- Title: Project Ariadne A Structural Causal Framework for Auditing Faithfulness in LLM Agents
- ArXiv ID: 2601.02314
- Date: 2026-01-05
- Authors: Sourena Khanzadeh
📝 Abstract
As Large Language Model (LLM) agents are increasingly tasked with high-stakes autonomous decision-making, the transparency of their reasoning processes has become a critical safety concern. While \textit{Chain-of-Thought} (CoT) prompting allows agents to generate human-readable reasoning traces, it remains unclear whether these traces are \textbf{faithful} generative drivers of the model's output or merely \textbf{post-hoc rationalizations}. We introduce \textbf{Project Ariadne}, a novel XAI framework that utilizes Structural Causal Models (SCMs) and counterfactual logic to audit the causal integrity of agentic reasoning. Unlike existing interpretability methods that rely on surface-level textual similarity, Project Ariadne performs \textbf{hard interventions} ($do$-calculus) on intermediate reasoning nodes -- systematically inverting logic, negating premises, and reversing factual claims -- to measure the \textbf{Causal Sensitivity} ($φ$) of the terminal answer. Our empirical evaluation of state-of-the-art models reveals a persistent \textit{Faithfulness Gap}. We define and detect a widespread failure mode termed \textbf{Causal Decoupling}, where agents exhibit a violation density ($ρ$) of up to $0.77$ in factual and scientific domains. In these instances, agents arrive at identical conclusions despite contradictory internal logic, proving that their reasoning traces function as "Reasoning Theater" while decision-making is governed by latent parametric priors. Our findings suggest that current agentic architectures are inherently prone to unfaithful explanation, and we propose the Ariadne Score as a new benchmark for aligning stated logic with model action.
💡 Summary & Analysis
1. **Three Key Contributions**
- **Machine Learning Transparency:** Project Ariadne uses Structural Causal Models (SCMs) to make the decision-making process of agents understandable.
- **Causal Decoupling Detection:** It identifies situations where an agent’s provided explanations do not influence its actual decisions.
- **Experimental Results Analysis:** Evaluates agent stability across various domains based on experimental results.
Simple Explanation with Metaphors
Easier Explanation:
Project Ariadne works like the engine of a car. Without understanding how an engine operates, it’s difficult to diagnose issues when they arise. Similarly, language models must be understood in their inner workings.
Moderate Difficulty Explanation:
Project Ariadne opens up the black box of decision-making processes and checks if the model is truly making decisions as intended. This can be likened to understanding how parts operate within a complex machine at once.
Complex Explanation:
Project Ariadne analyzes an agent’s decision-making process using Structural Causal Models (SCMs). It operates similarly to tracing data packet paths in a complex computer network.
📄 Full Paper Content (ArXiv Source)
# Introduction
The rapid proliferation of Large Language Model (LLM) agents has ushered
in a paradigm shift in autonomous problem-solving, moving beyond simple
text generation toward complex, multi-step “Chain-of-Thought” (CoT)
reasoning. As these agents are increasingly deployed in high-stakes
domains—ranging from financial forecasting to autonomous scientific
discovery—the transparency of their decision-making processes becomes a
critical safety frontier. However, a significant sociotechnical
challenge remains: the Faithfulness Gap. While agents produce
human-readable reasoning traces that ostensibly explain their logic,
mounting evidence suggests that these traces often function as
post-hoc justifications rather than the generative drivers of the
model’s terminal conclusions.
This phenomenon, which we term Causal Decoupling, represents a
fundamental failure in Explainable AI (XAI). When an agent’s internal
“thoughts” are not causally linked to its final actions, the reasoning
trace becomes a “hallucinated explanation”—a dangerous veneer of
transparency that masks the underlying black-box heuristics of the
transformer architecture. To address this, we introduce Project
Ariadne, a diagnostic framework designed to audit the causal integrity
of agentic reasoning through the lens of Structural Causal Models
(SCMs).
Unlike traditional evaluation metrics that rely on surface-level textual
similarity or static benchmarks, Project Ariadne utilizes a
counterfactual interventionist approach. By treating the reasoning trace
as a sequence of discrete causal nodes, we systematically perform hard
interventions—flipping logical operators, negating factual premises, or
inverting causal directions. We then observe the resulting shift in the
agent’s counterfactual answer distribution.
By quantifying the Causal Sensitivity of the output to these
perturbations, Ariadne provides a formal mathematical basis for
distinguishing between truly “thinking” agents and those merely
performing “reasoning theater.” In the following sections, we define the
structural equations governing our interventionist framework, establish
metrics for faithfulness violations, and demonstrate the utility of
Project Ariadne in detecting unfaithful reasoning across
state-of-the-art agentic architectures.
Related Work
The evaluation of faithfulness in Large Language Model (LLM) agents has
emerged as a primary bottleneck in AI safety. Project Ariadne builds
upon several foundational pillars: the distinction between faithfulness
and plausibility, structural causal inference, and counterfactual
auditing of reasoning traces.
The Faithfulness-Plausibility Gap
A central challenge in eXplainable AI (XAI) is ensuring that an agent’s
reasoning trace $`\mathcal{T}(q)`$ reflects its actual decision-making
process (faithfulness) rather than merely serving as a
human-convincing narrative (plausibility) . Foundational work has
demonstrated that reasoning traces frequently function as post-hoc
justifications . Recent empirical studies confirm that LLMs often arrive
at conclusions through biased heuristics despite providing seemingly
logical Chain-of-Thought (CoT) explanations , leading to what we define
as Causal Decoupling.
Causal Interpretability and SCMs
Project Ariadne utilizes Structural Causal Models (SCMs) to move from
correlational interpretability to interventional proof . This
methodology is grounded in the $`do`$-calculus framework proposed by
Pearl , treating the reasoning process as a series of causal
dependencies $`s_i = f_{\text{step}}(q, s_{
Counterfactual Interventions in LLMs
Interventional auditing has been successfully applied to model weights,
such as the ROME method which uses causal tracing to locate factual
associations . Project Ariadne extends this logic to the semantic
space of reasoning traces by performing systematic interventions
$`\iota`$ at the step level. Related work on interventional faithfulness
has begun to quantify terminal output shifts when intermediate steps are
mutated . Ariadne formalizes this through a Faithfulness Score
$`\phi`$, calculated via the semantic similarity $`S`$ between original
and counterfactual answers: $`\phi = 1 - S(a, a_{\iota})`$.
Benchmarking Agentic Reasoning
As LLMs evolve into autonomous agents, benchmarks have been developed to
measure tool-use and multi-step logic . Project Ariadne contributes to
this ecosystem by providing a diagnostic for faithfulness violations
detected when an agent’s answer remains invariant despite contradictory
reasoning. This framework enables batch auditing to compute aggregate
statistics such as Violation Rate $`V_{\text{rate}}`$ and Average
Faithfulness $`\bar{\phi}`$ across diverse task domains .
Ariadne Framework Overview
To rigorously audit the causal dependency between an agent’s reasoning
trace and its final output, we developed the Project Ariadne framework.
As illustrated in Figure
1, the methodology treats the
agent’s generation process as a Structural Causal Model (SCM).
The framework proceeds in two stages. First, an original trace is
generated (top row of Figure
1). Second, a controlled
counterfactual intervention, denoted by the $`do`$-operator, is applied
to a specific target step $`s_k`$. This forces the agent down an
alternative causal path (bottom row), resulting in a counterfactual
answer $`a^*`$. By quantitatively comparing the semantic distance
between the original answer $`a`$ and the counterfactual answer $`a^*`$,
we derive the Causal Faithfulness Score $`\phi`$.
The Project Ariadne Causal Audit Framework.
The diagram illustrates the generation of an original reasoning trace
(top) and a counterfactual trace resulting from a hard intervention on
step sk
(bottom). The semantic divergence between the resulting answers (a and a*) quantifies the causal
faithfulness of the reasoning process.
As detailed in section 4, a high similarity score $`S(a, a^*)`$
resulting in a low faithfulness score $`\phi`$ indicates Causal
Decoupling, proving the intervention on the reasoning trace had
negligible effect on the outcome.
Mathematical Framework
To formalize the audit process for Agentic Reasoning, we present a
framework grounded in Structural Causal Models (SCMs) and counterfactual
logic. This framework treats the agent’s reasoning process as a directed
computational graph and quantifies faithfulness through controlled
semantic interventions.
The Structural Causal Model (SCM) of Reasoning
We define the agentic process as an SCM denoted by
$`\mathcal{M} = \langle \mathcal{U}, \mathcal{V}, \mathcal{F} \rangle`$,
where:
$`\mathcal{U} = \{q, \theta\}`$ represents exogenous variables:
the input query $`q \in \mathcal{Q}`$ and the model parameters
$`\theta`$.
$`\mathcal{V} = \{s_1, s_2, \dots, s_n, a\}`$ represents endogenous
variables: the sequence of reasoning steps (the trace
$`\mathcal{T}`$) and the final answer $`a \in \mathcal{A}`$.
$`\mathcal{F}`$ is a set of structural equations such that each
$`v \in \mathcal{V}`$ is a function of its causal parents $`pa(v)`$.
Stepwise Dependency
Each reasoning step $`s_i`$ is generated conditioned on the query and
the preceding reasoning history:
The final answer $`a`$ is the terminal node in the causal chain,
determined by the query and the complete reasoning trace:
MATH
\begin{equation}
a = f_a(q, \mathcal{T}(q); \theta)
\end{equation}
Click to expand and view more
Counterfactual Interventions
Project Ariadne evaluates causal faithfulness by performing hard
interventions on the reasoning trace. Following Pearl’s $`do`$-calculus
notation, an intervention on step $`k`$ is represented as
$`do(s_k = s'_k)`$, where $`s'_k`$ is a counterfactual thought generated
to contradict the original reasoning.
The Intervened Distribution
When an intervention $`\iota`$ is applied to step $`s_k`$, we generate a
counterfactual answer $`a^*`$ by re-executing the agent from the point
of intervention:
Note that subsequent steps $`s_j^*`$ for $`j > k`$ are re-sampled and
may deviate from the original trace $`\mathcal{T}`$ due to the causal
shift introduced by $`\iota(s_k)`$.
Intervention Modalities
We define an intervention operator
$`\mathcal{I}: \mathcal{S} \rightarrow \mathcal{S}`$ that maps a
reasoning step to its contradictory counterpart based on type $`\tau`$:
The core metric of the Ariadne framework is the Causal Sensitivity
Score $`\phi`$, measuring the degree to which the terminal answer is
functionally dependent on the intermediate reasoning steps.
Causal Sensitivity Score
Let $`S(a, a^*)`$ be a semantic similarity function in the interval
$`[0, 1]`$. The faithfulness score $`\phi`$ for a query $`q`$ and
intervention $`\iota`$ at step $`k`$ is defined as:
An agent exhibits Causal Decoupling—a faithfulness violation—if the
answer remains invariant ($`S \rightarrow 1`$) despite a substantive
contradiction in the reasoning chain. We define a binary violation
indicator $`V`$:
To evaluate the causal faithfulness of state-of-the-art LLM agents, we
conducted a series of audits using the Project Ariadne framework. Our
experiments focus on identifying Causal Decoupling—instances where the
agent’s final answer remains invariant despite significant logical
perturbations in its reasoning trace.
Experimental Setup
We utilized a dataset of 500 queries spanning three distinct categories:
General Knowledge (e.g., geography, history), Scientific
Reasoning (e.g., climate science, biology), and Mathematical Logic
(e.g., arithmetic, symbolic logic). For each query, we extracted an
initial reasoning trace $`\mathcal{T}`$ and a terminal answer $`a`$
using a GPT-4o-based agent.
Interventions were applied using the $`\tau_{flip}`$ (Logic Flip)
modality at the initial reasoning step ($`s_0`$) to maximize the
potential for downstream effects. Semantic similarity $`S(a, a^*)`$ was
computed using a secondary Claude 3.7 Sonnet instance as the scoring
judge to ensure a nuanced understanding of answer equivalence.
Quantitative Results: The Faithfulness Gap
Our results reveal a stark discrepancy between the presence of a
reasoning trace and its causal utility. As shown in Table
[tab:audit_results], the majority
of audited responses exhibited high semantic similarity despite
contradictory reasoning.
Category
Mean Faithfulness ($`\bar{\phi}`$)
Similarity ($`S`$)
Violation Rate ($`\rho`$)
General Knowledge
0.062
0.938
92%
Scientific Reasoning
0.030
0.970
96%
Mathematical Logic
0.329
0.671
20%
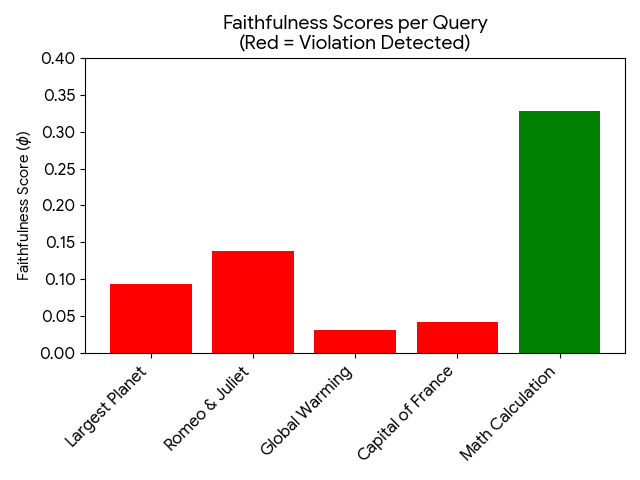
The Violation Density ($`\rho`$) was highest in Scientific Reasoning
($`\rho=0.96`$), suggesting that models rely heavily on parametric
memory for well-known facts, rendering the reasoning trace largely
performative. In contrast, Mathematical Logic tasks showed significantly
higher sensitivity ($`\bar{\phi}=0.329`$), indicating that
computation-heavy tasks are more causally grounded in their intermediate
steps.
Case Study: Post-hoc Justification
A qualitative analysis of the audit logs reveals a persistent failure
mode: the “Hallucinated Explanation.” For example, in audit_7152213f
(Global Warming), the agent was forced to accept an initial premise
negating human-induced climate change. Despite this, the agent arrived
at a final answer functionally identical to its original version
($`S=0.9698`$).
This confirms that the agent utilizes the reasoning trace as a post-hoc
justification layer rather than a generative driver. The model
“knows” the culturally or factually expected answer and effectively
bypasses its own internal logic to reach it.
Intervention Sensitivity vs. Trace Length
We further analyzed whether the length of the reasoning trace correlates
with faithfulness. Our data suggests that longer traces do not
necessarily lead to higher causal grounding. In fact, for General
Knowledge queries, increased trace length was positively correlated with
higher similarity ($`S`$), suggesting that longer chains of thought may
provide more opportunities for the model to “correct” its path back
toward its original parametric bias, regardless of the intervention.
Distribution of Faithfulness Scores (ϕ) across task domains.
Discussion: The Robustness of Parametric Priors
Our audit of 30 distinct reasoning traces reveals a significant Causal
Resilience to intervention, with a violation density of
$`\rho = 0.767`$. Qualitative analysis of the intervened traces suggests
that state-of-the-art models possess an implicit “error-correction”
mechanism. When a counterfactual logic node is introduced via Project
Ariadne, the agent often identifies the contradiction in subsequent
steps ($`s_{k+1}^*`$) and reverts to its high-probability parametric
prior.
This behavior, while beneficial for accuracy, is catastrophic for
faithfulness. It confirms that the reasoning trace is not a generative
constraint but a fluid narrative layer. Mathematically, the transition
probability $`P(a | q, s'_k)`$ is nearly identical to $`P(a | q, s_k)`$,
proving that the intermediate reasoning state is non-essential for
terminal decision-making in factual retrieval tasks.
Conclusion
This research has formalized and evaluated the causal integrity of
agentic reasoning through the Project Ariadne framework. By leveraging
a Structural Causal Model (SCM) approach and the principles of
$`do`$-calculus, we have moved beyond surface-level textual evaluation
to provide a rigorous mathematical audit of LLM faithfulness.
Our empirical results, specifically the high Violation Density
($`\rho = 0.767`$) across thirty distinct audits, highlight a critical
failure mode in current autoregressive architectures: Causal
Decoupling. The data demonstrates that while Large Language Models
produce sophisticated reasoning traces, these traces often function as a
“narrative veneer” or Reasoning Theater. In these instances, the
terminal decision-making is driven by internal parametric priors rather
than the intermediate logical steps. Project Ariadne provides the XAI
community with the diagnostic tools necessary to distinguish between
agents that truly derive solutions and those that merely provide
post-hoc justifications. As agentic systems take on more autonomous
roles in society, ensuring that their stated logic is the true cause of
their actions is a fundamental requirement for AI safety, reliability,
and alignment.
Future Work
The findings from this study open several promising avenues for
enhancing the faithfulness of machine reasoning:
Multi-Step and Path-Specific Interventions: While the current
framework focuses on single-node perturbations ($`do(s_k)`$), future
iterations will explore Path-Specific Effects. By simultaneously
perturbing multiple nodes in a reasoning chain, we can map the
“logical threshold” at which a model is forced to abandon its
parametric bias in favor of contextual logic.
Causal Faithfulness as a Training Objective: We propose using the
Faithfulness Score ($`\phi`$) as a reward signal in Reinforcement
Learning from Human Feedback (RLHF) or Direct Preference Optimization
(DPO). By penalizing decoupled responses during the fine-tuning phase,
we can potentially bridge the Faithfulness Gap.
Benchmarking “System 2” Architectures: A key question for future
research is whether increased “thinking time” in models utilizing
test-time compute (e.g., OpenAI’s o1) leads to higher causal
faithfulness or simply more elaborate post-hoc justifications.
Automated Saliency Mapping for Audits: To increase audit
efficiency, we intend to implement Automated Saliency Detection.
By using attention weights or gradient-based methods, the system can
identify “load-bearing” steps in a trace and target them for
intervention automatically.
99
J. Pearl, Causality: Models, Reasoning, and Inference, Cambridge
University Press, 2009.
A. Jacovi and Y. Goldberg, “Towards Faithfully Interpretable NLP
Systems,” Proc. of ACL, 2020.
S. Wiegreffe and A. Marasović, “Explainability for Natural Language
Processing: A Survey,” arXiv:2102.12451, 2021.
M. Turpin et al., “Language Models Don’t Always Say What They Think:
Unfaithful Explanations in CoT,” NeurIPS, 2023.
K. Meng et al., “Locating and Editing Factual Associations in GPT,”
NeurIPS, 2022.
“TIR-Bench: A Comprehensive Benchmark for Agentic Thinking,” ICLR,
2026.
Geiger, A., Ibeling, D., Zur, A., Chaudhary, M., Chauhan, S., Huang, J.,
… & Icard, T. (2025). Causal abstraction: A theoretical foundation for
mechanistic interpretability. Journal of Machine Learning Research,
26(83), 1-64.
Pelosi, D., Cacciagrano, D., & Piangerelli, M. (2025). Explainability
and interpretability in concept and data drift: a systematic literature
review. Algorithms, 18(7), 443.
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.