SingingBot An Avatar-Driven System for Robotic Face Singing Performance
📝 Original Paper Info
- Title: SingingBot An Avatar-Driven System for Robotic Face Singing Performance- ArXiv ID: 2601.02125
- Date: 2026-01-05
- Authors: Zhuoxiong Xu, Xuanchen Li, Yuhao Cheng, Fei Xu, Yichao Yan, Xiaokang Yang
📝 Abstract
Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.💡 Summary & Analysis
1. **Proposed Framework**: - **Simple Explanation**: This paper suggests a method for robots to mimic complex human expressions while singing. - **Intermediate Explanation**: Unlike previous data-driven approaches that were limited to simple facial expressions, this framework can generate more nuanced emotional responses. - **Advanced Explanation**: The proposed framework leverages large-scale pre-trained models grounded in extensive human priors to enable realistic robotic singing performances.-
Measuring Expressive Range (EDR):
- Simple Explanation: This paper introduces a new way to measure how many different emotions a robot can express.
- Intermediate Explanation: The EDR metric evaluates the emotional range of robotic expressions, ensuring more natural singing performances.
- Advanced Explanation: Using the Valence-Arousal space, this paper proposes Emotion Dynamic Range (EDR) as a quantitative indicator to measure the breadth of emotional expression.
-
Experimental Results:
- Simple Explanation: The experiments show that the proposed method outperforms previous approaches in both emotional expression and lip-sync accuracy.
- Intermediate Explanation: Comparing various singing strategies, this paper demonstrates superior performance with enhanced emotional richness and precise lip synchronization.
- Advanced Explanation: Through extensive experimentation, it was shown that the SingingBot framework achieves state-of-the-art performance, particularly excelling in emotional breadth and synchronized lip movements.
📄 Full Paper Content (ArXiv Source)
Robotic Face, Facial Animation, Motor Control
Introduction
Singing is a universal way to express emotion that goes beyond language or culture. Unlike speech, singing demands continuous articulation constrained by melody and rhythm, requiring longer vowel sounds and specific lyrical expressions. Consequently, endowing humanoid robots with singing capabilities serves as a critical benchmark for evaluating human behaviour replication and represents a crucial step toward natural human-robot interaction in companionship, reception, and entertainment. However, the higher requirements for expressive coherence and emotional breadth make this task highly challenging.
Early approaches to robotic facial animation primarily relied on interpolating between preset expression sets or pre-programmed hardwares . These methods are constrained by the expression library size and struggle to capture the nuanced expressions and emotions inherent in singing. To address these problems, recent data-driven studies focus on automatic motor control via learning from paired data. One category generates audio-sync animations using kinematics but primarily targets talking, failing to produce the lyrical singing animation. Another category transfers image-space human expressions to robots, but typically focuses on static expression matching, neglecting the coherent emotional expression critical for singing performances. Both of these types struggle to be applied to robot singing trivially.
Distinct from previous works, we present a framework that leverages the robust human priors within video diffusion models to enable realistic robotic singing. Specifically, we employ a human-centric video diffusion transformer to synthesize controllable 2D portrait animations, serving as the driving source for robotic performance. We then transfer the avatar’s facial features to the physical robot by applying a semantic-oriented piecewise mapping strategy to generate motor control values. Contrary to the existing data-driven methods , the semantic-based mapping spans a larger expression space, ensuring the final performance preserves both emotional nuance and lip-sync accuracy.
Furthermore, quantifying robot singing performance at the perceptual level remains a significant challenge. Existing audio-driven animation methods focus on lip synchronization but overlook emotional richness. Drawing inspiration from affective computing, we leverage the Valence-Arousal (VA) space derived from the Circumplex Model of Affect to capture subtle emotional differences, where any emotion can be represented by two continuous, orthogonal dimensions. Specifically, we propose the Emotion Dynamic Range (EDR) as a metric to quantify the emotional breadth. By comparing the area of the convex hull formed by the emotion trajectory in the VA space, we demonstrate that our method achieves expressive performances while maintaining precise lip synchronization, significantly outperforming the baselines.
Our contributions are summarized as follows: (1) We propose a framework to transfer prompt-controlled avatar animations to robotic faces, bridging the gap between digital humans and physical robots with vivid lip movements and emotions. (2) We reveal the importance of evaluating emotional richness in singing performances and propose Emotion Dynamic Range (EDR) as a quantitative indicator of emotional breadth based on the VA space. (3) We conduct extensive experiments comparing various singing strategies, quantitatively and qualitatively demonstrating that our system achieves SOTA performance.
Related Works
Animatronic Robotic Face Control. Generating robotic expressions is hindered by the structural gap between biological muscles and sparse motors, alongside the complex non-linear deformations of silicone skin . Traditional methods rely on interpolating predefined expression bases but lack expressiveness and generalization. Recent learning-based approaches utilize neural networks to map audio or images to motor parameters either directly or via a trained imitator . However, constrained by the scarcity of paired data, these works typically target simple conversational scenarios, often neglecting temporal coherence and continuous emotional expression. While works like UGotMe introduce emotion classification for empathetic interaction, they rely on fixed emotion bases and fail to jointly generate emotional expressions with synchronized lip movements for singing. Our work distinguishes itself by focusing on robotic singing, utilizing large-scale human priors to achieve high realism and emotional richness.
Audio Driven Avatar Facial Animation. A fundamental challenge in audio-driven avatar and robot animation lies in modeling the complex mapping between audio and facial dynamics. The 3D talking head methods often struggle to generalize to exaggerated expressions or singing due to limited annotated data. Conversely, 2D methods leverage web-scale data to extract robust human priors, enabling the generation of realistic videos with rich emotions, micro-expressions, and prompt-based control. We leverage these pre-trained 2D human priors as a high-fidelity and flexible driving source, bridging the gap between avatars and robots. By transferring these virtual avatar facial features to the physical robotic domain, we endow the robot with singing capabilities, satisfying the high requirements for continuous emotional and expressive articulation.
Methodology
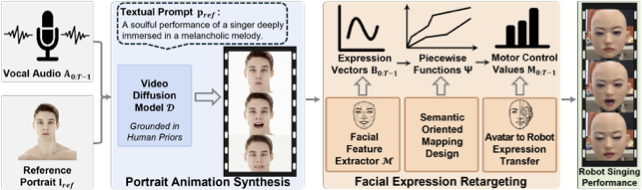 />
/>
Our goal is to generate lyrical robotic facial animation synchronized with the vocals of a song. Specifically, given $`\mathbf{T}`$ frame vocal $`\mathbf{A}_{0:T-1}`$, our framework generates robotic facial motions $`\mathbf{M}_{0:T-1}=\{\mathbf{m}_i\in \mathbb{R}^{d}\}_{i=0}^{T-1}`$ with each motion vector having $`d`$ Degrees of Freedom (DoFs) represented by a control value ranging from 0 to 1.
To this end, we propose SingingBot, as illustrated in Fig. 1. First, we employ a pretrained video diffusion model, grounded in extensive human priors, to synthesize realistic 2D portrait videos from vocal audio (Sec. 3.1). These generated videos serve as the intermediate driving source for our robotic face. Our method then utilizes a facial feature extractor to derive expression vectors from the synthesized video. Subsequently, we apply a well-designed piecewise mapping function to translate these expression vectors into motor actuation parameters, yielding the final robotic facial animation (Sec. 3.2).
Portrait Animation Synthesis
Directly regressing motor parameters poses a significant challenge due to the scarcity of large-scale paired motor and expression data. Consequently, many prior works leverage intermediate representations, such as facial landmarks or drivable robot imitators, to drive robotic faces. However, these approaches struggle to be applied to singing scenarios. Since singing performances demand continuous and emotionally charged expressions, landmark-driven methods struggle to convey emotion due to their sparsity and lack of appearance. Similarly, virtual robot imitators, constrained by limited training data, fail to generalize to the diverse emotions and complex expressions required for realistic singing. Inspired by the recent progress of video diffusion transformers pretrained on large-scale human-centric data, we posit that the embedded extensive human priors can provide sufficient facial expression and emotional guidance for robotic face singing animations. Specifically, we employ a pre-trained video diffusion model $`\mathcal{D}`$ to synthesize 2D singing videos $`\mathbf{V}_{0:T-1}=\{\mathbf{v}_i\in \mathbb{R}^{h \times w \times 3}\}_{i=0}^{T-1}`$ aligned with the input vocal. To control the style of the singing performance, we utilize an reference portrait image $`\mathbf{I}_{ref}`$ and a text prompt $`\mathbf{p}_{ref}`$ as conditions:
\begin{equation}
\mathbf{V}_{0:T-1}=\mathcal{D}(\mathbf{A}_{0:T-1}, \mathbf{I}_{ref}, \mathbf{p}_{ref})
\label{eq:diffusion}.
\end{equation}The extensive human priors ensure that the synthesized singing videos exhibit rich emotional fidelity and coherent expressions.
Facial Expression Retargeting
Leveraging the synthesized portrait singing video as the driving source, we proceed to retarget the expressive facial dynamics onto the robot’s physical action space.
Avatar Facial Dynamics Extraction. We adopt the 52-dimensional blendshape coefficient vector that complies with the ARKit standard as the parameterized representation of facial expressions. These coefficients quantify the intensity of specific muscle actions, e.g., jawOpen and mouthStretch. Unlike previous methods relying on raw 2D facial landmarks, blendshapes offer a semantically meaningful feature space that is identity-invariant and highly compatible with existing animation pipelines. Specifically, we employ MediaPipe $`\mathcal{M}`$ to extract frame-wise blendshape coefficients $`\mathbf{B}_{0:T-1}=\{\mathbf{b}_i\in \mathbb{R}^{52}\}_{i=0}^{T-1}`$ from the synthesized video:
\begin{equation}
% Insert BS extraction formula here: e.g., \beta_t = \mathcal{E}(I_t)
\mathbf{B}_{0:T-1} = \mathcal{M}(\mathbf{V}_{0:T-1}).
\label{eq:bs_extraction}
\end{equation}We post-process the extracted expression vectors using Gaussian smoothing to alleviate the temporal jitter that can cause jerky robotic motion. This ensures smooth motion dynamics while preserving significant expressive details.
Semantic-Oriented Avatar to Robot Expression Transfer. The core challenge in driving the robot face lies in mapping visual expression features to the robotic motion space. To circumvent the generalization limitations inherent in previous data-driven approaches, we avoid learning black-box mappings from paired datasets. Instead, we propose a Semantic-Oriented Piecewise Function Design, which maps blendshape parameters to motor control values based on semantic correspondence. Formally, given the intensity scalar $`\beta_{j} \in \mathbf{b}`$ of the $`j`$-th ARKit-compliant semantic expression, we define its corresponding function $`\Psi_j(\cdot)`$ as:
\begin{equation}
\Delta{\mathbf{m}}_j = \Psi_j(\beta_j) = \mathbf{w}_{j,k} \cdot \beta_j + \mathbf{c}_{j,k}, \quad \text{for } \beta_j \in [\tau_{j,k}, \tau_{j,k+1}),
\label{eq:mapping_def}
\end{equation}where $`\Delta\mathbf{m}_j \in \mathbb{R}^{d}`$ represents the contributing motion control value to the robot’s $`d`$ actuators. The function $`\Psi_j`$ is defined by a set of $`K`$ intervals, where $`\mathbf{w}_{j,k}`$ and $`\mathbf{c}_{j,k}`$ represent the slope and intercept vectors for the $`k`$-th linear segment bounded by thresholds $`[\tau_{j,k}, \tau_{j,k+1})`$. We manually design these piecewise functions for each semantic expression, and highly non-linear expression bases typically require denser pieces to ensure expressiveness.
Since the DoF of the robot is significantly sparser than the blendshapes, certain semantic expressions (e.g., cheekPuff) lack direct physical counterparts and are excluded as $`\Psi_j(\beta_j)=0`$. Furthermore, to address mechanical constraints where some of the asymmetric expressions (e.g., noseSneerLeft/Right) share a single actuator, we unify them into a single symmetric mapping and use their average as the input density. Please refer to the Supplementary Material for design details.
Finally, by blending the control values obtained from all valid mappings, we obtain the final control value $`\mathbf{m}`$:
\begin{equation}
\mathbf{m} = \mathbf{m}_{rest} + \sum\nolimits_{{\beta}_j \in \mathbf{b}} \Psi_j({\beta}_j),
\label{eq:final_motor}
\end{equation}where $`\mathbf{m}_{rest}`$ denotes the initial rest pose. Additionally, we linearly map the 3-DoF pose extracted via MediaPipe to the three neck motors to control head motions.
EXPERIMENTS
Implementation Details
Robotic Face Platform. We test our method on the Hobbs robot platform, which features 32 Degrees of Freedom, including 29 motors for facial motions and 3 for head/neck movements. The motors are connected to silicone skin through articulated linkages. The portrait animations are synthesized using Hallo3 on a remote server equipped with a single NVIDIA A800 GPU, while the expression transfer module is executed locally on the robot’s embedded RK3588 processor.
Data Preparation. We collected a test set comprising 40 singing vocal clips, each ranging from 3 to 4 seconds in duration. The dataset encompasses multiple languages and emotional styles to ensure diversity in phonetic coverage and emotional expression.
Baselines. We evaluate our method against three data-driven baselines: (1) Random Sampling (RT), which randomly samples control values from the training set; (2) Nearest Neighbor Retrieval (NNR), which finds the closest sample in the training set based on blendshapes; and (3) a direct regression approach proposed by Zhu et al. , which maps blendshape coefficients directly to motor control values. We generate blendshapes using EmoTalk . All baselines are re-implemented and trained on our collected dataset, consisting of 10K randomly sampled pairs.
Quantitative Comparisons
We utilize the widely used Lip Sync Error Distance (LSE-D) and Lip Sync Error Confidence (LSE-C) to measure the synchronization between the singing audio and the robotic performance . A lower LSE-D value indicates a higher consistency between the lip and the audio, while a higher LSE-C reflects a better alignment between the audio and the performance. Additionally, we propose the Emotion Dynamic Range (EDR) metric to quantify the emotional breadth based on the Valence-Arousal (VA) space. Specifically, we utilize a pre-trained emotion recognition model $`\Phi(\cdot)`$ to extract the per-frame emotion coordinates from the robotic performance, yielding a set of discrete VA-space points $`\mathcal{P} = \{p_t \mid p_t = (v_t, a_t)\}_{t=0}^{T-1}`$, where $`v_t, a_t \in [-1, 1]`$ represent valence and arousal. Formally, let $`\mathcal{H}`$ be the smallest convex polygon containing all points in $`\mathcal{P}`$ after removing the top $`5\%`$ of outliers. The EDR is calculated as the geometric area of $`\mathcal{H}`$. A larger EDR value indicates a wider distribution of emotional states, reflecting a more expressive performance.
The quantitative results are reported in Tab. [tab:metric]. Our method significantly outperforms the baselines in terms of both lip-audio synchronization and emotional expressiveness. Notably, our method achieves an EDR one order of magnitude higher than the competing methods. While RT covers a broad expression space, it tends to generate unnatural expressions misclassified as “Surprise," whereas NNR and Zhu et al. fail to produce rich emotions or expressive lip movements. Our method benefits from human priors and semantic-oriented mapping, allowing it to exhibit rich emotions while maintaining high-quality lip-sync. Besides, by utilizing a photorealistic avatar to provide reliable expression and emotion signals, our method yields significantly enhanced generalizability and emotion diversity compared with the data-limited methods.
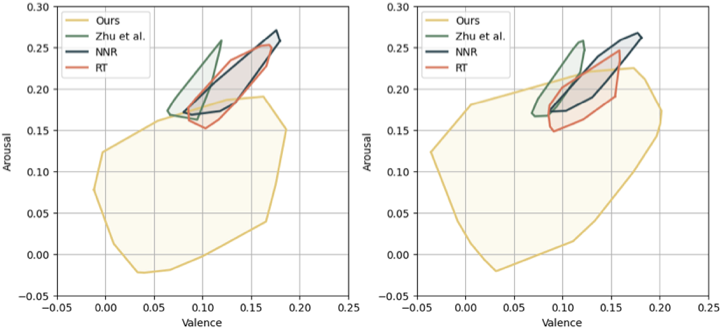 />
/>
Visualization of Emotion Dynamic Range. The Emotion Dynamic Range (EDR) metric reflects the distribution range of emotions within singing performances in the Valence-Arousal (VA) space. To intuitively visualize the geometric interpretation of EDR, we sample two clips and plot the results. As shown in the Fig. 2, the emotional ranges of different methods are depicted by polygons of varying colors, where the polygonal area stands for the EDR metric. Since NNR and Zhu et al. generate ambiguous lip motions without distinct emotional state, they occupy only a small region. Although RT covers a vast area of robotic expression space, the generated expressions typically lack valid emotional semantics, resulting in a limited EDR. In contrast, our method demonstrates significantly richer emotional expressiveness, which is critical for achieving engaging singing performances.
User Study
We conduct a user study to further evaluate the audience’s preferences for robotic singing performances generated by different methods. Specifically, the study consists of 16 questions, each presenting the participants with a 7-second-long clip of the singing performance. Participants are asked to rate on a scale of 1 to 5 according to the expression realism, emotional resonance, and lip-audio synchronization of the performance. We eventually receive 40 valid submissions. As is demonstrated in Tab. [tab:user], our method produces the most realistic singing performance and excels at emotional expressiveness, achieving the best perceptual quality.
Qualitative Comparisons
 />
/>
Fig. 3 shows a visual comparison between the robotic performance generated by different methods. RT uses random sampling from the dataset, resulting in intense but unnatural expressions that produce the Uncanny Valley effect. Although NNR and Zhu et al. generate lip movements that are somewhat consistent with the audio, the results are overly conservative and lack expressiveness. In contrast, our method produces more plausible lip shapes, effectively capturing the large-amplitude movements and prolonged vowels featured in singing performances. Furthermore, while maintaining lip synchronization, our method simultaneously exhibits micro-expressions that convey rich emotions, such as the slightly raised mouth corners (Row 1) and widened eyes (Row 2).
Ablation Study
 />
/>
Analysis of Avatar-based Driving. To assess the contribution of the avatar-based driving source, we excluded the intermediate avatar video generation phase. Instead, we employ the blendshape coefficients predicted by EmoTalk as the input to our piecewise functions (denoted as w/o Avatar-driven). As shown in Tab. 4, all metrics significantly decrease. The results in Fig. 4 show that the robot can only produce ambiguous mouth shapes and slight emotional changes. In contrast, our method can transfer the visual expression and emotion features embedded in the portrait animation, achieving expressive performance.
Analysis of Diffusion Human Priors. Video diffusion models leverage extensive human priors to achieve portrait animation quality significantly superior to methods trained on limited datasets. To investigate the impact of diffusion priors on robotic animation quality, we utilize rendered avatar animations generated by EmoTalk as the driving animation (denoted as w/o Diffusion Prior). All metrics decline in this setting, as reported in Tab. [tab:ablation]. This degradation demonstrates that although rendered 3D avatar animations provide basic visual motion signals, they lack the subtle micro-expressions and appearance features embedded in diffusion priors. These features are crucial for recognizing emotional state and expression strength. Consequently, the resulting robotic performance suffers from constrained lip movements and emotional misalignment, as illustrated in Fig. 4.
Analysis of Reference Portrait.
 />
/>
Our method can benefit from the controllability of the diffusion generation model, generating different styles of singing performances by changing conditions, and further achieving diverse robotic face animations. Fig. 5 showcases the robotic face performance generated from the same vocal input, using 4 distinct reference portraits to synthesize the driving animation. By switching reference portraits, our method enables diverse singing performance styles.
Conclusion
In this paper, we present SingingBot, a novel framework for robotic singing performance. To address the limitations of existing methods in handling singing scenarios which demand superior lip articulation and emotional expressiveness, our method utilizes a portrait animation model pre-trained on large-scale data to generate realistic avatar singing videos as driving sources, leveraging embedded human priors to provide abundant expression and emotion guidance. Through a set of semantic-oriented mapping functions, our method transfers virtual facial features to the physical robotic motion space, achieving appealing robotic singing performances. Furthermore, we introduce the Emotion Dynamic Range metric to quantify emotional diversity. By analyzing the emotional breadth within the Valence-Arousal space, we reveal that a rich emotional spectrum is critical for performance expressiveness. Extensive experiments prove that our method achieves superior performance over existing methods both in lip-audio synchronization and emotional richness, taking a meaningful step towards empathetic Human-Robot Interaction.
In the supplementary material, we provide further information about our work, including the specific design of our user study, the hardware design of our humanoid robots, and more details about our mapping function. We also present a short description of our supplementary video and mapping function configuration data. The code and configuration data will be publicly released after publication.
User Study Details

Fig. 6 shows the designed user study interface. The study consists of 16 questions, each presenting the participants with a random 7-second-long clip of the robot singing performance driven by baselines and our method. The order of different methods is disrupted. For each video, participants are instructed to rate the anonymous animation on a scale of 1-5 based on the ground truth, with higher ratings indicating better performance. Each question consists of three sub-items: “Realism: are the expressions real or are the expressions lack a sense of reality?", “Reasonance: Is the character rich in emotions?", and “Lip-sync: Is the lip shape consistent with the audio?" To ensure the participants are fully engaged in the user study, only when they watch the entire video and rate all the items can they proceed to the next question, otherwise a warning message would pop up. Only when all questions are answered will they be included in the final results. Finally, we collect valid submissions from 40 participants.
Hardware Design
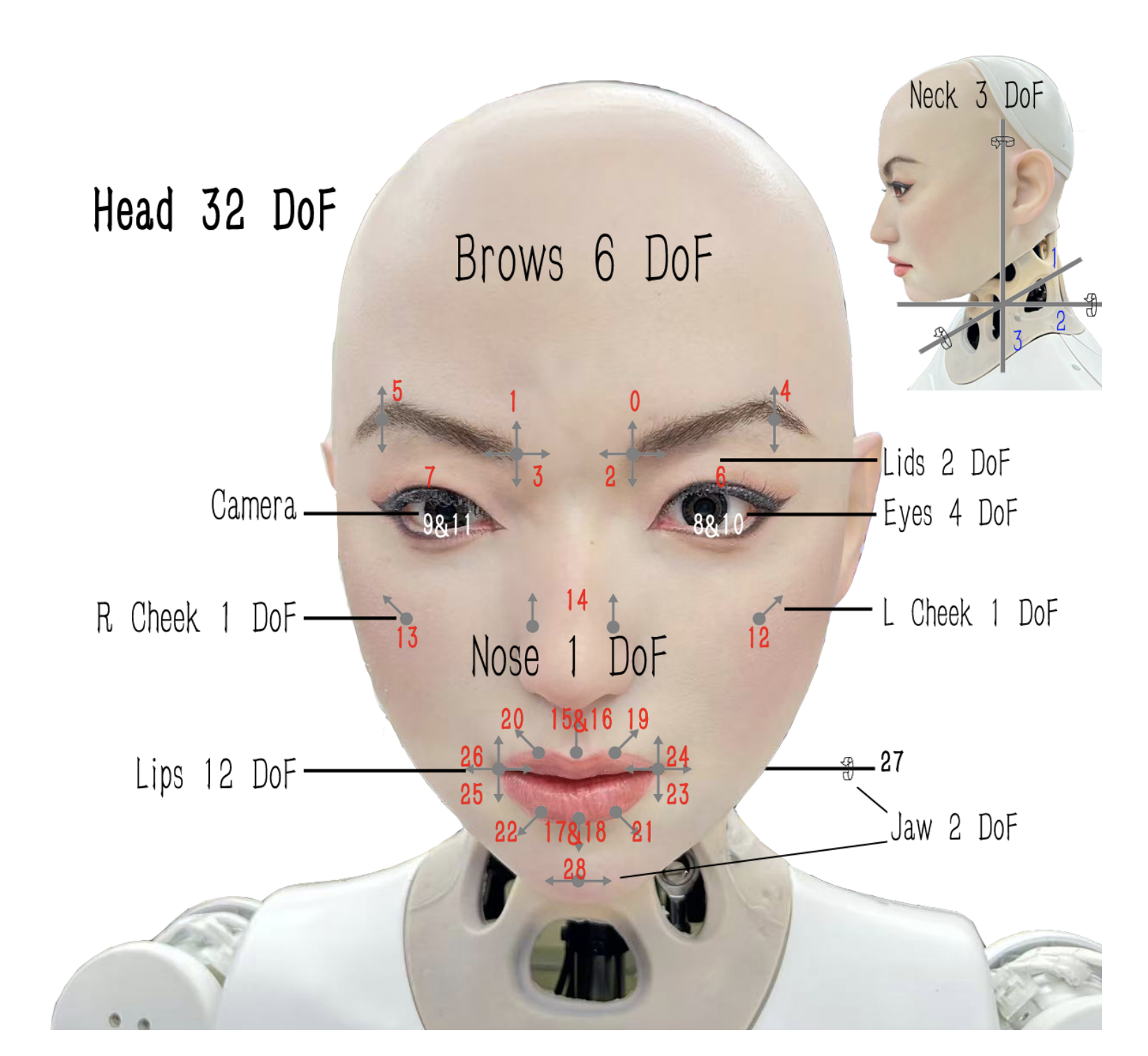
To evaluate the physical performance of our SingingBot framework, we utilize a high-fidelity humanoid robotic platform as the hardware backend. The robotic head is specifically engineered for expressive facial animation, featuring a bio-inspired mechanical structure covered by a flexible silicone skin.
The robotic head integrates a total of 32 independent DoF, enabling the execution of complex micro-expressions and high-frequency lip movements required for singing. The distribution of these actuators is strategically designed to mimic human facial musculature, as illustrated in Fig. 7.
Mapping Function Details
To bridge the gap between the generated digital facial coefficients and the physical robotic hardware, we implement a robust mapping pipeline, termed BS2Action. This process translates 52 standard ARKit-compatible Blendshapes into control signals for the 32 DoF of our robotic platform.
The mapping is grounded in a set of high-fidelity anchor pairs created by the assistance of professional animators. For each key Blendshape (e.g., JawOpen, MouthFunnel, BrowInnerUp), we chose one or more intensities, and an animator manually adjusted the robot’s 32 actuators to achieve the most precise similarity. Given the set of manually defined anchor points, we employ a piecewise interpolation strategy to determine the actuator values for any arbitrary set of Blendshape weights.
The complete configuration file and the mapping dictionary are provided in the attached supplementary ZIP archive for further reference. In the yaml file, each Blendshape has one or more servo parameter files of different Blendshape intensities, which contain the rotation angles of each servo.
Video Dynamic Results
We provide additional dynamic experimental results in the supplementary video for better demonstration of our work. Specifically, we present visual comparisons against baseline methods and ablation variants. Additionally, the video also shows the dynamic results of our method in generating different styles of performances by changing the reference portrait. Finally, we include 3 continuous singing performance lasting approximately 30 seconds to demonstrate the temporal stability of our method.
📊 논문 시각자료 (Figures)
