SwinIFS Landmark Guided Swin Transformer For Identity Preserving Face Super Resolution
📝 Original Paper Info
- Title: SwinIFS Landmark Guided Swin Transformer For Identity Preserving Face Super Resolution- ArXiv ID: 2601.01406
- Date: 2026-01-04
- Authors: Habiba Kausar, Saeed Anwar, Omar Jamal Hammad, Abdul Bais
📝 Abstract
Face super-resolution aims to recover high-quality facial images from severely degraded low-resolution inputs, but remains challenging due to the loss of fine structural details and identity-specific features. This work introduces SwinIFS, a landmark-guided super-resolution framework that integrates structural priors with hierarchical attention mechanisms to achieve identity-preserving reconstruction at both moderate and extreme upscaling factors. The method incorporates dense Gaussian heatmaps of key facial landmarks into the input representation, enabling the network to focus on semantically important facial regions from the earliest stages of processing. A compact Swin Transformer backbone is employed to capture long-range contextual information while preserving local geometry, allowing the model to restore subtle facial textures and maintain global structural consistency. Extensive experiments on the CelebA benchmark demonstrate that SwinIFS achieves superior perceptual quality, sharper reconstructions, and improved identity retention; it consistently produces more photorealistic results and exhibits strong performance even under 8x magnification, where most methods fail to recover meaningful structure. SwinIFS also provides an advantageous balance between reconstruction accuracy and computational efficiency, making it suitable for real-world applications in facial enhancement, surveillance, and digital restoration. Our code, model weights, and results are available at https://github.com/Habiba123-stack/SwinIFS.💡 Summary & Analysis
1. **Integration of Landmark Maps and Swin Transformer**: The paper proposes a method that integrates landmark maps to provide structural guidance while leveraging the long-range dependency modeling capability of Swin Transformers for face super-resolution (FSR). This is akin to setting up the basic structure first and then adding details, like constructing a building with its foundation before adding intricate designs.-
Multi-Scale Support: The proposed approach demonstrates superior performance at both 4x and 8x upscaling factors. It can be likened to a camera capturing clear images under various conditions.
-
Structural Consistency Maintenance: The method maintains structural consistency while performing high-resolution restoration, similar to replicating an artwork with all its details while preserving the original spirit of the piece.
📄 Full Paper Content (ArXiv Source)
Face super-resolution (FSR) aims to reconstruct high-resolution (HR) facial images from low-resolution (LR) inputs while preserving structural coherence and identity-specific details. Reliable recovery of facial features is essential for applications such as surveillance, biometrics, forensics, video conferencing, and media enhancement . Unlike generic super-resolution , FSR benefits from the strong geometric regularity of human faces, where the spatial arrangement of key components (eyes, nose, mouth) provides valuable prior information for reconstruction. The LR observation process is typically modeled as
\begin{equation}
I_\mathrm{LR}=\downarrow_{s}(I_\mathrm{HR} \ast k) + \eta,
\label{eq:1}
\end{equation}where $`I_\mathrm{HR}`$ is the HR image, $`I_\mathrm{LR}`$ is the LR image, $`k`$ denotes the blur kernel, $`\downarrow_{s}`$ is the downsampling operator, and $`\eta`$ represents noise. In practical environments, degradation is further compounded by compression artifacts, illumination variations, and sensor noise. At moderate upscaling factors (e.g., $`4\times`$), some structural cues remain; however, at extreme scales (e.g., $`8\times`$; $`16\times`$ inputs), most identity cues are lost, rendering the reconstruction highly ill-posed.
Early face hallucination methods relied on interpolation, example-based patch retrieval, or sparse coding . Although pioneering, these approaches produced overly smooth results and lacked robustness to domain variation. The introduction of deep learning significantly advanced SR performance. CNN-based methods improved texture reconstruction but remained limited by their local receptive fields, often leading to globally inconsistent facial structures.
Generative adversarial networks (GANs) improved perceptual realism by learning to synthesize sharper textures . FSRNet and Super-FAN demonstrated that combining GAN objectives with facial priors such as landmarks or parsing maps enhances structural alignment. However, GAN-based methods are susceptible to hallucinating unrealistic details and may compromise identity preservation, especially when LR inputs are highly degraded.
Transformer architectures have recently emerged as powerful tools for image restoration due to their ability to capture long-range dependencies through self-attention . The Swin Transformer introduces hierarchical window-based attention, offering an effective balance of global modeling and computational efficiency. Despite their strengths, Transformers alone struggle when key facial cues are absent in severely degraded inputs. Incorporating explicit geometric priors can alleviate this ambiguity.
Facial landmarks provide compact, reliable structural information about the geometry of key facial regions. When encoded as heatmaps, they supply spatial guidance that helps maintain feature alignment, facial symmetry, and identity consistency during reconstruction . Motivated by these insights, this work proposes a landmark-guided multiscale Swin Transformer framework designed to address both moderate ($`4\times`$) and extreme ($`8\times`$) FSR scenarios.
Our proposed method fuses RGB appearance information with landmark heatmaps to jointly model facial texture and geometry. The Swin Transformer backbone captures global contextual relationships, while landmark priors enforce structural coherence. This unified approach enables robust reconstruction across multiple upscaling factors and significantly improves identity fidelity. Experiments on CelebA demonstrate that the proposed framework achieves superior perceptual quality, structural accuracy, and quantitative performance compared to representative CNN, GAN, and Transformer-based baselines.
Related Work
Face super-resolution has evolved significantly over the past two decades, transitioning from early interpolation schemes to modern deep learning, adversarial, and transformer-based frameworks. Unlike generic single-image super-resolution (SISR), FSR requires strong preservation of identity and facial geometry, making structural modeling a core research challenge .
Early work relied on interpolation and example-based methods . Although computationally efficient, these approaches produced overly smooth textures and failed to recover high-frequency facial details. Learning-based extensions, including sparse coding and manifold models , partially improved texture synthesis but struggled under severe degradation and exhibited limited generalization.
Deep learning significantly advanced FSR performance. CNN-based architectures such as SRCNN , VDSR , and EDSR demonstrated that hierarchical feature learning could outperform traditional methods. Face-specific extensions, including FSRNet and URDGN , incorporated structural priors, such as landmark heatmaps or facial parsing maps. These models improved alignment and structural consistency, but their reliance on pixel-wise losses often produced smooth outputs and limited high-frequency synthesis.
The introduction of GAN frameworks shifted the focus toward perceptual realism. SRGAN demonstrated sharper textures using adversarial and perceptual losses. Face-specific GAN models such as Super-FAN , FSRGAN , and DICGAN incorporated identity losses, alignment modules, or cycle consistency to improve realism and identity preservation. While effective, GAN-based FSR remains sensitive to training instability and may hallucinate unrealistic facial features under extreme downsampling.
More recently, attention and transformer-based methods have advanced FSR by modeling long-range dependencies. Vision Transformers introduced global patch-based attention, but their high computational cost limited their use for low-level restoration. The Swin Transformer addressed this by employing hierarchical shifted-window attention, enabling efficient modeling of global context. Several FSR methods have since incorporated transformer modules, including FaceFormer , UFSRNet , and W-Net , which combine attention with CNN branches or semantic priors. These approaches achieve strong perceptual and structural performance but often require large memory and long training times, and are typically trained for a single upscaling factor. Moreover, explicit geometric priors such as facial landmarks remain underutilized in many transformer-based designs despite their effectiveness in guiding facial structure .
Overall, existing CNN and GAN methods struggle to balance high-frequency detail reconstruction with identity fidelity. At the same time, transformer models provide superior global modeling at the cost of complexity and limited structural conditioning. These limitations motivate a unified approach that integrates explicit landmark priors with an efficient Swin Transformer backbone to improve structural coherence, identity preservation, and multi-scale robustness in face super-resolution.
In addition, recent studies emphasize the growing need for multi-scale FSR systems capable of handling diverse real-world degradations such as compression, occlusion, and significant pose variation. Most current models are trained on a single fixed scale or under controlled laboratory conditions, limiting their generalization to practical scenarios in which facial resolution varies widely. Moreover, despite their demonstrated value in CNN and GAN architectures, structural priors are rarely embedded deeply into transformer backbones. This gap highlights the opportunity for new frameworks that seamlessly fuse geometric cues with global attention to achieve stable, identity-consistent reconstruction across both moderate and extreme upscaling factors.
SwinIFS
Face super-resolution is an inherently ill-posed problem, as a single low-resolution input may correspond to multiple plausible high-resolution facial configurations. This ambiguity arises because the LR image lacks fine-grained texture details, subtle identity cues, and structural regularities present in HR images. To resolve this, our methodology integrates structural priors from facial landmarks with the hierarchical modeling capabilities of Swin Transformers. Landmark heatmaps provide explicit geometric guidance, ensuring that the network focuses on identity-sensitive regions such as the eyes, nose, and mouth. Simultaneously, Swin Transformers enable global spatial reasoning by capturing both localized texture patterns and long-range dependencies across facial regions.
The overall pipeline is illustrated in Fig. 1. The framework proceeds through four primary stages: landmark encoding and input construction, shallow and deep feature extraction, transformer-based refinement with Residual Swin Transformer Blocks (RSTBs), and reconstruction with sub-pixel upsampling. Each stage is carefully designed to preserve structural alignment, enhance identity consistency, and recover high-frequency details in degraded facial images.
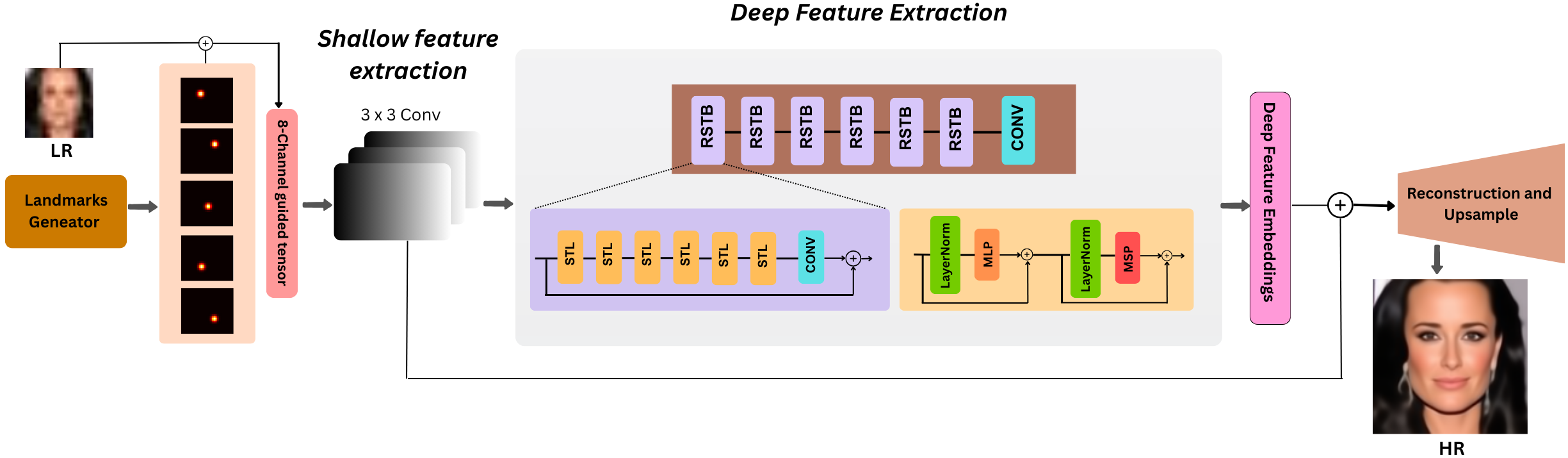
Landmark Encoding and Input Construction
To integrate meaningful geometric information into the network, we begin by generating a low-resolution image from an aligned high-resolution input using bicubic interpolation, $`I_{\mathrm{LR}} = \downarrow_{S}(I_{\mathrm{HR}}),~where~S \in \{4,8\}`$. This provides the baseline visual input. However, LR faces often lack crucial structural cues, making it difficult for SR models to infer identity-consistent high-frequency content. To mitigate this, we extract five key landmarks (left eye, right eye, nose, and mouth corners) and convert each point into a Gaussian heatmap, $`M_i`$. These heatmaps produce a soft, spatially aware representation that indicates the locations of critical facial components, rather than providing only discrete landmark coordinates. Stacking the five heatmaps yields $`M_{\mathrm{c}} \in \mathbb{R}^{C\times H \times W}`$, where $`C=5`$. Finally, the LR RGB image and the landmark maps are concatenated:
\begin{equation}
I_{\mathrm{in}} = [I_{\mathrm{LR}}|| M_{\mathrm{c}}],
\label{eq:2}
\end{equation}where $`||`$ stands for concatenation. This produces an 8-channel tensor that explicitly encodes both appearance and geometry, allowing the network to fuse structural priors and texture information from the earliest stages of processing. By embedding geometry directly into the input, the model avoids depending solely on visual cues that may be missing or ambiguous in LR images.
Shallow and Deep Feature Extraction
The SwinIFS network begins processing this 8-channel input by projecting it into a high-dimensional feature space using a convolution $`H_{\mathrm{SF}}`$:
\begin{equation}
F_0 = H_{\mathrm{SF}}(I_{\mathrm{LR}}),
\label{eq:3}
\end{equation}where $`F_0`$ is the extracted features. This preserves spatial resolution while expanding representational capacity. The shallow features capture local edges, coarse textures, and the spatial distribution of the landmark heatmaps. These encoded cues serve as the foundation for deeper reasoning. Next, the feature tensor is passed through a hierarchy of $`D`$ stacked Residual Swin Transformer Blocks (RSTBs). Each RSTB learns progressively more complex semantic information, building from local texture patterns in early layers to global structure and identity-relevant features in deeper layers. The pipeline follows a recursive formulation:
\begin{equation}
F_i = \mathrm{RSTB}_i(F_{i-1}),
\label{eq:4}
\end{equation}within each block, multiple Swin Transformer Layers (STLs) refine the feature maps:
\begin{equation}
F_{i,j} = \mathrm{STL}_{i,j}(F_{i,j-1}).
\label{eq:5}
\end{equation}Swin Transformer Layers divide the feature map into local windows and compute multi-head self-attention within each window. This operation enables the model to selectively enhance relevant regions based on their spatial and contextual relationships. Alternating between regular and shifted window partitions allows cross-window communication, effectively expanding the receptive field. Thus, the model learns global facial geometry (overall head shape and symmetry) and fine structural relationships (eye distance and mouth curvature) simultaneously. To preserve stability and prevent loss of low-frequency content, a global skip connection merges shallow and deep features:
\begin{equation}
F_{\mathrm{res}} = F_0 + H_{\mathrm{Conv}}(F_D).
\label{eq:6}
\end{equation}This fusion ensures that early structural cues from the input remain intact while deeper layers refine high-frequency textures and identity-specific details.
Residual Swin Transformer Block
The RSTB is the fundamental module enabling SwinIFS’s hierarchical representation learning. Given an input $`F_{i,0}`$, the block applies $`L`$ sequential Swin Transformer Layers as shown in Eq. [eq:5]. In each STL, multi-head self-attention is performed within local windows of size $`M\times M`$. For a window feature $`X \in \mathbb{R}^{M^2 \times C}`$, query, key, and value matrices are computed as $`Q = XW_Q,\quad K = XW_K,\quad V = XW_V`$. Local attention is then evaluated as, $`\mathrm{Attention}(Q,K,V) = \mathrm{Softmax}\!\left(\frac{QK^\top}{\sqrt{d}} + B\right)V,`$ where $`B`$ adds learnable relative positional encoding, this formulation enables the model to detect correlations between pixels that belong to the same semantic region (e.g., corners of the eyes or boundary of the mouth).
Window shifting significantly enhances the module’s capacity by enabling cross-window interaction. Without this mechanism, signals would remain trapped within fixed windows, preventing the learning of long-range facial relationships. The alternating partition design ensures that information flows smoothly across the entire face. After the $`L`$ STLs, a convolution fuses the refined features before residual addition:
\begin{equation}
F_{i,\mathrm{out}} = H_{\mathrm{Conv}_i}(F_{i,L}) + F_{i,0}.
\label{eq:7}
\end{equation}This design offers two significant advantages. Translational consistency: The convolutional layer introduces spatially-invariant filtering, which complements the spatially-varying transformer attention. Identity preservation: The residual skip ensures that essential structural information propagates across blocks without degradation. Thus, the RSTB forms a powerful hierarchical refinement module that models both fine structural details and global relationships.
Reconstruction and Upsampling
The refined feature map $`F_{\mathrm{res}}`$ is compressed with a channel-reduction convolution $`F_{\mathrm{red}} = H_{\mathrm{red}}(F_{\mathrm{res}})`$. Similarly, to increase the feature resolution, SwinIFS uses PixelShuffle, a highly efficient sub-pixel convolution that rearranges channels into spatial dimensions: $`F_{\mathrm{up}} = \mathrm{PixelShuffle}_{S}\left(H_{\mathrm{up}}(F_{\mathrm{red}})\right)`$. This operation produces a smooth, high-resolution feature map free from checkerboard artifacts common with transposed convolutions. A final $`3\times3`$ convolution maps the features to the RGB image domain, $`\tilde{I}_{\mathrm{HR}} = H_{\mathrm{rec}}(F_{\mathrm{up}})`$. To strengthen identity consistency and stabilize reconstruction, a global skip connection adds the bicubically upsampled LR image, $`I_{\mathrm{HR}}^{\mathrm{final}} = \tilde{I}_{\mathrm{HR}} + \mathrm{Up}_{\mathrm{bicubic}}(I_{\mathrm{LR}})`$. This ensures the preservation of global structure while the learned features restore missing high-frequency details.
Loss Functions
Training SwinIFS requires balancing pixel-level accuracy with perceptual realism. The primary objective is the $`\ell_1`$ reconstruction loss:
\begin{equation}
\ell_1 = \frac{1}{N}\sum_{i=1}^{N} \|I_{\mathrm{HR}}^{(i)} - I_{\mathrm{GT}}^{(i)}\|_1,
\label{eq:l1}
\end{equation}which penalizes pixel-level deviations and encourages sharp, clean results. However, pixel-level losses do not fully capture perceptual similarity or the structure of identity. To address this, we incorporate a perceptual loss based on VGG-19 activations $`\Phi`$:
\begin{equation}
\ell_{\mathrm{VGG}} = \|\Phi(I_{\mathrm{HR}}) - \Phi(I_{\mathrm{GT}})\|_2^2.
\label{eq:lvvg}
\end{equation}This encourages the SR output to preserve semantic details such as eye shape, mouth curvature, skin texture, and other identity-related cues. The total loss driving model optimization is:
\begin{equation}
\ell_{\mathrm{total}} = \lambda_1 \ell_1 + \lambda_2 \ell_{\mathrm{VGG}}.
\label{eq:total-loss}
\end{equation}This hybrid objective ensures the network achieves both quantitative accuracy and perceptual quality, yielding reconstructed faces that are structurally consistent and visually realistic.
Experiments
This section presents a comprehensive experimental evaluation of the proposed SwinIFS framework. The objective of the experiments is to assess reconstruction fidelity, perceptual realism, and structural consistency under challenging $`4\times`$ and $`8\times`$ upscaling scenarios. All experiments were designed to provide a fair and rigorous comparison with existing face super-resolution methods, accounting for both quantitative performance and visual quality. The evaluation protocol also aims to demonstrate the contribution of landmark-guided structural priors and hierarchical Swin Transformer modeling to identity preservation and fine-detail restoration.
Dataset and Preprocessing
All experiments were conducted on the CelebA dataset , a widely used large-scale facial benchmark containing over 200,000 images of more than 10,000 identities. CelebA provides substantial diversity in pose, illumination, age, and facial attributes, along with five key facial landmarks, making it particularly suitable for landmark-guided face super-resolution. Each image is first aligned and then processed using a structure-aware cropping strategy inspired by DIC-Net . A bounding box enclosing the five facial landmarks is expanded by a fixed margin to retain contextual facial regions such as the hairline and jaw contour. The cropped images are resized to $`128\times128`$, forming the high-resolution supervision set.
Low-resolution images are synthesized via bicubic downsampling with scale factors $`S=\{4,8\}`$, yielding inputs of size $`32\times32`$ and $`16\times16`$, respectively. To incorporate structural priors, the five landmark coordinates for each LR image are converted into Gaussian heatmaps, thereby providing spatially continuous geometric guidance. These heatmaps are stacked with the LR RGB channels to form an eight-channel tensor that serves as the model input. A total of 168,854 images from the CelebA training split are used for model training, while 1,000 identity-disjoint images from the official test split are reserved for evaluation. This strict separation ensures unbiased generalization performance.
Evaluation Metrics
The evaluation of SwinIFS employs three widely accepted full-reference metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). PSNR quantifies pixel-level fidelity as the mean squared error between the reconstructed and ground-truth images. While higher PSNR generally reflects greater fidelity, it tends to correlate poorly with human perception, especially in tasks involving facial details and texture.
To complement PSNR, SSIM measures perceptual similarity between two images across luminance, contrast, and structural information. SSIM is calculated on the luminance channel (Y) of the YCbCr color space, as luminance is most sensitive to visual distortions. LPIPS further extends perceptual assessment by comparing deep feature representations obtained from pretrained neural networks. This metric has been shown to correlate strongly with human judgments of perceptual similarity, making it particularly relevant for facial image restoration, where texture realism and identity consistency are crucial. Together, these metrics provide a balanced assessment of pixel-level accuracy, structural coherence, and perceptual quality.
Experimental Implementation Details
All experiments were conducted using PyTorch on a workstation equipped with dual NVIDIA RTX A6000 GPUs (48GB VRAM each). Mixed-precision FP16 computation was employed to reduce memory consumption and improve training efficiency. The SwinIFS model accepts an eight-channel input consisting of RGB image data and five landmark heatmaps. It processes the input through a shallow convolutional feature extractor, six Residual Swin Transformer Blocks, and a PixelShuffle-based reconstruction module to generate outputs at a resolution of $`128\times128`$.
The model is trained from scratch without any pretrained face SR weights. Convolutional layers are initialized with the initialization, and transformer layers are initialized with truncated normal initialization to ensure stable optimization. Training is performed using the Adam optimizer with $`(\beta_1,\beta_2)=(0.9,0.999)`$ and an initial learning rate of $`10^{-4}`$. A MultiStepLR schedule is applied with decay milestones at 250,000 and 400,000 iterations.The loss function is a weighted combination of $`\ell_1`$ reconstruction loss and VGG-based perceptual loss, with weights $`(\lambda_{\ell_1},\lambda_2)=(1.0,0.1)`$.
All images are normalized to the $`[0,1]`$ range, and no data augmentation techniques, such as flipping or rotation, are applied. To maintain deterministic behavior, NumPy, PyTorch, and CUDA are configured with fixed random seeds, and CuDNN is configured in deterministic mode. Periodic checkpointing and TensorBoard logging are used to monitor loss curves and evaluation metrics throughout training. This experimental configuration ensures reproducibility, fairness, and consistency across all comparisons presented in the following sections. The results reported next highlight the strengths of SwinIFS in both objective and perceptual evaluation settings.
| 4× Upscaling | 8× Upscaling | |||||
|---|---|---|---|---|---|---|
| 2-4 Model | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS |
| Bicubic | 27.38 | 0.8002 | 0.1857 | 23.46 | 0.6776 | 0.2699 |
| SRGAN | 31.05 | 0.8880 | 0.0459 | 26.63 | 0.7628 | 0.1043 |
| FSRNet | 31.37 | 0.9012 | 0.0501 | 26.86 | 0.7714 | 0.1098 |
| DIC | 31.58 | 0.9015 | 0.0532 | 27.35 | 0.8109 | 0.0902 |
| SPARNet | 31.52 | 0.9005 | 0.0593 | 27.29 | 0.7965 | 0.1088 |
| SISN | 31.55 | 0.9010 | 0.0587 | 26.83 | 0.7786 | 0.1044 |
| MRRNet | 30.48 | 0.8720 | 0.0374 | 25.94 | 0.7417 | 0.0562 |
| WIPA | 30.35 | 0.8711 | 0.0619 | 26.23 | 0.7652 | 0.0961 |
| UFSRNet | 31.42 | 0.8987 | 0.0643 | 27.10 | 0.7887 | 0.1102 |
| W-Net | 31.63 | 0.9029 | 0.0425 | 27.40 | 0.8014 | 0.0760 |
| SwinIFS (Ours) | 32.01 | 0.9520 | 0.0404 | 27.97 | 0.8513 | 0.0720 |
Results and Discussion
The performance of the proposed SwinIFS framework is assessed through extensive quantitative and qualitative comparisons against a wide range of state-of-the-art face super-resolution methods. These include classical CNN-based models such as SRCNN and FSRNet, GAN-based methods such as SRGAN and SPARNet, and more recent landmark-aware and Transformer-based methods, including DIC, WIPA, UFSRNet, and W-Net. All evaluations are performed under identical conditions using the CelebA test set, ensuring a fair and consistent benchmarking environment.
The quantitative results presented in Table 1 demonstrate that SwinIFS achieves the highest PSNR and SSIM values for both $`4\times`$ and $`8\times`$ upscaling, while maintaining one of the lowest LPIPS scores. These results indicate that SwinIFS excels at both pixel-level fidelity and perceptual similarity, which are essential for restoring realistic, identity-consistent facial details. The improvements are particularly pronounced at $`8\times`$ upscaling, where most methods struggle due to severe information loss. SwinIFS achieves a PSNR of 27.97dB and an SSIM of 0.851, outperforming recent Transformer-based competitors such as W-Net and UFSRNet, and significantly surpassing classical CNN or GAN-based approaches. The low LPIPS score further underscores SwinIFS’s perceptual advantage, reflecting its ability to generate natural textures without introducing GAN-related artifacts.


The qualitative comparisons in Fig. [fig:x4_visual] and 2 further substantiate these findings. For $`4\times`$ upscaling, SwinIFS reconstructs faces with sharper contours, clearer eye regions, and more realistic mouth textures than competing models. Many CNN- and GAN-based baselines produce overly smooth or plastic-like textures, while specific recent architectures tend to hallucinate details that distort identity. In contrast, SwinIFS restores features in a manner that remains faithful to the ground truth, owing to its integration of landmark-guided geometric priors and hierarchical attention mechanisms.
At the more challenging $`8\times`$ scale, illustrated in Fig. 2, most competing models fail to recover meaningful structure from the highly degraded LR inputs. Their outputs exhibit blurred contours, incorrect shape reconstruction, and a loss of characteristic identity cues. SwinIFS, by contrast, reconstructs the global facial geometry while restoring high-frequency detail around the eyes, nose, and lips. The advantage is most evident in cases involving significant pose variations or harsh illumination, where our model preserves identity coherence and reduces artifacts.


To further examine the reconstruction of identity critical regions, Fig. [fig:x4_facial] and 3 present region-specific comparisons focusing on the eyes and mouth. These areas are particularly challenging because they contain fine structural cues essential for identity recognition. At both scaling factors, SwinIFS restores sharper eye boundaries, more accurate iris structure, and more realistic eyelid geometry than all other baselines. Similarly, the mouth region reconstructed by SwinIFS retains natural shading, lip curvature, and texture continuity, avoiding the smudging or over-smoothing seen in alternative approaches. These region-focused comparisons confirm that incorporating landmark heatmaps enables SwinIFS to allocate attention effectively to semantically meaningful facial regions, thereby improving structural fidelity.
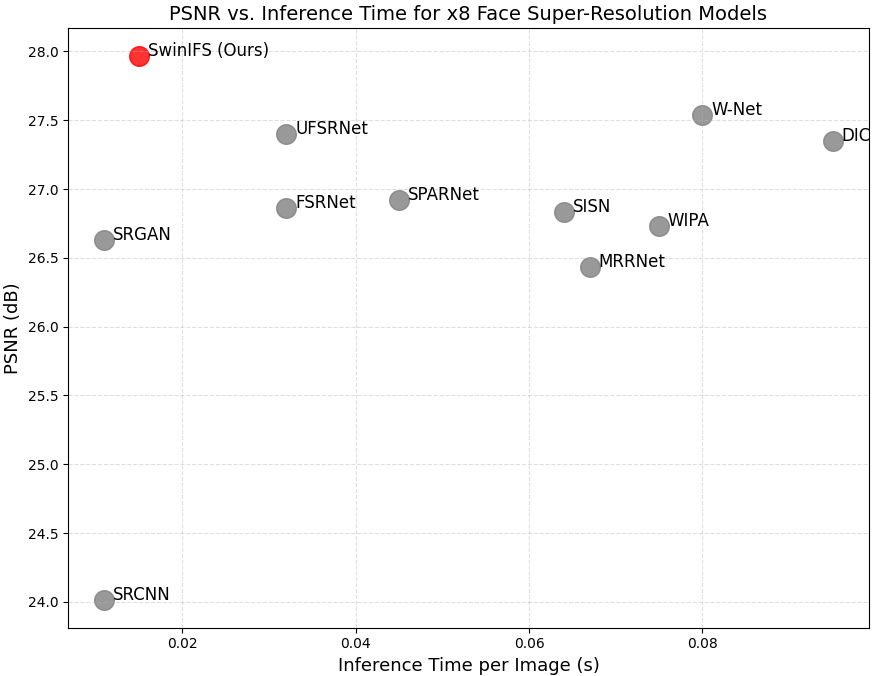
Beyond reconstruction quality, practical face super-resolution systems must also consider computational efficiency. Fig. 4 presents the relationship between PSNR and inference time for a range of competing models. While methods such as DIC, WIPA, and W-Net achieve competitive PSNR values, they incur significantly higher inference times due to deeper architectures or multi-stage refinement. Lightweight models such as SRCNN and SRGAN offer faster inference but fail to recover detailed and identity-relevant structures, especially at higher upscaling factors. SwinIFS achieves a favourable balance between accuracy and efficiency, reaching the highest PSNR while maintaining an inference time of only 0.015 seconds per $`128\times128`$ face. This positions SwinIFS on the Pareto frontier, demonstrating that its design, built on efficient window-based attention and compact hierarchical blocks, supports both real-time performance and high-fidelity reconstruction.
Taken together, the results clearly show that SwinIFS achieves a superior combination of perceptual realism, structural consistency, and computational efficiency compared to prior state-of-the-art methods. The model’s ability to integrate geometric priors, hierarchical feature refinement, and efficient Transformer-based modelling enables it to produce photorealistic and identity-faithful results even at extreme magnification levels. The consistency of improvements across quantitative metrics, global visual comparisons, and region-specific analyses demonstrates the robustness and reliability of SwinIFS for real-world face super-resolution applications.
Conclusion
This work introduces SwinIFS, a landmark-guided face super-resolution framework that addresses the challenges posed by severely degraded facial inputs. By integrating dense structural priors with a hierarchical Swin Transformer backbone, the proposed method effectively recovers fine‐grained textures while preserving global facial geometry and identity. Extensive experiments on the CelebA dataset demonstrate that SwinIFS consistently outperforms existing CNN, GAN, and Transformer-based approaches across both $`4\times`$ and $`8\times`$ upscaling factors. The model achieves superior quantitative performance and produces visually convincing high-resolution reconstructions, particularly in identity-critical regions such as the eyes and mouth. Moreover, SwinIFS offers a favorable trade-off between accuracy and inference speed, making it suitable for real-world applications where both quality and efficiency are essential. While the framework demonstrates strong robustness, it still relies on accurate landmark predictions and has been evaluated primarily on frontal and near-frontal facial images. Future research may extend this work by exploring a wider range of landmarks, integrating landmark-free geometric priors, adapting the architecture to accommodate significant pose variations, and incorporating generative components to enhance texture realism. Additionally, evaluating the model on multi-domain or real-world degraded datasets would strengthen its applicability. Overall, SwinIFS presents a significant step toward reliable, identity-preserving face super-resolution and provides a strong foundation for further advancements in facial enhancement technologies.
📊 논문 시각자료 (Figures)