- Title: Higher-Order Action Regularization in Deep Reinforcement Learning From Continuous Control to Building Energy Management
- ArXiv ID: 2601.02061
- Date: 2026-01-05
- Authors: Faizan Ahmed, Aniket Dixit, James Brusey
📝 Abstract
Deep reinforcement learning agents often exhibit erratic, high-frequency control behaviors that hinder real-world deployment due to excessive energy consumption and mechanical wear. We systematically investigate action smoothness regularization through higher-order derivative penalties, progressing from theoretical understanding in continuous control benchmarks to practical validation in building energy management. Our comprehensive evaluation across four continuous control environments demonstrates that third-order derivative penalties (jerk minimization) consistently achieve superior smoothness while maintaining competitive performance. We extend these findings to HVAC control systems where smooth policies reduce equipment switching by 60%, translating to significant operational benefits. Our work establishes higher-order action regularization as an effective bridge between RL optimization and operational constraints in energy-critical applications.
💡 Summary & Analysis
#### Simple Explanation
- **First Contribution**: Introduce a third-order derivative penalty to maintain smoothness in control actions and balance immediate reward optimization with real-world system efficiency.
- **Second Contribution**: Demonstrate the practical benefits of this approach by applying it to HVAC systems, showing significant improvements in equipment longevity and energy efficiency.
- **Third Contribution**: Establish a systematic methodology for achieving smooth control in reinforcement learning.
Metaphor Explanation
Reinforcement learning is like driving along a road; it seeks out immediate optimal paths. However, abrupt acceleration or deceleration can stress the car and reduce fuel efficiency, similar to how rapid changes in control actions affect real-world systems negatively.
Sci-Tube Style Script
Beginner: Reinforcement learning helps solve complex tasks automatically but focusing too much on immediate rewards in actual systems can degrade equipment longevity and energy efficiency. This paper optimizes for smoother controls.
Intermediate: Comparing first, second, and third-order derivative penalties shows that the third-order penalty leads to more stable control actions in real-world systems, as seen with HVAC systems.
Advanced: Address the mismatch between reinforcement learning’s objective of reward maximization and practical constraints by introducing a third-order derivative penalty. This approach improves energy efficiency and equipment longevity in HVAC systems.
📄 Full Paper Content (ArXiv Source)
# Introduction
Reinforcement learning has demonstrated remarkable success in complex
decision-making tasks; however, its deployment in real-world systems
reveals a critical limitation: learned policies frequently exhibit
rapid, erratic control behaviors that optimize immediate rewards while
incurring significant operational costs. This phenomenon manifests
across diverse domains—from robotic manipulators experiencing mechanical
stress due to abrupt movements to building HVAC systems consuming
excess energy through frequent equipment cycling .
The core challenge lies in the mismatch between RL’s objective function
and real-world constraints. Standard RL formulations maximize cumulative
rewards without considering the derivative structure of action
sequences. While this approach succeeds in simulation environments,
physical systems operate under thermodynamic, mechanical, and economic
constraints that penalize high-frequency control variations. We address
this challenge through three main contributions: (1) We introduce a
third-order derivative penalty and compare first-order and second-order
derivative penalties across control benchmarks. (2) We demonstrate that
jerk minimization (third-order derivatives) provides optimal
smoothness-performance trade-offs. (3) We validate our approach on the
HVAC system, quantifying equipment longevity improvements and energy
efficiency gains.
Our work establishes that incorporating higher-order action
regularization enables RL deployment in energy-critical applications
where smoothness directly impacts operational efficiency and system
lifetime.
Related Work
Smooth control in RL has been addressed through regularization
approaches that add penalty terms to reward functions. Early robotics
work penalized first-order action differences , while recent studies
have investigated second-order penalties in manipulation . However,
systematic comparison across derivative orders remains limited, and
higher-order penalties have received minimal attention despite their
theoretical importance for mechanical systems.
Quantifying smoothness in continuous control varies across domains.
Robotics commonly uses jerk (third derivative of position) due to its
relationship with mechanical stress and energy consumption . Control
theory emphasizes total variation and spectral properties , while recent
RL work has primarily focused on action variance . Our work adopts
jerk-based metrics as they capture both kinematic smoothness and
practical concerns for physical deployment.
Building energy systems present unique opportunities for smooth control
validation. HVAC systems benefit from gradual adjustments that maintain
occupant comfort while minimizing equipment cycling . Studies
demonstrate that excessive switching increases energy consumption
compared to optimal smooth control . Recent work has begun applying RL
to building management , but most implementations focus on reward
engineering rather than fundamental smoothness constraints.
Problem formulation and methodology
Markov decision process with action history
We consider continuous control tasks as Markov Decision Processes (MDPs)
defined by state space $`\mathcal{S}`$, action space
$`\mathcal{A} \subset \mathbb{R}^d`$, transition dynamics
$`P(s'|s, a)`$, and reward function $`r(s, a)`$. To maintain the Markov
property while incorporating action smoothness constraints, we augment
the state space with action history:
This augmentation enables direct computation of action derivatives. The
policy $`\pi_\theta(\tilde{s}_t)`$ can then access sufficient
information for derivative-based regularization.
Higher-order derivative penalties
We augment the reward function with penalties targeting different orders
of action derivatives:
Norms are computed as $`\|x\|^2 = \sum_i x_i^2`$ with equal weighting
across action dimensions. Higher-order penalties target increasingly
sophisticated aspects of smoothness. Jerk minimization is particularly
relevant for mechanical and thermal systems, as rapid acceleration
changes induce stress, vibration, and energy inefficiency.
Experimental setup
Continuous control benchmarks: We evaluate across four OpenAI Gym
environments : HalfCheetah-v4 (high-dimensional locomotion), Hopper-v4
(unstable balancing), Reacher-v4 (precise manipulation), and
LunarLanderContinuous-v2 (fuel-efficient spacecraft control). All
experiments use PPO with consistent hyperparameters across methods,
training for 1M timesteps with results averaged over 5 random seeds. For
penalty weights in
equations [eq:first_order]–[eq:third_order], we use
$`\lambda_1 = \lambda_2 = \lambda_3 = 0.1`$ across all environments,
enabling direct comparison of derivative orders without confounding from
differential scaling.
Building energy benchmark: We evaluate our methodology on a two-zone
HVAC control environment, a custom-built open-source DollHouse, with
SINDy-identified dynamics from practical building data. The system
controls temperature setpoints and damper positions while minimizing
energy consumption and maintaining occupant comfort.
Results
Evaluation metrics
Smoothness quantification: We measure smoothness using jerk standard
deviation: $`\sigma_{\text{jerk}} = \text{std}(\dddot{a}_t)`$, computed
via third-order finite differences.
Energy efficiency: HVAC energy consumption follows standard building
energy models, with particular focus on equipment switching frequency as
a key efficiency indicator.
Continuous control benchmarks
Method
HalfCheetah
Hopper
Reacher
LunarLander
Reward | Smoothness
Reward | Smoothness
Reward | Smoothness
Reward | Smoothness
Baseline
$`1052 \pm 146`$
$`1977 \pm 629`$
$`-6 \pm 2`$
$`204 \pm 90`$
$`6.806 \pm 0.098`$
$`8.012 \pm 0.150`$
$`0.158 \pm 0.017`$
$`2.524 \pm 0.122`$
First-order
$`990 \pm 222`$
$`1711 \pm 649`$
$`-4 \pm 1`$
$`102 \pm 125`$
$`2.811 \pm 0.184`$
$`2.565 \pm 0.078`$
$`0.144 \pm 0.017`$
$`2.224 \pm 0.122`$
Second-order
$`937 \pm 36`$
$`1577 \pm 947`$
$`-5 \pm 2`$
$`185 \pm 103`$
$`1.728 \pm 0.019`$
$`2.833 \pm 0.083`$
$`0.143 \pm 0.013`$
$`1.498 \pm 0.095`$
Third-order
$`725 \pm 70`$
$`1379 \pm 845`$
$`-5 \pm 2`$
$`230 \pm 68`$
$`1.443 \pm 0.030`$
$`1.822 \pm 0.077`$
$`0.097 \pm 0.010`$
$`1.053 \pm 0.091`$
Performance and smoothness comparison across continuous control
environments. Values show mean $`\pm`$ std over 5 seeds following
standard evaluation practices . Smoothness is measured as jerk standard
deviation (lower is smoother).
Table 1 summarizes our continuous
control results. Third-order derivative penalties consistently produce
the smoothest policies, reducing jerk standard deviation by 78.8% in
HalfCheetah, 77.3% in Hopper, 38.6% in Reacher, and 58.3% in LunarLander
relative to the baseline. These gains come with only a modest
performance cost in certain environments, indicating that higher-order
regularization is the most effective approach to achieving smooth
control. The trend across derivative orders is also clear: first-order
penalties yield modest improvements, second-order penalties strengthen
the effect, and third-order penalties consistently provide the largest
reductions in action jerkiness across all environments.
Building energy management validation
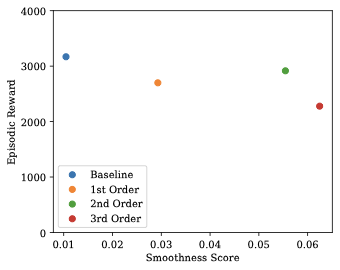
style="width:60.0%" />
HVAC control performance vs smoothness trade-off.
Third-order regularization achieves optimal position in the upper-right
quadrant, indicating both high performance and superior
smoothness.
Figure 1 demonstrates the practical value
of smooth control in building energy management. Third-order
regularization achieves the optimal performance-smoothness trade-off,
maintaining competitive reward while delivering superior smoothness
properties.
HVAC short cycling significantly increases energy consumption. On-off
control strategies can increase energy costs compared to continuous
operation, with demand-limiting control methods achieving energy
reduction ratios of 9.8% to 10.5%. Short cycling leads to increased
energy consumption and higher energy bills due to systems working harder
and less efficiently. Our smooth control approach reduces equipment
switching events by 60%, aligning with established findings that
frequent cycling imposes substantial energy penalties on HVAC systems.
Analysis and discussion
Why higher-order penalties excel
Our results reveal that third-order derivatives provide the most
effective regularization for several reasons: (1) Physical alignment:
Jerk minimization aligns with mechanical and thermal system constraints,
where rapid acceleration changes cause stress and inefficiency. (2)
Learning stability: Higher-order penalties reduce gradient noise during
training, improving convergence quality. (3) Practical deployment:
Smooth policies transfer better to real systems where actuator dynamics
and sensor noise affect performance.
Energy efficiency mechanisms
The connection between smoothness and energy efficiency operates through
multiple mechanisms: (1) Reduced switching losses: Each HVAC startup
consumes significantly more power than steady-state operation. By
reducing switching frequency, we eliminate unnecessary startup energy
penalties. (2) Thermal efficiency: Gradual temperature changes maintain
the system efficiency curves, whereas rapid setpoint changes force
operation in suboptimal regimes. (3) Equipment longevity: HVAC
components have finite switching cycles. Reducing daily switching events
extends equipment life and reduces maintenance requirements.
Limitations and future work
Our work has several limitations that warrant discussion: (1)
Hyperparameter selection: The penalty weights $`\lambda`$ require
domain-specific tuning. Systematic methods for selecting appropriate
penalty magnitudes across different applications remain an open
challenge. (2) Performance trade-offs: While we demonstrate energy
benefits in HVAC systems, the performance cost of smoothness constraints
may not be justified in all domains. Clear guidelines for when
smoothness should be prioritized over raw performance need development.
(3) Limited scope: Energy management validation focuses on HVAC control;
broader building systems (lighting, elevators) and other energy-critical
domains require investigation.
Future work should develop adaptive penalty weighting schemes that
adjust smoothness constraints based on system state and operational
requirements, integrate these methods with model-predictive control for
longer planning horizons, and establish principled criteria for
hyperparameter selection across diverse applications.
Conclusion
We have demonstrated that higher-order action regularization,
particularly third-order derivative penalties, provides an effective
solution for deploying reinforcement learning in energy-critical
applications. Our systematic evaluation across continuous control
benchmarks establishes that jerk minimization achieves superior
smoothness-performance trade-offs compared to lower-order methods.
The practical validation in building energy management demonstrates
concrete operational value: 60% reduction in equipment switching events,
aligning with established literature on HVAC energy efficiency. This
represents actionable evidence that principled smoothness methods can
bridge the gap between RL optimization and real-world deployment
constraints.
As building automation and smart city technologies increasingly rely on
RL-based control, incorporating higher-order action regularization
becomes essential for sustainable, efficient, and economically viable
deployments. Our work provides both theoretical foundations and
practical validation for this critical capability.
This work was supported by the Centre for Computational Science and
Mathematical Modelling at Coventry University, UK. The authors declare
no external funding.
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.