Not All Needles Are Found How Fact Distribution and Don t Make It Up Prompts Shape Literal Extraction, Logical Inference, and Hallucination Risks in Long-Context LLMs
📝 Original Paper Info
- Title: Not All Needles Are Found How Fact Distribution and Don t Make It Up Prompts Shape Literal Extraction, Logical Inference, and Hallucination Risks in Long-Context LLMs- ArXiv ID: 2601.02023
- Date: 2026-01-05
- Authors: Amirali Ebrahimzadeh, Seyyed M. Salili
📝 Abstract
Large language models (LLMs) increasingly support very long input contexts. Yet it remains unclear how reliably they extract and infer information at scale. Performance varies with context length and strongly interacts with how information is distributed in real-world corpora. Motivated by these observations, we study how fact placement, corpus-level fact distributions, and Don't Make It Up prompts influence model behavior. We introduce an extended needle-in-a-haystack benchmark across four production-scale models: Gemini-2.5-flash, ChatGPT-5-mini, Claude-4.5-haiku, and Deepseek-v3.2-chat. Unlike prior work, we separately evaluate literal extraction, logical inference, and hallucination risk. Our study considers both positional effects and realistic distributions of evidence across long contexts, as well as prompts that explicitly discourage fabrication. We find that longer contexts alone do not guarantee better performance and can be detrimental when relevant evidence is diluted or widely dispersed. Performance varies substantially across models: some show severe degradation under realistic conditions, while others remain more robust at longer context lengths. Anti-hallucination (AH) instructions can make some models overly conservative, sharply reducing accuracy in literal extraction and logical inference. While we do not directly compare retrieval-augmented generation (RAG) and cache-augmented generation (CAG), our results suggest many failures stem from ineffective context utilization. Models often struggle to identify and prioritize relevant information even when it is present. These findings have direct practical implications, as enterprise workflows increasingly involve pasting large volumes of unfiltered documents into LLM prompts. Effective context length and model-specific robustness to long contexts are therefore critical for reliable LLM deployment in research and business.💡 Summary & Analysis
1. **Key Contribution 1: New Evaluation Framework** - Metaphor: Just like finding a needle in a haystack, LLMs need to sift through large documents for important information. This study extends the “Needle-in-a-Haystack” test by distributing multiple needles across various locations and evaluating how well models find them. - Explanation: The paper introduces an advanced evaluation framework that goes beyond traditional benchmarks to assess literal extraction and logical inference in real document contexts.-
Key Contribution 2: Anti-hallucination Prompt Analysis
- Metaphor: Imagine telling a model, “Don’t make things up!” This study looks at how such prompts affect the model’s ability to accurately infer information from the input context.
- Explanation: The paper examines the impact of anti-hallucination prompts on extraction, inference, and overall faithfulness in long-context settings.
-
Key Contribution 3: Model Performance Comparison
- Metaphor: Like testing different cars, this study compares multiple LLMs to understand their strengths and weaknesses.
- Explanation: The paper evaluates four state-of-the-art models (Gemini-2.5-flash, ChatGPT-5-mini, Claude-4.5-haiku, Deepseek-v3.2-chat) across various metrics to provide a comprehensive comparison of their long-context processing capabilities.
📄 Full Paper Content (ArXiv Source)
Belief is growing in research and enterprise that long-context Large Language Models (LLMs) could reshape information retrieval. As LLMs’ context windows expand, sometimes to 1 million tokens or beyond , users may bypass complex retrieval pipelines and paste documents or databases directly into prompts for grounded responses. LLM Providers now highlight these larger context windows as a competitive edge in the fast-moving AI marketplace .
Despite this, it remains unclear how effective and reliable long-context LLMs are for specific use cases. While context window size is a key marketing and evaluation metric, its real usability varies by task. Recent research shows LLMs’ performance drops as input context grows, especially when relevant information is dispersed , often due to positional effects such as being “lost-in-the-middle” or “lost-in-the-later” . Widespread adoption of these tools could make reliability issues more significant.
A key limitation in assessing LLMs is reliance on synthetic corpora or benchmarks such as needle-in-a-haystack (NIAH) tests, in which a single fact is hidden within a long document. In real applications, facts are often dispersed, and cross-references are common . Evaluations that focus on isolated facts may overestimate LLMs’ performance in long contexts, particularly when neglecting latent multi-hop reasoning or the “Two-Hop Curse” .
Prompt engineering strategies such as anti-hallucination (AH) instructions, including “Don’t Make It Up” and “Don’t hallucinate,” are used in production to improve faithfulness . Their impact on literal extraction, logical inference, and overall faithfulness in long-context settings is not well understood. Such prompts may reduce hallucinations but also make models more conservative, leading to failures in extracting or inferring facts . This raises an important question: how much recall and inference accuracy is sacrificed for lower hallucination risk?
This study provides a benchmark analysis of long-context LLMs and introduces a new evaluation approach that avoids complex metrics . It examines context length, fact placement, anti-hallucination prompts, and model differences, exploring their impact on extraction, inference, and hallucination. Four large LLMs are evaluated to clarify these effects . The analysis focuses on four core dimensions:
-
Effective context length is defined as the maximum span of tokens that a model can meaningfully utilize (that is, actually use for factual retrieval or inference as opposed to merely accept as input).
-
Fact distribution, which examines how the spatial and statistical arrangement of relevant information across a corpus influences literal extraction, logical inference, and hallucination risks.
-
Hallucination behavior under constraint, analyzing how explicit anti-hallucination prompts alter model outputs, including conservative failure modes and omission errors.
-
Identifying the LLM from the ones tested that has optimal performance vis-‘a-vis the three aforementioned metrics.
The experimental design extends NIAH by separating literal extraction and logical inference. It introduces probabilistic fact distributions, such as the normal and exponential information distributions across a corpus, which better mimic real documents . The “Safety Tax”, the trade-off between lowering hallucinations and reducing extraction or inference, is measured by comparing outputs with and without anti-hallucination prompts. In other words, safety tax is the measurable degradation in literal extraction and logical inference accuracy that occurs when explicit anti-hallucination constraints trigger over-conservative refusal behaviors despite the information being present in the input context. This clarifies the model’s performance and reliability with respect to these criteria .
Findings show that a longer context does not guarantee better performance. Performance drops when relevant information is diluted, even when it is present. Models vary in robustness to realistic distributions . Anti-hallucination prompts reduce hallucinations but can also suppress correct, inference-heavy responses, showing a trade-off in conservative behavior .
Organizations rapidly adopting Generative AI often feed large, unfiltered corpora into their LLMs, making LLM outputs influential in decision-making. Failures stem more from poor model choice, context use, and safety calibration than missing information. Prioritizing effective context length and robustness to fact distribution for reliable long-context LLM use.
Related Work
Early observations of long-context LLMs, followed by empirical evidence, have demonstrated that LLMs struggle when fed a long input document for several potential reasons, including attention dilution, training distribution mismatch, and architectural constraints . A well-known phenomenon, referred to as “U-shaped memory,” shows strong positional biases in attention: LLMs perform better when relevant information is placed at the beginning or end of the input context, whereas the middle performs significantly worse . Studies have confirmed that these models’ lack of attention to the middle of the context worsens as context length increases, leading to missed information and increased hallucinations . Recent frameworks have expanded this to the “lost-in-the-later” effect, where models deprioritize information in the latter part of the context .
More recent studies have shown the same pattern in multi-turn conversations, where LLMs get lost due to the continuous accumulation of context, leading to a drastic decline in task accuracy . Plus, these findings suggest that long-context failures are not solely due to architectural design but may also stem from limitations in how these LLMs prioritize compressing and retaining information across extended sequences, often failing as the “instruction distance” increases .
The needle-in-a-haystack test has become a de facto standard for examining LLMs’ long-context abilities. Greg Kamradt pioneered the test as an improvised “pressure test” to see whether LLMs could leverage massive context windows . He famously used it to evaluate GPT-4 after OpenAI increased its context window to 128,000 . While useful as a stress test, this benchmark typically relied on single-point, literal extraction of a random fact that does not belong in the surrounding text . This offered limited insight into reasoning over distributed evidence, as is the case in most real-world scenarios . Our work builds on these ideas by introducing multiple facts with controlled corpus-level distributions. We explicitly separate extraction from inference and measure hallucination under both permissive and conservative prompting regimes. Recent extensions have addressed the gap by evaluating long-context LLMs through sequential needle extraction and semantic inference . Other research focused on context length, hallucination, and missing information , or extended testing to the 1 million token limit .
A multitude of studies have focused on the difference between parametric knowledge (stored in the model weights) and contextual knowledge supplied at inference time . As the context length increases, LLMs may default to parametric priors rather than probing into provided contextual evidence , maintaining a consistent reliance ratio of approximately 70% contextual to 30% parametric knowledge . This is more often the case when the contextual evidence is less explicit or more dispersed, frequently leading to the “Two-Hop Curse” where models fail to perform latent multi-hop reasoning without explicit intermediate steps . This finding has been further corroborated in multilingual or multi-domain use cases, where aligning contextual clues is harder .
Despite these observations, the distribution of performance remains sparse due to the lack of a systematic evaluation. Most of the literature focuses on varying context lengths rather than on how information structure affects results; other studies suggest that the specific ordering of that information are equally critical for successful reasoning . Our work specifically demonstrates that altering the distributional properties of evidence, such as the relative density and positioning of relevant facts, impacts downstream performance, providing key insights into context structuring .
Hallucination has been widely studied, and researchers have developed numerous mitigating strategies such as retrieval-augmented generation (RAG), self-consistency, and chain-of-thought prompting . Chain-of-thought reasoning can improve performance in some tasks, but its effectiveness in reducing hallucination, especially in long-context settings, is contested . Although anti-hallucination prompt engineering is common in instructions and courses, production systems have not received sufficient quantitative scrutiny, with human-verified benchmarks showing up to 40% hallucination rates in SOTA models . Recent studies have shown over-conservatism and abstention, leading to failure to answer even obvious and explicit questions . Our study formalizes this phenomenon by measuring the trade-off between hallucination reduction and accuracy loss, framing it as a safety tax that varies across models and task types .
Finally, several works have drawn analogies between LLMs’ in-context inference-time behavior and human memory systems . These studies show that overwhelming the memory with irrelevant or unwanted information promotes forgetting important data, a phenomenon called “more is less” . Some analyses also argue that LLMs display human memory-like behavior, such as recent findings of U-shaped memory, despite lacking similar mechanisms . These perspectives offer a lens on our findings: when models are overloaded with poorly structured, scattered context, the salience of relevant facts drops, increasing the risks of omission and hallucination .
Methodology
Experimental Design and Evaluation Framework
To rigorously evaluate long-context performance, we extend the traditional “Needle-in-a-Haystack” paradigm to account for realistic literal extraction challenges. Rather than on relying solely on uniform fact placement, which may artificially simplify the task, we introduce varying “haystack” topologies governed by probabilistic distributions. As illustrated in Figure 1, our framework manipulates four key variables: context length (up to the model’s maximum limit), information depth (position within the context), prompt sensitivity, and the statistical distribution of “needles” (facts).
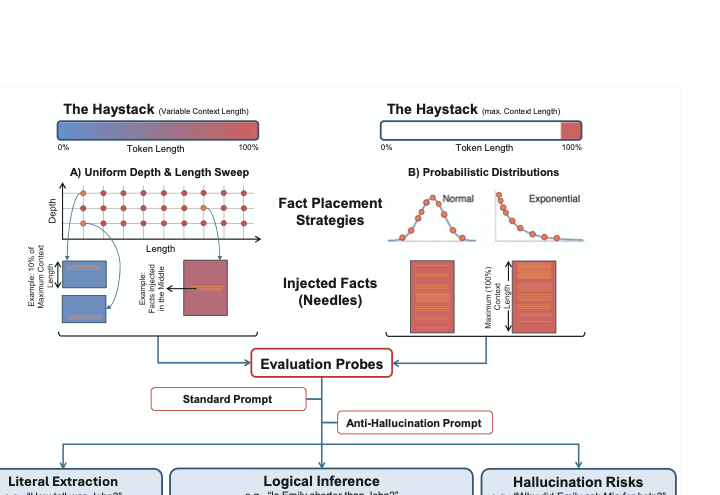 style="width:95.0%" />
style="width:95.0%" />
We specifically test two distinct prompting strategies: a Standard Prompt that asks for the answer directly, and an Anti-Hallucination Prompt (“Don’t Make It Up”) that explicitly instructs the model to refuse answering if the information is not present. This dual-probe approach allows us to disentangle extraction failures from hallucination risks, measuring not only whether a model retrieves the correct information (Literal Extraction), but also its ability to infer upon information (Logical Inference) and its adherence to truth (Faithfulness).
In this study, literal extraction refers to the accurate identification and reproduction of facts that are explicitly present in the input context at inference time, appearing verbatim and requiring no semantic transformation or inference. Logical inference, by contrast, refers to non-abductive reasoning over one or more provided facts to derive conclusions that are entailed or directly supported by the evidence, rather than plausible explanations unsupported by the input .
Corpus Construction and Processing
To ensure the “haystack” presents a realistic cognitive load, we constructed a large-scale narrative dataset derived from Honoré de Balzac’s La Comédie Humaine. The initial corpus comprises the first 38 novels, loosely connected and set in 19th-century France, sourced from the public domain via Project Gutenberg. Long-form narrative fiction presents a challenging retrieval environment, characterized by complex entity relationships and sustained discourse, in contrast to repetitive synthetic corpora and traditional needle-in-a-haystack tests, where the needle is semantically incongruent with the surrounding text.
The raw corpus contains approximately 2,000,000 tokens (measured via
tiktoken). To generate variable context lengths without breaking
narrative coherence, we employed a piece-wise Recursive Context
Contraction method. The base corpus was sliced into segments and
summarized to meet specific target token counts (e.g., contracting a
100k segment by 20% to yield 80k tokens). This allowed us to produce
naturalistic haystacks at fractions of, and up to, the maximum context
window size of each model while preserving the semantic flow of the
text.
Model Configuration and Hyperparameters
We evaluated four production-scale models, selected to represent the current state-of-the-art in long-context processing. Table 1 details the maximum context window size of each model.
| Model | Max Context (Tokens) |
|---|---|
| Gemini-2.5-flash | 1,000,000 |
| ChatGPT-5-mini | 272,000 |
| Claude-4.5-haiku | 175,000 |
| Deepseek-v3.2-chat | 128,000 |
Model Name and Maximum Context Window Size. Note: Claude-4.5-haiku
tokens are reported using tiktoken; the native limit is approximately
200k.
To ensure reproducibility and minimize hallucination variance, we enforced a deterministic decoding strategy where the API permitted. The hyperparameters were standardized as follows:
-
Temperature: $`0.0`$ – To maximize determinism and reduce creative drift.
-
Top_p: $`1.0`$ – To consider the full probability mass of the logits.
-
Frequency Penalty: $`0.0`$ – To prevent the model from being penalized for repeating specific entity names (needles) essential for the answer.
-
Presence Penalty: $`0.3`$ – A slight penalty was applied to subtly encourage the model to attend to new tokens present in the input context rather than reverting to high-probability generic responses from its parametric memory.
Evaluation Probes and Prompt Engineering
Our evaluation relies on a “Quiz” paradigm, where we inject story-congruent factual elements (“needles”) into a narrative context (“haystack”) and evaluate the model using a set of 30 questions. The model is explicitly instructed to adopt the persona of a person who has read the story carefully and is prepared to answer detailed questions about it.
To ensure objective scoring and automated parsability, the prompt enforces strict output constraints:
-
Inference Logic: The model is directed to review the story for relevant information. If the answer is not explicitly stated, it must provide the most logical answer or a reasonable inference based on the context.
-
Strict Formatting: Answers must be provided in the format “Question X: [ANSWER]”, with each answer on a separate line. The final output must contain only the answers, without any additional explanation or commentary.
As outlined in Section 3.1, we implemented two specific prompt conditions using this template:
-
Standard Prompt: A direct instruction asking the model to answer the questions based on the provided story using the constraints described above.
-
Anti-Hallucination (AH) Prompt: Identical to the Standard Prompt but augmented with strict negative constraints (e.g., “Do not guess,” “If the answer is not explicitly in the text, state that you do not know”).
The full templates for both the Standard and Anti-Hallucination prompts are provided in Appendix 8. Additionally, to ensure objective scoring, all model responses were graded by an independent LLM judge using a standardized Grading Prompt (also provided in Appendix 9) and a strict answer key.
Experimental Protocols
We conducted two distinct sweeps to stress-test the models’ literal extraction, logical inference and faithfulness.
Protocol A: Uniform Depth and Length Sweep
This protocol evaluates performance as a function of context saturation and information position (see Figure 1A).
-
Context Length ($`i`$): We swept context lengths from 10% to 100% of each model’s maximum capacity in 10% increments ($`i \in [10, 20, \dots, 100]`$).
-
Fact Depth ($`j`$): A single paragraph containing all target facts was injected at relative depths ranging from 10% to 100% of the total context ($`j \in [10, 20, \dots, 100]`$).
This resulted in a dense grid of 200 quizzes per model (10 lengths $`\times`$ 10 depths $`\times`$ 2 prompt conditions), allowing us to map the precise “failure frontiers” where models lose track of information.
Protocol B: Probabilistic Distribution Analysis
Real-world information is rarely concentrated in a single contiguous block. To simulate realistic dispersion, we designed a “Distributed Needle” protocol (see Figure 1B). In this setup, ten distinct fact sentences were scattered across the full context window (100% length) according to nine statistical distributions, each implemented to be as close as possible to its nominal form: Uniform, Normal, Exponential, Exponential Flipped, Bimodal Gaussian Mixture, Arcsine, Lorentzian, Rayleigh, and Rayleigh Flipped.
The haystack was divided into 20 segments (5% bins), and facts were injected into these bins based on the probability density function of each distribution. This yielded 18 additional quizzes per model (9 distributions $`\times`$ 2 prompt conditions), testing whether models bias their attention toward specific regions (e.g., the beginning or end) when information is sparse and scattered.
Results and Analysis
Aggregate Model Performance and Context Frontiers
To establish a baseline for long-context capabilities, we evaluate the four models across a bivariate sweep of context length and information depth. Table 2 summarizes the performance, reporting both the aggregate accuracy across all tested conditions (Aggregate) and the specific performance observed at the model’s maximum token capacity (Capacity). This distinction allows us to isolate how behavior changes as models approach their architectural limits.
max width=, center
| Model | Max Context | Prompt | Literal Extr. (%) | Logical Inf. (%) | Faithfulness (%) | |||
|---|---|---|---|---|---|---|---|---|
| 4-5 (lr)6-7 (lr)8-9 | (Tokens) | Aggregate | Capacity | Aggregate | Capacity | Aggregate | Capacity | |
| Gemini-2.5-flash | 1,000,000 | S | 98.4 | 99.0 | 98.5 | 98.0 | 86.5 | 86.0 |
| AH | 98.0 | 97.0 | 98.9 | 99.0 | 87.0 | 86.0 | ||
| ChatGPT-5-mini | 272,000 | S | 96.4 | 89.0 | 95.8 | 88.0 | 74.1 | 73.0 |
| AH | 90.3 | 72.0 | 92.1 | 68.0 | 89.8 | 90.0 | ||
| Claude-4.5-haiku | 175,000 | S | 78.7 | 68.0 | 58.5 | 48.0 | 83.2 | 78.0 |
| AH | 78.8 | 67.0 | 58.0 | 48.0 | 82.4 | 77.0 | ||
| Deepseek-v3.2-chat | 128,000 | S | 99.4 | 99.0 | 93.6 | 92.0 | 86.7 | 84.0 |
| AH | 98.7 | 97.0 | 94.0 | 94.0 | 91.2 | 86.9 | ||
We observe a distinct bifurcation in reliability at scale. Gemini-2.5-flash and Deepseek-v3.2-chat demonstrate remarkable stability; their performance at the context frontier (Capacity) is nearly identical to, or in some cases slightly better than, their global average. For instance, Gemini-2.5-flash maintains a Logical Inference score of 98.0% even at one million tokens, closely tracking its global aggregate score of 98.5%.
In contrast, other models exhibit clear signs of strain at their maximum capacity. Claude-4.5-haiku shows a notable degradation in literal extraction at its 175k token limit (68.0%) compared to its global average (78.7%). Furthermore, the safety tax introduced by Anti-Hallucination (AH) prompts becomes disproportionately severe at the context frontier. While ChatGPT-5-mini achieves a respectable global aggregate score of 90.3% for literal extraction under AH prompting, its performance drops sharply to 72.0% at its maximum context of 272k tokens. This divergence between Aggregate and Capacity scores suggests that while safety mechanisms remain effective in shorter contexts, they induce excessive refusal behaviors when models are pushed to their token limits.
Scalability and the Impact of Context Length
We next investigate whether performance degradation is linear with respect to input context size. Figure 2 illustrates the trajectory of performance as context length scales from 10k to 1M tokens (where supported). For each context length, the reported performance is averaged across all tested fact placement depths. Contrary to the assumption that models support their full context window equally, we find that performance is rarely uniform. Gemini-2.5-flash and Deepseek-v3.2-chat maintain near-perfect stability across their entire range. However, Claude-4.5-haiku exhibits early instability, with extraction and inference performance becoming volatile beyond the 100k token mark. ChatGPT-5-mini shows a “performance cliff,” where performance remains stable up to approximately 100k tokens before degrading sharply as it approaches its limit. This indicates that effective context length, the length at which literal extraction is reliable, is often significantly shorter than the technical maximum advertised.
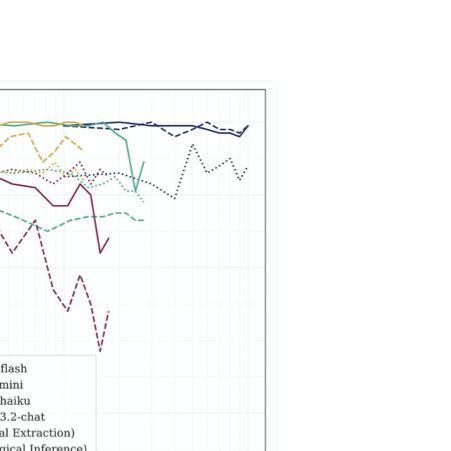 style="width:50.0%" />
style="width:50.0%" />
Positional Bias and Depth Sensitivity
To understand how the spatial location of information impacts model performance, we analyzed the average performance as a function of fact depth (Figure 3). This analysis aggregates performance across all context lengths to isolate positional sensitivity from total context volume.
Our results reveal distinct behaviors across the four models:
-
Gemini-2.5-flash and Deepseek-v3.2-chat: Both models demonstrate high robustness to positional bias. While Deepseek-v3.2-chat maintains near-perfect accuracy for literal extraction across all depths, Gemini-2.5-flash shows a slight, uniform degradation in faithfulness but remains the most consistent overall.
-
ChatGPT-5-mini: This model exhibits a unique “performance cliff” at the 50% depth mark. While performance is near 100% at the beginning and end of the context, accuracy for both literal extraction and logical inference tasks drops sharply to approximately 80% at the exact midpoint, suggesting a specific architectural sensitivity to middle-positioned tokens.
-
Claude-4.5-haiku: Of all models tested, Claude-4.5-haiku exhibits the most pronounced “U-shaped” performance curve, characteristic of the “lost-in-the-middle” phenomenon. This is particularly visible in the logical inference, where accuracy drops to nearly 50% between the 20% and 60% depth intervals before recovering toward the end of the context window.
 style="width:95.0%" />
style="width:95.0%" />
These findings suggest that while literal extraction is increasingly becoming a solved problem for top-tier models, logical inference remains highly sensitive to the relative position of the evidence within the context.
Contextual Failure Modes and Prompt Sensitivity
To probe the literal extraction performance, we visualize the interaction between context length, fact depth, and prompting strategy in Figure 4.
 style="width:95.0%" />
style="width:95.0%" />
Under standard prompting (Panel a), Gemini-2.5-flash and Deepseek-v3.2-chat remain largely consistent (green), with only minor, sporadic errors. However, under Anti-Hallucination prompting (Panel b), a distinct failure pattern emerges for ChatGPT-5-mini. We observe a “red zone” of systematic failure in the middle-to-late depth regions (40-100%) once the context length exceeds roughly 60% of its maximum. This confirms that the performance drop observed in Table 2 is not random but structurally tied to specific context configurations. Similar heatmaps detailing both logical inference accuracy and faithfulness are provided in Appendix Figures 7 and 8.
Safety at a Price: Hallucination Mitigation and Performance Degradation
We quantify the net impact of restricting model creativity in Figure 5, which displays the performance delta ($`\Delta`$) when switching from Standard to Anti-Hallucination prompts. Blue indicates improvement (reduced hallucinations), while red indicates degradation (refusal to answer valid queries). Panel (a) clearly visualizes the safety tax paid by ChatGPT-5-mini: the deep red blocks indicate substantial drops in literal extraction accuracy, suggesting the model frequently defaults to a refusal response when the needle is buried deep in the context. Conversely, Deepseek-v3.2-chat and Claude-4.5-haiku show a mix of blue and light red, indicating a more complex trade-off where faithfulness improves (Panel c) without catastrophically sacrificing extraction capabilities.
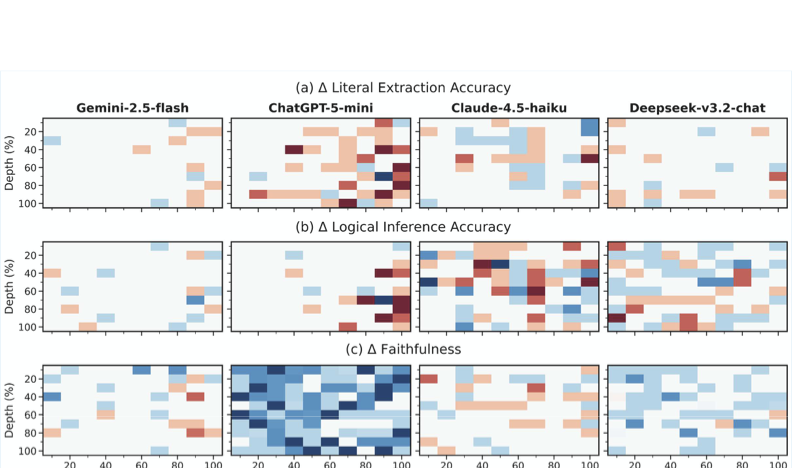 style="width:95.0%" />
style="width:95.0%" />
Robustness to Real-World Fact Distributions
To move beyond simple needle-in-a-haystack tests, we evaluated the spatial invariance of model performance across nine distinct statistical distributions of fact placement. Figure 6 presents the resulting “performance signatures” for the four frontier models across three critical metrics: Literal Extraction, Logical Inference, and Faithfulness (raw data provided in Appendix Table 3). The results highlight a critical vulnerability in ChatGPT-5-mini: e.g., under “Normal” and “Lorentzian” distributions, where information is clustered centrally, its performance collapses to 0% in Literal Extraction and Logical Inference under Anti-Hallucination prompts. This catastrophic failure suggests that when evidence is concentrated rather than spread out, the model’s attention mechanism (or safety filter) may flag the dense cluster as noise or irrelevant context. In contrast, Gemini-2.5-flash and Deepseek-v3.2-chat maintain high robustness (polygon coverage approaching the outer edge) regardless of how the facts are statistically distributed across the haystack.
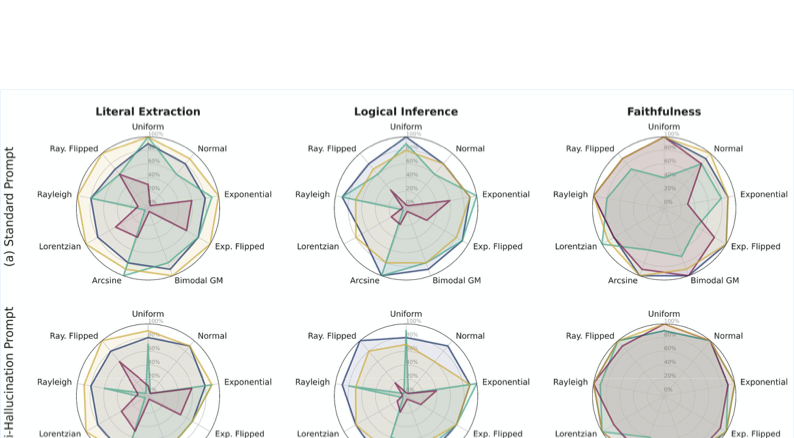 style="width:100.0%" />
style="width:100.0%" />
Discussion
Our findings show that, for this specific use case, models from Google and DeepSeek demonstrate stronger long-context handling than those from OpenAI or Anthropic. Google’s model offers a much larger effective context length. These results challenge existing assumptions and partially confirm the view that sufficiently advanced long-context LLMs can streamline or replace Retrieval-Augmented Generation (RAG) in operational workflows.
From an operational perspective, some long-context LLMs continue to face challenges with accurate literal extraction, logical inference, and faithfulness. These limitations become more pronounced when safety-focused prompts, intended to reduce hallucinations and replace RAG-style grounding, trigger refusal behaviors that obstruct correct outputs. While RAG systems are not immune to hallucinations, a well-designed and optimized RAG pipeline typically resolves issues without introducing over-refusal or negatively affecting literal extraction and logical inference, which are critical to real-world business applications.
The results indicate that Google is nearing enterprise-ready reliability for long-context performance, with capabilities that begin to approximate RAG-like grounding in practical settings. For business decision-makers, future benchmarking should directly compare these results, along with cost and response time, against mature RAG solutions. Crucially, this study focuses on models that deliver moderate reasoning at lower cost and latency, since these reflect the trade-offs prioritized in AI solutions development and their business deployments, where operational efficiency often outweighs minor gains in reasoning quality.
When testing long-context performance, we identify a key limitation of needle-in-a-haystack benchmarks. These benchmarks depend on hiding a single fact within a large mass of irrelevant text. However, they fail to reveal distributional collapse, in which model performance degrades when relevant information is unevenly distributed across a corpus. Real-world enterprise applications require models that are robust across various information distributions, not merely idealized retrieval conditions.
Our study shows that Claude-4.5-haiku and ChatGPT-5-mini exhibit similar surface-level degradation trends under long-context stress. As shown in Figure 3, when relevant information varies across the corpus, both models demonstrate the well-documented lost-in-the-middle effect . In this effect, recall of centrally located information declines due to positional biases favoring primacy and recency .
As shown in Figure 2, increasing context length produces a sharp performance cliff for both models, although their failure characteristics differ. In ChatGPT-5-mini, literal extraction degrades more rapidly than logical inference. In Claude-4.5-haiku, both degrade simultaneously. These patterns suggest different forms of information reduction or attention limits under long-context pressure, though no claim is made regarding specific internal mechanisms.
Figure 6 further demonstrates distributional fragility in both models. Claude-4.5-haiku exhibits more severe degradation, with performance becoming highly sensitive to information placement. When content is unevenly distributed, both literal extraction and logical inference degrade sharply.
In contrast, Gemini-2.5-flash and DeepSeek-v3.2-chat show substantially stronger robustness across different information distributions. These models maintain semantic continuity over long contexts, avoid catastrophic performance drops, and exhibit more stable behavior across varied conditions.
Figure 5 shows that anti-hallucination prompts impose a significant performance penalty on ChatGPT-5-mini. This manifests as safety over-refusal, in which the model refuses valid queries when its internal confidence falls below conservative thresholds. Prior work shows that safety prompts demand strict retrieval confidence . Under long-context pressure, internal representations weaken, and accurate information may fail to meet these thresholds, resulting in refusals and substantial performance degradation.
Taken together, our findings indicate that long-context reliability is not solely a function of nominal context window size, but rather of how models manage and preserve information internally. Models that rely on selective retention and rigid sparsity tend to trade literal recall and safety calibration for efficiency, leading to performance cliffs and over-refusal. In contrast, models employing attributes such as adaptive attention, distributed computation, and stronger semantic continuity exhibit greater robustness at scale. These results underscore the importance of architectural strategies that preserve semantic structure across long sequences for reliable deployment in extended-context settings.
Overall, these findings demonstrate that expanding context windows alone does not eliminate the need for retrieval, careful model selection, or prompt design. While improvements in long-context handling are narrowing the gap between long-context LLMs and RAG systems, hybrid approaches remain essential for reliability, safety, and scalability. Future research should develop evaluation frameworks that explicitly measure distributional robustness, positional bias, and the trade-off between faithfulness and reasoning, particularly for mission-critical and high-stakes applications.
Limitations
Several limitations bound the findings of this study. First, given the rapid pace of model development and the associated computational and financial costs, our evaluation was restricted to four specific production-scale models (Gemini-2.5-flash, ChatGPT-5-mini, Claude-4.5-haiku, and Deepseek-v3.2-chat); while these represent the current frontier, results may differ for larger parameter variants or emerging open-source architectures. Second, our choice of metrics, literal extraction, non-abductive logical inference, and faithfulness was selected from an ever-expanding array of evaluation frameworks as those most critical for general-purpose grounding, yet other dimensions of long-context performance remain unexplored. Third, the use of a narrative literary corpus (Honoré de Balzac’s La Comédie Humaine) provides a challenging general-purpose testbed, but LLM behavior may shift significantly in specialized domains such as healthcare, legal documentation, or software engineering, where structural and linguistic patterns differ. Furthermore, due to resource constraints, we did not perform exhaustive statistical significance testing across all prompt variations and fact distributions; thus, while our results highlight clear performance trends, they should be interpreted as a high-resolution snapshot rather than a definitive statistical proof. Finally, although we standardized hyperparameters (e.g., temperature and penalties) to ensure comparability, we acknowledge that model performance can be sensitive to specific decoding regimes, and alternative configurations might yield different failure frontiers or robustness profiles.
Conclusion
In this study, we systematically analyzed the performance frontiers of long-context Large Language Models. We uncovered a significant divergence between nominal context windows and effective information utilization. Our evaluation included four frontier models: Gemini-2.5-flash, ChatGPT-5-mini, Claude-4.5-haiku, and Deepseek-v3.2-chat. As token counts scale, some models show “performance cliffs” or positional biases, such as the “lost-in-the-middle” effect. These issues are especially apparent in higher-order logical inference tasks. We identify a measurable “Safety Tax”: explicit anti-hallucination prompts can induce over-conservative refusal behaviors. We also observe a “Distributional Collapse,” in which models struggle when relevant evidence is dispersed across the corpus rather than concentrated in more favorable locations. Gemini-2.5-flash and Deepseek-v3.2-chat exhibit high robustness and spatial invariance throughout their context windows. In contrast, other models exhibit distributional fragility, suggesting that expanding context capacity alone is not sufficient for reliable enterprise deployment. These findings underscore the need for evaluation frameworks that prioritize distributional robustness and semantic continuity. Such frameworks can help ensure reliable extraction and inference of evidence in large, uncurated contexts. The stability shown by top-tier models is promising and suggests we are close to achieving the grounding and precision of Retrieval-Augmented Generation (RAG) systems that long-context LLMs reliably approximate.
Funding and Disclosure
This research was conducted entirely with independent personal funding. The authors declare that no financial support, grants, compute credits, or preferential API access were received from any of the AI model providers evaluated in this study (Google, OpenAI, Anthropic, or DeepSeek). The research, analysis, interpretations, and conclusions presented herein were conducted in a personal capacity and reflect solely the views of the authors. They do not represent the views, positions, or policies of the authors’ current or past employers or affiliated institutions, which were not involved in, did not sponsor, and did not review this work.
Evaluation Prompt Templates
Standard Prompt
You are a person who has read the following story carefully with all details to be able to answer questions about it:
<story> {STORY} </story>
Now, you will answer the following questions based on the story you just read:
<questions> {QUESTIONS} </questions>
Instructions for answering:
-
Read each question carefully.
-
Review the story to find the relevant information.
-
If the information is not explicitly stated in the story, respond with the most logical answer that can be directly and clearly inferred from the text without adding new assumptions.
Provide your answers in the following format:
Question 1: [YOUR ANSWER]
Question 2: [YOUR ANSWER]
…
Question 8: [YOUR ANSWER]
Each answer must be on a separate line.
Your final output should consist of only the answers in the specified format, without any additional explanation or commentary.
Anti-Hallucination Prompt
You are a person who has read the following story carefully with all details to be able to answer questions about it:
<story> {STORY} </story>
Now, you will answer the following questions based on the story you just read:
<questions> {QUESTIONS} </questions>
Instructions for answering:
-
Read each question carefully.
-
Review the story to find the relevant information.
-
If the information is not explicitly stated in the story, respond with the most logical answer that can be directly and clearly inferred from the text without adding new assumptions.
-
If the information was neither explicitly nor implicitly mentioned, answer “Not mentioned in the text or story.” Any assumption, inference beyond the text, or hallucination is strictly prohibited. Don’t make it up.
Provide your answers in the following format:
Question 1: [YOUR ANSWER]
Question 2: [YOUR ANSWER]
…
Question 8: [YOUR ANSWER]
Each answer must be on a separate line.
Your final output should consist of only the answers in the specified format, without any additional explanation or commentary.
Grading Prompt Template
You are a strict grader.
You will be given:
-
An Answer Key containing the correct answers to 30 questions.
-
An Answer Sheet containing the Model’s answers to the same 30 questions, in the same order.
Grading Rules:
-
If the Model’s answer is completely correct and matches the Answer Key in meaning (paraphrases are allowed if they do not add, remove, or change information). $`\rightarrow`$ give 1 point.
-
If the Model’s answer is incorrect, partially correct, irrelevant, off-topic, a hallucination, or missing $`\rightarrow`$ give 0 points.
-
There is no partial credit.
Output Rules:
-
Output only the grades, one per line, from Question 1 to Question 30.
-
The output must contain exactly 30 lines.
-
Each line must be either 1 or 0.
-
Do not output anything else — no explanations, no extra text, no punctuation, no headings.
Answer Key:
{GROUND_TRUTH}
Model’s Answer Sheet:
{MODEL_RESPONSE}
Extended Performance Analysis
Granular Analysis of Logical Inference
While literal extraction measures basic fact identification, logical inference acts as a stricter stress test for long-context reasoning, requiring the model to often extract more than two distinct pieces of information and synthesize a conclusion. Figure 7 visualizes the logical inference accuracy across the full context-depth spectrum.
 style="width:95.0%" />
style="width:95.0%" />
Comparing this to literal extraction heatmaps (main text, Figure 4), we observe a steeper performance degradation for Claude-4.5-haiku under standard prompting, where accuracy wavers significantly in the 40-60% depth range (indicated by yellow/orange zones).
Most notably, the safety tax observed in ChatGPT-5-mini is even more pronounced here. Under the Anti-Hallucination condition (Panel b), the model exhibits a catastrophic loss of reasoning capability in the final quartile of context length and depth (bottom-right quadrant), indicated by the deep red regions where accuracy falls to near zero. This confirms that restrictive prompting can disproportionately impair higher-order reasoning tasks compared to simple literal extraction.
Faithfulness and Hallucination Patterns
To understand the inverse of extraction failure, we examine the faithfulness of model responses, specifically the ability to correctly identify when information is absent. Figure 8 details the faithfulness scores, where higher intensity (green) indicates successful adherence to the “don’t make it up” constraint. Under Standard Prompts, most models show high faithfulness, though sporadic hallucinations (lighter green) appear in Claude-4.5-haiku at lower depths.
 style="width:95.0%" />
style="width:95.0%" />
The introduction of Anti-Hallucination prompts (Panel b) universally tightens this behavior, pushing most models toward near-perfect faithfulness (dark green). However, when viewed alongside the extraction failures, this visual confirms that the high faithfulness scores for ChatGPT-5-mini in complex contexts are likely false positives; the model is “faithful” simply because it refuses to answer, not because it correctly discriminated between presence and absence.
Detailed Distributional Robustness
To determine if models remain reliable under realistic, non-uniform information densities, we evaluated performance across nine distinct fact distributions (e.g., Normal, Exponential, or Lorentzian) as visualized in Figure 6. The raw numerical data supporting these radar charts is detailed in Table 3. Crucially, these stress tests were conducted exclusively at 100% of each model’s maximum context limit, representing the most challenging deployment scenario where attention mechanisms are stretched to their full capacity and positional biases are most acute.
The results reveal a sharp divergence in model behavior when facts are clustered rather than uniformly spread. Most notably, ChatGPT-5-mini exhibits a structural fragility we term “Distributional Collapse.” Distributional collapse identifies the specific failure mode where an LLM’s retrieval and reasoning performance degrades because the relevant facts are dispersed and scattered across the corpus rather than being a single factoid placed at a single location. While the model performs adequately on Uniform or Exponential distributions, its retrieval capabilities evaporate under distributions such as “Normal” and “Lorentzian,” ones whose information is concentrated heavily in the center of the context window. Applying Anti-Hallucination (AH) prompts drives ChatGPT-5-mini’s Literal Extraction and Logical Inference scores to exactly 0.0% in these information distributions. This suggests that the model’s safety filters may aggressively misinterpret dense clusters of relevant evidence as redundant noise or hallucination risks, a critical vulnerability for enterprise workflows involving ranked or sorted document sets.
Claude-4.5-haiku presents a distinct failure mode characterized by the decoupling of extraction from reasoning. Although the model retains partial extraction capabilities across most distributions (typically maintaining 30-60% accuracy), its ability to perform Logical Inference frequently collapses to near zero, particularly under Uniform and Normal distributions (0% accuracy). This results in a “hollow” performance profile in the radar charts, indicating that even when the model can technically locate the needle, the cognitive load imposed by the distribution prevents it from successfully synthesizing that information into a valid conclusion.
G: Gemini-2.5-flash | C: ChatGPT-5-mini | K: Claude-4.5-haiku | D: Deepseek-v3.2-chat
| Distribution | Prompt | Literal Extr. (%) | Logical Inf. (%) | Faithfulness (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3-6 (lr)7-10 (lr)11-14 | G | C | K | D | G | C | K | D | G | C | K | D | |
| Uniform | S | 90 | 100 | 30 | 100 | 100 | 90 | 0 | 80 | 100 | 40 | 100 | 100 |
| AH | 80 | 70 | 10 | 90 | 80 | 90 | 0 | 70 | 90 | 90 | 100 | 100 | |
| Normal | S | 80 | 60 | 0 | 90 | 80 | 60 | 0 | 80 | 90 | 80 | 80 | 100 |
| AH | 90 | 0 | 0 | 90 | 90 | 0 | 0 | 60 | 100 | 100 | 100 | 100 | |
| Exponential | S | 80 | 90 | 60 | 100 | 90 | 100 | 60 | 90 | 90 | 80 | 30 | 90 |
| AH | 80 | 90 | 60 | 90 | 90 | 100 | 40 | 90 | 100 | 90 | 90 | 100 | |
| Exp. Flipped | S | 80 | 80 | 60 | 100 | 90 | 90 | 30 | 80 | 100 | 50 | 80 | 100 |
| AH | 70 | 70 | 50 | 70 | 80 | 80 | 20 | 80 | 100 | 100 | 90 | 100 | |
| Bimodal GM | S | 90 | 80 | 0 | 100 | 90 | 80 | 0 | 80 | 100 | 70 | 100 | 90 |
| AH | 80 | 80 | 0 | 80 | 90 | 80 | 0 | 70 | 100 | 90 | 100 | 90 | |
| Arcsine | S | 80 | 100 | 40 | 90 | 100 | 100 | 20 | 80 | 100 | 60 | 90 | 100 |
| AH | 90 | 70 | 50 | 90 | 100 | 60 | 20 | 80 | 100 | 60 | 90 | 100 | |
| Lorentzian | S | 80 | 0 | 50 | 100 | 70 | 0 | 20 | 80 | 80 | 100 | 80 | 90 |
| AH | 80 | 0 | 40 | 100 | 80 | 0 | 10 | 80 | 100 | 100 | 80 | 100 | |
| Rayleigh | S | 80 | 80 | 10 | 100 | 90 | 90 | 0 | 70 | 100 | 80 | 100 | 100 |
| AH | 80 | 60 | 10 | 90 | 90 | 80 | 0 | 70 | 100 | 90 | 100 | 100 | |
| Ray. Flipped | S | 70 | 60 | 60 | 100 | 80 | 60 | 30 | 70 | 90 | 70 | 90 | 90 |
| AH | 80 | 0 | 60 | 100 | 100 | 0 | 20 | 80 | 100 | 100 | 90 | 100 | |
In contrast, Gemini-2.5-flash and Deepseek-v3.2-chat demonstrate high distributional invariance, forming broad, consistent polygons in Figure 6. Their performance remains robust (consistently $`>80`$–$`90\%`$) regardless of whether facts are biased toward the start (Exponential), the middle (Normal), or spread evenly (Uniform). This indicates that their attention mechanisms are significantly more resilient to the “distractor” noise inherent in varied document structures, rendering them safer choices for processing uncurated, large-scale contexts where the location of key evidence cannot be predicted.
📊 논문 시각자료 (Figures)