Scalable Data-Driven Reachability Analysis and Control via Koopman Operators with Conformal Coverage Guarantees
📝 Original Paper Info
- Title: Scalable Data-Driven Reachability Analysis and Control via Koopman Operators with Conformal Coverage Guarantees- ArXiv ID: 2601.01076
- Date: 2026-01-03
- Authors: Devesh Nath, Haoran Yin, Glen Chou
📝 Abstract
We propose a scalable reachability-based framework for probabilistic, data-driven safety verification of unknown nonlinear dynamics. We use Koopman theory with a neural network (NN) lifting function to learn an approximate linear representation of the dynamics and design linear controllers in this space to enable closed-loop tracking of a reference trajectory distribution. Closed-loop reachable sets are efficiently computed in the lifted space and mapped back to the original state space via NN verification tools. To capture model mismatch between the Koopman dynamics and the true system, we apply conformal prediction to produce statistically-valid error bounds that inflate the reachable sets to ensure the true trajectories are contained with a user-specified probability. These bounds generalize across references, enabling reuse without recomputation. Results on high-dimensional MuJoCo tasks (11D Hopper, 28D Swimmer) and 12D quadcopters show improved reachable set coverage rate, computational efficiency, and conservativeness over existing methods.💡 Summary & Analysis
1. **Scalable Koopman-based Reachability Framework** - **Simple Explanation**: A method to understand complex and unknown robot behaviors. - **Metaphor**: It's like drawing a simple diagram of a complex building to better understand it. - **Sci-Tube Style Script**: "We present a new way to understand the complex dynamics of robots, ensuring safety while getting quick results."-
Approach for Inflating Koopman Reachable Sets Using Conformal Prediction
- Simple Explanation: Considers Koopman model errors to ensure probabilistic safety.
- Metaphor: This is akin to weather forecasting where conditions are adjusted based on changing meteorological factors.
- Sci-Tube Style Script: “We account for the errors in our Koopman models by providing a probabilistic guarantee that ensures safe operation.”
-
Control Design and Reusable Predictive Control
- Simple Explanation: Enables efficiency across multiple controllers by reusing computed information.
- Metaphor: It’s like using various tools to complete construction tasks, where each tool can be reused efficiently.
- Sci-Tube Style Script: “Our design allows for the efficient use of different control strategies, enabling robots to perform a variety of tasks effectively.”
📄 Full Paper Content (ArXiv Source)
safety-critical control, reachability, Koopman operators, conformal prediction
 />
/>
Introduction
Computing reachable sets, i.e., the set of states reachable over a time horizon, is key to robot safety. However, reachability analysis for robots is difficult as they often (i) lack analytical models, (ii) have high-dimensional nonlinear dynamics, and (iii) require reasoning over long horizons. Even if analytical dynamics are available, challenges (ii) and (iii) cause nonlinear reachability tools to become prohibitive or to suffer from excessive overapproximation over long horizons . Data-driven reachability can be used without analytical models, but can be data-inefficient or lack guarantees that the estimated sets contain all possible trajectories. In contrast, linear reachability scales to long horizons and high dimensions . The Koopman framework learns linear dynamics in a lifted state space, e.g., via neural networks (NNs), to approximate the nonlinear system . While computing reachable sets for the Koopman linearization can be more scalable than using the original nonlinear dynamics, existing methods only provide guarantees for the approximate lifted dynamics. Thus, safety may not hold for the true system . Moreover, existing Koopman reachability methods analyze a single dynamical system. However, robots often require multiple controllers to complete different tasks, which forces existing methods to recompute reachable sets from scratch for each new controller, which is inefficient. Reusing previously computed information would enable more efficient reachability analysis across controllers.
To close these gaps in scalability, speed, and reusability, we propose ScaRe-Kro (Scalable Reachability via Koopman Operators), which uses Koopman theory with an NN lifting function to perform reachability analysis and control. Unlike prior Koopman reachability methods for autonomous systems, we also design a linear controller in this lifted space to track a distribution of reference trajectories, each completing a different task. ScaRe-Kro efficiently computes closed-loop reachable sets under the induced linear tracking error dynamics in the lifted Koopman space and maps them to the original state space via NN verification tools. To account for Koopman model error, we apply conformal prediction (CP) to derive statistically-valid error bounds. By inflating the mapped reachable sets with these CP bounds, they are guaranteed to contain the true system trajectories with a user-specified probability (e.g., 97.5%). Moreover, as the CP bounds are calibrated across the trajectory distribution, they can be reused across different references and thus closed-loop systems, unlike prior Koopman approaches that certify only a single autonomous system. Overall, using linear reachability and CP, our method enables scalable data-driven probabilistic verification and control, improving both efficiency and conservativeness over prior work. Our contributions are:
-
A scalable Koopman-based reachability framework for unknown nonlinear dynamics, using NN lifting functions and NN verification to estimate reachable sets in the original state space.
-
An approach for inflating the resulting Koopman reachable sets using CP, to obtain probabilistic guarantees of overapproximation for the true dynamics.
-
Control design in the lifted space for closed-loop tracking of a reference trajectory distribution, with CP-based inflation bounds calibrated to be reusable across the distribution.
-
Extensive evaluation, showing reliable verification for high-dimensional robotic systems (up to 28D), outperforming baselines in safety rate, computation speed, and conservativeness.
Related Work
Reachability via Linear Relaxation
While exact reachable set computation for nonlinear systems is typically intractable, reachable set overapproximations (RSOAs) can often be efficiently computed to certify safety . When the closed-loop system involves NN components (e.g., learned dynamics or controller), RSOAs can be computed via linear relaxation-based NN verification (NNV) tools (e.g., CROWN ) . Here, conservativeness grows with the number of nonlinearities and can be excessive for nonlinear robot dynamics. Symbolic and one-shot methods mitigate this but raise runtime and memory costs . We instead model the robot with Koopman-linearized dynamics, reducing the number of nonlinearities in the CG and improving scalability (i.e., computation time, conservativeness).
Koopman Reachability
Koopman and Carleman linearizations accelerate reachability but introduce approximation error. Moreover, while error bounds exist, these derivations are limited to quadratic or polynomial dynamics , which do not apply to many robot dynamics models. Prior Koopman reachability methods also lack reachable set coverage calibration or guarantee containment only for a finite set of observed trajectories , failing to ensure safety for previously-unseen trajectories of the true system. Prior methods also do not support NN liftings and consider autonomous systems, which corresponds to fixing a single controller. Changing controllers, as often done in robotics, requires repeating the calibration , which is inefficient. In contrast, we support NN liftings, provide probabilistic coverage guarantees for the true dynamics, and integrate control design, enabling data-efficient reachability across multiple controllers.
Data-Driven Reachability
Data-driven reachability uses black-box trajectory data. Some methods adapt Hamilton-Jacobi analysis , but this is costly for high-dimensional systems. Others learn reachability functions but require dense data to accurately generalize, or yield ellipsoidal RSOAs assuming privileged system data (e.g., Lipschitz constants). Sampling-based methods are limited to short horizons. Scenario optimization provides probabilistic guarantees but is slower than Koopman-based methods . Moreover, these methods assume a fixed controller, yet robots often switch controllers to achieve different goals, altering the closed-loop dynamics and forcing reachable sets to be recomputed. Trajectory-tracking reachability provides reusable tracking-error sets across reference trajectories . Data-driven variants learn contraction metrics for tracking-based reachability of unknown systems, but finding such metrics is generally difficult. We build on this work, yielding Koopman reachable sets that are fast to compute, scalable to long horizons, and reusable for various closed-loop dynamics induced by tracking different trajectories.
Preliminaries
We consider unknown, black-box nonlinear systems, either in open-loop [eq:open_loop_dynamics] or closed-loop [eq:closed_loop_dynamics]:
%\label{eq:open_loop_dynamics}
\begin{align}
x_{t+1} &= f(x_t, u_t),
\label{eq:open_loop_dynamics}
\end{align}
\vspace{-30pt}
\begin{align}
x_{t+1} &= f(x_t, \pi(x_t, t)) \doteq \tilde f(x_t),
\label{eq:closed_loop_dynamics}
\end{align}with timestep $`t \in \{0, \dots, T\} \doteq \mathcal{T}`$, state $`x_t \in \mathcal{X}\subseteq \mathbb{R}^n`$, control $`u_t \in \mathcal{U}\subseteq \mathbb{R}^m`$, and feedback control law $`\pi: \mathcal{X} \times \mathcal{T} \rightarrow \mathcal{U}`$. The initial state $`x_0`$ lies in set $`\mathcal{X}_0 \subseteq \mathcal{X}`$. Denote $`\textsf{Int}(\underline{a}, \overline{a}) = \{a \mid \underline{a} \le a \le \overline{a}\}`$, as an interval, where $`\underline{a}, \overline{a} \in \mathbb{R}^A`$ and inequalities hold element-wise, i.e., $`\underline{a}_i \le a_i \le \overline{a}_i`$, $`1 \le i \le A`$. Denote the $`a`$-ball as $`\mathcal{B}_a(c) \doteq \{ x \mid \Vert x - c \Vert_\infty \le a\}`$ and sequence $`q_{1:Q} \doteq \{q_1, q_2, \ldots, q_Q\} = \{q_i\}_{i=1}^Q`$. We use $`\oplus`$ and $`\ominus`$ to denote the Minkowski sum and difference, respectively.
Koopman Operators
As our work relies on Koopman operators, we discuss the basic concepts here. Consider autonomous discrete-time nonlinear dynamics $`x_{t+1} = f(x_t)`$. A Koopman operator $`\mathcal{K}`$ is an infinite-dimensional linear operator that evolves the observables $`\phi^\infty`$ of the state $`\mathcal{K}\phi^\infty(x) = \phi^\infty \circ f(x)`$ according to $`\phi^\infty(x_{t+1}) = \mathcal{K}\phi^\infty(x_t)`$, where $`\circ`$ denotes function composition. As infinite-dimensional Koopman operators are intractable to obtain in practice, we define an approximation to $`\mathcal{K}`$ using a finite-dimensional lifting function $`\phi: \mathcal{X} \rightarrow \mathcal{Z} \subseteq \mathbb{R}^{l}`$ and matrix $`K_{A}\in \mathbb{R}^{l \times l}`$, which define lifted dynamics $`z_{t+1} = K_{A}z_{t}`$, where $`z_t = \phi(x_t)`$ is the lifted state and $`z_{t} \in \mathcal{Z} \subseteq \mathbb{R}^{l}`$. Here, $`l`$ can be arbitrarily selected by the choice of the lifting function $`\phi`$. For systems with control input [eq:open_loop_dynamics], the lifted dynamics can be similarly written as $`z_{t+1} = K_{A}z_{t} + K_{B}u_t`$, where $`K_{B}\in \mathbb{R}^{l \times m}`$. In practice, $`\phi`$, $`K_A`$, and $`K_B`$ can be learned from data, with the lifting function $`g`$ parameterized using polynomials or NNs . In this work, we utilize an NN-based autoencoder architecture, where the encoder $`\phi: \mathcal{X} \rightarrow \mathcal{Z}`$ defines the lifting function and the decoder $`\psi: \mathcal{Z} \rightarrow \hat{\mathcal{X}}`$ defines its learned inverse, i.e., $`\psi(\phi(x)) \approx x`$; if $`\psi`$ is a perfect inverse, $`\psi(\phi(x)) = x`$ and $`\hat{\mathcal{X}} = \mathcal{X}`$.
Reachability via NN Verification (NNV)
We use NNV to compute reachable sets for closed-loop systems involving
NN-based lifting and inverse functions. NNV tools represent an NN as a
computational graph (CG) – a directed acyclic graph encoding the
sequence of operations applied to an input . For some CG $`G`$ with
input set $`\mathcal{S} \subseteq \mathbb{R}^{n_i}`$ and output
$`G(\mathcal{S}) \subseteq \mathbb{R}^{n_o}`$, we can compute a
guaranteed overapproximation of its image $`G(\mathcal{S})`$ using
CROWN-based tools like auto_LiRPA . These tools provide guaranteed
affine lower and upper bounds, $`\underline{G}`$ and $`\overline{G}`$,
on the output $`G(\mathcal{S})`$ for any interval $`\mathcal{S}`$,
formalized in this proposition:
-1For some CG $`G`$ and interval $`\mathcal{S} \doteq \{s \in \mathbb{R}^{n_i} \mid \underline{s} \le s \le \overline{s}\}`$, there are affine functions $`\underline{G}`$, $`\overline{G}`$ such that $`\forall s \in \mathcal{S}`$, $`\underline{G}(s) \leq G(s) \leq \overline{G}(s)`$. The inequalities hold element-wise and $`\underline{G}(s) = \Psi s + \alpha`$, $`\overline{G}(s) = \Phi s + \beta`$, with $`\Psi, \Phi \in \mathbb{R}^{n_o \times n_i}`$ and $`\alpha, \beta \in \mathbb{R}^{n_o}`$.
Given controller $`\pi`$, dynamics
[eq:open_loop_dynamics], and
initial set $`\mathcal{X}_0`$, the $`T`$-timestep exact reachable set is
denoted as
$`\mathcal{X}_{0:T} \doteq \{\mathcal{X}_0, f(\mathcal{X}_t, \pi(\mathcal{X}_t,t)) \}_{t=0}^{T-1}\}`$.
While exact reachability analysis is generally intractable for nonlinear
systems , it is often feasible to compute a reachable set
overapproximation (RSOA) $`\overline{\mathcal{X}}_{0:T}`$, which
satisfies $`\mathcal{X}_t \subseteq \overline{\mathcal{X}}_t`$ for all
$`t \in \{0,\ldots,T\}`$. To obtain $`\overline{\mathcal{X}}_{0:T}`$,
Prop. [thm:cg_robustness] can be
applied to the CG $`F`$ of the $`T`$-step composition
$`{\tilde f^{T}}(\cdot) \doteq \tilde{f} \circ \dotsb \circ \tilde{f}(\cdot)`$
of the closed-loop dynamics $`\tilde f`$
[eq:closed_loop_dynamics],
i.e.,
$`F(x_0) \doteq \{\tilde f(x_t) \doteq f(x_t, \pi(x_t, t)) \}_{t=0}^{T}`$,
with auto_LiRPA computing the RSOA.
Conformal Prediction (CP)
Our RSOA computations also rely on CP. In this work, we adopt split CP, which partitions i.i.d. input-output pairs $`(v^{(i)}, y^{(i)}) \in \mathcal{V}\times\mathcal{Y}`$ from a dataset $`\mathcal{D} \doteq\{(v^{(i)}, y^{(i)})\}_{i=1}^{L+K}`$ into a size-$`L`$ training set $`\mathcal{D}_T`$ and a size-$`K`$ calibration set $`\mathcal{D}_C`$. For a given prediction function $`\mu:\mathcal{V}\!\to\!\mathcal{Y}`$, we compute a nonconformity score $`R^{(i)}\!\doteq s(y^{(i)},\mu(v^{(i)}))`$ for each of the $`K`$ calibration pairs in $`\mathcal{D}_C`$, where $`s: \mathcal{Y}\times \mathcal{Y} \rightarrow \mathbb{R}_{\ge 0}`$ is a chosen nonconformity score function. As an example, we can express the $`\ell_2`$ prediction error of a learned dynamics model $`\hat f`$ in this framework by defining $`v = (x_t, u_t)`$, $`y = x_{t+1}`$, $`\mu(v) = \hat f(v)`$, and $`s(y, \mu(v)) = \Vert y - \mu(v)\Vert_2`$. Given a miscoverage level $`\delta\in(0,1)`$, a threshold $`C`$ is defined as the ($`1-\delta`$)-quantile of the calibration scores, $`C \doteq \text{Quantile}_{1-\delta}(R^{(1)},\dots,R^{(K)},\infty)`$. This threshold defines the prediction set $`\mathcal{Y}(v) \doteq \{\,y\in\mathcal{Y} \mid s(y,\mu(v))\le C \,\}`$, which satisfies the marginal coverage guarantee $`\mathbb{P}(y^{(0)}\in\mathcal{Y}(v^{(0)})) \ge 1-\delta`$ for an unseen data-point $`(y^{(0)}, v^{(0)})`$ that is exchangeable with $`\mathcal{D}`$ .
Problem Statement
-1We are given black-box access to $`f`$ [eq:open_loop_dynamics], i.e., we do not know its analytical form and its output can only be estimated via data. We are a planner $`P: \mathcal{X} \rightarrow \mathcal{X}^{T+1} \times \mathcal{U}^T`$ that generates open-loop reference trajectories $`(x^\textrm{ref}_{0:T}, u^\textrm{ref}_{0:T-1})`$ that satisfy [eq:open_loop_dynamics], starting from an initial condition $`x_0^\textrm{ref} \in \mathcal{X}_0 \ominus \mathcal{B}_\epsilon(0)`$ that is uniformly distributed over $`\mathcal{X}_0 \ominus \mathcal{B}_\epsilon(0)`$. We assume nothing further about $`P`$; it can be a learned or traditional planner. At runtime, the true initial state $`x_0`$ may be perturbed from $`x_0^\textrm{ref}`$, i.e., $`x_0 \in \mathcal{B}_\epsilon(x_0^\textrm{ref})`$, where $`x_0`$ is uniformly distributed over $`\mathcal{B}_\epsilon(x_0^\textrm{ref})`$. To be robust to this error, we design a controller $`\pi: \mathcal{X}\times \mathcal{T}\rightarrow \mathcal{U}`$ that tracks references from $`P`$ and compute high-probability RSOAs $`\overline{\mathcal{X}}_{0:T}`$ for the resulting closed-loop dynamics [eq:closed_loop_dynamics], such that $`\mathbb{P}\big(\bigwedge_{t=0}^T (x_t \in \overline{\mathcal{X}}_t) \big) \ge 1-\delta`$. This process should scale to high-dimensional nonlinear systems over long horizons (e.g., $`n \ge 25`$, $`T \ge 200`$). We solve:
Problem 1 (Model learning & controller design). Given $`N`$ length-$`(T+1)`$ open-loop, dynamically-feasible trajectories generated by $`P`$ via black-box queries of [eq:open_loop_dynamics], forming dataset $`\mathcal{D}=\{(x_{0:T}^{(i)},u_{0:T-1}^{(i)}\}_{i=1}^N`$, (a) train a Koopman model $`(\phi,\psi,K_{A},K_{B})`$ and (b) use the Koopman model to design a time-varying trajectory-tracking controller $`\pi: \mathcal{X} \times \mathcal{T} \rightarrow \mathcal{U}`$ to stabilize to references generated by $`P`$.
Problem 2 (($`1-\delta`$)-confident RSOA computation). Given $`M`$ length-$`(T+1)`$ closed-loop trajectories generated by tracking references from $`P`$ with the controller $`\pi`$ from Prob. 1, compute a ($`1-\delta`$)-confident RSOA $`\overline{\mathcal{X}}_{0:T}`$ for the closed-loop dynamics [eq:closed_loop_dynamics], which guarantees for any random reference $`(x^\textrm{ref}_{0:T}, u^\textrm{ref}_{0:T-1})`$ produced by the planner $`P`$ with $`x_0^\textrm{ref} \in \mathcal{X}_0`$ and initial state $`x_0 \in \mathcal{B}_\epsilon(x_0^\textrm{ref})`$, the closed-loop trajectory remains in $`\overline{\mathcal{X}}_{0:T}`$ with probability at least $`1-\delta`$, i.e., $`\mathbb{P}\big(\bigwedge_{t=0}^T (x_t \in \overline{\mathcal{X}}_t) \big) \ge 1-\delta`$.
Methodology
Our method (Fig. 2, Alg. [alg:online_ckrs]) learns a Koopman operator (Sec. 5.1), uses it for control design (Sec. 5.2), performs fast linear reachability analysis on the closed-loop lifted Koopman dynamics (Sec. 5.3), and inflates these reachable sets via CP to obtain probabilistic coverage guarantees (Sec. 5.4).
Koopman Operator Training
To solve Prob. 1, we train a Koopman operator model $`(\phi, \psi, K_{A}, K_{B})`$ on a dataset $`\mathcal{D} \doteq \{(x_{0:T}^{(i)}, u_{0:T-1}^{(i)})\}_{i=1}^N`$ of open-loop trajectories from a planner $`P`$ (details in Sec. 6). We use a composite loss $`\mathcal{L} = \sum_{i=1}^N(\lambda_1 \mathcal{L}_1^{(i)} + \lambda_2 \mathcal{L}_2^{(i)})`$. The first term, $`\mathcal{L}_{\text{1}}^{(i)} = \sum_{j=0}^{T} \big[\|x_{j}^{(i)} - \psi(\phi(x_{j}^{(i)}))\|^2 + \|\phi(x_j^{(i)}) - \phi(\psi(\phi(x_j^{(i)})))\|^2\big]`$, enforces autoencoder accuracy via state reconstruction error and a latent consistency loss. The second term, $`\mathcal{L}_{\text{2}}^{(i)} = \sum_{j=t+1}^{t+H} \big[\| x_{j}^{(i)} - \psi(\check z_{j}^{(i)})\|^2 + \|\phi(x_{j}^{(i)}) - \check z_j^{(i)}\|^2\big]`$, where $`\check z_j^{(i)} \doteq K_{A}\check z_{j-1}^{(i)} + K_{B}u_{j-1}^{(i)}`$ and $`\check z_0^{(i)}=\phi(x_0^{(i)})`$, is a multi-step (horizon $`H`$) dynamics loss penalizing prediction errors from the linear model ($`K_{A}`$, $`K_{B}`$) in both latent and state space.The latent consistency term is crucial for long-horizon prediction accuracy. We initialize $`K_{A}`$ as identity and $`K_{B}`$ with Xavier uniform, train via learning rate annealing and weight decay, and set ($`\phi, \psi`$) to have ReLU or GELU activations.
Koopman Tracking LQR Design
To reliably imitate state/control reference trajectories generated by the planner $`P`$ in the lifted state space $`\mathcal{Z}`$, a tracking controller $`\pi`$ is required to stabilize against initial condition perturbations $`x_0 - x_0^\textrm{ref}`$ and to reject disturbances due to model error in the learned lifted dynamics $`z_{t+1} = K_{A}z_t + K_{B}u_t`$. To obtain $`\pi`$, we use the linearity of the lifted dynamics to design a linear quadratic regulator (LQR) that tracks trajectories in $`\mathcal{Z}`$. Given a reference state-space trajectory $`x_{0:T}^{\text{ref}}`$ produced by $`P`$, we map it to the lifted state space as $`z_{0:T}^{\text{ref}} \doteq \{\phi(x_t^{\text{ref}})\}_{t=0}^T`$. The corresponding feedforward control trajectory $`u_{0:T-1}^{\text{ref}}`$ which minimizes the lifted-state imitation error is then computed as:
\begin{equation}
\label{eq:u_ff}
u_{t}^{\text{ref}} = K_{B}^{\dagger} (z_{t+1}^{\text{ref}} - K_{A}z_{t}^{\text{ref}}),
\end{equation}where $`K_{B}^{\dagger}`$ is the pseudo-inverse of $`K_{B}`$. The error states $`\delta z_{t} = z_{t} - z^{\text{ref}}_{t}`$ and controls $`\delta u_{t} = u_{t} - u^{\text{ref}}_{t}`$ follow linear error dynamics $`\delta z_{t+1} = K_{A}\delta z_{t} + K_{B}\delta u_{t}`$, starting from an initial error $`\delta z_0 = \phi(x_0) - z^{\text{ref}}_0`$, where $`x_0 \in \mathcal{B}_{\epsilon}(x_{0}^{\text{ref}})`$. We solve an LQR problem, finding the feedback controls $`\delta u_{0:T-1}`$ that minimize the finite-horizon quadratic cost $`\delta z_T^\top Q_T \delta z_T + \sum_{t=0}^{T-1} (\delta z_t^\top Q \delta z_t + \delta u_t^\top R \delta u_t)`$, subject to the linear dynamics $`\delta z_{t+1} = K_{A}\delta z_t + K_{B}\delta u_t`$, where $`Q \succ 0`$, $`R \succ 0`$, and $`Q_T \succ 0`$. In particular, we solve a backward Riccati recursion to obtain the optimal feedback gains $`G_{0:T-1}`$. This yields the tracking control law in the lifted state space [eq:u_latent_cl], which can be applied on the nonlinear system [eq:open_loop_dynamics] as [eq:u_real_cl] by measuring and encoding the state $`x_t`$:
\begin{equation}
\label{eq:u_latent_cl}
u_t = u^{\text{ref}}_t - G_t (z_t - z^{\text{ref}}_t),
\end{equation}\begin{equation}
\label{eq:u_real_cl}
u_t = u^{\text{ref}}_t - G_t (\phi(x_t) - z^{\text{ref}}_t).
\end{equation}Reachability Analysis for Closed-Loop Koopman Dynamics
The high computational cost of nonlinear reachability motivates our use of Koopman operators. Standard RSOA computation repeatedly overapproximates nonlinearities at each timestep in both $`f`$ and $`\pi`$ (which typically must be nonlinear to stabilize $`f`$), leading to high conservativeness. A $`T`$-step RSOA requires $`2T`$ nonlinear function evaluations, causing reachable sets to become vacuously loose as $`T`$ increases. To reduce conservativeness, partition-based methods split the input set $`\overline{\mathcal{X}}_t`$, propagate each partition element, and union the result; however, this incurs computational and memory costs that increases with the cardinality of the partition. In contrast, Koopman-based reachability improves scalability and reduces conservativeness without partitioning overhead by reducing the number of nonlinearities. Mapping to the lifted space $`\mathcal{Z}`$ creates linear dynamics, eliminating the need to bound nonlinearities during propagation. The linear dynamics also permit a linear tracking controller. Consequently, computing an RSOA $`\overline{\mathcal{X}}_t`$ for any timestep $`t`$ requires bounding only a single application of the nonlinear encoder ($`\phi`$) and decoder ($`\psi`$), reducing the number of nonlinear bounding operations from $`2T`$ to just $`2`$. To apply this insight formally for RSOA computation, we define the Tracking Koopman Feedback Loop (TKFL), denoted $`\Gamma`$, as a CG the describes the closed-loop dynamics for tracking $`z_{0:T}^{\text{ref}} \doteq \{\phi(x_t^{\text{ref}})\}_{t=0}^T`$ in the lifted state space using the feedback control law [eq:u_real_cl]. Specifically, the TKFL $`\Gamma: \mathcal{X}_0 \times \mathcal{U}^T \times \mathcal{Z}^{T+1} \rightarrow \hat{\mathcal{X}}^{T+1}`$ maps the initial state $`x_0 \in \mathcal{B}_{\epsilon}(x_{0}^{\text{ref}})`$, the feedforward control trajectory $`u_{0:T-1}^{\text{ref}}`$ [eq:u_ff], and the lifted reference $`z_{0:T}^{\text{ref}}`$ to the decoded trajectory $`\hat{x}_{0:T} \doteq \{\psi(z_{t})\}_{t=0}^T`$ representing the predicted closed-loop trajectory [eq:latent_rollout_tnfl] in the original state space, where the lifted states $`z_t`$ are updated via the closed-loop lifted dynamics [eq:latent_closed_loop]:
\begin{equation}
\label{eq:latent_rollout_tnfl}
\hspace{-23pt}\hat{x}_{0:T} = \{x_0, \{\psi(\tilde f_z(z_t))\}_{t=0}^{T-1}\},
\end{equation}\begin{equation}
\label{eq:latent_closed_loop}
\hspace{-30pt} z_{t+1} = K_{A}z_t + K_{B}(u_t^\textrm{ref} - G_t(z_t - z_t^\textrm{ref})) \doteq \tilde f_z(z_t).\hspace{-20pt}
\end{equation}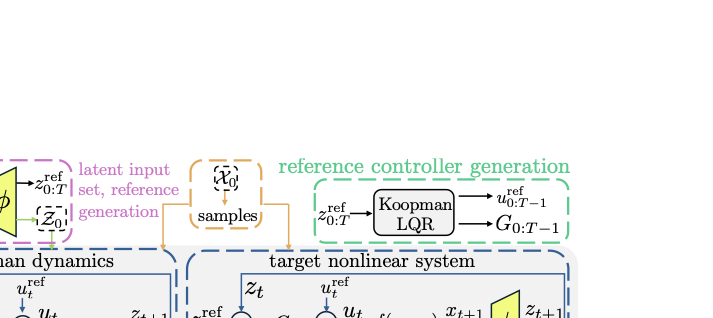 style="width:85.0%" />
style="width:85.0%" />
To summarize, the CG is constructed as follows (see Fig.
2 for visualization). First, we map
the initial state via $`\phi`$ into the latent space, computing
$`z_0 = \phi(x_0)`$. Second, we unroll the $`T`$-fold recursive
application of the single-step latent dynamics,
$`z_{t+1} = K_{A}z_t + K_{B}u_t`$, where $`u_t`$ is the closed-loop
tracking control computed using
[eq:u_latent_cl], to obtain the
latent trajectory $`z_{0:T} = \{z_0, z_2, \cdots, z_T\}`$. Third,
$`z_{0:T}`$ is mapped back to the original state space via the decoder
$`\psi`$ to obtain $`\hat{x}_{0:T}`$. The CG $`\Gamma`$ is passed to the
auto_LiRPA library , which enables set-based bound propagation through
$`\Gamma`$ using CROWN . auto_LiRPA computes vector-valued affine
bounding functions, $`\underline{\Gamma}`$ and $`\overline{\Gamma}`$,
which enables us to compute an RSOA
$`\hat{\overline{\mathcal{X}}}_{0:T}`$ for the decoded closed-loop
lifted dynamics
[eq:latent_rollout_tnfl] by
considering specific components of $`\Gamma`$, $`\underline{\Gamma}_t`$
and $`\overline{\Gamma}_t`$, that bound the states reached under
[eq:latent_rollout_tnfl] at
timestep $`t`$, starting from any initial condition
$`x_0 \in {\mathcal{X}}_0`$. This resulting hyper-rectangular set
$`\hat{\overline{\mathcal{X}}}_{0:T}`$, which we refer to as the Koopman
reachable set (KRS), is found by solving the optimization
[eq:Koopman_RSOA], which is
computed efficiently by auto_LiRPA:
\begin{equation}
\small
\hspace{-5pt}
\hat{\overline{\mathcal{X}}}_{0:T} \doteq \big\{ \textsf{Int}\big( \textstyle\min_{\substack{x_0 \in \mathcal{X}_0}} \underline{\Gamma}_t(x_0, u^{\text{ref}}_{0:T-1}, z^{\text{ref}}_{0:T}), \max_{\substack{x_0 \in \mathcal{X}_0}} \overline{\Gamma}_t(x_0, u^{\text{ref}}_{0:T-1}, z^{\text{ref}}_{0:T}) \big) \big\}_{t=0}^{T}
\hspace{-3pt}
\label{eq:Koopman_RSOA}
\end{equation}-1The KRS $`\hat{\overline{\mathcal{X}}}_{0:T}`$ overapproximates $`\hat{x}_{0:T}`$ so that $`\hat{x}_{t} \in \hat{\overline{\mathcal{X}}}_{t}`$, for all $`t \in \mathcal{T}`$, ensuring the decoded closed-loop lifted dynamics [eq:latent_rollout_tnfl] remain in $`\hat{\overline{\mathcal{X}}}_{0:T}`$. Formally, we state the following result (proof in App. 8.1):
Let $`\Gamma`$ denote the closed-loop CG of TKFL, and let $`\mathcal{X}_0`$ be the initial set. Suppose the KRS $`\hat{\overline{\mathcal{X}}}_{0:T}`$ is defined as in [eq:Koopman_RSOA]. Then, for any initial state $`x_0 \in \mathcal{X}_0`$, the decoded closed-loop trajectory [eq:latent_rollout_tnfl], i.e., $`\hat{x}_{0:T} = \Gamma(x_0, z^{\text{ref}}_{0:T}, u^{\text{ref}}_{0:T-1})`$ satisfies $`\hat{x}_t \in \hat{\mathcal{X}}_t`$ for all $`t \in \mathcal{T}`$.
Crucially, the KRS overapproximates the reachable set for the decoded Koopman linearized dynamics [eq:latent_rollout_tnfl], not the true nonlinear dynamics [eq:closed_loop_dynamics], due to Koopman model error. This motivates Sec. 5.4.
Conformalizing Koopman Reachable Sets
We now explain how to inflate the KRS to guarantee it contains the true system [eq:closed_loop_dynamics] trajectories with a user-specified probability $`1-\delta`$. We use CP to compute a high-probability upper bound on the state-space prediction error of the decoded closed-loop lifted dynamics [eq:latent_rollout_tnfl]. Specifically, we adapt the single nonconformity score approach (SNSA) to compute state- and dimension-dependent error bounds using a calibration dataset $`\mathcal{D}_C = \{(x_{0:T}^{(i)}, \hat x_{0:T}^{(i)})\}_{i=1}^{K^\textrm{cal}}`$ of trajectories of the true closed-loop dynamics $`x_{0:T}`$ [eq:closed_loop_dynamics] and the decoded closed-loop lifted dynamics $`\hat x_{0:T}`$ [eq:latent_rollout_tnfl]. To construct each data tuple in $`\mathcal{D}_C`$, we sample a reference trajectory $`x_{0:T}^{\text{ref},(i)}`$ from planner $`P`$ and an initial state $`x_0^{(i)}`$ uniformly from $`\mathcal{B}_{\epsilon}(x_{0}^{\text{ref}})`$. We then compute the latent reference trajectory $`z_{0:T}^{\text{ref}, (i)} = \{\phi(x_{t}^{\text{ref},(i)})\}_{t=0}^T`$ and the feedforward control sequence $`u_{0:T-1}^{\text{ref}, (i)}`$ using [eq:u_ff]. We use $`u_{0:T-1}^{\text{ref}, (i)}`$ to calculate the trajectory returned by 1) tracking $`z_{0:T}^{\text{ref}}`$ in the lifted state space ([eq:latent_rollout]) and decoding to the state space via $`\psi`$ and 2) executing the Koopman controller on the true nonlinear dynamics ([eq:actual_rollout]):
\begin{equation}
\small
\label{eq:latent_rollout}
\hspace{-5pt}\hat{x}_{1:T}^{(i)} =
\bigl\{\, \psi\bigl(K_{A}z_{t} + K_{B}\bigl(u^{\text{ref}}_t - G_t(z_t - z^{\text{ref}}_t)\bigr)\bigr) \,\bigr\}_{t=0}^{T-1}\hspace{-6pt}
\end{equation}\begin{equation}
\small
\label{eq:actual_rollout}
\hspace{-1pt}x_{1:T}^{(i)} = \{f(x_t, u^{\text{ref}}_t - G_t (\phi(x_t) - z^{\text{ref}}_t)\}_{t=0}^{T-1}
\end{equation}The prediction error for each state dimension $`j \in \{1, \dots, n\}`$ at time $`t`$ is denoted $`e_{t,j}^{(i)} = x_{t,j}^{(i)} - \hat{x}_{t,j}^{(i)}`$. This gives a calibration set of error trajectories $`\mathcal{D}_{E} = \{\{e_{t}^{(i)}\}_{t=0}^{T}\}_{i=1}^{K^{\text{cal}}}`$, where each $`e_t^{(i)} \in \mathbb{R}^n`$. Each error trajectory $`e^{(i)}`$ is normalized into a single non-conformity score $`R^{(i)} = \max_{t,j} ( \lambda_{t,j} |e_{t,j}^{(i)}|)`$, which is the maximum weighted error over all time steps $`t \in \{0, \dots, T\}`$ and state dimensions $`j \in \{1, \dots, n\}`$. Here, the normalization constant $`\lambda_{t,j} \doteq 1 / (e_{t,j}^{\text{max}} + \sigma) \in \mathbb{R}_{> 0}`$ is computed using a separate normalization dataset $`\mathcal{D}_N`$. This dataset, $`\mathcal{D}_N`$, consists of $`M^{\lambda}`$ additional error trajectories, $`\{e^{(i)}\}_{i=K^{\text{cal}}+1}^{K^{\text{cal}}+M^{\lambda}}`$, collected using the same process as the calibration data. Here, $`\sigma`$ is a small positive constant to prevent division by zero. The term $`e_{t,j}^{\text{max}}`$ is the dimension-wise and time-wise maximum absolute error observed across $`\mathcal{D}_N`$, i.e., $`e_{t,j}^{\text{max}} = \max_{i} |e_{t,j}^{(i)}|`$ where $`i \in \{K^{\text{cal}}+1, \dots, K^{\text{cal}}+M\}`$.
Now, given a user-defined miscoverage rate $`\delta \in (0, 1)`$, we compute the $`(1-\delta)`$ quantile of the non-conformity scores $`C = \text{Quantile}_{1-\delta}(\{R^{(i)}\}_{i=1}^{K^{\text{cal}}} \cup \{\infty\})`$ by finding the $`p`$-th smallest value of the scores $`\{R^{(i)}\}_{i=1}^{K^{\text{cal}}}`$, where $`p \equiv \lceil (K^{\text{cal}} + 1)(1-\delta) \rceil`$. The final, time- and dimension-dependent error bound $`\bar e_{t,j} \in \mathbb{R}_{\ge 0}`$ is obtained by reversing the normalization $`\bar e_{t,j} = C / \lambda_{t,j}`$. These bounds ensure that for an unseen test data-point $`(x_{0:T}^{(0)}, \hat x_{0:T}^{(0)})`$, the true prediction error $`|e_{t,j}^{(0)}|`$ will be contained within the bound $`\bar e_{t,j}`$ for all $`t`$ and $`j`$, with probability at least $`1-\delta`$, i.e.,
\mathbb{P}\big( |e_{t,j}^{(0)}| \le \bar e_{t,j}, \forall t \in \{0, \dots, T\}, \forall j \in \{1, \dots, n\} \big) \ge 1 - \deltaWe use these bounds to inflate the KRS computed in [eq:Koopman_RSOA] to compute RSOAs for the original closed-loop dynamics [eq:closed_loop_dynamics] that are valid with probability at least $`1-\delta`$, using [eq:conformal_inflation] (proof in App. 8.1):
Let $`\hat{\overline{\mathcal{X}}}_{0:T}`$ be the KRS defined in [eq:Koopman_RSOA] and let $`\bar e_t = [\bar e_{t,1}, \ldots, \bar e_{t,n}]^\top \in \mathbb{R}^n`$. Define the conformalized Koopman reachable set (CKRS) as
\begin{equation}
\overline{\mathcal{X}}_{0:T}^{1-\delta} \equiv \bigl\{ \hat{\overline{\mathcal{X}}}_t \oplus \mathrm{diag}(\bar e_t) \mathcal{B}_1(0) \bigr\}_{t=0}^T,
\label{eq:conformal_inflation}
\end{equation}where $`\mathrm{diag}(\bar e_t) \in \mathbb{R}^{n\times n}`$ is a diagonal matrix with $`\bar e_t`$ on its diagonal. Then, for a new reference trajectory $`x_{0:T}^{\textrm{ref}, (0)}`$ drawn from the same distribution, the CKRS contains the true closed-loop system trajectory generated by [eq:closed_loop_dynamics] with probability at least $`1-\delta`$, i.e., $`\mathbb{P}\big( \bigwedge_{t=0}^T x_t^{(0)} \in \overline{\mathcal{X}}_t^{1-\delta} \big) \ge 1-\delta`$.
Offline Calibration
As discussed so far, the method in Sec. 5.4 is reference-specific, as the calibration trajectories $`\mathcal{D}_C`$ and error bounds $`\bar e_t`$ hold specifically for a single reference $`x_{0:T}^{\text{ref}}`$. We propose an offline approach that pre-computes a single, global set of error bounds $`\bar e_{t,j}`$ valid for any reference $`x_{0:T}^{\text{ref}}`$ sampled from the planner $`P`$. This is done by building a larger, more diverse calibration set. We first sample $`N^{\text{ref}}`$ reference trajectories $`\{x_{0:T}^{\text{ref},(i)}\}_{i=1}^{N^{\text{ref}}} \sim P`$. For each reference, we generate a calibration trajectory by sampling $`x_0^{(i)} \sim \mathcal{B}_\epsilon(x_{0}^{ \text{ref},(i)})`$, yielding an error trajectory $`e_t^{(i)} = x_t^{(i)} - \hat x_{t}^{(i)}`$, where $`x_t^{(i)}`$ and $`\hat x_{t}^{(i)}`$ are as defined in [eq:latent_rollout] and [eq:actual_rollout], respectively. The SNSA procedure (computing $`R^{(i)}`$, $`C`$, and $`\bar e_{t,j}`$ via $`\lambda_{t,j}`$) is then performed exactly once on this entire aggregated set.
At runtime, given a new reference $`x_{0:T}^{\text{ref}, (0)}`$ sampled from $`P`$, two efficient computations are performed: 1) we compute the nominal KRS $`\hat{\overline{\mathcal{X}}}_{0:T}`$ specific to $`x_{0:T}^{\text{ref}, (0)}`$ via [eq:Koopman_RSOA]), and 2) we inflate this set using the pre-computed offline bounds $`\bar e_t`$ via the Minkowski sum $`\overline{\mathcal{X}}_{t}^{1-\delta} = \hat{\overline{\mathcal{X}}}_{t} \oplus \textrm{diag}(\bar e_{t})\mathcal{B}_1(0)`$, as defined in [eq:conformal_inflation]. This enables fast reachable set computation at runtime but may increase conservativeness of the resulting CKRS, since the bounds $`\bar e_t`$ must now hold uniformly for all references drawn from $`P`$, rather than for a single fixed reference. The validity of this offline approach relies on the exchangeability of the non-conformity scores, which is met since each score $`R^{(i)}`$ is a deterministic function of the data pair $`(x_{0:T}^{\text{ref},(i)}, x_0^{(i)})`$. Each of these pairs is sampled i.i.d. from the joint distribution defined by $`x_{0:T}^{\text{ref}} \sim P`$ and $`x_0 \sim \mathcal{B}_\epsilon(x_{0}^{\text{ref}})`$. Hence, the resulting scores are i.i.d. and thus exchangeable, ensuring that the standard CP guarantee $`\mathbb{P}\big( \bigwedge_{t=0}^T x_t^{(0)} \in \overline{\mathcal{X}}_t^{1-\delta} \big) \ge 1-\delta`$ holds.
Experiments
-1We first compare our method against reachability baselines and then evaluate it on reachability analysis for a unicycle (3D), planar quadcopter (6D), 3D quadcopter (12D), MuJoCo hopper (11D), and MuJoCo swimmer (28D). All experiments are run on a desktop with an Intel i9-14900K CPU, 64 GB RAM, and an NVIDIA RTX 4090 GPU. For the MuJoCo examples, we set the planner $`P`$ to be an expert PPO policy; for the other systems, we use a trajectory optimizer on the analytical dynamics to serve as $`P`$. We report four key metrics: (i) reachability runtime (s), where lower is better; (ii) average log-volume of reachable sets, where lower indicates less conservativeness; (iii) safety rate over rollouts, where higher is better; and (iv) coverage variability for CP-based verification, where lower Beta-posterior variance of empirical coverage across calibration sizes indicates more stable coverage. Some metrics apply only to specific baselines (e.g., safety filters report safety rate only). Comprehensive results are presented in Table 1.
Baselines
-1We select baselines to highlight four gaps in data-driven reachability. (i) Learned reachability estimators lack overapproximation guarantees, motivating formal NN verification. (ii) Existing hybrid CP-NNV (CP-NNV) methods struggle to scale to high-dimensional, nonlinear dynamics and long horizons, motivating the Koopman lift. (iii) Pure CP-based reachability approaches suffer coverage degradation as calibration data or sample budgets shrink, motivating sample-efficient reachability analysis that remains reliable under limited data. (iv) Pure NNV-based RSOA computation provides deterministic guarantees but can be slow, motivating fast Koopman-based linear reachability.
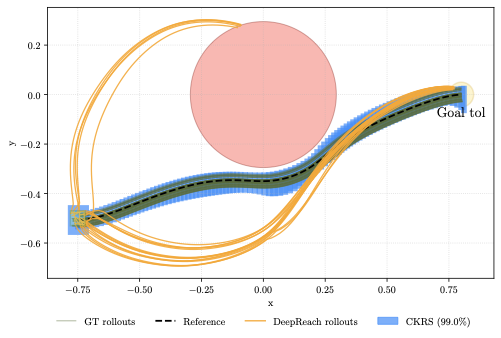
** Under unicycle dynamics [eq:unicycle], a value-function-based safety filter – an approximate reachability method – fails to consistently enforce reach-avoid safety, with only 70% of 250 rollouts satisfying the constraint (Fig. 5). Because the learned value function is an approximate neural PDE solution, small errors in the value and its gradient can cause safety violations, and the method lacks formal guarantees. In contrast, our method provides calibrated probabilistic guarantees that the closed-loop system remains in the CKRS computed via [eq:conformal_inflation] (100% in our experiments) while preserving goal-reaching.
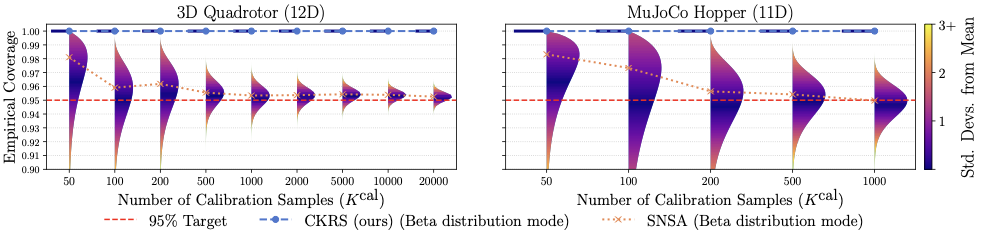
** Because our learned Koopman lift closely matches the training dynamics, the resulting KRS are already tight; conformalization then serves only to absorb the small residual model error. We compare to a pure SNSA baseline , which aggregates all heterogeneous trajectory and state errors into a single nonconformity score. As the horizon or state dimension grows, this forces the baseline to either inflate its sets or require much larger calibration sets to achieve the target $`\delta`$, causing it to suffer from slow convergence to the target coverage level. At practical data budgets (e.g., 1000 samples), a large coverage variance remains, e.g., as much as 5% under-coverage of the true system trajectories (Fig. 3), which can compromise system safety. In contrast, our method attains $`100\%`$ empirical coverage across all tested calibration set sizes, avoiding this variance-data trade-off and achieving target coverage with far fewer samples.
 />
/>
** -1For a 3D quadcopter [eq:3D_Quad_dyn], we compare with a hybrid data-driven/NNV reachability method (denoted CP-NNV), that computes an RSOA by applying NNV on a learned NN trajectory predictor and using CP to bound RSOA underapproximation error induced by learning error. As shown in Fig. 6, CP-NNV yields much larger reachable sets (avg. log volume: -23.35), especially in attitude and velocity. This reflects difficulties in scaling NNV and CP to high-dimensional state spaces and long horizons, which we address with Koopman operators. Our method produces tighter RSOAs (avg. log volume: -40.66) while maintaining coverage, improving scalability with horizon and reducing conservativeness.
** On a unicycle model, we compare with our prior work , which used NNV tools for one-shot RSOA computation, requiring $`51.95`$s and achieving an average log-volume of $`-3.98`$. In contrast, our method computes the RSOA in $`0.32`$s with a log-volume of $`-11.54`$ (Table 1). This highlights that our method is much faster and also reduces conservativeness.
| Experiment | ||||||||||
| dimension | ||||||||||
| steps | ||||||||||
| Level | ||||||||||
| $`(1-\delta)`$ | ||||||||||
| time | ||||||||||
| time | ||||||||||
| time | ||||||||||
| (online) | ||||||||||
| volume | ||||||||||
| (online) | ||||||||||
| volume | ||||||||||
| (offline) | ||||||||||
| dataset | ||||||||||
| size | ||||||||||
| coverage | ||||||||||
| Unicycle | 3 | $`100`$ | $`99.0\%`$ | $`0.038`$s | $`0.277`$s | $`0.315`$s | $`-11.543`$ | $`-8.690`$ | $`100`$ | $`100\%`$ |
| 2D Quad | 6 | $`100`$ | $`99.0\%`$ | $`0.055`$s | $`0.349`$s | $`0.404`$s | $`-21.491`$ | $`-5.333`$ | $`100`$ | $`100\%`$ |
| 3D Quad | 12 | $`200`$ | $`99.0\%`$ | $`0.175`$s | $`0.500`$s | $`0.675`$s | $`-42.954`$ | $`-35.275`$ | $`100`$ | $`100\%`$ |
| Hopper | 11 | $`225`$ | $`99.0\%`$ | $`10.597`$s | $`0.387`$s | $`10.983`$s | $`-4.969`$ | $`-1.806`$ | $`100`$ | $`100\%`$ |
| Swimmer | 28 | $`400`$ | $`95.0\%`$ | $`20.818`$s | $`0.593`$s | $`21.411`$s | $`32.595`$ | $`42.617`$ | $`100`$ | $`99.5\%`$ |
Numerical RSOA results for SCaRe-Kro on unicycle, quadcopters and MuJoCo models.
Unicycle
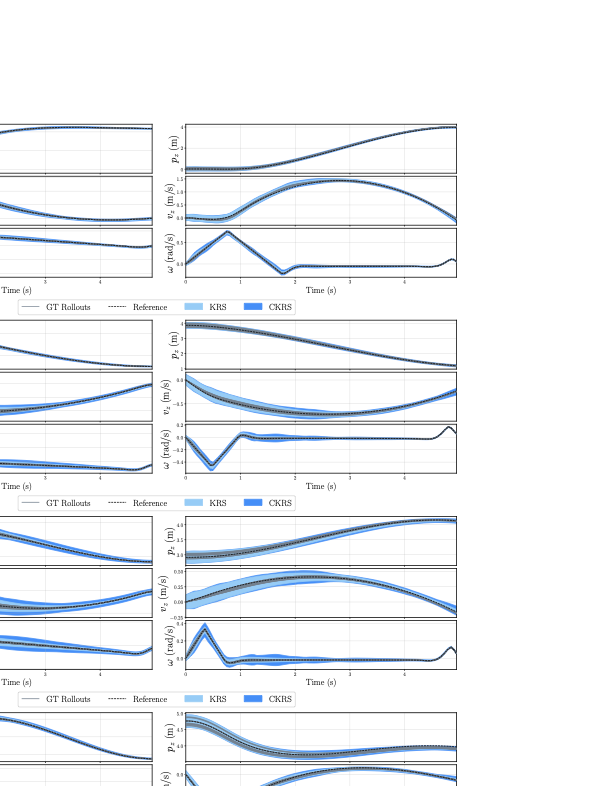
We evaluate on CKRS computations on a unicycle model [eq:unicycle], where $`\phi`$ and $`\psi`$ have 3 hidden layers with 128 neurons each, and $`z \in \mathbb{R}^{10}`$. As shown in Fig. 7, the certified reachable sets verify both safety and goal attainment. Full metrics are in Table 1. We view this benchmark as a sanity check on a simple system, paving the way for more substantive scalability results.
Planar Quadcopter
-1We evaluate a 6-state planar quadcopter [eq:2dquad] navigating around a circular obstacle for $`T=100`$. Here, $`\phi`$ and $`\psi`$ have 3 hidden layers with 128 neurons each, and $`z \in \mathbb{R}^{24}`$. We visualize offline-calibrated CKRSs for multiple reference trajectories in Fig. 8; metrics are in Table 1. An NNV-only baseline required $`59.85\,\mathrm{s}`$ and achieved an average log-volume of $`-18.709`$. Overall, these results support our claim of reduced RSOA conservativeness.
3D Quadcopter
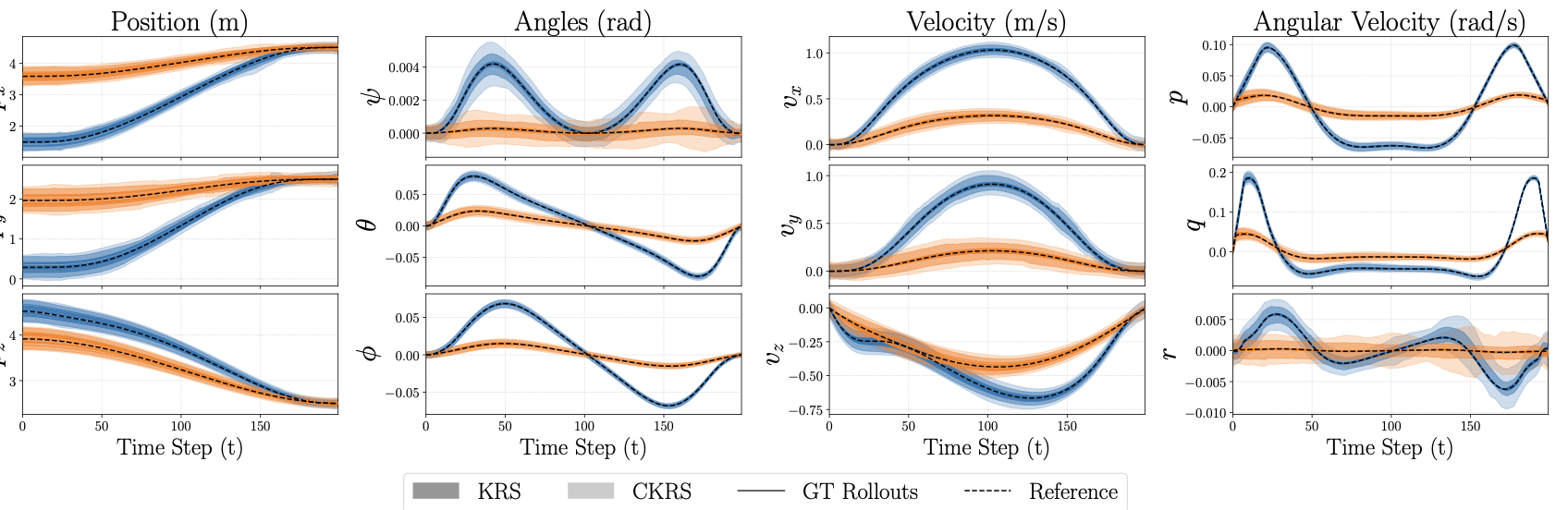
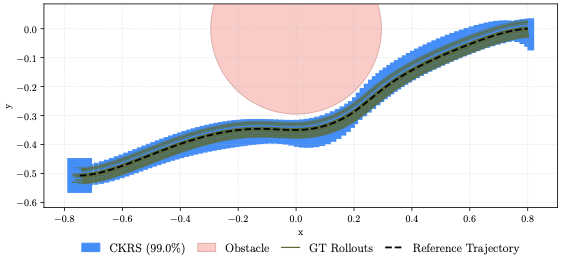
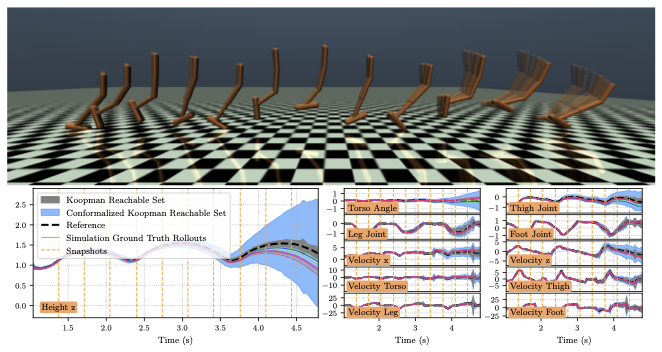
We evaluate an analytical 12-state quadcopter [eq:3D_Quad_dyn] navigating around a $`1\,\mathrm{m}`$ radius obstacle for $`T=200`$. Here, $`\phi`$ and $`\psi`$ have 3 hidden layers with 128 neurons each, and $`z \in \mathbb{R}^{24}`$. The computed CKRS (Fig. 4) verifies safety and goal reaching; metrics are in Table 1. To show that the offline CP inflation generalizes across controllers, we compute the CKRS for two references (Fig. 4, one orange, one blue) using the same offline-calibrated bounds; we visualize additional CKRSs in Fig. 9. An NNV-only baseline is much slower and more conservative, requiring $`2153.45\,\mathrm{s}`$ with an average log-volume of $`-30.32`$. Overall, these results show our method’s efficiency, tightness, and offline CP generalization for high-dimensional systems.
 />
/>
MuJoCo: Hopper
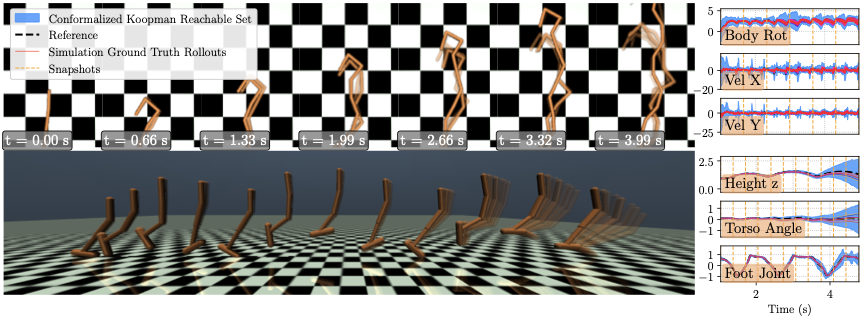
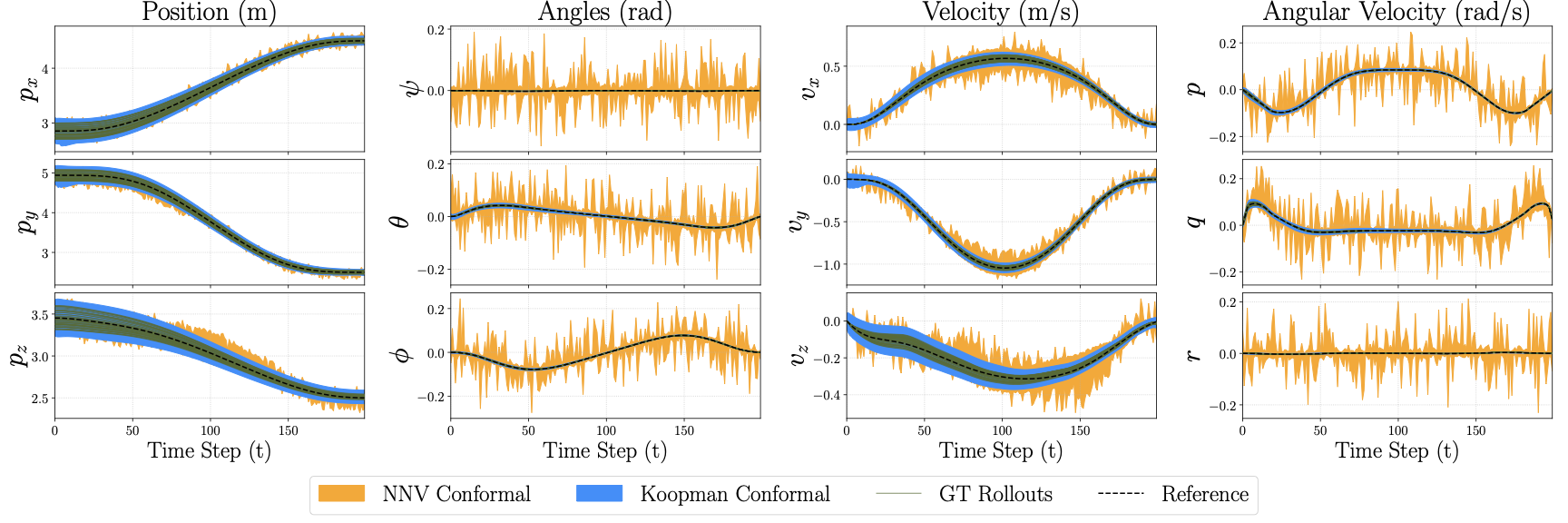
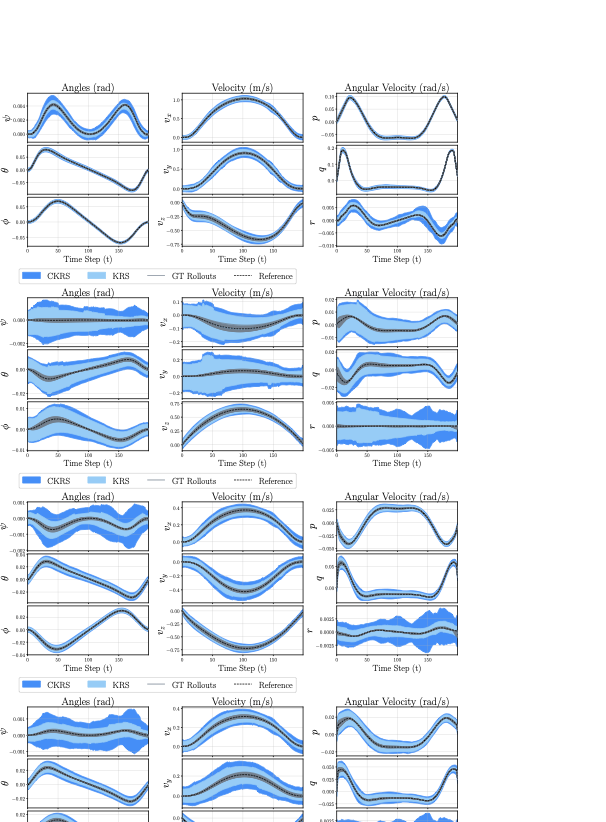
We evaluate on MuJoCo’s Hopper-v5 , a nonlinear, underactuated system with black-box dynamics. A PPO agent (Stable-Baselines3, default hyperparameters) trained for $`2\times 10^6`$ steps is used as the planner $`P`$ that generates trajectories for the training dataset. Here, $`\phi`$ and $`\psi`$ have 3 hidden layers with 128 neurons each, and $`z \in \mathbb{R}^{24}`$. Numerical results are in Table 1 and RSOA slices for a few state dimensions are shown in Fig. 1 (see Fig. 11 for all 11 dimensions). This experiment highlights that our approach scales to black-box, high-dimensional contact-rich dynamics while maintaining low runtimes and probabilistic coverage guarantees.
MuJoCo: Customized Swimmer
We further assess scalability on a customized MuJoCo Swimmer-v5 with extended links, yielding a 28-dimensional state. The planner $`P`$ is a PPO agent (Stable-Baselines3 MLP) trained for $`1\times10^{7}`$ steps with modified hyperparameters (LR $`1\times10^{-3}`$, $`\gamma=0.9999`$, batch size $`512`$; others default). Here, $`\phi`$ and $`\psi`$ have 3 hidden layers with 128 neurons each, and $`z \in \mathbb{R}^{38}`$. Numerical results are in Table 1 and RSOA slices for a few state dimensions are shown in Fig. 1 (see Fig. 12 for all 28 dimensions). This experiment indicates that our approach maintains certified probabilistic safety while tractably computed RSOAs for high-dimensional systems over long horizons for black-box dynamical systems in MuJoCo.
Conclusion
We present ScaRe-Kro, a method for scalable reachability analysis of complex, nonlinear black-box dynamics that provides formal coverage guarantees. Our approach learns a lifted linear representation of the nonlinear dynamics through data, which facilitates tracking control design and the efficient propagation of closed-loop reachable sets. We then “conformalize" this reachable set by inflating it such that rollouts of the target nonlinear system are guaranteed to stay within the inflated set with a specified probability (i.e., at least $`1-\delta`$). Across several benchmarks, including a unicycle, planar/3D quadrotors, MuJoCo hopper, and a 13-link MuJoCo swimmer, our method computes reachable sets efficiently and over long time horizons. Future work aims to: 1) remove the dependence on reference trajectories and 2) replace LQR with a robust control policy that satisfies constraints despite model error to increase the time horizon over which the system can be verified.
Appendix
We provide proofs for our theoretical results (App. 8.1), an algorithm block detailing our method (App. 8.2), and additional experiments and experimental details (App. 8.3).
Proofs
Let $`\Gamma`$ denote the closed-loop CG of TKFL, and let $`\mathcal{X}_0`$ be the initial set. Suppose the KRS $`\hat{\overline{\mathcal{X}}}_{0:T}`$ is defined as in [eq:Koopman_RSOA]. Then, for any initial state $`x_0 \in \mathcal{X}_0`$, the decoded closed-loop trajectory [eq:latent_rollout_tnfl], i.e., $`\hat{x}_{0:T} = \Gamma(x_0, z^{\text{ref}}_{0:T}, u^{\text{ref}}_{0:T-1})`$ satisfies $`\hat{x}_t \in \hat{\mathcal{X}}_t`$ for all $`t \in \mathcal{T}`$.
Proof. The closed-loop graph $`\Gamma`$ is a computational graph $`G`$
as defined in
Proposition [thm:cg_robustness]. Using the
auto_LiRPA library , we compute sound, vector-valued affine bounding
functions $`\underline{\Gamma}_t`$ and $`\overline{\Gamma}_t`$
(corresponding to $`\underline{G}`$ and $`\overline{G}`$ in
Proposition [thm:cg_robustness]) for the
$`t`$-th state output.
By Proposition [thm:cg_robustness], these bounds are guaranteed to be sound. That is, for any specific input $`x_0 \in \mathcal{X}_0`$, the predicted state $`\hat{x}_t = \Gamma_t(x_0, z^{\text{ref}}_{0:T}, u^{\text{ref}}_{0:T-1})`$ satisfies
\underline{\Gamma}_t(x_0, z^{\text{ref}}_{0:T}, u^{\text{ref}}_{0:T-1})
\le \hat{x}_t
\le \overline{\Gamma}_t(x_0, z^{\text{ref}}_{0:T}, u^{\text{ref}}_{0:T-1}).The KRS $`\hat{\overline{\mathcal{X}}}_t`$ is defined in [eq:Koopman_RSOA] as the interval $`\textsf{Int}(\hat{x}_t^L, \hat{x}_t^U)`$, where $`\hat{x}_t^L = \min_{x_0' \in \mathcal{X}_0} \underline{\Gamma}_t(x_0', \dots)`$ and $`\hat{x}_t^U = \max_{x_0' \in \mathcal{X}_0} \overline{\Gamma}_t(x_0', \dots)`$. By the definitions of the minimum and maximum, we have
\begin{align*}
\hat{x}_t
&\ge \underline{\Gamma}_t(x_0, \dots)
\ge \min_{x_0' \in \mathcal{X}_0} \underline{\Gamma}_t(x_0', \dots)
= \hat{x}_t^L,\\
\hat{x}_t
&\le \overline{\Gamma}_t(x_0, \dots)
\le \max_{x_0' \in \mathcal{X}_0} \overline{\Gamma}_t(x_0', \dots)
= \hat{x}_t^U.
\end{align*}Hence, $`\hat{x}_t \in \textsf{Int}(\hat{x}_t^L, \hat{x}_t^U) = \hat{\overline{\mathcal{X}}}_t`$. Since this holds for all $`t \in \mathcal{T}`$, the trajectory $`\hat{x}_{0:T}`$ is contained within $`\hat{\overline{\mathcal{X}}}_{0:T}`$. ◻
Let $`\hat{\overline{\mathcal{X}}}_{0:T}`$ be the KRS defined in [eq:Koopman_RSOA] and let $`\bar e_t = [\bar e_{t,1}, \ldots, \bar e_{t,n}]^\top \in \mathbb{R}^n`$. Define the conformalized Koopman reachable set (CKRS) as
\begin{equation}
\overline{\mathcal{X}}_{0:T}^{1-\delta} \equiv \bigl\{ \hat{\overline{\mathcal{X}}}_t \oplus \mathrm{diag}(\bar e_t) \mathcal{B}_1(0) \bigr\}_{t=0}^T,
\label{eq:conformal_inflation}
\end{equation}where $`\mathrm{diag}(\bar e_t) \in \mathbb{R}^{n\times n}`$ is a diagonal matrix with $`\bar e_t`$ on its diagonal. Then, for a new reference trajectory $`x_{0:T}^{\textrm{ref}, (0)}`$ drawn from the same distribution, the CKRS contains true closed-loop system trajectory generated by [eq:closed_loop_dynamics] with probability at least $`1-\delta`$:
\mathbb{P}\Big( \bigwedge_{t=0}^T x_t^{(0)} \in \overline{\mathcal{X}}_t^{1-\delta} \Big) \ge 1-\delta.Proof. The proof combines a deterministic containment guarantee with a probabilistic coverage guarantee.
Step 1: KRS Containment. By Lemma [lem:koopman_containment], the decoded closed-loop lifted trajectory $`\hat{x}_{t,j}^{(0)}`$ is deterministically contained within the hyper-rectangular KRS:
\hat{x}_{t,j}^{(0)} \in \hat{\overline{\mathcal{X}}}_{t,j} = \textsf{Int}(\hat{x}_{t,j}^L, \hat{x}_{t,j}^U), \quad \forall t \in \mathcal{T},\quad \forall j \in \{1,\ldots,n\}.Step 2: Probabilistic Coverage. The CP guarantee requires exchangeability of the nonconformity scores $`\{R^{(i)}\}_{i=0}^{K^{\mathrm{cal}}}`$. In our framework, all calibration and test trajectories share the same reference $`(z_{0:T}^{\mathrm{ref}}, u_{0:T-1}^{\mathrm{ref}})`$ and controller $`G_t`$, and their initial states $`x_0^{(i)}`$ are sampled i.i.d. from $`\mathcal{B}_\epsilon(x_0^{\mathrm{ref}})`$. Since the decoded closed-loop lifted trajectory [eq:latent_rollout], true closed-loop trajectory [eq:actual_rollout], and the nonconformity score are deterministic functions of $`x_0^{(i)}`$, the resulting scores $`R^{(i)}`$ are also i.i.d., and hence exchangeable. By the CP guarantee, the event
\mathcal{E} \equiv \{ |e_{t,j}^{(0)}| \le \bar e_{t,j}, \forall t,j \}occurs with probability at least $`1-\delta`$.
Step 3: Combined Guarantee. The true state can be decomposed as $`x_{t,j}^{(0)} = \hat{x}_{t,j}^{(0)} + e_{t,j}^{(0)}`$. When $`\mathcal{E}`$ occurs, we have
\hat{x}_{t,j}^L - \bar e_{t,j} \le \hat{x}_{t,j}^{(0)} + e_{t,j}^{(0)} \le \hat{x}_{t,j}^U + \bar e_{t,j},which by definition implies $`x_{t,j}^{(0)} \in \overline{\mathcal{X}}_{t,j}^{1-\delta}`$. Since this holds for all $`t`$ and $`j`$, the trajectory $`x_{0:T}^{(0)}`$ is contained in the CKRS $`\overline{\mathcal{X}}_{0:T}^{1-\delta}`$ with probability at least $`1-\delta`$. ◻
Algorithm
Algorithm [alg:online_ckrs] details the
procedure for computing the CKRS. The process begins by lifting the
planner-provided reference trajectory $`x_{0:T}^\textrm{ref}`$ into the
latent space to compute the feedforward control $`u^\textrm{ref}`$ via
least-squares, and synthesizing a time-varying LQR controller to track
this reference. To account for the discrepancy between the learned
Koopman dynamics and the true system, the algorithm generates
calibration data from system rollouts and utilizes SNSA-based conformal
prediction to derive statistically-valid error bounds $`\bar e_t`$. In
parallel, the nominal KRS, $`\overline{\mathcal{X}}_{0:T}`$, is computed
by constructing a computational graph of the closed-loop tracking
dynamics in the lifted Koopman state space and computing reachable sets
for the linear Koopman dynamics via auto_LiRPA. Finally, the algorithm
returns a conformalized Koopman reachable set (CKRS),
$`\mathcal{X}_{0:T}^{1-\delta}`$, obtained by inflating the nominal KRS
with the derived conformal error bounds via a Minkowski sum. Crucially,
the CKRS guarantees coverage of the trajectories generated by the true
system with probability $`1-\delta`$.
Koopman model ($`\phi, \psi, K_{A}, K_{B}`$); true dynamics $`f`$ (simulator); reference trajectory $`x^{\text{ref}}_{0:T}`$; initial set $`\mathcal{X}_0 = \mathcal{B}_\epsilon(x_0^{\text{ref}})`$; RSOA confidence $`1-\delta`$; calibration sizes $`M^{\lambda}, K^{\text{cal}}`$; cost matrices $`Q, R`$; verification tool $`\texttt{auto\_LiRPA}`$ Conformalized Koopman reachable set $`\overline{\mathcal{X}}^{1-\delta}_{0:T}`$ (CKRS) $`z^{\text{ref}}_{0:T} \gets \phi(x^{\text{ref}}_{0:T})`$ $`u^{\text{ref}}_{0:T-1} \gets`$ Equation [eq:u_ff] $`G_{0:T-1} \gets`$ LQR$`(K_A, K_B)`$ $`\pi(\cdot) \gets`$ Equation [eq:u_latent_cl] $`\mathcal{D}_E, \mathcal{D}_N \gets \texttt{GenerateCalibrationData}(M^{\lambda}, K^{\text{cal}})`$ $`\bar e_t \gets \texttt{SNSA}(\mathcal{D}_N, \mathcal{D}_E)`$ $`\Gamma(\cdot) \gets \psi(\texttt{PropagateLatent}(\phi(\cdot), z^{\text{ref}}, u^{\text{ref}}, G))`$ $`\hat{\overline{\mathcal{X}}}_{0:T} \gets \texttt{AutoLiRPA}(\Gamma, \mathcal{X}_0)`$ $`\overline{\mathcal{X}}^{1-\delta}_{0:T} \gets \hat{\overline{\mathcal{X}}}_{0:T} \oplus \textrm{diag}(\bar e_t) \mathcal{B}_1(0)`$ return $`\overline{\mathcal{X}}^{1-\delta}_{0:T}`$
Experiment Details and Additional Experiments
The following section contains the the analytical dynamics we used in this paper (App. 8.3.1) and additional experiment results. In particular, we benchmark our approach with a baseline Koopman dynamics learning approach that leverages polynomial liftings (App. 8.3.2), a baseline learned reachable set prediction method (App. 8.3.3), and a baseline conformal prediction-based reachable set computation method that does not leverage Koopman-based propagation (App. 8.3.4). We also present additional experiment figures, including full reachable set visualizations on a per-state breakdown for the unicycle system (App. 8.3.5), planar quadcopter system (App. 8.3.6), MuJoCo hopper system (App. 8.3.8), and MuJoCo swimmer system (App. 8.3.9).
Dynamics.
For unicycle experiments ($`x \in \mathbb{R}^3`$, $`u \in \mathbb{R}^2`$), we used the dynamics model, time-discretized via forward Euler ($`dt =0.1`$s)
\begin{equation}
\label{eq:unicycle}
\dot{\mathbf{x}}\;=\; f(\mathbf{x},\mathbf{u})=
\begin{bmatrix}
u_1 \cos(x_2) \\ u_1 \sin(x_2) \\ u_2
\end{bmatrix}.
\end{equation}For planar quadcopter experiments ($`x \in \mathbb{R}^6`$, $`u \in \mathbb{R}^2`$), we used the parameters $`m=0.5\textrm{kg}`$, $`g=-9.81\textrm{m/s}^2`$, $`I_y=0.01\textrm{kg} \cdot \textrm{m}^2`$ for the dynamics model, and time-discretized with $`dt = 0.05\,\mathrm{s}`$:
\begin{equation}
\label{eq:2dquad}
\dot{\mathbf{x}}\;=\; f(\mathbf{x},\mathbf{u})=\begin{bmatrix}
x_4 \\ x_5 \\ x_6 \\ -\frac{u_1}{m} \sin(x_3)\\ g+\frac{u_1}{m}\cos(x_3)\\\frac{u_2}{I_y}
\end{bmatrix}
\end{equation}For 3D quadcopter experiments, we used the parameters $`m=1`$kg, $`g=-9.81`$ m/s$`^2`$, $`I_{x,y,z}=[0.5,0.1,0.3]`$ kg·m$`^2`$ for the dynamics, with a time-discretization of $`dt = 0.025\,\mathrm{s}`$:
\begin{equation}
\dot{\mathbf{x}} \;=\; f(\mathbf{x},\mathbf{u})=
\begin{bmatrix}
\dot{x} \\
\dot{y} \\
\dot{z} \\
q \cdot \sin(\phi)/\cos{\theta}+r\cdot \cos{\phi}/\cos{\theta} \\
q \cdot \cos{\phi} - r\cdot \sin{\phi} \\
p + q \cdot \sin{\phi}\cdot \tan{\theta} +r\cdot \cos{\phi} \cdot \tan{\theta} \\
\frac{u_1}{m} \cdot (\sin{\phi} \cdot \sin{\psi} + \cos{\phi} \cdot \cos{\psi} \cdot \sin{\theta}) \\
\frac{u_1}{m} \cdot (\cos{\phi} \cdot \sin{\phi} - \cos{\phi} \cdot \sin{\psi} \cdot \sin{\theta}) \\
g + u_1 \cdot (\cos{\phi} \cdot \cos{\theta}) / m\\
((I_y - I_z) / I_x) \cdot q\cdot r + \frac{u_2}{I_x} \\
((I_z - I_x) / I_y) \cdot p\cdot r + \frac{u_3}{I_y} \\
((I_x - I_y) / I_z) \cdot p\cdot q + \frac{u_4}{I_z} \\
\end{bmatrix}
\label{eq:3D_Quad_dyn}
\end{equation}Comparison between neural Koopman liftings and polynomial liftings
We compare root mean square error (RMSE) between a polynomial-lifted
extended dynamic mode decomposition baseline and our neural lifting
approach on the Hopper system. For the polynomial lift, we use PyKoopman
with degree-3 monomials and identical training data/preprocessing.
During open-loop evaluation, the polynomial model becomes numerically
unstable, that is, its predictions grow without bound and diverge by the
eighth timestep, so we report RMSE only over the first 5 prediction
steps in Table 2. In contrast, our neural
lifting yields a stable latent dynamics model that tracks accurately
across three complete hops, enabling longer-horizon evaluation. These
results highlight that for certain systems, e.g., those with strongly
nonlinear, contact-rich dynamics (like the MuJoCo hopper), fixed
polynomial bases are insufficient, whereas a neural network lifting
function captures the necessary structure and remains stable over
extended rollouts. Together, these results motivate the development of a
Koopman reachable-set computation framework that incorporates neural
networks in the loop, which we enable using auto_LiRPA.
| State | Polynomial Lifting | Ours |
|---|---|---|
| z-coord (height) | 2728.481591 | 0.009848 |
| torso angle | 117.374908 | 0.004201 |
| thigh joint | 2832.025934 | 0.013581 |
| leg joint | 10791.162550 | 0.015690 |
| foot joint | 8063.167273 | 0.017901 |
| vel x-coord | 321013.541866 | 0.047526 |
| vel z-coord | 1691803.060196 | 0.059763 |
| vel torso | 4512148.680118 | 0.082879 |
| vel thigh | 596074.452102 | 0.073777 |
| vel leg | 6164730.041985 | 0.164258 |
| vel foot | 135554800.971296 | 0.259034 |
RMSE comparison for the hopper (11D) system on rollouts performed by the learned model and the polynomial fitted model.
Baseline comparison with .
Figure 5 offers a qualitative comparison of safety violations between the baseline DeepReach method and ScaRe-Kro. While the main text statistics indicate a lower safety rate for the baseline, this visualization explicitly captures the “reach-avoid" failure mode: the orange trajectories generated by the DeepReach value function clearly drift into the red obstacle region. This highlights the risks of relying on approximate neural PDE solutions for safety-critical constraints. In contrast, the reachable set (shown in blue) computed by our method creates a tight, verified corridor that contains the ground truth rollouts with high, calibrated probability, visually confirming that the controller successfully steers the dynamics clear of the hazard while adhering to the probabilistic bounds.
 style="width:100.0%" />
style="width:100.0%" />
Baseline comparison with .
Figure 6 provides a state-by-state breakdown of the conservativeness gap between the reachable sets computed via the baseline CP-NNV approach (yellow) and our proposed method (blue). While the tabular results in Section 6 quantify the volume difference, Figure 6 illustrate where that difference originates visually. Overall, one of the key differences between our approach and is in using a learned multi-step predictor instead of learned Koopman dynamics to compute reachable sets. We note that the CP-NNV method suffers from more conservative reachable sets, particularly in the angular velocity ($`p, q, r`$) and angle ($`\phi, \theta, \psi`$) dimensions. We attribute this to the difficulty of computing reachable sets accurately with a learned multi-step predictor over long horizons. Conversely, ScaRe-Kro maintains consistently tight bounds across all 12 dimensions, demonstrating that the Koopman linearization effectively mitigates the “wrapping effect" that causes over-approximation in standard neural network verification.
 style="width:100.0%" />
style="width:100.0%" />
Additional results on unicycle system.
Figure 7 depicts the spatial evolution of the CKRS for the unicycle. Beyond the numerical coverage rates of Sec. 6, this plot serves as a geometric sanity check, showing the reachable set’s ability to contain the reference trajectory (black dashed line) and closed-loop trajectories (green) while navigating tight constraints. The blue tube is the CKRS that represents the region where the system is guaranteed to remain with with probability at least $`1-\delta`$, illustrating that even with the reachable set inflation induced by the conformalization step, the resulting set remains sufficiently compact to verify safety despite the closeness of the closed-loop rollouts to the red obstacle.
 style="width:100.0%" />
style="width:100.0%" />
Additional results on planar quadcopter system.
We present the full dimensional trajectory evolution for the 6D planar quadcopter in Figure 8. These plots isolate the performance of the Koopman tracking controller on an underactuated system. Notably, the reachable sets (light blue) and their conformalized counterparts (dark blue) accurately capture the behavior in all state dimensions, bounding the closed-loop trajectories. This confirms that the learned linear structure in the lifted Koopman space preserves the critical coupling effects of the original nonlinear dynamics, while the conformal bounds effectively absorb the residual error in the predicted KRS. We also note that the conformalization of the KRS in this example has a relatively small impact on the overall volume of the reachable set estimates, though we note that this is not always the case, e.g., the hopper system shown in Fig. 11. Moreover, this experiment showcases the offline CP inflation bounds (described in Sec. 5.4) generalize across multiple reference trajectories, we compute the CKRS for four reference trajectories total (Fig. 8a-d) and show that the resulting closed-loop trajectories remain within the computed set. This indicates that a single offline CP calibration can be reused to efficiently inflate reachable sets computed online.
 style="width:100.0%" />
style="width:100.0%" />
Additional results on 3D quadrotor system.
To verify that the offline CP inflation bounds (described in Sec. 5.4) generalize across multiple reference trajectories, we compute the CKRS for three alternative reference trajectories and show that the resulting closed-loop trajectories remain within the computed set (Fig. 9). This indicates that a single offline CP calibration can be reused to efficiently inflate reachable sets computed online. We also visualize two of these CKRSs together with the obstacle that the quadrotor is navigating around (Fig. 10), showing that since the RSOAs do not intersect with the obstacle, the closed-loop system is guaranteed to avoid collision when tracking either reference.
 style="width:100.0%" />
style="width:100.0%" />
 style="width:100.0%" />
style="width:100.0%" />
Additional results on MuJoCo hopper system.
Figure 11 illustrates the full state-space evolution of the 11-dimensional MuJoCo Hopper system during a forward hopping maneuver. This system poses a unique challenge due to its hybrid dynamics, characterized by non-smooth transitions during ground impacts. The periodic stability of the gait is clearly visible in the “height z" and “torso angle" trajectories, where the ScaRe-Kro framework successfully captures the complex dynamics associated with the flight and stance phases. Notably, while the position states exhibit tight confinement around the reference trajectory (dashed black line), the velocity dimensions (e.g., “Velocity Foot") display a necessary inflation of the conformal bounds. This expansion correctly accounts for the instantaneous jumps in state caused by contact forces and modeling uncertainties at impact, yet the ground truth rollouts remain strictly contained within the predicted tube, validating the robustness of the Koopman tracking controller under discontinuous contact dynamics.
 style="width:100.0%" />
style="width:100.0%" />
Additional results on MuJoCo swimmer system.
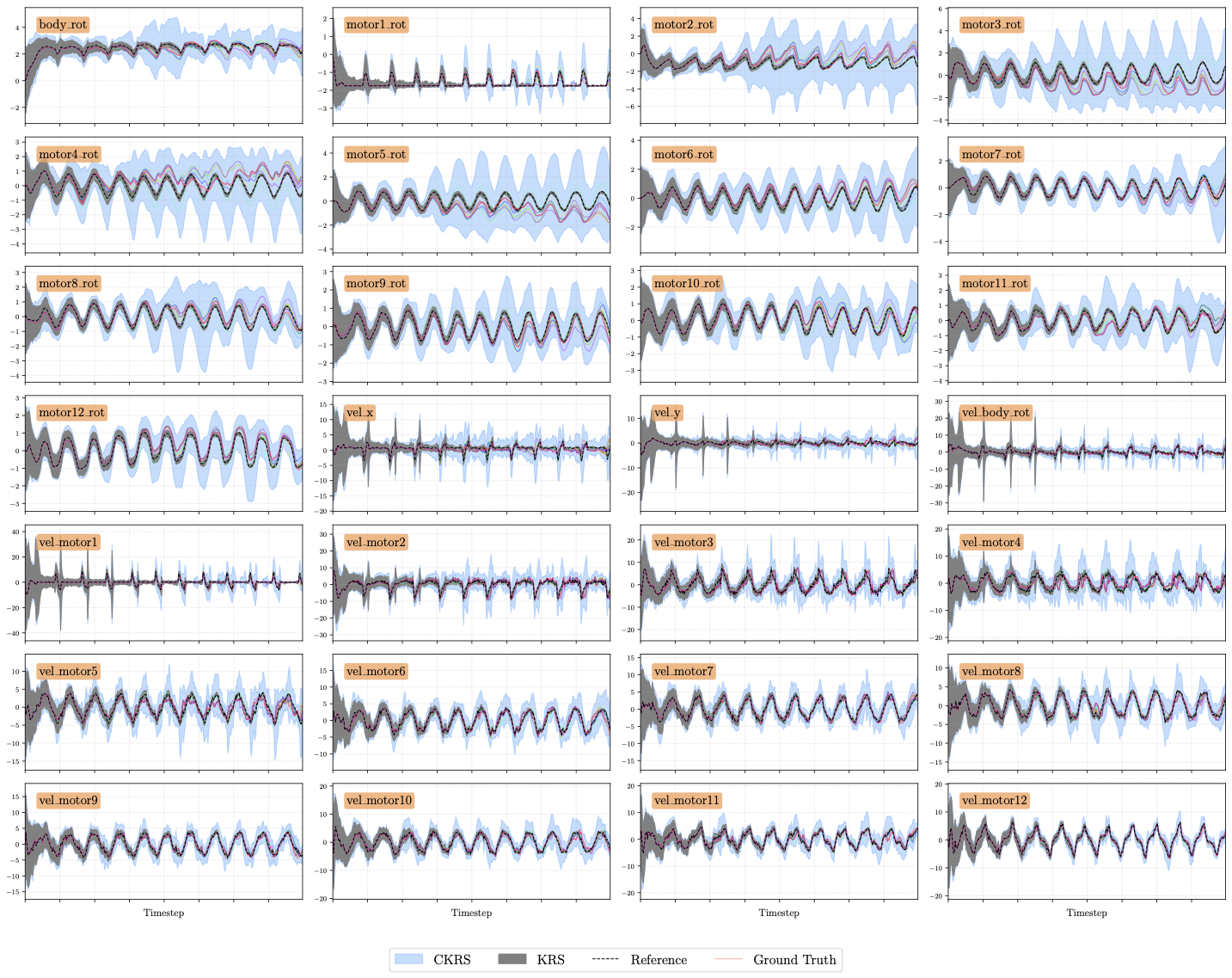
Figure 12 presents the component-wise reachability analysis for the 28-dimensional MuJoCo Swimmer , representing the most high-dimensional validation of our framework. The plots display the highly coupled, undulatory gait required for locomotion, evidenced by the phase-shifted oscillations across the chain of link joints and velocities. Despite the significant increase in state dimensionality, the CKRS maintain consistent coverage of the closed-loop trajectories across all 28 dimensions. The uniform tightness of the bounds across the swimmer link segments confirms that the learned globally-linear dynamics structure effectively encodes the multi-body dynamics, enabling safe, long-horizon verification for complex, articulated robots while maintaining tractable computation.
 style="width:100.0%" />
style="width:100.0%" />
📊 논문 시각자료 (Figures)