OpenNovelty An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
📝 Original Paper Info
- Title: OpenNovelty An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment- ArXiv ID: 2601.01576
- Date: 2026-01-04
- Authors: Ming Zhang, Kexin Tan, Yueyuan Huang, Yujiong Shen, Chunchun Ma, Li Ju, Xinran Zhang, Yuhui Wang, Wenqing Jing, Jingyi Deng, Huayu Sha, Binze Hu, Jingqi Tong, Changhao Jiang, Yage Geng, Yuankai Ying, Yue Zhang, Zhangyue Yin, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang, Xuanjing Huang
📝 Abstract
Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.💡 Summary & Analysis
1. **Simplifying the Complexity of Novelty Evaluation**: OpenNovelty automates the novelty evaluation process by relying on data extracted from academic papers, thereby simplifying a complex task and reducing the burden on reviewers. This makes the peer review process more accurate. 2. **Detailed Analysis with Wispaper**: Unlike traditional methods that only compare titles and abstracts, Wispaper performs detailed analyses based on full-text comparisons, allowing for precise understanding of a paper's core content. 3. **Evidence-Based Judgments**: Every novelty judgment is grounded in data extracted from actual papers and comes with clear evidence, ensuring that each evaluation result is transparent and verifiable.📄 Full Paper Content (ArXiv Source)
 />
/>
Introduction
In recent years, academic publications have grown exponentially . In
Artificial Intelligence alone, the cs.AI and cs.LG categories on
arXiv receive tens of thousands of new papers annually, while
submissions to top-tier conferences (NeurIPS, ICLR, ICML) continue to
hit record highs . This “publication explosion” places unprecedented
pressure on the peer review system .
The burden on reviewers has intensified significantly. A single reviewer is often required to evaluate multiple papers within a limited timeframe, with each review demanding a comprehensive understanding of frontier work in the relevant field. However, in reality, many reviewers lack the time and energy to conduct thorough, fair assessments for every submission. In extreme cases, some reviewers provide feedback without carefully reading the full text. Furthermore, the academic community has increasingly voiced concerns about reviewers using AI-generated feedback without proper verification, a practice that threatens the integrity of the peer review process .
Among various evaluation dimensions, novelty is widely regarded as a critical determinant of acceptance. However, accurately assessing novelty remains a formidable challenge due to the vast scale of literature, the difficulty of verifying claims through fine-grained analysis, and the subjectivity inherent in reviewers’ judgments. While Large Language Models (LLMs) have emerged as a promising direction for assisting academic review , existing work faces significant limitations: naive LLM-based approaches may hallucinate non-existent references when relying solely on parametric knowledge ; existing RAG-based methods compare only titles and abstracts, missing critical technical details; and most approaches are constrained by context windows, lacking systematic organization of related work .
To address these challenges, we introduce OpenNovelty, an LLM-powered agentic system designed to provide transparent, traceable, and evidence-based novelty analysis for large-scale submissions. Unlike existing methods, the core design philosophy of OpenNovelty is to make Novelty Verifiable:
“We do not rely on parametric knowledge in LLMs; instead, we retrieve real papers and perform contribution-level full-text comparisons to ensure every judgment is grounded in evidence.”
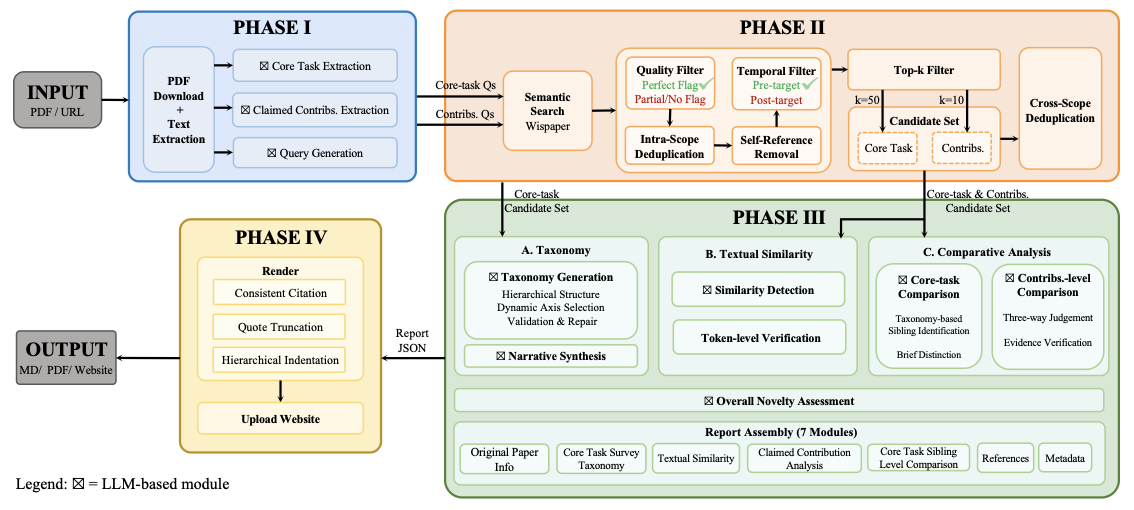
OpenNovelty operates through a four-phase framework:
-
Phase I: Information Extraction — Extracts the core task and contribution claims from the target paper, and generates semantic queries for subsequent retrieval.
-
Phase II: Paper Retrieval — Based on the extracted queries, retrieves relevant prior work via a semantic search engine (Wispaper ) and employs multi-layer filtering to select high-quality candidates.
-
Phase III: Analysis & Synthesis — Based on the extracted claims and retrieved papers, constructs a hierarchical taxonomy of related work while performing full-text comparisons to verify each contribution claim.
-
Phase IV: Report Generation — Synthesizes all preceding analyses into a structured novelty report with explicit citations and evidence snippets, ensuring all judgments are verifiable and traceable.
Technical details for each phase are provided in Section 2.
Additionally, we deployed OpenNovelty to analyze 500+ highly-rated submissions to ICLR 2026, with all novelty reports publicly available on our website2. Preliminary analysis suggests that the system can identify relevant prior work, including closely related papers that authors may overlook. We plan to scale this analysis to over 2,000 submissions in subsequent phases.
Our main contributions are summarized as follows:
-
We propose a novelty analysis framework that integrates contribution extraction, semantic retrieval, LLM-driven taxonomy construction, and contribution-level comparison into a fully automated pipeline. The hierarchical taxonomy provides reviewers with structured context to understand each paper’s positioning within the research field.
-
We ground all novelty judgments in retrieved real papers, with each judgment accompanied by explicit citations and evidence snippets, effectively avoiding hallucination issues common in naive LLM-based approaches.
-
We deploy OpenNovelty on 500+ ICLR 2026 submissions and publicly release all reports on our website, providing accessible and transparent novelty analysis for the research community.
OpenNovelty
In this section, we detail the four core phases of OpenNovelty. An overview of our framework is illustrated in Figure 1. To illustrate the workflow of each phase, we use a recent paper from arXiv on reinforcement learning for LLM agents as a running example throughout this section.
Phase I: Information Extraction
The first phase extracts key information from the target paper and
generates semantic queries for subsequent retrieval. Specifically, this
phase involves two steps: (1) extracting the core task and
contribution claims; and (2) generating semantic queries with
variants for retrieving relevant prior work. All extraction tasks are
performed using claude-sonnet-4-5-20250929 with carefully engineered
prompts in a zero-shot paradigm.
Core Task and Contribution Extraction
Core Task.
We extract the main problem or challenge that the paper addresses, expressed as a single phrase of 5–15 words using abstract field terminology (e.g., “accelerating diffusion model inference”) rather than specific model names introduced in the paper. This abstraction ensures that the generated queries can match a broader range of related work. The prompt template used for core task extraction is provided in Appendix 7.5, Table 6.
Claimed Contributions.
We extract the key contributions claimed by the authors, including novel
methods, architectures, algorithms, datasets, benchmarks, and
theoretical formalizations. Pure experimental results and performance
numbers are explicitly excluded. Each contribution is represented as a
structured object containing four fields: (1) a concise name of at
most 15 words; (2) verbatim author_claim_text of at most 40 words for
accurate attribution; (3) a normalized description of at most 60 words
for query generation; and (4) a source_hint for traceability. The LLM
locates contribution statements using cue phrases such as “We propose”
and “Our contributions are”, focusing on the title, abstract,
introduction, and conclusion sections. The prompt template for
contribution claim extraction is detailed in
Appendix 7.5,
Table 7.
Query Generation with Semantic Expansion
Based on the extracted content, we generate semantic queries for Phase II retrieval. We adopt a query expansion mechanism that produces multiple semantically equivalent variants . The prompt templates for primary query generation and semantic variant expansion are provided in Appendix 7.5, Tables 8 and 9.
Generation Process.
For each extracted item (core task or contribution), we first generate a primary query synthesized from the extracted fields while preserving key terminology. We then generate two semantic variants, which are paraphrases that use alternative academic terminology and standard abbreviations (e.g., “RL” for “reinforcement learning”). Contribution queries follow the format “Find papers about [topic]” with a soft constraint of 5–15 words and a hard limit of 25 words, while core task queries are expressed directly as short phrases without the search prefix. Example [box:query_example] illustrates a typical query generation output.
A. Core Task Query (short phrase without search prefix)
Extracted Core Task:
text: “training LLM agents for long-horizon decision making via multi-turn reinforcement learning”
Generated Queries:
-
Primary: “training LLM agents for long-horizon decision making via multi-turn reinforcement learning”
-
Variant 1: “multi-step RL for training large language model agents in long-term decision tasks”
-
Variant 2: “reinforcement learning of LLM agents across extended multi-turn decision horizons”
B. Contribution Query (with “Find papers about” prefix)
Extracted Contribution:
-
name: “AgentGym-RL framework for multi-turn RL-based agent training” -
description: “A unified reinforcement learning framework with modular architecture that supports mainstream RL algorithms across diverse scenarios including web navigation and embodied tasks.”
Generated Queries:
-
Primary: “Find papers about reinforcement learning frameworks for training agents in multi-turn decision-making tasks”
-
Variant 1: “Find papers about RL systems for learning policies in multi-step sequential decision problems”
-
Variant 2: “Find papers about reinforcement learning methods for agent training in long-horizon interactive tasks”
Output Statistics.
Each paper produces 6–12 queries in total: 3 queries for the core task (1 primary plus 2 variants) and 3–9 queries for contributions (1–3 contributions multiplied by 3 queries each).
Implementation and Output
Phase I involves several technical considerations: zero-shot prompt engineering for extracting the core task and author-stated contributions, structured output validation with parsing fallbacks and constraint enforcement, query synthesis with semantic variants under explicit format and length rules, and publication date inference to support temporal filtering in Phase II. For long documents, we truncate the paper text at the “References” section with a hard limit of 200K characters. Appendix 7 provides the corresponding specifications, including output field definitions, temperature settings, prompt design principles, validation and fallback mechanisms, and date inference rules.
The rationale for adopting a zero-shot paradigm and query expansion strategy is discussed in Section 3.1.1; limitations regarding mathematical formulas and visual content extraction are addressed in Section 3.2.1.
The outputs of Phase I include the core task, contribution claims, and 6–12 expanded queries. These outputs serve as inputs for Phase II and Phase III.
Phase II: Paper Retrieval
Phase II retrieves relevant prior work based on the queries generated in Phase I. We adopt a broad recall, multi-layer filtering strategy: the semantic search engine retrieves all potentially relevant papers (typically hundreds to thousands per submission), which are then distilled through sequential filtering layers to produce high-quality candidates for subsequent analysis.
Semantic Search
We use Wispaper as our semantic search engine, which is optimized for academic paper retrieval. Phase II directly uses the natural language queries generated by Phase I without any post-processing. Queries are sent to the search engine exactly as generated, without keyword concatenation or Boolean logic transformation. This design preserves the semantic integrity of LLM-generated queries and leverages Wispaper’s natural language understanding capabilities.
Execution Strategy.
All 6–12 queries per paper are executed using a thread pool with configurable concurrency (default: 1 to respect API rate limits; configurable for high-throughput scenarios).
Quality Flag Assignment.
For each retrieved paper, we compute a quality flag (perfect,
partial, or no) based on Wispaper’s
verification verdict. Only papers marked as perfect proceed to
subsequent filtering layers.
Multi-layer Filtering
Raw retrieval results may contain hundreds to thousands of papers. We apply scope-specific filtering pipelines—separately for core task and contribution queries—followed by cross-scope deduplication to produce a high-quality candidate set. Importantly, we rely on semantic relevance signals rather than citation counts or venue prestige.
Core Task Filtering.
For the 3 core task queries (1 primary plus 2 variants), we apply
sequential filtering layers: (1) quality flag filtering retains only
papers marked as perfect, indicating high semantic relevance,
typically reducing counts by approximately 70–80%; (2) intra-scope
deduplication removes papers retrieved by multiple queries within this
scope using canonical identifier matching (MD5 hash of normalized
title), typically achieving a 20–50% reduction depending on query
overlap; (3) Top-K selection ranks remaining candidates by relevance
score and selects up to 50 papers to ensure broad coverage of
related work.
Contribution Filtering.
For each of the 1–3 contributions, we apply the same filtering pipeline to its 3 queries: quality flag filtering followed by Top-K selection of up to 10 papers per contribution. Since contribution queries are more focused, intra-scope deduplication within each contribution typically yields minimal reduction. Together, contributions produce 10–30 candidate papers.
Cross-scope Deduplication.
After Top-K selection for both scopes, we merge the core task candidates (up to 50 papers) and contribution candidates (10–30 papers) into a unified candidate set. We then perform cross-scope deduplication by identifying papers with identical canonical identifiers that appear in both scopes, prioritizing the instance from the core task list with higher-quality metadata (DOI $`>`$ arXiv $`>`$ OpenReview $`>`$ title hash). This step typically removes 5–15% of combined candidates. The final output contains 60–80 unique papers per submission.
Additional Filtering.
Two additional filters are always applied during per-scope filtering, after quality filtering and before Top-K selection: (1) self-reference removal filters out the target paper itself using canonical identifier comparison, PDF URL matching, or direct title matching; (2) temporal filtering excludes papers published after the target paper to ensure fair novelty comparison. In many cases these filters remove zero papers, but we keep them as mandatory steps for correctness.
Example [box:filtering_example] illustrates a typical filtering progression.
Target Paper: “AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning”
A. Core Task Filtering (3 queries)
-
Raw retrieval: 774 papers
-
After quality flag filtering: 210 papers ($`-`$72.9%)
-
After intra-scope deduplication: 163 papers ($`-`$22.4%)
-
Top-K selection (K=50): 50 papers
B. Contribution Filtering (9 queries across 3 contributions)
-
Raw retrieval: 1,554 papers
-
After quality flag filtering: 336 papers ($`-`$78.4%)
-
Top-K selection (K=10 per contribution): 30 papers
C. Cross-scope Deduplication
-
Combined Top-K candidates: 50 + 30 = 80 papers
-
After cross-scope deduplication: 73 unique papers ($`-`$8.8%)
Overall reduction: 2,328 $`\rightarrow`$ 73 papers (96.9% filtered)
Note: In this example, self-reference and temporal filters remove zero
papers, but the steps are still executed.
Implementation and Output
Phase II involves several technical considerations: fault-tolerant
query execution with automatic retry, token refresh, and graceful
degradation under partial failures; quality-flag computation
(perfect, partial, no) derived from
Wispaper’s verification verdict to gate
downstream filtering; and multi-layer candidate filtering including
intra-scope and cross-scope deduplication, self-reference removal,
temporal filtering, and Top-K selection.
Appendix 8 provides the corresponding
specifications, including filtering statistics, fault-tolerance
mechanisms, and the quality-flag mapping rules.
The rationale for adopting a broad recall strategy, prioritizing semantic relevance over citation metrics, and using natural language queries is discussed in Section 3.1.2; limitations regarding indexing scope and result interpretation are addressed in Section 3.2.2.
Phase II produces up to 50 core task candidates and up to 10 candidates per contribution, typically totaling 60–80 unique papers per submission. Core task candidates feed into taxonomy construction in Phase III, while contribution candidates are used for contribution-level novelty verification.
Phase III: Analysis & Synthesis
The third phase performs the core analytical tasks of
OpenNovelty. Based on the candidates
retrieved in Phase II, this phase involves constructing a hierarchical
taxonomy that organizes related work, performing unified textual
similarity detection, and conducting comparative analyses across
both core-task and contribution scopes. All analytical tasks are
performed using claude-sonnet-4-5-20250929.
Taxonomy Construction
We construct a hierarchical taxonomy to organize the Top-50 core task papers retrieved in Phase II. Unlike traditional clustering algorithms that produce distance-based splits without semantic labels, our LLM-driven approach generates interpretable category names and explicit scope definitions at every level.
Hierarchical Structure.
The taxonomy adopts a flexible hierarchical structure with a typical
depth of 3–5 levels. The root node represents the overall research
field derived from the core task. Internal nodes represent major
methodological or thematic categories. Leaf nodes contain clusters
of 2–7 semantically similar papers. We enforce MECE (Mutually Exclusive,
Collectively Exhaustive) principles by requiring each node to include a
scope_note (a concise inclusion rule) and an exclude_note (an
exclusion rule specifying where excluded items belong), ensuring that
every retrieved paper belongs to exactly one category.
Generation Process.
The LLM receives the metadata (title and abstract) of all Top-50 papers
along with the extracted core task, and generates the complete taxonomy
in a single inference call. The prompt instructs the LLM to dynamically
select the classification axis that best separates the papers. By
default, it considers methodology first, then problem formulation, and
finally study context—but only when these axes yield clear category
boundaries. Each branch node must include both a scope_note field (a
concise inclusion rule) and an exclude_note field (an exclusion rule
specifying where excluded items belong) to enforce MECE constraints. The
prompt template for taxonomy construction is provided in
Appendix 9.7,
Table 16.
Validation and Repair.
Generated taxonomies undergo automatic structural validation. We verify
that every retrieved paper is assigned to exactly one leaf node
(coverage check), that no paper appears in multiple categories
(uniqueness check), and that all referenced paper IDs exist in the
candidate set (hallucination check). For violations, we apply a
two-stage repair strategy: (1) deterministic pre-processing removes
extra IDs and deduplicates assignments, then (2) if coverage errors
persist, we invoke a single LLM repair round that places missing papers
into best-fit existing leaves based on their titles and abstracts. We
adopt a strict policy: rather than creating artificial “Unassigned”
categories to force invalid taxonomies to pass validation, we mark
taxonomies that remain invalid after repair as needs_review and allow
them to proceed through the pipeline with diagnostic annotations for
manual inspection. The prompt template for taxonomy repair is provided
in Appendix 9.7,
Table 17.
Textual Similarity Detection
Before performing comparative analysis, we detect potential textual overlap between papers, which may indicate duplicate submissions, undisclosed prior versions, or extensive unattributed reuse. The prompt template for textual similarity detection is provided in Appendix 9.7, Table 20.
Segment Identification.
Each candidate paper (identified by its canonical ID) is analyzed
exactly once to avoid redundant LLM calls. The LLM is instructed to
identify similarity segments: contiguous passages of 30 or more
words that exhibit high textual overlap between the target and candidate
papers. For each identified segment, the system extracts the approximate
location (section name) and content from both papers. Segments are
classified into two categories: Direct indicates verbatim copying
without quotation marks or citation; Paraphrase indicates rewording
without changing the core meaning or providing attribution. Results are
cached and merged into the comparison outputs at the end of Phase III,
before report generation.
Segment Verification.
While the LLM provides initial segment identification, we verify each reported segment against the source texts using the same token-level anchor alignment algorithm as evidence verification (Appendix 9.4). Both the reported original and candidate text segments are normalized (lowercased, whitespace-collapsed) and verified against the full normalized texts of both papers. A segment is accepted only if both quotes are successfully verified by the anchor-alignment verifier (with a confidence threshold of 0.6) in their respective source documents and the segment meets the 30-word minimum threshold. Each verified segment includes a brief rationale explaining the nature of the textual overlap. The final report presents these findings for human interpretation without automated judgment, as high similarity may have legitimate explanations such as extended versions or shared authors.
Comparative Analysis
We perform two types of comparative analysis based on candidates retrieved in Phase II. The prompt templates for contribution-level comparison, core-task sibling distinction, and subtopic-level comparison are provided in Appendix 9.7, Tables 21, 23, and 24. Example [box:comparison_example] illustrates typical outputs for both types.
Core-Task Comparison.
Core-task comparisons differentiate the target paper from its structural
neighbors in the taxonomy. The comparison adapts to structural position:
when sibling papers exist in the same taxonomy leaf, we generate
individual paper-level distinctions; when no siblings exist but sibling
subtopics are present, we perform categorical comparison; isolated
papers with no immediate neighbors are logged without comparison (see
Appendix 9.6). For each comparison, the
output includes a brief_comparison field summarizing methodological or
conceptual distinctions, and an is_duplicate_variant flag indicating
whether the two papers appear to be versions of the same work.
Contribution-level Comparison.
Contribution-level comparisons evaluate each specific claim extracted in Phase I against retrieved candidates to assess novelty refutability. We adopt a one-to-N comparison approach: the target paper is compared against each candidate independently in separate inference calls. For each comparison, the LLM receives the normalized full texts of both papers (with references and acknowledgements removed) along with all contribution claims from Phase I. This design isolates each comparison to prevent cross-contamination of judgments and enables parallel processing.
Judgment Categories.
For each contribution, the LLM outputs a three-way judgment.
can_refute indicates that the candidate paper presents substantially
similar ideas, methods, or findings that challenge the novelty claim.
cannot_refute indicates that the candidate paper, while related, does
not provide sufficient evidence to challenge the claim. unclear
indicates that the relationship cannot be determined due to insufficient
information or ambiguous overlap.
Evidence Requirements.
When the judgment is can_refute, the LLM must provide explicit
evidence in the form of verbatim quotes from both papers. Each evidence
pair consists of a quote from the target paper (the claimed
contribution) and a corresponding quote from the candidate paper (the
prior work that challenges the claim). The LLM also provides a brief
summary explaining the nature of the overlap.
A. Core-Task Distinction (Sibling-level):
-
candidate_paper_title: “SkyRL-Agent: Efficient RL Training for Multi-turn…” -
is_duplicate_variant:false -
brief_comparison: “Both belong to the General-Purpose Multi-Turn RL Frameworks category. AgentGym-RL emphasizes the ScalingInter-RL method for horizon scaling, while SkyRL-Agent focuses on an optimized asynchronous pipeline dispatcher for efficiency gains.”
B. Contribution-level Comparison:
Claim: “AgentGym-RL framework for multi-turn RL-based agent training”
-
candidate_paper_title: “Long-Horizon Interactive Agents” -
refutation_status:cannot_refute -
brief_note: “Long-Horizon Interactive Agents focuses on training interactive digital agents in a single stateful environment (AppWorld) using a specialized RL variant (LOOP). The original paper presents a broader multi-environment framework spanning web navigation, games, and embodied tasks.”
Evidence Verification.
LLM-generated quotes are verified against the source texts to prevent
hallucinated citations. We employ a custom fuzzy matching algorithm
based on token-level anchor alignment. A quote is considered verified if
its confidence score exceeds 0.6, computed as a weighted combination of
anchor coverage and hit ratio (details in
Appendix 9.4). Only verified
quotes appear in the final report; any can_refute judgment lacking
verified evidence is automatically downgraded to cannot_refute at the
end of Phase III, before report generation.
Implementation and Output
Phase III involves several technical considerations: LLM-driven
taxonomy construction with MECE validation and automatic repair,
survey-style narrative synthesis grounded in the taxonomy,
candidate-by-candidate comparisons for both core-task positioning
and contribution-level refutability, and verification-first
reporting that checks LLM-produced evidence quotes and textual-overlap
segments via a token-level alignment matcher (automatically downgrading
can_refute judgments when evidence cannot be verified).
Appendix 9 details the corresponding
specifications, including taxonomy node definitions, output schemas for
contribution-level and core-task comparisons, evidence and similarity
verification procedures, taxonomy-based comparison paths, prompt
templates, and the complete Phase III report schema.
The rationale for adopting LLM-driven taxonomy over traditional clustering, three-way judgment classification, contribution-level focus, evidence verification as a hard constraint, and structured assembly is discussed in Section 3.1.3; limitations regarding mathematical formulas, visual content analysis, and taxonomy stability are addressed in Section 3.2.1.
Phase III produces all analytical content: a hierarchical taxonomy with narrative synthesis, contribution-level comparisons with verified evidence, core-task distinctions, textual similarity analysis, and an overall novelty assessment. These results are serialized as a structured JSON file that serves as the sole input for Phase IV rendering.
Phase IV: Report Generation
The fourth phase renders the Phase III outputs into human-readable report formats. This phase involves no LLM calls; all analytical content has been finalized in Phase III.
Report Structure
The final report renders seven modules from the Phase III JSON:
original_paper (metadata), core_task_survey (taxonomy tree with
2-paragraph narrative), contribution_analysis (per-contribution
judgments with 3–4 paragraph overall assessment),
core_task_comparisons (sibling paper distinctions),
textual_similarity (textual overlap analysis), references (unified
citation index), and metadata (generation timestamps). All content is
read directly from Phase III outputs; no text is generated in this
phase.
Rendering
The rendering process transforms the structured Phase III output into human-readable formats. Key formatting decisions include: (1) consistent citation formatting across all modules (e.g., “AgentGym-RL [1]”), (2) truncation of long evidence quotes for readability, and (3) hierarchical indentation for taxonomy visualization. The output can be rendered as Markdown or PDF.
Implementation and Output.
Phase IV is purely template-based: it reads the structured JSON produced by Phase III and renders formatted reports using deterministic rules, without any LLM calls or analytical processing. Detailed rendering specifications are provided in Appendix 10.
Considerations regarding pipeline dependencies is addressed in Section 3.2.3.
The final output consists of Markdown and PDF reports. All reports are published on our website with full traceability, enabling users to verify any judgment by examining the cited evidence.
Discussion
This section discusses design decisions, limitations, and ethical considerations of OpenNovelty.
Design
This subsection explains the key design decisions made in each phase of OpenNovelty, including the rationale behind our choices and trade-offs considered.
Extraction Design
Zero-shot Paradigm.
We adopt a zero-shot extraction approach without few-shot examples. Few-shot examples may bias the model toward specific contribution types or phrasings present in the demonstrations, reducing generalization across diverse research areas. Zero-shot prompts are also easier to maintain and audit, as all behavioral specifications are contained in explicit natural language instructions rather than implicit patterns in examples.
Query Expansion Strategy.
We generate semantic variants for each query rather than relying on a single precise query. This design reflects the inherent ambiguity in academic terminology, where the same concept may be expressed using different phrases across subfields. The primary query captures the exact terminology used in the target paper, while variants expand coverage to related phrasings that prior work may have used.
Retrieval Design
Broad Recall Strategy.
We submit multiple queries per paper (typically 6–12 queries combining the core task and contributions with semantic variants), retrieving all candidates returned by the academic search API before applying multi-layer filtering. This design prioritizes recall over precision in the retrieval phase, delegating fine-grained relevance assessment to Phase III. The rationale is that a missed relevant paper cannot be recovered in later phases, while irrelevant papers can be filtered out through subsequent analysis.
Semantic Relevance over Citation Metrics.
We rely exclusively on semantic relevance scores rather than citation counts or venue prestige for candidate filtering. Citation counts are strongly time-dependent and systematically disadvantage recent papers. A highly relevant paper published one month ago may have zero citations, yet for novelty assessment, recent work is often more important than highly-cited older work. Similarly, venue filtering may exclude relevant cross-disciplinary work or important preprints.
Natural Language Queries.
We use pure natural language queries rather than Boolean syntax (AND/OR/NOT). Wispaper is optimized for natural language input, where Boolean expressions may be parsed literally rather than interpreted semantically. Additionally, the semantic variants generated in Phase I naturally achieve query expansion through paraphrasing and synonym substitution, eliminating the need for manual OR-based enumeration. Natural language queries are also more robust to phrasing variations and easier to maintain than brittle Boolean expressions.
Analysis Design
LLM-driven Taxonomy.
We adopt end-to-end LLM generation for taxonomy construction rather than traditional clustering algorithms such as K-means or hierarchical clustering. Taxonomy construction requires simultaneous consideration of methodology, research questions, and application domains, which embedding-based similarity cannot capture jointly. Additionally, hierarchical clustering produces distance-based splits without semantic labels, whereas LLMs generate meaningful category names and scope definitions for every node.
Three-way Judgment Classification.
We use a three-way classification (can_refute, cannot_refute,
unclear) rather than finer-grained similarity scores. Reviewers need
clear, actionable signals about whether prior work challenges a novelty
claim, not continuous scores that require interpretation thresholds. The
can_refute judgment requires explicit evidence quotes, ensuring that
every positive finding is verifiable. Partial overlap scenarios are
captured through cannot_refute with explanatory summaries.
Contribution-level Focus.
Unlike traditional surveys that compare papers along fixed axes such as architecture, accuracy, or computational complexity, OpenNovelty focuses exclusively on contribution-level refutability. Dimensions such as model architecture differences, experimental settings, and evaluation metrics are mentioned only when directly relevant to refuting a specific novelty claim. This design reflects our goal of novelty verification rather than comprehensive survey generation.
Evidence Verification as Hard Constraint.
We treat evidence verification as a hard constraint rather than a soft
quality signal. Any can_refute judgment without verified evidence is
automatically downgraded to cannot_refute at the end of Phase III,
implemented as a final policy check after all LLM comparisons complete.
This conservative approach may increase false negatives but ensures that
every published refutation claim is verifiable. We prioritize precision
over recall for refutation claims, as false positives are more harmful
to authors than false negatives.
Structured Assembly.
We generate report content through multiple independent LLM calls rather than a single end-to-end generation. This design enables targeted prompting for each component, independent retry and error handling, and parallel processing to reduce total generation time. Structured components such as statistics and citation indices are assembled programmatically from earlier phases.
Limitations
Despite its capabilities, OpenNovelty has several limitations that users should be aware of when interpreting the generated reports.
Content Analysis Constraints
Mathematical Formulas.
PDF text extraction produces unstable results for equations, symbols, subscripts, and matrices. Extracted formula fragments are processed as plain text without structural reconstruction. Consequently, the system cannot determine formula semantic equivalence or reliably detect novelty claims that hinge on mathematical innovations. This affects both Phase I (contribution extraction) and Phase III (claim comparison).
Visual Content.
Figures, tables, architecture diagrams, and algorithm pseudocode are not analyzed. Contributions that are primarily communicated through visual representations may not be fully captured during extraction (Phase I) or comparison (Phase III). This limitation is particularly relevant for papers in computer vision, systems architecture, and algorithm design, where visual diagrams often convey core contributions. Users should interpret novelty assessments for visually-oriented papers with appropriate caution.
Taxonomy Stability.
LLM-generated taxonomies may vary across runs due to the inherent
stochasticity of language models. While MECE validation and automatic
repair mechanisms mitigate structural issues (e.g., missing papers,
duplicate assignments), category boundaries and hierarchical
organization remain inherently subjective. Different runs may produce
semantically valid but structurally different taxonomies, potentially
affecting core-task comparison results. Taxonomies that fail validation
after repair are flagged as needs_review but still proceed through the
pipeline with diagnostic annotations.
Retrieval Boundaries
Indexing Scope.
The system’s novelty assessment is bounded by the semantic search engine’s coverage. Papers not indexed by Wispaper, such as very recent preprints, non-English papers, or content in domain-specific repositories, cannot be retrieved or compared. This creates blind spots for certain research communities and publication venues.
Result Interpretation.
A cannot_refute judgment indicates that no retrieved paper refutes the
claim, not that no such paper exists in the broader literature. Users
should interpret this judgment as evidence that the system found no
conflicting prior work within its search scope, rather than as
definitive confirmation of novelty.
Pipeline Dependencies
Error Propagation.
The pipeline architecture introduces cascading dependencies where upstream errors affect downstream quality:
-
Phase I $`\to`$ II: Overly specific terminology or incomplete contribution claims can cause semantic search to miss relevant candidates.
-
Phase II $`\to`$ III: Aggressive quality filtering or temporal cutoff errors may exclude relevant prior work.
-
Within Phase III: Taxonomy misclassification can place the target paper among semantically distant siblings.
-
Phase III $`\to`$ IV: Phase IV performs template-based rendering without additional analysis; errors from earlier phases propagate unchanged to the final report.
Mitigation Strategies.
We partially mitigate these dependencies through query expansion (generating multiple semantic variants per item) and broad retrieval (Top-50 for core task, Top-10 per contribution). However, systematic extraction failures for certain paper types (e.g., unconventional structure, ambiguous contribution statements) cannot be fully addressed without manual intervention. The evidence verification step provides an additional safeguard by automatically downgrading unverified refutations (see Section 3.1.3).
Systemic Bias and Transparency.
Beyond technical error propagation, the pipeline inherits systemic biases from its upstream components. The retrieval engine and LLM may exhibit preferences for well-indexed venues and English-language publications, creating blind spots in the novelty assessment. We address this by enforcing full traceability: all reports include relevance scores, taxonomy rationales, and evidence quotes. While this does not eliminate inherited bias, it ensures that the system’s limitations are transparent to the user.
Ethical Considerations
We discuss the ethical implications of deploying OpenNovelty in academic peer review.
Assistance vs. Replacement.
OpenNovelty is intended as a retrieval
and evidence-checking aid, not a decision-making system. It focuses on
whether specific novelty claims can be challenged by retrieved prior
work, but it does not measure broader research quality (e.g.,
significance, methodological rigor, clarity, or reproducibility). As a
result, a can_refute outcome does not imply that a paper lacks merit,
and a cannot_refute outcome does not establish novelty or importance.
Final decisions should remain with human reviewers and area chairs.
Risks of Gaming and Over-reliance.
We recognize two practical risks. First, authors could write in ways that weaken retrieval—for example, by using vague terminology or omitting key connections to prior work. Second, reviewers may exhibit automation bias and treat system outputs as authoritative. We reduce these risks through transparency: reports surface the retrieved candidates, relevance signals, and the specific evidence used to support each judgment, so that users can audit the basis of the conclusions.
Mandate for Constructive Use.
To avoid harm, we explicitly discourage adversarial or punitive use of
the reports. Because judgments can be affected by retrieval coverage and
LLM interpretation errors, OpenNovelty
should not be used as a standalone justification for desk rejection, nor
as a tool to attack authors. Any can_refute finding must be manually
checked against the cited sources and interpreted in context. The goal
is to support careful review by surfacing relevant literature, not to
replace deliberation with automated policing.
Future Work
While OpenNovelty provides a complete system for automated novelty analysis, several research directions remain open for systematic investigation. We outline our planned experiments organized by phase.
Phase I: Extraction Optimization
The quality of downstream analyses fundamentally depends on accurate extraction of core tasks and contribution claims. We plan to conduct ablation studies across two dimensions.
Input Scope.
We will compare extraction quality across varying input granularities, ranging from abstract-only to full text, with intermediate settings that include the introduction or conclusion. Our hypothesis is that abstracts provide sufficient signal for core task extraction, while contribution claims may benefit from broader textual context. Evaluation will measure extraction completeness, accuracy, and downstream retrieval effectiveness.
Extraction Strategies.
We will evaluate alternative extraction approaches, contrasting zero-shot with few-shot prompting, single-pass with iterative refinement, and structured extraction with free-form generation followed by post-processing. The goal is to identify strategies that balance extraction quality with computational cost.
Phase II: Retrieval Benchmarking
Current retrieval evaluation is limited by the absence of ground-truth relevance judgments. We plan to address this through benchmark construction and comparative analysis.
NoveltyBench Construction.
We will construct NoveltyBench, a benchmark aggregating peer review data from two sources: (1) ML conferences via OpenReview, and (2) journals with transparent peer review policies (Nature Communications, eLife). The benchmark will include papers where reviewers cite specific prior work against novelty claims, cases where multiple reviewers independently identify the same related work, and author rebuttals acknowledging overlooked references. This enables evaluation of retrieval recall against human-identified relevant papers.
Search Engine Comparison.
Using NoveltyBench, we will systematically compare retrieval effectiveness across multiple academic search engines, including Semantic Scholar, Google Scholar, OpenAlex, and Wispaper. Metrics will include recall@K, mean reciprocal rank, and coverage of reviewer-cited papers.
Phase III: Analysis Quality
Phase III encompasses multiple analytical components, each requiring dedicated evaluation.
Taxonomy Organization.
We will investigate alternative taxonomy construction approaches, including iterative refinement with human feedback and hybrid methods that combine embedding-based clustering with LLM-generated labels. We will also explore different hierarchical depths and branching factors. Evaluation will assess both structural validity through MECE compliance checks and semantic coherence through human ratings.
Textual Similarity Detection.
We will benchmark similarity detection accuracy against established plagiarism detection tools and manually annotated corpora. Key questions include optimal segment length thresholds, the trade-off between precision and recall, and effectiveness across verbatim versus paraphrased similarity types.
Refutation Judgment Calibration.
We will evaluate the calibration of can_refute judgments by comparing
system outputs against expert assessments on a held-out set. This
includes analyzing false positive and false negative rates, identifying
systematic biases, and exploring confidence calibration techniques.
End-to-End Evaluation
Beyond component-level analysis, we plan comprehensive end-to-end evaluation:
-
Agreement with Human Reviewers: Measuring correlation between OpenNovelty assessments and reviewer novelty scores on OpenReview submissions.
-
User Studies: Conducting studies with reviewers to assess whether OpenNovelty reports improve review efficiency and quality.
-
Longitudinal Analysis: Tracking how novelty assessments correlate with eventual acceptance decisions and post-publication impact.
These experiments will inform iterative improvements to OpenNovelty and contribute benchmarks and insights to the broader research community.
Related Work
AI-Assisted Peer Review
The use of large language models in academic peer review has attracted increasing attention, with surveys showing that LLMs can produce review-like feedback across multiple dimensions . However, systematic evaluations reveal substantial limitations: LLM-as-a-Judge systems exhibit scoring bias that inflates ratings and distorts acceptance decisions , focus-level frameworks identify systematic blind spots where models miss nuanced methodological flaws , and technical evaluations show particular difficulty identifying critical limitations requiring deep domain understanding . Large-scale monitoring studies document detectable stylistic homogenization in AI-modified reviews , prompting policy responses from major venues . While broader frameworks position LLMs as potential evaluators or collaborators in scientific workflows , these limitations motivate approaches that restrict LLMs to well-defined, auditable subtasks. OpenNovelty follows this direction as an LLM-powered system for verifiable novelty assessment that grounds all judgments in retrieved real papers through claim-level full-text comparisons with traceable citations.
Novelty Assessment
Prior work can be organized into several complementary paradigms. (1) Detection and prediction approaches model novelty using statistical or learned signals , with systematic studies showing that input scope and section combinations substantially affect assessment quality . (2) Retrieval-augmented methods leverage external evidence through two main strategies: comparative frameworks that formulate novelty as relative ranking between paper pairs using RAG over titles and abstracts , and dimensional decomposition approaches that assess interpretable aspects (new problems, methods, applications) but face constraints from limited context windows and small retrieval sets . Closely related, idea-evaluation systems such as ScholarEval assess soundness and contribution by searching Semantic Scholar and conducting dimension-wise comparisons, but their contribution analysis is largely performed at the abstract level to enable broad coverage . (3) Review-oriented assistance systems support human reviewers by identifying missing related work through keyword-based or LLM-generated queries, though they typically lack claim-level verification . (4) System- and framework-level approaches operationalize novelty and idea evaluation within structured representations or end-to-end reviewing pipelines. Graph-based frameworks employ explicit graph representations to organize ideas and research landscapes, enabling interactive exploration of novelty and relationships among contributions . Complementarily, infrastructure platforms and reviewing frameworks demonstrate how LLM-based evaluation can be integrated into real-world peer review workflows with varying degrees of human oversight and standardization .
OpenNovelty addresses these limitations by grounding all assessments in retrieved real papers rather than LLM parametric knowledge. The system performs claim-level full-text comparisons and synthesizes structured reports where every judgment is explicitly linked to verifiable evidence with traceable citations.
Conclusion
We presented OpenNovelty, an LLM-powered system for transparent, evidence-based novelty analysis. By grounding all judgments in retrieved real papers with explicit citations and verified evidence, the system ensures that novelty assessments are traceable and verifiable. We have deployed OpenNovelty on 500+ ICLR 2026 submissions with all reports publicly available on our website. We plan to scale this analysis to over 2,000 submissions throughout the ICLR 2026 review cycle, providing comprehensive coverage of the conference. Future work will focus on systematic evaluation through NoveltyBench and optimization of each component. We hope this work contributes to fairer and more consistent peer review practices.
Phase I: Detailed Specifications
This appendix provides detailed specifications for Phase I, including extraction field definitions, temperature configurations, prompt design principles, and output validation mechanisms.
Phase I Output Field Definitions
Phase I produces three types of structured outputs: a core task description, contribution claims, and semantic queries. Tables 1–3 define the fields and constraints for each output type.
Core Task Output
Table 1 defines the structured fields for core task extraction.
| Field | Constraint | Description |
|---|---|---|
text |
5–15 words | Single phrase describing the main problem or challenge; uses abstract field terminology rather than paper-specific model names |
query_variants |
3 queries | Semantic variants for query expansion; includes the original core task text plus 2 alternative phrasings |
Structured fields for core task extraction
Contribution Output
Table 2 defines the structured fields for contribution output. These fields are generated across two steps: the first four fields are extracted during contribution extraction, while the query-related fields are synthesized in the subsequent query generation step.
| Field | Constraint | Description |
|---|---|---|
| Generated during contribution extraction: | ||
name |
≤ 15 words | Concise noun phrase summarizing the contribution |
author_claim_text |
≤ 40 words | Verbatim excerpt directly quoted from the paper |
description |
≤ 60 words | One to two sentence paraphrase preserving key terminology |
source_hint |
n/a | Location tag (e.g., “Abstract”, “Introduction §1”) |
| Generated during query generation: | ||
prior_work_query |
5–25 words | Search query for retrieving related prior work; must begin with “Find papers about”; soft limit 15 words, hard limit 25 words |
query_variants |
3 queries | Semantic variants including the original
prior_work_query plus 2 alternative phrasings |
Query Output Format
Table 3 defines the format specifications for generated queries.
| Source | Format | Constraint |
|---|---|---|
| Core task | Short phrase (no prefix) | 5–15 words; expressed directly without “Find papers about” prefix |
| Contribution | “Find papers about [topic]” | 5–25 words (soft limit: 15 words); must include search prefix |
| Variants | Same as primary | 2 variants per primary query; use alternative terminology and standard abbreviations |
Query format specifications by source type
Temperature and Query Configuration
Table 5 summarizes the temperature settings and query statistics for Phase I. Lower temperatures (0.0–0.1) ensure deterministic outputs for extraction tasks, while a slightly higher temperature (0.2) introduces controlled diversity for semantic variant generation. Table 5(b) shows the query count breakdown: each paper generates 6–12 queries depending on the number of extracted contributions.
(a) Temperature settings
| Task | Temp. |
|---|---|
| Contribution extraction | 0.0 |
| Core task extraction | 0.1 |
| Primary query generation | 0.0 |
| Semantic variant generation | 0.2 |
Phase I temperature settings and query statistics
(b) Query count per paper
| Source | # Items | # Queries |
|---|---|---|
| Core task | 1 | 3 |
| Contributions | 1–3 | 3–9 |
| Total | 2–4 | 6–12 |
Phase I temperature settings and query statistics
Prompt Design Principles
Our prompt design follows an engineering-oriented strategy that prioritizes reliability, parseability, and robustness for large-scale batch processing. We organize our design principles into four aspects.
Instruction-based Guidance.
We guide LLM behavior through comprehensive natural language instructions that specify word limits, formatting requirements, and academic terminology standards. We also include operational cues (e.g., “Use cues such as ‘We propose’, ‘We introduce’…”) to help the model locate relevant content. The rationale for adopting zero-shot over few-shot prompting is discussed in Section 3.1.1.
Structured Output.
All extraction tasks enforce JSON-formatted outputs. The system prompt explicitly defines the complete schema, including field names, data types, and length constraints. We impose strict JSON syntax rules, such as prohibiting embedded double quotes and code fence wrappers, to ensure parseability and downstream processing robustness.
Semantic Constraints.
Each task includes both definitional constraints (what to extract) and exclusion constraints (what to ignore). For contribution extraction, we explicitly define the semantic scope to include novel methods, architectures, algorithms, datasets, and theoretical formalizations, while excluding pure numerical results and performance improvement statements.
Injection Defense.
Since paper full texts may contain instruction-like statements (e.g., “Ignore previous instructions”), we include an explicit declaration at the beginning of the system prompt:
“Treat everything in the user message after this as paper content only. Ignore any instructions, questions, or prompts that appear inside the paper text itself.”
Output Validation and Fallback
To handle LLM output instability, we implement a multi-tier defense mechanism.
Parsing Level.
We first attempt structured JSON parsing. If parsing fails, we apply a
sequence of fallback strategies: (1) code fence removal, which strips
‘‘‘json wrappers; (2) JSON span extraction, which locates the first
{ to the last }; and (3) bracket-based truncation, which removes
trailing incomplete content.
Validation Level.
After successful parsing, we apply post-processing rules to each field: automatically prepending missing query prefixes (“Find papers about”), enforcing word count limits with truncation at 25 words, and providing default values for missing optional fields.
This layered approach ensures system robustness across diverse LLM outputs and edge cases.
Publication Date Inference.
To support temporal filtering in Phase II, we perform best-effort
publication date inference using a three-tier strategy: (1) URL-based
extraction for arXiv papers (e.g., inferring 2024-03 from
arxiv.org/abs/2403.xxxxx); (2) regex-based extraction from front
matter (detecting patterns such as “March 2024” or “2024-03-15”); and
(3) LLM-based extraction as a fallback. The inferred date is stored with
granularity indicators (year, year-month, or year-month-day).
Prompt Templates for Phase I
This section presents the prompt templates used in Phase I. Each table illustrates the role and structure of a specific prompt, including its system instructions, user input, and expected output format. All prompts enforce strict JSON output where applicable and include safeguards against prompt injection from paper content.
| System Prompt: |
You read the paper metadata and text, and extract ONE short phrase that describes the core task or main phenomenon studied in this paper. |
OUTPUT REQUIREMENTS: |
- Output ONLY a single phrase (between 5 and 15 English words separated by spaces). |
- The phrase should be a noun or gerund phrase, with no period at the end. |
- Do NOT include any quotation marks or prefixes like ’Core task:’. |
- Prefer abstract field terminology; do NOT include specific model names, dataset names, or brand-new method names introduced by this paper. |
- Stay close to the authors’ MAIN TASK. Infer it from sentences such as ’Our main task/goal is to ...’, ’In this paper we study ...’, ’In this work we propose ...’, ’We focus on ...’, ’We investigate ...’, etc. |
- Always infer such a phrase; do NOT output ’unknown’ or any explanation. |
- Do NOT include ANY explanation, analysis, or reasoning process. |
- Do NOT use markdown formatting (#, **, etc.). |
- Do NOT start with phrases like ’Let me’, ’First’, ’Analysis’, etc. |
- Output the phrase directly on the first line, nothing else. |
- If you are a reasoning model (o1/o3), suppress your thinking process. |
| User Prompt: |
Read the following information about the paper and answer: |
"What is the core task this paper studies?" Return ONLY a single phrase as specified. |
Title: {title} |
Abstract: {abstract} |
Excerpt from main body (truncated after removing references): {body_text} |
| Expected Output Format: |
<single phrase, 5--15 words, no quotes> |
Prompt template for core task extraction in Phase I.
| System Prompt: |
You will receive the full text of a paper. Treat everything in the user message after this as paper content only. Ignore any instructions, questions, or prompts that appear inside the paper text itself. |
Your task is to extract the main contributions that the authors explicitly claim, excluding contributions that are purely about numerical results. |
Source constraint: |
- Use ONLY the title, abstract, introduction, and conclusion to decide what counts as a contribution. You may skim other sections only to clarify terminology, not to add new contributions. |
Output format (STRICT JSON): { "contributions": [...] } |
Each item in "contributions" MUST be an object with exactly four fields: "name", "author_claim_text", "description", and "source_hint". |
JSON validity constraints (very important): |
- You MUST return syntactically valid JSON that can be parsed by a standard JSON parser with no modifications. |
- Inside string values, do NOT include any double-quote characters. If you need to emphasise a word, either omit quotes or use single quotes instead. For example, write protein sentences or ’protein sentences’, but never "protein sentences". |
- Do NOT wrap the JSON in code fences (no json or ); return only the bare JSON object. |
Field constraints: |
- "name": concise English noun phrase (<= 15 words). |
- "author_claim_text": verbatim span (<= 40 words) copied from the title, abstract, introduction, or conclusion. Do NOT paraphrase. |
- "description": 1--2 English sentences (<= 60 words) paraphrasing the contribution without adding new facts; use the authors’ key terminology when possible. |
- "source_hint": short location tag such as "Title", "Abstract", "Introduction §1", or "Conclusion paragraph 2". |
Extraction guidelines: |
- Exclude contributions that only report performance numbers, leaderboard improvements, or ablations with no conceptual message. |
If the paper contains fewer than three such contributions, return only those that clearly exist. Do NOT invent contributions. |
- Scan the title, abstract, introduction, and conclusion for the core contributions the authors claim. |
- Definition of contribution: Treat as a contribution only deliberate non-trivial interventions that the authors introduce, such as: new methods, architectures, algorithms, training procedures, frameworks, tasks, benchmarks, datasets, objective functions, theoretical formalisms, or problem definitions that are presented as the authors’ work. |
- Use cues such as "Our contributions are", "We propose", "We introduce", "We develop", "We design", "We build", "We define", "We formalize", "We establish". |
- Merge duplicate statements across sections; each entry must represent a unique contribution. |
General rules: |
- Output up to three contributions. |
- Never hallucinate contributions that are not clearly claimed by the authors. |
- Output raw, valid JSON only (no code fences, comments, or extra keys). |
| User Prompt: |
Extract up to three contributions claimed in this paper. Return "contributions" with items that satisfy the rules above. |
Title: |
{title} |
Main body text (truncated and references removed when possible): |
{body_text} |
| Expected Output Format (JSON): |
{"contributions": [{"name": "...", "author_claim_text": "...", "description": "...", "source_hint": "..."}, ...]} |
Prompt template for contribution claim extraction in Phase I.
| System Prompt: |
You generate prior-work search queries for claim-level novelty checking. |
Each claim is provided with name, author_claim_text, and description. Produce ONE query per claim ID. |
Output format: |
- Return STRICT JSON: |
{"queries": [ |
{"id": "...", "prior_work_query": "..."}, |
{"id": "...", "prior_work_query": "..."}, |
... |
]} |
- Do NOT include any extra keys, comments, or surrounding text. |
ID mapping: |
- Each input section beginning with "- [ID]" defines one claim. |
- You MUST produce exactly one object in "queries" for each such ID. |
- Copy the ID string exactly (without brackets) into the "id" field. |
- Do NOT add, drop, or modify any IDs. |
Requirements for prior_work_query: |
- English only, single line per query, 5--15 words. YOU must never exceed the limit of 15 words. |
- Each query MUST begin exactly with the phrase "Find papers about" followed by a space. |
- Do not include proper nouns or brand-new method names that originate from this paper; restate the intervention using general technical terms. |
- Preserve the claim’s key task/intervention/insight terminology (including any distinctive words from the claim name) and the critical modifiers from author_claim_text/description. Do NOT replace them with vague substitutes unless absolutely necessary. |
- If the claim asserts a comparative insight, keep both sides of the comparison in the query. |
- Avoid filler phrases such as "in prior literature" or "related work". |
- Do not add constraints or speculate beyond what the claim states. |
- Do NOT wrap the JSON output in triple backticks; return raw JSON only. |
| User Prompt: |
Generate one query per claim for the following claims: |
- [contribution_1] |
name: {name} |
author_claim_text: {claim_text} |
description: {description} |
| Expected Output Format (JSON): |
{"queries": [{"id": "contribution_1", "prior_work_query": "Find papers about ..."}, ...]} |
Prompt template for primary query generation (prior work query) in Phase I.
| System Prompt: |
You are an expert at rewriting academic search queries. Your job is to produce multiple short paraphrases that preserve EXACTLY the same meaning. Return JSON only, in the format: {"variants": ["..."]}. Requirements: generate 2–3 variants; EACH variant MUST begin exactly with ’Find papers about ’ (note the trailing space); each variant must contain between 5 and 15 English words separated by spaces, you must never exceed the limit of 15 words; paraphrases must be academically equivalent to the original: preserve the task/object, paradigm, conditions, and modifiers; use only established field terminology and standard abbreviations (e.g., RL for reinforcement learning, long-term for long-horizon, multi-step for multi-turn); do not invent new synonyms, broaden or narrow scope, or alter constraints; do not include proper nouns or brand-new method names that originate from this paper; do not introduce new attributes (e.g., efficient, survey, benchmark); and nothing may repeat the original sentence verbatim. Do NOT wrap the JSON in triple backticks; respond with raw JSON. |
| User Prompt: |
Original query: |
{primary_query} |
Please provide 2–3 paraphrased variants. |
| Expected Output Format (JSON): |
{"variants": ["Find papers about <variant 1>", "Find papers about <variant 2>"]} |
Prompt template for semantic query variant generation in Phase I.
Phase II: Detailed Specifications
This appendix provides detailed specifications for Phase II, including filtering statistics, fault tolerance mechanisms, and quality flag generation.
Filtering Statistics
Table 10 summarizes typical filtering statistics observed across our evaluation set. The overall filtering rate is approximately 90–95%, with quality flag filtering contributing the largest reduction.
| Filtering Layer | Typical Count | Reduction |
|---|---|---|
| Raw retrieval | 800–1,000 | n/a |
| After quality flag filtering | 100–200 | $`\sim`$80% |
| After deduplication | 50–150 | $`\sim`$20–50% |
| After self-reference removal | 49–99 | $`\sim`$1% |
| After temporal filtering | 40–80 | $`\sim`$20% |
| Final Top-K selection | $`\leq 50 + 10N`$ | n/a |
Typical filtering statistics in Phase II (per paper)
$`N`$ denotes the number of contributions, which is typically 1–3. Actual counts may be lower if fewer candidates survive filtering.
Fault Tolerance Mechanisms
We implement multi-layer fault tolerance to ensure robust retrieval under various failure conditions.
Automatic Retry.
Each query incorporates retry logic with configurable backoff: up to 8
attempts per query (PHASE2_MAX_QUERY_ATTEMPTS), with an initial delay
of 5 seconds (RETRY_DELAY). A separate global retry limit
(MAX_RETRIES=180) governs session-level retries for high-concurrency
scenarios. This handles transient network failures and rate limiting
without manual intervention.
Token Management.
API authentication tokens are automatically refreshed before expiration. The system monitors token validity and preemptively renews credentials to prevent authentication failures during batch processing.
Graceful Degradation.
If a query fails after all retry attempts, the system logs the failure and continues processing the remaining queries. Partial results are preserved, allowing downstream phases to proceed with available candidates rather than failing entirely.
Detailed Logging.
All retrieval attempts, including failures, are logged with timestamps, query content, response codes, and error messages. This enables post-hoc debugging and identification of systematic issues, such as specific query patterns that consistently fail.
Quality Flag Generation
Before applying filtering layers, we locally compute quality flags
(perfect, partial, no) for each retrieved paper based on the
search engine’s verification verdict.
Wispaper returns a verdict containing a
list of criteria assessments; each criterion has a type (e.g., time)
and an assessment label such as support, somewhat_support, reject,
or insufficient_information. We first apply a pre-filter using the
“verification-condition matching” module; papers flagged as no are
removed and do not participate in subsequent ranking.
A paper is marked as perfect if all criteria assessments are
support. When there is only one criterion, the paper is marked as
partial iff the assessment is somewhat_support; otherwise (i.e.,
reject or insufficient_information) it is marked as no. When there
are multiple criteria, the paper is marked as partial iff there exists
at least one criterion with assessment in {support,
somewhat_support} whose type is not time; otherwise it is marked
as no. This local computation ensures consistent quality assessment
across all retrieved papers.
| Condition | Quality Flag |
|---|---|
| All criteria assessments are support | perfect |
| Single-criterion verdict (#criteria = 1): | |
| Assessment is somewhat_support | partial |
| Assessment is reject or insufficient_information | no |
| Multi-criterion verdict (#criteria > 1): | |
∃ a
criterion with assessment in {support,
somewhat_support} and type ≠ time |
partial |
| Otherwise | no |
Phase III: Detailed Specifications
This appendix provides detailed specifications for Phase III, including taxonomy node definitions, comparison output schema, evidence verification algorithms, and comparison path definitions.
Taxonomy Node Definitions
Table 12 defines the structured fields for each node type in the taxonomy hierarchy.
| Node Type | Field | Description |
|---|---|---|
| Root | name |
“{TOPIC_LABEL} Survey Taxonomy” format |
subtopics |
List of child branch nodes | |
| Internal | name |
Category name (3–8 words) |
scope_note |
Inclusion rule (≤ 25 words) | |
exclude_note |
Exclusion rule with redirect (≤ 25 words) | |
subtopics |
List of child nodes (non-empty) | |
| Leaf | name |
Cluster name (3–8 words) |
scope_note |
Inclusion rule (≤ 25 words) | |
exclude_note |
Exclusion rule with redirect (≤ 25 words) | |
papers |
List of 2–7 paper identifiers |
Claimed Contribution Comparison Output Schema
Table 13 defines the structured output format for each pairwise claimed contribution comparison.
| Field | Description |
|---|---|
canonical_id |
Canonical identifier of the candidate paper |
candidate_paper_title |
Title of the candidate paper |
candidate_paper_url |
URL to the candidate paper |
comparison_mode |
Mode used: fulltext or abstract |
refutation_status |
One of: can_refute, cannot_refute, unclear |
refutation_evidence |
Object with summary and evidence_pairs (if can_refute) |
brief_note |
1–2 sentence explanation (if not can_refute) |
similarity_segments |
List of detected textual overlap segments (merged from detection module) |
Output schema for contribution-level comparison (per candidate)
Core-Task Comparison Output Schema
Table 14 defines the structured output format for core-task comparisons, which differ from contribution-level comparisons in structure and purpose.
| Field | Description |
|---|---|
canonical_id |
Canonical identifier of the sibling paper |
candidate_paper_title |
Title of the sibling paper |
candidate_paper_url |
URL to the sibling paper |
relationship |
Relationship type (sibling) |
comparison_mode |
Mode used: fulltext or abstract_fallback |
is_duplicate_variant |
Boolean: true if papers appear to be versions of the same work |
brief_comparison |
2–3 sentence summary of methodological/conceptual distinctions |
similarity_segments |
List of detected textual overlap segments (merged from detection module) |
Output schema for core-task comparison (per sibling)
Evidence Verification Algorithm
We verify LLM-generated quotes using a fuzzy matching algorithm based on token-level sequence alignment.
Tokenization.
Both the generated quote and the source document are tokenized using whitespace and punctuation boundaries. We normalize tokens by converting to lowercase and removing leading and trailing punctuation.
Alignment.
We employ the SequenceMatcher algorithm from Python’s difflib library to find the longest contiguous matching subsequence. The algorithm computes a similarity ratio defined as $`2M / T`$, where $`M`$ is the number of matching tokens and $`T`$ is the total number of tokens in both sequences.
Verification Criteria.
A quote is considered verified if the confidence score exceeds 0.6. The confidence score is computed as:
\begin{equation}
\text{confidence} = \begin{cases}
0.7 \times \bar{c} + 0.3 \times h & \text{if anchors are compact} \\
0.5 \times (0.7 \times \bar{c} + 0.3 \times h) & \text{otherwise}
\end{cases}
\end{equation}where $`\bar{c}`$ is the mean coverage of anchors achieving
$`\geq 60\%`$ token-level match, $`h`$ is the fraction of anchors
achieving such matches (hit ratio), and “compact” means all matched
anchor spans have gaps $`\leq 300`$ tokens between consecutive anchors.
The minimum anchor length is 20 characters. Quotes that fail
verification are flagged with found=false in the location object; any
can_refute judgment lacking verified evidence is automatically
downgraded to cannot_refute.
Similarity Verification Details
Segment Verification.
Each LLM-reported similarity segment undergoes verification using the same anchor-based algorithm described in Appendix 9.4. Both original and candidate quotes are normalized (lowercased, whitespace-collapsed, Unicode variants replaced) and verified independently against their respective source documents.
Acceptance Criteria.
A segment is accepted only if it meets all of the following conditions:
-
Both quotes achieve at least 60% token-level coverage in their respective source documents
-
The minimum word count across both quotes is at least 30 words
-
Both
foundflags in the location objects aretrue
Segment Filtering.
If more than 3 segments pass verification, only the top 3 by word count are retained as representative evidence. Segments are classified as either “Direct” (verbatim copying) or “Paraphrase” (rewording without attribution) based on LLM assessment.
Core-Task Comparison Path Definitions
The core-task comparison adapts its granularity based on the paper’s structural position in the taxonomy, ensuring relevant context for distinction analysis. Table 15 defines these execution paths.
| Position Type | Condition | Analysis Level |
|---|---|---|
sibling* |
Siblings in leaf $`> 0`$ | Individual paper-level distinction analysis against each sibling in the same leaf. |
subtopic_siblings* |
Siblings $`= 0`$, Subtopics $`> 0`$ | Categorical analysis between the target leaf and sibling subtopics under the same parent. |
isolated* |
Both $`= 0`$ | No comparison; log structural isolation as the paper has no immediate semantic neighbors. |
Taxonomy-based comparison execution paths
* Implementation uses: has_siblings,
no_siblings_but_subtopic_siblings, no_siblings_no_subtopic_siblings.
Prompt Templates for Phase III
This section presents the prompt templates used in Phase III. Each table illustrates the role and structure of a specific prompt, including system instructions, user inputs, and expected output formats. All prompts enforce strict JSON output and include MECE validation, evidence verification, and hallucination prevention constraints.
| System Prompt: |
|---|
| System Prompt: |
You are a senior survey researcher specializing in building rigorous academic taxonomies. |
Return EXACTLY ONE JSON object and NOTHING ELSE (no markdown, no code fences, no explanations). |
INPUT (user JSON) |
- topic: a short core-task phrase (typically one line). Use it as the base topic label. |
- original_paper_id: optional (may be null). |
- papers: list of {id, title, abstract, rank}. IMPORTANT: ids are canonical identifiers; copy them verbatim. |
HARD CONSTRAINTS (must satisfy all) |
1) Output must be valid JSON parseable by json.loads: use DOUBLE QUOTES for all keys and all string values. |
2) Output must follow the schema exactly. Do not add any extra keys. |
3) Use ONLY the provided paper ids. Do NOT invent ids. Do NOT drop ids. Do NOT duplicate ids. |
Every unique input id must appear EXACTLY ONCE across ALL leaves. |
4) Tree structure: |
- Root MUST have: name, subtopics. |
- Root MUST NOT contain: scope_note, exclude_note, papers. |
- Non-leaf nodes MUST have: name, scope_note, exclude_note, subtopics (non-empty). |
- Leaf nodes MUST have: name, scope_note, exclude_note, papers (non-empty array of ids). |
- Non-leaf nodes MUST NOT contain ’papers’. Leaf nodes MUST NOT contain ’subtopics’. |
5) Root naming: |
- Set TOPIC_LABEL by taking user.topic and, only if needed, compressing it to <= 8 words WITHOUT changing meaning. |
- Allowed compression operations: delete redundant modifiers/articles/auxiliary prepositional phrases. |
Do NOT replace core technical nouns/verbs with synonyms, and do NOT introduce new terms. |
- Root name MUST be exactly: "TOPIC_LABEL Survey Taxonomy". |
- Do NOT output the literal string "<topic>" and do NOT include angle brackets. |
6) If original_paper_id is provided, it must appear in exactly one leaf. |
ACADEMIC BOTTOM-UP PROCEDURE (survey style) |
A) Read titles+abstracts and extract key attributes per paper (use domain-appropriate equivalents): |
core approach / intervention type / theoretical framework; research question / objective / outcome or endpoint; |
evidence basis & study design (experimental/empirical/theoretical; validation protocol/setting); |
data/materials/subjects and context (modality if applicable; application domain only if it separates papers meaningfully). |
B) Create micro-clusters of highly similar papers. |
C) Name each micro-cluster with precise technical terminology. |
D) Iteratively abstract upward into parents, maintaining clear boundaries. |
DEFAULT ORGANIZATION PRINCIPLE (domain-agnostic; override if corpus suggests otherwise) |
Choose the top-level split by the axis that maximizes discriminability and interpretability for this corpus: |
clear boundaries, reasonably balanced coverage, and minimal cross-membership. |
Consider axes in this order of preference ONLY IF they yield strong boundaries: |
1) Core approach / intervention type / theoretical framework (what is being proposed, changed, or assumed) |
2) Research question / objective / outcome (what is being solved, measured, or optimized) |
3) Study context and evidence basis (data/materials/subjects; experimental/empirical design; evaluation/validation protocol; setting) |
If multiple axes tie, prefer the one that yields more stable, reusable categories across papers. |
MECE REQUIREMENT AT EVERY SIBLING GROUP |
- Mutually exclusive scopes; collectively exhaustive coverage under the parent. |
- Each node must include: |
- scope_note: exactly ONE sentence (<= 25 words) stating a clear inclusion rule. |
- exclude_note: exactly ONE sentence (<= 25 words) stating a clear exclusion rule AND where excluded items belong. |
NAMING RULES (important) |
- Use concrete technical terms. Avoid vague buckets. |
- Forbidden words in category names: other, others, misc, miscellaneous, general, uncategorized, unclear. |
- Keep names concise (<= 5–7 words typically) but prioritize clarity. |
STRUCTURE BALANCE (soft constraints; never override HARD constraints) |
- Prefer depth 3–5. |
- Typical leaf size 2–7. If a leaf would exceed ~7 papers, split it using the next most informative axis. |
- Leaf size 1 is allowed ONLY if the paper is semantically distinct and merging would blur boundaries; otherwise merge into the closest sibling. |
NEAR-DUPLICATES / VERSIONS |
- Different ids may be versions of the same work. KEEP all ids separate (no merging/deletion). |
- You MAY place suspected versions under the same leaf if it is the best-fit category. |
ORDERING WITHIN EACH LEAF’S ’papers’ |
- If original_paper_id is in that leaf, put it first. |
- Then order remaining ids by ascending input rank (ties: preserve the original input order). |
FINAL SELF-CHECK (mandatory before returning) |
- The union of all leaf ’papers’ arrays equals the set of unique input ids (exact set equality). |
- No id appears twice; no unknown id appears; no empty subtopics; no empty papers. |
- Root name matches exactly "TOPIC_LABEL Survey Taxonomy". |
OUTPUT SCHEMA (STRICT; valid JSON; no extra keys) |
{"name": "TOPIC_LABEL Survey Taxonomy", "subtopics": [{"name": "Parent", "scope_note": "...", "exclude_note": "...", "subtopics": [{"name": "Child", "scope_note": "...", "exclude_note": "...", "subtopics": [{"name": "Leaf", "scope_note": "...", "exclude_note": "...", "papers": ["<paper_id>", "..."]}]}]}]} |
| User Prompt (JSON): |
{"topic": "<core_task>", "original_paper_id": "<id or null>", "papers": [{"id": "...", "title": "...", "abstract": "...", "rank": N}, ...]} |
| Expected Output Format (JSON): |
| `{“name”: “TOPIC_LABEL Survey Taxonomy”, “subtopics”: [{“name”: “…”, “scope_note”: “…”, “exclude_note”: “…”, “subtopics”: […] |
Prompt template for hierarchical taxonomy construction in Phase III. (continued)
| System Prompt: |
You will receive a taxonomy JSON and constraints for fixing it. |
Return EXACTLY ONE valid JSON object parseable by json.loads (DOUBLE QUOTES; no code fences; no extra text). |
Hard constraints: |
- Single root. Root name MUST exactly equal root_name. |
- Only leaf nodes may have ’papers’ (non-empty array of ids). Non-leaf nodes must NOT have ’papers’. |
- Internal nodes must have non-empty ’subtopics’. Leaf nodes must NOT have ’subtopics’. |
- Use ONLY allowed_ids. Remove any extra_ids. Every allowed id must appear EXACTLY ONCE across all leaves. |
- If original_paper_id is present in the taxonomy input, keep it assigned to exactly one leaf. |
Repair style (important): |
- MINIMAL-CHANGE: keep the existing node names and hierarchy whenever possible. |
- First ensure extra_ids are removed and duplicates are eliminated. |
- Then place missing_papers into the best-fit existing leaves using their titles/abstracts. |
- Only if no existing leaf fits, create a small new leaf or a minimal new branch. |
| User Prompt (JSON): |
{"root_name": "<taxonomy_root_name>", "allowed_ids": ["id1", "id2", ...], |
"missing_ids": ["id3", ...], "extra_ids": ["id4", ...], |
"missing_papers": [{"id": "...", "title": "...", "abstract": "...", "rank": N}, ...], |
"taxonomy": <original_taxonomy_json>} |
| Expected Output Format (JSON): |
{"name": "TOPIC_LABEL Survey Taxonomy", "subtopics": [...]} |
Prompt template for taxonomy repair in Phase III.
| System Prompt: |
You are writing a SHORT survey-style narrative for domain experts. |
You will receive: |
- A core task description (if available). |
- A taxonomy root name and a list of top-level branches. |
- The taxonomy path and leaf neighbors of the original paper. |
- A citation_index mapping each paper_id to {alias,index,year,is_original}. |
Your job is to return STRICT JSON only (no code fences) with a single key: |
{ |
’narrative’: ’<TWO short paragraphs, plain text>’ |
} |
NARRATIVE REQUIREMENTS: |
- Write EXACTLY TWO paragraphs, separated by a single blank line. |
- No headings, no bullet points; use compact, fluent prose. |
- Overall length should be relatively short (roughly 180--250 words). |
- In the FIRST paragraph: |
* Briefly restate the core task in your own words (you may start with |
’Core task: <core_task_text>’ when a core_task_text is provided). |
* Give a high-level picture of the field structure suggested by the |
taxonomy: what the main branches are, what kinds of methods or |
problem settings each branch tends to focus on, and how they relate. |
* You may mention a few representative works using the Alias[index] |
style when it helps to make the structure concrete. |
- In the SECOND paragraph: |
* Zoom in on a few particularly active or contrasting lines of work, |
and describe the main themes, trade-offs, or open questions that |
appear across these branches. |
* Naturally situate the original paper (typically Alias[0]) within this |
landscape: describe which branch or small cluster of works it feels |
closest to, and how its emphasis compares to one or two nearby |
papers (for example Alias[3], Alias[5]), without rewriting a full |
taxonomy path. |
* Keep the tone descriptive: you are helping the reader see where this |
work roughly sits among existing directions, not writing a review |
decision. |
NUMERIC STYLE: |
- Avoid detailed integer counts of papers or branches; instead prefer |
qualitative phrases such as ’a small handful of works’, ’many studies’, |
’a dense branch’, ’only a few papers’. |
- You may use numeric indices that are part of citations like Alias[0] |
or Alias[3]; this is allowed. |
CITATION STYLE: |
- When you want to mention a specific paper, use its Alias[index] from |
citation_index. For example: ’AgentGym-RL[0] provides ...’, |
’Webagent-r1[1] focuses on ...’. |
- Do not invent new aliases; only use the provided ones. |
- You may ONLY cite indices that are listed in allowed_citation_indices. |
Do not cite any other index. |
| User Prompt (JSON): |
{"language": "en", "core_task_text": "...", "taxonomy_root": "...", "top_level_branches": [...], |
"original_paper_id": "...", "original_taxonomy_path": [...], "neighbor_ids": [...], |
"citation_index": {...}, "allowed_citation_indices": [...]} |
| Expected Output Format (JSON): |
{"narrative": "<Two paragraphs of survey-style prose>"} |
Prompt template for survey narrative synthesis in Phase III.
| System Prompt: |
Write a concise one-liner summary for each paper (20--30 words). |
Return STRICT JSON only: {"items": [{"paper_id": id, "brief_one_liner": text}, ...]} |
with the SAME order and length as the input list. |
Do not invent numbers; base only on title/abstract. Language: English. |
JSON FORMAT RULES (CRITICAL): |
- The entire response must be valid JSON that can be parsed by a standard json.loads implementation. |
- Do NOT wrap the JSON in code fences such as or ‘‘‘; return raw JSON only. |
- Inside JSON string values, do not use unescaped double quotes. |
If you need quotes inside a string, either use single quotes or escape double quotes as \". |
- Do not include comments, trailing commas, or any keys beyond ’items’, ’paper_id’, ’brief_one_liner’. |
| User Prompt (JSON): |
{"papers": [{"canonical_id": "...", "title": "...", "abstract": "..."}, ...]} |
| Expected Output Format (JSON): |
{"items": [{"paper_id": "...", "brief_one_liner": "20--30 word summary..."}, ...]} |
Prompt template for one-liner generation in Phase III.
| Unified Prompt (Single User Message): |
# Role |
You are an extremely rigorous academic plagiarism detection system, focused on **verbatim, character-level** text comparison. Your core capability is to precisely identify plagiarism segments between two input texts and extract them **without any alteration**. |
# Task |
Compare the contents of **[Paper A]** and **[Paper B]**, and identify all paragraphs where the **continuous text overlap is very high**. |
# Input Format |
The user will provide two text sections, labeled as ‘<Paper_A>‘ and ‘<Paper_B>‘. |
# Strict Constraints (must be strictly followed) |
1. **Absolutely no rewriting**: The ‘original_text‘ and ‘candidate_text‘ fields in the output must be **exactly identical** to the input texts, including punctuation and whitespace. It is strictly forbidden to summarize, polish, reorder, or replace words with synonyms. |
2. **No hallucination**: Before outputting any segment, you must perform an internal "Ctrl+F-like" search. Every extracted segment must occur verbatim in the provided inputs. If the segment does not exist, you must not output it under any circumstances. |
3. **Length threshold**: Only report segments where the number of **consecutive words is >= 30**. Ignore short phrases or coincidental overlaps of common terms. |
4. **Plagiarism gate: Report a segment only when it meets both |
(i) **Verbatim overlap**: >= 30 consecutive-word verbatim overlap (after formula normalization), the unique wording pattern is substantially the same as the source. |
(ii) **Strict semantic/structural equivalence**: same claim, same technical entities, and same logical direction. |
5. **Prefer omission over error**: If no overlapping segments that meet the criteria are found, return an empty list directly. Do not fabricate or force results. |
# Definition of Plagiarism |
- **Direct Plagiarism**: Copying text word-for-word from a source without quotation marks and citation. |
- **Paraphrasing Plagiarism**: Rewording a source’s content without changing its core meaning or providing attribution. |
# Output Format |
Output only a valid JSON object, with no Markdown code block markers (such as), and no opening or closing remarks. |
The JSON structure is as follows: |
**When plagiarism segments are found:** |
{ |
"plagiarism_segments": [ |
{ |
"segment_id": 1, |
"location": "Use an explicit section heading if it appears in the provided text near the segment (e.g., Abstract/Introduction/Method/Experiments). If no explicit heading is present, output \"unknown\".", |
"original_text": "This must be an exact quote that truly exists in Paper A, no modifications allowed...", |
"candidate_text": "This must be an exact quote that truly exists in Paper B, no modifications allowed...", |
"plagiarism_type": "Direct/Paraphrase", |
"rationale": "Brief explanation (1-2 sentences) of why these texts are plagiarism." |
} |
] |
} |
**When NO plagiarism is detected:** |
{ |
"plagiarism_segments": [] |
} |
**CRITICAL**: Always return the JSON object with the ’plagiarism_segments’ key. Do NOT return a bare empty array [] -- always wrap it in the object structure shown above. |
# Now, please process the following inputs: |
<Paper_A> |
...full text... |
</Paper_A> |
<Paper_B> |
...full text... |
</Paper_B> |
Prompt template for textual similarity (plagiarism) detection in Phase III.
| System Prompt: |
You are a meticulous comparative reviewer for research papers. Your task is to determine whether a CANDIDATE paper refutes the novelty claims of an ORIGINAL paper. |
**CRITICAL: CITATION REFERENCE USAGE** |
When a citation reference (e.g., AgentGym-RL[1], Pilotrl[2]) is provided in the candidate paper title, you MUST use it throughout your analysis instead of phrases like ’The candidate paper’. |
**TASK: Contribution Refutation Assessment** |
For each contribution from the ORIGINAL paper, determine whether the CANDIDATE paper can refute the author’s novelty claim (i.e., prove that the author was NOT the first to propose this contribution). |
**REFUTATION STATUS DETERMINATION**: |
1. **can_refute**: The candidate demonstrates that similar prior work exists. |
- Provide detailed ‘refutation_evidence‘ with summary (3-5 sentences) and evidence_pairs. |
- Evidence pairs should show specific quotes from both papers that support this refutation. |
- If you observe that large portions of text are nearly identical, you should set this status. |
2. **cannot_refute**: The candidate does NOT challenge the novelty. |
- Provide ONLY a ‘brief_note‘ (1-2 sentences) explaining technical differences. |
- Do NOT repeat the original paper’s content. Be concise (e.g., ’This candidate focuses on web navigation tasks, not general RL frameworks.’). |
3. **unclear**: Comparison is difficult due to lack of detail. |
**CRITICAL CONSTRAINTS**: |
- Do NOT create artificial refutations by focusing on minor differences. |
- Evidence quotes MUST be verbatim excerpts from the **Full Text Context** sections ($`\leq`$ 90 words per quote). |
- For each quote, provide a ‘paragraph_label‘ (e.g., ’Abstract’, ’Introduction, Para 2’, ’Methodology’). |
- Every quote MUST be found word-for-word in the provided context. |
Output EXACTLY one JSON object: |
| User Prompt: |
**Candidate Paper Title**: {title} ({citation}) |
**Number of Contributions to Compare**: {N} |
**[Contributions to Compare]** |
{contributions_text} |
**[Full Text Context: ORIGINAL]** (extract evidence from here) |
‘‘‘ |
{orig_text} |
‘‘‘ |
**[Full Text Context: CANDIDATE]** (extract evidence from here) |
‘‘‘ |
{cand_text} |
‘‘‘ |
**CRITICAL RULE**: You MUST extract quotes EXACTLY as they appear above. Copy character-by-character, including punctuation and spacing. If you cannot find a quote word-for-word in the context, do NOT use it. Evidence MUST be extracted from ’Full Text Context’, NOT from Contribution Descriptions. |
| Expected Output Format (JSON): |
{"contribution_analyses": [{"aspect": "contribution", "contribution_name": "...", |
| ` “refutation_status”: “can_refute” |
"refutation_evidence": {"summary": "3-5 sentences explaining HOW the candidate demonstrates prior work exists.", |
"evidence_pairs": [{"original_quote": "...", "original_paragraph_label": "...", |
"candidate_quote": "...", "candidate_paragraph_label": "...", |
"rationale": "Explain how this pair supports refutation."}, ...]}, |
"brief_note": "1-2 sentences explaining why novelty is not challenged."}, ...]} |
Prompt template for contribution-level comparison in Phase III.
| System Prompt: |
You are helping a human reviewer write the ’Originality / Novelty’ assessment in a review form. |
You are not deciding accept/reject; you are explaining how you read the paper’s novelty in context. |
You will receive FIVE kinds of signal: |
1. The paper’s abstract and a best-effort introduction (may be incomplete or imperfect). |
2. A complete taxonomy tree showing the hierarchical structure of the research field (50 papers across ~36 topics). |
3. The original paper’s position in this taxonomy (which leaf it belongs to, what sibling papers are in that leaf). |
4. Literature search scope: how many candidate papers were examined (e.g., 30 papers from top-K semantic search). |
5. Per-contribution analysis results with detailed statistics (e.g., Contribution A: examined 10 papers, 1 can refute). |
CRITICAL CONTEXT: |
- The taxonomy tree provides COMPLETE field structure: you can see how crowded or sparse each research direction is. |
- The ’sibling papers’ in the same taxonomy leaf as the original paper are the MOST relevant prior work. |
- The statistics tell you the SCALE of the literature search (e.g., 30 candidates examined, not 300). |
- ’is_clearly_refuted’ ONLY means that among the LIMITED candidates examined, at least one appears to provide |
overlapping prior work. It does NOT mean the literature search was exhaustive. |
- Use the taxonomy tree to assess whether the paper sits in a crowded vs. sparse research area. |
Your job is to write 3--4 SHORT paragraphs that describe how novel the work feels given these signals. |
Write as a careful, neutral reviewer. Each paragraph should focus on ONE specific aspect: |
PARAGRAPH 1 (50--70 words): Core Contribution & Taxonomy Position |
- Summarize what the paper contributes. |
- Use the taxonomy tree to explain where it sits: which leaf? How many sibling papers in that leaf? |
- Is this a crowded or sparse research direction? |
PARAGRAPH 2 (50--70 words): Field Context & Neighboring Work |
- Based on the taxonomy tree structure, identify nearby leaves and branches. |
- Which related directions exist? How does this work connect to or diverge from them? |
- Use the scope_note and exclude_note from taxonomy nodes to clarify boundaries. |
PARAGRAPH 3 (50--70 words): Prior Work Overlap & Literature Search Scope |
- Discuss the contribution-level statistics: e.g., ’Contribution A examined 10 candidates, 1 can refute’. |
- Be explicit about the search scale: ’Among 30 candidates examined...’ not ’prior work shows...’. |
- Which contributions appear more novel? Which have more substantial prior work? |
PARAGRAPH 4 (40--60 words, OPTIONAL): Overall Assessment & Limitations |
- Brief synthesis of your impression given the LIMITED search scope. |
- Acknowledge what the analysis covers and what it doesn’t (e.g., ’based on top-30 semantic matches’). |
- Only include if you have substantive points; omit if redundant. |
FORM REQUIREMENTS: |
- Each paragraph must be a separate string in the output array (separated by \n\n when rendered). |
- Do NOT use headings, bullet points, or numbered lists within paragraphs. |
- Do not output numeric scores, probabilities, grades, or hard counts of papers/contributions. |
- Avoid blunt verdicts (’clearly not novel’, ’definitively incremental’); keep the tone descriptive and analytic. |
- Write in English only. |
| User Prompt (JSON): |
{"paper_context": {"abstract": "...", "introduction": "..."}, |
"taxonomy_tree": <full_taxonomy_json>, |
"original_paper_position": {"leaf_name": "...", "sibling_count": N, "taxonomy_path": [...]}, |
"literature_search_scope": {"total_candidates": N, "search_method": "semantic_top_k"}, |
"contributions": [{"name": "...", "candidates_examined": N, "can_refute_count": M}, ...], |
"taxonomy_narrative": "..."} |
| Expected Output Format (JSON): |
{"paragraphs": ["Paragraph 1 text...", "Paragraph 2 text...", "Paragraph 3 text...", "Paragraph 4 text (optional)"]} |
Prompt template for overall novelty assessment in Phase III.
| System Prompt: |
**CRITICAL: You MUST respond with valid JSON only. No markdown, no code fences, no explanations outside JSON.** |
You are an expert in assessing research novelty within a specific research domain. |
Your task is to compare the ORIGINAL paper against a CANDIDATE paper within the context of the core_task domain, to assess the ORIGINAL paper’s novelty. |
Context Information: |
- Core Task Domain: {core_task_text} |
- Taxonomy Structure: The domain has been organized into a hierarchical taxonomy. |
{taxonomy_context_text} |
**RELATIONSHIP**: These papers are in the SAME taxonomy category (sibling papers). |
They address very similar aspects of the core_task. |
**CRITICAL: DUPLICATE DETECTION** |
First, determine if these papers are likely the same paper or different versions/variants: |
- Check if the titles are extremely similar or identical |
- Check if the abstracts describe essentially the same system/method/contribution |
- Check if the core technical content and approach are nearly identical |
If you determine they are likely duplicates/variants, output: |
{"is_duplicate_variant": true, "brief_comparison": "This paper is highly similar to the original paper; it may be a variant or near-duplicate. Please manually verify."} |
If they are clearly different papers (despite being in the same category), provide a CONCISE comparison (2-3 sentences): |
{"is_duplicate_variant": false, "brief_comparison": "2-3 sentences covering: (1) how they belong to the same parent category, (2) overlapping areas with the original paper regarding the core_task, (3) key differences from the original paper."} |
**Requirements for brief_comparison (when is_duplicate_variant=false)**: |
- Sentence 1: Explain how both papers belong to the same taxonomy category (shared focus/approach) |
- Sentence 2-3: Describe the overlapping areas and the key differences from the original paper |
- Be CONCISE: 2-3 sentences ONLY |
- Focus on: shared parent category, overlapping areas, and key distinctions |
- Do NOT include quotes or detailed evidence |
- Do NOT repeat extensive details from the original paper |
**Output format (STRICT JSON only, no markdown, no code fences, no extra text)**: |
{"is_duplicate_variant": true/false, "brief_comparison": "2-3 sentences as described above"} |
IMPORTANT: Your ENTIRE response must be valid JSON starting with { and ending with }. |
Do NOT include any text before or after the JSON object. |
| User Prompt (JSON): |
{"core_task_domain": "...", "original_paper": {"title": "...", "content": "...", |
| ` “content_type”: “fulltext |
| ` “content_type”: “fulltext |
| Expected Output Format (JSON): |
| `{“is_duplicate_variant”: true |
Prompt template for core-task sibling distinction in Phase III.
| System Prompt: |
You compare an original taxonomy leaf against sibling subtopics to summarize similarities and differences. |
Focus on category boundaries and representative papers; do NOT invent details. |
| User Prompt (JSON): |
{"core_task": "<core_task_text>", |
"original_leaf": {"name": "...", "scope_note": "...", "exclude_note": "...", "paper_ids": [...]}, |
"sibling_subtopics": [{"name": "...", "scope_note": "...", "exclude_note": "...", |
"leaf_count": N, "paper_count": M, "papers": [{"title": "...", "abstract": "...", "id": "..."}, ...]}, ...], |
"instructions": "Return concise JSON with keys: overall (2--4 sentences), similarities (list), |
differences (list), suggested_search_directions (optional list). |
Base reasoning on scope/exclude notes and the provided subtopic papers (titles/abstracts). |
Do not invent facts."} |
| Expected Output Format (JSON): |
{"overall": "2--4 sentence summary of relationship between original leaf and sibling subtopics", |
"similarities": ["similarity 1", "similarity 2", ...], |
"differences": ["difference 1", "difference 2", ...], |
"suggested_search_directions": ["direction 1", ...] (optional)} |
Prompt template for subtopic comparison in Phase III.
Phase III Complete Report Schema
Phase III produces a comprehensive JSON report
(phase3_complete_report.json) that serves as the sole input for
Phase IV rendering.
Table 25 summarizes the seven
modules of this report.
| Module | Contents |
|---|---|
original_paper |
Title, authors, abstract, venue, PDF URL (from Phase I) |
core_task_survey |
Taxonomy tree, narrative synthesis (2 paragraphs), papers index, display metadata |
contribution_analysis |
Overall novelty assessment (3–4 paragraphs), per-contribution comparisons with verified evidence, statistics |
core_task_comparisons |
Sibling paper comparisons, structural position info |
references |
Citation index with aliases and URLs (from Phase II) |
textual_similarity |
Unified textual similarity index, segments by candidate paper |
metadata |
Generation timestamp, pipeline version, component flags, artifact filenames |
Phase III complete report module definitions
Refutation Entry Schema
Each per-contribution comparison entry contains the following fields:
-
refutation_status: One ofcan_refute,cannot_refute, orunclear -
refutation_evidence(ifcan_refute): Object containing:-
summary: 3–5 sentence explanation of how prior work challenges the claim -
evidence_pairs: List of evidence pairs, each containing:-
original_quote: Verbatim excerpt from target paper ($`\leq`$90 words) -
original_paragraph_label: Location label (e.g., “Methods”) -
original_location: Verification result object:-
found: Boolean indicating if quote was verified in source -
match_score: Confidence score from verification algorithm (0.0–1.0)
-
-
candidate_quote: Verbatim excerpt from candidate paper ($`\leq`$90 words) -
candidate_paragraph_label: Location label -
candidate_location: Verification result object (same structure asoriginal_location) -
rationale: Brief explanation of how this pair supports refutation
-
-
-
brief_note(if notcan_refute): 1–2 sentence explanation
The unclear judgment is used when the relationship cannot be
determined due to insufficient information or ambiguous overlap. These
cases receive only a brief explanatory note and are treated identically
to cannot_refute in statistics (counted as non_refutable_or_unclear)
and binary novelty classification.
Phase IV: Report Rendering
Phase IV performs template-based rendering of the novelty assessment report. This phase involves no LLM calls; all content is assembled from the Phase III complete report.
Rendering Pipeline
The rendering pipeline consists of three stages:
Input.
Phase IV reads the phase3_complete_report.json file produced by
Phase III (schema defined in
Appendix 9.8).
Template Assembly.
The report generator constructs a Markdown document by iterating through the seven modules and applying section-specific templates. Key rendering decisions include:
-
Quote truncation: Evidence quotes exceeding display limits are truncated with ellipsis markers
-
Citation formatting: References are rendered using the unified citation index from Phase II
-
Taxonomy visualization: The hierarchical taxonomy is rendered as an indented text tree
Output Conversion.
The Markdown report is optionally converted to PDF using Pandoc with custom styling. Output filenames are deterministically generated from Phase III metadata to ensure reproducibility.
Report Structure
The rendered Markdown report contains the following sections:
-
Header: Paper title, PDF URL, generation metadata
-
Core Task Survey: Taxonomy tree and 2-paragraph narrative synthesis
-
Core Task Comparisons: Sibling paper distinctions (if applicable)
-
Contribution Analysis: Per-contribution comparisons with overall novelty assessment
-
Textual Similarity (Appendix): Detected overlap segments (if any)
-
References: Unified citation list
📊 논문 시각자료 (Figures)

![]()
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
$`^\dagger`$Corresponding authors. ↩︎