ITSELF Attention Guided Fine-Grained Alignment for Vision-Language Retrieval
📝 Original Paper Info
- Title: ITSELF Attention Guided Fine-Grained Alignment for Vision-Language Retrieval- ArXiv ID: 2601.01024
- Date: 2026-01-03
- Authors: Tien-Huy Nguyen, Huu-Loc Tran, Thanh Duc Ngo
📝 Abstract
Vision Language Models (VLMs) have rapidly advanced and show strong promise for text-based person search (TBPS), a task that requires capturing fine-grained relationships between images and text to distinguish individuals. Previous methods address these challenges through local alignment, yet they are often prone to shortcut learning and spurious correlations, yielding misalignment. Moreover, injecting prior knowledge can distort intra-modality structure. Motivated by our finding that encoder attention surfaces spatially precise evidence from the earliest training epochs, and to alleviate these issues, we introduceITSELF, an attention-guided framework for implicit local alignment. At its core, Guided Representation with Attentive Bank (GRAB) converts the model's own attention into an Attentive Bank of high-saliency tokens and applies local objectives on this bank, learning fine-grained correspondences without extra supervision. To make the selection reliable and non-redundant, we introduce Multi-Layer Attention for Robust Selection (MARS), which aggregates attention across layers and performs diversity-aware top-k selection; and Adaptive Token Scheduler (ATS), which schedules the retention budget from coarse to fine over training, preserving context early while progressively focusing on discriminative details. Extensive experiments on three widely used TBPS benchmarks showstate-of-the-art performance and strong cross-dataset generalization, confirming the effectiveness and robustness of our approach without additional prior supervision. Our project is publicly available at https://trhuuloc.github.io/itself💡 Summary & Analysis
1. **ITSELF Framework:** - We propose a new attention-guided implicit local alignment framework for TBPS. - This framework leverages the model's own attention maps to extract fine-grained cues and reinforce global alignment. - Think of it as focusing on specific details (like clothing or accessories) in an image based on what stands out.-
Robust Selection & Scheduling:
- We combine attention information across multiple layers to select the most important regions.
- This process uses a scheduler that starts broad and narrows down over time, ensuring stable learning.
- It helps the model focus on critical areas while discarding unnecessary details.
-
Strong Empirical Results:
- Our method shows state-of-the-art performance across various TBPS benchmarks.
- Demonstrating that ITSELF can achieve fine-grained alignment without relying on external resources or additional supervision.
📄 Full Paper Content (ArXiv Source)
 />
/>
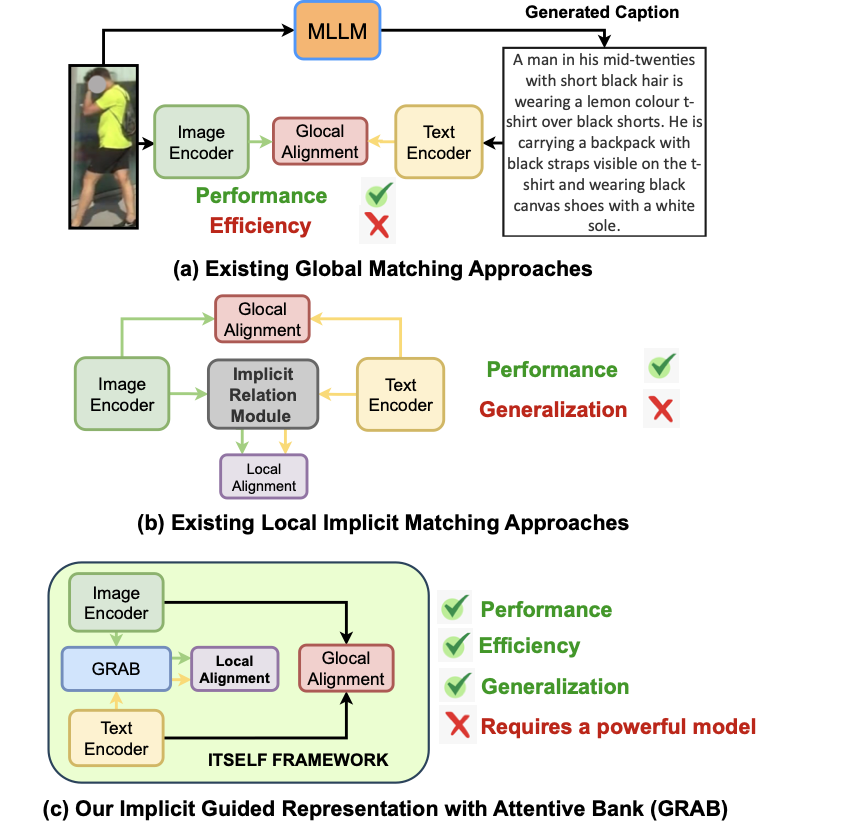
Text-based person search (TBPS) aims to identify, from a large image gallery, the person best matching a textual query . Solving it requires extracting identity-discriminative cues from both image and text to distinguish individuals with subtle differences. Recent advances in vision language models (VLMs) , notably CLIP , have shown strong potential for tackling these fine-grained challenges. Building on this foundation, TBPS-CLIP was the pioneer to apply CLIP to TBPS, followed by extensions that further narrow the text–image gap. However, many recent methods rely on costly external resources. For example, using MLLMs to synthesize auxiliary data (1(a)), while effective, increase compute and annotation costs, and hinder scalability and robustness.
To motivate the limitation, we pose a simple question: How can a TBPS model capture fine-grained, discriminative details on its own without costly external supervision? To minimize this, recent work pursues implicit local alignment (1(b)) to explore discriminative cues without burdensome external supervision. Embedding-space correspondence methods infer region–phrase matches from implicit signals, yet sparse labels leave these alignments weakly constrained and unstable. Fully implicit feature learning optimizes local losses but overlooks the semantics of specific text–region pairs, offering no guarantee of precise correspondences. Masked-modeling–style alignment encourages grounding via cross-modal reconstruction, but global-context shortcuts can bypass true dependencies. Across these lines, the core issue persists: locality constraints remain too weak, diffusing supervision, weakening discriminative region selection, and limiting robust local feature learning.
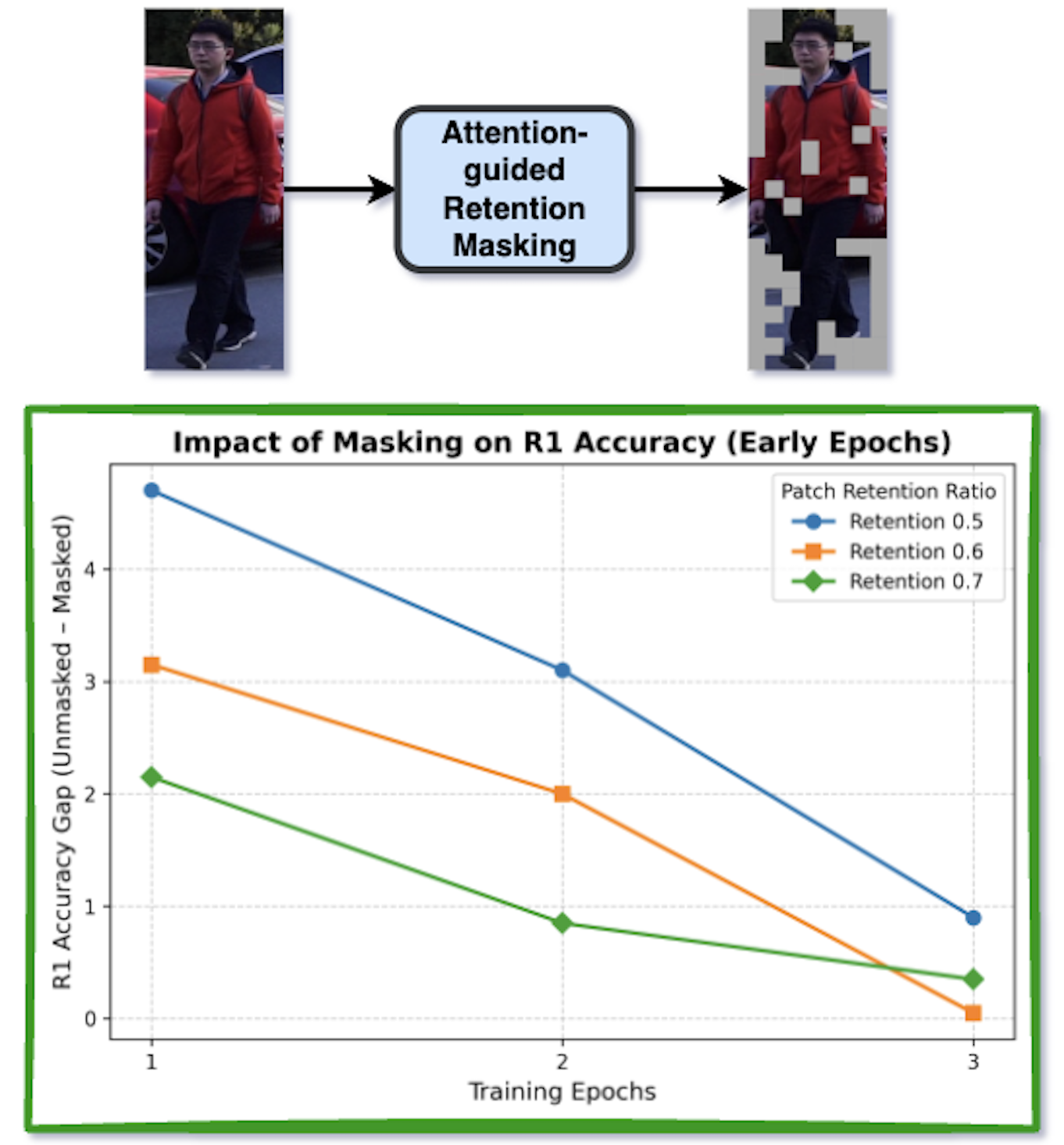
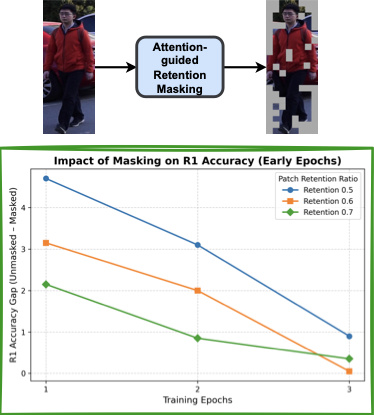
Attention is well suited to surface fine-grained cues and strengthen cross-modal correspondence, yet its potential remains underexplored thoroughly in TBPS. We probe this with a simple diagnostic: attention-guided retention masking (2). For each image, we compute attention from the image encoder’s last layer, retain the top-$`k`$ patches, and mask the rest. We then measure the R1 accuracy gap between the original input and its counterpart over early epochs and multiple retention ratios on RSTP-Reid . This analysis reveals two consistent patterns. First, saliency appears early: by epoch 3, the R1 gap falls below 1 percentage point for every retention setting, indicating that the retained patches already capture nearly all discriminative evidence. Second, attention is spatially precise: selected patches consistently align with semantically meaningful parts and carried objects, providing reliable localization cues for discriminative region–phrase correspondence.
 />
/>
Building on these findings, we present ITSELF, an attention-guided framework for implicit local alignment in TBPS. ITSELF optimizes a global text–image alignment loss and augments it with Guided Representation with Attentive Bank (GRAB), an attention-driven local branch that builds an Attentive Bank by selecting discriminative tokens from both modalities using model’s own attention without additional supervision (1(c)). Unlike previous methods that keep local alignment fully implicit, providing no direct constraints on phrase–region correspondence and thus inviting shortcut learning and spurious correlations that cause misalignment, our method injects an attention-derived locality prior that focuses learning on the most informative regions and aligns them consistently across modalities, thereby suppressing noise and reinforcing global alignment. In essence, our key innovation is an attention-driven implicit locality mechanism that turns internal saliency maps into reliable anchors for fine-grained alignment.
Based on analyses showing different attention heads specialize in complementary cues, with distinct patterns emerging at different depths. We introduce Multi-Layer Attention for Robust Selection (MARS) inside GRAB to avoid repeatedly picking the same dominant tokens from a single attention map. MARS aggregates attention across layers and performs diversity-aware top-$`k`$ selection across modalities, ensuring complementary coverage. The selected tokens populate GRAB’s Attentive Bank, where local objectives reinforce both inter- and intra-modal structure.
As suggested by (2) where the R1 gap between unmasked and attention-retained inputs quickly narrows in early epochs, we further introduce an Adaptive Token Scheduler (ATS) that maintains a larger retention budget at the start to avoid discarding important cues and the resulting training instability, then progressively anneals the budget to focus on high-confidence, fine-grained tokens. This schedule reduces redundancy and false negatives and stabilizes local learning. Finally, following recent practice, we adopt CLIP as the backbone, allowing ITSELF to transfer pretrained knowledge while continuing to learn cross-modal, implicit local correspondences on TBPS. In summary, our main contributions are as follows:
-
ITSELF Framework: A novel attention-guided implicit local alignment framework, ITSELF, with GRAB leveraging encoder attention to mine fine-grained cues and reinforce global alignment without additional supervision.
-
Robust Selection & Scheduling: We propose MARS, which fuses attention across layers and performs diversity-aware top-$`k`$ selection; and ATS, which anneals the retention budget from coarse to fine over training to stabilize learning and prevent early information loss.
-
Strong Empirical Results: Extensive experiments establish SOTA performance on 3 widely used TBPS benchmarks and improved cross-dataset generalization, confirming the effectiveness and robustness of our approach.
Related Work
Text-based Person Search (TBPS)
Over the last few years, the computer vision community has shown a lot of interest in TBPS . With the rise of Vision-Language Pretraining such as , TBPS research increasingly uses large-scale pretraining to achieve stronger cross-modal representations. A recent line of work enhances TBPS performance by incorporating auxiliary signals. For example, some methods utilize human parsing or pose estimation to highlight semantic regions, while others adopt external REID datasets to better adapt to pedestrian domain. These strategies improve fine-grained alignment but introduce additional training cost, annotation dependency, or domain bias. In contrast, our method autonomously extracts and aligns fine-grained local features from both modalities without relying on external datasets or tools, effectively addressing granularity and information gaps in TBPS.
Local Alignment for TBPS
Previous studies enhance fine-grained alignment using either explicit or implicit methods. Explicit approaches leverage external cues, such as human parsing networks or large-scale pretraining . However, their reliance on extensive external supervision, extra annotations and computational resources often limits their generalization. In contrast, implicit methods learn local correspondences directly through network without external data. While this removes the dependency on annotations, these methods often suffer from weak semantic grounding, as the relationship between textual descriptions and specific image regions is not explicitly enforced . Consequently, it remains uncertain whether the learned representations truly capture fine-grained cross-modal details. Our method builds upon implicit, annotation-free work, but introduces a key distinction. Instead of using external models or learning weakly grounded features, we directly exploit the intrinsic attention maps within CLIP. By mining fine-grained cues across multiple layers and selecting the most informative regions, our approach produces more discriminative representations. This lightweight design improves local alignment without requiring additional supervision or pretraining.
Methodology
This section provides an overview of our proposed framework, ITSELF, in 3.1. We then detail the core mechanism, GRAB, which incorporates MARS and ATS, in 3.2. Finally, 3.3 presents the training strategy and inference process of the overall pipeline.
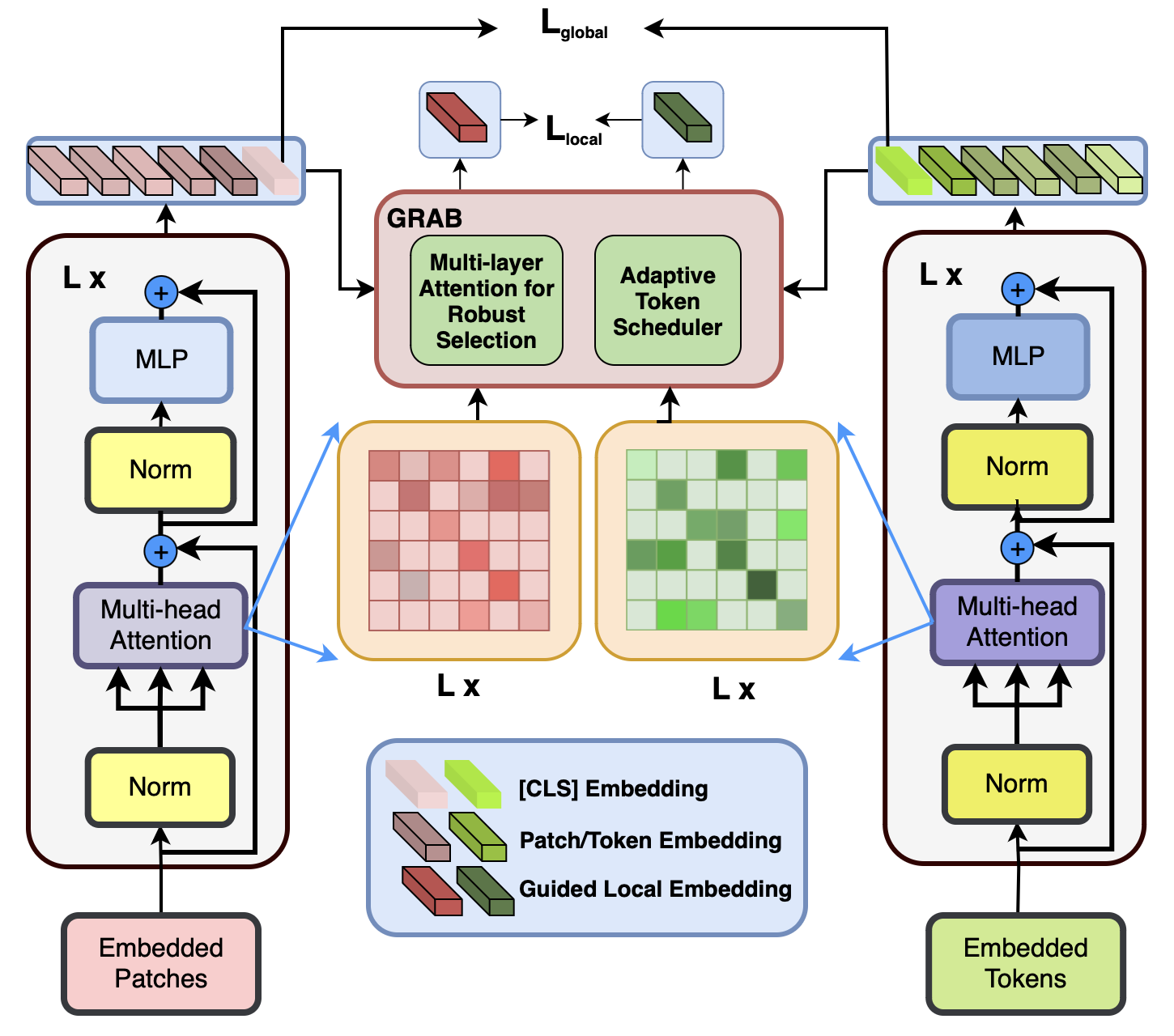
ITSELF Framework
Our framework consists of three main components 3: (a) an Image Encoder $`f_{v}`$ that encodes images into embeddings, (b) a Text Encoder $`f_{t}`$ that generates textual embeddings from captions, and (c) GRAB (Guided Representation with Attentive Bank), which leverages the model’s own attention to construct an attentive bank of high-saliency tokens. Local objectives are then applied on this bank, enabling the model to learn fine-grained correspondences without requiring additional supervision. Following prior works , we adopt CLIP ViT-B/16 as the backbone for both the visual and textual modalities.
Image Encoder: Given an input image $`I_i \in V`$, we divide it into $`N=H\times W / P^2`$ non-overlapping patches of size $`P`$, flatten and project them into a $`D`$-dimensional space, and prepend a learnable [CLS] token with positional embeddings. The sequence is fed into a transformer encoder, yielding visual embeddings $`\mathcal{V}_i = f_v(I_i) = \{ v^i_{\text{global}}, v^i_{local} \} \in \mathbb{R}^{(1+N)\times D}`$, where $`{v^i_{global}} = {v}^i_{\text{cls}}`$ is the global embedding and $`v^i_{local} = \{v^i_j\}_{j=1}^N`$ are patch embeddings.
Text Encoder: For text, we adopt CLIP’s Transformer-based encoder. Given a caption $`T_i \in T`$, it is tokenized with BPE and wrapped with [SOS]/[EOS] tokens. The sequence is embedded and passed through the transformer to produce $`\mathcal{T}_i = f_t(T_i) = \{ t^i_{\text{global}}, t^i_{\text{local}} \} \in \mathbb{R}^{(L+2)\times D},`$ where $`t^i_{\text{global}} = t^i_e`$ (from [EOS]) is the global embedding, and $`t^i_{\text{local}} = \{t^i_j\}_{j=1}^L`$ are token-level embeddings. The [SOS] token $`t^i_s`$ is retained but unused.
Guided Representation with Attentive Bank
Multi-layer Attention for Robust Selection
To learn robust implicit local representations, we design the GRAB, which retains a diverse set of highly discriminative tokens. Building on our finding 2 that tokens with consistently high attention values encode core identity cues, even from the earliest training epochs. However, selecting tokens based solely on a single fixed layer is inherently suboptimal, since different Transformer layers capture different types of information: shallow layers emphasize low-level textures, middle layers capture broader context, and deeper layers encode semantic abstractions that may suppress fine-grained details. To overcome this limitation, we introduce Multi-layer Attention for Robust Selection (MARS), which aggregates attention information across multiple layers to provide a more stable and reliable estimate of patch importance. Formally, given attention maps $`\mathbf{A}^{(\ell)} \in \mathbb{R}^{ N \times N}`$ from selected layers $`\ell \in \mathcal{L}`$, we denoise by removing the lowest $`\delta_\ell`$ fraction of attention weights, thereby filtering out non-informative links. The pruned attention map is then combined with the identity matrix I to preserve self-dependencies and normalized as:
\begin{equation}
\hat{\mathbf{A}}^{(\ell)} = \operatorname{Norm}\left(\frac{\operatorname{Discard}\left(\mathbf{A}^{(\ell)}, \delta_\ell\right) + \mathbf{I}}{2}\right),
\end{equation}where, $`\operatorname{Discard}(\cdot, \delta_\ell)`$ sets the lowest $`\delta_\ell`$ proportion of elements to zero while preserving the rest.
The aggregated attention across the selected layers is then computed by sequential composition:
\begin{equation}
\mathbf{R} = \prod_{\ell \in \mathcal{L}} \hat{\mathbf{A}}^{(\ell)}_b,
\quad \mathbf{R} \in \mathbb{R}^{ N \times N}.
\end{equation}Based on the aggregated map $`\mathbf{R}`$, we obtain local features $`\mathbf{f}^{\text{loc}}_{i}, \ \mathbf{f}^{\text{loc}}_{t}`$ by selecting the most informative tokens:
\begin{equation}
\mathbf{f}^{\text{loc}}_{i}, \ \mathbf{f}^{\text{loc}}_{t}
= \operatorname{TopK}\big(\mathbf{R}_{i}, \mathbf{R}_{t}, v^i_{local}, t^i_{local}),
\end{equation}where $`\mathbf{R}_{i}`$ and $`\mathbf{R}_{t}`$ denote the aggregated attention maps for image and text modalities.
By ranking and selecting the diversity-aware top-$`k`$ tokens according to $`\mathbf{R}`$, MARS implicitly captures fine-grained feature, amplify discriminative signals, suppress background noise, strengthens the global embedding and yields a more robust, identity-aware feature space.
Adaptive Token Scheduler
To further strengthen local feature learning, we introduce the Adaptive Token Scheduler (ATS). Unlike a fixed token budget, which may retain excessive background information or prematurely discard useful details, ATS anneals the number of selected tokens over training, This design follows a coarse-to-fine paradigm: in early stages, a larger proportion of tokens is preserved to avoid losing critical identity cues; in later stages, the selection increasingly focuses on highly discriminative patches. Formally, the number of retained tokens at step $`t`$ is defined as:
\begin{equation}
k_t =
\begin{cases}
\left\lfloor N\, \rho_{\text{start}} \left(\dfrac{\rho_{\text{end}}}{\rho_{\text{start}}}\right)^{\tfrac{t}{T}} \right\rfloor, & \text{if } t \le T, \\[8pt]
\left\lfloor N\, \rho_{\text{end}} \right\rfloor, & \text{if } t > T,
\end{cases}
\end{equation}where $`N`$ is the number of tokens, $`\rho_{\text{start}}`$ and $`\rho_{\text{end}}`$ are the initial and final retention ratios, $`t`$ is the current training step, and $`T`$ is the schedule length. This gradual narrowing mitigates early information loss and stabilizes training, while ultimately emphasizing fine-grained signals that complement the global embedding.
Implicit Local Learning Alignment
Algorithm description. To populate the Attentive Bank with the most discriminative cues from both modalities, we score each patch/token by the aggregated attention $`\mathbf{R}`$ returned by MARS. In early training, to stabilize optimization and avoid missing salient regions, we use ATS to schedule a decaying token budget $`k`$ decreasing over steps. At each step, we select the top-$`k`$ patches/tokens with the highest attention in $`\mathbf{R}`$ and insert them into the bank. To bridge modality shift and refine local features while preserving the original signal, the selected tokens are passed through a lightweight Adapter (MLP) with a residual connection. We then apply $`\mathrm{GPO}`$ to obtain Guided Local Embedding $`\mathbf{v}, \boldsymbol{\tau}`$ and compute the local-alignment loss $`\mathcal{L}_{\text{local}}`$. The complete procedure is summarized in [alg:grab].
Patch/Token features $`v^i_{local}, v^t_{local}`$; attention maps $`\{\mathbf{A}^{(\ell)}\}`$; $`\text{Adapter}(\cdot)`$, $`\operatorname{GPO}(\cdot)`$; loss $`\mathcal{L}_{\text{local}}(\cdot,\cdot)`$ Local-alignment loss $`\mathcal{L}`$ Aggregated attention (MARS): $`\mathbf{R}_i, \mathbf{R}_t\leftarrow`$ calculated by Eq. (2). Token budget (ATS): $`k \leftarrow`$ calculated by Eq. (4). Select informative tokens: $`(\mathbf{f}^{\mathrm{loc}}_i,\mathbf{f}^{\mathrm{loc}}_t) \leftarrow`$ calculated by Eq. (3) using $`\mathbf{R}_i,\mathbf{R}_t`$ and $`k`$.
Local adaptation (residual): $`(\mathbf{f}^{\mathrm{loc}}_i,\mathbf{f}^{\mathrm{loc}}_t) \leftarrow \text{Adapter}(\mathbf{f}^{\mathrm{loc}}_i,\mathbf{f}^{\mathrm{loc}}_t) + (\mathbf{f}^{loc}_i,\mathbf{f}^{loc}_t)`$. Pooling: $`\mathbf{v} \leftarrow \operatorname{GPO}(\mathbf{f}^{\mathrm{loc}}_i)`$, $`\boldsymbol{\tau} \leftarrow \operatorname{GPO}(\mathbf{f}^{\mathrm{loc}}_t)`$. Loss: $`\mathcal{L} \leftarrow \mathcal{L}_{\text{local}}(\mathbf{v}, \boldsymbol{\tau})`$. $`\mathcal{L}`$.
Training and Inference
Training. To optimize both global appearance and fine-grained discriminative tokens, our approach combines Triplet Alignment Loss (TAL) and Cross-Modal Identity Loss (CID) . By applying these specialized losses to separate global and local embeddings, the model learns a more comprehensive and robust representation for matching textual descriptions to pedestrian images.
Given an image-text pair $`(I,T)`$, the loss is defined as:
\begin{equation}
\mathcal{L} = \mathcal{L}_{tal} + \mathcal{L}_{cid}
\end{equation}We apply this loss to the global embedding $`(v_{global}, t_{global})`$ and the guided local representation $`(\mathbf{v}, \tau)`$, yielding
\begin{equation}
\mathcal{L}_{global} = \mathcal{L}(v_{global}, t_{global}), \mathcal{L}_{local} = \mathcal{L}(\mathbf{v}, \tau)
\end{equation}The overall training objective is the sum of the two:
\begin{equation}
\mathcal{L}_{total} = \mathcal{L}_{global} + \mathcal{L}_{local}
\end{equation}Inference. In the inference process, the final image-text pair similarity is computed by combining both global and local similarity. Here is the specific computation formula:
\begin{equation}
\mathcal{S} = \lambda_S\times\mathcal{S}_{global} + (1-\lambda_S)\times\mathcal{S}_{local}
\end{equation}where $`\mathcal{S}_{global}`$ and $`\mathcal{S}_{local}`$ represent global similarity and local similarity, respectively, and $`\lambda_S`$ is the weighting factor.
Experiment
Experimental Setup
Datasets. We evaluate the effectiveness of the proposed method on widely used public datasets for TBPR tasks, including CUHK-PEDES , ICFG-PEDES , and RSTPReid . Additional details about these datasets are provided in the Supplementary Material.
Evaluation Metrics. For evaluation, we employ the widely used Rank-k accuracy (k = 1, 5, 10) and mean Average Precision (mAP) metrics across all three datasets.
Quantitative Results
Comparison with state-of-the-art methods. We present comparison results with SOTA methods on three widely used benchmark datasets [tab:all_datasets]. Our approach clearly stands out, outperforming all CLIP-based competitors on every metric. Within CLIP-backbone methods, we set new SOTA R@1 on all datasets, improving over the strongest prior by +1.01%, +1.55%, and +1.95%, and we also obtain the best mAP on every benchmark, with the largest gain on RSTP-Reid (+2.17% mAP). These gains persist at deeper ranks, R@5/R@10 are best or tied-best, indicating broad retrieval improvements rather than a single-metric bump. Crucially, we achieve this without ReID-domain pretraining by mining multi-layer attention (MARS) to guide implicit local alignment. Despite this minimalist setup, we still surpass methods that leverage extra resources or larger backbones (e.g., CFAM(L/14), DP, UniPT). Notably, using only CLIP, we attain the top R@1 on ICFG-PEDES over all methods.
Domain Generalization. We further evaluate the cross-domain robustness of our model by training on one source dataset and directly testing on another unseen target dataset without fine-tuning. Using CUHK-PEDES (C), ICFG-PEDES (I), and RSTPReid (R), we form six transfer settings (e.g., C→I, I→R). Existing local implicit matching methods such as IRRA often achieve strong in-domain performance but generalize poorly, mainly because their relational modules overfit to dataset-specific patterns such as clothing styles or annotation bias. As a result, their learned correspondences fail to transfer effectively across domains. In contrast, our method avoids such overfitting by integrating attentive bank guidance with balanced local–global alignment, enabling more semantically stable representations. As shown in 1, our approach achieves the best results in all six transfer settings. For instance, in the C→I scenario, we obtain 50.58% R@1 and 27.32% mAP, surpassing RDE by 2.40% and 2.32%. Similarly, in the challenging I→R transfer, we improve the previous best R@1 by over 2%. These results demonstrate that unlike prior local implicit methods, our model achieves both high performance and strong domain generalization—crucial for real-world TBPS scenarios with diverse and shifting data distributions.
| Method | R1 | R5 | R10 | mAP | |
|---|---|---|---|---|---|
| C$`\to`$I | IRRA | 42.41 | 62.11 | 69.62 | 21.77 |
| CLIP | 43.04 | - | - | 22.45 | |
| RDE | 48.18 | 66.30 | 73.70 | 25.00 | |
| 2-6 | Ours | 50.58 | 67.81 | 74.68 | 27.32 |
| I$`\to`$C | IRRA | 33.48 | 56.29 | 66.33 | 31.56 |
| CLIP | 33.90 | - | - | 31.65 | |
| RDE | 38.11 | 59.24 | 68.44 | 34.16 | |
| 2-6 | Ours | 41.05 | 63.30 | 72.08 | 37.79 |
| I$`\to`$R | IRRA | 45.30 | 69.25 | 78.80 | 36.82 |
| CLIP | 47.45 | - | - | 36.83 | |
| RDE | 49.25 | 72.10 | 80.20 | 38.46 | |
| 2-6 | Ours | 51.30 | 73.30 | 80.40 | 41.07 |
| R$`\to`$I | IRRA | 32.30 | 49.67 | 57.80 | 20.54 |
| CLIP | 33.58 | - | - | 19.58 | |
| RDE | 42.17 | 58.32 | 65.49 | 26.37 | |
| 2-6 | Ours | 43.32 | 59.17 | 66.16 | 27.57 |
| C$`\to`$R | CLIP | 52.55 | - | - | 39.97 |
| IRRA | 53.25 | 77.15 | 85.35 | 39.63 | |
| RDE | 54.90 | 77.50 | 86.50 | 41.27 | |
| 2-6 | Ours | 58.05 | 79.30 | 86.85 | 43.72 |
| R$`\to`$C | IRRA | 32.80 | 55.26 | 65.81 | 30.29 |
| CLIP | 35.25 | - | - | 32.35 | |
| RDE | 36.94 | 58.22 | 67.58 | 33.65 | |
| 2-6 | Ours | 40.32 | 61.70 | 71.04 | 36.65 |
Comparisons with state-of-the-arts(domain generalization). Here “C” denotes CUHK-PEDES, “I” represents ICFG-PEDES and “R” means RSTPReid.
Qualitative Results
Top-5 Retrieval Examples. 4 qualitatively demonstrates our method’s superiority over RDE on the RSTPReid benchmark. For a query about a man in a black jacket and blue down jacket, our method retrieves all five correct matches, whereas RDE finds only three. With a query for a man in an orange coat with a hand-in-pocket pose, our approach correctly retrieves three images in the top ranks, while RDE secures only two, ranking the second true positive fourth. For a boy in a black jacket with white patterns, our method again excels with three correct top-ranked retrievals, contrasting with RDE’s single correct match at R3. These examples highlight our framework’s enhanced ability to align fine-grained textual descriptions with relevant visual details.
 />
/>
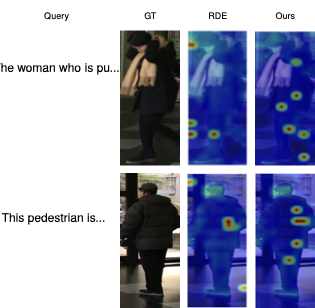
Attention Comparison. 5 presents Grad-CAM visualizations comparing RDE and our method. Our approach achieves sharper localization by focusing on query-specific elements (e.g., clothing and accessories) with minimal spillover, effectively isolating the target pedestrian in multi-person scenes. In contrast, RDE produces diffuse, often irrelevant hotspots, leading to fragmented text-image associations. These results highlight our framework’s stronger attribute-level fidelity and reduced cross-identity confusion, crucial for real-world person search.

Analysis on Top-K token Selection. The comparison in 12 shows our proposed top-K token selection is more effective than the baseline. While the baseline produces a scattered attention map misaligned with the query, our method generates a focused, semantically relevant map. It successfully pinpoints image regions corresponding to keywords demonstrating a superior ability to ground textual descriptions in their correct visual context for accurate retrieval.

Ablation Study
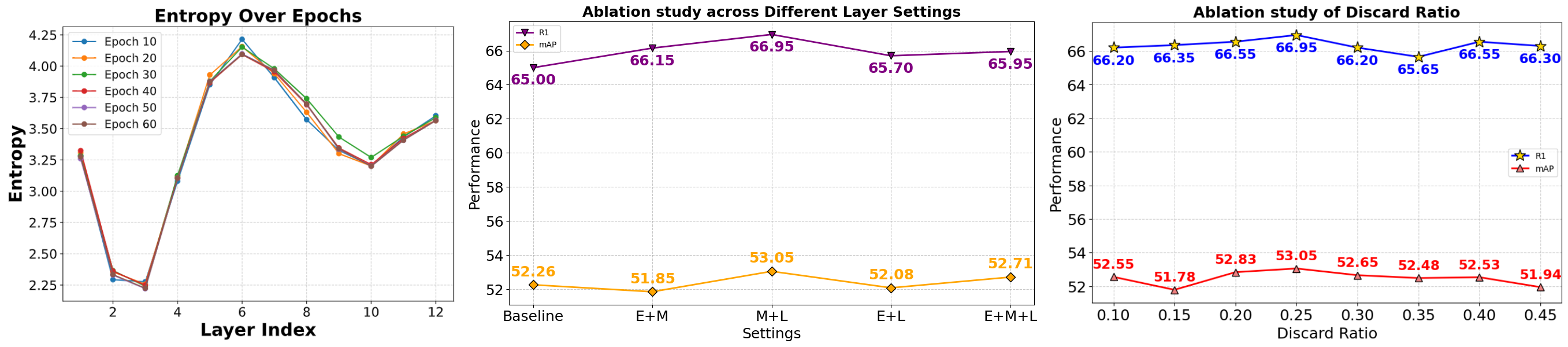
Effectiveness of each component: To comprehensively evaluate the contribution of each component in our proposed ITSELF framework, we conduct a systematic empirical analysis on three publicly available datasets. The detailed experimental results are presented in [tab:benchmarks]. MARS module: To evaluate the effectiveness of MARS, we first compare it with a fixed single-layer strategy (SL). Following our entropy of attention distributions (7 (Left)), we select layer 3 as SL since it exhibits the lowest entropy, indicating higher confidence. While both SL and MARS outperform the baseline, MARS consistently achieves superior results across all datasets, with notable R1 gains of +2.24%, +3.01%, and +5.65%, demonstrating its clear advantage over relying on a fixed SL. ATS Module: Adding ATS on top of the SL-only baseline already yields consistent gains in R1. When combined with MARS in the full model, we achieve the strongest performance overall, with substantial improvements over the baseline (+2.29%, +3.17%, +6.00%) on three datasets. These results confirm that ATS not only prevents the loss of discriminative cues in early training but also contributes to more stable optimization.
Analysis of Layer Selection and Discard Ratio in MARS: From the middle plot in 7, multi-layer configurations in MARS consistently outperform the baseline, with the Middle+Late (M+L) combination achieving the best R1 and mAP among all layer-type combinations (E, M, L and their pairings). The left plot explains why: early layer’s attention (notably layer 3) have the lowest entropy, meaning attention is sharply peaked on a few low-level tokens (edges/textures or background), which offers weak semantic grounding and can inject noise when fused. By contrast, middle layers show the higher entropy, capturing broader context and relations, while late layers re-focus attention onto salient, semantic regions. Fusing “M+L” therefore balances contextual coverage with discriminative focus, outperforming any option that includes Early Layer’s Attention. Finally, the right plot shows the best performance at a discard ratio of 0.25, indicating that removing a small fraction of low-attention tokens during fusion filters noise and sharpens discriminative cues.
Conclusion
In this paper, we introduce ITSELF, a novel attention-guided framework for implicit local alignment in TBPS that turns CLIP’s multi-layer attention into an Attentive Bank without extra supervision or inference-time cost. Building on this idea, GRAB harvests and optimizes fine-grained correspondences through an implicit local objective that complements the global loss. To realize GRAB, MARS adaptively aggregates and ranks attention across layers to select the most discriminative patches/tokens. In parallel, ATS schedules the token-retention budget from coarse to fine, mitigating early information loss and stabilizing training. Extensive experiments on three widely used TBPS benchmarks demonstrate state-of-the-art performance among CLIP-based methods across all metrics and improved cross-dataset generalization, confirming the effectiveness, robustness, and practicality of our approach.
Acknowledgement
This research is supported by VNUHCM-University of Information Technology’s Scientific Research Support Fund.
Supplementary Material
Experimental Details
Datasets. We conduct experiments on three widely used text-to-image person retrieval benchmarks.
-
CUHK-PEDES provides 40,206 pedestrian images paired with 80,412 textual descriptions corresponding to 13,003 identities, with splits of 11,003 for training, 1,000 for validation, and 1,000 for testing.
-
ICFG-PEDES consists of 54,522 image-text pairs from 4,102 individual IDs, which are split into 34,674 and 19,848 for training and testing, respectively.
-
RSTPReid contains 20,505 images of 4,101 individual IDs, with each ID having 5 images and each image associated with the corresponding two annotated text descriptions.
Implementation Details For a fair comparison with prior work, we initialize our modality-specific encoders using the pre-trained CLIP-ViT/B-16 model, the same version used by IRRA . To increase data diversity, we apply random horizontal flipping, random cropping, and erasing for images, along with random masking, replacement, and removal for text tokens. Input images are resized to 384 × 128, and the maximum text length is set to 77 tokens. We train the model for 60 epochs using the Adam optimizer with a learning rate initialized to $`1\times10^{-5}`$ and a cosine learning rate scheduler. The batch size is 256 and temperature parameter $`\tau`$ is set to 0.015. The hyperparameter for MARS is Middle and Late Layer and the discard ratio is 0.25. Normalization Strategy is L1 Normalization. For ATS, p_start and p_end value are 0.65 and 0.5, respectively. We set t_small value equal to the time when the epoch that baseline achieves the best results.
More Quantitative Results
To further validate our approach, we conduct extensive quantitative experiments and ablation studies. We analyze the impact of our Adaptive Token Scheduler (ATS), demonstrating in 2 that a step-level application yields the best results. We also assess the generalizability of our method with different CLIP backbones in 3, confirming consistent performance gains over the baseline. Finally, we provide a detailed comparison of our MARS selection strategy against several heuristic-based alternatives in 4, which confirms the superiority of our proposed method.
| Setting | R@1 | R@5 | R@10 | mAP |
|---|---|---|---|---|
| Baseline | 65.00 | 85.45 | 90.15 | 52.26 |
| Epoch (ATS) | 65.25 | 83.85 | 89.95 | 51.39 |
| Step (ATS) | 65.95 | 85.70 | 90.10 | 52.71 |
Ablation study on the effect of the Adaptive Token Scheduler (ATS). The baseline does not use the scheduler, while ATS is applied either at the epoch or step level. The results show that step-level scheduling achieves the best performance, yielding improvements in both R@1, R@5 and mAP compared to the baseline.
| Setting | R@1 | R@5 | R@10 | mAP |
|---|---|---|---|---|
| using ViT/B-16 CLIP as backbone | ||||
| Baseline | 61.30 | 80.85 | 87.65 | 49.12 |
| Ours | 67.30 | 85.60 | 90.50 | 53.05 |
| using ViT/B-32 CLIP as backbone | ||||
| Baseline | 59.65 | 79.35 | 86.35 | 47.40 |
| Ours | 64.50 | 84.10 | 90.40 | 50.28 |
| Setting | R@1 | R@5 | R@10 | mAP |
|---|---|---|---|---|
| A | 60.25 | 79.70 | 88.10 | 48.27 |
| B | 66.25 | 84.45 | 90.20 | 52.29 |
| C | 60.95 | 81.40 | 87.60 | 48.99 |
| D | 65.65 | 84.00 | 89.95 | 51.58 |
| MARS | 66.95 | 85.15 | 90.40 | 53.05 |
Ablation study of different strategies for selecting top-K patches based on attention statistics. We compare our method (MARS) against four baseline strategies: selecting patches with the minimum mean attention (A), maximum mean attention (B), minimum standard deviation of attention (C), and maximum standard deviation of attention (D). The results clearly demonstrate that our MARS method outperforms all baseline approaches across every evaluation metric. MARS achieves the highest performance with R@1 of 66.95% and mAP of 53.05%. This underscores the effectiveness of our selection strategy compared to simpler heuristics based only on the mean or standard deviation of attention scores.
More Qualitative Results
More Retrieval Results. 8, 9, 10 and 11 provide additional qualitative comparisons across the CUHK-PEDES, ICFG-PEDES, and RSTPReid benchmarks. The examples consistently demonstrate that our method retrieves visually and semantically accurate matches, even in challenging cases involving fine-grained attributes, small accessories, and visually similar distractors. Compared to the baseline, RDE , and other strong methods such as IRRA and TBPSCLIP , our approach shows superior robustness in capturing subtle cues like clothing textures, color combinations, and carried objects (e.g., backpacks, purses, or phones). Notably, our model remains reliable under domain shifts, handling diverse scenarios ranging from crowded street scenes to low-light images. These results further validate the effectiveness of our framework in producing more discriminative and generalizable text-image alignments.




More Attention Map Visualization. 12 presents additional qualitative comparisons of attention maps between our method and RDE on the RSTPReid benchmark. The results show that our model consistently attends to more discriminative and semantically relevant regions described in the text queries, such as specific clothing colors, accessories, and carried items (e.g., backpacks, bags, or bicycles). In contrast, RDE often produces diffuse or misaligned attention, failing to capture fine-grained cues. These visualizations further highlight the effectiveness of our approach in leveraging textual guidance to localize meaningful visual regions, thereby enabling more accurate text-based person retrieval.

📊 논문 시각자료 (Figures)