RefSR-Adv Adversarial Attack on Reference-based Image Super-Resolution Models
📝 Original Paper Info
- Title: RefSR-Adv Adversarial Attack on Reference-based Image Super-Resolution Models- ArXiv ID: 2601.01202
- Date: 2026-01-03
- Authors: Jiazhu Dai, Huihui Jiang
📝 Abstract
Single Image Super-Resolution (SISR) aims to recover high-resolution images from low-resolution inputs. Unlike SISR, Reference-based Super-Resolution (RefSR) leverages an additional high-resolution reference image to facilitate the recovery of high-frequency textures. However, existing research mainly focuses on backdoor attacks targeting RefSR, while the vulnerability of the adversarial attacks targeting RefSR has not been fully explored. To fill this research gap, we propose RefSR-Adv, an adversarial attack that degrades SR outputs by perturbing only the reference image. By maximizing the difference between adversarial and clean outputs, RefSR-Adv induces significant performance degradation and generates severe artifacts across CNN, Transformer, and Mamba architectures on the CUFED5, WR-SR, and DRefSR datasets. Importantly, experiments confirm a positive correlation between the similarity of the low-resolution input and the reference image and attack effectiveness, revealing that the model's over-reliance on reference features is a key security flaw. This study reveals a security vulnerability in RefSR systems, aiming to urge researchers to pay attention to the robustness of RefSR.💡 Summary & Analysis
1. **RefSR-Adv: Revealing Security Vulnerabilities** This paper introduces a new adversarial attack, RefSR-Adv, which targets the reference image in Reference-based Super-Resolution (RefSR) systems without altering the low-resolution input. By subtly modifying the reference image, it can degrade the output quality, bypassing integrity checks on the LR inputs.-
Auxiliary Surface Attacks
RefSR-Adv is a novel method that introduces subtle perturbations into the reference image to induce significant degradation in the super-resolved output. This approach exploits the fact that reference images are rarely scrutinized by end-users, making such attacks hard to detect. -
Correlation Between LR-Ref Similarity and Attack Performance
The effectiveness of RefSR-Adv is positively correlated with the similarity between low-resolution inputs and reference images. This highlights a security vulnerability in RefSR systems due to their reliance on external reference features for texture synthesis.
📄 Full Paper Content (ArXiv Source)
Reference-based Super-resolution, Adversarial Attack
Introduction
Single Image Super-Resolution (SISR) has evolved through various architectures to recover high-resolution details from low-resolution (LR) inputs. However, due to the lack of sufficient information in low-resolution inputs, SISR inevitably synthesizes unrealistic artifacts or texture hallucinations. To overcome these limitations, Reference-based Super-Resolution (RefSR) has emerged by introducing an high-resolution reference (Ref) image as external high-frequency texture library. By leveraging feature matching and fusion, RefSR transfers similar textures from the reference image to achieve superior restoration. Despite it has demonstrated immense potential in security-sensitive domains such as satellite remote sensing , medical imaging , and intelligent surveillance, the security vulnerabilities of these dual-input systems remain largely unexplored.
Current security research on super-resolution primarily focuses on two dimensions: (i) adversarial attacks on SISR by perturbing low-resolution inputs, and (ii) backdoor attacks on RefSR , which assume the attacker can contaminate training data. Unlike the single-input architecture of SISR, RefSR possesses a unique dual-input structure (LR and Ref). This architectural characteristic reveals a previously overlooked attack surface: Could an attacker exploit the RefSR model’s dependence on a reference image to inject subtle perturbations into the reference image to degrade the output?
In this paper, we systematically expose an inherent security vulnerability in RefSR and propose a novel adversarial attack named RefSR-Adv. Unlike traditional adversarial attack that must tamper with the LR input, RefSR-Adv achieves indirect manipulation by perturbing only the reference image. This strategy offers two core advantages:
-
Integrity of LR Input: RefSR-Adv maintains the bit-wise integrity of the LR input. In systems where strict integrity audits (e.g., hash verification or digital signatures ) are deployed on the LR input, traditional attacks fail due to verification errors. RefSR-Adv perfectly bypasses such defenses by ensuring the LR input remains untouched.
-
Enhanced Stealthiness: In practical workflows, reference images serve as auxiliary inputs and are rarely presented to end-users. Since human scrutiny typically focuses on the final super-resolved result, pixel-level changes in the Ref image are naturally camouflaged and extremely difficult to detect.
The primary contributions of this work are summarized as follows:
-
We propose RefSR-Adv, revealing the security vulnerability of “auxiliary surface attacks” in RefSR systems. To the best of our knowledge, this work represents the first adversarial attack specifically targeting the reference image.
-
We conduct extensive experiments across four popular RefSR models (CNN, Transformer, and Mamba). Results confirm that this security flaw is universal across different architectures, indicating a general lack of security verification for reference images.
-
We uncover a positive correlation between the LR-Ref similarity and the performance of the attack, revealing that the excessive reliance on external reference features constitutes a security vulnerability in the RefSR architecture.
Related Work
Image Super-Resolution
Image Super-Resolution (SR) aims to recover high-resolution (HR) details from low-resolution inputs. Depending on the input sources and prior information utilized, SR can be broadly categorized into SISR and RefSR.
SISR relies on implicit priors learned within the model to reconstruct images from a single LR input. Over the past decade, SISR has evolved from CNNs and Transformers to recent State Space Models (SSMs) and Diffusion Models . However, since the information contained in the LR input is inherently limited, SISR models often struggle to reconstruct fine details, leading to unrealistic artifacts or texture hallucinations in the output.
To overcome the inherent information limitations of LR inputs, RefSR incorporates an external high-resolution reference image to migrate high-frequency textures. Through feature matching and adaptive fusion mechanisms, RefSR migrates and transfers similar textures from the Ref image to the reconstructed output, achieving superior detail recovery. The evolution of RefSR has primarily focused on alignment challenges, progressing from early patch matching to Transformer-based mechanisms for enhanced robustness against disparity. Recently, integrated the Mamba architecture for efficient long-range dependency modeling. While recent works like RefDiff explore dual-input diffusion models, their stochastic denoising mechanisms fundamentally differ from the deterministic feature mapping used in CNN, Transformer, and SSM architectures, this study specifically focuses on the security vulnerabilities in these deterministic architectures.
Security Threats in Super-Resolution
Security research in image super-resolution primarily investigates two distinct threat categories: Adversarial Attacks and Backdoor Attacks.
Adversarial attacks aim to induce catastrophic performance degradation by introducing subtle, intentionally designed perturbations into the input data during the inference phase. Early pioneering work systematically evaluated the vulnerability of various SISR architectures, while revealed that adversarial attacks on SISR can serve as “upstream interference” to mislead downstream tasks. Subsequently, for complex scenarios, SIAGT achieved scale-invariant attacks, and explored the deployment challenges of adversarial samples in edge device inference streams. However, current adversarial research in super-resolution primarily concentrates on compromising single-input SISR models by perturbing the low-resolution (LR) stream. Due to the unique dual-input architecture of RefSR, which integrates both LR and Ref features, the vulnerability of the reference path to adversarial attack remains entirely unexplored. To fill this gap, RefSR-Adv introduces a adversarial attack that targets the previously overlooked “auxiliary surface”. By injecting subtle perturbations into the reference image, our framework successfully induces catastrophic output degradation.
Backdoor attacks involve embedding hidden malicious behaviors into a model by injecting triggers into the training dataset, a process known as “data poisoning”. Recent research, BadRefSR, has explored this threat in RefSR systems by adding triggers to reference images during the training phase. While these studies highlight significant risks, they assume the attacker has the capability to contaminate training data, which may not be feasible in many real-world scenarios. Unlike backdoor-based “data poisoning,” RefSR-Adv operates as an adversarial threat during the deployment or inference process, requiring no access to the training phase. While backdoor threats have been investigated, the adversarial attacks targeting the reference image during the inference process remains unexplored. RefSR-Adv fills this research gap.
METHODOLOGY
In this section, we first provide a formal definition of RefSR. We then analyze the limitations of existing attacks on SISR and propose our threat model. Finally, we elaborate on the optimization objectives and algorithmic details of the RefSR-Adv attack.
Preliminary
Unlike SISR, which relies on implicit priors within the model for reconstruction, RefSR introduces a high-resolution reference image $`I_{Ref}`$ as an external high-frequency texture library. Formally, given a low-resolution input $`I_{LR} \in \mathbb{R}^{H \times W \times C}`$ containing the primary structure and a reference image $`I_{Ref} \in \mathbb{R}^{H_{ref} \times W_{ref} \times C}`$ providing detail priors, the RefSR model $`\mathcal{M}`$ aims to reconstruct a high-resolution image $`I_{SR} \in \mathbb{R}^{sH \times sW \times C}`$ ($`s`$ is the upsampling factor):
\begin{equation}
I_{SR} = \mathcal{M}(I_{LR}, I_{Ref}; \theta),
\end{equation}where the parameters $`\theta`$ are typically optimized via one of two mainstream strategies:
-
Reconstruction-only ($`L_{rec}`$): This strategy focuses on ensuring pixel-level signal fidelity. The reconstruction loss is typically formulated using the $`L_1`$-norm to measure the absolute discrepancy between the super-resolved output and the ground-truth $`I_{GT}`$ image:
MATH\begin{equation} L_{rec} = \frac{1}{N} \sum_{i=1}^{N} \| \mathcal{M}(I_{LR}^i, I_{Ref}^i; \theta) - I_{GT}^i \|_1, \end{equation}Click to expand and view morewhere $`N`$ is the number of training samples. While optimization under this objective yields high numerical scores in terms of PSNR and SSIM, the individual $`L_1`$ loss tends to cause over-smoothed results that lack fine-grained textures.
-
Full-loss ($`L_{full}`$): To improve perceptual quality and generate more visually favorable details, a composite total loss is employed: $`L_{full} = L_{rec} + \lambda_{1} L_{per} + \lambda_{2} L_{adv}`$.The hyperparameters $`\lambda_{1}`$ and $`\lambda_{2}`$ are used as balancing coefficients to adjust the trade-off between pixel-level signal fidelity and higher-level perceptual realism.
Perceptual Loss ($`L_{per}`$): By utilizing feature maps from a pre-trained VGG model, $`L_{per}`$ constrains the model in a high-dimensional feature space:
MATH\begin{equation} L_{per} = \frac{1}{N} \sum_{i=1}^{N} \| \phi_{j}(I_{SR}^i) - \phi_{j}(I_{GT}^i) \|_F, \end{equation}Click to expand and view morewhere $`\phi_{j}(\cdot)`$ denotes the $`j`$-th layer output of the VGG model and $`\|\cdot\|_F`$ denotes the Frobenius norm.
Adversarial Loss ($`L_{adv}`$): Typically implemented via Generative Adversarial Networks (GANs), this loss encourages the model to synthesize realistic high-frequency textures by penalizing the distribution gap between generated and real images:
MATH\begin{equation} L_{adv} = -\mathbb{E}_{I_{SR}} [\log(D(I_{SR}))], \end{equation}Click to expand and view morewhere $`D`$ is the discriminator tasked with distinguishing real ground-truth images from reconstructed ones. This strategy significantly enhances the model’s ability to migrate and reconstruct intricate textures, but it potentially increases the network’s sensitivity and “excessive trust” toward reference features.
Threat Model and Problem Formulation
In this study, we investigate the adversarial robustness of RefSR models under a white-box attack setting, which serves as a rigorous evaluation of the model’s security boundary.
Attacker Capability
Following the standard adversarial settings in super-resolution research, we assume the attacker has full knowledge of the target RefSR model $`\mathcal{M}`$, including its specific architecture, internal parameters $`\theta`$, and the gradients required for optimization. The attacker’s capability is confined to injecting a subtle, pixel-level adversarial perturbation $`\delta`$ into the high-resolution reference image $`I_{Ref}`$, while the primary low-resolution input $`I_{LR}`$ remains unmodified.
Problem Formulation
The objective of RefSR-Adv is to identify an optimal adversarial perturbation $`\delta`$ that, when added to the reference image, induces the maximum reconstruction error in the super-resolved output. Let $`I_{GT}`$ represent the ground-truth high-resolution image. We formulate the attack as a constrained optimization problem aimed at maximizing the loss between the model’s output and the ground truth:
\begin{equation}
\max_{\delta} \mathcal{L} \Big( \mathcal{M}(I_{LR}, I_{Ref} + \delta), I_{GT} \Big),
\end{equation}subject to the following constraints:
\begin{equation}
||\delta||_{\infty \le} \epsilon, \quad (I_{Ref} + \delta) \in [0, 1]^{H_{ref} \times W_{ref} \times C},
\end{equation}where $`\mathcal{L}(\cdot)`$ denotes a loss function (e.g., $`L_2`$ loss) utilized to quantify the degradation in signal fidelity. The term $`\epsilon`$ signifies the maximum allowable perturbation budget, ensuring that the adversarial modifications remain imperceptible to human observers.
RefSR-Adv Attack
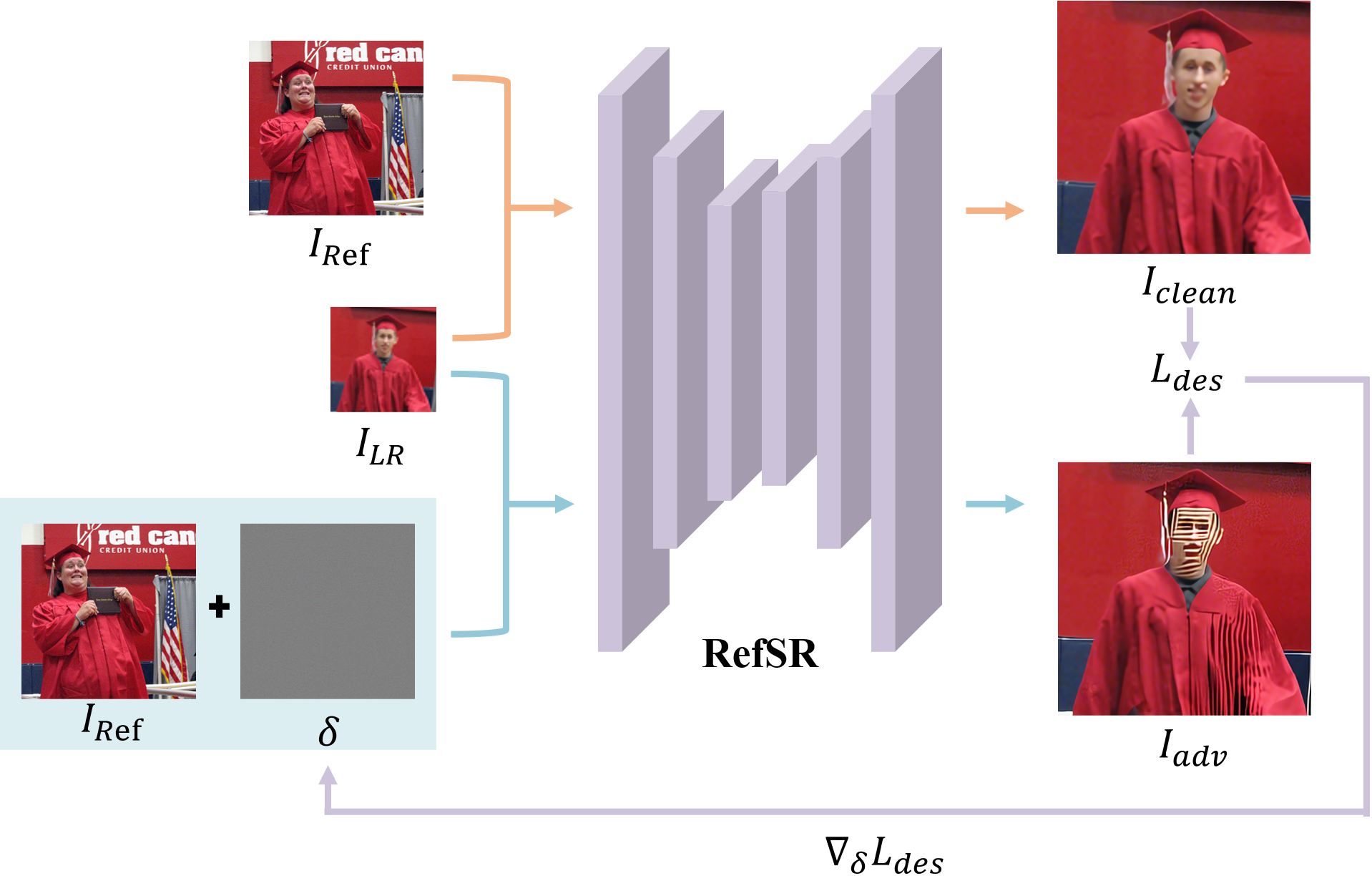
As shown in Fig. 1, RefSR-Adv employs a gradient-based iterative optimization paradigm consisting of three core components:
Pseudo Ground-Truth Strategy
In practical inference scenarios, the actual high-resolution ground-truth image $`I_{\text{GT}}`$ is inherently unavailable to the attacker. To address this, we adopt a pseudo ground-truth strategy , utilizing the model’s own output under benign conditions as the reference baseline. Specifically, we define the clean super-resolution output, generated from the original low-resolution image $`I_{LR}`$ and the clean reference image $`I_{Ref}`$, as the baseline:
\begin{equation}
I_{clean} = \mathcal{M}(I_{LR}, I_{Ref}; \theta).
\end{equation}By treating $`I_{clean}`$ as a high-fidelity proxy for the intended reconstruction, we can precisely quantify the degree of adversarial deviation. This strategy ensures the attack’s effectiveness in real-world deployment environments where the ground-truth is unknown, providing a stable “intended” baseline for optimization.
Destruction Loss Formulation
To induce maximum degradation in signal fidelity, we formulate a destruction loss $`\mathcal{L}_{des}`$ aimed at maximizing the discrepancy between the adversarial output $`I_{adv}`$ and the clean baseline $`I_{clean}`$. Let $`I_{adv} = \mathcal{M}(I_{LR}, I_{Ref} + \delta; \theta)`$ denote the output generated from the perturbed reference image. We utilize the $`L_2`$ norm to formalize the objective:
\begin{equation}
\mathcal{L}_{des}(\delta) = \| I_{adv} - I_{clean} \|_2.
\label{eq:loss_des}
\end{equation}The choice of the $`L_2`$ norm is motivated by two key factors. First, maximizing the Euclidean discrepancy effectively disrupts the pixel-level reconstruction consistency inherent in deterministic architectures such as CNN, Transformer and Mamba. Second, since maximizing the Mean Squared Error (MSE) is mathematically equivalent to minimizing the Peak Signal-to-Noise Ratio (PSNR), the $`L_2`$ norm serves as a robust and natural proxy for inducing catastrophic reconstruction error.
Optimization via Projected Gradient Descent
To solve the constrained maximization problem defined by the destruction loss, we employ the Projected Gradient Descent (PGD) algorithm . Unlike simpler methods, PGD utilizes random initialization to more comprehensively explore the adversarial loss landscape within the perturbation budget $`\epsilon`$. In each iteration $`t`$, the learnable perturbation $`\delta`$ is updated along the direction of the gradient sign:
\begin{equation}
\delta^{(t+1)} = \Pi_{\epsilon} \left[ \delta^{(t)} + \alpha \cdot \text{sign}\left( \nabla_{\delta} \mathcal{L}_{des}(\delta^{(t)}) \right) \right],
\end{equation}where $`\alpha`$ denotes the step size and $`\Pi_{\epsilon}(\cdot)`$ represents the projection operator ensuring the perturbation remains within the $`\ell_\infty`$-norm constraint $`\|\delta\|_\infty \le \epsilon`$ and valid pixel range $`[0, 1]`$. By exploiting the differentiable nature of modern texture matching and fusion modules, RefSR-Adv backpropagates output discrepancies directly to the reference image pixels to identify the most damaging perturbations. The complete optimization logic is summarized in Algorithm [alg:pgd].
Target RefSR model $`\mathcal{M}`$ with parameters $`\theta`$; Clean primary input $`I_{LR}`$; Clean auxiliary reference image $`I_{Ref}`$; Perturbation budget $`\epsilon`$; Step size $`\alpha`$; Total iterations $`T`$. Adversarial reference image $`I_{Ref}^{adv}`$.
Step 1: Baseline Generation $`I_{clean} \leftarrow \mathcal{M}(I_{LR}, I_{Ref}; \theta)`$
Step 2: Perturbation Initialization $`\delta^{(0)} \leftarrow \text{Uniform}(-\epsilon, \epsilon)`$ $`\delta^{(0)} \leftarrow \text{Clip}(I_{Ref} + \delta^{(0)}, 0, 1) - I_{Ref}`$
Step 3: Iterative Adversarial Optimization $`I_{adv} \leftarrow \mathcal{M}(I_{LR}, I_{Ref} + \delta^{(t)}; \theta)`$ $`\mathcal{L}_{des} \leftarrow \| I_{adv} - I_{clean} \|_2`$ $`G \leftarrow \nabla_{\delta} \mathcal{L}_{des}(\delta^{(t)})`$ $`\delta^{(t+1)} \leftarrow \delta^{(t)} + \alpha \cdot \text{sign}(G)`$ $`\delta^{(t+1)} \leftarrow \text{Clip}(\delta^{(t+1)}, -\epsilon, \epsilon)`$ $`\delta^{(t+1)} \leftarrow \text{Clip}(I_{Ref} + \delta^{(t+1)}, 0, 1) - I_{Ref}`$
$`I_{Ref}^{adv} = I_{Ref} + \delta^{(T)}`$
EXPERIMENTS
In this section, we conduct quantitative and qualitative evaluations to assess the effectiveness and stealthiness of RefSR-Adv. We first describe the experimental setup, followed by a performance analysis across four popular RefSR models to demonstrate the universality of the identified vulnerabilities.
Experimental Settings
Datasets
We evaluate our method on three standard datasets:
-
CUFED5, featuring 126 groups with varying reference similarity levels;
-
WR-SR , containing web-crawled images with diverse viewpoints and lighting to simulate real-world scenarios;
-
DRefSR , focused on diverse texture exploitation across categories like architecture and animals.
To balance computational efficiency with detail preservation, we adopt a $`600 \times 600`$ center-cropping strategy for high-resolution datasets (WR-SR and DRefSR).
Victim Models
To verify the universality of RefSR-Adv, we select four popular models covering three mainstream paradigms (CNN, Transformer, Mamba) :
-
TTSR: A pioneering Transformer-based RefSR model that utilizes “Hard-Soft Attention" mechanisms to improve the accuracy of texture feature transfer from Ref images.
-
MASA-SR: A classic CNN-based representative that employs spatial adaptation modules and coarse-to-fine matching to significantly enhance feature alignment efficiency.
-
DATSR: An advanced Transformer architecture that adopts Deformable Attention to achieve robust feature matching and detail recovery, especially under large parallax conditions.
-
SSMTF: The latest Mamba-based model that leverages State Space Models for efficient long-range dependency modeling and multi-scale texture fusion.
Evaluation Metrics
We utilize standard SR metrics: Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM).
-
PSNR measures the pixel-level reconstruction fidelity based on the Mean Squared Error.
-
SSIM evaluates the structural similarity by considering luminance, contrast, and texture information.
We record three categories of results: (i) SR quality under clean references; (ii) SR quality under adversarial references; (iii) Fidelity of the adversarial reference relative to the clean image to measure Stealthiness.
Implementation Details
We employ the PGD optimizer with a perturbation budget of $`\epsilon=8/255`$ and $`T=50`$ iterations to generate adversarial samples. All experiments are conducted for $`4\times`$ super-resolution. Notably, since all victim models are re-implemented locally using official source codes, the baseline performances may exhibit discrepancies from the results reported in the original papers.
Attack Performance Evaluation
To evaluate the effectiveness of our framework, we conduct quantitative assessments of RefSR-Adv across four state-of-the-art models on three standard datasets. Table [tab:main_results] illustrates the quantitative impact of the proposed attack.
As shown in the results, while TTSR and MASA exhibit relative robustness, DATSR and SSMTF suffer severe performance collapses, with PSNR drops often exceeding 7dB. This discrepancy stems from their specific feature-matching strategies. TTSR and MASA downsample reference images to handle scale disparities; mathematically, this acts as a low-pass filter that inadvertently mitigates high-frequency perturbations. Conversely, DATSR and SSMTF interact with features at original resolutions to pursue superior detail recovery. Without the filtering protection, these models fully absorb and amplify adversarial textures, leading to catastrophic degradation.
Furthermore, a comparative analysis of different training objectives reveals that models optimized with the full-loss function ($`L_{full}`$) generally exhibit higher vulnerability to RefSR-Adv than those trained with reconstruction-only ($`L_{rec}`$) objectives, particularly for the TTSR, MASA, and DATSR. While perceptual and adversarial losses ($`L_{per}`$ and $`L_{adv}`$) are designed to encourage the synthesis of realistic high-frequency textures, RefSR-Adv strategically exploits this mechanism by misleading the network to misinterpret adversarial noise as valid textural details, thereby inducing severe visual artifacts. Conversely, the inherent tendency of $`L_{rec}`$-optimized models toward over-smoothed reconstructions provides a natural suppression mechanism against such high-frequency perturbations. However, SSMTF presents a notable exception where the reconstruction-only version suffers a slightly more pronounced performance drop than its full-loss counterpart. This phenomenon is attributed to Mamba’s unique global state evolution, which causes pixel-level perturbations to propagate and accumulate throughout the entire sequence when the model is constrained by strict pixel-level fidelity. In this specific case, the high-level semantic regularization provided by the full-loss objective functions as a robust buffer, effectively mitigating the global amplification of low-level adversarial noise.
Overall, these results demonstrate that RefSR-Adv maintains high stealthiness (PSNR $`>`$ 35dB) to ensure that adversarial perturbations remain imperceptible. The significant performance degradation reveals a universal security vulnerability across mainstream CNN, Transformer, and Mamba architectures. This fundamental flaw stems from the models’ excessive reliance on untrusted reference images, proving that the auxiliary reference stream constitutes a critical and vulnerable attack surface.
Qualitative Analysis
To visually assess the impact of RefSR-Adv, we provide qualitative comparisons across the CUFED5, WR-SR, and DRefSR datasets in Figs. 2, 3, 4. For each victim model, we present a vertically aligned pair of super-resolved results: the top image represents the output generated using the original clean reference, while the bottom image illustrates the output synthesized under the perturbed adversarial reference.



Visual results demonstrate that this attack precisely disrupts the texture synthesis mechanism during super-resolution processing. While the global geometry of the generated image remains constrained by the low-resolution input, preventing complete collapse, high-frequency texture details guided by the reference image are severely compromised. Consequently, RefSR-Adv successfully induces significant texture illusions within the output, where previously coherent and valid semantic textures are systematically replaced by chaotic and perceptible visual artifacts. This specific disruption is notably more pronounced in advanced models designed for extreme detail restoration and high-fidelity texture migration, such as the DATSR and SSMTF. Furthermore, the consistency of these distortions across different data distributions further confirms the effectiveness and universality of the attack.
Ablation Study
In this section, we conduct a comprehensive ablation analysis to evaluate the key factors influencing the performance of RefSR-Adv. All experiments are performed on the CUFED5 using the full-loss version of the victim models.
Impact of Perturbation Budget $`\epsilon`$
As shown in Table [tab:epsilon], attack potency increases monotonically with perturbation budget $`\epsilon`$. However, $`\epsilon=8/255`$ provides the optimal balance between attacking performance and stealthiness (PSNR $`>35`$dB).
Impact of Iteration Count $`T`$
Table [tab:iterations] indicates that while increasing iteration count $`T`$ slightly enhances the attack, $`T=50`$ is sufficient to achieve significant attacking performance with reasonable computational cost.
Impact of Reference Similarity
To evaluate how the similarity between the low-resolution ($`I_{LR}`$) and reference ($`I_{Ref}`$) images affects attack performance, we conducted a comprehensive ablation study leveraging the five distinct similarity levels defined within the CUFED5 dataset. The quantitative results, as presented in Table [tab:similarity], demonstrate that at higher similarity levels (e.g., Level 1), RefSR models engage in more aggressive texture migration and feature fusion to maximize detail recovery. While this behavior is beneficial under benign conditions, it inadvertently facilitates the transmission and amplification of adversarial perturbations, leading to the most severe performance degradation. Conversely, at lower similarity levels (e.g., Level 5), the models’ intrinsic correlation filtering mechanisms are more frequently triggered to reject mismatched features, which serves as a spontaneous and unintended defense that suppresses the propagation of adversarial noise. These observations indicate that the effectiveness of RefSR-Adv exhibits a significant positive correlation with the consistency between the $`I_{LR}`$ and $`I_{Ref}`$ input pairs.
Comparison with Random Noise
To confirm that the performance degradation is caused by specific adversarial perturbation rather than random noise, we compare RefSR-Adv with Gaussian noise at $`\epsilon = 8/255`$. Table [tab:noise] shows that popular models are inherently robust to random noise. This confirms that RefSR-Adv can accurately exploit the model’s dependence on reference features to induce severe artifacts, thus effectively distinguishing our targeted attacks from simple random noise interference.
POTENTIAL DEFENSE STRATEGIES
To mitigate the identified threats, we suggest employing non-differential input purification, such as JPEG re-compression or bit-depth quantization to disrupt the high-frequency structures of adversarial perturbations, rendering them ineffective during the feature matching stage. Alternatively, a content-based matching gating mechanism could be introduced to block feature fusion when abnormal matching scores or semantic inconsistencies are detected. Furthermore, drawing on the findings by Huang et al. , adversarial fine-tuning can be utilized to force the model to learn more robust feature matching representations.
CONCLUSION
This study reveals the security vulnerabilities of reference-based adversarial attacks in RefSR and proposes RefSR-Adv, a white-box attack framework targeting the reference image. Our results show that popular RefSR models are highly vulnerable to minute perturbations, which induce severe artifacts and degrade output quality. Crucially, we found a positive correlation between the similarity of the reference image and the attack success rate: higher-quality reference images exacerbate the model’s vulnerability, confirming that over-reliance on reference features is a critical security flaw.
Despite its superior performance in white-box settings, the cross-model transferability of the attack remains challenging due to the architectural heterogeneity in feature matching and fusion mechanisms. Future work will focus on exploring black-box attacks by integrating meta-learning or query-based optimization, as well as developing similarity-aware defense mechanisms to enhance the robustness of RefSR systems.
📊 논문 시각자료 (Figures)