Surprisal and Metaphor Novelty Judgments Moderate Correlations and Divergent Scaling Effects Revealed by Corpus-Based and Synthetic Datasets
📝 Original Paper Info
- Title: Surprisal and Metaphor Novelty Judgments Moderate Correlations and Divergent Scaling Effects Revealed by Corpus-Based and Synthetic Datasets- ArXiv ID: 2601.02015
- Date: 2026-01-05
- Authors: Omar Momen, Emilie Sitter, Berenike Herrmann, Sina Zarrieß
📝 Abstract
Novel metaphor comprehension involves complex semantic processes and linguistic creativity, making it an interesting task for studying language models (LMs). This study investigates whether surprisal, a probabilistic measure of predictability in LMs, correlates with annotations of metaphor novelty in different datasets. We analyse the surprisal of metaphoric words in corpus-based and synthetic metaphor datasets using 16 causal LM variants. We propose a cloze-style surprisal method that conditions on full-sentence context. Results show that LM surprisal yields significant moderate correlations with scores/labels of metaphor novelty. We further identify divergent scaling patterns: on corpus-based data, correlation strength decreases with model size (inverse scaling effect), whereas on synthetic data it increases (quality-power hypothesis). We conclude that while surprisal can partially account for annotations of metaphor novelty, it remains limited as a metric of linguistic creativity. Code and data are publicly available: https://github.com/OmarMomen14/surprisal-metaphor-novelty💡 Summary & Analysis
1. **Distinguishing Conventional and Novel Metaphors**: Traditional NLP systems struggled with understanding metaphors, but this paper explores how to distinguish between conventional and novel ones using language models (LMs). This opens up new avenues for studying creative language.-
Measuring Creativity through Surprisal Scores: ‘Surprisal’ scores are computed based on word probabilities in context and can predict human processing difficulty. The paper uses surprisal to measure metaphor creativity, offering a novel approach to linguistic analysis.
-
The Cloze-Surprisal Methodology: Traditional surprisal only considers the left context of words, limiting its understanding of full sentence contexts. By incorporating right context through cloze-surprisal, this method provides more accurate measurements of metaphor novelty.
📄 Full Paper Content (ArXiv Source)
Recent advances in language modelling have led to a renewed interest in studying linguistic creativity, an aspect of language that was notoriously challenging for traditional NLP systems. A well-known instance of creative language is metaphor, which arises through mapping of a source domain–a lexical unit’s literal meaning–onto a target domain–its figurative meaning-. Yet, not all metaphors are equally novel or creative as many of such mappings are highly conventionalized, such as in the famous example “to attack an argument,” where the mapping from the source domain “WAR” onto the target domain “ARGUMENT” corresponds to a conventional sense of the verb “attack” which can be found in dictionaries. Other metaphors, as in “The arrested water” (Figure 1) establish a more unconventional or novel mapping that is considered creative.
 style="width:100.0%" />
style="width:100.0%" />
The distinction between conventional and novel metaphors is well established in theory and studied in experimental work on cognitive processing . Novel metaphors require greater interpretative effort compared to conventional metaphors, as the unfamiliar mapping requires speakers to construct new connections between domains .
However, separating novel metaphors from conventional ones remains a challenging task for human annotators . While computational methods on metaphor analysis do not often take the novelty dimension into account , and some existing studies highlight that novel metaphors are more difficult to detect than conventional ones . In this work, we propose to fill this gap by studying questions related to LMs’ processing of novel and conventional metaphors and investigating correlations between LM-based metrics and different setups of metaphor novelty annotations.
We draw on a line of research that has studied the ability of LMs to account for effects of difficulty in human sentence processing and that goes back to surprisal theory . Surprisal is computed with LMs as the negative log probability of a word in context and has been found to provide a robust predictor for human processing difficulty (e.g., of reading times) .
However, recent work draws a mixed picture in terms of which LMs can provide the most robust and cognitively plausible predictors for processing difficulty. observe an inverse scaling effect when testing surprisal estimates from GPT-2 models of different sizes, showing that surprisal computed with smaller model sizes achieved a better fit with human reading times than larger models. , on the other hand, train LMs of small and medium size on a range of languages and find that LM quality generally correlates with its predictive power of reading times.
In this paper, we investigate surprisal of metaphoric words computed using a selection of LMs as a metric of metaphor novelty. We find significant, positive and moderate correlations between LMs’ surprisal and different metaphor novelty annotations. We perform our experiments on four different datasets coming from corpus-based and synthetic setups, using LMs of different sizes. Most interestingly, we observe effects supporting the “inverse scale” pattern on the two corpus-based novelty datasets, and contrary patterns supporting the counter-argument, “Quality-Power” hypothesis on the two synthetic datasets. We also investigate the effect of instruction-tuning on surprisal correlation to metaphor novelty. Moreover, we conduct a deeper analysis of the genre splits, revealing that genre, metaphor density, and LM perplexity are potential factors underlying the quality of surprisal as a predictor of metaphor novelty. Finally, we introduce a new method of computing surprisal, cloze-surprisal, to include the right context of the word in its conditional probability. We find that this method can boost the correlation of surprisal with metaphor novelty annotations by a few points. In general, our study establishes a promising direction for studying linguistic creativity with LMs and calls for novel measures and datasets that provide systematic annotations of metaphor novelty across genres.
Related Work
Metaphor Annotations
The most common annotation scheme in corpus-based metaphor studies is the Metaphor Identification Procedure Vrije Universiteit (MIPVU) , designed as a reliable step-by-step framework for identifying metaphorically used words. This method was used to construct the VU Amsterdam Metaphor Corpus (VUAMC) , a large-scale, genre-balanced corpus containing 186,673 words sampled from fiction, news, academic writing, and conversations splits in the BNC Baby edition. The VUAMC has become a benchmark for metaphor research, inspiring developments in further English corpora and more recent multilingual efforts .
Several studies have extended annotation beyond binary literal/metaphoric labels. introduced a four-point metaphoricity scale, considering factors such as vividness and familiarity. proposed the concept of deliberateness, distinguishing metaphors intended to be recognized as metaphors; novel metaphors are typically deliberate under this framework. Direct novelty annotations were first introduced by , who asked annotators to rate metaphorical word pairs from the VUAMC on a 0–3 novelty scale. proposed a more comprehensive approach considering all metaphor words in VUAMC, and by aggregating ranked novelty judgments into continuous scores. More recently, proposed a dictionary-based method that labels a metaphor as novel when its contextual meaning is absent from dictionary entries.
Psycholinguistic studies also produce datasets of metaphors, but these are smaller in size and feature controlled synthetic sentences (fixed words, structures, sentence length, etc.), cf. . Some of these also created datasets of metaphors that are classified as conventional or novel metaphors .
Predictive Powers of Surprisal
Surprisal estimates from LMs have been shown to capture human processing difficulty across multiple behavioural and neural measures. In self-paced reading and eye-tracking studies, token-level surprisals from causal models significantly predict reading times beyond lexical and syntactic factors . Similar effects have been reported for acceptability judgments, where LM surprisals align with human sensitivity to grammaticality .
LM-Based Metrics for Metaphor Novelty
Recent work has explored diverse LM-based approaches—prompting, surprisal, embedding similarity, and attention patterns—for the analysis of metaphorical language. demonstrate that metaphor-relevant information is encoded in mid-layer embeddings of multilingual pre-trained LMs. show that GPT-4 generates interpretations of novel literary metaphors that are favoured by human judges over interpretations by college students, suggesting sensitivity to metaphorical meaning beyond lexical overlap. tested BERT’s masked token probabilities across conventional, novel, and nonsensical metaphors, showing that novel metaphors tend to receive lower probabilities, but distinctions between novelty and nonsense remained unclear. We extend this study towards more recent LMs and broader comparisons between models, datasets, and genres. trained a BERT-based classifier to predict novelty scores jointly with the task of metaphor detection.
Metaphor Novelty Datasets
This Section describes the four datasets we use in our experiments and explains how metaphor novelty is annotated in different approaches. Datasets statistics are reported in Tables [tab: data_stats] and [tab: data_stats2] (Appendix 8.1).
Corpus‐based Datasets
Following the MIPVU procedure, all words in the VUAMC are annotated as being a metaphor-related word (MRW) or not. Out of 186,673 words in VUAMC, 24,762 words (15,155 content words) are labelled as MRWs. While the original VUAMC does not include novelty annotations, we utilise two annotation studies that offer different annotation protocols for metaphor novelty on the same corpus.
VUA-ratings
collected crowd-sourced ratings of metaphor novelty for VUAMC. In their set-up, annotators were presented four sentences containing an MRW (content words only) and asked to select the best (most novel) and worst (most conventional). Each MRW appeared in six different best-worst scaling comparisons. These annotations were then converted into continuous Best-Worst Scaling scores in the range of (-1, +1), with -1 being the most conventional and +1 being the most novel. Additionally, they also convert these scores to binary labels using a threshold of 0.5. This results in labelling 353 metaphors as novel out of 15,155 content metaphoric words in VUA.
VUA-dictionary
proposed a dictionary-based method that labels a metaphor as novel when its contextual meaning is absent from dictionary entries. They applied this method to VUAMC. In particular, they re-annotated the potentially novel metaphors in VUA according to VUA-ratings and ’s metaphor deliberateness annotations (1,160 potentially novel metaphors in total). Their procedure resulted in labelling only 409 content1 metaphoric words as novel out of the 1,160 potentially novel metaphors. We assume the remaining metaphors in VUA to be conventional in our study.
Synthetic Datasets
Another class of metaphor novelty datasets is synthetic datasets, which are mainly characterised by being generated from a fixed source. They usually have comparable sentences in terms of the target metaphoric words. We consider two cases of such datasets, a dataset from a psycholinguistic study concerned with novel metaphors. And a toy dataset that we generated from GPT-4o.
Lai2009
investigated how our brains handle conventional and novel metaphors differently. To this end, they constructed a set of controlled experimental items featuring metaphors with two degrees of novelty. Two linguists selected 104 words and constructed 4 sentences for each word, according to the Conceptual Metaphor Theory (CMT) . For each word, the items include one (i) literal use, (i) conventional metaphor, (iii) novel metaphor, and (iv) anomalous use, with the target word as the last word in each sentence. Familiarity and interpretability tests showed a significant difference between the conventional and novel metaphoric senses. For our experiments, we select only the conventional and novel metaphor senses for each word, resulting in 208 sentences (104 conventional and 104 novel metaphors).
GPT-4o-metaphors
To test our experiments in a setting that is more controlled (in contrast to VUA) but features more varied sentence lengths, structures and degrees of novelty (in contrast to Lai2009), we construct a synthetic dataset by prompting GPT-4o to generate sentences that include conventional and novel metaphoric senses. We do not assume that LLMs are able to generate ideal novel metaphors, or that this dataset is a benchmark of any kind; we are only interested in exploring a new quick setting of potential metaphor novelty annotations. We prompt GPT-4o to generate 5 verbs and 5 nouns that can be used in a metaphoric sense. For each word, we prompt the model again to generate 10 different sentences using the target word in a conventional metaphor sense, and 10 different sentences in a novel metaphor sense. This results in a dataset of 200 sentences, 100 contain conventional metaphors, and 100 contain novel metaphors.
Methods & Experiments
We describe our experiments designed to investigate whether and to what extent surprisal scores computed from LMs correlate with different annotations of metaphor novelty.
Surprisal of a target word
In information theory , the information content of an event $`x`$ with
probability $`p(x)`$ is defined as: $`I(x) = -\log p(x)`$. In the
context of LMs trained to predict the next token in a sequence, this
quantity is called surprisal and computed for a $`w_i`$ in a sequence
such that: $`\mathrm{Surprisal}(w_i) = -\log p(w_i \mid w_{
In our experiments, we measure word-level surprisal of metaphoric words in their sentence-level context. We feed every sentence to an LM in an independent teacher-forced forward pass, and record surprisal of the target (metaphoric) word(s). We denote this quantity as direct-surprisal to distinguish it from cloze-surprisal.
Most LMs operate on subwords rather than words, so deriving word-level
probabilities requires implementation choices that can affect surprisal
estimates and, in turn, downstream measures . For transparency and
reproducibility, we report two choices in our implementation that affect
the computed surprisal values. First, we choose to align tokens
(subwords) to words by precomputing the offsets of the exact3 target
words in their corresponding sentences, and then searching for the
minimal span of tokens in the LM’s tokenisation of the input sentence
covering the target word’s offsets. This usually results in a proper
alignment with the target word in addition to a leading whitespace
character (e.g. ‘‘Ġarrested’’ for “arrested”), with very rare cases
when the last token is attached to a punctuation (e.g.
[‘‘Ġindivid’’, ‘‘ual’’, ‘‘ism,’’] for “individualism”). We also apply
the corrections made by that address the problem of leading whitespaces
in tokenisations of most causal LMs. Second, surprisal is computed
using the conditional probability of the current word being the target
word given the preceding words in a sentence. This makes computing
surprisal of the first word in a sentence an issue4. To compute
surprisal of the first word in a sentence, we prepend the input sentence
with a “beginning of sequence” special token.
Cloze-surprisal
A key limitation of standard (left-to-right) surprisal as a proxy for semantic contextual properties (e.g., metaphor novelty) is that it does not condition on future (right) context in the sentence. This matters in naturally occurring corpus data (e.g VUA datasets), where metaphorical words can appear in many sentence positions, and in some cases in the GPT-4o-metaphors dataset (see Table [tab: data_examples]). To incorporate the right context while retaining an autoregressive setup, we compute cloze-surprisal: for each target word, we prompt the model to predict a missing word in a sentence, and we replace the target in the sentence by a blank space, and then we append the same sentence again as the intended completion (Figure 1). We measure surprisal for the target word at its position in the second occurrence of the sentence. Because the first occurrence exposes the full right context, the resulting conditional probability effectively incorporates both left and right contexts of the target word.
Evaluating the correlation
To determine whether LMs’ surprisal correlates with different metaphor novelty annotations, we use multiple correlation metrics between surprisal and metaphor novelty scores/labels. For continuous novelty scores (as in VUA-ratings), we compute Pearson’s $`r`$ and Spearman’s $`\rho`$ correlations. For binary labels (conventional vs. novel), we compute the Rank-biserial $`r_b`$ correlation. Rank-biserial estimates the probability that a random observation from the set of novel metaphors has a larger surprisal than one from the set of conventional metaphors, minus the reverse probability. We also estimate the potential of surprisal as a discriminator for binary novelty labels using the Area Under the ROC Curve (AUC) . We also compute the significance of all these estimates. All our metrics and tests do not assume normality, except for Pearson’s, for which we also provide a non-parametric alternative (Spearman).
Settings
Surprisal measures are derived from the learnt $`p(x)`$ of pre-trained LMs and, hence, depend substantially on the model architecture and the training data. Also, human annotations of metaphor novelty depend on the annotation process. Additionally, novelty norms may vary by genre: a metaphor considered novel in academic texts might appear conventional in fiction. We thus investigate how all these factors affect the correlation by experimenting with multiple settings.
Models
We examine three families of decoder-only causal LMs (GPT-2, Llama 3 and Qwen2.5) . For each model family, we select 3-4 different sizes, to represent the effect of model size on the correlation. To investigate the effect of instruction-tuning on the correlation, we include the instruction-tuned variants of Llama 3 and Qwen2.5.
Datasets
As explained in Section 3, we perform experiments on four datasets (Tables [tab: data_stats] and [tab: data_stats2]). As VUA-ratings has continuous novelty scores, we evaluate the correlation of its continuous scores to surprisal. In addition, we convert these scores to binary labels using a threshold of $`0.5`$ and evaluate their correlation to surprisal, allowing us to compare the results of VUA-ratings to VUA-dictionary, Lai2009 and GPT-4o-metaphors, which only have binary novelty annotations.
Genre variables
VUA provides genre splits (see Section 3.1), allowing us to analyse the correlation between surprisal and novelty separately for each genre.
Perplexity
Scales of surprisal can differ from one genre to another, and from one model to another. To this end, we investigate perplexity as a potential factor in our study. Perplexity of a model on a certain dataset is the exponential of the average token-level surprisal of all tokens in the dataset. In that sense, perplexity indicates how much a certain model is “surprised” on average when predicting a certain dataset. We measure models’ perplexity on the genre splits of VUA by feeding sentences one by one to the model, measuring token-level surprisals accordingly and averaging and exponentiating them to obtain perplexity. This yields higher values of perplexity than common values reported in literature, as we use a shorter context (single sentences).
Summary
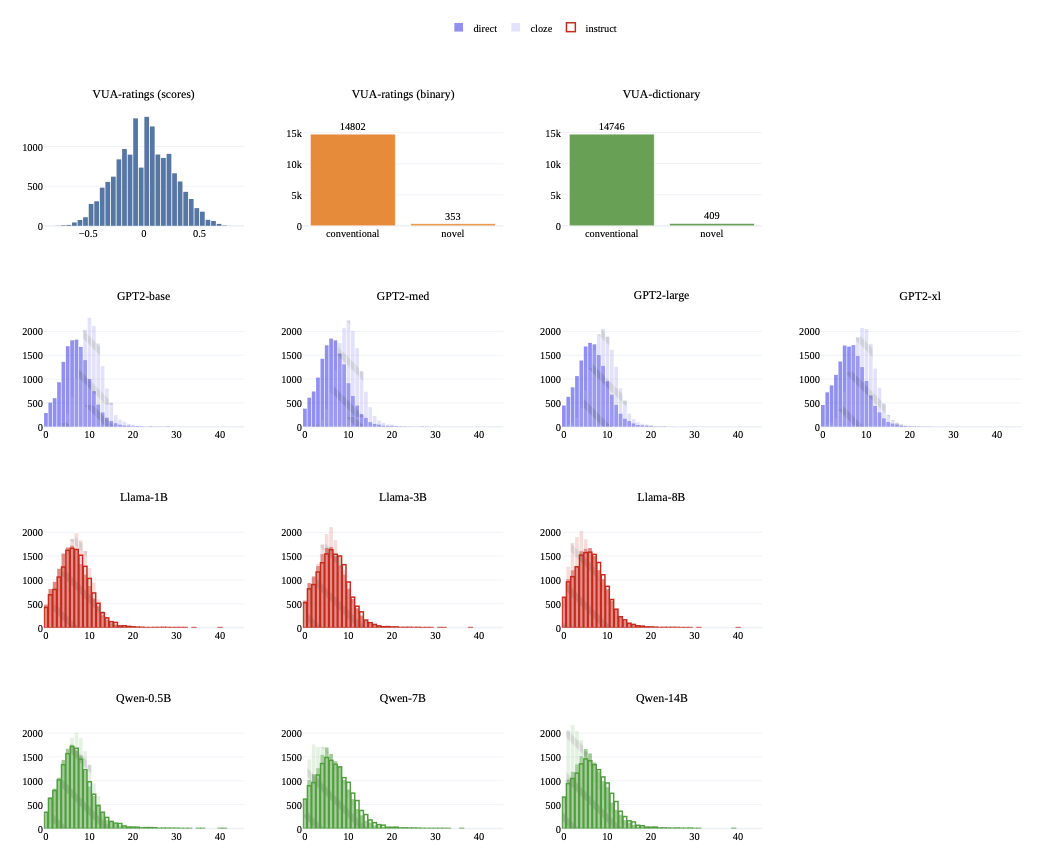
Our experiments rely on a large collection of surprisal measures for each metaphor word in the four datasets: 32 different surprisal values (including direct and cloze) for 15,155 metaphoric words of the VUA dataset and for 208 and 200 metaphoric words of Lai2009 and GPT-4o-metaphors, respectively. In Figure 3 (Appendix 8.6), we plot the distributions of surprisal values by model, in addition to metaphor novelty scores/labels from VUA. From these plots and further normal distribution tests, we find that novelty scores and surprisal values are not strictly normally distributed.
Results
We report the correlation measures for the corpus-based datasets in Table 1, and for synthetic datasets in Table 2. We also report the gains (in terms of rank-biserial) of the instruction-tuned variants over their base models in Table 3. And the gains of the cloze-surprisal method over the direct-surprisal method in Table 4.
Overall Correlation Results
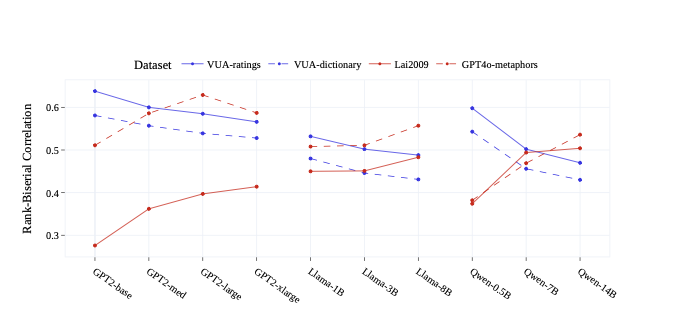
Generally, we find LMs’ direct surprisal values correlate positively with metaphor novelty annotations across the four datasets (Tables 1 and 2). All correlation estimates are statistically significant for both the corpus-based and synthetic datasets 5. Overall, for direct surprisal, the largest Pearson correlation $`r=.419`$, largest Spearman correlation $`\rho=.417`$, largest rank-biserial correlation $`r_b=.638`$ and largest $`AUC=.819`$ come from GPT2-base on VUA-ratings. These values indicate a significant positive correlation, yet its strength is moderate.
We also find that the correlation strengths’ ranges differ across the different annotation datasets. By comparing the rank-biserial estimate $`r_b`$ across the four datasets, we find its ranges as follows: (.47-.64) for VUA-ratings, (.43-.58) for VUA-dictionary, (.28-.50) for Lai2009, and (.38-.63) for GPT-4o-metaphors. These results show that surprisal correlates more strongly with the corpus-based data than with the synthetic data. Also, surprisal correlates more strongly with human ratings on VUA than the dictionary-based annotation approach. While the most controlled dataset (Lai2009) gets the weakest correlations with surprisal.
| Model | VUA-ratings | VUA-dict. | ||||
|---|---|---|---|---|---|---|
| r | ρ | rb | auc | rb | auc | |
| GPT2-base | .419 | .417 | .638 | .819 | .581 | .791 |
| GPT2-med | .389 | .383 | .600 | .800 | .557 | .778 |
| GPT2-large | .381 | .373 | .585 | .793 | .539 | .769 |
| GPT2-xl | .373 | .362 | .566 | .783 | .539 | .769 |
| Llama-1B | .345 | .329 | .532 | .766 | .480 | .740 |
| Llama-3B | .328 | .308 | .502 | .751 | .446 | .723 |
| Llama-8B | .314 | .293 | .488 | .744 | .431 | .716 |
| Qwen-0.5B | .384 | .377 | .598 | .799 | .543 | .771 |
| Qwen-7B | .334 | .314 | .502 | .751 | .456 | .728 |
| Qwen-14B | .316 | .295 | .470 | .735 | .430 | .715 |
| Model | Lai2009 | GPT-4o-met. | ||
|---|---|---|---|---|
| rb | auc | rb | auc | |
| GPT2-base | .276 | .638 | .511 | .756 |
| GPT2-med | .362 | .681 | .586 | .793 |
| GPT2-large | .397 | .699 | .629 | .814 |
| GPT2-xl | .414 | .707 | .587 | .794 |
| Llama-1B | .450 | .725 | .508 | .754 |
| Llama-3B | .451 | .725 | .511 | .755 |
| Llama-8B | .483 | .742 | .557 | .778 |
| Qwen-0.5B | .374 | .687 | .382 | .691 |
| Qwen-7B | .494 | .747 | .469 | .734 |
| Qwen-14B | .504 | .752 | .536 | .768 |
| Model | VUA-r | VUA-d | Lai | GPT-4o |
|---|---|---|---|---|
| Llama-1B-It. | $`+4.0`$ | $`+1.5`$ | $`+0.4`$ | $`-5.1`$ |
| Llama-3B-It. | $`+4.0`$ | $`+2.4`$ | $`-5.8`$ | $`-5.6`$ |
| Llama-8B-It. | $`+1.6`$ | $`+0.6`$ | $`-2.3`$ | $`-5.1`$ |
| Qwen-0.5B-It. | $`-1.6`$ | $`-0.8`$ | $`+0.1`$ | $`+2.2`$ |
| Qwen-7B-It. | $`-1.7`$ | $`-1.9`$ | $`-8.9`$ | $`-13.7`$ |
| Qwen-14B-It. | $`-3.9`$ | $`-3.1`$ | $`-3.7`$ | $`-14.0`$ |
Instruction-tuning % gains (over corresponding base variants) in Rank-biserial’s correlation estimates between surprisal and novelty scores/labels in the four datasets: VUA-ratings, VUA-dictionary, Lai2009 and GPT-4o-metaphors.
Model Size Effects
The effect of model size is consistent (but diverging in direction) across the two dataset types. We plot the rank-biserial correlations of the ten model variants for the four datasets in Figure 2. For the two corpus-based datasets (blue), surprisal–novelty correlation is monotonically decreasing as model size increases (per model family). On the other hand, for the two synthetic datasets (red), surprisal–novelty correlation increases as model size increases, with a single minor exception at the GPT2 model family on the GPT-4o-metaphors dataset.
 />
/>
Instruction-tuning Effects
We report percentage gains in rank-biserial correlation for the instruction-tuned variants over their base variants across the four datasets in Table 3. This shows the effect of extracting surprisals from an instruction-tuned variant over a base variant with the same experimental setting. We do not add a prompt/instruction to the instruction-tuned models’ inputs. The results suggest that instruction-tuning does not always improve the correlation between surprisal and novelty annotations. Only Llama instruction-tuned variants could improve the correlations over their base variants on the VUA datasets; otherwise, instruction-tuning deteriorates the correlations over the base variants. Also, instruction-tuning fails to improve the correlations over more basic models such as GPT2-base.
Cloze-surprisal
In Table 4, we report the percentage gains in rank-biserial correlations for cloze-surprisal over direct-surprisal from same model variants across the four datasets. We find cloze-surprisal to be boosting the correlations with extra points in many cases; however, it also deteriorates the correlations heavily in other cases. For the GPT2 model family, cloze-surprisal consistently improves the corpus-based datasets’ correlations, yielding the strongest correlations in this study. Out of the 32 recorded surprisals on each dataset, cloze surprisal from GPT2-base achieves the highest correlations on VUA-ratings, with $`r=.499`$, $`\rho=.499`$, $`r_b=.687`$ and $`auc=.843`$. However, cloze-surprisal of GPT2 models consistently deteriorates the correlations on the synthetic datasets. Llama and Qwen model families also show positive gains from cloze surprisal in most of the cases, however, not as consistently as for GPT2 models on VUA. Most importantly, unlike the GPT2 model family, Llama and Qwen boost correlations on the synthetic datasets except for a very few cases. Cloze-surprisal achieves the overall strongest correlation on the Lai2009 dataset using the Qwen-14B model, with $`r_b=.539`$ and $`auc=.779`$. Also, it achieves the overall strongest correlation on the GPT-4o-metaphors dataset using the Llama-8B model, with $`r_b=.684`$ and $`auc=.842`$.
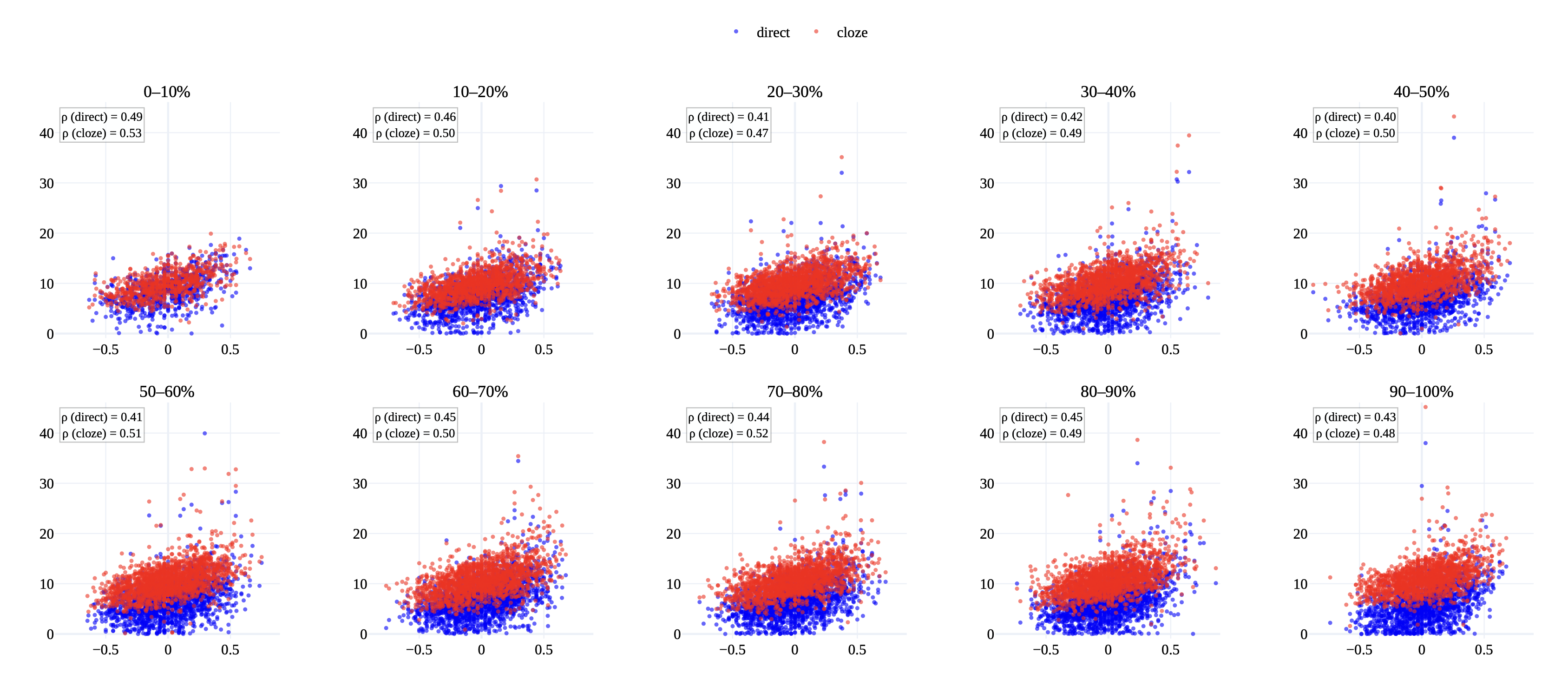
To investigate the effect of incorporating the whole sentence context in surprisal computation, we plot the distribution of LMs’ direct and cloze surprisals of metaphoric words in VUA in Figure 3 (Appendix 8.6). We observe that the distribution of direct-surprisal is often right-skewed with many values near zero. While cloze-surprisal shifts the distribution away from zero and approaches a normal distribution. Furthermore, we plot the distribution of GPT2-base direct and cloze surprisal of metaphoric words in VUA at different sentence positions in Figure 4 (Appendix 8.6). Again, we observe that cloze-surprisal shifts the distributions away from near zero values. However, against our intuition, the effect of cloze-surprisal is not more impactful in cases where the metaphor is located earlier in the sentence than later. The effect of cloze-surprisal, although positive, is not related to the position of the metaphoric word in the sentence.
| Model | VUA-r | VUA-d | Lai | GPT-4o |
|---|---|---|---|---|
| GPT2-base | $`+4.9`$ | $`+4.0`$ | $`-7.7`$ | $`-16.7`$ |
| GPT2-med | $`+6.8`$ | $`+4.5`$ | $`-11.8`$ | $`-26.9`$ |
| GPT2-large | $`+6.2`$ | $`+8.2`$ | $`-14.2`$ | $`-25.1`$ |
| GPT2-xl | $`+6.3`$ | $`+2.5`$ | $`-16.0`$ | $`-28.1`$ |
| Llama-1B | $`+7.3`$ | $`+8.0`$ | $`-13.3`$ | $`-15.7`$ |
| Llama-1B-It. | $`-3.8`$ | $`-1.2`$ | $`-2.4`$ | $`-10.3`$ |
| Llama-3B | $`-0.5`$ | $`+5.6`$ | $`+0.3`$ | $`+0.7`$ |
| Llama-3B-It. | $`-11.1`$ | $`-2.3`$ | $`+4.7`$ | $`+6.5`$ |
| Llama-8B | $`+1.9`$ | $`+2.7`$ | $`+2.5`$ | $`+12.7`$ |
| Llama-8B-It. | $`-7.8`$ | $`-0.2`$ | $`+6.0`$ | $`+10.9`$ |
| Qwen-0.5B | $`-2.1`$ | $`+2.1`$ | $`-2.5`$ | $`+6.2`$ |
| Qwen-0.5B-It. | $`-4.5`$ | $`-1.6`$ | $`-3.9`$ | $`+7.0`$ |
| Qwen-7B | $`+3.7`$ | $`+5.6`$ | $`+2.4`$ | $`+12.8`$ |
| Qwen-7B-It. | $`-6.9`$ | $`-1.6`$ | $`+9.1`$ | $`+8.0`$ |
| Qwen-14B | $`+5.8`$ | $`+7.8`$ | $`+3.5`$ | $`+6.9`$ |
| Qwen-14B-It. | $`-4.4`$ | $`+0.7`$ | $`+4.6`$ | $`+12.8`$ |
Cloze-surprisal % gains (over direct-surprisal from the same model) in Rank-biserial’s correlation estimates between surprisal and novelty scores/labels in the four datasets: VUA-ratings, VUA-dictionary, Lai2009 and GPT-4o-metaphors.
| Genre | VUA-ratings | VUA-dictionary | |||
|---|---|---|---|---|---|
| ppl. | rb | Nov. % | rb | Nov. % | |
| Fiction | 108 | .693 | 2.97 | .478 | 3.56 |
| News | 89 | .653 | 2.80 | .413 | 3.88 |
| Academic | 73 | .588 | 1.85 | .413 | 1.85 |
| Conversation | 134 | .482 | 1.41 | .800 | 0.62 |
| All | 96 | .638 | 2.33 | .581 | 2.70 |
Genre Splits
In Table 5, we report the rank-biserial correlations between GPT2-base surprisals and binary novelty labels of VUA-ratings and VUA-dictionary on each genre split separately. We also report the share of novel metaphors within each genre to illustrate the variance in metaphor density across genres. Additionally, we report the perplexity of GPT2-base on each genre split separately.
For VUA-ratings, we find a positive relation between genres’ metaphor density and the correlation of surprisal with novelty. We also observe a positive relation between perplexity and surprisal-novelty correlations that is only violated on the conversation split. On the other hand, for VUA-dictionary, the relation between metaphor density and surprisal-novelty correlation is not preserved. While the perplexity positive relation with surprisal-novelty correlation is more concrete. Interestingly, in contrast to VUA-ratings, the dictionary-based annotations of the conversation split correlate strongly with surprisal values despite its tiny number of annotated novel metaphors (11 out of 1774 metaphors) and high perplexity (134).
Discussion
Is surprisal a good metric for metaphor novelty?
Across multiple novelty annotation setups—human ratings, dictionary-based binary labels, experimental contrastive items designed by experts, and LLM-generated conventional vs. novel senses—we find consistently moderate associations between LM surprisal and metaphor novelty (best: $`r=.49, \rho=.50, r_b=.69, \mathrm{AUC}=.84`$). While these results are not directly comparable to prior work due to differences in datasets and task formulations, their magnitudes are broadly in line with reported surprisal–behavior associations in acceptability judgments and reading times . The closest point of reference in the metaphor novelty literature is , who report $`r=.44`$ when predicting novelty scores from a wide range of linguistic features. They additionally report moderate inter-annotator agreement, underscoring that novelty itself is challenging to measure reliably by humans. At the same time, surprisal has clear theoretical limits as a standalone predictor: interpreting a metaphor involves semantic integration and cross-domain mapping, not only predictability. We therefore expect surprisal to be most informative when combined with measures that more directly target novel interpretations and domain mappings, especially for highly creative (novel) metaphors.
Model Sizes & Dataset Types:
Our results introduce a great opportunity to further understand the underlying factors of opposing negative and positive effects of model sizes on correlations with psycholinguistic and cognitive features. The negative and positive effects are present together in our study, and clearly contrasted by the type of metaphor novelty dataset under experiment.
The negative effect of model size observed in corpus-based datasets mirrors the inverse scaling effect reported in reading time studies . Recently, argued that this effect is largely driven by word frequency, with larger models assigning increasingly non-human-like expectations to rare words. Since corpus-based novelty scores are often correlated with word frequency , frequency can be an underlying factor for this negative scaling effect in our study. By contrast, the synthetic datasets control for lexical identity and frequency: conventional and novel senses are elicited for the same set of words, and stimuli are constructed to cleanly separate the two senses. Under these controls, scaling improves alignment with novelty labels, agreeing with reports of positive scaling effects in other behavioural settings such as acceptability judgments and other reading time studies . Overall, we see our results as evidence that these diverging scaling effects are due to the nature of the dataset types. While corpus-based datasets reflect metaphor novelty mainly through lexical properties such as word frequency, synthetic datasets more directly isolate the conventional–novel distinction by controlling for lexical properties confounds.
Cloze-surprisal and Instruction-tuning:
Our cloze-surprisal approach improves correlation across many model
variants. In
Figures 3
and 4, cloze-surprisal is found to be
shifting the surprisal values away from near-zero values and pushing
towards a normal distribution.
In examples from Table
[tab: data_examples],
cloze-surprisal often raises the surprisal of the metaphorical word,
consistent with the intuition that the full context is needed to process
the metaphor and realise its true predictability. Moreover, in cases
where the metaphorical word begins a sentence (e.g. example 14), direct
surprisal is naturally high—regardless of novelty—whereas
cloze-surprisal successfully moderates such inflated values.
Instruction-tuning—despite its goal of aligning model outputs with human
intent—does not enhance the human-likeness of surprisal. In fact,
similar to prior findings , instruction-tuned models tend to reduce
alignment between predicted probabilities and human annotation scores.
Genre Effects:
Our results show a significant effect of sentences’ genre on surprisal correlation with metaphor novelty. We suspect the difference in genre’s novel metaphor density can be an underlying factor. Also, our observations on perplexity relations to the correlations trigger the possibility that the amount of pretraining data contributing to each genre can significantly affect LM-based methods of detecting novel metaphors.
Conclusion
We have studied the distinction between conventional and novel metaphors and systematically investigated surprisal computed with LMs as a metric for metaphor novelty. In general, our experiments show some potential for surprisal in predicting aspects of linguistic creativity, but also call for novel measures and datasets that provide systematic annotations of metaphor novelty across genres and across corpus-based and experimental settings.
Limitations
We acknowledge a couple of limitations in this work. First, the scarcity of high-quality metaphor novelty annotations in existing literature constrains both coverage and generalizability. Second, we rely on pretrained language models whose training data and processes are not fully disclosed. Additionally, although we carefully analyse the effects of model architecture, size, and domain (genre), future work could adopt mixed-effects models to test the interaction of these variables.
Acknowledgments
This research has been funded by the Deutsche Forschungsgemeinschaft
(DFG, German Research Foundation) – CRC-1646, project number 512393437,
project A05.
We acknowledge the anonymous reviewers and area chairs for their
valuable comments and feedback. Furthermore, we thank Özge Alaçam,
Annett Jorschick, Vicky Tzuyin Lai and Tiago Pimentel for their
cooperation and responsiveness to our inquiries.
Appendix
Statistics and Examples
In Tables [tab: data_stats] and [tab: data_stats2], we describe in numbers the four datasets under study. In Table [tab: data_examples], we list 16 examples from the VUA datasets, 6 examples from the LAI2009 dataset, and 4 examples from the GPT-4o-metaphors dataset.
lcc|cc|c & & & & VUA-dictionary
Genre & # Metaphors & L$`_{sent}`$ & Novelty Score & # Novel & #
Novel
& & mean | std. & mean | std. & $`>=0.5`$ &
Fiction & 3170 & 26.0 | 16.5 & -.005 | .271 & 94 & 113
News & 4712 & 29.9 | 14.2 & .000 | .257 & 132 & 183
Academic & 5499 & 34.9 | 16.0 & .003 | .239 & 102 & 102
Conversation & 1774 & 17.5 | 15.9 & -.000 | .236 & 25 & 11
All & 15155 & 29.4 | 16.5 & .000 | .251 & 353 & 409
l|cc|cc & Lai2009 & GPT-4o-metaphors
Label & # & L$`_{sent}`$ & # & L$`_{sent}`$
& & mean | std. & & mean | std.
Conventional & 104 & 6.7 | 1.5 & 100 & 10.1 | 1.9
Novel & 104 & 6.7 | 1.4 & 100 & 12.7 | 2.3
All & 208 & 6.7 | 1.5 & 200 & 11.4 | 2.5
| VUA datasets | ||||
|---|---|---|---|---|
| Sentence | ratings | dictionary | direct | cloze |
| 1. ‘ Tell him I am very sorry, but I must fill the quota. ’ | -0.441 | conventional | 9.043 | 7.317 |
| 2. Adam might have escaped the file memories for years, suppressed them and jerked violently <14> by those events. | 0.531 | novel | 14.23 | 14.69 |
1-5 3. It was an excitement that <11> and I had long dreamed of that scatter of tiny, magically named islands strewn across one third of a globe. |
0.278 | conventional | 10.17 | 16.08 |
| 4. The seemingly random and <11> designed to disguise a boat’s shape from the prying eyes of U-Boat captains, so it <10> in the Bahamas. | 0.588 | conventional | 7.903 | 12.46 |
1-5 5. One Mr Clarke can not duck away from if he wants to avoid a second Winter of Discontent |
-0.094 | conventional | 3.165 | 7.454 |
| 6. This was conveniently encapsulated in the first try. | 0.500 | conventional | 7.918 | 14.54 |
1-5 7. Thrusts of resistance ( mass demonstrations, resignations, tax rebellions, etc ) would come in crests. |
0.382 | novel | 12.46 | 16.84 |
| 8. Travel: A pilgrimage sans progress Elisabeth de Stroumillo potters round Poitou | 0.514 | conventional | 8.188 | 14.81 |
1-5 9. The Tehuana dress is by no means the most decorative variant or the closest to pre-Hispanic forms of clothing. |
-0.194 | conventional | 6.466 | 11.92 |
| 10. Interwoven with these images are subtler references to the metaphorical borderlines which separate Latin American <5> and North America. | 0.529 | conventional | 10.16 | 12.57 |
1-5 11. This is often linked with a supposed denunciatory effect — the idea that the mandatory life sentence denounces murder as emphatically as possible <18> this crime. |
0.294 | conventional | 11.02 | 12.61 |
| 12. He certainly held deep convictions as to the <9>, but at least a part of his apparent hostility was assumed for the occasion, a hard <7> in the end. | 0.514 | conventional | 5.662 | 9.781 |
1-5 13. Me dad said he’s had enough Well, we were debating whether to give it to you or not. |
-0.633 | conventional | 3.752 | 8.038 |
| 14. Struggled with it a little | 0.552 | conventional | 17.13 | 14.92 |
1-5 15. That’s an old trick. |
0.310 | conventional | 4.013 | 11.92 |
| 16. Can you sort erm, madame out? | 0.567 | conventional | 8.820 | 9.591 |
| LAI2009 | ||||
| Sentence | label | direct | cloze | |
| 17. Upon hearing the news my spirits sank | conventional | 4.358 | 11.82 | |
| 18. Upon having the data my prediction sank | novel | 10.28 | 13.27 | |
1-5 19. Those chess players are prepared for battle |
conventional | 5.373 | 12.32 | |
| 20. Those plastic surgeons are prepared for battle | novel | 6.691 | 13.28 | |
1-5 21. His mental condition remains fragile |
conventional | 7.251 | 13.34 | |
| 22. His website popularity remains fragile | novel | 9.538 | 13.95 | |
| GPT-4o-metaphors | ||||
| 23. Her family was her emotional anchor during the crisis. | conventional | 4.322 | 14.12 | |
| 24. The smell of coffee became an anchor to mornings that no longer came. | novel | 7.518 | 12.42 | |
1-5 25. The software helps users navigate complex legal documents. |
conventional | 3.830 | 5.575 | |
| 26. He tried to navigate the silence like a sailor without stars. | novel | 8.041 | 8.402 | |
GPT-4o-metaphors Construction
To generate the sentences in GPT-4o-metaphors, we prompt GPT-4o once for
each word in the dataset. As we planned for 10 different words, we
prompted the model 10 consecutive times to construct this dataset.
‘‘I am curating a dataset to be used in a study about metaphoric knowledge in pretrained language models PLMs e.g. GPT-2. The dataset should consist of sentences that correspond to target nouns/verbs. For each target noun/verb, there should be 10 sentences. The target noun/verb should be used 10 times using conventional metaphoric meanings of the target noun/verb, and 10 times using novel metaphoric meanings of the target noun/verb. Please suggest a target noun, and generate 20 sentences following the requirements above: 10 sentences with Conventional Metaphor usages, and 10 sentences with Novel Metaphor usages.’’
Models Details
All the LMs used in this study are based on the HuggingFace HF models hub. Hence, we list here the exact HF models’ IDs that we used in our experiments. We use default HF parameters when forwarding the inputs through the model layers. For models meta-data and parameters, please refer to the models’ cards on HF using the links below:
Use of AI Assistants
AI assistants were used during manuscript preparation only for limited linguistic editing to improve clarity and style, and for writing auxiliary code (e.g., for visualisations). They were not used for scientific reasoning, evaluation decisions, or interpretation of results; all analyses and conclusions were drawn by the authors.
Scientific Artifacts
VUA datasets are publicly available datasets and intended for scientific research, and we follow this purpose in this study. Lai2009 dataset has copyright regulations; the author of this dataset approved our usage of the dataset, and she promised to share the data with anyone interested in reproducing our experiments. We double-checked that the datasets and prompts do not contain any personal data.
Distributions Visualisations
In Figure 3, we plot the distributions
of novelty scores/labels and surprisal of the VUA datasets.
In Figure 4, we plot scatter plots between
VUA-ratings scores and GPT2-base surprisal from both direct and cloze
methods, grouping instances based on the location of the metaphoric word
within the sentence.
 style="width:100.0%" />
style="width:100.0%" />
 style="width:100.0%" />
style="width:100.0%" />
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
We exclude non-content words from this dataset to allow comparison with VUA-ratings, which originally excluded non-content words. ↩︎
-
We use $`\log`$ of base $`e`$ for all surprisal/perplexity computations in our study. ↩︎
-
We make sure no punctuation or any other characters outside of the word boundary are included inside the offsets. ↩︎
-
In some cases in the VUA datasets, the target word is the first word in the sentence. ↩︎
-
The relatively large corpus-based datasets (15,155 datapoints) can bias the significance values; however, we get similar significance values for the relatively small synthetic datasets (100 datapoints). ↩︎