Slot-ID Identity-Preserving Video Generation from Reference Videos via Slot-Based Temporal Identity Encoding
📝 Original Paper Info
- Title: Slot-ID Identity-Preserving Video Generation from Reference Videos via Slot-Based Temporal Identity Encoding- ArXiv ID: 2601.01352
- Date: 2026-01-04
- Authors: Yixuan Lai, He Wang, Kun Zhou, Tianjia Shao
📝 Abstract
Producing prompt-faithful videos that preserve a user-specified identity remains challenging: models need to extrapolate facial dynamics from sparse reference while balancing the tension between identity preservation and motion naturalness. Conditioning on a single image completely ignores the temporal signature, which leads to pose-locked motions, unnatural warping, and "average" faces when viewpoints and expressions change. To this end, we introduce an identity-conditioned variant of a diffusion-transformer video generator which uses a short reference video rather than a single portrait. Our key idea is to incorporate the dynamics in the reference. A short clip reveals subject-specific patterns, e.g., how smiles form, across poses and lighting. From this clip, a Sinkhorn-routed encoder learns compact identity tokens that capture characteristic dynamics while remaining pretrained backbone-compatible. Despite adding only lightweight conditioning, the approach consistently improves identity retention under large pose changes and expressive facial behavior, while maintaining prompt faithfulness and visual realism across diverse subjects and prompts.💡 Summary & Analysis
1. **Introduction to Slot-ID**: Slot-ID is a method for maintaining identity in DiT-based text-to-video diffusion models. It ensures that the generated videos maintain consistent facial features even under significant pose, expression, and lighting changes.-
Learnable Identity Slots: The core of Slot-ID lies in its learnable identity slots, which are compact tokens refined through Sinkhorn matching and a lightweight GRU mechanism. This allows for capturing dynamic and static cues that define an individual’s appearance across different frames.
-
Importance of Video References: Unlike traditional methods that rely on single images to infer identity, Slot-ID utilizes short video references. These videos capture the nuances of facial movements and expressions over time, leading to more accurate and consistent representation of identities in generated videos.
📄 Full Paper Content (ArXiv Source)
 />
/>
Introduction
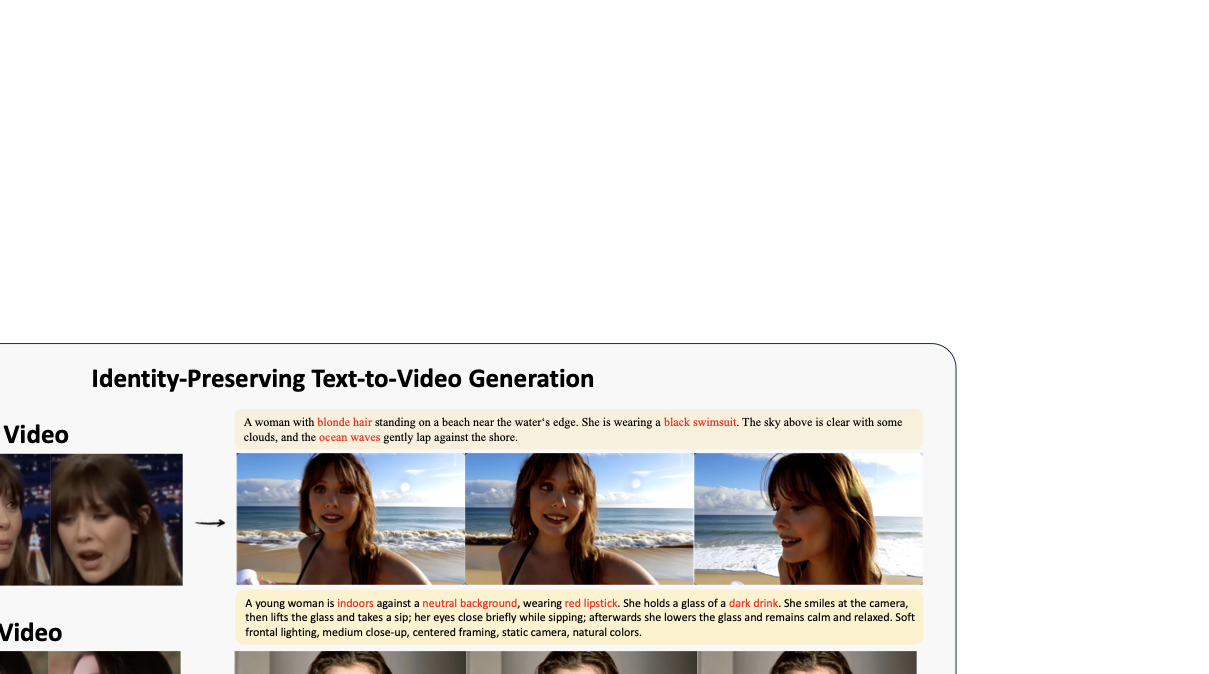
Using text prompts to generate realistic human videos has seen a recent spike in research interest , evolving from short, stylized clips to long, photo-realistic, prompt-faithful sequences with strong temporal coherence , enabling applications in personalized media, previsualization, advertising, and streaming . However, one particular challenge shared by all current research is identity preservation. Identity here refers to whether a viewer can recognize a person in the video mainly through facial features, despite changes in viewpoint, illumination, expressions, and motion. The required coherence across all frames in these factors is currently an open research problem and the topic of our paper.
The current popular solution extracts identity from a single reference portrait and injects it into a pretrained video backbone, either by reusing off-the-shelf encoders such as CLIP/ArcFace , or by designing simple image-based encoders . The former, built for recognition, overemphasizes a few discriminative cues (e.g., hairline), yielding faces that are identifiable yet often unnatural and brittle under distribution shifts . The latter avoids this mismatch but fails under pose and expression changes, frequently collapsing to an “average” face. Moreover, image-only conditioning induces pose locking : the generator treats the portrait as a canonical view and ignores prompted camera angles , as Fig. 1 illustrates.
 />
/>
(d) Pose locking: near-frontal yaw/pitch persists, yielding puppet-like motion.
We argue that the key missing information in the current research is motion in the reference. A single image cannot reveal how identity-bearing cues evolve across viewpoint, illumination, and expressions. An intuitive solution is to introduce a short video as reference and train a video encoder to learn a compact, dynamics-informed identity code for injection into the video backbone. This short video can contain variations of lighting, views, and facial muscle movements that make an identity recognizable beyond static appearance. The central challenge is to capture not only identifiable geometric and appearance features, but also how these cues move in space and time, which, to our knowledge, has not been investigated in prior work, most of which use static images as references. The second constraint is that extracted features need to be compatible with the chosen video backbone, so that the injection will not severely compromise its performance. Our experiments show that naively applying general video encoders fails to meet this goal, often yielding identity drift or “average faces” under large viewpoint changes or strong expressions.
To tackle these challenges, we condition the video generator on a short reference clip and learn a compact, dynamics-informed identity code that captures not only static facial appearance but also characteristic temporal cues—how the face moves across expressions and viewpoints. We generate this identity code with a slot-based encoder. Here, a slot is a learnable query that attends across time and space in the reference clip. We introduce a Sinkhorn-routed slot encoder to extract these identity tokens. We form a slot-token affinity matrix and apply Sinkhorn normalization to obtain an assignment that encourages coverage and prevents collapse. Slot states are iteratively refined with a lightweight GRU. Aggregating temporal evidence from a short reference clip of the target individual enables the model to learn person-specific facial dynamics rather than overfitting to a single frame. This yields strong identity preservation across large pose, expression, and lighting changes without per-identity fine-tuning, while maintaining realism and prompt fidelity. Qualitatively, our Slot-ID maintains crisp detail through rapid motion and highly expressive sequences, consistently outperforming single-image baselines by leveraging temporal evidence instead of overfitting to a canonical view.
Our main contributions can be summarized as follows.
-
We present Slot-ID, an identity-conditioning method for DiT-based text-to-video diffusion that achieves state-of-the-art (SOTA) identity preservation while maintaining visual realism and prompt fidelity.
-
We design learnable identity slots—compact tokens refined via Sinkhorn matching and a lightweight GRU—to form a dynamics-robust identity code stable across motion, pose, and illumination.
-
Extensive experiments across multiple datasets, subjects, and prompts show consistent gains, enabled by a minimal integration.
Related Work
Video diffusion backbones and control signals.
Modern video generation increasingly builds on diffusion transformers (DiT/MMDiT) operating in 3D VAE latents , largely replacing U-Nets . Open backbones such as CogVideoX, HunyuanVideo, and Wan leverage dual-stream attention, 3D VAEs, and large text encoders . Rather than attaching heavy control branches or modifying the base , Slot-ID derives an identity signal from a short reference clip and injects it into a frozen DiT/MMDiT backbone (e.g., Wan ) via lightweight conditioning, preserving the base checkpoint and compatibility with existing controllers/schedulers. Complementary to architecture-level control modules, Filter-Guided Diffusion (FGD) offers a training-free method to guide diffusion, utilizing a fast edge-aware filtering step to preserve the structure of a guide image while maintaining flexibility for prompt-driven appearance.
Personalization strategies: tuning-based vs. tuning-free.
Identity conditioning generally follows (i) tuning-based approaches—per-subject fine-tuning via DreamBooth , LoRA adapters , and textual inversion —which can achieve high fidelity from few images/clips but add per-identity compute and risk overfitting/background leakage; LoRA/text tokens demand careful hyperparameters to avoid overspecification and motion dampening . Numerous ready-to-use identity LoRAs exist in community hubs . (ii) Tuning-free methods extract identity embeddings from one/few references—often CLIP/ArcFace or image encoders —and inject them at inference as cross-attention visual tokens or identity-augmented text tokens . These plug-and-play designs scale to many identities but must reinforce identity during sampling to resist drift under pose/illumination changes . In DiT/MMDiT settings, tuning-free conditioning keeps a single immutable checkpoint and enables instant identity switching. Slot-ID is tuning-free, replacing static single-image cues with a temporal encoder that aggregates clip-wise evidence into motion-robust tokens.
Identity-preserving video generation.
Prior work splits into two camps. Per-subject fine-tuning of the backbone or lightweight adapters attains strong fidelity but scales poorly in training/storage . Tuning-free alternatives infer identity at inference from a reference image using ArcFace/CLIP and inject these features into mostly frozen diffusion backbones via cross-attention visual tokens or identity-augmented text tokens ; open-source variants often add a face adapter to a pretrained T2V model , while commercial systems keep models/training proprietary . Because single-image cues miss fine traits and are brittle under large pose or edits, plug-and-play designs route image features into frozen DiT backbones ; heavier end-to-end systems (e.g., Phantom) improve consistency at substantially higher cost . We take a video-referential route: a short reference clip is encoded by a temporal identity encoder into identity tokens and injected into a frozen DiT/MMDiT backbone, preserving identity across motion/view/illumination changes, mitigating multi-subject interference, and improving prompt alignment—without per-identity fine-tuning—as in Slot-ID.
Methodology
 />
/>
Overview
We address identity-preserving text-to-video generation with a system that augments a frozen Wan text-to-video backbone with a slot-based Temporal ID Encoder. Given a text prompt, a short reference clip, and a single near-frontal portrait extracted from video, the system builds a compact identity condition injected into the backbone. Our core module—the slot-based Temporal ID Encoder—extracts stable, person-specific cues using differentiable slot assignment. The resulting identity slots are embedded in the same VAE latent space as the video backbone, enabling seamless conditioning of the generator. It outputs a handful of identity tokens summarizing appearance across frames. These tokens are prepended to the text tokens so the backbone can attend to identity throughout the network. This lightweight conditioning preserves identity under pose, illumination, and expression changes while keeping the generator frozen and the additional parameters minimal.
Slot-ID: Slot-based Temporal ID Encoder
Input
Given a reference video $`\mathcal{V}^{ref}`$, we encode it with the same VAE as the base model to obtain latents $`\mathbf{Z}^{ref}`$. To explicitly encode frame-to-frame changes, we compute a temporal-difference volume $`\Delta\mathbf{Z}`$ along time with:
\Delta\mathbf{z}_t \ =\
\begin{cases}
\mathbf{0}, & t\ =\ 1,\\[2pt]
\mathbf{z}^{ref}_t - \mathbf{z}^{ref}_{t-1}, & t\ >\ 1,
\end{cases}where $`\mathbf{z}^{ref}_t \ \in \ \mathbb{R}^{B\times C\times H\times W}`$ denotes the latent slice at time $`t`$. We then channel-concatenate $`\tilde{\mathbf{Z}}\ =\ [\mathbf{Z}^{\mathrm{ref}}\!;\,\Delta\mathbf{Z}]`$. A strided 3D patch-embedding $`\,\mathrm{Conv3D}(\cdot)`$ with kernel $`(\tau, h, w)`$ projects $`\tilde{\mathbf{Z}}`$ to a $`D`$-dimensional token sequence $`\mathbf{X} \ \in \ \mathbb{R}^{B\times L\times D}`$, where:
L \ =\ \frac{T}{\tau}\cdot\frac{H}{h}\cdot\frac{W}{w}.Dual-source identity conditioning
From the reference clip we select a near-frontal frame and neutralize its background to obtain the identity image $`\mathcal{I}^{ref}`$. Encoding $`\mathcal{I}^{ref}`$ with the same VAE yields latents $`\mathbf{Z}_{\mathrm{img}}`$ for an image stream, while the Slot-ID encoder (3.2.3) provides a video stream. The two streams provide both prefix tokens and a global vector. Unlike prior work that neutralizes the entire reference (typically an image), we do not neutralize the background of the video clip. Applying per-frame matting/background replacement to long clips is brittle and often introduces artifacts—facial erosion and temporal flicker—that weaken identity cues and can collapse the benefit of having a video at all. We therefore only neutralize $`\mathcal{I}^{ref}`$ to obtain a clean, scene-agnostic appearance anchor, while keeping the reference clip intact to contribute stable dynamics and motion cues.
As illustrated in Fig. 2, the reference clip $`\mathbf{Z}^{\mathrm{ref}}`$ is summarized into $`S`$ temporal identity tokens $`\mathbf{C}_{\mathrm{id}}\ \in \ \mathbb{R}^{B\times S\times D}`$ that capture motion-stable, person-specific cues, while the white-background identity image $`\mathbf{Z}^{\mathrm{img}}`$ is projected into $`K`$ image-anchor tokens $`\mathbf{C}_{\mathrm{img}} \ \in \ \mathbb{R}^{B\times K\times D}`$. During both training and inference we use a schedule $`w \ \in \ [0,1]`$ to gate the two token sets before cross-attention:
\widehat{\mathbf{C}}_{\mathrm{id}}\ =\ (1-w)\,\mathbf{C}_{\mathrm{id}},\qquad
\widehat{\mathbf{C}}_{\mathrm{img}}\ =\ w\,\mathbf{C}_{\mathrm{img}},and prepend the weighted prefix $`[\widehat{\mathbf{C}}_{\mathrm{img}};\,\widehat{\mathbf{C}}_{\mathrm{id}}]`$ to the text tokens. In this way, early stages (larger $`w`$) bias cross-attention toward the clean, scene-agnostic anchors from the image, while later stages (smaller $`w`$) hand over to the richer temporal identity cues from the video.
In parallel, we compute global summaries $`\mathbf{g}_{\mathrm{vid}}`$ and $`\mathbf{g}_{\mathrm{img}}`$ and fuse them with the same gate $`w`$:
\mathbf{g} \ =\ (1-w)\,\mathbf{g}_{\mathrm{vid}} \;+\; w\,\mathbf{g}_{\mathrm{img}}.The fused vector $`\mathbf{g}`$ drives standard FiLM modulation, providing a lightweight continuous identity prior.
Sinkhorn-Routed Slot-ID Reader
Overview.
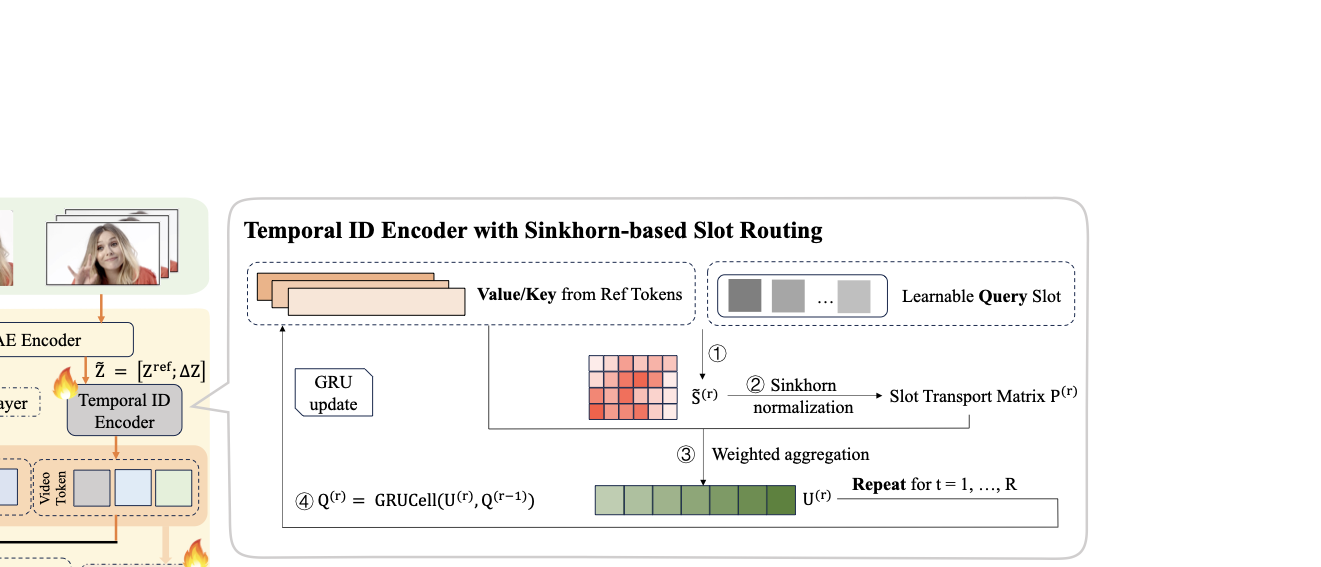
Given video VAE latents $`\mathbf{Z} \ \in \ \mathbb{R}^{B\times C\times T\times H\times W}`$, the encoder produces $`S`$ identity slots $`\mathbf{C}_{\mathrm{id}} \ \in \ \mathbb{R}^{B\times S\times D}`$. We first form a stacked latent volume $`\tilde{\mathbf{Z}}\ =\ [\mathbf{Z},\,\Delta\mathbf{Z}]`$ to expose short-term dynamics, apply a strided 3D patch embedding, and obtain a token sequence $`\mathbf{X} \ \in \ \mathbb{R}^{B\times L\times D}`$. A few lightweight spatio–temporal self-attention (STSA) blocks further mix context using 3D RoPE, and Flash-style kernels ; followed by a Sinkhorn-routed slot reader that converts $`\mathbf{X}`$ into identity slots. This reader distills motion-robust, person-specific evidence into a compact set of slots that condition the generator.
Slot routing with temperature-annealed Sinkhorn.
Let $`X \ \in \ \mathbb{R}^{B\times L\times D}`$ be the token sequence after the STSA stack, where $`B`$ is the batch size, $`L`$ the sequence length, and $`D`$ the channel dimension. We denote $`H\ =\ X`$ and set keys/values as $`K\ =\ H`$, $`V\ =\ H`$ (shape $`B\times L\times D`$). The reader maintains $`S`$ learnable slot queries $`Q^{(r)} \ \in \ \mathbb{R}^{B\times S\times D}`$ that are refined over $`r\ =\ 1,\dots,R`$ iterations.
At each refinement step we compute scaled dot-product scores between slots and tokens, followed by temperature scaling:
S^{(r)}\ =\ \frac{Q^{(r-1)}(K)^\top}{\sqrt{D}}\ \in\ \mathbb{R}^{B\times S\times L},\quad
\tilde{S}^{(r)}\ =\ \frac{S^{(r)}}{\tau(s)} .We refer to $`\tilde S^{(r)}`$ as the logits: they are unnormalized log-scores whose exponentiated-and-normalized form yields assignment probabilities. Here $`s`$ is the global training step and the temperature uses a step-conditioned linear schedule:
\tau(s)\ =\ \tau_{\text{start}}+\min\!\Big(1,\frac{s}{T_{\text{decay}}}\Big)\cdot\big(\tau_{\text{end}}-\tau_{\text{start}}\big),which anneals from a softer (high-entropy) regime to a sharper (near one-to-one) regime during early training.
Rather than turning $`S^{(r)}`$ into assignments with a simple softmax—which tends to over-concentrate a few slots and to jitter across near-identical frames—we project it to a near doubly-stochastic coupling $`P^{(r)}\ \in\ \mathbb{R}^{B\times S\times L}`$ with an entropic optimal-transport step with uniform marginals $`a\ =\ \tfrac{1}{S}\mathbf{1}_S,\ b\ =\ \tfrac{1}{L}\mathbf{1}_L`$. We run a Sinkhorn–Knopp normalization in the log domain to obtain:
P^{(r)} \ =\ \operatorname{Sinkhorn}\!\left(\frac{1}{\tau(s)} S^{(r)}\right)
\ \in\ \mathbb{R}^{B \times S \times L},whose rows (over tokens) and columns (over slots) are approximately normalized even when $`S\neq L`$. This OT projection is the key stabilizer: it keeps capacity balanced across slots by construction and, together with temperature annealing, moves gracefully from exploratory, soft coverage early in training to relatively confident, sharp assignments later.
Concretely, define the Sinkhorn kernel by $`\log K_{\mathrm{sh}}\ =\ \tilde{S}^{(r)}`$, and initialize $`\log u\ =\ \mathbf{0}`$, $`\log v\ =\ \mathbf{0}`$ and iterate for $`t\ =\ 1,\dots,n_{\text{iters}}`$:
\begin{aligned}
\log u &\leftarrow \log a - \operatorname{logsumexp}\!\big(\log K_{\text{sh}} + \log v\big)_{\text{col}},\\
\log v &\leftarrow \log b - \operatorname{logsumexp}\!\big(\log K_{\text{sh}} + \log u\big)_{\text{row}}.
\end{aligned}After convergence, we can assemble the log-coupling and exponentiate once:
\log P \ =\ \log K_{\text{sh}} + \log u + \log v.Algorithm details are provided in the Supplementary.
Since the Sinkhorn is stopped after finitely many floating-point iterations, the row/column marginals of $`P`$ can drift from 1. We correct this with a single row-then-column renormalization:
P \leftarrow \frac{P}{\sum_j P_{:,j}+\varepsilon},\quad
P \leftarrow \frac{P}{\sum_i P_{i,:}+\varepsilon}.which restores an (almost) doubly-stochastic coupling.
Using these nonnegative, approximately normalized weights $`P^{(r)}`$, we form slot-wise aggregates:
U^{(r)} \ =\ P^{(r)} V \ \in\ \mathbb{R}^{B\times S\times D},and update the slot queries with a small recurrent step:
Q^{(r)} \ =\ \mathrm{GRUCell}\!\big(U^{(r)},\,Q^{(r-1)}\big),followed by a LayerNorm–Linear “readout” after $`R`$ iterations to yield the identity slots:
C_{\mathrm{id}}\ =\ \mathrm{Proj}\!\big(Q^{(R)}\big)\ \in\ \mathbb{R}^{B\times S\times D}.Because each $`U^{(r)}`$ is a convex, column-normalized combination of token values, these updates act as a gentle low-pass filter in space and time: they damp short-range oscillations in the assignments and materially reduce frame-to-frame jitter without washing out identity cues. In summary, the reader is not a bag of heuristics but a routed, entropically-regularized alignment between a small, semantically interpretable set of slots and a long sequence of video tokens.
Training
We condition the frozen backbone by prepending a compact prefix to the text tokens. The prefix concatenates (i) $`K`$ image tokens $`\mathbf{C}_{\mathrm{img}}`$, and (ii) $`S`$ identity–slot tokens $`\mathbf{C}_{\mathrm{id}}`$:
\mathbf{C}\ =\ \big[\,\mathbf{C}_{\mathrm{img}},\ \mathbf{C}_{\mathrm{id}},\ \mathbf{C}_{\mathrm{text}}\,\big].To avoid early over-conditioning, we apply lightweight regularization before each cross-attention, and prefix-token dropout. A global identity vector $`g`$ provides gentle FiLM-style modulation to temporal features. For stability, we insert LoRA on cross-attention $`K/V/O`$ projections and keep all base weights frozen.
Training follows the base model’s latent-space velocity/flow-matching ($`v`$-prediction) objective (details in the Supplementary): for VAE latents $`z`$, sample $`\varepsilon\!\sim\!\mathcal{N}(0,I)`$ and $`t\!\sim\!\mathcal{U}[0,1]`$, set $`z_1 \ = \ z`$, $`z_0 \ = \ \varepsilon`$, $`z_t \ = \ (1-t)z_1+t z_0`$, and target $`v^*(z_t) \ = \ z_0-z_1`$. We minimize:
\mathcal{L} \ = \ \mathbb{E}_{z,\varepsilon,t}\big\|v_{\theta}(z_t,t,\mathbf{C},g)-(z_0-z_1)\big\|_2^2.Experiments
Setup
Implementation Details.
We train on the publicly released human-centric dataset introduced in . For each video we sample 65-frame clips at 480$`\times`$720. A reference facial video is extracted by detecting the dominant subject across the clip, consolidating detections into a temporally stable square crop, and resizing every frame; background is preserved. A reference facial image is selected by uniformly sampling frames, cropping the dominant face and parsing a background-free portrait at 512$`\times`$512; candidates are ranked by a joint quality score (sharpness, near-frontal, neutral expression) and the top one is chosen. We fine-tune a Wan-2.1 T2V-14B backbone with all base weights frozen. Cross-attention is adapted with LoRA (K/V only, rank = 32, $`\alpha`$ = 16). The temporal ID encoder adopts 6 slots, 3 iterations, 2 STSA layers, 16 heads, per-token dropout of 0.05 and a global branch for FiLM modulation on the last 50% of backbone blocks. We prepend $`K \ = \ 2`$ image-anchor tokens. Model details, full dataset preprocessing pipeline and ranking heuristics are provided in the Supplementary.
 />
/>
Comparison
Across all experiments, we report three complementary metrics (higher is better). Face Similarity measures identity preservation as the embedding similarity between the reference face and detected faces in generated frames, averaged over frames. Naturalness uses GPT4o to rate perceptual realism from uniformly sampled frames under a fixed 1–5 rubric; we report the mean score. Prompt Following evaluates text–video alignment by encoding the prompt and a clip with XCLIP (base–patch32) and taking the similarity.
We compare Slot-ID with ConsisID, Stand-In, HunyuanCustom, Phantom, ID-Animator, and EchoVideo. For each case, we sample a reference video, take its sharpest frontal frame as the image cue, and draw the prompt at random; Fig. 3 shows two subjects. Slot-ID preserves identity under viewpoint and motion changes while following prompts, while baselines behave as follows: ConsisID often ignores the given identity and hallucinates a prompt-biased face; ID-Animator is face-only with weak identity and fails on full-body or complex scenes; Stand-In/EchoVideo keep coarse appearance but lose distinctive facial cues in dynamic shots and further exhibit reference-copy stickiness, where clothing/pose from the reference leaks into the generation (e.g., a red sleeve and a hand-on-cheek pose persist despite a different prompt); HunyuanCustom exhibits identity washout under strong actions or camera motion and shows similar attire/pose stickiness tied to the reference; Phantom is the strongest baseline yet still shows facial warping and identity drift under fast motion/large view changes. Overall, Slot-ID best maintains facial structure and temporal stability with stronger prompt adherence.
Table 1 reports a broader quantitative comparison under a unified, reproducible protocol. Following Stand-In , we evaluate facial similarity and naturalness with OpenS2V , and measure text–video relevance with XCLIP . All open-source baselines are run with public checkpoints and identical settings. Slot-ID achieves the highest facial similarity and naturalness across datasets/prompt strata, while its prompt-following score ranks among the very best (trailing the top system by only a small margin). Metric computation details (framewise face embedding cosine similarity for identity; OpenS2V’s naturalness; XCLIP alignment on our prompts) and implementation choices are provided in the Supplementary.
| Method | Face Sim. $`\uparrow`$ | Naturalness $`\uparrow`$ | Prompt Following |
|---|---|---|---|
| ID-Animator | 0.298 | 2.897 | 0.560 |
| HunyuanCustom | 0.643 | 3.423 | 0.604 |
| ConsisID | 0.418 | 3.107 | 0.640 |
| Stand-In | 0.697 | 3.887 | 0.611 |
| EchoVideo | 0.671 | 3.856 | 0.635 |
| Phantom-1.3B | 0.467 | 3.478 | 0.643 |
| Phantom-14B | 0.699 | 3.912 | 0.615 |
| Slot-ID (Ours) | 0.729 | 3.917 | 0.634 |
Quantitative comparison with identity-preserving video generation methods. Higher is better; best and second-best are in bold and underlined.
Prompt-Stratified Stress Tests
Motivated by evidence that generative models fail in category-dependent failure modes, we stratify prompts by challenge factors—prompt attributes that systematically increase difficulty along a specific axis (e.g., motion magnitude or occlusion), following DrawBench , PartiPrompts and recent T2V benchmarks . Our groups target (1) large whole-body or viewpoint/camera motion, (2) exaggerated facial expressions, (3) multi-object interactions, and (4) partial occlusions. Across all challenge factors, our method consistently maintains identity and temporal coherence, while baselines exhibit identity drift, limb distortions, and background flicker. Representative cases are shown in Fig. 4 (whole-body motion); per-category details appear in the supplement.
As shown in Fig. 4, during rapid whole-body motion, ConsisID often collapses to a legs-only crop and fails to render the prompted facial region; other baselines drift to a different identity or exhibit facial deformations. Our method preserves on-model identity and frame-to-frame consistency, while maintaining global pose and silhouette through peak-motion frames. Under a wide $`180^\circ`$ orbit with substantial subject rotation, our method sustains identity and temporal continuity, avoiding jitter and preserving background coherence; by contrast, ConsisID tends toward identity collapse, Stand-In and EchoVideo keep coarse structure but produce unstable eye-region expressions, and Phantom/HunyuanCustom show facial deformation or off-model identity under rapid viewpoint changes. The camera-motion qualitative figure and additional stress categories—exaggerated expressions, multi-object interactions, and partial occlusions—together with extended examples are provided in the supplement.
 />
/>
User Study
To complement numerical evaluation, we conducted a human evaluation on identity-conditioned T2V generation. We sampled $`15`$ identities from our benchmark and, for each identity, generated one clip per method under identical prompts. More than $`50`$ participants rated anonymized, order-randomized comparisons on three 1–5 Likert scales: Face Similarity, Visual Quality, and Text Alignment. Mean Opinion Scores (MOS) were averaged across raters and identities. As summarized in Table 2, our method achieves the highest MOS on all three criteria, with particularly strong gains on Face Similarity and Visual Quality—especially under challenging motion and occlusion prompts. Full protocol details (recruitment, interface, randomization scheme, and statistical tests) are provided in the Supplementary.
| Method | Face Similarity | Visual Quality | Text Alignment |
|---|---|---|---|
| ConsisID | 2.515 | 2.535 | 2.842 |
| EchoVideo | 2.856 | 2.614 | 2.769 |
| ID-Animator | 2.447 | 1.727 | 1.644 |
| Phantom-14B | 3.462 | 3.345 | 3.258 |
| Phantom-1.3B | 3.352 | 3.061 | 3.098 |
| Stand-In | 3.199 | 3.249 | 3.131 |
| HunyuanCustom | 3.197 | 2.871 | 3.008 |
| Ours | 3.837 | 3.890 | 3.639 |
User study. Over $`50`$ raters evaluated videos for $`15`$ identities on three 5-point criteria—Face Similarity, Visual Quality, Text Alignment; numbers are mean opinion scores (higher is better). Shown in two blocks; Ours ranks first on all.
Ablation Study
Effectiveness of Slot-based Identity Encoding.
We study whether our slot-based Temporal ID Encoder is necessary by comparing it against two targeted variants under identical training data, schedules, optimizers, LoRA policy, and injection interfaces. Unless noted, the ID token budget $`S`$, channel size $`D`$, and 3D patchifying stride match our default.
(A) 3DConv-Pool Encoder. We replace the Temporal ID Encoder with a 3D-conv encoder that globally pools features to $`S`$ tokens, while keeping other settings unchanged. This 3D-conv variant consistently weakens identity preservation—more look-alikes, blur, and shape/texture artifacts, especially under pose changes and camera motion, indicating that pooled 3D-conv features lose fine, subject-specific cues that our slot-based encoder preserves.
(B) Orderless-Reference (shuffle the reference video frames). To test whether true temporal order is necessary, we uniformly sample $`K`$ frames from the reference video, randomly shuffle them, and then feed this permuted sequence to our Temporal ID Encoder without any other change. As Fig. 5 shows, shuffling consistently degrades identity robustness and increases temporal jitter, while prompt following remains similar. The drop is most visible under occlusions and rapid head motion, confirming that the encoder benefits from modeling ordered temporal evidence rather than an orderless set.
 />
/>
Conclusion
We present Slot-ID, a tuning-free identity module for DiT text-to-video. From a short reference clip, it encodes VAE latents into a few identity slots plus a global vector, enabling lightweight conditioning with a frozen backbone (optional low-rank adapters). Slot-ID preserves prompt fidelity and realism while reducing pose locking and temporal artifacts under large pose changes, fast motion, and strong expressions. The method assumes a short, clean reference; occlusions, very low quality, or multi-subject shots can hurt stability. The Sinkhorn reader adds minor overhead, and long-horizon videos may need stronger memory. Future work includes multi-identity interaction, geometry/3D-aware slot formation, and online/adaptive conditioning; deployments should respect consent and privacy.
📊 논문 시각자료 (Figures)