Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
📝 Original Paper Info
- Title: Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking- ArXiv ID: 2601.01022
- Date: 2026-01-03
- Authors: Shiao Wang, Xiao Wang, Haonan Zhao, Jiarui Xu, Bo Jiang, Lin Zhu, Xin Zhao, Yonghong Tian, Jin Tang
📝 Abstract
Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking💡 Summary & Analysis
The key contributions of this paper are: 1) The introduction of a novel amplitude and phase attention mechanism in the frequency domain, which integrates high-frequency event information with RGB images at an early stage. This enhances feature representations under challenging conditions while significantly reducing computational burden. 2) A motion-guided spatial sparsification strategy that selectively filters out redundant background information to enhance target-relevant features. 3) Extensive experiments on three public datasets (FE108, FELT, COESOT), which demonstrate the effectiveness of the proposed multimodal tracker.To explain this research in more detail:
- Object tracking has been a prominent focus in computer vision. RGB cameras dominate practical applications but struggle with fast motion or low-light conditions.
- Event cameras provide high dynamic range and temporal resolution, making them suitable for capturing subtle brightness changes that traditional RGB cameras miss.
- This study leverages these advantages to enhance the spatial structure of RGB images and integrate richer motion information from event data.
📄 Full Paper Content (ArXiv Source)
Event Camera; RGB-Event Tracking; Frequency Fusion; Spatial Sparsification; Vision Transformer
Introduction
Object Tracking (VOT) has long been a prominent research direction in the field of computer vision. In practical applications, conventional RGB cameras continue to be the dominant sensing modality, widely employed across diverse scenarios such as unmanned aerial vehicles, autonomous driving, intelligent surveillance, and other real-world settings. However, due to the inherent limitations of RGB cameras, such as their relatively low frame rate (typically 30 frames per second) and high sensitivity to illumination variations, they often exhibit unsatisfactory performance under extreme conditions, i.e., overexposure, low-light, and fast motion. These challenges can lead to motion blur and loss of critical information, significantly undermining the reliability of RGB-based tracking systems in dynamic environments. Consequently, researchers turn to alternative sensing modalities that complement and overcome the inherent limitations of traditional cameras, enabling more robust and effective visual tracking across a broader range of scenarios.
 />
/>
Bio-inspired event cameras have attracted increasing attention from researchers due to their high dynamic range and superior temporal resolution, enabling the capture of fast-moving scenes and subtle illumination changes that conventional frame-based cameras often fail to detect. By mimicking the human retina’s light perception mechanism, event cameras are highly sensitive to variations in scene brightness. An event signal with polarity (e.g., +1 or -1) is triggered only when the brightness of a scene increases or decreases beyond a predefined threshold. Unlike conventional RGB cameras, which output full image frames synchronously at a fixed frame rate, event cameras asynchronously record only brightness changes and generate corresponding event signals. As a result, event cameras impose minimal requirements on ambient illumination while capturing brightness variations with high temporal precision. Therefore, compared with traditional RGB cameras, they are particularly well-suited for tracking object motion in low-light or high-speed scenarios.
In recent years, an increasing number of tracking algorithms have emerged, combining event cameras with RGB cameras to leverage the unique advantages of event cameras under extreme conditions and enhance the robustness of multimodal tracking. For example, Tang et al. preserve more temporal information by combining event voxels with RGB frames, and employ a vision Transformer for unified multimodal feature extraction and fusion. Zhang et al. propose a high-frame-rate multimodal tracking framework that aligns and fuses RGB and event modalities, significantly improving the tracking performance. However, existing RGB–Event multimodal tracking algorithms suffer from two major limitations: (1) Challenges of Feature-level Fusion: Most existing methods formulate RGB–Event tracking as a conventional multimodal fusion problem, focusing on achieving high tracking accuracy through feature-level fusion. Nevertheless, they often fail to effectively exploit the intrinsic characteristics of event data, namely its high dynamic range and temporal density. (2) Limited Efficiency: The joint processing of RGB frames and event streams substantially increases computational complexity. As shown in Fig. 1 (a) and (b), conventional Siamese trackers and widely used single-stream trackers often need to process all visual tokens at once when performing multimodal fusion or feature extraction, which significantly increases the computational burden of the network. Therefore, effectively integrating event modality features to achieve efficient RGB-Event visual object tracking remains challenging.
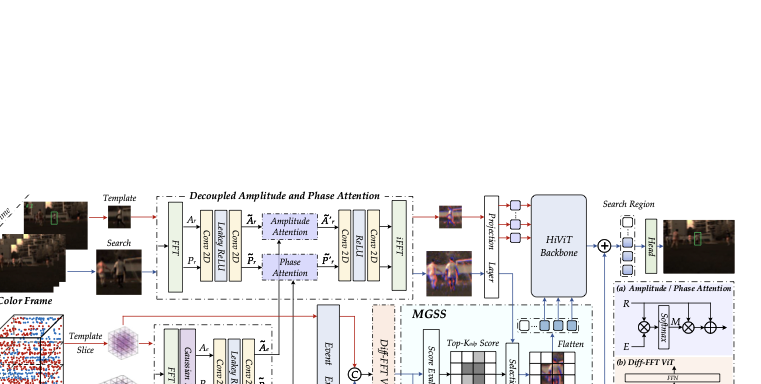
To address the aforementioned challenges, this work departs from conventional feature-level fusion by adopting early-stage modality fusion in the frequency domain, enabling selective aggregation of the complementary strengths of RGB and event modalities. As shown in Fig. 1(c), we introduce two core modules: the decoupled amplitude–phase attention module and the motion-guided spatial sparsification module. The first module leverages the high dynamic range of event cameras by employing an amplitude and phase attention aggregation method in the frequency domain. Specifically, the RGB and event modalities are first transformed from the spatial domain to the frequency domain, where their amplitude and phase components are decoupled. Using amplitude and phase attention, high-frequency information from the event modality is selectively integrated into the RGB modality, enhancing image quality under low illumination while simultaneously reducing the number of tokens input to the backbone by half.
For the motion-guided spatial sparsification module, a differential Transformer network based on the Fast Fourier Transform (FFT) extracts target-relevant motion information from the event voxels . A lightweight score estimator then computes the spatial probability distribution of the target, while an exponential decay function determines an adaptive Top-$`K`$ value. This mechanism allows for the flexible selection of target-related tokens and suppression of background interference, further reducing the number of tokens processed by the backbone and enhancing target-focused feature representation. Collectively, these two modules reduce computational cost and improve target-relevant feature extraction, enabling more effective RGB–Event tracking in challenging scenarios.
To sum up, the contributions of this work can be summarized as follows:
1). We propose a novel amplitude and phase attention mechanism in the frequency domain, which aggregates high-frequency event information with RGB images at an early stage, thereby enhancing feature representations in challenging scenarios while significantly reducing the computational burden of the backbone.
2). We introduce a motion-guided spatial sparsification strategy that selectively filters out redundant background information while enhancing target-relevant feature representations.
3). Extensive experiments on three public datasets, i.e., FE108, FELT, and COESOT, fully demonstrate the effectiveness of the proposed multimodal tracker.
Related Works
RGB-Event based Tracking
Integrating RGB and event cameras to enhance object tracking performance has garnered significant interest within the research community. In earlier work, Zhang et al. designed CDFI, which aligns frame and event representations and applies self- and cross-attention for robust tracking. Wang et al. presented a baseline tracker using a cross-modality Transformer for effective feature fusion. Later works focus on the precise spatiotemporal alignment and cross-modal interaction. STNet is proposed to capture global spatial information and temporal cues by utilizing a Transformer and a spiking neural network (SNN). AFNet adds an event-guided cross-modality alignment (ECA) module and a cross-correlation fusion head. Zhu et al. further reduce modality conflict with orthogonal high-rank loss function and modality-masked tokens. Benchmark efforts unify RGB-Event training and evaluation for long sequences and diverse scenes. Tang et al. provide a unified dataset and metric suite, and Wang et al. release a long-term benchmark with a strong baseline. More recently, lightweight architectures and state-space-model (SSM) based trackers, such as Mamba-FETrack , have achieved a balance between model complexity and accuracy. In parallel, ViPT , SDSTrack , and EMTrack allow for efficient parameter transfer by fine-tuning the trackers. Unlike the aforementioned works, we leverage the advantages of event cameras, using their high dynamic range to enhance the spatial structure representation of the RGB modality, while exploiting their high temporal resolution to integrate richer motion information.
Frequency-Domain Modeling
Frequency-domain modeling demonstrates a compelling paradigm for multimodal fusion. Specifically, classical correlation-filter trackers operate in the frequency domain using the Fast Fourier Transform (FFT). MOSSE learns an adaptive filter with FFT-based optimization. KCF exploits a circulant structure and kernelization for fast dense sampling.
With the rise of deep learning, frequency-aware approaches have been widely explored to selectively amplify informative components while suppressing noise . For instance, Jiang et al. propose focal frequency loss that directs the model to focus on challenging spectral components. Wang et al. explore frequency channel attention by injecting FFT priors to refine channel-wise features. Meanwhile, FDA decouples spectra by swapping low-frequency amplitude across domains while keeping high-frequency phase. FFConv adds a spectral branch (FFT mixing iFFT) for long-range context. Subsequently, Kong et al. develop frequency-domain transformers with spectral attention and spectral feed-forward layers for deblurring, emphasizing sharp components and reducing computation. Chen et al. adapt the dilation rate to the local frequency and reweight frequency bands to preserve fine details in the segmentation task. FDConv applies dynamic kernels per band to enhance structure and reduce noise for dense prediction. Zhang et al. propose DMFourLLIE, a dual-stage multi-branch Fourier network that effectively mitigates color distortion and noise in low-light image enhancement. Cao et al. fuse event frames and grayscale frames in the Fourier domain to achieve effective action recognition. Compared with existing research, we fuse RGB and event in the frequency domain using amplitude and phase attention, and introduce a FFT-based differential ViT to enable target interaction between event templates and search regions.
Event-based Motion Mining
Event cameras generate continuous event signals by asynchronously capturing changes in scene brightness, thereby achieving high temporal resolution and providing rich motion information. Capturing motion information from the event modality is essential. Gallego et al. introduce a contrast maximization framework to directly recover camera or object motion from events. Their subsequent survey provides a comprehensive overview of motion-compensation approaches that establish stable priors for tracking. End-to-end models like EV-FlowNet learns optical flow from events in a self-supervised manner, turning sparse spikes into dense motion fields for low-latency alignment. E2VID reconstructs high temporal resolution intensity frames from events, reducing motion blur and enabling reuse of frame-based modules. Liu et al. introduce an event-based optical flow estimation network, exploiting the complementarity of temporally dense motion features and cost-volume representations. In the field of visual tracking, Zhang et al. proposed the Spiking Transformer, which treats the event stream as a continuous-time spike sequence with membrane dynamics. CrossEI proposes a motion-adaptive event sampling method and designs a bidirectional enhancement fusion framework to align and fuse event and image data. In this work, we leverage event voxel representation to effectively preserve motion cues and further utilize these cues to guide the adaptive spatial sparsification of input tokens, enabling the model to focus on motion-relevant regions while suppressing redundant background information.
 />
/>
Our Proposed Approach
Overview
An overview of the proposed RGB-Event tracking framework is shown in Fig. 2, comprising two core modules. The Decoupled Amplitude and Phase Attention module integrates high-frequency information from the event modality, which represents target contours, into the RGB modality in the frequency domain. This enhances the spatial structure representation of the RGB feature while reducing the computational load on the backbone network. The Motion-Guided Spatial Sparsification module leverages motion information from the event modality. By modeling the temporal dynamics of sliced event voxels, it adaptively suppresses redundant background information while enhancing target-relevant feature representations. Together, these two modules fully exploit the high dynamic range and motion sensitivity of event cameras, enabling more efficient RGB-Event visual tracking. In the following sections, Section 3.2 introduces the input representations, including RGB frames and event voxels. Section 3.3 details the two core modules, and Section 3.4 presents the tracking head along with the loss function.
Input Representation
Given an RGB video sequence with $`N`$ frames, denoted as $`I = \{I_1, I_2, \dots, I_N\}`$ where $`I_i \in \mathbb{R}^{3 \times H \times W}`$ and $`H`$ and $`W`$ represent the spatial resolution of the camera, the corresponding asynchronous event stream can be represented as $`E = \{e_1, e_2, \dots, e_M\}`$. Each event point $`e_i`$ is defined as a quadruple $`\{x_i, y_i, t_i, p_i\}`$, where $`(x_i, y_i)`$ denotes its spatial coordinates, $`t_i \in [0, T]`$ and $`p_i \in \{-1,1\}`$ denote the timestamp and polarity, respectively.
Following standard practice in visual tracking (e.g., OSTrack ), the template $`Z_I \in \mathbb{R}^{3 \times H_z \times W_z}`$ and search region $`X_I \in \mathbb{R}^{3 \times H_x \times W_x}`$ are obtained by cropping the first frame and subsequent frames at different scaling ratios from the RGB video sequence. For the event stream, to fully leverage its high temporal resolution and preserve rich motion-related information, we convert the event stream into an event voxel sequence $`V = \{V_1, V_2, \dots, V_N\}`$, where $`V_i \in \mathbb{R}^{B \times H \times W}`$ represents $`B`$ time bins, constructed via spatiotemporal bilinear interpolation . Similarly, the event template $`Z_E \in \mathbb{R}^{B \times H_z \times W_z}`$ and event search region $`X_E \in \mathbb{R}^{B \times H_x \times W_x}`$ are extracted from the event voxel sequence and aligned with the corresponding RGB frames.
Network Architecture
$`\bullet`$ **Preliminary: Fast Fourier Transform. ** First, we provide a brief introduction to the Fast Fourier Transform (FFT) . FFT is an efficient algorithm for converting images from the spatial domain into the frequency domain. In this representation, the original image can be expressed as a superposition of sinusoidal waves at different frequencies, where each frequency component contains amplitude and phase information. The mathematical formulation of the FFT can be expressed as:
\begin{align}
\mathcal{F}(x)(u,v) &= X(u,v) \notag\\
&= \frac{1}{\sqrt{H \times W}}
\sum_{h=0}^{H-1} \sum_{w=0}^{W-1} x(h,w) \,
e^{-j 2 \pi \left( \frac{h u}{H} + \frac{w v}{W} \right)},
\label{2DFFT}
\end{align}and its inverse transformation, i.e., the inverse Fast Fourier transform (iFFT), can be expressed as:
\begin{align}
\mathcal{F}^{-1}(X)(h,w) &= x(h,w) \notag\\
&= \frac{1}{\sqrt{H \times W}}
\sum_{u=0}^{H-1} \sum_{v=0}^{W-1}
X(u,v) \, e^{j 2 \pi \left( \frac{h u}{H} + \frac{w v}{W} \right)},
\label{iFFT}
\end{align}where $`x(h,w)`$ and $`X(u,v)`$ denote the original image in the spatial domain and transformed representation in the frequency domain, respectively. Here, $`h`$ and $`w`$ represent the pixel coordinates along the height and width in the spatial domain, while $`u`$ and $`v`$ correspond to the vertical and horizontal frequency components in the frequency domain. $`j`$ is the imaginary unit. Each complex frequency component $`X(u,v)`$ can be decomposed into amplitude and phase, where the amplitude indicates the strength of the component in the image, while the phase determines its offset. These two components can be obtained by computing the magnitude and the angle of the complex component, respectively:
\begin{align}
\label{amplitude_phase}
\mathcal{A}(u,v) &= |X(u,v)|
= \sqrt{R(X(u,v))^2 + I(X(u,v))^2}, \\
\mathcal{P}(u,v) &= \arg(X(u,v))
= \arctan\frac{I(X(u,v))}{R(X(u,v))},
\end{align}where $`R(X(u,v))`$ and $`I(X(u,v))`$ denote the real part and imaginary part of $`X(u,v)`$, respectively.
$`\bullet`$ **Decoupled Amplitude and Phase Attention. ** RGB frames and event data offer complementary representations, with RGB frames providing rich texture and color information, while event data captures motion cues and temporal changes. Direct spatial-domain fusion, however, may introduce blurring or misalignment owing to the inherent heterogeneity between the two modalities. By transforming both modalities into the frequency domain, we can selectively fuse RGB low-frequency structures with event high-frequency details, preserving both global appearance and fine temporal changes for a more robust representation. Therefore, we first transform the templates and search regions of both RGB and event data from the spatial domain to the frequency domain using FFT. Taking the search region $`X_I`$ and $`X_E`$ from the RGB frame and event voxel as examples, which can be expressed as:
\begin{align}
X_I^f = \mathbf{FFT}(X_I), \quad X_E^f = \mathbf{FFT}(X_E).
\end{align}Subsequently, the complex frequency components are decomposed into amplitude and phase, where $`A_r`$ and $`P_r`$ represent the amplitude and phase of the RGB search. For event search, high-frequency information is first extracted via a Gaussian filter and then decoupled into $`A_e`$ and $`P_e`$. The amplitude and phase components of both modalities are then enhanced using 2D convolutions with the Leaky ReLU activation function, yielding $`\tilde{A}_r`$, $`\tilde{P}_r`$ for RGB, and $`\tilde{A}_e`$, $`\tilde{P}_e`$ for event modality.
To effectively fuse RGB and event modalities in the frequency domain and incorporate the high-frequency information of events into RGB, we introduce amplitude and phase attention mechanisms for the corresponding branches. In each branch, both RGB and event amplitude/phase are L2-normalized along the channel dimension to stabilize the subsequent computations. As shown in Fig. 2 (a), the features are then combined via element-wise multiplication, capturing interactions between the two modalities. A softmax function is applied to generate attention weights $`M`$, the RGB features are modulated by these weights $`M`$, with a residual connection applied, producing enhanced amplitude/phase features of RGB modality that incorporate high-frequency informative cues from the event modality. The process can be formulated mathematically as (the normalization operation is omitted):
\begin{align}
\tilde{A}_r' &= \mathbf{softmax} \Big( \tilde{A}_r \odot \tilde{A}_e \Big) \odot \tilde{A}_r + \tilde{A}_r, \\
\tilde{P}_r' &= \mathbf{softmax} \Big( \tilde{P}_r \odot \tilde{P}_e \Big) \odot \tilde{P}_r + \tilde{P}_r,
\end{align}where $`\tilde{A}_r'`$ and $`\tilde{P}_r'`$ denote the fused amplitude and phase for RGB modality, with $`\odot`$ representing the element-wise multiplication operation. After that, the fused amplitude and phase are converted into complex features and enhanced via Fast Fourier Convolution (FFC), implemented as a Convolution–ReLU–Convolution block. Finally, the enhanced features are restored from the frequency domain back to the spatial domain via the inverse Fast Fourier Transform (iFFT), yielding $`X_I' \in \mathbb{R}^{B \times H_x \times W_x}`$. Similarly, the RGB and event templates, i.e., $`Z_I`$ and $`Z_E`$, undergo the same process, producing $`Z_I' \in \mathbb{R}^{B \times H_z \times W_z}`$. Through the projection layer, $`Z_I'`$ and $`X_I'`$ are partitioned into non-overlapping patches and subsequently flattened into sequences $`F_I^z \in \mathbb{R}^{N_z \times C}`$ and $`F_I^x \in \mathbb{R}^{N_x \times C}`$, where $`N_z`$ and $`N_x`$ denote the number of tokens for the template and search region, respectively, and $`C`$ is the feature dimension.
The decoupled amplitude and phase attention module transforms the RGB and event modalities from the spatial domain to the frequency domain, decoupling them into amplitude and phase components. Through amplitude and phase attention, high-frequency motion information from the event modality is selectively integrated into the RGB modality. Only the fused RGB modality is retained as input to the backbone network, significantly reducing the computational cost.
$`\bullet`$ **Motion Representation Learning. ** The motion information contained in asynchronous event streams reflects the target’s state in the current scene. Accordingly, we model the event motion to capture the spatial distribution patterns triggered by the target’s movement across distinct scenarios. We represent the event stream using event voxel accumulated within temporal windows, denoted as $`Z_E \in \mathbb{R}^{B \times H_z \times W_z}`$ for event template and $`X_E \in \mathbb{R}^{B \times H_x \times W_x}`$ for event search. This representation encodes the event distribution over $`B`$ temporal bins, where each bin stores the spatial activation of events within its corresponding time interval.
To extract the feature representations of these temporal bins, both the event template and event search are fed into an event encoder. This encoder is composed of multi-scale Conv-BN-LeakyReLU blocks followed by linear projection layers, enabling the extraction of spatiotemporal features $`Z_E' \in \mathbb{R}^{B \times \frac{H_z}{16} \times \frac{W_z}{16} \times C}`$ and $`X_E' \in \mathbb{R}^{B \times \frac{H_x}{16} \times \frac{W_x}{16} \times C}`$ for the event template and search (Note that, to align the event sequence length with that of the RGB sequence, here $`\frac{H_z}{16} \times \frac{W_z}{16}`$ = $`N_z`$ and $`\frac{H_x}{16} \times \frac{W_x}{16}`$ = $`N_x`$). To capture continuous motion features, we warp the event feature maps to align with the RGB reference and then compute the dense difference maps. Specifically, we first warp the features $`Z_{E_i}' \in \mathbb{R}^{\frac{H_z}{16} \times \frac{W_z}{16} \times C}`$ and $`X_{E_i}' \in \mathbb{R}^{\frac{H_x}{16} \times \frac{W_x}{16} \times C}`$, $`i=1,2,\ldots, B`$, of temporal bins towards RGB template and search feature maps through bilinear interpolation, and obtain $`\tilde{Z}_{E_i}' \in \mathbb{R}^{\frac{H_z}{16} \times \frac{W_z}{16} \times C}`$ and $`\tilde{X}_{E_i}' \in \mathbb{R}^{\frac{H_x}{16} \times \frac{W_x}{16} \times C}`$, $`i=1,2,\ldots, B`$. Subsequently, we introduce a sampling stride $`s=1`$ to control the temporal interval between consecutive bins, yielding feature difference maps that reflect dense spatial displacements. The formulation is as follows:
\begin{align}
D_j^z &= \tilde{Z}_{E_{j+1}}' - \tilde{Z}_{E_{j}}', \quad j = 1, \ldots, B - 1, \\
D_j^x &= \tilde{X}_{E_{j+1}}' - \tilde{X}_{E_{j}}', \quad j = 1, \ldots, B - 1,
\end{align}where $`D_j^z \in \mathbb{R}^{\frac{H_z}{16} \times \frac{W_z}{16} \times C}`$ and $`D_j^x \in \mathbb{R}^{\frac{H_x}{16} \times \frac{W_x}{16} \times C}`$ represent the $`j`$-th difference maps of the event template and search region, respectively, capturing the motion evolution of events across consecutive temporal bins $`(j+1)`$-th and $`j`$-th.
$`\bullet`$ **Motion-Guided Spatial Sparsification. ** In the following, we detail how motion difference maps can be leveraged to perform spatial sparsification under diverse scene conditions. To exploit the dynamic frequency information in event signals, we introduce an FFT-based differential Transformer module (Diff-FFT ViT), which enables effective interaction between the event template and the search region to capture dynamic cues associated with the target object, as shown in Fig. 2(b). Inspired by , which reduces noise by computing the difference between two independent softmax attention maps, we adopt a similar differential strategy in our design. Specifically, the multi-time-scale difference maps of the template and the search region are first concatenated, followed by global average pooling, yielding the global motion representations $`D_z \in \mathbb{R}^{N_z \times C}`$ and $`D_x\in \mathbb{R}^{N_x \times C}`$, respectively. Then, we concatenate the global motion features of the template and the search region to obtain $`D \in \mathbb{R}^{N \times C}`$ (here $`N = N_z+N_x`$), which is subsequently fed into the Diff-FFT ViT module. Given an input $`D \in \mathbb{R}^{N \times C}`$, we first project it to the queries, keys, and values: $`Q_1, Q_2, K_1, K_2 \in \mathbb{R}^{N \times \frac{C}{2}}`$ and $`V \in \mathbb{R}^{N \times C}`$:
\begin{align}
[Q_1; Q_2] = D W_Q, \quad
[K_1; K_2] = D W_K, \quad
V = D W_V,
\end{align}where $`W_Q,W_K,W_V`$ are learnable projection matrices. Then, the FFT-based differential attention operator computes outputs via:
\begin{align}
ATT_1 &= \mathbf{softmax}\Big(\frac{Q_1 K_1^\top}{\sqrt{d}}\Big) V, \\
ATT_2 &= \mathbf{softmax}\Big(\frac{Q_2 K_2^\top}{\sqrt{d}}\Big) V,
\end{align}\begin{align}
D_{fft} = \Big(\, \mathbf{FFT}(ATT_1) - \lambda \, \mathbf{FFT}(ATT_2)\,\Big),
\end{align}where $`D_{fft}`$ is the output of the Diff-FFT attention operator in the frequency domain, and $`\lambda`$ is a learnable scalar. Afterwards, we apply the inverse FFT (iFFT) to transform the output from the frequency domain back to the spatial domain as follows:
\begin{align}
D_s = \mathbf{iFFT}(D_{fft} \odot f),
\end{align}where $`f`$ denotes the Gaussian window, which attenuates insignificant frequency components to further reduce the impact of noise on the resulting attention. Finally, the feed-forward network (FFN) is applied to further enhance the feature representations, mixing information across channels and outputting the target-enhanced motion representation $`D' \in \mathbb{R}^{N \times C}`$.
After obtaining the target-enhanced motion features, we extract the search region component $`D'_x \in \mathbb{R}^{N_x \times C}`$ and feed it into the MGSS (motion-guided spatial sparsification) module to guide spatial sparsification. As shown in Fig 2 (c), a score estimator, consisting of a multi-layer perceptron (MLP), is initially employed to project the motion representation of the search region into a corresponding score map $`\mathbf{S} \in \mathbb{R}^{N_x}`$, where each element $`S_{i} \in [0,1]`$ represents the probability score of the corresponding position belonging to the target-relevant motion region. We then calculate and normalize the variance of the score map to characterize the spatial distribution pattern of target motion-guided information in the current scene. Higher variance indicates that target-relevant information is concentrated in a few salient regions, whereas lower variance indicates a more spatially scattered distribution. Therefore, when the variance is low, a greater number of spatial regions must be preserved to adequately represent target information, whereas high variance permits more redundant background regions to be safely filtered out. Guided by this principle, we propose a variance-based adaptive Top-$`K`$ function that dynamically determines an appropriate $`K_{adp}`$ based on the scene-wise variance of target probabilities, enabling the adaptive pruning of redundant low-scoring regions. The functional relationship between $`K_{adp}`$ and $`Var_{norm}`$ is defined as:
\begin{align}
K_{adp} = K_{min} + (K_{max}-K_{min}) \cdot e^{- \beta x}, \quad (\beta \in \mathbb{N}^+)
\end{align}where $`K_{min}`$ and $`K_{max}`$ are used to determine the lower and upper bounds of $`K_{adp}`$, and $`x`$ denotes the normalized variance $`V_{norm}`$. $`\beta \in \mathbb{N}^+`$ is a hyperparameter. This exponential mapping enables smooth and adaptive control over the retained token ratio, preserving more high-scoring regions in complex scenes while effectively pruning redundancy when information is concentrated. Additional comparisons with alternative formulations are provided in the ablation experiments.
Subsequently, we perform a Top-$`K`$ selection on $`F_I^x`$, retaining the $`K`$ highest-scoring patches to obtain the selected search feature representation $`F_I^{\text{top}} \in \mathbb{R}^{N_x^{\text{top}} \times C}`$, where $`N_x^{\text{top}}`$ denotes the number of retained tokens. This representation is then concatenated with the template feature $`F_I^z`$ and fed into the HiViT backbone network for further feature learning and interaction. Similarly, a Top-$`K`$ selection is applied to the event search region, and the selected event search features are multiplied element-wise with the corresponding Top-$`K`$ scores, enhancing the relative importance of motion representations across different regions. Finally, the Top-$`K`$ search region features from both modalities are combined via summation and then, after zero-padding the spatially redundant regions, fed into the tracking head to obtain the final tracking predictions.
The motion-guided spatial sparsification module exploits the intrinsic motion sensitivity of event cameras to capture dynamic states across diverse scenes. It employs an FFT-based differential ViT to model target-related motion cues. A variance-driven function of the target probability distribution is used to identify the Top-$`K`$ salient regions in each scene, enabling selective suppression of redundant spatial areas while preserving target-focused information. This design enhances target-related feature representation while reducing computational overhead.
Tracking Head and Loss Function
Our tracking head design follows OSTrack . The enhanced search region features extracted from the ViT backbone are fed into the tracking head to predict the spatial location of the target. Specifically, the search features are first reshaped into a 2D feature map, which is subsequently processed by a series of Convolution–Batch Normalization–ReLU (Conv–BN–ReLU) blocks, and then produces four outputs: (1) a target classification score map indicating the probability of the target appearing at each spatial location; (2) local offset predictions for refining the estimated center coordinates of the bounding box; (3) normalized bounding box dimensions (width and height); and (4) the final predicted bounding box, representing the estimated target location in the current frame.
During training, we adopt a loss formulation similar to OSTrack , employing three distinct loss functions for comprehensive optimization: Focal Loss ($`L_{focal}`$) for target classification, L1 Loss ($`L_1`$) for offset regression, and GIoU Loss ($`L_{GIoU}`$) for bounding box size and overlap regression. The overall training objective $`L_{total}`$ is defined as a weighted combination of these terms:
\begin{equation}
L_{total} = \lambda_1 L_{focal} + \lambda_2 L_1 + \lambda_3 L_{GIoU},
\label{eq:total_loss}
\end{equation}where $`\lambda_1, \lambda_2, \lambda_3`$ are weighting coefficients balancing the contribution of each loss term.
Experiments
Datasets and Evaluation Metric
In this section, we compare with other state‑of‑the‑art (SOTA) trackers on existing event-based tracking datasets, including FE108 , FELT , and COESOT .
$`\bullet`$ FE108 Dataset: The dataset is a dual-modal single-object tracking benchmark collected using a grayscale DAVIS 346 event camera. It contains 108 video clips recorded in indoor environments, with a total duration of approximately 1.5 hours. Among them, 76 videos are used for training and 32 for testing. The dataset covers 21 categories of objects, which can be grouped into three types: animals, vehicles, and everyday items. In addition, the dataset includes four challenging scene conditions: low illumination (LL), high dynamic range (HDR), and fast-motion scenes where motion blur is either present or absent in APS frames (FWB and FNB). Please refer to the following GitHub for more details https://github.com/Jee-King/ICCV2021_Event_Frame_Tracking?tab=readme-ov-file .
| **SiamRPN ** | **SiamBAN ** | **SiamFC++ ** | **KYS ** | **CLNet ** | **CMT-MDNet ** | **ATOM ** | |
| 21.8/33.5 | 22.5/37.4 | 23.8/39.1 | 26.6/41.0 | 34.4/55.5 | 35.1/57.8 | 46.5/71.3 | |
| **DiMP ** | **PrDiMP ** | **CEUTrack ** | **FENet ** | **ViPT ** | **MamTrack ** | Ours | |
| 52.6/79.1 | 53.0/80.5 | 55.6/84.5 | 63.4/92.4 | 65.2/92.1 | 66.4/94.2 | 64.4/95.2 |
$`\bullet`$ FELT Dataset: The dataset is a large-scale, long-duration dual-modal single-object tracking benchmark collected using a DAVIS 346 event camera. It comprises 1,044 video sequences, each with an average duration of over 1.5 minutes, ensuring that every video contains at least 1,000 pairs of synchronized RGB and event frames. Among them, 730 sequences are used for training and 314 for testing. In total, the dataset provides 1,949,680 annotated frames, covering 60 object categories and defining 14 challenging tracking attributes, including occlusion, fast motion, and low-light conditions. Please refer to the following GitHub for more details https://github.com/Event-AHU/FELT_SOT_Benchmark .
$`\bullet`$ COESOT Dataset: This benchmark dataset is an RGB-Event-based, category-wide tracking dataset designed to evaluate the generalization ability of tracking algorithms across different object types. It contains 1,354 video sequences covering 90 object categories, with 827 sequences used for training and 527 for testing, providing a total of 478,721 annotated RGB frames. To facilitate fine-grained analysis of algorithm performance, the dataset explicitly defines 17 challenging factors, including fast motion, occlusion, illumination variation, background clutter, and scale changes. Please refer to the following GitHub for more details https://github.com/Event-AHU/COESOT .
| Trackers | Source | SR | PR | NPR | FPS |
|---|---|---|---|---|---|
| **01. STARK ** | ICCV21 | 52.7 | 67.9 | 62.8 | 42 |
| **02. OSTrack ** | ECCV22 | 52.3 | 65.9 | 63.3 | 75 |
| **03. MixFormer ** | CVPR22 | 53.0 | 67.5 | 63.8 | 36 |
| **04. AiATrack ** | ECCV22 | 52.2 | 66.7 | 62.8 | 31 |
| **05. SimTrack ** | ECCV22 | 49.7 | 63.6 | 59.8 | 82 |
| **06. GRM ** | CVPR23 | 52.1 | 65.6 | 62.9 | 38 |
| **07. ROMTrack ** | ICCV23 | 51.8 | 65.8 | 62.7 | 64 |
| **08. ViPT ** | CVPR23 | 52.8 | 65.3 | 63.1 | 29 |
| **09. SeqTrack ** | CVPR23 | 52.7 | 66.9 | 63.4 | 31 |
| **10. ARTrackv2 ** | CVPR24 | 52.3 | 65.2 | 62.8 | 42 |
| **11. HIPTrack ** | CVPR24 | 51.6 | 65.6 | 62.2 | 39 |
| **12. ODTrack ** | AAAI24 | 52.2 | 66.0 | 63.5 | 57 |
| **13. EVPTrack ** | AAAI24 | 53.8 | 68.7 | 64.8 | 45 |
| **14. AQATrack ** | CVPR24 | 54.0 | 69.1 | 64.7 | 41 |
| **15. SDSTrack ** | CVPR24 | 53.7 | 66.4 | 64.1 | 28 |
| **16. UnTrack ** | CVPR24 | 53.6 | 66.0 | 63.9 | 12 |
| **17. FERMT ** | ECCV24 | 51.8 | 66.1 | 62.9 | 70 |
| **18. LMTrack ** | AAAI25 | 50.9 | 63.9 | 61.8 | 72 |
| **19. AsymTrack ** | AAAI25 | 51.9 | 66.7 | 62.0 | 104 |
| **20. SUTrack ** | AAAI25 | 56.6 | 70.9 | 66.6 | 25 |
| **21. ORTrack ** | CVPR25 | 48.4 | 61.7 | 59.2 | 90 |
| **22. UNTrack ** | CVPR25 | 50.0 | 63.9 | 61.6 | 23 |
| 23. Ours | - | 56.5 | 72.3 | 67.9 | 27 |
Experimental results on FELT dataset.
| Trackers | Source | SR | PR |
|---|---|---|---|
| **01. TransT ** | CVPR21 | 60.5 | 72.4 |
| **02. STARK ** | ICCV21 | 56.0 | 67.7 |
| **03. OSTrack ** | ECCV22 | 59.0 | 70.7 |
| **04. MixFormer ** | CVPR22 | 55.7 | 66.3 |
| **05. AiATrack ** | ECCV22 | 59.0 | 72.4 |
| **06. SiamR-CNN ** | CVPR20 | 60.9 | 71.0 |
| **07. ToMP50 ** | CVPR22 | 59.8 | 70.8 |
| **08. ToMP101 ** | CVPR22 | 59.9 | 71.6 |
| **09. KeepTrack ** | ICCV21 | 59.6 | 70.9 |
| **10. PrDiMP50 ** | CVPR20 | 57.9 | 69.6 |
| **11. DiMP50 ** | ICCV19 | 58.9 | 72.0 |
| **12. ATOM ** | CVPR19 | 55.0 | 68.8 |
| **13. TrDiMP ** | CVPR21 | 60.1 | 72.2 |
| **14. MDNet ** | TCYB23 | 53.3 | 66.5 |
| **15. ViPT ** | CVPR23 | 68.3 | 81.0 |
| **16. SDSTrack ** | CVPR24 | 66.7 | 79.7 |
| **17. UnTrack ** | CVPR24 | 67.9 | 80.9 |
| **18. CEUTrack ** | PR25 | 62.7 | 76.0 |
| **19. LMTrack ** | AAAI25 | 58.4 | 71.1 |
| **20. CMDTrack ** | TPAMI25 | 65.7 | 74.8 |
| **21. MCITrack ** | AAAI25 | 64.7 | 78.1 |
| 22. Ours | - | 68.0 | 83.3 |
Tracking results on COESOT Dataset.
For evaluation, three commonly used metrics are employed: Precision (PR), Normalized Precision (NPR), and Success Rate (SR). Specifically, Precision (PR) measures the proportion of frames where the distance between the predicted and ground-truth centers is below a predefined threshold (default: 20 pixels). Normalized Precision (NPR) computes the Euclidean distance between the predicted and ground-truth centers and normalizes it using the diagonal matrix formed by the width and height of the ground-truth bounding box. Success Rate (SR) represents the proportion of frames in which the Intersection over Union (IoU) between the predicted and ground-truth bounding boxes exceeds a specified threshold.
Implementation Details
We adopt HiViT as the backbone network for deep feature interaction learning, initialized with the pretrained weights of SUTrack-B224 . Each event voxel is discretized into 5 time bins within each time window. The learning rate is set to 0.0001, and the weight decay is 0.0001. The model is trained for 50 epochs, with 60,000 template–search pairs per epoch, and a batch size of 32. The input resolution of the template and search region is fixed to $`112 \times 112`$ and $`224 \times 224`$, respectively. For the adaptive Top-$`K`$ function, we set $`K_{min}=\frac{N_x}{2}`$ and $`K_{max}=N_x`$ in this work, while the hyperparameter $`\beta`$ is set to 2.
We use AdamW as the optimizer, where the loss weighting coefficients $`\lambda_i`$ ($`i = 1,2,3`$) are set to 1, 5, and 2, respectively. Our implementation is based on Python and PyTorch . All experiments are conducted on a server equipped with an AMD EPYC 7542 32-core CPU and an NVIDIA RTX 4090 GPU. Further implementation details are provided in the released source code.
| No. | Concatenation | Amplitude-Attn | Phase-Attn | Diff-FFT ViT | MGSS | SR | PR | Params | FLOPs |
|---|---|---|---|---|---|---|---|---|---|
| $`\#1`$ | 66.9 | 81.9 | 74.1M | 1167.4G | |||||
| $`\#2`$ | 66.8 | 81.7 | 70.0M | 608.9G | |||||
| $`\#3`$ | 66.5 | 81.3 | 70.0M | 608.9G | |||||
| $`\#4`$ | 67.2 | 82.4 | 70.0M | 608.9G | |||||
| $`\#5`$ | 67.6 | 82.9 | 73.3M | 726.0G | |||||
| $`\#6`$ | 68.0 | 83.3 | 77.0M | 701.0G |
Comparison on Public Benchmark Datasets
$`\bullet`$ **Results on FE108 Dataset. ** As shown in Table [tab:fe108_results], we conduct a performance comparison on the FE108 dataset between our proposed method and several other SOTA approaches. The experiment results indicate that our method achieves superior performance, with SR and PR scores of 64.4 and 95.2, respectively. Although the SR metric is slightly lower than the best, we achieve the highest PR score, which indicates that our model offers more accurate target center localization. We attribute this to the fact that our framework emphasizes modeling the key target regions, leading to more precise localization, while boundary and scale estimation still have room for further improvement.
$`\bullet`$ **Results on FELT Dataset. ** As shown in Table 1, we evaluate our method on the FELT dataset and compare it with comprehensive SOTA visual trackers. Our approach achieves an SR of 56.5, a PR of 72.3, and an NPR of 67.9, achieving a new SOTA performance. It outperforms recent strong baselines such as AsymTrack and AQATrack , demonstrating superior tracking accuracy and stability. Moreover, compared with the second-best method, SUTrack , our approach attains improvements of +1.4 in PR and +1.3 in NPR, while achieving comparable performance in SR. These results confirm that our framework effectively exploits event-guided motion cues, delivering strong robustness under challenging long-term tracking conditions.
$`\bullet`$ **Results on COESOT Dataset. ** We also report the comparison results on the COESOT dataset, as shown in Table 2. Our method achieves an SR score of 68.0, ranking among the top methods and second only to ViPT (68.3). More notably, our approach achieves a PR score of 83.3, significantly outperforming all other trackers, including recent SOTA methods such as UnTrack (80.9) and SDSTrack (79.7). This substantial improvement in precision clearly demonstrates the effectiveness and robustness of our tracker. Overall, the results validate that our approach achieves highly competitive performance across various categories, establishing a new SOTA in terms of tracking precision on the COESOT benchmark.
Component Analysis
As presented in Table [CAResults], we analyze the core components of our framework individually, highlighting the contribution and necessity of each module. To begin with, we evaluate the feature-level concatenation strategy as a comparative baseline (first row), yielding SR and PR scores of 66.9 and 81.9, respectively. In rows 2-4, we decouple the amplitude and phase of the two modalities and evaluate three settings: amplitude-only attention, phase-only attention, and both jointly. The results show that using amplitude or phase alone leads to performance degradation, whereas combining both yields better results. In the fifth row, we introduce the MGSS (Motion-Guided Spatial Sparsification) module, which removes redundant regions and enhances the model’s focus on the target area, thereby improving accuracy. In the last row, we further incorporate the FFT-based Differential ViT, enabling more effective modeling of target-related motion cues. Finally, our framework achieves the best overall performance, resulting in 68.0 and 83.3 on SR and PR, respectively.
In addition, we investigate the overall parameter count and computational complexity of the tracker under different configurations. The naive concatenation operation incurs over 1,000 GFLOPs due to the large number of multimodal input tokens. In contrast, our two core designs significantly reduce computational complexity while simultaneously improving overall performance.
Ablation Study
$`\bullet`$ **Analysis of Input Data. ** Table [tab: Ablation_Studies] reports the tracking performance under four configurations: Event only, RGB only, RGB fused with event frames, and RGB fused with event voxels. Using only event frames yields limited results (SR 58.3, PR 71.1) due to sparsity and noise, whereas RGB frames alone achieve substantially higher performance, underscoring the richness of appearance cues. Fusing RGB frames with event frames improves tracking performance, achieving an SR of 67.5 and a PR of 82.4. Incorporating event voxels with RGB increases accuracy to an SR of 68.0 and a PR of 83.3, demonstrating that their rich motion cues effectively complement RGB frames to improve tracking performance.
$`\bullet`$ **Analysis of Different Fusion Methods. ** Table [tab: Ablation_Studies] presents a comparison between our proposed decoupled amplitude–phase attention aggregation method and two commonly used feature fusion methods. In the addition-based experiment, the event voxel is first aligned with the RGB image via a convolutional layer and then directly added to it before being passed through the projection layer. In contrast, the concatenation-based experiment performs token-level concatenation after the projection layer. It is important to note that both baseline experiments retain the MGSS module. The results indicate that our frequency-domain amplitude–phase fusion strategy more effectively incorporates informative cues from the event modality into the RGB modality, ultimately leading to superior tracking performance.
$`\bullet`$ **Analysis of Diff-FFT ViT Module. ** We further analyze the advantages of our Diff-FFT ViT module. As shown in Table [tab: Ablation_Studies], the standard ViT achieves an SR of 67.4 and a PR of 82.7, serving as a strong baseline. Diff-ViT further improves these results, reaching an SR of 67.6 and a PR of 83.1. In contrast, our Diff-FFT ViT extends Diff-ViT by performing differential attention in the frequency domain and applying a Gaussian window to suppress noise, thereby yielding the best overall performance. This performance gain suggests that Fourier-domain interactions enable more precise extraction of target-related motion cues while effectively mitigating the influence of noise on critical features.
$`\bullet`$ **Analysis of Spatial Sparsification Methods. ** This work adopts a motion-guided adaptive spatial sparsification approach to reduce spatial redundancy. In addition, we compare it with other commonly used sparsification methods, as summarized in Table [tab: Ablation_Studies]. It can be observed that randomly dropping some tokens inevitably results in the loss of critical information, leading to performance degradation. Candidate elimination and dynamic ViT methods can improve the accuracy of redundant token filtering to some extent. Finally, our approach achieves the best performance, demonstrating that motion information from events can more accurately reflect the spatial distribution pattern of the scene, thereby enabling a more robust and effective selection of informative tokens.
$`\bullet`$ **Analysis of Adaptive Top-$`K`$ Functions. ** To dynamically adjust the number of retained tokens, we explore three adaptive Top‑$`K`$ selection functions based on motion cues. As shown in Table [tab: Ablation_Studies], the first variant, which linearly decreases $`K_{\mathrm{adp}}`$, achieves an SR of 67.5 and PR of 82.5. The second, using a power-law decay $`(1 + x)^{-\beta}`$, performs slightly worse (SR: 67.2, PR: 82.0), indicating limited adaptation under complex backgrounds. Our third variant, based on an exponential decay $`e^{-\beta x}`$, achieves the best results, enabling smoother token pruning. These results show that exponential-based adaptive sparsification effectively balances efficiency and tracking accuracy for RGB-Event object tracking.
 style="width:48.0%" />
style="width:48.0%" />
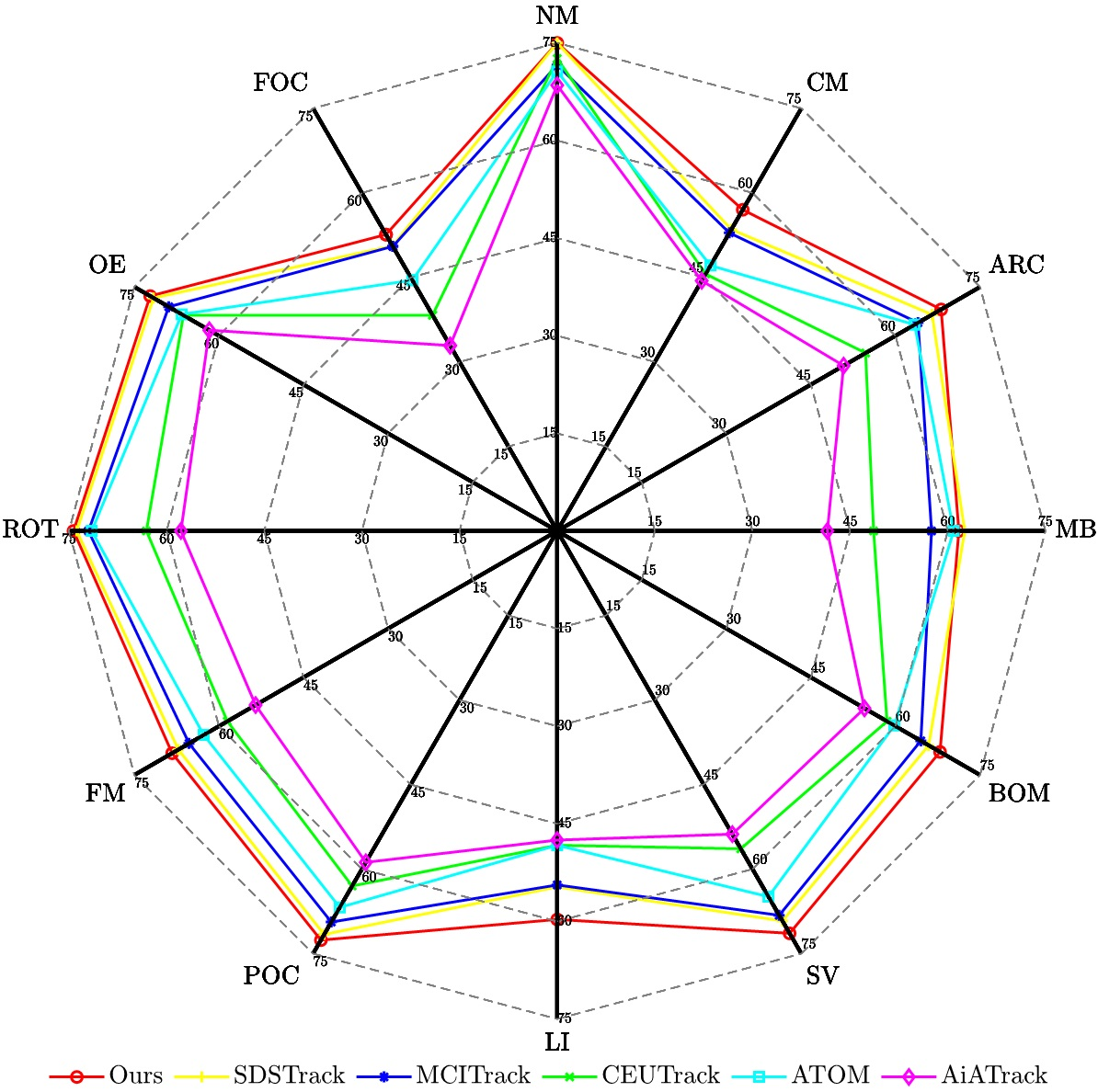
$`\bullet`$ **Success Rate Under Challenging Attributes. ** We further evaluate our proposed method on the COESOT dataset across 12 challenging attributes, providing a comprehensive assessment of its robustness and adaptability across diverse tracking scenarios. As shown in Fig. 3, our method achieves the highest success rate on 11 out of 12 attributes compared to SDSTrack, MCITrack, CEUTrack, ATOM, and AiATrack. In particular, it demonstrates a clear advantage in low-illumination (LI) scenarios, indicating that the proposed decoupled amplitude and phase attention effectively integrates high dynamic range information from the event data. Furthermore, its superior performance in background object motion (BOM), full occlusion (FOC), and camera motion (CM) scenarios validates that the motion-guided spatial sparsification efficiently removes redundant noise while focusing on target-relevant cues. These results demonstrate that our model provides highly reliable tracking performance in various real-world scenarios, effectively addressing dynamic environmental changes and complex target behaviors.
 style="width:44.0%" />
style="width:44.0%" />
 style="width:44.0%" />
style="width:44.0%" />
 style="width:90.0%" />
style="width:90.0%" />
Efficiency Analysis
Table [CAResults] compares the parameter count and computational complexity of different model components. Compared with conventional multimodal learning methods based on feature concatenation, our approach increases the parameter count by only 2.9M, while significantly reducing computational complexity. This improvement primarily stems from our proposed decoupled amplitude and phase attention aggregation strategy, which halves the number of input tokens fed into the backbone during early fusion. Simultaneously, motion-guided spatial sparsification further reduces spatial redundancy. Together, these mechanisms substantially alleviate the computational burden of the backbone while preserving effective utilization of multimodal information. In addition, we report the inference tracking speed of our framework on the FELT dataset, as shown in Table 1. Our model achieves 27 FPS, enabling effective real-time tracking performance.
Visualization
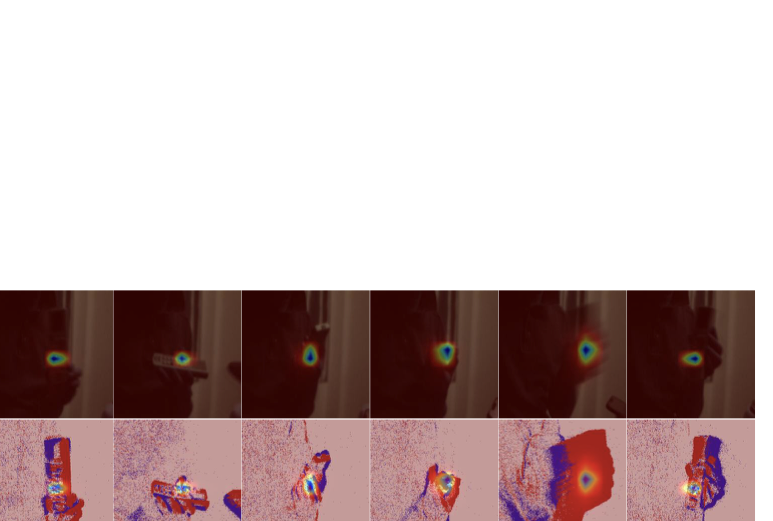
$`\bullet`$ Results of Early Fusion and Motion-Guided Spatial Sparsification. In addition to the quantitative results, in this section, we present several qualitative results to facilitate a clearer understanding of our framework. As illustrated in Fig. 4, we visualize the enhancement effects of the early fusion method, namely the decoupled amplitude and phase attention module, on the RGB inputs, as well as the results of the motion-guided spatial sparsification (MGSS) module. The visualization results show that the early fusion strategy effectively enhances the original RGB images by incorporating high-frequency information from the event modality, thereby alleviating tracking challenges in complex scenarios. Furthermore, MGSS dynamically suppresses spatially redundant background regions while preserving target-relevant tokens, which improves the model’s capability to discriminate between foreground and background.
$`\bullet`$ Attention Maps and Response Maps. As shown in Fig. 5, we visualize the attention activation maps produced by our model. Regions with colors closer to red indicate higher attention weights, while blue regions correspond to areas receiving little attention. It can be seen that our model consistently and accurately focuses on the template target across various challenging scenarios. Furthermore, Fig. 6 presents the final response maps generated by the tracker, where deep blue regions denote high response values. Even in challenging conditions such as target rotation and illumination variations, our method is able to generate strong and precise responses at the target locations within the search region. These results further demonstrate the robustness of our approach.
$`\bullet`$ Tracking Results. In addition, we provide detailed qualitative comparisons of tracking results to facilitate a deeper understanding of our framework. As shown in Fig. 7, we compare the tracking results of our method with several other SOTA trackers, including ATOM, SDSTrack, CEUTrack, and MCITrack, on the COESOT dataset. In video sequences with low illumination and fast motion, our method generates bounding boxes that align most closely with the ground truth. By contrast, the compared trackers often drift to background regions or nearby distractors, and occasionally misidentify the target when the event stream becomes dense. These results further demonstrate that our tracker effectively exploits complementary frame and event cues for more robust RGB-Event-based object tracking.
Limitation Analysis
Although our framework effectively integrates RGB and event modalities for visual object tracking, it still faces the following two limitations: (1) The issue of imbalanced multimodal learning still persists, as the model may overly rely on one modality. This can suppress the feature representation of weaker modalities, leading to insufficient learning of multimodal information. A potential solution is to dynamically assign modality-specific weights during training, enabling weaker modalities to receive more attention. (2) The current framework lacks tailored adaptation strategies for individual challenging scenarios, which may cause certain challenge attributes that degrade overall performance to be overlooked. To address this limitation, a promising future direction is to develop an attribute-based multi-expert strategy, where each expert is specialized in handling specific challenges, thereby further enhancing the algorithm’s robustness.
Conclusion
In this work, we propose APMTrack, an effective framework for RGB-Event multimodal visual object tracking. To overcome the limitations of conventional feature-level fusion, we first introduce a decoupled amplitude and phase attention module. In the frequency domain, this module decomposes the amplitude and phase components of the RGB and event modalities. High-frequency information from the event modality is then incorporated into the RGB modality. This not only strengthens the feature representation of the RGB modality but also substantially reduces the computational burden of the backbone network. In addition, we propose a motion-guided spatial sparsification strategy. By leveraging the motion-sensitive properties of event cameras, this strategy models the relationship between target-relevant motion cues and the spatial probability distribution, adaptively filtering out redundant background regions while enhancing target-relevant features. Consequently, these two modules reduce computational complexity and improve tracking performance, striking a balance between accuracy and efficiency and pushing forward the field of RGB-Event visual object tracking.
Acknowledgment
This work was supported by the National Natural Science Foundation of China (62102205, 62576004, 62572043), Anhui Provincial Natural Science Foundation-Outstanding Youth Project (2408085Y032), Natural Science Foundation of Anhui Province (2408085J037), and Beijing Natural Science Foundation (No. JQ24024). The authors acknowledge the High-performance Computing Platform of Anhui University for providing computing resources.
📊 논문 시각자료 (Figures)