Real-time Interaction (latency ≈ 500ms) [ ]
Smile Figure 1 . Overview of Avatar Forcing. It can generate a real-time interactive avatar video conditioned on user motion and audio, as well as avatar audio. The avatar naturally mirrors the user's expression, such as smiling when the user smiles, for more engaging interactions.
Talking head generation animates static portrait images into lifelike avatars that can speak like humans. These systems are increasingly used to create virtual presenters, hosts, and educators that can substitute for real human presence in many scenarios. They also support customized avatars that users can interact with, for instance, chatting with their favorite characters [20,42,52], offering a practical tool for content creation and visual communication.
However, existing avatar generation models fail to fully replicate the feeling of real face-to-face interaction. They primarily focus on generating audio-synchronized lip or natural head motions [27,32,38,53,[60][61][62][63] to deliver information accurately and naturally, rather than engaging in interactive conversations. Such one-way interaction overlooks the bidirectional nature of real-life conversations, where the continuous exchange of verbal and non-verbal signals plays a crucial role in communication. For instance, active listening behaviors such as nodding or empathic responses encourage the speaker to continue, while expressive speaking behaviors such as smiling or making eye contact contribute to a more realistic and immersive conversation.
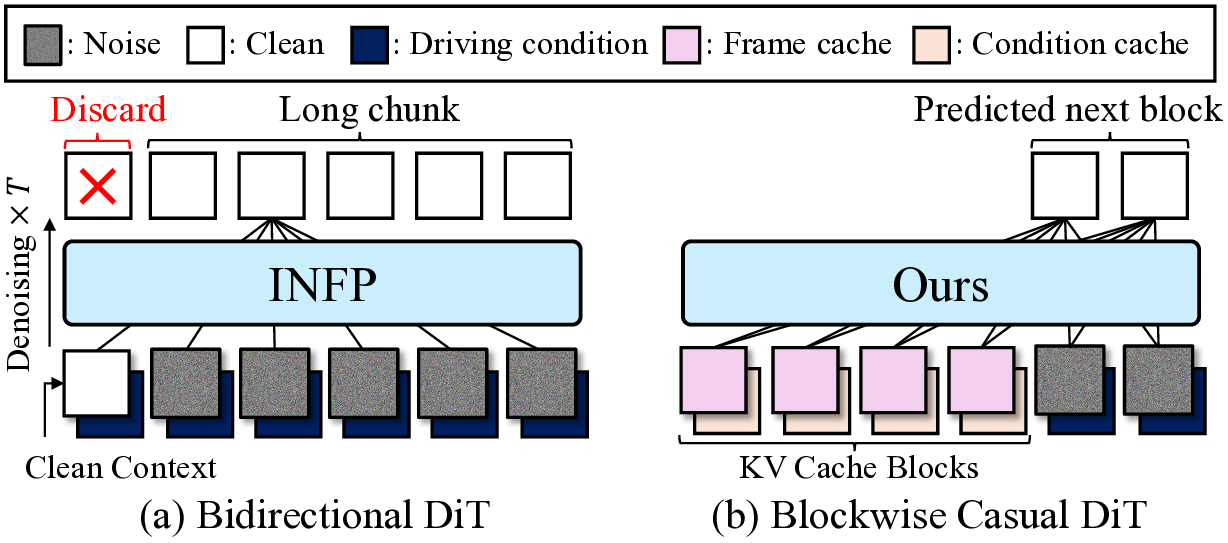
We identify two major challenges in generating truly interactive avatars. The first challenge is the real-time processing of users’ multimodal inputs. An interactive avatar system must continuously receive and respond to the user’s multimodal cues, such as speech, head motion, and facial expression, which requires both low inference time and minimal latency. Existing methods [69] achieve fast inference within a motion latent space [13] but have high latency because they need the full conversation context (e.g., over 3 seconds), including future frames. The model must wait for a sufficiently long audio segment before generating motion, causing a notable delay in user interaction, as illustrated in Fig. 4. This highlights the need for a causal motion generation framework that reacts immediately to live inputs.
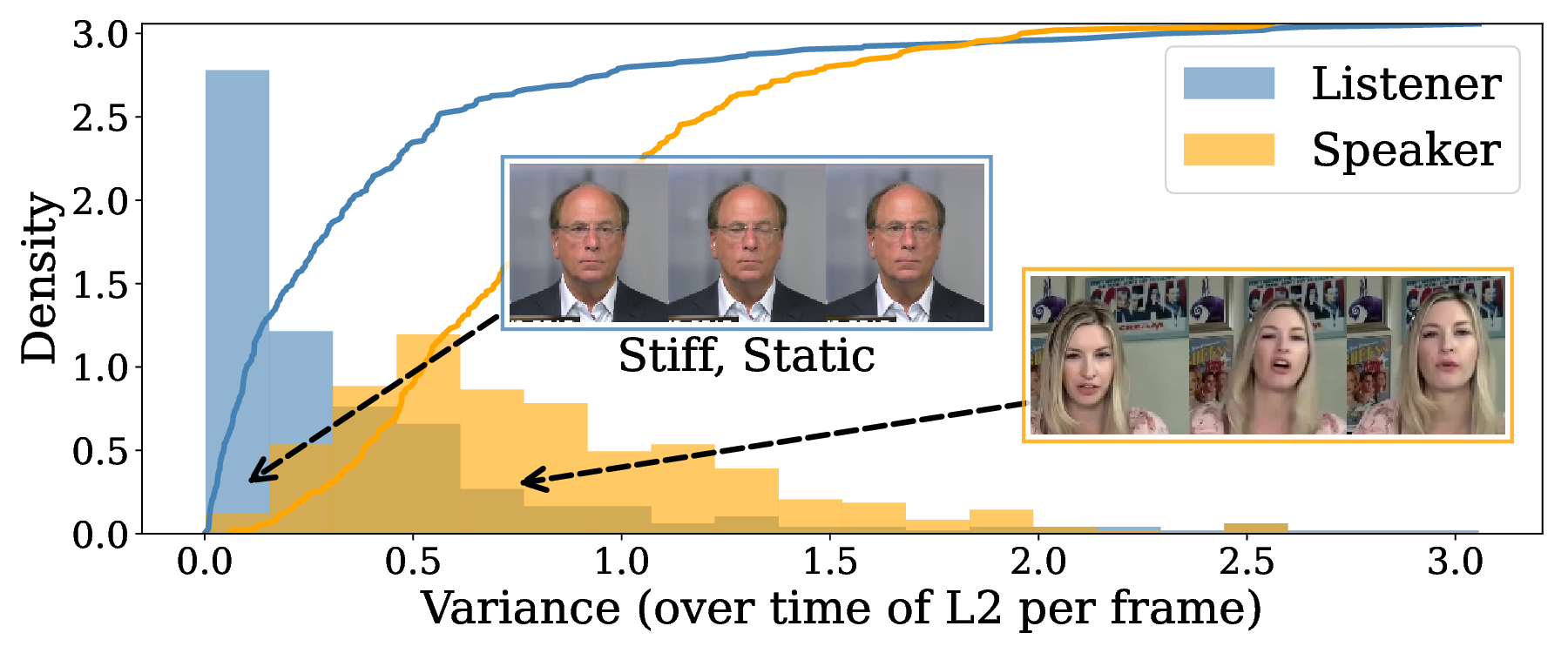
The second challenge is learning expressive and vibrant interactive motion. Expressiveness in human interactions is inherently difficult to define or annotate, and the lack of well-curated data makes the natural interactive behaviors hard to model. For listening behaviors in particular, we observe that most of the training data are less expressive and low-variant, often exhibiting stiff posture (See Fig. 5). Moreover, unlike lip synchronization, which is strongly tied with the avatar audio and therefore relatively easy to learn, reacting appropriately to user cues can correspond to a wide range of plausible motions. This ambiguity greatly increases learning difficulty, often resulting in less diverse, stiff motions, particularly in response to non-verbal cues.
To address these challenges, we present a new interactive head avatar generation framework, Avatar Forcing, which models the causal interaction between the user and the avatar in a learned motion latent space [27,58]. Inspired by recent diffusion-forcing-based interactive video generative models [2,24,64], we employ causal diffusion forcing [5,29,64] to generate interactive head motion latents while continuously processing multimodal user inputs in real-time. Unlike the previous approach [69] that requires the future conversation context (See Fig. 4), Avatar Forcing causally generates interactive avatar videos by efficiently reusing past information through key-value (KV) caching. This design enables real-time reactive avatar generation with minimal latency.
Moreover, following the learning-from-losing paradigm of preference optimization methods [40,45,57], we propose a preference optimization method to enhance the interactiveness of the avatar motion. By synthesizing underexpressive motion latents via dropping the user signals and using them as less-preferred samples, we achieve significantly improved expressiveness and reactiveness, without the need for additional human annotations for natural interaction. As a result, Avatar Forcing can produce more natural and engaging interactive videos as illustrated in Fig. 1.
Extensive experiments demonstrate that Avatar Forcing supports real-time interaction with a latency of roughly 500ms. Moreover, the proposed preference optimization significantly improves motion reactiveness and richness, producing more natural and engaging videos. In human evaluations, our method is preferred over 80% against the strongest baseline, demonstrating clear advantages in naturalness, responsiveness, and overall interaction quality.
Talking avatar generation aims to generate a lifelike talking avatar video from a given reference image and an audio. Earlier methods in this field had focused on synthesizing accurate lip movement from the driving audio [3,17,26,43,68]. These approaches are extended to generate holistic head movements, including a rhythmical head motion [27,53,61,68] and vivid facial expressions, such as eye blink and jaw movement [13,14,18,61,65]. SadTalker [65], for instance, leverages 3D morphable models (3DMM) [12] as an intermediate representation for the non-verbal facial expression. EMO [53] and its subsequent models [7,9,25] leverage the foundation image diffusion model (e.g., StableDiffusion [46]) for photorealistic portrait animation. Recent works [27,35,61] introduce generative modeling techniques, such as diffusion models or flow matching into a learned motion space [13,58], achieving real-time head motion generation.
Another line of works [23,34,37,39,48,67] focus on generating realistic listening head motions, such as nodding or focusing. Generating such responsive motions is challenging because the relationship between the speaker and listener is inherently one-to-many [39,59], and the cues are context-dependent and weakly supervised. Hence, most of the works generate the personalized listening motion [39,67] or leverage explicit control signals, such as text instruction [37] and pose prior [59].
Recently, several studies investigated dyadic motion generation [19,54,69], which involves modeling the interactive behavior of two participants engaged in a conversational setting. DIM [54] quantizes dyadic motions into two discrete latent spaces [56], one for the verbal and one for the non-verbal. However, it requires a manual roleswitching signal between the two spaces, resulting in discontinuous transitions between speaker and listener states. INFP [69] addresses this limitation by introducing audioconditioned verbal and non-verbal memory banks within a unified motion generator. However, this is ill-suited for real-time interactive generation as its bidirectional transformer [41] requires access to the entire context of the conversation. ARIG [19] generates implicit 3D keypoints [18] as its motion representation, primarily focusing on facial expressions. Yet it struggles with temporal consistency and fails to produce holistic head motions.
In this work, we focus on modeling the interactive behavior of both participants continuously influencing each other through verbal and non-verbal signals. We generate holistic interactive motions, for instance, talking, head movement, listening, and focusing, using a diffusion forcing framework that promptly responds to the multimodal user signals.
Diffusion Forcing Diffusion forcing [5] stands out as an efficient sequential generative model that predicts next token conditioned on the noisy past tokens. Let
denote a sequence of N tokens sampled from data distribution p 1 . Each token is corrupted with per-token independent noise levels
Here, we follow the noise scheduler of flow matching [33]. The training objective of diffusion forcing is to regress the vector field v θ toward the target vector field v n tn = x n 1 -x n 0 :
Diffusion forcing reformulates conventional teacher forcing in terms of diffusion models, allowing causal sequence generation with diffusion guidance [21] for controllable generation and flexible sampling procedure.
Direct Preference Optimization Direct Preference Optimization (DPO) [45] aligns a model with human preferences without explicitly training a reward model. The training objective L DP O is formulated as follows:
where c is the condition, x w and x l denote preferred and less preferred samples, respectively, and π ref is a frozen reference model during the optimization, typically initialized by the pre-trained weight of π θ . Here, σ(•) is the sigmoid function, and β is the deviation parameter. Dif-fusionDPO [57] extends DPO to diffusion models by reformulating the objective with diffusion likelihoods, enabling preference optimization using the evidence lower bound.
In this work, we present Avatar Forcing, which generates a video of a real-time interactive head avatar, conditioned on the avatar audio and the multimodal signals of the user. We provide an overview of our framework in Fig. 2. In Sec. 4.1, we present our framework for achieving realtime interactive head avatar generation based on causal diffusion forcing in the motion latent space. This consists of two key steps: encoding multimodal user and avatar signals, and causal inference of avatar motion. In Sec. 4.2, we introduce a preference optimization method for the interactive motion generation, which enhances expressive interaction without the need for additional human labels.
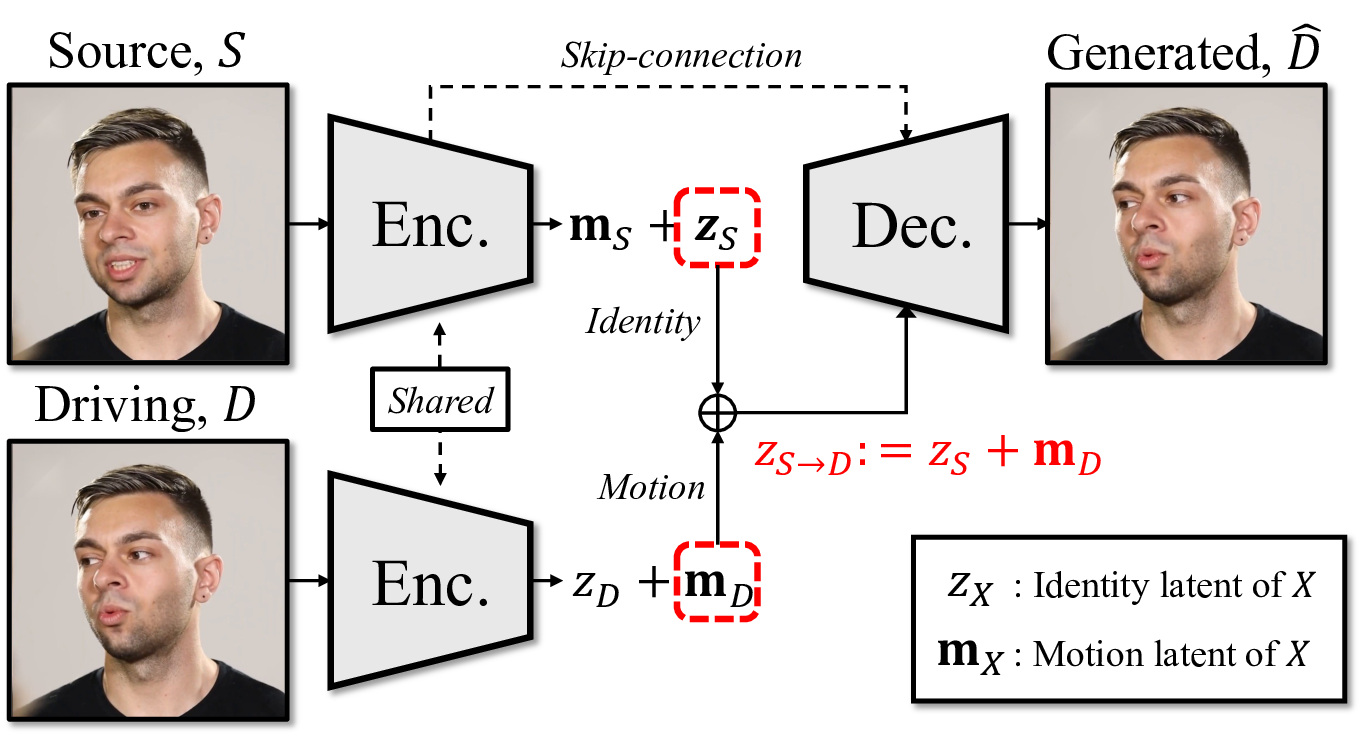
Motion Latent Encoding For motion encoding, we employ the motion latent auto-encoder from Ki et al. [27]. The latent auto-encoder maps an input image S ∈ R 3×H×W to a latent z ∈ R d whose identity and motion are decomposable:
where z S ∈ R d and m S ∈ R d are the identity and motion latents, respectively. The identity latent z S encodes identity representation of the avatar image S (e.g., appearance), while the motion latent m S encodes rich verbal and nonverbal features (e.g., facial expression, head motion). We use this latent representation to capture holistic head motion and fine-grained facial expression, which are crucial for realistic head avatar generation. We provide more details on the auto-encoder in Appendix B.
Interactive Motion Generation In Avatar Forcing, the motion latents are generated by conditioning on multimodal user signals and avatar audio. This can be formulated as an autoregressive model as follows:
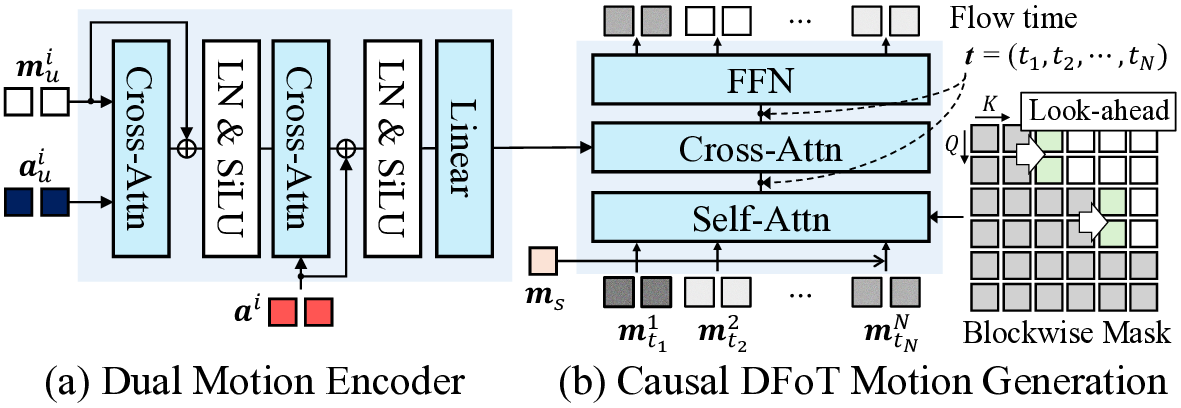
where each motion latent m i is predicted from past motion latents and the condition triplet c i = (a i u , m i u , a i ) consisting of user audio a i u , user motion m i u , and avatar audio a i . Based on this formulation, we introduce a diffusion forcing-based causal motion generator operating in the motion latent space, which is modeled using a vector field model v θ . As illustrated in Fig. 3, the model v θ comprises two main components: Dual Motion Encoder and Causal DFoT Motion Generation.
The goal of the Dual Motion Encoder is to capture the bidirectional relationship between multimodal user signals and avatar audio, and to encode them into a unified condition. As illustrated in Fig. 3(a), the encoder first takes the user signals (m i u and a i u ) and aligns them through a cross-attention layer, which captures the holistic user motion. This representation is then integrated with the avatar audio using another cross-attention layer, which learns the causal relation between the user and the avatar, producing a unified user-avatar-condition. In Sec. 5.5, we empirically validate the importance of using user motion m i u for generating an interactive avatar.
For the causal motion generator, we adopt the diffusion forcing transformer (DFoT) [49] with a blockwise causal structure [31,64]. The latent frames are divided into blocks to capture local bidirectional dependencies within each block while maintaining causal dependencies across different blocks. For each block, we assign a shared noise timestep to all frames and apply an attention mask that prevents the current block from attending to any future blocks.
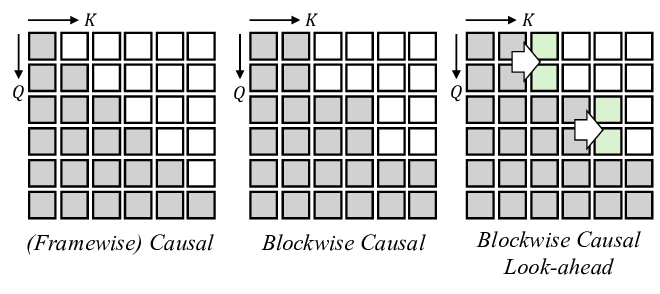
In Fig. 4, we compare our motion generator architecture with the standard bidirectional DiT architecture used in INFP [69]. Unlike INFP, which requires the full temporal context, our diffusion forcing allows stepwise motion generation under causal constraints and user-avatar interaction with low latency. However, we observe that the strict causal mask in the blockwise causal attention fails to ensure a smooth temporal transition across blocks. To address this issue, we introduce look-ahead in the causal mask, which allows each block to attend to a limited number of future frames while preserving overall causality. We define this blockwise look-ahead causal mask M as follows (illustrated in Fig. 3(b), right):
where i and j are the frame indices, B denotes the block size, and l is the look-ahead frame size. With look-ahead, we effectively mitigate severe per-frame motion jittering observed in the simple blockwise causal structure, which we provide video examples in the supplementary materials.
Based on the blockwise causal structure, the motion generator takes a noisy latent block as input, which is concatenated with the avatar motion latent m S serving as the reference motion. We use a cross-attention layer to condition on the unified condition from the Dual Motion Encoder. Additionally, we employ a sliding-window attention mask of size 2l along the time axis for temporal smooth conditioning. We provide the more details on v θ in Appendix B. Acquire User inputs (a i u , m i u ) and avatar audio a i .
6:
for j = 0 to T do 8:
Solve ODE:
end for 10:
KV.pop(0) and cKV.pop(0) KV.append(kvi) and cKV.append(ckvi) 16: end for Eq. ( 1) into a motion latent generation objective as follows:
where
tn ∈ R d is the noisy motion latent. For simplicity, we omit the reference motion condition m S in Eq. (6).
With the trained model, we can generate the interactive avatar motion given user inputs and avatar audio in an autoregressive rollout. We provide the pseudo code for motion sampling in Algorithm 1, which adopts rolling KV cache in a blockwise manner [24,64].
While our model enables real-time motion generation, we observe that it struggles to produce expressive motions crucial for natural human conversation. In contrast to achieving an accurate lip-sync that has an almost one-to-one match with the avatar audio, appropriate reaction to the user’s motion and audio is highly ambiguous, as there is no single correct response [37,39,59].
Moreover, as shown in Fig. 5, existing listening datasets generally exhibit lower motion expressiveness compared to speaking datasets, which leads models to learn passive and non-expressive listening behaviors. While prior work attempted to address it with personalized motion [39] or external text instructions [37], these methods do not address the core challenge of learning the true interactive behavior for natural interaction.
To generate vibrant and expressive reactions, we formulate this as an alignment problem and apply the Rein- forcement Learning from Human Feedback (RLHF) [40] approach. The main challenge lies in defining an explicit reward for the avatar’s interactive behavior, which must account for the interplay between avatar audio, user audio, user motion, and the generated video, which are difficult to evaluate even for humans.
We adapted a reward-free method, Direct Preference Optimization (DPO) [45,57], for fine-tuning our motion generation based on diffusion forcing. Specifically, we construct preference pairs of motion latents (m w , m l ) as follows:
• Preferred sample m w : the motion latent from the ground-truth video, exhibiting expressive and contextually appropriate responses. • Less preferred sample m l : the motion latent generated by a separately trained talking avatar model [27], conditioned solely on the avatar audio. This paired design yields a clear signal for enhancing expressiveness, emphasizing active listening and reactive motion while leaving other aspects, such as lip sync or speechdriven motion, unchanged.
Building on the original DPO objective L DPO (Eq. ( 2)) with our constructed pairs (m w , m l ), we fine-tune our diffusion forcing model v θ with the following objective:
where λ is a balancing coefficient. As a result, our model achieves efficient preference alignment without requiring a dedicated reward model, which we validate in Sec. 5.5. We provide the detailed formulation of L DPO in Appendix C.
We use dyadic conversation video datasets: RealTalk [16] and ViCo [67]. We first detect scene changes using PySceneDetect [44] to split the videos into individual clips. We then detect and track each face using Face-Alignment [4], crop and resize it to 512×512. Next, we separate and assign the speaker and listener audio using a visual-grounded speech separation model [30]. All videos are converted to 25 fps, and audio is resampled to 16 kHz. Additionally, we randomly select 50 videos from the talking-head dataset HDTF [66] to evaluate the performance of talking-head generation.
We use the Adam optimizer [28] with a learning rate of 10 -4 and a batch size of 8. We retrain the motion latent auto-encoder from Ki et al. [27] on our dataset. The latent dimension is set to d = 512. For our model v θ , we use 8 attention heads with a hidden dimension of h = 1024 and 1D RoPE [51]. It is trained with N = 50 frames over B = 5 blocks (i.e., 10 frames per block) and l = 2 look-ahead frames. For audio encoding, we extract 12 multi-scale features from Wav2Vec2.0 [1]. For motion sampling, we use 10 NFEs with the Euler solver and a classifier-free guidance [21] scale of 2. All the experiments are conducted on a single NVIDIA H100 GPU. We will release our code and models upon publication.
Metrics We evaluate our model across five aspects of interactive avatar generation: Latency, Reactiveness, Motion Richness, Visual Quality, and Lip Synchronization.
For Latency, we assume that the pre-extracted audio features and measure motion generation time using 10 NFEs.
For Reactiveness, we measure the motion synchronization between the user and the avatar by utilizing the residual Pearson correlation coefficients (rPCC) on facial expression (rPCC-exp) and head pose (rPCC-pose) [10]. For Motion Richness, we measure the Similarity Index for diversity (SID) [39] and variance (Var), following the previous studies [54,69]. For Visual Quality, we compute the Frechet inception distance (FID) [47] and the Frechet video distance (FVD) [55] for the generated videos. We also assess the identity preservation using the cosine similarity of identity embeddings (CSIM) [11] between the reference avatar image and the generated videos. In Lip Synchronization, we compute the lip sync error distance and confidence (LSE-C and LSE-D) using the generated video and the avatar’s audio. Please refer to Appendix D for details on the metrics.
We compare our model with the reproduced state-of-the-art dyadic talking avatar model, INFP* [69], since its official implementation is not publicly available. For reference, we also include a talking avatar generation model [27] which does not use user motion or audio. In Tab. 1, we provide a quantitative comparison on the RealTalk [16]
We conduct a human preference study comparing our model with the interactive head avatar generation model INFP*. We recruited 22 participants to evaluate 8 video sets using five perceptual metrics: Reactiveness measures how well the avatar reacts to user motion and audio, Motion Richness evaluates expressiveness of the avatar motion, Verbal Alignment evaluates the lip synchronization with the audio, Non-verbal Alignment assesses the non-verbal behaviors such as eye contact or nodding, and Overall Preference. We provide further details of the human study in the supplementary materials.
As shown in Tab. 2, our model is strongly preferred across all metrics, achieving over 80% preference in overall quality. In particular, our generated avatars exhibit expressive motion and strong non-verbal alignment, showing the effectiveness of the preference optimization (Sec. 4.2).
Comparison with Talking Head Avatar We evaluate the talking capability of the avatar. We compare Avatar Forcing with four state-of-the-art talking head avatar generation models: SadTalker [65], Hallo3 [9], FLOAT [27], and INFP * . We measure the visual quality with FID, FVD, and CSIM metrics, and assess lip synchronization using LSE-D and LSE-C used in Tab. 1. We provide the quantitative results on the HDTF dataset [66] in Tab. 3. Avatar Forcing shows competitive performance on all metrics and achieves the best image and video quality. We provide visual examples in Appendix D. Comparison with Listening Head Avatar We further evaluate the listening capability of our model. We compare Avatar Forcing with the listening head avatar generation models, including RLHG [67], L2L [39], DIM [54], and INFP*, using the ViCo [67]. We measure Frechet distance (FD) for the expression and pose, and rPCC, SID, and Var metrics used in Tab. 1 but with respect to expression and head pose, respectively. Since the baseline models are not publicly available, we take the results from DIM [54].
In Tab. 4, our model outperforms the baselines on almost all of the metrics. In particular, Avatar Forcing achieves the best user-avatar synchronized motion generation (rPCC).
In this section, we conduct ablation studies on (i) the necessity of using user motion in the Dual Motion Encoder and (ii) the importance of preference optimization. We provide further ablation studies, including the blockwise look-ahead attention mask, in Appendix D.
User Motion To validate the necessity of using user motion for interactive avatar generation, we compare our model with a variant that does not take user motion as input. As shown in Tab. 5, removing user motion leads to significantly less reactive behavior (Reactiveness) and reduced expressiveness in motion (Motion Richness). Furthermore, as visualized in Fig. 7, the model without user motion produces static behavior whenever the user’s audio is silent. This occurs even in the presence of strong non-verbal cues, such as smiling, as the model cannot perceive visual signals. In contrast, our model, which uses user motion, generates a reactive avatar that naturally smiles right after the user smiles (Fig. 7 red arrow) and becomes more focused when the user speaks (Fig. 7
Direct Preference Optimization To assess the impact of the preference optimization, we compare our model against a variant without fine-tuning. As shown in Tab. 5, preference optimization significantly improves the Reactiveness metrics (rPCC-Exp and rPCC-Pose), which quantify useravatar motion synchronization. It also substantially boosts the Motion Richness metrics (SID and Var), indicating more expressive and varied motion.
As visualized in Fig. 8, the model without preference optimization generates noticeably reduced diversity in facial expressions and head movement. It also exhibits weaker interaction, failing to respond to the user’s smile.
In contrast, our fine-tuned model generates an expressive avatar that shows natural head movement (Fig. 8 red box) and smiles more broadly along with the user (Fig. 8 red arrow). We provide further analysis of our DPO method in Appendix D.
We proposed Avatar Forcing, a real-time interactive head avatar model based on diffusion forcing, that generates reactive and expressive motion using both the verbal and nonverbal user signals. Avatar Forcing takes a step toward truly interactive virtual avatars and opens new possibilities for real-time human-AI communication. We also plan to release our code and pre-trained model weights to advance community development and accelerate future research. Discussion We leave further discussion, including ethical considerations, limitations, and future work, in the Appendix E. trices for the query q, key k, and value v ∈ R N ×d , respectively (N is the number of latents). In the first crossattention layer, the encoder captures holistic verbal and nonverbal user motion by using the user motion latent m u as the query. In the second layer, it integrates this aligned user motion with the avatar’s audio by taking the avatar audio as the query. We use four attention heads, each with a hidden dimension of d = 512, for both cross-attention layers.
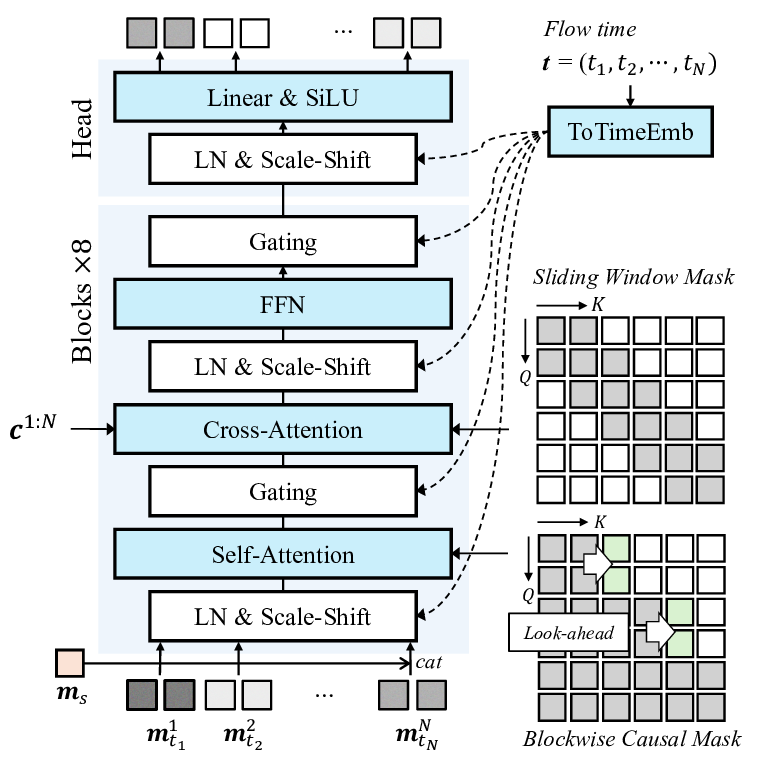
In Fig. 10, we provide a detailed architecture for the motion generator. It consists of eight DFoT transformer blocks followed by a transformer head. Specifically, in each DFoT block, noisy latents
AdaLN scale-shift coefficients (ToTimeEmb layer) [6].
For the attention modules, we use Blockwise Causal Look-ahead Mask (Eq. ( 5)) in self-attention and a Slidingwindow Attention Mask for aligning the driving signal c 1:N to the noisy latents. Specifically, we introduce the Blockwise Casual Look-ahead Mask to ensure the causal motion generation in our motion latent space, which significantly improves the temporal consistency of the generated video, as demonstrated in Sec. D.5. Unlike the recent video diffusion models that employ a spatio-temporal compression module [24,64] where each latent correlates to multiple video frames by the compression rate (e.g., 4× or 8×), our motion latent has one-to-one correspondence with each frame in pixel space. Under this setting, a simple (blockwise) causal mask alone produces the temporal inconsistencies across the frames or blocks.
Training Objective Formulation Inspired by Diffu-sionDPO [57], we formulate the training objective L DP O in the context of diffusion forcing [5]. Let (m l , m w ) denote a pair of less-preferred and preferred motion latents, each consisting of N frames, where m l := (m l,n ) N n=1 and m w := (m w,n ) N n=1 . Following the per-token independent noising process of diffusion forcing, we construct the noisy latent pairs as:
where n ∈ [1, N ] is the frame index, t n ∈ [0, 1] is the nth flow time, and m 0 := (m n 0 ) N n=1 ∈ R N ×d is the noise sequence. With these notations, we formulate L DP O as
where c n is the n-th unified condition, v ref is the reference vector field model, the target vector fields for less-preferred and preferred samples are given by v l,n tn := m l,nm n 0 and v w,n tn := m w,nm n 0 . (13)
We train the vector field model v θ in Eq. ( 6) for 2000k steps while freezing the motion latent auto-encoder. Through the training, we use L1 distance for ∥ • ∥.
For fine-tuning the model using the proposed preference optimization method in Eq. ( 7), we set the balancing coefficient to λ = 0.1 and the deviation parameter to β = 1000. We initialize the reference model v ref with the same weights as the trained v θ . We fine-tune v θ for 5k steps and observe that additional tuning does not yield further performance gains.
One major challenge of evaluating an interactive head avatar model is the absence of official implementation of baseline methods. To bridge this gap, we reproduce INFP [69] on the motion latent space of [27], following its core module, Motion Guider and denote the reproduced model as INFP*. Based on the description in the original paper, we adopt a bidirectional Transformer encoder for motion generation, where a single window consists of N = 75 frames and additional 10 frames serve as context frames. For Motion Guider, we set K = 64 for both verbal and non-verbal motion memory banks. We train INFP* on our dataset for 2000k steps.
In this section, we provide more details on the evaluation metrics used in the main paper.
Reactiveness and Motion Richness Reactiveness and Motion Richness are computed using the EMOCAbased [10] 3D morphable models (3DMMs) that model the facial dynamics via 50-dim expression parameters and 6dim pose parameters. We extract those parameters using an off-the-shelf 3DMM extractor, SPECTRE [15], for each video frame. Let us denote x ∈ R N ×d as the ground-truth user parameters, y ∈ R N ×d as the ground-truth avatar parameters, and ŷ ∈ R N ×d as the generated avatar parameters. L is the number of frames and d is the feature dimension. As reported in Tab. 1 and Tab. 4, we can compute rPCC, SID, Var, and FD for expression and pose, respectively.
• rPCC (residual Pearson Correlation Coefficients) [54] is to measure the motion synchronization between the
where i ∈ [0, N ] is the frame index, and z and x denote the mean of z and y, respectively. Based on this notation, we can define rPCC as |PCC(y|x) -PCC(ŷ|x)|. • SID (Shannon Index for Diversity) [39] is to measure the motion diversity of the generated avatars using K-means clustering on 3DMM parameters. Following [39], we compute the average entropy (Shannon index) of the clusters with K = 15, 9 for expression and pose, respectively. • Var is the variance of the parameters from generated avatars, which is computed along the time axis and then averaged along the feature axis. • FD (Frechet Distance) [47] measures the distance between the expression and pose distributions of the generated avatars and the ground truth by calculating
where µ and Σ are the mean and the covariance matrix, respectively.
Visual Quality We utilize FID [47] and FVD [55] to assess the image and video quality of the generated avatars, and CSIM [11] to measure the identity preservation performance of avatar generation models.
• FID (Frechet Inception Distance) measures the quality of the generated frames by comparing the distribution of image features extracted from a pre-trained feature extractor [47]. The FD computation in Eq. ( 15) is adopted using the extracted image features. • FVD (Frechet Video Distance) quantifies the spatiotemporal quality of the generated videos by comparing the feature distributions of real and generated videos in a learned video feature space [55]. It reflects both framewise quality and temporal consistency. The FD compu-tation in Eq. ( 15) is adopted using the extracted video features. • CSIM (Cosine Similarity for Identity Embedding) evaluates identity preservation by computing cosine similarity between the facial embeddings from the generated and the source image, extracted using ArcFace [11].
Lip Synchronization We compute LSE-D and LSE-C [8] to assess the alignment between the generated lip motion and the corresponding audio.
In Fig. 12, we show the interface used for our human evaluation. To improve the evaluation consistency, we additionally provided participants with a reference test and answer sheet. We asked 22 participants to compare 8 videos based on 5 evaluation metrics and indicate their preference. We also provide a video test sheet. Please refer to “04_hu-man_evaluation_XX.mp4”.
In Tab. 6, we present the ablation studies on our model with additional metrics, including Visual Qual-ity and Lip Synchronization.
We provide a video results of the ablation study.
Please refer to the videos “02_ablation_wo_user_motion.mp4” and “02_ab-lation_wo_DPO.mp4”.
Moreover, we provide video ablation results on the attention mask, where each masking method is illustrated in Fig. 11. The motion jittering observed when using only the blockwise causal mask is clearly visible in the video results, yet difficult to capture with quantitative metrics. We highly recommend watching the ablation video “02_ablation_attention_mask_XX.mp4”.
Comparison with Interactive Head Avatar We provide the video results to further support the visual results in Fig. 6.
Please refer to “01_inter-active_avatar_comparison_XX.mp4”. We also provide a video comparison results using the DEMO videos of Official INFP [69]. Please refer to “01_interac-tive_avatar_comparison_demo.mp4”
Comparison with Talking Head Avatar In Fig. 13, we compare our model with SadTalker [65], Hallo3 [9], FLOAT [27], and INFP* [69] for talking head avatar generation bu dropping the user condition at inference. Avatar Forcing can generate competitive results compared to stateof-the-art models, while our model successfully reflects user signals. We also provide the video comparison results. Please refer to “03_talking_XX.mp4”.
Comparison with Listening Head Avatar In Fig. 14, we compare our model with RLHG [67], L2L [39], DIM [54], and INFP* [69] for listening head avatar generation. Avatar Forcing can generate competitive results with more expressive facial expression. Please refer to “03_listen-ing_XX.mp4” for video results.
Ethical Consideration Our method can generate more engaging and interactive head-avatar videos, broadening positive applications such as virtual avatar chat, virtual education, and other communication tools by providing users with a more immersive experience. However, realistic interactive head avatar videos also pose risks of misuse, including identity spoofing or malicious deepfakes. Adding watermarks to generated videos and applying a restricted license can help mitigate these risks. We also encourage the community to use our generated data to train deepfake detection models.
Limitation and Future Work Our system focuses on modeling interactive conversations through a head-motion latent space, which enables natural and expressive interactions. However, this design limits the modeling of richer bodily cues, such as hand gestures, that contribute to more dynamic communication.
Moreover, while our model captures user-driven conversational cues via the motion latents, certain scenarios may require more explicit controllability, such as directing eye gaze or emphasizing emotional shifts. We believe that incorporating additional user signals, including eyetracking or emotion-tracking inputs, can address these limitations. Since our framework has no architecture constraints on adding new conditions, such signals can be incorporated into future extensions of our system.
u DPO rPCC-Exp ↓ rPCC-Pose ↓ SID ↑
This content is AI-processed based on open access ArXiv data.