Federated data sharing promises utility without centralizing raw data, yet existing embedding-level generators struggle under non-IID client heterogeneity and provide limited formal protection against gradient leakage. We propose FedHypeVAE, a differentially private, hypernetwork-driven framework for synthesizing embedding-level data across decentralized clients. Building on a conditional VAE backbone, we replace the single global decoder and fixed latent prior with client-aware decoders and class-conditional priors generated by a shared hypernetwork from private, trainable client codes. This bi-level design personalizes the generative layerrather than the downstream modelwhile decoupling local data from communicated parameters. The shared hypernetwork is optimized under differential privacy, ensuring that only noise-perturbed, clipped gradients are aggregated across clients. A local MMD alignment between real and synthetic embeddings and a Lipschitz regularizer on hypernetwork outputs further enhance stability and distributional coherence under non-IID conditions. After training, a neutral meta-code enables domain-agnostic synthesis, while mixtures of meta-codes provide controllable multi-domain coverage. FedHypeVAE unifies personalization, privacy, and distribution alignment at the generator level, establishing a principled foundation for privacy-preserving data synthesis in federated settings. Code: github.com/sunnyinAI/FedHypeVAE
Deep Neural Networks (DNNs) have driven remarkable progress in medical imaging, yet their widespread clinical deployment remains constrained by limited data availability and stringent privacy requirements [1,2]. Medical datasets are often siloed across institutions, while the low prevalence of certain diseases further restricts access to diverse, high-quality training data [3]. Although collaborative data sharing could mitigate these challenges, strict regulatory frameworks such as HIPAA and GDPR render centralized dataset aggregation infeasible.
To address these limitations, Federated Learning (FL) [4] has emerged as a distributed paradigm that enables multiple institutions to collaboratively train models without exposing raw data. The classical FedAvg algorithm [4] aggregates model updates from clients to construct a global model, ensuring that sensitive data remain within institutional boundaries. However, FL faces several persistent challenges. Communication overhead is substantial-especially with high-capacity architectures such as Vision Transformers (ViTs) [5]-and performance often degrades under non-IID client distributions. Recent efforts to improve efficiency through lightweight architectures [6,7] have reduced transmission cost but at the expense of robustness and diagnostic fidelity.
An emerging alternative is synthetic data sharing, where generative models produce privacy-preserving surrogate datasets instead of transmitting model updates [8,9]. Such methods reduce communication burden and improve cross-domain applicability. While Generative Adversarial Networks (GANs) [10] and diffusion models [11] achieve high-fidelity synthesis, they remain unstable or computationally expensive for federated environments. In contrast, Variational Autoencoders (VAEs) and their conditional extensions (CVAEs) offer stable, likelihood-based training and computational efficiency, albeit at the cost of reduced perceptual sharpness. Recent work [12] demonstrated that generating data in embedding space rather than image space can preserve task-relevant information while mitigating privacy leakage. This embedding-level paradigm is strengthened by the advent of foundation encoders such as DINOv2 [13], which provide compact, semantically rich representations that generalize across imaging domains [14]. Training CVAEs on such embeddings enables the generative model to capture diagnostic features efficiently while reducing redundancy and risk of reconstruction-based attacks. Despite these advances, two fundamental challenges persist. First, existing federated generative frameworks lack the ability to adapt to client-specific heterogeneity, leading to degraded performance under non-IID distributions. Second, formal privacy guarantees are rarely incorporated, with most prior methods relying on heuristic noise injection rather than certified Differential Privacy (DP). Addressing these limitations requires a framework capable of personalized, differentially-private generative modeling that remains consistent and generalizable across diverse clinical domains.
To this end, we propose FedHypeVAE-a Federated Hypernetwork-Generated Conditional Variational Autoencoder designed for privacy-preserving, semantically consistent data synthesis across decentralized medical institutions. Unlike prior embedding-based frameworks that rely on a shared global decoder, FedHypeVAE introduces a unified hypernetwork that generates client-specific decoder and class-conditional prior parameters from lightweight private client codes. This design enables client-level personalization while implicitly sharing higher-order generative structure through the hypernetwork, thereby improving adaptability under non-IID conditions. Each client trains a local conditional VAE on embeddings extracted from a frozen foundation model (e.g., DINOv2), while the shared hypernetwork parameters are optimized collaboratively via Differentially Private Stochastic Gradient Descent (DP-SGD), ensuring formal (ε, δ)privacy against gradient inversion and membership inference attacks. Furthermore, a Maximum Mean Discrepancy (MMD)-based alignment regularizer enforces cross-site distributional coherence, and a meta-code synthesis module learns a domain-agnostic latent code for globally representative embedding generation.
Contributions. Our main contributions are threefold:
• We introduce FedHypeVAE, the first federated framework that integrates hypernetwork-based parameter generation with conditional VAEs to enable privacy-preserving embedding synthesis.
• We formulate a principled bi-level federated optimization strategy that jointly learns personalized client decoders and a globally consistent hypernetwork under certified (ε, δ)-DP guarantees via gradient clipping and calibrated Gaussian noise.
• We propose an MMD-based alignment and meta-code generation mechanism that ensure cross-domain coherence and high-fidelity synthetic embedding generation with minimal privacy-utility trade-off.
Extensive multi-institutional experiments on diverse medical imaging datasets demonstrate that FedHypeVAE substantially outperforms existing federated generative baselines in terms of robustness, generalization, and privacy compliance. By combining foundation model embeddings, hypernetwork-driven personalization, and differential privacy, FedHypeVAE establishes a new paradigm for secure and effective data sharing in federated medical AI.
Federated learning (FL) reduces the need for centralized data aggregation by training models through decentralized gradient exchanges across clients. However, a substantial body of research on gradient inversion and reconstruction attacks has demonstrated that shared updates (gradients or parameter deltas) can leak sensitive information, including approximate input reconstructions, membership inference, and attribute disclosure [15,16,17]. These risks are amplified in regimes involving highcapacity vision encoders and heterogeneous, small-scale medical datasets, where local gradients become more tightly coupled to individual training samples. This vulnerability motivates defenses that either (i) minimize the exposure surface by communicating compressed or less informative representations, or (ii) alter the communication primitive so that only aggregated or masked informationrather than raw updatesis revealed to the central server.
Privacy-preserving FL methods primarily fall into three methodological categories. (1) Secure multi-party computation (SMC) and secure aggregation conceal individual updates by allowing the server to observe only aggregated results, thereby preventing direct reconstruction of any client’s gradients [18,19,20,21].
(2) Homomorphic encryption (HE) enables mathematical operations to be performed directly on encrypted parameters, but typically introduces prohibitive computational and communication overhead [22,23,24]. (3) Differential privacy (DP) enforces formal privacy guarantees by clipping and perturbing updates with calibrated noise [25,26,27,28,29]. In addition, empirical defensessuch as gradient pruning, masking, or stochastic noise injection [16,30,31,32]as well as specialized systems like Soteria, PRECODE, and FedKL [33,34,35]have been proposed to mitigate leakage. Nonetheless, these techniques often struggle with a persistent privacyutility trade-off, where stronger protection degrades model accuracy and crossdomain generalization. Such limitations motivate more structural solutionse.g., hypernetwork-based formulationsthat inherently decouple shared parameters from raw data while maintaining high expressivity [36].
Recent research has explored privacy-preserving data sharing through federated generative modeling. Di Salvo et al. [12] demonstrated that generating synthetic training data at the embedding level, rather than from raw medical images, can preserve data privacy while maintaining high downstream task performance. Building on this principle, the Embedding-Based Federated Data Sharing via Differentially Private Conditional VAEs framework [37] proposed a federated conditional VAE (CVAE) that learns to synthesize embeddings collaboratively across clients. In their approach, each client trains a CVAE with a symmetric architecturethree linear layers for both the class-conditional encoder and decoderoptimized via a reconstruction loss (mean squared error) and a KullbackLeibler divergence term to regularize the latent distribution towards a standard Gaussian prior. To ensure privacy, differential privacy (DP) noise is added during decoder aggregation using a federated averaging (FedAvg) procedure. This design enables privacy-preserving global generative modeling, yet it relies on a shared global decoder, which can underperform under non-IID data distributions and lacks adaptive capacity across diverse clinical domains.
Hypernetworks have recently gained traction as an effective mechanism for parameter generation in federated learning, offering a meta-learning perspective on personalization and model sharing. In this paradigm, a central meta-generator H ϕ maintained by the server maps a compact client representation e k to the full parameter set of the client model, [36,38,39,40,41,42]. This indirect parameterization decouples the global and local learning dynamics: the server learns a global mapping in parameter space, while each client is represented by a low-dimensional embedding capturing its data distribution. As a result, hypernetwork-based federated learning substantially reduces communication and storage overhead, enables smooth interpolation across clients in the embedding space, and provides an elegant mechanism for handling data heterogeneity.
Importantly, this indirection also enhances privacy and robustness. Since the hypernetwork H ϕ learns a higher-order mapping rather than directly exchanging model gradients, reconstructing raw client data would require jointly inverting both the hypernetwork and the latent client embeddinga substantially harder problem than conventional gradient inversion. Beyond privacy, this architecture offers greater expressivity and adaptability, as the hypernetwork can learn to generate task-or domain-specific parameters that capture client-level inductive biases without explicit parameter sharing.
Building on these insights, our proposed FedHypeVAE extends the role of hypernetworks beyond discriminative personalization to generative parameterization, where H ϕ produces client-aware decoder and prior parameters for conditional VAEs, thereby enabling privacy-preserving and domain-adaptive data synthesis across heterogeneous medical sites.
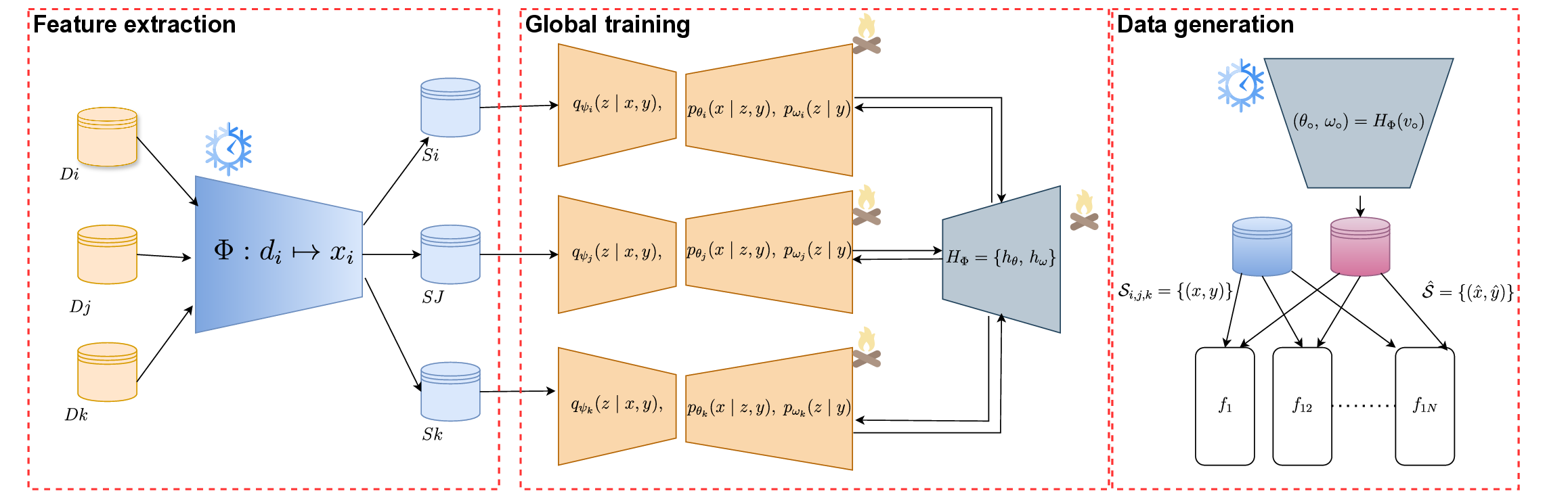
We consider a federated system comprising m clients (e.g., medical institutions), indexed by i ∈ {1, . . . , m}. Each client privately holds a local embeddinglabel dataset
where x (i) j ∈ R dx denotes a compact feature embedding (typically extracted from a frozen foundation encoder such as DINOv2 [13]) and y The goal is to collaboratively learn a federated generative model that can synthesize globally useful and statistically consistent embeddings across all clients, despite the presence of non-IID data heterogeneity. Formally, we aim to approximate the global data distribution p(x, y) through a conditional generative process
where (θ, ω) represent the decoder and prior parameters, respectively. In the federated setting, direct sharing of model parameters or data samples is restricted by privacy regulations; hence, each client trains its generative model locally and only communicates privacy-protected information to the central server.
Our proposed FedHypeVAE unifies three key components to address this challenge: (i) a conditional variational autoencoder (CVAE) that learns the local embedding distribution within each site; (ii) a shared hypernetwork H Φ that maps a lightweight, private client code v i to client-specific generative parameters (θ i , ω i ); and (iii) a federated optimization mechanism that aggregates knowledge across sites via differentially private stochastic gradient descent (DP-SGD). This formulation enables privacy-preserving personalization within the generative layer while ensuring global coherence and robustness under data heterogeneity.
Each client i models its local embedding distribution p i (x|y) using a conditional variational autoencoder (CVAE) parameterized by an encoder q ψi (z|x, y), a decoder p θi (x|z, y), and a class-conditional prior p ωi (z|y). The learning objective maximizes the evidence lower bound (ELBO):
-KL(q ψi (z|x, y) ∥ p ωi (z|y)) .
The first term enforces accurate reconstruction of local embeddings, while the KullbackLeibler term regularizes the latent space, promoting smoothness and global consistency across clients. This forms the foundational objective inherited from embedding-based federated CVAE frameworks [37,12].
To introduce personalization and privacy at the generative layer, we replace independent client decoders with a shared hypernetwork that generates client-specific parameters:
where v i ∈ R dv is a private, trainable client code and Φ = {Φ θ , Φ ω } are shared server-side hypernetwork parameters. This formulation allows each client’s generative model to adapt to its domain distribution while decoupling raw data from globally shared parameters, enhancing both privacy and non-IID robustness.
Row-Scaled Efficient Generation. To reduce the parameter footprint, each decoder layer with base weights W ℓ ∈ R r ℓ ×c ℓ is modulated by lightweight row-wise scaling and bias shifting:
where d ℓ (v i ) and ∆b ℓ (v i ) are predicted by h θ . This strategy follows the HyperLSTM principle [36], retaining expressivity while minimizing computation and communication overhead.
Hyper-Generated Class Priors. Similarly, the class-conditional Gaussian priors are generated as
where e(y) is a learnable label embedding. This parameterization enables the model to capture domain-specific feature styles and better calibrate latent priors across sites.
Each client minimizes a stability-regularized objective that combines the negative ELBO with structural constraints:
where R Lip enforces spectral-norm or Jacobian control for Lipschitz stability, and λ v constrains client code magnitudes.
Cross-Site Distribution Alignment. To align real and synthetic embeddings, each client computes a local Maximum Mean Discrepancy (MMD) loss:
where k(•, •) is a Gaussian multi-kernel function. This term promotes consistent latent distributions across domains without requiring any raw data exchange.
The shared hypernetwork parameters Φ are optimized collaboratively across clients via DP-SGD. The global federated objective aggregates client losses and alignment regularizers:
Each client optimizes its local encoder and code parameters:
Only these noise-perturbed gradients gi are sent to the server, ensuring (ε, δ)-differential privacy while keeping ψ i , v i , and raw data local.
Server-Side Aggregation. The server aggregates privatized gradients in a FedAvg-style update:
This completes one communication round under formal DP guarantees.
After convergence, the server learns a neutral meta-code v • using DP-noisy global statistics {μ y , Σy }:
Synthetic embeddings are generated as
where z ∼ N (0, I). This meta-code enables controllable, domain-agnostic synthesis under privacy constraints.
Mixture of Meta-Codes. For richer global synthesis, K meta-codes {v k } K k=1 with mixture weights π k ≥ 0, k π k = 1 can be used:
We impose spectral-norm constraints on (h θ , h ω ) for Lipschitz stability, bound ∥v i ∥ 2 ≤ r, and track privacy loss using moments accounting over (q, σ, T ). Cross-site MMD alignment mitigates non-IID drift, while mixture meta-codes improve global coverage and diversity. Client-side (for each i in parallel): 4:
Sample minibatch Bi ⊆ Si.
Compute local ELBO loss L ELBO i (Eq. 1).
Update local encoder ψi and client code vi (Eq. 9). 7:
Evaluate alignment loss MMD 2 i (Eq. 6). 8:
Compute privatized gradient:
Transmit gi to the server. 10:
Server-side: 11:
Aggregate and update global hypernetwork:
wigi, wi = ni j nj .
12: end for 13: Post-training: Learn meta-code v• (Eq. 12); generate synthetic embeddings x ∼ p θ• (x|z, y) where θ• = h θ (v•; Φ) and ω• = hω(v•; Φ); optionally mix K meta-codes (Eq. 13).
Ensure: Trained global hypernetwork Φ and synthetic dataset Ŝ.
Datasets and Metrics. We evaluate FedHypeVAE on two complementary multi-site medical imaging benchmarks.
(1) The ISIC 2025 MILK10k dataset [43] comprises 10,000 dermoscopic images annotated across multiple diagnostic categories, simulating a multi-institutional skin-lesion federation. (2) The Abdominal CT (Sagittal view) dataset [44] contains 25,211 CT slices across 11 anatomical classes and is widely adopted in cross-organ localization tasks. Following recent FL studies [45,46], each dataset is distributed among m = 10 clients under both IID and heterogeneous settings using a Dirichlet partition with α = 0.3. Raw medical images are converted into compact feature embeddings S i = {(x, y)} using a frozen DINOv2 encoder [13], ensuring representation consistency while preserving privacy. Evaluation metrics include per-client accuracy and balanced accuracy (BACC), averaged over three random seeds to assess robustness under domain skew.
Implementation Details. All downstream classifiers are implemented as single-layer linear models on top of DINOv2 embeddings [13]. FedHypeVAE and all baselines are trained for 50 communication rounds with 5 local epochs per round using SGD (η = 10 -3 ). Differential privacy is enforced via DP-SGD using the OPACUS library [47] with (ε, δ) = (1.0, 10 -4 ) and clipping norm 1.5, providing formal privacy guarantees [48,49]. Comparative baselines include FedAvg and FedProx [50], alongside a DP-CVAE variant [12]. All models are trained and evaluated under identical federation settings.
Table 1 reports results across both datasets under IID and non-IID conditions. FedHypeVAE consistently surpasses baseline federated classifiers in terms of generative fidelity, accuracy, and balanced accuracy. Its hypernetwork-based decoder and prior generation enable client-adaptive modeling, while the MMD alignment term mitigates cross-site distribution drift. Even under strict privacy budgets (ε ≤ 3.0, δ = 10 -5 ), the model preserves high reconstruction fidelity and generalization, outperforming DP-CVAE in both radiological and dermatological domains. Unlike parameterregularization-based personalization methods [51], FedHypeVAE achieves personalization directly within the generative layer, producing semantically consistent, privacy-preserving embeddings across diverse modalities.
FedHypeVAE was evaluated on multi-site medical imaging datasets under both IID and non-IID partitions, showing consistent gains in generative fidelity, robustness, and privacy over federated CVAE baselines [37,12,52]. Under comparable privacy budgets (ε ≤ 3.0, δ = 10 -5 ), it achieves higher accuracy and balanced accuracy while preserving strict differential privacy guarantees. These improvements stem from the hypernetwork’s ability to generate clientadaptive decoder and prior parameters that capture local variations without degrading global coherence. The inclusion of MMD-based cross-site alignment stabilizes latent representations across heterogeneous domains, mitigating embedding drift typical in federated settings. Moreover, gradient-level DP-SGD ensures a superior privacy-utility trade-off compared to weight-level noise injection, maintaining reconstruction quality under strong privacy constraints. Collectively, FedHypeVAE advances differentially private generative learning by achieving domain-consistent, semantically faithful, and privacy-compliant embedding synthesis across decentralized medical datasets.
We presented FedHypeVAE, a hypernetwork-driven, bi-level federated generative framework that extends embeddingbased differentially-private CVAE paradigms toward adaptive, privacy-preserving data synthesis. By introducing a shared hypernetwork that generates client-specific decoder and prior parameters from lightweight private codes, FedHypeVAE achieves fine-grained personalization without compromising data confidentiality. The incorporation of cross-site MMD alignment and meta-code synthesis ensures coherent global representation under severe non-IID conditions, while DP-SGD guarantees formal (ε, δ)-privacy throughout training. Collectively, these advances establish a unified approach that bridges generative modeling, personalization, and differential privacysetting a foundation for secure, generalizable, and data-efficient collaboration across medical institutions.
This content is AI-processed based on open access ArXiv data.