ScienceDB AI An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
📝 Original Paper Info
- Title: ScienceDB AI An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services- ArXiv ID: 2601.01118
- Date: 2026-01-03
- Authors: Qingqing Long, Haotian Chen, Chenyang Zhao, Xiaolei Du, Xuezhi Wang, Pengyao Wang, Chengzan Li, Yuanchun Zhou, Hengshu Zhu
📝 Abstract
The rapid growth of AI for Science (AI4S) has underscored the significance of scientific datasets, leading to the establishment of numerous national scientific data centers and sharing platforms. Despite this progress, efficiently promoting dataset sharing and utilization for scientific research remains challenging. Scientific datasets contain intricate domain-specific knowledge and contexts, rendering traditional collaborative filtering-based recommenders inadequate. Recent advances in Large Language Models (LLMs) offer unprecedented opportunities to build conversational agents capable of deep semantic understanding and personalized recommendations. In response, we present ScienceDB AI, a novel LLM-driven agentic recommender system developed on Science Data Bank (ScienceDB), one of the largest global scientific data-sharing platforms. ScienceDB AI leverages natural language conversations and deep reasoning to accurately recommend datasets aligned with researchers' scientific intents and evolving requirements. The system introduces several innovations: a Scientific Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using over 10 million real-world datasets, ScienceDB AI has demonstrated significant effectiveness. To our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services. The platform is publicly accessible at: https://ai.scidb.cn/en.💡 Summary & Analysis
**Contribution 1: Development of Experimental Intention Perceptor** - **Simple Explanation**: The experimental intention perceptor understands the complex requirements for datasets from researchers and extracts this information in a structured manner. - **Metaphor**: This system is akin to comprehending a cake recipe that a researcher desires, explicitly recording necessary ingredients and cooking methods.Contribution 2: Introduction of Structured Memory Compressor
- Simple Explanation: The structured memory compressor tracks user intent, dialogue context, tool invocations in multi-turn conversations, summarizing relevant historical information to address the limited context window issue of LLMs.
- Metaphor: It is like having a note-taking assistant that records all important details from long-term projects and organizes them for easy reference.
Contribution 3: Proposal of Trustworthy Retrieval-Augmented Generation (RAG) Framework
- Simple Explanation: The trustworthy RAG framework improves the accuracy of dataset recommendations, ensuring researchers find actual existing datasets.
- Metaphor: It is like a librarian providing specific information to locate books and confirming their availability in the library.
📄 Full Paper Content (ArXiv Source)
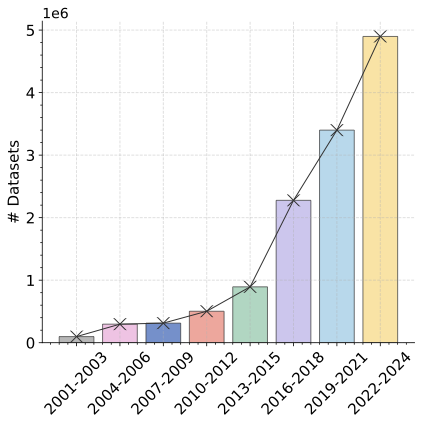
The rapid advancement of Artificial Intelligence for Science (AI4S) has highlighted the critical importance of high-quality scientific data in accelerating discoveries across domains, including biology, physics, chemistry, and earth sciences , etc. In response, governments and research institutions worldwide have established national scientific data centers and dataset-sharing platforms, such as the NCBI , OpenAIRE and ScienceDB . These initiatives promote open access and foster collaborative use of scientific data, thereby enhancing its reusability. Consequently, the number of newly released scientific datasets has been significantly increasing in recent years , as illustrated in Fig. 1 (a).
With the rapid growth of scientific datasets, enabling researchers to efficiently discover relevant datasets has become increasingly important. Effective dataset recommendation systems are therefore essential to facilitate data-driven scientific discovery . Traditional dataset recommenders generally fall into two categories. The first is behavior-based recommender, which leverages user interaction histories through methods like Collaborative Filtering (CF) and Graph Representation Learning (GRL) . The second is content-based recommender, which rely on the query itself, including keyword-based retrieval and semantic embedding-based matching . Existing dataset-sharing platforms, such as Google Dataset Search , DataCite Commons , OpenAIRE and Dryad , etc, all still rely heavily on keyword-based search engines. Their detailed information is shown in Table [tab:compare_product]. While these works have achieved certain success, scientific dataset recommendation at scale introduces unique challenges that are inadequately addressed:
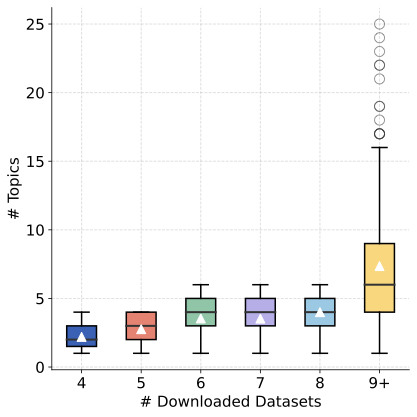
(1) Scientific dataset demands are often task-specific and unrelated to historical behavior. As illustrated in Fig. 1 (b), the x-axis denotes the number of datasets a researcher has previously downloaded in ScienceDB , while the y-axis indicates the number of distinct topics involved. Researchers with $`\geq`$9 downloads (about 10% of the total) are grouped together. The figure reveals weak topic consistency across a researcher’s download history, implying that their dataset needs are driven more by evolving research tasks than persistent preferences. However, the user behavior-based recommenders are unsuitable in our scenario.
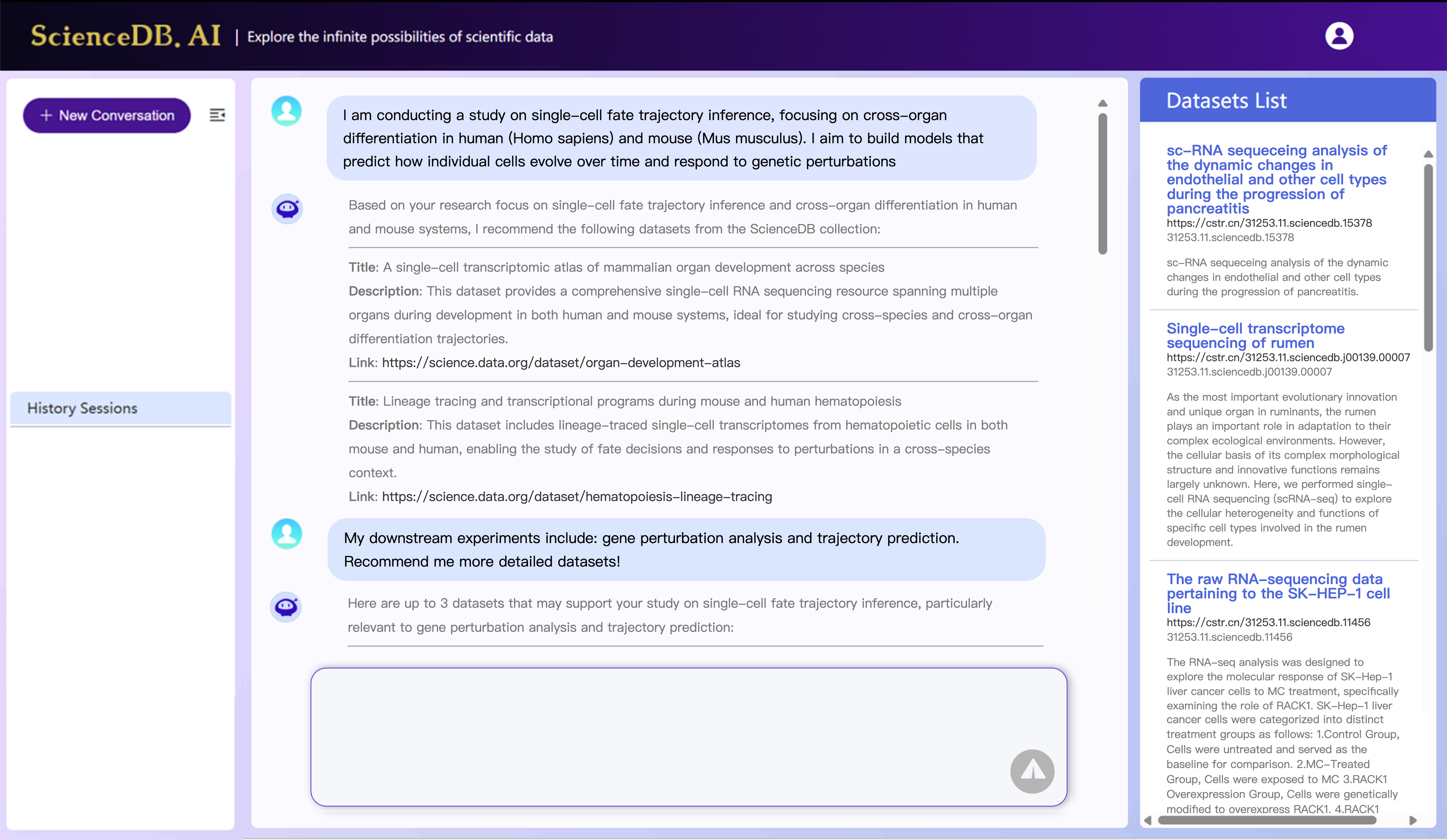
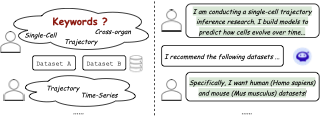
(2) Existing context-based recommenders fall short in understanding experiment-level dataset needs. Scientific exploration often involves highly specific, evolving, and nuanced dataset needs, expressed through rich natural language descriptions. Traditional keyword search or embedding-based matching falls short in understanding these complex requirements. For instance, as depicted in Fig.2, a researcher may query: “I am conducting a study on single-cell fate trajectory inference, focusing on cross-organ differentiation in human (Homo sapiens) and mouse (Mus musculus). I aim to build models that predict how individual cells evolve over time and respond to genetic perturbations”. Such detailed and domain-specific intents require deep contextual understanding, which existing context-based recommenders are not equipped to handle effectively.
Fortunately, recent advances of LLMs and Agents in conversational recommendation offers a promising direction for addressing our problem . However, these models are inherently prone to hallucination and forgetting issues . They can generate hallucinated, non-existent, or inaccessible datasets. This poses a critical challenge in scientific scenarios, where trustworthy, accessibility, and citable are of the basic requirements .
In response, we propose the ScienceDB AI, an intelligent agentic recommender system designed for large-scale scientific data sharing service. Our system operates on a repository of over 10 million available datasets and introduces several key components to support trustworthy, accessibility, and citable dataset recommendation. First, we develop a Experimental Intention Perceptor that extracts researchers’ data, topic, constraints, and evaluation criteria into a structured intent template. Second, we introduce a Structured Memory Compressor. It tracks user intent, dialogue context, and tool invocations in our multi-turn conversations, and summarize relevant historical information. This helps mitigate forgetting issues caused by the limited context window of LLMs. Third, to address the hallucination issues, we propose a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. It incorporates a two-stage retriever to balance retrieval effectiveness and efficiency in our large-scale setting. To ensure dataset traceability and citation, we associate each dataset with a Citable Scientific Task Record (CSTR) and include direct links to CSTRs in the system’s responses. We conduct extensive offline and online evaluations in over 10 million real-world scientific datasets from ScienceDB platform. ScienceDB AI achieves over a 30% improvement in offline metrics compared to existing agent-based recommenders. In online A/B testing, it yields more than a 200% increase in Click-Through Rate (CTR) compared to traditional keyword-based search systems. We summarize our contributions as follows:
-
To the best of our knowledge, ScienceDB AI is the first LLM-driven agentic recommender system for a large-scale scientific data sharing services.
-
We design a agentic framework, which consists of a experimental intention perceptor, a structured memory compressor, and a retriever-augmented recommender that attaches a CSTR to each dataset for trustworthy.
-
Through extensive experiments over 10 million real-world datasets, ScienceDB AI achieves significant improvement (30%+) in offline metrics, and remarkable increase (200%+) in online A/B tests.
Related Work
In this section, we first review existing scientific dataset sharing platforms, highlighting their advantages and limitations. We then examine studies on dataset recommenders aimed at facilitating dataset discoverability. Finally, we discuss recent advances in agent-based conversational recommenders.
| Product/Platform | # Disciplines | For Research | Sharing SourceData | # Datasets | CRS | ||
|---|---|---|---|---|---|---|---|
| DataCite Commons | >10 | 42,896,080 | |||||
| Google Dataset Search | >10 | (Only Metadata) | 25 Million | ||||
| Zenodo | <5 | 4 Million | |||||
| OpenAIRE | >10 | 8,382,956 | |||||
| PaddlePaddle | >10 | $`\sim`$10,000 | |||||
| Dataverse | >10 | 139,231 | |||||
| CKAN | >10 | 24,233 | |||||
| Dryad | <5 | $`\sim`$900,000 | |||||
| Snowflake Marketplace | Unknown | (Commercial) | Unknown | ||||
| DataBricks | Unknown | (Commercial) | Unknown | ||||
| HuggingFace | <3 | 461,199 | |||||
| RADx Data Hub | <2 | $`\sim`$5,000 | |||||
| NCBI | <3 | $`\sim`$1,000 | |||||
| FigShare | <3 | $`\sim`$380,000 | |||||
| ScienceDB AI (Ours) | All (>18) | 10 Million |
Scientific Dataset Sharing Platforms
The recent advancement of AI4S has shown the critical importance of high-quality scientific data . Governments and research institutions worldwide have established national scientific data centers and dataset-sharing platforms. Here we compare 14 existing dataset sharing platforms across five dimensions: (1) the number of supported disciplines, (2) whether they are designed for research use cases, (3) whether they provide source data, (4) the number of available datasets, and (5) the presence of Conversational Recommendation Systems (CRS). The number of disciplines is estimated based on the primary discipline taxonomy of OpenAlex . A detailed comparison is provided in Table [tab:compare_product]. Snowflake Marketplace and DataBricks are two commercial products, thus their dataset information is unknown. As shown in the table, half of the platforms support around 10 disciplines, while the rest support fewer than five. In contrast, our platform covers 18 first-level disciplines, providing broader subject coverage and more diverse, domain-specific datasets. Among all platforms, Google Dataset Search , ScienceDB and DataCite Commons host the largest number of datasets. However, Google Dataset Search only indexes metadata without providing source data, limiting its applicability for experimental research.
In summary, existing data platforms lack effective support for dataset sharing and recommendation. In contrast, ScienceDB AI stands out as the only data center that enables intelligent recommendations, allowing researchers to express complex data needs in natural language and efficiently discover relevant datasets, which ultimately accelerate scientific discovery.
Dataset Recommenders
Recent years there are only three representative works designed for the dataset recommendation task. DataFinder proposes a text similarity based dataset recommendation model. It takes BERT as the embedding model for dataset description and the user’s input query. Altaf et al. propose a variational graph autoencoder for query-based dataset recommendation tasks. It construct a set of research papers, which reflects a user’s research interest. The recommended datasets are based on the representation similarity of the dataset description and the constructed graph of research papers for the user. DataLinking uses concept frequency and TF-IDF to extract the similarity features of user queries and dataset descriptions. However, all these works are primarily keyword-based and cannot understand the researchers’ complex needs or support interactive, natural language-based queries.
Agent-based Conversational Recommenders
Sorts of studies have shown LLM and Agent-based conversational recommendation systems have the better performance of understanding user’s complicated intentions than traditional models. They have the ability to leverage specialized tools, which can relieve the limited knowledge due to model scale and pretrained data size constraints. Representative works include AgentCF , InteRecAgent and CoSearchAgent , etc. Specifically, CoSearchAgent, Fang et al. , and MACRec are multi-agent collaborative search systems. However, the multi-agent system has communication delays, which brings longer system response time, further can not suit well for a large-scale online recommendation scenario. Thus this work pay attention to the single-agent recommendation works. AgentCF designs agent-based collaborative filtering to simulate user-item interactions. InteRecAgent, ChatCRS , and RecMind design agent-based conversational frameworks, which contains mechanisms of planning, memory, web search, reflection and recommendation tools. Other agent-based works mainly focus on personalized recommendations in conversations.
However, all the above models are inherently prone to hallucination , often generating recommendations for non-existent or inaccessible datasets. This presents a critical challenge in scientific settings, where trustworthy, accessibility, and citable are of the basic requirements . Moreover, these models are primarily behavior-based models, and thus unsuitable for understanding experiment-level queries.
 />
/>
Technical Details of ScienceDB AI
In this section, we provide the technical detailed of ScienceDB AI. First, we provide a overview of our technical framework and problem definition. Then we introduce our framework components, i.e., Experimental Intention Perceptor, Structured Memory Compressor and a retriever-augmented recommender that attaches a unique identifier to each dataset for trustworthy.
Framework Overview
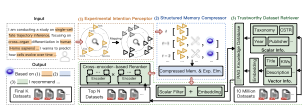
Framework Overview. The overall technical framework of ScienceDB AI is shown in Fig. 3, which consists of a experimental intention perceptor, a structured memory compressor, and a retriever-augmented recommender that attaches a unique identifier to each dataset for trustworthiness. Our online ScienceDB AI system can be visited at https://www.ai.scidb.cn/en . Our online web examples are shown in Fig. 4.
Problem Definition. Let $`\bm{Q} = \{\bm{q}_1,\bm{q}_2,...,\bm{q}_T\}`$ denote a multi-turn researcher’s query, where $`\bm{q}_t`$ denotes the $`t`$-th turn input query, which uses technical descriptions and contains research goals, methodological descriptions, experimental constraints, etc. Let $`\bm{D} = \{\bm{d}_1,\bm{d}_2,...,\bm{d}_N\}`$ denote the large-scale candidate datasets, where $`N`$ is larger than 10 million in this paper. Each dataset $`\bm{d}_i`$ has the corresponding metadata information and a textual description. This paper aims at designing a dataset recommender $`\mathcal{F}`$, which recommends the most suitable $`K`$ $`(K \ll N)`$ datasets for researchers with as few conversations as possible, i.e, making $`T`$ as small as possible.
Experimental Intention Perceptor
As shown in Fig.2 and Fig.9, the experimental inputs of researchers can be extremely complicated. To support experiment-level dataset recommendation for researchers, we design an Experimental Intention Perceptor that extracts a researcher’s long-passage natural language into structured experimental elements. Compared with traditional dataset recommendation models and general recommenders , this paper aims at a conversational dataset recommender, which is specially designed for scientific research scenarios.
The intention perceptor is designed based on the structured element system and typical process of scientific discovery . Specifically, Data, Topic, Experimental Constraints/Settings, and Evaluation Metrics are typical top-level elements. The Species and Data Modality, Source, and Annotation are typical second-level elements of Data. Take the input query in Fig. 3 as example, our intention perceptor identifies the research topic as cross-organ cell differentiation in human, the task as single-cell fate trajectory inference and cells evolve over time. The cross-organ scope and human tissue context are interpreted as experimental constraints. The extracted scientific intention of a query will be rewritten as $`\Tilde{\bm{q}_t}`$.
Structured Memory Compressor
Due to the complexity of researchers’ needs, their requests can be lengthy and often require more rounds of conversations compared with general recommendation tasks. To effectively support multi-turn, complicated queries in scientific scenarios, we design a Structured Memory Compressor that distills essential information from a long dialogue history while preserving context-dependent dependencies. This module addresses the challenges of inherently forgetting issues of LLMs.
We track all the real-time dialogue states and histories in our platform. Let $`\Theta_{1:T}`$ denote the dialogue history up to turn $`t`$, then
\begin{equation}
\Theta_{1:T} = \{(\Tilde{\bm{q}_1}, \bm{\tau}_1, \bm{r}_1), \dots, (\Tilde{\bm{q}_T}, \bm{\tau}_T, \bm{r}_T)\},
\end{equation}where $`\bm{\tau}_t`$ represents the tool calling and execution logs. The tool logs are able to avoid redundant operations in the next turns of conversation. $`\bm{r}_t`$ denotes the response of our ScienceDB AI at turn $`t`$. The memory budget is limited to $`L_{\text{max}}`$ tokens (e.g., 32K), and thus full inclusion of $`\Theta_{1:T}`$ is meaningful and challenging. If an extremely long conversation record is directly input into LLMs, it will cause the LLM to forget the system prompt or the given set of recommended candidate datasets, thereby leading to hallucinations in the response. In this paper, we aim to compress $`\Theta_{1:t}`$ into a structured memory $`\mathcal{S}_t`$ that retains information in the previous $`t-1`$ turns,
\begin{equation}
\mathcal{S}_t = \begin{cases}
\Theta_{1:1} , & t=1. \\
\mathcal{M}(\Tilde{\bm{q}_t}, \bm{\tau}_t, r_t, \mathcal{S}_{t-1}), & t>1.
\end{cases}
\end{equation}Besides, $`\mathcal{S}_t`$ is expected to be recency-aware conflict resolution, which prefers recent updates over stale or outdated ones. Here we conduct explicit compression, rather than implicit compression for maintaining the structured intention template. $`\mathcal{M}`$ denotes a LLM-based Agent to summarize the historical conversational logs into structured information. Then compressed structured memory $`\mathcal{S}_t`$ is taken as the context for the final response of LLMs. When conflicts are unresolved due to semantic ambiguity, we proactively generate a clarification question, such as “Do you want to override your previous dataset constraint …?”
Trustworthy Dataset Retriever
To enable more accurate retrieval candidates, we adopt a two-stage retriever for the trade-off between effectiveness and efficiency in our large-scale dataset sharing service. Each dataset $`\bm{d}_i`$ is associated with both dense embeddings and structured metadata, such as publication time and affiliated institution (as shown in Fig.8 in the Appendix). In the first stage, we retrieve top-$`N`$ candidate datasets using vector similarity with pre-filtering. If the input query explicitly includes or an LLM extracts, constraints such as publication date, taxonomy, or affiliated institution, we apply scalar filtering to reduce the candidate space. We then compute the cosine similarity between the query embedding $`\bm{e}(\Tilde{q_t})`$ and dataset descriptions $`\bm{e}(d_i)`$ and select the top-$`N`$ most similar datasets. In the second stage, we aims at deeply understanding a researcher’s intention, we then adopt ColBert as the reranker. The reranker performs fine-grained late interaction between the token-level embeddings of $`\Tilde{\bm{q}_t}`$ and $`N`$ candidates, and produces a final top-$`K`$ datasets. Note that the number of recommended dataset in the final response is based on the researcher’s needs. If not specifically specified in the input query, the $`K`$ is set to 3.
Furthermore, to ensure that the recommended datasets are both traceable and trustworthy, i.e., uniquely identifiable and citable, we attach a Citable Scientific Task Record (CSTR) to each dataset $`d_i`$ and include the corresponding CSTR links in our final response. The CSTR identifier provides a unique and standardized ID for scientific resources, similar to a DOI . However, CSTR supports a wider range of resource types. In our scenario, it can uniquely identify both the dataset and its source data files, while the DOI cannot. To be specific, it helps eliminate ambiguity caused by changes in names or storage locations of the dataset and its source files. To enforce this behavior, we incorporate a system prompt as: “For each selected dataset, you MUST return its CSTR identification.”
The pseudocode of our technical framework of ScienceDB AI is shown in Algorithm [alg:main].
Initialize: Structured memory $`\mathcal{S}_0 \leftarrow \varnothing`$
Step 1: Experimental Intention Perceptor $`\Tilde{\bm{q}_t} \leftarrow \textsc{LLMParse}(\bm{q}_t, \Theta_{1:t-1})`$ Decompose $`\Tilde{\bm{q}_t} = (\mathcal{U}, \mathcal{T}, \mathcal{D}, \mathcal{E}, \mathcal{Z})`$
Step 2: Structured Memory Compressor Update dialogue logs: $`\Theta_{1:t} \leftarrow \Theta_{1:t-1} \cup \{(\Tilde{\bm{q}_t}, \bm{\tau}_t, \bm{r}_t)\}`$ Compress $`\Theta_{1:t}`$ into structured memory: $`\mathcal{S}_t \leftarrow \textsc{SSRC}(\Theta_{1:t})`$
Step 3: Trustworthy Dataset Retriever Embed intent: $`\mathbf{h}_t \leftarrow \textsc{EmbedIntent}(\Tilde{\bm{q}_t}, \mathcal{S}_t)`$ Embed datasets: $`\mathbf{H}_\mathcal{D} = \{\mathbf{h}_d \mid d \in \mathcal{D}\}`$ Retrieve top-$`k`$ candidates via approximate nearest neighbor (ANN):
\{d_1, \dots, d_k\} \leftarrow \textsc{ANN}(\mathbf{h}_t, \mathbf{H}_\mathcal{D})Re-rank candidates via cross-encoder:
\text{score}(\Tilde{\bm{q}_t}, d_i) \leftarrow f_{\text{cross}}(\Tilde{\bm{q}_t}, \text{meta}(d_i))Step 4: Generate Final Response
r_t \leftarrow \textsc{LLMAnswer}(\Tilde{\bm{q}_t}, \mathcal{S}_t, \{(d_i, \text{meta}(d_i))\}_{i=1}^k, \text{SystemPrompt})Discussion.
Compared with other LLM or Agent-based recommendation models, we show that the researcher intent understanding, retriever, and memory modules have the most significant impact on meeting researchers’ scientific needs in large-scale data sharing service, more so than complex planning, web search, or reflection modules. Experimental evidence supporting this claim is provided in Section 4.2.
| Model | Recall | NDCG | MRR | AT | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-4 (lr)5-7 (lr)8-10 (lr)11-13 | @1 | @3 | @5 | @1 | @3 | @5 | @1 | @3 | @5 | @1 | @3 | @5 | ||||
| DataFinder | 0.0115 | 0.0726 | 0.1481 | 0.0115 | 0.0455 | 0.0764 | 0.0115 | 0.0363 | 0.0533 | 3.35 | 3.09 | 3.01 | ||||
| DataLinking | 0.2605 | 0.3003 | 0.3084 | 0.2605 | 0.2838 | 0.2871 | 0.2605 | 0.2781 | 0.2800 | 3.23 | 3.06 | 3.03 | ||||
| DeepSeek-V3 +RAG | 0.2277 | 0.2513 | 0.2530 | 0.2277 | 0.2420 | 0.2428 | 0.2277 | 0.2388 | 0.2392 | 3.33 | 3.24 | 3.23 | ||||
| Qwen3 +RAG | 0.2559 | 0.2778 | 0.2824 | 0.2559 | 0.2692 | 0.2712 | 0.2559 | 0.2662 | 0.2673 | 3.21 | 3.17 | 3.15 | ||||
| InteRecAgent | 0.2686 | 0.3083 | 0.3141 | 0.2686 | 0.2926 | 0.2950 | 0.2684 | 0.2871 | 0.2884 | 3.20 | 3.06 | 3.05 | ||||
| CoSearchAgent | 0.1608 | 0.1988 | 0.2386 | 0.1608 | 0.1822 | 0.1984 | 0.1608 | 0.1766 | 0.1854 | 3.41 | 3.31 | 3.25 | ||||
| Ours | 0.4064 | 0.4187 | 0.4196 | 0.4065 | 0.4142 | 0.4146 | 0.4065 | 0.4126 | 0.4128 | 3.19 | 2.89 | 2.83 | ||||
Experiment
In this section, we first introduce the experimental settings used to evaluate our approach. Then, we present the overall performance results and analyze the running efficiency of ScienceDB AI. Subsequently, we provide a detailed case study to illustrate practical effectiveness. Finally, we report results from an online A/B test to comprehensively validate our framework.
Experimental Settings
Dataset
We construct our offline evaluation dataset by randomly sampling user-dataset click logs from ScienceDB over the past two years. Specifically, we sample approximately 10,000 users and 15,000 corresponding downloaded datasets. For each researcher, the dataset they previously clicked is treated as the ground-truth target in the simulated conversation. Candidate datasets are retrieved from 10 million datasets based on cosine similarity. Following previous conversational recommendation works , we construct an offline dataset with multi-turn interactions to simulate the complex and professional needs of researchers. To better simulate these complexities, we leverage a LLM (Qwen-Plus) to generate experimental design plans based on dataset descriptions. Compared with existing offline conversational datasets, our input queries are significantly more detailed, lengthy, and nuanced, posing a more challenging conversational recommendation task. The conversation turn is set between 3 to 5. The detailed offline constructed process and samples are shown in Section in the Appendix.
Competitive Baselines
We select the following baselines as our competitors, which can be classified into three categories: (1) Dataset Recommenders. DataLinking and DataFinder . DataLinking uses concept frequency and TF-IDF to extract the similarity features of user query and dataset descriptions. DataFinder proposes a text similarity based dataset recommendation model, which takes BERT as the embedding model for dataset descriptions. (2) Dialogue Recommenders. DeepSeek-V3:671b (2025-03-24) and Qwen3:235B . (3) Agent-based Conversational Recommenders. CoSearchAgent and InteRecAgent . CoSearchAgent is a multi-agent collaborative system that effectively supports multi-user conversations.
Evaluation Metrics
Following previous works , we use popularly used recommendation metrics, i.e., top-$`K`$ Recall, Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR), as our offline evaluators. As this paper focus on accurate recommendation towards scientific scenarios, we focus on the @1, @3 and @5 of the above metrics. The detailed offline metric information is shown in 6.2 in the Appendix. We also adopt the Average Turns (AT) required for a successful recommendation in our multi-turn conversations. Unsuccessful recommendations within $`t`$ rounds are recorded as $`t+1`$ in calculating AT. For online performance evaluation, we consistently take the Click-Through-Rate (CTR) as the primary metric.
Implementation Details
We employ Qwen-Plus (2025-04-28) as the core LLM of our system for user intent parsing, tool planning, and the construction of offline conversational datasets. It supports a maximum input length of 126K tokens. The framework of ScienceDB AI is implemented using Python and LangGraph . We adopt a distributed Qdrant cluster as our online vector database. For dialogue-based models (e.g., DeepSeek and Qwen), we first use Approximate Nearest Neighbor (ANN) search to retrieve candidate datasets based on the researcher’s query (as the tool results shown in Fig. 9). The candidates are selected from over 10 million datasets in ScienceDB. These retrieved datasets are then provided as context to dialogue LLMs, which selects the final recommendation. All comparative baselines are conducted with their default hyper-parameters. For models that do not support multi-turn interactions (e.g., DataFinder and DataLinking), we decompose the multi-turn queries into a series of single-turn queries. For our framework, we set $`N`$ to 30 as the default.
Overall Performance
We first evaluate the overall performance of ScienceDB AI and its competitors in our offline multi-turn conversational recommendations. The results are shown in Table [tab:main_res]. We summarize our key findings as follows: (1) Existing models specifically designed for dataset recommendation (DataFinder and DataLinking), perform poorly. These models primarily rely on shallow semantic similarity between input queries and dataset descriptions, making them inadequate for understanding the complicated and domain-specific needs of researchers. Notably, DataFinder shows particularly poor performance due to its reliance on simple keyword-based similarity. (2) Agent-based models outperform dialogue-based LLMs, demonstrating the effectiveness of incorporating agent structures. (3) Our proposed ScenceDB.AI consistently outperforms all competitors across all evaluation metrics, validating the effectiveness of our framework. Compared to the strongest baseline, InteRecAgent, ScenceDB.AI achieves more than a 20% improvement. While InteRecAgent incorporates additional modules (e.g., the complicated planning and reflection module), it still underperforms relative to our more compact and efficient design. (4) Based on the results of AT, we conclude that ScenceDB.AI has the smallest turn to find the true answer. Compared with the best AT competitor, Qwen, ScenceDB.AI has achieves 8% and 10% improvement in AT@3 and AT@5. (5) We observe that most baseline models benefit significantly from increasing the value of $`k`$. For example, CoSearchAgent improves its Recall by 48.4% from @1 to @5. In contrast, ScienceDB AI shows only a modest 3.2% gain, as it already achieves high recall at top positions, reflecting its ability to rank the correct dataset near the top with high initial precision.
Running Efficiency
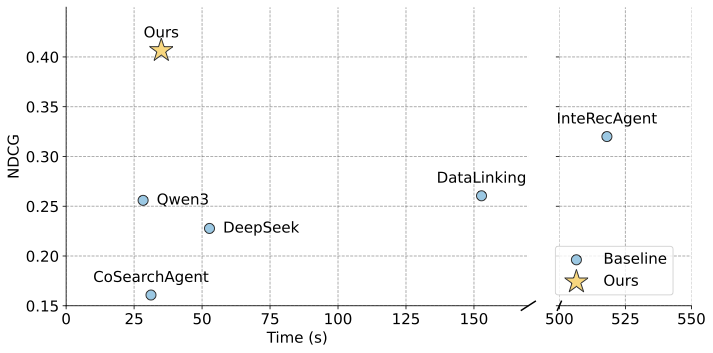
We evaluate the running efficiency of ScienceDB AI in comparison with other LLM- and agent-based conversational baselines. Fig. 5 reports the average inference time per offline conversational test sample. As shown in the figure, InteRecAgent, which incorporates a self-reflection module, exhibits significantly higher inference time (518s) than all other models. Despite being a single-agent model, InteRecAgent runs slower than the multi-agent-based CoSearchAgent, highlighting the computational cost introduced by self-reflection. Surprisingly, DataLinking, though based on simple keyword similarity rather than LLMs, still incurs longer inference time than several LLM-based approaches, indicating inefficiencies in its implementation. In contrast, ScienceDB AI demonstrates superior in both inference efficiency and effectivenss, making it highly practical for deployment in real-world, large-scale data sharing services.

Case Study
To effectively compare the performance, we present case studies in Fig. 6. We compare the outputs of two Agent-based recommenders, i.e., InteRecAgent and CoSearchAgent, and ScienceDB AI for a given experiment-level query. The input query is shown Fig.9 in the Appendix. Specifically, when a researcher requests datasets on pressure-buildup dynamics during water injection into molten lead-bismuth alloys. The request includes eutectic alloys (44.5% Pb–55.5% Bi), non-eutectic compositions, and pure bismuth. The user also specifies the need for synchronized diagnostic outputs and stratified thermal conditions. Both the InteRec Agent and CoSearch Agent return the PMCI dataset. This dataset includes eutectic LBE experiments with pressure and temperature measurements. However, it fails to meet several key requirements: it only covers eutectic compositions and lacks data on non-eutectic and pure-metal cases. In addition to semantic mismatches, CoSearch also exhibits structural errors. For example, it mislabels dataset enumeration numbers, causing mismatches between dataset IDs and their corresponding descriptions. In contrast, our ScienceDB AI correctly identifies a more appropriate dataset. This dataset features high-resolution pressure traces from pure lead experiments conducted between 2020 and 2022, synchronized acoustic and video diagnostics, and comprehensive metadata with full documentation.
Online A/B Test
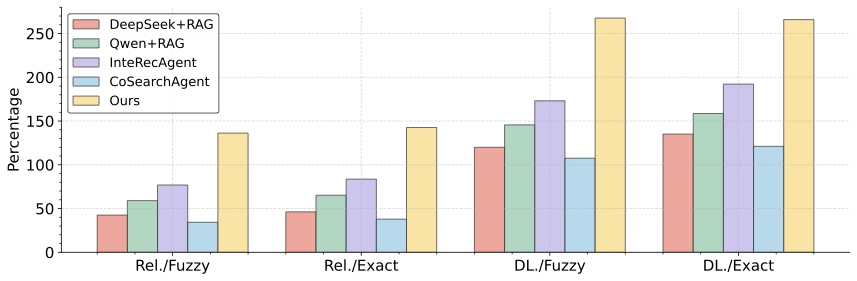
ScienceDB AI introduces a new search interface to the original ScienceDB platform, we compare the CTR of ScienceDB AI and its competitive baselines with the original online keyword-based search page at https://scidb.cn/en/list?searchList , focusing on Top-4 positions. The baseline system includes four retrieval configurations: (1) relevance-based with fuzzy matching (Rel./Fuzzy), (2) relevance-based with exact matching (Rel./Exact), (3) download-frequency-based with fuzzy matching (DL./Fuzzy), and (4) download-frequency-based with exact matching (DL./Exact). As shown in Fig. 7, all values indicate the relative improvements of our model and comparable baselines over the keyword-based search system, measured in percentage terms. We have the following findings: (1) ScienceDB AI achieves significantly higher CTRs, outperforming all baselines across all settings. The conclusion is consistent with the offline experiments in Table [tab:main_res]. Notably, the improvement is more pronounced under exact matching conditions. (2) The performance improvements of Rel- and DL-based matching show no significant difference between the fuzzy and exact settings. The result indicates that traditional keyword-based dataset search methods fail to capture the semantics of input queries. Instead they lie in string matching, whether through exact matches requiring full identity or fuzzy matches based on character similarity, neither approach understands researchers’ scientific intentions.
Conclusion
In this paper, we introduced ScienceDB AI, an intelligent agentic recommender system for large-scale scientific data sharing, built on a repository of over 10 million high-quality scientific datasets. The system introduces several innovations: a Experimental Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using large-scale real-world datasets, ScienceDB AI has demonstrated significant effectiveness, achieving about 30% improvement in offline metrics compared to advanced baselines and a over 200% increase in click-through rates compared to keyword-based search engines. To the best of our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services.
Appendix
Detailed Offline Dataset Information
Source Data
Fig. 8 presents a representative dataset entry with typical structured metadata, including title, authorship, taxonomy classification, keywords, and a textual description. Such entries capture essential information for indexing and retrieval, and serve as the foundation for downstream tasks like dataset recommendation and semantic understanding.
"title": "Experimental data about pressure-buildup
characteristics of a water lump immerged in a molten lead pool from 2020
to 2022",
"cstr": "31253.11.sciencedb.j00186.00022",
"dataSetPublishDate": "2023-02-24T06:52:19Z",
"author": [
{"name": "...", "organizations": [ "..." ] },
{"name": "...", "organizations": [ "..." ]} ],
"taxonomy": ["code": "490","nameZh": "","nameEn":
"Nuclear science and technology"],
"keywordEn": ["Lead-cooled fast reactor","Steam
generator tube rupture accident","Pressure-buildup
characteristics","Experimental study"],
"introduction": "To understand the pressure-buildup
characteristics of a water droplet immerged inside a molten lead pool,
which is a key phenomenon during a Steam Generator Tube Rupture accident
of Lead-cooled Fast Reactor, many experiments have been conducted by
injecting water lumps into a molten lead pool at Sun Yat-sen University
from 2020 to 2022. In order to deepen the understanding of the influence
of melt material, this lead experiment was compared with a
Lead-Bismuth-Eutectic (LBE) experiment in the literature. The parameters
employed in the experiments are water volume, water shape, water
subcooling, molten pool depth and melt temperature.The interaction
vessel in which the CCI occurs is a stainless steel cylindrical
container with an inner diameter of 250 mm, a height of 750 mm, and a
design pressure of 40 MPa. Many sensors are installed on the interaction
vessel wall to obtain the temperature and pressure trends of the melt
pool and cover gas."
Offline Evaluation Dataset Construction Pseudocode
Algorithm [alg:offline_dataset_process]
outlines the procedure for constructing a simulated multi-turn
conversation entry $`e`$ based on a user’s historical interactions.
Given a user ID $`u`$, a sequence of historical items
$`H = [h_1, h_2, ..., h_n]`$, a selected target index $`i`$, a template
module $`T`$, and the maximum number of interaction rounds $`R`$, the
algorithm generates a synthetic dialogue that reflects a realistic yet
challenging information-seeking process. In Step 1, the algorithm
selects a fixed-length history window $`H_{\text{sel}} = H[i{-}L:i]`$
preceding the target index $`i`$. The target item $`d = H[i]`$
represents the dataset the user truly intends to retrieve. A new
conversation entry $`e`$ is initialized using $`u`$, $`i`$, $`T`$, and
$`H_{\text{sel}}`$. The titles of items in $`H_{\text{sel}}`$ are
concatenated into a string $`s`$, which is passed to the system prompt
generator $`T.\texttt{sys\_prompt}(s)`$ and appended to the entry. In
Step 2, a camouflaged user query $`q_0`$ and its associated
supervision mask $`\text{mask}`$ are generated by GenFakeRequest based
on $`T`$, $`s`$, and the ground-truth dataset $`d`$. This query is
designed to indirectly express the user’s true intent The mask is stored
in $`e`$, and the query is formatted using
$`T.\texttt{fake\_request}(q_0)`$ before being appended as a user
message. Step 3 simulates the multi-turn conversation loop. In each
round $`r`$, the latest user and assistant messages $`(u_r, a_r)`$ are
extracted from $`e`$, and a new tool query $`q_r`$ is constructed using
$`T.\texttt{tool\_query}(s, a_r, u_r)`$. If $`q_r`$ contains a
predefined end-of-task marker, the loop terminates. Otherwise, the query
is sent to a retrieval backend via Search, and the returned documents
are formatted as $`R_r`$. The assistant then generates a response
$`a_{r+1} = T.\texttt{generate\_response}(s, a_r, u_r, R_r)`$, followed
by a user follow-up
$`u_{r+1} = T.\texttt{user\_followup}(s, d, a_{r+1})`$. Both messages
are appended to $`e`$, and the loop halts early if $`u_{r+1}`$ also
contains an end marker. Finally, in Step 4, the ground-truth answer
corresponding to the target dataset $`d`$ is generated via
$`T.\texttt{truth\_response}(d)`$ and appended to the conversation as
the assistant’s final reply.
$`H_{\text{sel}} \gets H[i{-}L : i]`$ $`d \gets H[i]`$ $`e \gets`$ InitEntry($`u`$, $`i`$, $`T`$, $`H_{\text{sel}}`$) $`s \gets`$ JoinTitles($`H_{\text{sel}}`$) Append $`(\texttt{System Prompt}, T.\texttt{sys\_prompt}(s))`$ to $`e`$
$`(q_0, \text{mask}) \gets \texttt{GenFakeRequest}(T, s, d)`$ $`e.\text{mask} \gets \text{mask}`$ Append $`(\texttt{User Request}, T.\texttt{fake\_request}(q_0))`$ to $`e`$
Append $`(\texttt{Final Answer}, T.\texttt{truth\_response}(d))`$ to $`e`$
{
"action_type":"Simulated User
Request",
"content": "
Dataset Scope: Experimental datasets documenting
pressure-buildup dynamics during water injection into molten
lead-bismuth alloys (including eutectic LBE: 44.5% Pb-55.5% Bi,
non-eutectic ratios like 20% Pb-80% Bi or 80% Pb-20% Bi) or pure
bismuth. Studies must report under both stratified (e.g., 400°C bottom,
500°C top) and uniform melt temperatures (∼500°C). Key Parameters:
1. Composition Data: Full alloy composition (%
mass of Pb/Bi), melt material properties (density, thermal conductivity,
viscosity).
2. Thermal-Pressure Metrics: High-resolution
pressure vs. time curves, temperature gradients with spatial resolution
(e.g., axial thermocouples), water injection parameters (50 mL volume,
80°C subcooled water, droplet morphology).
3. Diagnostic Outputs: Synchronized high-speed
video (fragmentation modes, vapor-layer collapse) and acoustic emissions
(frequency spectra, amplitude bursts tied to pressure spikes), with
metadata linking precursor signals (e.g., vapor collapse) to pressure
kinetics.
4. Experimental Setup: Vessel specifications
(e.g., stainless steel, 250 mm ID × 750 mm height, 40 MPa-rated), sensor
calibration logs for pressure/temperature, melt preparation/injection
protocols (induction heating, thermocouple arrays). Exclusions: -
Non-metallic melts or non-water coolants (e.g., sodium, CO2). Preferred
Sources: - OECD/NEA databases, IAEA reactor safety programs, FP7-MAXSIMA
datasets, or other EU/NRC-funded experiments on steam explosion physics.
- Replicated trials (≥5 per condition)
with timestamps aligning pressure, thermal, and diagnostic data. -
Comparative datasets for pure Pb vs. bismuth-rich alloys. Format
Requirements: - Structured time-series data (CSV, HDF5, MATLAB .mat,
Excel). - Timestamped video (AVI, MP4) with metadata. - Documentation:
README files, sensor calibration records, experimental schematics.
Search Keywords: Molten metal-water interaction, steam explosion
pressure dynamics, lead-bismuth alloy thermal stratification, bismuth
coolant safety experiments, acoustic precursors in vapor explosions,
reactor cooling system fragmentation studies. Purpose: Benchmark peak
pressure values, pressure rise rates, and acoustic precursors; validate
diagnostic synchronization (e.g., video-acoustic alignment) against
prior experimental data."
},
{
"action_type": "Tool Result",
"content": "[
[0.7737, dataset_id: e04...6c4, title:
Experimental data about pressure-buildup characteristics of a water lump
immerged in a molten lead pool from 2020 to 2022., dataset_introduction:
... ],
[0.7697, dataset_id: 1e0...19f, title: Pressure
build-up characteristics experimental data during a water jet injection
into a molten lead-bismuth eutectic pool in the PMCI facility,
dataset_introduction: ...],
...,
[0.6674, dataset_id: D_3d2...c64, title:
Turbulent flow of liquid lead alloy in oxygen-controlled corrosion
erosion test facility, dataset_introduction: ...],
..."
},
{
"action_type": "Model Response",
"content": "......"
},
{
"action_type": "True Answer",
"content": "According to your request, here is the
dataset you wanted: Experimental data about pressure-buildup
characteristics of a water lump immerged in a molten lead pool from 2020
to 2022. The dataset id is: e04...6c4."
}
Specific Dataset Instances/Samples
We provide a specific offline dataset instance, which is shown in Fig. 9. Each dataset sample consists of a simulated query of researchers, tool results, the response of model outputs, and true answer. We construct simulated user queries by modeling detailed experimental requirements, such as Composition Data, Thermal-Pressure Metrics, Diagnostic Outputs, and Experimental Setup. This method captures realistic user needs more comprehensively than simple keyword queries, enabling better evaluation of dataset recommendation systems. Based on this request, the system retrieves candidate datasets from a structured database this is recorded as the tool result (candidate datasets). Finally, the true answer provides the dataset the simulated user was actually intended to find.
Detailed Information of Evaluation Metrics
To assess the performance of the dataset recommendation models, we adopt the following widely used and representative ranking based metrics: Recall@k, NDCG@k, and MRR@k, with $`k \in \{1, 3, 5\}`$. These metrics are defined as follows:
Recall@k
Recall@k measures whether the ground-truth relevant item is ranked within the top-$`k`$ positions:
\text{Recall@}k =
\begin{cases}
1, & \text{if relevant item is ranked } \leq k. \\
0, & \text{otherwise}.
\end{cases}In our setting, each query has a single relevant dataset, so Recall@k evaluates the hit rate at position $`k`$.
NDCG@k (Normalized Discounted Cumulative Gain)
NDCG@k considers the position of the relevant item in the ranked list, assigning higher weights to items ranked higher. It is defined as:
\text{NDCG@}k = \frac{1}{\log_2(r+1)} \quad \text{if relevant item is at rank } r \leq kOtherwise, NDCG@k = 0. When there is only one relevant item, the ideal DCG (IDCG@k) is 1, so NDCG@k simplifies to a single-position discount.
MRR@k (Mean Reciprocal Rank)
MRR@k measures the inverse of the rank position of the first relevant item, truncated at $`k`$:
\text{MRR@}k =
\begin{cases}
\frac{1}{r}, & \text{if relevant item is at rank } r \leq k. \\
0, & \text{otherwise}.
\end{cases}We report the average MRR@k over all queries. All metrics are averaged over the test set and evaluated at $`k = 1, 3, 5`$ to assess ranking quality at various depths.
To further evaluate recommendation efficiency in multi-turn dialogues, we propose a new metric: AT (Average Turn). This metric measures how early the model is able to recommend the correct dataset within a conversation. Formally, for each multi-turn dialogue, we identify the first turn $`t`$ in which the model’s response includes the ground-truth dataset in the top-$`k`$ results. The AT score for that dialogue is defined as:
\text{AT} =
\begin{cases}
t, & \text{if the correct dataset appears in turn } t \leq T \\
T + 2, & \text{if the correct dataset is not found in any turn}
\end{cases}where $`T`$ denotes the total number of dialogue turns. The penalty of $`T + 2`$ ensures that dialogues where the model fails entirely are appropriately penalized. The final AT score is computed as the average over all dialogues.
Metric Extension for Multi-turn Dialogues
In contrast to traditional single-turn settings, our dataset features multi-turn conversational queries where users iteratively refine their requests. To reflect this process, we adopt a global top-$`k`$ evaluation strategy: instead of averaging metrics (Recall@k, NDCG@k, MRR@k) over individual turns, we concatenate model responses in reverse chronological order (from last to first turn) and compute metrics on the resulting ranked list, prioritizing later, more specific intents.
However, standard metrics do not distinguish whether the correct dataset is identified early or late. To capture interaction efficiency, we propose AT to reflect the earliest turn at which the correct dataset is recommended. A lower AT indicates quicker task resolution and better understanding. By combining AT with standard metrics, we provide a more holistic evaluation of both recommendation quality and efficiency.
📊 논문 시각자료 (Figures)