose to continue the experimental evaluation using the CNC-TP variant that computes closures for All Values of attributes whose pertinence exceeds the threshold of 0.775, as it consistently delivers better classification results.
CNC-TP Compared to Other Classifiers
Since the proposed CNC-TP method generates classification rules, we begin by comparing it with several well-known rule-based classifiers from the literature. These include: ConjunctiveRule , DTNB , DecisionTable , FURIA , JRip , NNge , OLM , OneR , PART , Ridor , RoughSet , and ZeroR .
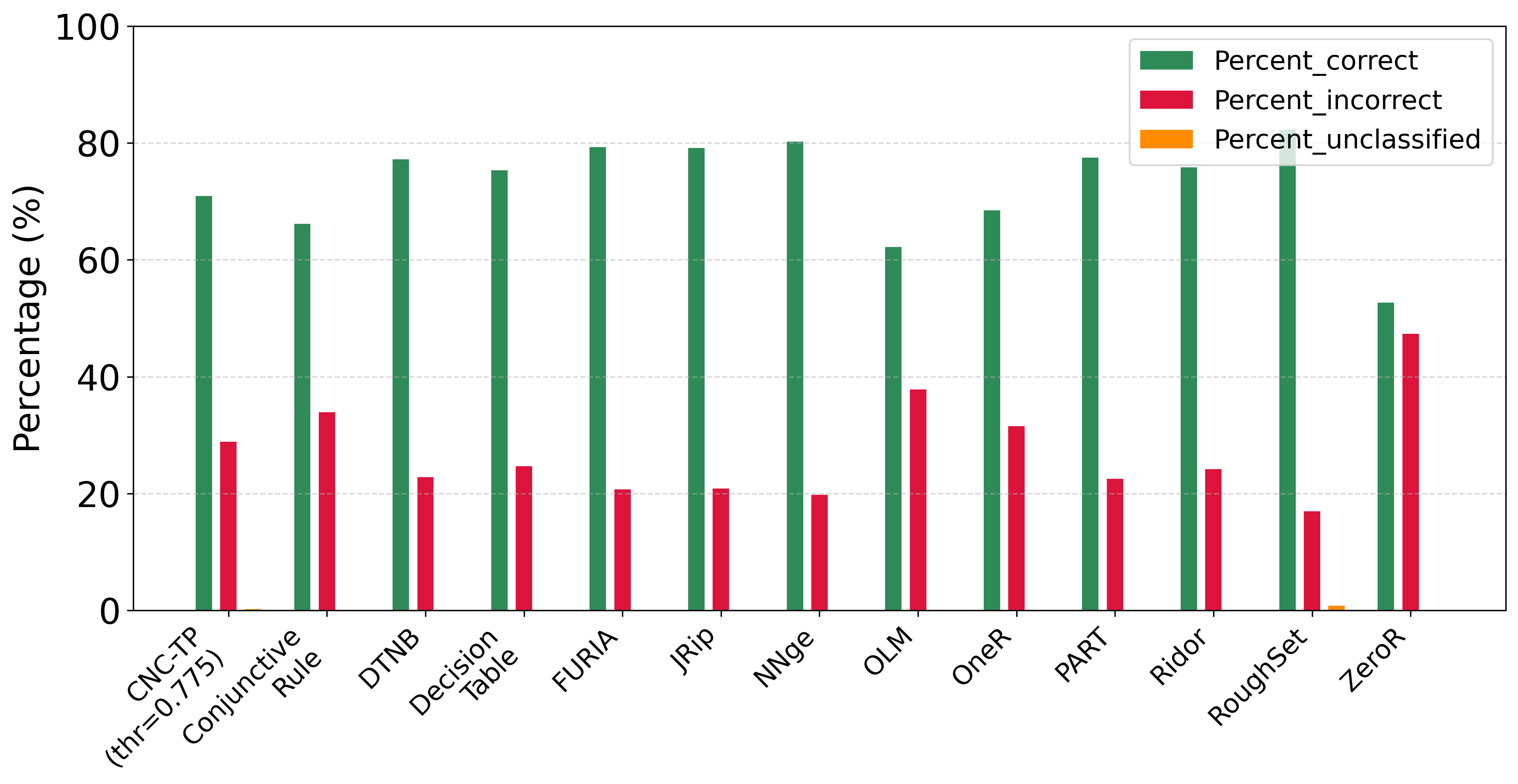
As shown in Figure 6, CNC-TP demonstrates a lower rejection rate compared to RoughSet, and outperforms ConjunctiveRule, OLM, OneR, and ZeroR in terms of classification accuracy. Furthermore, its performance is comparable to more advanced rule-based classifiers such as DTNB, DecisionTable, FURIA, NNge, PART, and Ridor.
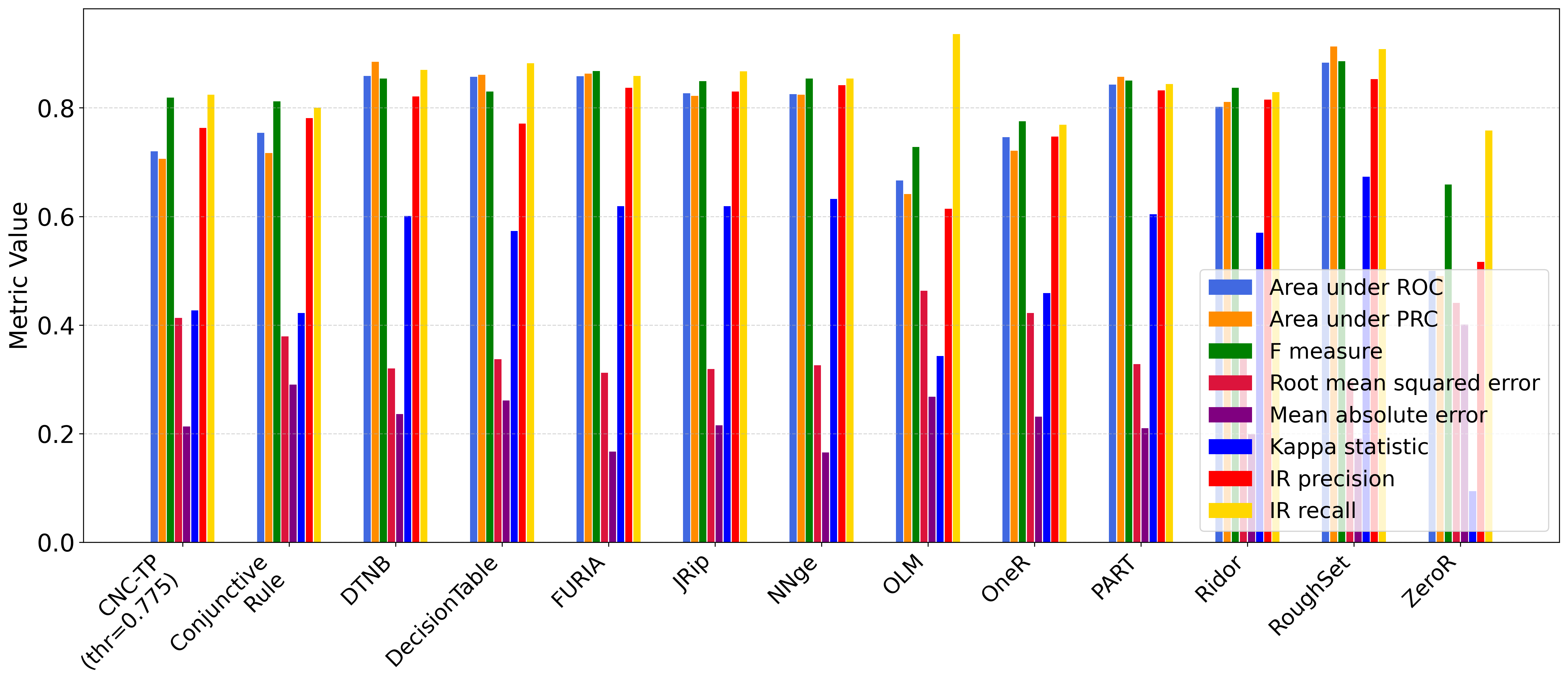
Figure 7 further highlights the strengths of CNC-TP. It achieves one of the highest F1-scores, close to 1, indicating an excellent balance between precision and recall. Both precision and recall values are around 0.8, suggesting that CNC-TP produces few false positives while successfully identifying most positive instances.
Regarding the Kappa statistic, CNC-TP ranks in the mid-range among the compared classifiers. While RoughSet achieves the highest Kappa value (0.673), and OLM the lowest (0.343), CNC-TP maintains a solid agreement between predictions and actual labels. Notably, ZeroR stands out with a near-zero Kappa, reflecting its inability to capture any meaningful classification pattern.
Overall, CNC-TP proves to be a competitive rule-based classifier, offering a strong compromise between interpretability, accuracy, and robustness. Its performance is on par with or superior to several established methods, making it a viable alternative for interpretable machine learning tasks.
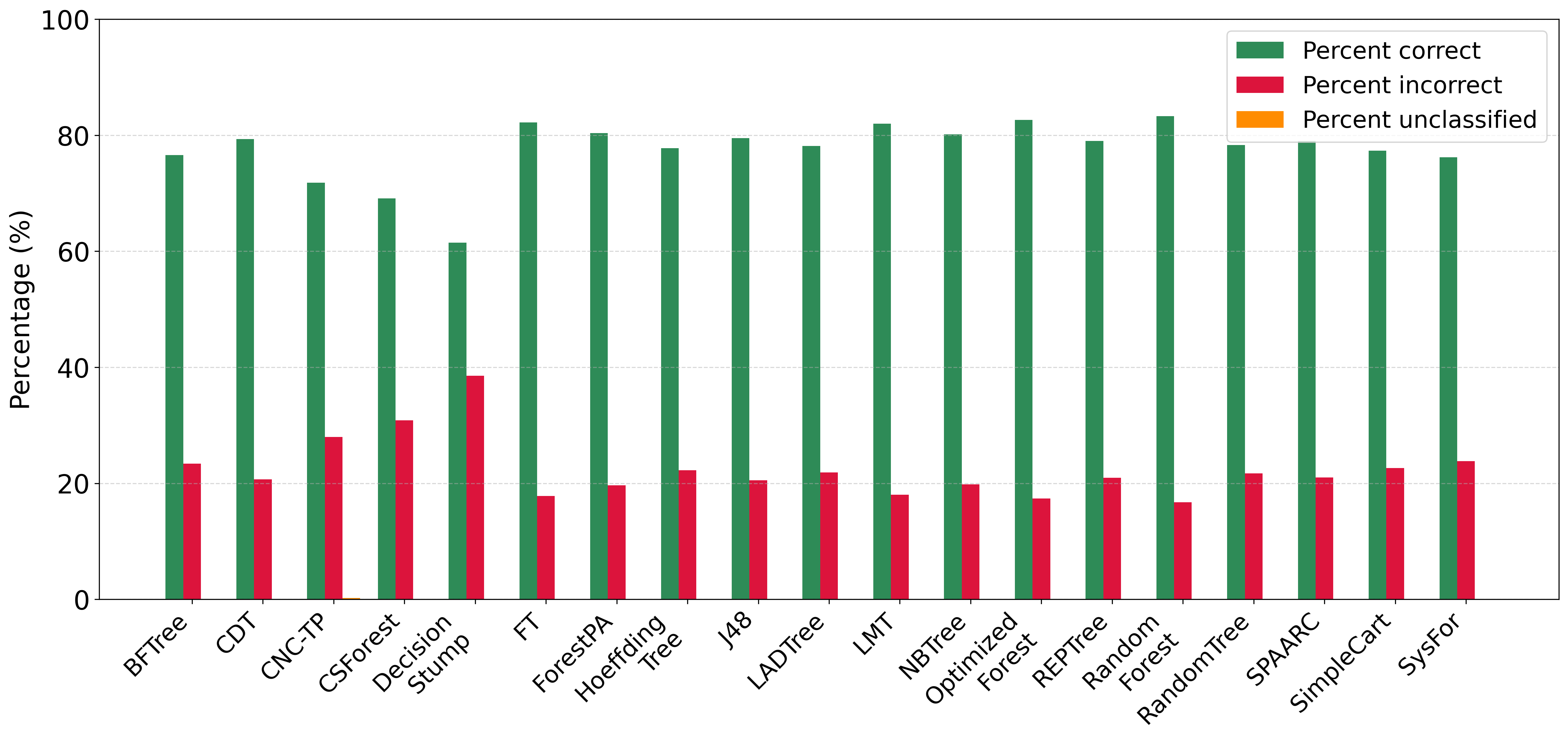
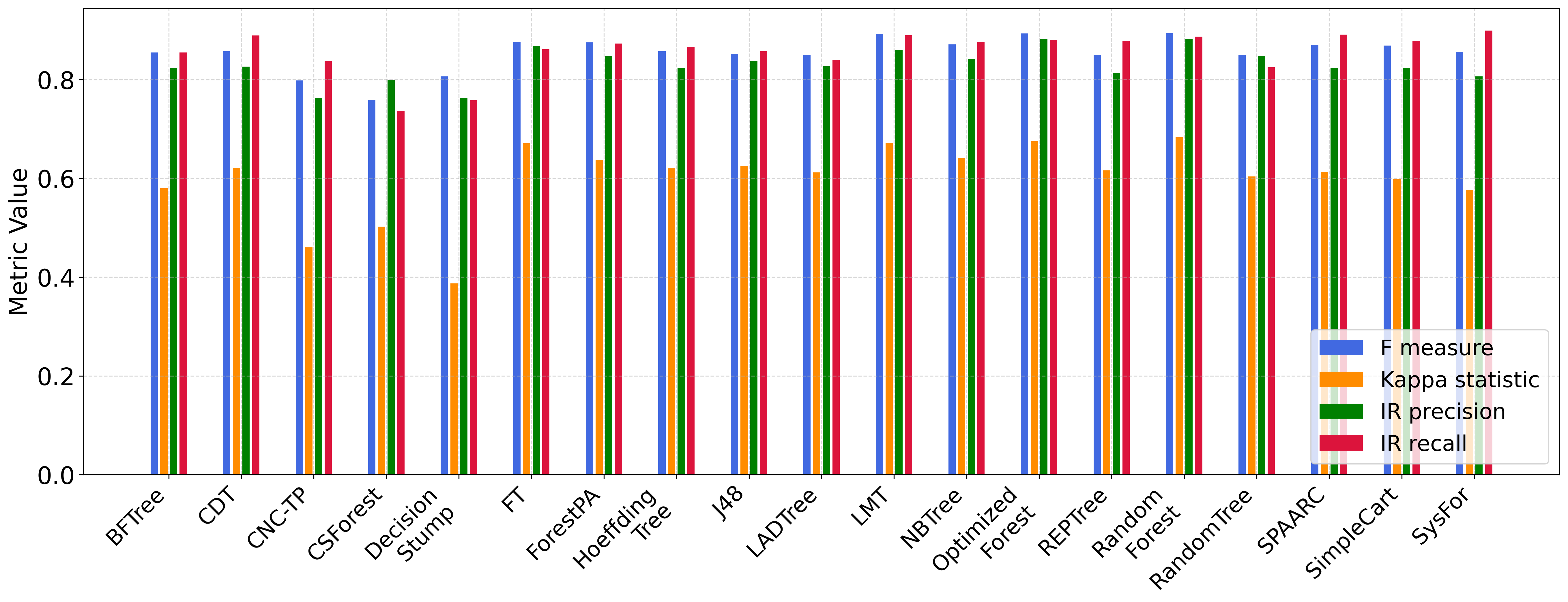
In the continuation of our experiments, we compare CNC-TP with a set of interpretable and explainable classifiers based on decision trees. These include: BFTree, CDT, CSForest, DecisionStump, FT, ForestPA, HoeffdingTree, J48, LADTree, LMT, NBTree, OptimizedForest, REPTree, RandomForest, RandomTree, SPAARC, SimpleCart, and SysFor. According to Figures 8 and 9, CNC-TP demonstrates globally competitive performance. It achieves classification accuracy and F-measure values comparable to, and in some cases better than, several tree-based methods such as CSForest and DecisionStump. Moreover, CNC-TP maintains a relatively low rejection rate while preserving a strong balance between precision and recall.
These results confirm that CNC-TP is not only interpretable and rule-based, but also competitive with state-of-the-art decision tree classifiers in terms of predictive performance. This makes it a promising alternative for applications requiring both transparency and accuracy.
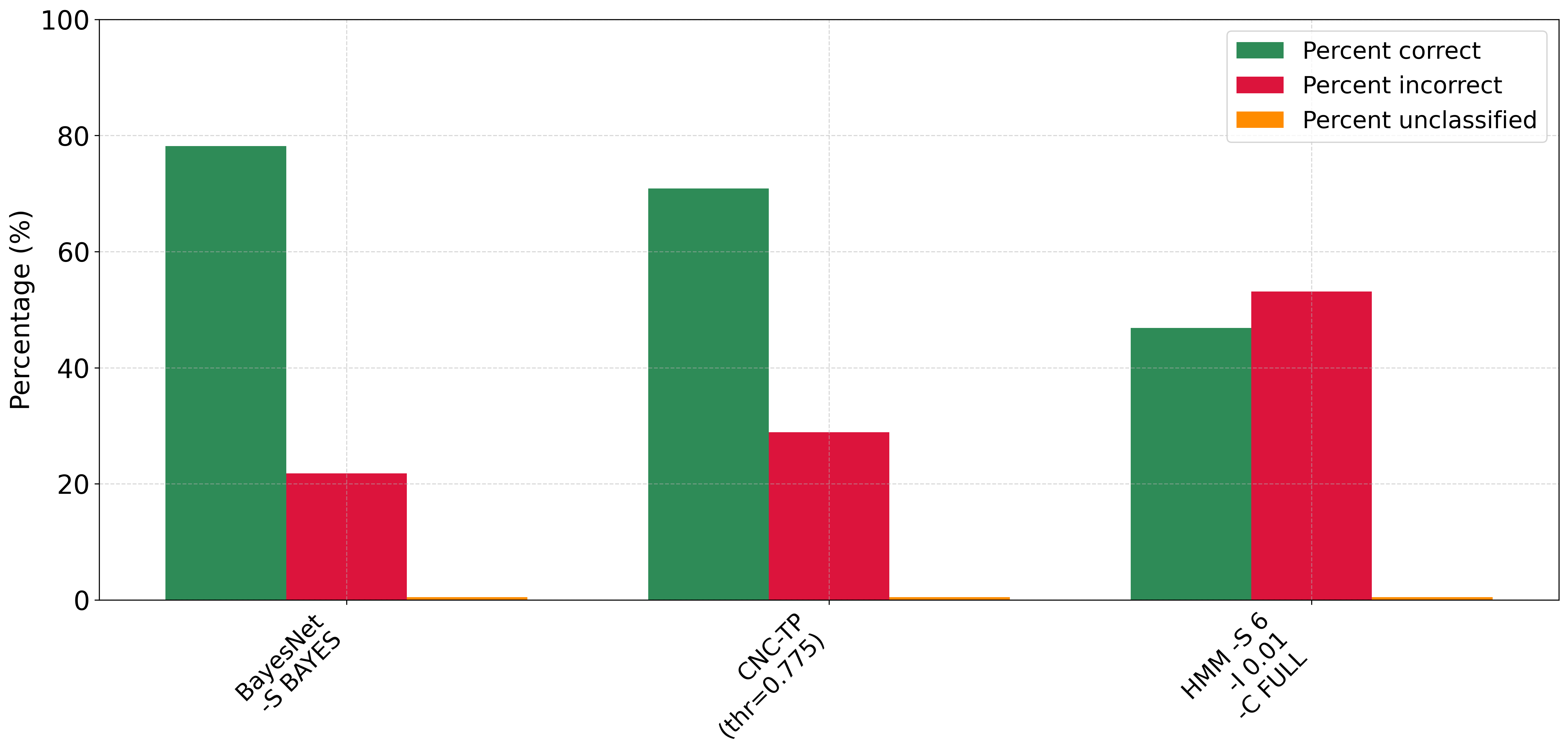
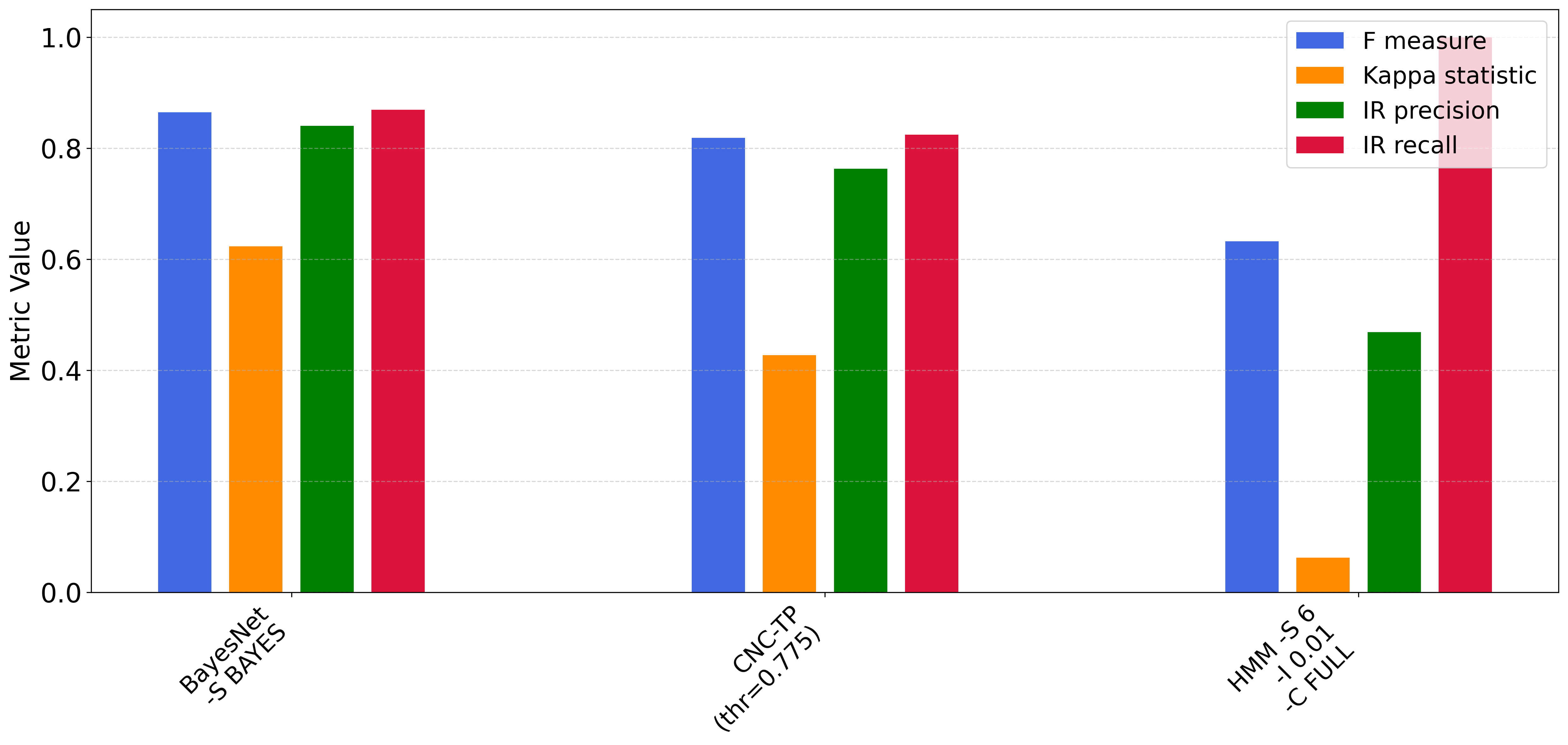
In the next part of our experimental study, we compare CNC-TP with two well-known Bayesian classifiers: BayesNet and HMM (Hidden Markov Model) . As shown in Figure 10, CNC-TP achieves a higher classification accuracy than HMM and performs comparably to BayesNet. It also maintains a lower rejection rate than both Bayesian methods, indicating better rule coverage and generalization. Figure 11 provides further insights. CNC-TP achieves precision, recall, and F1-score values close to those of BayesNet, confirming its ability to balance false positives and false negatives effectively. However, CNC-TP shows slightly lower performance in terms of the Kappa statistic, suggesting a slightly weaker agreement between predicted and actual labels compared to BayesNet. HMM, on the other hand, exhibits relatively low precision, F1-score, and Kappa values, despite achieving a higher recall. This indicates that while HMM is sensitive to positive instances, it tends to produce more false positives and lacks overall predictive reliability. In summary, CNC-TP proves to be a competitive alternative to probabilistic classifiers, offering comparable performance to BayesNet while maintaining the advantages of interpretability and rule-based reasoning.
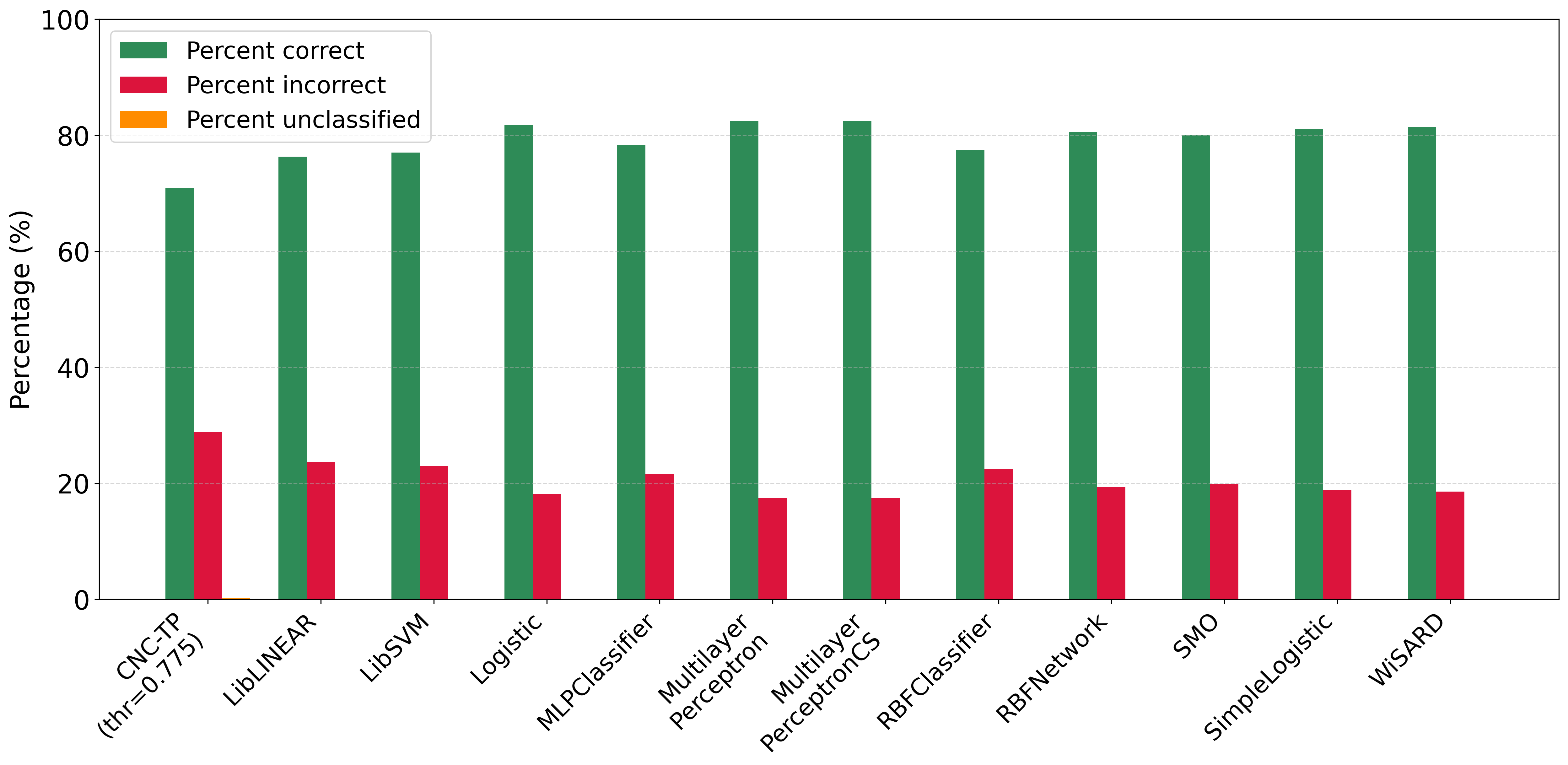
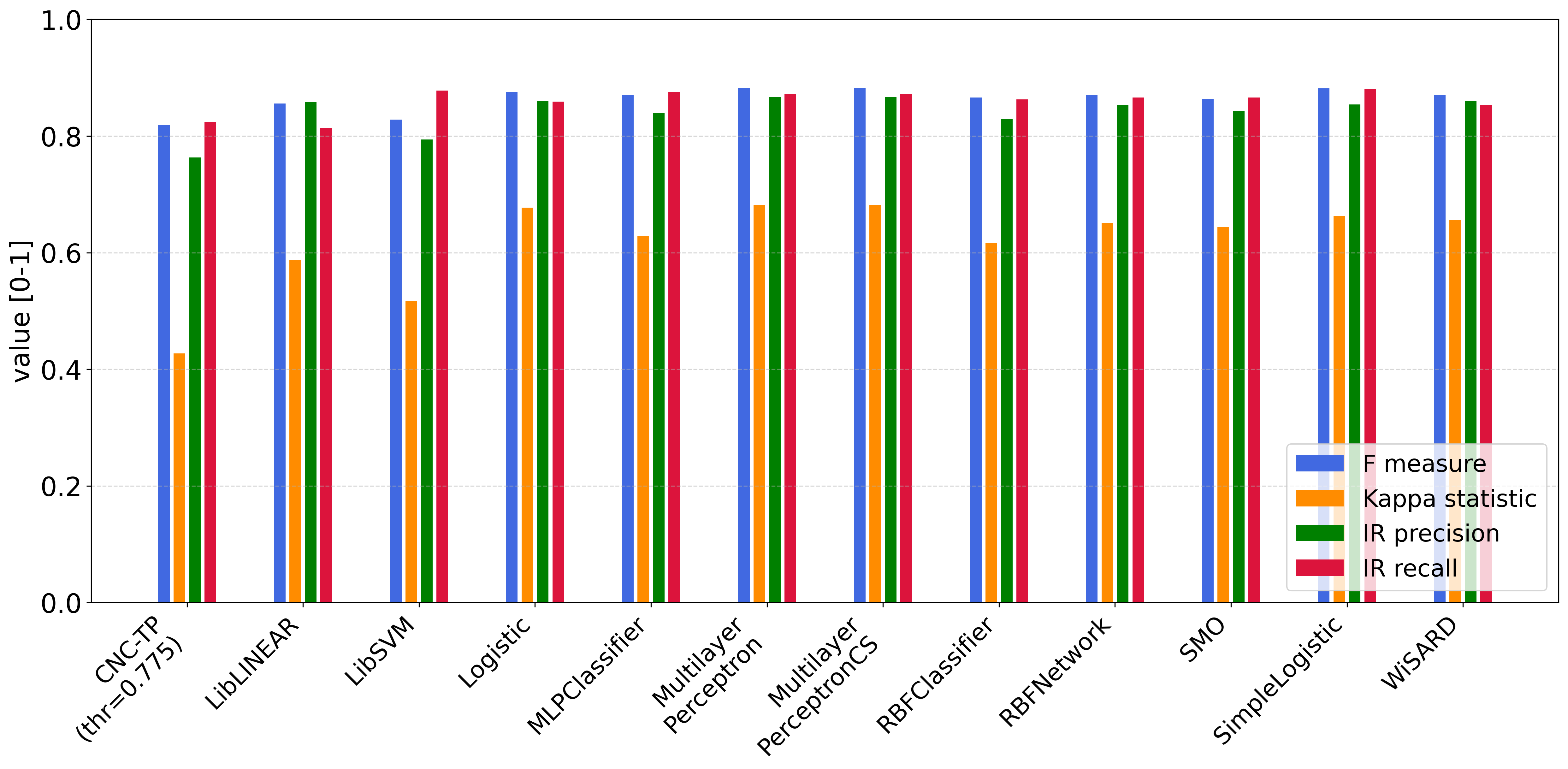
We also compare CNC-TP with a set of machine learning methods grounded in statistical modeling. These include: LibLINEAR, LibSVM, Logistic Regression, MLPClassifier, MultilayerPerceptron, MultilayerPerceptronCS, RBFClassifier, SMO, SimpleLogistic, and WiSARD. According to Figures 12 and 13, CNC-TP consistently demonstrates performance that is comparable to these statistical classifiers. It achieves competitive accuracy, precision, and recall, while maintaining a low rejection rate. Although some methods such as LibSVM or MLPClassifier may slightly outperform CNC-TP in certain metrics, the proposed method offers the added advantage of interpretability and rule-based transparency, which are often lacking in black-box statistical models. These results confirm that CNC-TP is a viable alternative to traditional statistical learning techniques, particularly in contexts where explainability and decision traceability are essential.
Conclusion
In this study, we introduced CNC-TP, a novel classification approach based on Formal Concept Analysis (FCA), which integrates attribute selection using the Gain Ratio measure with rule-based learning. Two concept extraction strategies were explored: one using all values of the top-ranked attributes, and another using only their most frequent (relevant) values.
Experimental results across 16 diverse datasets demonstrated that the variant using all values of the top-$`p\%`$ attributes (with $`p = 0.775`$) consistently outperformed the majority-value variant in terms of accuracy, F1-score, and error minimization. This configuration also achieved a strong balance between precision and recall, while maintaining a low rejection rate.
When compared to a wide range of classifiers—including rule-based learners, decision trees, Bayesian models, and statistical machine learning methods CNC-TP showed competitive performance. It outperformed several interpretable models such as ConjunctiveRule, OneR, and DecisionStump, and achieved results comparable to more advanced classifiers like FURIA, J48, BayesNet, and LibSVM. While some models slightly surpassed CNC-TP in specific metrics (e.g., Kappa statistic), CNC-TP maintained the advantage of interpretability and explainability through its rule-based structure.
Overall, CNC-TP offers a promising trade-off between performance and interpretability. Its ability to adapt to different data characteristics, combined with its transparent decision-making process, makes it a valuable tool for domains where explainability is essential. Future work may explore hybrid strategies that combine both concept extraction variants or integrate fuzzy logic to further enhance classification robustness.
📊 논문 시각자료 (Figures)