Direct Preference Optimization (DPO) has shown strong potential for mitigating hallucinations in Multimodal Large Language Models (MLLMs). However, existing multimodal DPO approaches often suffer from overfitting due to the difficulty imbalance in preference data. Our analysis shows that MLLMs tend to overemphasize easily distinguishable preference pairs, which hinders fine-grained hallucination suppression and degrades overall performance. To address this issue, we propose Difficulty-Aware Direct Preference Optimization (DA-DPO), a cost-effective framework designed to balance the learning process. DA-DPO consists of two main components: (1)Difficulty Estimation leverages pre-trained vision-language models with complementary generative and contrastive objectives, whose outputs are integrated via a distribution-aware voting strategy to produce robust difficulty scores without additional training; and (2) Difficulty-Aware Training reweights preference pairs based on their estimated difficulty, down-weighting easy samples while emphasizing harder ones to alleviate overfitting. This framework enables more effective preference optimization by prioritizing challenging examples, without requiring new data or extra finetuning stages. Extensive experiments demonstrate that DA-DPO consistently improves multimodal preference optimization, yielding stronger robustness to hallucinations and better generalization across standard benchmarks, while remaining computationally efficient. The project page is available at https://artanic30.github.io/project_pages/DA-DPO.
Recent advancements in Multimodal Large Language Models (MLLMs) (Liu et al., 2023a;OpenAI, 2023;Li et al., 2024) have significantly improved vision-language tasks, such as image captioning (Lin et al., 2014), visual question answering (Agrawal et al., 2015;Mathew et al., 2021;Marino et al., 2019). By combining powerful large language models with state-of-the-art vision models, MLLMs have enhanced multimodal understanding and reasoning. However, a persistent challenge for MLLMs is their tendency to produce Despite their effectiveness in reducing hallucinations, vanilla DPO methods trained on existing pairwise preference data often lead to noticeable degradation in general multimodal capabilities, as shown in Figure 1a. We attribute this limitation to an imbalance between easy and hard samples in the training data, as illustrated in Figure 1b. Easy samples typically involve clearly distinguishable faithful and hallucinated responses, whereas hard samples require more nuanced reasoning to differentiate. This imbalance leads to a training bias where models overfit to easy cases while failing to learn from more challenging examples. We provide a detailed empirical analysis of this phenomenon in Section 3, showing that while models quickly adapt to easy samples, they struggle to generalize to hard ones, ultimately limiting the effectiveness of preference-based alignment.
To address this limitation, we propose a difficulty-aware training framework that dynamically balances the contribution of easy and hard samples during preference optimization. A key challenge in implementing this strategy is the lack of explicit supervision for estimating sample difficulty. We tackle this by introducing a lightweight, training-free strategy: by aggregating signals from multiple pre-trained vision-language models (VLMs) trained under diverse paradigms, we obtain robust difficulty scores that estimate the difficulty of pairwise preference data without explicit training a specific model. These difficulty scores are then used to reweight preference data, enabling effective difficulty-aware training that emphasizes harder samples while preventing overfitting to easier ones. Specifically, we propose Difficulty Aware Direct Preference Optimization (DA-DPO), a framework that consists of two steps: difficulty estimation and difficulty-aware training. The first step assesses the difficulty of each pairwise preference sample using multiple VLMs. In particular, we leverage both contrastive VLMs (e.g., CLIP (Radford et al., 2021)) and generative VLMs (e.g., LLaVA (Liu et al., 2023b)) to estimate difficulty from complementary perspectives. Their outputs are aggregated through a distribution-aware voting strategy, in which the weight of each VLM is adaptively derived from its observed classification reliability over the training data. Building on these scores, the second step performs difficulty-aware training by dynamically adjusting the optimization strength of each sample in DPO. Specifically, the difficulty scores adjust the degree of divergence permitted between the learned policy and the initial policy. This mechanism strengthens learning from challenging samples while limiting unnecessary drift on trivial ones.
We conduct experiments on three popular MLLMs with different scales and abilities. To provide a comprehensive comparison, we report the performance comparison and analysis on two sets of benchmarks, hallucination benchmarks (Wang et al., 2023a;Rohrbach et al., 2018;Sun et al., 2023b;Li et al., 2023e) and general MLLM benchmarks (Hudson & Manning, 2019;Liu et al., 2023b;Fu et al., 2023;Li et al., 2023a), which demonstrate the effectiveness of our approach.
Our main contributions are summarized as follows:
• We conduct analysis on the multimodal preference optimization training and empirically demonstrate the existence of an overfitting issue, which can lead to suboptimal performance.
• We propose a cost-effective framework that leverages vision-language models (VLMs) to estimate the sample difficulty without additional training and utilize the estimation to improve preference modeling via difficulty-aware training. (1b) Easy and hard pairwise samples: “Easy Samples” have a large score gap due to clear differences between preferred and dispreferred responses, while “Hard Samples” show minor differences, making them more valuable for learning.
• We evaluate our method on hallucination and comprehensive benchmarks, and experimental results show that it significantly enhances the performance of various MLLMs in a cost-efficient manner.
In this section, we provide a brief overview of the Reinforcement Learning from Human Feedback (RLHF) to Direct Preference Optimization (DPO) pipelines.
RLHF Reinforcement Learning from Human Feedback (RLHF) is a widely used framework for aligning LLMs with human values and intentions. The standard approach (Bai et al., 2022a;Ouyang et al., 2022) first trains a reward model and then optimizes a KL-regularized reward objective to balance preference alignment with output diversity. The optimization can be written as:
where π ref is a reference policy (typically the SFT model) and β controls the trade-off between reward maximization and staying close to π ref .
The objective is usually optimized with PPO (Ouyang et al., 2022).
Pair-wise Preference Optimization Despite the success of the above RLHF, PPO is challenging to optimize. To enhance the efficiency of PPO, DPO (Rafailov et al., 2024) reparameterizes the reward function with the optimal policy:
where Z(x) denotes the partition function ensuring proper normalization. The hyperparameter β, analogous to the KL weight in Eq. ( 1), controls the trade-off: a larger value encourages π θ to remain closer to the reference policy, preserving generalization and robustness, while a smaller value places greater emphasis on preference alignment but risks overfitting.
Building on this reward formulation, we can directly integrate it into the Bradley-Terry model, which treats pairwise preferences probabilistically. By doing so, we can optimize the preference objective without learning a separate reward model. The optimization objective is described as:
where r(x, y) can be any reward function parametrized by π θ , such as those defined in Eq. ( 2) and y c and y r denote the chosen and rejected responses in pairwise preference data, respectively.
In this section, we present a systematic investigation of the prevalent overfitting challenge in multimodal preference optimization. Through empirical analysis, we demonstrate that models exhibit a tendency to overfit to simpler training samples, while progressively reducing their effective learning from harder instances. This phenomenon is particularly pronounced in pairwise training paradigms like DPO (Rafailov et al., 2024). This overfitting behavior ultimately compromises model performance when applied to diverse real-world scenarios. We substantiate these findings with quantitative evidence drawn from training dynamics and reward trend analyses.
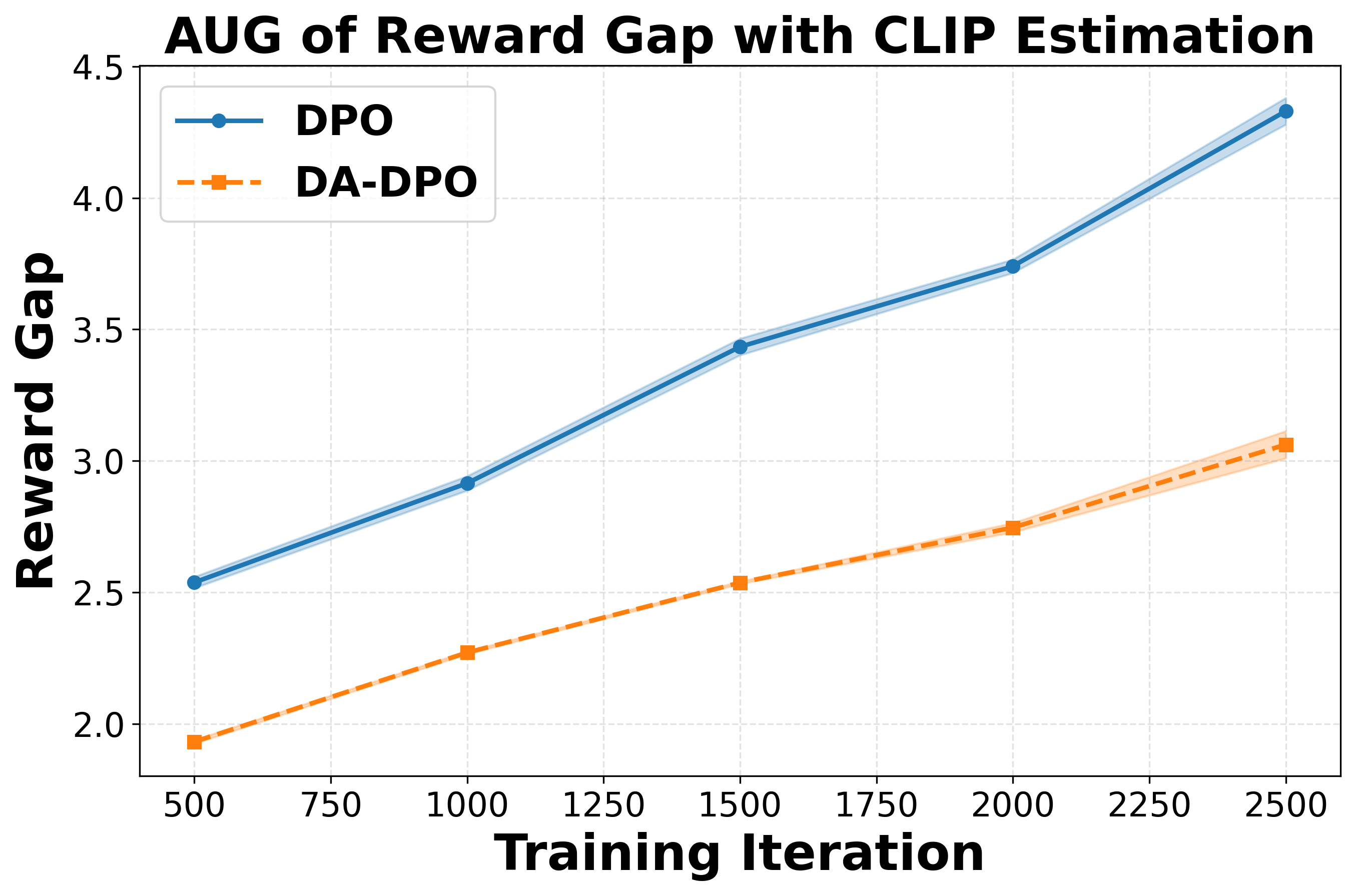
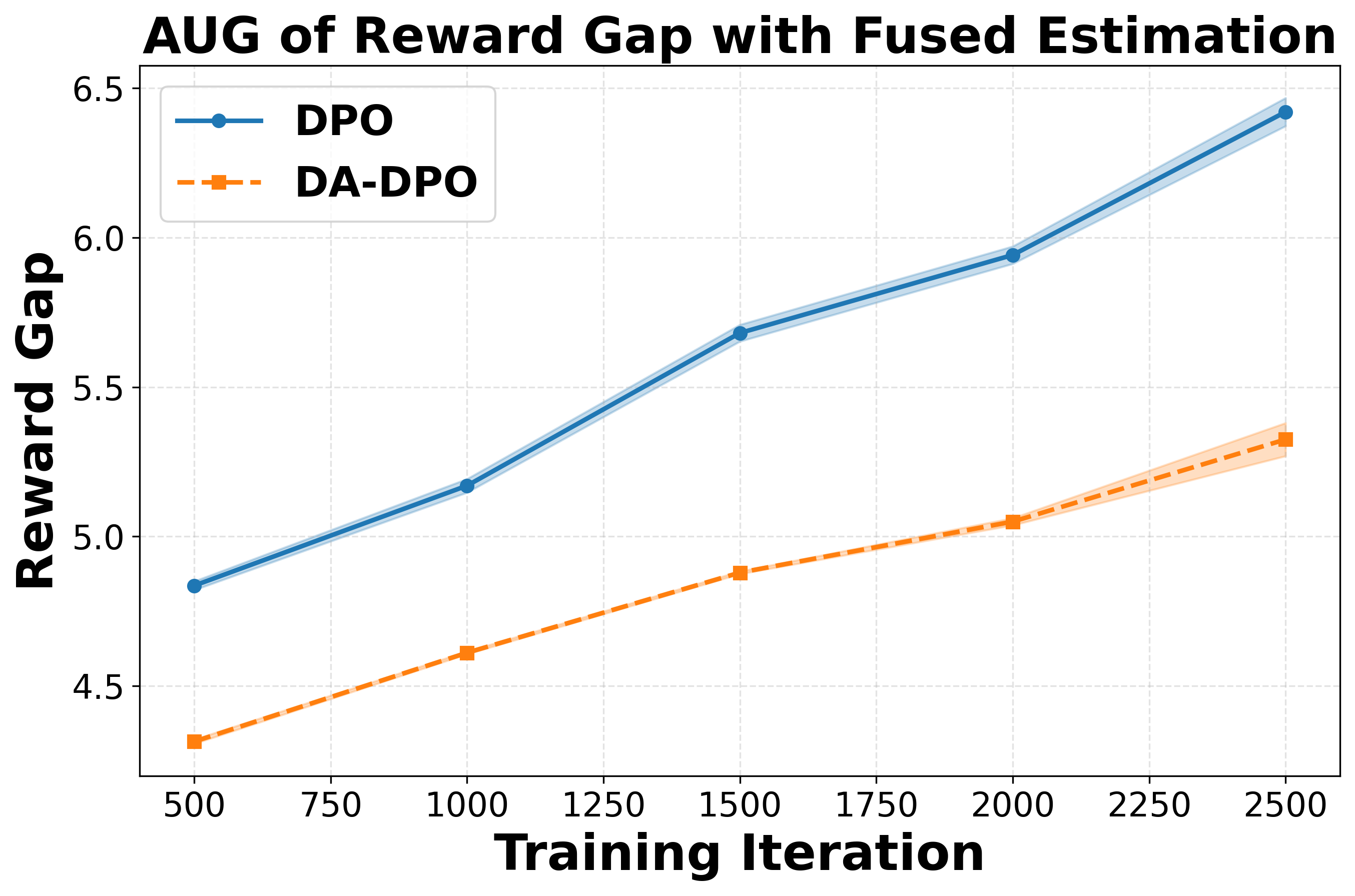
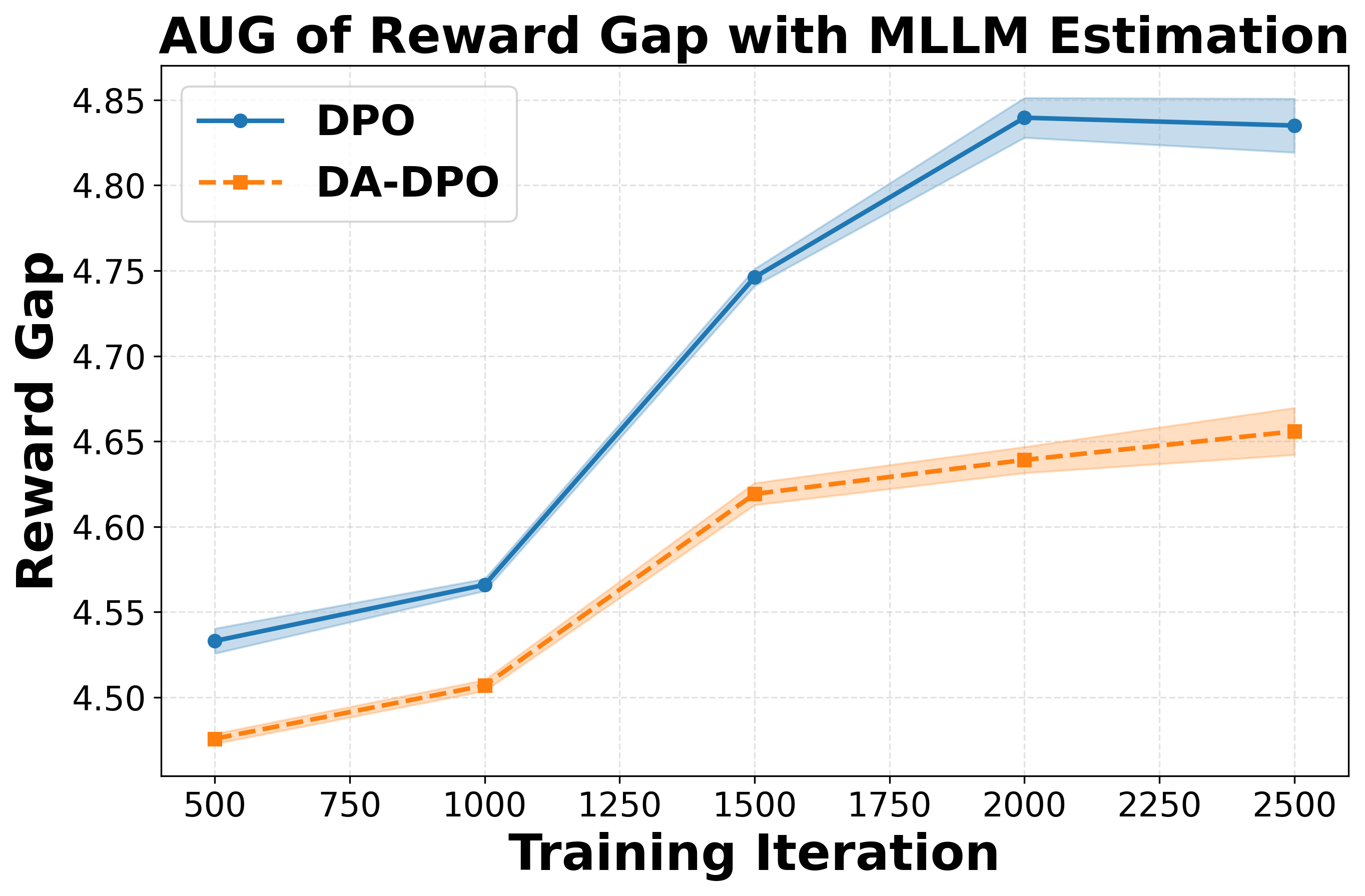
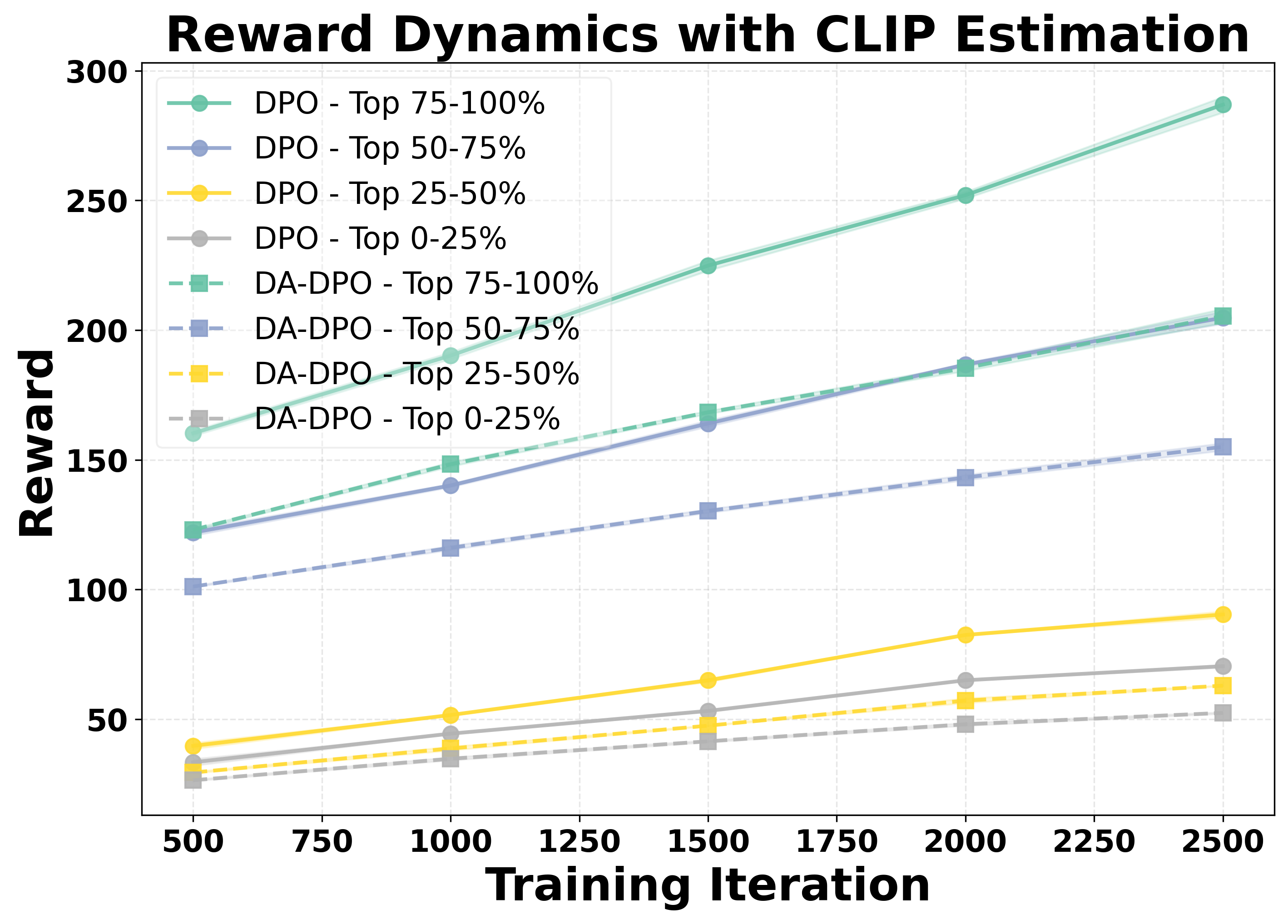
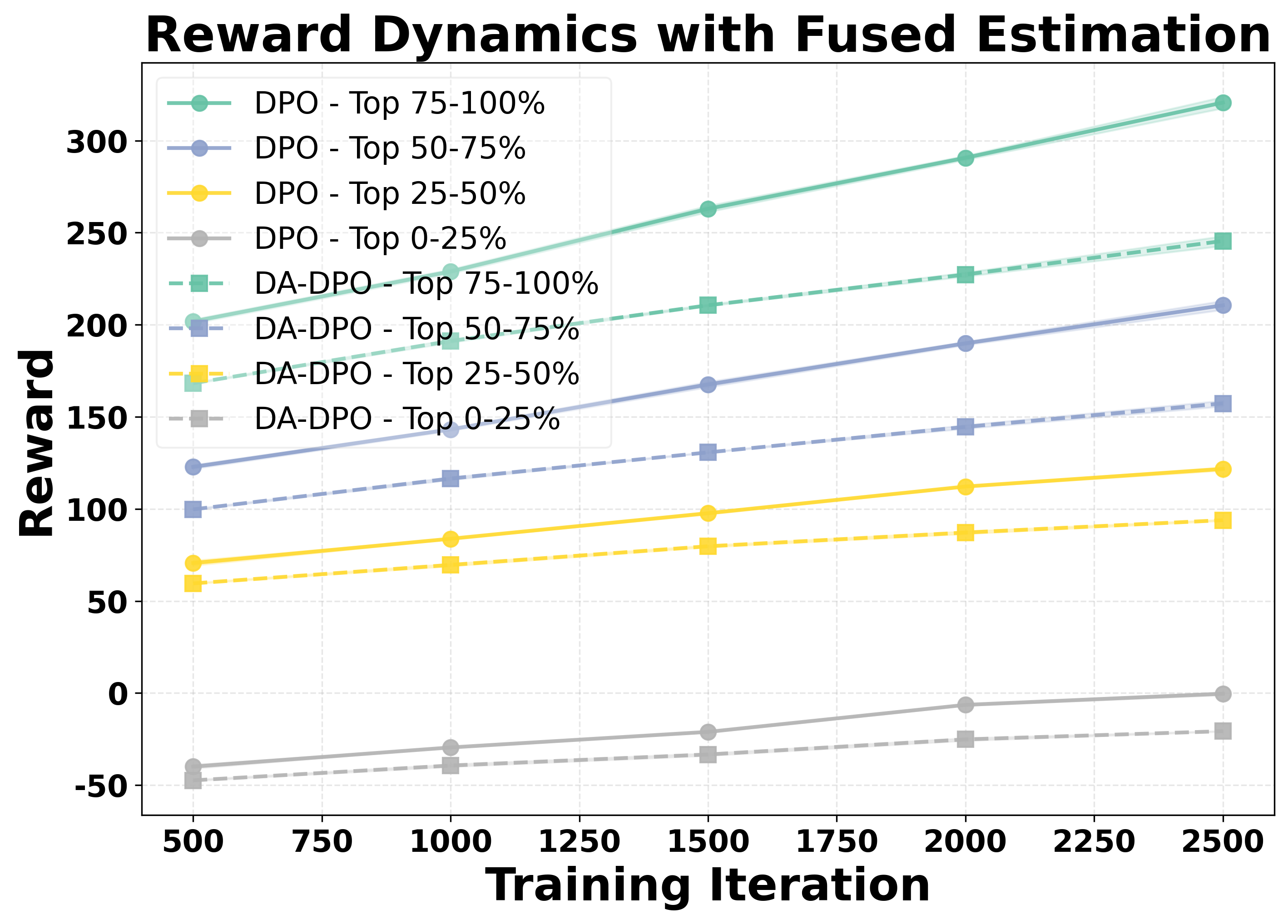
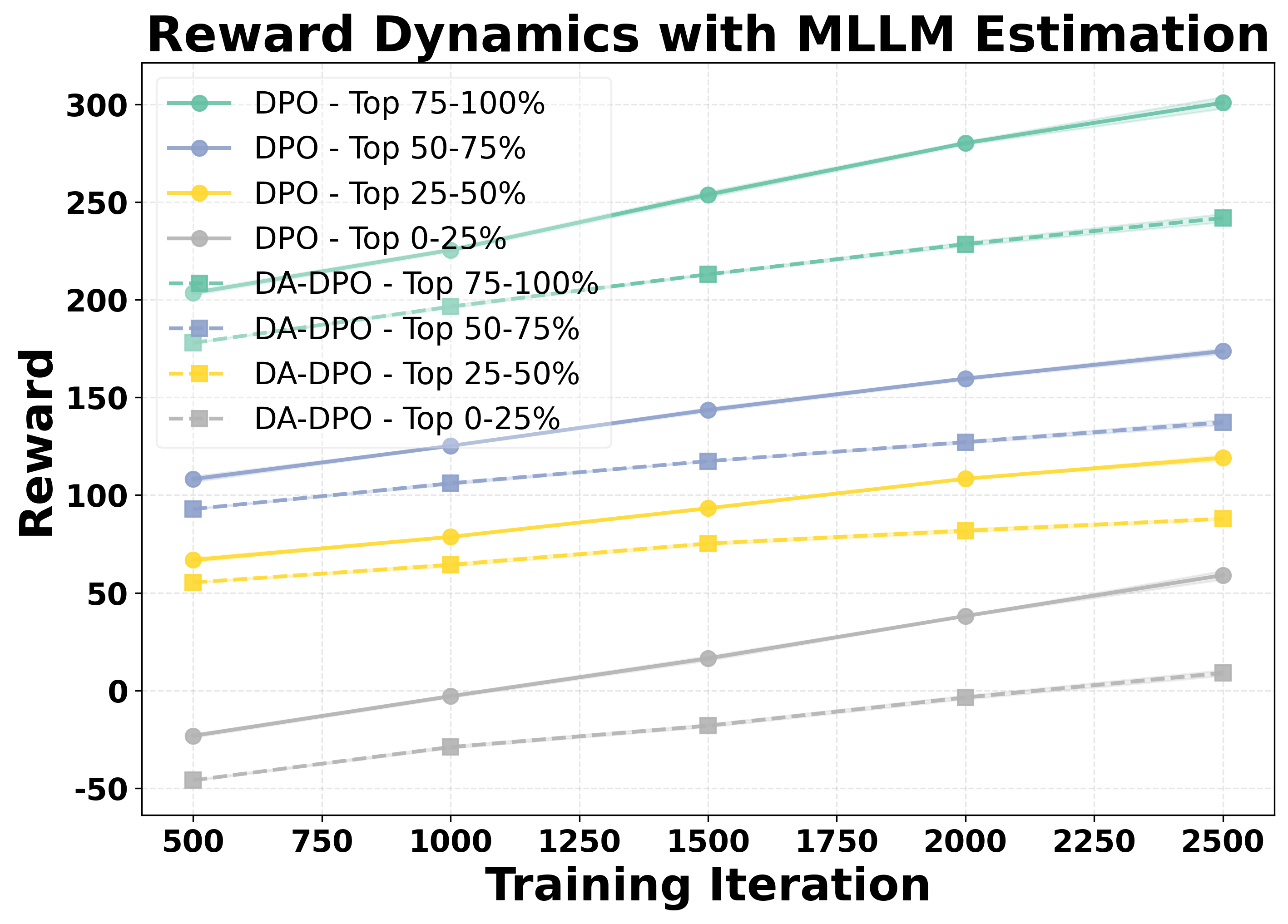
To systematically analyze overfitting in preference optimization, we construct a controlled evaluation setup. We split the dataset into a training set and a held-out validation set with a ratio of 90% to 10%. Both DPO and DA-DPO models are trained on the 90% training portion, while their reward performance is periodically evaluated on the validation set across training iterations. Since there is no oracle annotation for sample difficulty, we estimate the difficulty of each validation sample using three different proxy metrics, as introduced in Section 4.1. Based on the difficulty ranking derived from each proxy, we partition the validation samples into four equally sized buckets, ranging from the easiest to the hardest. This setup allows us to examine how the model’s reward evolves for samples of varying difficulty, thereby providing insights into overfitting behavior during preference optimization. To assess the statistical reliability of the results, we repeat the experiments with three different random seeds and report the corresponding standard deviations.
We analyze the reward dynamics from two complementary perspectives. The first perspective examines how the rewards of samples with different difficulty evolve throughout the training process. Based on three different proxy metrics (as detailed in Section 4.1), the validation samples are ranked by difficulty and partitioned into multiple buckets, from the easiest to the hardest. As shown in the first row of Figure 2, we observe that for both DPO and our proposed DA-DPO, the rewards of harder buckets consistently remain lower than those of easier buckets. This trend indicates a limited capacity to fit hard samples, which typically require fine-grained understanding capabilities. Moreover, we observe that in DA-DPO, the reward of the easier buckets increases more slowly compared to that in naive DPO. This slower growth is a result of DA-DPO’s adaptive weighting mechanism, which adjusts the importance of each training instance based on its estimated difficulty. By doing so, DA-DPO effectively reduces over-optimization on easier samples, thereby alleviating the overfitting tendency frequently observed in standard DPO training.
To further quantify this phenomenon, we introduce a second perspective: the Area Under Gap (AUG) between the easiest and hardest samples. The AUG is computed by first taking the difference between the reward of the easiest bucket and that of the hardest bucket at each evaluation point across training iterations, and then integrating this gap over the entire training trajectory. This provides a cumulative measure of the reward disparity between easy and hard samples throughout training. A larger AUG indicates a stronger optimization bias toward easier samples. As shown in the second row of Figure 2, the AUG in DA-DPO remains consistently smaller than that in naive DPO, demonstrating that DA-DPO achieves a more balanced optimization across samples of varying difficulty. These analyses collectively highlight the presence of overfitting in multimodal preference optimization and the effacacy of DA-DPO in mitigating it.
In this section, we introduce the DA-DPO framework, which addresses the overfitting issue in standard multimodal DPO training in a cost-efficient manner. In Section 4.1, we first discuss the estimation of preference data, where CLIP and MLLMs to evaluate the difficulty of preference data. In Section 4.2, we explain how the data difficulty estimation from pretrained VLMs informs and guides the difficulty-aware DPO training.
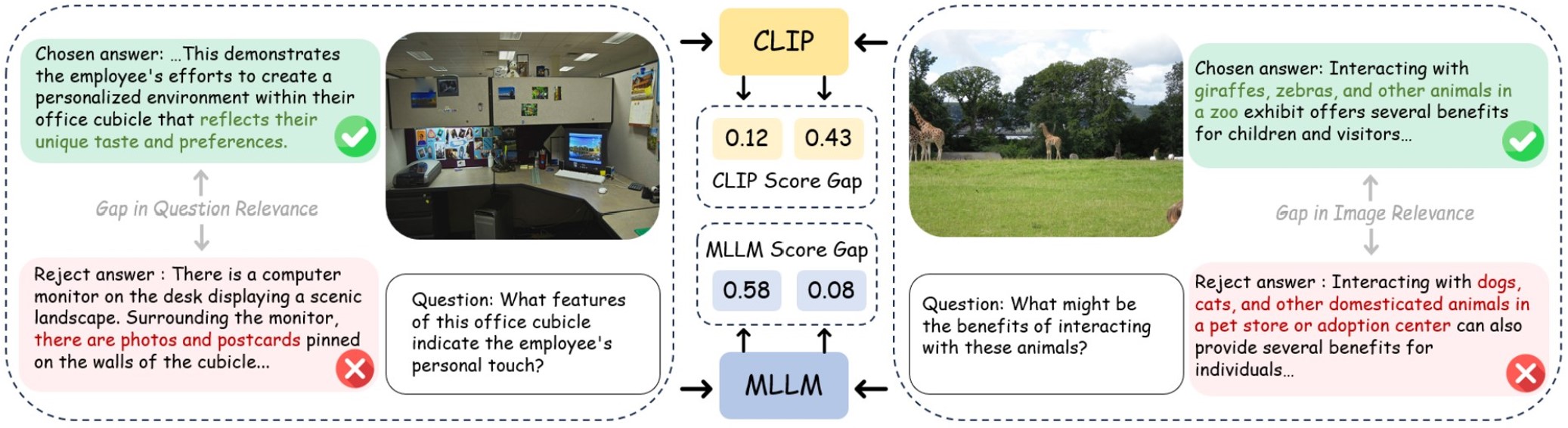
The key challenge in evaluating the difficulty of preference data is the lack of explicit supervision. To address this, we propose a lightweight, training-free strategy that leverages pre-trained contrastive and generative VLMs to estimate sample difficulty from complementary perspectives, as illustrated in Figure 3. To combine the estimates from multiple models, we adopt a distribution-aware voting strategy, where each model’s contribution is proportional to its preference classification accuracy on the training set. This results in a robust difficulty score for each sample without requiring additional model training. The details are described in the following sections.
Contrastive Estimation CLIP is trained on web-scale image captions via contrastive training objectives and is proven to contain generalized knowledge regarding image and text relevance. We utilize CLIP to evaluate the difficulty of pairwise DPO data. Specifically, we first compute the CLIP text embeddings for the chosen response y c and rejected response y r (denoted as f c and f r , respectively), and the CLIP image embedding for the image in DPO data m (denoted as v m ). The CLIP scores c c and c r represent the image-text relevance of both responses is computed as follows:
We then introduce CLIP score gap c g , which reflects the difficulty of a DPO sample; a larger gap indicates that the chosen and rejected responses are easily distinguishable in terms of image-text relevance. Formally, the CLIP score gap c g is defined as follows:
To integrate this metric with other VLM-based estimates, we normalize c g to a common scale via dataset-level Gaussian projection. Given a dataset of N samples, the normalized score is computed as follows:
where µ cg and σ cg are the mean and variance of all CLIP score gaps c g in the DPO dataset. The normalized CLIP score gap ĉg ∈ [0, 1], and Φ(•) denotes the cumulative distribution function of the standard Gaussian distribution.
Generative Estimation Recent Multimodal large language models (MLLMs) are built on large language models (LLMs) and learn to interact with the visual world by connecting a visual encoder to an LLM with language modeling objectives. For simplification, we denote this as a generative VLM. Although such models are prone to hallucination, they provide an informative evaluation of DPO data difficulty from another perspective complementary to CLIP. We extract the MLLM score for the chosen responses y c and rejected responses y r , denoted as m c ∈ R and m r ∈ R, which is defined as follows:
where y t c and y t r are the t th tokens in the chosen and rejected responses, and T is the sequence length. To evaluate the difficulty of pairwise DPO data, the MLLM score gap m g is computed as follows:
For a similar reason as the normalization of CLIP score, we utilize a Gaussian normalization to acquire a normalized MLLM score gap mg ∈ [0, 1]. The process is defined as follows:
where µ mg , σ mg is the mean and variance of all the MLLM score gaps m g in the DPO dataset.
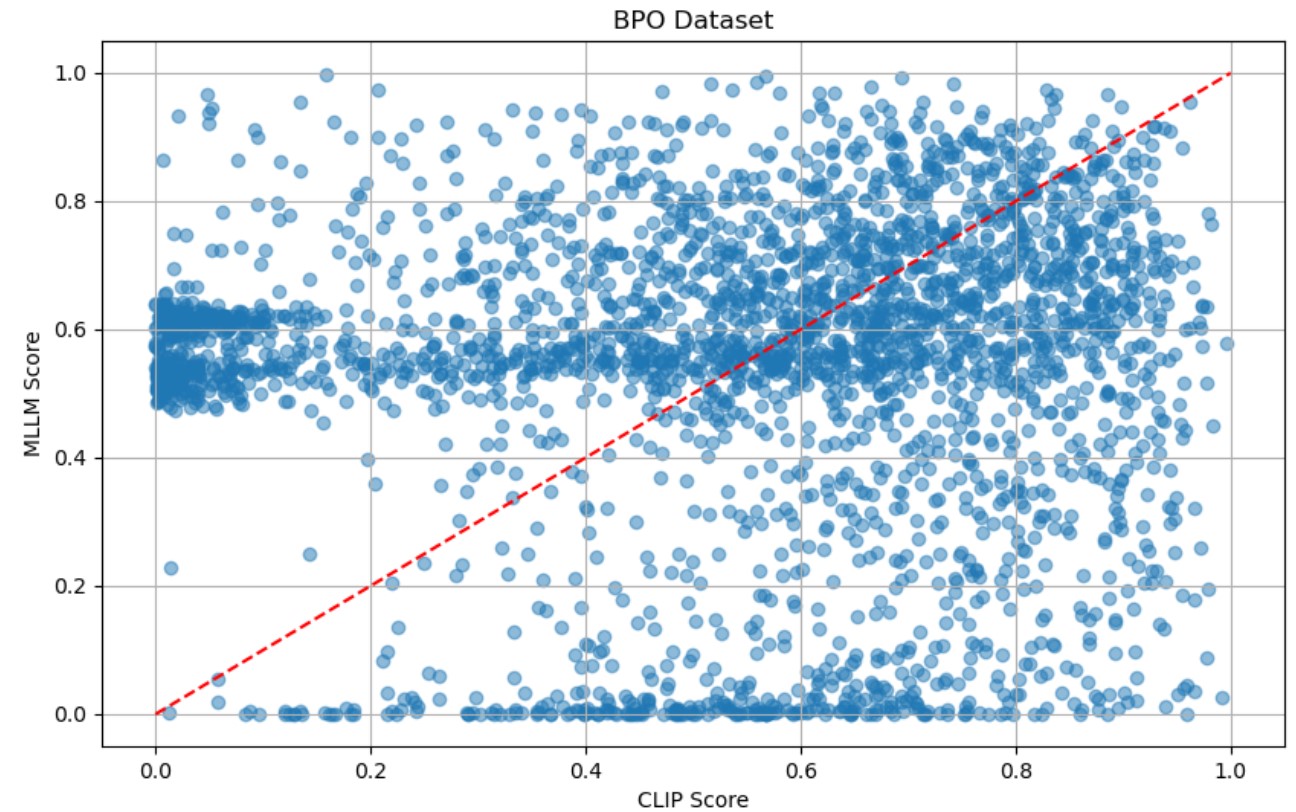
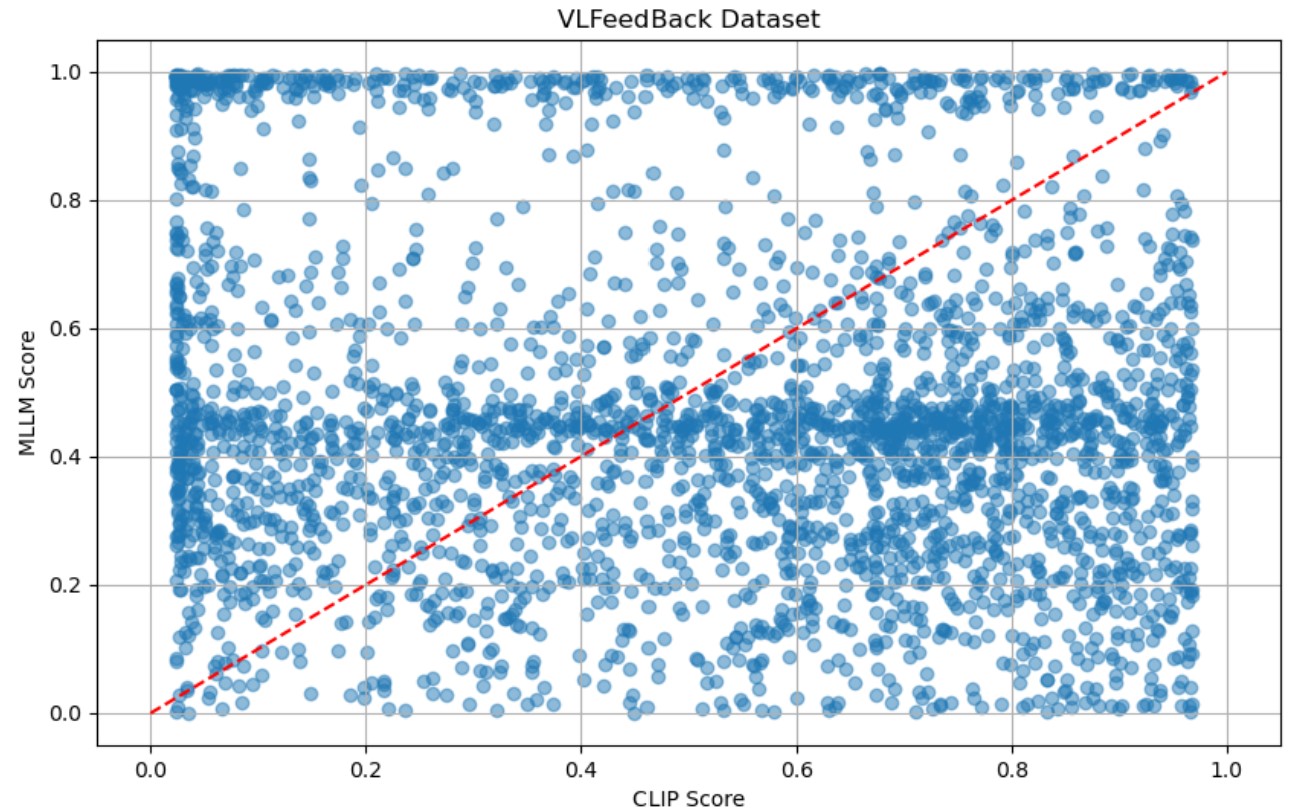
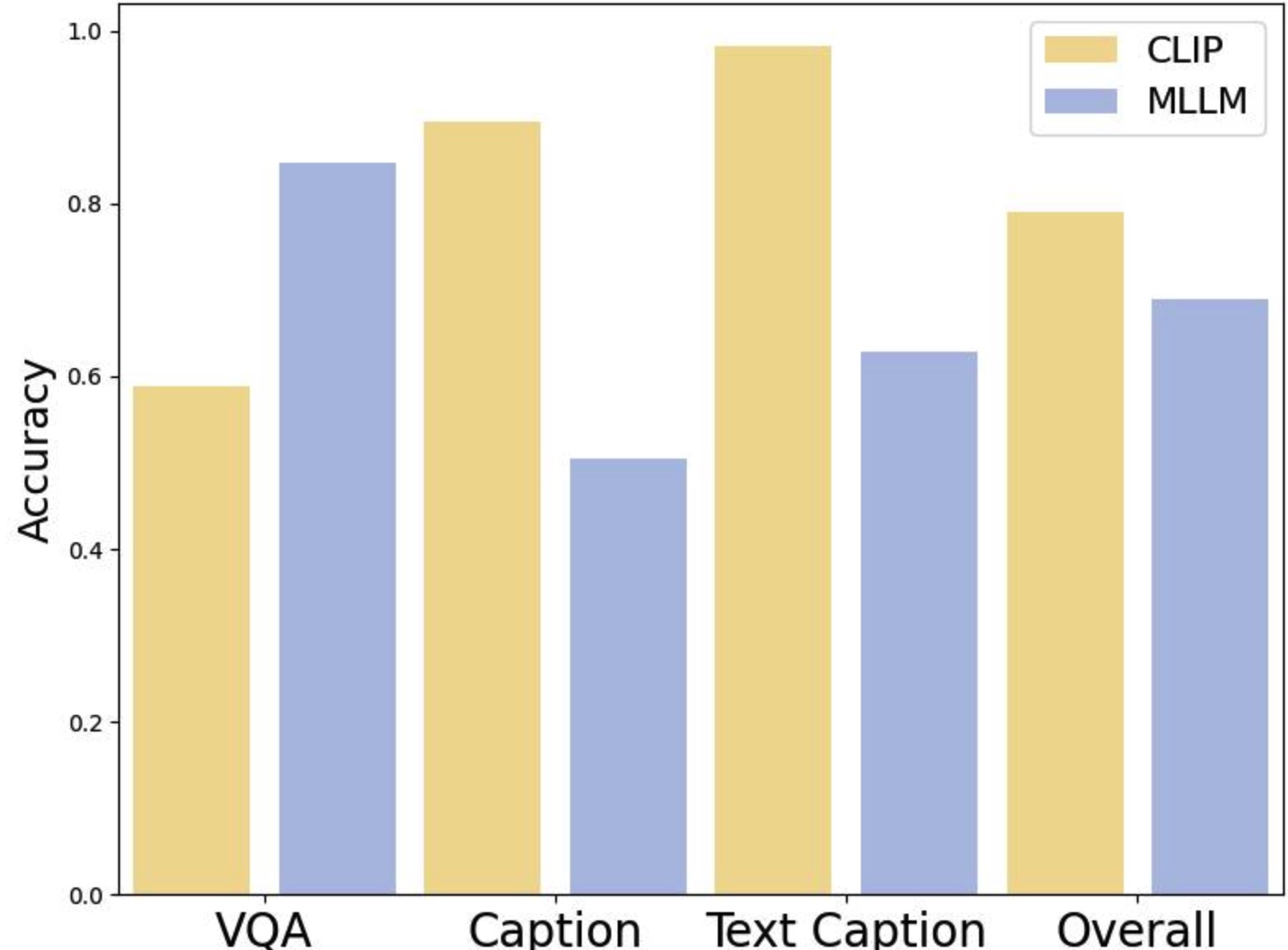
To this end, we evaluate the pairwise DPO data from two perspectives, resulting in two difficulty scores. As shown in Figure 4, the two VLMs perform differently in preference classification: CLIP excels on caption-related preference data, while MLLM performs better on VQA-related data. We propose a data-driven voting strategy to adaptively combine the difficulty scores based on the preference classification results. Specifically, we use the classification accuracies of CLIP and MLLM, denoted as cls c and cls m , to determine the weight of beta for each DPO sample, as described below:
where we add a constant term of 1 to improve the stability of the training process. Without this term, when both ĉg and mg are close to zero, the resulting β would also approach zero, potentially leading to training collapse.
After estimating the difficulty of the preference pairs, we obtain a robust score that reflects the difficulty of the pairwise DPO data. Building on previous work (Wu et al., 2024), we perform difficulty-aware DPO training by adaptively calibrating the β in Eq. ( 1). This approach allows us to adjust the weight of each training sample, reducing overfitting on easy samples compared to standard DPO training. Formally, the proposed difficulty-aware DPO objective is defined as:
where β is the difficulty-aware scaling factor, r(x, y) denotes the reward function as defined in Eq. ( 2), which itself incorporates the temperature coefficient β, y c and y r are the chosen and rejected responses, respectively, and σ(•) is the sigmoid function.
Training Setup To validate the effectiveness of the proposed methods, we use the pair preference datasets from BPO (Pi et al., 2024). This dataset contains 180k pairwise preference data, where the negative responses are generated by the Image-Weakened prompting and LLM Error Injection. For training parameters, we train the model for 1 epoch and set the β to 0.2. For LLaVA V1.5, we follow previous work (Pi et al., 2024) to adopt the LoRA (Hu et al., 2021) training with rank 32 and LoRA alpha 256. The learning rate is set to 2e-6. For LLaVA-OneVision, we use the recommended official training script to perform full finetuning where the learning rate is 5e-7. The training takes about 7 hours for LLaVA V1.5 7B models and 22 hours for LLaVA-OneVision 7B. For the analysis section, we preserve the top and bottom 20% scores as high-confidence CLIP-based predictions.
For the choice of VLMs, we employ the CLIP (Radford et al., 2021) ViTL/14@336.
For the preferred and negative text responses in each data sample, we encode the longest possible text from The * symbol denotes the evaluation results of the official model weights from BPO (Pi et al., 2024). We clarify that ‡ focuses on utilizing CLIP knowledge to construct preference data, whereas we leverage CLIP to address the overfitting issue in standard DPO training. The mDPO † provides an alternative approach to improving multimodal preference optimization by addressing the over-prioritization of language preference, which is orthogonal to the DA-DPO approach. the start and truncate the rest of the text. For MLLM, we use the LLaVA v1.5 7B (Liu et al., 2023a) to compute the probability of responses given the image and question. We also provide an ablation study on the choice of these models in Section 5.5.
To comprehensively evaluate the impact of preference optimization on MLLMs, we select two types of benchmarks. Hallucination benchmarks measure the model’s ability to reduce factual errors, which is the primary goal of multimodal preference alignment. Comprehensive benchmarks assess general multimodal capabilities, ensuring that improvements in hallucination do not come at the cost of overall performance.
Hallucination Evaluation. Following previous works (Pi et al., 2024;Wang et al., 2024a;Ouali et al., 2024), we comprehensively evaluate the DA-DPO on various hallucination benchmarks such as AM-BER (Wang et al., 2023a), MMHalBench (Sun et al., 2023b), Object HalBench (Rohrbach et al., 2018), and POPE (Li et al., 2023e). 1) AMBER provides a multidimensional framework suitable for assessing both generative and discriminative tasks. 2) MMHalBench is a question-answering benchmark with eight question types and 12 object topics. We follow the official evaluation scripts with GPT-4. 3) Object HalBench is a standard benchmark for assessing object hallucination, and we follow the settings in (Wang et al., 2024a). 4) POPE utilizes a polling-based query to evaluate the model’s hallucination. We report the average F1 score of three kinds of questions in POPE.
Comprehensive Evaluation. For evaluating MLLM helpfulness, we use: 1) LLaVA-Bench (Liu et al., 2023b), a real-world benchmark with 60 tasks assessing LLaVA’s visual instruction-following and questionanswering abilities. We use official scripts to compute scores with GPT-4. 2) Seedbench (Li et al., 2023a), which consists of 14k multiple-choice VQA samples to evaluate the comprehensive ability of MLLMs. 3) MME (Fu et al., 2023) which measures both perception and cognition abilities using yes/no questions. 4) GQA Hudson & Manning (2019) evaluates real-world visual reasoning and compositional question-answering
abilities in an open-ended answer generation format.
The proposed DA-DPO framework is designed to improve pairwise preference optimization by introducing the pretrained VLMs in a cost-efficient manner. We mainly compare DA-DPO with standard DPO (Rafailov et al., 2024) under three MLLMs, LLaVA V1.5 7B/13B (Liu et al., 2023a) and LLaVA-OneVision 7B (Li et al., 2024). Additionally, we provide results from other multimodal LLMs, such as GPT4-V (OpenAI, 2023), CogVLM (Wang et al., 2023b), mPLUG-Owl2 (Ye et al., 2023), InstructBLIP (Dai et al., 2023), Qwen-VL (Bai et al., 2023), HA-DPO (Zhao et al., 2023), CLIP-DPO (Ouali et al., 2024), mDPO (Wang et al., 2024a) for reference.
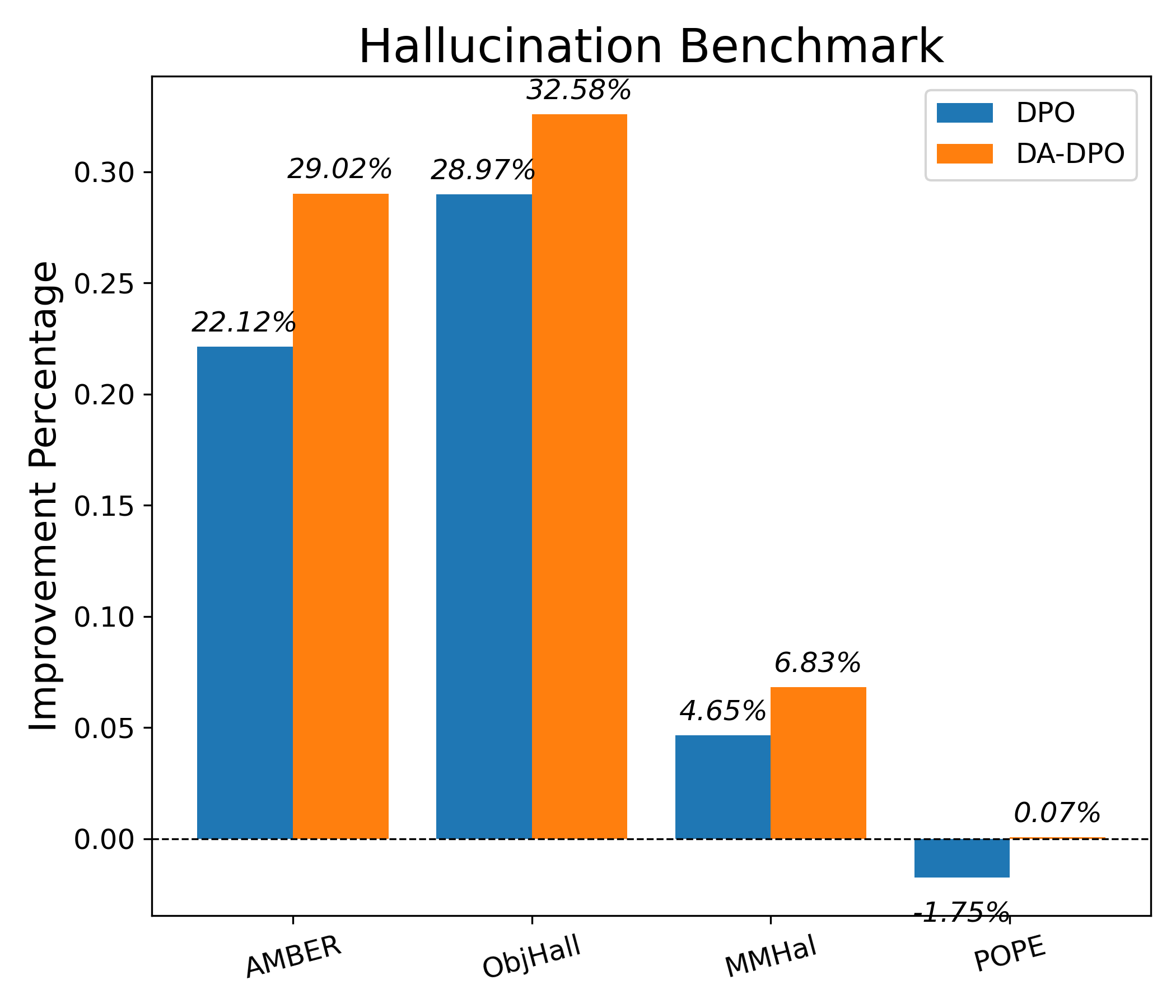
Hallucination Benchmarks To demonstrate the effectiveness of the proposed methods in reducing hallucinations, we present evaluation results on various hallucination benchmarks in Table 1. We observe that the DA-DPO improves model performance on most benchmarks compared to DPO, such as the HalRate in AM-BER generative decrease from 35.7 to 28.0 when training with LLaVA v1.5 7B. Moreover, the performance of three MLLMs is improved significantly on the Object Hallucination benchmark, which demonstrates that the DA-DPO greatly reduces the hallucination in the caption.
We evaluate the proposed methods on five comprehensive benchmarks.
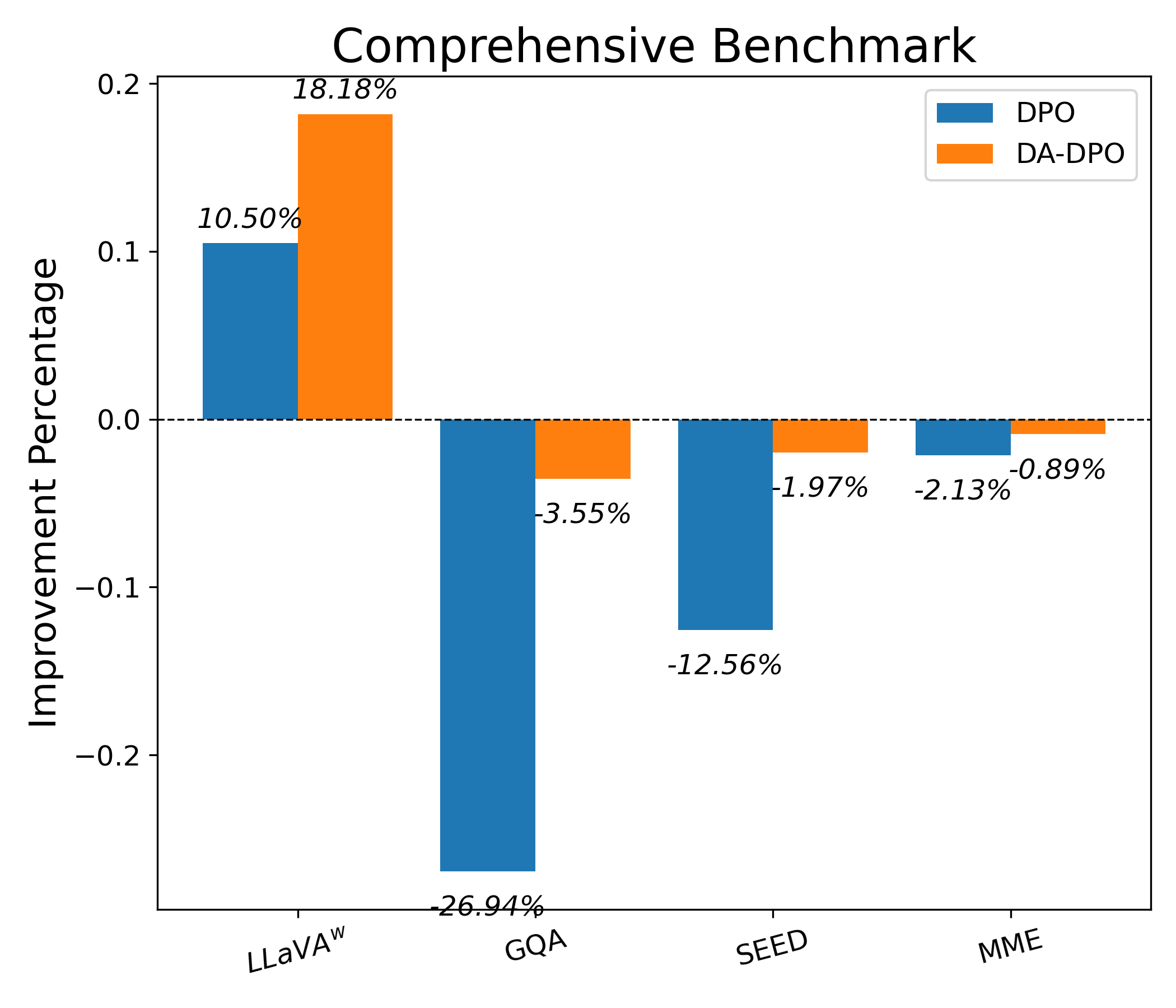
The results, shown in Table 1, indicate that while preference optimization reduces hallucination, performance on general abilities suffers. However, DA-DPO mitigates this degradation on most benchmarks when compared to standard DPO. Furthermore, DA-DPO significantly enhances conversational ability, with performance on the LLaVA-Bench reaching 75.4, compared to 70.5 for DPO using LLaVA v1.5 7B.
To better understand the proposed methods, we conduct an ablation study to assess the effectiveness of each design. As shown in Table 2, we begin with the standard Direct Preference Optimization (DPO) (Rafailov et al., 2024). We then add the reward score from the CLIP to control sample weight during training, followed by results for DPO with only the MLLM’s reward score. Finally, we combine both reward scores using the adaptive fusion strategy. The results show that using either CLIP or MLLM’s reward score improves both HalRate and CHAIR s , with the combination of both achieving the best performance, highlighting the necessity of each framework design.
To demonstrate that the proposed methods mitigate data bias in different types of multimodal pairwise preference data, we use VLFeedBack (Li et al., 2023d), which consists of 80k responses generated by MLLMs with varying levels of ability, and rated by GPT4-V (OpenAI, 2023). This dataset is automatically generated through a different approach compared to BPO (Pi et al., 2024), and it covers the mainstream data generation pipeline for multimodal preference data. We follow the settings of mDPO (Wang et al., 2024a) to select 10k preference data samples. Moreover, we trained on LLaVA-RLHF (Sun et al., 2023b), the most widely used human-annotated multimodal preference dataset with 10k samples. As shown in Table 3, DA-DPO outperforms DPO on most benchmarks, demonstrating that overfitting is a common issue in multimodal preference data, and DA-DPO effectively alleviates this problem in a cost-efficient manner.
We present an ablation study on the selection of VLMs. These models estimate the difficulty of pairwise preference data and guide difficulty-aware preference optimization during training in the proposed framework. We experiment with two CLIP models of varying parameter scales: CLIP ViT-L/14@336 (Radford et al., 2021) and EVA-CLIP 8B (Sun et al., 2023a). For MLLMs, we use LLaVA v1.5 7B (Liu et al., 2023a) and LLaVA-OneVision 7B (Li et al., 2024). As shown in Table 4, we observe that performance remains similar across VLMs with different capabilities, which is attributed to the Gaussian normalization in Eq. ( 10) and Eq. ( 6). This normalization ensures that the VLMs only provide a ranking of preference data, making our proposed framework robust to variations in the choice of VLMs.
To further validate the effectiveness of our sample reweighting strategy, we compare DA-DPO against a baseline that directly filters out easy samples from the training data. Specifically, we remove 10%, 25%, and 50% of the easy samples from the BPO dataset based on our difficulty metric and train a model using the DPO algorithm. Table 5 summarizes the performance of DA-DPO and the direct filtering baselines across a wide range of benchmarks. We observe that DA-DPO consistently outperforms the filtering-based approaches on most metrics, especially on hallucination-related benchmarks such as POPE, MMHal, and Object Hallucination. Notably, the performance of the direct filtering baseline fluctuates across different filtering ratios, with no consistent improvement as more easy samples are removed.
We attribute the limited effectiveness of direct filtering to its inherent trade-off: while it removes truly uninformative samples, it also discards a portion of valuable training data, thereby reducing the diversity and coverage of preference information. In contrast, DA-DPO addresses this issue by softly down-weighting easy samples instead of hard filtering, preserving data diversity while emphasizing informative examples. This allows DA-DPO to maintain robustness across benchmarks with varying difficulty and annotation styles.
To examine the relationship between the reward gap and hallucination behavior, we design a controlled validation experiment. Specifically, we utilize CLIPbased and MLLM-based proxies to estimate the reward gaps of training samples and evenly divide the data into four buckets according to the estimated gap range. We then train a vanilla DPO model on each bucket independently to analyze how sample difficulty affects preference optimization. As shown in Table 6, we observe that the largest reduction in hallucination occurs for samples in the 25-50% bucket, while the extent of hallucination reduction gradually decreases as the reward gap increases. Interestingly, the bucket with the smallest reward gap (0-25%) does not yield the most significant hallucination improvement. We attribute this to noisy or confusing samples within this subset during data construction-such as cases where the “rejected” answer is actually semantically correct-which may interfere with effective model optimization.
6 Related Works
Vision-Language Models (VLMs) (Radford et al., 2021;Jia et al., 2021;Li et al., 2022) have substantially advanced multimodal understanding, achieving strong performance across a wide range of downstream tasks (Guo et al., 2022;Ning et al., 2023). Contrastive VLMs, such as CLIP (Radford et al., 2021), align images and text via large-scale contrastive objectives and demonstrate impressive zero-shot transfer on recognition tasks (Nukrai et al., 2022;Qiu et al., 2024;Liao et al., 2022;Ning et al., 2023;Yao et al., 2022;Peebles & Xie, 2022). With the rise of large language models (LLMs), subsequent works integrate LLMs with visual encoders to enhance image-conditioned text generation (Li et al., 2023b;Dai et al., 2023;Liu et al., 2023b;Zhu et al., 2023;Chen et al., 2023;Lin et al., 2023), enabling instruction following and open-ended reasoning. More recent efforts (Liu et al., 2023a;Li et al., 2024;Gao et al., 2024;Bai et al., 2025) further improve visual capabilities by leveraging higher-resolution inputs, multi-image contexts, and even video sequences. Despite these advances, VLMs remain prone to hallucinations when aligning visual evidence with textual responses, motivating preference-based optimization approaches to improve faithfulness.
The alignment problem (Leike et al., 2018) aims to ensure that agent behaviors are consistent with human intentions. Early approaches leveraged Reinforcement Learning from Human Feedback (RLHF) (Bai et al., 2022a;b;Glaese et al., 2022;Nakano et al., 2021;Ouyang et al., 2022;Scheurer et al., 2023;Stiennon et al., 2020;Wu et al., 2021;Ziegler et al., 2019), where policy optimization methods such as PPO (Schulman et al., 2017) were used to maximize human-labeled rewards. More recently, Direct Preference Optimization (DPO) (Rafailov et al., 2024) reformulates alignment as a direct optimization problem over offline preference data, avoiding the need for reinforcement learning. Extensions such as Gibbs-DPO (Xiong et al., 2023) enable online preference optimization, while β-DPO (Wu et al., 2024) addresses sensitivity to the temperature parameter β by introducing dynamic calibration with a reward model. However, such approaches are less effective in multimodal domains, where reward models are vulnerable to reward hacking (Sun et al., 2023b).
Other works explore alternative strategies, such as self-rewarding mechanisms or data reweighting (Wang et al., 2024b;Zhou et al., 2024a), to mitigate issues like overconfident labeling and distributional bias in preference data.
Recent efforts have extended preference alignment from language-only models to the multimodal domain.
A major line of work focuses on constructing multimodal preference datasets. (Sun et al., 2023b;Yu et al., 2024a) collect human annotations, while others rely on powerful multimodal models such as GPT-4V (Li et al., 2023c;Yu et al., 2024b;Zhou et al., 2024d;Yang et al., 2025) to generate preference signals.
However, both human annotation and large model inference incur prohibitive costs, limiting scalability. To address this, alternative approaches (Deng et al., 2024;Pi et al., 2024) explore automatic or self-training methods for preference data generation. These works synthesize dis-preferred responses from corrupted images or misleading prompts, enabling the model to learn preferences without external supervision. Another direction (Ouali et al., 2024) leverages CLIP to score diverse candidate responses, ranking preferred versus dispreferred outputs using image-text similarity. From the perspective of training objectives, most multimodal alignment methods adopt the standard DPO objective (Li et al., 2023c;Zhao et al., 2023;Zhou et al., 2024b) to optimize preferences on paired data. Other approaches employ reinforcement learning (Sun et al., 2023b) or contrastive learning (Sarkar et al., 2024;Jiang et al., 2024) to improve alignment. To further reduce overfitting to language-only signals, (Ouali et al., 2024) extends DPO by jointly optimizing both textual and visual preferences. Despite these advances, multimodal DPO remains vulnerable to overfitting, especially when trained on imbalanced preference data. In this work, we introduce a general difficultyaware training framework that explicitly accounts for sample difficulty, thereby mitigating overfitting and improving robustness in multimodal preference optimization.
In this work, we present an empirical analysis of the overfitting issue in multimodal preference optimization, which often stems from imbalanced data distributions. To address this, we introduce DA-DPO, a costefficient framework consisting of difficulty estimation and difficulty-aware training. Our method leverages pretrained contrastive and generative VLMs to estimate sample difficulty in a training-free manner, and uses these estimates to adaptively reweight data-emphasizing harder samples while preventing overfitting to easier ones. Experiments across hallucination and general-purpose benchmarks demonstrate that this paradigm effectively improves multimodal preference optimization.
Limitations Despite these promising results, our framework relies on the assumption that pretrained VLMs provide reliable evaluations of preference data. Although the adaptive voting strategy shows robustness on existing datasets, its generalizability to domains that differ substantially from the pretraining objectives of these VLMs remains uncertain. Future work may explore integrating domain-adaptive or selfimproving mechanisms to further enhance robustness.
The proposed framework integrates two types of pretrained VLMs to assess the difficulty of pairwise preference data. We design an adaptive score fusion mechanism to determine the weight of each reward model without requiring hyperparameter selection from the data perspective. As shown in Table 7, we present the results for multiple fixed fusion scores. We observe that the adaptive score fusion achieves the best performance.
We propose a difficulty-aware preference optimization strategy that aims to alleviate the overfitting-to-easysample issue during alignment training. To achieve this, we dynamically calibrate the β, which is described in the main paper. However, our method affects the scale of the β in the DPO objective. As shown in Table 8, we provide the ablation of the β between the DPO and DA-DPO. From the results, we observe that varying β leads to mixed performance across different benchmarks for both DPO and DA-DPO. Nevertheless, the proposed DA-DPO consistently achieves better overall performance compared to vanilla DPO, indicating that our difficulty-aware calibration effectively enhances robustness while mitigating hallucinations.
In our proposed DA-DPO framework, we utilize the CLIP and the MLLM to evaluate the difficulty of preference data from different perspectives. To validate this claim, we provide the score of difficulty correlation between the two VLMs. As shown in Figure 5, the scores from the two models exhibit no significant positive correlation, as evidenced by their weak correlation coefficient. This indicates that the two models capture different aspects of the response evaluation, and their scoring patterns do not align consistently across the datasets.
To provide a comprehensive understanding of the score fusion process, we supplement the main text with detailed numerical results and evaluation metrics. Score fusion is conducted at the dataset level, where distinct fusion scores are employed for the BPO and VLFeedback datasets.
Evaluation Metric. We compute classification accuracy on pairwise preference data using the following criterion: for each sample, the VLM assigns a score to both the chosen and rejected answers. A sample is considered correctly classified if the chosen answer receives a higher score than the rejected one.
Results. Table 9 reports classification accuracy for each category (VQA, Caption, and Text VQA, where applicable) and the overall accuracy on both datasets. We evaluate two types of VLMs: a vision encoder (CLIP) and a multimodal large language model (MLLM). Specifically, we use EVA-CLIP 8B as the CLIP model and LLaVA-1.5 7B as the MLLM.
To validate the efficiency advantage of our proposed framework, we compare the computational cost in terms of FLOPs and wall-clock time between traditional reward model training and evaluation, and our estimationbased approach. As summarized in Table 10, training a full reward model requires over 6 times the wallclock time of MLLM-based estimation and approximately 345 times that of CLIP-based estimation. These results clearly demonstrate that our method achieves significantly higher efficiency compared to conventional approaches.
To evaluate the impact of different normalization strategies on data difficulty estimation, we conducted experiments with two alternative approaches. The first strategy, Ranked-based, normalizes scores by ranking the data and projecting the values linearly into the [0, 1] range, instead of using Gaussian normalization.
The second strategy, Length-controlled, is applied during the MLLM generative estimation: the sum of log probabilities in Equations 7 and 8 is divided by the response token length to mitigate length bias. As shown in Table 11, all three normalization strategies achieve performance improvements over vanilla DPO. We also observe that the Ranked-based approach slightly underperforms the other two strategies, suggesting that preserving the original distribution of estimated scores is beneficial for effective difficulty estimation.
To validate the effectiveness of our proposed method beyond the LLaVA series, we conduct a small-scale experiment on Qwen2.5-VL 3B. We use a subset of 50k samples from the BPO dataset to train both the baseline DPO and our proposed DA-DPO. The results are presented in Table 12. We observe that DA-DPO achieves better reductions in hallucination metrics compared to DPO, while retaining performance on comprehensive benchmarks. This demonstrates that DA-DPO is a general framework, not limited to LLaVA-series models.
AMB. G AMB. D ObjHal MMHal POPE LLaVA W GQA Seed I MME P MME C Cs ↓ Cov. ↑ Hal. ↓ Cog. ↓ F1 ↑ Cs ↓ Ci ↓ Score ↑ HalRate ↓ F1 ↑ Score ↑ Acc↑ Acc↑ Score↑ Score↑
AMB. G AMB. D ObjHal POPE GQA Seed I MME P MME C Cs ↓ Cov. ↑ Hal. ↓ Cog. ↓ F1 ↑ Cs ↓ Ci ↓ F1 ↑ Score ↑ Acc ↑ Score ↑ Score ↑
AMB. GAMB. D
AMB. G
This content is AI-processed based on open access ArXiv data.