UltraEval-Audio A Unified Framework for Comprehensive Evaluation of Audio Foundation Models
📝 Original Paper Info
- Title: UltraEval-Audio A Unified Framework for Comprehensive Evaluation of Audio Foundation Models- ArXiv ID: 2601.01373
- Date: 2026-01-04
- Authors: Qundong Shi, Jie Zhou, Biyuan Lin, Junbo Cui, Guoyang Zeng, Yixuan Zhou, Ziyang Wang, Xin Liu, Zhen Luo, Yudong Wang, Zhiyuan Liu
📝 Abstract
The development of audio foundation models has accelerated rapidly since the emergence of GPT-4o. However, the lack of comprehensive evaluation has become a critical bottleneck for further progress in the field, particularly in audio generation. Current audio evaluation faces three major challenges: (1) audio evaluation lacks a unified framework, with datasets and code scattered across various sources, hindering fair and efficient cross-model comparison;(2) audio codecs, as a key component of audio foundation models, lack a widely accepted and holistic evaluation methodology; (3) existing speech benchmarks are heavily reliant on English, making it challenging to objectively assess models' performance on Chinese. To address the first issue, we introduce UltraEval-Audio, a unified evaluation framework for audio foundation models, specifically designed for both audio understanding and generation tasks. UltraEval-Audio features a modular architecture, supporting 10 languages and 14 core task categories, while seamlessly integrating 24 mainstream models and 36 authoritative benchmarks. To enhance research efficiency, the framework provides a one-command evaluation feature, accompanied by real-time public leaderboards. For the second challenge, UltraEval-Audio adopts a novel comprehensive evaluation scheme for audio codecs, evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality. To address the third issue, we propose two new Chinese benchmarks, SpeechCMMLU and SpeechHSK, designed to assess Chinese knowledge proficiency and language fluency. We wish that UltraEval-Audio will provide both academia and industry with a transparent, efficient, and fair platform for comparison of audio models. Our code, benchmarks, and leaderboards are available at https://github.com/OpenBMB/UltraEval-Audio.💡 Summary & Analysis
1. **Unified Evaluation Framework**: UltraEval-Audio is the first comprehensive evaluation framework for audio models, supporting a wide range of languages and task types. It integrates multiple models and benchmarks into one cohesive environment, allowing for comparable evaluations. 2. **Multi-dimensional Audio Codec Evaluation Scheme**: This scheme evaluates audio codecs based on semantic accuracy, timbre fidelity, and acoustic quality, providing systematic performance metrics that were previously lacking. 3. **New Chinese Language Benchmarks**: With SpeechCMMLU and SpeechHSK, the framework addresses the gap in evaluating models' proficiency with the Chinese language.📄 Full Paper Content (ArXiv Source)
Following the groundbreaking success of large language models (LLMs), the rapid development of multimodal large models has ensued. Notably, the release of OpenAI’s GPT-4o marked the advent of the native audio interaction era, accelerating the explosive development of audio foundation models (AFMs). Subsequently, a series of models with complex understanding and generation capabilities emerged, including Qwen2.5-Omni , Moshi , GLM-4-Voice , Step-Audio , Kimi-Audio , and MiniCPM-o 2.6 , significantly expanding the boundaries of human-computer interaction. With the rapid iteration of model capabilities, the challenge of objectively and systematically evaluating these models has become a focal point of academic interest. However, current audio evaluation lacks a unified framework, with datasets and code scattered across various sources, greatly hindering fair and efficient comparisons between models.
In addition to the issue of fragmented evaluation frameworks, the existing evaluation systems also exhibit significant limitations in terms of evaluation depth and language coverage. Traditional evaluation tools are often designed for specific tasks, such as automatic speech recognition (ASR) or automatic speech translation (AST), making it difficult to adapt them to audio foundation models (AFMs) with general-purpose interactive capabilities. This is particularly true in areas like prompt management and inference parameter tuning, both of which are critical for the comprehensive assessment of AFMs. As model capabilities rapidly evolve, user-centered speech benchmarks are emerging in addition to traditional ASR and AST tasks. However, these benchmarks still face the following core challenges:
(1) Audio codecs, which serve as the backbone of AFMs, lack systematic performance metrics. A codec consists of an audio tokenizer (which converts audio into discrete tokens) and a vocoder (which reconstructs audio from generated tokens). The design of audio codecs directly affects the fidelity and efficiency of the audio representation, which significantly impacts the overall performance of AFMs . Existing methods are broad and provide limited insight into specific performance dimensions.
(2) Current benchmarks are heavily reliant on English, making it challenging to objectively assess models’ performance on Chinese. Mainstream benchmarks, such as SpeechTriviaQA , SpeechWebQuestions , and SpeechAlpacaEval , are primarily English-centric, leading to inadequate measurement of models’ knowledge and language proficiency in the Chinese context.
To address these challenges, we propose UltraEval-Audio, a unified evaluation framework for audio foundation models. By decoupling data loading, prompt management, inference parameter control, and diverse post-processing and aggregation methods, this framework provides researchers with a unified and flexible evaluation environment. Users can quickly initiate the evaluation process using a simple “one-click” automated script. This decoupled framework design not only enhances the reproducibility of experiments but also facilitates rapid adaptation and agile extension for researchers. Furthermore, UltraEval-Audio innovatively introduces an audio codec evaluation scheme and several Chinese-language evaluation benchmarks, filling the gaps from both model components and evaluation benchmarks. Through this full-stack integration, UltraEval-Audio aims to standardize and enhance the transparency the entire evaluation process. By providing real-time public audio leaderboards, it strives to advance the field of audio foundation models towards greater interpretability and fairness. Our contributions are summarized as follows:
-
The first unified audio evaluation framework: UltraEval-Audio supports a wide range of input-output modalities, including “Text → Audio”, “Text + Audio → Text”, “Audio → Text”, and “Text + Audio → Audio”. The framework supports 10 languages, 14 core task categories and deeply integrates 24 mainstream models and 36 authoritative benchmarks, covering three key areas: speech, environmental sound, and music. With its user-friendly design, the framework offers a “one-click” evaluation feature and publicly available leaderboards for transparent comparisons.
-
A multi-dimensional evaluation scheme for audio codecs: We have established a systematic evaluation scheme that covers semantic accuracy, timbre fidelity, and acoustic quality, addressing the lack of widely accepted and systematic multi-dimensional performance metrics for audio codecs.
-
Two new Chinese evaluation benchmarks: We propose SpeechCMMLU and SpeechHSK, which are designed to systematically measure the knowledge proficiency and language fluency of AFMs in the Chinese context.
Related Work
In this section, we introduce the latest developments in audio foundation models, audio evaluation frameworks, evaluation benchmarks, and evaluation of audio codecs.
The Advancements of Audio Foundation Models. Emerging audio foundation models typically adopt an Audio Codec+LLM architecture, which generally comprises three core components: (1) an audio tokenizer, which converts raw audio signals into discrete tokens while preserving both semantic and acoustic information; (2) an LLM backbone, responsible for contextual modeling and autoregressive token prediction; and (3) a vocoder, which synthesizes natural speech waveforms from the generated audio tokens. Based on whether they incorporate a vocoder, audio foundation models can be classified into two categories: (1) audio understanding foundation models, which accept both audio and text as input and produce only text as output (e.g., Qwen-Audio , Gemini-1.5 ). (2) audio generation foundation models, which accept both audio and text as input and generate both speech and text as output (e.g., GPT-4o-Realtime , Moshi , MiniCPM-o 2.6 , Qwen2.5-Omni , and Kimi-Audio ).
Meanwhile, audio codecs are also rapidly evolving. SoundStream is the first universal audio codec capable of handling diverse audio types. EnCodec , DAC (descript-audio-codec) , HiFi-Codec , X-codec , BigCodec , and BiCodec further improve reconstruction quality, codebook efficiency, and compatibility with LLM-based speech generation, reflecting a clear trend toward scalable, low-latency, and generative audio tokenizers.
The Development of Audio Evaluation Frameworks. Many comprehensive frameworks have been proposed for evaluating textual and visual foundation models such as OpenCompass , OpenAI Evals 1, UltraEval , and VLMEvalKit . However, a comprehensive evaluation framework for audio foundation models has been lacking.
Before the emergence of audio foundation models, audio models were usually designed for specific tasks, with their evaluation typically being ad hoc and often included alongside the model repository. Audio foundation models have demonstrated strong general capabilities across various tasks, making it increasingly necessary to develop a comprehensive evaluation framework that integrates multiple tasks. Several audio evaluation frameworks have been proposed. For instance, AudioBench collects 8 distinct tasks and 26 benchmarks for evaluating audio foundation models. AHELM aggregates various datasets to holistically measure the performance of AFMs across 10 aspects. But they lack coverage of audio generation tasks. Kimi-Audio-Evalkit integrates all benchmarks mentioned in Kimi-Audio evaluation for reproduction. However, its evaluation process requires five steps, making it cumbersome to use. Additionally, modifying prompts is inconvenient, as changes must be made directly in the code rather than through configuration files. AU-Harness offers an efficient evaluation engine supporting over 380 tasks, but it requires users to manually adapt open-source audio foundation models into standardized vLLM services.
The Development of Audio Evaluation Benchmarks. Beyond traditional ASR and AST benchmarks, the field has begun developing user-centric benchmarks that use raw speech as input without additional task description and directly evaluate model responses. For audio understanding, AIR-Bench collects spoken question answering (QA) samples from existing datasets and employs GPT-4 as an automatic evaluator. VoiceBench further expands this direction by including both naturally spoken QA samples and synthetic spoken instructions, which are generated from text-based instruction-following datasets (e.g. AlpacaEval , IFEval ) using Google TTS. For audio generation, the first dedicated speech question-answering benchmark, Llama-Question , introduced a synthetic speech QA dataset with a novel evaluation paradigm: it employs ConformerASR to transcribe reply audio into text before assessing answer accuracy. SpeechWebQuestions , SpeechTriviaQA , and SpeechAlpacaEval are derived from corresponding textual benchmarks WebQuestions , TriviaQA , and AlpacaEval. However, all these benchmarks are currently limited to English, leaving multilingual speech benchmarks largely unexplored.
The Development of Audio Codec Evaluation. The evaluation of audio codecs employs both subjective and objective metrics. Subjective evaluation typically follows the MUSHRA protocol, which uses both a hidden reference and a low anchor. Objective evaluation includes several approaches: ViSQOL measures spectral similarity to the ground truth as a proxy for mean opinion score; Scale-Invariant Signal-to-Noise Ratio (SI-SNR) quantifies the similarity between reconstructed and original audio while ignoring signal scale; Mel distance computes the difference between the log-Mel spectrograms of reconstructed and ground truth waveforms; STOI assesses speech intelligibility; and speaker similarity (SIM) is calculated as the cosine similarity between speaker vectors of the reconstructed audio and ground truth using an embedding model. Beyond these direct metrics, recent works like that of also employ downstream tasks such as TTS to indirectly evaluate codec performance.
Audio Evaluation Design and Methodology
This section outlines a systematic audio evaluation design and methodology for audio foundation models. Section [sec:Audio_Evaluation_Taxonomy] introduces a unified audio evaluation taxonomy that organizes tasks and their corresponding benchmark instantiations. Building upon this taxonomy, Section [sec:codec_evaluation] focuses on codec evaluation and develops a comprehensive methodology for assessing audio codecs, a core component of audio foundation model architectures. Finally, Section [sec:chinese_benchmarks] introduces two Chinese speech benchmarks, SpeechCMMLU and SpeechHSK, to address the lack of systematic evaluation resources for Chinese in existing audio evaluation research.
Audio Evaluation Taxonomy
Audio foundation models cover a wide range of modalities, tasks, languages and domains. Existing evaluation efforts typically focus on isolated tasks or specific modalities, underscoring the need for a unified and extensible evaluation framework. Rather than simply aggregating existing benchmarks, UltraEval-Audio introduces a reusable and extensible evaluation taxonomy that offers methodological guidance for future evaluation design.
Task taxonomy: What Capabilities Are Evaluated
UltraEval-Audio adopts a capability-driven task taxonomy to organize the evaluation of audio foundation models. Evaluation tasks are grouped into core categories that reflect distinct model capabilities and typical input–output settings. As summarized in Table [tab:task_overview_en], the taxonomy consists of three high-level categories: audio understanding, audio generation, and audio codec. Within each category, tasks are further organized by application domains, including speech, music, and environment sounds.
Notes: WER: Word Error Rate; CER: Character Error Rate; BLEU/ROUGE-L: text generation quality; Acc.: classification accuracy; SIM: speaker embedding cosine similarity; UTMOS: An objective speech quality evaluation metric; G-Eval: GPT-based evaluation metric; ASR-WER: computed by transcribing the generated or reconstructed speech with an ASR model and then calculating WER on the transcriptions.
Audio understanding tasks evaluate a model’s ability to extract and interpret semantic information from audio inputs. This category spans multiple levels of analysis across speech and non-speech domains. In the speech domain, tasks range from low-level recognition such as ASR and AST to higher-level semantic reasoning such as speech QA. In the non-speech domain, tasks include low-level classification like instrument recognition and higher-level comprehension such as audio captioning.
Audio generation tasks assess a model’s ability to synthesize or transform audio under given conditions. In the speech domain, tasks include TTS, voice clone (VC), and spoken answer generation for speech QA tasks. In audio understanding tasks, Speech QA evaluates the accuracy of textual responses. In audio generation tasks, it additionally assesses the quality of generated audio responses in terms of acoustics, naturalness, and intelligibility.
Additionally, audio codec evaluation is treated as a separate task category. Although audio codecs are not traditional application tasks, they play an important role in audio foundation models. Audio codec tasks systematically assess a codec’s ability to compress and reconstruct audio while preserving both semantic content and acoustic characteristics.
Each task category is associated with standardized evaluation metrics aligned with its target capabilities. For example, ASR uses word error rate (WER) or character error rate (CER); translation and captioning tasks rely on text similarity metrics such as BLEU and ROUGE; attribute and sound classification tasks use accuracy; and audio generation and codec tasks are evaluated with ASR-based WER or dedicated speech quality metrics.
By organizing tasks and metrics in this way, UltraEval-Audio provides a reusable and extensible evaluation taxonomy that offers methodological guidance for future evaluation design, ensuring consistent and comparable coverage of capabilities across audio domains and model types.
Benchmark Instantiation: How Capabilities Are Measured
Building on the task taxonomies, UltraEval-Audio instantiates each evaluated capability through a carefully selected set of widely adopted benchmarks. As summarized in Table [tab:supported_benchmarks], the framework integrates 36 benchmarks covering 14 tasks and 10 languages. Each benchmark is explicitly mapped to a predefined task category, ensuring consistency between capability definitions and specific evaluation details.
Within each task, multiple benchmark datasets are aggregated to enable multidimensional and robust assessment of model capabilities. For the ASR task, we support over ten datasets. These datasets span clear read speech (e.g., LibriSpeech) to complex noisy scenarios (e.g., WenetSpeech), and cover single-language (e.g., AISHELL-1 for Chinese) as well as multilingual conditions (e.g., MLS, FLEURS). This design allows evaluation not only of absolute recognition accuracy (WER/CER) but also of models’ generalization and robustness across accents, domains, noise levels, and languages. Similarly, for Speech QA, we incorporate multiple knowledge-based and instruction-based benchmarks, including SpeechTriviaQA and SpeechAlpacaEval.
Across all tasks, the selected benchmarks cover multiple languages and diverse acoustic domains, and are evaluated using metrics specified in the task taxonomy and tailored to each task. This instantiation strategy ensures that the evaluation framework is comprehensive, extensible, and tightly aligned with the underlying capability definitions, providing a clear foundation for systematic and reproducible assessment.
Codec Evaluation
Audio codecs are a fundamental component of audio foundation models, as their design directly affects the fidelity of audio representations and overall model performance. Existing evaluation approaches, however, rely on diverse metrics with inconsistent standards, and lack a systematic, comparable assessment framework. To address this, we propose a three-dimensional codec evaluation methodology encompassing semantics, timbre fidelity, and acoustic quality.
For semantics, we measure how well reconstructed audio preserves the original content using WER. Specifically, the reconstructed audio is transcribed by high-performance ASR models and compared to the original transcript. We employ Whisper-large-v3 for English and Paraformer-zh for Chinese. For timbre fidelity, we extract audio embeddings using WavLM-large fine-tuned on speaker verification, and compute the cosine similarity between embeddings of the original and reconstructed audio. This quantifies the codec’s ability to retain speaker characteristics. For acoustic quality, we assess the naturalness and perceptual comfort of audio using a combination of UTMOS to predict overall naturalness, alongside DNSMOS P.835 and P.808 to evaluate speech quality in noisy environments.
This three-dimensional evaluation framework provides complementary perspectives across content, speaker characteristics, and perceptual quality, enabling a more comprehensive and reliable characterization of codec performance and potential limitations, and offering a fine-grained diagnostic tool for model development and optimization.
Chinese Benchmarks
The development of audio foundation models shift speech evaluation from traditional low-level metrics like WER, toward higher-level capabilities including complex semantic understanding and knowledge reasoning. However, existing high-level speech benchmarks are largely focused on English, such as SpeechTriviaQA, SpeechWebQuestions, and SpeechAlpacaEval, leaving a relative scarcity of resources in the Chinese context. To address this gap, we introduce two new benchmarks: SpeechCMMLU evaluates models’ ability to comprehend and reason over Chinese world-knowledge tasks, while SpeechHSK measures Chinese language proficiency.
SpeechCMMLU extends the widely recognized Chinese knowledge reasoning benchmark CMMLU into the audio modality through systematic speech synthesis. The construction and quality assurance process is as follows:
-
Text instruction construction. Each multiple-choice question is formatted as a unified instruction, combining the question stem, options, and answer constraints into a standardized prompt.
-
Audio instruction synthesis. Considering the high cost of manual recording and the large scale of the dataset (11,583 items), we employ the high-quality TTS model CosyVoice2 to generate the speech prompts. This model demonstrates consistent performance in Chinese pronunciation and specialized terminology, making it suitable for large-scale speech dataset creation.
-
Automated quality control. To ensure semantic fidelity, all synthesized audio is transcribed via a ASR process. Only samples whose transcription exactly matches the original text (CER = 0%) are retained, effectively eliminating potential pronunciation errors or terminology deviations introduced during TTS synthesis.
Following this procedure, the released SpeechCMMLU dataset contains 3,519 high-quality speech samples spanning diverse academic subjects, suitable for evaluating models’ Chinese knowledge comprehension and reasoning capabilities in professional domains.
SpeechHSK leverages the Hanyu Shuiping Kaoshi (HSK), the standardized global Chinese proficiency test established by the Chinese Ministry of Education, widely recognized for its authority and scientific rigor. SpeechHSK converts the listening comprehension portion of HSK into an audio benchmark, providing a hierarchical and practical measure of models’ Chinese language skills.
-
Data sources and construction. The benchmark draws from official HSK listening comprehension questions. Each sample consists of a question and four options, where the question audio uses the original exam recordings, while the options are originally provided in text form. To adapt textual options for speech evaluation, native Chinese speakers re-record them as audio, ensuring naturalness of the audio.
-
Difficulty-level structure. The dataset follows HSK’s six proficiency levels (Level 1: beginner; Level 6: advanced), with an increasing number of questions at higher levels, totaling 170 samples. This structure supports progressive, diagnostic assessment of models’ Chinese language comprehension.
Together, SpeechCMMLU and SpeechHSK form a multi-level evaluation suite for Chinese speech. SpeechCMMLU focuses on knowledge reasoning, while SpeechHSK emphasizes general language proficiency. Both benchmarks are constructed via automated pipelines with rigorous quality control, ensuring reproducibility and scalability.
UltraEval-Audio Framework
This section presents the engineering architecture of UltraEval-Audio. To address the integration challenges in the evaluation of audio foundation models arising from diversity in input modalities and model interfaces, the framework adopts a decoupled modular design together with a configuration-driven workflow. This design enables components to be developed independently, extended flexibly, and reused efficiently. All datasets, models, and evaluation pipelines are declaratively specified through unified YAML configuration files, enabling end-to-end evaluation without manual scripting.
As illustrated in Figure 1, the framework consists of three main modules: data preparation, model deployment, and evaluation. The following subsections provide a detailed description of each component. Section [sec:data_preparation] details data loader and prompt management, section [sec:model_delpoyment] presents the model deployment mechanisms, and section [sec:evaluation] describes the evaluation pipeline and automated scoring modules.
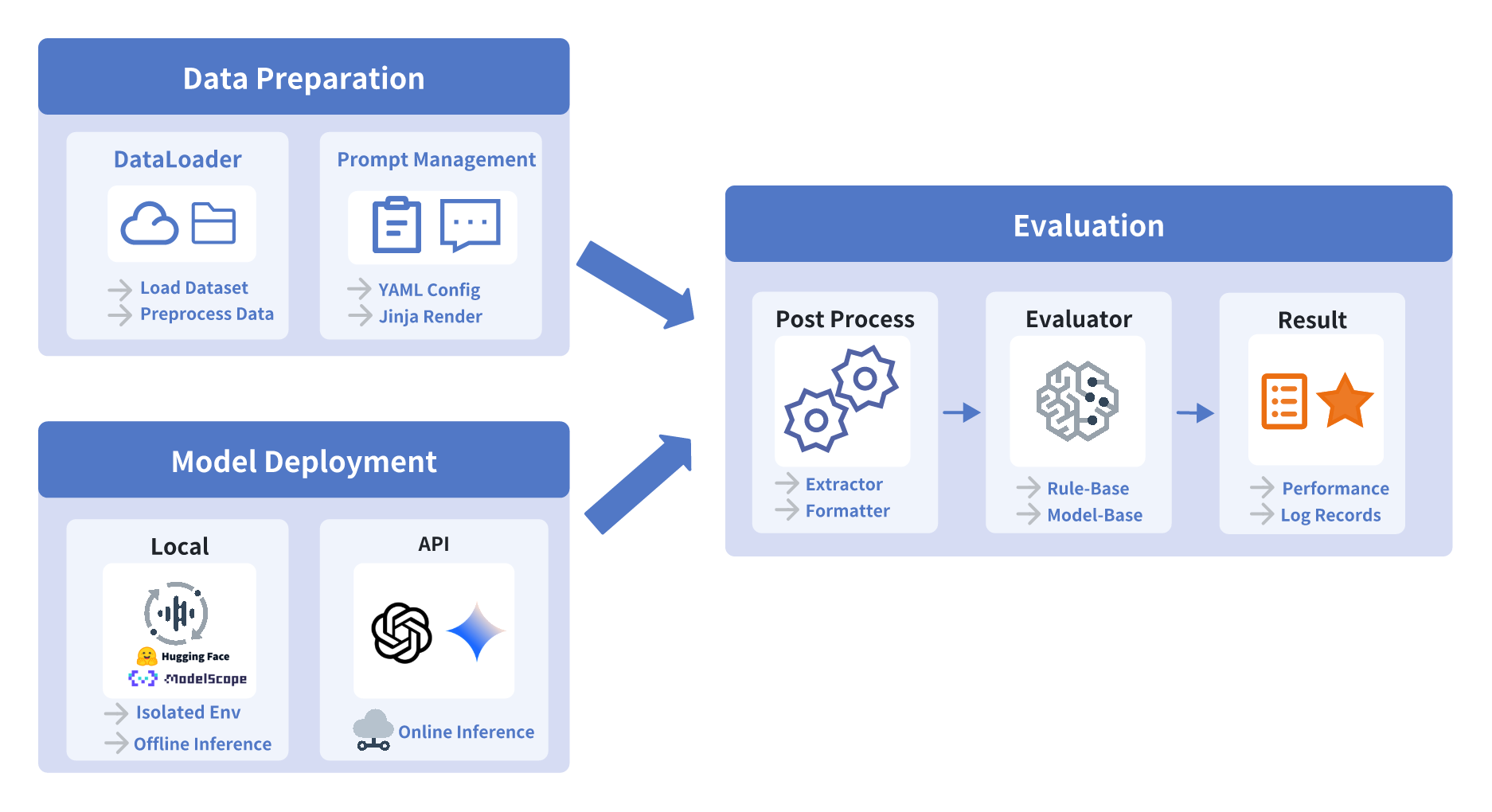
Data Preparation
Data loader. Data loading and management form the foundational infrastructure of audio evaluation. Unlike textual datasets, which typically have simple structures, audio datasets involve a strong coupling between audio signals and textual annotations. This coupling introduces significant data management challenges, including managing dispersed file paths, handling diverse audio encoding formats, and normalizing inconsistent sampling rates.
To address these challenges, UltraEval-Audio adopts an audio-centric dataset organization scheme. In this design, a reserved field audio is used to store audio content. The framework provides built-in automated pipelines that dynamically manage audio resource acquisition during the loading, including automatic downloading and caching from open-source repositories such as HuggingFace, as well as decoding and format standardization.
The framework decouples complex multimodal preprocessing into a standardized data interface, significantly simplifying the preparation workflow and ensuring efficient execution of subsequent model inference and evaluation.
Prompt management. Prompts play a critical role in guiding models to produce relevant task outputs. Prompt design not only relate to the format of model input but also directly affects the stability and comparability of evaluation results. However, due to differences in training strategies, models are often highly sensitive to prompt, such as the use of special tokens or role definitions, and this sensitivity can vary substantially across tasks. The combination of model-specific sensitivity and task-dependent variation makes hard-coded prompts difficult to reuse and undermines fair comparison across models.
To address this issue, UltraEval-Audio introduces a configuration-driven prompt management mechanism. Prompt structures are defined using YAML-based configurations and combined with the Jinja templating engine to support variable injection and conditional logic. This design enables flexible prompt construction at the task, model, and even sample level. Consequently, researchers can define or replace prompt templates for different tasks without modifying any code, greatly enhancing the maintainability and extensibility of the evaluation workflow.
In practice, the prompt management module in UltraEval-Audio comprises three components:
-
Prompt Registry, which registers and indexes prompt templates associated with different tasks.
-
YAML Parser, which interprets declarative configuration files and loads prompt definitions for specific models or tasks.
-
Template Renderer, which leverages Jinja-based rendering to inject dataset fields (e.g., {{audio}}, {{question}}, {{choice_a}}) into templates and produce the final model inputs.
This mechanism supports not only fixed templates but also more complex prompt constructions involving dynamic variables and conditional branches. The following is an example of a MiniCPM-o 2.6 ASR prompt:
mini-cpm-omni-asr-en:
class: audio_evals.prompt.base.Prompt
args:
template:
- role: user
contents:
- type: text
value: 'Please listen to the audio snippet carefully and transcribe the content. Please
output in low case.'
- type: audio
value: '{{audio}}'
the {{audio}} placeholder is dynamically replaced at inference time with the audio field from the corresponding data sample. To adapt the prompt for different ASR models, users only need to define a model-specific prompt and select it at runtime via the –prompt $prompt argument, without modifying any code.
For tasks that require sample-dependent prompt structures, such as multiple-choice questions with a variable number of options, the template can incorporate conditional rendering logic. An example is shown below:
single_choice_extended:
class: audio_evals.prompt.base.Prompt
args:
template:
- role: user
contents:
- type: audio
value: "{{audio}}"
- type: text
value: "Choose the most suitable answer from options A, B, C, D{% if choice_e is defined
and choice_e %}, and E{% endif %} to respond to the question below.
You may only choose A, B, C, or D{% if choice_e is defined and choice_e %},
or E{% endif %}.
{{question}}
A. {{choice_a}}
B. {{choice_b}}
C. {{choice_c}}
D. {{choice_d}}{% if choice_e is defined and choice_e %}
E. {{choice_e}}{% endif %}"
The prompt management mechanism achieves unified and automated evaluation through configuration-driven design, template reuse, and dynamic rendering. On the one hand, it fully decouples prompt design from the core evaluation logic, reducing integration overhead across tasks and models. On the other hand, it ensures that prompt definitions are reproducible, extensible, and easily shareable, laying a solid foundation for standardized evaluation of audio foundation models.
Model Deployment
Model deployment is a critical link between data and evaluation. Audio models are typically deployed in one of two forms: (1) Remote API models, which perform inference via official SDKs or HTTP API endpoints, and (2) Locally deployed models, which rely on local hardware resources for inference. Differences in environment dependencies, hardware requirements, and execution modes between these two types pose significant engineering challenges for a unified evaluation framework.
This challenge is especially pronounced for locally deployed models, where dependency conflicts are a common issue. Different models may require incompatible versions of deep learning frameworks, drivers, or audio processing libraries. For instance, audio quality evaluation modules (such as UTMOS, SIM, DNSMOS) and ASR-WER evaluators often depend on specific environment versions that may conflict with the dependency stacks of the models under evaluation. Mixing multiple models in the same runtime environment may lead to contamination or inference failures, compromising the reproducibility of evaluation results.
To address this challenge, UltraEval-Audio introduces an Isolated Runtime mechanism ensuring environment independence and safe execution at the system level. The core design features are as follows:
-
Environment-level isolation: Each evaluated model is allocated an independent virtual runtime environment with only the dependencies it requires. This setup is completely isolated from the main evaluation process, eliminating dependency conflicts at the source.
-
Subprocess-based model execution: Models run as independent subprocesses in a daemonized manner, maintaining a persistent loaded state to support continuous inference and significantly reduce the overhead associated with frequent model loading.
-
Inter-process communication (IPC): The main evaluation process communicates with each model subprocess via system pipes, exchanging data and inference results securely and with low latency.
At the design level, this mechanism effectively implements a microservice-style inference architecture. Users do not need to manually manage or install additional dependencies, and the system significantly reduces the engineering complexity of large-scale, multi-model evaluation. Furthermore, to standardize the interface across different model types, the framework provides a unified .inference() method at the deployment layer, which accepts inputs from the prompt management module and returns the inference results.
Through this design, UltraEval-Audio achieves full decoupling and automated management of model execution at the system level. On one hand, the isolated runtime eliminates dependency conflicts and environment contamination between models, ensuring reproducibility and consistency of evaluation results. On the other hand, the unified inference interface abstracts away underlying model implementations, lowering the technical barrier for cross-model comparison and framework extension. Overall, this module provides a stable, scalable, and transparent runtime foundation for large-scale audio model evaluation.
Evaluation
Following model inference, UltraEval-Audio proceeds to the evaluation phase, in which raw model outputs are converted into structured and quantifiable results to enable objective performance assessment across models. The evaluation workflow comprises two core components: post-processing and evaluator. The post-processing module standardizes and semantically aligns the model outputs, while the evaluator computes metrics according to task. This two level structure enables a fully automated and standardized pipeline from output generation to metric calculation.
Post-processing. In multimodal audio evaluation, model outputs often include extraneous prefixes or suffixes, formatting artifacts, or unstructured text unrelated to the task objectives, which can compromise accurate metric computation. To ensure consistent and well-structured inputs for evaluation, UltraEval-Audio employs a flexible post-processing mechanism that parses and standardizes outputs at multiple levels.
This mechanism adopts a modular and composable design, enabling adaptive workflows based on task specifications. The framework includes several built-in post-processing modules—such as Option Extraction, Yes/No Parser, and JSON Field Parser—which can be sequentially combined to form multi-step pipelines for handling complex tasks.
Evaluator. The evaluator module processes model outputs that are standardized via post-processing and is responsible for computing the final performance metrics. UltraEval-Audio categorizes evaluators into two types:
-
Rule-based Evaluators: For tasks with reference answers, classical algorithmic metrics are applied. The framework includes WER for ASR tasks, BLEU for AST, accuracy for classification tasks as well as other similar measures.
-
Model-based Evaluators: For audio generation quality or open-ended generative tasks, pretrained evaluation models are employed to approximate human judgment. This includes Speaker Similarity (SIM) for assessing timbre or voice cloning fidelity, UTMOS and DNSMOS for evaluating naturalness and perceptual quality of speech, and GPT-based open-domain QA scorers (LLM-as-a-Judge).
All evaluators are registered and orchestrated through a unified interface, with their outputs automatically aggregated into a consolidated results summary. This design ensures compatibility across metrics from different tasks while facilitating rapid integration of new evaluators, rendering the framework highly modular and maintainable.
By employing standardized post-processing and a multidimensional evaluation framework, UltraEval-Audio establishes an end-to-end automated pipeline from model outputs to quantifiable metrics. This design enhances consistency, transparency, and reproducibility, providing a systematic foundation for objective comparison and ongoing development of multimodal audio foundation models.
Evaluation Results
UltraEval-Audio provides a unified solution for systematically assessing the performance of audio-processing models in various testing environments. In this section, we carefully select representative evaluation tasks and build three leaderboards: audio understanding, audio generation, and audio codec. Then we evaluate 13 leading audio foundation models and 9 audio codecs, introduced in Section [eval:models]. We present the leaderboards of audio understanding, audio generation, and audio codec in Section [eval:audio understanding], [eval:audio generation] and [eval:audio codec] respectively.
| Model | Institution | Type | Modality (Input$`\rightarrow`$Output) | Languages |
|---|---|---|---|---|
| GPT-4o-Realtime | OpenAI | Proprietary | Audio + Text $`\rightarrow`$ Audio + Text | Multilingual |
| Qwen3-Omni-30B-A3B-Instruct | Alibaba | Open-Source | Audio + Text $`\rightarrow`$ Audio + Text | Multilingual |
| Qwen2.5-Omni | Alibaba | Open-Source | Audio + Text $`\rightarrow`$ Audio + Text | English, Chinese |
| MiniCPM-o 2.6 | OpenBMB | Open-Source | Audio + Text $`\rightarrow`$ Audio + Text | English, Chinese |
| Kimi-Audio-7B-Instruct | Moonshot | Open-Source | Audio + Text $`\rightarrow`$ Audio + Text | English, Chinese |
| Gemini-1.5-Flash | Proprietary | Audio + Text $`\rightarrow`$ Text | Multilingual | |
| Gemini-1.5-Pro | Proprietary | Audio + Text $`\rightarrow`$ Text | Multilingual | |
| Gemini-2.5-Flash | Proprietary | Audio + Text $`\rightarrow`$ Text | Multilingual | |
| Gemini-2.5-Pro | Proprietary | Audio + Text $`\rightarrow`$ Text | Multilingual | |
| Qwen2-Audio-7B | Alibaba | Open-Source | Audio + Text $`\rightarrow`$ Text | Multilingual |
| Qwen2-Audio-7B-Instruct | Alibaba | Open-Source | Audio + Text $`\rightarrow`$ Text | Multilingual |
| MiDaShengLM-7B | Xiaomi | Open-Source | Audio + Text $`\rightarrow`$ Text | Multilingual |
| GLM-4-Voice | Zhipu AI | Open-Source | Audio $`\rightarrow`$ Audio | English, Chinese |
Evaluated Models
We evaluate emerging audio foundation models and audio codecs to build leaderboards. The evaluated audio foundation models are shown in Table [tab: support audio foundation models], including leading proprietary models such as GPT-4o-Realtime and Gemini-2.5-Pro, as well as the latest open-source models like Qwen3-Omni-30B-A3B-Instruct and Kimi-Audio-7B-Instruct. Audio codecs include Encodec , ChatTTS-DVAE2, the Mimi family, WavTokenizer-large-speech-75token (denoted as WavTokenizer-large-75)3 , WavTokenizer-large-unify-40token (denoted as WavTokenizer-large-40)4 and Spark .
Several models design different prompts and parameters for specific tasks, for example, Kimi-Audio-7B-Instruct has specific prompts for ASR tasks. To replicate these results, we run the tasks using the prompts and parameters provided by the publisher. For tasks where the publisher has not provided these configurations, we use the official inference parameters and prompts for evaluation. Furthermore, we do not perform additional prompt or parameter optimizations, ensuring a fair and consistent evaluation protocol.
Audio Understanding
Notes: WER/CER values can be greater than 100 when the total number of recognition errors exceeds the number of reference words/characters.
For audio understanding, we select well-established and widely cited benchmarks that are commonly used in existing papers. Specifically, we use LibriSpeech (en), TED-LIUM (en), Common Voice 15 (en/zh), AISHELL-1 (zh), FLEURS (zh), WenetSpeech-test-net (zh) for ASR, covost2-en2zh, covost2-zh2en for AST, and MELD for emotion recognition (EMO). The final results are shown in Table [tab: audio understanding leaderboard], from which we can make the following key observations:
(1) GPT-4o-Realtime faces strong competition in the field of audio understanding, with open-source models such as Qwen3-Omni-30B-A3B-Instruct, Kimi-Audio-7B-Instruct, MiniCPM-o 2.6 as well as proprietary models like Gemini-2.5-Pro, achieving superior performance in the evaluation. A key reason for this is GPT-4o-Realtime’s relatively underwhelming performance on Chinese ASR benchmarks, especially when evaluated on datasets such as Wenet-test-net and Common Voice 15 (CV-15).
(2) Qwen3-Omni-30B-A3B-Instruct demonstrates superior performance across all tasks, consistently delivering high-quality results in various domains. Kimi-Audio-7B-Instruct excels in ASR and EMO tasks but underperforms in AST, indicating improvement room in the latter area.
(3) For models from Gemini family, we observe that each generation’s Flash model performs weaker than the Pro model. However, compared to Gemini 1.5, the Flash model of Gemini 2.5 performs better, while the Pro models show similar performance.
Audio Generation
Note: The average score is computed as the average of 6 scores: five speech-task scores and normalized acoustic scores. For acoustic scores (UTMOS | DNSMOS P.835 | DNSMOS P.808), each value (0–5) is multiplied by 20 to map to 0–100, then averaged to obtain the normalized acoustic score.
To build the audio generation leaderboard, we select SpeechWebQuestions, SpeechTriviaQA, and SpeechAlpacaEval for English capability evaluation. Our self-proposed benchmarks SpeechCMMLU and SpeechHSK are also used to assess Chinese audio generation capabilities. We first evaluate the models’ performance on each dataset by answer accuracy (Acc.), then assess the acoustic quality of the generated audio.
To ensure better alignment with existing evaluation results, we adopt different evaluation settings for different datasets. Specifically:
-
For SpeechWebQuestions and SpeechTriviaQA, we follow the evaluation approach in and . We transcribe the model’s spoken responses using Whisper-large-v3, and a response is considered correct if the ground-truth answer appears in the transcription.
-
For SpeechAlpacaEval, we adopt the evaluation protocol of , employing GPT-4o-mini to assess the quality of the transcribed responses. Responses are rated on a scale of 1 to 10, following the MT-Bench rubric .
-
For SpeechCMMLU and SpeechHSK, we employ Paraformer-zh to transcribe the generated audio. The transcriptions are then matched with the multiple-choice options to calculate accuracy.
We further evaluate acoustic values of the generated audio responses from the aforementioned benchmarks, employing UTMOS, DNSMOS P.835, and DNSMOS P.808 as metrics. The performance of all models is summarized in Table [tab: audio generation leaderboard], with key findings as follows:
(1) GPT-4o-Realtime performs best in audio generation, particularly excelling in English benchmarks. It consistently produces high-quality, accurate, and natural-sounding speech, making it one of the top performers;
(2) Qwen3-Omni-30B-A3B-Instruct and Qwen2.5-Omni outperform GPT-4o-Realtime in acoustic metrics, demonstrating superior sound quality. These models offer more nuanced audio generation, providing richer and more realistic speech outputs;
(3) Kimi-Audio-7B-Instruct underperforms in acoustic quality, with its generated speech lacking some naturalness and clarity. This suggests that improvements are needed to make the output sound more natural and human-like.
Audio Codec
We evaluate audio codecs using clean speech corpora, including LibriSpeech-dev-clean (en), LibriSpeech-test-clean (en), and AISHELL-1 (zh). For each dataset, we use the ASR-WER/CER metric to measure the codec accuracy, SIM (short for similarity) to measure timbre fidelity and acoustic scores to measure the acoustic quality. The results are shown in Table [tab: audio codec leaderboard], from which we observe the following:
Note: For acoustic scores we also use UTMOS, DNSMOS P.835, and DNSMOS P.808 metrics. To calculate the average score, for ASR-WER and ASR-CER, we calculate $`100-\text{val}`$. For acoustic scores, each available value (ranges from 0 to 5) is normalized by $`20\times\mathrm{val}`$ (mapping to 0–100), and the acoustic score is their average (the hyphen ‘-’ is ignored). The final score is the average of 9 metric scores.
(1) ASR-WER performance shows only limited disparity across models, whereas timbre fidelity and acoustic quality exhibit substantially larger variation. These latter dimensions provide more discriminative signals for assessing codec performance.
(2) The Mimi model performs best in codec accuracy and timbre fidelity, indicating that its token representation effectively captures both linguistic and timbral information from raw audio. However, its acoustic scores lag behind Spark and WavTokenizer-large-75, suggesting that improvements could be made to its decoder.
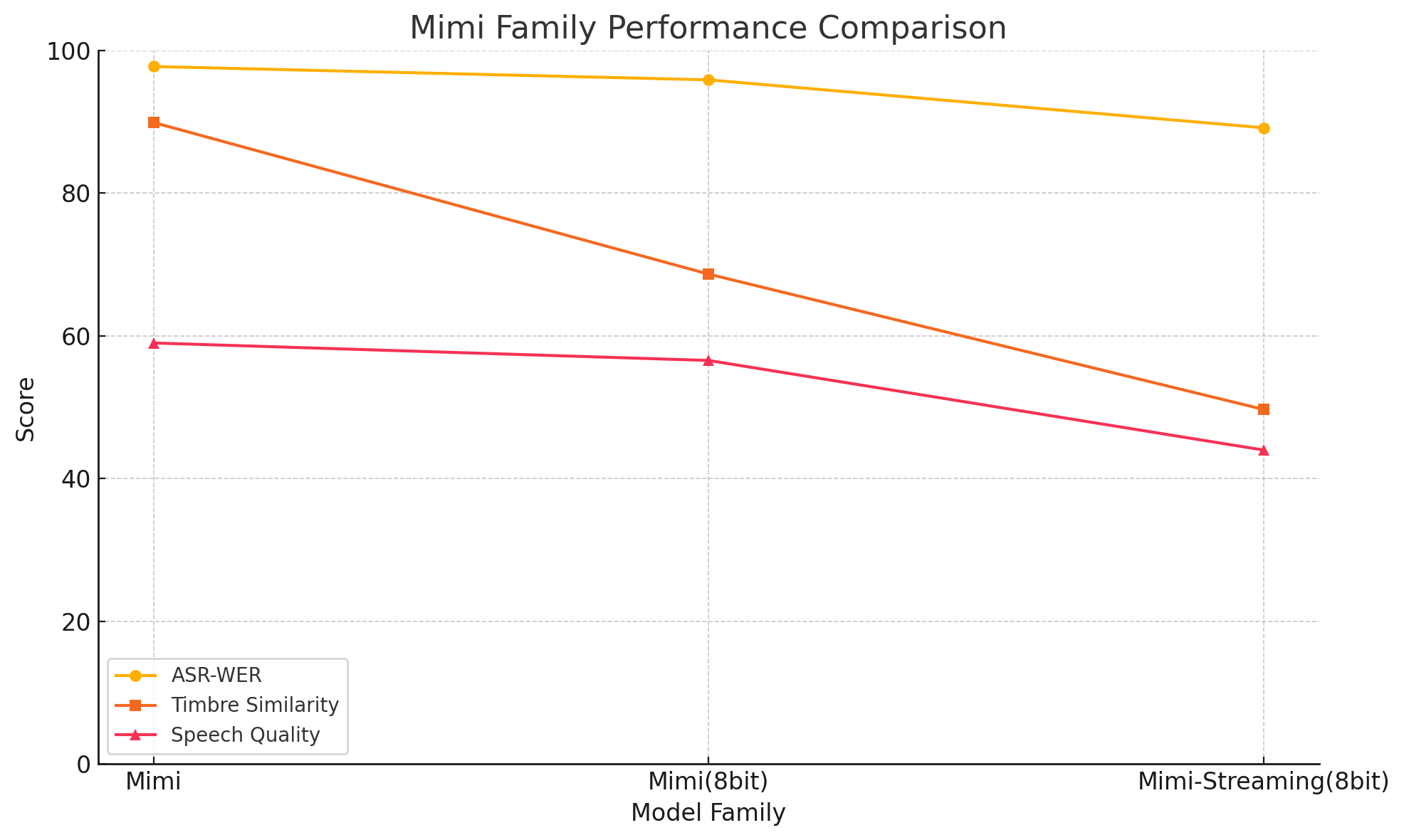
(3) We further propose Figure 2 to compare Mimi codec variants. Comparing Mimi (default 32-bit) with Mimi (8bit), the performance drop is most pronounced in timbre fidelity, while ASR-WER slightly decreases, and acoustic quality drops modestly. This indicates that timbre information relies more heavily on higher bit depths. The streaming variant further degrades on both timbre fidelity and acoustic quality.
(4) ChatTTS-DVAE, WavTokenizer-large-40, and Mimi-Streaming (8bit) underperform on the AISHELL-1 dataset, indicating a need for improved handling of Chinese-language audio.
Conclusion
In this paper, we introduce UltraEval-Audio, the first unified evaluation framework for comprehensive assessment of audio foundation models. We first construct a complete audio evaluation taxonomy encompassing tasks and benchmarks. To enrich the evaluation, we develop a systematic methodology for assessing audio codecs and introduce two Chinese benchmarks: SpeechCMMLU and SpeechHSK. Building upon this, we implement a modular evaluation framework, which we then use to evaluate and analyze the performance of popular models across audio understanding, audio generation, and audio codec tasks.
Limitations and Future Directions
Our limitations are as follows. First, some current speech benchmarks rely on transcribed text as input for GPT-based evaluators rather than raw audio. This design introduces a dependency on ASR performance, which may propagate transcription errors into downstream judgments. Future work should therefore explore evaluation pipelines that operate directly on raw audio signals. In addition, the existing evaluation metrics are predominantly technical and do not adequately capture human perceptual factors, such as prosody, emotion, and whether the tone of the system’s reply is appropriate for a given conversational context.
For future work, we plan to continuously update and refine the leaderboards, imporve inference capabilities (e.g. multi-GPU support), and incorporate evaluation methods that evaluate responses directly from raw audio. These enhancements will increase the comprehensiveness and reliability of audio foundation model evaluation, providing clearer guidance for the advancement of the field.
📊 논문 시각자료 (Figures)

![]()