Title: Empowering Small Language Models with Factual Hallucination-Aware Reasoning for Financial Classification
ArXiv ID: 2601.01378
Date: 2026-01-04
Authors: Han Yuan, Yilin Wu, Li Zhang, Zheng Ma
📝 Abstract
Small language models (SLMs) are increasingly used for financial classification due to their fast inference and local deployability. However, compared with large language models, SLMs are more prone to factual hallucinations in reasoning and exhibit weaker classification performance. This raises a natural question: Can mitigating factual hallucinations improve SLMs' financial classification? To address this, we propose a three-step pipeline named AAAI (Association Identification, Automated Detection, and Adaptive Inference). Experiments on three representative SLMs reveal that: (1) factual hallucinations are positively correlated with misclassifications; (2) encoder-based verifiers effectively detect factual hallucinations; and (3) incorporating feedback on factual errors enables SLMs' adaptive inference that enhances classification performance. We hope this pipeline contributes to trustworthy and effective applications of SLMs in finance.
📄 Full Content
Language models (LMs) are increasingly being deployed for financial classification (Guo, Xu, and Yang 2023;Li et al. 2023b;Chen et al. 2024;Hu et al. 2025). Two main development paths have emerged: one focuses on large language models (LLMs) with superior performance, while the other targets small language models (SLMs) suitable for local deployability (Cheng et al. 2024). Although SLMs offer advantages in fast inference and privacy protection, they are prone to factual hallucinations (Li et al. 2023a). A reasoning path containing factual errors undermines both the trustworthiness of an SLM's output and the quality of downstream classification (Lin et al. 2024). Therefore, enabling SLMs to recognize factual hallucinations in their reasoning potentially enhances the quality of their overall generation.
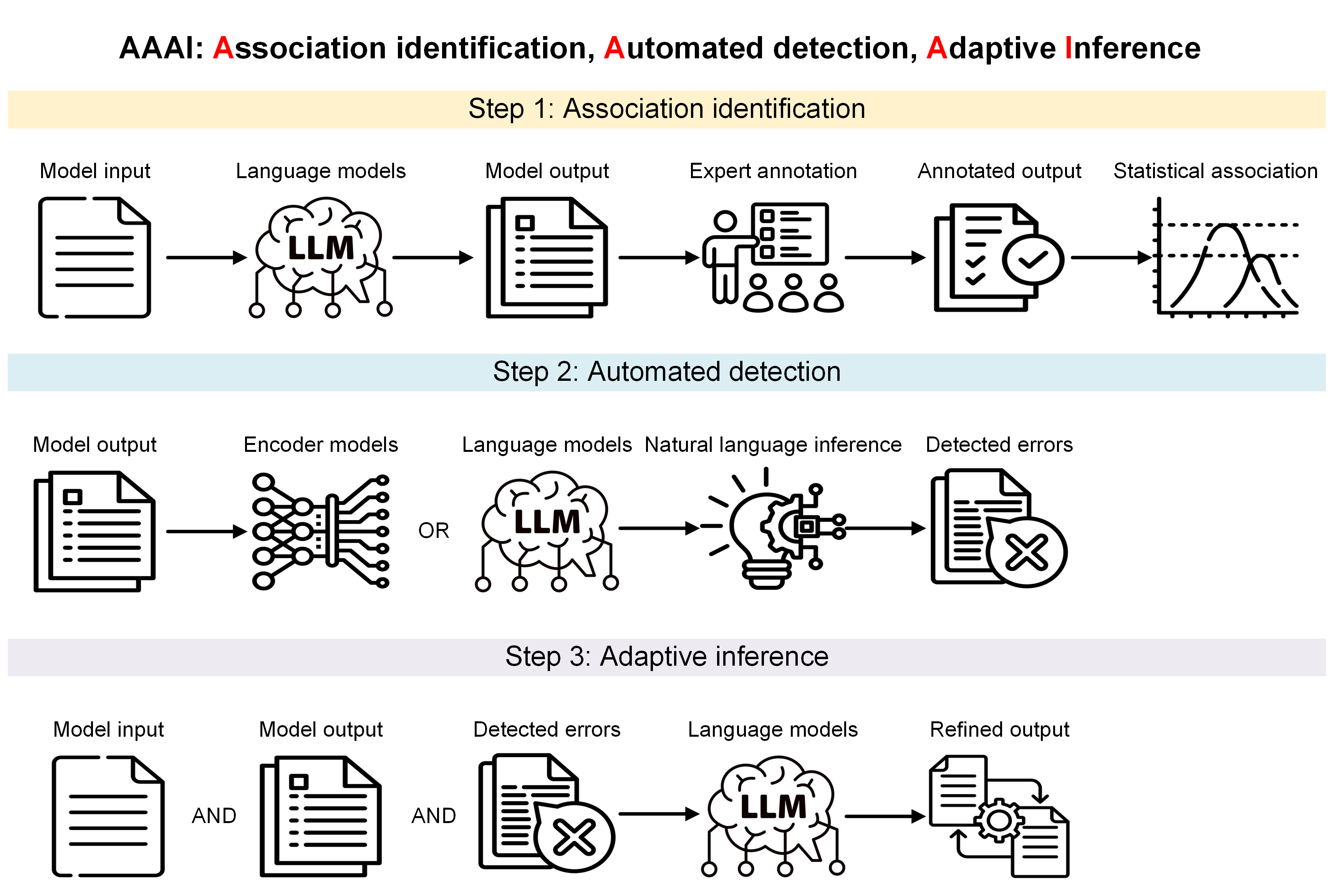
To demonstrate the practical applicability of this approach in finance, we implement a three-step analytical pipeline, abbreviated as AAAI (Association identification, Automated detection, and Adaptive Inference), and Figure 1 visualizes each step of this pipeline. First, statistical analysis is conducted to identify the positive association between factual Figure 1: The pipeline for factual error-aware reasoning hallucinations in SLMs’ reasoning and the accuracy of classifications derived from that reasoning in the initial inference round. This step provides a rationale for improving classification by guiding SLMs to recognize and correct factual errors in their adaptive inference. Second, various methods are used to automatically detect factual errors in the reasoning of the initial inference. This step includes statistical analysis to demonstrate the discriminative ability of the detection models, supporting the scalability of factual error identification. Third, the detected errors are used as feedback for SLMs, prompting adaptive refinement of their inference. Quantitative metrics show that feedback from some methods enhances SLMs’ financial classification, while feedback from others degrades it, highlighting the importance of feedback quality in factual error-aware reasoning (Huang et al. 2024).
We emphasize that, unlike studies that use classification correctness to guide SLMs (Shinn et al. 2024;Kim, Baldi, and McAleer 2023), all feedback in this work focuses on factual issues in LMs’ reasoning, which aligns with realworld scenarios where users lack access to the ground truth (Lightman et al. 2024;Wang et al. 2024). If the answer were already known, collaboration with LMs would be unnecessary (Huang et al. 2024). However, users can readily identify errors in LMs’ reasoning, particularly factual hallucinations that contradict the given context in self-contained analyses where external information is not required (Uesato et al. 2022;Chakraborty, Ornik, and Driggs-Campbell 2025).
Recent advancements such as DeepSeek (Liu et al. 2024a) show the potential of reasoning to enhance model classification performance without explicit user instructions. Although overall performance gains have been observed, some studies further explore the role of reasoning in enhancing generation by LMs (Zhao et al. 2023;Yuan, Zhang, and Ma 2025). Lampinen et al. (2022) examine the effect of providing a few in-context examples to LMs’ prompts and concluded that explanations improved model performance in general domains. Ye and Durrett (2024) investigate the use of triplets comprising a question, classification, and explanation in few-shot examples, proving LMs tend to generate nonfactual explanations when making wrong predictions. Turpin et al. (2023) also reveal a close relationship between reasoning and decision, showing that even when the decision is incorrect, LMs tend to adjust their explanations to justify it. Our study advances this line by statistically quantifying the relationship between reasoning and classification, providing evidence that factually erroneous reasoning is correlated with misclassification.
Verifying factual statements and detecting hallucinations are essential for ensuring the trustworthiness and safety of LMs (Tang et al. 2024;Chen et al. 2025). For LMs’ outputs that include both reasoning and classification, hallucination detection can be broadly divided into two types: outcome detection and process detection (Welleck et al. 2023;Lightman et al. 2024). As discussed previously, outcome detection assumes prior knowledge of whether the outcome is correct, which is often impractical in real-world settings. Former studies have trained process verifiers and demonstrated their effectiveness as feedback to LMs. Lightman et al. (2024) fine-tune GPT-4 to predict the correctness of each reasoning step in mathematical problems. Wang et al. (2024) further extend it by using relatively smaller LMs to provide feedback on each reasoning step and demonstrating that model-generated feedback can guide SLMs to produce better outputs through proximal policy optimization. In this study, we also focus on process verification, specifically examining factual hallucinations within each reasoning step. For backbone models, we adopt transformer encoders for their efficiency and effectiveness as step verifiers of LMs’ reasoning (Li et al. 2023c;Tang et al. 2023;Sun et al. 2024).
Adaptive inference has gained popularity in recent research as a means to enhance LMs’ performance through feedback from diverse sources. The previous section reviewed studies that use externally fine-tuned models to verify the factuality of LMs’ reasoning, representing one source of feedback. Beyond this, three common sources are knowledge databases, human experts, and other LMs. Feedback from experts serves as the ground truth for assessing the factuality of LMs’ reasoning and represents human-in-the-loop practices (Yuan et al. 2024). Knowledge databases are excluded because we focus on self-contained scenarios where all factual context required for correct inference is provided. Feedback from LMs can be categorized into two types: LLM-asa-judge (Jang, Lee, and Kim 2022;Koutcheme et al. 2024;Ye et al. 2025) and self-reflection (Dou et al. 2024;Gupta et al. 2024;Liu et al. 2024b;Zhao et al. 2024;Li et al. 2024). Both approaches use LMs to identify errors and guide LMs to iteratively refine earlier outputs. The key difference is that LLM-as-a-judge typically relies on other, often more capable, models, whereas self-reflection uses the same one for initial inference, feedback, and iterative improvement. Compared with general feedback investigated in most former studies, our work focuses specifically on factual hallucinations. Some research also examines adaptive inference based on factuality of LMs’ initial outputs. For example, Ji et al. ( 2023) employ a customized scorer to assess knowledge generated by LMs for open-ended medical tasks. In contrast, our study targets closed-end financial tasks.
To illustrate the potential for improving SLMs’ financial classification through reflection on factual hallucinations, we implement a three-step AAAI pipeline1 (Figure 1).
We use the German credit financial classification dataset (Hofmann 1994), a widely recognized benchmark in financial natural language processing (NLP). In this context, L = 1 indicates a good profile and L = 0 represents a bad profile. Prior studies (Xie et al. 2023;Bhatia et al. 2024) on this dataset overlook the critical role of data processing in enhancing the signal-to-noise ratio and revealing the true capabilities of SLMs. Specifically, the original dataset includes outdated information and pre-existing bias (Zehlike et al. 2017) that pose challenges for SLMs. For instance, certain features are denominated in Deutsche Marks, a currency that has been obsolete for over two decades. Also, SLMs often exhibit limited sensitivity to numeric reasoning (Mishra et al. 2022). To address these issues, we exclude features misaligned with contemporary SLMs development contexts and converted numeric features into percentile representations. All processing steps were conducted ad hoc and did not involve any operations related to the labels, ensuring that performance was not affected by information leakage. Also, we conduct all experiments using all minority cases paired with an equal number of majority cases to avoid the adverse impact of data imbalance on the analyses.
We utilize three SLMs to generate structured content, containing both reasoning and decision, as the initial responses (Yuan et al. 2025): Meta’s Llama-3.2-3B (Touvron et al. 2023), Google’s Gemma-2-2B (Mesnard et al. 2024), and Microsoft’s Phi-3.5-3.8B (Abdin et al. 2024). Following Madaan et al. (2023), given an input X, prompt P gen and model M , an initial generation Y is obtained: Y = M (P gen X). Here, P gen is a task-specific prompt for
For classification metrics, we adopt the standard metrics of F1 score by comparing Y cls with L. In addition, financial classification prioritizes weighted costs, emphasizing the greater consequence of false positive to false negative and a lower cost indicates superior performance. As specified in the original dataset documentation (Hofmann 1994), the cost associated with a false negative is quantified as 5, while that of a false positive is 1. Therefore, the weighted cost is
. We identify a consistent improvement in weighted cost across all models when using the processed dataset. For F1 score, a substantial enhancement is achieved with Llama, while performance remained comparable for the other two.
After evaluating financial classification performance, we conduct an association analysis to examine the relationship between factual hallucinations and misclassifications using Pearson correlation (Pearson 1895). Basically, for each reasoning point Y rsn i , we annotate whether it contains factual hallucinations, where H rsn i = 1 denotes that Y rsn i contains factual hallucinations. If any Y rsn i contains a factual hallucination, the overall reasoning Y rsn is considered factually erroneous in terms of reasoning (H rsn = 1). We then examine the correlation between the subgroup of H rsn = 1 and the subgroup of Y cls ̸ = L. A positive correlation coefficient indicates that reasoning containing factual errors is more likely to occur with incorrect decisions. Also, we calculate the false decision risk difference: P rob(Y cls ̸ = L|H rsn = 1)-P rob(Y cls ̸ = L|H rsn = 0), where | stands for the conditional probability. Similar to the Pearson correlation coefficient, a positive risk difference demonstrates that the risk of misclassification is higher in cases with factual errors than in those without. Table 1 presents the correlation results and risk differences, demonstrating the positive relationship between factual hallucinations and incorrect decisions, thereby supporting our subsequent experiments of improving SLMs’ classification by mitigating factual errors. SLMs (Ji et al. 2023;Wu et al. 2025). To prevent data leakage, full-parameter fine-tuning (FPFT) of V is conducted using a three-fold split, ensuring that P rob v i is collected under the fold where X and Y rsn i serves as test data. Table 2 shows verifiers’ performance by comparing P rob v i with H rsn i . Due to the limited sample size, we do not employ an independent validation set and instead use a fixed threshold: If P rob v i ≥ 0.5, the prediction P red v i = 1 means that Y rsn i contains factual hallucinations. Also, given the class imbalance, where reasoning points with factual hallucinations are fewer than those without, we evaluate performance using area under the precision-recall curve (AUPRC) and balanced accuracy (BA). In certain cases, a model may achieve a perfect AUPRC score of 1, while the BA remains below 1. In addition to aggregated metrics such as AUPRC, Figure 2 illustrates the probability density distributions of fine-tuned verifiers, showing that they assign substantially higher probabilities to reasoning points with factual errors (H rsn i = 1) than to those without errors (H rsn i = 0). We further validate this discriminability using Wilcoxon rank-sum tests (Wilcoxon 1947), with p-values reported at the top of each subplot. Except for RoBERTa-large on Phi, all p-values are below 0.01, confirming the verifiers’ identification ability. Table 3 compares classification performance across various SLMs and feedback sources. Consistent with Huang et al. ( 2024) and Madaan et al. (2023), our experiments underscore the importance of feedback quality for adaptive inference of SLMs, which can either improve or decline after factual hallucination-aware reasoning. Oracle feedback from human experts consistently enhances, or at least does not reduce, SLMs’ performance. Compared with self-reflection, verifiers yield better classification performance in Llama and Gemma, highlighting the need for caution against overreliance on LMs in NLP tasks (Tang et al. 2024).
Also, we observe that self-reflection improves Gemma’s classification performance, demonstrating the potential of SLMs to correct their own generations without external feedback (Wu et al. 2024). Gemma achieves even better classification with feedback from verifiers than from the oracle, indicating that SLMs can produce correct classifications even when feedback is inaccurate, which is reported in Madaan et al. (2023). Among these cases, some contain no factual hallucinations in the reasoning, yet classifi- (Yan et al. 2024). Moreover, we notice varying levels of steerability across SLMs, where steerability refers to a model’s likelihood of adjusting its output behavior in response to external instructions such as feedback (Miehling et al. 2025). Table 3 shows that Phi exhibits the lowest steerability, as feedback from oracle, verifiers, or self-reflection does not induce any change from its initial classification, a behavior also observed in Vicuna (Madaan et al. 2023). Although low steerability limits adjustments to LMs’ inherent beliefs, it becomes a desirable property when invalid feedback is given during adaptive inference, as robust LMs should defend their reasoning and decision rather than being easily misled (Wang et al. 2023).
In addition to experiments in the former sections, we implement supplementary analyses under alternative settings.
First, we fine-tune SLMs to detect factual errors in their own reasoning and use this feedback to trigger error-aware reasoning. To prevent bias in SLMs’ generation ability, the fine-tuned models are solely used for feedback generation, while the foundation SLMs perform the hallucination-aware reasoning and classification. The resulting classification performance is shown in Table 4. For Llama, feedback from the fine-tuned model improves classification performance, whereas for the other two SLMs, fine-tuning has marginal effect. Also, compared with feedback from encoder-based verifiers, feedback from either fine-tuned or foundation SLMs does not yield superior performance, indicating that transformer encoders are effective and efficient for initiating SLMs’ factual hallucination-aware reasoning.
Second, our former experiments adopt a granularity at reasoning point level for self-reflection to maintain comparability with the verifiers. Previous studies (Kim, Baldi, 5 compares the performance of these two granularities and their impact on SLMs’ classification performance. For Llama and Gemma, reasoning at the single point granularity yields better performance across all metrics, likely due to their superior capability on short-context tasks. For Phi, using the entire reasoning content achieves higher F1 score. A possible explanation for this phenomenon is that Phi exhibits lower steerability than the other two SLMs. Since single point granularity provides weaker instructional signals than entire content granularity, Phi’s behavior adaptation is consequently less pronounced.
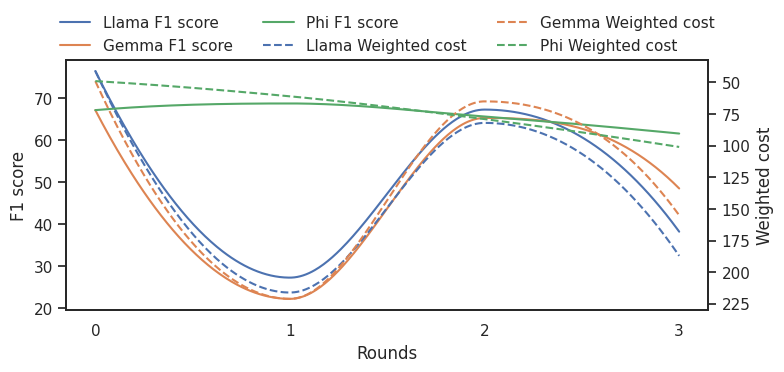
Third, we explore multiple rounds of self-reflection and adaptive inference. Due to constraints in annotation budget, SLMs’ input token length, and GPU memory, we leverage granularity at the entire content level and retain only the latest response and the original context for each additional round of inference. Figure 3 shows the impact of additional inference rounds on SLMs’ classification performance. Consistent with findings from Huang et al. ( 2024) in general domain, additional rounds of adaptive inference do not always improve SLMs’ performance compared with the initial generation without feedback in financial contexts. Another notable observation is that when a round of hallucinationaware reasoning yields weak performance, the next round often restores it, whereas when a round achieves strong performance, the following round frequently impairs it. Based on the identified positive association between reasoning and classification, we hypothesize that current LMs tend to overcriticize prior reasoning when its quality is high, but provide constructive criticism when its quality is low. The drastic fluctuation across self-reflection rounds presents an opportunity for future foundation model development.
We present a three-step approach that allows SLMs to enhance their financial classification by realizing factual errors in their reasoning paths. Compared with prior studies on model reflection, our work introduces statistical analyses to quantify the relationship between erroneous reasoning and misclassifications and to validate the discriminative power of automated detectors. Furthermore, we highlight the importance of pinpointing specific erroneous reasoning steps, which can provide valuable annotation guidance for future SLMs’ development (Lightman et al. 2024).
The positive relationship provides an empirical basis for developing a proxy confidence metric for LMs’ classification, such as the proportion of factual errors in the reasoning path. In real-world settings, for example classifying the hawkish or dovish stance in Federal Open Market Committee speeches, even experts often struggle to make accurate decisions. As a result, they cannot always judge whether LMs’ classifications are trustworthy, whereas hallucinations of reasoning are easier to evaluate. A proxy confidence value enables users to make more informed decisions about adopting LMs’ suggestions. We hope that our study can drive further research on LMs’ adaptive inference in finance.
This work presents a three-step pipeline for studying factual hallucinations in SLMs’ reasoning for financial classification and demonstrates the potential to improve SLMs’ classification by incorporating factuality into the reasoning. Due to annotation constraints, the experiments are based on 50 positive and 50 negative cases from a public dataset. To validate the generalizability of our findings, future work should include more tasks and SLMs. Beyond the experimental aspect, the technical implementation can also be enhanced. First, the current self-reflection feedback relies on SLMs’ zero-shot capability, while providing sufficient few-shot examples may improve their capability. Second, the current work only evaluates factual hallucinations in the initial generation. Although adaptive inference enhances classification, we do not evaluate its impact on reasoning. Further annotation can confirm whether it facilitates self-corrected generation of reasoning sequences (Welleck et al. 2023).
This paper is provided solely for informational purposes as an academic contribution by the authors to the research community and does not represent, reflect, or constitute the views, policies, positions, or practices of American Express or its affiliates. Nothing in this paper should be cited or relied upon as evidence of, or support for, the business views, policies, positions, or practices of American Express or its affiliates.
Next, we adopt three encoder-based architectures of DeBERTa-v3-large(He et al. 2021), RoBERTa-large(Liu et al. 2019), and BART-large (Lewis et al. 2020) as verifiers V to predict probability of factual errors P rob
Next, we adopt three encoder-based architectures of DeBERTa-v3-large(He et al. 2021), RoBERTa-large(Liu et al. 2019)
Next, we adopt three encoder-based architectures of DeBERTa-v3-large(He et al. 2021), RoBERTa-large
Next, we adopt three encoder-based architectures of DeBERTa-v3-large(He et al. 2021)
Next, we adopt three encoder-based architectures of DeBERTa-v3-large