Online Estimation and Manipulation of Articulated Objects
📝 Original Paper Info
- Title: Online Estimation and Manipulation of Articulated Objects- ArXiv ID: 2601.01438
- Date: 2026-01-04
- Authors: Russell Buchanan, Adrian Röfer, João Moura, Abhinav Valada, Sethu Vijayakumar
📝 Abstract
From refrigerators to kitchen drawers, humans interact with articulated objects effortlessly every day while completing household chores. For automating these tasks, service robots must be capable of manipulating arbitrary articulated objects. Recent deep learning methods have been shown to predict valuable priors on the affordance of articulated objects from vision. In contrast, many other works estimate object articulations by observing the articulation motion, but this requires the robot to already be capable of manipulating the object. In this article, we propose a novel approach combining these methods by using a factor graph for online estimation of articulation which fuses learned visual priors and proprioceptive sensing during interaction into an analytical model of articulation based on Screw Theory. With our method, a robotic system makes an initial prediction of articulation from vision before touching the object, and then quickly updates the estimate from kinematic and force sensing during manipulation. We evaluate our method extensively in both simulations and real-world robotic manipulation experiments. We demonstrate several closed-loop estimation and manipulation experiments in which the robot was capable of opening previously unseen drawers. In real hardware experiments, the robot achieved a 75% success rate for autonomous opening of unknown articulated objects.💡 Summary & Analysis
#### 1. Key Contribution 1: Uncertainty-aware Affordance Prediction - **Simple Explanation**: When robots interact with objects, they often face uncertainties in how the object will move based on visual data alone. This research introduces a neural network that incorporates uncertainty into predictions. - **Metaphor**: Imagine trying to open a door by looking at it from afar; you might not know if it swings left or right until you touch and feel the mechanism.2. Key Contribution 2: Introduction of Force Sensing Factor
- Simple Explanation: The research incorporates force sensing into the estimation process, allowing robots to update their understanding based on how an object reacts when touched.
- Metaphor: This is akin to feeling a door handle and knowing whether it’s sliding or swinging by the way it moves under your hand.
3. Key Contribution 3: Full System Integration
- Simple Explanation: The paper presents a comprehensive method for robots to estimate and interact with articulated objects using vision, force sensing, and kinematic data in real-time.
- Metaphor: This is like opening an unfamiliar door by first observing it, then touching it to feel how it moves, and finally opening it based on the information gathered.
📄 Full Paper Content (ArXiv Source)
If service robots are to assist humans in performing common tasks such as cooking and cleaning, they must be capable of interacting with and manipulating common articulated objects such as dishwashers, doors, and drawers. To manipulate these objects, a robot would need an understanding of the articulation, either as an analytical model (e. g. revolute, prismatic, or screw joint) or as a model implicitly learned through a neural network. Many recent works have shown how deep neural networks can predict articulated object affordance using point cloud measurements. To achieve this, common household articulated objects are rendered in simulation with randomized states as training examples. Because most common household objects have reliably repeatable articulations, such as refrigerator doors, the learned models effectively generalize to real data. However, predicting articulation from visual data alone can often be unreliable.
For example, the cabinet in Fig. 1 has four doors which appear identical when closed. It is impossible for humans or robots to reliably predict the articulation from vision alone. However, once a person or robot interacts with them, they are revealed to open in completely different ways. This is challenging for robotic systems that rely exclusively on vision for understanding articulations and are not capable of updating their articulation estimate online. In this work, we propose a novel method for jointly optimizing visual, force, and kinematic sensing for online estimation of articulated objects.
There is another branch of research that has focused on probabilistic estimation of articulations. These works have typically used analytical models of articulation and estimate the object articulation through observations of the motion of the object during interaction. However, these works largely rely on a good initial guess of articulation so that the robot can begin moving the object.

In this work, we significantly improve upon our previous work presented in in which we first investigated estimation of articulated objects. The first of these improvements is a neural network for affordance prediction which incorporates uncertainty in predictions and a completely new method of including learned articulation affordances into a factor graph to provide a good initial guess of articulation. We have also incorporated kinematic and force sensing in the factor graph which updates the estimate online during interaction. The result is a robust multi-modal articulation estimation framework. The contributions of this paper are as follows:
-
We propose online estimation of articulation parameters using vision and proprioceptive sensing in a factor graph framework. This improves upon our previous work with a new uncertainty-aware articulation factor leading to improved robustness in articulation prediction.
-
We additionally introduce a new force sensing factor for articulation estimation.
-
We demonstrate full system integration with shared autonomy for unseen opening articulated objects.
-
We validate our system with extensive real-world experimentation, opening visually ambiguous articulations with the estimation running in a closed loop. We demonstrate improvements over by opening all doors for the cabinet in Fig. 1, which was not previously possible.
Related Work
In this section, we provide a summary of related works on the estimation of articulated objects. This is a challenging problem that has been investigated in many different ways in computer vision, and robotics. In this work, we are concerned with robotic manipulation of articulated objects. Therefore, in the following section, we first cover related works in interactive perception (), which has a long history of use for estimation and manipulation of articulated objects. Then, we briefly cover the most relevant, recent deep learning methods for vision-based articulation prediction. Finally, we discuss some methods that have integrated different systems together for robot experiments.
Interactive Perception
Interactive perception is the principle that robot perception can be significantly facilitated when the robot interacts with its environment to collect information. This has been applied extensively in the estimation of articulated objects, as once the robot has grasped an articulated object and started to move it, there are many sources of information from which to infer the articulation parameters. Today, few works use proprioception for estimating articulation due to challenges in identifying an initial grasp point and pulling direction. In 2010, simplified the problem by assuming a prior known grasp pose and initial opening force vector. This allowed their method to autonomously open several everyday objects, such as cabinets and drawers, while only using force and kinematic sensing. They demonstrated that once a robot is physically interacting with an articulated object and is given a good initial motion direction, proprioception alone can be sufficient to manipulate most articulated objects.
More commonly in recent research, proprioception is either fused with vision, or vision alone is used. introduced a probabilistic framework for maximizing the probability of a joint type and joint parameters given an observed pose trajectory of the moving part of an articulated object (e.g., a cabinet door). To track the trajectory of the moving part, they demonstrate several different sensing methods, including visual tracking of fiducial markers, depth image-based markerless tracking, and kinematic sensing. They integrated their method with for real robot experiments, specifying the initial grasp point and direction of motion.
Later work would focus on visual perception, using bundle adjustment to track visual features throughout the course of an interaction (). also introduced a framework that can estimate online from vision and tactile sensing. As in previous work, they track the motion of visual features while the robot is interacting with the object. This is fused with force/torque sensing, haptic sensing from a soft robotic hand, and end-effector pose measurements. proposed a visual neural network for tracking the motion of the object parts from vision. The tracked poses are connected by a factor graph to estimate the joint parameters. In their experiments, they estimated an unknown articulation; however, their controller used a prescribed motion to open the object, giving sufficient information to the estimator.
All of these interactive perception methods require a prior grasp point and a good initial guess of the articulation. In our previous work () we used a factor graph to merge learned visual predictions with kinematic sensing. This allowed our method to automatically make an initial guess of opening direction and then update the estimate online during interaction. However, in this early work, we could only demonstrate opening of objects that require pulling motions to be opened and could not demonstrate opening of sliding doors, such as the bottom right door in Fig. 1.
In this work, like and , we use a factor graph to fuse measurements of part poses to estimate a joint screw model. However, unlike these previous works, we use an uncertainty-based deep neural network prediction from visual sensing to give the robot an initial estimate of the articulation. This is then updated using both force sensing and kinematic sensing to enable the opening of any articulation, including sliding doors. Our use of both interactive perception and learning-based predictions allows us to perform closed-loop control and estimation while opening unknown articulated objects.
Learning-Based Articulation Prediction
Many recent works have investigated using only visual information with deep learning to predict articulation without the need for object interaction (). Often, these works use simulated datasets such as the PartNet-Mobility dataset (), which contains examples of common articulated objects. Since many common household objects have predictable articulations (e.g., refrigerator doors), these works assume that articulation can be predicted in most cases through visual inspection.
Earlier learning-based works explicitly classified objects for the prediction of articulation, but more recently, there has been a focus on learning category-free articulation affordances (), which describe how a user can interact with an object without classifying the object from vision. This is typically parameterized as a normalized vector that describes the motion of a point on the articulated part of an object. used a neural network to also predict grasp pose on the object as well as the opening trajectory from human demonstrations. Some recent learning-based work has incorporated interaction. used point cloud data collected before and after human interaction with the target articulated object. introduced a method that predicts articulation as well as proposes an interaction through which to observe the motion and update the articulation estimate.
All of these learning-based works have similar limitations that hinder their use on real robots. They use only visual information and have large computational requirements, which prevents online estimation. Therefore, when they are used with real data, they typically take a single “snapshot” of the object and make a single inference. If there is any error in the prediction, there is no way to update the estimate. Additionally, due to the reliance on recognizing visual similarity in objects compared to past training experiences, these methods exhibit poor performance on an object like in Fig. 1, which has no visual indicators as to how it opens. If the predictions are wrong, then these methods are reliant on highly compliant controllers to account for the error due to a lack of online estimation.
Systems
In our work, we provide not only an estimation method but also a full system for opening articulated objects with shared autonomy. Therefore, we also discuss some related work that developed systems for the manipulation of articulated objects. introduced a system for whole-body mobile manipulation. They used the category-level object pose prediction network from . This meant their method needed prior information about the category of object with which the robot interacted. Also, in their method, they make a single prediction before interaction and then rely on controller robustness to account for mistaken predictions.
A closed-loop learning estimation method was proposed by . This method estimates articulation affordance from vision at multiple time steps during the interaction. A sampling-based controller solves for the optimal opening trajectory. When opening, the object becomes stagnant due to torque limits, the robot releases the object and moves to a configuration to view the full object again, then makes a new vision-based estimate of the articulation. The requirement to let go of the object to re-view it, slows the opening down, and assumes the object’s door will not snap back shut or fall open when released. These approaches have relied heavily on robust and compliant controllers to account for any errors in articulation estimation. In contrast, our work updates the estimation of the articulation model seamlessly during interaction, enabling the use of much simpler methods for motion generation and control.
Screw Theory Background
Screw theory is the geometric interpretation of twists that can be used to represent any rigid body motion (Chasles theorem) (). Screw motions are parameterized by the twist $`\xi = ( \mathbf{v}, \boldsymbol{\omega}), \text{where} ~ \mathbf{v}, \boldsymbol{\omega}\in \mathbb{R}^3`$. The variable $`\mathbf{v}`$ represents the linear motion and $`\boldsymbol{\omega}`$ the rotation. We can convert this to a tangent space to $`\mathrm{SE}(3)`$ using $`\hat{\xi}`$ as
\begin{equation}
\label{eq:xi_hat}
\hat{\xi} = \begin{bmatrix}
\hat{\boldsymbol{\omega}} & \mathbf{v}\\
0 & 0
\end{bmatrix} \in \mathfrak{se}(3),
\end{equation}where the hat operator $`\hat{(\cdot)}`$ is defined as:
\begin{equation}
\label{eq:hat}
\hat{\boldsymbol{\omega}} = \begin{bmatrix}
0 & -\omega_z & \omega_y\\
\omega_z & 0 & -\omega_x\\
-\omega_y & \omega_x & 0
\end{bmatrix}.
\end{equation}In screw theory, $`\xi`$ is a parametrization of motion direction and $`\theta`$ is a signed scalar representing the motion amount. In the pure rotation case, $`\theta`$ has the units of radians, and in the pure translation case, meters. The tangent space Eq. ([eq:xi_hat]) can be converted to the homogeneous transformation $`\mathbf{T}(\hat{\xi}, \theta) \in \mathrm{SE}(3)`$ using the exponential map $`\exp: \mathfrak{se}(3) \to \mathrm{SE}(3)`$ from where
\begin{align}
\exp{(\hat{\xi}\theta)} &=\begin{bmatrix}
\exp{(\hat{\boldsymbol{\omega}}\theta)} & (\mathbf{I}- \exp{(\hat{\boldsymbol{\omega}}\theta)})(\boldsymbol{\omega}\times \mathbf{v}) + \boldsymbol{\omega}\boldsymbol{\omega}^T\mathbf{v}\theta \\
0 & 1
\end{bmatrix},
\end{align}and $`\exp{(\hat{\boldsymbol{\omega}}\theta)}`$ is solved by using the Rodriguez Formula:
\begin{align}
\exp{(\hat{\boldsymbol{\omega}}\theta)} &= \mathbf{I}+ \hat{\boldsymbol{\omega}}\theta + \frac{(\hat{\boldsymbol{\omega}}\theta)^2}{2!} + \frac{(\hat{\boldsymbol{\omega}}\theta)^3}{3!} + ...\\
&= \mathbf{I}+ \hat{\boldsymbol{\omega}}\sin{\theta} + \boldsymbol{\omega}^2(1-\cos{\theta}).
\end{align}If we define a fixed world frame $`\mathtt{W}`$, then the frame attached to the moving part of an articulated object (e.g., the cabinet door) is given the frame $`\mathtt{A}`$ and the homogeneous transform between them is given as $`\mathbf{T}_\mathtt{WA} \in \mathrm{SE}(3)`$. The other non-moving part of the object (e.g., the cabinet base) is given the frame $`\mathtt{B}`$ and its pose in $`\mathtt{W}`$ is defined as $`\mathbf{T}_\mathtt{WB} \in \mathrm{SE}(3)`$. Since $`\exp{(\hat{\boldsymbol{\omega}}\theta)} \in \mathrm{SE}(3)`$ defines the homogeneous transform from the object base $`\mathtt{B}`$ and articulated part $`\mathtt{A}`$, we can express the screw transform as:
\begin{align}
\label{eq:expmap}
\mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta) = \exp{(\hat{\xi}\theta)},
\end{align}where $`\theta \in \mathbb{R}`$ is the articulation configuration. The two object parts are then connected by
\begin{align}
\label{eq:transform}
\mathbf{T}_\mathtt{WA} = \mathbf{T}_\mathtt{WB}\mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta).
\end{align}Preliminaries
The goal of this work is to estimate online the Maximum-A-Posteriori (MAP) state of a single joint from visual and proprioceptive sensing. We define the state $`\boldsymbol{x}(t)`$ at time $`t`$ as
\begin{equation}
\boldsymbol{x}(t) \coloneqq
\left[\xi,\theta(t) \right] \in \mathbb{R}^{7},
\end{equation}where $`\xi`$ are the screw parameters which we assume to be constant for all time and $`\theta(t)`$ is the configuration of articulation at time $`t`$. We assume the object is composed of only two parts connected by a single joint. This encompasses the vast majority of articulated objects and therefore is a reasonable simplification. We define the pose of each part in the world frame $`\mathtt{W}`$ as $`\mathbf{T_{\mathtt{WA}}}, \mathbf{T_{\mathtt{WB}}} \in \mathrm{SE}(3)`$ where $`\mathbf{T_{\mathtt{WB}}}`$ is the base part that is static and $`\mathbf{T_{\mathtt{WA}}}`$ is the articulated part which the robot grasps, e.g. the door.
We jointly estimate $`\mathsf{K}`$ states and part poses with time indices $`k`$; so that the set of all estimated states and articulated part poses can be written as $`{\cal X}= \{\boldsymbol{x}_k, \mathbf{T_{\mathtt{A}}}_{k}, \mathbf{T_{\mathtt{B}}}_{k}\}_{k \in \mathsf{K}}`$, dropping world reference frames for brevity. Our method fuses measurements from three sources: point cloud measurements from an initial visual inspection, force measurements from a wrist-mounted 6-axis force/torque sensor, and kinematic measurements from joint encoders in the robot’s arm. We use $`\mathsf{P}`$ point clouds, which are each associated with a prediction on $`\xi`$. Without loss of generality, we set $`\mathsf{P} = 1`$ with one visual measurement at the beginning. In future work, we seek to add multiple vision-based predictions that can be added to the factor graph asynchronously during manipulation. Force measurements are added at time indices $`f`$ up to a maximum of $`\mathsf{F}`$ measurements. We use $`\mathsf{K}`$ kinematic measurements at times $`k`$, which are each associated with a state estimate. The times $`k`$ are only selected while the robot is in contact with the object and after the articulated part has been moved a certain distance $`d`$ to avoid taking too many measurements.
Finally, the set of all measurements are then grouped as $`{\cal Z}= \{{\cal P}, {\cal F}_{f}, {\cal K}_{k}\}_{f \in \mathsf{F} k \in \mathsf{K}}`$ where $`{\cal P}`$ is the point cloud measurement, $`{\cal F}`$ are the force measurements and $`{\cal K}`$ the pose measurements from the robot’s forward kinematics.
Factor Graph Formulation
We maximize the likelihood of the measurements $`{\cal Z}`$, given the history of states $`{\cal X}`$:
\begin{equation}
{\cal X}^* = \mathop{\mathrm{arg\,max}}_{{\cal X}} p({\cal X}|{\cal Z}) \propto p(\boldsymbol{x}_0)p({\cal Z}|{\cal X}),
\label{eq:posterior}
\end{equation}where $`{\cal X}^*`$ is our MAP estimate of the articulation.
We assume the measurements are conditionally independent and corrupted by zero-mean Gaussian noise. Therefore, Eq. ([eq:posterior]) can be expressed as the following least squares minimization:
\begin{align}
\begin{split}
{\cal X}^{*} = \mathop{\mathrm{arg\,min}}_{{\cal X}} \|\mathbf{r}_\textup{0}\|^2_{\Sigma_\textup{0}}
&+ \|\mathbf{r}_{{\cal P}}\|^2_{\Sigma_{{\cal P}}}
+ \sum_{f \in \mathsf{F}} \|\mathbf{r}_{{\cal F}_{f}}\|^2_{\Sigma_{{\cal F}}}\\
&+ \sum_{k \in \mathsf{K}} \Big( \|\mathbf{r}_{{\cal A}_{k}} \|^2_{\Sigma_{{\cal A}}} + \|\mathbf{r}_{{\cal K}_{k}} \|^2_{\Sigma_{{\cal K}}} \Big),
\label{eq:cost-function}
\end{split}
\end{align}where each term is a residual $`\mathbf{r}`$ associated with a measurement type and assumed to be corrupted by zero-mean Gaussian noise with covariance according to the measurement. A factor graph can be used to graphically represent Eq. ([eq:cost-function]) as shown in Fig 2, where large white circles represent the variables we would like to estimate and the smaller colored circles represent the residuals as factors. The implementation of the factors is detailed in the following section.
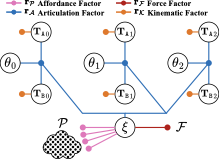 />
/>
A(t), TB(t), θ(t)
and ξ, which exists at only
one time step in the factor graph. We show three time steps, including
the initial visual affordance factor, which provides a prior estimate on
ξ as a unary
factor.Method
In this section, we describe how the three type of measurement (point cloud $`{\cal P}`$, force $`{\cal F}`$ and kinematics $`{\cal K}`$) are fused together in our factor graph, using four factors (Affordance $`\mathbf{r}_{{\cal P}}`$, Articulation $`\mathbf{r}_{{\cal A}}`$, Force $`\mathbf{r}_{{\cal F}}`$ and Kinematics $`\mathbf{r}_{{\cal K}}`$) to estimate articulation online.
Uncertainty-aware Articulation Prediction from Vision
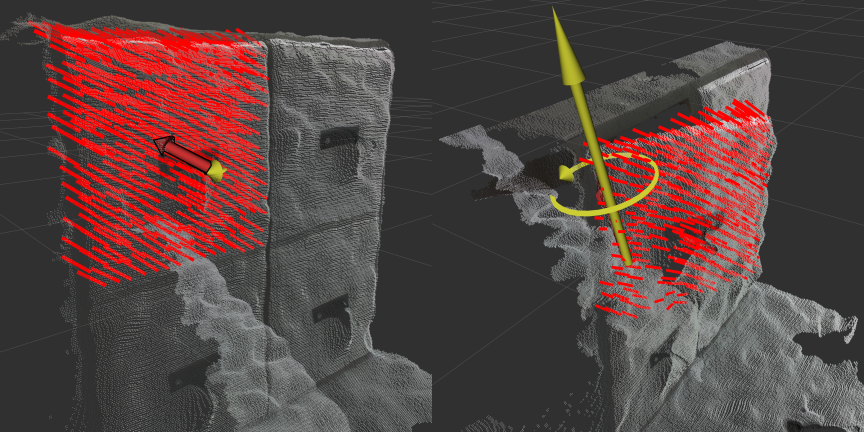
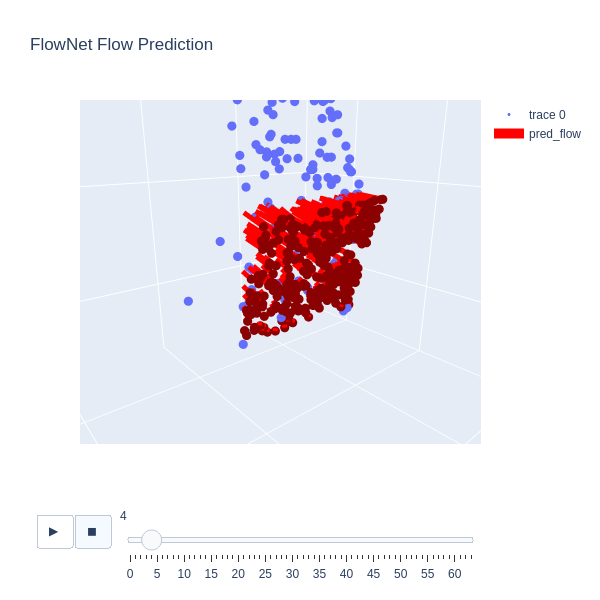
We are interested in using a deep neural network to predict articulation affordance from visual measurements. This affordance can be parameterized as a point cloud whereby each 3-dimensional point encodes a normalized, instantaneous velocity of that point given a small amount of articulation. As shown in Fig. 3, for a prismatic joint, all vectors will point along the axis of motion equally. For a revolute joint, all vectors will point tangent to the circular trajectory, with the vectors further from the axis of rotation longer. first introduced this representation of articulation affordance, describing it as a motion residual flow. Later, improved the implementation with Flowbot3D and used the network from Flowbot3D in their framework.
We introduce a new neural network which, like Flowbot3d, uses PointNet++ () as the underlying architecture. Our neural network takes in a point cloud $`{\cal P}`$ consisting of $`\mathsf{N}`$ points where $`n \in \mathsf{N}`$ and $`\textbf{p}_n \in \mathbb{R}^4`$ which encode 3-dimensional position and a mask indicating whether the point belongs to the articulated part or the fixed-base part. The network then predicts flow $`\hat{\mathbf{f}}_n \in \mathbb{R}^3`$ for each point on the articulated part.
In our previous work () we used the Mean Squared Error (MSE) loss function to train the network to only predict flow:
\begin{align}
{\cal L}_{\text{MSE}}(\mathbf{f}, \hat{\mathbf{f}}) = \frac{1}{p}\sum_{i=1}^{p}\left\lVert\mathbf{f}_i - \hat{\mathbf{f}}_i\right\rVert^2,
\end{align}In this work, we seek to train the neural network to also predict its aleatoric uncertainty for each point-wise prediction of flow. To achieve this, we use change the loss function to the method shown in to change the loss function to the following Gaussian Maximum Likelihood (ML) loss:
\begin{align}
\begin{split}
&{\cal L}_{\text{ML}}(\mathbf{f}, \hat{\mathbf{\Sigma}}, \hat{\mathbf{f}}) \\
&= \frac{1}{N}\sum_{n=1}^{N}-\text{log} \left( \frac{1}{\sqrt{8\pi^3\text{det}(\hat{\mathbf{\Sigma}}_n)}} e^{-\frac{1}{2}\left\lVert\mathbf{f}_n - \hat{\mathbf{f}}_n\right\rVert_{\hat{\mathbf{\Sigma}}_n}^{2}} \right).
\end{split}
\end{align}This enables the network to learn to predict articulation flow in a supervised manner from the labels $`\mathbf{f}`$, and learn the uncertainty $`\hat{\mathbf{\Sigma}}`$ in an unsupervised manner. The network function $`f`$ with trained weights $`\Theta`$ can then be represented as:
\begin{align}
f_\Theta : \left({\cal P}\right) \mapsto (\hat{\mathbf{f}}_i,
\hat{\mathbf{u}}_i),
\end{align}where $`\hat{\mathbf{u}}_i \in \mathbb{R}^3`$, can be formulated into a covariance matrix using
\begin{align}
\hat{\mathbf{\Sigma}}_i(\hat{\mathbf{u}}_i) = \text{diag}(e^{2\hat{u}_x}, e^{2\hat{u}_y}, e^{2\hat{u}_z}).
\label{eq:pred-cov}
\end{align}An example output of this new articulation prediction is shown in Fig. 4. In this simulated sliding door example, the door is almost fully open, which makes the articulation visually ambiguous. The prediction of the network shows a belief that the door is revolute about the door frame. However, inspection of the covariance shows there is the largest uncertainty in the $`x`$ direction, followed by $`y`$, with the lowest uncertainty in the $`z`$ direction. This will be useful later when we introduce the force factor, which will “correct” motion in the $`x`$ direction to be zero with very low uncertainty, allowing the articulation estimation to collapse to the $`y`$ direction.
New Affordance Factor
In previous work on articulation estimation from deep learning affordance predictions, a hand-crafted approach was used to incorporate flow predictions into the factor graph (). This involved fitting two planes to the initial point cloud and to the point cloud representing a small articulation. The intersection of these planes represented a measurement on a revolute joint. If the intersection was very far away, then the direction of flow was used as a measurement on a prismatic joint. These articulation predictions $`\hat{\xi}`$ were used directly on the articulation estimate as unary factors with the following residual:
\begin{align}
\mathbf{r}_{{\cal P}} = \xi - \hat{\xi}.
\end{align}This required a hand-tuned uncertainty ($`\sigma_{{\cal P}} = 1e^{-3}`$) which did not capture the true uncertainty of the neural network.
 style="width:17.5cm" />
style="width:17.5cm" />
In our work, we instead introduce a new affordance factor which directly integrates the predicted uncertainty $`\hat{\mathbf{\Sigma}}`$. First, we change the single articulation factor from to instead be a sum of per-point factors for each of the $`\mathsf{N}`$ points in the point cloud $`{\cal P}`$:
\begin{align}
\label{eq:sum-art}
\begin{split}
\mathbf{r}_{{\cal P}} &= \sum_{i \in N} \mathbf{r}_{{\cal P}_{i}},
\end{split}
\end{align}As discussed in Sec. 6.1, each flow vector represents a position change of a point lying on the moving part of the object as a result of a small change in articulation angle: $`\theta = 0.05`$ (this $`\theta`$ increment is also used for generating training data in simulation). The new point position after the articulation can be written as:
\begin{align}
\label{eq:flow-move}
\hat{\mathbf{p}}^{+}_{i} = \hat{\mathbf{f}}_i + \mathbf{p}_i.
\end{align}Equivalently, using the equation for articulation homogeneous transform1, we can write:
\begin{align}
\label{eq:flow-transform}
\mathbf{p}^{+}_{i} = \mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta)\mathbf{p}_i.
\end{align}If we set $`\theta`$ to be very small ($`\approx0.05`$), then we can expect $`\hat{\mathbf{p}}^{+}_{i}`$ from Eq. ([eq:flow-move]) to be equivalent to $`\mathbf{p}^{+}_{i}`$ from Eq. ([eq:flow-transform]), and therefore we can use the following residual on a per-point basis:
\begin{align}
\begin{split}
\mathbf{r}_{{\cal P}_{i}} &=\mathbf{p}^{+}_{i} - \hat{\mathbf{p}}^{+}_{i}\\
&= \mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta)\mathbf{p}_i - \hat{\mathbf{f}}_i - \mathbf{p}_i,
\label{eq:art-residual}
\end{split}
\end{align}which is conditioned on the predicted covariance $`\hat{\mathbf{\Sigma}}_i`$ from the neural network in Eq. ([eq:pred-cov]). Therefore, the point cloud articulation residual $`\mathbf{r}_{{\cal P}}`$ in Eq. ([eq:cost-function]) is replaced with a sum of per-point residuals (Eq. ([eq:art-residual]) and Eq. ([eq:sum-art])) and is visually represented in Fig. 2.
Force Factor
Another limitation of previous works in this area was the requirement for the initial opening direction to be pulling away from the object. This meant revolute doors or prismatic drawers could be estimated, but not prismatic sliding doors such as the bottom right door of the cabinet shown in Fig. 1. This was because the neural network would make a prediction of a drawer-like prismatic joint, and the robot would pull backwards on the door. However, because the door would not move, there was no opportunity to collect kinematic measurements and update the articulation estimate.
As a solution in this work, we propose using force measurements from a wrist-mounted force sensor to infer articulation. We use force measurements at the beginning of the interaction, after grasping the articulated part, but before any motion. If the reaction force measurement reaches a given threshold when attempting to open the door, then the factor graph incorporates this force $`\hat{\mathbf{F}}`$ as an additional factor when solving for the new estimate of the articulation. Although force and torque can be used to guide a robot controller to minimize torque during opening, it is less straightforward to use these measurements to infer the articulation parameters. This is because a reaction force/torque measurement only informs that a particular direction is not a valid motion, rather than informing which alternative motion would be correct.
 />
/>
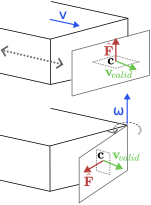
However, we can still use this information about invalid motion to rule out possible articulations. If a robot attempts to open an articulated object, and there is no motion, then the direction of force must be orthogonal to the valid direction of motion. This can be viewed as a simplified version of the approach used in in which we do not require a particle filter.
The direction of force can be expressed as:
\begin{align}
\label{eq:force}
\mathbf{v}_{valid} \cdot \hat{\mathbf{F}} = 0,
\end{align}where $`\hat{\mathbf{F}} \in \mathbb{R}^3`$ is the measured reaction force measurement and $`\mathbf{v}_{valid} = \mathbf{v}+ \boldsymbol{\omega}\times \ensuremath{\mathbf{c}}`$ defines the true, valid instantaneous direction of motion for a point $`\ensuremath{\mathbf{c}}`$ on the articulated part. This relationship is demonstrated for both prismatic and revolute joints in Fig. 5.
Intuitively, this means if a robot attempts to pull backward on a sliding door, it can be inferred that the door only opens in a direction that spans the vertical plane (i.e., left/right or up/down). For this to hold, we make a few assumptions:
-
If the articulation is a revolute joint, the grasp point is not on the hinge. We can make this assumption because a human operator is providing the grasp point to the robot.
-
While applying the force, the articulated object does not move.
If these two assumptions hold, we can use Eq. ([eq:force]) to correct the estimated direction of motion $`\mathbf{v}_{est}`$ so that it lies on a plane with normal $`\hat{\mathbf{F}}`$. To perform the rotation, we first find a vector orthogonal to both $`\mathbf{v}_{est}`$ and $`\hat{\mathbf{F}}`$:
\begin{equation}
\ensuremath{\mathbf{t}} = \mathbf{v}_{est} \times \hat{\mathbf{F}}.
\end{equation}If $`\ensuremath{\mathbf{t}}`$ is a zero vector (i.e., $`\mathbf{v}_{est}`$ is parallel or anti-parallel to $`\hat{\mathbf{F}}`$), we select an alternative perpendicular vector by taking the cross product of $`\hat{\mathbf{F}}`$ with a standard basis vector while ensuring:
\begin{equation}
\hat{\ensuremath{\mathbf{t}}} = \frac{\ensuremath{\mathbf{t}}}{\|\ensuremath{\mathbf{t}}\|}.
\end{equation}This guarantees $`\hat{\ensuremath{\mathbf{t}}}`$ lies in the plane and is orthogonal to both $`\mathbf{v}_{est}`$ and $`\hat{\mathbf{F}}`$. The vector is then rotated by $`90^\circ`$ using the cross product:
\begin{equation}
\ensuremath{\mathbf{v}}_{\text{rot}} = \hat{t} \times \mathbf{v}_{est}
\end{equation}Therefore, we can then define a residual as:
\begin{align}
\label{eq:force-residual}
\mathbf{r}_{{\cal F}_{f}} &= \mathbf{v}_{est} - \ensuremath{\mathbf{v}}_{\text{rot}}
\end{align}This will push the estimate of $`\mathbf{v}_{est} = \mathbf{v}+ \boldsymbol{\omega}\times \ensuremath{\mathbf{c}}`$ onto the plane where a possible direction of motion exists. When used with the affordance factors as described in Sec. 6.2, this will push the optimized result towards the next most likely articulation with a motion that lies on the plane. For the force factor, we hand-tune the uncertainty to be very low ($`\Sigma_{{\cal F}}=1e^{-6}`$) so that a single factor can correct for the affordance factors.
Kinematic Factor
We optimize for both the articulation state $`\boldsymbol{x}`$ and the part poses $`\mathbf{T_{\mathtt{A}}}`$ and $`\mathbf{T_{\mathtt{B}}}`$. At time $`k`$, the forward kinematics of the robot are used to compute the end-effector pose, which is assumed to have a rigid grasp of the articulated part of the object. This provides measurements on $`\mathbf{T_{\mathtt{A}}}`$ during interaction. Additionally, we assume $`\mathbf{T_{\mathtt{B}}}`$ does not move and therefore, we reuse the initial grasp pose at every time $`k`$. To account for a small amount of slippage, we associate an uncertainty with these measurements, and the value is manually tuned $`\sigma_{\cal K}=1e^{-3}`$. The residual $`\mathbf{r}_{{\cal K}_{k}}`$ is the default $`\mathrm{SE}(3)`$ unary factor in GTSAM ().
Articulation Factor
The fourth and final factor we use is equivalent to the articulation factor as used in previous work (). This factor connects the variables $`\boldsymbol{x}`$, $`\mathbf{T_{\mathtt{A}}}`$ and $`\mathbf{T_{\mathtt{B}}}`$ in the factor graph using the articulation screw model explained in Sec. 3. We compare the estimated part poses to the expected articulation model in (Sec. [eq:transform]). As in , putting these together gives us the articulation residual as:
\begin{align}
\mathbf{r}_{{\cal A}_{k}} = \mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta_k) \boxminus {\mathbf{T_{\mathtt{B}}}^{-1}_k} \mathbf{T_{\mathtt{A}}}_k,
\end{align}where $`\boxminus`$ is a pose differencing over the manifold using the logarithm map:
\begin{align}
\mathbf{T_{\mathtt{A}}}\boxminus \mathbf{T_{\mathtt{B}}}= \text{Log}({\mathbf{T_{\mathtt{B}}}_k}^{-1} \mathbf{T_{\mathtt{A}}}_k) \in \mathfrak{so}(3).
\end{align}Implementation
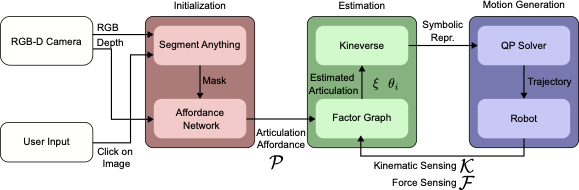 style="width:90.0%" />
style="width:90.0%" />
This section describes the full system implementation for shared autonomy as shown in Fig. 6. The system consists of three modules: Initialization, which occurs once at the beginning; Estimation, which runs online to estimate the articulation; and Motion Generation, which computes the robot’s trajectory to open the object. Estimation and Motion Generation both run online, generating a new trajectory for each new articulation estimate.
Initialization
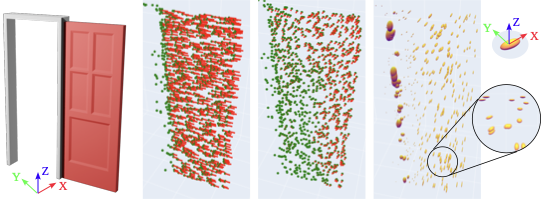
For the initialization module, we use the latest advances in deep learning for articulated objects and introduce a system of shared autonomy. First, a user is presented with a video feed of the object and clicks on the desired grasp point. With this query point, we use the publically available segmentation tool Segment Anything (SAM) () to segment a mask of the non-static part. We make use of the open-source ROS wrapper for SAM first presented in . The image mask and associated point cloud are then passed to the network, which predicts the articulation affordance for each masked point as described in Sec. 6.1. The neural network is trained from examples of articulated objects in PyBullet simulation using the PartNet-Mobility dataset (). Therefore, the output of the initialization step is the point cloud affordance $`{\cal P}`$, and the 3D point associated with the user’s click, which will be used as the first planning goal for the robot.
Estimation
Once the system has been initialized, the factor graph is first optimized using the affordance prediction $`{\cal P}`$. We use GTSAM () for the implementation of the factor graph. The first optimization results in the first prediction of articulation, which is immediately sent to the Motion Generation module. If the door that the robot is interacting with begins to move, kinematic measurements are then added to the factor graph for every distance $`d`$ the end-effector moves. We use the Kineverse articulation model framework () for representing both the robot and the articulated object forward kinematics and constraints. Kineverse uses the CasADi symbolic math back-end (), enabling effortless computation of gradients for arbitrary expressions, such as articulations.
A major limitation with previous work was that if the initial prediction of articulation was orthogonal to the actual articulation, then the end-effector would not move during interaction, and therefore, the estimation could not be updated from kinematic measurements. For example, in the bottom right drawer in Fig. 1, the door slides open to the right. However, the network usually predicted a prismatic joint pulling backwards. The robot arm would pull on the door handle and not move, thereby learning nothing new about the articulation. In this work, we are able to overcome this challenge using the new articulation factor as described in Sec. 6.1 in conjunction with force factor as described in Sec. 6.3. The robot has a force/torque sensor in its wrist. As it attempts to open the door, if the reaction force is larger than a set threshold and the door has not moved, this triggers the addition of a force factor and an additional optimization. This results in a new articulation estimation, which is passed to the Motion Generation module. In this way, the robot will continuously attempt to open the door and use the reaction force to guide the next estimate.
Motion Generation
This module computes the desired robot configurations $`\ensuremath{\mathbf{q}}\in\mathbb{R}^7`$, to open the object, given the latest estimate of the articulation $`\xi`$. We define the robot end-effector frame as $`\mathtt{E}`$ and model the forward kinematics of the robot end-effector as $`\ensuremath{\mathbf{T}}_{\mathtt{W}\mathtt{E}}(\ensuremath{\mathbf{q}})`$.
To compute the goal forward kinematics for opening the articulated object, we slightly rewrite Eq. ([eq:expmap]) as
\begin{align}
\mathbf{T_{\mathtt{WA}}}(\hat{\xi}, \theta_t) &= \mathbf{T_{\mathtt{WB}}}\cdot \mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta_t),
\end{align}with $`\mathbf{T}_{\mathtt{BA}}(\hat{\xi}, \theta_t)`$ provided from the latest estimate of $`\xi`$ and using a goal $`\theta_t`$. The pose $`\mathbf{T_{\mathtt{WB}}}`$ is a static transformation composed of the user defined grasp position $`\ensuremath{\mathbf{p}}_{\mathtt{W}\mathtt{B}}`$ and a predetermined grasp orientation $`\ensuremath{\mathbf{R}}_{\mathtt{W}\mathtt{B}}`$.
Once the robot grasps the object handle, we set $`\theta_0 = 0`$, which leads to $`\mathbf{T}_{\mathtt{BA}}(\hat{\xi}, 0) = \mathbf{I}_{4\times4}`$. We then progressively increment the desired articulation configuration $`\theta_{t + 1} = \theta_t + gv \Delta t`$, with $`gv`$ being a constant speed for opening/closing the articulation, up to the articulation limit after which we invert the sign of $`gv`$. For each $`\theta_t`$, and given an estimate of $`\xi`$, we solve the inverse kinematics (IK) problem, subject to the condition $`\ensuremath{\mathbf{T}}_{\mathtt{W}\mathtt{E}}(\ensuremath{\mathbf{q}}_{t+1}) = \mathbf{T_{\mathtt{WA}}}(\hat{\xi}, \theta_t)`$. More specifically, we define the IK problem as a non-linear optimization problem where we encode the following task space constraints
\begin{align}
\begin{split}
\left\lVert\ensuremath{\mathbf{p}}_{\mathtt{W}\mathtt{E}}(\ensuremath{\mathbf{q}}_{t+1}) - \ensuremath{\mathbf{p}}_{\mathtt{W}\mathtt{A}}(\hat{\xi}, \theta_t)\right\rVert_F^2 &= 0\\
\left\lVert\ensuremath{\mathbf{R}}_{\mathtt{W}\mathtt{E}}(\ensuremath{\mathbf{q}}_{t+1}) - \ensuremath{\mathbf{R}}_{\mathtt{W}\mathtt{A}}(\hat{\xi}, \theta_t)\right\rVert_F^2 &= 0
\end{split}
\label{eq:pose_constraint}
\end{align}where $`\left\lVert\cdot\right\rVert_F`$ denotes a Frobenius norm.
We exploit the differentiability of the constraints in Eq. ([eq:pose_constraint]) w.r.t. to $`\mathbf{q}`$, to linearize the problem, and solve it sequentially until constraint satisfaction as a quadratic program (QP):
\begin{equation}
\begin{aligned}
\mathop{\mathrm{arg\,min}}_{\mathbf{x}}\,\frac{1}{2}\mathbf{x}^T\mathbf{C}\mathbf{x} \quad
\textrm{s.t.} \quad & \mathbf{lb} \leq \mathbf{x} \leq \mathbf{ub} \\
& \mathbf{lb}_A \leq \mathbf{Ax} \leq \mathbf{ub}_A,
\end{aligned}
\label{eq:qp}
\end{equation}where $`\ensuremath{\mathbf{x}} = \langle \ensuremath{\mathbf{\ensuremath{\dot{q}}}}, \ensuremath{\mathbf{s}}\rangle`$ is a vector of joint velocities and slack variables $`\ensuremath{\mathbf{s}}`$, and $`\ensuremath{\mathbf{A}}`$ is the Jacobian of the task constraints and the associated slack variables. Eq. ([eq:qp]) also encodes bounds on robot joint positions and velocities. We use our Kineverse () symbolic representation for computing the Jacobians, as well as encoding and solving the problem in Eq. ([eq:qp]).
Finally, we command the resulting joint positions $`\ensuremath{\mathbf{q}}_{t+1}`$ to the robot in compliant mode. Therefore, if the articulation estimation $`\xi`$ is inaccurate, the robot can comply with the physical articulation, leading to an end-effector pose that is different from $`\ensuremath{\mathbf{T}}_{\mathtt{W}\mathtt{E}}(\ensuremath{\mathbf{q}}_{t+1})`$. The actual end-effector pose $`\mathbf{T_{\mathtt{WA}}}(\hat{\xi}, \theta_{t+1})`$ is added to the graph as a measurement on $`\mathbf{T_{\mathtt{WA}}}`$.
Experiments
In the following section, we describe the experiments we conducted to evaluate our method, and we report the results. Discussion of the results follows in Sec. 9.
 />
/>
Simulation Experiments
In these initial experiments, we compare our uncertainty-aware articulation prediction method to the affordance prediction method of Flowbot3D (). We simulated point cloud data in PyBullet for several unseen articulated objects from the PartNet-Mobility dataset, and then each neural network made predictions on the articulation of the object. For each method, we selected the grasp point in the same way as the authors of Flowbot3D, which is to select the point with the largest magnitude of predicted flow. The articulation is then predicted using each method, and an applied force is simulated on the object, at the grasp point, in the direction of articulation opening. Each object starts closed, and we consider an opening to be successful if the object has been opened 90% of its limit, which was the same criteria as .
We chose to simulate an applied force rather than use a floating end-effector because we found that the end-effector often was able to open objects using unrealistic methods, such as passing through the object and then opening it from the inside. Additionally, due to poorly modeled contact physics, the end-effector would sometimes experience unrealistically large forces, causing the grasp to slip.
We compared the case where a single articulation prediction is made at the beginning (Single), and where continuous point cloud measurements are simulated and articulation is continuously predicted during the interaction (Multi). In the Multi experiments, each new articulation prediction updates the pulling direction (but not the grasp point). This way, if the first prediction was sufficient to open the object a small amount, but not fully, additional predictions can take advantage of the slight opening to make better predictions.
We also compare our method with different numbers of articulation factors. We subsample the point cloud to 200, 500, and 1000 points. Each point results in an additional factor in the factor graph, which increases the time for optimization.
Results
The results are summarized in Tab. [tab:results], and some example experiments are shown in Fig. 7. It is clear that Multi inference is significantly superior to Single as it can update the prediction during interaction. However, for several reasons we believe that Multi inference is not realistic for deployment on robot hardware. Firstly, if the camera is installed on the robot end-effector, it would not be possible to observe the articulated object during interaction and would instead require the robot to let go of the object and re-observe the scene as in . If, on the other hand, the camera is installed externally or on another part of the robot, such as a humanoid robot’s head, there would still be the issue of occlusion due to the interacting robot arm, and the segmentation mask would need continuous updating while the articulated part is moved.
Instead, we believe the Single inference approach is more realistic when combined with the proposed kinematic and force-based sensing. Additionally, when comparing inference times in Tab. [tab:results], we see a significant increase in latency as more factors are added to the factor graph. Because we intend to only make a single inference at the beginning of interaction, this increase is acceptable. Finally, we note that our method with 500 and 1000 factors outperforms Flowbot3D by 8.7% and 11.2% respectively. This is because our approach integrates a large number of articulation points to optimize an overall solution for articulation. In contrast, Flowbot3D selects the single largest point. While this allows their method to have very little latency, it increases variability in predictions, which leads to an overall lower success rate. In our method, increasing the number of articulation factors improves performance; however, we noted no further improvement beyond 1000 points, and we used this value for later real robot experiments.
Hand Guiding Experiments
In these experiments, we investigated the accuracy of our kinematics-based articulation estimation. We compared our method against which also uses factor graphs to estimate a screw parameterization. The authors kindly granted us access to their code for direct comparison.

W while the small axis is the
estimated pose TA.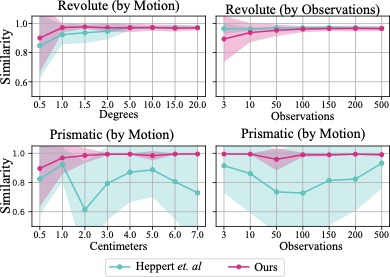 />
/>
These experiments were conducted on the real robot hardware. We used the compliant KUKA LBR iiwa robot and physically attached the robot’s end-effector to a box lid. We then hand-guided the robot motion in gravity compensation mode to open and close the box. For this experiment, we recorded both the robot joint positions, measured by the encoders, and the respective box lid poses, tracked with Vicon motion capture, as shown in Fig. 8. Similar to , we use the tangent similarity metric:
\begin{align}
J(\mathbf{v}_{gt}, \mathbf{v}_{est}) = \frac{1}{\theta_{max} - \theta_{min}} \int_{\theta_{min}}^{\theta_{max}} \frac{\mathbf{v}_{gt}}{\left\lVert\mathbf{v}_{gt}\right\rVert} \cdot \frac{\mathbf{v}_{est}}{\left\lVert\mathbf{v}_{est}\right\rVert},
\end{align}where $`\mathbf{v}_{gt}`$ is the local linear velocity of the grasp point measured from Vicon and $`\mathbf{v}_{est}`$ is the estimated local velocity from the articulation model. We can compute $`\mathbf{v}_{est}`$ from $`\xi`$ using the equation: $`\mathbf{v}_{est} = \mathbf{v}+ \boldsymbol{\omega}\times \ensuremath{\mathbf{c}}`$ where $`\ensuremath{\mathbf{c}}`$ is the contact point from kinematics. Since $`\mathbf{v}_{gt}`$ and $`\mathbf{v}_{est}`$ are normalized, they represent the direction of motion; therefore, their tangent similarity will be 1 when identical and 0 when perpendicular.
We recorded two hand guiding experiments, one for a revolute joint and one for a prismatic. First, we performed optimization over fixed increments, for example, optimizing over every 1 ° of rotation or 1 cm of translation. Next, we tested using fixed numbers of measurements equally spaced over the entire configuration range, with full results shown in Fig. 9. In the factor graph, we make no distinction between prismatic or revolute. When estimating prismatic joints, $`\boldsymbol{\omega}`$ tends towards very small values. At the output, if $`\left\lVert\boldsymbol{\omega}\right\rVert < 0.01`$, we set $`\boldsymbol{\omega}= 0_{3\times1}`$ and normalize $`\mathbf{v}`$.
Results
Our results demonstrate a high degree of accuracy, even with a small number of measurements. After only 0.5 ° of rotation, our estimator has an average tangent similarly of 0.90, after 1.0 °, this improves to 0.97. This enables online articulation estimation in cases where the neural network prediction is wrong because the robot part will only need to move the articulated part a small amount for the estimate to be updated. Additionally, we show that for equally spaced measurements throughout the configuration range, as few as 3 measurements can be sufficient to accurately estimate the joint. In comparison with Heppert et al., both methods have similar performance for revolute joints, while our method is better at distinguishing prismatic joints. We suspect this is because we check for prismatic articulations, whereas their method tends to confuse prismatic joints with very large revolute articulations.


Shared-autonomy Robot Experiments
For the shared-autonomy robot experiments, we used the same KUKA iiwa robot, and for sensing and grasping, we used an Intel RealSense D435 camera, an ATI Delta force/torque sensor, and a Robotiq 140 two-finger gripper. In these experiments, we tested the full pipeline as described in Sec. 7 with the following experimental protocol: the human user views the robot’s camera feed, which is looking at the same cabinet as in Fig. 1, and clicks on the image where to gasp. The robot then moves to the grasp goal and closes the gripper. Next, the robot moves using the learned articulation prediction from $`\theta = 0`$ to a specified upper bound. If a force threshold is reached and the gripper has not moved, this triggers the addition of a force factor to the factor graph, which is then optimized to find the next MAP articulation. The robot arms again attempt to open the cabinet and are either successful or another force factor is added until the solution converges on a direction where the door begins to open.
As the estimation runs online, once the end-effector begins to open the door, even a small amount, kinematic sensing is added to the factor graph, and the model is updated. This is fed back to the controller in a closed loop. Eventually, the motion of the arm allows more of the door to open, which leads to more kinematic measurements, and the estimate converges to the correct estimate of the joint, and the controller continues to open and close the door. We performed a new optimization after every 20 new kinematic measurements and used a distance limit of $`d=\SI{2}{\milli\meter}`$ or $`d=\SI{0.5}{\degree}`$ to trigger adding a new kinematic measurement to the factor graph.
Results
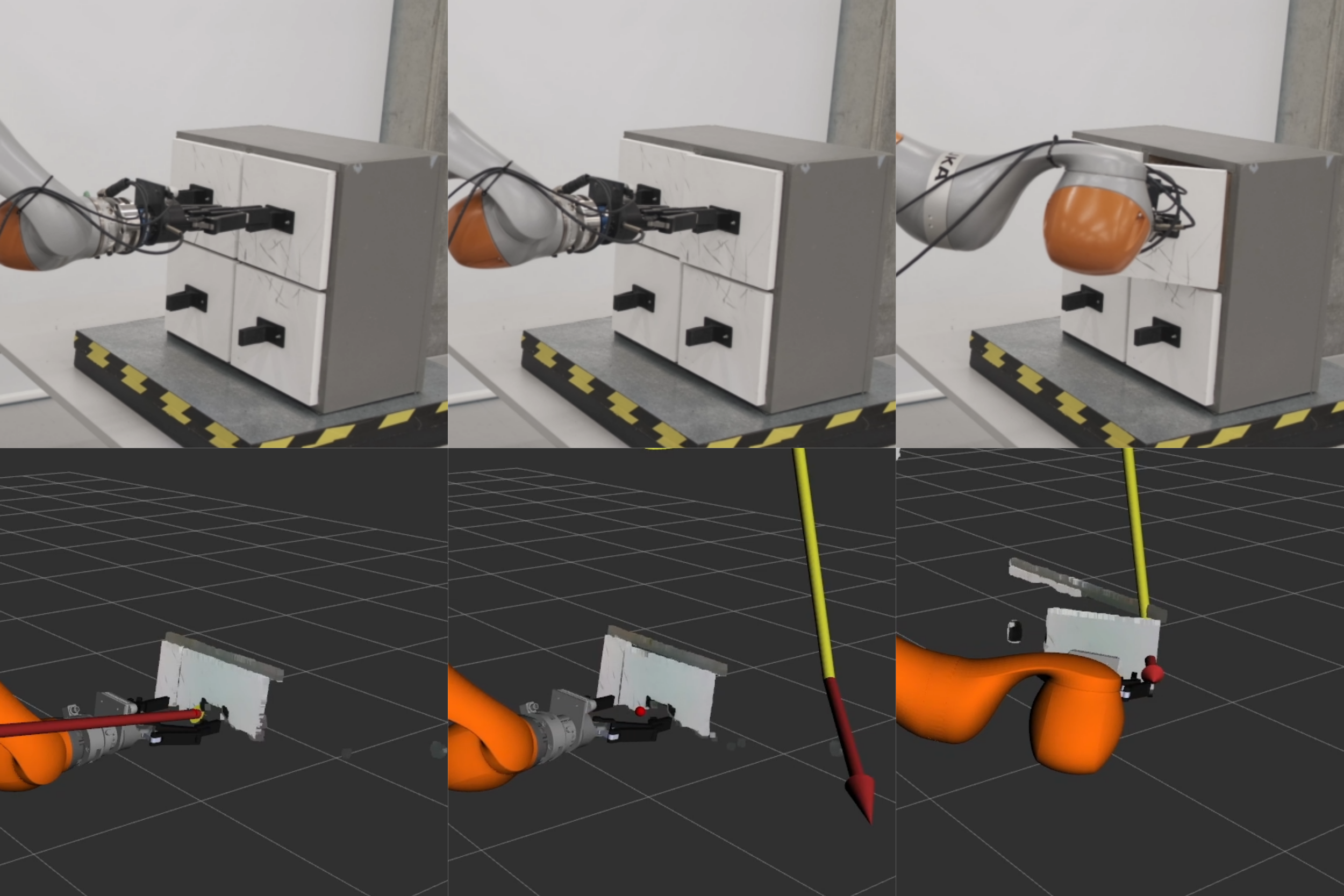
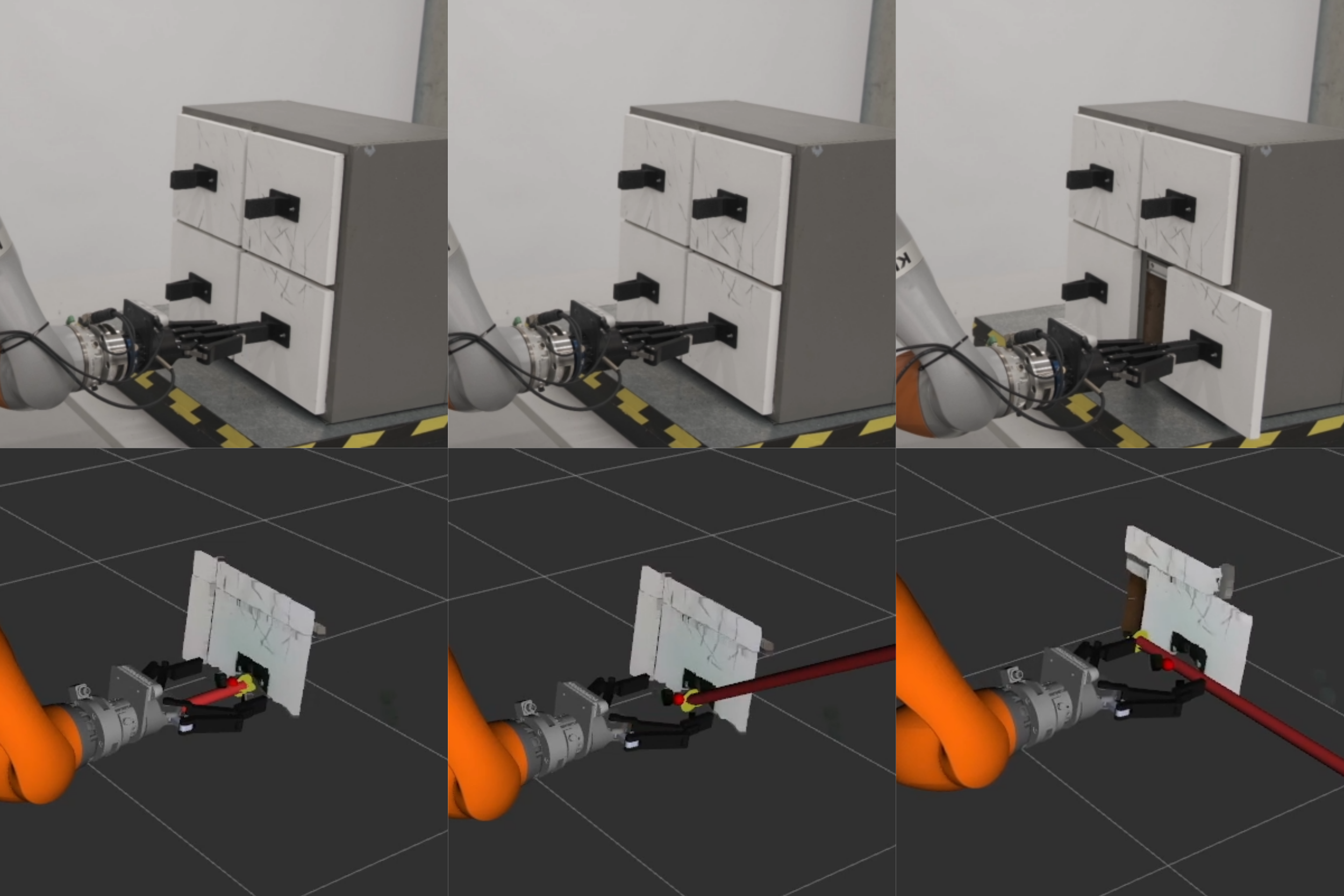
Four of the online estimation experiments are shown in Fig. 10. As similarly shown in previous work (), without visual cues for articulation, affordance-based neural networks tend to predict prismatic joints. In this work, because of our articulation prediction factor and the inclusion of the force plane factor, the robot was able to update the estimate even in the bottom right sliding door case. We repeated the full pipeline experiment 20 times on different doors and successfully opened the doors 15 times. Fig. 11 shows the estimated $`\xi`$ parameters during online experiments. Marginal covariances are computed for each optimization, and the $`3\sigma`$ range is depicted in Fig. 11 as a shaded area around the estimated mean value.
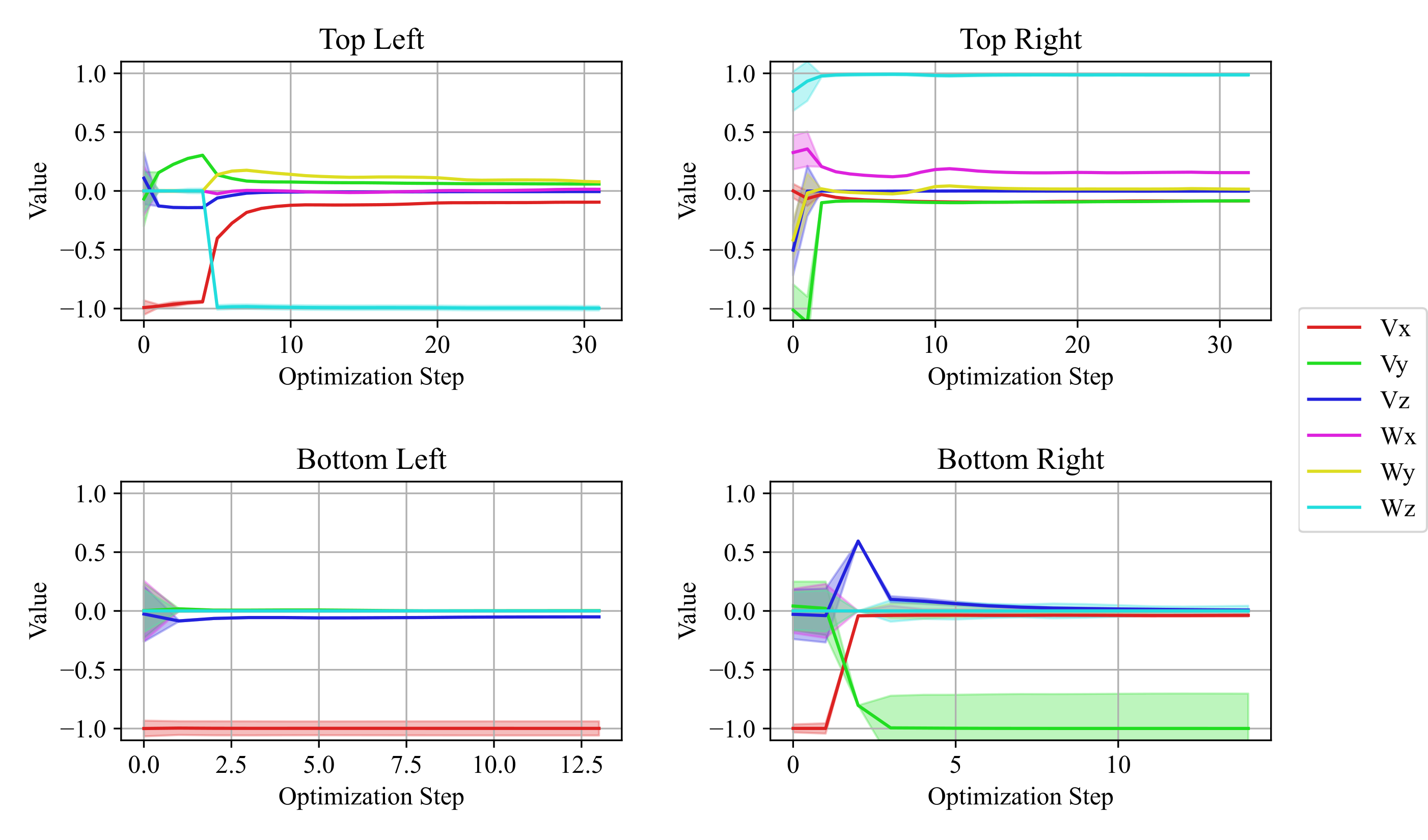
Discussion
Our method involves several advances that enable robots to open visually ambiguous objects of unknown articulation. First, by changing the neural network to provide a prediction of uncertainty and by changing the articulation factor, we enabled the initial prediction of articulation to include a learned uncertainty distribution rather than a hard-coded one as before. Fig. 4 shows an example network output of a sliding door with covariance largest along the $`x`$ direction, followed by $`y`$.
The addition of force sensing into the factor graph allows for the uncertainty to be used to update the estimate to the next most likely articulation. As an example in Fig. 4, the dominant prediction from the network is of a revolute door, however, it is clear from the uncertainty distribution that the network is less confident about lateral motion. When a force plane factor is added to the factor graph, the estimate will collapse along the $`y`$ direction, correctly updating the estimate as prismatic. This is the process that allowed the robot to open the bottom right sliding door in Fig. 10. Of the 20 full system trials attempted, 4 failed due to the slipping of the gripper. Because we rely on an assumption of rigid contact with only a small amount of slipping, we cannot differentiate between significant slipping and intentional movement opening a door. In future work, this could be detected using sensors on the fingertips of the gripper.
In our experiments, we found that the compliance in the robot arm could significantly affect the success rate. For example, if the robot arm is too compliant in a specific direction, it may not be able to overcome the friction in the joint to open the door. On the other hand, if the arm is too stiff, it could break the door. This presents an opportunity for future investigation by adapting the stiffness parameters online based on the estimate of the articulation. Model-based or learning-based approaches may equally be applied to this problem. Learning-based methods also present a path for learning priors for safe interaction forces. As it stands, the maximal force exerted by our system is a hyperparameter that has to be adjusted for the setup. While cabinet-sized objects all require very similar interaction forces, we would of course like a system that can also operate heavy doors and small jewelry boxes without the need for human intervention. We see a path for learning such priors on the basis of stable language-aligned visual features (), either incrementally or from human demonstrations ().
Finally, we use force sensing only at the beginning of the interaction for estimating the articulation; however, in future work, we intend to explore learning-based methods for estimating articulation from force sensing, similar to learning pose estimators (). Despite the Sim2Real gap for contact physics, we believe that leveraging training in simulation () can significantly improve success rates for real-world training of robot interactions with articulated objects.
Conclusion
In this work, we present a novel method for online estimation and opening of unknown articulated objects. Our method can enable a robot to open a wide variety of articulated objects including both common household items and objects whose articulation is not visually apparent. Our method fuses visual, force and kinematic sensing from both learned predictions from a neural network, and physics-based modeling of articulations using screw theory. The back-bone estimation framework is based on factor graphs which is integrated with a shared autonomy framework in which a user simply clicks where to open, and the robot opens a door.
This work significant expand on our previous work with several major advances. We modified the neural network to provide a prediction of uncertainty, and we introduced a new articulation factor to facilitate the incorporation of this uncertainty into the factor graph. We also added an entirely new sensing modality in force sensing. The combination of these changes made our system much more capable of opening different articulations, including where the articulation is not visually apparent. We implemented our method on a real robot for interaction with a visually ambiguous articulated object and achieved a high rate of success for interaction. While more work can be done on integrating force sensing into the framework, this article shows the major benefits of fusing proprioceptive sensing with learned vision priors for object manipulation.
📊 논문 시각자료 (Figures)

A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
In this case, $`\mathbf{p}_i`$ and $`\mathbf{p}_i^{+}`$ are represented in homogeneous coordinates. We convert $`\mathbf{p}_i`$ back to Cartesian coordinates later. ↩︎