DeCode Decoupling Content and Delivery for Medical QA
📝 Original Paper Info
- Title: DeCode Decoupling Content and Delivery for Medical QA- ArXiv ID: 2601.02123
- Date: 2026-01-05
- Authors: Po-Jen Ko, Chen-Han Tsai, Yu-Shao Peng
📝 Abstract
Large language models (LLMs) exhibit strong medical knowledge and can generate factually accurate responses. However, existing models often fail to account for individual patient contexts, producing answers that are clinically correct yet poorly aligned with patients' needs. In this work, we introduce DeCode, a training-free, model-agnostic framework that adapts existing LLMs to produce contextualized answers in clinical settings. We evaluate DeCode on OpenAI HealthBench, a comprehensive and challenging benchmark designed to assess clinical relevance and validity of LLM responses. DeCode improves the previous state of the art from $28.4\%$ to $49.8\%$, corresponding to a $75\%$ relative improvement. Experimental results suggest the effectiveness of DeCode in improving clinical question answering of LLMs.💡 Summary & Analysis
1. **Introduction of the DeCode Framework**: The DeCode framework is a modular approach for generating personalized medical responses from clinical conversations. It dissects existing interactions into multiple analytical perspectives and synthesizes them to produce a response that is both medically accurate and contextually relevant. 2. **Structured Response Generation**: Comprising four modules—Profiler, Formulator, Strategist, Synthesizer—DeCode ensures detailed extraction of patient-specific information, distillation of clinical indicators, strategic planning, and controlled generation of the final response. 3. **Performance Improvement**: DeCode demonstrates significant performance improvements on HealthBench, raising the benchmark from 28.4% to 49.8%.📄 Full Paper Content (ArXiv Source)
Large language models (LLMs) have recently achieved strong performance on a variety of medical natural language processing tasks, most notably medical question answering (QA), where models are evaluated on their ability to generate correct responses to clinically relevant questions . This progress has been demonstrated across a growing collection of medical QA benchmarks, spanning multiple-choice and generative settings, professional examination-style questions, and open-domain clinical knowledge assessments . Collectively, results on these evaluations suggest that contemporary LLMs exhibit substantial medical knowledge and reasoning capability under standardized testing conditions .
Existing medical QA benchmarks, however, are predominantly designed to measure answer correctness or reasoning accuracy, often via exact-match, multiple-choice selection, or expert-graded factual validity. While these metrics are well-suited for assessing knowledge recall and clinical reasoning, they provide only a partial characterization of model behavior in patient-facing or clinical communication settings . In particular, such evaluations do not capture whether model responses are understandable, appropriately calibrated to patient context, or aligned with norms of safe and empathetic medical communication.
This limitation motivates the need for evaluation frameworks that extend beyond accuracy-based metrics. OpenAI HealthBench was introduced to address this gap by evaluating medical LLM outputs along multiple qualitative dimensions, including context seeking, emergency referrals, and responding under uncertainty, in addition to factual correctness . Unlike prior medical QA datasets, which typically assume a single correct answer independent of delivery style or audience, HealthBench explicitly models the interactional aspects of medical responses, enabling a more fine-grained analysis of clinically relevant response quality.
Empirical results on HealthBench further show that models with comparable accuracy on traditional medical QA benchmarks can exhibit substantial variation across other non-accuracy dimensions, revealing a misalignment between standardized QA performance and patient-centered context awareness . Together, these findings suggest that accuracy alone is insufficient as a proxy for real-world clinical readiness and underscore the importance of multidimensional evaluation for medical LLMs.
In this work, we introduce the Decoupling Content and Delivery (DeCode) framework, a modular approach for generating patient-specific medical responses from clinical conversations. DeCode decomposes an existing clinical interaction into multiple complementary analytical perspectives, each implemented via a specialized LLM module. The outputs of these modules are subsequently synthesized to produce a final response that accounts for both medical correctness and patient context.
Importantly, DeCode operates in a training-free paradigm, orchestrating the generation process through explicit clinical formulation and structured discourse constraints. Empirically, we demonstrate that DeCode substantially improves performance on HealthBench, increasing the prior state-of-the-art score from $`28.4\%`$ to $`49.8\%`$. Furthermore, we show that DeCode generalizes consistently across multiple leading LLMs, suggesting that the framework captures model-agnostic principles for personalized medical response generation.
The remainder of this paper is organized as follows. Related works are introduced in Section 2. The proposed method is presented in Section 3. Experimental setup and results are provided in Section 4 and Section 5, respectively. Finally, Section 6 concludes the paper.
Related Work
Early evaluations of large language models (LLMs) in medical question answering have primarily focused on standardized multiple-choice benchmarks, including MedQA , MedMCQA , and PubMedQA . These benchmarks have catalyzed substantial research on assessing and improving medical knowledge in LLMs . However, such evaluations remain inherently static and accuracy-centric, limiting their ability to assess communicative competence, contextual sensitivity, and patient-centered delivery beyond factual correctness .
HealthBench introduces a multidimensional evaluation framework for medical QA based on open-ended, multi-turn clinical conversations. Unlike traditional multiple-choice benchmarks, HealthBench employs physician-authored rubrics to assess behavioral dimensions such as clinical accuracy, communication quality, and contextual awareness, enabling a more comprehensive evaluation of medical QA systems beyond factual correctness.
MuSeR targets HealthBench by proposing a self-refinement framework in which a student LLM is guided by high-quality responses from a reference teacher model. In its original formulation, MuSeR relies on data synthesis and supervised training: the student generates an initial response, performs structured self-assessment across multiple dimensions, and produces a refined final answer. While this training-based pipeline is computationally intensive and primarily applicable to trainable, open-source LLMs, the core self-refinement procedure can also be applied at inference time, enabling response refinement without model distillation or fine-tuning.
In parallel, multi-agent frameworks have been proposed to address complex medical QA by decomposing reasoning across specialized roles. MedAgents employs role-playing specialists for debate-based hypothesis refinement, while MDAgents dynamically configures expert teams based on query complexity. More recent approaches further extend this paradigm: KAMAC introduces on-demand expert recruitment to address knowledge gaps during generation, and AI Hospital evaluates agent-based systems in interactive patient simulation environments. However, these methods primarily emphasize diagnostic reasoning and accuracy on traditional benchmarks, often overlooking how complex reasoning outcomes are translated into clear, user-aligned responses.
Building on these observations, we introduce DeCode, a modular framework that explicitly decouples medical content reasoning from response delivery. Unlike training-based or agent-centric approaches, DeCode requires no additional training and is model-agnostic, while emphasizing structured generation that supports contextualized and user-aligned medical responses. We present our implementation in the following section.
Method
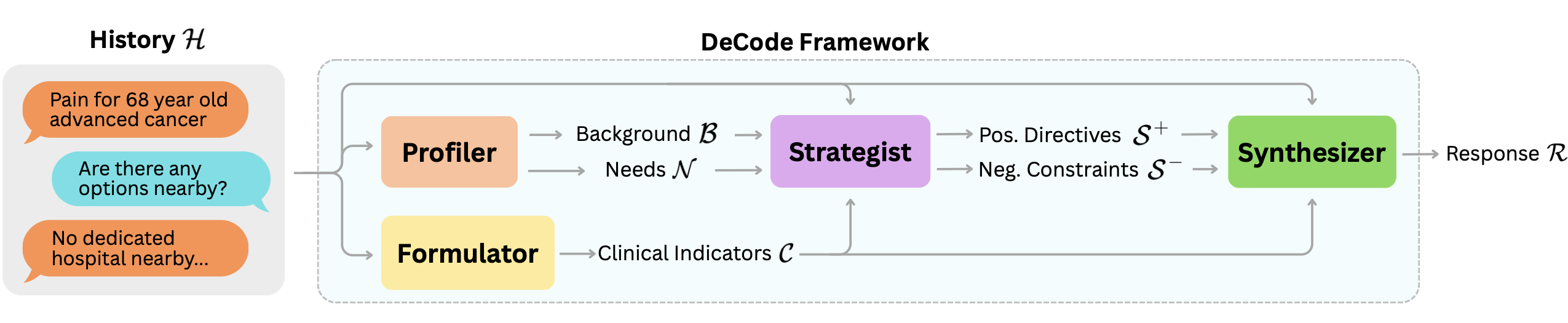 />
/>
Medical question answering with LLMs can be modeled as a form of conditional text generation $`P(\mathcal{R}\mid\mathcal{H})`$, where $`\mathcal{R}`$ denotes the response and $`\mathcal{H}`$ the conversation history. In practice, $`\mathcal{H}`$ contains rich patient-specific information—such as symptoms, risk factors, and health indicators—distributed across multiple dialogue turns. However, LLMs are typically trained to model this distribution directly, without mechanisms to explicitly aggregate these dispersed signals. As a result, specific patient details are frequently overlooked during response generation.
To address this limitation, we introduce DeCode, a framework that structures the generation process through four intermediate textual representations: user background $`\mathcal{B}`$, user needs $`\mathcal{N}`$, clinical indicators $`\mathcal{C}`$, and discourse strategy $`\mathcal{S}`$. As illustrated in Figure 1, these representations are orchestrated by four corresponding modules: Profiler $`\mathcal{M}_{prof}`$, Formulator $`\mathcal{M}_{form}`$, Strategist $`\mathcal{M}_{strat}`$, and Synthesizer $`\mathcal{M}_{syn}`$. By disentangling content from delivery, DeCode enables independent optimization of medical accuracy and communicative quality. The inference process is formalized as a sequential chain:
\begin{equation*}
\begin{split}
\mathcal{R} = \, & \underbrace{\mathcal{M}_{syn}(\mathcal{S}, \mathcal{C}, \mathcal{H})}_{\text{Synthesis}} \circ \underbrace{\mathcal{M}_{strat}(\mathcal{B}, \mathcal{N}, \mathcal{C}, \mathcal{H})}_{\text{Strategy}} \\
& \circ \underbrace{\{\mathcal{M}_{prof}(\mathcal{H}), \mathcal{M}_{form}(\mathcal{H})\}}_{\text{Extraction}}
\end{split}
\end{equation*}where $`\mathcal{M}`$ denotes the LLM modules tailored for specific sub-tasks. In the following sections, we detail the design of each module.
Profiler: User Context Disentanglement
Medical advice varies significantly across individuals. The same symptom may imply different risks depending on the user’s background and lifestyle. To capture this nuance beyond surface-level queries, the Profiler $`\mathcal{M}_{prof}`$ extracts the user’s specific context from the conversation history $`\mathcal{H}`$. We formalize this extraction as:
\begin{equation*}
(\mathcal{B}, \mathcal{N}) = \mathcal{M}_{prof}(\mathcal{H}).
\end{equation*}The user background $`\mathcal{B}`$ encapsulates critical attributes such as age, occupation, and living conditions that constrain actionable advice. Concurrently, the user needs $`\mathcal{N}`$ identifies the user’s core intent by synthesizing the conversation history $`\mathcal{H}`$. By decoupling the user information $`\mathcal{B}`$ and $`\mathcal{N}`$ from the history $`\mathcal{H}`$, we allow improved clarity in identifying user-specific constraints during response formulation. The user background $`\mathcal{B}`$ and user needs $`\mathcal{N}`$ are then sent to the Strategist module.
Formulator: Clinical Distillation
A critical challenge in medical dialogue is that diagnostic cues are often dispersed throughout the conversation history $`\mathcal{H}`$, making it difficult to verify if the response covers all relevant medical aspects. To address this, the Formulator $`\mathcal{M}_{form}`$ functions as a clinical information distiller. It extracts and aggregates a structured set of clinical indicators $`\mathcal{C}`$ (e.g., symptoms, possible causes, and potential red flags) from the user statements in $`\mathcal{H}`$. We formalize this process as
\begin{equation*}
\mathcal{C} = \mathcal{M}_{form}(\mathcal{H}).
\end{equation*}Crucially, this module operates purely on a factual level, decoupling the medical substance from the delivery style. By explicitly manifesting $`\mathcal{C}`$ as an intermediate representation, the system provides a rigorous checklist for the downstream modules. This ensures that the final response is grounded in verified medical evidence and that high-stakes safety indicators are duly addressed, regardless of the chosen empathy level or conversation tone.
Strategist: Discourse Orchestration
Beyond factual accuracy, effective medical dialogue requires determining the optimal delivery strategy tailored to the user’s cognitive and emotional context. The Strategist $`\mathcal{M}_{strat}`$ addresses this gap by synthesizing the conversation history $`\mathcal{H}`$, extracted user profile ($`\mathcal{B}, \mathcal{N}`$) and clinical indicators ($`\mathcal{C}`$) into a coherent strategy. We formalize this process as:
\begin{equation*}
\mathcal{S} = \{ \mathcal{S}^{+}, \mathcal{S}^{-} \} = \mathcal{M}_{strat}(\mathcal{B}, \mathcal{N}, \mathcal{C}, \mathcal{H}).
\end{equation*}The resulting discourse strategy $`\mathcal{S}`$ comprises two complementary sets. Positive directives $`\mathcal{S}^{+}`$ prescribe the prioritization of clinical content and establish the appropriate level of technical detail, crucially instructing the model to actively seek clarification when information is insufficient. Conversely, negative constraints $`\mathcal{S}^{-}`$ serve as behavioral guardrails, preventing counterproductive styles (e.g., overly academic tones) and filtering out content that may be overwhelming or potentially misleading for the specific user. By enforcing these strategies, the module ensures that the final response is not only medically grounded but also empathetic and strictly aligned with the user’s preferences.
Synthesizer: Controlled Generation
Finally, the Synthesizer $`\mathcal{M}_{syn}`$ generates the response $`R`$ by integrating the clinical indicators $`\mathcal{C}`$ with the discourse strategy $`\mathcal{S}`$. We formalize this process as:
\begin{equation*}
R = \mathcal{M}_{syn}(\mathcal{S}, \mathcal{C}, \mathcal{H}).
\end{equation*}By separating content formulation from delivery planning, the Synthesizer operates as a constrained generator. It articulates the verified information in $`\mathcal{C}`$ while adhering to the directives defined in $`\mathcal{S}`$. This ensures that the generation process focuses on realization rather than reasoning, producing outputs that are clinically accurate and contextually appropriate.
Taken together, the Profiler, Formulator, Strategist, and Synthesizer form a coherent generation pipeline that transforms the conversation history $`\mathcal{H}`$ into a personalized and clinically grounded response $`R`$. Each module addresses a distinct stage of the reasoning–generation process, enabling explicit control over user understanding, clinical content, discourse planning, and surface realization. For reproducibility and clarity, the prompts corresponding to each module are provided in the appendix.
Experiments
Dataset and Evaluation
We evaluate on OpenAI HealthBench , which contains $`5{,}000`$ simulated multi-turn patient–clinician conversations ending in a user query. Each conversation is annotated by medical professionals and assigned to one of seven themes: emergency referrals, context seeking, global health, health data tasks, complex responses, hedging, and communication. HealthBench additionally provides physician-authored rubrics per conversation, grouped into five evaluation axes: accuracy, completeness, communication quality, context awareness, and instruction following. For more details regarding the conversation themes and evaluation axes, please refer to the original paper .
Metric.
We follow the official HealthBench protocol : each conversation is graded using its rubric and scored by GPT-4.1 . Reported numbers are the mean normalized score over the evaluated set.
Splits.
We report results on the full HealthBench dataset for the primary evaluation. Owing to the computational cost, all subsequent experiments are conducted on the Hard subset of $`1{,}000`$ challenging conversations.
Implementation Details
Base LLMs.
We use OpenAI o3 as the primary base model and additionally evaluate GPT-5.2 , Claude-Sonnet 4.5 , and DeepSeek R1 to assess generalization across model families.
Comparison Methods.
We compare against: (i) Zero-shot, which directly prompts the base LLM using the conversation history; (ii) MDAgents , which recruits specialized experts based on query complexity and aggregates their responses; (iii) KAMAC , which dynamically recruits experts during generation; and (iv) MuSeR , which applies a self-refinement generation strategy. For KAMAC, the model selects the initial number of experts and the discussion is fixed to two rounds. For MuSeR, we use the authors’ self-refinement prompts at inference time, without model distillation or fine-tuning. A detailed cost and latency breakdown for all frameworks is included in the appendix.
Results and Analysis
Main Results
In this experiment, we compare DeCode with a zero-shot baseline built on the same underlying LLM, OpenAI o3. Both methods are evaluated on the full HealthBench dataset as well as its hard subset, with results summarized in Table [tab:main_results].
A clear performance gap emerges between the full dataset and the hard subset. On the full set, the zero-shot baseline performs weakest on health data tasks. Performance further degrades on the hard subset, where the baseline struggles across nearly all conversation themes; the highest score achieved is only $`31.8\%`$ under the global health theme, highlighting the increased difficulty of this split.
In contrast, DeCode improves response quality across all conversation themes on the full set, with the exception of the complex responses category. Further analysis suggests that DeCode occasionally generates overly detailed responses for relatively simple or straightforward queries. While this behavior can enrich informational content, it may negatively affect perceived communication quality, contributing to the observed performance drop along this evaluation axis.
On the hard subset, DeCode yields substantial gains in overall performance. Notably, the lowest-scoring health data theme improves to $`35.6\%`$, while all remaining themes exceed $`40\%`$. These results underscore the effectiveness of DeCode in enhancing both the content and delivery of medical question answering under more challenging evaluation conditions.
Generalizability Across Backbone Models
In this experiment, we examine the generalizability of DeCode across different base LLMs. A key advantage of the proposed framework is its model-agnostic design, which allows it to be applied to a wide range of base LLMs while consistently improving medical question answering performance. We evaluate DeCode on the hard subset using several leading LLMs from different providers, with results reported in Table [tab:model_results].
Based on the zero-shot performance of the base LLMs, health data tasks emerge as a particularly challenging category for GPT-5.2, OpenAI o3, and DeepSeek R1. In contrast, Claude-4.5 exhibits its weakest performance on global health tasks. Across evaluation axes, context awareness and completeness are especially challenging: OpenAI o3, Claude-4.5, and DeepSeek R1 all record single-digit scores on these dimensions in certain cases, indicating systematic deficiencies in handling complex contextual and informational requirements.
Consistent with the observations in Section 5.1, DeCode delivers substantial improvements over the corresponding zero-shot baselines across all tested models. Notably, Claude-4.5, which attains an initial overall score of $`12.4\%`$, improves to $`40.0\%`$ when integrated with DeCode. Similarly, the strongest baseline model, GPT-5.2, improves from $`36.6\%`$ to $`56.0\%`$. Importantly, in all experiments the underlying base LLM remains unchanged. By explicitly decoupling content from delivery, DeCode systematically enhances the performance of diverse base LLMs across nearly all medical QA scenarios. These results demonstrate that the benefits of DeCode are robust and largely LLM-agnostic, extending across a wide range of model architectures and providers.
Comparison with LLM Frameworks
In this experiment, we evaluate representative LLM-based medical QA frameworks on the HealthBench hard subset using OpenAI o3 as the base LLM. Specifically, we consider MDAgents , KAMAC , and MuSeR with results summarized in Table [tab:sota_comparison_full].
Relative to the zero-shot baseline, MDAgents demonstrates consistent improvements across all conversation themes and four of the five evaluation axes. Notably, it achieves the strongest performance on instruction following among all compared methods. This behavior can be attributed to its complexity-driven orchestration strategy: MDAgents first estimates the difficulty of a given medical query and determines whether it can be handled by a single agent or requires a coordinated team of specialized experts. Once the team composition is selected, it remains fixed throughout the generation process. This upfront complexity assessment enables stable role assignment and coherent multi-agent collaboration, which appears particularly effective for instruction-heavy medical QA scenarios.
In contrast, KAMAC does not yield consistent gains over the zero-shot baseline and, in several cases, exhibits notable degradations in context awareness, communication quality, and instruction following. Unlike MDAgents, KAMAC follows a knowledge-driven strategy that dynamically recruits new specialists during the generation process when existing agents identify missing domain knowledge. While this adaptive recruitment mechanism is intended to enhance coverage, our analysis suggests that introducing new experts mid-stream can disrupt conversational coherence. Specifically, the newly added agents often generate responses that overlap with existing contributions or shift the discussion focus, leading to redundancy and task-level confusion. These effects are amplified in longer, multi-round discussions, ultimately degrading response quality.
Among the compared LLM-based frameworks, MuSeR’s self-refinement approach yields the largest performance gains, particularly on context seeking and health data tasks, and achieves the strongest improvement in context awareness. This is consistent with MuSeR’s design, where structured self-assessment guides targeted response refinement to recover missing contextual signals. Our results show that such self-refinement remains effective even when applied purely at inference time. However, MuSeR does not explicitly disentangle clinical content from discourse strategy, limiting its ability to independently optimize medical accuracy and communicative quality—an aspect directly addressed by DeCode.
Taken together, these results indicate that multi-agent medicalQA performance depends critically on how contextual information and communicative intent are structured during generation. While fixed-team orchestration and self-refinement improve context sensitivity, dynamically introducing new experts can incur coordination overhead that degrades coherence. Explicitly separating clinical content from discourse strategy provides a more stable alternative, enabling balanced optimization of medical accuracy and communication quality, as demonstrated by DeCode.
Ablation Study
We conduct an ablation study to assess the individual contribution of each component in the DeCode framework. Specifically, we independently remove the Profiler, Formulator, and Strategist modules and compare their performance against the full DeCode model on the HealthBench hard subset. The results are summarized in Table [tab:ablation_full].
Impact of the Profiler
The Profiler module is designed to extract the user’s background and underlying needs, enabling personalized response generation. Removing this component is therefore expected to reduce personalization in scenarios that require a deeper understanding of the user. As shown in Table [tab:ablation_full], the absence of the Profiler leads to notable performance drops in communications and complex responses. These degradations align with our expectations, as removing the Profiler limits the model’s ability to infer the appropriate level of detail and tailor responses to user-specific contexts.
Impact of the Formulator
The Formulator module is responsible for identifying and structuring salient clinical indicators from the conversation history. Without this module, the model must rely on unstructured context, which can hinder coherent reasoning over clinical details. Consistent with this intuition, removing the Formulator results in substantial declines in completeness and context awareness, along with a modest reduction in accuracy. These findings highlight the importance of the Formulator in organizing clinical information and ensuring that relevant conditions are explicitly addressed during medical question answering.
Impact of the Strategist
The Strategist module governs response delivery by shaping tone, framing, and discourse strategy. Its removal primarily affects how information is communicated rather than what information is presented. As observed in our results, ablating the Strategist leads to a pronounced drop in communication quality and a smaller but consistent decline in instruction following. Both axes reflect how effectively responses engage with and adapt to user expectations. These results underscore the role of the Strategist in ensuring that medically relevant content is conveyed in an appropriate, user-receptive manner.
Conclusion
In this work, we introduce Decoupling Content and Delivery (DeCode), a modular framework for contextualized medical question answering. DeCode adapts a base LLM into four specialized components—Profiler, Formulator, Strategist, and Synthesizer—that jointly structure response generation by explicitly separating medical content reasoning from discourse and delivery. This design enables the model to produce medically accurate responses while remaining sensitive to user context and communication needs.
Experiments on the OpenAI HealthBench benchmark demonstrate that DeCode consistently outperforms a zero-shot baseline and remains competitive with leading multi-agent frameworks across both full and hard evaluation settings. Moreover, evaluations across multiple base LLMs show that DeCode generalizes well across different model families and architectures, highlighting its model-agnostic nature.
Future work may explore mechanisms for caching and updating patient-specific information across multi-round interactions. Additionally, extending the DeCode paradigm beyond medical QA to other user-centered domains represents a promising direction. Taken together, these results suggest that DeCode provides a principled foundation for advancing contextualized medical QA.
Limitations
Our evaluation is conducted on simulated patient–clinician conversations, which may not fully reflect the complexity, uncertainty, and risk profiles of real-world clinical settings. Although DeCode improves response quality without additional training, outputs generated by large language models may still contain errors or omissions and should not be used as a substitute for professional medical judgment. Validation and safeguards are necessary before deploying systems in clinical practice.
Cost & Latency Analysis
In this section, we analyze the cost and latency of the DeCode framework. In addition, we include the cost and latency of MDAgents , KAMAC , and MuSeR . To ensure fair comparison, we assume an output token rate of $`70`$ tokens/second to avoid latency fluctuations due to API re-routing. The details of the DeCode framework is listed in Table [tab:component_stats]. Comparisons between the various LLM-based medical QA frameworks are provided in Table [tab:comparative_stats].
Prompt Templates
The prompts for each module of DeCode are provided below. The Profiler module uses two independent prompts to extract the user background $`\mathcal{B}`$ and user needs $`\mathcal{N}`$. The prompt to extract the user background $`\mathcal{B}`$ and user needs $`\mathcal{N}`$ is provided in Figure 2 and Figure 3. The Formulator prompt to extract the clinical indicators $`\mathcal{C}`$ is listed in Figure 4. The Strategist prompt is given in Figure 5. Finally, the Synthesizer prompt is presented in Figure 6.
User Background (ℬ)
You are a medical intake specialist. Analyze the following conversation and extract the user’s background information.
CONVERSATION:
{conversation_history}
Extract and infer the following information about the user (if
available in the conversation):
- Age or age group
- Career/Occupation
- Economic condition (inferred from context)
- Living place/location
- Living situation (alone, with family, etc.)
- Any other relevant personal context
IMPORTANT: Only include information that can be reasonably inferred from the conversation. Do NOT make up information.
Respond in this EXACT format:
AGE: [age or age group, or "Not specified"]
CAREER: [occupation, or "Not specified"]
ECONOMIC_CONDITION: [economic status inferred from context, or "Not
specified"]
LIVING_PLACE: [location/region, or "Not specified"]
LIVING_SITUATION: [living arrangement, or "Not specified"]
OTHER_CONTEXT: [any other relevant information, or "None"]
Be concise and factual. If information is not available, write "Not specified" or "None".
User Need (𝒩)
You are analyzing a medical conversation to understand what the user needs.
CONVERSATION:
{conversation_history}
Identify what the user explicitly asks for or clearly needs. Be
conservative - only include needs that are:
1. Explicitly stated by the user
2. Clearly implied by the user’s questions or concerns
DO NOT include:
- Things the user might need but didn’t mention
- General medical advice that wasn’t requested
- Assumptions about what the user should want
Respond in this EXACT format:
NEEDS:
1. [First explicit need]
2. [Second explicit need]
3. [Third explicit need]
...
If the user doesn’t clearly state what they want, respond with:
NEEDS:
None specified
Be strict and conservative.
Clinical Indicators (𝒞)
You are a clinical safety and completeness planner.
Your ONLY job is to identify the medically important content that
MUST be covered
for this case to be safe, accurate, and reasonably complete. You are NOT
deciding tone or style.
You are optimizing for clinical accuracy and completeness, not
brevity.
CONVERSATION:
{conversation_history}
Create a numbered list of key clinical content items that the final
answer should try to cover, such as:
- Important symptom details or history that should be addressed or
clarified
- Key possible causes or differentials (described in a cautious,
non-diagnostic way)
- Red-flag or emergency warning signs that should be mentioned if
relevant
- What the user can monitor or do at home (if appropriate)
- When and how urgently they should seek in-person care
- Any important limitations or uncertainties of online advice
Rules:
- Focus on clinical content ONLY (WHAT to cover), not HOW to phrase
it.
- Err on the side of including any clinically important point that might
affect safety.
- Each item should be 1–2 sentences max.
- Avoid repeating the same content in multiple items.
- Do not invent new symptoms; only build on what is in the
conversation.
- It is acceptable to mention reasonable possible causes or scenarios
even if the user did not use those exact words, as long as they
logically follow from the described symptoms.
Respond in this EXACT format:
1. [Clinical content item]
2. [Clinical content item]
3. [Clinical content item]
...
Discourse Strategy (𝒮)
You are a response-strategy planner for a medical assistant.
You receive:
- The original conversation
- A brief user background profile
- A list of what the user clearly needs
- A clinical content checklist (what should be covered for
safety/completeness)
Your job is to design HOW the assistant should answer for THIS user: what to prioritize, how deep to go, what style and structure to use, and what to avoid.
CONVERSATION:
{conversation_history}
USER BACKGROUND PROFILE:
{user_profile}
USER NEEDS (what the user clearly wants):
{needs_formatted}
CLINICAL CONTENT CHECKLIST (what should be covered):
{content_formatted}
Pay particular attention to:
- Whether the user’s needs are clearly stated or
vague/unspecified.
- Whether there is sufficient information available for a safe medical
assessment.
- When needs or information are unclear, the plan should usually include
a brief strategy for clarifying key gaps (e.g., 1–2 focused questions),
while still guiding the assistant to give the best possible provisional
answer based only on what is already known.
IMPORTANT:
- The assistant MUST still give concrete, practical, medically useful
information even when information is incomplete. Use conditional
language (e.g., "If X..., then Y...") rather than refusing to say
anything.
- Do NOT tell the assistant to avoid discussing possible causes or next
steps entirely.
- Clarification questions should be few (0–2 of the most important ones)
and should not dominate the answer.
Design a plan with TWO sections:
1. WHAT TO DO/COVER (TO DO):
- How the assistant should prioritize and present the content for THIS
user.
- What level of technical detail is appropriate for this user.
- Whether to keep the answer short vs. more detailed.
- Whether to explicitly ask clarification questions (0–2 key questions
only), and if so, in what style and at what point (usually after giving
main guidance).
- Which content items from the checklist are highest priority to cover
explicitly.
- How to adapt the response to the user’s apparent role, location, and
constraints.
2. WHAT NOT TO DO/COVER (NOT TO DO):
- Things that would likely confuse, overwhelm, or frustrate THIS
user.
- Styles to avoid (e.g., too technical, too casual, too vague, overly
long).
- Types of content to avoid (e.g., extremely long, low-yield lists of
differential diagnoses; strong reassurance when red flags are possible;
rigid instructions when access is limited).
- Any ways of answering that would clearly conflict with the user’s
instructions.
You are NOT writing the final medical answer. You are only writing the plan.
Respond in this EXACT format:
TO DO:
1. [Response strategy / priority tailored to user]
2. [Another response strategy / priority]
3. [Continue as needed]
NOT TO DO:
1. [Specific thing to avoid for this user]
2. [Another thing to avoid]
3. [Continue as needed]
Controlled Generation (R)
You are an experienced medical professional providing personalized advice.
Your highest priorities are:
1) Clinical accuracy and completeness of the information you
provide.
2) Clear, practical guidance for the user.
3) Safe and appropriate communication.
ORIGINAL CONVERSATION:
{conversation_history}
PRESENTATION GUIDELINES (HOW TO ANSWER):
TO DO:
{to_do_formatted}
NOT TO DO:
{not_to_do_formatted}
CONTENT CHECKLIST (WHAT YOU MUST COVER CLINICALLY):
{content_formatted}
Your task:
1. Cover ALL items in the CONTENT CHECKLIST as clearly and concretely as
possible. Aim for at least one explicit sentence or short paragraph
addressing each item.
2. Follow the TO DO / NOT TO DO guidelines for how to present the
information in a way that fits THIS user’s background and needs.
3. Be explicit about uncertainty and information gaps, but still give
the BEST POSSIBLE DIRECT ANSWER based only on the conversation.
- Use conditional language (e.g., "If X..., then Y...") rather than
refusing to answer.
4. You may ask up to 1–2 of the most important clarification questions,
but they should be placed near the end and should NOT replace giving
guidance.
5. Keep the response user-centered and practical, and explain what the
user can do next (e.g., monitor, self-care, when/where to seek in-person
care).
6. End with a brief reminder that this information does not replace an
in-person medical evaluation and that the user should seek care if they
are worried or if concerning symptoms arise.
Provide your response:
📊 논문 시각자료 (Figures)