DrivingGen A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
📝 Original Paper Info
- Title: DrivingGen A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving- ArXiv ID: 2601.01528
- Date: 2026-01-04
- Authors: Yang Zhou, Hao Shao, Letian Wang, Zhuofan Zong, Hongsheng Li, Steven L. Waslander
📝 Abstract
Video generation models, as one form of world models, have emerged as one of the most exciting frontiers in AI, promising agents the ability to imagine the future by modeling the temporal evolution of complex scenes. In autonomous driving, this vision gives rise to driving world models: generative simulators that imagine ego and agent futures, enabling scalable simulation, safe testing of corner cases, and rich synthetic data generation. Yet, despite fast-growing research activity, the field lacks a rigorous benchmark to measure progress and guide priorities. Existing evaluations remain limited: generic video metrics overlook safety-critical imaging factors; trajectory plausibility is rarely quantified; temporal and agent-level consistency is neglected; and controllability with respect to ego conditioning is ignored. Moreover, current datasets fail to cover the diversity of conditions required for real-world deployment. To address these gaps, we present DrivingGen, the first comprehensive benchmark for generative driving world models. DrivingGen combines a diverse evaluation dataset curated from both driving datasets and internet-scale video sources, spanning varied weather, time of day, geographic regions, and complex maneuvers, with a suite of new metrics that jointly assess visual realism, trajectory plausibility, temporal coherence, and controllability. Benchmarking 14 state-of-the-art models reveals clear trade-offs: general models look better but break physics, while driving-specific ones capture motion realistically but lag in visual quality. DrivingGen offers a unified evaluation framework to foster reliable, controllable, and deployable driving world models, enabling scalable simulation, planning, and data-driven decision-making.💡 Summary & Analysis
1. **Diverse Driving Conditions Dataset** - Unlike existing datasets that focus on sunny weather and urban settings, this paper uses data collected from various weather conditions, time of day, and global regions to provide a more realistic evaluation. This helps assess how well models perform in real-world driving scenarios.-
Driving-Specific Evaluation Metrics - The paper introduces new metrics tailored for driving scenarios, including measures for video and trajectory distribution, human perceptual quality, kinematic feasibility, etc., providing a comprehensive assessment.
-
Extensive Benchmarking Across Models - By evaluating 14 generative world models, the paper reveals insights into their strengths and weaknesses, guiding future research in realistic driving simulation.
📄 Full Paper Content (ArXiv Source)
Introduction
Driven by scalable learning techniques, generative video models have made remarkable progress in recent years, enabling the synthesis of high-fidelity videos across diverse scenes and motions. These models suggest a promising path toward “world models” – predictive simulators capable of imagining the future, which can support planning, simulation, and decision-making in complex, dynamic environments. Inspired by this vision, there has been an accelerating surge in developing driving world models: generative models specialized for predicting future driving scenarios. Given an initial scene and optional conditions (e.g., text prompts, driving actions), a driving world model predicts both the ego-vehicle’s future movements and the evolution of surrounding agents’ trajectories. Such models enable closed-loop simulation and synthetic data generation, reducing reliance on real-world data and offering a promising means to explore out-of-distribution scenarios safely . Driving world models are also tightly coupled with end-to-end autonomous driving systems, where errors in predicted future scenes and trajectories can directly lead to unsafe decisions .
While a vibrant exploration of a wide range of approaches for driving world models is underway, a well-designed benchmark – which not only measures progress but also guides research priorities and shapes the trajectory of the entire field – has not yet emerged. Current evaluations fail to fully capture the unique requirements of the driving domain, and are limited in several ways. 1) Visual Fidelity First, most benchmarks rely on distribution-level metrics such as Fréchet Video Distance (FVD) to assess video realism, and some adopt human-preference-aligned models (e.g., vision-language models) to score visual quality or semantic consistency. However, driving imposes unique constraints on imaging: sensor artifacts, glare, or other corruptions can have critical safety implications that general video metrics fail to capture. 2) Trajectory Plausibility Second, the ego-motion trajectories underlying the generated videos are crucial. High-quality video generation in driving must produce trajectories that are natural, dynamically feasible, interaction-aware, and safe—properties that go beyond mere visual realism. 3) Temporal and Agent-Level Consistency Third, temporal consistency is crucial for driving, where surrounding objects directly impact safety and decision-making. Prior benchmarks often focus on scene-level consistency but neglect agent-level consistency, such as abrupt appearance changes or abnormal disappearances of agents—imperfections that can severely compromise the realism and reliability of driving simulations. 4) Motion Controllability Finally, for ego-conditioned video generation, it is critical to assess whether the generated motion faithfully follows the conditioning trajectory. This aspect of controllability is largely overlooked in existing benchmarks, yet it is essential for safe planning and reliable closed-loop driving, where misalignment can lead to catastrophic consequences.
Another major limitation in existing benchmarks for driving world models is the lack of diversity along crucial dimensions essential for real-world deployment. 1) First, Weather and Time of Day coverage is heavily skewed: datasets like nuScenes are dominated by clear-weather, daytime driving, leaving rare but safety-critical conditions (night, snow, fog) underrepresented. 2) Second, Geographic Coverage is limited, often confined to a few cities or countries, which restricts evaluation across varied scene appearance and with local traffic rules. 3) Third, Driving Maneuvers and Interactions rarely capture the full diversity of agent behaviors and complex multi-agent dynamics, such as pedestrians waiting at crosswalks, aggressive driver cut-ins, or dense traffic scenarios . This lack of diversity makes it difficult to assess whether generative models can handle the wide range of scenarios encountered in real-world driving, undermining their reliability and safety for large-scale deployment.
 style="width:85.0%" />
style="width:85.0%" />
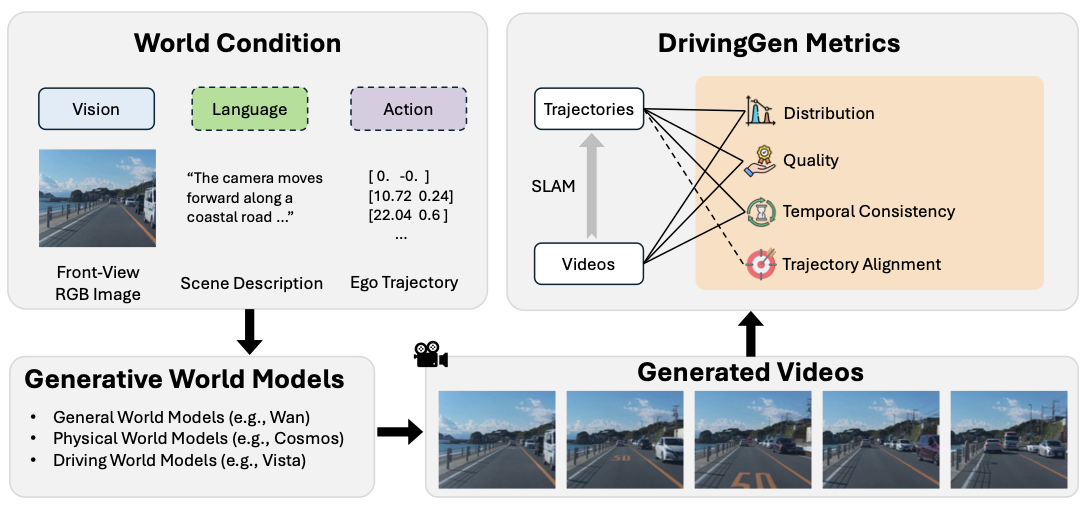
To address the above gaps, this work proposes DrivingGen, a comprehensive benchmark for generative world models in the driving domain with a diverse data distribution and novel evaluation metrics. DrivingGen evaluates models from both a visual perspective (the realism and overall quality of generated videos) and a robotics perspective (the physical plausibility, consistency and accuracy of generated trajectories). Our benchmark makes the following key contributions:
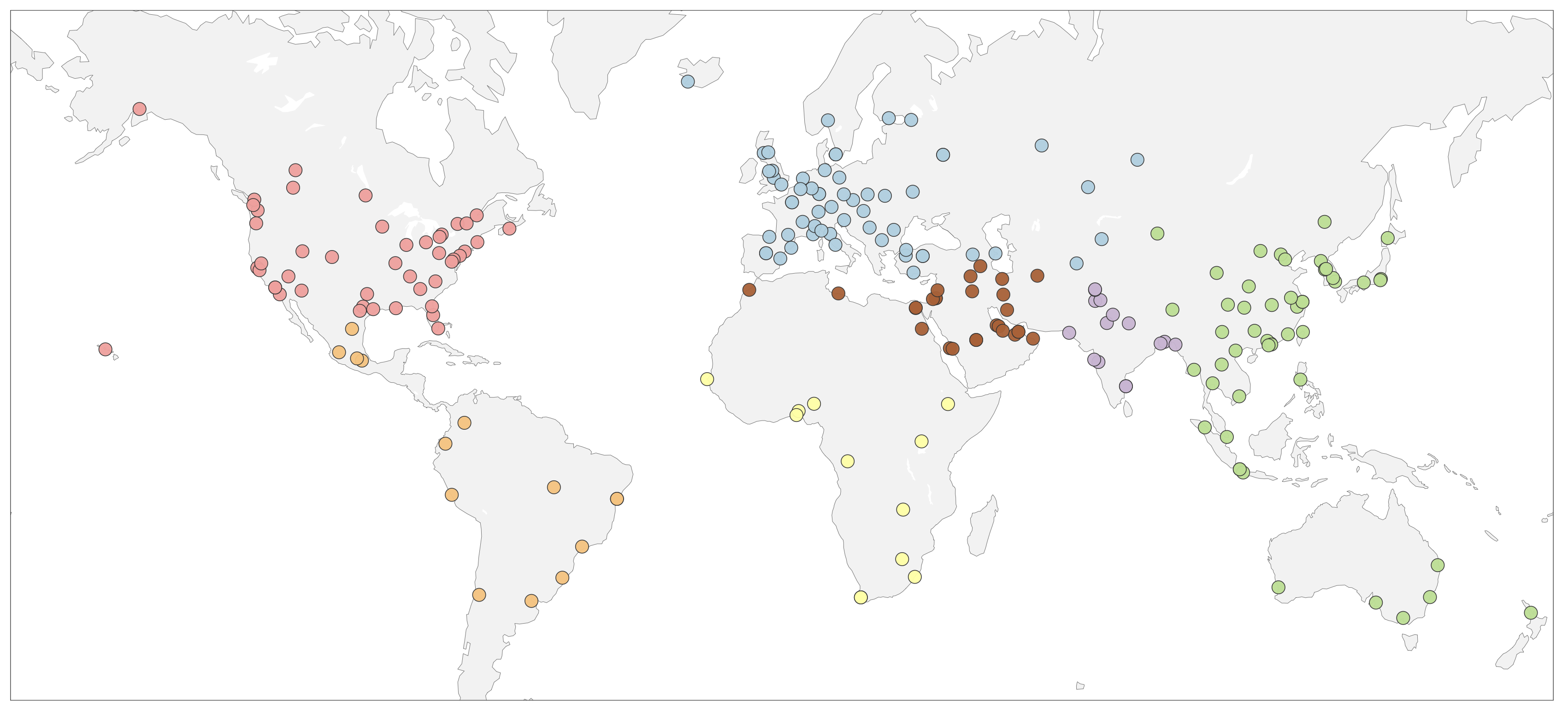
Diverse Driving Dataset. We present a new evaluation dataset that captures diverse driving conditions and behaviors. Unlike prior datasets biased toward sunny, daytime urban scenes, ours includes varied weather (rain, snow, fog, floods, sandstorms), times of day (dawn, day, night), global regions (North America, Europe, Asia, Africa, etc.), and complex scenarios (dense traffic, sudden cut-ins, pedestrian crossings). This diversity enables more robust and unbiased evaluation of generative models under realistic driving distributions. Besides, considering that inference for video generation is generally time-consuming, we carefully limit the number of samples to 400 to ensure efficient testing and iteration, achieving a balance between efficiency and meaningful evaluation.
Driving-Specific Evaluation Metrics. We introduce a novel suite of multifaceted metrics specifically designed for driving scenarios. These include distribution-level measures for both video and trajectory outputs, quality metrics that account for human perceptual quality, driving-specific imaging factors (such as illumination flicker, motion blur, etc.), temporal consistency checking at both the scene level and individual agent level (e.g., appearance discrepancy or unnatural disappearances in videos), and trajectory realism metrics that evaluate kinematic feasibility and alignment to intended paths (e.g., smoothness, physical plausibility, and accuracy in following a given route). Together, these metrics provide a comprehensive 4-dimensional evaluation along distribution realism, visual quality, temporal coherence, and control/trajectory fidelity – covering aspects that generic metrics or single-number scores fail to capture.
Extensive Benchmarking and Insights. We benchmark 14 generative world models on DrivingGen spanning three categories – general video world models, physics-based world models, and driving-specialized world models. This evaluation, the first of its kind in the driving domain, reveals important insights and open challenges. For example, we find that certain general world models produce visually appealing traffic scenes yet break physical consistency in vehicle motion, and some driving-specific models excel in trajectory accuracy but lag in image fidelity. By analyzing performance across our metrics, we reveal the strengths and failure modes of each approach, offering insights for future research. All components of DrivingGen—dataset and evaluation code—are publicly released to support reproducible research and advance realistic driving simulation.
 style="width:99.0%" />
style="width:99.0%" />
 style="width:95.0%" />
style="width:95.0%" />
 style="width:95.0%" />
style="width:95.0%" />
Related Works
In this work, we focus on two primary research areas: generative world models applied to autonomous driving and benchmarks for evaluating these models. Due to space constraints, we provide a comprehensive review of the relevant literature, including recent advancements in general video generation and specific driving-world evaluations, in Appendix 7.
DrivingGen Benchmark
The goal of DrivingGen is to establish a comprehensive benchmark to evaluate generative world models under driving-specific constraints and criteria. To achieve this, the proposed benchmark includes several key components: 1) a carefully collected dataset that is diverse in weather, time of day, regions (and their driving styles), and driving maneuvers to support reasonable evaluation; 2) multifaceted metrics that not only evaluate the video quality from a general visual perspective (e.g., appearance), but also from a driving and robotics perspective (e.g., the physical feasibility of trajectories). To showcase the distinguishing capability of DrivingGen, we evaluate general world models, physics-based models, and driving-specific models. An overview is given in Fig. 1, with dataset details in Sec. 3.1 and metrics in Sec. 3.2.
Benchmark Dataset
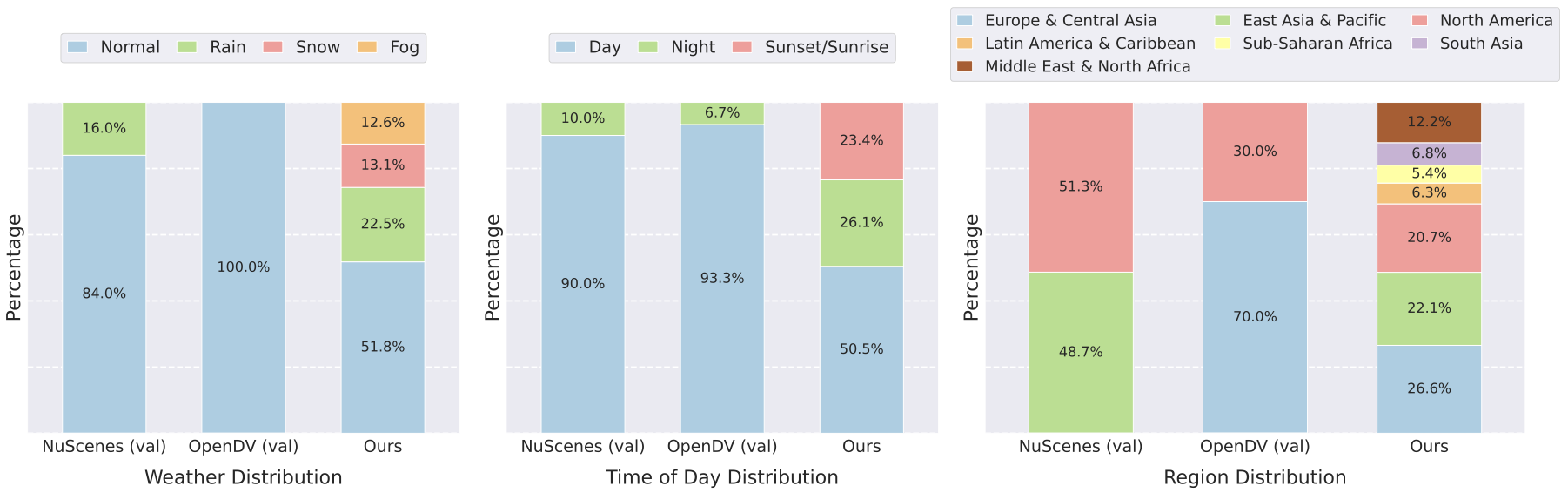
Generative video models, as a form of world models, offer a promising way to anticipate future driving scenarios, simulate rare or safety-critical events, and ultimately support planning and decision-making. However, real-world driving unfolds under highly variable conditions, encompassing different weather, lighting, regions, and complex maneuvers. Therefore, evaluating generative models across diverse scenarios is crucial to ensure their robustness and reliability. To this end, the majority of existing works in driving world models mainly utilize nuScenes and OpenDV datasets for evaluation. However, the diversity of weather, region, time of day, and driving maneuvers in these datasets is limited and highly biases the data distribution. For example, as shown in Fig. 2, over 80% of the nuScenes validation data and 90% of the OpenDV validation data are collected during normal sunny daytime conditions. Additionally, the data are collected from a limited number of vehicles and locations, which further limits the comprehensiveness. Based on this observation, we curated a significantly more diverse dataset. An overview of our dataset is presented in Fig. 2 and Fig. 3.
Dataset Construction. We organize our dataset into two complementary tracks, offering distinct perspectives for evaluating driving videos.
-
Open-Domain Track is designed to evaluate models’ generalization to open-domain, diverse, unseen driving scenarios. We construct this track using Internet-sourced data spanning multiple cities and regions worldwide, ensuring broad coverage beyond the training distribution.
-
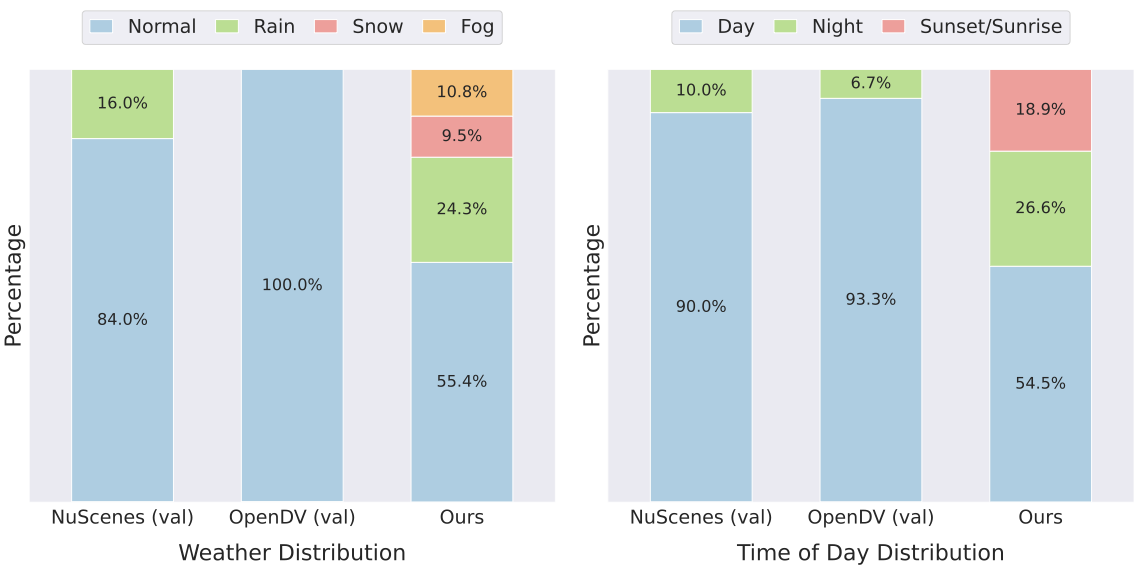
Ego-Conditioned Track complements the open-domain track. While the open-domain setting evaluates generalization to diverse unseen scenarios, it does not verify whether the generated trajectories follow a specified conditioning trajectory—a property that is critical for robotics and self-driving applications. The ego-conditioned track therefore focuses on trajectory controllability, measuring how well the trajectories derived from generated videos align with the given ego-trajectory instructions. The ego trajectory is optional for model input and only provided in this track. To construct it, we aggregate data from five open-source driving datasets: Zod (Europe), DrivingDojo (China), COVLA (Japan), nuPlan (US), and WOMD (US).
Each data sample in the dataset consists of three components: a front-view RGB image (vision), a scene description (language), and an optional ego trajectory (action). For each scene, we employ Qwen to capture descriptions of the future dynamics and camera movements within the scene. Given the time-consuming nature of video generation, we limit the number of samples for efficient testing and iteration, while ensuring quality and diversity. The dataset includes 400 samples—200 per track—striking a balance between efficiency and meaningful evaluation.
Balanced Data Dsitribution The overall distribution of our dataset, along with a gallery of representative video examples, is shown in Fig. 4. To ensure meaningful evaluation, we explicitly control diversity across several dimensions:
-
Weather and Time of Day. Existing benchmarks are often dominated by, if not fully composed of, normal weather and daytime conditions. In contrast, our benchmark aims for a more balanced distribution. For the open-domain track, we limit normal weather and daytime clips to below 60% and increase the proportion of other conditions, such as snow (13.1%), fog (12.6%), and night/sunset/sunrise driving (50%), to ensure a more comprehensive evaluation. Extreme events, including sandstorms, floods, and heavy snowfall at night, are also included. A similar strategy is applied to the ego-conditioned track, where normal weather/daytime clips make up 60% of the data, while the remainder covers diverse conditions to support trajectory controllability evaluation across different scenarios.
-
Geographic Coverage. Prior benchmarks are often limited to a small number of cities or countries, restricting the diversity of driving scenarios. For the open-domain track, we collect data from a wide range of regions worldwide, including North America (20.7%), East Asia & Pacific (22.1%), Europe & Central Asia (26.6%), the Middle East & North Africa (12.1%), Latin America & Caribbean (6.3%), South Asia (6.8%) and South-Saharan Africa (5.4%), to ensure broad geographic coverage. For the ego-conditioned track, data are drawn from existing datasets covering North America, Asia and Europe, providing diverse driving scenarios to evaluate ego-trajectory alignment and controllability.
-
Driving Maneuvers and Interactions. Capturing diverse driving behaviors and multi-agent interactions is critical for evaluating generative world models. For the open-domain track, scenarios include complex interactions such as waiting pedestrians at crosswalks, other agents cutting in, and dense traffic, testing the model’s understanding of the driving world. For the ego-conditioned track, scenarios are similarly diverse, emphasizing multi-agent interactions and challenging conditions to evaluate controllability and alignment with ego-trajectory instructions.
Benchmark Metrics
For all video models, our DrivingGen metrics cover three key dimensions: distribution, quality, and temporal consistency, evaluated for both videos and trajectories. We extract trajectories using standard PnP method within a SIFT and RANSAC scheme and UniDepthV2 . We provide the details of our SLAM pipeline , including guaranteeing that all videos reconstruct trajectories and a discussion to compare other benchmarks’ trajectory reconstruction methods in Appendix 8.2. For models conditioned on ego trajectories, we include a fourth dimension: trajectory alignment, measuring adherence to the input. Table [tab:metric] lists the metrics, grouped into four categories detailed below, each targeting a different aspect of video fidelity.
Distribution
How far is the generative distribution from the data distribution? A common practice is to measure Fréchet Video Distance (FVD) on generated videos. However, our key insight is that video quality is not solely determined by visual realism—equally important, especially for self-driving and embodied agents, is the realism of the induced ego-motion. Focusing only on visual fidelity gives an incomplete picture. Therefore, we evaluate distributional closeness across both videos and trajectories, capturing complementary perspectives from visual perception and robotics.
For the video distribution, we utilize FVD to quantify the similarity between generated videos and real videos. Specifically, we follow the standardized computation protocol from the original StyleGAN-V . For the trajectory distribution, we introduce a novel metric, Fréchet Trajectory Distance (FTD), a distributional metric tailored for evaluating driving trajectories. The key requirement is a trajectory encoder that maps trajectories into a latent space suitable for measuring distributional distance. To this end, we draw from the motion prediction domain—where models themselves are generative of future trajectories, and adopt the encoder of Motion Transformer (MTR) as our encoding model. Details of FTD computation are provided in Appendix 8.3.
Quality
How good are the generated videos and trajectories? To evaluate the fidelity of generated videos and trajectories in driving scenarios, we propose a comprehensive quality suite covering three aspects: perceptual video quality, domain-specific video quality, and trajectory quality.
Visual Quality. A common practice in generative video evaluation is to assess general perceptual quality with automatic, reference-free estimators aligned with human judgments. Specifically, we adopt CLIP-IQA+ , which leverages CLIP’s vision-language representations to predict perceptual quality scores consistent with human subjective assessments. While effective, such subjective perceptual quality does not always align with what matters for driving, which unfolds outdoors, involves multiple agents, and occurs under real-world constraints. To additionally consider driving-specific imaging quality, we further adopt the Modulation Mitigation Probability (MMP) metric from the IEEE Automotive P2020 standard . MMP targets Pulse-Width Modulation (PWM)-induced flicker that can disrupt perception and tracking, and reports the fraction of time windows where residual temporal luminance modulation falls below a small threshold. Implementation details are in Appendix 8.4.
Trajectory Quality. While prior evaluations often rely on video-based scores, they typically neglect whether the underlying motions are physically and kinematically plausible. To reduce the gap, DrivingGen introduces a composite, reference-free metric to assess the kinematic plausibility and ride comfort. Three individual submetrics are proposed and aggregated into a single score: 1) a comfort score penalizes extremes of longitudinal jerk, lateral acceleration, and yaw-rate, yielding a score to reward smoother, more comfortable motion; 2) a motion score that discourages under-mobility, as some trajectories barely move and stay static due to the model’s weak ability; 3) a curvature score summarizes how much the path turns, discouraging zig-zags and unrealistically sharp bends. Together, these submetrics directly target properties that affect controllability, planning, and perceived comfort. Calculation details appear in Appendix 8.5.
Temporal Consistency
How temporally consistent is the generated world? We assess the temporal consistency of both videos and trajectories. For videos, we evaluate scene-level consistency, agent-level consistency, and explicitly emphasize abnormal agent disappearance. For trajectories, we measure the consistency of speed and acceleration over time, independent of path shape and absolute mobility.
Video Consistency. Existing metrics directly calculate the consistency between consecutive frames (or each frame to the first) at a fixed rate. However, it is easily hackable by generating near-static videos. To measure temporal consistency while accounting for the actual motion in the scene, we first pass the generated videos through an off-the-shelf optical flow model to compute the median optical flow magnitude per frame. We then adaptively downsample: videos with lower motion are sampled more sparsely so that the per-step displacement becomes comparable to normal/high-speed driving. After this, the similarity of the DINOv3 features between consecutive frames of the downsampled videos is reported as the video consistency score. Unlike fixed-stride metrics, our approach fairly measures temporal consistency across videos with varying motion speeds, preventing static or near-static videos from obtaining artificially high scores.
Agent Appearance Consistency. Measuring only scene-level features can overlook small temporal changes in individual agents, such as shifts in color, texture, or shape, while these agents are often the key focus for driving, as they would more directly impact driving behavior and safety. To measure the agent’s temporal consistency, we therefore detect agents in the first frame, track them across the video, crop their bounding boxes, and compute consistency purely at the agent level. We use YOLOv10 as the detector and SAM2 for tracking. We measure DINOv3 feature similarity across consecutive frames and to the first frame.
Agent Abnormal Disappearance. In addition to appearance stability, agents in driving scenes must persist in a physically plausible manner. Sudden, non-physical disappearances of surrounding agents are commonly observed in generated videos, which can compromise realism and safety. DrivingGen quantifies this by diagnosing whether an agent’s disappearance is normal (e.g., leaving the field of view or being occluded) or abnormal. We consider three key frames for each disappearing agent: the first and the last frames where the agent is visible, and the first frame after it vanishes. A vision large language model (VLM) , Cosmos-Reason1 , is prompted to judge disappearance based on visual and motion continuity, and the agent’s local interactions with surrounding agents. We report the percentage of videos with no abnormal disappearances as the score. Implementation Details can be found in Appendix 8.6.
Trajectory Consistency. Realistic driving exhibits predictable kinematics: speed varies slowly around a cruise level and acceleration does not oscillate. To reveal this property, we compute how stable a trajectory’s velocity and acceleration are over time. The average of the two scores is taken as the overall trajectory consistency score. Trajectories that jitter, stop–go, or oscillate score low, while steady cruising with gradual changes scores high. Calculation details are provided in Appendix 8.7.
Trajectory Alignment
In addition to trajectory consistency, the alignment of the trajectories underlying the generated videos with the conditioning (ego) trajectory is also critical, especially for trajectory-grounded video generation. To assess this, we propose two complementary metrics.
Average Displacement Error (ADE). As a common practice, ADE measures the mean pointwise distance between the generated and input trajectories across the prediction horizon. It emphasizes local, step-by-step fidelity and is standard in motion prediction and planning.
Dynamic Time Warping (DTW). In addition to ADE, which compares trajectories at each time step, we introduce a complementary metric that captures the overall contour and shape of the trajectory. Specifically, DTW aligns predicted and reference trajectories via non-linear time warping and measures their path-shape discrepancy using Euclidean point-wise cost.
Experiments
Evaluation Setup. We evaluate 14 competitive generative world models on DrivingGen, spanning three categories. 1) First, we include 7 general video world models, comprising two commercial closed-source models, Gen-3 and Kling , and five well-known open-source models: CogVideoX , Wan , HunyuanVideo , LTX-Video , and SkyReels . 2) Second, we evaluate 2 physical world models that are developed specifically for the physical robotics domain, Cosmos-Predict1 and Cosmos-Predict2 . 3) Third, we assess 5 driving-specific world models: Vista , DrivingDojo , GEM , VaViM , and UniFuture . All models are evaluated on a prediction horizon of 100 frames. We report the time and resource cost for our DrivingGen benchmark in Appendix 8.8.
Observations and Challenges
Table [tab:evaluation_results] presents the results. We provide the full table of metrics in a transparent way to evaluate the models comprehensively, and the average rank serves as a quick summary but not a definitive score. We also show that our results align well with human judgement, by calculating the Spearman’s correlation coefficient (see details in Appendix 8.9.) In the following, we will discuss key findings from our results.
Closed-source models lead in visual quality and overall ranking. Across both tracks, closed-source models consistently occupy the top positions, achieving strong perceptual scores and maintaining stable agent behavior. They rarely exhibit abnormal object disappearance and generally preserve scene coherence over time, demonstrating robust overall world generation capabilities.
Top open-source general world models are competitive on specific metrics. Several open-source models approach or match the closed-source leaders on individual dimensions. For example, CogVideoX and Wan achieve strong video distributional realism (low FVD) across both tracks, suggesting that open-source models can excel in targeted aspects even if they do not lead overall.
No single model excels in both visual realism and trajectory fidelity. We observe distinct “personas”: some models achieve high visual quality but only moderate trajectory adherence and per-agent consistency, while driving-specialized models accurately follow commanded paths with physically plausible motion (low ADE/DTW) yet underperform in visual fidelity, exhibiting noticeable artifacts. Currently, no model successfully combines strong photorealism with precise, physically consistent motion, highlighting a key frontier for driving world generation.
Trajectory alignment remains limited, revealing substantial gaps. Under ego-trajectory conditioning, models exhibit significant ADE/DTW errors, indicating poor adherence to commanded paths. This can stem from two main factors: 1) artifacts in the generated videos (e.g., texture repetition, blur, unstable geometry) that impair SLAM-based trajectory recovery, and 2) imperfect motion generation, where the model itself fails to follow the intended trajectory. These observations highlight that both video fidelity and trajectory modeling need further improvement.
DrivingGen exposes failure modes hidden from prior single metric. Existing benchmarks often rely solely on distribution-level metrics such as FVD to evaluate generated driving videos. While useful for assessing overall distribution similarity, good FVD/FTD alone does not necessarily imply plausible driving—videos can appear distribution-close yet exhibit stop–go jitter, identity drift, or non-physical disappearances. Similarly, high objective quality (e.g., low flicker) can coexist with poor subjective quality or unstable agent behavior. By jointly reporting distribution, perceptual quality, temporal consistency, and trajectory alignment, DrivingGen exposes these hidden failure modes and highlights precisely where each model falls short.
Conclusion
This work introduces DrivingGen, a comprehensive benchmark designed to evaluate generative world models for autonomous driving. DrivingGen integrates a diverse dataset spanning varied weather, time of day, global regions, and complex driving maneuvers with a multifaceted metric suite that jointly measures visual realism, trajectory plausibility, temporal coherence, and controllability. By benchmarking a broad spectrum of state-of-the-art models, DrivingGen reveals critical trade-offs among visual fidelity, physical consistency, and controllability, providing clear insights into the strengths and limitations of current approaches. The benchmark establishes a unified and reproducible framework that can guide the development of reliable and deployment-ready driving world models, fostering progress toward safe and scalable simulation, planning, and decision making in autonomous driving.
Future Work and Limitations
As DrivingGen is the first comprehensive benchmark for generative world models in autonomous driving, several intriguing ideas can be explored further in follow-up work.
Expanding More Meaningful Data. Currently, we collect 400 data samples (from the web and aggregated from existing driving datasets) to balance efficiency and practicality, because generating and evaluating videos is resource-intensive. With this limited number, we may not fully cover the long tail of driving scenarios. In future expansions, scaling up the dataset is an exciting future direction. As generative models become faster and datasets become more readily available, scaling up to thousands of clips is feasible and will further improve long-tail coverage.
Interactive and Closed-Loop Simulation. Ensuring reliable closed-loop performance (e.g., for safe planning) is crucial for Autonomous Driving, and DrivingGen is a step toward that by first benchmarking open-loop predictive quality and realism. In the current work, all considered generative video world models are designed for open-loop video generation and no standardized closed-loop world generation framework exists yet. Performing a fair, unified closed-loop benchmark is infeasible at this stage. An exciting future direction is to consider closed-loop evaluation for driving world models (e.g., integrating generative models into an interactive simulator like CARLA or combining with closed-loop dataset simulation like Navsim).
Downstream Tasks Metrics and Enriching data modality. DrivingGen focuses on metrics that directly measure video realism, physical consistency, and controllability in the generated footage itself. One complementary direction is to incorporate metrics from downstream tasks in Autonomous Driving (e.g., how well an autonomous driving stack performs using synthetic videos). However, it may require collecting synchronized multi-camera footage and Map knowledge for a fair and meaningful benchmark. Our current dataset is limited to a single front-view camera feed, which poses challenges for more structural driving generation. A possible future direction is expanding the benchmark to multi-view video and sensor data (LiDAR, HD Map, etc.) to construct a more structured driving world generation and novel metrics (e.g., view consistency) can be proposed.
Evaluation of Scene Controllability and State Transformation. Evaluating controllability over scene content (e.g., controlling other agents, road layout in the scene) would be highly useful for autonomous applications. We did not include such metrics in our benchmark because implementing a unified evaluation for different models with scene-level control faces challenges both in model support and dataset complexity. Due to these challenges, we believe it is a great topic for driving world generation which controls scene content and map layout and assessing whether state transformations of the world model are reasonable. One could imagine controlling the presence or behavior of a pedestrian or the configuration of lanes, and checking if the model can follow those constraints.
Counterfactual Reasoning Evaluation. In our current benchmark, we did not explicitly evaluate counterfactual reasoning. The main reason is that DrivingGen focuses on real driving videos. We are limited to evaluating the scenarios that actually happened. One novel future direction would be counterfactual reasoning evaluation. One can introduce hypothetical events or modifications (like an astronaut on a horse crossing the road, or a car jumping off the ground to overtake other agents, and other unrealistic edge cases) and propose new metrics to check whether the model follows this counterfactual generation.
Overall Score. We provide the full table of metrics transparently to evaluate the models, and the average rank serves as a quick summary but not a definitive score. Exploration of a composite, single-index score is an interesting topic, which requires normalized distribution and alignment metrics (e.g., FVD and ADE).
Related Works
Generative World Models and their application in Driving
Driven by advances in image generative modeling , the landscape of large-scale video models has evolved significantly, particularly in diffusion-based frameworks. Closed-source models , mainly developed by major technology companies, aim at high-quality, professional video generation with extensive resources invested. Sora , introduced by OpenAI, marked a significant leap in Video Generation. Open-source models , typically based on stable diffusion and flow matching , are quickly expanding and making real contributions to video generation as well. Wan , an open-source model, is widely used for video generation and has achieved SOTA results on many benchmarks. Recent years have also seen remarkable progress in both multimodal understanding and generation models .
Besides general video generation, driving-focused generative models use sensor data such as lidar point clouds or images . Since this work emphasizes video generation, we focus on image-based methods. Early approaches before Vista rely on multi-view RGB inputs and high-definition maps or 3D boxes, limiting generalization to new datasets and open-domain videos. Vista-based methods simplify inputs to a single front-view image with optional ego trajectories, improving scalability to YouTube videos and enabling broader open-domain evaluation.
Benchmarks for evaluating generative world models
The rapid progress of open- and closed-source video generation has driven the creation of many benchmarks , such as VBench, which evaluates models with multifaceted metrics based on human-collected prompts. Recently, evaluations have expanded to open, dynamic, and complex world-simulation scenarios . WorldScore measures generated videos using explicit camera trajectory layouts. However, a comprehensive driving-world benchmark is still lacking due to limited test sample diversity, heterogeneous input modalities, and the absence of driving-specific metrics. Recent works mainly adopt Frechet Video Distance (FVD) and Average Displacement Error (ADE) for trajectory alignment, while GEM adds human video evaluations that are subjective and hard to scale. The closest effort, ACT-Bench , focuses solely on trajectory alignment and overlooks key aspects such as video and trajectory distribution, quality, and temporal consistency.
Appendix
Gallery of the Ego-conditioned Track
 />
/>
0.45
 style="width:95.0%" />
style="width:95.0%" />
We present the distribution and gallery of our ego-conditioned track in Fig. 5 and Fig. 6. We curated data from five open-sourced driving datasets to diversify the distribution of weather, time of day, and locations (with various driving styles). The videos and ego-trajectories provided in these datasets are used as the target distribution for calculating metrics such as FVD and FTD.
Details of Our SLAM Pipeline and compariision with Others
Dealing with Unsuccessful Trajectory Reconstruction. Not every generated video will yield a successful SLAM reconstruction, especially if the video has tremendous artifacts or very low texture. Simply discarding those cases would bias the evaluation, because typically it’s the worst videos (the most unrealistic ones) that cause SLAM to fail. Dropping them would artificially inflate those poor-performing models’ scores. We tackled this issue explicitly to ensure no video is left unevaluated. Our approach was to build a custom SLAM+depth estimation pipeline that is robust to failures. We ensure a trajectory is obtained for every video by applying a failure-recovery strategy: if at any frame the SLAM algorithm cannot estimate the next camera pose (e.g., fails in feature matching, solving PnP, etc.), we take the last known pose and extrapolate it forward. Specifically, we propagate the last pose with a constant velocity model. To avoid giving an unrealistic advantage, we add small random perturbations to the pose orientation during this extrapolation. This injects a bit of uncertainty to mimic the fact that the current estimation is noisy, preventing the extrapolated path from appearing “too perfect” in our metrics. We chose not to simply freeze the camera (no movement) upon failure, because a completely static continuation could skew certain trajectory metrics. By using this continuous-and-jitter method, we obtain a complete trajectory from start to end for every video, no matter how poor its quality. This allows all videos to count toward the trajectory-based metrics, holding models accountable for cases where a naive SLAM would have given up.
Comparison with Other SLAM Pipelines. We evaluated our reconstruction pipeline against those used in recent driving world-model systems. Concretely, we compare the successful reconstruction rate and trajectory accuracy (ADE) on 20 nuPlan videos generated with Vista from our early experiments. A run is counted as successful if the SLAM system returns a valid camera trajectory without numerical failure. The results are summarized in Table [tab:slam_abl]. Compared to the GEM pipeline (DROID-SLAM + Depth-Anything v2 ) and the DrivinDojo pipeline (COLMAP with scale aligned to ground truth), our basic version (Ours w/o failure handling) achieves a similar successful reconstruction rate (17/20 vs. 17/20 and 16/20) and a comparable ADE (15.18 vs. 14.61 and 14.99). When we enable our failure-handling strategy (Ours w/ failure handling), the successful rate increases to 20/20, while the ADE remains in the same ballpark (16.84). This trade-off is important for DrivingGen: the benchmark needs robust reconstruction on all videos rather than dropping harder cases and evaluating on a subset of “easy’’ videos. Overall, our SLAM pipeline is more robust than existing pipelines by handling reconstruction failure explicitly.
| Pipeline | Success rate $`\uparrow`$ | ADE $`\downarrow`$ |
|---|---|---|
| GEM: DROID-SLAM + Depth-Anything v2 | 17 / 20 | 14.61 |
| DrivinDojo: COLMAP + scale to GT | 16 / 20 | 14.99 |
| Ours w/o failure handling | 17 / 20 | 15.18 |
| Ours w/ failure handling | 20 / 20 | 16.84 |
Fréchet Trajectory Distance (FTD)
Idea. FTD applies the FID-style Gaussian Fréchet distance to trajectory embeddings, replacing image/video features with a driving-domain encoder.
Representation model and input. We use MTR’s
agent_polyline_encoder $`\phi(\cdot)`$ . Crucially, MTR consumes a
fixed temporal horizon $`H`$.
Window embeddings & trajectory pooling. We slice the trajectory into windows to fit into the MTR encoder. Each window is encoded as $`\mathbf{f}=\phi(\text{window})\in\mathbb{R}^d`$. A trajectory’s embedding is the mean over its window embeddings, which stabilizes statistics and removes dependence on the number of windows.
Distributional distance. For generated embeddings $`X=\{\bar{\mathbf{f}}(\tau_i^{\text{gen}})\}_{i=1}^{n}`$ and reference embeddings $`Y=\{\bar{\mathbf{f}}(\tau_j^{\text{ref}})\}_{j=1}^{m}`$ with empirical means/covariances $`\hat{\boldsymbol{\mu}}_{X/Y}`$, $`\hat{\Sigma}_{X/Y}`$, define
\boxed{
\mathrm{FTD}(X,Y)=\|\hat{\boldsymbol{\mu}}_X-\hat{\boldsymbol{\mu}}_Y\|_2^2
+\operatorname{Tr}\!\left(\hat{\Sigma}_X+\hat{\Sigma}_Y
-2\big(\hat{\Sigma}_X^{1/2}\hat{\Sigma}_Y\hat{\Sigma}_X^{1/2}\big)^{1/2}\right)}We add $`\varepsilon I`$ ($`\varepsilon{=}10^{-6}`$) before the matrix
square root and symmetrize products by $`(A{+}A^\top)/2`$ if needed.
Optional Ledoit–Wolf shrinkage can be used when $`n`$ or $`m Practical recipe (defaults). Encoder: MTR Horizon & slicing: $`H{=}10`$ steps; stride $`s{=}H`$
(non-overlapping); same slicing for generated and reference. Normalization: agent-centric translation/rotation per window; MTR
schema constants $`(\ell,w,h)=(4.5,2.0,1.8)`$ m; type=vehicle;
validity=1. Aggregation: mean over a trajectory’s window embeddings; FTD on
the two sets of trajectory-level embeddings. Motivation and background. Pulse–width modulation (PWM) in vehicle
lighting and roadside luminaires induces temporal luminance modulation
that, when sampled by rolling-shutter cameras, can alias into
low-frequency flicker and degrade detection and tracking. The IEEE
Automotive P2020 standard formalizes Modulation Mitigation Probability
(MMP) to quantify whether such modulation is sufficiently suppressed
during operation . We implement MMP on the frame-mean luminance to
provide a robust and efficient evaluation signal. Definition. Given frames $`\{I_t\}_{t=1}^{T}`$ at sampling rate
$`\textsf{fps}`$, form the luminance sequence
$`L_t=\operatorname{mean}(\mathrm{gray}(I_t))`$ and its periodogram
$`\widehat{P}(f)=\lvert\mathcal{F}\{L\}(f)\rvert^2`$ (real FFT). Let the
dominant non-DC peak be If $`f^\star<0.2\,\mathrm{Hz}`$, set $`\mathrm{MMP}=1`$. Computation. With the band
$`B(f^\star)=\{f:\,|f-f^\star|<\Delta f\}`$, define the band-power ratio The metric is Defaults. $`\Delta f=\texttt{band\_hz}=0.5\,\mathrm{Hz}`$,
$`\tau=\texttt{thr}=0.05`$, $`\textsf{fps}=10`$. The procedure uses a
single FFT per clip with complexity $`O(T\log T)`$. Motivation. Video-only scores can miss whether motions are
plausible and comfortable. We define a trajectory quality that
aggregates three kinematic submetrics—comfort, motion, and curvature—via
a weighted geometric mean (equal weights by default). Each submetric
lies in $`[0,1]`$ with larger being better; we report per-trajectory
scores and dataset means, skipping Preliminaries. A trajectory $`\tau{=}\{(x_t,y_t)\}_{t=1}^T`$.
Velocities, accelerations, and jerks use centered finite differences.
Heading comes from velocity, and yaw rate uses wrapped heading
differences. Path length is the cumulative step distance. A trajectory
is marked moving if any speed exceeds $`v_{\text{static}}{=}0.1`$ m/s. Comfort ($`S_{\text{comf}}`$). We score comfort from three per-meter
peaks: longitudinal jerk, lateral acceleration, and yaw rate.
Trajectories that are non-moving (speed $`< v_{\text{static}}`$) or too
short ($`\le 1`$ m) are set to Motion ($`S_{\text{speed}}`$). We penalize under-mobility using a
trajectory’s mean speed. A monotone log mapping compresses high speeds
and scales by $`v_{\max}{=}k\,v_{\text{ref}}`$ (defaults:
$`v_{\text{ref}}{=}6.0`$ m/s, $`k{=}2.5`$) to obtain
$`S_{\text{speed}}\in[0,1]`$. Never-moving trajectories receive $`0`$. Curvature ($`S_{\text{curv}}`$). Discrete curvature is formed from
first/second derivatives of $`(x_t,y_t)`$. We then compute an RMS
curvature $`\kappa_{\mathrm{rms}}`$, then map Non-moving trajectories return Motivation. Agents should not vanish without a plausible cause
(e.g., occlusion or leaving the view). We detect such cases directly
from video with a minimal vision–language check. Method. For each agent that disappears, we prepare three frames:
(1) the first frame where the agent is visible, (2) the last frame where
it is visible (both with the agent box drawn in green), and (3) the
first frame after it disappears (no box). We ask a VLM to classify the
disappearance with the following prompt: Scoring. A tracklet is abnormal if the VLM outputs Definition. From positions sampled at step $`\Delta t`$, form the
speed series $`v_t`$ and the acceleration series $`a_t`$ by finite
differences. Measure each signal’s dispersion relative to its typical
level using a simple ratio, then squash with an exponential: The trajectory consistency score is the average where higher indicates smoother, more realistic kinematics. In our experiments, the bottleneck is
primarily the video generation itself: many of the state-of-the-art
generative models we benchmark are slow and memory hungry (e.g.,
Wan2.2-14B takes about 20-30 minutes to generate one 100-frame video on
a single GPU with at least 40 GB memory). In contrast, the evaluation
suite is comparatively manageable. The approximate wall-clock time for
each metric group on 400 videos is summarized in
Table [tab:metric_time]. On a single
modern GPU, running all metrics for 400 videos with 100 frames takes
roughly 1–2 days. Within this budget, the main cost on the
evaluation side comes from image quality and video consistency metrics,
which require running heavy visual backbones over every frame. The most
time-consuming metrics would be agent consistency and disappearance
consistency, which run models for each agent in the first frame of the
video. Trajectory measures (FTD, quality, consistency and alignment) are
much cheaper (minutes), since they operate on compact embeddings or
low-dimensional trajectories. These numbers are indicative and may vary
with hardware and implementation, but they show that: (i) video
generation dominates the overall runtime, and (ii) among the metrics,
the image, video and agent quality and consistency components are the
main contributors, while the rest of the metrics are comparatively
fast. We employ a similar method in VBench to determine whether each category
aligns with human preferences. Given the human labels, we calculate the
win ratio of each model. During pairwise comparisons, if a model’s video
is selected as better, then the model scores 1 and the other model
scores 0. If there is a tie, then both models score 0.5. For each model,
the win ratio is calculated as the total score divided by the total
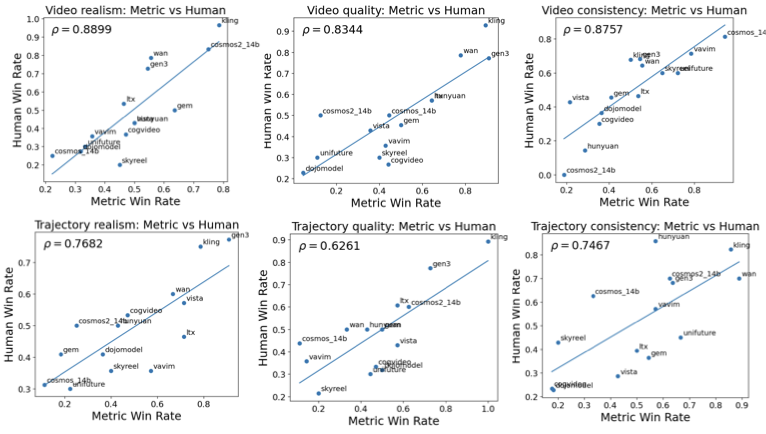
number of pairwise comparisons in which it participated. For fast and reasonable evaluation, we select three categories:
distribution, quality and consistency. We evaluate with both videos and
trajectories and use the primary metric in each category. Metrics are
FVD and FTD, Subjective image quality and trajectory quality, video
consistency and trajectory consistency. The results are shown in
Fig. 7.
agent_polyline_encoder.Objective Image Quality
f^\star \;=\; \arg\max_{\,f>0}\,\widehat{P}(f).A \;=\; \frac{\sum_{f\in B(f^\star)} \widehat{P}(f)}{\sum_{f}\widehat{P}(f)+\varepsilon},
\qquad \varepsilon=10^{-8}.\boxed{\ \mathrm{MMP} \;=\; \mathbf{1}\!\left[A<\tau\right]\ }\in\{0,1\}.Trajectory Quality
NaNs.NaN. Each peak is then mapped to a
$`[0,1]`$ component score with an inverse transform
$`S_q = 1/(1 + q/s_q)`$ (higher is better), where $`s_q`$ are scale
factors (default 1.0). The final comfort score is the geometric mean of
the three components.S_{\text{curv}}=\frac{1}{1+\kappa_{\mathrm{rms}}}\in(0,1].NaN.Agent Abnormal Disappearance
Given three frames around the moment a green-boxed object disappears, classify the disappearance as Natural(e.g., occlusion or leaving the field of view) orUnnatural (abrupt or non-physical). Base your decision on visual and motion continuity and interactions with nearby objects. Output one word: Natural or Unnatural.Unnatural;
otherwise it is not abnormal. A video is clean only if all evaluated
tracklets are not abnormal. The final score is the percentage of clean
videos (higher is better).
Component
Example
Approx. Time
Video Generation
Wan2.2-14B
Days
Vista
About One Day
Trajectory Reconstruction
SLAM + Depth model
Hours
Distribution Metrics
FVD
Hours
FTD
Minutes
Quality Metrics
Subjective Image Quality
Hours
Objective Image Quality
Minutes
Trajectory Quality
Minutes
Consistency Metrics
Video Consistency
Hours
Agent Consistency
More Hours
Agent Disappearance Consistency
Hours
Trajectory Consistency
Minutes
Trajectory Alignment
Metrics
ADE
Minutes
DTW
Minutes
All Metrics (Total)
All Above Metric Groups
1–2 Days on a Single GPU
Trajectory Consistency
R_v=\frac{\mathrm{std}(v)}{\mathrm{mean}(v)},\quad
R_a=\frac{\mathrm{std}(a)}{\mathrm{mean}(|a|)},\qquad
S_v=\exp(-R_v),\ \ S_a=\exp(-R_a).S_{\text{cons}}=\tfrac{1}{2}\,(S_v+S_a)\in(0,1],Time and Resource for DrivingGen
Human Alignment of DrivingGen
 style="width:95.0%" />
style="width:95.0%" />
📊 논문 시각자료 (Figures)