Small language models (SLMs) offer significant deployment advantages but often struggle to match the dialogue quality of larger models in open-domain settings. In this paper, we propose a multi-dimensional prompt-chaining framework that integrates Naturalness, Coherence, and Engagingness dimensions to enhance human-likeness in open-domain dialogue generation. We apply the framework to two SLMs, TinyLlama and Llama-2-7B, and benchmark their performance against responses generated by substantially larger models, including Llama-2-70B and GPT-3.5 Turbo. We then employ automatic and human evaluation to assess the responses based on diversity, contextual coherence, as well as overall quality. Results show that the full framework improves response diversity by up to 29%, contextual coherence by up to 28%, and engagingness as well as naturalness by up to 29%. Notably, Llama-2-7B achieves performance comparable to substantially larger models, including Llama-2-70B and GPT-3.5 Turbo. Overall, the findings demonstrate that carefully designed prompt-based strategies provide an effective and resource-efficient pathway to improving open-domain dialogue quality in SLMs.
💡 Summary & Analysis
1. **Performance Gap Between Large Language Models (LLMs) and Small Language Models (SLMs):** The paper addresses how to use prompt chaining techniques to make SLMs achieve performance levels similar to LLMs with fewer resources.
2. **Multidimensional Prompt Chaining Framework:** This framework is designed in three stages, focusing on improving contextual coherence, naturalness, and engagingness of the generated responses.
3. **Evaluation Metrics and Experimental Design:** The paper employs rigorous evaluation metrics like UniEval, Utterance Entailment (UE) score, and Distinct-N to systematically analyze the performance of the framework.
Simplified Explanation:
Metaphor 1: Large language models are like high-performance supercars whereas small-scale language models resemble economical compact cars. The paper suggests methods to upgrade the smaller car to deliver similar performance as a supercar.
Metaphor 2: Enhancing contextual coherence is akin to smoothly transitioning storylines, naturalness means speaking naturally in conversations, and engagingness refers to captivating the listener’s interest.
Metaphor 3: The experimental design evaluates the framework’s performance like testing a car on various road conditions to understand its capabilities.
Sci-Tube Style Script:
Level 1 (Beginner): Large language models show great performance but require significant resources. This paper proposes ways for small-scale models to achieve similar levels of performance.
Level 2 (Intermediate): The prompt chaining framework emphasizes three key elements in improving dialogue quality through its stages, focusing on enhancing contextual coherence, naturalness, and engagingness.
Level 3 (Advanced): The paper uses a range of experimental designs and evaluation metrics to systematically analyze the framework’s performance. This enables understanding the impact of each element and validating overall quality improvements.
📄 Full Paper Content (ArXiv Source)
# Introduction
Large language models (LLMs) have revolutionized natural language
processing, demonstrating remarkable capabilities in understanding
context and generating human-like responses . These advances in
open-domain dialogue generation enable more meaningful and engaging
conversations with users, with promising applications ranging from
enhanced user engagement to mental health support . Recent researches
has focused on improving response quality through various approaches,
including generating more diverse responses , adapting flexible
strategies or frameworks , and incorporating social norms and
expressions .
However, these advances are predominantly confined to large-scale models
that require substantial computational resources to operate efficiently.
In contrast, Small Language Models (SLMs) offer significant advantages
in terms of computational efficiency, cost-effectiveness, and
adaptability , but struggle to achieve comparable dialogue quality. To
bridge this performance gap between LLMs and SLMs, prompt-based
techniques - especially few-shot in-context learning - has emerged as a
promising approach for enhancing model performance without additional
training or modifying model parameters, with demonstrated effectiveness
for both LLMs and SLMs .
Hence, in this paper, we introduce a novel multidimensional prompt
chaining framework that enables SLMs to achieve performance comparable
to larger models in open-domain dialogue generation. Prompt chaining
decomposes complex tasks into sequential subtasks, where intermediate
outputs from one prompt feed into subsequent prompts. Our framework
leverages this approach to iteratively refine generated responses
through a structured chain in which each prompt focuses on enhancing a
distinct dimension of response quality, specifically contextual
coherence, naturalness, and engagingness. Through systematic
experimentation with various few-shot learning configurations, we
provide empirical evidence that our approach significantly enhances
response quality across both quantitative metrics and qualitative
assessments, enabling SLMs to perform on par with substantially larger
and more resource-intensive LLMs.
The remainder of this paper is organized as follows: We first present
our methodology, including the few-shot generation approach and response
generation workflow. We then describe our experimental variations and
evaluation metrics, followed by automatic metrics and human evaluation
results and discussion of our findings.
Methodology
In this paper, we propose an In-Context Learning prompt chaining
framework to improve the coherence, engagingness and naturalness of
open-domain dialogue responses. We selected these three dimensions to
prioritize human-likeness in open-ended conversational settings . The
quality of the performance is then evaluated, typically based on
multiple dimensions of the response, namely, coherence, engagement and
naturalness.
The framework iterates refinement based on specific qualitative
criteria, as illustrated/outlined below.
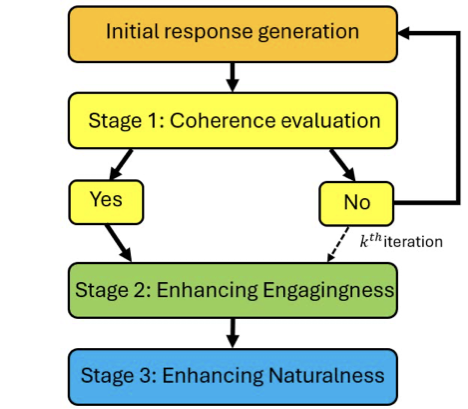
Workflow of the
response generation framework. The process includes: initial response
generation, (1) coherence evaluation with up to k iterations, (2) engagingness
improvement if coherence is achieved and (3) naturalness improvement to
finalize the response.
Initial Response Generation
The first response is generated using a zero-shot approach, with the
utterance–response dialogue history provided as input to the SLM. The
model is instructed to adopt the speaker’s persona and continue the
conversation based on the preceding context. This setup enables the
generation of contextually coherent responses without requiring explicit
demonstration samples.
style="width:75.0%" />
Prompt templates for Stage 1,2 and 3 of the
pipeline.
Stage 1: Coherence Evaluation
The first stage evaluates whether the generated response is contextually
coherent with respect to the dialogue history. Coherence is required to
maintain good conversational flow by being consistent and minimizing
repetition, disfluency and semantic errors . This evaluation employs a
three-shot in-context learning prompt, where each demonstration
comprises a dialogue context, a reference response, and a randomly
selected utterance from a separate conversation. The dialogue context
paired with its reference response serves as a positive example, while
the utterance from the unrelated conversation serves as a negative
example.
To construct these demonstrations, we leverage the training set of the
DailyDialog dataset, which provides the dialogue context and reference
response for each sample. Using an LLM, we generated incoherent
responses for each dialogue context to serve as negative counterparts.
Both the reference and incoherent responses were scored using UniEval, a
top-performing unified evaluator that employs a question-answering
framework to assess multiple dimensions of text generation quality,
including coherence, engagingness, and naturalness . UniEval Coherence
scores are used to select positive and negative demonstrations,
corresponding to the highest and lowest-scoring context-response pairs
respectively.
Following these demonstrations, the model is tasked with classifying its
own response as coherent (“Yes”) or incoherent (“No”). If the response
is deemed incoherent, the process returns to the initial generation
stage (Section 2.1) to produce a new response. This
loop terminates once either a contextually coherent response is
generated or $`k`$ iterations have been reached. In our evaluation, the
iteration limit $`k`$ was set to 5 as preliminary experiments indicated
diminishing returns beyond this threshold.
Stage 2: Enhancing Engagingness
If the response is contextually coherent, the SLM is prompted to revise
the response to enhance its engagingness. Engagement ensures that the
chatbot’s response is novel while encouraging the conversation to
continue . This stage employs a three-shot prompt, with demonstrations
drawn from the DailyDialog training set. For this stage, we generate
unengaging responses for each dialogue context by explicitly prompting
an LLM to generate laconic and passive responses. Both these generated
responses and the reference responses were then evaluated using
UniEval’s engagingness dimension:
where $`S_{\text{ref}}^{\text{E}}`$ and $`S_{\text{uneng}}^{\text{E}}`$
refer to the UniEval engaginess score of the reference response and the
unengaging response respectively. The three dialogues exhibiting the
highest $`\text{Diff}_{\text{eng}}`$ values are used as demonstrations,
with the unengaging responses presented as negative examples and the
corresponding reference responses as positive examples of engaging
output.
Stage 3: Enhancing Naturalness
In Stage 3, the SLM is prompted to improve the naturalness of the
response. Naturalness draws the distinction between the phrasing of the
response, targeting enhanced conversational flow and more human-like
expression . This stage also follows a three-shot approach, again
utilizing the DailyDialog training set. Similarly, to generate a pool of
demonstration samples, we explicitly prompt an LLM to generate unnatural
responses for each dialogue context, and scored both these responses and
the reference responses using UniEval’s naturalness dimension.
Demonstrations are selected based on the largest differences between
reference and unnatural response scores:
where $`S_{\text{ref}}^{\text{N}}`$ and $`S_{\text{uneng}}^{\text{N}}`$
refer to the UniEval naturalness score of the reference response and the
unnatural response respectively.
Experimental Design
We evaluate our proposed framework on TinyLlama and the chat variant of
Llama-2-7B . Dialogue contexts are sourced from the DailyDialog dataset
obtained from HuggingFace, which consists of multi-turn open-domain
conversations that reflect human daily communication without predefined
roles or knowledge grounding . The dataset is human-annotated and
captures natural expressions and emotions, making it an ideal benchmark
for evaluating conversational quality in naturalistic settings. We
compare the results with the language models’ unprompted baseline
generated responses, and, ablate prompt variations to identify the
significance of each dimensions.
Ablation Study
To investigate the contribution of each dimension to the improved
overall quality, we tested 4 configurations of the framework in addition
to the base SLM.
Full framework: Full pipeline.
w/o coherence: Only Stage 2 and 3 of the pipeline.
w/o engagingness: Only Stage 1 and 2 of the pipeline.
w/o naturalness: Only Stage 1 and 3 of the pipeline.
Base: Directly prompting the base SLM without applying our
pipeline.
Each combination was applied for the same dialogue context and response
to generate four responses for each set of dialogue context.
Additionally, we also benchmark our approach by evaluating responses
generated by directly prompting the chat variant of Llama2-70b and
gpt=3.5-turbo.
Evaluation Metrics
To assess the quality of the generated responses across all
configurations, we employed three evaluation metrics to ensure robust
statistical analysis.
UniEval: Using the UniEval LLM-as-a-judge framework , we
extracted scores for coherence, engagingness, and naturalness.
Utterance Entailment (UE) score: Metric that quantifies
contextual coherence by computing the Natural Language Inference
score between the generated response and each utterance in the
dialogue context .
Distinct-N: A diversity metric that measures the proportion of
unique n-grams, which we applied unigrams, bigrams and trigrams in
generated responses . Higher values indicate more varied and less
repetitive outputs.
We normalized the scores where necessary to allow for a fair comparison
across the metrics.
columneven = c, column3 = c, hline1-2,5 = -, stretch=0, colsep = 3.0pt,
rowsep=2pt & Win & Tie & Loss Full vs Base & 59% & 22% & 19% Full vs Llama2-70b & 34% & 42% & 24% Full vs gpt-3.5-turbo & 33% & 35% & 32%
Quantitative human evaluation shows that the full framework in Llama
2-7B achieves results comparable to Llama 2-70B and GPT-3.5. The full
framework achieves the highest lexical diversity for both TinyLlama
and Llama-2-7B, with Distinct-1 scores outperforming their respective
baselines by 0.03. This indicates a broader vocabulary in responses,
enhancing engagement through varied word choice. The full framework also
yields high phrase diversity for Distinct-2 and 3, with TinyLlama
scoring 0.71 (Distinct-2) and 0.86 (Distinct-3) compared to baseline
0.55 and 0.82, respectively, and Llama-2 7B scoring 0.79 and 0.91
against baseline 0.62 and 0.83. These gains reflect stronger diversity
in multi-word sequences, supporting engaging and less repetitive
dialogues when the full framework is applied. More natural and engaging
dialogues lead to stronger phrase diversity as they force the model to
use a wider vocabulary, generating responses that are less cursory and
less generic.
Individual dimension scoring and ablation studies reveal a degree of
Naturalness-Engagingness interdependence. For Tinyllama, the
UniEval-Engagingness scored the highest (2.21) when Naturalness prompt
is excluded, suggesting that Naturalness constraint may over-regularize
or limit the linguistic creativity. While Naturalness scoring favours
conventional and grammatically neutral phrasing, engaging responses
often rely on expressiveness, emotional tone, and stylistic variation.
Enforcing the Naturalness component may unintentionally bias Tinyllama
toward safer, more formulaic outputs—thereby dampening its engaging
qualities. However, the interdependence trend is not reflected in
Llama-2-7B. Although the ablation without Naturalness still has a high
UniEval-Engagingness score (2.22), the full framework remains the
highest scoring for UniEval-Engagingness (2.45). Llama-2-7B may
intrinsically generate more expressive or stylized text. The Naturalness
requirement helps refine and stabilize that expressiveness. In this
case, Naturalness and Engagingness are complementary rather than
competing components. Overall, the interaction between Naturalness and
Engagingness is model-dependent, functioning as competing objectives in
smaller models but complementary dimensions in larger ones.
Coherence introduces a mild trade-off, modestly constraining Naturalness
and Engagingness while remaining critical to overall response quality.
Coherence plays a stabilising role, with its removal allowing
greater stylistic freedom and expressiveness. Nevertheless, the full
framework consistently achieves the highest scores across all
dimensions, indicating that Coherence remains essential in maintaining
structural clarity even if it slightly constraints creativity. This is
further supported by the highest UE-scoring full framework response,
reduced dimension ablations reduced UE scores. Overall, these findings
indicate that Coherence contributes to precision and structure, with
subtle creativity trade-offs in expressiveness.
Overall, the full pipeline produces more diverse, natural, coherent, and
engaging responses, achieving significantly greater scores on all
automatic metrics. Human evaluations corroborate these quantitative
results, consistently rating outputs from the full framework as superior
to those from the base SLM. Additionally, when the full pipeline is
applied, responses generated by SLMs are generally comparable to those
generated by much larger counterparts such as Llama2-70b and
gpt-3.5-turbo in terms of both automatic metrics and human evaluation.
Notably, when compared against Llama-2-70B, applying our pipeline to
Llama2-7b yields even better performance, effectively narrowing the
quality gap between SLMs and LLMs.
Related Work
In-context learning, pioneered by GPT-3 , has emerged as a powerful
paradigm that enables language models to adapt to new tasks by
conditioning on a few demonstration examples within the input prompt,
without requiring parameter updates. In recent years, researchers have
developed more sophisticated techniques including chain-of-thought
prompting , tree-of-thought prompting , and self-consistency prompting.
In the context of dialogue generation, in-context learning has shown
promise. Recent studies have applied few-shot prompting to enhance
dialogue systems, demonstrating improvements in empathetic response
generation , information-seeking dialogue , and persona-consistent
dialogue . With regard to open-domain dialogue specifically, prior work
have leveraged in-context learning to learn implicit pattern information
between contexts and responses , model the one-to-many relationship ,
and to generated relevant questions in mixed initiative open-domain
conversations.
Conclusion
This study shows that integrating Naturalness, Coherence, and
Engagingness within a multi-dimensional prompt-chaining framework
significantly improves the response quality of smaller language models.
The full framework consistently enhances lexical and phrasal diversity,
producing more natural, coherent, and engaging dialogue, with both
automatic metrics and human evaluations indicating increased
human-likeness. Ablation results reveal model-dependent trade-offs
between expressiveness and structure, but demonstrate that combining all
dimensions yields the most balanced outputs. Overall, these findings
highlight that our approach offers a practical and resource-efficient
pathway for narrowing the quality gap between SLMs and larger LLMs in
open-domain dialogue generation. Future work could explore refined
prompt engineering at each stage of the framework, as well as supervised
fine-tuning approaches, to further close the performance gap between
SLMs and their larger counterparts.
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.