Beyond Demand Estimation Consumer Surplus Evaluation via Cumulative Propensity Weights
📝 Original Paper Info
- Title: Beyond Demand Estimation Consumer Surplus Evaluation via Cumulative Propensity Weights- ArXiv ID: 2601.01029
- Date: 2026-01-03
- Authors: Zeyu Bian, Max Biggs, Ruijiang Gao, Zhengling Qi
📝 Abstract
This paper develops a practical framework for using observational data to audit the consumer surplus effects of AI-driven decisions, specifically in targeted pricing and algorithmic lending. Traditional approaches first estimate demand functions and then integrate to compute consumer surplus, but these methods can be challenging to implement in practice due to model misspecification in parametric demand forms and the large data requirements and slow convergence of flexible nonparametric or machine learning approaches. Instead, we exploit the randomness inherent in modern algorithmic pricing, arising from the need to balance exploration and exploitation, and introduce an estimator that avoids explicit estimation and numerical integration of the demand function. Each observed purchase outcome at a randomized price is an unbiased estimate of demand and by carefully reweighting purchase outcomes using novel cumulative propensity weights (CPW), we are able to reconstruct the integral. Building on this idea, we introduce a doubly robust variant named the augmented cumulative propensity weighting (ACPW) estimator that only requires one of either the demand model or the historical pricing policy distribution to be correctly specified. Furthermore, this approach facilitates the use of flexible machine learning methods for estimating consumer surplus, since it achieves fast convergence rates by incorporating an estimate of demand, even when the machine learning estimate has slower convergence rates. Neither of these estimators is a standard application of off-policy evaluation techniques as the target estimand, consumer surplus, is unobserved. To address fairness, we extend this framework to an inequality-aware surplus measure, allowing regulators and firms to quantify the profit-equity trade-off. Finally, we validate our methods through comprehensive numerical studies.💡 Summary & Analysis
1. **New Consumer Surplus Estimation Method**: We propose a new method for estimating consumer surplus that does not require modeling demand. This allows us to directly estimate the surplus without needing an accurate demand model. 2. **Inequality-Aware Surplus Estimation**: Developed a methodology that evaluates the distribution of surplus across different customer groups, taking into account income inequality. 3. **Flexible Machine Learning Integration**: We incorporate modern machine learning techniques and complex nonparametric models to enhance the accuracy of our estimation process.Simple Explanation with Metaphors:
- Beginner Level: Estimating consumer surplus is like determining the price of an item in a market by identifying hidden variables between prices and purchase decisions. Our method directly estimates these hidden variables, providing accurate insights into consumer surplus.
- Intermediate Level: Traditional demand modeling involves piecing together various factors to connect prices with purchasing behavior, much like solving a puzzle. However, our approach bypasses this step by directly estimating consumer surplus.
- Advanced Level: Previous demand models relied on complex assumptions for precise estimation of demand functions; however, our method achieves accurate surplus estimates without these assumptions. This enables us to effectively evaluate the distribution and inequality of consumer surplus.
📄 Full Paper Content (ArXiv Source)
With the proliferation of data on consumer behavior and the development of sophisticated Artificial Intelligence (AI), firms are increasingly adopting autonomous, targeted algorithmic strategies to price goods and offer personalized loans. For example, many e-commerce firms will dynamically adjust prices based on an individual’s purchasing history, demographics, or even browsing behavior (e.g., ), while financial firms employ similar targeted algorithms to set interest rates for auto loans, mortgages, and credit cards. Indeed, the setting of interest rates is widely recognized as a form of targeted pricing, with recent studies utilizing auto loan datasets to empirically demonstrate the efficacy of algorithmic pricing strategies . Although these prescriptive AI technologies promise to enhance market efficiency, boost firms’ revenues, and broaden inclusion through personalized service, there are also concerns regarding their potential adverse impact on consumers.
A primary concern is that increased firm revenues due to targeted algorithms come at the expense of consumer surplus, with recent models from the academic literature suggesting that this burden can be unfairly distributed . In addition, there is a growing concern that marginalized groups might be disproportionately affected by these pricing practices, facing steeper prices and lower surplus. For example, ride-hailing services have been found to charge higher fares in neighborhoods with larger non-white populations and higher poverty levels, indicating that these communities face larger price hikes due to algorithmic pricing strategies . These concerns have drawn significant attention from policymakers and the media . For example, a White House report highlighted the risks associated with algorithmic decision-making in pricing, the Federal Trade Commission (FTC) recently initiated investigations into potential discriminatory pricing practices by mandating transparency from companies employing personalized pricing schemes , and lawmakers have called for scrutiny of major retailers’ pricing practices . Although there is significant interest, it is not yet clear what the impact of more targeted algorithmic pricing policies will be .
These developments underscore the need for robust auditing tools capable of evaluating the impact of algorithmic pricing on consumer surplus and its distribution across customers. For regulators like the FTC, such tools can help ensure firms are abiding by relevant laws and regulations, such as the Gender Tax Repeal Act of 1995 (commonly known as the “Pink Tax”), which prohibits gender-based pricing discrimination , or the Equal Credit Opportunity Act (ECOA) that prohibits creditors from discriminating against demographic factors. They can also help policymakers understand the impacts of various types of algorithmic pricing and who is adversely affected, leading to better guidelines and rules. Such tools can also help firms assess regulatory or reputational risks of existing algorithms, and simulate outcomes to ensure future compliance. They also provide the opportunity to strike a better balance between short-term profit and long-term customer relationships by ensuring consumer surplus remains at sustainable levels for all customer types.
Despite this need, there are issues regarding the efficacy of existing consumer surplus estimation methods. Typically, estimation techniques rely on first estimating demand and then integrating demand to calculate surplus (e.g., ), so the accuracy of the surplus estimate is highly dependent on the accuracy of the demand estimate. This approach is inherently indirect and requires estimating demand as a potentially complex function of price, even when the surplus target can be a simple scalar. Classical demand models depend on parametric assumptions and can be biased when behavior deviates from the assumed form . More flexible nonparametric and machine learning methods, such as neural networks , relax functional assumptions but often require very large datasets and careful tuning to achieve reliable accuracy, and typically have slower convergence rates. Given these shortcomings, it is useful to explore more direct alternatives for consumer surplus estimation that are less dependent on accurate demand estimation, and to investigate how to incorporate machine learning estimates while still achieving fast convergence rates.
One key feature of many successful modern pricing algorithms that can be leveraged for new methods of surplus estimation is that they involve a degree of price experimentation. In practice, market conditions, competitor actions, and consumer preferences evolve over time, so pricing algorithms must continuously explore the demand curve rather than solely exploit current prices to maintain optimality . Recent empirical work has observed severe bias in the estimation of price sensitivity at a large supermarket chain when using relatively static historic pricing data compared to experimental data, while have demonstrated that prices set after a period of price experimentation drastically improved profitability at ZipRecruiter. These examples also indicate an increased willingness among firms to engage in experimentation, which has become more ubiquitous as e-commerce platforms enable continuous price updates. While primarily intended to support profit maximization, this inherent randomization also provides a rich source of quasi-experimental variation that can be leveraged to estimate the consumer surplus.
One natural approach to utilizing such data and potentially avoiding explicit demand estimation is to adapt inverse-propensity-score weighting (IPW) from causal inference . However, the availability of quasi-experimental data alone does not solve the fundamental difficulty of measuring consumer welfare. Unlike revenue, which is entirely determined by the price and the observed purchase decision, consumer surplus relies on the customer’s valuation, a variable that is inherently latent. In the observational data, we do not observe the surplus. Instead, we only observe a binary purchase decision, which serves as a coarse approximation indicating that the valuation exceeded the price. Because the true outcome of interest is never directly seen, standard causal inference techniques such as weighting observed outcomes cannot be directly applied.
Motivated by these challenges, we propose the new cumulative propensity weight (CPW) estimator, which directly estimates consumer surplus and bypasses the need for explicit demand modeling. This approach leverages the randomness already present in the observational data due to the need to balance exploration and exploitation in many modern algorithmic pricing strategies. Intuitively, each observed purchase outcome at a randomized price is an unbiased estimate of demand. By carefully reweighting that observation according to how often a target pricing policy would offer a price at or below the one observed for similar customers, relative to how frequently that price level appeared historically, we are able to reconstruct the consumer surplus, i.e., the integral or the area under the demand curve, when these weighted outcomes are aggregated. When the historical pricing policy is known or well documented, the approach is straightforward to implement and is entirely model-free. When it is unknown, the cumulative weights can be estimated from transaction data.
Building on the cumulative-weights idea, we introduce a doubly robust estimator with cross-fitting that delivers reliable surplus estimates even when either the demand model or the historical pricing distribution is misspecified. Specifically, when the historical pricing policy is known or can be estimated accurately, consistency holds even with a biased demand model. In contrast, when demand is asymptotically unbiased, consistency holds even with a misspecified historical pricing model. Furthermore, mirroring standard doubly robust estimators in causal inference, our estimator achieves efficiency under weak rate conditions without imposing the Donsker condition on either demand or cumulative-weight estimation. This flexibility enables the use of modern machine learning techniques and complex nonparametric models. We formally establish that our proposed estimators are asymptotically equivalent to the efficient influence function, and therefore achieve the lowest possible asymptotic variance. Finally, we prove the asymptotic normality of the proposed estimators, enabling the construction of valid confidence intervals, enabling policymakers to assess the reliability of these estimates.
To address fairness, we extend our objective from estimating the standard consumer surplus to estimating an inequality-aware surplus. This new target captures both the magnitude of surplus a policy creates and its distribution across different customer types via a single pre-specified parameter. At its baseline, this parameter replicates the standard arithmetic average of customers’ surplus, but as it decreases, it places progressively greater weight on outcomes for worse-off groups. This approach is based on generalized mean aggregates as studied by and . To achieve this objective, we derive the efficient influence function of this new target and adapt our cumulative weights approach to construct an efficient estimator. Due to the nonlinearity of the objective, this estimator does not inherit full double robustness. Instead, it is singly robust with respect to the demand model, in that consistency holds as long as the demand is correctly specified, even if the cumulative weights are misspecified. This alters the theoretical requirements for establishing the asymptotic properties compared to the previous case: while incorporating cumulative weights still has the benefit of relaxed rate conditions, i.e., allowing flexible machine learning models, demand estimation requires stricter control, specifically satisfying standard nonparametric rates. Nevertheless, we derive valid asymptotic properties for this new estimator and show it has the minimal asymptotic variance among all regular estimators, which enables auditors to report valid confidence intervals for both aggregate and equity-sensitive surplus.
Our experiments confirm the reliability and robustness of the proposed framework. For the standard aggregate surplus, our doubly robust estimator accurately recovers the true surplus even when either the demand or pricing model is misspecified, achieving the best convergence rate when both are well specified. We further evaluate our inequality-aware surplus, studying its estimation error and confidence interval coverage. Despite the theoretical shift to single robustness for this nonlinear objective, our results demonstrate that the estimator remains highly effective, producing accurate point estimates and valid confidence intervals across varying equity settings.
To further demonstrate the power of this framework, we apply it to a large-scale financial dataset of U.S. automobile loans. The global automotive market size was estimated at USD 2.75 trillion in 2025 and is projected to reach USD 3.26 trillion by 2030 . It is an important driver of household financial stability and is increasingly dominated by algorithmic underwriting. We compare the welfare outcomes of a historical pricing policy against a trained AI pricing agent. Our analysis reveals an aggregate consumer surplus–equity tradeoff: personalized pricing reduces total consumer surplus while narrowing disparities across credit and political groups, demonstrating the framework’s value for auditing and regulatory evaluation.
Related Work
Consumer Surplus Estimation
There is a substantial literature on consumer surplus evaluation in both discrete choice environments, where consumers typically choose one alternative from a set (e.g., ), and continuous demand settings (e.g., ), such as gasoline purchases . Our work is more closely aligned with discrete choice models, but we focus on a single-item setting in which we observe individual customer characteristics and a binary outcome indicating whether they purchase the item. Initially, parametric models of demand were used for surplus estimation , for example, the widely used logsum formula . This relies on strong assumptions about preferences and customer heterogeneity, such as additive extreme-value error distributions, which may lead to misleading welfare conclusions if the model is misspecified.
To overcome such restrictive assumptions and make inferences in a broader range of settings, many semiparametric and nonparametric methods for estimating demand have been developed . These typically involve flexible nonparametric regression to fit the demand function directly, followed by an integration to calculate the surplus. For example, in the continuous setting, fit demand using series and kernel estimators, and use it to solve a differential equation based on Shephard’s Lemma. Subsequent research has focused on incorporating unobserved consumer heterogeneity into these models . Similarly, in the discrete choice setting, estimates a conditional nonparametric probability of purchase for each item (demand in this setting), then integrates to estimate consumer surplus. Recent machine learning approaches have used neural networks to flexibly estimate demand and surplus with minimal functional-form assumptions , including in discrete choice models . Tree ensemble methods have also been proposed . A comprehensive account of nonparametric consumer surplus estimation can be found in and .
A critical trade-off in these nonparametric demand estimation methods is that convergence can be slower, leading to worse finite-sample performance than in well-specified parametric models. In either case, the consumer surplus estimates are only as accurate as the demand model. In contrast, we present approaches that do not require modeling demand at all, and show that we can achieve faster convergence when we have a slowly converging demand model.
Some recent applications of consumer surplus estimation can be found, for example, in , who use an ordered probit to analyze Netflix data. employ a Bayesian parametric framework to estimate surplus from a large-scale randomized price experiment at ZipRecruiter. Other research has leveraged quasi-experimental variation in prices. For instance, uses a regression discontinuity design to estimate price elasticities and surplus from Uber’s surge pricing data.
Much of this literature is focused on incorporating income effects, which is not the focus of our paper. We focus on settings where the expenditure represents a small fraction of the consumer’s total budget. In such regimes, the income effects are negligible, and the Marshallian consumer surplus provides a near-exact approximation of the Hicksian compensating variation . Alternatively one can interpret our analysis as applying when consumer utilities are quasilinear.
Causal Inference and Off-Policy Evaluation
Much of the recent work on auditing pricing algorithms can be viewed through the lens of off-policy evaluation (OPE). The OPE literature initially centered on the inverse propensity weighting (IPW) framework: each observed outcome is weighted by the reciprocal of its treatment (in our setting, price) assignment probability, or propensity score, yielding an unbiased estimate of the counterfactual reward when the propensity model is correct . A complementary line of research advocates the direct method (DM), which replaces missing counterfactuals with fitted values from an outcome model. When that model is correctly specified, the DM can be more efficient than IPW . Recognizing that either component may be misspecified in practice, the doubly‑robust estimator blends the two ideas and remains consistent so long as either the propensity model or the outcome model is estimated without systematic error. Empirical evidence suggests that, when at least one nuisance model is reasonably accurate, the doubly robust estimator achieves lower mean‑squared error than either IPW or the DM on their own . The idea of the doubly robust method originates from the missing data literature and has been widely adopted in causal inference and policy learning/evaluation .
In the management science community, there is a growing body of literature that leverages off-policy learning techniques to estimate revenue in pricing settings. This stream of research is often grounded in the “predictive to prescriptive” analytics framework , which formally integrates machine learning predictions with optimization models to derive decision policies from observational data. Complementing this methodological foundation, recent studies have developed rigorous statistical learning frameworks for personalized revenue management and demonstrated the practical efficacy of these data-driven pricing algorithms through large-scale field experiments . Specifically, researchers have used OPE techniques to address pricing settings characterized by binary demand , as well as censored demand resulting from inventory shortages , and unobserved confounding . In contrast to these works, our primary objective is the estimation of consumer surplus rather than revenue. This shift substantially alters the estimation problem: unlike the standard OPE setting, where the outcome is directly observed, surplus relies on consumer valuations that are never seen. In our context, we observe only a binary purchase decision, a coarse proxy indicating whether valuation exceeds price rather than the continuous valuation itself. Because the true outcome variable is latent, conventional causal inference techniques cannot be directly applied, necessitating the development of the novel methodological tools presented here.
Organization
The remainder of this paper is organized as follows. Section 3 formalizes the consumer surplus estimation problem. Section 4 introduces the Cumulative Propensity Weighting (CPW) estimator, a novel approach that leverages the randomness in algorithmic pricing to estimate surplus without explicit demand integration. Section 5 develops the Augmented CPW (ACPW) estimator, establishing its double robustness. Section 6 extends the framework to inequality-aware surplus measures, introducing a parameter to trade off aggregate surplus against equity. Section 7 provides the theoretical analysis, proving the asymptotic normality and efficiency of the proposed estimators. Section 8 presents numerical experiments validating the method’s robustness and demonstrates its application to a large-scale U.S. auto loan dataset. Finally, Section 9 concludes with managerial implications. The appendices contain proofs of all theorems and auxiliary lemmas. Lastly, we provide an extension on partial identification bounds for settings where the overlap assumption is violated in Appendix 19.
Problem Formulation
Consider a population of heterogeneous consumers with features $`X \in \mathcal X`$, and valuations (i.e., willingness to pay), $`V\in \mathbb{R}^+`$, interested in purchasing at most one unit of an item. For a fixed price $`p`$, the average consumer surplus can be defined as the average excess of each consumer’s valuation over the price they pay,
\begin{align*}
{\cal S}(p) = \mathbb{E}\left[\left(V - p\right)_+\right],
\end{align*}where $`x_+=\max(x,0)`$. Alternatively, in a lending scenario, we can consider $`p`$ as a periodic interest payment and interpret $`V`$ as the maximum interest the customer is willing to pay, with the surplus being the positive difference between them. Note, we may be interested in assessing the conditional surplus $`{\cal S}(p|X) = \mathbb{E}_V[\left(V - p\right)_+ \, | \,X]`$ associated with a particular group of interest for comparison purposes, or population surplus $`{\cal S}(p) = \mathbb{E}_X\mathbb{E}_V[\left(V - p\right)_+ \, | \,X]`$, which is the surplus over all customers. For notational simplicity, we focus on the latter, but our results also hold for the former, unless otherwise noted. We highlight that this definition is consistent with traditional “area under the demand curve" calculation of consumer surplus , where the demand curve is defined as the probability of purchase, as highlighted in Section 3.1. We do not incorporate income effects into the model and focus on goods where expenditure represents a small fraction of the consumer’s total budget. In this case, the income effects are negligible . Alternatively, but resulting in the same framework, we focus on customers with quasilinear utility.
In general, firms are interested in offering and evaluating pricing policies that can be both targeted and stochastic, where the price offered to the customer with feature $`X`$ is associated with a pricing policy $`\pi: {\cal X}\rightarrow \Delta({\cal P})`$, which is a conditional probability mass/density over the price space $`{\cal P}`$ given the feature $`X \in {\cal X}`$. Then the average consumer surplus under the pricing policy $`\pi`$ is defined as
\begin{align}
\label{def: consumer surplus for random p}
{\cal S}(\pi) = \mathbb{E}\left[\int_{\cal P}\pi(p \, | \,X)\left(V - p\right)_+ \text{d}p\right],
\end{align}where the underlying expectation is taken with respect to the joint distribution of $`(X, V)`$. If $`V`$ is observed, then one can estimate $`{\cal S}(\pi)`$ by directly using the sample average to approximate the expectation in Equation [def: consumer surplus for random p]. However, in practice, consumers’ valuations $`V`$ are typically unobserved, which presents a challenge for the estimation task. While a consumer’s valuation $`V`$ is often unobserved, typically their binary purchase decision $`Y`$ is often recorded at the price they were offered $`P \in {\cal P}`$. This purchase decision is determined by whether their valuation exceeds the offered price $`P`$:
\begin{align}
\label{model: true model}
Y &= \mathbb{I}(V > P).
\end{align}where $`\mathbb{I}(\cdot)`$ denotes the indicator function. Here, $`Y=1`$ denotes a purchase (the condition is met), and $`Y=0`$ denotes no purchase. In addition to $`V`$ being unobserved, we often face a distribution shift, where we may want to evaluate surplus under a pricing policy that is different from the historical policy that generated the data. In general, we consider three objectives: (i) evaluating consumer surplus of a new pricing strategy (also referred as the target policy) $`\pi`$; (ii) evaluating the consumer surplus of a current or previously used pricing strategy $`\pi_D`$ from the historical data (also referred as the behavioral policy); and (iii) evaluating the change in surplus between historical and new policies:
\begin{align}
\label{def: difference in consumer surplus}
\Delta(\pi) = \mathbb{E}\left[\int_{\cal P}\left(\pi(p \, | \,X)- \pi_D(p \, | \,X)\right)\left(V - p\right)_+ \text{d}p\right],
\end{align}We note that the historical pricing distribution $`\pi_D`$ may be known or unknown, while $`\pi`$ is always known. When the firm is engaged in algorithmic pricing, often the historical pricing policy is encoded digitally and is therefore known. When it is unknown, it can typically be estimated from the data. Generally, the difference between evaluating (i) and (ii) arises from unknown $`\pi_D`$, which can introduce additional challenges in the estimation. We will focus on this case when evaluating (ii) unless otherwise noted. The offline dataset can thus be represented as $`{(X_i, P_i, Y_i)}_{i=1}^n`$, consisting of i.i.d. samples of $`(X, P, Y)`$ generated under a historical pricing policy $`\pi_D`$.
Next, we present some conditions necessary for the identification of the average consumer surplus $`{\cal S}(\pi)`$ under the observational data-generating distribution. First, we provide the formal definition of identification.
Definition 1 (Identifiability). A parameter of interest $`\theta`$ in a probabilistic model $`\{\mathcal{P}_\theta: \theta \in \Theta \}`$ is said to be identifiable if the mapping $`\theta \mapsto \mathcal{P}_\theta`$ is injective, i.e., $`\mathcal{P}_{\theta_1} = \mathcal{P}_{\theta_2} \implies \theta_1 = \theta_2`$.
For identification in this setting, we require two conditions to hold:
Assumption 1. (Ignorability) $`P \protect\mathpalette{\protect\independenT}{\perp}V |X`$.
Assumption 2. (Overlap) The price data generating distribution satisfies $`\pi_D(p \, | \,x)>0`$, for all $`p \in {\cal P}`$, and every $`x\in {\cal X}`$. In addition, the support $`{\cal P}`$ contains the support of the valuation $`V`$. For identifying $`\Delta(\pi)`$, we only require the support of $`\pi_D`$ to contain the support of $`\pi`$.
Assumption 1 is similar to the classical causal assumptions of ignorability or exchangeability, see, e.g., . It states that, conditional on consumer characteristics $`X`$, the distribution of valuations is unaffected by the offered price, facilitating the identification of surplus. It is commonly satisfied as long as the factors that drove the historical pricing decisions are recorded and available in the observed data. It is worth noting that Assumption 1 does not impose any parametric structure on the consumer valuations model. Assumption 2 requires that every possible price $`p \in {\cal P}`$ has a positive probability of being observed for the observational data. This means the previous pricing policy must involve some degree of randomization, which, as previously discussed, is necessary for a pricing policy to obtain and maintain optimality. Such a condition is similar to the positivity condition in causal inference for identifying the average treatment effect. Without this coverage assumption, nonparametric identification of the demand function, and consequently, the absolute consumer surplus, is impossible without relying on strong extrapolation assumptions. However, we note that the requirements are significantly relaxed when evaluating the difference in surplus between two policies. In that context, we only require overlap over the prices proposed by the new policy $`\pi`$, rather than the entire price space. While identifying absolute surplus requires observing demand at extreme prices (to capture total willingness to pay), estimating policy differences is often sufficient for decision-making and aligns with standard practices in the literature . While we establish identification and estimation results for both quantities, we acknowledge the difference is easier to practically implement.
To address settings where Assumption 2 does not hold, Appendix 19 introduces an extension that exploits demand function properties (specifically monotonicity and log-concavity) to bound the surplus. Experimental results in Appendix 19.3 confirm the validity of these partial identification bounds and illustrate their superior tightness compared to naive bounds derived from the natural [0, 1] support of purchase probability.
Next, we present a commonly used baseline approach for estimating $`{\cal S}(\pi)`$ and discuss its limitations. Without loss of generality, we assume $`\mathcal P = [0, \infty)`$.
Baseline Solution: Direct Method
A classic approach to calculate the consumer surplus is to calculate the area under the demand curve above a particular price (for example, ). Under Assumption 1 we show this form is equivalent to our consumer surplus definition ([def: consumer surplus for random p]) for the stochastic pricing policy setting
\begin{align}
\label{eqn: identification}
&{\cal S}(\pi) = \mathbb{E}\left[\int_0^\infty\pi(p \, | \,X) \int_{z=p}^\infty \mu(X,z)dzdp \right],
\end{align}where $`\mu(x,z) \equiv \mathbb{E}[Y \, | \,X=x, P = z] \equiv\mathbb{P}[V > z \, | \,X=x]`$ is the probability of purchase, which can be considered the demand function in this setting. A brief proof showing the equivalence is provided in Proposition 3 in Appendix 10.1 and follows from carefully changing the order of integration. While Assumption 2 is not strictly required for the derivation of this identity, it is necessary for the identification and estimation of $`\mu(x,z)`$ over the integration range. This equation shows that even when the valuation $`V`$ is unobserved, the surplus can still be identified by first computing the integral of the demand function $`\mu(x,z)`$ over prices above $`p`$, and then taking a weighted average over price using the target policy $`\pi`$. When surplus under the behavior policy $`\pi_D`$, or the difference in surplus is of interest, it simplifies to
\begin{gather}
\label{eqn: identification behavioral}
{\cal S}(\pi_D) = \mathbb{E}_{X, P\sim \pi_D}\left[\int_{P}^{\infty}
\mu(X,z)dz\right], ~~ \Delta(\pi) = {\cal S}(\pi) - {\cal S}(\pi_D).
\end{gather}In practice, the demand function $`\mu(x, p)`$ is generally unknown and must be estimated by regressing $`Y`$ on $`X`$ and $`P`$, yielding an estimator $`\widehat \mu(x, p)`$. Then the direct method (DM) uses the sample average to approximate Equations [eqn: identification] and [eqn: identification behavioral] and gives
\begin{gather}
\label{eqn:dm_estimator}
\widehat {\cal S}_{DM}(\pi)= \frac{1}{n}\sum_{i=1}^n \int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu(X_i, z)dzdp, ~~ \widehat {\cal S}_{DM}(\pi_D)= \frac{1}{n}\sum_{i=1}^n \int_{P_i}^\infty \widehat \mu(X_i, z)dz, \\
\widehat \Delta_{DM}(\pi) = \widehat {\cal S}_{DM}(\pi) - \widehat {\cal S}_{DM}(\pi_D),
\end{gather}where $`\widehat \mu(\cdot, \cdot)`$ is the estimator of the demand function. We note that the historic surplus estimator $`\widehat{\mathcal{S}}_{DM}(\pi_D)`$ has the advantage of not requiring an estimate of the historic pricing policy distribution $`\widehat{\pi}_D`$ (when it is unknown), compared to the naive approach of substituting $`\widehat{\pi}_D`$ into $`\widehat{\mathcal{S}}_{DM}(\pi)`$, highlighting the suitability of each estimator for its particular task.
As discussed previously, the performance of the DM estimator depends critically on the accuracy of the outcome model $`\widehat \mu(x, p)`$, which can be challenging to estimate in practice. Traditional demand estimators that impose fixed parametric forms can yield biased results whenever actual purchasing behavior strays from those assumptions. In contrast, modern fully non‑parametric techniques, such as neural‑network demand models , avoid functional‑form misspecification but generally require a very large sample before they deliver reliable accuracy, limiting their practicality in many observational settings. Furthermore, the DM relies on numerical integration of estimated functions. This step requires the underlying estimation to be uniformly accurate across $`\mathcal{P}`$. Lastly, the numerical integration procedure itself can introduce bias and raise computational burden since the integration must occur over all prices for every datapoint.
These limitations associated with the DM estimator motivate the exploration of alternative approaches. In the next section, we present our newly proposed solutions for identifying and estimating $`\mathcal{S}(\pi)`$.
Cumulative Propensity Weights Representation and Estimation
We next present an alternative approach for consumer surplus estimation that avoids the challenges of estimating a demand function and numerical integration. This estimator leverages the price variation already present in modern algorithmic pricing due to the need to balance exploration and exploitation. Rather than explicitly integrating to get the area under an estimated demand curve, the estimator approximates this area by an aggregate of weighted purchase outcomes, each of which is an unbiased estimate of demand at a given price. By carefully weighing the observations, we can recover the consumer surplus in expectation. Formally, our estimator is motivated by the following alternative identification result.
Theorem 1. *Under Assumptions 1 and 2, we have
\begin{align}
\label{eqn: identification CPW}
{\cal S}(\pi) =\mathbb{E}\left[\frac{F^\pi(P \, | \,X)}{\pi_D(P \, | \,X)}Y\right],
\end{align}where $`F^\pi(p|x)`$ denotes the cumulative distribution function under the target policy, i.e., $`F^\pi(p|x) \equiv \int_0^p \pi(u|x) du`$.*
Proof. The proof follows from the law of iterated expectations and a change of the order of integration:
\begin{align*}
& \underbrace{\mathbb{E}\!\left[ \int_{p=0}^\infty \pi(p\mid X) \int_{z=p}^\infty \mu(X,z) \, dz \, dp \right]}_{\mbox{Equation \eqref{eqn: identification}} }
= \mathbb{E}\!\left[ \int_{p=0}^\infty \int_{z=p}^\infty \pi(p\mid X)\,\mu(X,z) \, dz \, dp \right] \\
= & \; \mathbb{E}\!\left[ \int_{z=0}^\infty \int_{p=0}^z \pi(p\mid X)\,\mu(X,z) \, dp \, dz \right] = \mathbb{E}\!\left[ \int_{z=0}^\infty \Big(\int_{p=0}^z \pi(p\mid X)\,dp\Big)\,\mu(X,z) \, dz \right] \\
= & \;\mathbb{E}\!\left[ \int_{z=0}^\infty \frac{F^\pi(z\mid X)}{\pi_D(z\mid X)}\,\mu(X,z) \,\pi_D(z\mid X)\,dz \right] = \mathbb{E}\!\left[ \frac{F^\pi(P\mid X)}{\pi_D(P\mid X)}\,Y \right].
\end{align*}◻
Analogously, the historical consumer surplus and change in surplus can be identified by replacing $`\pi`$ with $`\pi_D`$ in Equation [eqn: identification CPW] and taking the difference:
\begin{equation}
{\cal S}(\pi_D) =\mathbb{E}\left[\frac{F^{\pi_D}(P \, | \,X)}{\pi_D(P \, | \,X)}Y\right], \mbox{ and } \Delta(\pi_D) =\mathbb{E}\left[\frac{\left(F^{\pi}(P \, | \,X)-F^{\pi_D}(P \, | \,X)\right)}{\pi_D(P \, | \,X)}Y\right].
\end{equation}Based on Theorem 1, our proposed CPW estimators can be derived by taking the sample average of Equation [eqn: identification CPW]:
\begin{align}
\label{eqn:ips_estimator}
\widehat {\cal S}_{CPW}(\pi)=& \frac{1}{n}\sum_{i=1}^n \frac{F^\pi(P_i | X_i)}{\widehat \pi_D(P_i | X_i)}Y_i,~~
\widehat {\cal S}_{CPW}(\pi_D)= \frac{1}{n}\sum_{i=1}^n \frac{\widehat F^{\pi_D}(P_i | X_i)}{\widehat \pi_D(P_i | X_i)}Y_i,\\
&\widehat \Delta_{CPW}(\pi)= \frac{1}{n}\sum_{i=1}^n \frac{(F^\pi(P_i | X_i)-\widehat F^{\pi_D}(P_i | X_i))}{\widehat \pi_D(P_i | X_i)}Y_i,
\end{align}where $`\widehat \pi_D`$ and $`\widehat F^{\pi_D}`$ are the estimators for the density and cumulative density for the historic policy, respectively.
We next present a simple example, illustrated in Figure 1, to give further intuition behind the CPW estimator.
Example 1.
Suppose that we are estimating the consumer surplus for a
target-pricing policy that assigns equal probability to three discrete
prices $`p_1
Now assume that the historical data were generated by a (known) historical pricing policy, uniformly distributed from 0 to 1. In the historical data, we happen to observe 13 random realized prices $`\{p_i'\}_{i=1}^{13}`$, which is a sparse representation of what would occur with more samples. Each realized pair $`(p_i', Y_i)`$ gives an unbiased snapshot of expected demand at that threshold, i.e., $`\mathbb{E}[Y\mid P=p_i']`$, where the black circles indicate the conditional expectations to which empirical averages converge with sufficient data for each price point. If we were to aggregate the outcomes $`Y_i`$ (or expected outcomes with enough data), we would approximate the total area under the demand curve. However, to approximate the consumer surplus for the target pricing policy by aggregation, we need different weights. In particular, to recreate the previous surplus calculation, we must weight observations at $`p'_{11}, p'_{12}, p'_{13}`$ by three times as much as at $`p'_5, p'_6, p'_7,p'_8`$, since the area under the curve in $`[p_3, 1)`$ is included in the surplus calculation for all three prices under the target policy (dark pink), whereas $`[p_1,p_2)`$ is only included once (light pink). $`[0,p_1)`$ is not included at all, while $`[p_2,p_3)`$ is included twice. This weight is the fraction of target policy prices whose surplus includes that historical price and is proportional to the cumulative target mass, which for the three-point target policy is $`F^{\pi}(p_i') \;=\; \frac{1}{3}\sum_{j=1}^{3}\mathbf 1\{p_i'\ge p_j\}`$ (i.e., $`F^{\pi}(p_1')=0, F^{\pi}(p_5')=1/3, F^{\pi}(p_9')=2/3, F^{\pi}(p_{11}')=1`$). This is shown in the lower panel of Figure 1. As a result, with more sampled price points along the range of prices, the weighted average $`\frac{1}{n}\sum_{i=1}^n \frac{F^{\pi}(p'_i )}{ \pi_D(p'_i )}Y_i`$ will eventually approximate the area under the demand curve, weighted by the frequency it is included in the target surplus calculation, i.e., $`\frac{1}{3}\sum_{i=1}^{3} \pi(p_i) \int_{z=p_i}^{\infty} \mathbb{E}[Y \, | \,P = z]dz`$, as the number of samples gets large. 1
This approach contrasts with standard IPW in off-policy evaluation in two significant ways. First, the observable $`Y`$ is not the unobserved surplus, $`(V-P)_+`$, we are trying to estimate under the new pricing policy. Second, the numerator of the weighting term is the cumulative target policy density $`F^\pi(P\mid X)`$, not the target density $`\pi(P|X)`$ at $`P`$ that typically appears in IPW. This is due to the need to estimate the average of an integral (or area) rather than the usual average outcome. As such, standard IPW techniques cannot be applied.
Compared to the direct method (Equation [eqn: identification]), this result requires knowledge, or an estimate, of the pricing distribution $`\pi_D`$ instead of the demand function $`\mu(X, P)`$. When the historic pricing policy is known, this estimator is unbiased and completely model-free. This may occur if a company is investigating the consumer surplus implications of its own algorithmic pricing policy, or a policymaker mandates that the algorithm be made available for audit. Alternatively, if the historical pricing policy is relatively simple, it may be much easier to estimate than a complex demand function. Furthermore, the DM requires numerical integration over the price space $`P`$ for every observation, which can be computationally expensive. In contrast, the CPW estimator is a simple weighted average, making it computationally efficient for large datasets. This alternative estimator provides the regulator or firm with crucial flexibility in surplus estimation.
Nevertheless, the performance of the CPW estimator remains sensitive to the accuracy of the estimated historical pricing policy distribution when it is not available and may be subject to misspecification. To further address this issue, we introduce the augmented CPW (ACPW) estimator, which combines elements of both the DM and CPW approaches, remaining consistent if either component is correctly specified, and is therefore more robust.
Doubly Robust Representation and Estimation
The construction of the ACPW estimator is grounded in the theory of the efficient influence function (EIF). The EIF is pivotal for two main reasons: it characterizes the semiparametric efficiency bound (the minimal asymptotic variance of any regular estimator), and it provides a constructive mechanism for achieving this bound. Intuitively, the EIF acts as a correction term that removes the first-order bias from a naive plug-in estimator (e.g., DM or CPW estimators in our context). This correction is essential for ensuring that the final estimator remains $`\sqrt{n}`$-consistent and asymptotically normal, even when the nuisance components (such as the demand function and cumulative weights) converge at slower rates. Formally, the EIF is defined as the canonical gradient of the target parameter, e.g., $`\mathcal{S}(\pi)`$, $`\mathcal S(\pi_D)`$ and $`\Delta(\pi)`$, with respect to the underlying data distribution. By constructing our estimator based on this gradient, we ensure it is asymptotically efficient (i.e., minimax optimal). For a comprehensive treatment of this theory, we refer readers to . We now present the derived EIF for $`{\cal S}(\pi)`$ under our semi-parametric model [model: true model]. Let $`\mathcal D = (X, P, Y)`$.
Theorem 2. *Suppose Assumptions 1 and 2 hold, the EIF for $`{\cal S}(\pi)`$ is
\begin{gather}
\label{eqn: eif}
\psi^\pi(\mathcal{D}) = \int_0^\infty \pi(p| X) \int_{p}^\infty \mu(X, z)dzdp + \frac{F^\pi(P | X)}{\pi_D(P | X)}(Y - \mu(X,P))-{\cal S}(\pi).
\end{gather}If the behavior policy $`\pi_D`$ is evaluated, then the EIF takes the form
\begin{gather}
\label{eqn: eif behav}
\psi^{\pi_D}(\mathcal {D})= \int_{P}^\infty \mu(X, z)dz + \frac{F^{\pi_D}(P | X)}{\pi_D(P | X)}(Y - \mu(X,P))-{\cal S}(\pi_D).
\end{gather}Finally, the EIF for the difference in surplus $`\Delta(\pi)`$ is given as $`\psi^{\Delta}(\cal{D}) = \psi^\pi(\cal {D}) -\psi^{\pi_D}(\cal {D})`$.*
This is formally proved in Appendix 11. A key property of the EIF is that it has mean zero. This motivates the following estimators, defined by setting the empirical mean of the EIFs in Equations [eqn: eif] and [eqn: eif behav] to zero:
\begin{align}
\label{eq:empirical dr}
\widetilde {\cal S}_{ACPW}(\pi) &= \frac{1}{n} \sum_{i=1}^n \bigg[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat\mu(X_i, z)dzdp + \frac{F^\pi(P_i | X_i)}{\widehat \pi_D(P_i | X_i)}(Y_i - \widehat \mu(X_i,P_i))\bigg], \\
\label{empirical dr2}\widetilde {\cal S}_{ACPW}(\widehat \pi_D) &= \frac{1}{n} \sum_{i=1}^n \bigg[\int_{P_i}^\infty \widehat\mu(X_i, z)dz + \frac{ \widehat F^{\pi_D}(P_i | X_i)}{\widehat\pi_D(P_i | X_i)}(Y_i - \widehat \mu(X_i,P_i))\bigg], \\
\widetilde \Delta_{ACPW}(\pi) &= \widetilde {\cal S}_{ACPW}(\pi)- \widetilde {\cal S}_{ACPW}(\widehat \pi_D).
\end{align}One can observe that the ACPW estimator integrates elements of both the DM and CPW approaches, and it can be shown that the ACPW estimator remains consistent if either the demand function or the behavior policy is correctly specified, a property known as double robustness. The double robustness property is formally stated in the following proposition for the case of the known target policy, but the other cases also hold with near identical proofs.
Proposition 1. *Let $`\bar{\mu}(x,p)`$ and $`\bar{\pi}_D(p|x)`$ denote the population limits of the estimators $`\widehat{\mu}(x,p)`$ and $`\widehat{\pi}_D(p|x)`$, respectively, such that:
\sup_{x,p} |\widehat{\mu}(x,p) - \bar{\mu}(x,p)| =o_p(1) \quad \text{and} \quad \sup_{x,p} |\widehat{\pi}_D(p|x) - \bar{\pi}_D(p|x)| =o_p(1).If either of the following conditions holds: (i) $`\bar\mu(X,P)=\mu(X,P)`$, almost surely; (ii) $`\bar \pi_D(P|X)= \pi_D(P|X)`$, almost surely. Then we have consistency such that:
\begin{gather*}
\left|\widetilde {\cal S}_{ACPW}(\pi)-{\cal S}(\pi)\right|=o_p(1),
\end{gather*}where $`o_p(1)`$ denotes a quantity that converges to zero in probability as the sample size $`n \to \infty`$.*
The proof of Proposition 1 can be found in Appendix 12. This property is important because it provides the regulator with flexibility in surplus estimation, depending on whether consistent demand estimation or historical pricing policy density estimation is possible to achieve. Besides the desirable doubly robust property, another advantage of the ACPW estimator is that, under minimal rate conditions on the two nuisance estimators (the demand function and the behavior policy density), it can achieve the lowest possible variance bound when combined with data splitting or a cross-fitting procedure . We next outline the $`K`$-fold cross-fitting procedure, a minor algorithmic modification of the vanilla ACPW estimators in Equations [eq:empirical dr] and [empirical dr2]. Specifically, we partition the sample indices $`\{1,\ldots,n\}`$ into $`K`$ disjoint folds of approximately equal size, with any finite number $`K`$. For each observation $`i`$, let $`k(i)`$ denote the fold containing $`i`$. Denote by $`\widehat \mu^{-k(i)}(x,p)`$ and $`\widehat \pi_D^{-k(i)}(p \mid x)`$ the estimators of the demand function and the behavior policy, respectively, which are trained using only the data excluding the $`k(i)`$-th fold (hence the notation $`-k(i)`$). The resulting ACPW estimator with cross-fitting is denoted as
\begin{gather*}
\widehat {\cal S}_{ACPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i,z) dzdp + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D^{-k(i)} (P_i | X_i)}(Y_i - \widehat \mu^{-k(i)}(X_i,P_i))\right],\\
\widehat {\cal S}_{ACPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i,z) dzdp + \frac{F^{\widehat \pi_D, -k(i)}(P_i | X_i)}{\widehat\pi_D^{-k(i)} (P_i | X_i)}(Y_i - \widehat \mu^{-k(i)}(X_i,P_i))\right].
\end{gather*}This cross-fitting approach ensures that each observation is evaluated using nuisance estimates fitted on independent data, thereby reducing overfitting bias and enabling valid asymptotic inference even when the nuisance functions are estimated by flexible machine learning methods, as will be detailed in Section 7.
Inequality-Aware Surplus
A common concern among policymakers when evaluating a pricing policy is not only how the aggregate surplus changes, but also how it is distributed among consumers. In particular, there are concerns about equity and the impact on those who are worst off. One approach used in welfare economics to address these issues is to emphasize outcomes for customers with the lowest surplus when aggregating surpluses across the population. We follow this direction by extending the proposed off-policy consumer surplus estimation techniques to welfare measures that are sensitive to how surplus is distributed across customer types.
Let $`\mathcal{S}(\pi\mid X)`$ denote the surplus for customers with characteristics $`X`$, which represent customer types. Earlier sections implicitly aggregated welfare using the arithmetic mean, $`\mathcal{S}(\pi)=\mathbb{E}_{X}[\mathcal{S}(\pi\mid X)]`$, effectively averaging across all customer types. Following the Atkinson tradition and related work , we instead consider the generalized-mean family
\begin{equation}
\label{eq:atkinson-agg}
(\mathcal{S}^r(\pi))^{1/r},
\end{equation}where $`\mathcal{S}^r(\pi):=\mathbb{E}_{X}\big[\mathcal{S}(\pi\mid X)^r\big]`$. This coincides with the standard arithmetic average when $`r=1`$ and increasingly prioritizes lower-surplus groups as $`r`$ decreases, becoming more inequality averse. This supplies a transparent policy parameter $`r`$ that trades off aggregate surplus against its dispersion across customer segments. The continuous extension at $`r=0`$ yields the geometric mean, and $`r=-1`$ yields the harmonic mean. In the following, for brevity, we focus on $`r\neq 0`$ to avoid restating results that are functionally the same. For a finite sample $`\{X_i\}_{i=1}^{n}`$, the standard DM estimator is:
\begin{equation}
\label{eq:atkinson-agg-sample}
\left(\frac{1}{n}\sum_{i=1}^{n}\widehat{\mathcal{S}}(\pi\mid X_i)^{r}\right)^{1/r}=\left[\frac{1}{n}\sum_{i=1}^{n} \left(\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat\mu(X_i, z)dzdp\right)^r\right]^{1/r},
\end{equation}Without loss of generality, we will focus on estimating $`\mathcal{S}^r(\pi)`$, which can be transformed after estimation to recover $`\mathcal{S}^r(\pi) ^{1/r}`$. Next, we derive the efficient influence function for the target $`\mathcal{S}^r(\pi)`$ and behavioral $`\mathcal{S}^r(\pi_D)`$ policies and their corresponding efficient estimators. The EIF is given by the following theorem.
Theorem 3. *Under Assumptions 1 and 2, for $`r\neq 0`$, the EIF for $`{\cal S}^r(\pi)`$ is
\begin{gather}
\nonumber r \frac{(Y-\mu(X,P))F^\pi(P|X)}{\pi_D(P|X)} \left(\int_0^\infty\pi(p | X) \int_{p}^\infty \mu(X, z)dzdp \right)^{r-1}\\
+\left( \int_0^\infty\pi(p | X) \int_{p}^\infty \mu(X, z)dzdp \right)^r-{\cal S}^r(\pi), \label{eqn: eif aware}
\end{gather}and the EIF for $`{\cal S}^r(\pi_D)`$ is
\begin{gather}
\nonumber r \left[\frac{(Y-\mu(X,P))F^{\pi_D}(P|X)}{\pi_D(P|X)} + \int^\infty_P \mu(X,z)dz \right]\left(\int_0^\infty\pi_D(p | X) \int_{p}^\infty \mu(X, z)dzdp \right)^{r-1}
\\
+ (1-r)\left( \int_0^\infty\pi_D(p | X) \int_{p}^\infty \mu(X, z)dzdp \right)^r-{\cal S}^r(\pi_D).
\end{gather}By linearity, the EIF of $`\Delta^r(\pi)`$ follows by taking the difference between the above two EIFs.*
Theorem 3 establishes the EIF for the inequality-aware surpluses, $`{\cal S}^r(\pi)`$, $`{\cal S}^r(\pi_D)`$ and their difference $`\Delta_r(\pi)`$ and is proved in Appendix 13. In more detail, Equation [eqn: eif aware] shares a structure analogous to the EIF for the standard surplus in Equation [eqn: eif]: the $`\int_0^\infty\pi(p | X) \int_{p}^\infty \mu(X, z)dzdp`$ term corresponds to the DM component, while $`\frac{(Y-\mu(X,P))F^\pi(P|X)}{\pi_D(P|X)}`$ is a mean-zero de-biasing term incorporating cumulative weights, which plays a crucial role in variance reduction, enabling the resulting estimator to attain the semiparametric efficiency bound. Naturally, Theorem 3 motivates the following estimators to estimate $`{\cal S}^r(\pi)`$ and $`{\cal S}^r(\pi_D)`$ respectively, obtained by setting the empirical mean of the EIF to zero together with cross-fitting:
\begin{align}
\label{eq:aware estimator}
\widehat {\cal S}^r(\pi)= \frac{1}{n}\sum_{i=1}^n \Bigg[ &r \frac{(Y_i-\widehat \mu^{-k(i)}(X_i,P_i))F^\pi(P_i|X_i)}{\widehat{\pi}^{-k(i)}_D(P_i|X_i)} \left(\int_0^\infty \pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp\right)^{r-1} \nonumber \\
&+ \left(\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp \right)^r \Bigg],
\end{align}\begin{align*}
\nonumber \widehat {\cal S}^r(\pi_D) = \frac{1}{n}\sum_{i=1}^n &\Bigg[r \left(\frac{(Y_i-\widehat \mu^{-k(i)}(X_i,P_i))\widehat F^{\pi_D,-k(i)}(P_i|X_i)}{\widehat\pi_D^{-k(i)}(P_i|X_i)} + \int^\infty_{P_i} \widehat \mu^{-k(i)}(X_i,z)dz \right) \\
& \quad \times \left(\int_0^\infty \widehat \pi_D^{-k(i)}(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp \right)^{r-1} \\
& + (1-r)\left( \int_0^\infty \widehat\pi_D^{-k(i)}(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp \right)^r\Bigg]
\end{align*}Then $`\widehat \Delta^r(\pi)=\widehat {\cal S}^r(\pi) - \widehat {\cal S}^r(\pi_D)`$.
We refer to this class of estimators as the inequality-aware ACPW estimator (IA-ACPW). Although the estimator $`\widehat{\mathcal{S}}^r(\pi)`$ in Equation [eq:aware estimator] is derived from the EIF in [eqn: eif aware] and incorporates both DM and CPW elements, it does not possess the double robustness property typically associated with the ACPW estimator. This stems from the fact that the functional $`S^r(\pi)`$ is nonlinear when $`r \neq 1`$. For example, the functional reweights observations such that small surpluses gain more leverage for $`r < 1`$. Consequently, a single data point perturbs the estimator differently than it would under a simple arithmetic mean. Due to this nonlinearity, $`\widehat{\mathcal{S}}^r(\pi)`$ is consistent only if the demand model is correctly specified, although the historic pricing policy $`\widehat \pi_D`$ can be misspecified. The necessity of consistency for the demand estimation can clearly be seen in Equation [eq:aware estimator], where the first term disappears when $`\frac{1}{n}\sum_{i=1}^n \left(Y_i-\widehat \mu^{-k(i)}(X_i,P_i)\right)`$ converges to 0, leaving the second term which is clearly only consistent when demand is consistent. However, as we will show in the asymptotic analysis in Section [sec:normality_aicpw], the cumulative weights play an important role in reducing variance, enabling the use of flexible machine learning policies with slower convergence rates.
The estimation of the inequality-aware surplus of the behavioral policy $`\mathcal{S}^r(\pi_D)`$ presents an even greater challenge. Unlike $`\widehat{\mathcal{S}}^r(\pi)`$, the estimator $`\widehat {\cal S}^r(\pi_D)`$ does not enjoy even single robustness; it requires the simultaneous consistency of both the demand model $`\widehat \mu`$ and the propensity model $`\widehat \pi_D`$. This added fragility arises because $`\pi_D`$ is not known but estimated, and it serves a dual role: it acts as the propensity weight in the debiasing term and explicitly defines the integration measure in the demand term. Consequently, if $`\widehat \pi_D`$ is misspecified, the estimator converges to a functional of the wrong policy, preventing consistency even if the demand model $`\widehat \mu`$ is perfect.
An example showing inconsistency of $`\widehat{\mathcal{S}}^r(\pi)`$ with a misspecified demand model is given next.
Example 2. *(Inequality-aware ACPW estimator is not robust to demand misspecification) Consider estimating the functional
{\cal S}^r(\pi) = \biggl(\int_0^\infty \pi(p) \int_{z=p}^\infty \mu(z)\,dz\,dp\biggr)^r
\quad\text{with}\quad r=\tfrac12,in a setting without covariates, where $`\mu(\cdot)\equiv \mathbb{E}[Y\mid P=\cdot]`$ denotes the demand function.*
*Assume $`P\sim\mathrm{Uniform}[0,1]`$, so the behavior policy satisfies $`\pi_D(p)=1`$ for all $`p\in[0,1]`$. Let the target policy also be $`\pi(p)=1`$, which implies $`F^\pi(z)=z`$, and suppose the true demand function is $`\mu(p)=1-p^2.`$ Under this setup, define
\theta^*=\int_0^1 \pi(p) \int_p^1 \mu(z)\,dz\,dp
= \int_0^1 1 \cdot \left[ z - \frac{z^3}{3} \right]_p^1 \,dp
= \int_0^1 \left(\frac{2}{3} - p + \frac{p^3}{3}\right)\,dp
= \frac14,so that $`\mathcal{S}^r(\pi)=(\theta^*)^{1/2}=\frac12.`$*
*Now, suppose the analyst uses a misspecified linear demand model whose limiting fit is $`\bar\mu(p)=1-\tfrac12 p .`$ The corresponding first-stage limit is
\bar\theta
=\int_0^1 \pi(p) \int_p^1 \bar\mu(z)\,dz\,dp
=\int_0^1 1 \cdot \left[ z - \frac{z^2}{4} \right]_p^1 \,dp
=\int_0^1 \left(\frac{3}{4} - p + \frac{p^2}{4}\right)\,dp
=\frac13.Hence, the population limit of the IA-ACPW estimator is
\bar\theta^{1/2}
\;+\;
\frac12\,\bar\theta^{-1/2}
\,
\underbrace{\mathbb{E}\!\left[
\frac{F^\pi(P)}{\pi_D(P)}\,
\bigl(Y-\bar\mu(P)\bigr)
\right]}_{\int_0^1 z(0.5 z-z^2)\,dz
=-1/12}=\sqrt{\frac13}
\;-\;
\frac{\sqrt{3}}{24},which differs from the true value $`1/2`$. Therefore, even when the behavior policy is correctly specified, misspecification of the demand model combined with the nonlinearity of the target functional yields a non-vanishing second-order remainder term and leads to bias.*
Theoretical Analysis
In this section, we establish the asymptotic normality of our proposed estimators and highlight the conditions required to achieve this. These results are particularly important, since they enable statistical inference and the construction of confidence intervals for surplus estimates. In practice, this allows firms to rigorously assess whether changes in their pricing strategy lead to statistically significant improvements in overall surplus or consumer welfare. For example, an e-commerce company may wish to evaluate whether a newly deployed dynamic pricing algorithm $`\pi`$ yields a higher expected consumer surplus than the existing pricing strategy $`\pi_D`$. By constructing confidence intervals for the respective estimators, the firm can formally test whether the observed improvement is statistically meaningful, rather than the result of random variation in sales data.
We also show that these estimators attain the semiparametric efficiency bounds. This means that, among all regular and asymptotically linear estimators, our proposed estimators achieve the lowest possible asymptotic variance. Although all estimators for the same target achieve this bound, the assumptions required to achieve it can differ, and in particular we show that the conditions for ACPW are relatively mild, allowing fast rates of convergence even if the demand function or historical price density estimates converge at slower rates. Throughout, we assume that all derived EIFs have finite second moments, $`\widehat \pi_D(p|x) > c`$ for some constant $`c`$, and that $`\widehat \mu(x,p)`$ is bounded for all $`p`$ and $`x`$.
In what follows, we start with the standard consumer surplus $`(r=1)`$, where the strongest results can be established, before progressing to the inequality-aware surplus, which presents additional challenges. We focus on analyzing the estimators for the surplus of a known policy $`\pi`$. Analogous results for the behavior policy surplus $`{\cal S}(\pi_D)`$ and difference $`\Delta(\pi)`$ follow similar techniques and can be found in Appendix 15. For completeness, we additionally present the results for the DM method, which forms part of our theoretical contribution.
Analysis of Standard Consumer Surplus $`(r=1)`$
We impose three sets of technical conditions corresponding to three estimators: CPW, ACPW, and DM, although we cover assumptions for DM in Appendix 14.1 for brevity. We begin with the assumptions required for the CPW estimator.
Required Assumptions
Assumption 3 (Assumptions required for the CPW). *(i)
$`\sqrt{\mathbb{E}\left[\widehat \omega(X,P)-\omega(X,P)\right]^2}=o_p(1)`$
, where $`\omega(x,p)\equiv\frac{F^\pi(p | x)}{\pi_D(p | x)}`$, and
$`\widehat \omega(x,p)\equiv\frac{F^\pi(p | x)}{\widehat\pi_D(p | x)}`$
is the estimator of $`\omega(x,p)`$.
(ii) The behavior policy is estimated using a function class that
satisfies the Donsker property.
(iii) There exist basis functions $`\phi(x,p) \in \mathbb{R}^L`$ and a
vector $`\beta \in \mathbb{R}^L`$ such that
\begin{gather}
\label{eq:approximation}
\sup_{x,p} |\mu(x,p)-\phi(x,p)^\top \beta | =O(L^{-s/d}),
\end{gather}where $`s`$ is a fixed positive constant and $`O(\cdot)`$ is the
standard big-$`O`$ term.
(iv) The estimated CPW weights satisfy
\begin{gather*}
\left \lVert\frac{1}{n} \sum_{i=1}^n \phi^\pi(X_i)- \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\phi(X_i,P_i) \right \rVert_2 =o_p(n^{-1/2}),
\end{gather*}where $`\| \cdot \|_2`$ is denoted as Euclidean norm, $`\phi(\cdot, \cdot)`$ is the basis function that satisfy Equation [eq:approximation], and $`\phi^\pi(x)=\int^\infty_0 \pi(p | x) \int_p \phi(x,z)dz dp`$.*
Assumption 3 (i) is relatively mild, as it merely requires $`\widehat \pi_D`$ to be consistent, with no rate specified. Assumption 3 (ii) imposes a complexity (size) constraint on the function class used for estimating the behavior policy. Before further discussing this assumption, we formally define the Donsker class as follows.
Definition 2 ($`P`$-Donsker Class). Let $`(\mathcal{X}, \mathcal{A}, P)`$ be a probability space and $`\mathcal{F}`$ be a class of measurable functions. We denote by $`L_2(P)`$ the space of all measurable functions that are square-integrable with respect to $`P`$. The associated $`L_2`$-norm is defined as $`\|\cdot \|_{P,2}`$. We define the following components to characterize the complexity of $`\mathcal{F}`$:
-
Brackets: for any two functions $`l, u \in L_2(P)`$, the bracket $`[l, u]`$ is the set of functions $`\{f : l(x) \leq f(x) \leq u(x) \text{ for all } x \in \mathcal{X}\}`$. An $`\epsilon`$-bracket in $`L_2(P)`$ is a bracket $`[l, u]`$ such that $`\|u - l\|_{P,2} < \epsilon`$.
-
Bracketing number: the bracketing number $`N_{[]}(\epsilon, \mathcal{F}, L_2(P))`$ is the minimum number of $`\epsilon`$-brackets in $`L_2(P)`$ needed to cover $`\mathcal{F}`$.
-
*Bracketing integral: the entropy integral is defined as
MATHJ_{[]}(\delta, \mathcal{F}, L_2(P)) = \int_{0}^{\delta} \sqrt{\log N_{[]}(\epsilon, \mathcal{F}, L_2(P))} \, d\epsilon ```*Click to expand and view more
Assume that there exists a measurable function $`F`$ such that $`|f(x)| \leq F(x)`$ for all $`f \in \mathcal{F}`$ and $`x \in \mathcal{X}`$, with $`\mathbb{E}(F^2) < \infty`$. Then the class $`\mathcal{F}`$ is called a $`P`$-Donsker class if $`J_{[]}(\delta, \mathcal{F}, L_2(P)) < \infty`$, for some $`\delta > 0`$.
Intuitively speaking, a Donsker class is a collection of functions that is not too large or too complex. This helps ensure that the average behavior of these functions becomes stable as we collect more data. Many commonly used machine learning models form Donsker classes. These include standard parametric models such as linear and generalized linear models, as well as nonparametric regression methods like wavelets and tensor product B-splines (see Section 6 of for a review). However, it is important to note that many modern black-box machine learning algorithms do not inherently satisfy the Donsker property. High-capacity models, such as over-parameterized deep neural networks, unpruned random forests, or gradient boosting machines, often operate in function spaces with massive complexity. Without explicit structural constraints (e.g., sparsity, norm regularization, or bounded depth), these classes can be too rich to admit a uniform Central Limit Theorem. Nevertheless, under specific technical conditions, even these state-of-the-art models can be shown to satisfy the Donsker property. For instance, discusses conditions for decision trees, while (Lemma 4) and (Lemma 5) provide the necessary sparsity and boundedness constraints for decision trees and neural networks, respectively, to remain within the Donsker regime.
Assumption 3(iii) is commonly adopted in the policy evaluation literature, see, for example, . When the demand function $`\mu(x,p)`$ lies within a Hölder or Sobolev smoothness class, Assumption 3(iii) is automatically satisfied, with $`s`$ as the Hölder smoothness parameter of the function $`\mu(x,p)`$. In such cases, one can approximate $`\mu(x,p)`$ using wavelet or tensor product B-spline basis functions. It can be observed from Equation [eq:approximation] that the smoother the function and the greater the number of basis functions, the smaller the approximation error.
Assumption 3(iv) requires the estimated CPW weight to have the approximately balancing property. It is relatively mild, since Lemma 1 (see Appendix 10.2) establishes that the true weight satisfies
\begin{align*}
\mathbb{E}\left[\phi^\pi(X) - \omega(X,P)\phi(X,P)\right] = 0.
\end{align*}In fact, exact balance over empirical data, meaning equality with $`0`$ rather than convergence at rate $`o_p(n^{-1/2})`$, can be achieved when the number of basis functions $`L`$ is fixed . Note that the $`o_p(n^{-1/2})`$ balance can still be achieved in settings where the number of basis functions $`L`$ grows with the sample size , and one can similarly follow the approach therein to construct a CPW estimator that satisfies Assumption 3 (iv).
Next, we present assumptions to show the asymptotic properties of ACPW.
Assumption 4 (Assumptions required for the ACPW). *Assume $`\pi_D(p \, | \,x)>c`$, for all $`p \in {\cal P}`$, and every $`x`$, for some constant $`c`$. In addition, suppose that the estimators for the demand function and the behavior policy are constructed using the cross-fitting procedure, and that they achieve the following convergence rate for $`k = 1, \cdots, K`$:
\begin{align}
\label{eq: product rate}
\sqrt{\mathbb{E}[(\widehat \mu^{-(k)}(X,P)-\mu(X,P))^2]} =O_p(n^{-\alpha_1}), \mbox{ and } \; \sqrt{\mathbb{E}[(\widehat \omega^{-(k)}(X,P)-\omega(X,P))^2]}=O_p(n^{-\alpha_2}),
\end{align}with $`\alpha_1, \alpha_2>0`$, and $`\alpha_1+\alpha_2>1/2`$.*
Assumption 4 allows the nuisances to be estimated at rates slower than the parametric $`O_p(n^{-1/2})`$, making it a mild condition. For example, it is satisfied when both estimators achieve $`o_p(n^{-1/4})`$, thereby accommodating flexible machine learning methods for consumer surplus estimation. Given these assumptions, we are able to show asymptotic normality of the proposed estimators.
Asymptotic Normality
Theorem 4. *Under Assumptions
1 and
2, the following results hold:
(i) Suppose Assumption 3 holds, and further assume that the
number of basis functions $`L`$ satisfies $`L \gg n^{d/2s}`$, then
\begin{gather*}
\sqrt{n} \left( \widehat {\cal S}_{CPW}(\pi)-{\cal S}(\pi)\right)\rightarrow\mathcal{N}\left(0,\Sigma(\pi) \right),
\end{gather*}where $`\Sigma(\pi)\equiv \mbox{Var}[\psi^\pi(\cal {D})]`$, and $`\psi^\pi(\cal {D})`$ is the EIF for $`{\cal S}(\pi)`$ given by Equation [eqn: eif].*
*(ii) Under Assumption 4,
\begin{gather*}
\sqrt{n} \left( \widehat {\cal S}_{ACPW}(\pi)-{\cal S}(\pi)\right)\rightarrow \mathcal{N}\left(0,\Sigma(\pi) \right),
\end{gather*}
```*
*(iii) Under Assumption <a href="#asmp: dm" data-reference-type="ref"
data-reference="asmp: dm">5</a> in Appendix
<a href="#sec:assumptions_DM" data-reference-type="ref"
data-reference="sec:assumptions_DM">14.1</a>,
``` math
\begin{gather*}
\sqrt{n} \left( \widehat {\cal S}_{DM}(\pi)-{\cal S}(\pi)\right)\rightarrow \mathcal{N}\left(0,\Sigma(\pi) \right).
\end{gather*}
```*
</div>
This is proved in Appendix
<a href="#sec:normality_target" data-reference-type="ref"
data-reference="sec:normality_target">14</a>. Theorem
<a href="#thm:dr rate" data-reference-type="ref"
data-reference="thm:dr rate">4</a> shows that all three proposed
estimators achieve the semiparametric efficiency bound, i.e., among all
regular asymptotically linear estimators, they attain the minimal
asymptotic variance $`\psi^\pi(\cal {D})`$. They also converge to the
same asymptotic distribution. However, the conditions required for
attaining the efficiency bound differ across methods. In particular, the
DM and CPW estimators rely on their respective nuisance functions being
estimated within a Donsker class, together with additional requirements
such as smoothness and balancing. In contrast, the ACPW estimator avoids
such high-level conditions, requiring only a mild product-rate
assumption and sample splitting during estimation. This is significant
as it ensures that the ACPW estimator can have a fast convergence rate
even when the DM and CPW methods have slower convergence rates (such as
with more complicated machine learning estimators). As a result, ACPW
has the flexibility to be used across a wider range of settings for
surplus estimation.
It is also instructive to discuss why the plug-in estimators such as CPW
estimator can achieve the asymptotic normality with the same rate and
variance as ACPW. The intuition is that Assumption 3 elevates the CPW
estimator from an inverse-probability weighting method to a calibrated
estimator. The empirical average of the de-biasing term in
$`\psi^\pi(\mathcal D)`$ (i.e.,
$`\int_0^\infty\pi(p | X) \int_{p}^\infty \mu(X, z)dzdp - \frac{F^\pi(P | X)}{\pi_D(P | X)}\mu(X,P)`$)
is asymptotically negligible under Assumption 3. Specifically,
Assumption 3(iv) enforces a constraint that forces the estimated weights
to balance the empirical moments of the historical data against the
target policy, using the basis functions $`\phi`$ as the balancing
features. This connects directly to the demand model: since Assumption
3(iii) guarantees that the true demand function $`\mu`$ can be
accurately approximated by a linear combination of these same basis
functions, balancing $`\phi`$ effectively balances the demand function
itself. Quantitatively, provided the number of basis functions $`L`$ is
chosen sufficiently large (specifically $`L \gg n^{d/2s}`$), the
approximation error becomes negligible at the root-$`n`$ scale
($`o(n^{-1/2})`$). By calibrating the weights to remove the variation
explained by the covariates, the CPW estimator achieves the same error
reduction as explicitly subtracting a control variate. Consequently, it
attains the same semiparametric efficiency bound and asymptotic
normality as the doubly robust ACPW estimator, even without explicitly
estimating the demand function.
An analogous result to Theorem
<a href="#thm:dr rate" data-reference-type="ref"
data-reference="thm:dr rate">4</a> applies to the estimation of the
behavior policy surplus, $`{\cal S}(\pi_D)`$, and the difference in
surplus $`\Delta(\pi)`$. For a complete statement, see Theorem
<a href="#thm:dr rate behavior" data-reference-type="ref"
data-reference="thm:dr rate behavior">6</a> and Corollary
<a href="#thm:dr rate behavior difference" data-reference-type="ref"
data-reference="thm:dr rate behavior difference">1</a> in Appendix
<a href="#sec:behavioral_theory" data-reference-type="ref"
data-reference="sec:behavioral_theory">15</a>.
### Confidence Intervals
Based on the asymptotic normality established in Theorem
<a href="#thm:dr rate" data-reference-type="ref"
data-reference="thm:dr rate">4</a>, we can construct valid confidence
intervals for $`{\cal S}(\pi)`$. A key theoretical insight from our
analysis is that, although $`\widehat {\cal S}_{CPW}`$,
$`\widehat {\cal S}_{ACPW}`$, and $`\widehat {\cal S}_{DM}`$ rely on
different modeling strategies, they are all asymptotically linear
estimators governed by the same efficient influence function,
$`\psi^{\pi}(\mathcal{D})`$. Consequently, they share the same
asymptotic variance,
$`\Sigma(\pi) = \text{Var}(\psi^{\pi}(\mathcal{D}))`$.
To perform inference, we estimate this variance using the empirical
second moment of the estimated EIF. This provides a unified approach to
variance estimation, since regardless of whether the point estimate is
derived via direct modeling or propensity weighting, the uncertainty is
quantified by the variability of the underlying influence function. The
variance estimators for each method are given by:
``` math
\begin{align*}
&\widehat \Sigma_{CPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu(X_i,z) dzdp + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D (P_i | X_i)}(Y_i - \widehat \mu(X_i,P_i))-\widehat {\cal S}_{CPW}(\pi)\right]^2,\\
&\widehat \Sigma_{ACPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \bigg[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i,z) dzdp \\
&\qquad \qquad \qquad \qquad \qquad + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D^{-k(i)} (P_i | X_i)}(Y_i - \widehat \mu^{-k(i)}(X_i,P_i))-\widehat {\cal S}_{ACPW}(\pi)\bigg]^2,\\
& \widehat \Sigma_{DM}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu(X_i,z) dzdp + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D (P_i | X_i)}(Y_i - \widehat \mu(X_i,P_i))-\widehat {\cal S}_{DM}(\pi)\right]^2.
\end{align*}Note that for $`\widehat \Sigma_{CPW}(\pi)`$, we utilize the estimated demand function $`\widehat \mu`$ to construct the variance estimator, even though it is not used for the point estimate $`\widehat {\cal S}_{CPW}(\pi)`$ itself. Similarly, for $`\widehat \Sigma_{CPW}(\pi)`$, we utilize the estimated propensity weights $`\widehat \pi_D`$ to construct the variance estimator. The following proposition establishes the consistency of these variance estimators.
Proposition 2. *Under the assumptions of Theorem 4, the following consistency results hold:
\begin{gather*}
|\widehat \Sigma_{CPW}(\pi) - \Sigma(\pi)| = o_p(1), \quad
|\widehat \Sigma_{ACPW}(\pi) - \Sigma(\pi)| = o_p(1), \quad
\text{and} \quad |\widehat \Sigma_{DM}(\pi) - \Sigma(\pi)| = o_p(1).
\end{gather*}
```*
</div>
This is proved in Appendix
<a href="#sec:variance_consistency" data-reference-type="ref"
data-reference="sec:variance_consistency">16</a>. Accordingly, a
$`(1-\alpha)`$ confidence interval for $`\mathcal S(\pi)`$ can be
constructed using any of the three estimators. For example, using the
ACPW estimator, the interval is given by:
``` math
\begin{equation*}
\left[\widehat{\mathcal S}_{ACPW}(\pi) \; \pm\; z_{1-\alpha/2} \sqrt{\widehat \Sigma_{ACPW}(\pi)/n} \right],
\end{equation*}where $`z_{1-\alpha/2}`$ denotes the upper $`(1-\alpha/2)`$-quantile of the standard normal distribution. In large samples, this interval contains the true value $`\mathcal S(\pi)`$ with probability $`(1-\alpha)`$. Intervals for the CPW and DM estimators are constructed analogously. This allows firms and regulators to establish whether surplus improvements or declines are statistically meaningful, and is important for rigorous evaluation.
Asymptotic Normality of Inequality-Aware Surplus $`(r\neq 1)`$
We next establish the asymptotic normality of $`\widehat {\cal S}^r(\pi)`$ and show that it attains the semiparametric efficiency bound.
Theorem 5. *Suppose that Assumptions 1, 2, and 4 hold. In addition, assume that $`\alpha_1>1/4`$, then for $`r\neq 0`$, we have
\begin{align*}
\sqrt{n} (\widehat {\cal S}^r(\pi)- {\cal S}^r(\pi))\rightarrow \mathcal{N}(0,\Sigma^r(\pi)),
\end{align*}where $`\Sigma^r(\pi)`$ is the variance of the EIF in Equation [eqn: eif aware].*
Theorem 5 establishes that the proposed inequality-aware estimator achieves the semiparametric efficiency bound, and is proved in Appendix 17. A key distinction of this result, compared to the aggregate surplus case ($`r=1`$) presented in Theorem 4, is the requirement that the demand model converges at a rate faster than $`n^{-1/4}`$ (i.e., $`\alpha_1 > 1/4`$). This condition is stricter than the product-rate condition ($`\alpha_1 + \alpha_2 > 1/2`$), which is sufficient for the standard ACPW estimator.
This divergence arises from the nonlinearity of the target functional $`\mathcal{S}^r(\pi) = \mathbb{E}[(\cdot)^r]`$ when $`r \neq 1`$. In the analysis of the linear aggregate surplus ($`r=1`$), the remainder term of the estimator takes the form of a cross-product of errors between the demand and propensity models, $`(\widehat \omega - \omega)(\widehat{\mu} - \mu)`$. This product structure allows for a trade-off in accuracy between the two nuisance functions, underpinning the double robustness property. In contrast, expanding the nonlinear functional $`\mathcal{S}^r(\pi)`$ via a second-order Von Mises expansion introduces a purely quadratic error term associated with the curvature of the functional. Consequently, the remainder term includes a component proportional to $`\|\hat{\mu} - \mu\|^2`$. For the estimator to be $`\sqrt{n}`$-consistent and asymptotically normal, this quadratic term must vanish faster than $`n^{-1/2}`$. This necessitates that $`\|\hat{\mu} - \mu\| = o_p(n^{-1/4})`$, forcing the demand estimator to satisfy a stricter individual convergence rate. This mathematical necessity aligns perfectly with our observation that the IA-ACPW estimator is only single-robust: because the propensity score cannot cancel out the quadratic error introduced by the nonlinearity, the consistency of the final estimator becomes dependent on the quality of the demand model.
Despite this stricter condition, the IA-ACPW estimator offers an important advantage over a direct method estimator that integrates a plug-in model of demand, with the inequality-aware aggregation applied. Such an estimator typically inherits the first-order bias of the demand model (i.e., error terms proportional to $`|\hat{\mu} - \mu|`$). When flexible machine learning methods are used to estimate demand, this bias often decays too slowly to permit valid statistical inference, rendering confidence intervals unreliable. In contrast, the IA-ACPW estimator leverages the cumulative propensity weights to perform a one-step bias correction. This correction effectively removes the first-order bias, leaving only the second-order quadratic remainder described above. Consequently, even if the demand model converges at a slower nonparametric rate (provided $`\alpha_1 > 1/4`$), the bias of the IA-ACPW estimator becomes negligible relative to its variance. This property is important for practitioners, as it enables the construction of valid confidence intervals while utilizing high-complexity machine learning models for demand estimation.
We prove similar results of inequality-aware for the behavioral policy in Appendix 18. However, establishing the asymptotic normality of $`\widehat{\mathcal{S}}^r(\pi_D)`$ imposes strictly stronger conditions on the nuisance estimators than those required for the counterfactual policy $`\pi`$. Specifically, the theory requires that both the demand model $`\widehat{\mu}`$ and the propensity model $`\widehat{\pi}_D`$ converge at a rate faster than $`n^{-1/4}`$ in the $`L_2`$-norm (i.e., $`\|\widehat{\mu}-\mu\| = o_p(n^{-1/4})`$ and $`\|\widehat{\pi}_D-\pi_D\| = o_p(n^{-1/4})`$). This simultaneous requirement is a direct consequence of the estimator’s lack of robustness. Unlike the standard setting, where the error term factorizes into a product of nuisance errors allowing for a rate trade-off (e.g., a slower propensity model can be compensated by a faster demand model), the nonlinearity of the functional $`\mathcal{S}^r(\pi_D)`$ with respect to the generated distribution introduces independent quadratic error terms for both models. Consequently, there is no safety net: if either model converges slower than $`n^{-1/4}`$, the second-order bias terms will not vanish at the $`\sqrt{n}`$-rate, preventing the estimator from achieving asymptotic normality. This highlights the inherent difficulty of evaluating inequality metrics on the behavioral policy itself when that policy must be estimated from the same data.
Experiments
This section presents the experimental results. In Section 8.1, we demonstrate that our proposed estimator has the double robustness property, unlike existing surplus estimators, and the validity of the confidence intervals. We then evaluate the performance of the proposed inequality-aware surplus estimators in Section 8.2 and analyze their confidence intervals in Section 8.3. Finally, to illustrate the practical application of our method, Section 8.4 applies our framework to a dataset from an auto loan company to measure consumer surplus.
Double Robustness
This section empirically validates the double robustness of the proposed augmented cumulative propensity weighting (ACPW) estimator. By simulating scenarios where either the demand model or the pricing (propensity) model is intentionally misspecified, we demonstrate that the ACPW estimator remains consistent as long as at least one of these components is correctly specified.
Direct Model Misspecification: We assume $`X\sim U[-0.5,0.5], \beta \sim U[-0.1,0.1], V=90+3000\beta X^2 + \epsilon, \epsilon\sim U[0,10], P\sim U[\min(V)-0.05, \max(V)+0.05], Y=\mathbb{I}[V>P]`$. We use a linear model to model the direct model $`\mu(x,p)`$, which is misspecified. The propensity model is correctly specified using a top-hat kernel density estimator.
Propensity Model Misspecification: We assume $`X\sim U[0,1], \beta \sim U[-1,1], V=100+300\beta X + \epsilon, \epsilon\sim U[0,10], P\sim U[\min(V)-0.05, \max(V)+0.05], Y=\mathbb{I}[V>P]`$. We use a Gaussian density model to model the propensity model $`\pi_D(p|x)`$, which is misspecified. The direct model is correctly specified using a linear model.
In both scenarios, we evaluate the Mean Squared Error (MSE) for surplus estimates under both the historical “Behavior” policy and a new “Target” personalized pricing policy (trained via gradient boosting trees). Specifically, we employ Gradient Boosted Trees (GBT) to estimate the demand function, $`\mu(x, p)`$. For the target policy, the final price is then determined by applying a softmax transformation over the expected revenue, $`p \cdot \mu(x, p)`$, evaluated across a discrete grid of five price points.
The results are shown in Figures 4 and 7, respectively. When the demand model is misspecified, the direct method (DM) exhibits significant, non-vanishing errors compared to the CPW and ACPW methods, whose estimation errors diminish to zero as the sample size increases. A similar trend is observed for DM and ACPW when the propensity scores are misspecified. CPW has a large MSE (approximately 5) that does not reduce with more samples. Compared to DM and CPW, the proposed ACPW method performs robustly across both conditions, which adds an additional layer of protection for accurate surplus identification in practice. By combining the strengths of both DM and CPW, it ensures reliable consumer surplus identification even when the underlying economic behavior or historical pricing data is complex or poorly understood.
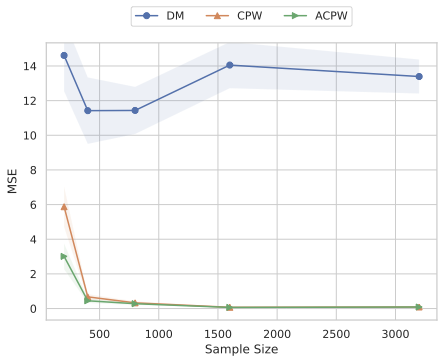 />
/>
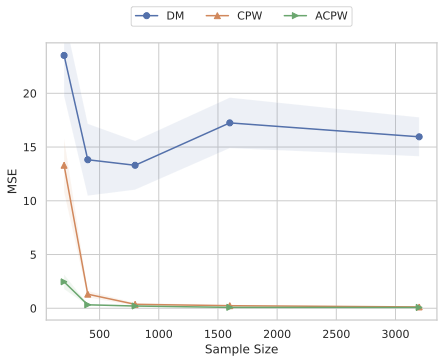 />
/>
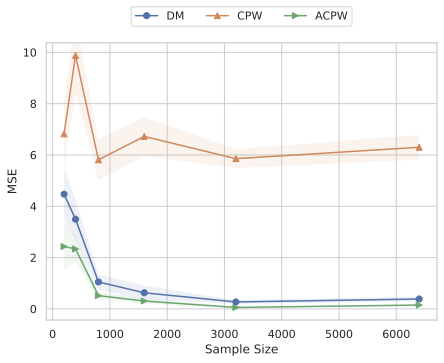 />
/>
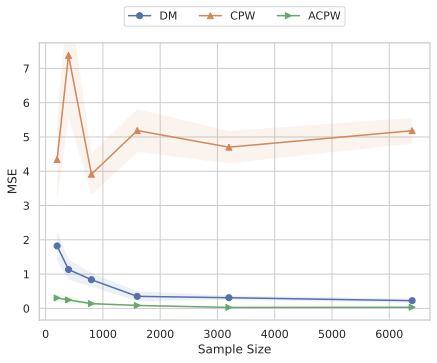 />
/>
Convergence Rate: We assume $`X\sim U[0,1], \beta \sim U[-1,1], V=100+300\beta X + \epsilon, \epsilon\sim U[0,10], P\sim U[\min(V)-0.05, \max(V)+0.05], Y=\mathbb{I}[V>P]`$. We use the kernel density model with the tophat kernel. The direct model is correctly specified using a linear model. If both models are well-specified, ACPW has a faster convergence rate, as shown in Figure 10. Here we plot on a log-scale for better visualization. ACPW provides a “best of both worlds” solution: it is robust to the failure of one model and achieves the fastest possible statistical convergence when models are accurate, making it a highly reliable tool for regulatory auditing.
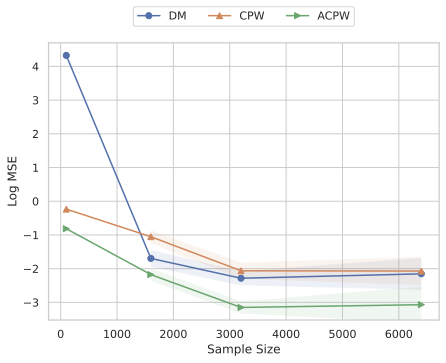 />
/>
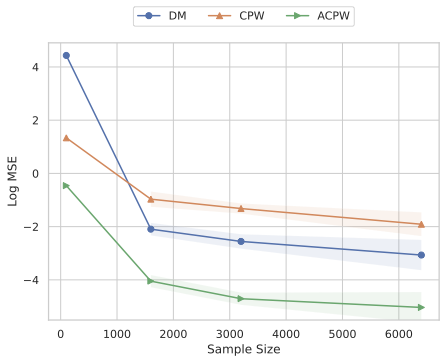 />
/>
Inequality-Aware Surplus
To evaluate the performance of our inequality-aware surplus estimators, we conduct simulations under a correctly specified model setting. The data is generated as follows: the feature vector $`X`$ is drawn from $`U[0,1]`$, and a consumer’s valuation $`V`$ is a linear function $`V=100+300\beta^T X + \epsilon`$, where coefficients $`\beta \sim U[-1,1]`$ and the error $`\epsilon \sim U[0,1]`$. The price $`P`$ is drawn from $`U[9,12]`$, and the purchase outcome is $`Y=\mathbb{I}[V>P]`$. For our estimators, the direct model is correctly specified as linear, and the propensity score model is correctly specified using a kernel density estimator with a tophat kernel. We report the results with 200 replications.
We evaluate the estimators’ Mean Squared Error (MSE) when $`r=0.5`$. Intuitively, the parameter $`r`$ controls the sensitivity of the surplus measure to the welfare of the worst-off consumers. As $`r`$ decreases, the estimator places increasingly higher weight on low-surplus outcomes. By choosing $`r=0.5`$, we adopt a moderate aversion to inequality. This criterion can help prioritize policies that are more beneficial to disadvantaged customer groups.
We compare the IA-ACPW estimator against the standard direct method (DM) baseline. The results are presented in Figure 11. Both the DM and IA-ACPW estimators exhibit decreasing MSE as the sample size increases. The IA-ACPW estimator consistently achieves lower estimation error than the DM baseline. This variance reduction is driven by the influence-function-based construction of the estimator, which leverages the cumulative propensity weights.
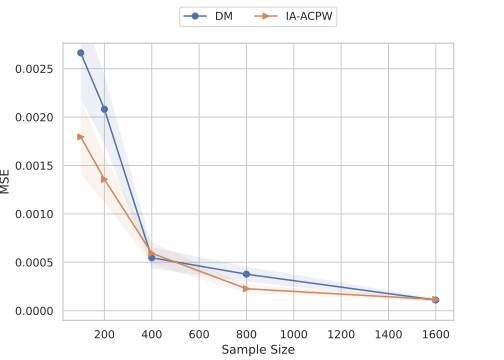 />
/>
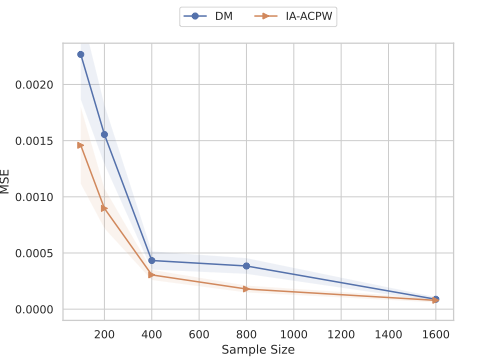 />
/>
Confidence Intervals
This section empirically validates the reliability and coverage of the proposed confidence intervals for surplus estimation. A robust auditing tool must not only provide a point estimate but also a mathematically sound measure of uncertainty, allowing regulators and firms to determine if changes in welfare are statistically significant.
We generate data with a feature vector $`X \sim U[0,1]`$. The valuation $`V`$ follows a linear model, $`V = 10 + 300\beta^T X + \epsilon`$, where $`\beta \sim U[-1,1]`$ and $`\epsilon \sim U[0,1]`$. The price is drawn from $`P \sim U[9,11]`$, and the outcome is $`Y = \mathbb{I}[V>P]`$.
To assess the robustness of our method, we pair a propensity score model (a kernel density estimator with a tophat kernel) with a direct model (a gradient boosting tree). We test the confidence interval coverage over 200 simulation runs for sample sizes of 2000, 4000, and 8000, with a nominal coverage rate of 90%.
The results with $`r=1`$ are shown in Figure 14 for the behavior and target policy. We test the confidence intervals for DM, CPW, and ACPW. The results are presented in Figure 17 for $`r=0.5`$ under both a behavior and a target policy. We test the confidence intervals for DM and IA-ACPW for the inequality-aware surplus.
Across both the Behavior and Target policies, the empirical coverage rates for the IA-ACPW estimator consistently hover around the 90% target. The intervals remain accurate not just for the standard average surplus ($`r=1`$), but also for the inequality-averse variant with $`r=0.5`$. The ability of these intervals to maintain proper coverage, even when utilizing flexible models like gradient boosting, is critical for many applications. It ensures that a firm or regulator can construct a $`(1-\alpha)`$ confidence interval $`[ \hat{\mathcal{S}} \pm z_{1-\alpha/2}\sqrt{\hat{\Sigma}/n} ]`$ and have high confidence that the true consumer welfare impact lies within that range.
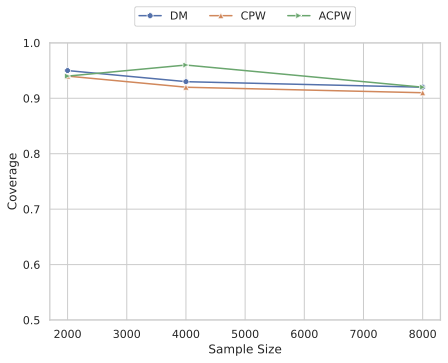 />
/>
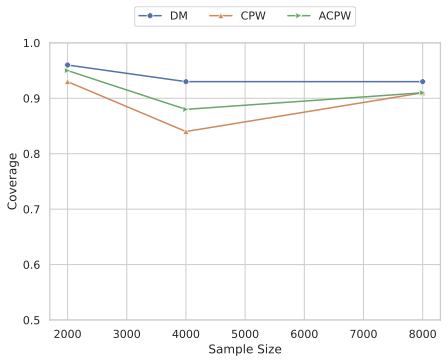 />
/>
 />
/>
 />
/>
Automobile Loans
To demonstrate the practical utility of our framework, we apply it to a real-world dataset on personalized pricing. We utilized the CPRM-12-001: On-Line Auto Lending dataset from Columbia University, a comprehensive collection of U.S. auto loan applications from July 2002 to November 2004. It includes details such as application date, requested loan terms (amount and duration), applicant personal information (e.g., state, car type, FICO score), approval status, the Annual Percentage Rate (APR) offered for approved loans, and whether a contract was ultimately executed. We remove the last 45 days before ‘11/16/2004’ since these records may not have an accurate outcome .
The price is computed as the net present value of future payments minus the loan amount:
\begin{align*}
p = Monthly\ Payment \times \sum_{\tau=1}^{Term} (1 + Rate)^{-\tau} - Loan\ Amount,
\end{align*}where $`Rate`$ is the monthly London interbank offered rate. Following , we set the price range to $`[0, 7500]`$.
We define a feature set for each loan application. The set of continuous predictors includes the applicant’s FICO score, the loan term in months, the approved loan amount, the one-month interest rate, and a relative competitor interest rate. These features are standardized to have a mean of zero and a standard deviation of one. The set of categorical predictors includes loan term class, partner binary, car type, application type, customer tier, and state. These are converted into numerical representations via label encoding. The final feature vector, denoted by $`\boldsymbol{x}`$, is the concatenation of the standardized continuous features and the encoded categorical features.
We segment applicants into four groups based on their credit history (Good vs. Bad Credit, proxied by FICO score) and the political affiliation of their state (Red State vs. Blue State). The red and blue state groups are based on the state’s political affiliation in the 2000 U.S. presidential election. Blue States are: CA, CT, DC, DE, HI, IA, IL, MA, MD, ME, MI, MN, NJ, NM, NY, OR, PA, RI, VT, WA, and WI. Red States are then defined as all other states present in our final dataset. This classification allows for a comparative analysis of policy effects across distinct economic and political environments. The price distributions for these distinct groups are visualized in Figure 18. While the historical behavior policy clearly assigns higher prices to the Low FICO groups, there is no discernible difference in the prices assigned to Red versus Blue states within the same credit tier.
We evaluate the surplus under a behavior policy (historical pricing from the lender) against a personalized pricing policy trained on the data to maximize the lender’s revenue. First, we estimate the baseline inequality-aware surplus for each group using the ACPW estimator under the behavior policy, which is the historical price prescribed by the insurance company in the original dataset. Next, we show the results for the inequality aversion parameter $`r=0.5`$. Then we evaluate the impact of a personalized pricing policy trained on the historical data. The demand function is trained using a gradient boosting tree. The final price is then determined by applying a softmax transformation over the expected revenue, $`p \cdot \mu(x, p)`$, sampled from a discrete grid of five price points. The results are shown in Table [tab:autoloan_dr].
Empirical Observations
We apply the ACPW and IA-ACPW estimators to the auto loan dataset to
quantify the welfare implications of algorithmic personalization and the
trade-off between aggregate surplus and equity. Our analysis begins by
examining the aggregate consumer surplus ($`r=1`$) and highlights
disparities in consumer welfare across geographic and credit segments
under the historical behavior policy. For the good-credit segment, the
estimated consumer surplus in red states is $`\$1,313.00 \pm 47.40$, which is approximately 9% higher than the $$1,204.61 \pm 43.79$ observed in blue states. This geographic premium persists within the bad-credit segment, where surplus in red states exceeds that of blue states by more than 7% ($$952.59 \pm 36.12$ vs $$888.20 \pm 36.03`$). As the price distributions across these states
are similar, as shown in Figure
18, these consistent welfare gaps
are likely driven by underlying differences in the distributions of
consumers’ willingness to pay between regions.
We next analyze the impact of introducing a personalized pricing algoritm. Consumer surplus decreases for every demographic group, with the Red State, Good Credit group experiencing the sharpest decline of roughly 26% ($1,313.00 $`\to`$ $965.44), representing a significant loss in aggregate surplus. However, despite this aggregate loss, the distribution of welfare becomes less unequal. Under the historical policy, the most advantaged group (Red State, Good Credit) had a surplus 1.48 times that of the least advantaged group (Blue State, Bad Credit). Under personalization, this ratio compresses to 1.30 times. This dynamic, where aggregate surplus falls but inequality reduces, mirrors the findings of , suggesting the personalized pricing can act as a progressive transfer mechanism.
To capture nuances regarding the most vulnerable consumers, we utilize the inequality-aware surplus metric ($`r=0.5`$). While the hierarchy between groups remains consistent with the standard surplus for the historical policy, the relative difference between the best (Red State, Good Credit) and worst (Blue State, Bad Credit) outcomes is notably smaller, with a ratio of 1.22 compared to 1.48. This indicates that the worst-off individuals within these demographic groups already experience more similar surplus levels, regardless of their group label. Furthermore, the decline in inequality-aware surplus under personalization is notably reduced (ranging from 7% for Red State, Bad Credit to approximately 17% for Red State, Good Credit and Blue State, Good Credit) compared to the standard surplus declines (12% for Red State, Bad Credit to 26% for Red State, Good Credit). This suggests that the surplus lost to personalization is primarily extracted from high-valuation customers, who are weighted less heavily in this metric. Consequently, with personalized pricing, the relative inequality-aware surplus difference between the best and worst surplus becomes even smaller, dropping to a ratio of just 1.11. This provides further evidence that personalized pricing functions as a leveler, disproportionately extracting value from the top to flatten the welfare distribution, thereby protecting the relative standing of those who are worst off. However, this reduction in inequality must be traded-off against the fact that all segments have declining absolute surplus even for the inequality-aware surplus.
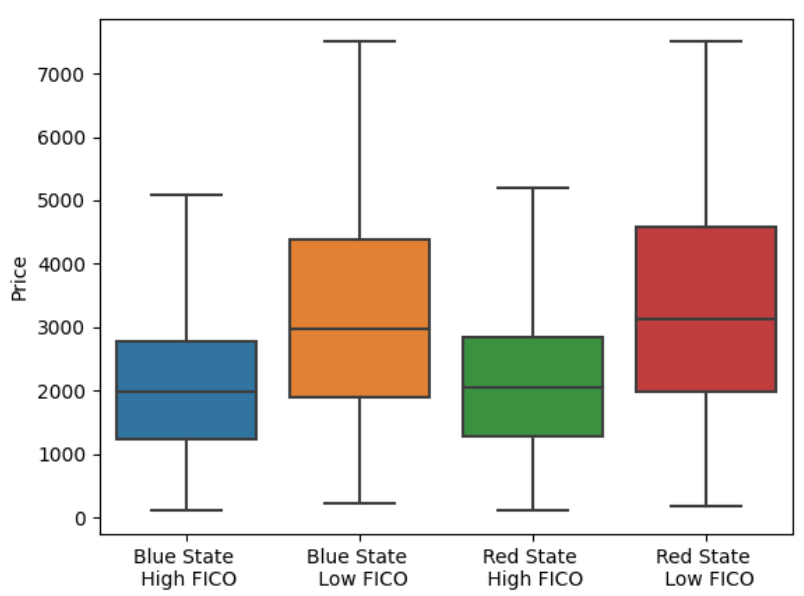
Conclusions and Managerial Implications
This paper proposes a data-driven way to measure consumer welfare using transactional data. Our cumulative-weights framework provides a robust mechanism to audit the economic and distributional consequences of targeted pricing strategies, even when demand estimation is prohibitively difficult.
We establish the theoretical foundations for three primary estimators: cumulative propensity weighting, a direct method plug-in, and an augmented cumulative propensity weighting variant, demonstrating that all three achieve the semi-parametric efficiency bound under different assumptions. The ACPW estimator, in particular, offers a “best of both worlds” solution for practitioners: it remains consistent if either the demand model or the historical pricing policy is consistent. In addition, it attains fast convergence even when flexible machine learning methods are used to estimate the nuisance functions at slower nonparametric rates. Furthermore, we extend this framework to accommodate inequality-aware surplus measures, enabling welfare assessments that prioritize disadvantaged customer segments through a tunable inequality-aversion parameter.
For pricing managers, the ACPW estimator serves as a critical internal auditing tool to de-risk algorithmic deployments. Managers can now quantify how different customer segments are affected by specific pricing policies, enabling the proactive identification of potential fairness issues or disparate impacts before they escalate into legal or reputational crises. Furthermore, integrating these methods into the policy design phase allows firms to simulate the impact of new pricing strategies on both the average surplus and its distribution. This facilitates a more balanced long-term strategy that optimizes for both profitability and the maintenance of a healthy, sustainable customer ecosystem.
From a regulatory standpoint, this research addresses the critical gap between the growing sophistication of personalized pricing and the limited tools available for public oversight. The ACPW estimator offers a statistically defensible methodology for bodies such as the Federal Trade Commission to assess whether current pricing practices harm consumers or specific protected groups. By establishing credible upper and lower bounds on surplus, regulators can make evidence-based judgments even when price variation is sparse, thereby avoiding the need for firms to undertake commercially risky or unprofitable experiments. Ultimately, these cumulative-weight-based methods deliver transparent, regulator-ready tools for diagnosing the social and economic consequences of the modern algorithmic pricing landscape.
Auxiliary Results
Throughout, we use $`C`$ to denote a generic constant that can vary from line to line.
Equivalence of the Area Under the Demand Curve Surplus Representation
Proposition 3. *Under Assumption 1,
\mathbb{E}\big[(V-P)_+\big]
=\mathbb{E}_X\left[\int_{p=0}^{\infty} \pi_D(p\mid X)
\int_{z=p}^{\infty} \mu(X,z)\, dz\, dp \right].
```*
</div>
<div class="proof">
*Proof.* This result follows from carefully changing the order of
integration:
``` math
\begin{align*}
\mathbb{E}\big[(V-P)_+\big]
&= \mathbb{E}_X\left[\int_{p=0}^{\infty}
\left( \int_{v=p}^{\infty} (v-p)\, f_{V\mid X}(v\mid X)\, dv \right) \pi_D(p\mid X)\, dp \right] \\
&\overset{s=v-p}{=}\; \mathbb{E}_X\left[\int_{p=0}^{\infty}
\left( \int_{s=0}^{\infty} s\, f_{V\mid X}(s+p\mid X)\, ds \right) \pi_D(p\mid X)\, dp \right] \\
&=\; \mathbb{E}_X\left[\int_{p=0}^{\infty}
\left( \int_{s=0}^{\infty} \int_{t=0}^{s} f_{V\mid X}(s+p\mid X)\, dt\, ds \right) \pi_D(p\mid X)\, dp \right] \\
&=\; \mathbb{E}_X\left[\int_{p=0}^{\infty}
\left( \int_{t=0}^{\infty} \int_{s=t}^{\infty} f_{V\mid X}(s+p\mid X)\, ds\, dt \right) \pi_D(p\mid X)\, dp \right] \\
&=\; \mathbb{E}_X\left[\int_{p=0}^{\infty}
\left( \int_{t=0}^{\infty} \bar F_{V\mid X}(t+p\mid X)\, dt \right) \pi_D(p\mid X)\, dp \right] \\
&\overset{p+t=z}{=}\; \mathbb{E}_X\left[\int_{p=0}^{\infty}
\int_{z=p}^{\infty} \bar F_{V\mid X}(z\mid X)\, \pi_D(p\mid X)\, dz\, dp \right] \\
&=\; \mathbb{E}_X\left[\int_{p=0}^{\infty} \pi_D(p\mid X)
\int_{z=p}^{\infty} \mu(X,z)\, dz\, dp \right].
\end{align*}The last equality uses the identity
\mu(X,z)=\mathbb{E}[Y\mid X,P=z]=\mathbb{P}[Y=1\mid X,P=z]
=\mathbb{P}[V>z\mid X,P=z].By Assumption 1 ($`V \perp P \mid X`$), we have $`\mathbb{P}[V > z \mid X, P=z] = \mathbb{P}[V > z \mid X] = \bar{F}_{V \mid X}(z \mid X)`$, which completes the proof. ◻
Auxiliary Lemmas
Lemma 1 (Balancing Property). *For any measurable function $`\phi(X,P)`$, the following holds
\begin{gather}
\label{eq:balance}
\mathbb{E}\left[ \int_0^\infty\pi(p | X) \int_{p}^\infty \phi(X,a)dadp \right] = \mathbb{E}\left[\frac{F^\pi(P | X)}{\pi_D(P | X)}\phi(X,P) \right]
\end{gather}
```*
</div>
<div class="proof">
*Proof.*
``` math
\begin{gather*}
\mathbb{E}\left[ \int_0^\infty\pi(p | X) \int_{p}^\infty \phi(X,a)dadp \right]= \mathbb{E}\left[ \int_0^\infty \int_0^a \pi(p|X) dp \; \phi(X,a)da \right] \mbox{ (exchanging the integral order) } \\
= \mathbb{E}\left[ \int_0^\infty F^\pi(p | X) \; \phi(X,p)dp \right]=\mathbb{E}\left[ \int_0^\infty \frac{F^\pi(p | X) }{\pi_D(p|X)} \pi_D(p|X) \phi(X,p)dp \right]= \mathbb{E}\left[\frac{F^\pi(P | X)}{\pi_D(P| X)}\phi(X,P) \right].
\end{gather*}This completes the proof. ◻
Lemma 2. *Assume there exists a constant $`c`$ such that $`\pi_D(p|x)>c`$, for all $`p`$ and $`x`$, then
\mathbb{E}\!\left[(\widehat h(X)-h(X))^2\right]
\;\lesssim\;
\mathbb{E}\!\left[(\widehat \mu(X,P)-\mu(X,P))^2\right],where
h(x)= \int F^\pi(p \mid x)\,\mu(x, p)\,dp,
\qquad
\widehat h(x)= \int F^\pi(p \mid x)\,\widehat \mu(x, p)\,dp .
```*
</div>
<div class="proof">
*Proof.* We have
``` math
\begin{align*}
\mathbb{E}[(\widehat h(X)-h(X))^2]
&= \mathbb{E}\left[\left(\int F^\pi(p \mid X)\bigl(\widehat \mu(X,p)-\mu(X,p)\bigr)\,dp\right)^2\right].
\end{align*}Using the identity $`F^\pi(p\mid X) = \frac{F^\pi(p\mid X)}{\pi_D(p\mid X)}\pi_D(p\mid X),`$ we obtain
\begin{align*}
\mathbb{E}[(\widehat h(X)-h(X))^2]&= \mathbb{E}\left[\left(\int \frac{F^\pi(p\mid X)}{\pi_D(p\mid X)}\,
\pi_D(p\mid X)\bigl(\widehat \mu(X,p)-\mu(X,p)\bigr)\,dp\right)^2\right] \\
&= \mathbb{E}\left[\left(\mathbb{E}_{P\mid X}\!\left[\frac{F^\pi(P\mid X)}{\pi_D(P\mid X)}\,
(\widehat \mu(X,P)-\mu(X,P))\right]\right)^2\right].
\end{align*}Applying Jensen’s inequality to the conditional expectation yields
\begin{align*}
\mathbb{E}[(\widehat h(X)-h(X))^2] &\le \mathbb{E}\left[\mathbb{E}_{P\mid X}\!\left[\left(\frac{F^\pi(P\mid X)}{\pi_D(P\mid X)}\right)^2
(\widehat \mu(X,P)-\mu(X,P))^2\right]\right].
\end{align*}By the strong overlap condition, $`\frac{F^\pi(P\mid X)}{\pi_D(P\mid X)} \le 1/c,`$ and hence
\begin{align*}
\mathbb{E}[(\widehat h(X)-h(X))^2]&\le 1/c^2\,\mathbb{E}\left[(\widehat \mu(X,P)-\mu(X,P))^2\right].
\end{align*}Absorbing the constant into the $`\lesssim`$ notation completes the proof. ◻
Proof of Theorem <a href="#thm:eif" data-reference-type=“ref”
data-reference=“thm:eif”>2 : Deriving EIFs for Consumer Surplus (r=1)
Following , to derive the EIF, we first find the tangent space and its orthogonal complement. We begin with the following auxiliary Lemmas for the corresponding results.
Lemma 3. *The orthogonal complement of the observed tangent space is
\begin{align*}
\Lambda^\perp = \{ M(X,P,Y): E(M|P,X)=\mathbb{E}(M|V,X)=0 \},
\end{align*}any measurable function $`M(X,P,Y).`$*
Proof. We start by characterizing the full data tangent space. It can be shown that the full data tangent space $`\Lambda^F`$ is $`\Lambda_X^F\bigoplus\Lambda_V^F\bigoplus\Lambda_P^F`$, where $`\bigoplus`$ is the direct sum,
\begin{gather*}
\Lambda_X^F=\{g_X(X): \mathbb{E}(g_X(X))=0 \},\\
\Lambda_P^F=\{g_P(P,X): \mathbb{E}(g_P(P,X)|X)=0 \}, \\
\mbox{and } \Lambda_V^F=\{g_V(V,X): \mathbb{E}(g_V(V,X)|X)=0 \}.
\end{gather*}By Theorem 7.1 in , the observed tangent space $`\Lambda`$ is $`\mathbb{E}(\Lambda^F| P,X,Y)`$. Hence, an element in $`\Lambda`$ can be written as
\begin{align*}
g_X(X)+g_P(P,X)+\mathbb{E}(g_V(V,X) | Y,P,X),
\end{align*}for $`g_X(X) \in \Lambda_X^F, \; g_P(P,X) \in \Lambda_P^F, \mbox{ and } g_V(V,X) \in \Lambda_V^F,`$
Denote $`\Delta = \{ M(X,P,Y): E(M|P,X)=\mathbb{E}(M|V,X)=0 \}`$, the aim is to show that $`\Delta=\Lambda^\perp`$. We first show that $`\Delta \subseteq \Lambda^\perp`$. For any $`M(X,P,Y) \in \Delta`$, $`g_X(X) \in \Lambda_X^F, \; g_P(P,X) \in \Lambda_P^F, \mbox{ and } g_V(V,X) \in \Lambda_V^F,`$
\begin{align*}
& \mathbb{E}\left[ M(X,P,Y) \left( g_X(X)+g_P(P,X)+\mathbb{E}(g_V(V,X) | Y,P,X) \right ) \right] \\
= & \mathbb{E}\left( M(X,P,Y) g_X(X) \right) +\mathbb{E}\left( M(X,P,Y) g_P(P,X) \right)+
\mathbb{E}\left[ M(X,P,Y) \mathbb{E}(g_V(V,X) | Y,P,X) \right]\\
= & \mathbb{E}(g_X(X) \underbrace{\mathbb{E}(M|X)}_0)+ \mathbb{E}\left( \underbrace{\mathbb{E}(M|P,X)}_0 g_P(P,X) \right) +\mathbb{E}\left( \underbrace{\mathbb{E}(M|V,X)}_0 g_V(V,X) \right)\\
= & 0.
\end{align*}Thus, $`\Delta \subseteq \Lambda^\perp`$.
We next show $`\Lambda^\perp \subseteq \Delta.`$ For any function $`h(X,P,Y) \in \Lambda^\perp`$, let $`g_X(X)=\mathbb{E}(h|X)`$, $`g_P(P,X)=0`$, and $`g_V(V,X)=0`$. It can be verified that $`g_X \in \Lambda_X^F`$, $`g_P \in \Lambda_P^F`$, $`g_V \in \Lambda_V^F`$. Since $`h(X,P,Y) \in \Lambda^\perp`$, we have $`\mathbb{E}(\mathbb{E}^2(h|X))=0`$ if and only if $`\mathbb{E}(h|X)=0`$.
Now let $`g_X(X)=\mathbb{E}(h|X)`$, $`g_P(P,X)=\mathbb{E}(h|P,X)`$, and $`g_V(V,X)=0`$. It can be verified that such a construction also meets the condition that $`g_X \in \Lambda_X^F`$, $`g_P \in \Lambda_P^F`$, $`g_V \in \Lambda_V^F`$. Since $`h(X,P,Y) \in \Lambda^\perp`$. Since $`h(X,P,Y) \in \Lambda^\perp`$, we have $`\mathbb{E}(\mathbb{E}^2(h|P,X))=0`$ if and only if $`\mathbb{E}(h|P, X)=0`$.
Finally, let $`g_X(X)=\mathbb{E}(h|X)`$, $`g_P(P,X)=\mathbb{E}(h|P,X)`$, and $`g_V(V,X)=\mathbb{E}(h|V,X)`$. Using a similarly argument, we have $`\mathbb{E}(h|V, X)=0`$.
Thus, $`\Lambda^\perp = \{ M(X,P,Y): \mathbb{E}(M|P,X)=\mathbb{E}(M|V,X)=0 \}.`$ This completes the proof. ◻
Lemma 4. Any element in the space $`\{M(P,Y,X): \mathbb{E}(M|V,X)=0 \}`$ can be written as $`h(P,X)-E(h|X)`$, meaning that the space consists of functions that depend only on $`P`$ and $`X`$.
Proof. Since $`Y`$ is binary, any function $`M(P,Y,X)`$ can be written as $`YM_1(P,X)+(1-Y)M_0(P,X)=Y(M_1-M_0)+M_0`$.
For any $`M \in \{M(P,Y,X): \mathbb{E}(M|V,X)=0 \}`$, we have
\begin{align*}
& \mathbb{E}(Y(M_1-M_0)+M_0 | V,X)=0, \\
\implies & \mathbb{E}(Y(M_1-M_0) |V,X)=\mathbb{E}(-M_0 | V,X).
\end{align*}Since $`A \protect\mathpalette{\protect\independenT}{\perp}V |X`$, we have $`\mathbb{E}(M_0 (P,X)|V,X)=\mathbb{E}(M_0|X)`$. Hence, we have
\begin{align*}
\mathbb{E}(Y(M_1-M_0) |V,X)=\mathbb{E}(-M_0 | X).
\end{align*}In the above equation, the LHS is a function of $`V`$ and $`X`$, while the RHS is only a function of $`X`$. Therefore, the above equation holds if and only if $`M_1=M_0`$, and $`\mathbb{E}(M_0(P,X)|X)=0`$. This completes the proof. ◻
Lemma 5. The observed tangent space is the entire Hilbert space.
Proof. Since all the elements in the space $`\{M(P,Y,X): \mathbb{E}(M|V,X)=0 \}`$ are only a function of $`P,X`$. We have
\begin{gather*}
\{M(P,Y,X): \mathbb{E}(M|V,X)=0 \} \bigcap \{M(P,Y,X): \mathbb{E}(M|P,X)=0 \} =\{0\}.
\end{gather*}Thus the orthogonal complement of the observed tangent space is $`\{0\}`$, which means that the observed tangent space is the entire Hilbert space. ◻
Proof. Using Lemma 3, 4, and 5, the tangent space is the entire Hilbert space. Correspondigly, there exists a unique influence function. Moreover, it is the efficient influence function.
Next, we show an equivalent form of consumer surplus that is more convenient to use, starting with the definition from Equation [eqn: identification] :
\begin{align*}
& \mathbb{E}\!\left[ \int_{p=0}^\infty \pi(p\mid X) \int_{z=p}^\infty \mathbb{E}[Y \mid X,P=z] \, dz \, dp \right]
= \mathbb{E}\!\left[ \int_{p=0}^\infty \int_{z=p}^\infty \pi(p\mid X)\,\mu(X,z) \, dz \, dp \right] \\
= & \; \mathbb{E}\!\left[ \int_{z=0}^\infty \int_{p=0}^z \pi(p\mid X)\,\mu(X,z) \, dp \, dz \right] = \mathbb{E}\!\left[ \int_{z=0}^\infty \Big(\int_{p=0}^z \pi(p\mid X)\,dp\Big)\,\mu(X,z) \, dz \right] \\
= & \;\mathbb{E}\!\left[ \int_{z=0}^\infty F^\pi(z\mid X) \,\mu(X,z) dz \right],
\end{align*}where $`\mu(X, z) = \mathbb{E}[Y|X, P=z]`$ and $`F^\pi(z|X) = \int_0^z \pi(s|X) ds`$. We study two cases: (i) where we are evaluating a target pricing policy $`\pi`$, in which case $`F^\pi(z|X)`$ is a fixed and known weight function, and (ii) we are evaluating an unknown behavior pricing policy $`\pi_D`$, in which case $`F^{\pi_D}(z|X)`$ is also a function of the data.
Case 1: known target pricing policy $`\pi`$
We define the estimand of interest we will work with:
\Psi(\mathcal{P}) \equiv \mathcal{S}(\pi) = \mathbb{E}_X \left[ \int_{z=0}^{\infty} \mu(X, z) F^\pi(z|X) dz \right]This is a function of the true observed distribution $`\mathcal{P}`$. We follow the approach to finding the efficient influence function (EIF) and notation from . In particular, we follow the pathwise differentiability approach, defining a parametric submodel $`\mathcal{P}_t = (1-t)\mathcal{P} + t\delta_{\tilde{x}, \tilde{y}, \tilde{p}}`$, where $`\delta`$ is a point mass at the observed data $`\{\tilde{x}, \tilde{y}, \tilde{p}\}`$. Under this parametric model, a generic joint distribution is $`f_{X,Y,P,t}(x,y,p)=(1-t)f_{X,Y,P}(x,y,p)+ t\delta_{\tilde{x}, \tilde{y}, \tilde{p}}`$
The pathwise derivative is given by:
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} = \frac{d}{dt} \int f_{X,t}(x) \int_{z=0}^{\infty} \mu_t(x, z) F^\pi(z|x) dz dx \Big|_{t=0}First, we show an identity for the derivative of a generic conditional density, $`\frac{\partial f_t(a|x)}{\partial t}\big|_{t=0} = \frac{\delta_{\tilde{x}}(x)}{f_X(x)} (\delta_{\tilde{a}}(a) - f(a|x))`$. Recall that the conditional density is defined as $`f_t(a|x) = \frac{f_t(x,a)}{f_t(x)}`$. The pathwise derivative of the marginal density is $`\frac{\partial f_t(x)}{\partial t}\big|_{t=0} = \delta_{\tilde{x}}(x) - f_X(x)`$. The pathwise derivative of the joint density is $`\frac{\partial f_t(x,a)}{\partial t}\big|_{t=0} = \delta_{\tilde{x}}(x)\delta_{\tilde{a}}(a) - f(x,a)`$. Applying the quotient rule at $`t=0`$:
\begin{align*}
\frac{\partial f_t(a|x)}{\partial t}\Big|_{t=0} &= \frac{f_X(x) \frac{\partial f_t(x,a)}{\partial t} - f(x,a) \frac{\partial f_t(x)}{\partial t}}{f_X(x)^2} \\
&= \frac{f_X(x)[\delta_{\tilde{x}}(x)\delta_{\tilde{a}}(a) - f(x,a)] - f(x,a)[\delta_{\tilde{x}}(x) - f_X(x)]}{f_X(x)^2} \\
&= \frac{\delta_{\tilde{x}}(x) f_X(x) \delta_{\tilde{a}}(a) - f(x,a)\delta_{\tilde{x}}(x)}{f_X(x)^2} \\
&= \frac{\delta_{\tilde{x}}(x)}{f_X(x)} \left( \delta_{\tilde{a}}(a) - \frac{f(x,a)}{f_X(x)} \right) \\
&= \frac{\delta_{\tilde{x}}(x)}{f_X(x)} (\delta_{\tilde{a}}(a) - f(a|x))
\end{align*}Using the product rule and this identity the derivative decomposes into two primary components:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} &= \int \left[ \int_{0}^{\infty} \mu(x, z) F^\pi(z|x) dz \right] (\delta_{\tilde{x}}(x) - f_X(x)) dx \\
&\quad + \mathbb{E}_X \left[ \int_{0}^{\infty} \frac{\partial \mu_t(X, z)}{\partial t}\Big|_{t=0} F^\pi(z|X) dz \right]
\end{align*}Let $`h(X) = \int_{0}^{\infty} \mu(X, z) F^\pi(z|X) dz`$. Evaluating the first integral yields $`h(\tilde{x}) - \Psi(\mathcal{P})`$. For the second term, we apply the quotient rule to $`\mu(X, z) = \frac{f_{Y,P}(1,z|X)}{\pi_D(z|X)}`$, where this equality follows from Bayes (and the definition $`f_{Y,P}(1,z|X)=\mathbb{P}(Y=1, P=z|X))`$:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} &= h(\tilde{x}) - \Psi(\mathcal{P}) \\
&\quad + \mathbb{E}_X \Bigg[ \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \int_{0}^{\infty} \frac{F^\pi(z|X)}{\pi_D(z|X)} (\delta_{\tilde{y}, \tilde{p}}(1, z|X) - f_{Y,P}(1, z|X)) dz \\
&\quad - \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \int_{0}^{\infty} \frac{f_{Y,P}(1, z|X) F^\pi(z|X)}{\pi_D(z|X)^2} (\delta_{\tilde{p}}(z|X) - \pi_D(z|X)) dz \Bigg]
\end{align*}Evaluating the inner integrals at the point mass $`(\tilde{y}, \tilde{p})`$ yields:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} &= h(\tilde{x}) - \Psi(\mathcal{P}) + \frac{F^\pi(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})} \tilde{y} - \int_0^\infty \frac{f_{Y,P}(1, z|\tilde{x})}{\pi_D(z|\tilde{x})} F^\pi(z|\tilde{x}) dz \\
&\quad - \frac{\mu(\tilde{x}, \tilde{p}) F^\pi(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})} + \int_0^\infty \mu(\tilde{x}, z) F^\pi(z|\tilde{x}) dz \\
&= h(\tilde{x}) - \Psi(\mathcal{P}) + \frac{F^\pi(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})} (\tilde{y} - \mu(\tilde{x}, \tilde{p})) - h(\tilde{x}) + h(\tilde{x})
\end{align*}For the specific functional provided, the EIF is:
\begin{align*}
\frac{F^\pi(P|X)}{\pi_D(P|X)} (Y - \mu(X, P)) + h(X) - \Psi(\mathcal{P})
\end{align*}Case 2: unknown behavior pricing policy $`\pi_D`$
This case is similar to above, but with an extra term corresponding to the unknown $`F^{\pi_D}(z|X) = \int_0^z \pi_D(s|X) ds`$ which is now a functional of $`\mathcal{P}`$.
The estimand of interest is defined as:
\Psi(\mathcal{P}) \equiv \mathcal{S}(\pi_D) = \mathbb{E}_X \left[ \int_{z=0}^{\infty} \mu(X, z) F^{\pi_D}(z|X) dz \right]The pathwise derivative is given by:
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} = \frac{d}{dt} \int f_{X,t}(x) \int_{z=0}^{\infty} \mu_t(x, z) F_{t}^{\pi_D}(z|x) dz dx \Big|_{t=0}Using the product rule and the identities for the derivative of a conditional density and a cumulative distribution, the derivative decomposes into three primary components:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} &= \int \left[ \int_{0}^{\infty} \mu(x, z) F^{\pi_D}(z|x) dz \right] (\delta_{\tilde{x}}(x) - f_X(x)) dx \\
&\quad + \mathbb{E}_X \left[ \int_{0}^{\infty} \frac{\partial \mu_t(X, z)}{\partial t}\Big|_{t=0} F^{\pi_D}(z|X) dz \right] \\
&\quad + \mathbb{E}_X \left[ \int_{0}^{\infty} \mu(X, z) \frac{\partial F_{t}^{\pi_D}(z|X)}{\partial t}\Big|_{t=0} dz \right]
\end{align*}Where the third term is in addition to the terms in case (i), and which we will focus on. Recall that the conditional cumulative distribution is defined as $`F_t^{\pi_D}(z|x) = \frac{H_t(x,z)}{f_t(x)}`$, where $`H_t(x,z) = \int_{-\infty}^z f_t(x, p) dp`$ is the joint cumulative mass. The pathwise derivative of the denominator is $`\frac{\partial f_t(x)}{\partial t} = \delta_{\tilde{x}}(x) - f_X(x)`$. The pathwise derivative of the numerator is $`\frac{\partial H_t(x,z)}{\partial t} = \delta_{\tilde{x}}(x)\mathbb{I}(\tilde{p} \le z) - H(x,z)`$. Applying the quotient rule at $`t=0`$:
\begin{align*}
\frac{\partial F_t^{\pi_D}(z|x)}{\partial t} &= \frac{f_X(x) \frac{\partial H_t}{\partial t} - H(x,z) \frac{\partial f_t}{\partial t}}{f_X(x)^2} \\
&= \frac{f_X(x)[\delta_{\tilde{x}}(x)\mathbb{I}(\tilde{p} \le z) - H] - H[\delta_{\tilde{x}}(x) - f_X(x)]}{f_X(x)^2} \\
&= \frac{\delta_{\tilde{x}}(x) f_X(x) \mathbb{I}(\tilde{p} \le z) - H \delta_{\tilde{x}}(x)}{f_X(x)^2} \\
&= \frac{\delta_{\tilde{x}}(x)}{f_X(x)} \left( \mathbb{I}(\tilde{p} \le z) - \frac{H(x,z)}{f_X(x)} \right) \\
&= \frac{\delta_{\tilde{x}}(x)}{f_X(x)} (\mathbb{I}(\tilde{p} \le z) - F^{\pi_D}(z|x))
\end{align*}Let $`h_D(X) = \int_{0}^{\infty} \mu(X, z) F^{\pi_D}(z|X) dz`$. Evaluating the first integral yields $`h_D(\tilde{x}) - \Psi(\mathcal{P})`$, while for the second term, we apply the quotient rule to $`\mu(X, z)`$, as before. For the third term, we use the identity $`\frac{\partial F_{t}^{\pi_D}(z|X)}{\partial t}\big|_{t=0} = \frac{\delta_{\tilde{x}}(X)}{f_X(X)}(\mathbb{I}(\tilde{p} \le z) - F^{\pi_D}(z|X))`$:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} &= h_D(\tilde{x}) - \Psi(\mathcal{P}) \\
&\quad + \mathbb{E}_X \Bigg[ \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \int_{0}^{\infty} \frac{F^{\pi_D}(z|X)}{\pi_D(z|X)} (\delta_{\tilde{y}, \tilde{p}}(1, z|X) - f_{Y,P}(1, z|X)) dz \\
&\quad - \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \int_{0}^{\infty} \frac{f_{Y,P}(1, z|X) F^{\pi_D}(z|X)}{\pi_D(z|X)^2} (\delta_{\tilde{p}}(z|X) - \pi_D(z|X)) dz \Bigg] \\
&\quad + \mathbb{E}_X \Bigg[ \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \int_{0}^{\infty} \mu(X, z) (\mathbb{I}(\tilde{p} \le z) - F^{\pi_D}(z|X)) dz \Bigg]
\end{align*}Evaluating the inner integrals at the point mass $`(\tilde{y}, \tilde{p})`$ yields:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt}\Big|_{t=0} &= h_D(\tilde{x}) - \Psi(\mathcal{P}) + \frac{F^{\pi_D}(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})} \tilde{y} - \int_0^\infty \frac{f_{Y,P}(1, z|\tilde{x})}{\pi_D(z|\tilde{x})} F^{\pi_D}(z|\tilde{x})- \frac{\mu(\tilde{x}, \tilde{p}) F^{\pi_D}(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})} dz \\
&\quad - \int_0^\infty \mu(\tilde{x}, z) \mathbb{I}(\tilde{p} \le z) dz+ \int_0^\infty \mu(\tilde{x}, z) F^{\pi_D}(z|\tilde{x}) dz -\int_0^\infty \mu(\tilde{x}, z) F^{\pi_D}(z|\tilde{x}) dz\\
&= h_D(\tilde{x}) - \Psi(\mathcal{P}) + \frac{F^{\pi_D}(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})} (\tilde{y} - \mu(\tilde{x}, \tilde{p})) + \int_{\tilde{p}}^\infty \mu(\tilde{x}, z) dz - h_D(\tilde{x})
\end{align*}For the specific functional provided, the EIF is:
\begin{align*}
\frac{F^{\pi_D}(P|X)}{\pi_D(P|X)} (Y - \mu(X, P)) + \int_{P}^{\infty} \mu(X, z) dz - \Psi(\mathcal{P})
\end{align*}◻
Proof of Proposition <a href="#prop: DR" data-reference-type=“ref”
data-reference=“prop: DR”>1 : Double Robustness
Proof. We establish that $`\left|\widetilde {\cal S}_{ACPW}(\pi)-{\cal S}(\pi)\right|=o_p(1)`$ by considering the two conditions of model specification.
Case 1: If the demand model is correctly specified such that $`\sup_{x,p} |\widehat{\mu}(x,p) - {\mu}(x,p)| =o_p(1)`$. We decompose the estimator as:
\begin{align*}
\widetilde {\cal S}_{ACPW}(\pi) &= \frac{1}{n} \sum_{i=1}^n \int_0^\infty \pi(p | X_i) \int_{p}^\infty \widehat\mu(X_i, z) dz dp + \frac{1}{n} \sum_{i=1}^n \frac{F^\pi(P_i | X_i)}{\widehat \pi_D(P_i | X_i)} (Y_i - \widehat \mu(X_i,P_i))\\
&= \frac{1}{n} \sum_{i=1}^n \int_0^\infty \pi(p | X_i) \int_{p}^\infty \mu(X_i, z) dz dp + \frac{1}{n} \sum_{i=1}^n \frac{F^\pi(P_i | X_i)}{\bar \pi_D(P_i | X_i)} (Y_i - \mu(X_i,P_i)) + o_p(1)
\end{align*}Since $`\mathbb{E}[Y_i | X_i, P_i] = \mu(X_i, P_i)`$, the conditional expectation of the second term is:
\mathbb{E}\left[ \frac{F^\pi(P_i | X_i)}{\bar \pi_D(P_i | X_i)} (Y_i - \mu(X_i,P_i)) \bigg| X_i, P_i \right] = \frac{F^\pi(P_i | X_i)}{\bar \pi_D(P_i | X_i)} \big( \mu(X_i, P_i) - \mu(X_i, P_i) \big) = 0Thus, by the Law of Large Numbers, the second term converges to $`0`$. The first term converges to $`{\cal S}(\pi)`$, ensuring consistency even if $`\widehat \pi_D`$ converges to an incorrect limit $`\bar \pi_D \neq \pi_D`$.
Case 2: If the behavior policy is correctly specified in the sense that $`\sup_{x,p} |\widehat{\pi}_D(p|x) - \pi_D(p|x)| =o_p(1)`$. We rewrite the estimator to isolate the effect of the nuisance demand model $`\bar \mu`$:
\begin{align*}
\widetilde {\cal S}_{ACPW}(\pi) &= \frac{1}{n} \sum_{i=1}^n \frac{F^\pi(P_i | X_i)}{\widehat \pi_D(P_i | X_i)} Y_i + \frac{1}{n} \sum_{i=1}^n \left[ \int_0^\infty \pi(p | X_i) \int_{p}^\infty \widehat\mu(X_i, z) dz dp - \frac{F^\pi(P_i | X_i)}{\widehat \pi_D(P_i | X_i)} \widehat \mu(X_i,P_i) \right] \\
&= \frac{1}{n} \sum_{i=1}^n \frac{F^\pi(P_i | X_i)}{\pi_D(P_i | X_i)} Y_i + \underbrace{\mathbb{E} \left[ \int_0^\infty \pi(p | X) \int_{p}^\infty \bar\mu(X, z) dz dp - \frac{F^\pi(P | X)}{\pi_D(P | X)} \bar \mu(X,P) \right]}_{\text{0 by Lemma \ref{lemma: balancing}}} + o_p(1)
\end{align*}The remaining term converges to $`{\cal S}(\pi)`$ by Theorem 1. ◻
Proof of Theorem <a href="#thm:eif aware" data-reference-type=“ref”
data-reference=“thm:eif aware”>3 : EIF Derivation for Inequality-Aware Surplus
Proof. Lemma 5 establishes that the observed tangent space constitutes the entire Hilbert space. Since the tangent space is the entire Hilbert space. There exists a unique influence function. Moreover, it is the efficient influence function.
It remains to calculate the canonical gradient of the functional $`\mathcal{S}^r(\pi)`$. Following the procedure outlined in the proof of Theorem 2, the gradient can be derived in a similar fashion.
Case 1: Target policy evaluation.
Let the inner functional be defined as:
h(X) = \int_0^\infty \pi(p|X) \int_p^\infty \mu(X, z) dz dp = \int_0^\infty \mu(X, z) F^\pi(z|X) dz,where $`\mathcal{S}^r(\pi) = \Psi(\mathcal{P})`$. The full estimand of interest is $`\Psi(\mathcal{P}) = \mathbb{E}_X [h(X)^r]`$. We define the parametric submodel $`\mathcal{P}_t = (1-t)\mathcal{P} + t\delta_{\tilde{x}, \tilde{y}, \tilde{p}}`$. Then the pathwise derivative of the full functional is:
\frac{d\Psi(\mathcal{P}_t)}{dt} \bigg|_{t=0} = \left( h(\tilde{x})^r - \Psi(\mathcal{P}) \right) + \mathbb{E}_X \left[ r h(X)^{r-1} \frac{d h_t(X)}{dt} \bigg|_{t=0} \right]We focus on the conditional derivative $`\frac{d h_t(X)}{dt}`$. Since $`F^\pi`$ is fixed, only $`\mu(X,z)`$ is perturbed. Note that $`\mu(X,z) = \frac{f_{Y,P}(1,z|X)}{\pi_D(z|X)}`$. Applying the chain rule to the perturbation:
\begin{align*}
\frac{d \mu_t(X,z)}{dt} \bigg|_{t=0} &= \frac{d}{dt} \left( \frac{f_{Y,P,t}(1,z|X)}{\pi_{D,t}(z|X)} \right) \bigg|_{t=0} \\
&= \frac{\pi_D(z|X) \frac{d}{dt}f_{Y,P,t}(1,z|X) - f_{Y,P}(1,z|X) \frac{d}{dt}\pi_{D,t}(z|X)}{\pi_D(z|X)^2} \\
&= \frac{1}{\pi_D(z|X)} \left( \delta_{\tilde{y}, \tilde{p}}(1, z|X) - f_{Y,P}(1, z|X) \right) \\
&\quad - \frac{\mu(X,z)}{\pi_D(z|X)} \left( \delta_{\tilde{p}}(z|X) - \pi_D(z|X) \right)
\end{align*}Now, substitute this into the integral for $`h(X)`$:
\begin{align*}
\frac{d h_t(X)}{dt} \bigg|_{t=0} &= \int_0^\infty \frac{d \mu_t(X,z)}{dt} F^\pi(z|X) dz \\
&= \mathbb{I}(X=\tilde{x}) \left[ \frac{F^\pi(\tilde{p}|X)}{\pi_D(\tilde{p}|X)} \tilde{y} - \int \mu(X,z)F^\pi(z|X) dz \right] \\
&\quad - \mathbb{I}(X=\tilde{x}) \left[ \frac{\mu(X,\tilde{p})F^\pi(\tilde{p}|X)}{\pi_D(\tilde{p}|X)} - \int \mu(X,z)F^\pi(z|X) dz \right]
\end{align*}Notice that the integral terms $`\int \mu(X,z)F^\pi(z|X)dz`$ (which equal $`h(X)`$) cancel out:
\begin{align*}
\frac{d h_t(X)}{dt} \bigg|_{t=0} &= \mathbb{I}(X=\tilde{x}) \left[ \frac{F^\pi(\tilde{p}|X)}{\pi_D(\tilde{p}|X)} \tilde{y} - \frac{\mu(X,\tilde{p})F^\pi(\tilde{p}|X)}{\pi_D(\tilde{p}|X)} \right] \\
&= \mathbb{I}(X=\tilde{x}) \left[ \frac{F^\pi(\tilde{p}|X)}{\pi_D(\tilde{p}|X)} (\tilde{y} - \mu(X, \tilde{p})) \right]
\end{align*}Finally, substitute this back into the derivative of $`\Psi(\mathcal{P})`$ and combine with the marginal $`X`$ variation, the resulting EIF is:
\begin{align*}
h(X)^r - \mathcal{S}^r(\pi) + r h(X)^{r-1} \left[ \frac{F^\pi(P|X)}{\pi_D(P|X)} (Y - \mu(X, P)) \right]
\end{align*}Case 2: Behavior policy evaluation.
The estimand is $`\Psi(\mathcal{P}) = \mathbb{E}_X [h(X)^r]`$, where $`h(X) = \int_0^\infty \mu(X, z) F_P(z|X) dz`$. The pathwise derivative is:
\begin{align*}
\frac{d\Psi(\mathcal{P}_t)}{dt} \bigg|_{t=0} &= (h(\tilde{x})^r - \Psi(\mathcal{P})) + \mathbb{E}_X \left[ r h(X)^{r-1} \frac{d h_t(X)}{dt} \bigg|_{t=0} \right]
\end{align*}We now derive the conditional derivative $`\frac{d h}{dt}`$ using the product rule on the two unknown components, $`\mu`$ and $`F_P`$:
\begin{align*}
\frac{d h_t(X)}{dt} \bigg|_{t=0} &= \underbrace{\int_0^\infty \frac{d \mu_t(X,z)}{dt} F_P(z|X) dz}_{\text{Part A: Outcome variation}} + \underbrace{\int_0^\infty \mu(X,z) \frac{d F_{P,t}(z|X)}{dt} dz}_{\text{Part B: CDF variation}}
\end{align*}Evaluating Part A (as derived previously):
\text{Part A} = \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \left[ \frac{F_P(\tilde{p}|X)}{\pi_D(\tilde{p}|X)}(\tilde{y} - \mu(X, \tilde{p})) \right]Evaluating Part B (using the derivative of the CDF $`\frac{d F_{P,t}(z|X)}{dt} = \frac{\delta_{\tilde{x}}(X)}{f_X(X)} (\mathbb{I}(\tilde{p} \leq z) - F_P(z|X))`$):
\begin{align*}
\text{Part B} &= \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \int_0^\infty \mu(X,z) (\mathbb{I}(\tilde{p} \leq z) - F_P(z|X)) dz \\
&= \frac{\delta_{\tilde{x}}(X)}{f_X(X)} \left[ \int_{\tilde{p}}^\infty \mu(X,z) dz - h(X) \right]
\end{align*}Substituting these back into the expectation over $`X`$, the $`\frac{\delta_{\tilde{x}}(X)}{f_X(X)}`$ terms sift the expression to the observed point $`\tilde{x}`$:
\begin{align*}
\text{EIF}(\tilde{x}, \tilde{y}, \tilde{p}) &= h(\tilde{x})^r - \Psi(\mathcal{P}) + r h(\tilde{x})^{r-1} \left[ \frac{F_P(\tilde{p}|\tilde{x})}{\pi_D(\tilde{p}|\tilde{x})}(\tilde{y} - \mu(\tilde{x}, \tilde{p})) + \int_{\tilde{p}}^\infty \mu(\tilde{x}, z) dz - h(\tilde{x}) \right]
\end{align*}Dropping the tildes for the general form $`(X, Y, P)`$:
\text{EIF} = h(X)^r + r h(X)^{r-1} \left[ \frac{(Y - \mu(X,P))F_P(P|X)}{\pi_D(P|X)} + \int_P^\infty \mu(X,z) dz - h(X) \right] - \mathcal{S}^r(\pi_D)◻
Proof of Theorem <a href="#thm:dr rate" data-reference-type=“ref”
data-reference=“thm:dr rate”>4 : Asymptotic Normality for Target Policy
We prove results for CPW, ACPW, and DM in the following sections. First we state the necessary assumptions to prove this result for the DM,
Assumptions for the Direct Method
Assumption 5 (Assumptions required for the DM). *(i)
$`\sqrt{\mathbb{E}\left[\widehat \mu(X,P)-\mu(X,P)\right]^2}=o_p(1).`$
(ii) The demand function is estimated using a function class
$`\mathcal{R}`$ that satisfies the Donsker property.
(iii) The estimated demand function satisfies
\begin{align*}
\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- Y_i \right)=o_p(n^{-1/2}), \mbox{ where } \omega(x,p)=\frac{F^\pi(p | x)}{\pi_D(p | x)}.
\end{align*}(iv) Assume $`\pi_D(p \, | \,x)>c`$, for all $`p \in {\cal P}`$, and every $`x`$, for some constant $`c`$.*
Assumption 5 (i) is relatively mild, as it merely requires $`\widehat \mu`$ to be consistent, with no rate specified. Assumption 5 (ii) imposes a complexity (size) constraint on the function class used for estimating the demand function. Intuitively speaking, a Donsker class is a collection of functions that is not too large or too complex. This helps ensure that the average behavior of these functions becomes stable as we collect more data. Assumption 5 (iii) is mild and holds when the ratio $`\omega(x,p)`$ belongs to the function class $`\mathcal{R}`$. For instance, when $`\mathcal{R}`$ contains Hölder smooth functions, a series logistic regression estimator based on the sieve approach satisfies Assumption 5 (iii).
Proof for Part (iii): CPW for Target Policy Evaluation
Proof. Denote $`\epsilon_i \equiv Y_i-\mu(X_i,P_i)`$. Recall that the EIF is
\begin{align*}
h(X_i) + \omega(X_i,P_i)(Y_i-\mu(X_i,P_i))-\mathcal S(\pi)=h(X_i) + \omega(X_i,P_i)\epsilon_i-\mathcal S(\pi),
\end{align*}where $`h(X)\equiv \int_0^\infty\pi(p | X) \int_{p}^\infty \mu(X, z)dzdp .`$
Then the CPW estimator $`\widehat S_{CPW}(\pi)`$ is
\begin{align*}
& \widehat S_{CPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i) Y_i= \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i) \mu(X_i,P_i)+\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i\\
= &\; \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i) \phi(X_i,P_i)^\top \beta +\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i + \underbrace{O(L^{-s/d}) }_{o_p(n^{-1/2}) \mbox{ by Assumption \ref{asmp: CPW}}} \\
= &\; \frac{1}{n} \sum_{i=1}^n \phi^\pi(X_i)^\top \beta +\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i +o_p(n^{-1/2}) \\
= &\; \frac{1}{n} \sum_{i=1}^n \int_0^\infty\pi(p | X_i) \int_{p}^\infty \mu(X_i, z) dzdp +\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i +o_p(n^{-1/2})\\
= &\; \underbrace{ \frac{1}{n} \sum_{i=1}^n h(X_i) +\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i)\epsilon_i}_{\frac{1}{n} \sum_{i=1}^n \psi^\pi({\cal D}_i)+S(\pi)}+\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i -\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i)\epsilon_i +o_p(n^{-1/2}).
\end{align*}Thus, it remains to show that
\begin{align*}
\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i -\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i)\epsilon_i =o_p(n^{-1/2}).
\end{align*}According to Lemma 19.24 in , the above holds by noticing that $`\widehat w`$ belongs to the Donsker class and satisfies
\sqrt{\mathbb{E}\left[\widehat \omega(X,P)-\omega(X,P)\right]^2}=o_p(1),and $`\mathbb{E}\left[(\widehat \omega(X,P)-\omega(X,P))\epsilon \right]=0`$.
Rearranging the terms establishes that $`\sqrt{n}(\widehat S_{CPW}(\pi) - S(\pi)) = \frac{1}{\sqrt{n}} \sum_{i=1}^n \psi^\pi(\mathcal{D}_i) + o_p(1)`$. Since the Efficient Influence Functions $`\psi^\pi(\mathcal{D}_i)`$ are i.i.d. with mean zero and finite variance, the Central Limit Theorem implies that this leading term converges in distribution to a normal random variable with variance $`\text{Var}(\psi^{\pi}(\mathcal{D}))`$. This completes the proof. ◻
Proof for Part (ii): ACPW for Target Policy
The proof is based on the cross-fitting technique , which we demonstrated below. We divide the data into $`K`$ approximately equal-sized folds. For each observation $`i`$, we train the nuisance models, i.e., the behavior policy $`\widehat{\pi}_D(P \mid X)`$ and the reward model $`\widehat \mu(X, P)`$, using only the data that does not include observation $`i`$’s fold, denoted by $`-k(i)`$. This yields estimators $`\widehat{\pi}_D^{-k(i)}(P_i \mid X_i)`$ and $`\widehat \mu^{-k(i)}(X_i, P_i)`$ evaluated on the held-out observation $`i`$. This procedure ensures that the nuisance estimates are independent of the data used for evaluation, mitigating overfitting and allowing for valid statistical inference.
Given the propensity score model $`\widehat{\pi}_D^{-k(i)}(P_i|X_i)`$ and reward model $`\widehat \mu^{-k(i)}(X_i,P_i)`$ fitted by cross fitting, the corresponding empirical estimator is
\begin{align}
\widehat{\cal S}_\text{ACPW}(\pi) = \frac{1}{n} \sum_{i=1}^n \bigg[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat\mu^{-k(i)}(X_i, z)dzdp + \frac{F^\pi(P_i | X_i)}{\widehat \pi_D^{-k(i)}(P_i | X_i)}(Y_i - \widehat \mu^{-k(i)}(X_i,P_i))\bigg]
\end{align}Let the oracle estimator be
\begin{align}
\bar{\cal S}_\text{ACPW}(\pi) = \frac{1}{n} \sum_{i=1}^n \bigg[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \mu(X_i, z)dzdp + \frac{F^\pi(P_i | X_i)}{\pi_D(P_i | X_i)}(Y_i - \mu(X_i,P_i))\bigg]
\end{align}We have the following lemma:
Lemma 6. *Under assumptions in Theorem 4 (ii), we have
\bigl|\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi)
-
\bar{\mathcal S}_{\mathrm{ACPW}}(\pi)\bigr|
=o_p(n^{-1/2}),where $`\bar{\mathcal S}_{\mathrm{ACPW}}(\pi)`$ denotes the oracle ACPW estimator.*
Proof. Let $`\{I_k\}_{k=1}^K`$ be a partition of the indices $`\{1, \dots, n\}`$ such that $`|I_k| = n/K`$. We denote $`n_k = |I_k|`$. We decompose the difference as:
\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi) - \bar{\mathcal S}_{\mathrm{ACPW}}(\pi) = D_1(\pi) + D_2(\pi) + D_3(\pi)where each $`D_j(\pi) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \psi_{j,i}`$ for appropriate summands $`\psi_{j,i}`$.
D_1(\pi) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \underbrace{ \left( \frac{F^\pi(P_i \mid X_i)}{\widehat{\pi}_D^{-k(i)}(P_i \mid X_i)} - \frac{F^\pi(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} \right) (Y_i - \mu(X_i, P_i)) }_{\psi_{1,i}}.D_2(\pi) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \underbrace{ \left[ \frac{F^\pi(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} (\mu(X_i, P_i) - \widehat{\mu}^{-k(i)}(X_i, P_i)) - \int F^\pi(z \mid X_i) (\mu(X_i, z) - \widehat{\mu}^{-k(i)}(X_i, z)) dz \right] }_{\psi_{2,i}}D_3(\pi) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \underbrace{ \left( \frac{F^\pi(P_i \mid X_i)}{\widehat{\pi}_D^{-k(i)}(P_i \mid X_i)} - \frac{F^\pi(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} \right) (\mu(X_i, P_i) - \widehat{\mu}^{-k(i)}(X_i, P_i)) }_{\psi_{3,i}}.Term $`D_1(\pi)`$. For a fixed fold $`k`$, let $`\mathcal{D}_k^c`$ denote the data used to estimate $`\widehat{\pi}_D^{-k(i)}`$. For $`i \in I_k`$, the summands are:
\psi_{1,i} = \left( \frac{F^\pi(P_i \mid X_i)}{\widehat{\pi}_D^{-k(i)}(P_i \mid X_i)} - \frac{F^\pi(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} \right) (Y_i - \mu(X_i, P_i))Conditioning on $`\mathcal{D}_k^c`$, the terms $`\{\psi_{1,i}\}_{i \in I_k}`$ are i.i.d. and:
\mathbb{E}[\psi_{1,i} \mid \mathcal{D}_k^c] = \mathbb{E}\left[ \mathbb{E}[\psi_{1,i} \mid X_i, P_i, \mathcal{D}_k^c] \mid \mathcal{D}_k^c \right] = 0since $`\mathbb{E}[Y_i - \mu(X_i, P_i) \mid X_i, P_i] = 0`$. The variance of $`D_1(\pi)`$ satisfies:
\text{Var}(D_1(\pi)) = \frac{1}{n^2} \sum_{k=1}^K \mathbb{E}\left[ \left( \sum_{i \in I_k} \psi_{1,i} \right)^2 \right] = \frac{1}{n^2} \sum_{k=1}^K n_k \mathbb{E}[\psi_{1,i}^2].Under the $`L_2`$-consistency of $`\widehat{\pi}_D^{-k(i)}`$ and bounded overlap, $`\mathbb{E}[\psi_{1,i}^2] = o(1)`$. Thus, $`\text{Var}(D_1(\pi)) = o(n^{-1})`$, which implies $`D_1(\pi) = o_p(n^{-1/2})`$ by Chebyshev’s inequality.
Term $`D_2(\pi)`$. For $`i \in I_k`$, define:
\psi_{2,i} = \frac{F^\pi(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} \Delta\mu_i - \int F^\pi(z \mid X_i) \Delta\mu(X_i, z) dzwhere $`\Delta\mu(X_i, \cdot) = \mu(X_i, \cdot) - \widehat\mu^{-k(i)}(X_i, \cdot)`$. By the balancing property (Lemma 1):
\mathbb{E}\left[ \frac{F^\pi(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} \Delta\mu_i \;\middle|\; X_i, \mathcal{D}_k^c \right] = \int F^\pi(z \mid X_i) \Delta\mu(X_i, z) dzThus $`\mathbb{E}[\psi_{2,i} \mid \mathcal{D}_k^c] = 0`$. Similar to Step 1, the cross-fitting ensures these are uncorrelated across $`i \in I_k`$. Given the $`L_2`$-consistency of $`\widehat{\mu}`$, we also have $`L_2`$-consistency of $`\int F^\pi(z \mid X_i) \widehat \mu(X_i, z) dz`$ (Lemma 2). Similarly by bounding the first term, we have $`\mathbb{E}[\psi_{2,i}^2] = o(1)`$, leading to $`D_2(\pi) = o_p(n^{-1/2})`$.
Term $`D_3(\pi)`$. This is the “product” error term. For each fold $`k`$:
|D_{3,k}(\pi)| \leq \left\| \frac{F^\pi}{\widehat{\pi}_D^{-k(i)}} - \frac{F^\pi}{\pi_D} \right\|_{L_{2,P_k}} \left\| \mu - \widehat\mu^{-k(i)} \right\|_{L_{2,P_k}}where $`L_{2,P_k}`$ denotes the empirical $`L_2`$ norm over fold $`k`$. Under the assumption that $`\|\widehat{\mu}-\mu\|_{L_2} = O_p(n^{-\alpha_1})`$ and $`\|\widehat{\omega}-\omega\|_{L_2} = O_p(n^{-\alpha_2})`$, we have:
|D_3(\pi)| \leq \sum_{k=1}^K \frac{n_k}{n} O_p(n^{-(\alpha_1+\alpha_2)}) = O_p(n^{-(\alpha_1+\alpha_2)})Since $`\alpha_1 + \alpha_2 > 1/2`$, it follows that $`D_3(\pi) = o_p(n^{-1/2})`$.
The result follows from $`D_1(\pi) + D_2(\pi) + D_3(\pi) = o_p(n^{-1/2})`$.
Observing the definition of the Oracle estimator $`\bar{\mathcal S}_{\mathrm{ACPW}}(\pi)`$, we see that it is exactly the sample average of the Efficient Influence Functions plus the true parameter:
\bar{\mathcal S}_{\mathrm{ACPW}}(\pi) = \mathcal{S}(\pi) + \frac{1}{n} \sum_{i=1}^n \psi^\pi(\mathcal{D}_i)where $`\psi^\pi(\mathcal{D}_i)`$ are i.i.d. with mean zero and variance $`\Sigma(\pi) = \text{Var}(\psi^\pi(\mathcal{D}))`$. By the Central Limit Theorem, $`\sqrt{n}(\bar{\mathcal S}_{\mathrm{ACPW}}(\pi) - \mathcal{S}(\pi)) \xrightarrow{d} \mathcal{N}(0, \Sigma(\pi))`$. By Slutsky’s theorem, since the difference between the empirical and oracle estimator is $`o_p(n^{-1/2})`$, the empirical estimator $`\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi)`$ shares the same asymptotic distribution:
\sqrt{n}(\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi) - \mathcal{S}(\pi)) \xrightarrow{d} \mathcal{N}(0, \Sigma(\pi)).◻
Proof for Part (iii): DM for Target Policy
Proof. The direct method estimator $`\widehat S_{DM}(\pi)`$ is obtained by
\begin{gather*}
\widehat S_{DM}(\pi)=\frac{1}{n} \sum_{i=1}^n \widehat h(X_i),
\end{gather*}where
\begin{gather*}
\widehat h(x)= \int_0^\infty\pi(p | x) \int_{p}^\infty \widehat \mu(x, a) dadp.
\end{gather*}It follows that
\begin{align*}
& \widehat S_{DM}(\pi)= \frac{1}{n} \sum_{i=1}^n \widehat h(X_i)-\frac{1}{n} \sum_{i=1}^n h(X_i)+\frac{1}{n} \sum_{i=1}^n h(X_i)\\
= & \, \underbrace{\frac{1}{n} \sum_{i=1}^n \widehat h(X_i)-\frac{1}{n} \sum_{i=1}^n h(X_i)-\mathbb{E}\left[ \widehat h(X)- h(X)\right]}_{o_p(n^{-1/2}) \mbox{ by Lemma 19.24 in \citet{van2000asymptotic}}}+\mathbb{E}\left[ \widehat h(X)- h(X)\right]\\
& \,+\frac{1}{n} \sum_{i=1}^n h(X_i)\\
= & \, \mathbb{E}\left[ \widehat h(X)- h(X)\right]+\frac{1}{n} \sum_{i=1}^n h(X_i)+o_p(n^{-1/2})\\
= & \, \mathbb{E}\left[ \omega(X,P) \left(\widehat \mu(X,P)- \mu(X,P)\right)\right]+\frac{1}{n} \sum_{i=1}^n h(X_i)+o_p(n^{-1/2}),
\end{align*}where the last equation simply follows Equation [eq:balance] in Lemma 1. Denote $`\epsilon_i \equiv Y_i-\mu(X_i,P_i)`$. It then follows that
\begin{align*}
& \mathbb{E}\left[ \omega(X,P) \left(\widehat \mu(X,P)- \mu(X,P)\right)\right]+\frac{1}{n} \sum_{i=1}^n h(X_i)+o_p(n^{-1/2})\\
= & \, \underbrace{\mathbb{E}\left[ \omega(X,P) \left(\widehat \mu(X,P)- \mu(X,P)\right)\right]-\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- \mu(X_i,P_i)\right)}_{o_p(n^{-1/2}) \mbox{ by Lemma 19.24 in \citet{van2000asymptotic}}}\\
& + \frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- \mu(X_i,P_i)\right) +\frac{1}{n} \sum_{i=1}^n h(X_i)+o_p(n^{-1/2})\\
= & \, \frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- \mu(X_i,P_i)\right) +\frac{1}{n} \sum_{i=1}^n h(X_i)+o_p(n^{-1/2})\\
= & \, \frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- Y_i +\epsilon_i \right) +\frac{1}{n} \sum_{i=1}^n h(X_i)+o_p(n^{-1/2})\\
= & \, \underbrace{\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- Y_i \right)}_{o_p(n^{-1/2}) \mbox{ by Assumption \ref{asmp: dm}}} + \underbrace{\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \epsilon_i + \frac{1}{n} \sum_{i=1}^n h(X_i)}_{\frac{1}{n} \sum_{i=1}^n \psi^\pi({\cal D}_i)+S(\pi)}+o_p(n^{-1/2}).
\end{align*}Thus we have
\begin{gather*}
\widehat S_{DM}(\pi)= \frac{1}{n} \sum_{i=1}^n \psi^\pi({\cal D}_i)+o_p(n^{-1/2}).
\end{gather*}Since the EIF $`\psi^\pi(\mathcal{D}_i)`$ are i.i.d. with mean zero and finite variance, the Central Limit Theorem implies that this leading term converges in distribution to a normal random variable with variance $`\text{Var}(\psi^{\pi}(\mathcal{D}))`$. This completes the proof. ◻
Asymptotic Normality of Behavioral Policy
This section presents the results for the behavioral surplus estimation. To maintain conciseness, proofs that follow standard procedures or duplicate previous logic have been omitted.
Since the behavior policy $`\pi_D`$ is unknown, the cumulative distribution function $`F^{\pi_D}(p|x)`$ must also be estimated from the data. Consequently, the estimated weight function is given by $`\widehat{\omega}(p|x) = \frac{\widehat{F}^{\pi_D}(p|x)}{\widehat{\pi}_D(p|x)}`$. With a slight abuse of notation, we continue to denote this ratio as $`\widehat{\omega}`$ to reflect its role as the plug-in estimator for the true ratio. We now introduce the following assumptions for the CPW estimator.
Assumption 6 (Assumptions required for the CPW). *(i)
$`\sqrt{\mathbb{E}\left[\widehat \omega(X,P)-\omega(X,P)\right]^2}=o_p(1)`$
, where $`\omega(x,p)\equiv\frac{F^{\pi_D}(p | x)}{\pi_D(p | x)}`$, and
$`\widehat \omega(x,p)\equiv\frac{\widehat F^{\pi_D}(p | x)}{\widehat\pi_D(p | x)}`$
is the estimator of $`\omega(x,p)`$.
(ii) The ratio $`\widehat \omega`$ is estimated using a function class
that satisfies the Donsker property.
(iii) There exist basis functions $`\phi(x,p) \in \mathbb{R}^L`$ and a
vector $`\beta \in \mathbb{R}^L`$ such that
\begin{gather}
\label{eq:approximation_behavior}
\sup_{x,p} |\mu(x,p)-\phi(x,p)^\top \beta | =O(L^{-s/d}),
\end{gather}where $`s`$ is a fixed positive constant.
(iv) The estimated CPW weights satisfy
\begin{gather*}
\left \lVert\frac{1}{n} \sum_{i=1}^n \int_{P_i} \phi(X_i,z)dz- \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\phi(X_i,P_i) \right \rVert_2 =o_p(n^{-1/2}),
\end{gather*}where $`\phi(\cdot, \cdot)`$ is the basis function that satisfy Equation [eq:approximation_behavior].*
Next, we state the asymptotic normality result under the behavioral policy.
Theorem 6. *Suppose that the assumptions in Theorem
3 hold, we have the following
results:
(i) Suppose Assumption
6 holds, and further assume that
the number of basis functions $`L`$ satisfies $`L \gg n^{d/2s}`$, then
the CPW estimator $`\widehat {\cal S}_{CPW}(\pi_D)`$ attains the
semiparametric efficiency bound,
\begin{gather*}
\sqrt{n} \left( \widehat {\cal S}_{CPW}(\pi_D)-{\cal S}(\pi_D)\right)\rightarrow\mathcal{N}\left(0,\mbox{Var}[\psi^{\pi_D}(\cal {D})] \right).
\end{gather*}
```*
*(ii) Under Assumption
<a href="#asmp: ACPW behavior" data-reference-type="ref"
data-reference="asmp: ACPW behavior">7</a>, the ACPW estimator
$`\widehat {\cal S}_{ACPW}(\pi_D)`$ attains the semiparametric
efficiency bound:
``` math
\begin{gather*}
\sqrt{n} \left( \widehat {\cal S}_{ACPW}(\pi_D)-{\cal S}(\pi_D)\right)\rightarrow \mathcal{N}\left(0,\mbox{Var}[\psi^{\pi_D}(\cal {D})] \right).
\end{gather*}(iii) Under Assumption 5, the DM estimator $`\widehat {\cal S}_{DM}(\pi_D)`$ attains the semiparametric efficiency bound,
\begin{gather*}
\sqrt{n} \left( \widehat {\cal S}_{DM}(\pi_D)-{\cal S}(\pi_D)\right)\rightarrow \mathcal{N}\left(0,\mbox{Var}[\psi^{\pi_D}(\cal {D})] \right),
\end{gather*}where $`\psi^{\pi_D}(\cal {D})`$ is the EIF for $`{\cal S}(\pi_D)`$.*
Proof for CPW for Behavioral Policy
Proof. Denote $`\epsilon_i \equiv Y_i-\mu(X_i,P_i)`$. Recall that the EIF is
\begin{align*}
g(X_i,P_i) + \omega(X_i,P_i)(Y_i-\mu(X_i,P_i))-S(\pi_D)=g(X_i,P_i) + \omega(X_i,P_i)\epsilon_i-S(\pi_D),
\end{align*}where $`g(X,P)\equiv \int_{P}^\infty \mu(X, z)dz.`$
Then the CPW estimator $`\widehat S_{CPW}(\pi_D)`$ is
\begin{align*}
& \widehat S_{CPW}(\pi_D)= \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i) Y_i= \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i) \mu(X_i,P_i)+\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i\\
= &\; \frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i) \phi(X_i,P_i)^\top \beta +\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i + \underbrace{O(L^{-s/d}) }_{o_p(n^{-1/2}) \mbox{ by Assumption \ref{asmp: CPW behavior}}} \\
= &\; \frac{1}{n} \sum_{i=1}^n \int_{P_i} \phi(X_i,z)^{\top} \beta dz +\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i +o_p(n^{-1/2}) \\
= &\; \frac{1}{n} \sum_{i=1}^n \int_{P_i}^\infty \mu(X_i, z) dz +\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i +o_p(n^{-1/2})\\
= &\; \underbrace{ \frac{1}{n} \sum_{i=1}^n g(X_i,P_i) +\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i)\epsilon_i}_{\frac{1}{n} \sum_{i=1}^n \psi^{\pi_D}({\cal D}_i)+S(\pi)}+\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i -\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i)\epsilon_i +o_p(n^{-1/2}).
\end{align*}Thus, it remains to show that
\begin{align*}
\frac{1}{n} \sum_{i=1}^n \widehat \omega(X_i,P_i)\epsilon_i -\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i)\epsilon_i =o_p(n^{-1/2}).
\end{align*}According to Lemma 19.24 in , the above holds by noticing that $`\widehat w`$ belongs to the Donsker class and satisfies
\sqrt{\mathbb{E}\left[\widehat \omega(X,P)-\omega(X,P)\right]^2}=o_p(1),and $`\mathbb{E}\left[(\widehat \omega(X,P)-\omega(X,P))\epsilon \right]=0`$.
Rearranging the terms establishes that $`\sqrt{n}(\widehat S_{CPW}(\pi_D) - S(\pi_D)) = \frac{1}{\sqrt{n}} \sum_{i=1}^n \psi^\pi(\mathcal{D}_i) + o_p(1)`$. Since the Efficient Influence Functions $`\psi^{\pi_D}(\mathcal{D}_i)`$ are i.i.d. with mean zero and finite variance, the Central Limit Theorem implies that this leading term converges in distribution to a normal random variable with variance $`\text{Var}(\psi^{\pi_D}(\mathcal{D}))`$. This completes the proof. ◻
Proof for ACPW for Behavioral Policy
Assumption 7 (Assumptions required for the ACPW). *Assume $`\pi_D(p \, | \,x)>c`$, for all $`p \in {\cal P}`$, and every $`x`$, for some constant $`c`$. Suppose that the estimators for the demand function and the behavior policy are constructed using the cross-fitting procedure, and that they achieve the following convergence rate:
\begin{align}
\label{eq: product rate}
\sqrt{\mathbb{E}[(\widehat \mu(X,P)-\mu(X,P))^2]} =O_p(n^{-\alpha_1}), \mbox{ and } \; \sqrt{\mathbb{E}[(\widehat \omega(X,P)-\omega(X,P))^2]}=O_p(n^{-\alpha_2}),
\end{align}with $`\alpha_1, \alpha_2>0`$, and $`\alpha_1+\alpha_2>1/2`$. Note here that $`\widehat \omega =\widehat F^{\pi_D}/\widehat \pi_D.`$*
Proof. We rely on the cross-fitting technique. Let $`\{I_k\}_{k=1}^K`$ be a partition of the indices $`\{1, \dots, n\}`$ such that $`|I_k| = n/K`$. We denote $`n_k = |I_k|`$.
The behavioral ACPW estimator is:
\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi_D) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \left[ \frac{\widehat{F}^{\pi_D,-k(i)}(P_i|X_i)}{\widehat{\pi}_D^{-k(i)}(P_i|X_i)}(Y_i - \widehat{\mu}^{-k(i)}(X_i, P_i)) + \int_{P_i}^\infty \widehat{\mu}^{-k(i)}(X_i, z) dz \right]We compare this to the Oracle estimator (which uses true nuisance parameters but the same observed integral structure):
\bar{\mathcal S}_{\mathrm{ACPW}}(\pi_D) = \frac{1}{n} \sum_{i=1}^n \left[ \frac{F^{\pi_D}(P_i|X_i)}{\pi_D(P_i|X_i)}(Y_i - \mu(X_i, P_i)) + \int_{P_i}^\infty \mu(X_i, z) dz \right]We decompose the difference as:
\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi_D) - \bar{\mathcal S}_{\mathrm{ACPW}}(\pi_D) = D_1(\pi_D) + D_2(\pi_D) + D_3(\pi_D)Term $`D_1(\pi_D)`$:
D_1(\pi_D) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \underbrace{ \left( \frac{\widehat{F}^{\pi_D,-k(i)}(P_i \mid X_i)}{\widehat{\pi}_D^{-k(i)}(P_i \mid X_i)} - \frac{F^{\pi_D}(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} \right) (Y_i - \mu(X_i, P_i)) }_{\psi_{1,i}}.Conditioning on the nuisance training data $`\mathcal{D}_k^c`$, the terms $`\{\psi_{1,i}\}_{i \in I_k}`$ are i.i.d. with mean zero, since $`\mathbb{E}[Y_i - \mu(X_i, P_i) \mid X_i, P_i] = 0`$. The variance of $`D_1`$ is determined by the expected squared error of the weights: $`\mathbb{E}\left[ \left( \widehat \omega-\omega\right)^2 \right]`$. Then, under the $`L_2`$-consistency of $`\widehat \omega`$ (Assumption 7), we have $`\mathbb{E}[\psi_{1,i}^2] = o(1)`$, and by Chebyshev’s inequality, $`D_1(\pi_D) = o_p(n^{-1/2})`$.
Term $`D_2(\pi_D)`$:
D_2(\pi_D) = \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \underbrace{ \left[ \frac{F^{\pi_D}(P_i \mid X_i)}{\pi_D(P_i \mid X_i)} (\mu(X_i, P_i) - \widehat{\mu}^{-k(i)}(X_i, P_i)) - \int_{P_i}^\infty (\mu(X_i, z) - \widehat{\mu}^{-k(i)}(X_i, z)) dz \right] }_{\psi_{2,i}}.Let $`\Delta\mu(X, z) = \mu(X, z) - \widehat{\mu}^{-k(i)}(X, z)`$. To show $`\mathbb{E}[\psi_{2,i} \mid \mathcal{D}_k^c] = 0`$, we check the expectations. The expectation of the integral term (using Fubini’s theorem to switch integration order) is:
\mathbb{E}\left[ \int_{P_i}^\infty \Delta\mu(X_i, z) dz \;\middle|\; X_i \right] = \int_0^\infty \pi_D(p|X_i) \int_p^\infty \Delta\mu(X_i, z) dz dp = \int_0^\infty \Delta\mu(X_i, z) F^{\pi_D}(z|X_i) dz.The expectation of the weighted term is:
\mathbb{E}\left[ \frac{F^{\pi_D}(P_i|X_i)}{\pi_D(P_i|X_i)} \Delta\mu(X_i, P_i) \;\middle|\; X_i \right] = \int_0^\infty \frac{F^{\pi_D}(z|X_i)}{\pi_D(z|X_i)} \Delta\mu(X_i, z) \pi_D(z|X_i) dz = \int_0^\infty \Delta\mu(X_i, z) F^{\pi_D}(z|X_i) dz.Since the expectations match, $`\mathbb{E}[\psi_{2,i} \mid \mathcal{D}_k^c] = 0`$. Given the $`L_2`$-consistency of $`\widehat{\mu}`$, $`\mathbb{E}[\psi_{2,i}^2] = o(1)`$, leading to $`D_2(\pi_D) = o_p(n^{-1/2})`$.
Term $`D_3(\pi_D)`$:
\begin{align*}
& D_3(\pi_D) =\frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \left( \frac{\widehat{F}^{\pi_D,-k(i)}}{\widehat{\pi}_D^{-k(i)}} - \frac{F^{\pi_D}}{\pi_D} \right) (\mu - \widehat{\mu}^{-k(i)}) \\
=& \frac{1}{n} \sum_{k=1}^K \sum_{i \in I_k} \underbrace{ \left( \widehat \omega^{-k(i)} - \omega_i \right) (\mu_i - \widehat{\mu}^{-k(i)}) }_{\psi_{3,i}}.
\end{align*}By the Cauchy-Schwarz inequality, $`|D_3|`$ is bounded by the product of the $`L_2`$ norm of this weight difference and the $`L_2`$ norm of the demand error $`\|\mu - \widehat{\mu}\|_{L_2}`$. Substituting the rates from Assumption 7:
|D_3(\pi_D)| \lesssim \|\widehat\omega - \omega\|_{L_2} \|\mu - \widehat{\mu}\|_{L_2} = O_p(n^{-\alpha_2}) \times O_p(n^{-\alpha_1}) = O_p(n^{-(\alpha_1+\alpha_2)}).Since $`\alpha_1 + \alpha_2 > 1/2`$, it follows that $`D_3(\pi_D) = o_p(n^{-1/2})`$.
We have shown that $`\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi_D) = \bar{\mathcal S}_{\mathrm{ACPW}}(\pi_D) + o_p(n^{-1/2})`$. Observing the definition of the Oracle estimator $`\bar{\mathcal S}_{\mathrm{ACPW}}(\pi_D)`$, we see that it is exactly the sample average of the Efficient Influence Functions plus the true parameter:
\bar{\mathcal S}_{\mathrm{ACPW}}(\pi_D) = \mathcal{S}(\pi_D) + \frac{1}{n} \sum_{i=1}^n \psi^{\pi_D}(\mathcal{D}_i)where $`\psi^{\pi_D}(\mathcal{D}_i)`$ are i.i.d. with mean zero and variance $`\Sigma(\pi_D) = \text{Var}(\psi^{\pi_D}(\mathcal{D}))`$. By the Central Limit Theorem, $`\sqrt{n}(\bar{\mathcal S}_{\mathrm{ACPW}}(\pi_D) - \mathcal{S}(\pi_D)) \xrightarrow{d} \mathcal{N}(0, \Sigma(\pi_D))`$. By Slutsky’s theorem, the empirical estimator $`\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi_D)`$ shares the same asymptotic distribution:
\sqrt{n}(\widehat{\mathcal S}_{\mathrm{ACPW}}(\pi_D) - \mathcal{S}(\pi_D)) \xrightarrow{d} \mathcal{N}(0, \Sigma(\pi_D)).◻
Proof for DM for Behavioral Policy
Proof. The direct method estimator $`\widehat S_{DM}(\pi_D)`$ is obtained by
\begin{gather*}
\widehat S_{DM}(\pi_D)=\frac{1}{n} \sum_{i=1}^n \widehat g(X_i,P_i),
\end{gather*}where
\begin{gather*}
\widehat g(x,p)= \int_{p}^\infty \widehat \mu(x, z) dz.
\end{gather*}It follows that
\begin{align*}
& \widehat S_{DM}(\pi_D)= \frac{1}{n} \sum_{i=1}^n \widehat g(X_i,P_i)-\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)\\
= & \, \underbrace{\frac{1}{n} \sum_{i=1}^n \widehat g(X_i,P_i)-\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)-\mathbb{E}\left[ \widehat g(X,P)- g(X,P)\right]}_{o_p(n^{-1/2}) \mbox{ by Lemma 19.24 in \citet{van2000asymptotic}}}+\mathbb{E}\left[ \widehat g(X,P)- g(X,P)\right]\\
& \,+\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)\\
= & \, \mathbb{E}\left[ \widehat g(X,P)- g(X,P)\right]+\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+o_p(n^{-1/2})\\
= & \, \mathbb{E}\left[ \omega(X,P) \left(\widehat \mu(X,P)- \mu(X,P)\right)\right]+\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+o_p(n^{-1/2}),
\end{align*}where the last equation simply follows Equation [eq:balance] in Lemma 1, by letting $`\pi=\pi_D`$. It then follows that
\begin{align*}
& \mathbb{E}\left[ \omega(X,P) \left(\widehat \mu(X,P)- \mu(X,P)\right)\right]+\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+o_p(n^{-1/2})\\
= & \, \underbrace{\mathbb{E}\left[ \omega(X,P) \left(\widehat \mu(X,P)- \mu(X,P)\right)\right]-\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- \mu(X_i,P_i)\right)}_{o_p(n^{-1/2}) \mbox{ by Lemma 19.24 in \citet{van2000asymptotic}}}\\
& + \frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- \mu(X_i,P_i)\right) +\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+o_p(n^{-1/2})\\
= & \, \frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- \mu(X_i,P_i)\right) +\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+o_p(n^{-1/2})\\
= & \, \frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- Y_i +\epsilon_i \right) +\frac{1}{n} \sum_{i=1}^n g(X_i,P_i)+o_p(n^{-1/2})\\
= & \, \underbrace{\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \left(\widehat \mu(X_i,P_i)- Y_i \right)}_{o_p(n^{-1/2}) \mbox{ by Assumption \ref{asmp: dm}}} + \underbrace{\frac{1}{n} \sum_{i=1}^n \omega(X_i,P_i) \epsilon_i + \frac{1}{n} \sum_{i=1}^n g(X_i,P_i)}_{\frac{1}{n} \sum_{i=1}^n \psi^\pi({\cal D}_i)+S(\pi_D)}+o_p(n^{-1/2}).
\end{align*}Thus we have
\begin{gather*}
\widehat S_{DM}(\pi_D)= \frac{1}{n} \sum_{i=1}^n \psi^\pi({\cal D}_i)+o_p(n^{-1/2}).
\end{gather*}Since the Efficient Influence Functions $`\psi^\pi(\mathcal{D}_i)`$ are i.i.d. with mean zero and finite variance, the Central Limit Theorem implies that this leading term converges in distribution to a normal random variable with variance $`\text{Var}(\psi^{\pi}(\mathcal{D}))`$. This completes the proof. ◻
Corollary 1. *Suppose that the assumptions in Theorem
3 hold, we have the following
results:
(i) Under Assumption 5, the DM estimator
$`\widehat \Delta_{DM}(\pi)`$ attains the semiparametric efficiency
bound,
\begin{gather*}
\sqrt{n} \left( \widehat \Delta_{DM}(\pi)-\Delta(\pi)\right)\rightarrow \mathcal{N}\left(0,\mbox{Var}[\psi^{\Delta}(\cal {D})] \right),
\end{gather*}where $`\psi^{\Delta}(\cal {D})=\psi^{\pi}(\cal {D}) - \psi^{\pi_D}(\cal {D})`$.*
*(ii) Suppose Assumption 3 holds, and further assume that the number of basis functions $`L`$ satisfies $`L \gg n^{d/2s}`$, then the CPW estimator $`\widehat \Delta_{CPW}(\pi)`$ attains the semiparametric efficiency bound,
\begin{gather*}
\sqrt{n} \left( \widehat \Delta_{CPW}(\pi)-\Delta(\pi)\right)\rightarrow\mathcal{N}\left(0,\mbox{Var}[\psi^{\Delta}(\cal {D})] \right).
\end{gather*}
```*
*(iii) Under Assumption <a href="#asmp: ACPW" data-reference-type="ref"
data-reference="asmp: ACPW">4</a>, the ACPW estimator
$`\widehat \Delta_{ACPW}(\pi)`$ attains the semiparametric efficiency
bound:
``` math
\begin{gather*}
\sqrt{n} \left( \widehat \Delta_{ACPW}(\pi)-\Delta(\pi)\right)\rightarrow \mathcal{N}\left(0,\mbox{Var}[\psi^{\Delta}(\cal {D})] \right).
\end{gather*}
```*
</div>
This follows directly from the linearity of the efficient influence
function and the asymptotic normality established in Theorems
<a href="#thm:dr rate" data-reference-type="ref"
data-reference="thm:dr rate">4</a> and
<a href="#thm:dr rate behavior" data-reference-type="ref"
data-reference="thm:dr rate behavior">6</a>.
# Proof of Proposition <a href="#prop:variance" data-reference-type="ref"
data-reference="prop:variance">2</a> : Consistency of Variance Estimators
<div class="proof">
*Proof.* Recall that the three variance estimators share a similar
structure,
``` math
\begin{align*}
&\widehat \Sigma_{CPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu(X_i,z) dzdp + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D (P_i | X_i)}(Y_i - \widehat \mu(X_i,P_i))-\widehat {\cal S}_{CPW}(\pi)\right]^2,\\
&\widehat \Sigma_{ACPW}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i,z) dzdp + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D^{-k(i)} (P_i | X_i)}(Y_i - \widehat \mu^{-k(i)}(X_i,P_i))-\widehat {\cal S}_{ACPW}(\pi)\right]^2,\\
& \widehat \Sigma_{DM}(\pi)= \frac{1}{n} \sum_{i=1}^n \left[\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu(X_i,z) dzdp + \frac{F^\pi(P_i | X_i)}{\widehat\pi_D (P_i | X_i)}(Y_i - \widehat \mu(X_i,P_i))-\widehat {\cal S}_{DM}(\pi)\right]^2.
\end{align*}Thus, all three estimators can be represented as
\begin{gather*}
\widehat{\Sigma}_j(\pi) = \frac{1}{n} \sum_{i=1}^n \left[\widehat h_j(X_i)+\widehat \omega_j(X_i,P_i)(Y_i-\widehat \mu_j(X_i,P_i)) - \widehat {\cal S}_j(\pi) \right]^2,
\end{gather*}for $`j \in \{\text{CPW, ACPW, DM}\}`$.
To show $`\widehat \Sigma_j(\pi)`$ is a consistent estimator, it suffices to show that $`\widehat \Sigma_j(\pi)-\bar\Sigma(\pi)=o_p(1)`$, where $`\bar\Sigma(\pi)`$ is the oracle estimator:
\begin{gather*}
\bar\Sigma(\pi) = \frac{1}{n} \sum_{i=1}^n \left[ h(X_i)+ \omega(X_i,P_i)(Y_i- \mu(X_i,P_i)) - {\cal S}(\pi) \right]^2.
\end{gather*}To establish the consistency of $`\widehat \Sigma_j(\pi)`$, we analyze the difference $`\widehat \Sigma_j(\pi) - \bar \Sigma(\pi)`$:
\begin{align*}
&\widehat \Sigma_j(\pi) - \bar \Sigma(\pi) = \frac{1}{n} \sum_{i=1}^n \Bigg( \left[\widehat h_j(X_i)+\widehat \omega_j(X_i,P_i)(Y_i-\widehat \mu_j(X_i,P_i)) - \widehat {\cal S}_j(\pi) \right]^2 \\
&\qquad - \left[ h(X_i)+ \omega(X_i,P_i)(Y_i- \mu(X_i,P_i)) - {\cal S}(\pi) \right]^2 \Bigg).
\end{align*}Using the identity $`a^2 - b^2 = (a-b)^2 + 2b(a-b)`$, we let the difference between the estimated and oracle terms for observation $`i`$ be:
\begin{align*}
D_{j,i} &= \left[\widehat h_j(X_i) - h(X_i)\right] + \left[\widehat \omega_j(X_i,P_i) - \omega(X_i,P_i)\right](Y_i - \mu(X_i,P_i)) \\
&\quad - \widehat \omega_j(X_i,P_i)(\widehat \mu_j(X_i,P_i) - \mu(X_i,P_i)) - (\widehat {\cal S}_j(\pi) - {\cal S}(\pi)).
\end{align*}Then the difference in variance estimators becomes:
\begin{align*}
\widehat \Sigma_j(\pi) - \bar \Sigma(\pi) &= \frac{1}{n} \sum_{i=1}^n D_{j,i}^2 + \frac{2}{n} \sum_{i=1}^n \left[ h(X_i)+ \omega(X_i,P_i)(Y_i- \mu(X_i,P_i)) - {\cal S}(\pi) \right] D_{j,i}.
\end{align*}By the Cauchy-Schwarz inequality, the second term is bounded by:
\begin{equation*}
2 \sqrt{\bar \Sigma(\pi)} \sqrt{\frac{1}{n} \sum_{i=1}^n D_{j,i}^2}.
\end{equation*}It thus suffices to show that $`\frac{1}{n} \sum_{i=1}^n D_{j,i}^2=o_p(1).`$
Under the assumptions in Theorem 4, all the nuisance estimators are $`L_2`$-consistent, and the resulting estimator $`\widehat {\cal S}_j(\pi)`$ is consistent for $`{\cal S}(\pi)`$. Now we apply the Cauchy-Schwarz inequality $`(a+b+c+d)^2 \leq 4(a^2+b^2+c^2+d^2)`$ to obtain:
\begin{align*}
\frac{1}{n} \sum_{i=1}^n D_{j,i}^2 &\leq \frac{4}{n} \sum_{i=1}^n (\widehat h_j(X_i) - h(X_i))^2 \\
&\quad + \frac{4}{n} \sum_{i=1}^n (\widehat \omega_j(X_i,P_i) - \omega(X_i,P_i))^2(Y_i - \mu(X_i,P_i))^2 \\
&\quad + \frac{4}{n} \sum_{i=1}^n \widehat \omega_j^2(X_i,P_i)(\widehat \mu_j(X_i,P_i) - \mu(X_i,P_i))^2 \\
&\quad + 4(\widehat {\cal S}_j(\pi) - {\cal S}(\pi))^2\\
& \lesssim \frac{1}{n} \sum_{i=1}^n (\widehat h_j(X_i) - h(X_i))^2 + \frac{1}{n} \sum_{i=1}^n (\widehat \omega_j(X_i,P_i) - \omega(X_i,P_i))^2\\
&\quad + \frac{1}{n} \sum_{i=1}^n (\widehat \mu_j(X_i,P_i) - \mu(X_i,P_i))^2 +\underbrace{(\widehat {\cal S}_j(\pi) - {\cal S}(\pi))^2}_{o_p(1) \text{ by Theorem \ref{thm:dr rate}}}.
\end{align*}For $`j \in \{\text{CPW, DM}\}`$, because $`\widehat{\omega}_j,`$ and $`\widehat{\mu}_j`$ belong to a Donsker class, by Lemma 19.24 in and the Slutsky’s theorem, we have:
\begin{align*}
\frac{1}{n} \sum_{i=1}^n (\widehat \mu_j(X_i,P_i) - \mu(X_i,P_i))^2 = \underbrace{\mathbb{E}[(\widehat \mu_j(X,P) - \mu(X,P))^2 ]}_{o_p(1)} + o_p(n^{-1/2}) = o_p(1), \\
\frac{1}{n} \sum_{i=1}^n (\widehat \omega_j(X_i,P_i) - \omega(X_i,P_i))^2 = \underbrace{\mathbb{E}[(\widehat \omega_j(X,P) - \omega(X,P))^2 ]}_{o_p(1)} + o_p(n^{-1/2}) = o_p(1).
\end{align*}By Lemma 2, we have
\begin{align*}
\frac{1}{n} \sum_{i=1}^n (\widehat h_j(X_i) - h(X_i))^2 = \underbrace{\mathbb{E}[(\widehat h_j(X) - g(X,P))^2 ]}_{o_p(1)} + o_p(n^{-1/2}) = o_p(1).
\end{align*}Thus, we have
\frac{1}{n} \sum_{i=1}^n D_{j,i}^2=o_p(1).For $`j = \text{ACPW}`$, the proof follows a procedure similar to that of Theorem 4; we omit the details here for brevity. This thus completes the proof. ◻
Proof of Theorem <a href="#thm: aware rate" data-reference-type=“ref”
data-reference=“thm: aware rate”>5: Asymptotic Normality for Inequality-Aware Surplus
Proof. It suffices to show that
\begin{align*}
\frac{1}{n}\sum_{i=1}^n \Bigg[ r \frac{(Y_i-\widehat \mu^{-k(i)}(X_i,P_i))F^\pi(P_i|X_i)}{\widehat{\pi}^{-k(i)}_D(P_i|X_i)} \left(\int_0^\infty \pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp\right)^{r-1} \\
+ \left(\int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp \right)^r \Bigg] \\
- \frac{1}{n}\sum_{i=1}^n \Bigg[ r \frac{(Y_i- \mu(X_i,P_i))F^\pi(P_i|X_i)}{{\pi}_D(P_i|X_i)} \left(\int_0^\infty \pi(p | X_i) \int_{p}^\infty \mu(X_i, z)dzdp\right)^{r-1} \\
+ \left(\int_0^\infty\pi(p | X_i) \int_{p}^\infty \mu(X_i, z)dzdp \right)^r \Bigg]= o_p(n^{-1/2}),
\end{align*}Recall that
\begin{gather*}
\widehat h (X_i)= \int_0^\infty\pi(p | X_i) \int_{p}^\infty \widehat \mu(X_i, z)dzdp, \mbox{ and } \widehat\omega(X_i,P_i) = \frac{F^\pi(P_i|X_i)}{\widehat{\pi}_D(P_i|X_i)}
\end{gather*}In what follows, we let $`\mu_i`$, $`\omega_i`$ and $`h_i`$ denote $`\mu(X_i, P_i)`$, $`\omega(X_i, P_i)`$, and $`h(X_i)`$ respectively. Where the context is clear, these symbols also apply to their corresponding estimators.
It follows that
\begin{align*}
&\widehat {\cal S}^r(\pi)=
\frac{1}{n}\sum_{i=1}^n \Bigg[ r \widehat\omega^{-k(i)}(X_i,P_i) (Y_i-\widehat \mu^{-k(i)}(X_i,P_i)) \widehat h^{-k(i)} (X_i)^{r-1}
+ \widehat h^{-k(i)} (X_i)^r \Bigg] \\
= & \frac{1}{n}\sum_{i=1}^n \Bigg[ r (\widehat \omega^{-k(i)}-\omega_i+\omega_i) (\mu_i+\varepsilon_i-\widehat \mu^{-k(i)}) \widehat h^{-k(i)} (X_i)^{r-1}
+ \widehat h^{-k(i)} (X_i)^r \Bigg]\\
= & \underbrace{\frac{1}{n}\sum_{i=1}^n \Bigg[ r (\widehat\omega^{-k(i)}-\omega_i) (\mu_i-\widehat \mu^{-k(i)}) \widehat h^{-k(i)} (X_i)^{r-1} \Bigg]}_{J_1}+ \underbrace{\frac{1}{n}\sum_{i=1}^n \Bigg[ r (\widehat \omega^{-k(i)}-\omega_i) \varepsilon_i \widehat h^{-k(i)} (X_i)^{r-1} \Bigg]}_{J_2}\\
& + \underbrace{\frac{1}{n}\sum_{i=1}^n \Bigg[ r \omega_i \varepsilon_i \widehat h^{-k(i)} (X_i)^{r-1} \Bigg]}_{J_3}+ \underbrace{\frac{1}{n}\sum_{i=1}^n \Bigg[ r \omega_i (\mu_i-\widehat \mu^{-k(i)}) \widehat h^{-k(i)} (X_i)^{r-1} \Bigg]+\frac{1}{n}\sum_{i=1}^n \widehat h^{-k(i)} (X_i)^r}_{J_4}.
\end{align*}Here, $`J_1`$ represents the product error term, since $`\widehat h^{-k(i)}`$ is uniformly bounded, $`J_1`$ can be bounded using an argument similar to that used for $`D_3`$ in the proof of Theorem 4.
As for $`J_2`$, it is mean zero. Also note that the term $`\widehat h^{-k(i)}`$ is uniformly bounded, thus $`J_2`$ can be bounded following the logic applied to $`D_1`$ in the same proof. It follows that both $`J_1`$ and $`J_2`$ are of order $`o_p(n^{-1/2})`$.
We now deal with $`J_3`$. By applying the mean value theorem to $`\widehat h^{-k(i)} (X_i)^{r-1}`$, we have
\begin{gather*}
\widehat h^{-k(i)} (X_i)^{r-1}=h_i^{r-1}+(r-1)\dot h_i ^{r-2} ( \widehat h^{-k(i)} (X_i)-h_i),
\end{gather*}where $`\dot h_i`$ is the intermediate value, i.e.,
$`\dot h_i=t\widehat h^{-k(i)} (X_i)+(1-t)h_i`$, for some $`0 Thus we have Since $`\widehat h^{-k(i)} (X_i)`$ and $`h_i`$ are uniformly bounded,
$`\bar h_i`$ is also bounded. Thus, the second term in the above
equation is $`o_p(n^{-1/2})`$, since it has mean zero and
$`\widehat h^{-k(i)}(X_i)`$ has $`L_2`$ consistency (the argument
parallels the bound for $`J_2`$ above). Thus we have shown that We finally deal with $`J_4`$. Recall that We first apply the mean value theorem to
$`\widehat h^{-k(i)} (X_i)^{r}`$, where $`\bar h_i`$ is the intermediate value. Then we apply the mean value theorem again to
$`\widehat h^{-k(i)} (X_i)^{r-1}`$, we have where $`\widetilde h_i`$ is intermediate value between
$`\widehat h^{-k(i)} (X_i)`$ and $`\bar h_i`$. Now plug Equations [eq: mvt 1] and
[eq: mvt 2] into term $`J_4`$, we have We first deal with the second term $`I_2`$, since $`\omega_i`$ and
$`\widetilde h_i`$ are uniformly bounded, by applying the
Cauchy-Schwarz, we have since $`\alpha_1>1/4.`$ It remains to show that $`I_1+I_3=o_p(\sqrt{1/n}).`$ By the balancing
property in Lemma 1, $`I_1+I_3`$ has mean zero. It
thus suffices to show that Similar to bound $`J_2`$ before, because $`\widehat \mu^{-k(i)}`$ and
$`\widehat h^{-k(i)}`$ are both $`L_2`$ consistent (Lemma
2), the above two equations
hold. Thus we have
$`J_4=\frac{1}{n}\sum_{i=1}^n h_i^{r}+o_p(\sqrt{1/n})`$. To summarize, we have shown that This thus completes the proof. ◻\begin{align*}
&J_3=\frac{1}{n}\sum_{i=1}^n r \omega_i \varepsilon_i \widehat h^{-k(i)} (X_i)^{r-1}\\
= & \frac{1}{n}\sum_{i=1}^n r \omega_i \varepsilon_i h_i (X_i)^{r-1}+\frac{1}{n}\sum_{i=1}^n r(r-1) \omega_i \varepsilon_i \dot h_i ^{r-2} ( \widehat h^{-k(i)} (X_i)-h_i).
\end{align*}\begin{align*}
J_3= \frac{1}{n}\sum_{i=1}^n r \omega_i \varepsilon_i h_i (X_i)^{r-1}+o_p(n^{-1/2}).
\end{align*}\begin{gather*}
J_4=\frac{1}{n}\sum_{i=1}^n \Bigg[ r \omega_i (\mu_i-\widehat \mu^{-k(i)}) \widehat h^{-k(i)} (X_i)^{r-1} \Bigg]+\frac{1}{n}\sum_{i=1}^n \widehat h^{-k(i)} (X_i)^r.
\end{gather*}\begin{gather}
\label{eq: mvt 1}
\widehat h^{-k(i)} (X_i)^{r}=h_i^{r}+r\bar h_i ^{r-1} ( \widehat h^{-k(i)} (X_i)-h_i),
\end{gather}\begin{gather}
\label{eq: mvt 2}
\widehat h^{-k(i)} (X_i)^{r-1}=\bar h_i^{r-1}+(r-1)\widetilde h_i ^{r-2} ( \widehat h^{-k(i)} (X_i)-\bar h_i),
\end{gather}\begin{align*}
& J_4=\frac{1}{n}\sum_{i=1}^n \Bigg[ r \omega_i (\mu_i-\widehat \mu^{-k(i)}) \widehat h^{-k(i)} (X_i)^{r-1} \Bigg]+\frac{1}{n}\sum_{i=1}^n \widehat h^{-k(i)} (X_i)^r\\
=\; & \frac{1}{n}\sum_{i=1}^n \Bigg[ r \omega_i (\mu_i-\widehat \mu^{-k(i)}) (\bar h_i^{r-1}+(r-1)\widetilde h_i ^{r-2} ( \widehat h^{-k(i)} (X_i)-\bar h_i)) \Bigg]\\
& +\frac{1}{n}\sum_{i=1}^n r\bar h_i ^{r-1} ( \widehat h^{-k(i)} (X_i)-h_i)+\frac{1}{n}\sum_{i=1}^n h_i^{r}\\
=\; & \underbrace{\frac{1}{n}\sum_{i=1}^n r \omega_i (\mu_i-\widehat \mu^{-k(i)}) \bar h_i^{r-1}}_{I_1}+\underbrace{\frac{1}{n}\sum_{i=1}^n \Bigg[ r(r-1) \omega_i (\mu_i-\widehat \mu^{-k(i)}) \widetilde h_i ^{r-2} ( \widehat h^{-k(i)} (X_i)-\bar h_i) \Bigg]}_{I_2}\\
& +\underbrace{\frac{1}{n}\sum_{i=1}^n r\bar h_i ^{r-1} ( \widehat h^{-k(i)} (X_i)-h_i)}_{I_3}+\frac{1}{n}\sum_{i=1}^n h_i^{r}.
\end{align*}\begin{align*}
I_2 & \leq C \sqrt{\frac{1}{n}\sum_{i=1}^n (\mu_i-\widehat \mu^{-k(i)})^2} \sqrt{\frac{1}{n}\sum_{i=1}^n ( \widehat h^{-k(i)} (X_i)-\bar h_i)^2} \\
& \leq C \sqrt{\frac{1}{n}\sum_{i=1}^n (\mu_i-\widehat \mu^{-k(i)})^2} \sqrt{\frac{1}{n}\sum_{i=1}^n ( \widehat h^{-k(i)} (X_i)-h_i)^2} =O_p(n^{-2\alpha_1})=o_p(n^{-1/2}),
\end{align*}\begin{gather*}
\mathbb{E}\left[ r \omega_i (\mu_i-\widehat \mu^{-k(i)}) \bar h_i^{r-1}\right]^2=o(1), \mbox{ and }
\mathbb{E}\left[r\bar h_i ^{r-1} ( \widehat h^{-k(i)} (X_i)-h_i)\right]^2=o(1).
\end{gather*}\begin{gather*}
\widehat {\cal S}^r(\pi)=J_3+J_4+o_p(n^{-1/2})=\frac{1}{n}\sum_{i=1}^n \left[ \underbrace{h_i^{r}+r \omega_i \varepsilon_i h_i (X_i)^{r-1}}_{\text{uncentered EIF for }{\cal S}^r(\pi)}\right]+o_p(n^{-1/2}).
\end{gather*}
Asymptotic Normality for Inequality-Aware Surplus for the Behavior Policy
We next present the result for inequality-aware surplus for the behavior policy.
Assumption 8. *Assume $`\pi_D(p \, | \,x)>c`$, for all $`p \in {\cal P}`$, and every $`x`$, for some constant $`c`$. In addition, suppose that the estimators for the demand function and the behavior policy are constructed using the cross-fitting procedure, and that they achieve the following convergence rate:
\begin{align}
\label{eq: product rate}
\sqrt{\mathbb{E}[(\widehat \mu(X,P)-\mu(X,P))^2]} =O_p(n^{-\alpha_1}), \mbox{ and } \; \sqrt{\mathbb{E}[(\widehat \pi_D(P|X)-\pi_D(P|X))^2]}=O_p(n^{-\alpha_2}),
\end{align}with $`\alpha_1>1/4`$, and $`\alpha_2>1/4`$.*
Theorem 7. *Suppose that Assumptions 1, 2, and 8 hold, then
\begin{align*}
\sqrt{n} (\widehat {\cal S}^r(\pi_D)- {\cal S}^r(\pi_D))\rightarrow \mathcal{N}(0,\Sigma^r({\pi_D})),
\end{align*}where $`\Sigma^r({\pi_D})`$ is the variance of the EIF of $`{\cal S}^r(\pi_D)`$.*
Proof. To establish the asymptotic normality of $`\widehat{\mathcal{S}}^r(\pi_D)`$, we show that the estimator is equivalent to the sample average of its efficient influence function (EIF) up to an $`o_p(n^{-1/2})`$ remainder.
Recall that
\begin{align*}
\nonumber \widehat {\cal S}^r&(\pi_D) = \frac{1}{n}\sum_{i=1}^n \Bigg[r \left(\frac{(Y_i-\widehat \mu^{-k(i)}(X_i,P_i))\widehat F^{\pi_D}(P_i|X_i)}{\widehat\pi_D(P_i|X_i)} + \int_{P_i} \widehat \mu^{-k(i)}(X_i,z)dz \right)\\
& \times \left(\int_0^\infty \widehat \pi_D(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp \right)^{r-1}
+ (1-r)\left( \int_0^\infty \widehat\pi_D(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp \right)^r\Bigg].
\end{align*}Let
\begin{gather*}
\widehat g_i=\int_{P_i} \widehat \mu^{-k(i)}(X_i,z)dz,\\
\widehat h_i= \int_0^\infty \widehat\pi_D(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp, \\
\widetilde h_i= \int_0^\infty \pi_D(p | X_i) \int_{p}^\infty \widehat \mu^{-k(i)}(X_i, z)dzdp.
\end{gather*}Note that $`|\widehat h-\widetilde h|_{L_2}=|\widehat \pi_D-\pi_D|_{L_2}=O_p(n^{-\alpha_2})`$, thus $`|\widehat h_i- h_i|_{L_2}=O_p(n^{-\alpha_1}+n^{-\alpha_2})`$
To simplify notation, we suppress the $`-k(i)`$ subscript, noting that nuisance functions are always trained on out-of-sample observations.
Thus, we have
\begin{align*}
\widehat {\cal S}^r(\pi_D) =& \frac{1}{n}\sum_{i=1}^n \Bigg[r \left((Y_i-\widehat \mu_i)\widehat \omega_i + \widehat g_i \right) \widehat h_i^{r-1} + (1-r)\widehat h_i^r\Bigg]\\
=&\frac{1}{n}\sum_{i=1}^n \Bigg[r \left((\varepsilon_i+\mu_i-\widehat \mu_i)(\widehat \omega_i-\omega_i+\omega_i) + \widehat g_i \right) \widehat h_i^{r-1} + (1-r)\widehat h_i^r\Bigg]\\
=&\underbrace{\frac{1}{n}\sum_{i=1}^n r \varepsilon_i(\widehat \omega_i-\omega_i)\widehat h_i^{r-1}}_{o_p(n^{-1/2})} +\underbrace{\frac{1}{n}\sum_{i=1}^n r (\mu_i-\widehat\mu_i)(\widehat \omega_i-\omega_i)\widehat h_i^{r-1}}_{o_p(n^{-1/2})}+\underbrace{\frac{1}{n}\sum_{i=1}^n r \varepsilon_i\omega_i\widehat h_i^{r-1}}_{\frac{1}{n}\sum_{i=1}^n r \varepsilon_i\omega_i h_i^{r-1}+o_p(n^{-1/2})} \\
&+\frac{1}{n}\sum_{i=1}^n r \omega_i ( \mu_i-\widehat\mu_i) \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n r \widehat g_i \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n (1-r) \widehat h_i^{r}.
\end{align*}The first three terms of the above equation can be bounded by applying the exact techniques used for terms $`J_1`$, $`J_2`$ and $`J_3`$ in the proof of Theorem 5.
It follows that
\begin{align*}
\widehat {\cal S}^r(\pi_D) =\frac{1}{n}\sum_{i=1}^n r \varepsilon_i\omega_i h_i^{r-1} +\underbrace{\frac{1}{n}\sum_{i=1}^n r \omega_i ( \mu_i-\widehat\mu_i) \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n r \widehat g_i \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n (1-r) \widehat h_i^{r}}_{Q_1}+o_p(n^{-1/2}).
\end{align*}We now analyze $`Q_1.`$
\begin{align*}
Q_1 &=\frac{1}{n}\sum_{i=1}^n r \omega_i ( \mu_i-\widehat\mu_i) \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n r \widehat g_i \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n (1-r) \widehat h_i^{r}\\
=& \underbrace{\frac{1}{n}\sum_{i=1}^n r \omega_i ( \mu_i-\widehat\mu_i) \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n r (\widehat g_i-g_i) \widehat h_i^{r-1}}_{E_1} +\underbrace{\frac{1}{n}\sum_{i=1}^n r g_i \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n (1-r) \widehat h_i^{r}}_{E_2}\\
\end{align*}We next show the first term $`E_1=o_p(n^{-1/2})`$. Note that $`E_1`$ has zero mean because:
\begin{equation*}
\mathbb{E}[\omega(\mu - \hat{\mu})] = \mathbb{E}[h - \widetilde{h}] = \mathbb{E}[g - \hat{g}],
\end{equation*}where the first equality follows from Lemma 1 and the second arises from the two different representations of demand. By Chebyshev’s inequality, it thus suffices to show that
\begin{gather*}
\mathbb{E}\left[r\omega ( \mu-\widehat\mu) \widehat h^{r-1}+r (\widehat g-g) \widehat h^{r-1} \right]^2=o(1).
\end{gather*}Since $`(a+b)^2 \leq 2(a^2+b^2)`$, it is therefore sufficient to show that
\begin{gather*}
\mathbb{E}\left[r\omega ( \mu-\widehat\mu) \widehat h^{r-1}\right]^2=o(1), \mbox{ and } \mathbb{E}\left[ r (\widehat g-g) \widehat h^{r-1}\right]^2=o(1).
\end{gather*}Since $`r`$, $`\omega`$, and $`\widehat h`$ are bounded, and $`\widehat \mu`$ and $`\widehat g`$ are $`L_2`$ consistent, the above two equations hold. Thus, we have
\begin{gather*}
Q_1=E_2+o_p(n^{-1/2}).
\end{gather*}We now deal with $`E_2`$. It follows that
\begin{align*}
E_2=& \frac{1}{n}\sum_{i=1}^n r g_i \widehat h_i^{r-1}+\frac{1}{n}\sum_{i=1}^n (1-r) \widehat h_i^{r}\\
=& \frac{1}{n}\sum_{i=1}^n r g_i \left[h_i^{r-1} +(r-1)\dot h_i^{r-2}(\widehat h_i-h_i) \right]+\frac{1}{n}\sum_{i=1}^n (1-r) \left[ h_i^{r} +r\bar h_i^{r-1}(\widehat h_i-h_i) \right],
\end{align*}where both $`\dot h_i`$ and $`\bar h_i`$ are the intermediate values between $`\widehat h_i`$ and $`h_i`$. It follows that
\begin{align*}
E_2=\underbrace{\frac{1}{n}\sum_{i=1}^n r g_i h_i^{r-1} +
\frac{1}{n}\sum_{i=1}^n (1-r) h_i^{r}}_{\text{part of the EIF of} {\cal S}^r(\pi_D)} +r(r-1) \left[\underbrace{\frac{1}{n}\sum_{i=1}^n g_i \dot h_i^{r-2}(\widehat h_i-h_i) -\frac{1}{n}\sum_{i=1}^n \bar h_i^{r-1}(\widehat h_i-h_i)}_{G_1}\right],
\end{align*}It remains to show that $`G_1=o_p(n^{-1/2})`$. It follows that
\begin{align*}
G_1=&\frac{1}{n}\sum_{i=1}^n (\widehat h_i-h_i) \left(g_i \dot h_i^{r-2}-\bar h_i^{r-1} \right) \\
=&\frac{1}{n}\sum_{i=1}^n (\widehat h_i-h_i) \left[g_i \left(h_i^{r-2} +(r-2) \ddot h_i^{r-3}(\dot h_i-h_i)\right) -\left(h_i^{r-1}+(r-1)\check h_i^{r-2}(\bar h_i-h_i) \right) \right],
\end{align*}where again $`\ddot h_i`$ and $`\check h_i`$ are the intermediate values. Then we have
\begin{align*}
G_1=&\underbrace{\frac{1}{n}\sum_{i=1}^n (\widehat h_i-h_i) (g_i h_i^{r-2}-h_i^{r-1})}_{H_1} +\underbrace{\frac{1}{n}\sum_{i=1}^n (r-2) g_i\ddot h_i^{r-3} (\widehat h_i-h_i) (\dot h_i-h_i)}_{H_2}\\
& +\underbrace{\frac{1}{n}\sum_{i=1}^n (r-1)\check h_i^{r-2}(\widehat h_i-h_i) (h_i-\bar h_i)}_{H_3}
\end{align*}Here, $`H_1`$ is zero mean, because $`\mathbb{E}(g|X)=h(X)`$. Thus, we have
\mathbb{E}[(\widehat h_i-h_i)^2(g_i h_i^{r-2}-h_i^{r-1})^2]\leq C \mathbb{E}[(\widehat h_i-h_i)^2(g_i h_i^{r-2}-h_i^{r-1})^2]=o(1),and by the Chebechev’s inequality, $`H_1=o_p(n^{-1/2})`$
Then, we have
\begin{align*}
H_2=&\frac{1}{n}\sum_{i=1}^n (r-2) g_i\ddot h_i^{r-3} (\widehat h_i-h_i) (\dot h_i-h_i) \\
\lesssim & \sqrt{\frac{1}{n}\sum_{i=1}^n (\widehat h_i-h_i)^2 }\sqrt{\frac{1}{n}\sum_{i=1}^n (\dot h_i-h_i)^2}\\
\lesssim & \frac{1}{n}\sum_{i=1}^n (\widehat h_i-h_i)^2=O_p\left(n^{-2\alpha_1}\right)+O_p\left(n^{-2\alpha_2}\right).
\end{align*}Here, $`|\widehat h_i- h_i|_{L_2}=O_p(n^{-\alpha_1}+n^{-\alpha_2})`$, since the estimation of $`h_i`$ also requires the estimation of $`\pi_D`$. By Assumption 8, $`\alpha_1>1/4`$, and $`\alpha_2>1/4`$. Thus, $`H_2=o_p(n^{-1/2}).`$
Similarly, we have
\begin{align*}
H_3=O_p\left(n^{-2\alpha_1}\right)+O_p\left(n^{-2\alpha_2}\right)=o_p(n^{-1/2}).
\end{align*}To summarize, we have
\begin{align*}
\widehat {\cal S}^r(\pi_D) =\underbrace{\frac{1}{n}\sum_{i=1}^n r \varepsilon_i\omega_i h_i^{r-1} +\frac{1}{n}\sum_{i=1}^n r g_i h_i^{r-1} +
\frac{1}{n}\sum_{i=1}^n (1-r) h_i^{r}+{\cal S}^r(\pi_D)}_{\text{EIF for } {\cal S}^r(\pi_D) }+o_p(n^{-1/2})
\end{align*}By the Central Limit Theorem, and the Slutsky’s theorem, we have
\sqrt{n}(\widehat{\mathcal S}^r(\pi_D) - \mathcal{S}^r(\pi_D)) \xrightarrow{d} \mathcal{N}(0, \Sigma^r(\pi_D)).◻
Partial Identification
In practice, the overlap assumption (Assumption 2), which requires that every price we wish to evaluate has a positive probability of being assigned under the historical policy, may fail when the firm is unwilling to conduct extensive price experimentation. This may occur when regularly updating prices is logistically challenging (such as in brick-and-mortar retail), in scenarios where changing prices risks customer backlash, or when firms do not want to sacrifice short-term profit. In this case, the surplus is not point-identified—recall Definition 1 for the formal definition. An alternative choice is to establish partial identification bounds for the surplus estimation. For example, if historical data only contains prices between $10 and $20, but the target policy we wish to evaluate includes prices at $5 or $25, the demand in these unobserved regions is unknown. Partial identification provides a credible range (i.e., a minimum and maximum possible value) for the true surplus, rather than a single, unreliable point estimate. To tighten the identification region, we impose a mild regularity condition on the valuation distribution.
Assumption 9 (Log-concavity). For all $`x`$, the demand function $`\mu(x,\cdot)`$ is log-concave.
The log-concavity assumption implies that the hazard rate is monotone, which is a common assumption in the pricing literature . It encompasses a broad range of valuation distributions, including normal, exponential, and uniform . Importantly, it rules out pathological “thick tailed” beliefs that would yield implausibly large surplus in the unobserved price regions. We also note that equation ([model: true model]) directly implies that the purchase probabilities are monotonically decreasing, which further restricts the set of feasible demand functions. Given these conditions, we next present how to construct the partial identification bounds when the overlap assumption is violated.
Partial Identification Bound
We begin by briefly outlining our main idea: consider the purchase probability curve $`\mu(x,z)`$. In regions where the firm experimented, we estimate this curve nonparametrically. In regions without experimentation, the curve is unknown but must lie within the smallest region consistent with Assumption 9 while interpolating the observed points.
Lower Envelope
We denote by $`z_1`$ and $`z_2`$ the closest observed prices to the left and right of $`z`$ for covariate value $`x`$. If no observation lies to the left of $`z`$, we invoke the boundary condition $`z_1 = 0`$, implying $`\mu(x,0)=1`$ for all $`x`$. Conversely, if there is no observation to the right of $`z`$, we set $`z_2 = V_{\max}`$, where $`V_{\max}`$ is the smallest price at which $`Y=0`$ almost surely, so that $`\mu(x, V_{\max}) = 0`$, for all $`x`$. Because $`\log \mu(x,\cdot)`$ is concave, any chord connecting $`(z_1,\log \mu(x, z_1))`$ and $`(z_2,\mu(x, z_2))`$ lies below the graph. Taking the maximum of that chord with the last observed point to the left yields the tightest feasible lower bound at $`z`$. Formally, Lemma 7 establishes this lower bound.
Lemma 7 (Lower Bound). *Under the binary purchasing model in Equation [model: true model], Assumptions 1, and 9, we have $`F_{l}(z, z_1,z_2,x) \equiv e^{l(z, z_1,z_2,x)} \leq \mu(x, z)`$, for all $`x`$, where
\begin{align}
l(z, z_1,z_2,x) = \frac{z-z_2}{z_1-z_2}\log(\mu(x, z_1)) + \frac{z_1-z}{z_1-z_2}\log(\mu(x, z_2)).
\end{align}
```*
</div>
This is proven in Appendix
<a href="#sec:proof_lower_bound_partial" data-reference-type="ref"
data-reference="sec:proof_lower_bound_partial">19.4</a>. Intuitively,
the bound lets the demand curve fall as steeply as the concavity
constraint permits while still passing through the neighbouring data
points. The graphical illustration of the lower bound is shown in
<a href="#fig:lower_bound" data-reference-type="ref"
data-reference="fig:lower_bound">19</a>.
### Upper envelope
The upper bound combines two concavity constraints, one interpolating
the closest pair on the left $`(z_1,z_2)`$ and another interpolating the
closest pair on the right $`(z_3,z_4)`$. The bound at $`z`$ is the
minimum of these two extrapolations as shown in
Lemma <a href="#lemma:upper" data-reference-type="ref"
data-reference="lemma:upper">8</a>. When only one side is observed, we
fall back on the boundary conditions at $`0`$ or $`V_{\max}`$ to close
the gap. The resulting envelope prevents the unobserved segment of the
curve from bending downwards too slowly, which would otherwise generate
unrealistically high surplus.
Now let $`z_1\leq z_2\leq z \leq z_3 \leq z_4`$, if there is no
empirical observed point smaller (larger) than $`z`$, then
$`z_1=\text{NA}, z_2=0`$ ($`z_3=V_\text{max}, z_4=\text{NA}`$). If there
is only one point $`z'`$ smaller (bigger) than $`z`$, then we can set
$`z_1=0,z_2=z'`$ ($`z_3=z', z_4=V_\text{max}`$). Define
``` math
\begin{align*}
u_1(z_1,z_2,x) = \log( \mu(x, z_2)) + \frac{z - z_2}{z_2 - z_1}(\log(\mu(x, z_2)) - \log(\mu(x, z_1))),\\
u_2(z_3,z_4,x) = \log(\mu(x, z_3)) - \frac{z_3 - z}{z_4 - z_3}(\log(\mu(x, z_4)) - \log(\mu(x, z_3))).
\end{align*}We formally state the upper bound in the subsequent lemma.
Lemma 8 (Upper Bound). *Under the assumptions in Lemma 7, we have $`\mu(x,z) \leq F_u(z_1,z_2,z_3,z_4,x)`$, for all $`x`$, where
\begin{align*}
F_u(z_1,z_2,z_3,z_4, x) =
\begin{cases}
\min(e^{u_1},e^{u_2})& z_1, z_2, z_3, z_4 \neq \text{NA}\\
\min(e^{u_1}, \mu(x, z_2)) & z_1, z_2, z_3 \neq \text{NA}, z_4 = \text{NA}\\
\min(e^{u_2}, \mu(x, z_2)) & z_2, z_3, z_4 \neq \text{NA}, z_1 = \text{NA}\\
1 & \text{otherwise}
\end{cases}.
\end{align*}
```*
</div>
### Combined Bound
Given Lemmas <a href="#lower_bound_partial" data-reference-type="ref"
data-reference="lower_bound_partial">7</a> and
<a href="#lemma:upper" data-reference-type="ref"
data-reference="lemma:upper">8</a>, the lower and upper bounds then can
be estimated by $`\widehat{\cal S}_{-}`$ and $`\widehat{\cal S}_{+}`$,
respectively, as defined below,
``` math
\begin{align*}
& \widehat {{\cal S}}_{-} = \frac{1}{n} \sum_{i=1}^n \int_{z=0}^{\infty}
\Big\{\mathbb{I}[\pi_D(z|X_i)\neq 0]\hat{\mathbb{E}}(Y|P=z,X_i) F^\pi(z|X_i) + \mathbb{I}[\pi_D(z|X_i)= 0] \widehat{F}_l(z_2(z),z_3(z),X_i)F^\pi(z|X_i)\Big\}dz,
\end{align*}\begin{align*}
\widehat {{\cal S}}_{+} = \frac{1}{n} \sum_{i=1}^n \int_{z=0}^{\infty}
\Big\{&\mathbb{I}[\pi_D(z|X_i)\neq 0]\hat{\mathbb{E}}(Y|P=z,X_i)F^\pi(z|X_i) \\
&+ \mathbb{I}[\pi_D(z|X_i)= 0]\widehat{F}_{u}(z_1(z),z_2(z),z_3(z),z_4(z),X_i)F^\pi(z|X_i)\Big\}dz
\end{align*}where $`z_1(z)\leq z_2(z)\leq z \leq z_3(z) \leq z_4(z)`$ are the closest empirical observations around $`z`$ given $`x`$. Here $`\widehat{F}_l`$ and $`\widehat{F}_u`$ are using the estimated demand function $`\widehat{\mu}`$ compared to $`F_l`$ and $`F_u`$. If there is no empirical observation, we can use 0 and $`V_\text{max}`$ as $`z_2`$ and $`z_3`$ and set $`z_1, z_4`$ as NA. We can get the similar CPW and ACPW estimators by replacing the first part of the estimator when $`\pi_D(z|X)\neq 0`$. The graphical illustration of the upper bound is shown in 20.
Statistical Properties
Next we provide the estimation error for the estimated partial identification bounds. Let $`z_1 = \max_{\pi_D(\tilde{z})>0, \tilde{z}\leq z} \tilde{z}`$ and $`z_2 = \min_{\pi_D(\tilde{z})>0, \tilde{z}\geq z} \tilde{z}`$, also define
\begin{align*}
{{\cal S}}_{-}^* = \mathbb{E} \int_{z=0}^{\infty}
\Big\{\mathbb{I}[\pi_D(z|X)\neq 0]\mathbb{E}[Y\mid P=z,X]F^\pi(z|X) + \mathbb{I}[\pi_D(z|X)= 0]{F}_{l}(z_1,z_2F^\pi(z|X)\Big\}dz,
\end{align*}\begin{align*}
{{\cal S}}_{+}^* = & \mathbb{E} \int_{z=0}^{\infty}
\Big\{\mathbb{I}[\pi_D(z|X)\neq 0]\mathbb{E}[Y\mid P=z,X]F^\pi(z|X) + \mathbb{I}[\pi_D(z|X)= 0]{F}_{u}(z_1,z_2,z_3,z_4)F^\pi(z|X)\Big\}dz.
\end{align*}We then have the following result.
Theorem 8. Suppose that the conditions in Lemma 7 hold. Furthermore, assume the following convergence rates for the nuisance parameters:
-
$`\sqrt{\mathbb{E}[(\widehat{\mu}(x,p) - \mu(x,p))^2]} = O(n^{-\alpha_1})`$,
-
$`\sqrt{\mathbb{E}[(\widehat{F}_{l}(z_1,z_2,x) - F_{l}(z_1,z_2,x))^2]} = O(n^{-\alpha_2})`$, and $`\sqrt{\mathbb{E}[(\widehat{F}_{u}(z_1,z_2,z_3,z_4, x) - F_{u}(z_1,z_2,z_3,z_4,x))^2]} = O(n^{-\alpha_2})`$,
-
The matching discrepancy satisfies $`\sqrt{\mathbb{E}[(F_{l}(z_1,z_2,x) - F_{l}(z_1(z),z_2(z),x))^2]} = O(n^{-\alpha_3})`$, and $`\sqrt{\mathbb{E}[(F_{u}(z_1,z_2,z_3,z_4,x) - F_{u}(z_1(z),z_2(z),z_3(z),z_4(z),x))^2]} = O(n^{-\alpha_3})`$ .
*Then, we have:
\begin{align*}
(i); |\widehat{\mathcal{S}}_{-} - \mathcal{S}_{-}| &= O_p(n^{-\min \{\alpha_1,\alpha_2,\alpha_3,1/2\}}); \
(ii) ; |\widehat{\mathcal{S}}_{+} - \mathcal{S}_{+}| = O_p(n^{-\min \{\alpha_1,\alpha_2,\alpha_3,1/2\}}).
\end{align*}
```*
</div>
Theorem <a href="#thm:partial_lower" data-reference-type="ref"
data-reference="thm:partial_lower">8</a> establishes the consistency of
our proposed estimators for the upper and lower bounds in regions where
the overlap assumption is violated and is proven in Appendix
<a href="#sec:proof_partial_lower" data-reference-type="ref"
data-reference="sec:proof_partial_lower">19.5</a>. Practically, this
result is crucial for managers seeking to assess the impact of future
pricing policies involving price points that have not been historically
tested.However, a key distinction arises in the convergence properties.
While the ACPW estimator for the point-identified region can achieve the
parametric rate of $`O_p(n^{-1/2})`$ via orthogonality, the partial
identification bounds in Theorem
<a href="#thm:partial_lower" data-reference-type="ref"
data-reference="thm:partial_lower">8</a> rely on the direct method. In
the absence of overlap, we cannot leverage propensity scores to debias
the estimate. Consequently, the convergence rate of the bound estimators
is dominated by the estimation error of the underlying nuisance
functions: the demand learner $`\widehat{\mu}`$, the bound learner
$`\widehat{F}_l`$, and the matching discrepancy (data samples close to
the boundary). Specifically, the error rate is
$`O_p(n^{-\min(\alpha_1, \alpha_2, \alpha_3,1/2)})`$, where these alphas
represent the convergence rates of the nuisance components. As outlined
in Assumption <a href="#asmp: ACPW" data-reference-type="ref"
data-reference="asmp: ACPW">4</a>, flexible nonparametric machine
learning models often achieve rates slower than $`n^{-1/2}`$. Therefore,
the resulting bounds will generally converge at a slower, nonparametric
rate compared to the point estimates in the overlap region.
## Experiments for Partial Identification
To evaluate our partial identification method, we designed a simulation
where the overlap assumption is intentionally violated. In this setup,
we generate a feature vector
$`X\sim U\{0,1\}^{d}, \beta \sim U[-1,1]^{d}, d=10, V=100+300\beta^T X + \epsilon, \epsilon\sim U[0,10], Y=\mathbb{I}[V>P]`$.
$`U\{0,1\}^{d}`$ represents randomly sample $`d`$ bernoulli variables
with a probability of 0.5. The direct model is correctly specified using
a linear model.
Crucially, the price $`P`$ is drawn from a distribution with a gap in
its support, $`P \sim U([9, 9.5] \cup [10, 10.5])`$, creating regions of
non-overlap $`[9.5, 10]`$. The target pricing policy is a uniform policy
sampled from $`[9.1, 9.425, 9.75, 10.075, 10.4]`$, therefore $`9.75`$
would fall into the non-overlap region. The purchase decision is then
given by $`Y = \mathbb{I}[V > P]`$. Our estimation correctly assumes the
linear functional form of the valuation model. We report the results
with 50 runs.
We compare our proposed method against two baselines for context:
- The **Naive** baseline imputes demand in non-overlapping regions with
extreme values (the lower bound is 0 and the upper bound is 1).
- The **Oracle** baseline serves as a theoretical benchmark by using the
true, known demand function.
We report the coverage length, which is the length of the partial
identification interval for each method. The results are presented in
<a href="#fig:partial" data-reference-type="ref"
data-reference="fig:partial">23</a>. The Naive Length (orange line)
remains high and constant regardless of sample size. This is expected.
Without shape constraints, the naive baseline simply uses 0 and 1 as the
demand lower and upper bound, resulting in a wide, uninformative
interval.
The results show that our proposed bounds (blue line) are substantially
tighter than the Naive approach and achieve near-perfect empirical
coverage rates, confirming the robustness of our method. The oracle
method (green) uses the ground-truth demand knowledge and is not
affected by sample size. Empirically, our method and oracle coverage
both achieve near-perfect coverage, however, we note that miscoverage
may happen due to the randomness with finite samples.
<figure id="fig:partial">
<figure id="fig:partial_length">
<img
src="/posts/2026/01/2026-01-03-190652-beyond_demand_estimation__consumer_surplus_evaluat/synthetic_discrete_multimode_ckdenw_lr_length.png" />
<figcaption>Bound Length</figcaption>
</figure>
<figure id="fig:partial_cover">
<img src="/posts/2026/01/2026-01-03-190652-beyond_demand_estimation__consumer_surplus_evaluat/synthetic_discrete_multimode_ckdenw_lr.png" />
<figcaption>Bound Coverage</figcaption>
</figure>
<figcaption>Partial Identification Bounds.</figcaption>
</figure>
## Proof of Lemma <a href="#lower_bound_partial" data-reference-type="ref"
data-reference="lower_bound_partial">7</a>
We omit the conditioning on $`x`$ part for simplicity. Assumption
<a href="#ass: log-concavity" data-reference-type="ref"
data-reference="ass: log-concavity">9</a> implies
``` math
\begin{align}
\log(\bar F(\theta x + (1-\theta))y) \geq \theta \log(\bar F(x)) + (1-\theta)\log(\bar F(y))
\end{align}Let $`\theta = \frac{z-z_2}{z_1-z_2}`$, then we have
\begin{align}
\log(\Bar F_V(z)) \geq \frac{z-z_2}{z_1-z_2}\log(\bar F(z_1 \mid x)) + \frac{z_1-z}{z_1-z_2}\log(\bar F(z_2 \mid x)).
\end{align}The proof is complete by utilizing the monotonicity property.
Proof of Theorem <a href="#thm:partial_lower" data-reference-type=“ref”
data-reference=“thm:partial_lower”>8
Proof. Here we use $`\theta`$ to represent $`S`$ in the main paper. Define
\begin{align}
\tilde {\theta}_{-} = \frac{1}{n} \sum_{i=1}^n \int_{z=0}^{\infty}
\Big\{\mathbb{I}[\pi_D(z|X)\neq 0]\mu(z)F^\pi(z|X) + \mathbb{I}[\pi_D(z|X)= 0]F_l(z,z_1,z_2,X) F^\pi(z|X)\Big\}dz
\end{align}\begin{align}
\mathbb{E}(\widehat{\theta}_{-} - {\theta}_{-}^*)^2 = \mathbb{E}(\widehat{\theta}_{-} - \tilde{\theta}_{-} + \tilde{\theta}_{-} - {\theta}_{-}^*)^2 \leq \mathbb{E}\underbrace{2(\widehat{\theta}_{-} - \tilde{\theta}_{-})^2}_{\text{(i)}} + \mathbb{E}\underbrace{2(\tilde{\theta}_{-} - {\theta}_{-}^*)^2}_{\text{(ii)}}
\end{align}We abbreviate $`F_l(z,z_1,z_2, X)`$ as $`F_l`$, $`\widehat{F}_l( z,z_1(z),z_2(z),X)`$ as $`\widehat{F}_l^o`$, and $`\widehat{F}_l(z,z_1,z_2,X)`$ as $`\widehat{F}_l`$. $`z_{1,2}(z)`$ is the empirical observation and $`z_{1,2}`$ is the closet point in the population.
\begin{align}
\text{(i)} &\leq \frac{2}{n} \sum_{i=1}^n \mathbb{E} \Big( \int_{z=0}^{\infty} \mathbb{I}[\pi_D(z|X)\neq 0](\mu(z)-\widehat \mu(z))F^\pi(z|X) + \mathbb{I}[\pi_D(z|X)= 0](F_l-\widehat{F}_l^o)F^\pi(z|X)\Big)^2 \\
&\leq \frac{4}{n}\sum_{i=1}^n \mathbb{E}\Big( \int_{z=0}^{\infty} \mathbb{I}[\pi_D(z|X)\neq 0](\mu(z)-\widehat \mu(z))F^\pi(z|X)\Big)^2 \\
& \qquad \qquad + \frac{4}{n} \sum_{i=1}^n \mathbb{E}\Big( \int_{z=0}^{\infty}\mathbb{I}[\pi_D(z|X)= 0](F_l-\widehat{F}_l^o)F^\pi(z|X)\Big)^2 \nonumber
\end{align}The first and second inequalities are from Cauchy-Schwartz inequality. Denote the first term as (iii) and the second term as (iv).
\begin{align}
\text{(iii)} & \leq \frac{4}{n} \sum_{i=1}^n \mathbb{E}\Big( \int_{z=0}^{P_\text{max}^D} (\mu(z)-\widehat \mu(z))^2\Big) \int_{z=0}^{P_\text{max}^D}(\mathbb{I}[\pi_D(z|X)\neq 0]F^\pi(z|X))^2 \\
& \leq 4P_\text{max}^D P_\text{max}^D \sup_z \mathbb{E}(\Bar F_V - \widehat \mu)^2 = C_1\epsilon_n
\end{align}We write $`\sup_z \mathbb{E}(\Bar F_V - \widehat{\Bar F}_V)^2 = \epsilon_n`$ and $`C_1 = 4P_\text{max}^D P_\text{max}^D`$.
\begin{align}
\text{(iv)} & = \frac{4}{n} \sum_{i=1}^n \mathbb{E}\Big( \int_{z=0}^{\infty}\mathbb{I}[\pi_D(z|X)= 0](\Bar F_l-{\Bar F}_l^o + {\Bar F}_l^o - \widehat{\Bar F}_l^o)F^\pi(z|X)\Big)^2 \\
& \leq \frac{8}{n} \sum_{i=1}^n\mathbb{E}\Big( \int_{z=0}^{\infty}\mathbb{I}[\pi_D(z|X)= 0](\Bar F_l-{\Bar F}_l^o)F^\pi(z|X)\Big)^2
\\
& \qquad \qquad + \frac{8}{n} \sum_{i=1}^n\mathbb{E}\Big( \int_{z=0}^{\infty}\mathbb{I}[\pi_D(z|X)= 0]({\Bar F}_l^o - \widehat{\Bar F}_l^o)F^\pi(z|X)\Big)^2 \nonumber
\end{align}Denote the first term as (v) and the second term as (vi).
\begin{align}
\text{(v)} & \leq \frac{8}{n}\sum_{i=1}^n\mathbb{E}\Big( \int_{z=0}^{P_\text{max}^D}({\Bar F_l} - {\Bar F}_l^o)\Big)^2 \Big( \int_{z=0}^{P_\text{max}^D}(\mathbb{I}[\pi_D(z|X)= 0]F^\pi(z|X))^2\Big) \\
& \leq {8P_\text{max}^D}^2 \mathbb{E} \sup_{z}(({\Bar F_l} - {\Bar F}_l^o))^2 = 2C_1 \xi_n
\end{align}Assume $`\mathbb{E} \sup_{z}(({\Bar F_l} - {\Bar F}_l^o))^2\leq \xi_n`$,
\begin{align}
\text{(vi)} & \leq \frac{8}{n} \sum_{i=1}^n\mathbb{E}\Big( \int_{z=0}^{P_\text{max}^D}({\Bar F_l}^o - \widehat{\Bar F}_l^o)\Big)^2 \Big( \int_{z=0}^{P_\text{max}^D}(\mathbb{I}[\pi_D(z|X)= 0]F^\pi(z|X))^2\Big) \\
& \leq {8P_\text{max}^D}^2 \sup_z \mathbb{E}({\Bar F}_l^o - \widehat{\Bar F}_l^o)^2 = 2C_1\delta_n.
\end{align}We write $`\sup_z \mathbb{E}(\Bar F_l^0 - \widehat{\Bar F}_l^o)^2 = \delta_n`$.
\begin{align}
\text{(ii)} = \frac{1}{n} 2\text{Var}\left(\int_{z=0}^{\infty}
\Big\{\mathbb{I}[\pi_D(z|X)\neq 0]\mu(z)F^\pi(z|X) + \mathbb{I}[\pi_D(z|X)= 0]F_l(\Bar{F}_V,z_1(z),z_2(z))F^\pi(z|X)\Big\}dz\right)
\end{align}By Popoviciu’s inequality, we have
\begin{align}
\text{(ii)} \leq \frac{2}{n}.
\end{align}Then
\begin{align}
\mathbb{E}(\widehat{\theta}_{-} - {\theta}_{-}^*)^2 \leq 2C_1(\epsilon_n + \xi_n + \delta_n) + \frac{2}{n}.
\end{align}Given the assumptions, we have
\begin{align*}
|\widehat{\theta}_{-} - {\theta}_{-}^*| = O_p\left( n^{-\alpha_1} + n^{-\alpha_2} + n^{-\alpha_3} + n^{-1/2} \right) = O_p(n^{-\min \{\alpha_1,\alpha_2,\alpha_3,1/2\}})
\end{align*}The upper bound’s proof can be constructed similarly. ◻
Implementation of the Personalized Pricing Policy
The personalized pricing policy is implemented as follows. We first fit a demand function $`\widehat{d}(x,p) = \widehat{Pr}(Y=1|x,p)`$, then calculate the estimated reward as $`\widehat \mu(x,p) = p\widehat{d}(x,p)`$. The price is selected using $`P \sim \text{softmax}_{p} \gamma \widehat \mu(x,p)`$, where $`\gamma`$ is the temperature. In all experiments, we set $`r=1`$. When $`r\rightarrow\infty`$, this will correspond to a myopic personalized pricing policy that maximizes reward based on the current best demand estimation.
📊 논문 시각자료 (Figures)
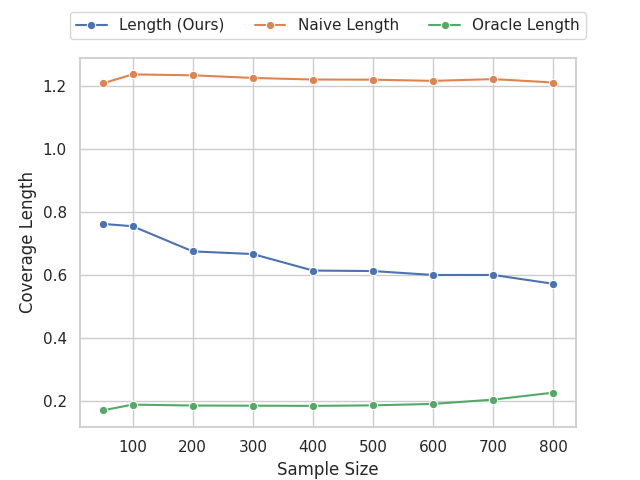
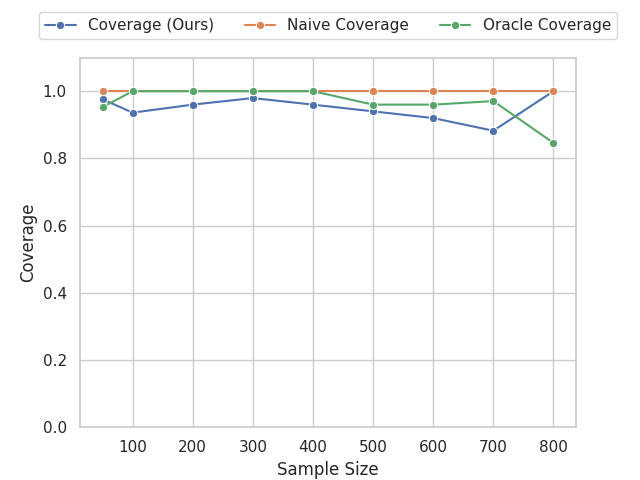
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
In this case, the historic pricing policy is uniform, $`\pi(p'_i )=1`$, so the denominator does not impact the calculation, but would otherwise be the usual inverse propensity correction to make the historical policy as if it were uniform in expectation. ↩︎
Related Posts
Start searching
Enter keywords to search articles
No results found
Try using different keywords