Code for Machines, Not Just Humans Quantifying AI-Friendliness with Code Health Metrics
📝 Original Paper Info
- Title: Code for Machines, Not Just Humans Quantifying AI-Friendliness with Code Health Metrics- ArXiv ID: 2601.02200
- Date: 2026-01-05
- Authors: Markus Borg, Nadim Hagatulah, Adam Tornhill, Emma Söderberg
📝 Abstract
We are entering a hybrid era in which human developers and AI coding agents work in the same codebases. While industry practice has long optimized code for human comprehension, it is increasingly important to ensure that LLMs with different capabilities can edit code reliably. In this study, we investigate the concept of ``AI-friendly code'' via LLM-based refactoring on a dataset of 5,000 Python files from competitive programming. We find a meaningful association between CodeHealth, a quality metric calibrated for human comprehension, and semantic preservation after AI refactoring. Our findings confirm that human-friendly code is also more compatible with AI tooling. These results suggest that organizations can use CodeHealth to guide where AI interventions are lower risk and where additional human oversight is warranted. Investing in maintainability not only helps humans; it also prepares for large-scale AI adoption.💡 Summary & Analysis
1. **Relationship between Code Quality and AI-Friendliness:** The study uses the 'CodeHealth' metric to analyze how code quality influences AI-friendly design. CodeHealth measures maintainability, and this research elucidates its impact on compatibility with AI tools. 2. **Importance of AI-Friendly Code Design:** Building upon the existing notion that "code should be written for people," the paper argues that designing AI-friendly code not only improves readability but also enhances effectiveness when using AI-assisted coding tools. 3. **Comparison of PPL and SLOC:** The research shows that the CodeHealth metric outperforms Perplexity (PPL) and Source Lines of Code (SLOC) in predicting refactoring success rates.Simple Explanation with Metaphors:
- The CodeHealth metric is like organizing a bookshelf so books are easy to find. When books are well organized, readers can quickly locate the information they need.
- AI-friendly code design is akin to setting up a library where books are systematically arranged for users to easily access required information.
Sci-Tube Style Script:
- Beginner: “Creating code that both humans and AI can understand is crucial. How does the CodeHealth metric help with this?”
- Intermediate: “We used the CodeHealth metric to analyze how code quality affects AI compatibility. What did we find out?”
- Advanced: “Reiterating the importance of code quality, our research explains the relationship between CodeHealth and PPL/SLOC metrics in assessing AI-friendly code design.”
📄 Full Paper Content (ArXiv Source)
<ccs2012> <concept> <concept_id>10011007.10011006.10011073</concept_id> <concept_desc>Software and its engineering Software maintenance tools</concept_desc> <concept_significance>500</concept_significance> </concept> </ccs2012>
Introduction
For decades, the maxim has been that “programs must be written for people to read, and only incidentally for machines to execute” . Human-readable code is essential for maintaining secure, reliable, and efficient software development . But with the advent of AI-assisted coding, source code now has a broader audience: machines need to understand its intent, too.
Early field observations collected by Thoughtworks1 suggest that AI-assisted coding tools perform better on high-quality code. In particular, well-factored modular code seems to reduce the risk of hallucination and lead to more accurate suggestions. They refer to this as “AI-friendly code design” in their April 2025 Technology Radar, and discuss how established best practices so far align with AI-friendliness . If this observation holds, it implies that code optimized for human comprehension is also easier for Large Language Models (LLMs) to process and evolve.
The implications of AI-friendliness are profound: as of 2025, about 80% of developers already use AI tools in their work , with adoption projected to grow rapidly. Gartner predicts an increase from 14% in early 2024 to 90% by 2028 . At the same time, less than 10% of organizations have been reported to methodically track technical debt , and developers have been found to waste up to 42% of their time due to poor code quality . These figures suggest that much of today’s production code may be structurally unfit for reliable AI intervention, increasing the risk of bugs and expensive rework.
In this paper, we investigate the relationship between code quality and AI-friendliness. We measure quality using the CodeHealth (CH) metric, which has been validated as predictive of defects and development effort in previous studies . The metric has also been used in recent industry-facing AI studies . We use the success rate of AI-generated refactoring, i.e., improving the design of existing code without changing its behavior, as a proxy for AI-friendliness. Refactoring lets us use passing unit tests as an oracle for functional correctness. Thus, an AI refactoring is correct if tests pass and beneficial if CH increases.
Our results confirm that human-friendly code is more compatible with AI tooling. LLMs tasked with refactoring have significantly lower break rates on code in the Healthy CodeHealth range ($`CH\ge9`$), with corresponding risk reductions of 15-30%. Furthermore, we show that CH outperforms perplexity (PPL, an LLM-intrinsic confidence metric) and Source Lines of Code (SLOC) as a predictor of refactoring correctness.
These findings can support software organizations in the adoption of AI-assisted coding. We propose using CH to identify parts of the code that are ready for AI processing, as well as highlighting code with too much risk of breaking. More broadly, this research adds a missing piece to AI adoption: a shared code-quality metric that aligns humans and machines. While earlier research positioned code quality as a business imperative, we posit that code quality is a prerequisite for safe and effective use of AI – which might prove existential for software organizations in the next decade.
The remainder of this paper is organized as follows. Section 2 describes background and related work. In Section 3, we introduce our research questions, dataset, and method. Section 4 reports our results. Finally, Section 5 discusses the implications before Section 6 concludes with directions for future work.
Background and Related Work
This section first introduces CH and PPL, then presents related work on code comprehension and AI refactoring.
Maintainability and CodeHealth
CodeHealth™ (CH) is a quality metric used in the CodeScene software engineering intelligence platform. Its goal is to capture how cognitively difficult it is for human developers to comprehend code. CodeScene identifies code smells , e.g., God classes, deeply nested logic, and duplicated code. For Python, which we target in this paper, CodeScene detects 25 code smells.
CodeScene combines the number and severity of detected smells into a file-level score from 1 to 10. Lower scores indicate higher cognitive load for humans, i.e., higher maintenance effort. CodeScene categorizes files as belonging to one of three CH intervals: Healthy (CH $`\ge 9`$), Warning ($`4 \le \text{CH} < 9`$), and Alert ( $`< 4`$). In this study, we refer to both Warning and Alert files as Unhealthy.
We have previously validated the CH metric in a series of studies. In a study on the manually annotated Maintainability Dataset , we reported that CH aligns better with human maintainability judgments than competing metrics and the average human expert . Furthermore, we have validated the metric from a business perspective through the association between CH on the one hand and file-level defect density and development time on the other hand . Building on our previous work, we now investigate the relation between CH and AI-friendliness.
LLM Confidence and Perplexity
Several metrics have been proposed to assess the confidence of LLM output. Internal metrics such as entropy, mutual information, and PPL can potentially be used as proxies of output correctness and hallucination risk. In the software domain, Sharma et al. showed that higher entropy and mutual information correlate with lower functional correctness of the generated code . Earlier work by Ray et al. also showed that code containing defects had higher entropy than correct code , which in turn builds on the foundational work on the naturalness of code by Hindle et al. .
Ppl, originally proposed for speech recognition tasks , is the exponential of the prediction model’s average entropy over a sequence. Considering entropy to represent “average surprise,” PPL rather turns this into a scale of “how many choices.” It is used as a measure of how confident an LLM is in predicting the next token based on the previous tokens – a higher score means lower confidence. Mathematically, let $`t_{1:N}`$ be a token sequence. The average cross-entropy ($`H`$) is:
H = -\frac{1}{N}\sum_{i=1}^{N}\log p(t_i \mid t_{<i}).PPL is $`\exp(H)`$. In this work, we get PPL directly from the five Hugging Face models under study .
Code Comprehension and Perplexity
Gopstein et al. coined the term atoms of confusion to refer to
small, isolated patterns in code that confuse humans . An atom is the
smallest unit of code that can cause confusion. Through controlled
experiments, they identified a set of atoms that significantly increased
the rate of misunderstandings. Examples include “Assignment as Value,”
e.g., V1 = V2 = 3; and “Logic as Control Flow,” e.g., V1 && F2();.
Building on the atoms concept, Abdelsalam et al. discussed the risks of comprehension differences between human programmers and LLMs in the current hybrid development landscape . They argue that if humans and LLMs are confused by different characteristics in code, there is a risk of misalignment. By comparing LLM PPL and EEG responses, they found that LLMs and humans struggle with similar issues in code. A previous controlled experiment by Casulnuovo et al., also suggests a connection between human comprehension and how surprising a code snippet is to LLMs .
Kotti et al. explored the PPL of different programming languages . Based on 1,008 files from GitHub projects representing different languages, they found systematic differences between strongly-typed and dynamically typed languages. For example, across LLMs, they found that Perl resulted in high PPL and Java in low. They speculate that their PPL findings could be used to assess the suitability of LLM-based code completion in specific projects. In this study, we explore the PPL concept for Healthy vs. Unhealthy Python code.
AI Refactoring
Research in automated code refactoring has, like so many software engineering applications, been disrupted by LLMs. Several studies investigate the potential of various combinations of LLMs and prompts to improve design and remove code smells effectively. Pomian et al. introduced the tool EM-Assist to automatically suggest and perform extract method refactorings. The same team has continued working on the more sophisticated refactoring operation move method . Tornhill et al. have developed the tool ACE to automatically remove five CodeScene code smells .
During 2025, agentic AI has been a major trend in industry and research. Coding agents are driven by LLMs, but they typically claim to 1) understand codebases beyond limited context windows and to 2) maintain a memory. This enables agents to take on larger tasks and operate more autonomously. The arguably most popular agent in industry at this time of writing is Anthropic’s Claude Code, carefully described by Watanabe et al. . We refer to reviews by He et al. and Wang et al. for contemporary overviews of the academic literature.
Refactoring is one of the many tasks investigated for coding agents. For example, Xu et al. presented MANTRA, a multi-agent framework for refactoring . MANTRA organizes three agents into 1) developer, 2) reviewer, and 3) repair roles for the refactoring task, and outperforms direct LLM-usage. However, Claude is also a capable refactoring agent despite not being a multi-agent solution. In this study, we study Claude (v2.0.13) as a representative example of contemporary agentic AI refactoring. Moreover, MANTRA is not publicly available at the time of this writing.
Method
Our goal is to explore how code characteristics influence the capabilities of AI refactoring, with a particular focus on CH. We formulate three Research Questions (RQs) that explore code characteristics in light of AI-friendliness. First, we take an LLM-intrinsic perspective and study PPL. This connects to related work and provides a baseline. Second, we look at how the CH is associated with the success rate of a downstream AI task. Third, we examine the predictive power of CH compared to SLOC and PPL.
-
How does perplexity differ between Healthy and Unhealthy code?
-
How does the AI refactoring break rate differ between Healthy and Unhealthy code?
-
To what extent can CodeHealth predict the AI refactoring break rate?
Dataset Creation
We sample from the CodeContests dataset hosted on GitHub2 by Google DeepMind. The dataset was introduced by Li et al. as training data for AlphaCode and contains more than 12 million solutions (correct and incorrect) to competitive programming problems from five sources. We study code in this domain because the problems come with carefully crafted test cases that verify functional correctness, providing a practical oracle after refactoring.
We construct a dataset of 5,000 solutions based on four design choices.
First, we decided to focus on solutions written in Python to increase
novelty and convenience. While CodeContests also contains solutions in
Java and C++, Java has been extensively studied in refactoring research,
and C++ has a more complex compile-and-test procedure. Second, we
require at least one CodeScene code smell in the solutions. Removing
code smells is a realistic refactoring goal. Third, we chose to only
study solutions containing between 60 and 120 SLoC. There is a strong
correlation between maintainability and size , thus we control for this,
at least partly, already during the sampling. Fourth, we actively seek
diversity in the dataset, as many solutions are highly similar. We use
CodeBleu for similarity calculations using the following weights:
n-gram=0.1, weighted-n-gram=0.4, ast-match=0.5, and
dataflow-match=0.
The practical sampling process followed these steps (number of remaining solutions in parentheses):
-
Download the full CodeContests dataset (13,210,440).
-
Filter to only Python 3 solutions (1,502,532).
-
Remove all identical (Type 1 clone) solutions (1,390,531).
-
Remove all solutions with no CodeScene code smells (88,156).
-
Strip comments and unbound string literals.
-
Filter to solutions with $`60`$–$`120`$ SLOC (18,074).
-
Partition into two strata: Healthy and Unhealthy code3.
-
For each stratum, repeat until 2,500 solutions are included:
-
Sample a random candidate solution.
-
Run its corresponding test cases; skip if any test case fails.
-
Compute CodeBleu similarity to existing samples; skip if similarity $`\geq 0.9`$.
-
Add the solution to the stratum.
-
-
Merge the two strata to constitute the final dataset (5,000).
Selection of Large Language Models
We select six LLMs for evaluation. Five are open-weight models with about 20-30B parameters, runnable on our local datacenter. We select four models based on popularity and download statistics from Hugging Face and complement them with an LLM recently published by IBM – we refer to these as medium-sized LLMs. Moreover, we include a State-of-the-Art (SotA) LLM that we prompt using Anthropic’s API.
-
gemma-3-27b-it (Google) – Mar 2025.
-
GLM-4-32B-0414 (Zhipu AI) – Apr 2025.
-
Granite-4.0-H-Small (IBM) – Oct 2025.
-
gpt-oss-20b (OpenAI) – Aug 2025.
-
Qwen3-Coder-30B-A3B-Instruct (Alibaba Cloud) – Aug 2025.
-
claude-sonnet-4-5-20250929 (Anthropic) – Sep 2025.
We set the sampling temperature to 0.7 for all LLMs to enable refactoring diversity under a uniform setting and we cap generation to a maximum of 8,192 new tokens. All other settings use defaults.
RQ$`_1`$ Perplexity
We extract PPL scores for all 5,000 samples for the five LLMs under study. Then we split the samples into Healthy and Unhealthy and state the following null hypothesis for each LLM:
- The perplexity distributions for Healthy and Unhealthy code are identical.
Descriptive statistics revealed a small set of outliers with extremely high PPL. Manual analysis showed specific patterns that substantially inflate the LLMs’ next-token uncertainty. In competitive programming, some contestants hard-code astronomically big integers or very long strings for later use in the solutions. To mitigate this, we applied one-sided robust z-score filtering and removed samples with z>2.5 from the output from the LLMs (about 5%).
PPL scores are typically right-skewed, and we assess normality using the Shapiro–Wilk test. Even after filtering upper-tail outliers, we rejected normality for all LLM outputs. Subsequently, we rely on non-parametric Mann-Whitney U tests for significance testing. Finally, we use Holm correction (Holm-Bonferroni step-down) to adjust for multiple comparisons across the five models (family-wise $`\alpha`$=0.05). We report two-sided Holm-corrected p-values and Cliff’s $`\delta`$ as the effect size.
RQ$`_2`$ Refactoring Break Rate
We tasked all medium-sized LLMs to refactor the 5,000 samples. For Sonnet, which has a high token price, we refactor 1,000 random samples equally split between Healthy and Unhealthy. For each combination of LLM and sample, we used the same prompt following a general structure, designed to be generic:
-
Context in the form of a role description to steer the model toward the right parts of its knowledge.
-
A concrete task for the model to perform.
-
Instructions for how the model should format the response.
-
Input data for which the task shall be completed.
()Act as an expert software
engineer.()Your task is to refactor
the following Python code for maintainability and clean
code.() Respond ONLY with the
complete, refactored Python code block. Do not add any explanations,
comments, or introductory sentences.
()Original code to refactor:
python <CODE>
We complemented the LLMs with Claude (v2.0.13) to also investigate a SotA agentic approach to refactoring. We selected Claude specifically because it is considered industry-leading and currently tops public SWE-bench results . While Claude operates in an interactive mode in the terminal, we controlled the environment and presented the task in a manner consistent with the LLM setup. Claude is a costly service, and we decided to target the same 1,000 samples as for Sonnet. We aimed at a final cost of less than $100 for Anthropic’s solutions.
We organized batches of random samples in separate folders to mimic how
a developer might work, starting with a small sample of 20 files for a
pilot run – followed by 200, 400, and 380. We provided the instructions
(A–C) in a CLAUDE.md file in the common parent folder, appended with:
“Each file in this folder is independent; you do not have to worry about dependencies between them.”
For each sample folder used with Claude, we added a configuration file
(.claude/settings.json) to pin the model version and restrict the
agent’s tool use. Specifically, we set the model to
claude-sonnet-4-5-20250929, explicitly disabled Bash, WebFetch,
and WebSearch, and also disabled any MCP use.
For each refactoring session, we followed these steps:
-
Launch Claude in the current folder.
-
Answer yes to “Do you trust the files in this folder?”
-
Ask Claude “Can you see CLAUDE.md in the parent folder?” and grant read permission.
-
Give the instruction: “Refactor the Python files in this folder for maintainability.”
-
When Claude requests edit permission, approve editing of all files for the session.
After each single refactoring pass, we recorded descriptive statistics of the output code, calculated its CH, and executed the corresponding test cases to determine whether behavior was preserved. If any test cases failed, we refer to the refactoring as broken. We state the following null hypothesis for each refactoring approach:
- There is no difference in refactoring break rate between Healthy and Unhealthy code.
We compare break rates using a chi-square ($`\chi^2`$) test of independence and report Risk Difference (RD) and Relative Risk (RR) with 95% confidence intervals. We control family-wise error ($`\alpha`$=0.05) using Holm correction, in line with RQ$`_1`$.
RQ$`_3`$ Predictive Power of CodeHealth
We train decision trees on the data from the medium-sized LLMs’ refactoring outputs to investigate which code features influence the probability that a refactoring breaks its test suite. Our feature set aims to cover three complementary dimensions while avoiding redundancy, motivated as follows:
-
CodeHealth is our primary explanatory variable of interest, reflecting human-oriented maintainability.
-
Perplexity is included because the LLMs’ internal confidence can carry a predictive signal. Moreover, RQ$`_1`$ found that it is orthogonal to CH (see Section 4.2).
-
SLOC is included as a simple size metric, which often is an effective proxy for structural complexity. Kotti et al. (and our corroborating results for RQ$`_1`$) found that SLOC and PPL are not correlated.
-
Token count is excluded to minimize redundancy as it is correlated with SLOC (and showed small but consistent correlations with PPL in RQ$`_1`$).
We use a fixed, shallow decision tree (max depth = 3, min samples per leaf = 25, class-weighted) to prioritize interpretability and comparability across results for the six LLMs. We perform 5-fold cross-validation with these fixed hyperparameters, then refit the tree on all data for final visualization and rule extraction. Finally, we report the area under the ROC curve (AUC) for the final decision trees, i.e., a threshold-independent metric robust to class imbalance. Note, however, that we train decision trees for explanatory purposes rather than accurate predictions.
As a robustness check, we fit logistic regression models on the same data and features. Logistic regression provides Odds Ratios (OR), which show the change in odds that tests pass associated with a one-standard-deviation increase in a predicting feature, while holding all others constant.
Results
This section first presents descriptive statistics of the dataset, followed by results for the three RQs. All related Jupyter Notebooks are available in the replication package .
Descriptive Statistics
Figure 3 shows the SLOC and CH distributions of the 5,000 solutions in the dataset. For SLOC, the solutions are concentrated around the lower bound and then declines steadily with size. For CH, the distribution is left-skewed and we observe the effect of the stratified sampling. For both strata, the density piles up for solutions with higher CH, which explains the dip just over CH $`=9`$. Overall, the CH distributions resemble patterns reported in previous work , though the skew is less pronounced for the short competitive programming tasks under study in this paper.
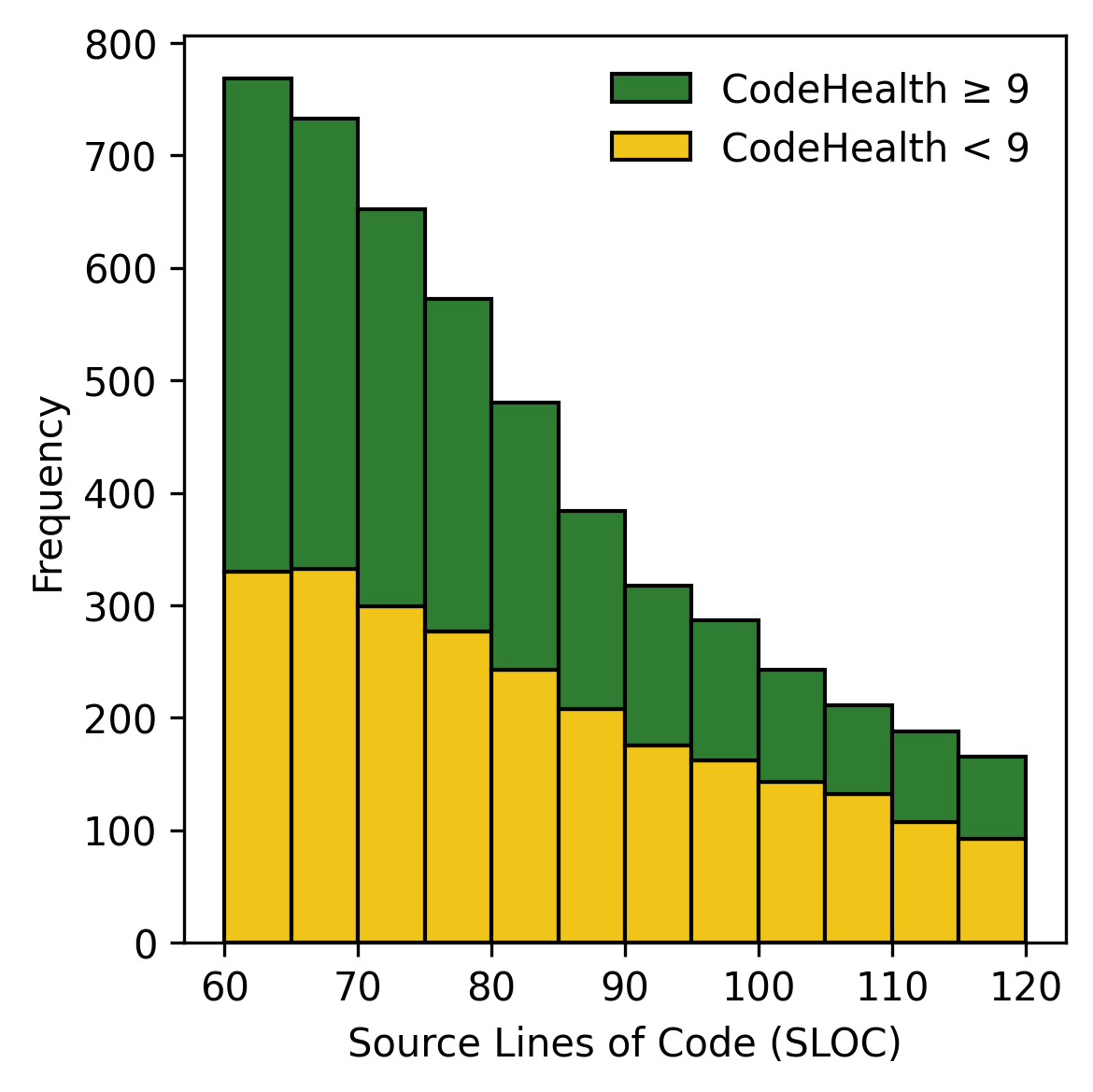
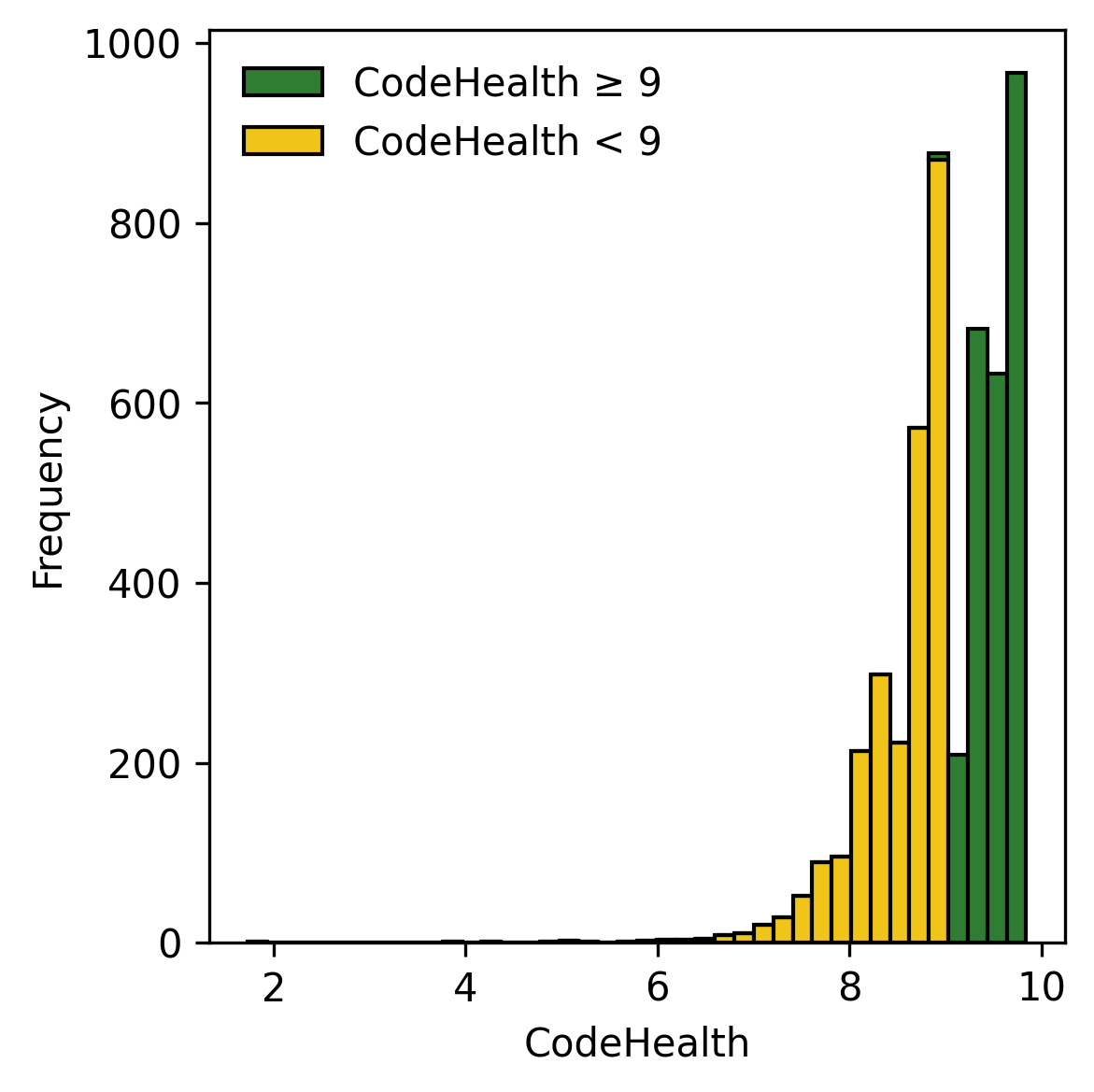
CodeScene identifies nine different code smells in the dataset. The five most common smells (and their counts) are: 1) Bumpy Road Ahead (n=4,901). A function contains multiple chunks of nested control structures, suggesting missing abstractions that make the code harder to understand. 2) Complex Method (n=3,572). A function has a high cyclomatic complexity, meaning it contains many independent logical execution paths. 3) Deep, Nested Complexity] (n=2,433). Control structures, such as loops and conditionals, are nested within each other to multiple levels. 4) Complex Conditionals (n=1,328). There are expressions that combine multiple logical operations, such as conjunctions and disjunctions, within a single condition. 5) Excessive Function Arguments (n=724). A function take too many parameters, indicating that the function is doing too much or that it lacks a proper abstraction.
RQ$`_1`$ Perplexity
Table [tab:rq1] summarizes PPL by the CH groups for each medium-sized LLM. We find that the PPL distributions are significantly different for all of them except Granite. However, the directions are mixed across models and the effect sizes are negligible for all models. Overall, our study yields a negative result, i.e., we find no practically meaningful association between PPL and CH.
l l S[table-format=4.0] S[table-format=1.3] S[table-format=1.3]
S[table-format=1.3] r r r & & & & & & & &
& Healthy & 2369 & 2.092 & 0.515 & 3.127 & & &
& Unhealthy & 2396 & 2.023 & 0.552 & 3.071 & & &
& Healthy & 2375 & 1.577 & 0.493 & 2.529 & & &
& Unhealthy & 2404 & 1.594 & 0.492 & 2.533 & & &
& Healthy & 2214 & 2.943 & 1.473 & 6.226 & & &
& Unhealthy & 2216 & 2.706 & 1.559 & 6.299 & & &
& Healthy & 2369 & 1.764 & 0.582 & 2.932 & & &
& Unhealthy & 2395 & 1.759 & 0.617 & 2.923 & & &
& Healthy & 2335 & 1.728 & 0.610 & 2.915 & & &
& Unhealthy & 2388 & 1.769 & 0.622 & 2.968 & & &
We revisit a negative finding from Kotti et al. , who reported no correlation between file size and PPL. Using Spearman correlations ($`\rho`$) on our filtered dataset, we largely confirm this: for SLOC, all models show negligible associations except GPT, which shows a low positive correlation ($`\rho = +0.197`$).
We also examined token counts, for which four models yielded small negative correlations: Gemma ($`\rho = -0.197`$), GLM ($`\rho=-0.245`$), Granite ($`\rho = -0.242`$), and Qwen ($`\rho = -0.223`$). Again, GPT stood out, this time with a small positive correlation ($`\rho = +0.153`$). Still, in general, LLMs’ PPL on the code tends to decrease slightly as token count increases, while there is no corresponding pattern for SLOC.
Across models, directions are mixed and effect sizes are trivial, indicating no practically meaningful association between PPL and CH.
RQ$`_2`$ Refactoring Break Rate
Table [tab:rq2_breakrate] lists test verdicts per refactoring approach, split by Healthy and Unhealthy code. The LLMs are ordered from lower to higher break rates and the agentic solution Claude is presented below the double horizontal lines.
| Total | Tests passed | χ2 (Healthy vs. Unhealthy) | ||||||
|---|---|---|---|---|---|---|---|---|
| 3-3(lr)4-5(lr)6-8 Model | Group | N | % | p | RD (pp) [95% CI] | RR [95% CI] | ||
| Sonnet | Healthy | 499 | 433 | 86.77 | 0.439 | −2.74 [−7.11, 1.63] | 0.828 [0.613, 1.120] | |
| Unhealthy | 501 | 421 | 84.03 | |||||
| Qwen | Healthy | 2501 | 2019 | 80.72 | <0.001 | −8.58 [−10.92, −6.24] | 0.692 [0.625, 0.766] | |
| Unhealthy | 2499 | 1803 | 72.16 | |||||
| GPT | Healthy | 2501 | 1604 | 64.13 | <0.001 | −11.15 [−13.87, −8.44] | 0.763 [0.713, 0.816] | |
| Unhealthy | 2499 | 1324 | 52.98 | |||||
| GLM | Healthy | 2501 | 1504 | 60.14 | <0.001 | −10.16 [−12.90, −7.41] | 0.797 [0.749, 0.848] | |
| Unhealthy | 2499 | 1249 | 50.02 | |||||
| Gemma | Healthy | 2501 | 1394 | 55.74 | <0.001 | −15.12 [−17.86, −12.38] | 0.745 [0.706, 0.787] | |
| Unhealthy | 2499 | 1015 | 40.58 | |||||
| Granite | Healthy | 2501 | 1162 | 46.46 | <0.001 | −9.29 [−12.01, −6.56] | 0.852 [0.813, 0.894] | |
| Unhealthy | 2499 | 929 | 37.17 | |||||
| Claude | Healthy | 499 | 480 | 96.19 | 0.439 | −1.38 [−3.95, 1.19] | 0.734 [0.411, 1.308] | |
| Unhealthy | 501 | 475 | 94.81 | |||||
The results show that all medium-sized LLMs consistently have lower break rates for Healthy code. The risk differences, all statistically significant, are between -8.58 percentage points for Qwen and -15.12 for Gemma. The relative risks range from 0.692 for Qwen to 0.852 for Granite. This means that for the most capable medium-sized LLM in the study, the risk reduction is over 30%. For the SotA LLM Sonnet, there is no significant difference between Healthy and Unhealthy code. Claude demonstrates a substantially more conservative risk profile. In the first refactoring task, Claude breaks only about 5% of the test suites regardless of whether the code is Healthy or Unhealthy – again, no statistically significant difference.
To further investigate what the refactoring approaches accomplish during their tasks, we analyze their impact on CH. Table [tab:rq2_codehealth] presents the results, using the same sorting as in Table [tab:rq2_breakrate]. We report CH deltas among the refactoring outputs that pass the test suite, partitioned as increase (CH $`\uparrow`$), no change (CH $`\leftrightarrow`$), and decrease (CH $`\downarrow`$). In the final column (%Success), we report the fraction of successful refactorings, i.e., improved CH and tests pass.
l l S[table-format=4.0] S[table-format=4.0] S[table-format=2.2]
S[table-format=4.0] S[table-format=2.2] S[table-format=4.0]
S[table-format=2.2] S[table-format=4.0] S[table-format=2.2]
S[table-format=2.2] & & & & &
(lr)3-3 (lr)4-5 (lr)6-11 (lr)12-12 & & & N & % & CH $`\uparrow`$
& % & CH $`\leftrightarrow`$ & % & CH $`\downarrow`$ & % &
& Healthy & 499 & 433 & 86.77 & 250 & 57.74 & 69 & 15.94 & 114 &
26.33 & 50.10
& Unhealthy & 501 & 421 & 84.03 & 347 & 82.42 & 30 & 7.13 & 44 &
10.45 & 69.26
& Healthy & 2501 & 2019 & 80.72 & 539 & 26.71 & 934 & 46.28 & 545 &
27.01 & 21.56
& Unhealthy & 2499 & 1803 & 72.16 & 853 & 47.28 & 581 & 32.21 & 370
& 20.51 & 34.12
& Healthy & 2501 & 1604 & 64.12 & 961 & 59.95 & 305 & 19.03 & 337 &
21.02 & 38.44
& Unhealthy & 2499 & 1324 & 53.00 & 1088 & 82.11 & 107 & 8.08 & 127
& 9.58 & 43.52
& Healthy & 2501 & 1504 & 60.12 & 679 & 45.18 & 414 & 27.54 & 410 &
27.29 & 27.16
& Unhealthy & 2499 & 1249 & 50.00 & 880 & 70.40 & 158 & 12.64 & 212
& 16.96 & 35.20
& Healthy & 2501 & 1394 & 55.76 & 627 & 44.98 & 426 & 30.56 & 341 &
24.46 & 25.08
& Unhealthy & 2499 & 1015 & 40.60 & 685 & 67.49 & 162 & 15.96 & 168
& 16.55 & 27.40
& Healthy & 2501 & 1162 & 46.44 & 417 & 35.90 & 540 & 46.52 & 204 &
17.58 & 16.68
& Unhealthy & 2499 & 929 & 37.20 & 454 & 48.82 & 347 & 37.31 & 129 &
13.87 & 18.16
& Healthy & 499 & 480 & 96.19 & 96 & 20.00 & 331 & 68.96 & 53 &
11.04 & 19.24
& Unhealthy & 501 & 475 & 94.81 & 124 & 24.75 & 288 & 60.63 & 63 &
13.26 & 24.75
CH deltas among behavior-preserving refactorings vary considerably across LLMs. All LLMs sometimes decrease CH, which means either that 1) new code smells have been added or 2) the severity of an existing smell has increased. We also observe consistent differences between Healthy and Unhealthy code: when the starting code is Unhealthy, LLMs more frequently increase CH. The largest difference appears for Sonnet and GLM (about 25 pp) whereas the smallest can be seen for Granite (about 13 pp). Sonnet outperforms the medium-sized LLMs with 57.74% and 82.42% CH improvements for Healthy and Unhealthy code, respectively.
For medium-sized LLMs, the results reveal a trade-off between preserving behavior and improving CH. The most behavior-preserving among them, Qwen, improves CH less frequently, especially on Healthy code, where no change is common (46.28%) and improvements occur in 26.71% of the cases. All other medium-sized LLMs have higher fractions of CH increases, both for Healthy and Unhealthy code. Looking at the last column, we find that GPT has the highest fractions of successful refactorings (38.44% and 43.52%, respectively) among the medium-sized LLMs, followed by GLM and Qwen. The results illustrate the LLMs’ balance between bolder refactoring attempts and behavioral preservation. For comparison, Sonnet provides 50.10% and 69.26% successful refactorings for Healthy and Unhealthy code, respectively.
The results for Claude demonstrate how the trade-off can be balanced when building an agentic product on top of an LLM. We find that Claude is the most conservative of all refactoring approaches under study, with unchanged CH in 68.81% and 60.76% of the cases for Healthy and Unhealthy code, respectively. This is also consistent with the typical output summaries from Claude provided after completing a batch of refactoring operations, describing changes focusing on: 1) renaming variables to match the intent of the code, 2) organizing code according to conventions, and 3) formatting related to white space (see summary in Appendix 8). We manually analyzed a sample of the refactorings to confirm this behavior. Because these operations rarely affect CodeScene’s code smells, they typically do not alter CH, which explains why it often remains unchanged.
However, Claude sometimes makes bolder refactoring attempts that result in more intrusive code changes. The second summary in Appendix 8 shows such an example. The quote lists several completed refactoring operations that can potentially increase CH, including: function extraction, simplification of complex conditionals, elimination of code duplication, and flattening of nested structures. We did not find any pattern in when Claude chooses conservative versus bolder refactoring attempts. At the same time, we observe that Claude’s statements about “zero functionality changes” and “file maintains its original functionality” are overconfident – sometimes the agent indeed breaks behavior.
All five medium-sized LLMs have significantly lower break rates on healthy code, with relative risk reductions of about 15% for the weakest model and 30% for the strongest. Results are less clear for Sonnet, and when used as the LLM in the agentic Claude configuration, the solution is uniformly conservative ($`\approx`$5% breaks).
RQ$`_3`$ Predictive Power of CodeHealth
Table 1 presents results from training explanatory decision trees on the refactoring data from the medium-sized LLMs. “%Break” shows the break rate, AUC shows how well the fitted trees separate passing vs. breaking tests. The last three columns show the relative importance of the three features under study: CH, PPL, and SLOC.
| LLM | %Break | AUC | Feature importance | |||
|---|---|---|---|---|---|---|
| 4-6 | CodeHealth | Perplexity | SLOC | |||
| Qwen | 0.236 | 0.553 | 0.707 | 0.160 | 0.132 | |
| GPT | 0.414 | 0.559 | 0.683 | 0.268 | 0.049 | |
| GLM | 0.449 | 0.546 | 0.572 | 0.360 | 0.068 | |
| Gemma | 0.518 | 0.565 | 0.880 | 0.120 | <0.001 | |
| Granite | 0.582 | 0.544 | 0.583 | 0.417 | <0.001 | |
While all the fitted decision trees are poor at classifying breaking tests, CH consistently emerges as the most discriminative feature. It appears as the root split in all five trees, with the LLM-specific top-level decision thresholds listed below. The numbers in parentheses give the naïve classification accuracy achieved if one were to follow only this single rule, i.e., the share of samples correctly classified as breaking. For four of the LLMs, the learned threshold lies close to CodeScene’s default boundary for Healthy code ($`CH=9`$), which has previously been shown to align with human maintainability judgments .
-
CodeHealth $`\le`$ 8.895 (63% – 1163 fail, 848 pass)
-
CodeHealth $`\le`$ 8.775 (61% – 1070 fail, 683 pass)
-
CodeHealth $`\le`$ 9.195 (55% – 1495 fail, 1230 pass)
-
CodeHealth $`\le`$ 8.875 (62% – 866 fail, 572 pass)
-
CodeHealth $`\le`$ 8.285 (60% – 398 fail, 234 pass)
PPL is the second most important feature across all decision trees. However, its relative importance compared to SLOC differs substantially between LLMs. For Qwen, PPL and SLOC are roughly equally important. For Granite and Gemma, on the other hand, SLOC carries no predictive signal at all.
Figure 4 shows the complete decision tree for
Qwen as a representative example. The tree illustrates how CH forms the
root decision, with subsequent splits on PPL and SLOC – or again CH. We
let fail denote breaking refactorings and pass denote
non-breaking refactorings. Most failed refactorings are concentrated
in branches with low CH values, supporting the overall trend discussed
above.
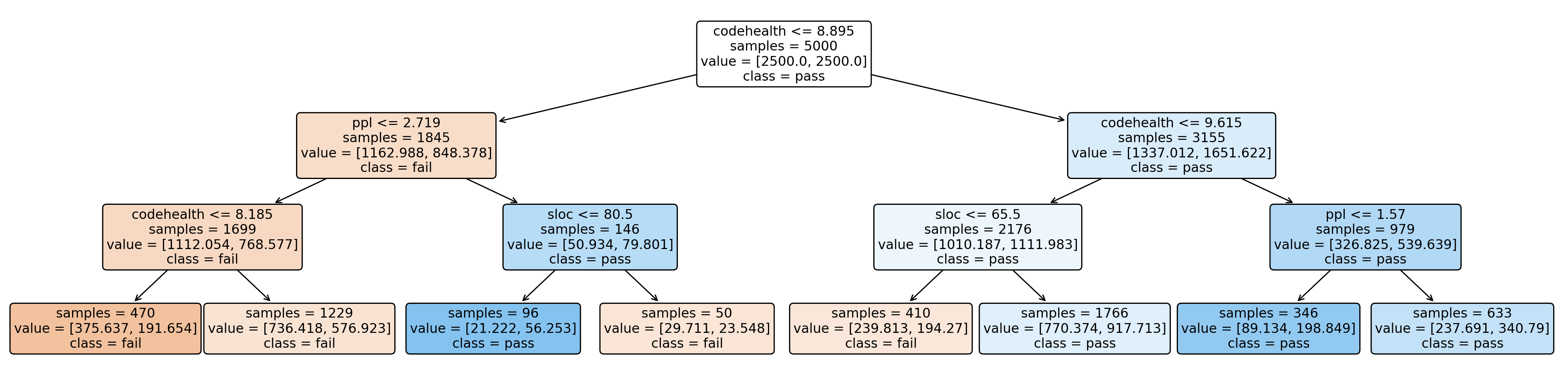
[fail, pass], and 4)
the predicted majority class, also indicated also by color.As a robustness check, we trained logistic regression models on the same data as the decision trees. Models were again evaluated with 5-fold cross-validation to fit models on all available data, and the resulting AUC scores were on par with the trees. More importantly, the odds ratios for CH were: Qwen 1.347, GPT 1.307, GLM 1.215, Gemma 1.420, and Granite 1.240. This means a one–standard-deviation increase in CH (about 0.65 in the dataset) raises the odds of a successful (non-breaking) refactoring by roughly 20–40%, confirming that healthier code is less likely to break during AI refactoring using medium-sized LLMs.
Figure 5 illustrates the refactoring break rates as a function of CH. All LLMs exhibit a clear negative trend, i.e., refactorings on healthier code break tests less often. We notice that this hold also for Sonnet, despite no significant Healthy-Unhealthy difference for that LLM in RQ$`_2`$. Instead, our results indicate that more capable LLMs shift the threshold to lower values, i.e., Sonnet safer interval might begin around CH$`\approx8`$. However, for the agentic solution Claude, the most conservative refactoring approach under study, the results show no clear trend.
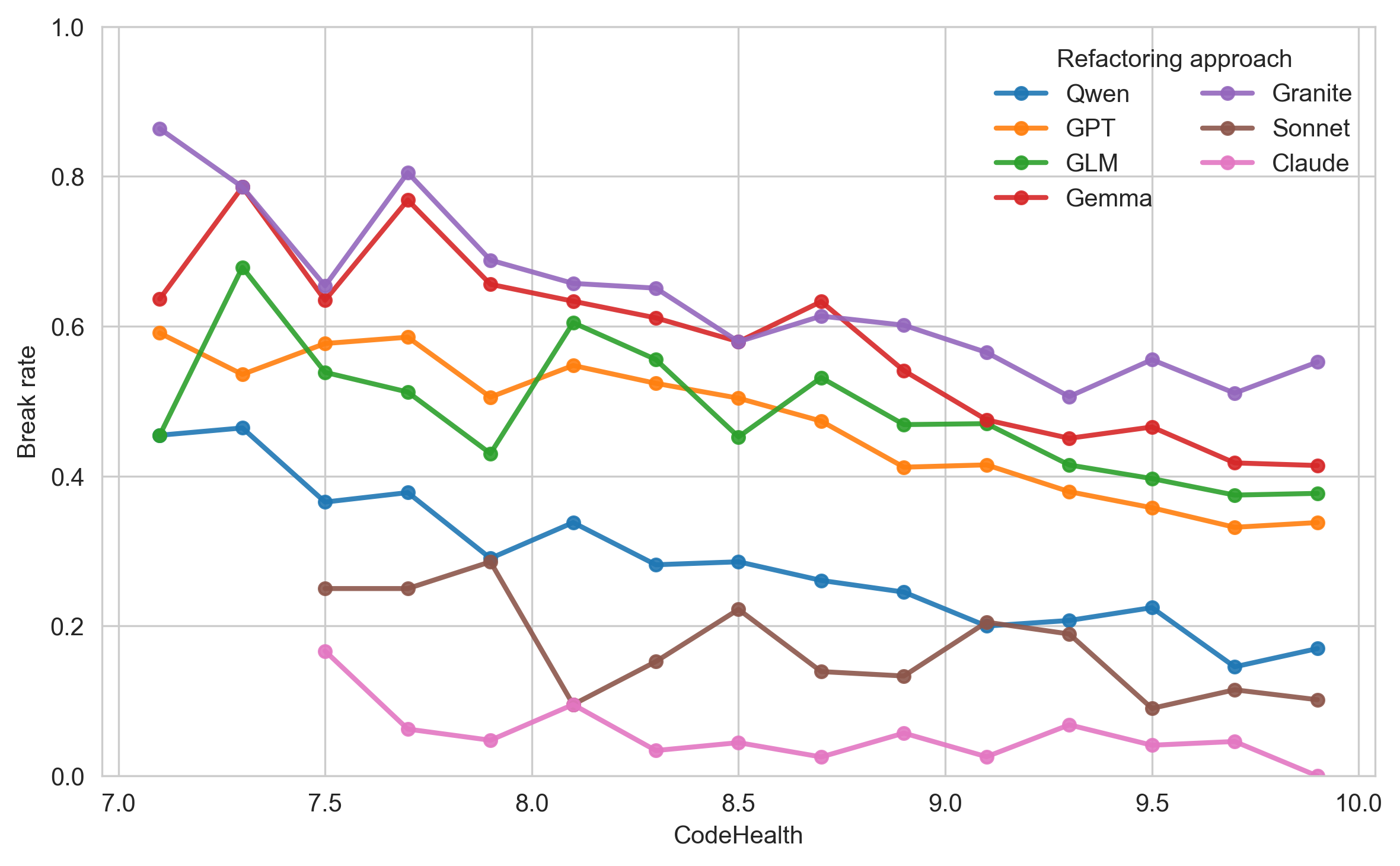
CH provides a modest but consistent signal of refactoring success and carries $`\approx`$3–10$`\times`$ more predictive information than Perplexity or SLOC. The “Healthy” threshold (CH=9), calibrated for humans, also delineates lower break risk for AI refactoring.
Discussion
This section discusses our findings in light of previous work, their implications, and the most important threats to validity.
Synthesis and Interpretation
First, we find that CH and PPL are largely orthogonal. As previous work shows that CH aligns well with human perception of maintainability , this finding contrasts previous work suggesting an association between human code comprehension and PPL . Simply relying on PPL to assess whether code is comprehensible appears too naïve.
Second, we identify differences between break rates for Healthy and Unhealthy code. In our larger runs with 5,000 samples, all medium-sized LLMs exhibit significant and practically meaningful risk differences. In the smaller 1,000-sample runs with Anthropic’s SotA approaches, we observe the same direction, but the effects are smaller and do not reach statistical significance. Nonetheless, higher CH implies better structure, which appears to make it easier for LLMs to preserve semantics – a finding in line with Thoughtworks’ early observations about “AI-Friendly code design” . Finally, Claude stands out as more conservative than direct LLM usage, which likely reflects a deliberate product decision by the company.
Third, we observe a consistent decrease in refactoring break rates as CH increases. This is a strong indication that both human developers and LLMs struggle more when code is plagued by CodeScene’s code smells. Although we find no meaningful association with PPL, our results support the overall sentiment by Abdelsalam et al., i.e., “that humans and LLMs are similarly confused.” Finally, CH carries more predictive information for refactoring break risk than PPL and the simple size measure SLOC.
Implications for Practice
Planning for the adoption of AI-assisted software development is now a priority in most software organizations. Each organization must decide how to position itself in the ongoing AI shift and assess the competitive impact. Previous work recommends controlled rollouts and careful governance , stresses keeping humans-in-the-loop , calls for a focus on human code review processes , and highlights the need for high-quality test suites .
Our findings suggest that CH-aware deployment policies could be part of informed AI-adoption. Just like humans, LLMs perform better on code with high CH. We therefore recommend either 1) focusing early AI deployment on Healthy code that is “AI-friendly,” or 2) explicitly increasing the CH in target areas of the codebase before scaling LLM-driven solutions. Prior work emphasizes humans-in-the-loop practices, and our study adds nuance: expect more human involvement with lower CH. With the current AI capabilities, no quick gains can be expected in the hairiest of old legacy parts.
High CH can act as a soft gate for AI deployment, but the exact threshold must be task-specific and LLM-dependent. In our refactoring setting, CH$`=9`$ is a reasonable reference for medium-sized LLMs, while more capable refactoring approaches may tolerate more challenging code of lower CH. Going forward, finding the most effective balance between LLM costs and task complexity will be an important business decision, in line with Zup Innovation’s first lesson learned when customizing a coding agent .
For conservative AI solutions, such as tasking Claude to complete an initial round of refactoring, expect primarily formatting and naming changes. While the effects of such changes do not improve CH, it can still provide value as it might remove fog and help humans spot what matters. Previous work shows that developers find defects in code faster if variables have appropriate names .
Finally, previous work reports amplified value gains at the upper end of CH . We anticipate that widespread adoption of code agents will intensify this effect. We already know that humans can evolve Healthy code significantly faster; our results suggest that this also holds true for machines. As code agents become commonplace, failing to maintain Healthy codebases will let faster competitors, accelerated by AI, overtake you – similar to what we experienced during the agile shift .
Implications for Research
Our results open an avenue for measurement-based studies of AI-assisted development feasibility, i.e., AI-friendliness. A promising direction is to discover better a priori estimates of where AI solutions are likely to succeed across a codebase.
PPL is not a good AI-friendliness metric on the file level. Yet we find that humans and machines, at least partly, struggle with the same smells, and Abdelsalam et al. report an association between token-level surprisal and human confusion . This suggests potential at finer granularity. Future work should examine how to better harness PPL for AI-friendliness purposes, without file-level averaging that masks localized confusion.
CH better captures AI-friendliness at the file level. Still, there is a need for research into combinations of CH with additional aspects that reflect structural editability and behavioral preservation. Example candidates include cross-file dependency metrics, type-safety coverage, and the side-effect surface.
Interest in multi-agent solutions is rising in both academia and industry. We see strong potential in combining coding agents with CH information, either via a separate code-quality agent or as a tool in the coding agent’s toolbox – similar to running tests or linting. The Model Context Protocol (MCP) is currently a popular integration approach, but further research is needed to understand its implications for maintainability and security in these growing ecosystems .
Threats to Validity
In this subsection, we discuss the major threats to validity, ordered by their importance. First, we introduce the construct of code-level AI-friendliness. Two questions follow : 1) is the concept valid? and 2) is our measurement sufficiently complete? We posit that code contains patterns that make it easier or harder for LLMs to modify, so the concept is valid. However, using AI refactoring outcomes as a proxy for the construct is limited. Other tasks may be easier for LLMs, e.g., test case generation, documentation, and explaining the intent of code. Our measurement of AI readiness targets intrusive code changes, so results may differ for other development tasks.
Second, our dataset consists of Python solutions from competitive programming. This niche focuses on quickly producing functionally correct code , i.e., maintainability barely matters. We have seen snippets that would never enter production repositories. Also, the code is algorithmic and far from what most developers do for a living. Still, we argue that studying how AI refactoring performs on such code is a meaningful lens for AI-friendliness. Future work should study other types of code across multiple languages.
Finally, we report threats to internal and conclusion validity that we consider minor. First, there are aspects of run-to-run variance as the LLMs are non-deterministic. The large number of samples mitigates this threat sufficiently, and we do not apply repeated attempts or pass@k metrics. Second, there is a power asymmetry between our experimental runs for medium-sized LLMs (N=5,000) and the SotA solutions (N=1,000). This might have led to non-significant effects that are real but underpowered.
Conclusion and Future Work
Future codebases must serve a mixed workforce of human developers and coding agents. Decades of program comprehension research have provided us with guidelines for how to write code that fits the human brain. Recently, Thoughtworks coined the term “AI-Friendly Code Design.” In this work, we investigate whether coding practices designed for humans also help machines. We study this through CodeHealth, a maintainability metric calibrated to human cognition, and related it to the success rates of AI refactoring.
Our results confirm that human-friendly code is more amenable to AI interventions. The higher the CodeHealth, the more often AI refactoring preserves program semantics. Across medium-sized LLMs, break rates are significantly lower on Healthy code. The SotA LLM Sonnet-4.5 shows the same trend, but it is shifted towards lower break rates. Claude Code is generally conservative, i.e., prioritizes correctness over benefit, and shows no significant Healthy-Unhealthy difference.
Alongside organizational and process factors, code quality should inform deployment decisions for AI-assisted development. Healthy code highlights safer starting points in the codebases whereas Unhealthy code calls for tighter guardrails and more human oversight. In practice, code quality will likely be a prerequisite to realize the promised benefits of the AI acceleration.
As future work, we will expand our empirical study. First, we will move beyond competitive programming and include additional languages. We are particularly interested in production code that better reflects industrial software engineering. Second, we will study refactoring break rates in very poor code, as our dataset contain too few samples of CodeHealth $`<`$ 7. Worse code certainly exists both in proprietary and open-source projects. Finally, as there are always new LLMs available, we will re-evaluate new releases to test whether the observed trends persist.
Acknowledgments
This work was partially supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) and partly by the Competence Centre NextG2Com funded by the VINNOVA program for Advanced Digitalisation with grant number 2023-00541.
Appendix A – Ethical Statement
While the CodeContests dataset is released under a permissive Apache 2.0 license, its reuse has sparked some ethical discussion. DeepMind aggregated competitive programming submissions into the dataset to train AlphaCode, yet it remains unclear to what extent competitors provided explicit consent for this secondary use. In our work, the dataset is employed only to evaluate LLM output in the context of public research, not to train new models, which lessens the associated ethical concerns. We note that this is part of a larger debate on ethical LLM training.
Appendix B – Claude Output
Two examples of output summaries from Claude after refactoring a batch
of samples. The first one describes conservative refactoring and the
second one more ambitious operations.
Claude v2.0.13 — after conservative refactoring
Refactoring Principles Applied to All Files:
1. Descriptive Naming: Replaced generic variable names (a, b, c, arr, l, n, m) with meaningful names (array, count, total, num_tests, etc.)
2. Organized Imports: Grouped imports logically (standard library first, then third-party, then local)
3. Constants at Top: Moved all constants (MOD, BUFSIZE, INF, EPSILON, etc.) to the top of files after imports
4. Proper Spacing: Added appropriate blank lines between functions, classes, and logical sections
5. Preserved Functionality: All original logic, algorithms, and behavior maintained exactly
Code Quality Improvements:
- Enhanced readability and maintainability
- Consistent code structure across all files
- Following clean code and PEP 8 principles
- Zero functionality changes - all algorithms work identically
The refactoring successfully transforms 400
independent Python files into more maintainable,
readable code while preserving all original
functionality as specified in CLAUDE.md.
Claude v2.0.13 — after bolder refactoring
The refactored files now follow clean code principles
with improved maintainability, better naming
conventions, proper class extraction for related
functionality, and consistent code organization
throughout. Each file maintains its original
functionality while being significantly more
readable and maintainable.
Key Refactoring Improvements Applied Across All Files:
1. Improved Naming
- Cryptic variable names -> Descriptive names
- Single-letter functions -> Meaningful function names
- Better constant naming (UPPER_CASE)
2. Code Structure
- Extracted complex logic into separate functions
- Better separation of concerns
- Improved class organization
3. PEP 8 Compliance
- Consistent naming conventions (snake_case)
- Proper spacing and indentation
- Fixed line length issues
4. Code Smells Removed
- Magic numbers -> Named constants
- Complex conditionals simplified
- Duplicate code eliminated
- Unnecessary global variables removed
- Deeply nested structures flattened
5. Maintainability
- Single responsibility principle
- Improved readability
- Better function decomposition
- Self-documenting code
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
A minor threshold-specification issue in the sampling script treated CH $`=9`$ as Unhealthy. All analyses in this paper use the intended convention (Healthy: $`\ge 9`$). ↩︎