Length-Aware Adversarial Training for Variable-Length Trajectories Digital Twins for Mall Shopper Paths
📝 Original Paper Info
- Title: Length-Aware Adversarial Training for Variable-Length Trajectories Digital Twins for Mall Shopper Paths- ArXiv ID: 2601.01663
- Date: 2026-01-04
- Authors: He Sun, Jiwoong Shin, Ravi Dhar
📝 Abstract
We study generative modeling of \emph{variable-length trajectories} -- sequences of visited locations/items with associated timestamps -- for downstream simulation and counterfactual analysis. A recurring practical issue is that standard mini-batch training can be unstable when trajectory lengths are highly heterogeneous, which in turn degrades \emph{distribution matching} for trajectory-derived statistics. We propose \textbf{length-aware sampling (LAS)}, a simple batching strategy that groups trajectories by length and samples batches from a single length bucket, reducing within-batch length heterogeneity (and making updates more consistent) without changing the model class. We integrate LAS into a conditional trajectory GAN with auxiliary time-alignment losses and provide (i) a distribution-level guarantee for derived variables under mild boundedness assumptions, and (ii) an IPM/Wasserstein mechanism explaining why LAS improves distribution matching by removing length-only shortcut critics and targeting within-bucket discrepancies. Empirically, LAS consistently improves matching of derived-variable distributions on a multi-mall dataset of shopper trajectories and on diverse public sequence datasets (GPS, education, e-commerce, and movies), outperforming random sampling across dataset-specific metrics.💡 Summary & Analysis
1. **Introduction of Length-Aware Sampling (LAS)**: This paper introduces LAS to handle the variability in sequence lengths within mini-batches, allowing for a focus on behavioral structure rather than just length-related signals. It's akin to sorting clothes by size before trying them on. 2. **Distribution Matching Evaluation**: The goal is to match derived-variable distributions between generated and real sequences. This ensures that key differences are minimized. Think of it as aligning two groups' positions in a photo taken at the same spot. 3. **Theoretical Background**: The paper provides theoretical justification for why LAS improves distribution matching, similar to focusing on specific areas during exercise to achieve overall balance.📄 Full Paper Content (ArXiv Source)
Learning realistic trajectory and sequence models—and increasingly, trajectory generators for simulation and counterfactual analysis—is important in domains such as mobility analytics , recommender systems , and sequential decision logs in education . A key difficulty shared across these settings is variable trajectory length: real sequences can range from a few steps to hundreds, and length is often strongly correlated with other characteristics (e.g., dwell time, inter-event timing, or item/category diversity).
In practice, we train deep generative models with stochastic mini-batches. When trajectory lengths are highly heterogeneous, mini-batches mix very short and very long sequences, encouraging the discriminator/critic to exploit length-correlated signals rather than within-length behavioral structure. This is especially damaging when the goal is distribution matching for trajectory-derived variables—statistics computed from an entire sequence (e.g., total duration, average per-step time, transition structure, or entropy-like measures). As a result, the adversarial objective may improve while important derived-variable distributions remain mismatched, limiting fidelity for downstream simulation.
We address this with a length-aware sampling (LAS) scheme that (i) partitions trajectories into length buckets and (ii) draws each mini-batch from a single bucket. LAS is a training-time intervention (no model changes) that controls within-batch length heterogeneity and makes discriminator/generator updates more consistent in practice. We combine LAS with a conditional trajectory GAN and auxiliary time-alignment losses to build digital twins for trajectory data—generators that can be conditioned on scenario variables to support counterfactual simulation.
Mall digital twin as a motivating case study.
Shopping malls remain among the most data-rich yet under-optimized physical marketplaces . We study a proprietary dataset of anonymized foot-traffic trajectories collected from four large malls, enabling counterfactual questions such as: How would closing an anchor store, changing the tenant mix, or re-routing flows affect dwell time and the distribution of visits? While the mall application motivates the paper, our method and evaluation are domain-agnostic and are validated on additional public sequence datasets.
Contributions.
-
We formalize trajectory generation with derived-variable distribution matching as an evaluation target.
-
We propose length-aware sampling (LAS), a simple length-bucket batching strategy, and show how to integrate it into GAN training.
-
We provide theory: (i) a Wasserstein bound for derived-variable distributions under boundedness and controlled training losses, and (ii) an IPM/Wasserstein mechanism explaining why LAS improves distribution matching by removing length-only shortcut critics and targeting within-bucket discrepancies.
-
We demonstrate empirical gains of LAS over random sampling on a multi-mall dataset and multiple public sequence datasets.
Related Work
Our work connects to (i) modeling and generating sequential/trajectory data, (ii) digital twins and counterfactual simulation, and (iii) stabilizing adversarial/stochastic training under heterogeneous data.
Trajectory and sequence modeling.
Trajectory data are central in mobility analytics . Beyond mobility, generative sequence modeling has been explored in settings such as pedestrian motion and in general-purpose sequence generators, including GAN-style methods for discrete sequences and synthetic time-series generation . In recommender systems, sequential models are widely used to represent and generate user–item trajectories (e.g., recurrent or attention-based models) . Our focus differs: we optimize and evaluate distribution matching of trajectory-derived statistics and study how batching by length shapes this objective.
Digital twins and counterfactual simulation.
Digital twins aim to create forward simulators for complex systems . In many operational settings (including retail), counterfactual analysis is often addressed with observational causal methods that are inherently backward-looking . We contribute a complementary generative angle: a learned simulator calibrated on observed trajectories that can be conditioned on scenario variables to support “what-if” analyses.
Mall retail analytics and shopper trajectories.
Marketing and operations research have studied mall design, tenant mix, and shopper flows, traditionally using aggregate footfall, surveys, and structural models . More recent work leverages fine-grained in-store/indoor mobility traces and path data to study store transitions, dwell-time distributions, and consumer search behavior . Our setting aligns with this line of work but focuses on learning a generative simulator whose distribution matches derived-variable statistics and supports counterfactual scenario testing.
Stability under heterogeneous mini-batches and adversarial training.
Stochastic optimization and stability in non-convex settings have been widely studied , and curriculum/ordering strategies are a classic tool for handling heterogeneous difficulty/structure . GAN training introduces additional instability due to the adversarial objective , and prior work proposes stabilization strategies such as Wasserstein/gradient-penalty critics . LAS is complementary to these lines: rather than changing the objective or architecture, it controls mini-batch composition to reduce length-only shortcuts and focus learning on within-length discrepancies that matter for distribution matching.
Positioning.
Prior work has typically examined mall-level analytics, spatiotemporal modeling, or adversarial training stability in isolation. Our contribution is to unify these strands within a single framework: we instantiate a mall digital-twin setting, introduce length-aware sampling as a simple training intervention, and provide theory and empirical evidence linking LAS to improved matching of length-dependent derived variables.
Problem Setup
We consider conditional generation of variable-length trajectories. A trajectory is a sequence
x=\{(j_t,\tau_t^{(\mathrm{intra})},\tau_t^{(\mathrm{inter})})\}_{t=1}^{T},where $`j_t`$ is a discrete location/item identifier, $`\tau_t^{(\mathrm{intra})}`$ is the time spent at step $`t`$, and $`\tau_t^{(\mathrm{inter})}`$ is the transition time to the next step.1 The length $`T`$ varies across trajectories.
Conditional generation.
Each trajectory is associated with observed context $`c`$ (e.g., entry time, user segment, scenario variables). Let $`p_{\mathrm{data}}(x\mid c)`$ denote the true conditional distribution and $`p_G(x\mid c)`$ the generator distribution. Our goal is to learn $`p_G`$ so that generated trajectories match the real distribution both at the sequence level and in terms of trajectory-derived variables.
Derived variables and evaluation.
Let $`f:\mathcal{X}\to\mathbb{R}`$ be a scalar derived variable computed from a full trajectory (e.g., total duration, average dwell time, number of visits, entropy of categories, or dataset-specific statistics). Let $`P_f`$ and $`Q_f`$ be the distributions of $`f(x)`$ when $`x\sim p_{\mathrm{data}}(\cdot\mid c)`$ and $`x\sim p_G(\cdot\mid c)`$, respectively (marginalizing over $`c`$ when appropriate). We quantify distribution mismatch using distances such as Wasserstein-1 for continuous variables and KL/JS divergence after discretization for discrete/histogram variables. In the mall domain, we report a broad set of derived variables capturing dwell, transitions, and visit patterns; in the other domains we use a compact set of dataset-specific derived variables.
Method
Conditional trajectory GAN
We instantiate $`p_G(x\mid c)`$ with a conditional generator $`G_\theta`$ and discriminator (critic) $`D_\phi`$. We summarize the main architectural components below and provide full details in Appendix 8.
Architecture summary.
We use a three-stage design: (1) store-feature embedding with attention-based neighborhood fusion, (2) an LSTM-based conditional generator that outputs the next store and timing heads, and (3) a bidirectional LSTM discriminator/critic over the full sequence.
Store and context encoding.
We represent each mall as a graph $`G=(V,E)`$ with stores as nodes and spatial adjacencies as edges. Each store $`v_i`$ is described by a feature vector $`\mathbf{x}_i`$ (identity, floor, category, traffic/open features, and neighborhood statistics; see Appendix 8). A learned encoder maps $`\mathbf{x}_i`$ to an embedding $`\mathbf{e}_i\in\mathbb{R}^{d_e}`$ and fuses neighbor information via attention,
\tilde{\mathbf{e}}_i
= \mathbf{e}_i + \sum_{j\in\mathcal{N}(i)} \alpha_{ij}\,\mathbf{W}\mathbf{e}_j,
\qquad
\alpha_{ij}=\mathrm{softmax}_{j}\big(\mathbf{q}_i^\top \mathbf{k}_j\big),yielding a context-aware store representation $`\tilde{\mathbf{e}}_i`$. Mall-level day context $`c`$ (calendar/campaign/weather indicators) is embedded and concatenated to the generator inputs at every step.
Generator and discriminator heads.
At step $`t`$, the generator conditions on the previous hidden state, the previous visited store embedding, and the context $`c`$ to produce (i) a categorical distribution over the next store (implemented with a Gumbel-Softmax relaxation for differentiability), and (ii) nonnegative intra- and inter-store times using separate regression heads. The discriminator processes the full sequence with a bidirectional LSTM and outputs a sequence-level realism score.
Training objective
We use a non-saturating GAN objective:
\mathcal{L}_D(\phi)
=
-\mathbb{E}_{x\sim p_{\mathrm{data}}}\big[\log D_\phi(x)\big]
-\mathbb{E}_{\hat{x}\sim p_G}\big[\log(1-D_\phi(\hat{x}))\big],\mathcal{L}_{\mathrm{adv}}(\theta)
=
-\mathbb{E}_{\hat{x}\sim p_G}\big[\log D_\phi(\hat{x})\big].To better align timing statistics, we add auxiliary time losses (detailed in Appendix 9):
\mathcal{L}_G(\theta)
=
\mathcal{L}_{\mathrm{adv}}(\theta)
+
\lambda_{\mathrm{time}}\Big(\mathcal{L}_{\mathrm{intra}}+\mathcal{L}_{\mathrm{inter}}\Big),where, for a real trajectory of length $`T`$ and a generated trajectory of length $`\hat{T}`$,
\mathcal{L}_{\mathrm{intra}}
=
\frac{1}{\min(T,\hat{T})}\sum_{t=1}^{\min(T,\hat{T})}
\left|\hat{\tau}_t^{(\mathrm{intra})}-\tau_t^{(\mathrm{intra})}\right|,\mathcal{L}_{\mathrm{inter}}
=
\frac{1}{\min(T,\hat{T})}\sum_{t=1}^{\min(T,\hat{T})}
\left|\hat{\tau}_t^{(\mathrm{inter})}-\tau_t^{(\mathrm{inter})}\right|.We alternate gradient updates for $`\phi`$ and $`\theta`$ (Appendix 10).
Dataset-specific objectives.
In the mall domain, we train with the adversarial loss together with the
auxiliary intra/inter time alignment terms above. For the public
sequential datasets, we do not use the mall-specific time losses and
instead use a dataset-appropriate adversarial objective: Education
and GPS use the standard adversarial loss (treating each example as
a sequence and relying on the discriminator to learn timing/structure
implicitly); Movie uses the adversarial loss augmented with a
feature matching regularizer (feature_matching_loss); and Amazon
uses a Wasserstein (WGAN-style) objective for improved training
stability. Full loss definitions are in
Appendix 9.
Training procedure and complexity.
Each iteration samples a minibatch of real trajectories using RS or LAS (Section 4.3), generates a matched minibatch from $`G_\theta`$, and performs alternating updates of $`D_\phi`$ and $`G_\theta`$. The dominant cost is the forward/backward pass over $`B`$ sequences of length at most $`T_{\max}`$, i.e., $`O(BT_{\max})`$ per update up to architecture-dependent constants; LAS adds only a small bookkeeping overhead for bucket sampling.
Length-aware sampling (LAS)
Let $`\ell(x)=T`$ denote trajectory length. We partition the training set into $`K`$ length buckets $`\{\mathcal{D}_k\}_{k=1}^K`$ using length quantiles. LAS draws each mini-batch from a single bucket: first sample a bucket index $`K_s\sim w`$ (with weights $`w_k`$), then sample all $`m`$ examples uniformly from $`\mathcal{D}_{K_s}`$. In our experiments, we use the empirical bucket mixture $`w_k \propto p_k`$, where $`p_k:=|\mathcal{D}_k|/|\mathcal{D}|`$ is the empirical bucket mass.2 This removes within-batch length heterogeneity and can make discriminator/generator updates more consistent for length-correlated objectives, while still exposing the model to all lengths over training.
Sample bucket index $`k \sim \text{Categorical}(w_1,\dots,w_K)`$ Sample $`x_1,\dots,x_m \sim \text{Unif}(\mathcal{D}_k)`$ $`\mathcal{B}=\{x_i\}_{i=1}^m`$
Theory
We state two types of results: (i) distribution-level bounds for derived variables, and (ii) optimization-level an IPM/Wasserstein mechanism explaining why LAS improves distribution matching by removing length-only shortcut critics and targeting within-bucket discrepancies.
Assumptions
Assumption 1 (Boundedness and controlled training losses). *(i)
Trajectory length is bounded: $`T\le T_{\max}`$ almost surely.
(ii) Per-step time contributions are bounded: for all $`t`$,
$`0\le \tau_t^{(\mathrm{intra})}+\tau_t^{(\mathrm{inter})}\le B`$.
(iii) After training, the sequence-level divergence and auxiliary losses
are controlled:
\begin{aligned}
\mathrm{JS}(p_{\mathrm{data}}\Vert p_G) &\le \delta,\\
\mathcal{L}_{\mathrm{intra}} &\le \epsilon_{\mathrm{intra}},\\
\mathcal{L}_{\mathrm{inter}} &\le \epsilon_{\mathrm{inter}}.
\end{aligned}
```*
</div>
Let $`C_{\mathrm{JS}}`$ denote a universal constant such that
$`\mathrm{TV}(P,Q)\le C_{\mathrm{JS}}\sqrt{\mathrm{JS}(P\Vert Q)}`$.
## Derived-variable distribution bounds
For derived variables we use in the mall domain
(Appendix <a href="#app:theory_full" data-reference-type="ref"
data-reference="app:theory_full">11</a>),
``` math
\begin{aligned}
\mathrm{Tot}(x)
&=\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}
+\sum_{t=1}^{T-1}\tau_t^{(\mathrm{inter})},\\
\mathrm{Avg}(x)
&=\frac{1}{T}\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})},\\
\mathrm{Vis}(x)
&=T.
\end{aligned}and more generally for any scalar $`f(x)`$ that is Lipschitz under an appropriate trajectory semi-metric (Appendix 11). Let $`P_f`$ and $`Q_f`$ be the distributions of $`f(x)`$ under $`p_{\mathrm{data}}`$ and $`p_G`$.
We measure distributional closeness via the 1-Wasserstein distance (Kantorovich–Rubinstein duality):
W_1(P_f, Q_f)
=
\sup_{\|g\|_{\mathrm{Lip}}\le 1}
\left|
\mathbb{E}_{x\sim p_{\mathrm{data}}}\!\big[g(f(x))\big]
-
\mathbb{E}_{\hat{x}\sim p_G}\!\big[g(f(\hat{x}))\big]
\right|.Theorem 1 (Distributional closeness for derived variables). *Under Assumption 1, for each $`f \in \{\mathrm{Tot}, \mathrm{Avg}, \mathrm{Vis}\}`$,
W_1(P_f, Q_f) \;\le\;
\begin{cases}
\begin{aligned}
& T_{\max}\big(\epsilon_{\mathrm{intra}}+\epsilon_{\mathrm{inter}}\big)\\
&\quad + B\,T_{\max}\,C_{\mathrm{JS}}\sqrt{\delta},
\end{aligned} & f=\mathrm{Tot},\\[0.35em]
\begin{aligned}
& \epsilon_{\mathrm{intra}}\\
&\quad + B\,T_{\max}\,C_{\mathrm{JS}}\sqrt{\delta},
\end{aligned} & f=\mathrm{Avg},\\[0.35em]
2T_{\max}\,\mathrm{TV}\!\big(p_{\mathrm{data}}(T),p_G(T)\big), & f=\mathrm{Vis}.
\end{cases}
```*
</div>
#### Proof sketch.
For any 1-Lipschitz test function $`g`$, the gap
$`\big|\mathbb{E}[g(f(x))]-\mathbb{E}[g(f(\hat{x}))]\big|`$ decomposes
into (i) mismatch between real and generated sequences, controlled by
the sequence-level divergence via
$`\mathrm{TV}\!\le C_{\mathrm{JS}}\sqrt{\mathrm{JS}}`$, and (ii)
per-step timing mismatch, controlled by $`\mathcal{L}_{\mathrm{intra}}`$
and $`\mathcal{L}_{\mathrm{inter}}`$. For $`\mathrm{Tot}`$, summing
per-step errors yields the
$`T_{\max}(\epsilon_{\mathrm{intra}}+\epsilon_{\mathrm{inter}})`$ term;
for $`\mathrm{Avg}`$, normalization removes the factor $`T_{\max}`$ for
the intra contribution; and for $`\mathrm{Vis}`$, the derived variable
depends only on the length marginal, giving a bound in terms of
$`\mathrm{TV}(p_{\mathrm{data}}(T),p_G(T))`$. See
Appendix <a href="#app:theory_full" data-reference-type="ref"
data-reference="app:theory_full">11</a> for full statements and proofs.
#### Additional implications.
We summarize additional consequences for distribution matching; full
proofs are in
Appendix <a href="#app:theory_full" data-reference-type="ref"
data-reference="app:theory_full">11</a>.
Theorem <a href="#thm:w1_main" data-reference-type="ref"
data-reference="thm:w1_main">1</a> isolates two drivers of
derived-variable mismatch: within-sequence timing errors and mismatch in
the length marginal. The results below make precise why length-aware
batching targets these terms and reduces shortcut signals for the
discriminator.
<div class="corollary">
**Corollary 2** (From $`W_1`$ control to CDF control (informal)). *For
any derived variable $`f`$ supported on a bounded interval, small
$`W_1(P_f,Q_f)`$ implies a small Kolmogorov–Smirnov distance between the
corresponding CDFs, up to constants depending on the support radius.*
</div>
<div class="lemma">
**Lemma 3** (Bucket-only (length-only) critics are a null space). *Let
$`K(x)`$ denote the length bucket index used by LAS. Any critic that
depends only on $`K(x)`$ has identical expectation under the data and
generator when evaluated *within a fixed bucket*, and therefore cannot
provide an “easy” within-batch shortcut signal for the discriminator
under LAS.*
</div>
<div class="lemma">
**Lemma 4** (Global Wasserstein dominated by length mismatch +
within-bucket discrepancy). *Let $`p_{\mathrm{data}}=\sum_k w_k p_k`$
and $`p_G=\sum_k \hat{w}_k q_k`$ be mixtures over length buckets. Then
the global $`W_1`$ distance decomposes into (i) a term proportional to
$`\mathrm{TV}(w,\hat w)`$ capturing length-marginal mismatch and (ii) a
weighted sum of within-bucket discrepancies $`W_1(p_k,q_k)`$.*
</div>
Proofs are provided in
Appendix <a href="#app:theory_full" data-reference-type="ref"
data-reference="app:theory_full">11</a>.
## Why LAS improves distribution matching in practice
LAS changes mini-batch construction so that each discriminator/generator
update is computed on a *single* length regime. This reduces
within-batch length heterogeneity and prevents length from becoming an
easy within-batch shortcut feature for the discriminator. Crucially for
our empirical goal (derived-variable *distribution matching*), LAS also
controls *exposure* to different lengths via the bucket weights $`w`$:
over $`S`$ updates, each length bucket is selected about $`w_k S`$
times, ensuring all length regimes contribute training signal. Since
many derived variables are length-dependent
(Theorem <a href="#thm:w1_main" data-reference-type="ref"
data-reference="thm:w1_main">1</a>), improved coverage and length-level
supervision translate into better distribution matching in our
evaluations. To make this mechanism explicit, we provide a simple
structural statement: under LAS, any *length-only* (bucket-only)
discriminator feature becomes uninformative within an update, forcing
the critic to focus on within-bucket structure. A more detailed
IPM/Wasserstein view is given in
Appendix <a href="#subsec:las_app" data-reference-type="ref"
data-reference="subsec:las_app">11.5</a>.
<div id="prop:las_projection_main" class="proposition">
**Proposition 5** (LAS removes length-only shortcut critics). *Let
$`K(x)\in\{1,\dots,K\}`$ denote the length bucket of a trajectory $`x`$.
For any function $`a:\{1,\dots,K\}\to\mathbb{R}`$, define the
bucket-only term $`\phi(x):=a(K(x))`$. In a LAS update conditioned on
bucket $`k`$, we have $`\phi(x)=a(k)`$ almost surely under both the real
and generated bucket-conditional distributions, and thus
``` math
\mathbb{E}\!\big[\phi(X)\mid K(X)=k\big]-\mathbb{E}\!\big[\phi(\hat X)\mid K(\hat X)=k\big] = 0.Therefore bucket-only (length-only) components lie in a null space of the LAS discriminator objective within a bucket and cannot provide an “easy” within-batch shortcut signal.*
Experiments
We evaluate random sampling (RS) versus length-aware sampling (LAS) in adversarial training for sequential trajectory data. Across all experiments, we keep the model architecture and optimization hyperparameters fixed. For each dataset, RS and LAS also share the same training objective; only the mini-batch construction rule changes. Note that the objective can be dataset-specific for public benchmarks (e.g., Wasserstein for Amazon for stability); see Appendix 9. Our primary goal is distributional fidelity of derived variables (e.g., trajectory length, total time, diversity) that are used downstream for planning, simulation, and analytics.
Datasets and derived variables
Table 1 summarizes the evaluation datasets and the derived variables we compare between ground-truth and generated samples. For the mall datasets, each trajectory is a sequence of store visits with associated intra-store and inter-store durations; for the public datasets, each user trajectory is a variable-length sequence (e.g., ratings, GPS points, or question attempts), optionally with continuous attributes.
| Dataset | Domain | Derived variables (distributional evaluation) |
|---|---|---|
| Mall A–D | Indoor mobility | Total time in mall; number of store visits (trajectory length); avg/total intra-store time; avg/total inter-store time; store-type mix; time spent per category; floor distribution; store diversity. |
| Amazon | E-commerce ratings | Sequence length; item diversity; mean inter-event days; duration (days); mean rating. |
| Movie | Movie ratings | Trajectory length; inter-rating time (minutes); mean rating; rating std. |
| Education | Student learning | Trajectory length (#questions); mean correctness; std correctness. |
| GPS | GPS mobility | Trajectory length; total distance (km); average speed (km/h). |
Evaluation datasets and derived variables. Mall identifiers are anonymized.
Derived variables and evaluation metric.
For each real or generated trajectory
$`\pi=\{(j_t,\tau_t^{(\text{intra})},\tau_t^{(\text{inter})})\}_{t=1}^{T}`$,
we compute a set of scalar summaries (“derived variables”) and compare
their empirical distributions between real and synthetic data on the
held-out test set. Our primary distributional metric is the
Kolmogorov–Smirnov (KS) distance:
\mathrm{KS}(P,Q)=\sup_{x}\left|F_{P}(x)-F_{Q}(x)\right|,where $`F_{P}`$ and $`F_{Q}`$ are the empirical CDFs of the derived variable under real and generated trajectories, respectively (for discrete variables we apply KS to the cumulative mass function under a fixed ordering).
For the mall datasets, we report KS for the following derived variables:
-
Total intra-store time: $`M_{\text{intra}}^{\text{tot}}=\sum_{t=1}^{T}\tau_t^{(\text{intra})}`$.
-
Total inter-store time: $`M_{\text{inter}}^{\text{tot}}=\sum_{t=1}^{T}\tau_t^{(\text{inter})}`$.
-
Avg. intra-store time: $`M_{\text{avg-intra}}=\frac{1}{T}\sum_{t=1}^{T}\tau_t^{(\text{intra})}`$.
-
Avg. inter-store time: $`M_{\text{avg-inter}}=\frac{1}{\max(T-1,1)}\sum_{t=1}^{T}\tau_t^{(\text{inter})}`$.
-
Total time in mall: $`M_{\text{tot}}=M_{\text{intra}}^{\text{tot}}+M_{\text{inter}}^{\text{tot}}`$.
-
Trajectory length (#visits): $`M_{\text{len}}=T`$.
-
Store diversity: $`M_{\text{div-store}}=\big|\{j_t\}_{t=1}^{T}\big|`$.
For category/floor summaries, with $`c(j_t)`$ the store category and $`f(j_t)`$ the floor, we form per-trajectory histograms such as visit counts $`N_{c}=\sum_{t=1}^{T}\mathbf{1}[c(j_t)=c]`$ and floor counts $`N_{f}=\sum_{t=1}^{T}\mathbf{1}[f(j_t)=f]`$, as well as time-by-category $`T^{(\text{intra})}_{c}=\sum_{t=1}^{T}\tau_t^{(\text{intra})}\mathbf{1}[c(j_t)=c]`$, and compare their induced marginals across trajectories. Analogous trajectory-level summaries are used for the public datasets (Table 1).
Implementation details
Model configuration (notation $`\rightarrow`$ value).
For the mall experiments, dataset-specific constants are set from the data (e.g., number of stores/floors/categories), while embedding sizes and network widths are shared across experiments. For one representative mall, we use:
| Symbol | Description | Value |
|---|---|---|
| $` | \mathcal{S} | `$ |
| $`F`$ | number of floors | $`3`$ |
| $`C`$ | number of store categories | $`19`$ |
| $`d_e`$ | store embedding dimension | $`32`$ |
| $`h`$ | LSTM hidden size | $`128`$ |
| $`z`$ | latent dimension (generator) | $`16`$ |
| $`d_{\text{type}}`$ | store–type embedding dimension | $`16`$ |
| $`d_{\text{floor}}`$ | floor embedding dimension | $`8`$ |
Training protocol.
Training follows the procedure described in the algorithmic section, with the same loss notation and objectives: the adversarial loss for realism and $`\ell_1`$ losses for time heads (intra/inter) weighted as in the loss section. We use Adam optimizers ($`\beta_1{=}0.5,\ \beta_2{=}0.999`$) with learning rate $`10^{-4}`$ for both generator and discriminator, batch size $`128`$, spectral normalization on linear layers, and Gumbel–Softmax sampling for store selection with an annealed temperature from $`1.5`$ down to $`0.1`$. Training runs for up to $`18`$ epochs with early stopping (patience $`=3`$) based on generator loss.
Evaluation protocol
For each dataset, we train two models with identical architectures and hyperparameters: one using random sampling (RS) and one using length-aware sampling (LAS); the only difference is how mini-batches are constructed during training. We evaluate on held-out test data. For the mall domain, we split by unique days (80%/20%) to prevent temporal leakage and generate trajectories under the same day-level context as the test set (Appendix [app:exp_full]). For public datasets, we use a held-out split as described in Appendix [app:exp_full].
Our goal is distributional fidelity of the derived variables in Table 1. On the test set, we compare empirical distributions between real and generated samples and report the Kolmogorov–Smirnov statistic (KS) for each derived variable (lower is better). We also visualize distribution overlays for representative variables; additional diagnostics (e.g., $`t`$-tests, KL divergence) and full plots are provided in Appendix [app:exp_full].
Mall digital-twin results
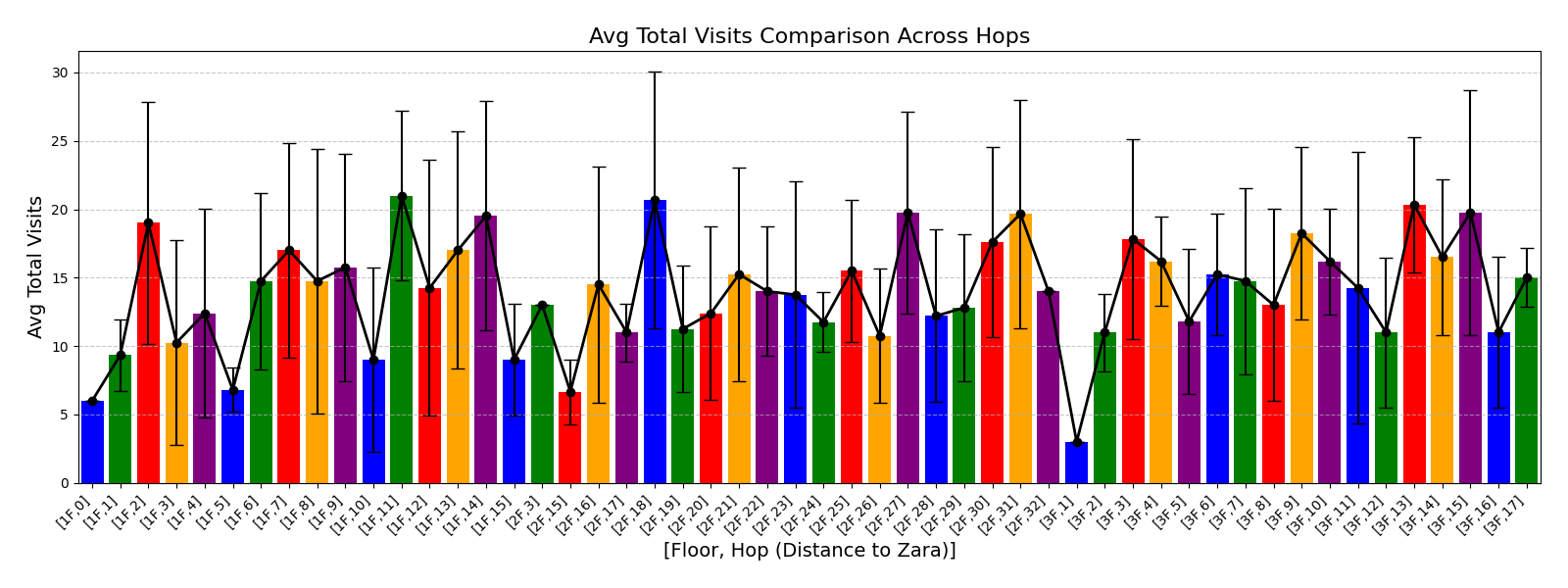
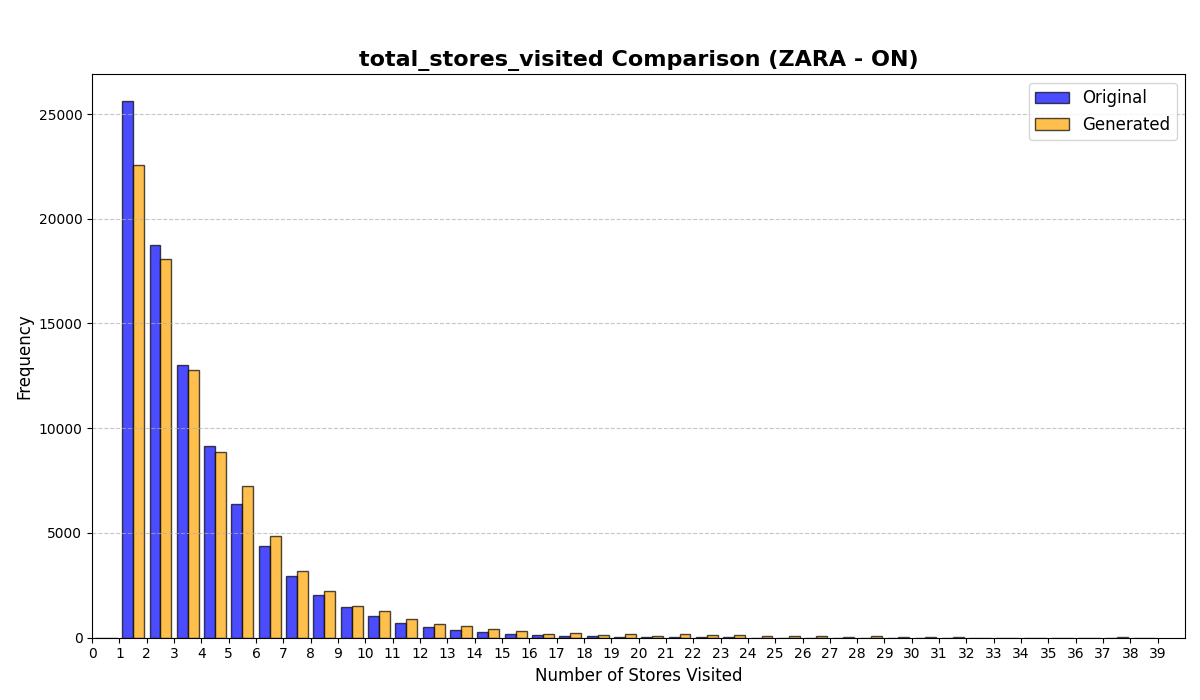
Table [tab:mall_4_results] reports KS statistics on six key derived variables across four proprietary mall datasets. LAS consistently improves the length-related and time-related marginals (e.g., #visits and total time), and reduces the overall mean KS across these metrics from 0.737 (RS) to 0.253 (LAS), a 65.7% relative reduction. Figure 1 visualizes representative distributions on Mall D.
| Mall A | Mall B | Mall C | Mall D | |||||
|---|---|---|---|---|---|---|---|---|
| 2-3(lr)4-5(lr)6-7(lr)8-9 Derived variable | RS | LAS | RS | LAS | RS | LAS | RS | LAS |
| Total time in mall | 0.528 | 0.056 | 0.538 | 0.152 | 0.630 | 0.269 | 0.661 | 0.072 |
| Trajectory length / #visits | 0.955 | 0.047 | 0.947 | 0.048 | 0.953 | 0.048 | 0.951 | 0.044 |
| Avg intra-store time | 0.975 | 0.005 | 0.978 | 0.066 | 0.975 | 0.382 | 0.959 | 0.034 |
| Avg inter-store time | 0.622 | 0.289 | 0.645 | 0.380 | 0.684 | 0.404 | 0.767 | 0.456 |
| Store category mix | 0.278 | 0.333 | 0.506 | 0.287 | 0.467 | 0.333 | 0.477 | 0.303 |
| Floor distribution | 1.000 | 0.667 | 1.000 | 0.333 | 1.000 | 0.667 | 0.200 | 0.400 |
| Mean across metrics | 0.726 | 0.233 | 0.769 | 0.211 | 0.785 | 0.350 | 0.669 | 0.218 |



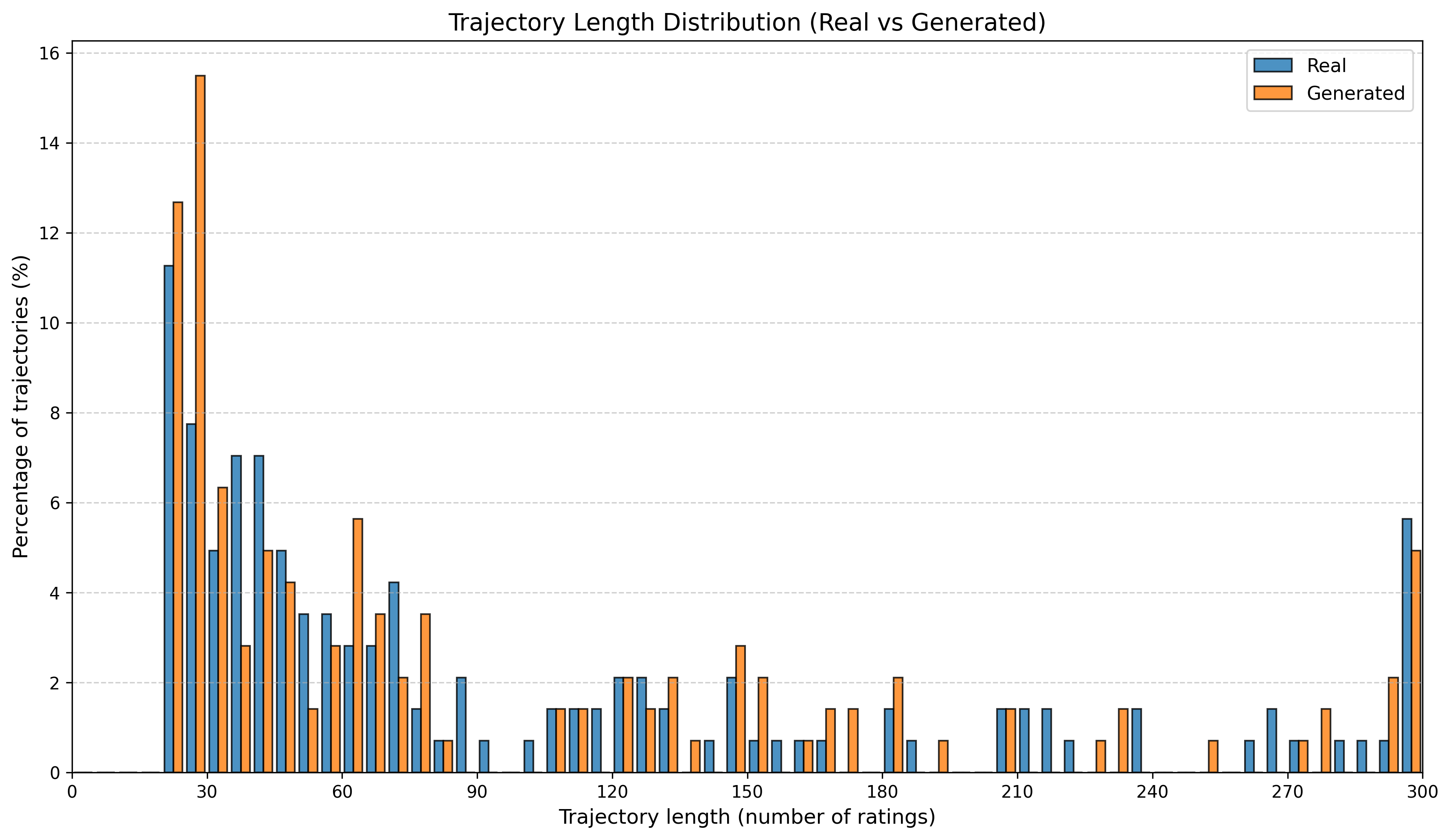
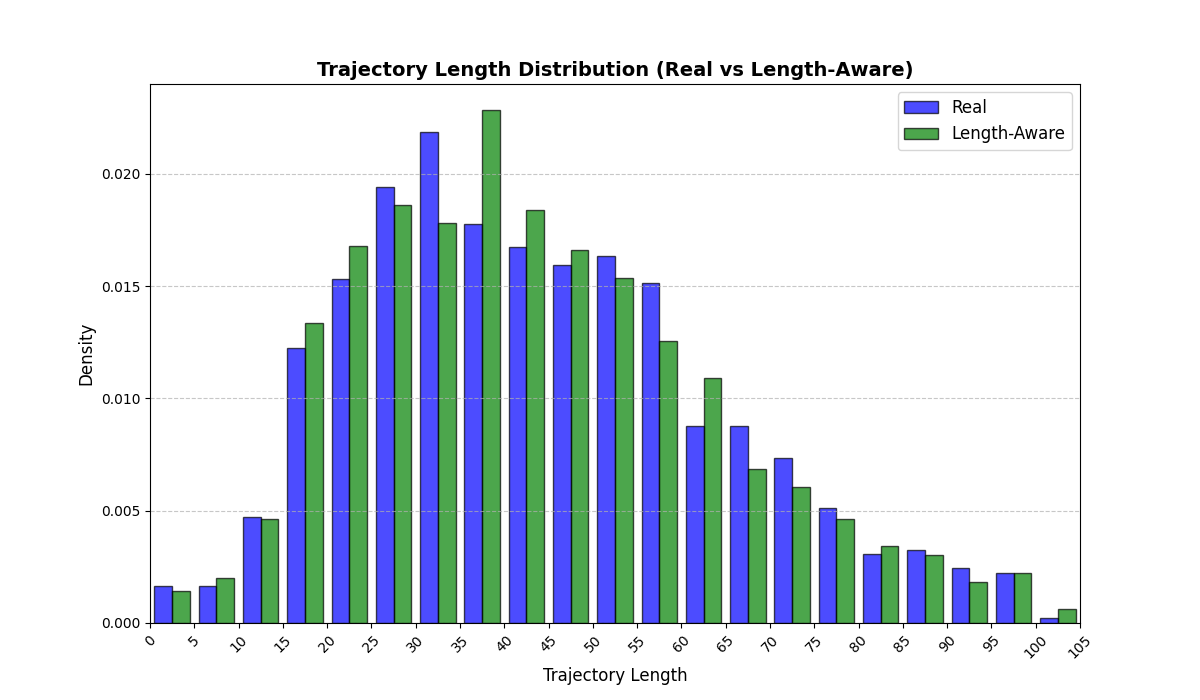
To summarize performance across a broader set of mall-derived variables, Table 2 reports the average KS across all ten mall metrics (timing, diversity, and categorical marginals). On average, LAS reduces mean KS from 0.697 (RS) to 0.247 (LAS), a 64.5% reduction. Figure 6 further shows trajectory-length distributions across all four malls.
| Derived variable | |||
| (RS) | |||
| (LAS) | |||
| reduction | |||
| Avg intra-store time | 0.972 | 0.122 | 87.5% |
| Number of visits | 0.951 | 0.047 | 95.1% |
| Floor distribution | 0.800 | 0.517 | 35.4% |
| Total intra-store time | 0.796 | 0.119 | 85.1% |
| Total inter-store time | 0.763 | 0.380 | 50.3% |
| Avg inter-store time | 0.679 | 0.382 | 43.8% |
| Total time in mall | 0.589 | 0.137 | 76.7% |
| Store diversity | 0.556 | 0.066 | 88.1% |
| Store type distribution | 0.432 | 0.314 | 27.3% |
| Time spent per category | 0.426 | 0.390 | 8.4% |
| All metrics (mean) | 0.697 | 0.247 | 64.5% |
Mall datasets: mean KS across malls for each derived variable. The final row is the mean across all metrics.
See Appendix 12.1 for per-mall trajectory-length (#visits) distribution plots under RS and LAS.
Public sequential datasets
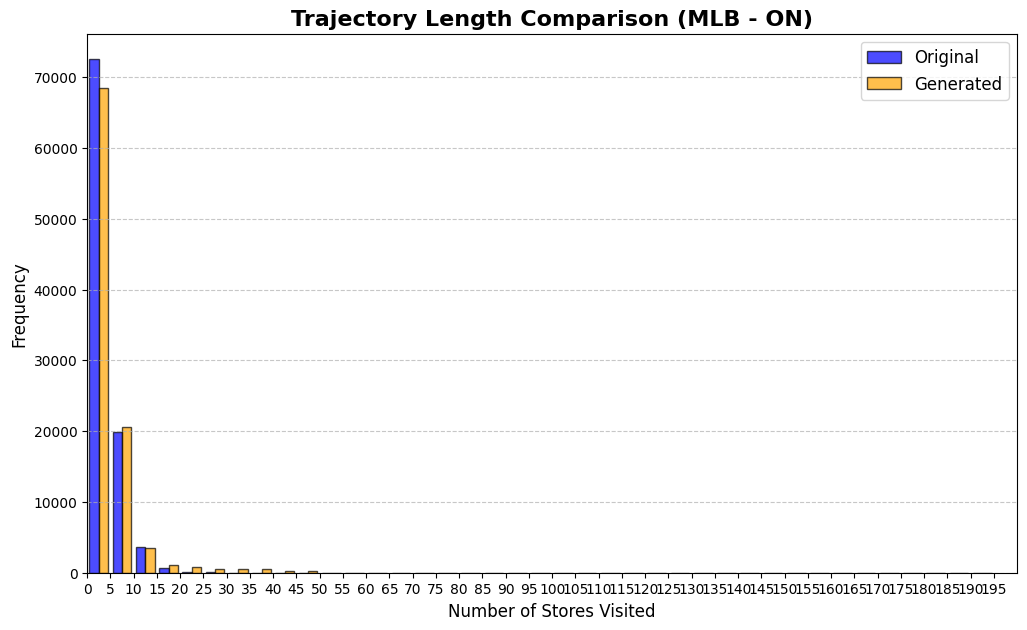
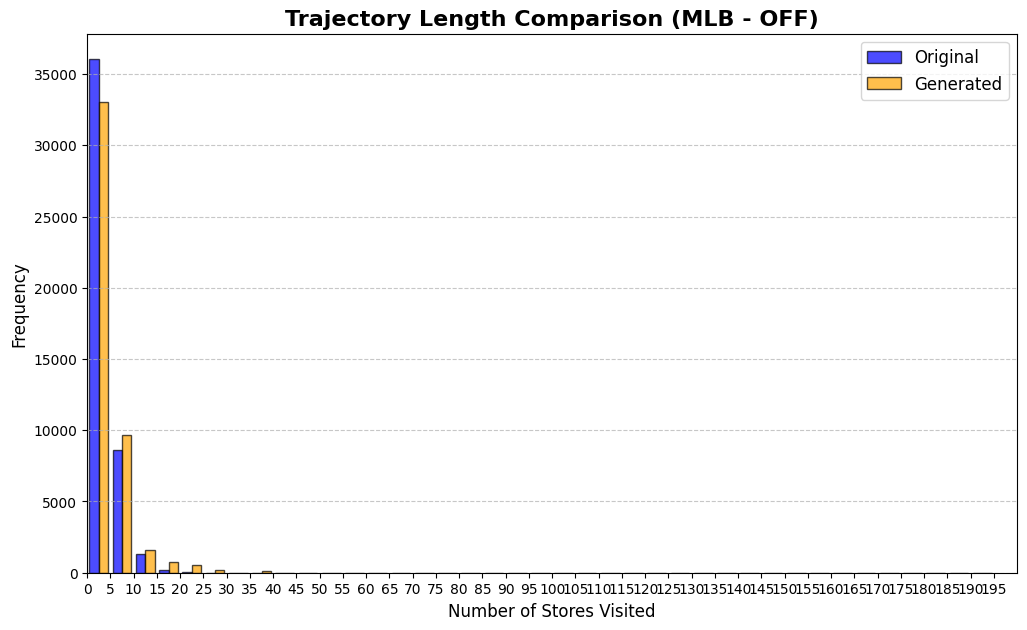
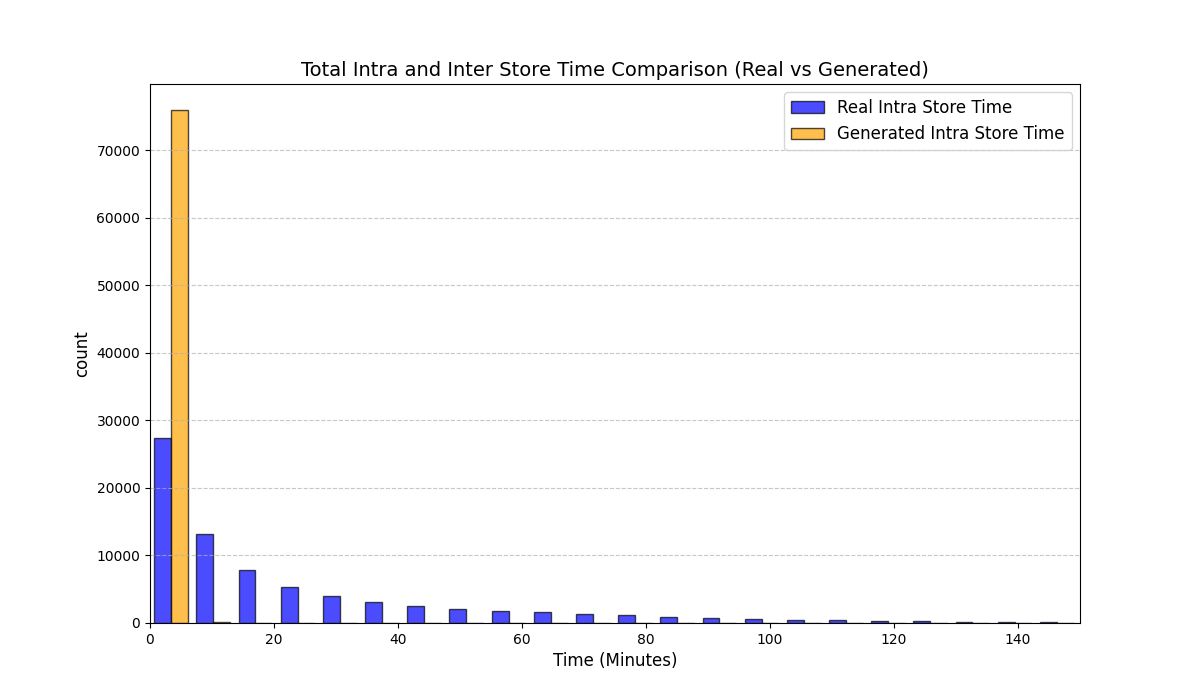
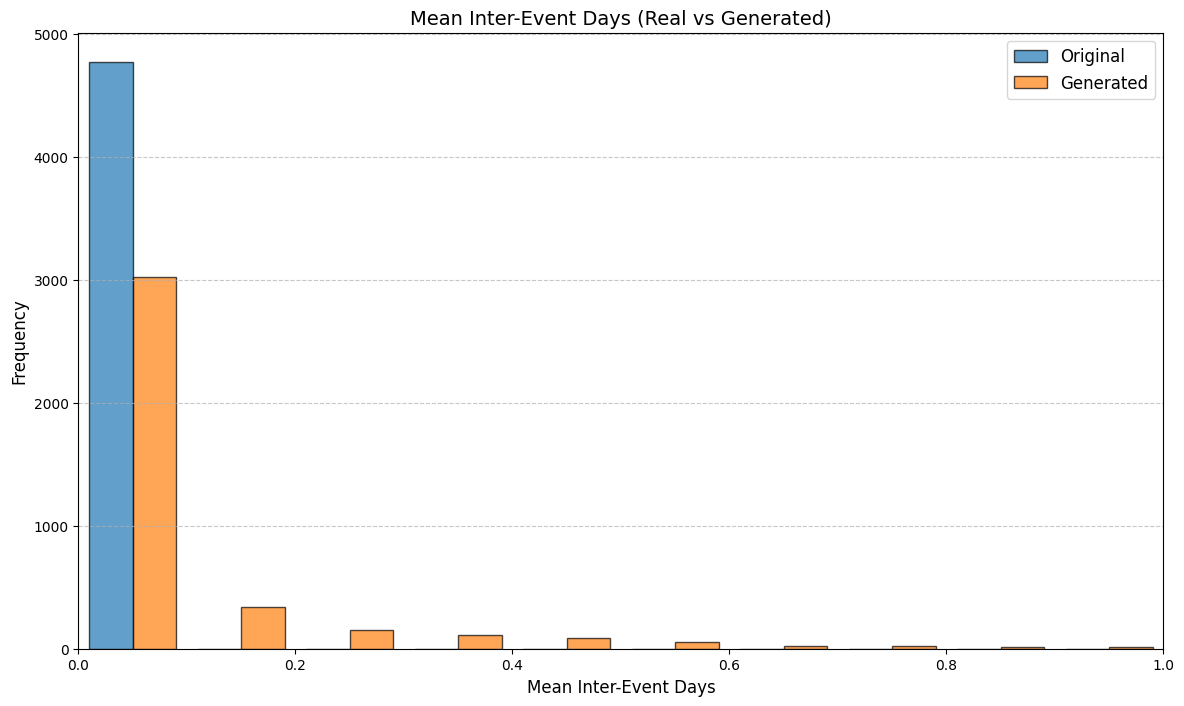
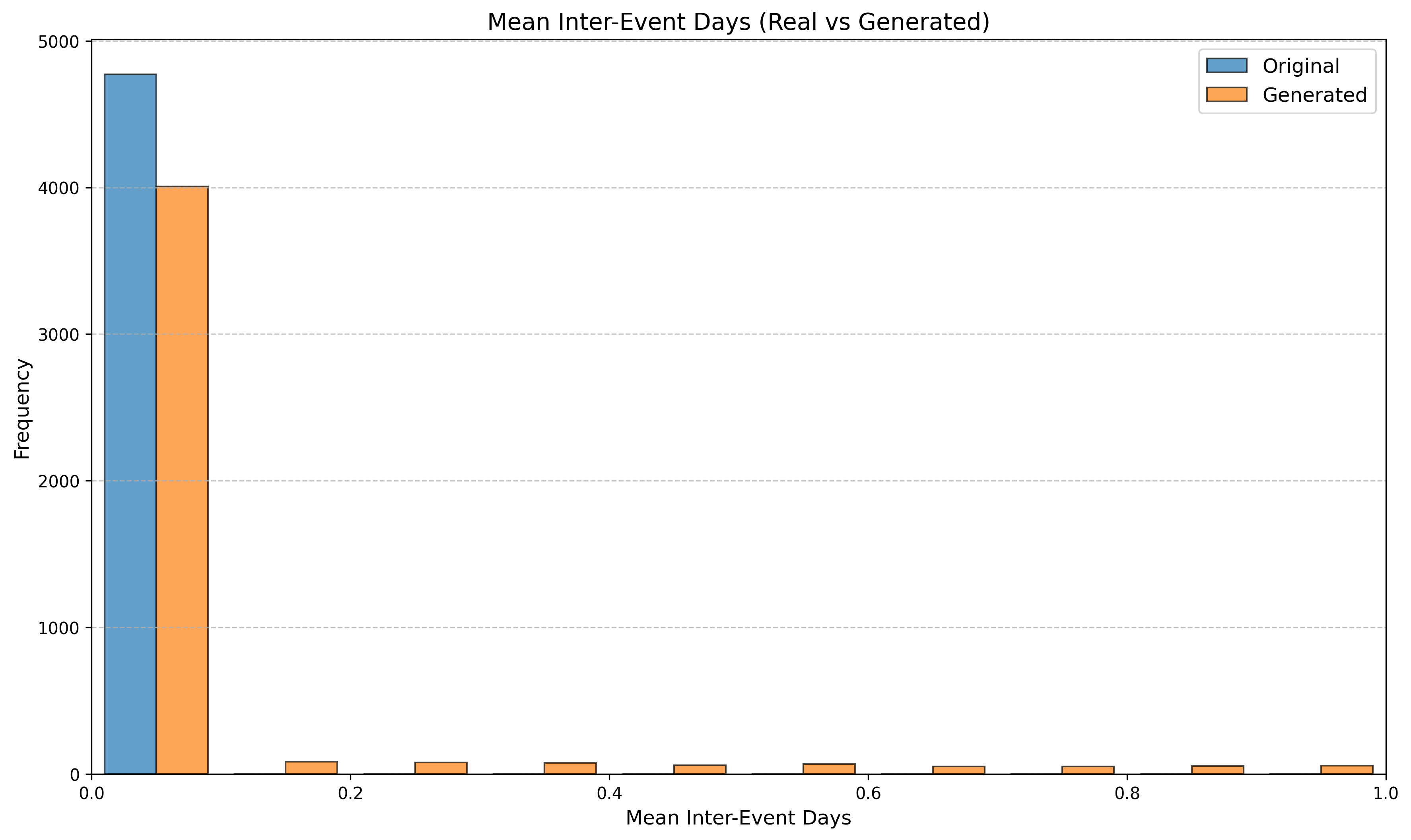
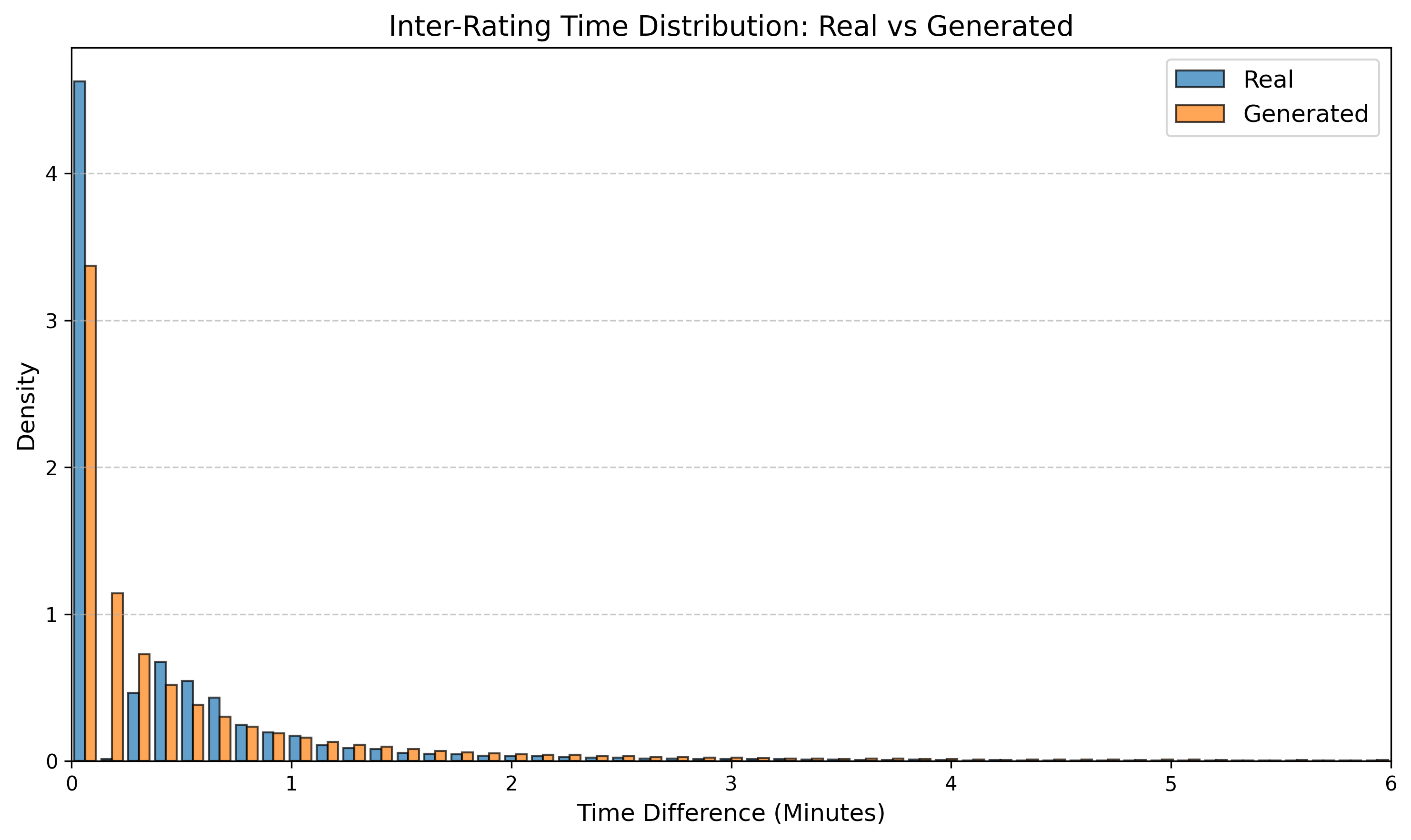
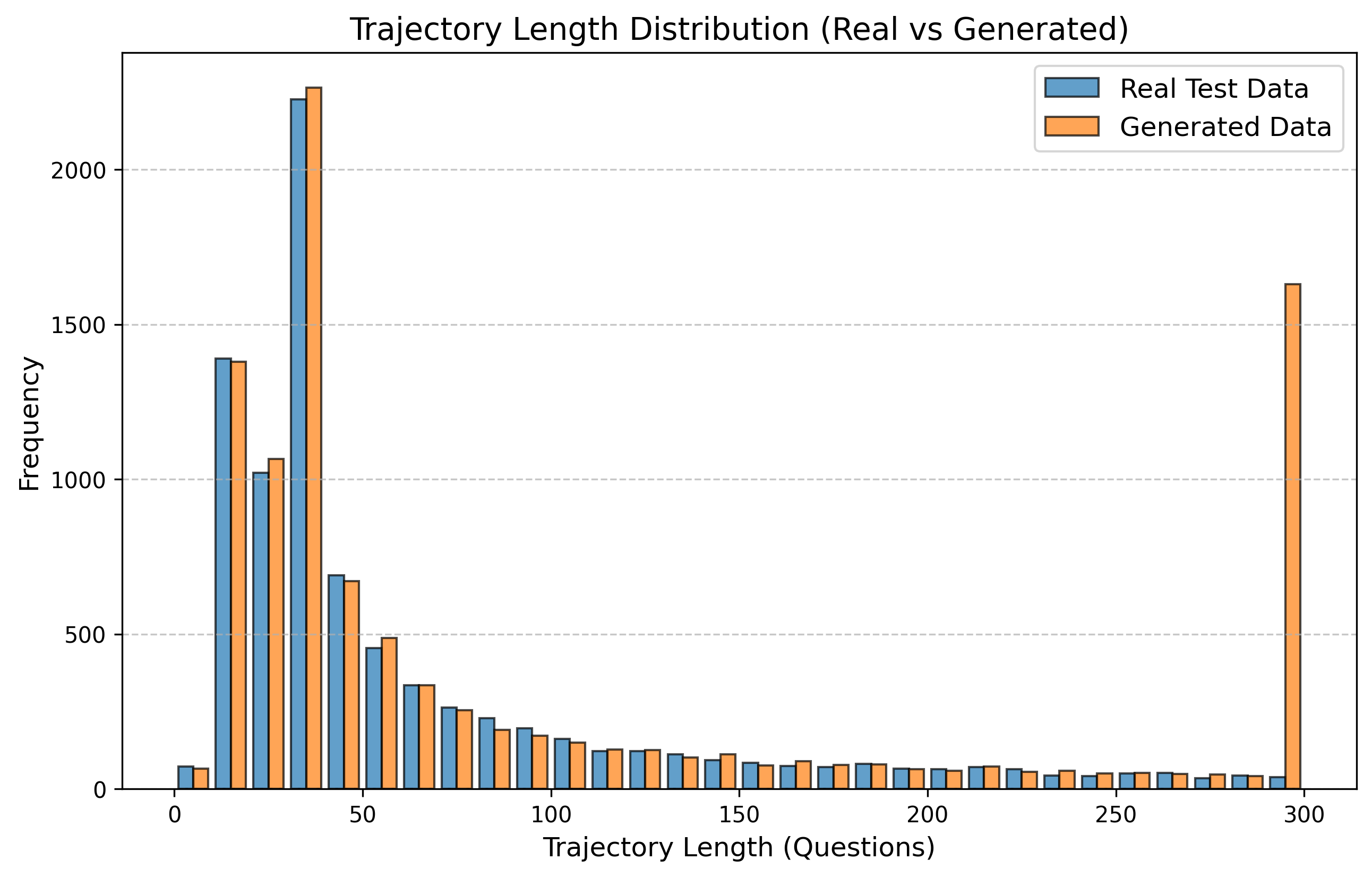
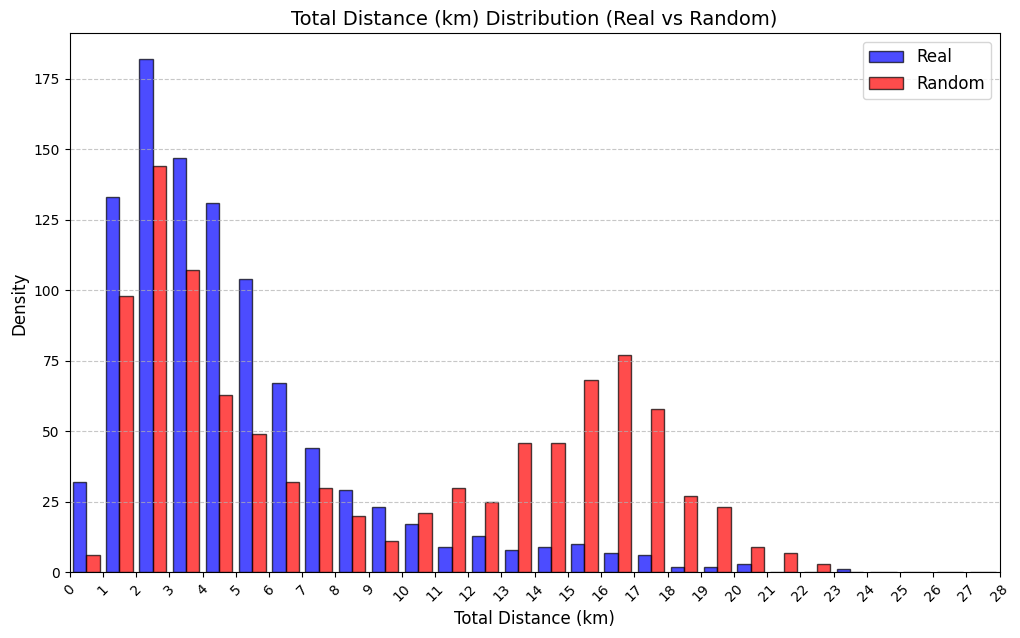
Table 3 reports KS statistics on four public datasets: Amazon (e-commerce ratings), Movie (movie ratings), Education (student learning sequences), and GPS (mobility trajectories). We observe the largest gains on duration and diversity related metrics on Amazon, consistent improvements on Movie inter-event timing, and clear reductions on GPS and Education derived-variable mismatches (especially length-related marginals). Figures 2–5 visualize representative marginals.
| Dataset | Derived variable | RS | LAS |
|---|---|---|---|
| Amazon | Sequence length | 0.002 | 0.002 |
| Amazon | Item diversity | 0.338 | 0.020 |
| Amazon | Inter-event days | 0.456 | 0.170 |
| Amazon | Duration (days) | 0.413 | 0.046 |
| Amazon | Mean rating | 0.632 | 0.590 |
| Movie | Trajectory length | 0.120 | 0.067 |
| Movie | Inter-rating time (min) | 0.466 | 0.294 |
| Movie | Mean rating | 0.155 | 0.106 |
| Movie | Rating std | 0.754 | 0.669 |
| Education | Trajectory length | 0.411 | 0.164 |
| Education | Mean correctness | 0.9997 | 0.529 |
| Education | Std correctness | 0.9994 | 0.350 |
| GPS | Trajectory length | 0.243 | 0.0287 |
| GPS | Total distance (km) | 0.284 | 0.142 |
| GPS | Average speed (km/h) | 0.312 | 0.108 |
| Amazon | Mean across metrics | 0.368 | 0.166 |
| Movie | Mean across metrics | 0.373 | 0.284 |
| Education | Mean across metrics | 0.803 | 0.348 |
| GPS | Mean across metrics | 0.280 | 0.093 |
Public datasets: KS statistics (lower is better). For each dataset, RS and LAS share the same model and objective; only the batching strategy differs.
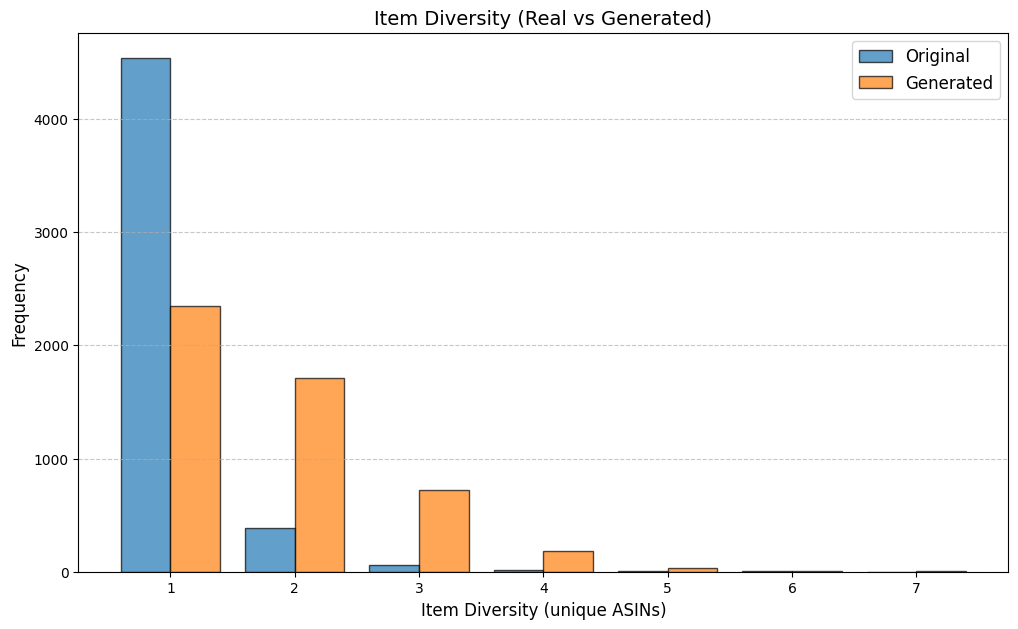
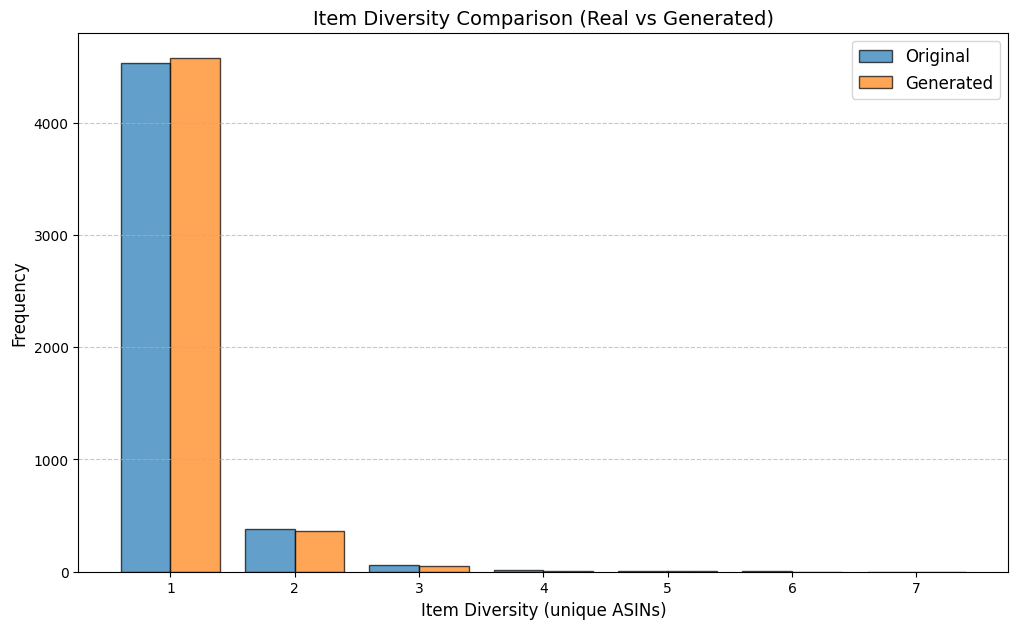







Discussion
LAS is most effective when the dataset exhibits substantial length heterogeneity, where RS mixes short and long trajectories within a mini-batch and can make length an easy shortcut feature for the discriminator. In such settings, we find LAS often yields more consistent adversarial updates and better distribution matching for length- and time-related derived variables. We occasionally observe smaller gains (or mild regressions) on certain categorical marginals (e.g., store-type or floor distributions in some malls), suggesting that controlling length alone may not fully resolve capacity or representation limits of the underlying generator/discriminator. Overall, LAS provides a strong “drop-in” improvement that improves distributional fidelity of key derived variables, and in many cases leads to more stable training behavior in practice.
Controllability and what-if analyses
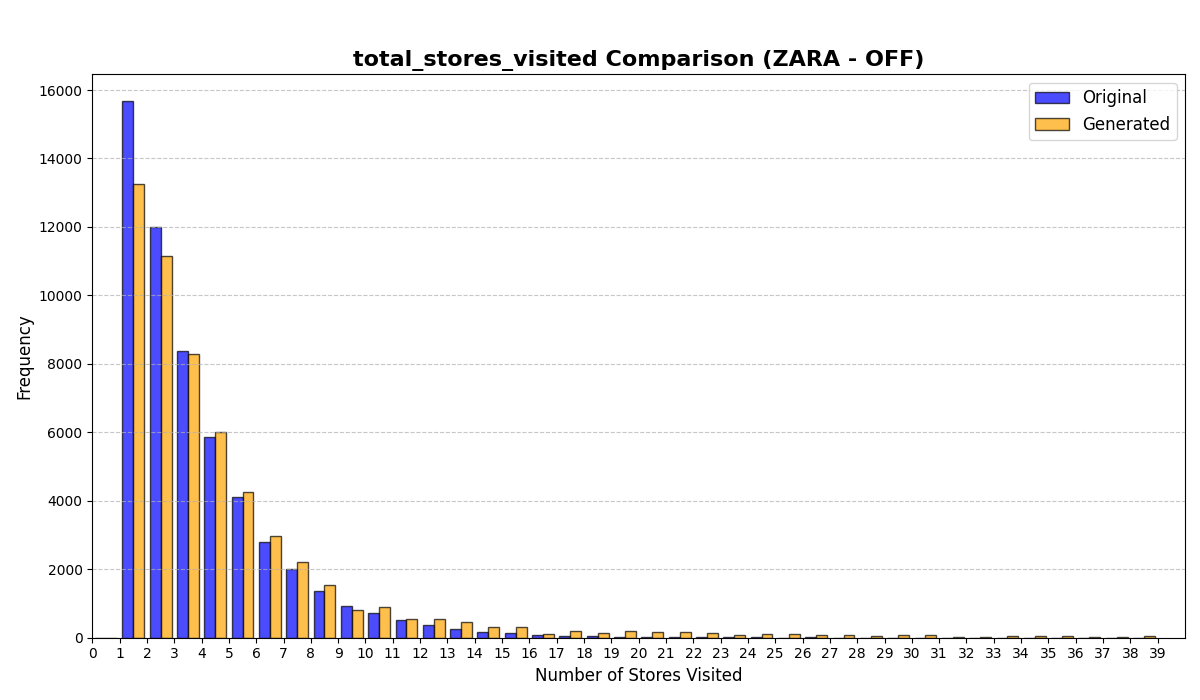
Beyond unconditional distributional fidelity, we also test whether the trained generator responds in intuitive directions to context and spatial perturbations. These checks support downstream “what-if” analyses while remaining lightweight (full figures and additional details are in Appendix 12).
Conditional store influence (ON/OFF).
We condition on whether a focal store $`s^\ast`$ is open and compare the generated distributions of visitation and dwell-time variables on ON days versus OFF days (Appendix 12.3). The model shifts visitation and time-allocation in the expected direction: when $`s^\ast`$ is open, trajectories exhibit increased propensity to include $`s^\ast`$ and reallocate time budget accordingly, whereas OFF days behave more like shorter, targeted trips. This indicates the generator can reflect exogenous availability constraints rather than merely matching unconditional marginals.
Swapping experiments with gate distance.
To probe sensitivity to mall layout, we “swap” (relocate) a target brand across stores at varying distances to the nearest gate and re-generate trajectories under the modified mapping (Appendix 12.4). We observe smooth, distance-dependent changes in visitation and time-related metrics, consistent with learned spatial attractiveness rather than brittle length-only artifacts. Together, these analyses suggest LAS-stabilized training yields a model that is not only accurate on marginal distributions but also meaningfully controllable under structured perturbations.
Conclusion
We introduced length-aware sampling (LAS) for stabilizing variable-length trajectory generation and evaluated distributional fidelity on dataset-specific derived variables across proprietary mall data and additional trajectory datasets. Full model/training details, theory proofs, and additional plots are provided in the appendix.
Model Architecture (Full Details)
Section 4 provides a compact architecture summary; this appendix gives full details for reproducibility.
We model the mall environment and shopper behavior using a three-stage architecture: 1) Store Feature Embedding with Attention Fusion, 2) LSTM-based Conditional Trajectory Generator, 3) Bidirectional LSTM-based Discriminator.
Store Feature Embedding with Attention Fusion
We represent the mall as a graph $`G = (V, E)`$, where:
-
$`V = \{ v_1, \ldots, v_N \}`$ is the set of stores;
-
$`E`$ is the adjacency set representing spatial connections between stores.
Store features and preprocessing.
Each store $`v_i`$ is associated with a feature vector $`\mathbf{x}_i \in \mathbb{R}^{F_{\text{store}}}`$. All store vectors form the matrix:
\mathbf{X} =
\begin{bmatrix}
\mathbf{x}_1^\top \\
\vdots \\
\mathbf{x}_N^\top
\end{bmatrix}
\in \mathbb{R}^{N \times F_{\text{store}}}The feature vector for store $`v_i`$ is constructed as:
\mathbf{x}_i =
\Big[
\begin{aligned}[t]
&\mathbf{x}_i^{(\text{id})};\ \mathbf{x}_i^{(\text{floor})};\ \mathbf{x}_i^{(\text{traffic})};\ \mathbf{x}_i^{(\text{open})};\\
&\mathbf{x}_i^{(\text{degree})};\ \mathbf{x}_i^{(\text{neighbor-counts})};\ \mathbf{x}_i^{(\text{neighbor-pct})};\\
&\mathbf{x}_i^{(\text{hop})};\ \mathbf{x}_i^{(\text{scope})}
\end{aligned}
\Big].Preprocessing steps:
-
$`\mathbf{x}_i^{(\text{id})}`$: one-hot encoding of store identity ($`N`$-dim).
-
$`\mathbf{x}_i^{(\text{floor})}`$: one-hot encoding of floor identity.
-
$`\mathbf{x}_i^{(\text{traffic})}`$: daily visitor count, clipped at the 95th percentile, log-transformed, and standardized:
MATHx_{\text{traffic}} = \frac{\log(1 + \min(\text{count}, p_{95})) - \mu}{\sigma}Click to expand and view morewhere $`p_{95}`$ is the 95th percentile, $`\mu, \sigma`$ are mean and std.
-
$`\mathbf{x}_i^{(\text{open})}`$: binary open/closed indicator.
-
$`\mathbf{x}_i^{(\text{degree})}`$: graph degree of store $`v_i`$ (the number of directly connected neighboring stores), min-max scaled to $`[0,1]`$.
-
$`\mathbf{x}_i^{(\text{neighbor-counts})}`$: log-scaled raw counts of neighboring categories, aggregated by category type rather than the total number of neighbors.
-
$`\mathbf{x}_i^{(\text{neighbor-pct})}`$: normalized percentages of neighboring categories, where the proportions across all neighboring categories sum to 1.
-
$`\mathbf{x}_i^{(\text{hop})}`$: shortest hop distance to key facilities (elevators, escalators, gates), normalized to $`[0,1]`$.
-
$`\mathbf{x}_i^{(\text{scope})}`$: binary nationwide vs. regional scope indicator.
Mall-level context features.
At day $`\delta`$, the mall-level context vector is defined as:
\begin{aligned}
\mathbf{m}^{(\delta)} &=
\left[
\begin{aligned}[t]
&\mathbf{m}^{(\text{theme},\delta)};\ \mathbf{m}^{(\text{campaign},\delta)};\ \mathbf{m}^{(\text{temp},\delta)};\\
&\mathbf{m}^{(\text{precip},\delta)};\ \mathbf{m}^{(\text{sunshine},\delta)};\ \mathbf{m}^{(\text{wind},\delta)};\
\mathbf{m}^{(\text{weather},\delta)}
\end{aligned}
\right],\\
\mathbf{m}^{(\delta)} &\in \mathbb{R}^{F_{\text{mall}}}.
\end{aligned}| Feature group | Description | Dim. |
|---|---|---|
| Store ID | One-hot identity | $`N`$ |
| Floor | One-hot floor encoding | #floors |
| Traffic | Daily visitor count (log-scaled and standardized) | 1 |
| Open status | Binary open/closed | 1 |
| Degree | Graph degree (number of neighboring stores) | 1 |
| Neighbor counts | Counts of neighboring categories (log-scaled) | #categories |
| Neighbor percentages | Normalized proportions of neighboring categories | #categories |
| Hop distance | Shortest path to key facilities (normalized) | #facilities |
| Scope | Nationwide vs. regional indicator | 1 |
| Mall context | Theme, campaigns, weather, and related mall-level factors | $`F_{\text{mall}}`$ |
Summary of feature categories and their dimensions.
Attention-based Feature Fusion.
We project the three feature groups—store, neighbor, and mall—into a shared embedding space using linear transformations followed by ReLU activations:
\begin{aligned}
\mathbf{s}_i^{(\text{store})}
&= \operatorname{ReLU}\!\left(\mathbf{W}_{\text{store-emb}}\,\mathbf{x}_i^{(\text{store})}\right),\\
\mathbf{W}_{\text{store-emb}} &\in \mathbb{R}^{d_{\text{embed}}\times d_{\text{store}}},\quad
\mathbf{s}_i^{(\text{store})}\in \mathbb{R}^{d_{\text{embed}}},\\[0.4em]
\mathbf{s}_i^{(\text{neighbor})}
&= \operatorname{ReLU}\!\left(\mathbf{W}_{\text{neighbor-emb}}\,\mathbf{x}_i^{(\text{neighbor})}\right),\\
\mathbf{W}_{\text{neighbor-emb}} &\in \mathbb{R}^{d_{\text{embed}}\times d_{\text{neighbor}}},\quad
\mathbf{s}_i^{(\text{neighbor})}\in \mathbb{R}^{d_{\text{embed}}},\\[0.4em]
\mathbf{s}_i^{(\text{mall})}
&= \operatorname{ReLU}\!\left(\mathbf{W}_{\text{mall-emb}}\,\mathbf{m}^{(\delta)}\right),\\
\mathbf{W}_{\text{mall-emb}} &\in \mathbb{R}^{d_{\text{embed}}\times d_{\text{mall}}},\quad
\mathbf{s}_i^{(\text{mall})}\in \mathbb{R}^{d_{\text{embed}}}.
\end{aligned}These projected embeddings are stacked to form a matrix:
\mathbf{S}_i =
\begin{bmatrix}
\mathbf{s}_i^{(\text{store})} \\
\mathbf{s}_i^{(\text{neighbor})} \\
\mathbf{s}_i^{(\text{mall})}
\end{bmatrix}
\in \mathbb{R}^{3 \times d_{\text{embed}}}We then compute attention weights using a shared linear transformation followed by LeakyReLU and Softmax:
\begin{aligned}
\boldsymbol{\alpha}_i^{(\text{attn})}
&= \operatorname{Softmax}\!\left(
\operatorname{LeakyReLU}\!\left(\mathbf{S}_i\,\mathbf{w}_{\text{attn}}\right)\right),\\
\mathbf{w}_{\text{attn}} &\in \mathbb{R}^{d_{\text{embed}}},\quad
\boldsymbol{\alpha}_i^{(\text{attn})}\in \mathbb{R}^{3}.
\end{aligned}The final attention-fused embedding is the weighted sum:
\mathbf{s}_i^{\text{embed}} = \sum_{j \in \{\text{store}, \text{neighbor}, \text{mall}\}} \alpha_i^{(\text{attn}, j)} \cdot \mathbf{s}_i^{(j)}
\in \mathbb{R}^{d_{\text{embed}}}Conditional Sequence Generator (LSTM)
To avoid notation clashes, we explicitly denote the store index at timestep $`t`$ as $`j_{t}`$. The generator is modeled as a conditional LSTM that recursively produces the next store in the trajectory until it outputs a special end-of-trajectory token. The generated trajectory can have variable length $`\hat{T}`$.
At each timestep $`t`$:
\mathbf{h}_t, \mathbf{c}_t = \text{LSTMCell}(\mathbf{u}_t, \mathbf{h}_{t-1}, \mathbf{c}_{t-1})where $`\mathbf{u}_t`$ is the input vector:
\begin{aligned}
\mathbf{u}_t &=
\left[
\mathbf{s}_{j_{t-1}}^{\text{embed}};\ \mathbf{z}_{\text{latent}};\ \mathbf{v};\
\tau_t^{(\text{intra})};\ \tau_t^{(\text{inter})}
\right],\\
\mathbf{u}_t &\in \mathbb{R}^{d_{\text{embed}} + d_{\text{latent}} + d_{\text{visitor}} + 2}.
\end{aligned}Input components.
-
$`\mathbf{s}_{j_{t-1}}^{\text{embed}} \in \mathbb{R}^{d_{\text{embed}}}`$ — attention-fused embedding of the previously visited store;
-
$`\mathbf{z}_{\text{latent}} \in \mathbb{R}^{d_{\text{latent}}}`$ — latent noise vector sampled from a prior distribution (e.g., $`\mathcal{N}(0, I)`$) to introduce diversity in the generated sequences;
-
$`\mathbf{v} \in \mathbb{R}^{d_{\text{visitor}}}`$ — visitor demographic or context embedding;
-
$`\tau_t^{(\text{intra})},\ \tau_t^{(\text{inter})} \in \mathbb{R}^1`$ — intra- and inter-visit time intervals.
LSTM cell details.
We use an LSTM with hidden state dimension $`H`$. Its gate equations are:
\begin{align*}
\mathbf{i}_t &= \sigma \!\left( \mathbf{W}_i \mathbf{u}_t + \mathbf{U}_i \mathbf{h}_{t-1} + \mathbf{b}_i \right), \\
\mathbf{f}_t &= \sigma \!\left( \mathbf{W}_f \mathbf{u}_t + \mathbf{U}_f \mathbf{h}_{t-1} + \mathbf{b}_f \right), \\
\mathbf{o}_t^{(\text{gate})} &= \sigma \!\left( \mathbf{W}_o \mathbf{u}_t + \mathbf{U}_o \mathbf{h}_{t-1} + \mathbf{b}_o \right), \\
\tilde{\mathbf{c}}_t &= \tanh \!\left( \mathbf{W}_c \mathbf{u}_t + \mathbf{U}_c \mathbf{h}_{t-1} + \mathbf{b}_c \right), \\
\mathbf{c}_t &= \mathbf{f}_t \odot \mathbf{c}_{t-1} + \mathbf{i}_t \odot \tilde{\mathbf{c}}_t, \\
\mathbf{h}_t &= \mathbf{o}_t^{(\text{gate})} \odot \tanh(\mathbf{c}_t).
\end{align*}Here $`\sigma(\cdot)`$ is the sigmoid function, $`\odot`$ denotes element-wise multiplication, and $`\mathbf{h}_t,\mathbf{c}_t \in \mathbb{R}^H`$ are the hidden and cell states.
Because the generator stops when the end-of-trajectory token is sampled, the length $`\hat{T}`$ of the generated sequence may vary from sample to sample.
where:
-
$`\sigma(\cdot)`$ is the sigmoid activation function,
-
$`\odot`$ denotes element-wise multiplication,
-
$`\mathbf{h}_t, \mathbf{c}_t \in \mathbb{R}^H`$ are the hidden and cell states.
Because the generator stops when the end-of-trajectory token is sampled, the length $`\hat{T}`$ of the generated sequence may vary from sample to sample.
Output layer.
At each timestep $`t`$, the generator produces three outputs from the hidden state $`\mathbf{h}_t \in \mathbb{R}^{H}`$:
1. Store index prediction (plus end-of-trajectory token):
\begin{aligned}
\mathbf{o}_t^{\text{store}} &= \mathbf{W}_{\text{store-out}} \mathbf{h}_t + \mathbf{b}_{\text{store}},\\
\mathbf{W}_{\text{store-out}} &\in \mathbb{R}^{(N+1)\times H},\quad
\mathbf{b}_{\text{store}} \in \mathbb{R}^{N+1},\quad
\mathbf{o}_t^{\text{store}} \in \mathbb{R}^{N+1}.
\end{aligned}A softmax is applied:
\mathbf{p}_t^{\text{store}} = \text{Softmax}(\mathbf{o}_t^{\text{store}}),
\quad \mathbf{p}_t^{\text{store}} \in [0,1]^{N+1},
\quad \sum_{k=1}^{N+1} p_{t,k}^{\text{store}} = 1where the $`(N+1)`$-th entry is a special token indicating the end of the trajectory.
2. Intra-visit time prediction:
\begin{aligned}
\hat{\tau}_t^{(\text{intra})} &= \mathbf{w}_{\text{intra}}^\top \mathbf{h}_t + b_{\text{intra}},\\
\mathbf{w}_{\text{intra}} &\in \mathbb{R}^{H},\quad
b_{\text{intra}} \in \mathbb{R}.
\end{aligned}3. Inter-visit time prediction:
\begin{aligned}
\hat{\tau}_t^{(\text{inter})} &= \mathbf{w}_{\text{inter}}^\top \mathbf{h}_t + b_{\text{inter}},\\
\mathbf{w}_{\text{inter}} &\in \mathbb{R}^{H},\quad
b_{\text{inter}} \in \mathbb{R}.
\end{aligned}Thus, the generator outputs a predicted next-store distribution, along with intra- and inter-visit time estimates, for as many timesteps as needed until the special end-of-trajectory token is predicted, resulting in a variable-length generated sequence.
Discriminator Architecture
At each timestep $`t`$, the discriminator receives the store embedding and the corresponding time intervals:
\mathbf{x}_t^{\text{disc}}
=\big[\,\mathbf{s}_{j_t}^{\text{embed}};\ \tau_t^{(\text{intra})};\ \tau_t^{(\text{inter})}\,\big]
\in \mathbb{R}^{d_{\text{embed}} + 2}.The input sequence is variable-length,
x = \big(\mathbf{x}_1^{\text{disc}}, \ldots, \mathbf{x}_L^{\text{disc}}\big),where $`L=T`$ for real trajectories and $`L=\hat{T}`$ for generated trajectories. This sequence is processed by a bidirectional LSTM with hidden size $`H_D`$:
\begin{align*}
\mathbf{h}_t^{\rightarrow} &= \operatorname{LSTM}_{\text{fwd}}\!\left(\mathbf{x}_t^{\text{disc}},\ \mathbf{h}_{t-1}^{\rightarrow}\right),\\
\mathbf{h}_t^{\leftarrow} &= \operatorname{LSTM}_{\text{bwd}}\!\left(\mathbf{x}_t^{\text{disc}},\ \mathbf{h}_{t+1}^{\leftarrow}\right).
\end{align*}Intuition of bidirectionality and variable-length handling.
Unlike the generator, the discriminator is not constrained to operate sequentially in one direction. Using a bidirectional LSTM allows it to incorporate both past and future context when evaluating each timestep. For example, whether a visit to a particular store is realistic may depend not only on the previous visits but also on the subsequent visits. This holistic view of the entire sequence enables the discriminator to more effectively detect unrealistic transitions or inconsistencies that might otherwise be missed if it only processed the sequence forward in time.
Because LSTMs process sequences one timestep at a time, they naturally support variable-length inputs: they unroll for as many timesteps as are available in the input trajectory and then stop. For real trajectories of length $`T`$ and generated trajectories of length $`\hat{T}`$, the bidirectional LSTM runs until the end of each sequence without requiring padding or truncation. At the sequence level, the discriminator uses the forward hidden state at the last valid timestep $`\mathbf{h}_L^{\rightarrow}`$ and the backward hidden state at the first timestep $`\mathbf{h}_1^{\leftarrow}`$, ensuring that the entire trajectory is fully represented regardless of its length.
The final feature vector concatenates the last forward and backward states with the visitor context vector $`\mathbf{v}`$:
\mathbf{f}^{\text{disc}} =
\left[ \mathbf{h}_L^{\rightarrow};\ \mathbf{h}_1^{\leftarrow};\ \mathbf{v} \right]
\in \mathbb{R}^{2H_D + d_{\text{visitor}}}Finally, the discriminator outputs the real/fake probability:
\begin{aligned}
\hat{y} &= \sigma\!\left(\mathbf{W}_{d\text{-out}}\,\mathbf{f}^{\text{disc}} + b_{d\text{-out}}\right),\\
\mathbf{W}_{d\text{-out}} &\in \mathbb{R}^{1 \times (2H_D + d_{\text{visitor}})},\quad
b_{d\text{-out}} \in \mathbb{R},\quad
\hat{y}\in(0,1).
\end{aligned}Loss Functions (Full Details)
The main text states the training objective at a high level; we collect full loss definitions and dataset-specific variants here. The training objective consists of separate losses for the generator and the discriminator.
The generator loss $`\mathcal{L}_G`$ combines an adversarial term with optional auxiliary terms, while the discriminator loss $`\mathcal{L}_D`$ is purely adversarial.
Mall objective (timing-aligned adversarial training).
For the mall experiments, we use an adversarial objective augmented with explicit intra-/inter-event timing alignment:
\mathcal{L}_G
\;=\; \mathcal{L}_{\mathrm{adv}}
\;+\; \lambda_{\mathrm{time}} \big( \mathcal{L}_{\mathrm{intra}} + \mathcal{L}_{\mathrm{inter}} \big),where $`\lambda_{\mathrm{time}}>0`$ controls the relative weight of the temporal alignment terms. Here $`\mathcal{L}_{\mathrm{intra}}`$ penalizes mismatches in intra-store (within-stop) timing, and $`\mathcal{L}_{\mathrm{inter}}`$ penalizes mismatches in inter-store transition timing.
Public dataset objectives.
For the public datasets, we use dataset-specific adversarial objectives (and keep the objective fixed when comparing RS vs. LAS within each dataset; only the batching strategy differs): Education: adversarial loss only (treating the data as a generic sequence; the discriminator implicitly learns timing/structure); GPS: adversarial loss only; Movie: adversarial loss with an additional feature-matching term $`\mathcal{L}_{\mathrm{fm}}`$; Amazon: Wasserstein (WGAN-style) loss for improved training stability.
We explored additional auxiliary terms in preliminary experiments; unless stated otherwise, the results in the paper use the objectives specified above.
Adversarial Loss
The adversarial loss encourages the generator to produce realistic trajectories that fool the discriminator:
\mathcal{L}_{\text{adv}} =
- \mathbb{E}_{\hat{x} \sim G}
\left[ \log D(\hat{x}) \right]Here, $`\hat{x}`$ represents a generated trajectory, defined as the sequence:
\hat{x} = \left\{
\mathbf{s}_{j_t}^{\text{embed}},
\hat{\tau}_t^{(\text{intra})},
\hat{\tau}_t^{(\text{inter})}
\right\}_{t=1}^{\hat{T}}where $`\mathbf{s}_{j_t}^{\text{embed}}`$ is the embedding of the predicted store index $`j_t`$, $`\hat{\tau}_t^{(\text{intra})}, \hat{\tau}_t^{(\text{inter})}`$ are the generator-predicted time intervals, and $`\hat{T}`$ is the (possibly variable) generated sequence length. This matches the discriminator input described in the previous section: the discriminator never sees the raw store index $`j_t`$ directly but instead receives the corresponding embeddings and predicted time intervals.
Intra-Store Time Prediction Loss
This term enforces accurate prediction of intra-store visit durations:
\mathcal{L}_{\text{intra}} =
\frac{1}{\min(T, \hat{T})}
\sum_{t=1}^{\min(T, \hat{T})}
\left| \hat{\tau}_t^{(\text{intra})} - \tau_t^{(\text{intra})} \right|where $`T`$ is the length of the real trajectory and $`\hat{T}`$ is the length of the generated trajectory.
Inter-Store Time Prediction Loss
Similarly, the inter-store travel time loss is:
\mathcal{L}_{\text{inter}} =
\frac{1}{\min(T, \hat{T})}
\sum_{t=1}^{\min(T, \hat{T})}
\left| \hat{\tau}_t^{(\text{inter})} - \tau_t^{(\text{inter})} \right|Note.
For $`\mathcal{L}_{\text{intra}}`$ and $`\mathcal{L}_{\text{inter}}`$, if the generated sequence length $`\hat{T}`$ does not match the real sequence length $`T`$, the losses are only computed up to $`\min(T, \hat{T})`$. This avoids penalizing valid early stopping (when the generator predicts the end-of-trajectory token earlier) and ensures that sequence misalignment does not dominate the loss.
Discriminator Loss
The discriminator is trained with the standard binary cross-entropy loss:
\mathcal{L}_D =
- \mathbb{E}_{x \sim \text{real}} \left[ \log D(x) \right]
- \mathbb{E}_{\hat{x} \sim G} \left[ \log \left( 1 - D(\hat{x}) \right) \right]where:
\begin{aligned}
x &=
\left\{
\mathbf{s}_{j_t}^{\text{embed}},
\tau_t^{(\text{intra})},
\tau_t^{(\text{inter})}
\right\}_{t=1}^T,\\
\hat{x} &=
\left\{
\mathbf{s}_{j_t}^{\text{embed}},
\hat{\tau}_t^{(\text{intra})},
\hat{\tau}_t^{(\text{inter})}
\right\}_{t=1}^{\hat{T}}.
\end{aligned}Importantly, the discriminator loss does not include the intra and inter-time; those are used exclusively for the generator.
Training Algorithm (Full Details)
This appendix provides pseudocode details complementing the main-text protocol summary.
Initialize $`\theta, \phi`$, temperature $`\tau \leftarrow \tau_{\text{init}}`$
Theory (Full Statements and Proofs)
The main text presents the key bound and intuition; this appendix contains full statements and proofs.
We give distribution-level guarantees for the derived variables we ultimately report: $`\mathrm{Tot}(x)=\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}+\sum_{t=1}^{T-1}\tau_t^{(\mathrm{inter})}`$, $`\mathrm{Avg}(x)=\frac{1}{T}\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}`$, $`\mathrm{Vis}(x)=T`$.
Each $`f\in\{\mathrm{Tot},\mathrm{Avg},\mathrm{Vis}\}`$ is a deterministic, scalar-valued post-processing map from a full trajectory to a summary statistic; it is not the model architecture. We will compare the distributions of these derived variables under the data and generator.
A (random) customer trajectory is
x=\{(j_t,\tau_t^{(\mathrm{intra})},\tau_t^{(\mathrm{inter})})\}_{t=1}^{T},where $`j_t`$ is the store at step $`t`$, $`\tau_t^{(\mathrm{intra})}\ge 0`$ is in–store time, $`\tau_t^{(\mathrm{inter})}\ge 0`$ is inter–store time, and $`T`$ is the (random) visit length. We let $`T_{\max} \in \mathbb{N}`$ denote a fixed upper bound on possible visit lengths. Let $`p_{\mathrm{data}}`$ denote the data distribution over trajectories and $`p_G`$ the generator distribution.
Training objective (matches implementation).
The generator loss is
\mathcal{L}_G\;=\;\mathcal{L}_{\mathrm{adv}}\;+\;\lambda_{\mathrm{time}}\!\left(\mathcal{L}_{\mathrm{intra}}+\mathcal{L}_{\mathrm{inter}}\right),with
\begin{aligned}
\mathcal{L}_{\mathrm{intra}}
&=\mathbb{E}\!\left[\frac{1}{T_{\min}}
\sum_{t=1}^{T_{\min}}
\big|\hat{\tau}^{(\mathrm{intra})}_t-\tau^{(\mathrm{intra})}_t\big|\right],\\
\mathcal{L}_{\mathrm{inter}}
&=\mathbb{E}\!\left[\frac{1}{T_{\min}}
\sum_{t=1}^{T_{\min}}
\big|\hat{\tau}^{(\mathrm{inter})}_t-\tau^{(\mathrm{inter})}_t\big|\right].
\end{aligned}where $`T_{\min}=\min(T,\hat{T})`$. The adversarial term is the standard generator BCE against the discriminator. In practice, we also use length-aware sampling (LAS), which buckets sequences by length (defined precisely below).
Standing assumptions.
(i) $`T\le T_{\max}`$ almost surely; (ii) per-step contribution is bounded: $`0\le \tau_t^{(\mathrm{intra})}+\tau_t^{(\mathrm{inter})}\le B`$; (iii) after training, the losses are controlled:
\mathrm{JS}(p_{\mathrm{data}}\Vert p_G)\le \delta,\qquad
\mathcal{L}_{\mathrm{intra}}\le \epsilon_{\mathrm{intra}},\qquad
\mathcal{L}_{\mathrm{inter}}\le \epsilon_{\mathrm{inter}}.We will use a generic constant $`C_{\mathrm{JS}}`$ for the inequality $`\mathrm{TV}(P,Q)\le C_{\mathrm{JS}}\sqrt{\mathrm{JS}(P\Vert Q)}`$ (Pinsker-type control).
Wasserstein Setup and the Derived-Variable Distributions
For a given derived variable $`f:\mathcal{X}\to\mathbb{R}`$, define the induced distributions
\begin{aligned}
P_f &:= \text{law of } f(x)\ \text{for } x\sim p_{\mathrm{data}},\\
Q_f &:= \text{law of } f(\hat{x})\ \text{for } \hat{x}\sim p_G.
\end{aligned}We measure distributional closeness via the 1-Wasserstein distance
W_1(P_f,Q_f)
=\sup_{\|g\|_{\mathrm{Lip}}\le 1}
\Big|
\mathbb{E}_{x\sim p_{\mathrm{data}}}\!\big[g(f(x))\big]
-\mathbb{E}_{\hat{x}\sim p_G}\!\big[g(f(\hat{x}))\big]
\Big|.where the supremum is over 1–Lipschitz $`g:\mathbb{R}\to\mathbb{R}`$ (Kantorovich–Rubinstein duality) and $`\|g\|_{\mathrm{Lip}}:=\sup_{u\neq v}\frac{|g(u)-g(v)|}{|u-v|}`$.
A Trajectory Semi-Metric and Lipschitz Transfers
Let $`B>0`$ denote a uniform per-step bound on the sum of intra- and inter-trajectory quantities, i.e.,
\tau^{(\mathrm{intra})}_t + \tau^{(\mathrm{inter})}_t \;\le\; B,
\quad
\hat{\tau}^{(\mathrm{intra})}_t + \hat{\tau}^{(\mathrm{inter})}_t \;\le\; B,for all steps $`t`$. This bound represents the maximum possible per-step contribution to the derived variables considered below.
Define the trajectory semi-metric
d_{\mathrm{traj}}(x,\hat{x})
:=\sum_{t=1}^{T_{\min}}\!\Big(
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
+\big|\tau^{(\mathrm{inter})}_t-\hat{\tau}^{(\mathrm{inter})}_t\big|
\Big)
+ B\,|T-\hat{T}|.Lemma 6 (Lipschitz control of derived variables). *For any trajectories $`x,\hat{x}`$,
|\mathrm{Tot}(x)-\mathrm{Tot}(\hat{x})| \;\le\; d_{\mathrm{traj}}(x,\hat{x}),Let $`M:=\max(T,\hat{T},1)`$.
\big|\mathrm{Avg}(x)-\mathrm{Avg}(\hat{x})\big|
\le \frac{1}{M}\sum_{t=1}^{T_{\min}}
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
+ \frac{B}{M}\,|T-\hat{T}|.
```*
</div>
<div class="proof">
*Proof.* Write $`T_{\min}:=\min\{T,\hat{T}\}`$ and denote the stepwise
differences
$`\Delta^{(\mathrm{intra})}_t:=\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t`$
and
$`\Delta^{(\mathrm{inter})}_t:=\tau^{(\mathrm{inter})}_t-\hat{\tau}^{(\mathrm{inter})}_t`$
for $`t\le T_{\min}`$. We also use the shorthand $`(a)_+:=\max\{a,0\}`$
so that $`T-T_{\min}=(T-\hat{T})_+`$ and
$`\hat{T}-T_{\min}=(\hat{T}-T)_+`$.
**(i) The case $`f=\mathrm{Tot}`$.** By definition,
``` math
\begin{aligned}
\mathrm{Tot}(x)
&=\sum_{t=1}^{T}\big(\tau^{(\mathrm{intra})}_t+\tau^{(\mathrm{inter})}_t\big),\\
\mathrm{Tot}(\hat{x})
&=\sum_{t=1}^{\hat{T}}\big(\hat{\tau}^{(\mathrm{intra})}_t+\hat{\tau}^{(\mathrm{inter})}_t\big).
\end{aligned}Then
\begin{aligned}
\mathrm{Tot}(x)-\mathrm{Tot}(\hat{x})
&=\sum_{t=1}^{T_{\min}}\!\big(\Delta^{(\mathrm{intra})}_t+\Delta^{(\mathrm{inter})}_t\big)
+\sum_{t=T_{\min}+1}^{T}\!\big(\tau^{(\mathrm{intra})}_t+\tau^{(\mathrm{inter})}_t\big) \\
&\quad -\sum_{t=T_{\min}+1}^{\hat{T}}\!\big(\hat{\tau}^{(\mathrm{intra})}_t+\hat{\tau}^{(\mathrm{inter})}_t\big).
\end{aligned}Taking absolute values and applying the triangle inequality gives
\begin{aligned}
\big|\mathrm{Tot}(x)-\mathrm{Tot}(\hat{x})\big|
&\le \sum_{t=1}^{T_{\min}}\!\Big(|\Delta^{(\mathrm{intra})}_t|+|\Delta^{(\mathrm{inter})}_t|\Big) \\
&\quad + \sum_{t=T_{\min}+1}^{T}\!\big(\tau^{(\mathrm{intra})}_t+\tau^{(\mathrm{inter})}_t\big)
+ \sum_{t=T_{\min}+1}^{\hat{T}}\!\big(\hat{\tau}^{(\mathrm{intra})}_t+\hat{\tau}^{(\mathrm{inter})}_t\big).
\end{aligned}By the standing per-step bound, each tail term is at most $`B`$. Therefore,
\sum_{t=T_{\min}+1}^{T}\big(\tau^{(\mathrm{intra})}_t+\tau^{(\mathrm{inter})}_t\big)
\le B\,(T-T_{\min})=B\,(T-\hat{T})_+,\sum_{t=T_{\min}+1}^{\hat{T}}
\big(\hat{\tau}^{(\mathrm{intra})}_t+\hat{\tau}^{(\mathrm{inter})}_t\big)
\le B\,(\hat{T}-T_{\min})=B\,(\hat{T}-T)_+.Adding the two tails yields $`B\,(T-\hat{T})_+ + B\,(\hat{T}-T)_+ = B\,|T-\hat{T}|`$. Thus
\big|\mathrm{Tot}(x)-\mathrm{Tot}(\hat{x})\big|
\le \sum_{t=1}^{T_{\min}}\!\Big(
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
+\big|\tau^{(\mathrm{inter})}_t-\hat{\tau}^{(\mathrm{inter})}_t\big|
\Big)+B|T-\hat{T}|
= d_{\mathrm{traj}}(x,\hat{x}).(ii) The case $`f=\mathrm{Avg}`$. Recall
\mathrm{Avg}(x)=\frac{1}{T}\sum_{t=1}^{T}\tau^{(\mathrm{intra})}_t,\qquad
\mathrm{Avg}(\hat{x})=\frac{1}{\hat{T}}\sum_{t=1}^{\hat{T}}\hat{\tau}^{(\mathrm{intra})}_t.Let $`\overline{T}:=\max\{T,\hat{T},1\}`$. Add and subtract the same “matched-length” terms to align denominators:
\begin{align*}
\mathrm{Avg}(x)-\mathrm{Avg}(\hat{x})
&= \frac{1}{T}\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}
\;-\; \frac{1}{\hat{T}}\sum_{t=1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})} \\[2pt]
&= \frac{1}{\overline{T}}\Bigg(\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}-\sum_{t=1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})}\Bigg)
+ \Big(\tfrac{1}{T}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}
- \Big(\tfrac{1}{\hat{T}}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})} \\[2pt]
&= \Big(\tfrac{1}{T}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}
+ \frac{1}{\overline{T}}\sum_{t=1}^{T_{\min}}\!\big(\tau_t^{(\mathrm{intra})}-\hat{\tau}_t^{(\mathrm{intra})}\big)
+ \frac{1}{\overline{T}}\sum_{t=T_{\min}+1}^{T}\tau_t^{(\mathrm{intra})} \\
&\quad - \Big(\tfrac{1}{\hat{T}}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})}
- \frac{1}{\overline{T}}\sum_{t=T_{\min}+1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})} \\[2pt]
&= \underbrace{\Big(\tfrac{1}{T}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{T}\tau_t^{(\mathrm{intra})}}_{\text{(A)}}
+ \underbrace{\tfrac{1}{\overline{T}}\sum_{t=1}^{T_{\min}}\!\big(\tau_t^{(\mathrm{intra})}-\hat{\tau}_t^{(\mathrm{intra})}\big)}_{\text{(B)}} \\
&\quad + \underbrace{\tfrac{1}{\overline{T}}\sum_{t=T_{\min}+1}^{T}\tau_t^{(\mathrm{intra})}}_{\text{(C)}}
- \underbrace{\Big(\tfrac{1}{\hat{T}}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})}}_{\text{(D)}}
- \underbrace{\tfrac{1}{\overline{T}}\sum_{t=T_{\min}+1}^{\hat{T}}\hat{\tau}_t^{(\mathrm{intra})}}_{\text{(E)}}.
\end{align*}We bound each term:
-
Matched steps:
MATH\big|\text{(B)}\big| \;\le\; \frac{1}{\overline{T}}\sum_{t=1}^{T_{\min}}\!\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|.Click to expand and view more -
Tails: by nonnegativity and the per-step bound,
MATH\begin{aligned} \big|\text{(C)}\big|+\big|\text{(E)}\big| &\le \frac{1}{\overline{T}}\!\left( \sum_{t=T_{\min}+1}^{T}\tau^{(\mathrm{intra})}_t +\sum_{t=T_{\min}+1}^{\hat{T}}\hat{\tau}^{(\mathrm{intra})}_t\right) \\ &\le \frac{B}{\overline{T}}\big((T-\hat{T})_+ + (\hat{T}-T)_+\big) = \frac{B}{\overline{T}}\,|T-\hat{T}|. \end{aligned}Click to expand and view more -
We treat (A) and (D) symmetrically and work with explicit algebra. For $`T\ge 1`$,
MATH\big|\text{(A)}\big| =\left|\Big(\tfrac{1}{T}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{T}\tau^{(\mathrm{intra})}_t\right| \le \Big|\tfrac{1}{T}-\tfrac{1}{\overline{T}}\Big|\,BT = \frac{B}{\overline{T}}\,|\,\overline{T}-T\,|.Click to expand and view moreSince $`\overline{T}=\max\{T,\hat{T},1\}`$ and $`T\ge 1`$, either $`\overline{T}=T`$ or $`\overline{T}=\hat{T}`$. Hence
MATH\begin{aligned} |\,\overline{T}-T\,| &=(\hat{T}-T)_+,\\ \text{and therefore}\qquad \big|\text{(A)}\big| &\le\frac{B}{\overline{T}}\,(\hat{T}-T)_+. \end{aligned}Click to expand and view moreSimilarly, for $`\hat{T}\ge 1`$,
MATH\big|\text{(D)}\big| =\left|\Big(\tfrac{1}{\hat{T}}-\tfrac{1}{\overline{T}}\Big)\sum_{t=1}^{\hat{T}}\hat{\tau}^{(\mathrm{intra})}_t\right| \le \frac{B}{\overline{T}}\,|\,\overline{T}-\hat{T}\,| = \frac{B}{\overline{T}}\,(T-\hat{T})_+.Click to expand and view moreAdding the two gives
MATH\big|\text{(A)}\big|+\big|\text{(D)}\big| \le \frac{B}{\overline{T}}\big((\hat{T}-T)_+ + (T-\hat{T})_+\big) = \frac{B}{\overline{T}}\,|T-\hat{T}|.Click to expand and view more
Combining the three parts (B), (C)+(E), and (A)+(D) yields
\big|\mathrm{Avg}(x)-\mathrm{Avg}(\hat{x})\big|
\le \frac{1}{\overline{T}}\sum_{t=1}^{T_{\min}}
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
+\frac{2B}{\overline{T}}\,|T-\hat{T}|.Finally, absorbing constants into $`B`$ if desired and recalling $`\overline{T}=\max\{T,\hat{T},1\}`$, we get
\text{Let } M:=\max(T,\hat{T},1).\qquad
\big|\mathrm{Avg}(x)-\mathrm{Avg}(\hat{x})\big|
\le \frac{1}{M}\sum_{t=1}^{T_{\min}}
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
+\frac{B}{M}\,|T-\hat{T}|.◻
From Training Losses to Expected Trajectory Discrepancy
Lemma 7 (Matched-step control via L1 losses). *With $`\mathcal{L}_{\mathrm{intra}}\le \epsilon_{\mathrm{intra}}`$ and $`\mathcal{L}_{\mathrm{inter}}\le \epsilon_{\mathrm{inter}}`$,
\begin{aligned}
\mathbb{E}\!\left[\sum_{t=1}^{T_{\min}}
|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t|\right]
&\le T_{\max}\,\epsilon_{\mathrm{intra}},\\
\mathbb{E}\!\left[\sum_{t=1}^{T_{\min}}
|\tau^{(\mathrm{inter})}_t-\hat{\tau}^{(\mathrm{inter})}_t|\right]
&\le T_{\max}\,\epsilon_{\mathrm{inter}}.
\end{aligned}
```*
</div>
<div class="proof">
*Proof.* Let
``` math
S_{\mathrm{intra}} := \sum_{t=1}^{T_{\min}}
|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t|.By definition,
\mathcal{L}_{\mathrm{intra}}
=
\mathbb{E}\!\left[\frac{1}{T_{\min}} S_{\mathrm{intra}}\right]
\le \epsilon_{\mathrm{intra}}.Since $`T_{\min}\le T_{\max}`$, we have $`\frac{1}{T_{\min}}\ge \frac{1}{T_{\max}}`$, hence
\frac{1}{T_{\max}}\,S_{\mathrm{intra}}
\le
\frac{1}{T_{\min}}\,S_{\mathrm{intra}}.Taking expectations gives
\frac{1}{T_{\max}}\mathbb{E}[S_{\mathrm{intra}}]
\le
\mathcal{L}_{\mathrm{intra}}
\le
\epsilon_{\mathrm{intra}},so $`\mathbb{E}[S_{\mathrm{intra}}]\le T_{\max}\epsilon_{\mathrm{intra}}`$. The inter-time bound is identical. ◻
Lemma 8 (Length tail controlled by divergence). *Let $`\pi^\star`$ be a maximal coupling of $`p_{\mathrm{data}}`$ and $`p_G`$. Here $`p_{\mathrm{data}}(T)`$ and $`p_G(T)`$ denote the marginal distributions over sequence length $`T`$ under $`p_{\mathrm{data}}`$ and $`p_G`$, respectively. Then
\mathbb{E}_{\pi^\star}\!\left[B|T-\hat{T}|\right]
\le BT_{\max}\,\mathbb{P}_{\pi^\star}(T\neq \hat{T})
= BT_{\max}\,\mathrm{TV}\!\big(p_{\mathrm{data}}(T),p_G(T)\big)
\le BT_{\max}C_{\mathrm{JS}}\sqrt{\delta}.
```*
</div>
<div class="proof">
*Proof.* Since $`0\le T,\hat{T}\le T_{\max}`$, we have the pointwise
bound
``` math
|T-\hat{T}|
\;\le\; T_{\max}\,\mathbf{1}_{\{T\neq \hat{T}\}}.Multiplying by $`B`$ and taking expectations under $`\pi^\star`$ yields
\mathbb{E}_{\pi^\star}[B|T-\hat{T}|]
\le BT_{\max}\,\mathbb{E}_{\pi^\star}\!\big[\mathbb{I}\{T\neq \hat{T}\}\big]
= BT_{\max}\,\mathbb{P}_{\pi^\star}(T\neq \hat{T}).By the defining property of a maximal coupling,
\mathbb{P}_{\pi^\star}(T\neq \hat{T}) \;=\; \mathrm{TV}\!\big(p_{\mathrm{data}}(T),p_G(T)\big).Finally, by the Pinsker-type control we assume (with constant $`C_{\mathrm{JS}}`$),
\mathrm{TV}\!\big(p_{\mathrm{data}}(T),p_G(T)\big)
\le C_{\mathrm{JS}}\sqrt{\mathrm{JS}\!\left(p_{\mathrm{data}}(T)\Vert p_G(T)\right)}
\le C_{\mathrm{JS}}\sqrt{\delta}.Combining the displays gives the stated bound. ◻
Wasserstein-1 Bounds for the Derived Variables
Theorem 9 (Distributional closeness for derived variables). *Under the standing assumptions in Section 5, for each $`f \in \{\mathrm{Tot}, \mathrm{Avg}, \mathrm{Vis}\}`$ let $`P_f`$ and $`Q_f`$ denote the distributions of $`f(x)`$ when $`x`$ is drawn from $`p_{\mathrm{data}}`$ and $`p_G`$, respectively (as in the previous subsection). Then
W_1(P_f,Q_f)\le
\begin{cases}
T_{\max}\big(\epsilon_{\mathrm{intra}}+\epsilon_{\mathrm{inter}}\big)
+BT_{\max}C_{\mathrm{JS}}\sqrt{\delta}, & f=\mathrm{Tot},\\
\epsilon_{\mathrm{intra}}+BT_{\max}C_{\mathrm{JS}}\sqrt{\delta}, & f=\mathrm{Avg},\\
2T_{\max}\,\mathrm{TV}\!\big(p_{\mathrm{data}}(T),p_G(T)\big), & f=\mathrm{Vis}.
\end{cases}
```*
</div>
<div class="proof">
*Proof.* **Case $`f=\mathrm{Tot}`$.** We start from the definition of
$`W_1`$ via Kantorovich–Rubinstein duality for $`(\mathbb{R},|\cdot|)`$:
``` math
W_1(P_{\mathrm{Tot}},Q_{\mathrm{Tot}})
=\sup_{\|g\|_{\mathrm{Lip}}\le 1}
\Big|\mathbb{E}_{x\sim p_{\mathrm{data}}}\!\big[g(\mathrm{Tot}(x))\big]
-\mathbb{E}_{\hat{x}\sim p_G}\!\big[g(\mathrm{Tot}(\hat{x}))\big]\Big|.Let $`\pi`$ be any coupling of $`p_{\mathrm{data}}`$ and $`p_G`$. We can rewrite the difference inside the supremum as
\mathbb{E}_{(x,\hat{x})\sim \pi}
\!\left[g(\mathrm{Tot}(x))-g(\mathrm{Tot}(\hat{x}))\right].Since $`g`$ is $`1`$–Lipschitz on $`\mathbb{R}`$ and $`\mathrm{Tot}`$ is $`1`$–Lipschitz with respect to $`d_{\mathrm{traj}}`$ (Lemma 6), the composition $`g\circ\mathrm{Tot}`$ is also $`1`$–Lipschitz on the trajectory space. Therefore
|g(\mathrm{Tot}(x))-g(\mathrm{Tot}(\hat{x}))| \le d_{\mathrm{traj}}(x,\hat{x}),and taking expectations gives
W_1(P_{\mathrm{Tot}},Q_{\mathrm{Tot}}) \le \mathbb{E}_{\pi}[d_{\mathrm{traj}}(x,\hat{x})].We now choose $`\pi = \pi^\star`$, the matched+tail coupling from Lemmas 7 and 8, and bound the right-hand side directly. By definition of $`d_{\mathrm{traj}}`$,
\Delta_{\mathrm{time}}(x,\hat{x})
:=\sum_{t=1}^{T_{\min}}\!\Big(
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
+\big|\tau^{(\mathrm{inter})}_t-\hat{\tau}^{(\mathrm{inter})}_t\big|
\Big),\mathbb{E}_{\pi^\star}[d_{\mathrm{traj}}(x,\hat{x})]
=\mathbb{E}_{\pi^\star}\!\left[\Delta_{\mathrm{time}}(x,\hat{x})\right]
+\mathbb{E}_{\pi^\star}\!\left[B|T-\hat{T}|\right].For the matched-step terms, Lemma 7 ensures that the expected per-step intra-store and inter-store differences are bounded by $`\epsilon_{\mathrm{intra}}`$ and $`\epsilon_{\mathrm{inter}}`$, respectively, and there are at most $`T_{\max}`$ matched steps. Thus
\begin{aligned}
\mathbb{E}_{\pi^\star}\!\Big[\sum_{t=1}^{T_{\min}}
|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t|\Big]
&\le T_{\max}\,\epsilon_{\mathrm{intra}},\\
\mathbb{E}_{\pi^\star}\!\Big[\sum_{t=1}^{T_{\min}}
|\tau^{(\mathrm{inter})}_t-\hat{\tau}^{(\mathrm{inter})}_t|\Big]
&\le T_{\max}\,\epsilon_{\mathrm{inter}}.
\end{aligned}For the tail term, Lemma 8 bounds the expected length difference as
\mathbb{E}_{\pi^\star}[\,|T-\hat{T}|\,] \le T_{\max}\,C_{\mathrm{JS}}\sqrt{\delta},so multiplying by $`B`$ gives
\mathbb{E}_{\pi^\star}[B\,|T-\hat{T}|] \le B\,T_{\max}\,C_{\mathrm{JS}}\sqrt{\delta}.Combining these three bounds, we obtain
\mathbb{E}_{\pi^\star}[d_{\mathrm{traj}}(x,\hat{x})]
\le T_{\max}\,(\epsilon_{\mathrm{intra}}+\epsilon_{\mathrm{inter}})
+ B\,T_{\max}\,C_{\mathrm{JS}}\sqrt{\delta}.Substituting back into the Wasserstein bound yields
W_1(P_{\mathrm{Tot}},Q_{\mathrm{Tot}})
\le T_{\max}\big(\epsilon_{\mathrm{intra}}+\epsilon_{\mathrm{inter}}\big)
+ B\,T_{\max}\,C_{\mathrm{JS}}\sqrt{\delta},as claimed.
Case $`f=\mathrm{Avg}`$. We now bound $`W_1(P_{\mathrm{Avg}},Q_{\mathrm{Avg}})`$. By Kantorovich–Rubinstein duality for $`(\mathbb{R},|\cdot|)`$, we can write
W_1(P_{\mathrm{Avg}},Q_{\mathrm{Avg}})
=\sup_{\|g\|_{\mathrm{Lip}}\le 1}\Phi(g)\Phi(g):=\Big|\mathbb{E}_{x\sim p_{\mathrm{data}}}\!\big[g(\mathrm{Avg}(x))\big]
-\mathbb{E}_{\hat{x}\sim p_G}\!\big[g(\mathrm{Avg}(\hat{x}))\big]\Big|.For any coupling $`\pi`$ of $`(x,\hat{x})`$ with those marginals, the difference inside the supremum becomes
\mathbb{E}_{(x,\hat{x})\sim\pi}\!\left[g(\mathrm{Avg}(x))-g(\mathrm{Avg}(\hat{x}))\right].Since $`g`$ is $`1`$–Lipschitz on $`\mathbb{R}`$, we have $`|g(u)-g(v)| \le |u-v|`$. Taking absolute values and the supremum over $`g`$ yields the bound
W_1(P_{\mathrm{Avg}},Q_{\mathrm{Avg}}) \le
\mathbb{E}_{(x,\hat{x})\sim\pi}\!\left[\,|\mathrm{Avg}(x)-\mathrm{Avg}(\hat{x})|\,\right],valid for any coupling $`\pi`$.
Next, we use the pointwise Lipschitz bound for $`\mathrm{Avg}`$ from Lemma 6: for any trajectories
W_1(P_{\mathrm{Avg}},Q_{\mathrm{Avg}})
=\sup_{\|g\|_{\mathrm{Lip}}\le 1}
\Big|\mathbb{E}_{x\sim p_{\mathrm{data}}}\!\big[g(\mathrm{Avg}(x))\big]
-\mathbb{E}_{\hat{x}\sim p_G}\!\big[g(\mathrm{Avg}(\hat{x}))\big]\Big|.Choosing the “matched+tail” coupling $`\pi^\star`$ from Lemmas 7 and 8, we take expectations under $`\pi^\star`$ to obtain
\begin{align*}
M &:= \max(T,\hat{T},1),\\
\Delta_{\mathrm{intra}}
&:= \sum_{t=1}^{T_{\min}}
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|,\\[2pt]
W_1(P_{\mathrm{Avg}},Q_{\mathrm{Avg}})
&\le
\mathbb{E}_{\pi^\star}\!\left[\frac{1}{M}\,\Delta_{\mathrm{intra}}\right]
+\mathbb{E}_{\pi^\star}\!\left[\frac{B}{M}\,|T-\hat{T}|\right].
\end{align*}Under $`\pi^\star`$, the steps $`t=1,\dots,T_{\min}`$ are perfectly matched. By the definition of $`\epsilon_{\mathrm{intra}}`$ and Lemma 7, the first expectation is at most $`\epsilon_{\mathrm{intra}}`$:
\mathbb{E}_{\pi^\star}\!\left[
\frac{1}{\max(T,\hat{T},1)}
\sum_{t=1}^{T_{\min}}\!\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|
\right] \le \epsilon_{\mathrm{intra}}.For the second term, since $`\max(T,\hat{T},1) \ge 1`$, we have
\mathbb{E}_{\pi^\star}\!\left[
\frac{B}{\max(T,\hat{T},1)}\,|T-\hat{T}|
\right] \le B\,\mathbb{E}_{\pi^\star}[\,|T-\hat{T}|\,].By Lemma 8 (length tail controlled by divergence),
\mathbb{E}_{\pi^\star}\!\left[
\frac{B}{\max(T,\hat{T},1)}\,|T-\hat{T}|
\right]
\;\le\; B\,T_{\max}\,C_{\mathrm{JS}}\,\sqrt{\delta}.Combining the two contributions, we conclude that
W_1(P_{\mathrm{Avg}},Q_{\mathrm{Avg}}) \le
\epsilon_{\mathrm{intra}} + B\,T_{\max}\,C_{\mathrm{JS}}\,\sqrt{\delta}.In words, the $`1`$–Wasserstein distance between the $`\mathrm{Avg}`$ distributions is controlled by the average intra-store discrepancy plus a tail-length mismatch term at scale $`B\,T_{\max}\sqrt{\delta}`$.
Case $`f=\mathrm{Vis}`$. Here $`f(x)=T`$ takes values in the finite set $`\{0,1,\dots,T_{\max}\}`$. Let $`P := p_{\mathrm{data}}(T)`$ and $`Q := p_G(T)`$ be the two discrete distributions on $`\{0,\dots,T_{\max}\}`$ with pmfs $`p(j),q(j)`$, and define the tail CDFs
\begin{aligned}
\Delta_{\mathrm{intra}}(x,\hat{x})
&:=\sum_{t=1}^{T_{\min}}
\big|\tau^{(\mathrm{intra})}_t-\hat{\tau}^{(\mathrm{intra})}_t\big|,\\
|\mathrm{Avg}(x)-\mathrm{Avg}(\hat{x})|
&\le \frac{1}{M}\,\Delta_{\mathrm{intra}}(x,\hat{x})
+\frac{B}{M}\,|T-\hat{T}|.
\end{aligned}On the integer line with ground metric $`|i-j|`$, Kantorovich–Rubinstein duality gives
W_1(P,Q) \;=\; \sup_{\|g\|_{\mathrm{Lip}}\le 1}
\Big|\sum_{j=0}^{T_{\max}} g(j)\,(p(j)-q(j))\Big|.For functions on $`\mathbb{Z}`$, define the forward difference $`\Delta g(k):=g(k)-g(k-1)`$ (with $`g(-1)`$ arbitrary). If $`\|g\|_{\mathrm{Lip}}\le 1`$ then $`|\Delta g(k)|\le 1`$ for all $`k`$.
We can rewrite the expectation difference by discrete summation by parts:
\sum_{j=0}^{T_{\max}} g(j)\,(p(j)-q(j))
\;=\; \sum_{k=1}^{T_{\max}} \Delta g(k)\,\big(S_P(k)-S_Q(k)\big).Hence
W_1(P,Q)
=\sup_{|\Delta g(k)|\le 1}\Big|\sum_{k=1}^{T_{\max}}\Delta g(k)\big(S_P(k)-S_Q(k)\big)\Big|
\le \sum_{k=1}^{T_{\max}}\big|S_P(k)-S_Q(k)\big|.where the last inequality follows by choosing the signs of $`\Delta g(k)`$ optimally.
For each $`k`$, expand the tail difference and use the triangle inequality:
\big|S_P(k)-S_Q(k)\big|
= \Big|\sum_{j=k}^{T_{\max}}\!(p(j)-q(j))\Big|
\;\le\; \sum_{j=k}^{T_{\max}}\! |p(j)-q(j)|.Summing over $`k=1,\dots,T_{\max}`$ and swapping the order of summation gives
\sum_{k=1}^{T_{\max}}\big|S_P(k)-S_Q(k)\big|
\le \sum_{k=1}^{T_{\max}}\sum_{j=k}^{T_{\max}}|p(j)-q(j)|
= \sum_{j=1}^{T_{\max}} j\,|p(j)-q(j)|.Since $`j \le T_{\max}`$ for every $`j`$, we have
j\,|p(j)-q(j)| \;\le\; T_{\max}\,|p(j)-q(j)|.Summing over $`j=1,\dots,T_{\max}`$ gives
\sum_{j=1}^{T_{\max}} j\,|p(j)-q(j)| \;\le\;
T_{\max} \sum_{j=1}^{T_{\max}} |p(j)-q(j)|.Recall that for discrete distributions $`P`$ and $`Q`$ on $`\{0,\dots,T_{\max}\}`$,
\mathrm{TV}(P,Q)
:=\max_{A\subseteq\{0,\ldots,T_{\max}\}}|P(A)-Q(A)|
= \sum_{j:\,p(j)>q(j)}(p(j)-q(j))
= \tfrac12\sum_{j=0}^{T_{\max}}|p(j)-q(j)|.The second equality follows because $`\sum_j [p(j)-q(j)] = 0`$, so the total positive and total negative differences are equal in magnitude, and the subset $`A`$ that attains the maximum is $`\{j : p(j) > q(j)\}`$. Dropping the nonnegative $`j=0`$ term in the sum only decreases its value, hence
\sum_{j=1}^{T_{\max}} |p(j)-q(j)|
\;\le\; \sum_{j=0}^{T_{\max}} |p(j)-q(j)|
= 2\,\mathrm{TV}(P,Q).Combining these gives
\sum_{j=1}^{T_{\max}} j\,|p(j)-q(j)|
\;\le\; 2T_{\max}\,\mathrm{TV}(P,Q).Putting everything together,
W_1(P,Q) \;\le\; 2T_{\max}\,\mathrm{TV}(P,Q).Applying this with $`P=p_{\mathrm{data}}(T)`$ and $`Q=p_G(T)`$ gives the stated bound. ◻
Effect of Length-Aware Sampling (LAS)
Definition (LAS).
Partition the set of possible lengths $`\{0,1,\dots,T_{\max}\}`$ into disjoint buckets $`\mathcal{B}_1,\dots,\mathcal{B}_K`$. Let $`w_k:=\mathbb{P}_{p_{\mathrm{data}}}(T\in\mathcal{B}_k)`$ and $`\hat{w}_k:=\mathbb{P}_{p_G}(T\in\mathcal{B}_k)`$ denote the marginal probabilities under data and generator, respectively. LAS draws training mini-batches by first sampling a bucket $`k`$ with probability $`w_k`$ (or an empirical estimate $`\tilde{w}_k \approx w_k`$), then sampling examples within that bucket from both data and generator. Thus, during training, the discriminator receives a mixture whose bucket weights closely match the data histogram.
An IPM/Wasserstein view of LAS.
Let $`d_{\mathrm{traj}}`$ be the trajectory semi-metric defined above. Define $`K(x)\in\{1,\dots,K\}`$ as the bucket index such that $`T(x)\in\mathcal{B}_{K(x)}`$.
For each bucket $`k`$, let $`\mathcal{X}_k:=\{x:\,T(x)\in\mathcal{B}_k\}`$ and let $`d_{\mathrm{traj}}^{(k)}`$ denote the restriction of $`d_{\mathrm{traj}}`$ to $`\mathcal{X}_k\times \mathcal{X}_k`$. Define the within-bucket Wasserstein-1 distance
\begin{aligned}
W_{1,k}\big(p_{\mathrm{data},k},p_{G,k}\big)
&:= \sup_{\phi_k}\ \Big(\mathbb{E}_{p_{\mathrm{data},k}}[\phi_k]-\mathbb{E}_{p_{G,k}}[\phi_k]\Big), \\
&\text{s.t.}\ \phi_k\in \mathrm{Lip}_1(\mathcal{X}_k).
\end{aligned}where $`\mathrm{Lip}_1(\mathcal{X}_k)`$ denotes 1-Lipschitz functions with respect to $`d_{\mathrm{traj}}^{(k)}`$. We also define the LAS discrepancy
W_{\mathrm{LAS}}\big(p_{\mathrm{data}},p_G\big)
\;:=\;
\sum_{k=1}^K w_k\, W_{1,k}\big(p_{\mathrm{data},k},p_{G,k}\big).Proposition 10 (LAS-aligned objective equals a weighted within-bucket IPM (matched weights)). *If the generator matches the data bucket weights, i.e., $`\hat w_k=w_k`$ for all $`k`$, then
W_{\mathrm{LAS}}\big(p_{\mathrm{data}},p_G\big)
\;=\;
\sup_{\substack{\phi(x)=\phi_{K(x)}(x)\\ \phi_k\in\mathrm{Lip}_1(\mathcal{X}_k)}}
\Big(\mathbb{E}_{p_{\mathrm{data}}}[\phi]-\mathbb{E}_{p_G}[\phi]\Big).
```*
</div>
<div class="proof">
*Proof.* Write $`p_{\mathrm{data}}=\sum_k w_k p_{\mathrm{data},k}`$ and
$`p_G=\sum_k w_k p_{G,k}`$ under the matched-weight assumption. For any
bucket-separable $`\phi(x)=\phi_{K(x)}(x)`$,
``` math
\mathbb{E}_{p_{\mathrm{data}}}[\phi]-\mathbb{E}_{p_G}[\phi]
=
\sum_{k=1}^K w_k\Big(\mathbb{E}_{p_{\mathrm{data},k}}[\phi_k]-\mathbb{E}_{p_{G,k}}[\phi_k]\Big).Taking the supremum over $`\phi`$ is equivalent to independently maximizing over each $`\phi_k\in\mathrm{Lip}_1(\mathcal{X}_k)`$, yielding $`\sum_k w_k W_{1,k}(p_{\mathrm{data},k},p_{G,k})=W_{\mathrm{LAS}}(p_{\mathrm{data}},p_G)`$. ◻
Lemma 11 (Bucket-only (length-only) critics are a null space under LAS). *Let $`a:\{1,\dots,K\}\to\mathbb{R}`$ and define $`\psi(x):=a(K(x))`$. Then for every bucket $`k`$,
\mathbb{E}_{p_{\mathrm{data},k}}[\psi]-\mathbb{E}_{p_{G,k}}[\psi]=0.Equivalently, adding any bucket-only term $`a\circ K`$ to a within-bucket critic does not change any $`W_{1,k}(p_{\mathrm{data},k},p_{G,k})`$ and thus does not change $`W_{\mathrm{LAS}}(p_{\mathrm{data}},p_G)`$.*
Proof. Under $`x\sim p_{\mathrm{data},k}`$ or $`x\sim p_{G,k}`$, we have $`K(x)=k`$ almost surely. Thus $`\psi(x)=a(k)`$ almost surely under both distributions, and the expectation difference is zero. ◻
Lemma 12 (Global Wasserstein can be dominated by length-marginal mismatch). *Let $`w,\hat w`$ be the bucket weights of $`p_{\mathrm{data}},p_G`$. Then the global Wasserstein-1 distance on trajectories (with cost $`d_{\mathrm{traj}}`$) satisfies
W_1\big(p_{\mathrm{data}},p_G\big)\;\ge\; B\,\mathrm{TV}(w,\hat w).
```*
</div>
<div class="proof">
*Proof.* For any coupling $`\pi`$ of $`p_{\mathrm{data}}`$ and $`p_G`$,
let $`(X,\hat X)\sim\pi`$. Since
$`d_{\mathrm{traj}}(X,\hat X)\ge B\,|T(X)-T(\hat X)|\ge B\,\mathbf{1}\{K(X)\neq K(\hat X)\}`$,
``` math
\mathbb{E}_{\pi}[d_{\mathrm{traj}}(X,\hat X)]\;\ge\; B\,\mathbb{P}_{\pi}\big(K(X)\neq K(\hat X)\big).Minimizing over couplings gives
W_1(p_{\mathrm{data}},p_G)\;\ge\; B\,\inf_{\pi}\mathbb{P}_{\pi}(K(X)\neq K(\hat X)).The minimum mismatch probability between two discrete distributions equals their total variation distance, so $`\inf_{\pi}\mathbb{P}_{\pi}(K(X)\neq K(\hat X))=\mathrm{TV}(w,\hat w)`$, which proves the claim. ◻
Corollary 13 (Within-bucket matching implies derived-variable distribution matching). *Let $`f\in\{\mathrm{Tot},\mathrm{Avg},\mathrm{Vis}\}`$. Then $`f`$ is 1-Lipschitz with respect to $`d_{\mathrm{traj}}`$ (Lemma 6), and
W_1\big(f_{\#}p_{\mathrm{data}},\, f_{\#}p_G\big)
\le \sum_{k=1}^K w_k\, W_{1,k}\big(p_{\mathrm{data},k},p_{G,k}\big)
+ C_f\,\mathrm{TV}(w,\hat w).
```*
*where one may take $`C_{\mathrm{Tot}}=B T_{\max}`$,
$`C_{\mathrm{Avg}}=B`$, and $`C_{\mathrm{Vis}}=T_{\max}`$.*
</div>
<div class="proof">
*Proof.* The 1-Lipschitz property implies
$`W_1(f_{\#}p_{\mathrm{data},k}, f_{\#}p_{G,k})\le W_{1,k}(p_{\mathrm{data},k},p_{G,k})`$
for each $`k`$. A standard mixture bound on $`W_1`$ then gives
``` math
W_1\!\big(f_{\#}p_{\mathrm{data}},\, f_{\#}p_G\big)
\le \sum_k w_k\, W_1\!\big(f_{\#}p_{\mathrm{data},k},\, f_{\#}p_{G,k}\big)
+ \mathrm{diam}\!\big(f(\mathcal{X})\big)\,\mathrm{TV}(w,\hat w).and $`\mathrm{diam}(f(\mathcal{X}))\le C_f`$ under Assumption 1. Combining the inequalities yields the result. ◻
Consequences and mechanism.
Lemma 11 formalizes that LAS projects out bucket-only (length-only) shortcut features within each update, so the critic must rely on within-bucket structure. Proposition 10 shows that, once bucket weights are aligned, LAS corresponds to optimizing a weighted sum of within-bucket Wasserstein/IPM objectives. Corollary 13 then connects within-bucket matching to the derived-variable distribution matching reported in our experiments. In contrast, Lemma 12 highlights that the global Wasserstein objective optimized under random sampling can be dominated by bucket-marginal mismatch, encouraging length-driven discrimination rather than improving within-bucket structure.
Experimental Evaluation (Full)
This appendix complements the main-text experimental protocol with additional plots, dataset details, and ablation results.
Additional mall plots
Figure 6 provides per-mall trajectory-length (#visits) overlays under random sampling (RS) and LAS.
RS (top row)
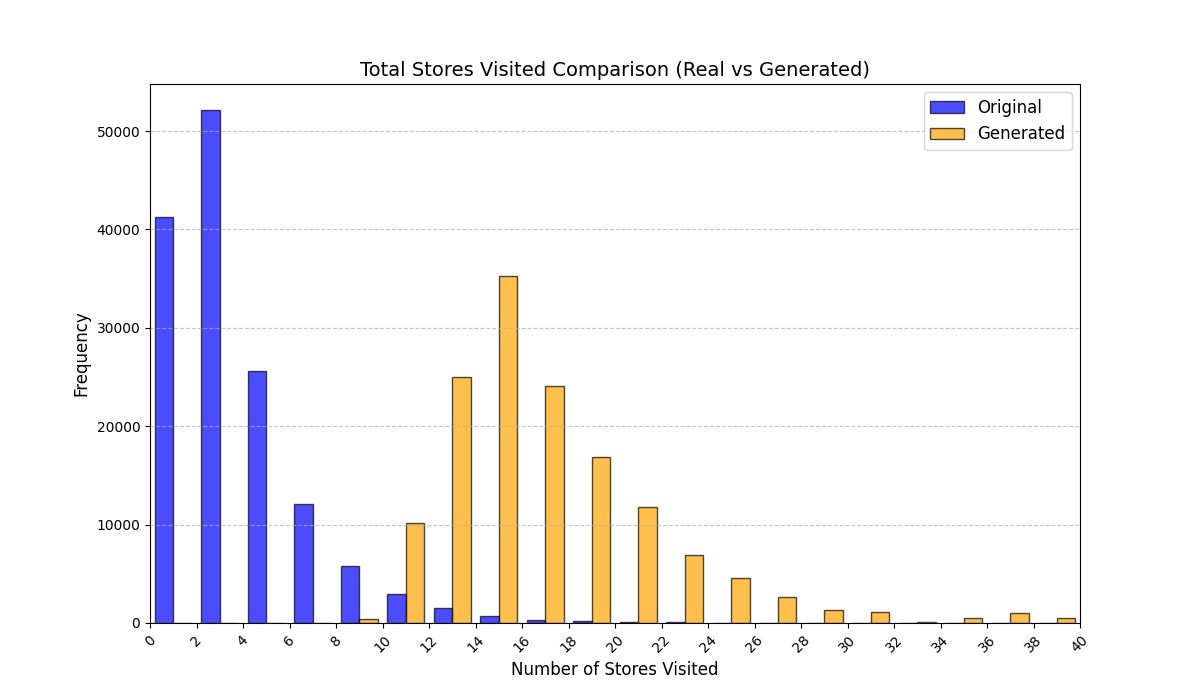
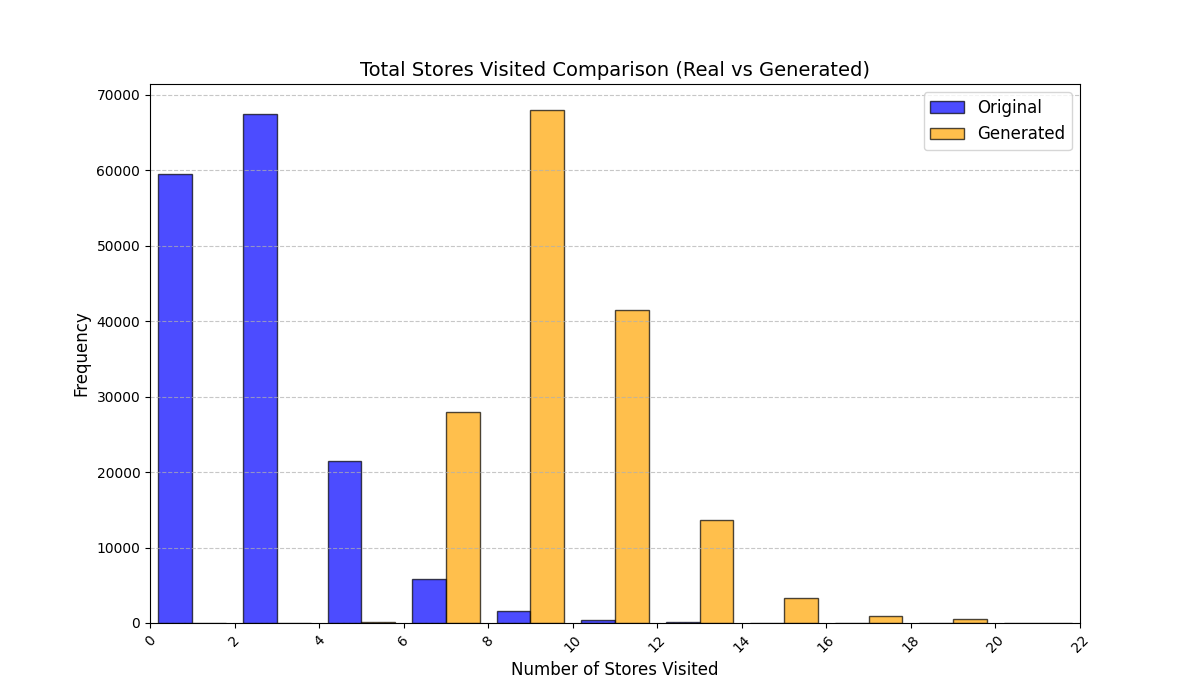

LAS (bottom row)


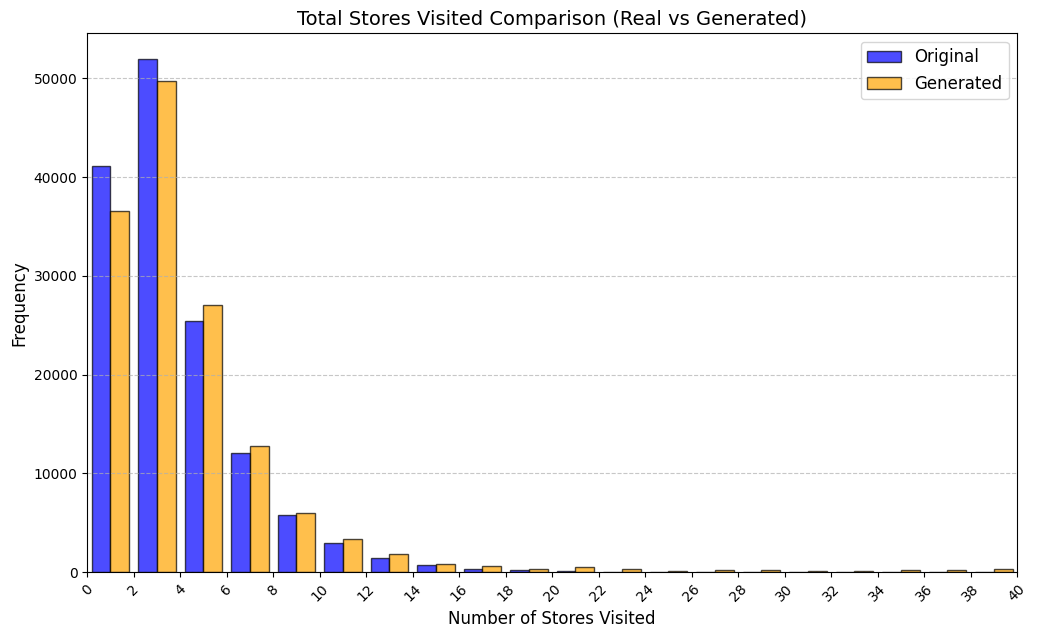
Data.
We use anonymized mall visit trajectories on held-out calendar days. Each trajectory $`\pi=\{(j_t,\tau_t^{(\text{intra})},\tau_t^{(\text{inter})})\}_{t=1}^{T}`$ records the visited store $`j_t`$, the intra–store dwell time $`\tau_t^{(\text{intra})}`$, and the inter–store (walking) time $`\tau_t^{(\text{inter})}`$ at step $`t`$. The corpus covers a single multi-floor mall with $`|\mathcal{S}|=202`$ stores across $`F=3`$ floors and $`C=19`$ categories, spanning a broad mix of weekdays/weekends and event days.
Train/test split.
To prevent temporal leakage, we split by unique days rather than by individual trajectories. We use an $`80\%`$/$`20\%`$ day-level split with a fixed seed and no overlap between sets. Unless otherwise noted, all figures compare real vs. generated distributions on the held-out test days only.
Model configuration (notation $`\rightarrow`$ value).
Model architecture and embedding dimensions are shared across experiments; dataset-specific constants (e.g., the number of stores/floors/categories) are set from each dataset. For a representative mall, we use:
| Symbol | Description | Value |
|---|---|---|
| $` | \mathcal{S} | `$ |
| $`F`$ | number of floors | $`3`$ |
| $`C`$ | number of store categories | $`19`$ |
| $`d_e`$ | store embedding dimension | $`32`$ |
| $`h`$ | LSTM hidden size | $`128`$ |
| $`z`$ | latent dimension (generator) | $`16`$ |
| $`d_{\text{type}}`$ | store–type embedding dimension | $`16`$ |
| $`d_{\text{floor}}`$ | floor embedding dimension | $`8`$ |
Training protocol.
Training follows the procedure described in the algorithmic section, with the same loss notation and objectives: the adversarial loss for realism and $`\ell_1`$ losses for time heads (intra/inter) weighted as in the loss section. We use Adam optimizers ($`\beta_1{=}0.5,\ \beta_2{=}0.999`$) with learning rate $`10^{-4}`$ for both generator and discriminator, batch size $`128`$, spectral normalization on linear layers, and Gumbel–Softmax sampling for store selection with an annealed temperature from $`1.5`$ down to $`0.1`$. Training runs for up to $`18`$ epochs with early stopping (patience $`=3`$) based on generator loss.
Evaluation protocol.
Our evaluation is both quantitative and visual. For each dataset, we define a set of trajectory-derived variables (e.g., total time, trajectory length/#visits, intra-/inter-event times, and categorical summaries such as store-type or floor distributions). We report scalar goodness-of-fit via the Kolmogorov–Smirnov (KS) statistic between the empirical distributions of real and generated trajectories (lower is better), and we additionally overlay the corresponding distributions using shared binning and axis ranges for visualization. Unless noted otherwise, the reference is the empirical distribution from real trajectories on the held-out test split, and comparisons are made against trajectories generated under the same day-level context and conditioning variables. The subsequent subsections (Unconditional, Conditional ON/OFF, Swapping by Gate Distance, Swapping by Anchor Distance) apply this protocol under their respective conditions.
Notation and metrics
A trajectory is $`\pi=\{(j_t,\tau_t^{(\text{intra})},\tau_t^{(\text{inter})})\}_{t=1}^{T}`$ with visited store $`j_t`$, intra-store time $`\tau_t^{(\text{intra})}`$, inter-store (walking) time $`\tau_t^{(\text{inter})}`$ at step $`t`$, and $`T`$ total store visits (trajectory length). We visualize overlays for:
-
Total time in mall: $`M_{\text{total}}=\sum_{t=1}^{T}\tau_t^{(\text{intra})}+\sum_{t=1}^{T}\tau_t^{(\text{inter})}`$
-
Total intra time: $`M_{\text{intra}}^{\text{tot}}=\sum_{t=1}^{T}\tau_t^{(\text{intra})}`$
-
Total inter time: $`M_{\text{inter}}^{\text{tot}}=\sum_{t=1}^{T}\tau_t^{(\text{inter})}`$
-
Avg. intra time per store: $`M_{\text{avg-intra}}=\frac{1}{T}\sum_{t=1}^{T}\tau_t^{(\text{intra})}`$
-
Avg. inter time per hop: $`M_{\text{avg-inter}}=\frac{1}{\max(T-1,1)}\sum_{t=1}^{T}\tau_t^{(\text{inter})}`$
-
Trajectory length: $`M_{\text{len}}=T`$
For category/floor summaries, with $`c(j_t)`$ the category and $`f(j_t)`$ the floor of $`j_t`$, we visualize:
-
Diversity of categories per trajectory: $`M_{\text{div}}=\big|\{c(j_t)\}_{t=1}^{T}\big|`$
-
Visit counts by category: $`N_c=\sum_{t=1}^{T}\mathbf{1}[c(j_t)=c]`$
-
Intra-store time by category: $`T_c=\sum_{t=1}^{T}\mathbf{1}[c(j_t)=c]\cdot \tau_t^{(\text{intra})}`$
-
Floor-level visit counts: $`N_f=\sum_{t=1}^{T}\mathbf{1}[f(j_t)=f]`$
Unconditional Distribution Matching
We pool all held-out test days—without conditioning on store status—and compare real vs. generated trajectories at the population level.
 Average intra-store time (real
vs. generated)
Average intra-store time (real
vs. generated)
 Average inter-store time (real
vs. generated)
Average inter-store time (real
vs. generated)
 Total time in mall (intra + inter)
Total time in mall (intra + inter)
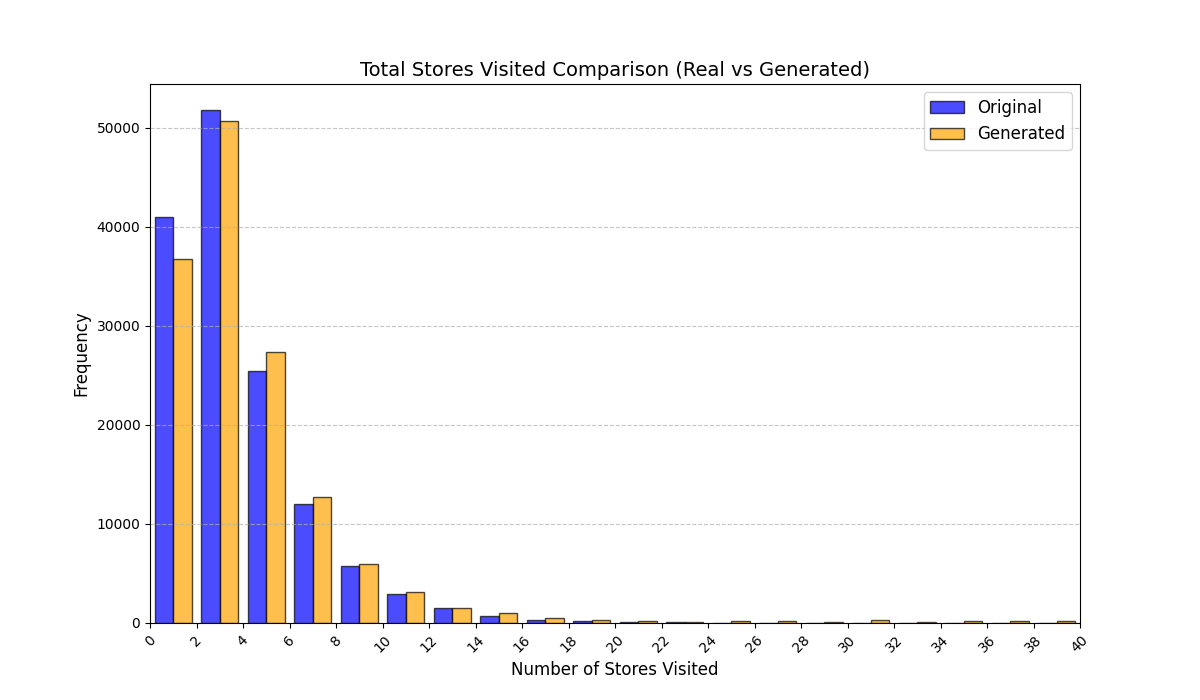 Trajectory length (T)
Trajectory length (T)
 Diversity: number of unique categories per
trajectory
Diversity: number of unique categories per
trajectory
 Store-type visit distribution (counts by
category)
Store-type visit distribution (counts by
category)
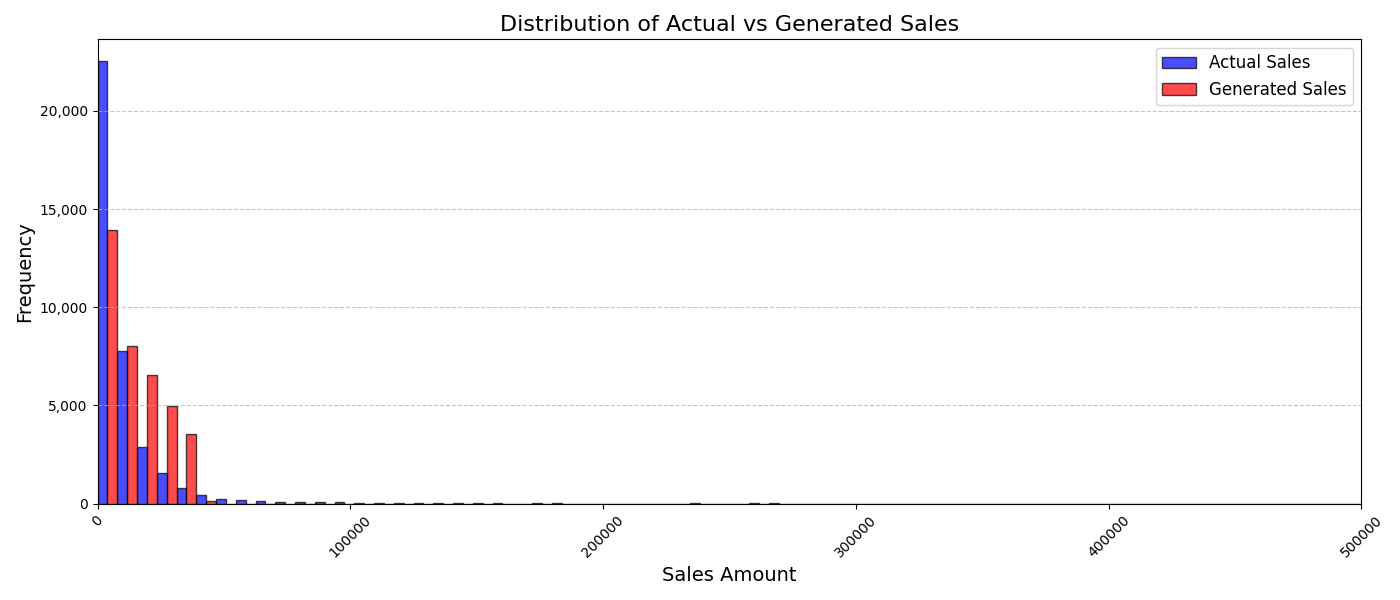 Store-level sales distribution
Store-level sales distribution
Observations. Across Figs. 7–8, the generator places more mass at shorter dwell times and under-represents the longest tails relative to real trajectories. In Fig. 9, clothing dominates, with sports and restaurants also prominent; generated trajectories slightly over-index on these high-traffic categories and under-index on smaller experiential types. These patterns indicate that long-stay cohorts (e.g., event days) are harder to reproduce without explicit conditioning, while category shares follow observed traffic but may need rebalancing for niche segments. Sales marginals (Fig. 10) track the shape of real distributions qualitatively; extremes are less frequent in the generated set.
Conditional Store Influence (ON/OFF)
We study behavioral shifts when a specific store $`s^*`$ is open (ON) versus closed (OFF). We partition real and generated trajectories by the observed status of $`s^*`$ and overlay the distributions of the metrics defined above. Representative results for ZARA and MLB are in Figs. 11–12. This analysis is conditional (not counterfactual).

Observations. ON days exhibit a heavier mid/long tail in trajectory length than OFF days, indicating more multi-store tours when the focal store is available. This suggests co-promotion or cross-windowing with nearby tenants on ON days, while OFF days behave more like quick, targeted trips.
Swapping Experiments: Gate Distance
We test sensitivity to placement by swapping a target brand (e.g., ZARA) with alternative stores grouped by their distance to the nearest gate. Stores are binned by $`(f,h)`$: floor $`f`$ and hop-from-gate group $`h`$. For each bin we regenerate trajectories under the same day context and visualize the metrics as means with dispersion; comparisons are qualitative.
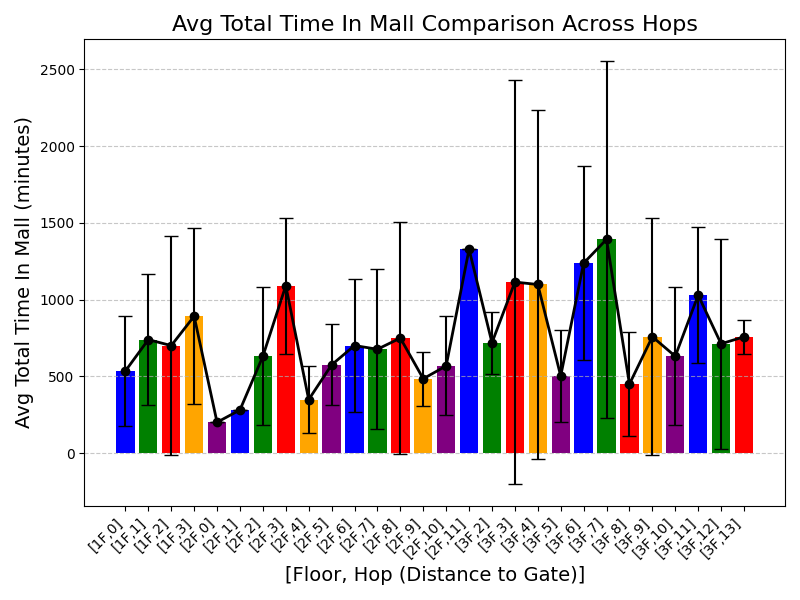
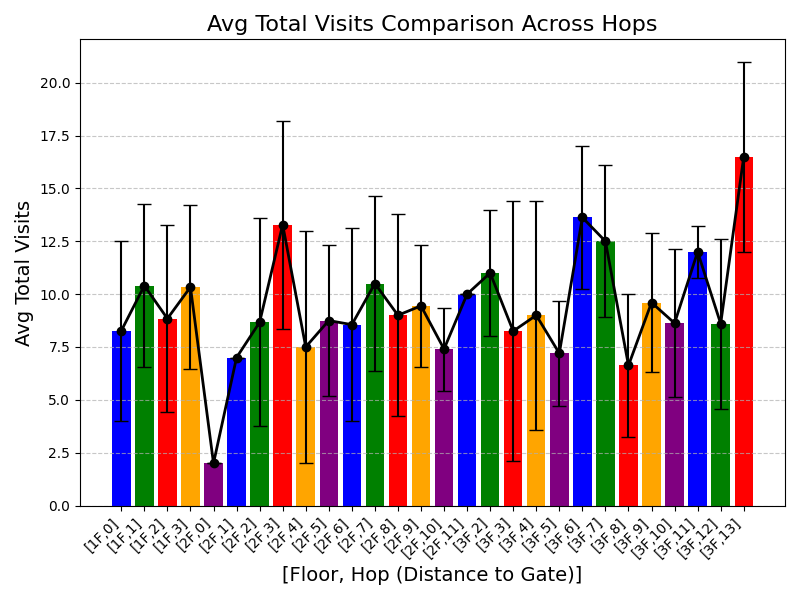
Observations. Placements a few hops from primary gates tend to exhibit higher mean total time in mall and higher visit counts than gate-adjacent or distant placements (Figs. 13–14); variance remains substantial and floor effects are visible. For dwell-oriented concepts, positions just beyond the entrances are associated with longer tours.
Swapping Experiments: Anchor-Store Distance
We analyze sensitivity to an anchor store $`s_c`$ (e.g., ZARA) by swapping a target brand (e.g., Uniqlo) with candidates binned by $`(f,h)`$, where $`f`$ is the floor and $`h`$ is the hop distance to $`s_c`$. For each $`(f,h)`$ bin we regenerate trajectories under the same day context and visualize qualitative summaries.
Observations. Bins with small $`h`$ (roughly $`h\in\{1,2,3\}`$) show higher average visit counts (Fig. 16), while the average intra-store time per stop is largely flat across $`(f,h)`$ (Fig. 15). Thus, proximity primarily affects circulation rather than dwell; changing dwell per stop likely requires adjustments to in-store experience or messaging rather than small relocations (see Figs. 15–16).

Four-mall evaluation: full results
Table [tab:mall_full_results] reports the KS statistic for all derived metrics we computed from mall trajectories. Figure 17 visualizes the total-mall-time marginals across all four malls for RS and LAS.
| Derived metric | Mall A | Mall B | Mall C | Mall D | ||||
|---|---|---|---|---|---|---|---|---|
| 2-3(lr)4-5(lr)6-7(lr)8-9 | RS | LAS | RS | LAS | RS | LAS | RS | LAS |
| Average inter-store time | 0.622 | 0.289 | 0.645 | 0.380 | 0.684 | 0.404 | 0.767 | 0.456 |
| Average intra-store time | 0.975 | 0.005 | 0.978 | 0.066 | 0.975 | 0.382 | 0.959 | 0.034 |
| Floor distribution | 1.000 | 0.667 | 1.000 | 0.333 | 1.000 | 0.667 | 0.200 | 0.400 |
| Store diversity | 0.641 | 0.074 | 0.611 | 0.045 | 0.523 | 0.108 | 0.450 | 0.039 |
| Store category mix | 0.278 | 0.333 | 0.506 | 0.287 | 0.467 | 0.333 | 0.477 | 0.303 |
| Time spent per category | 0.419 | 0.432 | 0.468 | 0.383 | 0.394 | 0.367 | 0.425 | 0.379 |
| Total inter-store time | 0.726 | 0.538 | 0.777 | 0.413 | 0.784 | 0.219 | 0.764 | 0.352 |
| Total intra-store time | 0.854 | 0.060 | 0.801 | 0.116 | 0.730 | 0.168 | 0.799 | 0.134 |
| Total time in mall | 0.528 | 0.056 | 0.538 | 0.152 | 0.630 | 0.269 | 0.661 | 0.072 |
| Trajectory length / #visits | 0.955 | 0.047 | 0.947 | 0.048 | 0.953 | 0.048 | 0.951 | 0.044 |
| Mean across metrics | 0.700 | 0.250 | 0.727 | 0.222 | 0.714 | 0.297 | 0.645 | 0.221 |
RS

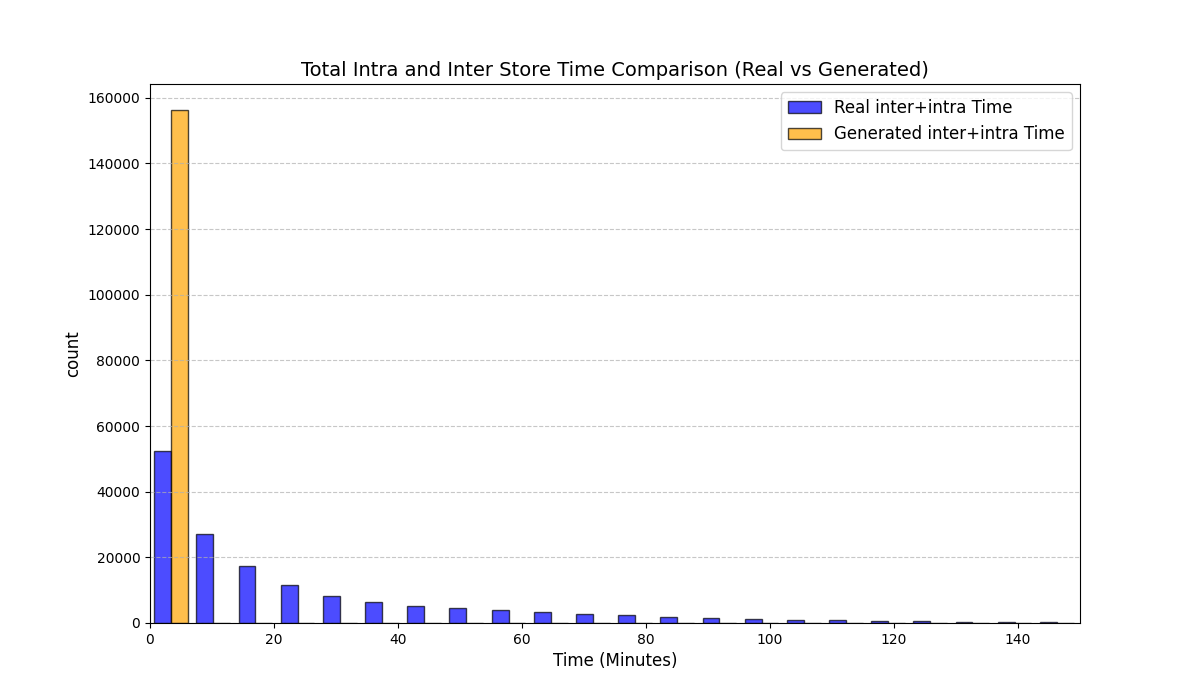

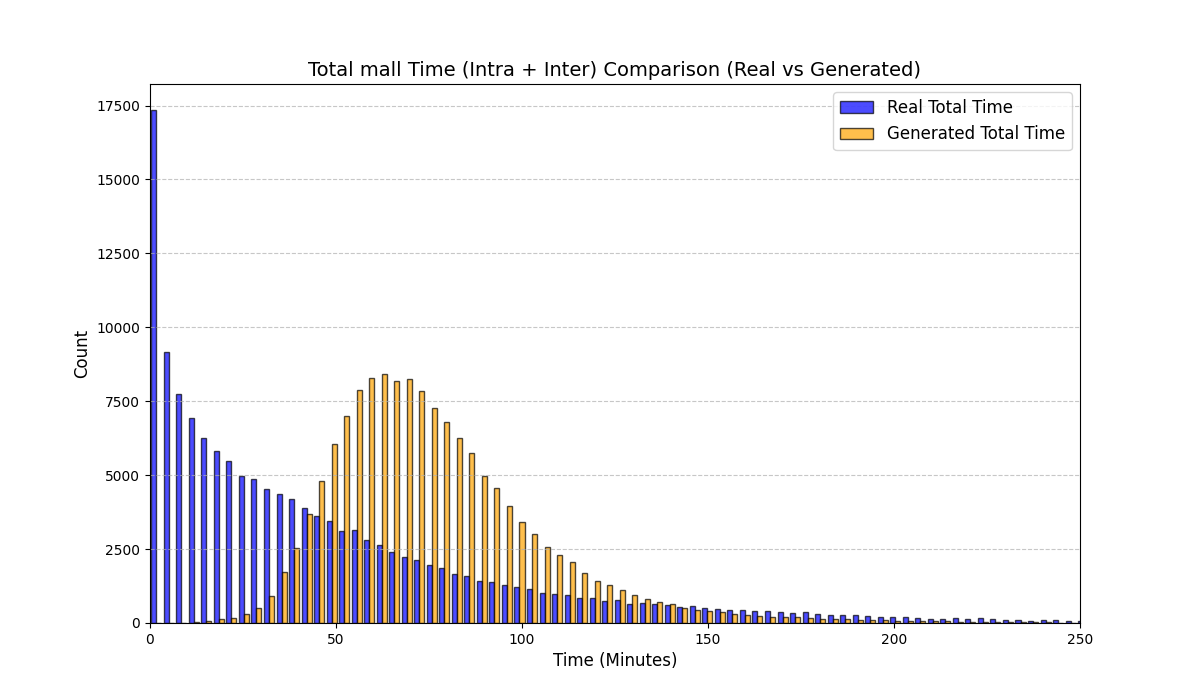
LAS


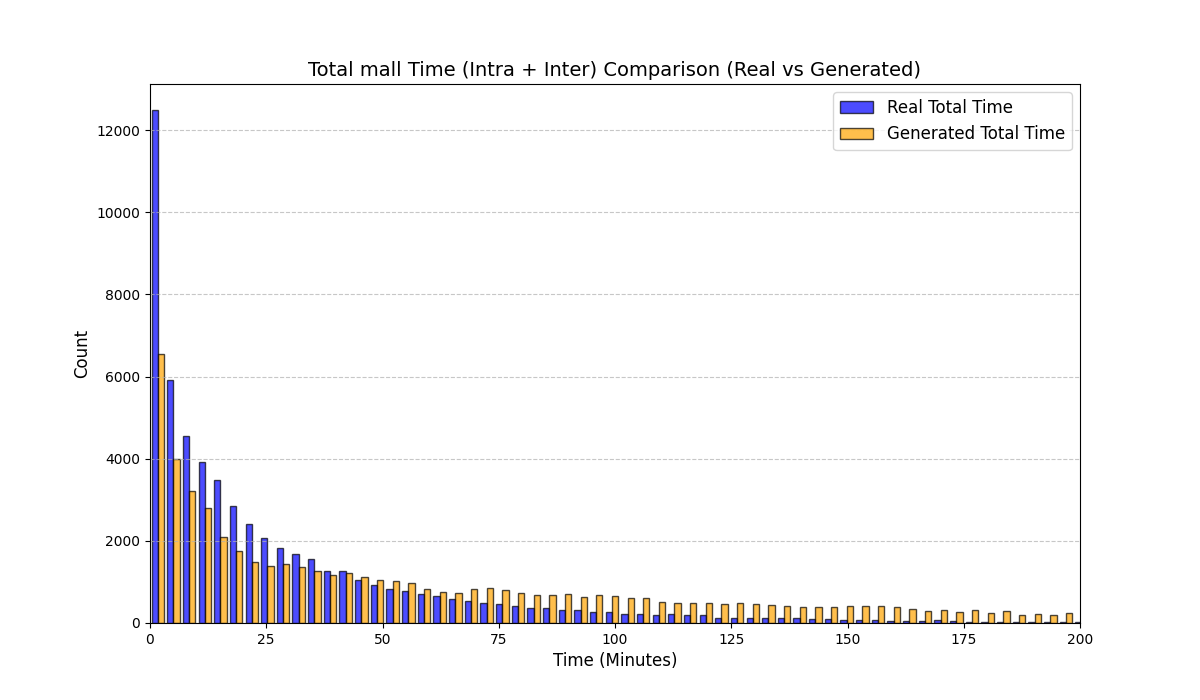

Public datasets: full results and extra plots
Table [tab:public_full_results] reports a full set of derived-metric KS errors on Amazon, Movie, Education, and GPS. Figures 18 and 19 provide additional visualizations that complement the main-text plots in Figs. 2–5.
| Dataset | Derived metric | RS | LAS |
|---|---|---|---|
| Amazon | Sequence length | 0.002 | 0.002 |
| Amazon | Item diversity | 0.338 | 0.020 |
| Amazon | Inter-event days | 0.456 | 0.170 |
| Amazon | Duration (days) | 0.413 | 0.046 |
| Amazon | Mean rating | 0.632 | 0.590 |
| Movie | Trajectory length | 0.120 | 0.067 |
| Movie | Inter-rating time (min) | 0.466 | 0.294 |
| Movie | Mean rating | 0.155 | 0.106 |
| Movie | Rating std | 0.754 | 0.669 |
| Education | Trajectory length | 0.411 | 0.164 |
| Education | Mean correctness | 0.9997 | 0.529 |
| Education | Std correctness | 0.9994 | 0.350 |
| GPS | Trajectory length | 0.243 | 0.0287 |
| GPS | Total distance (km) | 0.284 | 0.142 |
| GPS | Average speed (km/h) | 0.312 | 0.108 |
| Amazon | Mean across metrics | 0.368 | 0.166 |
| Movie | Mean across metrics | 0.373 | 0.284 |
| Education | Mean across metrics | 0.803 | 0.348 |
| GPS | Mean across metrics | 0.280 | 0.093 |

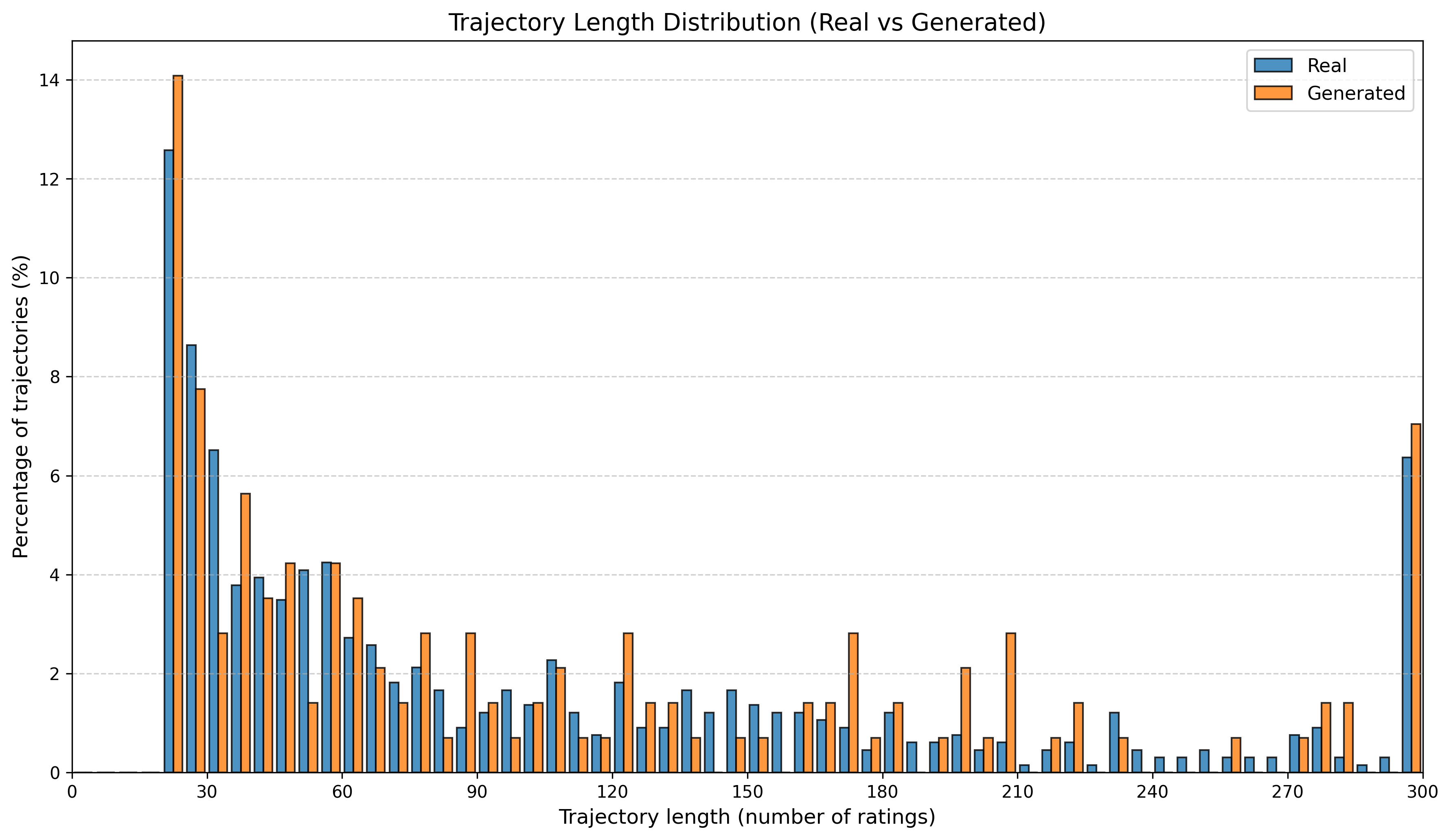
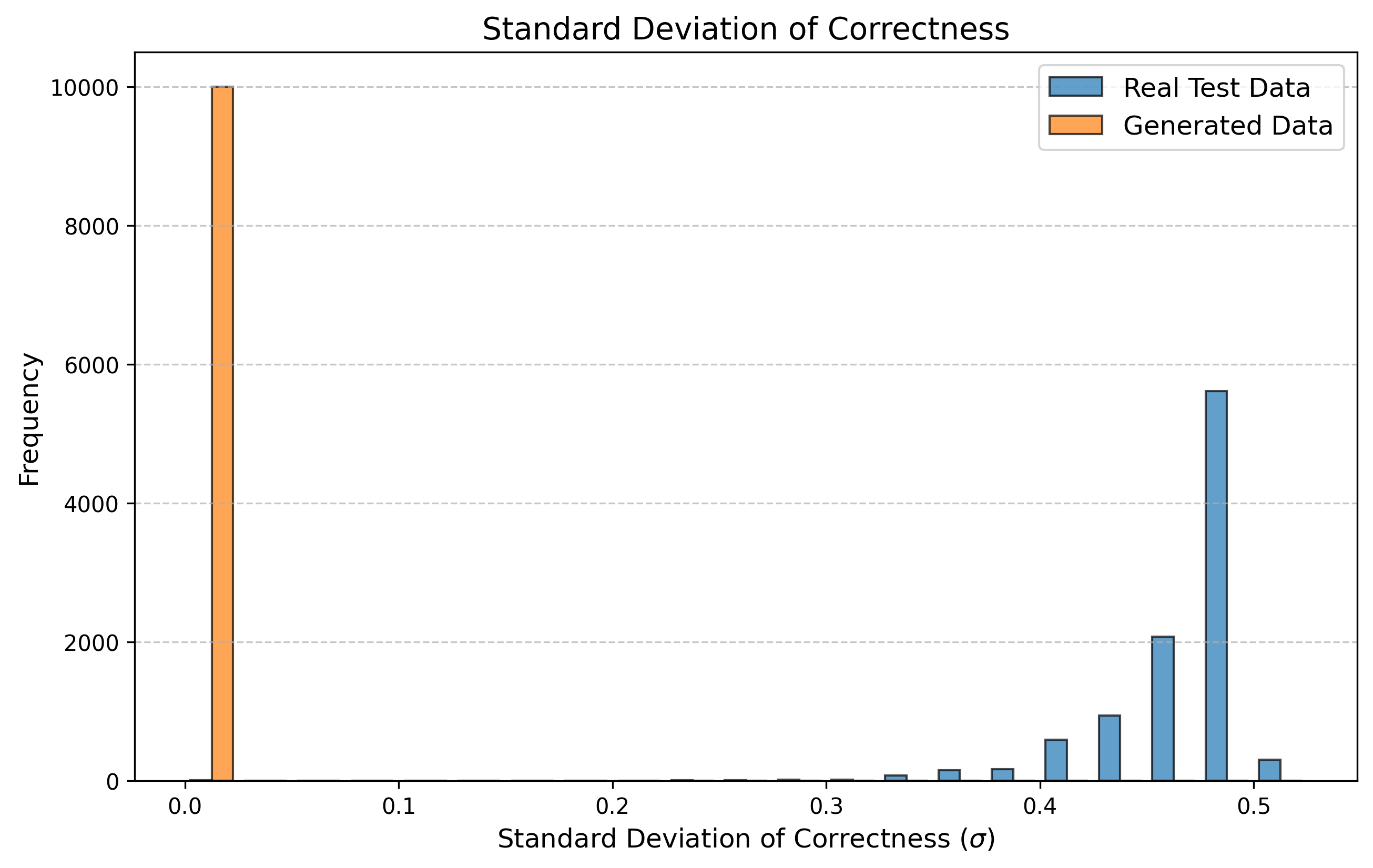

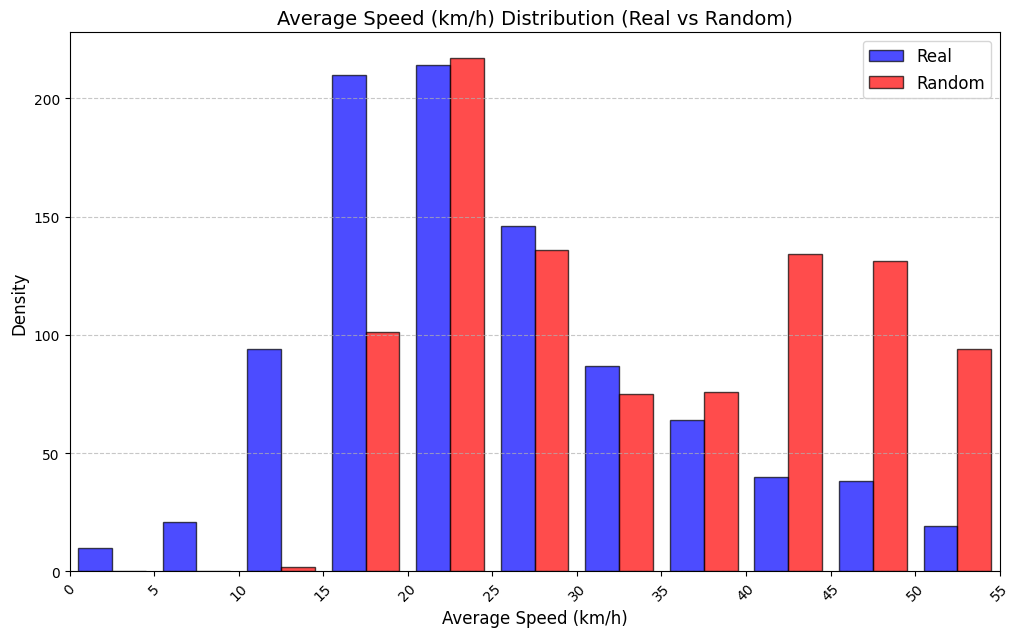

📊 논문 시각자료 (Figures)