Aggressive Compression Enables LLM Weight Theft
📝 Original Paper Info
- Title: Aggressive Compression Enables LLM Weight Theft- ArXiv ID: 2601.01296
- Date: 2026-01-03
- Authors: Davis Brown, Juan-Pablo Rivera, Dan Hendrycks, Mantas Mazeika
📝 Abstract
As frontier AIs become more powerful and costly to develop, adversaries have increasing incentives to steal model weights by mounting exfiltration attacks. In this work, we consider exfiltration attacks where an adversary attempts to sneak model weights out of a datacenter over a network. While exfiltration attacks are multi-step cyber attacks, we demonstrate that a single factor, the compressibility of model weights, significantly heightens exfiltration risk for large language models (LLMs). We tailor compression specifically for exfiltration by relaxing decompression constraints and demonstrate that attackers could achieve 16x to 100x compression with minimal trade-offs, reducing the time it would take for an attacker to illicitly transmit model weights from the defender's server from months to days. Finally, we study defenses designed to reduce exfiltration risk in three distinct ways: making models harder to compress, making them harder to 'find,' and tracking provenance for post-attack analysis using forensic watermarks. While all defenses are promising, the forensic watermark defense is both effective and cheap, and therefore is a particularly attractive lever for mitigating weight-exfiltration risk.💡 Summary & Analysis
1. **Defining a new threat model**: This research introduces a new threat model to quantify the risk of weight exfiltration attacks. It highlights that models are more compressible than previously thought, making it easier for attackers to steal weights from data centers. 2. **Identifying extreme compression feasibility**: The study found that with high decompression costs (additional fine-tuning), models can be compressed much more aggressively, indicating a higher risk of successful weight exfiltration attacks. 3. **Proposing reasonable defenses**: The paper reviews and evaluates several defense mechanisms, finding forensic watermarking to be particularly effective in making model weights harder to steal.Sci-Tube Style Explanation (English)
- Defining a new threat model: As the cost of training AI models has skyrocketed, securing these models against theft is crucial. This study introduces a novel way to measure how easily attackers can steal model weights.
- Identifying extreme compression feasibility: The research discovered that models are much more compressible than previously thought, allowing them to be stolen more easily by exploiting this high compression capability.
- Proposing reasonable defenses: To counteract these thefts, the paper suggests using forensic watermarking as an effective method to make it harder for attackers to steal model weights.
📄 Full Paper Content (ArXiv Source)
The cost of training frontier AI models has skyrocketed, with each new generation of models requiring exponentially more compute to train . Beyond their economic significance, advanced AI systems are increasingly viewed as critical assets in national security, given their rapidly improving capabilities. This dual economic and strategic importance has led to increased interest in securing model weights from theft .
Weight exfiltration attacks.
Of particular concern are weight exfiltration attacks, where the data center hosting the model weights is compromised by an attacker. This allows the attacker to steal the weights of the language model by smuggling them out over the network. However, the risk of weight exfiltration attacks remains poorly understood, with much uncertainty surrounding their feasibility.
A common tactic in standard data exfiltration attacks is to compress data before transmission over the network , reducing the likelihood of detection. However, this tactic has not been extensively studied in the context of weight exfiltration attacks. While prior work on large language model (LLM) compression has focused on optimizing models for efficient inference—achieving high fidelity with up to $`4\times`$ compression —the requirements for inference differ significantly from those in weight exfiltration scenarios. In particular, existing methods are designed to have an efficient forward pass after the initial compression— we refer to the cost of obtain useful weights after they have been compressed as the ‘decompression cost‘ in 1. These differences suggest that more aggressive lossy compression techniques, tailored for exfiltration, could be feasible, leading to a higher risk of successful attacks.
To study how to better defend language model weights from being stolen from servers, we investigate the impact of LLM compression on the feasibility of weight exfiltration attacks. We begin by proposing a simple quantitative model for exfiltration success, which is influenced by factors such as the compression ratio. Next, we show that compression techniques specifically optimized for exfiltration can significantly reduce exfiltration time and improve the likelihood of a successful attack. By relaxing the typical constraints for model compression that prioritize still being able to run the model efficiently for inference, we achieve substantially higher compression rates than existing methods, reaching well over $`16\times`$ compression with minimal trade-offs.
Finally, we consider three candidate ‘model-level’ defenses in detail. These defenses attempt to harden weights against an adversary in three ways: by making them harder to compress, via a moving target defense first proposed in , and by forensic watermarking. We find that forensic watermarking is the most promising— it is both cheap to implement and reasonably robust.
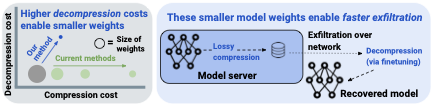 />
/>
In summary, we make the following contributions.
-
Defining a new threat model. We build a model to quantify the risk of weight exfiltration under various conditions and identify model compressibility as a crucial neglected factor. Indeed, model compressibility may make exfiltration attacks much more feasible.
-
Identifying new phenomena around extreme compression. We find that models are orders of magnitude (10-100x) more compressible than standard practice would suggest, when one allows for high decompression costs, in the form of additional finetuning. While high decompression costs are not feasible for model inference quantization, high costs are acceptable for attackers while stealing model weights.
-
Proposing reasonable defenses. We review and measure a few baseline model- and system-level defenses, and find that forensic watermarking of layer weights for the purpose of provenance is particularly appealing.
Our results suggest that LLM compression is a significant factor affecting the risk of weight exfiltration attacks. Attacks that would have taken months before may be feasible in days with advanced compression techniques. This motivates further research on the risk of weight exfiltration and further investment in securing model weights.
Related Work
Model Stealing.
Black-box model stealing attacks have demonstrated that an adversary with only API access to a machine learning service can steal a deployed model’s functionality. For example, extracts the exact weights of a logistic classifier with only API access and steals the exact final layer of a model without training. Another line of work attempts to distill the capabilities of a model with query-only access , however, the resulting models typically significantly underperform the teacher model.
Data exfiltration.
A long line of work in the security literature has studied data exfiltration threats. Particularly relevant to our setting are advanced persistent threats (APTs) . These attacks involve targeted infiltration and long dwell times on compromised servers to gather and slowly exfiltrate high-value data. In these settings, the amount of data to exfiltrate is a key consideration, and compression techniques are sometimes used . Several defenses against APTs have been studied. Moving target defenses periodically modify aspects of the infiltrated system to impede adversaries . In the context of LLM exfiltration, propose enforcing minimal upload limits on LLM servers to meet customer demand. Similarly, study a defense mechanism (inference verification) that makes steganography more difficult, assuming similar upload limits.
LLM quantization and compression.
A key factor in weight exfiltration attacks is the size of the weights to steal, which can be reduced through compression. note that there is much uncertainty around the effective size of model weights, with models commonly served at $`2\times`$ or even $`4\times`$ compression. This is enabled by recent work on model quantization for efficient inference, which achieves considerable performance through sophisticated quantization schemes . However, research on model quantization has not previously considered the weight exfiltration setting. A key contribution of our work is to demonstrate that this setting enables achieving far stronger compression, increasing the risk of weight exfiltration. Similarly, to our knowledge we are the first work to consider a defense to make model weights more difficult to compress in order to defend against weight exfiltration attacks.
Model weight watermarking.
Methods to watermark neural network embed a proof of ownership into model parameters to help protect the intellectual property of model owners . We consider the setting of watermarking for model weight provenance post-exfiltration.
Weight Exfiltration
Here, we describe the specific threat model that we consider. We base our quantitative model of attacker success on this threat model.
Threat Model
While standard data exfiltration attacks have been extensively studied and reported on in the cybersecurity literature , frontier AI inference workloads are significantly different from standard network and application architectures. Notably, the attacker must send a significant amount of data (the model weights) out of the datacenter. Compared to data exfiltration attacks to obtain e.g., individual customer data, this makes it harder on the attacker. We first formalize the objective and affordances of the attacker:
Objective. We consider a standard Advanced Persistent Threat (APT) with the goal of stealing model weights from an inference server that outputs text, image, video, or audio data to users. Note that the attacker is not attempting to distill the model from sampled inputs and outputs, but wants to exfiltrate the actual weights of the served language model.
Affordances. The attacker has already compromised the model server and gained access to unencrypted model weights. However, the attacker is not a physical insider, and thus cannot upload weights to a USB drive. They must instead extract the weights over the server’s network. The attacker is restricted in their upload rate because they need to evade detection until the attack is complete. Additionally, the attacker must hide exfiltrated data within legitimate outputs (for example, via steganography), as the defender uses deep packet inspection to ensure that all outgoing traffic conforms to expected formats.
Thus, we assume the attacker creates fake accounts and extracts information through responses generated by the model (a form of Sybil attack ). We assume that partial exfiltration of the model is far less valuable than full exfiltration. We do not consider hardware security measures. Likewise, the specifics of how the server was initially compromised are out of scope. Next, we consider the objective and affordances of the model provider:
Objective. The defender monitors server activity and network traffic for signs of APT activity. While detection is not guaranteed, prolonged adversary activity increases the likelihood that the defender will detect the attack attempt. We assume the defender has a fixed probability of detecting malicious behavior per unit time.
Affordances. The network bandwidth from the server is right-sized to the expected user traffic, and deep packet inspection is employed to ensure that all outgoing traffic matches expected formats. This forces the attacker to encode data via e.g. steganography.
Note that this threat model is only one possible set of assumptions. We discuss limitations of this threat model in 9.
Quantitative Model of Weight Exfiltration
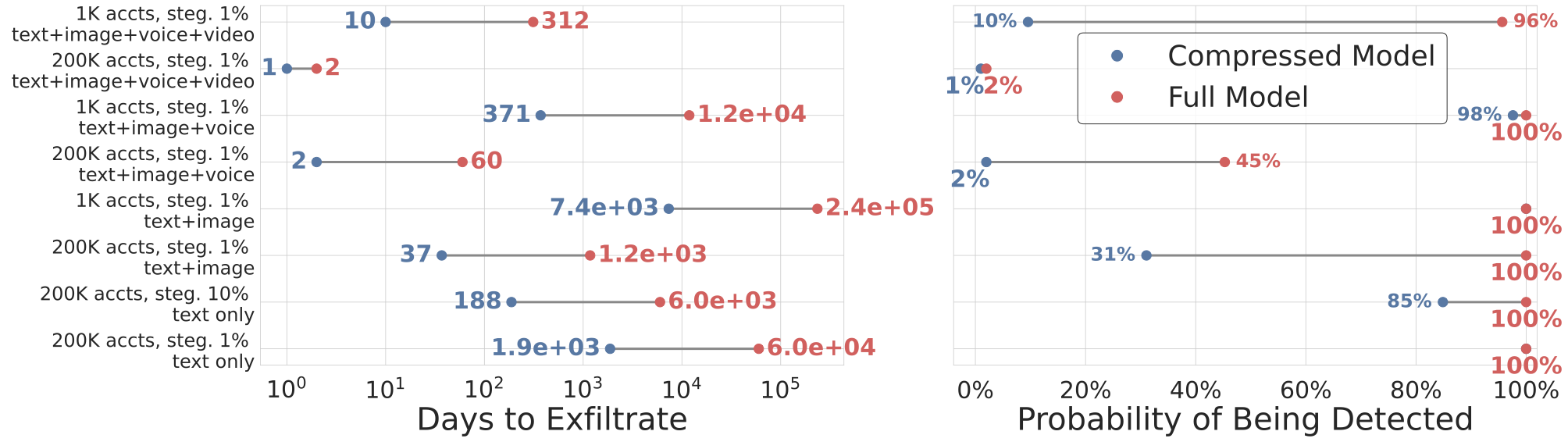 />
/>
To demonstrate that smaller, compressed weights are easier to steal, we use a simple quantitative model roughly calibrated to the scenario of a weight exfiltration attack on GPT-4 . Our model computes the time required for exfiltration and the probability of success given a fixed daily probability of detection. We say attack fails if it is detected before the model is fully exfiltrated, in keeping with our threat model. Our model incorporates various factors and three different usage profiles, allowing us to study a wide variety of attack scenarios. We describe these below.
Factors.
Our model starts from the assumption that the exfiltration occurs on an inference server for a public API. The API has daily users, some number of which are compromised or created by the attacker. The attacker then attempts to exfiltrate the weights over the network, while avoiding detection. We describe the factors in our model below.
-
Network egress per user per day ($`E`$): The number of bits sent to each user of the inference API per day.
-
Number of compromised daily users ($`N`$): We assume the attacker mounts a Sybil attack and can only receive data through steganography on legitimate channels. Note that the attacker may have more accounts than they use each day, swapping out accounts to mimic realistic usage patterns.
-
Steganography ratio ($`s`$): This is the fraction of output bits that the attacker can use for hiding arbitrary data, used for exfiltrating the model weights.
-
Model size ($`M`$): The size of the model to be extracted in bits, before compression is applied.
-
Compression ratio ($`c`$): The multiplicative reduction in model size after applying compression.
-
Probability of detection per day ($`p`$): The probability that the attacker’s activity is detected each day. For simplicity, we assume this is a fixed number.
Given these factors, we compute the time until exfiltration in days as
T = \frac{M \times c}{E \times N \times s}.The probability of successful exfiltration is computed as $`(1 - p)^T`$.
Usage profiles.
We consider four possibilities for the average daily user of an LLM inference API. These correspond to current and anticipated future modes of interaction with LLMs. In all cases, we assume that outputs are converted to standard media formats before being sent over the network to users. These usage profiles are described below.
-
Text Only: The average user in this scenario generates $`10`$ pages of text per day ($`500`$ English words per page). This is in the ballpark of current daily average usage of models such as GPT-4 . In reality, some users may generate far more or far less. We assume all users have equal consumption for simplicity.
-
Text + Images: In addition to the above text usage, users in this scenario generate $`1`$ image per day on average.
-
Text + Images + Voice: In addition to the usage of the previous scenario, the average user in this scenario generates $`30`$ minutes of voice/audio output per day. This may be used for talking with an LLM as an alternative mode of communication.
-
Text + Images + Voice + Video: This is a hypothetical future mode of interaction with LLMs involving real-time video output, possibly for interaction with chatbot avatars.
In Appendix D, we derive estimates for the factors in our model and for different usage profiles. In some cases, we consider ranges of values for a given factor.
Compression Experiments
Here, we describe our experiments demonstrating that compression techniques can be tailored to the weight exfiltration setting, enabling improvements to the compression ratio. We then evaluate how this affects exfiltration time and success rates under our quantitative model of exfiltration.
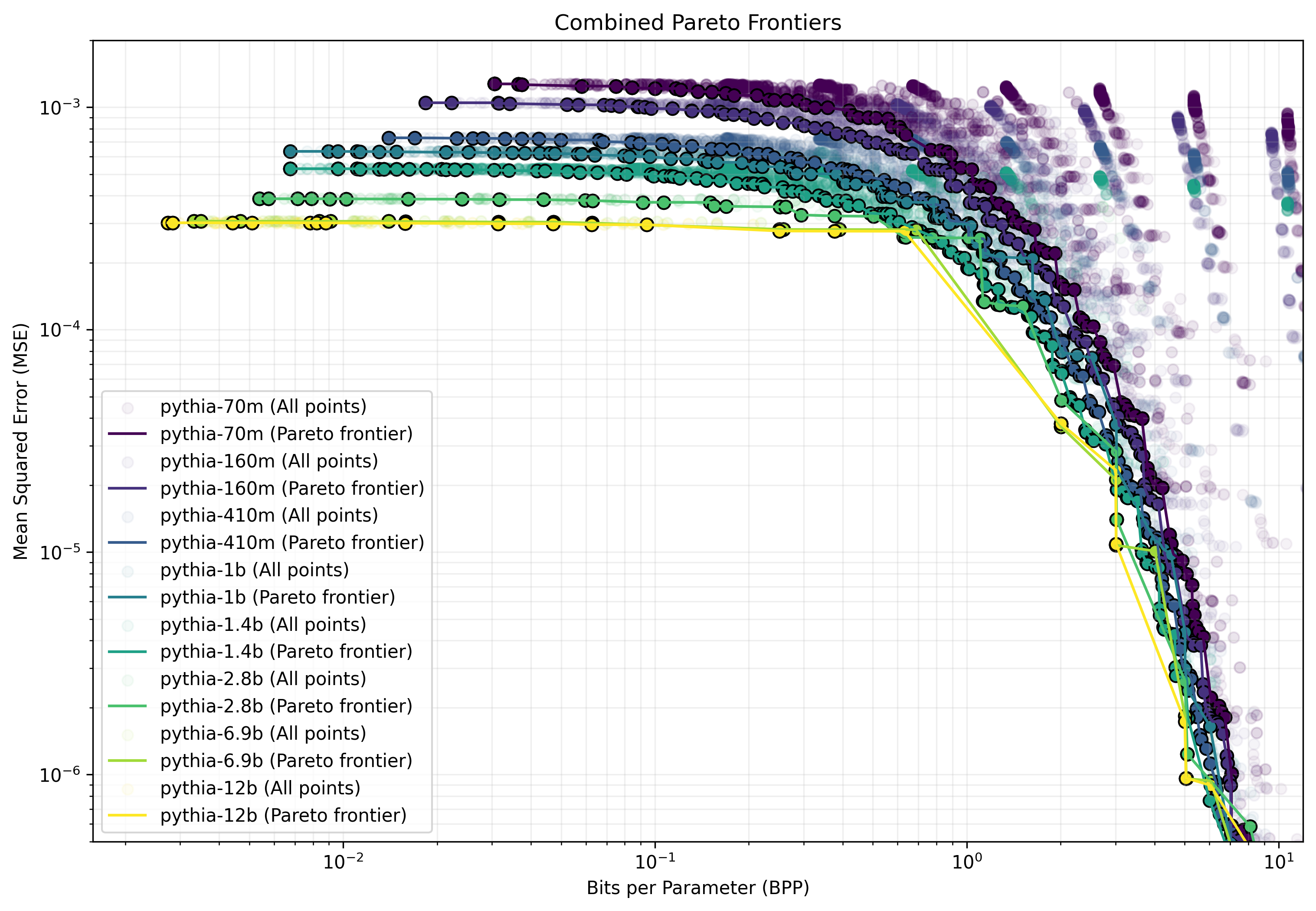
Rate-Distortion in Weight Space
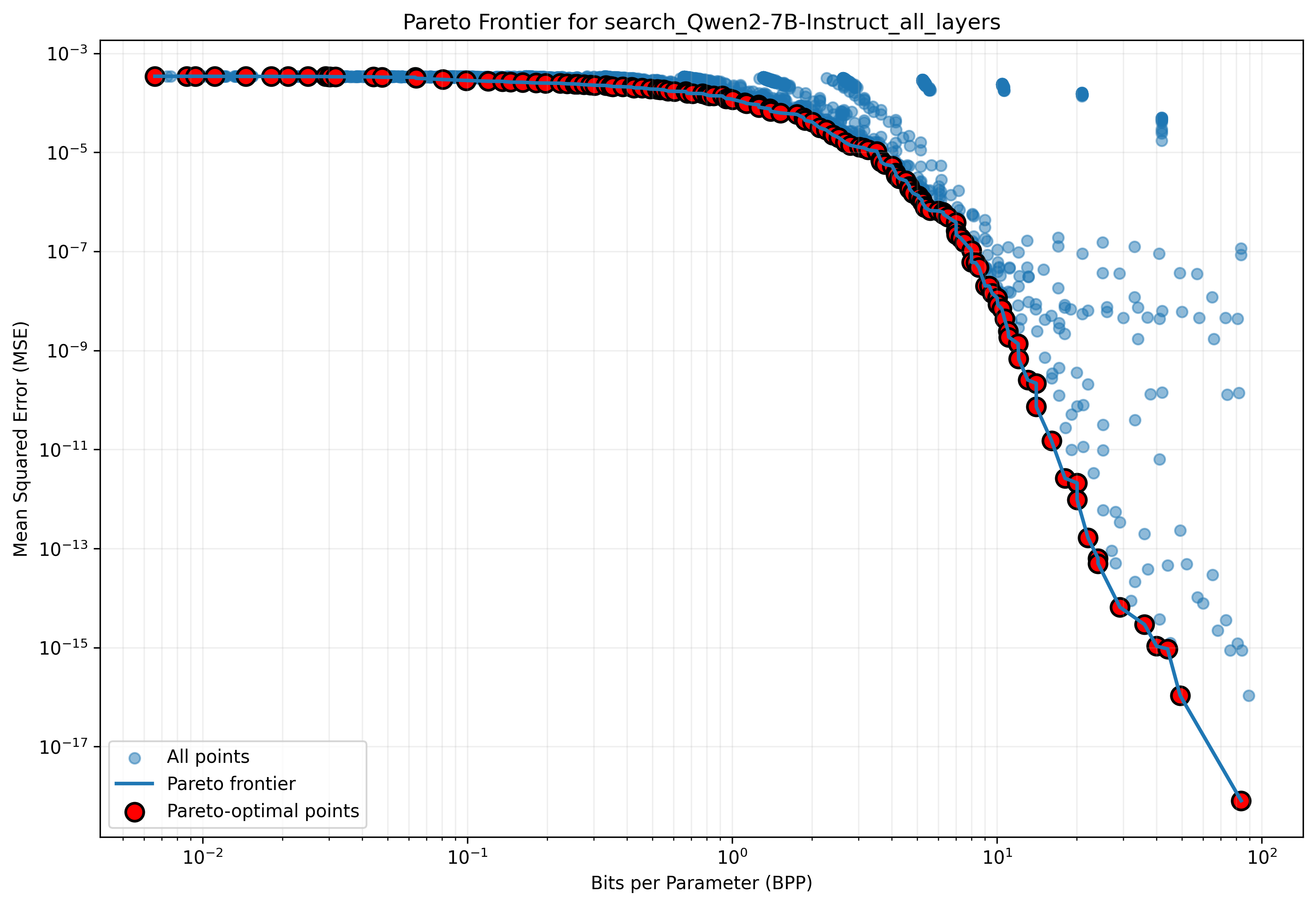
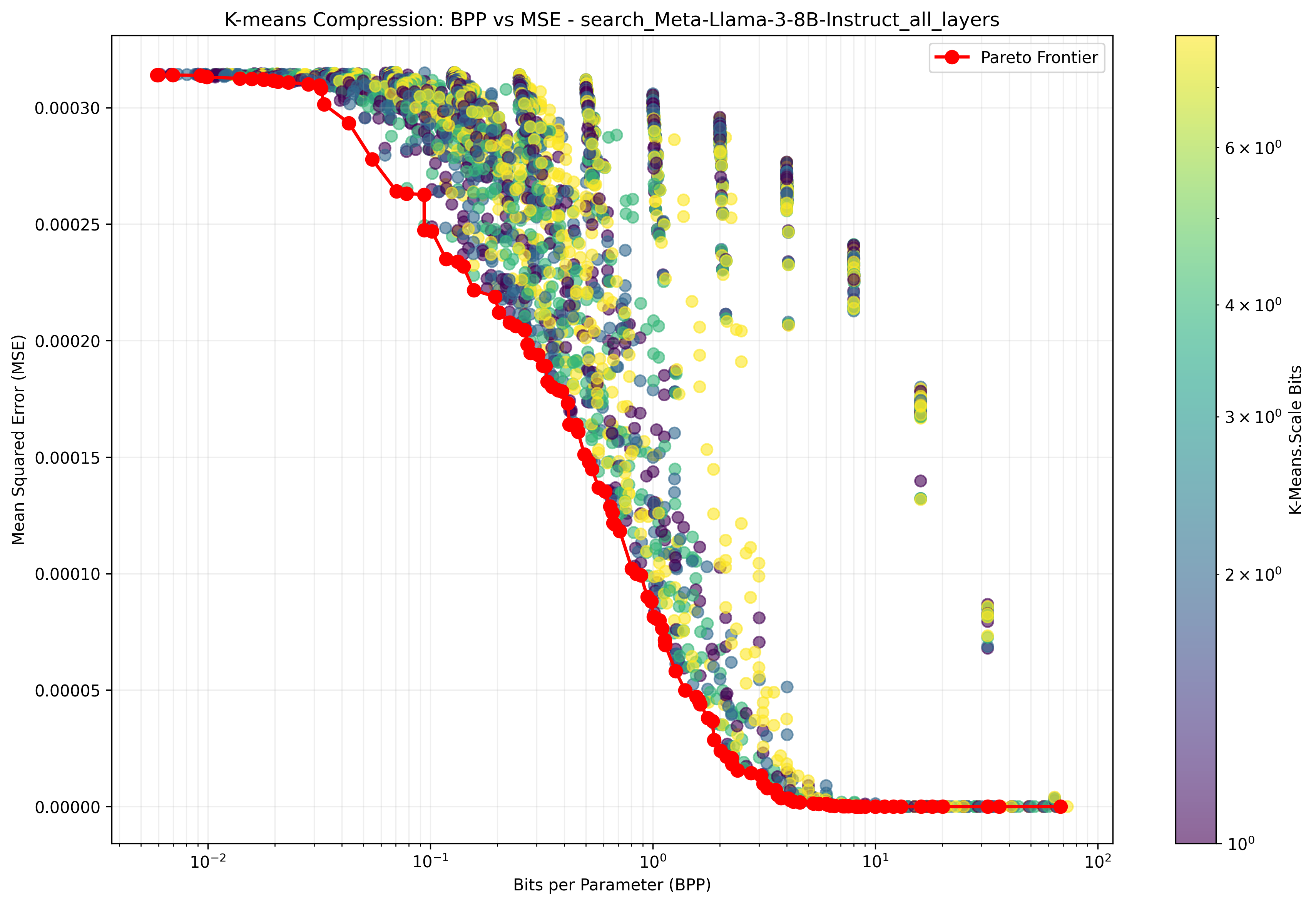
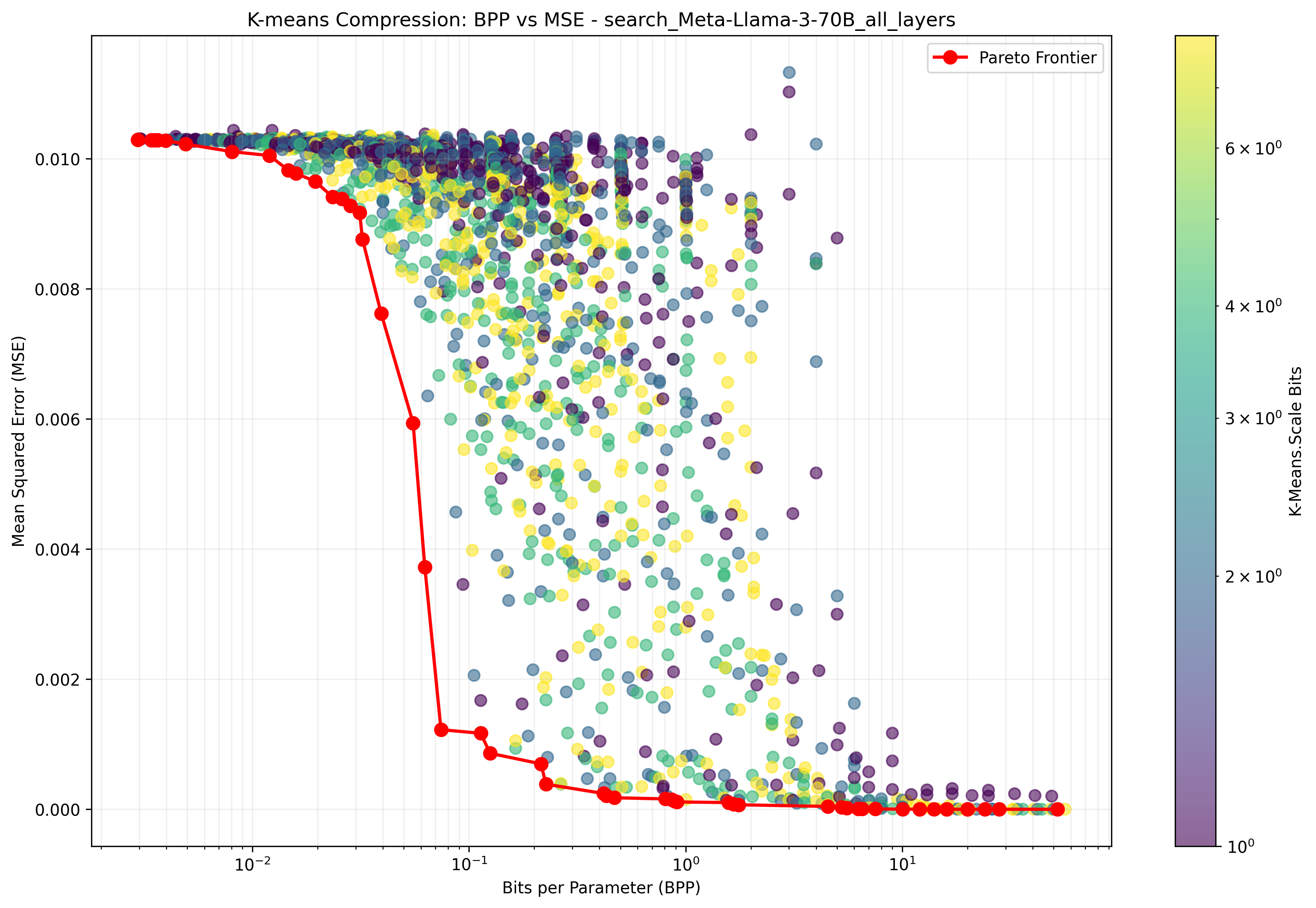
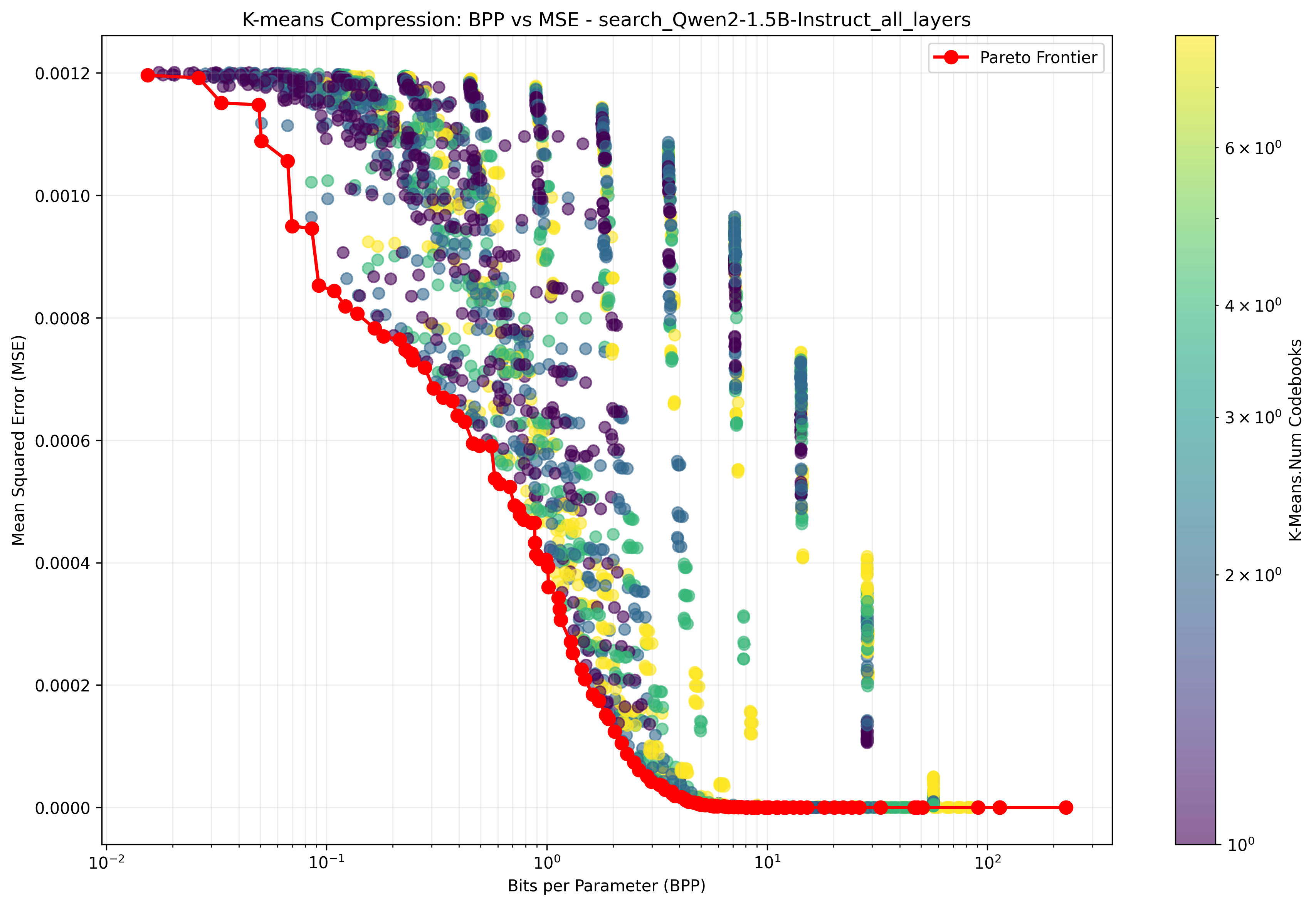
We find that model weights present a smooth tradeoff between how much they are compressed, measured in bits-per-parameter, and the fidelity of their compression, measured in MSE (mean square error between the original weights and the compressed weights). We sample from the Pareto frontier of the compression hyperparameters for our method, showing the results in 3, and [fig:compression-comparison-trends,fig:kmeans-comparison] in the appendix. For these experiments, we use a broader range of models than in the main experiments, including the Pythia suite and Llama 3 models . These results reveal several interesting phenomena, which we describe in the following paragraphs.
Rate-distortion curves reveal smooth trade-offs.
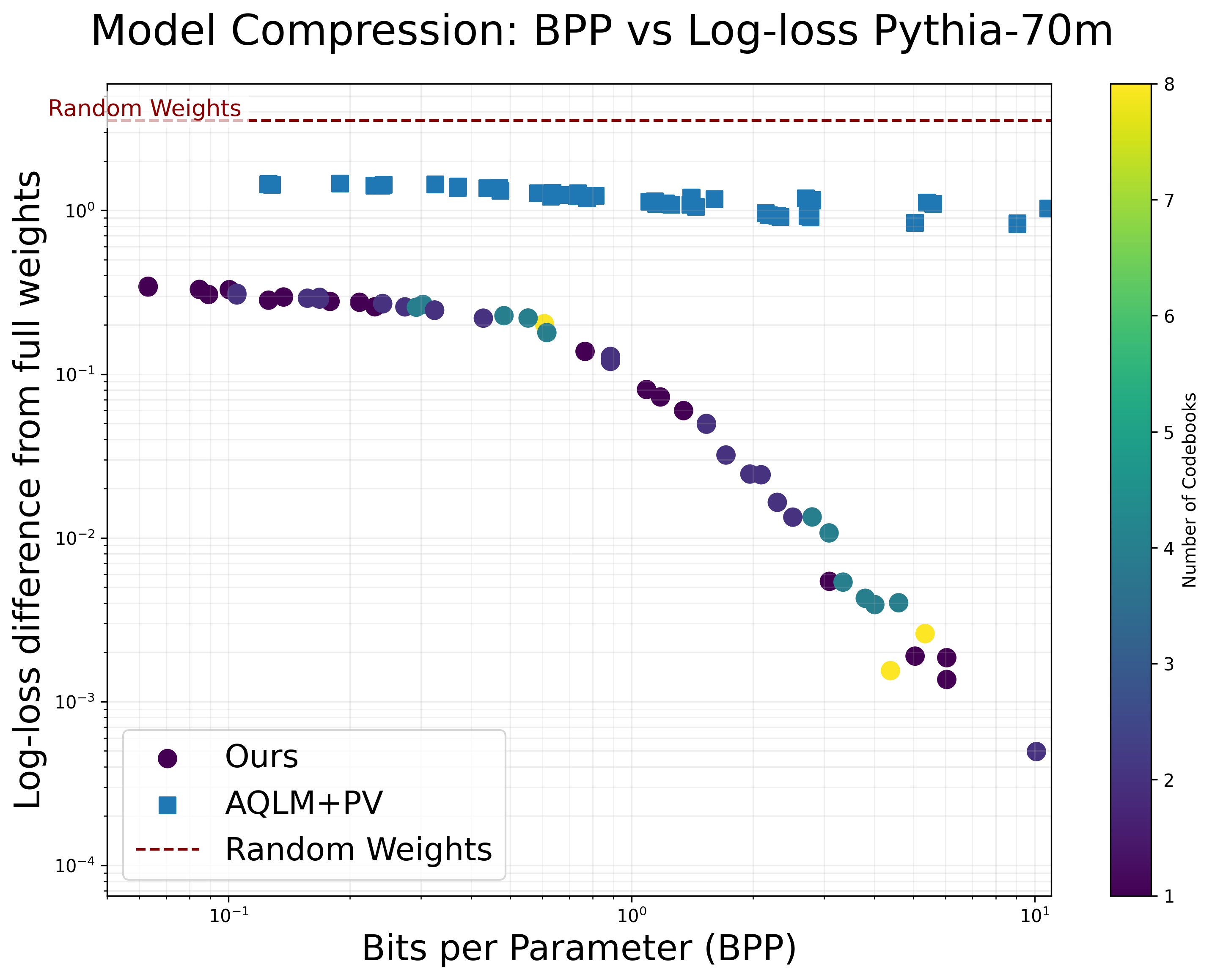
Our main results in [tab:compression-comparison-combined] show that models can be compressed using our method with very little degradation in downstream metrics like log-loss. To obtain a more fine-grained view of how our method performs at different BPP values, we applied it to a range of smaller models in the Pythia suite. In 10 (left), we show that the log-loss for our method starts out much closer to the original model than AQLM enhanced with PV tuning , a state-of-the-art quantization method. Performance of our method smoothly degrades with an elbow around $`0.1`$ BPP.
Larger models are potentially easier to compress.
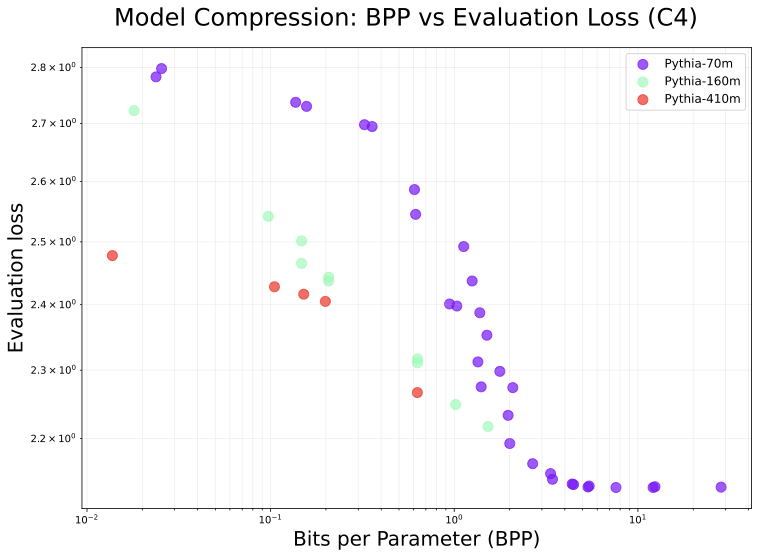
In 3, we show MSE rate distortion curves for models of various sizes. Interestingly, these reveal that within the Pythia family, the MSE of compressed models gradually improves as model size increases. This is surprising, as MSE is not dependent on the number of parameters. Even more surprising is the striking change in the Pareto frontier between Llama-3-8B and Llama-3-70B, the latter of which maintains very low MSE down to $`0.1`$ BPP with almost no degradation. These results provide evidence that larger models are easier to compress with our method, implying that the relative benefit of compression during exfiltration attacks may increase as models continue scaling up.
Improved LLM Compression
Method.
In our method, we employ a compression technique adapted from additive quantization, a generalization of k-means clustering. Specifically, we begin by splitting the weights of each layer of the large language model (LLM) into consecutive groups by rows and columns. For each group, we apply k-means clustering to compress the weights into vectors derived from a codebook . Following this initial compression, we subtract the reconstructed weight from the original weight and repeat the compression process with the residual for 1 to 4 iterations . After compressing the residuals, we apply a one-dimensional k-means clustering to learn a unique scaling factor for each group, further optimizing the storage requirement.
To determine optimal hyperparameters for compression at various bits per parameter values, we perform a hyperparameter sweep using MSE to the original weights as the metric for selection. We then computed the Pareto frontier and used points on this frontier to select hyperparameters for the main experiments. We visualize several such curves in 15 in the appendix.
| Qwen2-1.5B | Qwen2-7B | |||
|---|---|---|---|---|
| 2-3 (l)4-5 Method | MMLU | C4 Loss | MMLU | C4 Loss |
| Random Weights | 25.6 | 6.07 | 27.4 | 6.0 |
| Original Model (no compression) | 56.5 | 3.28 | 70.5 | 2.55 |
| Ours (VQ then train) | ||||
| Low compression | 48.4 | 4.27 | 48.5 | 3.22 |
| Medium compression | 54.9 | 3.69 | 61.2 | 3.16 |
| High compression | 55.5 | 3.33 | 65.5 | 2.81 |
| AQLM | ||||
| Low compression | 24.1 | 8.49 | 34.0 | 3.37 |
| Medium compression | 23.5 | 6.39 | 60.3 | 3.28 |
| High compression | 50.7 | 3.65 | 65.6 | 2.74 |
Decompression involves reconstructing the full parameter vector from its quantized representation. To ensure the functionality of the decompressed model, we perform fine-tuning initially on a pre-training dataset, followed by instruction tuning on a specific dataset if the original model had been instruction-tuned. Unlike previous quantization schemes that require the fine-tuned model to remain quantizable to the same bit depth, our method does not impose such restrictions, allowing for more flexibility in restoring the model’s performance.
Setup.
We compress Qwen2-1.5B at three different bits per parameter (BPP) levels, and we use a fixed token budget for decompression. As a baseline, we compare to Original Model with no compression and AQLM , a state-of-the-art LLM quantization method for efficient inference. For reference, we also show the performance of randomly initialized weights after applying the same fine-tuning procedure used in our method (Random Weights). We evaluate baselines and our method using three metrics: bits per parameter (BPP), MMLU accuracy, and C4 log loss.
Additionally, we conduct compression experiments on Qwen2-7B model compressing to 1.5 BPP, 2.26 BPP, and 3.01 BPP. The primary distinction between this setup and the previous experiments is the use of a significantly smaller fine-tuning dataset, limited to 50 million tokens. Similarly to the Qwen2-1.5B model, we also evaluated the baselines using the same metrics (BPP, MMLU accuracy, and C4 log loss).
For decompression of Qwen2-1.5B, we perform continued pre-training and supervised fine-tuning on RedPajama and Magpie , respectively. We train for a combined $`1`$ billion tokens on these two datasets, comprising approximately $`0.01\%`$ of the Qwen2 pre-training data of $`7`$ trillion tokens.
 style="width:75.0%" />
style="width:75.0%" />
Results.
Our results for Qwen2-1.5B are in [tab:compression-comparison-combined]. With AQLM, model performance sharply drops off below $`2.03`$ bits per parameter (BPP), while our method has much more graceful degradation. Our method maintains reasonable fidelity at $`1.15`$ BPP, with only a $`1.6\%`$ reduction in accuracy on MMLU. Thus, our method is able to obtain $`16\times`$ compression compared to the original model without reducing downstream performance. The Random Weights baseline obtains random chance performance, indicating that the amount of fine-tuning performed during decompression does not introduce new knowledge, and using the compressed weights as a starting point is crucial.
For the larger Qwen2-7B model, our method achieves an MMLU accuracy of 48.5 at 1.52 bits per parameter (BPP), compared to 34.0 for AQLM, representing a difference of 14.5 points. Additionally, our method generally achieves lower C4 log loss values than AQLM across multiple compression levels. Specifically, at 1.52 BPP, our method achieves a C4 log loss of 3.22 nats, whereas AQLM achieves 3.37 nats, indicating a modest improvement in language modeling performance.
These results demonstrate that when constraints on decompression time are relaxed, models can be compressed to far smaller sizes than was previously known. In 4.1, we show additional results that suggest larger models may be even easier to compress using our method. In particular, these results suggest that it may be possible to compress Llama-3-70B down to $`0.1`$ BPP using our method, a $`160\times`$ compression. This is highly concerning for the setting of exfiltration attacks.
Effect of Compression on Weight Exfiltration
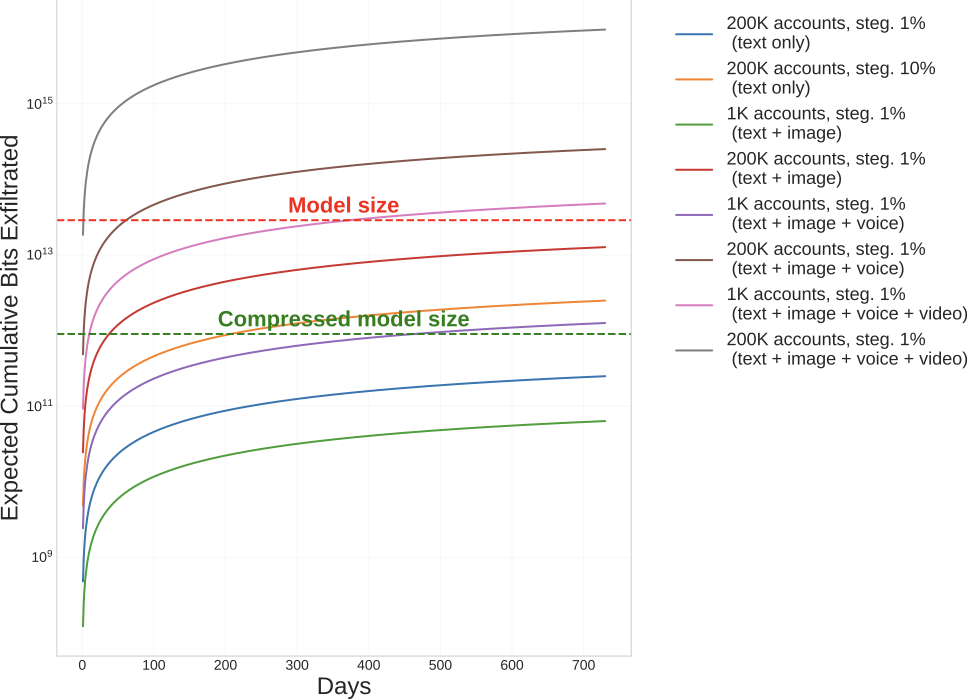
In 2, we show the effect of model compression on time until exfiltration and probability of attack success across various scenarios. Each scenario varies the number of compromised daily users, the steganography ratio, and the usage profile. We explore reasonable ranges for these values, discussed in 3.2. We find that model compression significantly affects the feasibility of an attack, reducing exfiltration times by multiple orders of magnitude and increasing the probability of attack success.
In 16, we directly visualize the amount of bits extracted as a function of time under our quantitative model. This clarifies that besides model compression, other factors, like the number of user accounts and output modality of the model(s), can have a large impact on exfiltration risk. Addressing these other factors could be a feasible direction for improving exfiltration defenses. We now turn to discussing defenses against LLM weight exfiltration.
Defenses
We consider three defenses that harden against three separate attack vectors: i) making models harder to compress, ii) making them harder to ‘find,’ and iii) making them easier to attribute post-attack. These are shown schematically in 4.
Finetuning compressibility resistance
We identify model compressibility as an important factor in weight security. To mitigate model compressibility, we apply finetuning for compressibility resistance. In particular, we finetune Qwen2.5-1.5B with an off-diagonal covariance penalty added to the standard task loss. This makes the weight elements less correlated, and therefore harder to compress. For each weight matrix $`W\in\mathbb{R}^{d_o\times d_i}`$, let
\mu = \frac{1}{d_i}W\,\mathbf{1},\qquad
\Sigma = \frac{(W - \mu\mathbf{1}^\top)\,(W - \mu\mathbf{1}^\top)^\top}{d_i - 1}be the row-wise covariance of $`W`$. We then include the regularizer $`\mathcal{R}(W) \;=\; \sum_{i\neq j} \Sigma_{ij}^2`$ in the training objective, which explicitly penalizes pairwise correlations between rows of $`W`$. The intuition here is that less correlated rows look more random and are thus harder to compress. Finetuning for 100M tokens with this penalty yields a modest $`~3-10\%`$ increase in compressibility cost.
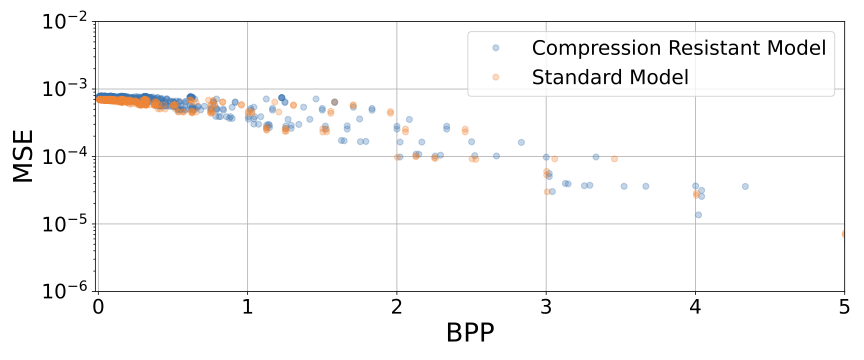
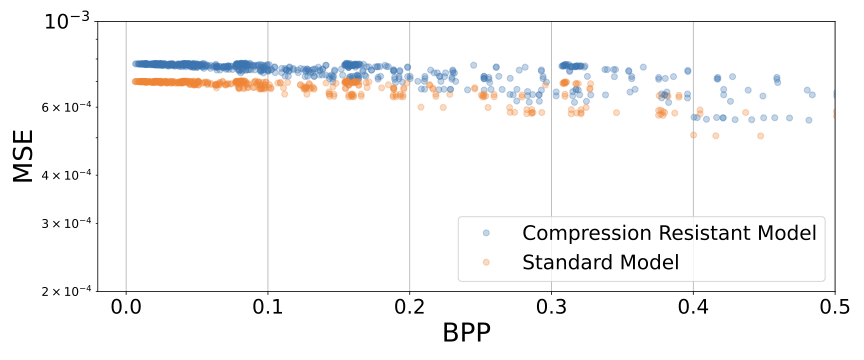
As noted, we finetune a Qwen2.5-1.5B model using an objective designed to make the weights harder to compress by making the neurons less correlated while maintaining the same training loss. We plot the bits-per-parameter vs mean squared error between the standard and finetuned (‘Compression Resistant’) model in 5. As noted, we find a modest (but noisy) increase in how difficult the new model is to compress across all compression levels. The largest and most consistent gains are at lower bits per parameter, shown in 6.
Moving-target weight transformation
In cybersecurity, moving target defenses continually re-configure a system’s exposed surface to make reconnaissance more difficult for attackers . We explore an idea from that protects weights by applying cheap weight-space symmetries that leave the network’s function unchanged, but make it hard to relate two weights between each other. In particular, the defender’s strategy here is to change the weights of the neural network so that, while network performance remains exactly the same, the attacker will struggle to ‘relate’ the weights within a layer at successive time steps. We use continuous rotations of self-attention projections . In the defense, an inference server hosts a neural network instance that is varied at periodic intervals according to the transformation. Any parameter fragments leaked in one interval will not align with those from another (due to the transformation), ideally making it so that the attacker cannot ‘stitch’ the weights together in the correct order.
 />
/>
Adaptive attack.
Unfortunately, an adversary can subvert this defense by running an explicit canonicalisation procedure. Canonicalisation transforms the weights so that they are in a consistent order, despite the moving target transformation. For the rotation example above, the attacker can use the singular value decomposition, which is invariant to transformations. That is, let $`W_Q, W_K \in \mathbb{R}^{d\times d}`$ be the canonical query- and key-projection matrices, and let $`O \in \mathbb{R}^{d\times d}`$ be any invertible matrix.1 A moving target defense can apply the gauge transform
W'_Q = O^{-\top} W_Q, \qquad W'_K = O W_K,where $`O^{-\top}`$ denotes $`(O^{-1})^\top`$. This preserves the attention scores, since
\begin{aligned}
W'_Q{}^\top W'_K
&= (O^{-\top} W_Q)^\top (O W_K) \\
&= W_Q^\top O^{-1} O W_K \\
&= W_Q^\top W_K.
\end{aligned}Thus the forward map of the attention layer is unchanged, and the model’s function remains the same even though the individual weights have moved.
 />
/>
Canonicalisation.
This scheme was first proposed in . The attacker first computes the singular value decomposition
W'_Q{}^\top W'_K = U \Sigma V^\top,then transforms into a canonical basis by setting
W_Q^\ast = W'_Q U, \qquad W_K^\ast = W'_K V.This yields
W_Q^{\ast\top} W_K^\ast
= U^\top W'_Q{}^\top W'_K V
= U^\top (U \Sigma V^\top) V
= \Sigma.Since $`W_{Q}^{\prime\top} W_{K}^{\prime} = W_Q^\top W_K`$, its SVD $`(U,\Sigma,V)`$ is stable across snapshots. This aligns the singular-vector bases, but not the canonicalised weights $`W_Q^* = W_Q' U`$ and $`W_K^* = W_K' V`$, which still depend on $`O_t`$. Below, we resolve the remaining degrees of freedom.
Recovering useful weights after canonicalisation
However, the attacker still needs to transform $`W_Q'`$ and $`W_K'`$ into ‘working’ neural network weights. We describe one such procedure, inspired by a neural network interpretability method in 11.1, and run it for a layer of a model to confirm that it is computationally inexpensive. In short, we canonicalize a layer from Qwen2.5-1.5B and insert it into a weaker model, Qwen2.5-0.5B (along with transformations to map between the different hidden layer sizes of the models). In 17, we find that we can recover performance for Qwen2.5-1.5B by recovering useful weights from this layer with only tens of steps. We also try to recover the full model without stitching, i.e., we canonicalize each layer and attempt to relearn the model end-to-end; this seems to be a much harder learning problem (17). We provide more detail on these experiments in Appendix E.
Forensic Watermarking
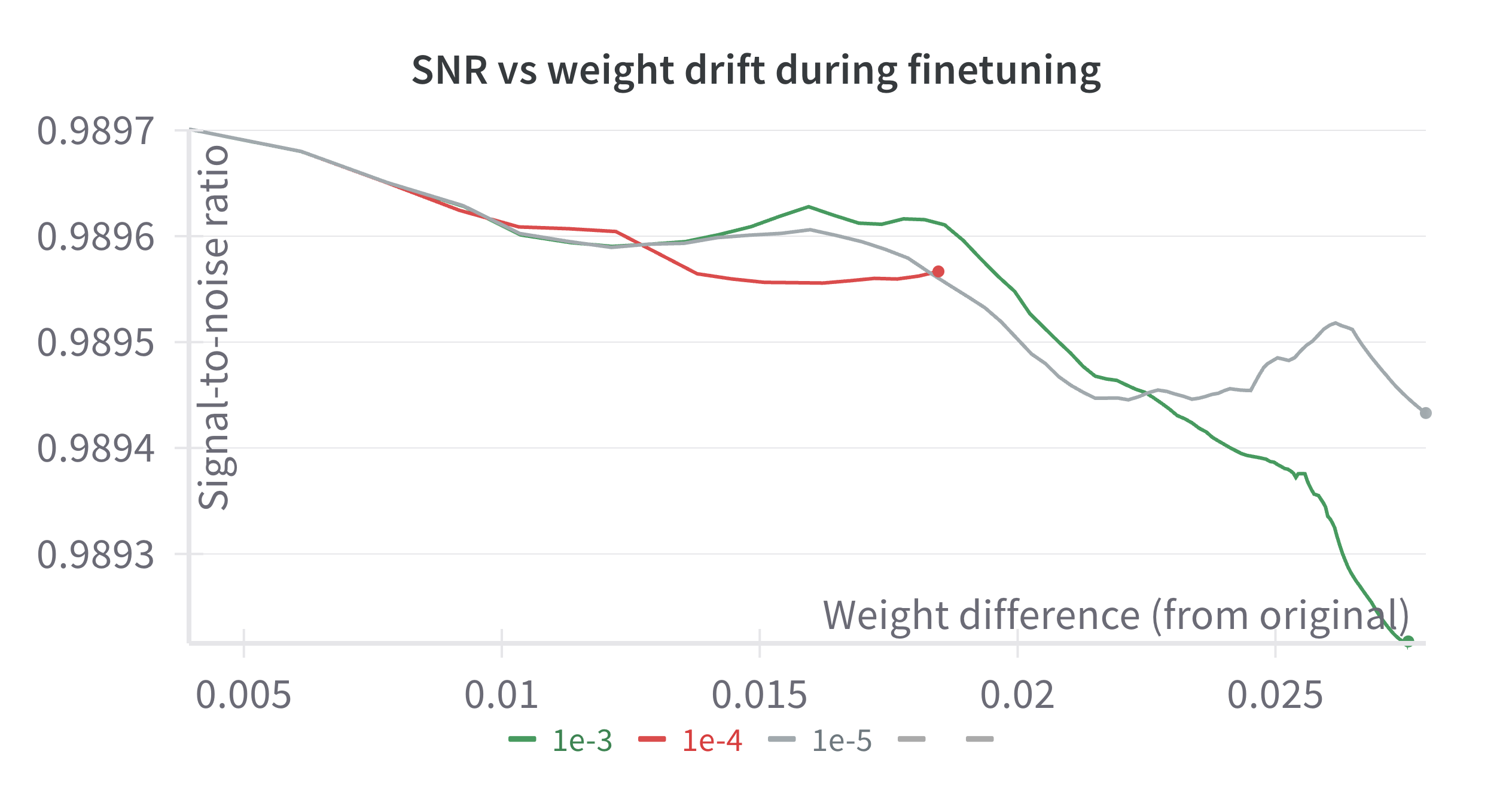
We also explore forensic watermarking—embedding an owner-controlled signature directly in a weight matrix so that provenance can be verified, even after fine-tuning. Watermarking is useful, because post-theft attribution allows organizations to identify stolen models in the wild, identify when and where the theft occurred (to e.g. strengthen safeguards), and pursue legal remedies.
Our approach builds on spread–spectrum watermarking for neural networks
. First, we encode a 128-bit payload specifying the exact time and
origin of the layer (e.g., the datacenter and/or server location) with a
BCH(511,447) code. We spread the code bits across randomly chosen
weights of each layer—for our experiments we choose a single layer,
model.layers.27.mlp.down_proj.weight, under the assumption that other
layers will behave similarly. After running hyperparameter sweeps, we
set a per-weight amplitude of $`\gamma = 6\sigma/\sqrt{R}`$, where
$`\sigma`$ is the layer’s weight standard deviation and $`R`$ the number
of selected weights. To make the watermark robust to subsequent
supervised fine-tuning, we compute a single backward pass on the input
and output of the layer an a single batch of RedPajama tokens, and
project the watermark to be orthogonal to that gradient. This extends
the scheme in to the case of single-layer watermarking. On an NVIDIA
A100, the watermark can be computed in 0.1s (assuming the weights and
data are pre-loaded). In our experiments, the raw bit-error-rate remains
below $`3\%`$ after 1.2M‐token supervised finetuning with the Magpie
dataset at learning-rates $`1\times10^{-5} - 1\times10^{-3}`$. The BCH
decoder therefore recovers the full payload with $`0`$ errors (see
7 for the signal to noise
throughout training). This suggests that weight attribution can succeed
even when the attacker chooses to further finetune the model. However,
we do not test robustness to adversarial removal strategies.
System-Level Defenses
So far, we have discussed several defenses that modify the parameters of the model under threat to mitigate exfiltration risks in various ways. Another line of defense involves standard system-level defenses designed for Advanced Persistent Threats (APTs). While these defenses are highly relevant, weight exfiltration attacks present unique challenges that could benefit from specialized approaches. In 8, we discuss several standard defense strategies for mitigating the risks of data exfiltration, along with considerations specific to LLM weight exfiltration.
Conclusion
In this work, we demonstrated that by relaxing decompression constraints in weight exfiltration scenarios, models can be compressed far more effectively than previously thought. Our results show that such aggressive compression greatly reduces the time required for model exfiltration, making attacks significantly more feasible. Towards mitigating this threat, we consider three defenses, two of which attempt to change structural properties of the weights to make them harder to steal along with a moving target defense. These findings emphasize the need for further investment into securing model weights as AIs become increasingly critical assets for both industry and national security.
Acknowledgments
We thank Aaron Scher, Adam Karvonen, Alex Cloud, Gabriel Mukobi, Nathaniel Li, Max Lamparth, Steven Basart, and Refine.ink for helpful discussions and feedback on this work. This work was supported by the MATS program, Open Philanthropy, and compute resources from the Center for AI Safety.
 />
/>
Ethical Considerations
This work has dual-use implications. We aim to support defenders by quantifying exfiltration feasibility and studying mitigations including egress limits, reducing compressibility, moving target defenses, and forensic watermarks.
System-Level Defenses
Here, we discuss additional defense strategies against exfiltration attacks that do not involve modifying model weights. These defenses are system-level, as opposed to the model-level defenses described in [sec:defenses].
Anomaly detection and monitoring.
Traditional APT detection methods typically rely on general anomaly detection, scanning for statistical deviations over large quantities of server activity and network logs. Weight exfiltration, however, occurs in a highly orchestrated environment where server behavior is predictable and narrowly focused. Inference servers handle a single task: processing user inputs and generating outputs in a consistent format. This makes it possible for defenders to apply simple packet inspection techniques to detect anomalies. However, a key challenge lies in the high variance of resource usage in LLM inference, which could allow adversarial activity to be obscured by normal fluctuations in system load.
Hardware-based security measures.
Hardware security features embedded in GPUs and CPUs can play a critical role in defending against weight exfiltration. Some NVIDIA GPUs, for instance, implement secure boot mechanisms that use cryptographic verification to ensure that only authorized firmware and software can be executed on the hardware. Although these capabilities are not universally implemented across all inference servers and may have limitations, they offer a promising layer of defense by preventing unauthorized access to model weights at the hardware level.
Upload rate limits.
One of the most straightforward and effective defenses is to impose strict upload rate limits on the server, ensuring that data egress is constrained to the minimum required for legitimate user workloads. This was recently proposed by , who also suggest compressing model outputs to restrict total data egress. Our quantitative model already accounts for such limits, but if these constraints are absent, exfiltration could become far easier for attackers.
Internal data transfer limits.
To further mitigate the risk of weight exfiltration, internal data transfer limits between system components could be enforced. In particular, many LLM-based systems include additional modules for tasks such as voice or image generation, which can require higher data transfer rates than text-based models. Our results in Section 4.3 in the main paper suggest that high network requirements for these additional modalities greatly increase exfiltration success rates. However, this assumes that servers where LLM weights are stored would have high internal bandwidth to servers that integrate different modalities and send outputs to users. By physically decoupling the LLM servers from where final integrated outputs are sent to users, exfiltration data rates could be effectively limited to the core LLM’s outputs.
Limitations
In this section, we discuss the limitations of our threat model and analysis. While we present a preliminary investigation of how model compression increases the risk of weight exfiltration, further research is needed to fully understand and model this threat. Some key limitations are described below.
Our threat model does not account for how increased activity by the attacker might increase the rate of detection. We also do not incorporate distributional estimates for the key factors in our quantitative model, although we consider ranges for certain factors. Finally, our model does not factor in the computational costs for the attacker to perform K-means clustering on the infiltrated servers. K-means requires computing and storing cluster centers, which could be detectable by the defender. However, the attacker might mitigate this by running K-means iteratively, uploading chunks of the weights and only storing a small number of cluster centers at a time. By doing so, they could adjust their resource usage to stay below detection thresholds.
 />
/>
Estimates for Quantitative Model Factors
In [tab:estimates], we show our estimates for the factors in our quantitative model. We calibrate these factors to the setting of an exfiltration attack on a model similar to GPT-4. Below, we describe how we arrive at these estimates.
-
Network egress per user per day: We estimate this using the different usage profiles. See below for details.
-
Number of compromised daily users: We start from an assumption of approximately $`100`$ million daily active users for the API and assume that no more than $`0.2\%`$ of these users could belong to a Sybil attack before suspicious activity would be easily detected. This corresponds to $`200,000`$ users.
-
Steganography ratio: For text steganography, values of up to $`5`$ bits per word are achievable . An average English word taking up 5 ASCII characters requires $`40`$ bits, corresponding to a ratio of roughly $`0.1`$. Steganography may be even more effective for continuous outputs like images, audio, or video. We use a fixed ratio of $`0.1`$ for simplicity.
-
Model size: We assume a model with $`1.8`$ trillion half-precision floating point parameters, corresponding to $`2.88 \times 10^{13}`$ bits.
-
Compression ratio: We use a compression ratio of $`1/32`$. This is an extreme level of compression that stresses our method, but we still obtain nontrivial performance at this level.
-
Probability of detection per day: We assume a value of $`0.1\%`$. This value is highly situational, but we assume attackers would adjust their activity to keep it fairly low.
We now describe the estimates of network egress per user per day for each usage profile.
-
Text Only: We assume each user generates approximately $`10`$ pages of text per day, each taking up $`500`$ English words. Each word is $`5`$ ASCII characters on average with a space, corresponding to $`6 \times 500 \times 10 \times 8 = 240,000`$ bits.
-
Text + Images: We assume images are generated at a resolution of $`1024 \times 1024`$ pixels with a $`24`$ bit color depth, corresponding to $`1024 \times 1024 \times 24 = 25,165,824`$ bits. We assume the image is compressed to $`1.5`$ MB after compression, yielding $`1.5 \times 1,000,000 \times 8 = 12,000,000`$ bits. This gives a total of $`240,000 + 12,000,000 = 12,240,000`$ bits.
-
Text + Images + Voice: We assume $`30`$ minutes of audio per day and that the data is provided as an MP3 with a bitrate of $`128`$ kilobits per second. This gives $`128 \times 60 \text{ seconds}/\text{minute } \times 30 \text{ minutes } = 230,400`$ kilobits, or $`230,400,000`$ bits. This gives a total of $`230,400,000 + 12,240,000 = 242,640,000`$ bits.
-
Text + Images + Voice + Video: We assume $`30`$ minutes of video per day and that the data is provided at $`1920 \times 1080`$ resolution at $`30`$ frames per second with an average bitrate of $`5`$ megabits per second. This gives $`5 \times 60 \text{ seconds}/\text{minute } \times 30 \text{ minutes } = 9,000`$ megabits, or $`9,000,000,000`$ bits. This gives a total of $`9,000,000,000 + 242,640,000 = 9,242,640,000`$ bits.
| Parameter | Assumption | Usage Profile |
|---|---|---|
| Network egress per user per day | $`240,000`$ bits | Text Only |
| Network egress per user per day | $`12,240,000`$ bits | Text+Images |
| Network egress per user per day | $`242,640,000`$ bits | Text+Images+Voice |
| Network egress per user per day | $`9,242,640,000`$ bits | Text+Images+Voice+Video |
| Number of compromised daily users | $`\leq 200,000`$ | All usage profiles |
| Steganography ratio | $`\leq 0.1`$ | All usage profiles |
| Model size | $`2.88 \times 10^{13}`$ bits | All usage profiles |
| Compression ratio | $`1/32`$ | All usage profiles |
| Probability of detection per day | $`0.001`$ | All usage profiles |
Formalizing our Threat Model
Attacker stitching algorithm
$`\mathcal{M}_\text{large}`$ — target backbone (e.g. Qwen 2.5-1.5B) $`\mathcal{M}_\text{small}`$ — size-compatible helper model (e.g. Qwen 2.5-0.5B) $`\{(W_Q',W_K')_\ell\}`$ — canonicalised projections of layer $`\ell`$ SGD hyper-parameters $`\eta,\;N_{\text{steps}}`$ function StitchAndRelearn($`\mathcal{M}_\text{large}, \mathcal{M}_\text{small}, (W_Q',W_K'), \eta, N_{\text{steps}}`$) 1. Dimension-bridging rotations. Select $`R_Q,R_K`$ s.t. $`W_Q'R_Q`$ and $`R_K^{\!-1}W_K'`$ match the input/output dims of the corresponding layer in $`\mathcal{M}_\text{small}`$. 1. Insert canonical layer. Replace the original $`(W_Q,W_K)`$ of layer $`\ell`$ in $`\mathcal{M}_\text{small}`$ by $`(W_Q'R_Q,\;R_K^{\!-1}W_K')`$, where Freeze all other parameters. 3. Rotation-only fine-tune. Compute loss on a proxy objective (e.g. next-token). Update $`R_Q,R_K`$ with SGD: $`R \leftarrow R - \eta\,\nabla_R\!\mathcal{L}`$ 4. Transfer to full model. Copy the relearned canonical layer (including $`R_Q,R_K`$) into the corresponding layer of $`\mathcal{M}_\text{large}`$. Optionally unfreeze neighbouring layers and run a brief global fine-tune. return updated $`\mathcal{M}_\text{large}`$ end function
Motivation and attacker model
We study an adversary who compromises an inference host, must remain under a flagging classifier’s outbound-traffic threshold $`\mathrm{TH}`$, and operates within a dwell-time budget $`T`$. Their objective is to exfiltrate a representation $`\mathcal{E}`$ that, after at most $`\Phi_{\mathrm{ft}}`$ additional FLOPs of fine-tuning, yields a model $`\widehat{W}`$ whose downstream performance exceeds a target threshold $`\tau`$. In the absence of active counter-measures, extreme compression (e.g. vector quantisation to $`<\!1\,\mathrm{bit/param}`$) lets the attacker keep $`\lvert\mathcal{E}\rvert\!\ll\!\lvert W\rvert`$ and evade detection.
Introducing gauge refreshes
The defender installs a scheduler that, every $`\Delta`$ minutes, samples a gauge transform $`g_t`$ from a low-cost symmetry, namely rotations of $`(W_Q,W_K)`$ and $`(W_O,W_V)`$ of the attention layer, wipes the GPU memory, and pushes the fresh weights $`W_t=g_t(W)`$ to the GPU server.
Original attack.
During round $`t`$:
-
Read $`W_t`$ and run in-place compression $`\mathcal{C}_t(\cdot)`$ to get a code $`\mathcal{E}_t`$.
-
Exfiltrate within the per-round bandwidth cap imposed by $`\mathrm{TH}`$.
After $`T' = \lceil T/\Delta\rceil`$ rounds the attacker holds fragments $`\{\mathcal{E}_t\}`$ plus any alignment metadata. The attacker now holds $`T'`$ ‘jumbled’ fragments. We claim that as $`T'`$ approaches the number of neurons in a model, the attacker incurs the full cost of pretraining the model.
Canonicalisation subverts the moving target defense.
Unfortunately, described next, canonicalization subverts the defense. Thus the moving-target scheme alone is insufficient; additional hardening, for example by injecting small structured noise, may be required.
Attacker’s new workflow.
During round $`t`$:
-
Read $`W_t`$ and run in-place compression $`\mathcal{C}_t(\cdot)`$ to get a code $`\mathcal{E}_t`$.
-
Perform canonicalisation—e.g. via SVD or QR decomposition $`\Phi_{\text{align},t}`$ FLOPs—to map $`\mathcal{E}_t`$ into a basis invariant to gauge refreshes.
-
Exfiltrate, where it is now not necessary to steal all of the layer weights in time $`\Delta`$.
After $`T' = \lceil T/\Delta\rceil`$ rounds the attacker holds fragments $`\{\mathcal{E}_t\}`$ plus any alignment metadata. They merge and fine-tune at cost $`\Phi_{\mathrm{ft}}`$ to produce $`\widehat{W}`$.
Cost-based success condition
Let
\Phi_{\text{tot}}
=\sum_{t=1}^{T'} \bigl(\Phi_{\mathrm{comp},t} + \Phi_{\text{align},t}\bigr)
+ \Phi_{\mathrm{ft}} .The attacker succeeds if they: (i) stay below $`\mathrm{TH}`$ in every round; (ii) keep total wall-clock time $`\le T`$; and (iii) obtain $`R(\widehat{W})\ge\tau`$ with $`\Phi_{\text{tot}} < \gamma\Phi_{\textsc{train}}`$ for some advantage factor $`\gamma<1`$.
Next steps
Future work might search for transformations whose inversion provably lacks efficient algorithms. For example, we experimented with strategically adding heavy-tailed and/or sparse noise, and found that it made SVD and QR decompositions increased the reconstruction error of each by nearly 50%, with only a 6% cost in MMLU. However, a sophisticated attacker could straightforwardly filter for this kind of naive noise.
Watermarking individual layers for attribution
For the encoding procedure, let $`\mathbf{W}\!\in\!\mathbb{R}^{d}`$ be the flattened target weight tensor and $`R\!\ll\!d`$ the watermark budget. We sample a fixed index set $`\mathcal{I} = \{i_1,\dots,i_R\} \subseteq \{1,\dots,d\}`$ and a spreading matrix $`\mathbf{S}\!\in\!\{\!-\!1, +1\}^{L\times R}`$ with i.i.d. Rademacher entries. A 128-bit Unix timestamp $`\mathbf{m}\!\in\!\{0,1\}^{128}`$ is zero-padded to 447 bits (message padding) and encoded with a $`\mathrm{BCH}(511,447)`$ code, yielding a 511-bit codeword. This codeword is then zero-padded to $`L=640`$ bits (length padding) to obtain $`\mathbf{c}\!\in\!\{0,1\}^{L}`$. We map $`\mathbf{c}\!\mapsto\!\mathbf{b}=2\mathbf{c}-1\in\{\!-\!1,+1\}^{L}`$ and set
\Delta w_{i_r}
= \gamma\sum_{k=1}^{L} b_k S_{kr},\quad
r = 1,\dots,R, \qquad
\gamma = \eta\,\sigma_{\mathbf{W}}/\sqrt{R},with $`\eta\!=\!6`$ fixed. All other weights remain untouched.
We update to watermark a single layer (instead of the whole network) by considering only the input/output map of the layer of interest. This also allows for an efficient implementation: for a layer $`\mathbf{W}`$, we run one forward/backward pass on cached activations from 2048 RedPajama tokens (which are cached and used for repeated watermarking, e.g., using the secure inference server described in [sec:defenses]), and obtain the gradient $`\mathbf{g}\!=\!\nabla_{\mathcal{I}} \mathcal{L}`$. We update $`\Delta\mathbf{w}\leftarrow\Delta\mathbf{w}-\frac{\mathbf{g}^T \Delta\mathbf{w}}{\lVert\mathbf{g}\rVert_2^2}\mathbf{g}`$ to ensure $`\mathbf{g}^T\Delta\mathbf{w}=0`$, eliminating first-order interference with our (proxy) fine-tuning task.
Decoding
At verification time we read $`\mathbf{W}`$, compute correlations $`r_k=\frac{1}{\gamma R}\sum_{j\in\mathcal{I}} W_j S_{k j}`$, threshold at zero to obtain hard bits $`\hat{\mathbf{c}}`$, and decode with the BCH decoder $`\mathcal{D}`$; attribution succeeds iff $`\mathcal{D}(\hat{\mathbf{c}})=\mathbf{m}`$.
Other compression methods
We also explore keeping the full precision of the top 1 percent of the weights with the highest magnitude, working from EasyQuant . This uses the intuition that not all of the weights in a model will contribute equally to model performance.
Given a weight matrix $`W \in \mathbb{R}^{m \times n}`$, we identify the subset of weights with the highest magnitude as outliers:
W_o = \{\, W_{ij} : \lvert W_{ij} \rvert \ge \tau \,\}where $`\tau`$ is the $`(100-p)`$-th percentile threshold of $`|W|`$ and $`p`$ is the outlier percentage at 1%. The remaining weights are considered normal:
W_n = \{\, W_{ij} : \lvert W_{ij} \rvert < \tau \,\}Unlike pruning approaches that remove parameters, this method preserves all weights but allocates precision non-uniformly. We maintain high precision for outliers while aggressively quantizing normal weights.
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
It is not necessary, but to preserve weight norms, $`O`$ might also be constrained to be orthogonal ↩︎