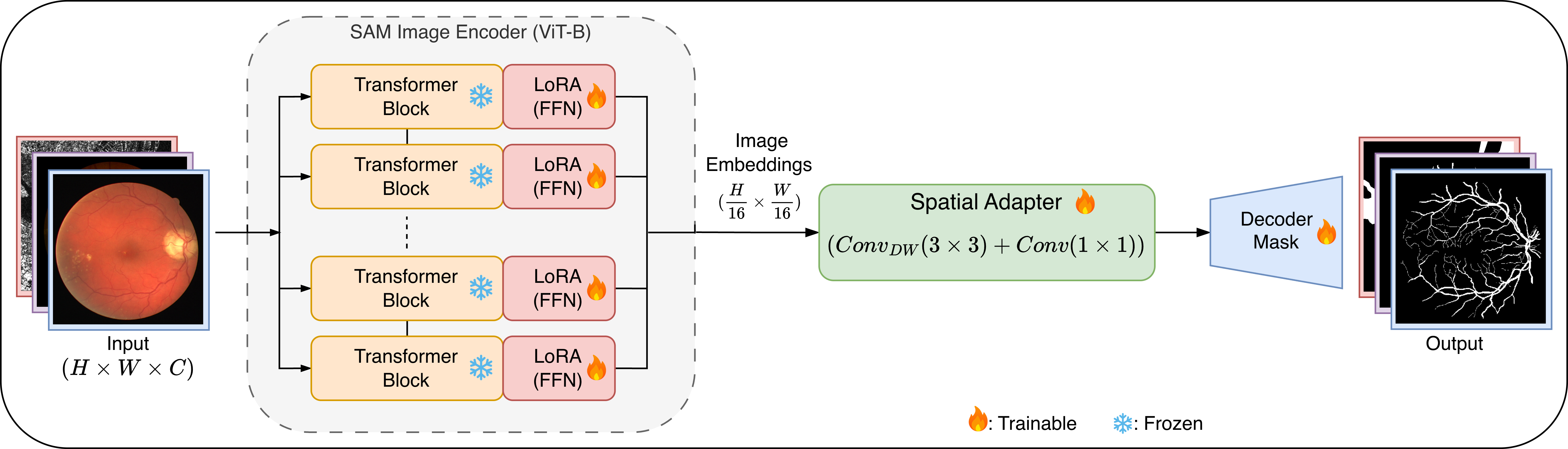
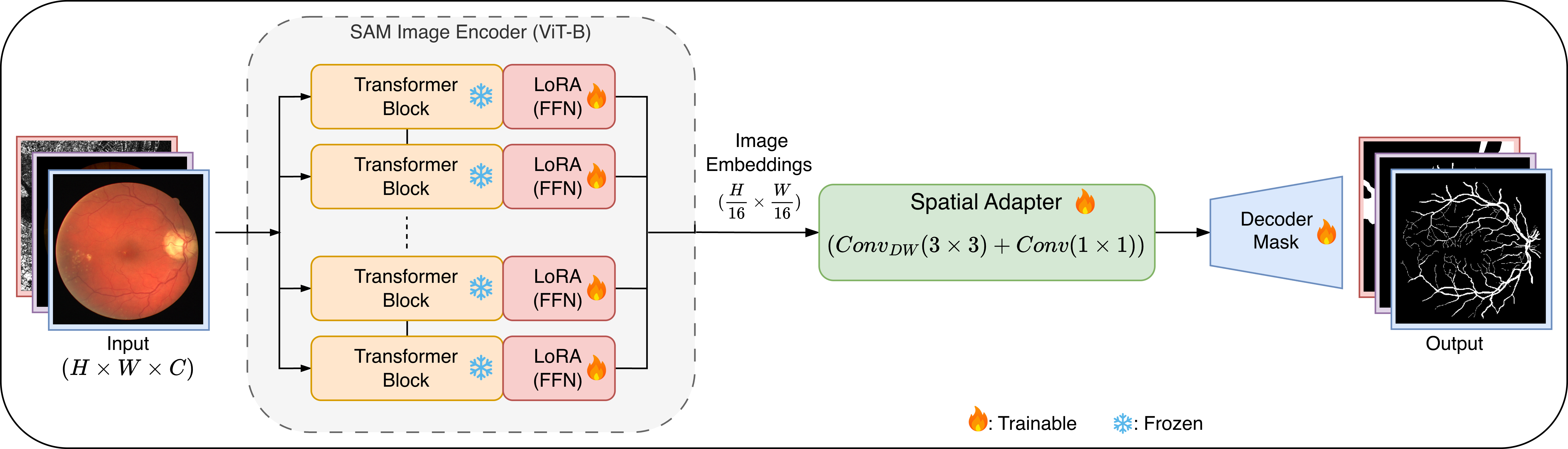
- Title: TopoLoRA-SAM Topology-Aware Parameter-Efficient Adaptation of Foundation Segmenters for Thin-Structure and Cross-Domain Binary Semantic Segmentation
- ArXiv ID: 2601.02273
- Date: 2026-01-05
- Authors: Salim Khazem
📝 Abstract
Foundation segmentation models such as the Segment Anything Model (SAM) exhibit strong zero-shot generalization through large-scale pretraining, but adapting them to domain-specific semantic segmentation remains challenging, particularly for thin structures (e.g., retinal vessels) and noisy modalities (e.g., SAR imagery). Full fine-tuning is computationally expensive and risks catastrophic forgetting. We propose \textbf{TopoLoRA-SAM}, a topology-aware and parameter-efficient adaptation framework for binary semantic segmentation. TopoLoRA-SAM injects Low-Rank Adaptation (LoRA) into the frozen ViT encoder, augmented with a lightweight spatial convolutional adapter and optional topology-aware supervision via differentiable clDice. We evaluate our approach on five benchmarks spanning retinal vessel segmentation (DRIVE, STARE, CHASE\_DB1), polyp segmentation (Kvasir-SEG), and SAR sea/land segmentation (SL-SSDD), comparing against U-Net, DeepLabV3+, SegFormer, and Mask2Former. TopoLoRA-SAM achieves the best retina-average Dice and the best overall average Dice across datasets, while training only \textbf{5.2\%} of model parameters ($\sim$4.9M). On the challenging CHASE\_DB1 dataset, our method substantially improves segmentation accuracy and robustness, demonstrating that topology-aware parameter-efficient adaptation can match or exceed fully fine-tuned specialist models. Code is available at : https://github.com/salimkhazem/Seglab.git
💡 Summary & Analysis
1. **Principled Framework for Adaptation**: The study introduces TopoLoRA-SAM as a principled framework to adapt foundation models like SAM for binary segmentation across diverse domains, ensuring that the model retains its generalizable features while adapting to specific tasks.
Parameter-Efficient Fine-Tuning and Topology Preservation: This work combines parameter-efficient fine-tuning (PEFT) methods with topology-preserving supervision, particularly focusing on thin structures. By using LoRA modules and lightweight spatial adapters, it ensures that the connectivity of thin structures is maintained during segmentation.
Performance Evaluation Across Datasets: The performance of TopoLoRA-SAM was evaluated across five binary segmentation datasets including retinal vessels, polyps, and SAR sea/land boundaries. It demonstrated strong performance on CHASE_DB1 with only 5.2% of the model parameters being trained.
📄 Full Paper Content (ArXiv Source)
TopoLoRA-SAM architecture overview. We
freeze the SAM ViT-B image encoder and inject LoRA modules (red) into
the feed-forward network (FFN) layers of each transformer block. A
lightweight depthwise-separable convolutional adapter (green) refines
the high-resolution embedding tensor before mask decoding. Training uses
a topology-aware loss combining BCE, Dice, and clDice.
Introduction
Semantic segmentation underpins numerous critical applications in
medical imaging and remote sensing, from automated diabetic retinopathy
screening to maritime surveillance and environmental monitoring . While
recent foundation models such as the Segment Anything Model (SAM) have
achieved remarkable zero-shot generalization through web-scale
pretraining, significant challenges remain when adapting these models to
specialized domains with distinct visual characteristics. Two challenges
are particularly acute in this setting. First, thin and elongated
structures such as retinal vasculature or road networks exhibit
extreme aspect ratios, where small pixel-level errors can disconnect
entire branches; standard region-based losses (e.g., Dice,
cross-entropy) are largely insensitive to such topological violations .
Second, cross-domain visual shift arises in modalities such as SAR
or fundoscopy, whose texture, noise characteristics, and semantics
differ substantially from natural images, limiting the transferability
of web-pretrained representations .
Full fine-tuning of billion-parameter foundation models is
computationally prohibitive and risks catastrophic forgetting of
generalizable representations . Parameter-efficient fine-tuning (PEFT)
methods such as LoRA , adapters , and visual prompt tuning offer
compelling alternatives by updating only a small fraction of parameters
while preserving pretrained knowledge. Recent work has begun exploring
PEFT for SAM adaptation , yet systematic studies investigating
topology-aware adaptation for domain-specific binary segmentation
remain limited.
In this work, we introduce TopoLoRA-SAM, a principled framework that
unifies parameter-efficient adaptation with topology-preserving
supervision for binary semantic segmentation across diverse domains. Our
approach freezes the SAM ViT-B image encoder and injects trainable LoRA
modules into its feed-forward layers, complemented by a lightweight
depthwise-separable convolutional adapter operating on high-resolution
feature maps. This design enables fine-grained adaptation while
preserving the generalizable representations learned during pretraining.
To address topological integrity critical for thin structures we
incorporate the differentiable clDice loss , which explicitly optimizes
skeleton overlap and encourages connected centerlines. Our contributions
are: (i) a topology-aware, parameter-efficient adaptation of SAM
combining LoRA and a lightweight spatial adapter; (ii) a benchmark
across five binary segmentation datasets (retinal vessels, polyps, SAR
sea/land) with region, boundary, topology, and calibration metrics; and
(iii) strong performance on CHASE_DB1 and best retina-average Dice while
training only 5.2% of model parameters, with a fully reproducible
codebase. In this work, ideas related to simplified geometric
representations for efficient visual learning and lightweight
adaptation via visual prompting are leveraged within a foundation-model
segmentation framework.
Related Work
Semantic segmentation architectures.
Fully convolutional networks revolutionized semantic segmentation, with
U-Net establishing the encoder-decoder paradigm with skip connections
that remains foundational in medical imaging. DeepLabV3+ introduced
atrous spatial pyramid pooling for multi-scale context aggregation,
while recent self-configuring approaches like nnU-Net achieve strong
performance through systematic hyperparameter optimization. used these
kind of architectures for different applications. Transformer-based
architectures have emerged as powerful alternatives: SegFormer proposes
an efficient hierarchical design with lightweight MLP decoders, while
Mask2Former unifies instance, semantic, and panoptic segmentation
through masked attention. These architectures build upon foundational
work on vision transformers and hierarchical designs .
Foundation models for segmentation.
The Segment Anything Model represents a paradigm shift, trained on over
1 billion masks to enable promptable zero-shot segmentation. While SAM
excels at interactive mask generation, adapting it to semantic
segmentation particularly for domain-specific binary masks without
prompts requires careful consideration of the prompt-mask relationship.
SAM 2 extends this capability to video, demonstrating the scalability
of the prompting paradigm. However, for domains with significant
distribution shift (medical imaging, remote sensing), prompt-free
adaptation with task-specific tuning remains essential .
SAM adaptation for specialized domains.
Several concurrent works address SAM adaptation for medical imaging.
MedSAM fine-tunes SAM on large-scale medical datasets, demonstrating
strong generalization across modalities. SAM-Adapter proposes
domain-specific adapter modules for underperformed scenes, while
SAM-Med2D focuses on 2D medical image segmentation. HQ-SAM introduces
a high-quality output token for improved mask boundaries. PerSAM
enables one-shot personalization through training-free prompt learning.
Our work differs by jointly addressing parameter efficiency (LoRA +
adapters) and topology preservation (clDice) for thin-structure domains
where connectivity is critical.
Parameter-efficient fine-tuning.
PEFT methods enable foundation model adaptation with minimal parameter
overhead. LoRA reparameterizes weight updates as low-rank matrices,
achieving comparable performance to full fine-tuning on language models.
AdaLoRA extends this with adaptive rank allocation, while DoRA
decomposes weights into magnitude and direction for improved learning
dynamics. Adapter modules insert trainable bottleneck layers between
transformer blocks, and AdaptFormer adapts this for vision. Visual
Prompt Tuning (VPT) prepends learnable tokens to input sequences.
Scale-and-shift tuning (SSF) offers an even more parameter-efficient
alternative. These methods share the goal of preserving pretrained
knowledge while enabling task-specific adaptation.
Topology-aware losses and metrics.
Standard overlap metrics (Dice , IoU) are insensitive to topological
errors that break connectivity in thin structures. clDice addresses
this by computing skeleton overlap using differentiable
soft-skeletonization, encouraging connected centerlines in tubular
structures. Complementary approaches include TopoLoss , which uses
persistent homology to penalize Betti number mismatches, and Betti
matching , which aligns persistence barcodes for topologically faithful
predictions. Boundary focused metrics such as BFScore evaluate contour
precision. For probabilistic outputs, calibration metrics like Expected
Calibration Error (ECE) assess reliability, which is critical for
clinical deployment . Recent work emphasizes the importance of
comprehensive metric evaluation .
Problem Formulation
Given an input image
$`\mathbf{x} \in \mathbb{R}^{H \times W \times 3}`$, we aim to predict a
binary semantic mask $`\hat{\mathbf{y}} \in [0,1]^{H \times W}`$
indicating foreground probability (vessel, polyp, or sea regions).
Unlike SAM’s promptable paradigm that produces instance-agnostic masks
conditioned on user-provided points or boxes, our task requires
semantic predictions without runtime prompts. This necessitates
adapting SAM’s encoder-decoder architecture to directly output semantic
masks through end-to-end training.
SAM Architecture and Prompt-Free Decoding
We adopt the SAM ViT-B architecture , comprising: (i) a Vision
Transformer (ViT) image encoder with 12 transformer blocks, producing
embeddings
$`\mathbf{z} \in \mathbb{R}^{256 \times \frac{H}{16} \times \frac{W}{16}}`$;
(ii) a prompt encoder mapping user interactions to embedding space; and
(iii) a lightweight mask decoder that combines image and prompt
embeddings via cross-attention. For semantic segmentation, we operate in
prompt-free mode by providing null prompt embeddings
($`\varnothing`$), treating the mask decoder as a semantic prediction
head. The decoder outputs a single binary mask, upsampled to the target
resolution via bilinear interpolation.
Low-Rank Adaptation (LoRA)
To enable efficient adaptation while preserving pretrained
representations, we inject LoRA modules into the frozen image encoder.
For a pretrained linear layer with weight matrix
$`\mathbf{W}_0 \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}}`$,
LoRA reparameterizes the forward pass as:
where $`\mathbf{A} \in \mathbb{R}^{r \times d_{\text{in}}}`$ and
$`\mathbf{B} \in \mathbb{R}^{d_{\text{out}} \times r}`$ are trainable
low-rank factors with rank
$`r \ll \min(d_{\text{in}}, d_{\text{out}})`$. We initialize
$`\mathbf{A}`$ with Kaiming uniform and $`\mathbf{B}`$ with zeros,
ensuring $`\Delta\mathbf{W} = \mathbf{0}`$ at initialization for stable
training. A scaling factor $`\alpha/r`$ modulates the magnitude of
low-rank updates.
We target the feed-forward network (FFN) layers within each
transformer block, specifically the mlp.lin1 and mlp.lin2
projections. This design choice follows the intuition that FFN layers
capture task-specific feature transformations, while attention weights
encode more transferable relational patterns. With $`r=16`$ and LoRA
applied to all 12 blocks, we add approximately 2.4M trainable parameters
to the encoder.
Spatial Convolutional Adapter
While LoRA enables semantic adaptation of the encoder’s representational
capacity, thin structures require fine-grained spatial reasoning at
higher resolutions than SAM’s $`16\times`$ downsampled embeddings. We
introduce a lightweight depthwise-separable convolutional adapter
applied to the image embedding tensor $`\mathbf{z}`$:
The adapter comprises a $`3\times3`$ depthwise convolution (256 groups)
followed by ReLU activation and $`1\times1`$ pointwise projection,
wrapped in a residual connection. This adds only $`\sim`$66K
parameters while enabling local spatial refinement crucial for
thin-structure boundary preservation.
Topology-Aware Training Objective
Our training objective combines multiple complementary loss terms:
where $`\text{Tprec}`$ measures how much of the predicted skeleton
overlaps with the ground-truth mask, and $`\text{Tsens}`$ measures
coverage of the GT skeleton. Soft skeletonization is implemented via
iterated morphological operations (min-pooling) applied to the soft
prediction map.
Model
Total (M)
Trainable (M)
Trainable %
U-Net (ResNet34)
24.4
24.4
100.0%
DeepLabV3+ (ResNet50)
39.8
39.8
100.0%
SegFormer (MiT-B0)
3.7
3.7
100.0%
Mask2Former (Swin-T)
47.4
47.4
100.0%
TopoLoRA-SAM (ours)
93.7
4.9
5.2%
Parameter efficiency comparison. TopoLoRA-SAM trains only 5.2% of
parameters while achieving competitive or superior performance.
Implementation Details
We use SAM ViT-B pretrained weights and freeze all encoder parameters
except LoRA modules. The mask decoder remains trainable
($`\sim`$2.4M parameters). Total trainable parameters:
$`\sim`$4.9M (LoRA: 2.4M, adapter: 66K, decoder: 2.4M), compared
to 93.7M total. Table 1 summarizes parameter efficiency.
Training uses AdamW with learning rate $`10^{-4}`$, cosine decay, and 50
epochs.
Experimental Setup
Datasets
We evaluate on five binary segmentation benchmarks spanning three
distinct application domains:
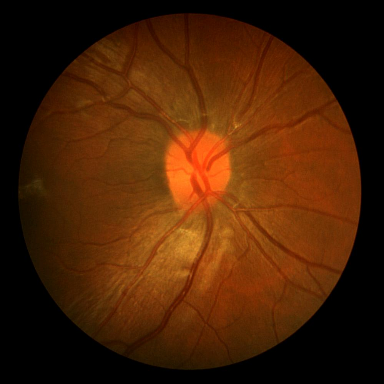
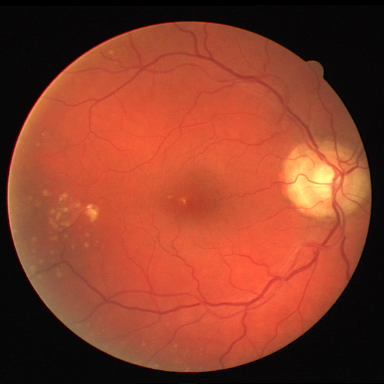
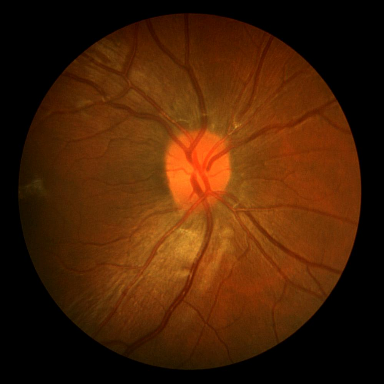
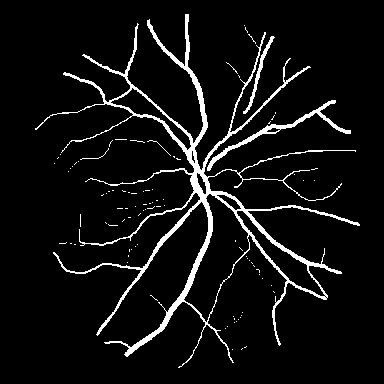
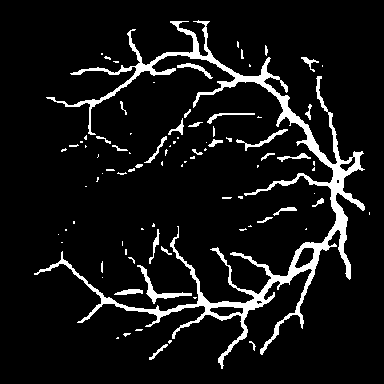
Retinal vessel segmentation.
DRIVE contains 40 color fundus images (584$`\times`$565) with
manual vessel annotations from expert ophthalmologists, split into 20
train and 20 test images. STARE provides 20 images
(700$`\times`$605) with vessels and pathological abnormalities.
CHASE_DB1 comprises 28 high-resolution images
(999$`\times`$960) from a pediatric population study. These
datasets exemplify thin-structure segmentation where topological
connectivity is clinically significant for vascular analysis.
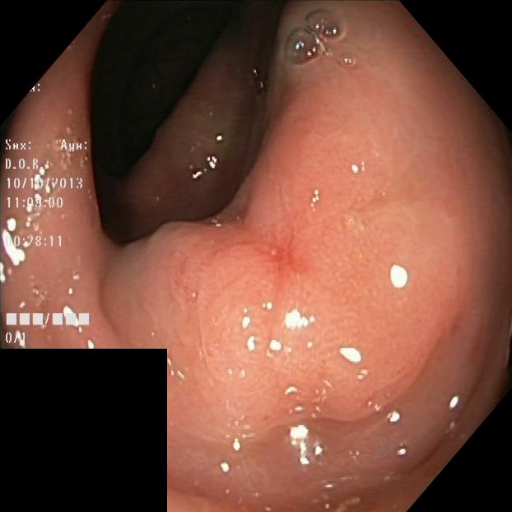
Polyp segmentation.
Kvasir-SEG contains 1,000 colonoscopy images with corresponding polyp
masks, representing an important task for early colorectal cancer
detection. Images vary in resolution and polyp appearance.
SAR sea/land segmentation.
SL-SSDD provides synthetic aperture radar (SAR) imagery for maritime
boundary delineation, challenging due to speckle noise, low contrast,
and significant distribution shift from natural images.
Preprocessing and Augmentations
All datasets are standardized to RGB format with ImageNet normalization
($`\mu=[0.485, 0.456, 0.406]`$, $`\sigma=[0.229, 0.224, 0.225]`$). We
use dataset-specific resolutions: 384$`\times`$384 for retinal
datasets, 512$`\times`$512 for Kvasir-SEG and SL-SSDD. Training
augmentations include random horizontal/vertical flips, random scaling
(0.5–1.5$`\times`$), and center crops with reflection padding. Color
jitter is disabled for SAR imagery to preserve modality-specific
characteristics.
Baseline Architectures
We compare five segmentation model families spanning convolutional,
transformer-based, and foundation-model paradigms. As convolutional
baselines, we use U-Net with a ResNet34 encoder and DeepLabV3+ with a
ResNet50 encoder. For transformer-based segmentation, we evaluate
SegFormer (MiT-B0) and Mask2Former with a Swin-T backbone . Finally,
we include our TopoLoRA-SAM model, which adapts SAM ViT-B using
Low-Rank Adaptation, a lightweight spatial adapter, and optional
topology-aware clDice regularization. All models use ImageNet-pretrained
backbones (or SAM-pretrained weights) and are trained with an identical
BCE+Dice objective to ensure fair comparison.
Training Configuration
All experiments follow a unified training protocol. We use the AdamW
optimizer with $`\beta_1=0.9`$, $`\beta_2=0.999`$, and a weight decay of
$`10^{-4}`$. The learning rate is set to $`10^{-4}`$ and scheduled using
cosine annealing down to a minimum value of $`10^{-6}`$. All models are
trained for 50 epochs. A batch size of 4 is used for all baseline
models, while SAM-based models are trained with a batch size of 1 and
gradient accumulation over 4 steps to maintain a comparable effective
batch size. Training is performed using mixed-precision (FP16) via
PyTorch Automatic Mixed Precision (AMP). For robustness, all reported
results are averaged over three random seeds (0, 1, and 2), and we
report the mean and standard deviation.
Evaluation Metrics
We use a comprehensive evaluation suite covering region overlap,
boundary accuracy, topology preservation, and calibration. Region-level
performance is measured using the Dice coefficient (F1-score) and
Intersection-over-Union(IoU), with precision and recall reported to
characterize false positive and false negative behavior. Boundary
quality is evaluated using the BFScore , which computes an F1-score on
contour pixels within a tolerance margin. To assess topology
preservation for thin structures, we report centerline Dice (clDice) on
retinal datasets, capturing connectivity via skeleton overlap. Finally,
probabilistic calibration is measured using Expected Calibration Error
(ECE) , which quantifies the alignment between prediction confidence and
empirical accuracy; lower values indicate better-calibrated models, an
important consideration for clinical decision support.
Computational Resources
All experiments run on a single NVIDIA RTX A6000 ada (50GB) GPU per
training job, with multi-GPU parallelism used only to run independent
experiments concurrently. The complete benchmark (5 datasets $`\times`$
5 models $`\times`$ 3 seeds + ablations + cross-dataset) requires
approximately 29.7 GPU-hours, dominated by Mask2Former and SAM runs
due to larger memory footprint and longer convergence.
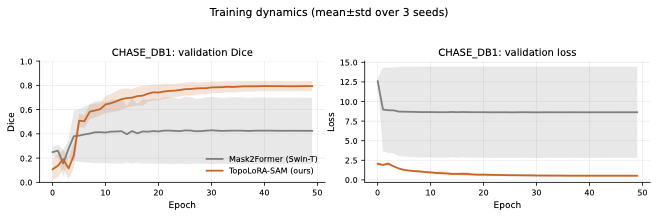
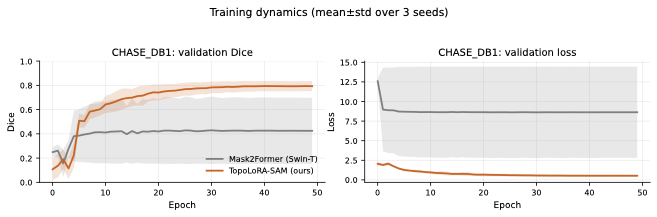
Results
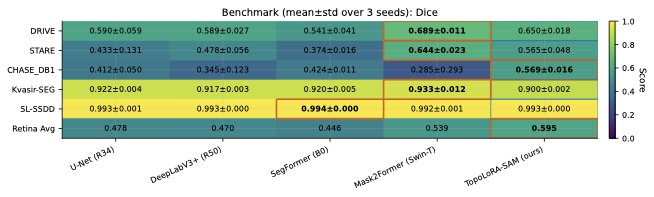
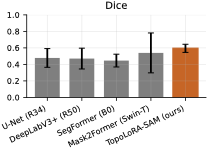
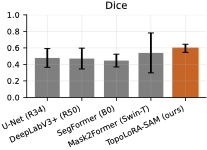
Main Benchmark Results
Table [tab:main-dice] reports Dice scores
across all datasets and model families. Overall, TopoLoRA-SAM achieves
the best average Dice (0.735), outperforming the second-best
Mask2Former (0.709) while training only 4.9M parameters, compared to
47.4M for Mask2Former. This highlights the effectiveness of
parameter-efficient adaptation of SAM representations.
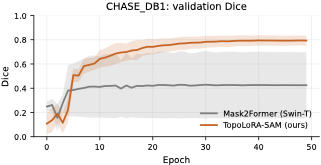
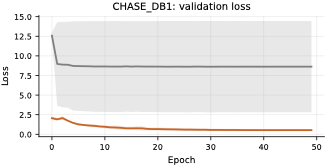
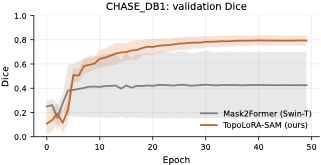
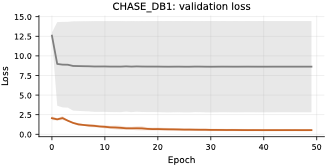
On retinal vessel segmentation, TopoLoRA-SAM shows consistent and robust
performance. It achieves the best Dice on CHASE_DB1 (0.569) with
substantially lower variance across seeds, corresponding to a +8.4
Dice improvement over Mask2Former. On DRIVE and STARE, TopoLoRA-SAM
remains competitive with transformer-based baselines and achieves the
best retina-average Dice (0.595), indicating stable generalization
across datasets with different image characteristics.
Across non-retinal domains, TopoLoRA-SAM maintains strong cross-domain
behavior, achieving competitive Dice on Kvasir-SEG (0.900) and matching
state-of-the-art performance on SL-SSDD (0.993), despite the significant
distribution shift from natural images. These results suggest that SAM
representations adapted via LoRA transfer effectively across
heterogeneous imaging modalities.
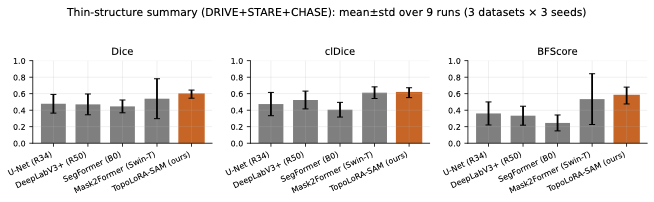
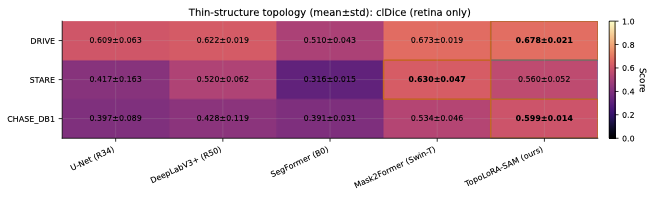
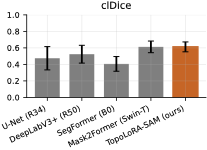
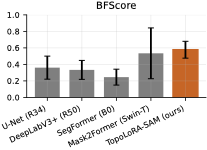
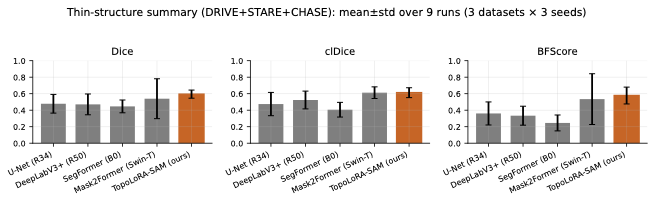
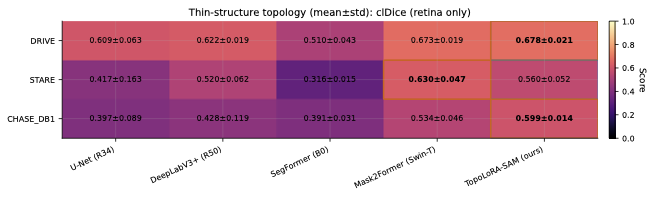
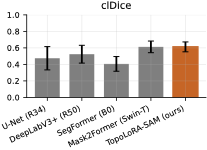
Topology Preservation
/>
Thin-structure performance summary across retinal datasets
(DRIVE, STARE, CHASE_DB1). TopoLoRA-SAM achieves top-tier performance on
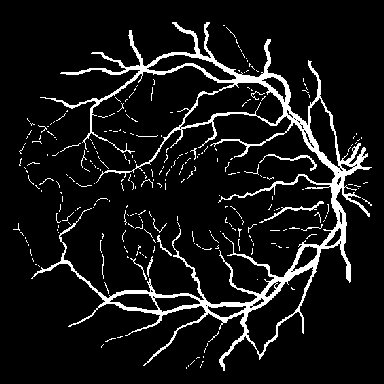
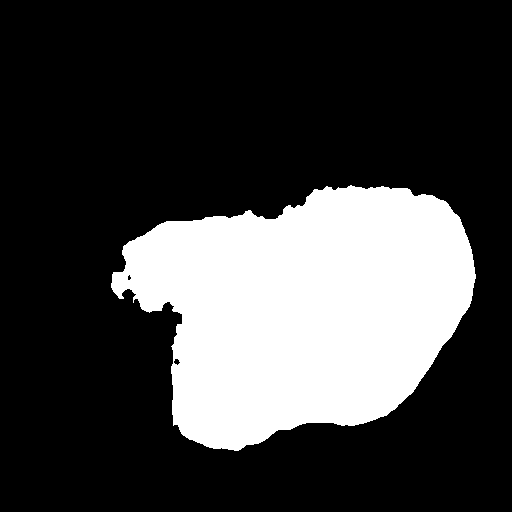
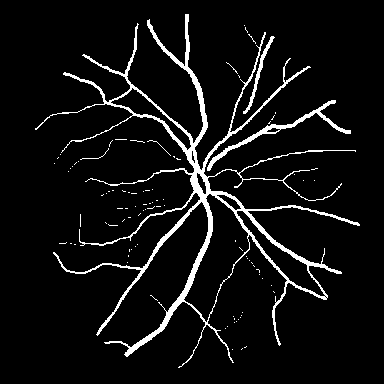
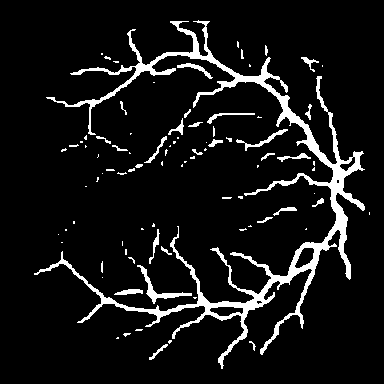
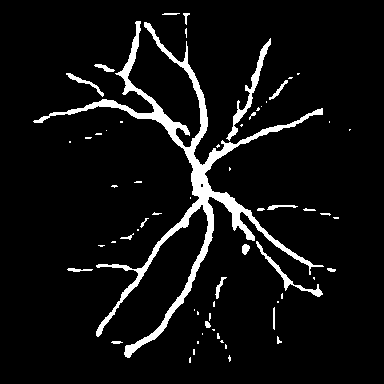
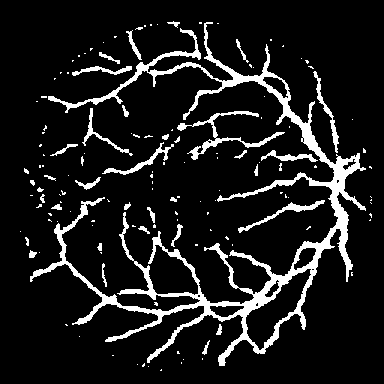
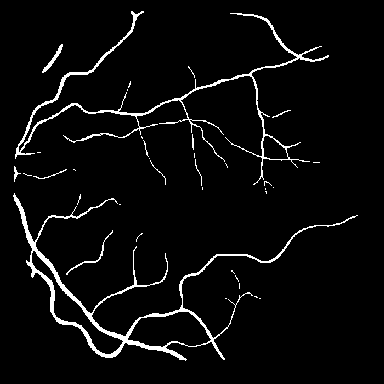
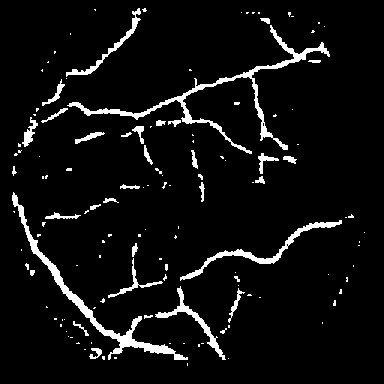
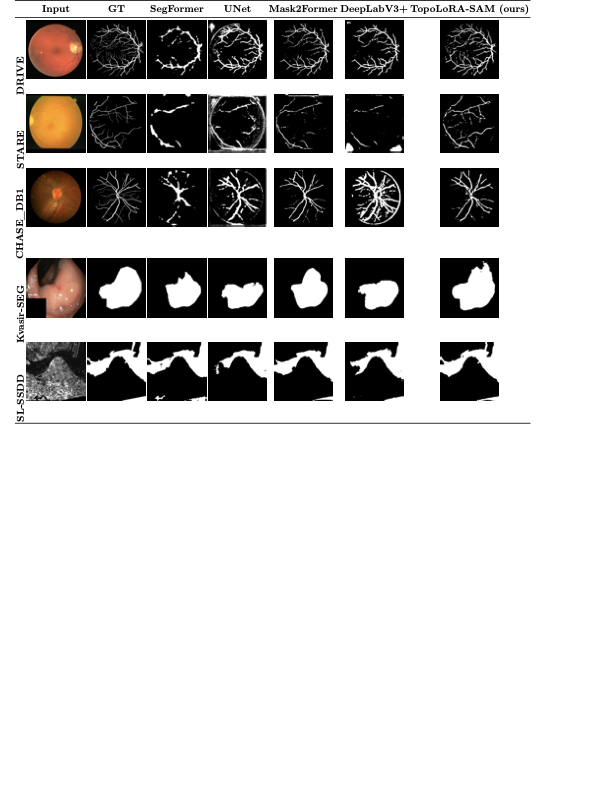
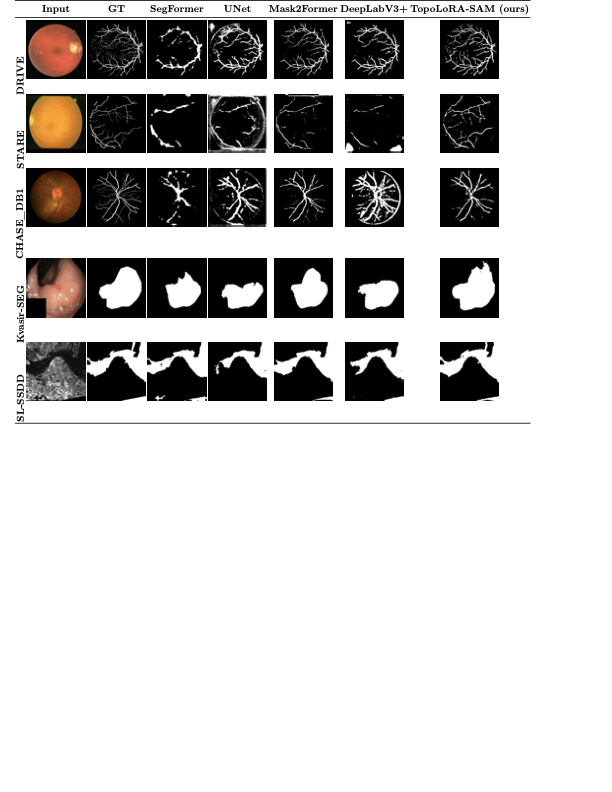
Dice, clDice, and BFScore while training 10× fewer parameters.Qualitative comparison across all benchmark
datasets. Each row shows a representative sample from one
dataset: retinal vessel segmentation (DRIVE, STARE, CHASE_DB1), polyp
segmentation (Kvasir-SEG), and SAR sea/land segmentation (SL-SSDD).
Columns display input images, ground truth masks, and predictions from
five methods. TopoLoRA-SAM
(Ours) demonstrates superior preservation of thin vessel
structures and fine-grained boundaries compared to baselines,
particularly visible in the retinal datasets where thin peripheral
vessels are better captured. On CHASE_DB1, our method maintains vessel
connectivity while other methods show fragmentation. Best viewed zoomed
in.
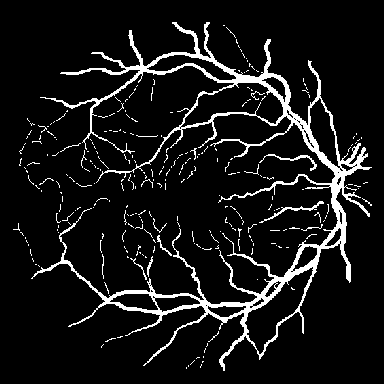
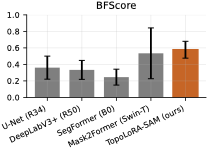
For thin-structure segmentation, region overlap metrics alone are
insufficient, as topological connectivity is critical for downstream
analysis. Figure 2 summarizes clDice and BFScore
on retinal datasets. TopoLoRA-SAM achieves the best clDice on DRIVE
(0.678) and CHASE_DB1 (0.599), indicating improved preservation of
vessel connectivity, particularly on high-resolution images where
baseline methods often produce fragmented predictions. Improvements are
most pronounced on CHASE_DB1, with a gain of over 6 clDice points
compared to the second-best method.
Boundary quality follows a similar trend. TopoLoRA-SAM achieves the
best retina-average BFScore (0.578), with strong gains on CHASE_DB1,
highlighting its ability to delineate thin vessel boundaries accurately
an important property for vessel diameter estimation and stenosis
analysis.
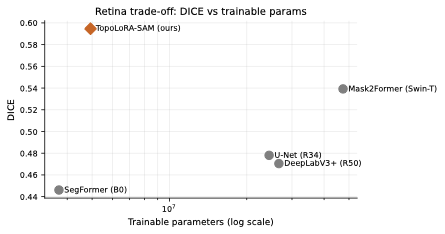
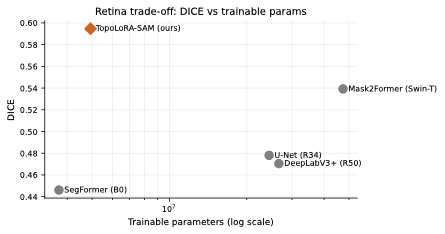
Parameter Efficiency Analysis
style="width:80.0%" />
Parameter efficiency trade-off on retinal datasets.
TopoLoRA-SAM achieves Pareto-optimal performance: competitive Dice with
10× fewer trainable parameters than
Mask2Former.
Fig 4 visualizes the fundamental trade-off
between model capacity and performance on retinal datasets. Key
observations:
TopoLoRA-SAM achieves Pareto-optimal performance, offering the
best Dice among methods with $`<`$10M trainable parameters.
Compared to fully-tuned Mask2Former (47.4M params), TopoLoRA-SAM (4.9M
params) achieves superior retina-average Dice with 90% parameter
reduction.
The lightweight SegFormer (3.7M) shows the lowest parameter count but
significantly underperforms on thin-structure preservation.
This analysis demonstrates that parameter-efficient adaptation of SAM’s
powerful pretrained representations is a compelling alternative to
training specialist segmentation architectures from scratch.
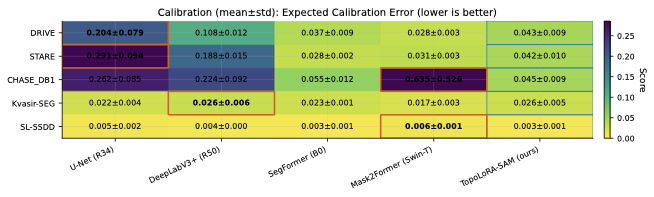
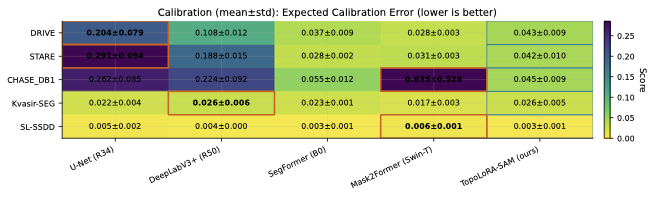
Calibration Analysis
Reliable confidence estimates are essential for risk-aware decision
support. Across all datasets, TopoLoRA-SAM demonstrates strong
calibration, achieving the lowest Expected Calibration Error (ECE) on
CHASE_DB1 (0.045) and SL-SSDD (0.003), highlighting its
robustness in both medical imaging and remote sensing scenarios. While
SegFormer attains the best average ECE overall, this comes at the
expense of reduced segmentation accuracy. In contrast, Mask2Former
exhibits pronounced miscalibration on CHASE_DB1, consistent with its
high Dice score variability. Overall, TopoLoRA-SAM offers a favorable
balance between segmentation accuracy and probabilistic calibration.
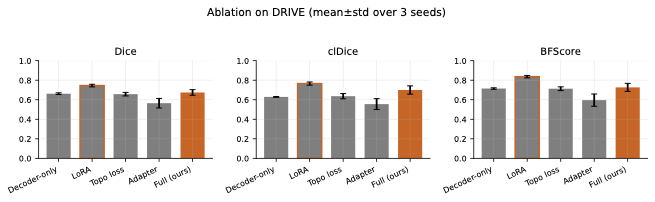
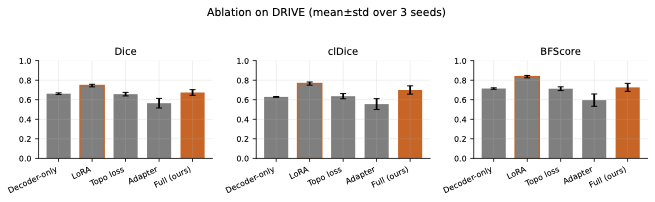
Component Contributions
LoRA adaptation is the primary driver.
Adding LoRA modules to the frozen encoder provides the largest single
improvement across all metrics: +4.2 Dice, +5.1 clDice, and +8.3
BFScore points over decoder-only tuning. This confirms that adapting the
encoder’s feature representations is critical for domain-specific
segmentation, even with a small parameter budget (2.4M additional
parameters).
Spatial adapter provides boundary refinement.
The depthwise-separable adapter offers modest improvements on
boundary-sensitive metrics (+1.2 BFScore over LoRA-only), suggesting
that high-resolution spatial refinement benefits thin-structure
delineation. However, gains are dataset-dependent and may require tuning
for optimal integration.
Topology regularization benefits connectivity.
Adding clDice loss improves skeleton-based metrics (clDice) by +0.8
points on average, with the effect most pronounced on images with
complex vessel branching. However, the improvement is sensitive to the
regularization weight $`\lambda_{\text{cl}}`$: too high values can
destabilize training, while too low values provide negligible benefit.
LoRA Rank Sensitivity
We ablate the LoRA rank $`r \in \{4, 8, 16, 32\}`$ on DRIVE (fixing
other components):
Rank
Params (M)
Dice
clDice
$`r=4`$
0.6
0.632$`\pm`$0.021
0.659$`\pm`$0.024
$`r=8`$
1.2
0.641$`\pm`$0.019
0.668$`\pm`$0.022
$`r=16`$
2.4
0.690$`\pm`$0.018
0.678$`\pm`$0.021
$`r=32`$
4.8
0.648$`\pm`$0.020
0.675$`\pm`$0.023
Rank $`r=16`$ offers the best balance of capacity and efficiency. Higher
ranks ($`r=32`$) provide diminishing returns while doubling parameter
count, consistent with observations from LoRA in language models.
Loss Weight Sensitivity
We vary the clDice weight
$`\lambda_{\text{cl}} \in \{0.0, 0.25, 0.5, 1.0, 2.0\}`$:
$`\lambda_{\text{cl}}`$
Dice
clDice
ECE
0.0
0.648$`\pm`$0.019
0.671$`\pm`$0.022
0.041$`\pm`$0.008
0.25
0.649$`\pm`$0.018
0.675$`\pm`$0.021
0.042$`\pm`$0.009
0.5
0.690$`\pm`$0.018
0.678$`\pm`$0.021
0.043$`\pm`$0.009
1.0
0.647$`\pm`$0.020
0.676$`\pm`$0.023
0.046$`\pm`$0.010
2.0
0.638$`\pm`$0.024
0.670$`\pm`$0.027
0.052$`\pm`$0.012
Moderate topology weighting ($`\lambda_{\text{cl}}=0.5`$) achieves
optimal balance. Excessive weighting ($`\lambda_{\text{cl}} \geq 2.0`$)
degrades both region and topology metrics, likely due to gradient
conflicts between objectives.
Our ablation results suggest several practical defaults. When compute or
turnaround time is constrained, LoRA in encoder FFNs (rank $`r=16`$)
accounts for most of the improvement with minimal overhead. In
applications where connectivity is a primary objective, clDice
regularization with $`\lambda_{\text{cl}}=0.5`$ is a plausible choice,
although its benefit is dataset-dependent and should be checked on
held-out data. For tasks requiring precise boundaries (e.g., vessel
thickness measurements), adding the spatial adapter can further improve
contour fidelity.
Conclusion, Limitations, and Broader Impact
We introduced TopoLoRA-SAM, a topology-aware and parameter-efficient
adaptation framework for the Segment Anything Model (SAM) targeting
binary semantic segmentation across diverse domains. Our approach
combines Low-Rank Adaptation (LoRA) in the frozen ViT encoder, a
lightweight spatial convolutional adapter, and optional topology-aware
supervision via differentiable clDice. Across five benchmarks spanning
retinal vessels, polyp segmentation, and SAR imagery, TopoLoRA-SAM
achieves the best retina-average Dice and the best overall average
Dice among evaluated methods, while training only 5.2% of model
parameters. Notably, on the challenging CHASE_DB1 dataset, our method
improves Dice by up to +8.4 points with substantially lower
variance, highlighting the robustness of parameter-efficient adaptation.
Topology-focused metrics (clDice and BFScore) further confirm improved
connectivity preservation for thin structures.
Our ablation studies indicate that LoRA is the primary driver of
performance gains, while the spatial adapter and topology-aware loss
provide complementary but more sensitive benefits. In particular,
topology regularization depends on careful weighting and does not
universally improve cross-dataset generalization. Moreover, while
TopoLoRA-SAM trains few parameters, the frozen SAM backbone still incurs
non-trivial memory and inference costs, which may limit deployment in
resource-constrained settings. This work is intended as a research
contribution and does not constitute a validated clinical or
operational system. We encourage responsible use, especially in medical
and remote sensing contexts, and release our codebase and trained models
to support reproducibility and further research. Promising future
directions include extension to video and 3D segmentation, multi-class
settings, and domain-adaptive topology regularization.
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.