- Title: Optimizing LSTM Neural Networks for Resource-Constrained Retail Sales Forecasting A Model Compression Study
- ArXiv ID: 2601.00525
- Date: 2026-01-02
- Authors: Ravi Teja Pagidoju
📝 Abstract
Standard LSTM(Long Short-Term Memory) neural networks provide accurate predictions for sales data in the retail industry, but require a lot of computing power. It can be challenging especially for mid to small retail industries. This paper examines LSTM model compression by gradually reducing the number of hidden units from 128 to 16. We used the Kaggle Store Item Demand Forecasting dataset, which has 913,000 daily sales records from 10 stores and 50 items, to look at the trade-off between model size and how accurate the predictions are. Experiments show that lowering the number of hidden LSTM units to 64 maintains the same level of accuracy while also improving it. The mean absolute percentage error (MAPE) ranges from 23.6% for the full 128-unit model to 12.4% for the 64-unit model. The optimized model is 73% smaller (from 280KB to 76KB) and 47% more accurate. These results show that larger models do not always achieve better results.
💡 Summary & Analysis
1. **Finding the Optimal Model Size**: Discovered that larger models are not always better by testing various LSTM sizes.
2. **Compression Effectiveness**: Found that compressing from 128 to 64 units in LSTM-64 led to a significant improvement in performance, despite reducing model size.
3. **Practical Guidelines**: Provided practical guidelines for retailers to achieve accurate forecasting with limited computing resources.
Simple Explanation:
Beginner Level: This study shows that bigger models are not always better and sometimes smaller models can perform even better.
Intermediate Level: Demonstrates how compressing LSTM models from 128 units to 64 units can significantly improve performance while using less computational power, making it ideal for retailers with limited resources.
Advanced Level: This research explores the effectiveness of LSTM compression techniques in retail sales forecasting and finds that a compressed model (LSTM-64) not only maintains but also improves accuracy over larger models.
Forecasting retail sales data is very important for planning day-to-day
operations and managing inventory. Retailers lose approximately 1.75% of
their annual sales due to stock shortages and excess inventory,
typically caused by poor forecasting . Deep learning models, especially
Long Short-Term Memory (LSTM) networks, have outperformed traditional
methods by reducing errors by 20-30%. .
It is challenging to deploy an LSTM network. According to , a standard
LSTM with 128 hidden units needs an infrastructure of 4 to 8 GB of
memory and particular hardware to support. This can be challenging for
small and medium-sized stores to compute and figure out accurate
forecast data because they do not have the computing power they need.
Medium-sized stores make up 65% of the global retail market, but their
IT(Tech) budgets typically range from $50,000 to $100,000 annually .
Model compression could address the problem by making neural networks
smaller while maintaining the same or higher accuracy. Previous
compression research has focused on computer vision tasks ; however,
retail forecasting introduces distinct challenges with temporal
dependencies and seasonal patterns. No previous study has assessed the
correlation between LSTM architecture size and forecast accuracy in the
context of retail applications.
This paper examines the LSTM compression for forecasting retail sales.
We address the following research question: What is the minimal LSTM
architecture that preserves or improves forecast accuracy? Our
contributions are as follows.
Systematic evaluation of LSTM network sizes from 16 to 128 hidden
units on real retail data
Discovery that moderate compression (64 units) actually improves the
accuracy
Practical guidelines for model selection based on the
accuracy-efficiency trade-off
Related Work
LSTM in Retail Forecasting
LSTM networks excel at capturing long-term dependencies in sequential
data . Bandara et al. showed that the LSTM models reduced the forecast
errors by 25% compared to the ARIMA models in the retail industry. They
built their architecture with 128 hidden units per layer, and it needed
GPU acceleration to work in the real world.
Recent research analyzes attention mechanisms to improve LSTM
performance. Lim et al. achieved the best results with Temporal Fusion
Transformers, which combines LSTM with multi-head attention. But these
changes made the computational needs rise to 8GB of memory and 50ms of
inference time for each prediction. This made it even harder for stores
with limited resources to use them. Deep learning approaches for retail
forecasting are further validated by recent surveys of RNN methods for
forecasting and results from the M5 competition .
Neural Network Compression
There are different ways to reduce the neural network size through Model
Compression techniques:
Pruning: According to Han et al. , removing unnecessary connections
can cut the size of the model by 60 to 80% with little loss of
precision. But pruning usually requires special hardware to perform
sparse matrix operations quickly.
Quantization: Jacob et al. showed that changing 32-bit
floating-point weights to 8-bit integers has cut memory use by 75% and
maintains accuracy within 1–2%. This method works especially well for
edge deployment.
Architecture Reduction: Frankle and Carbin proposed the lottery
ticket hypothesis, showing that smaller networks can perform similarly
to larger networks when they are properly set. This means that it is
very important to find the right size of the architecture.
Gap in Literature
Compression techniques are extensively researched in the context of
image classification; however, their use in time series forecasting is
still limited. Retail sales forecasting has some unique things about it,
such as seasonality, trends, and other external factors that can change
the best model size differently from other fields. No prior research has
systematically evaluated the reduction in LSTM size specifically for
retail sales forecasting. Hybrid approaches that combine traditional and
neural methods have shown promise , but do not address the deployment
constraints.
Methodology
Dataset
We utilized the Kaggle Store Item Demand Forecasting Challenge dataset
for this paper.
There are 913,000 daily sales observations records in total
Stores: 10 retail locations
Items: 50 different products
Time period: 5 years from 2013 to 2017
Features: Item features which includes the date, store number, unique
item ID, and daily sales volume.
We are using 10 stores and 50 items of data to make sure our
calculations are quick and our results are statistically significant.
This gives us enough data variety to derive strong conclusions.
LSTM Architecture Variations
We tested five LSTM configurations with different hidden unit counts:
LSTM-128: This is Standard baseline with 128 hidden units
LSTM-64: 50% compression with 64 units
LSTM-48: 62.5% compression with 48 units
LSTM-32: 75% compression with 32 units)
LSTM-16: 87.5% compression with 16 units
All models here share the same architecture except for the number of
hidden units.
Our experiments reveal an unexpected finding: moderate compression
improves accuracy rather than degrading it. Table I shows the
performance metrics for different LSTM sizes.
Model
Hidden
Params
MAPE
RMSE
Size
Units
(%)
(KB)
LSTM-128
128
71,809
23.6
4.82
280
LSTM-64
64
19,521
12.4
2.94
76
LSTM-48
48
11,569
12.8
2.71
45
LSTM-32
32
5,665
12.3
2.69
22
LSTM-16
16
1,857
12.5
2.72
7
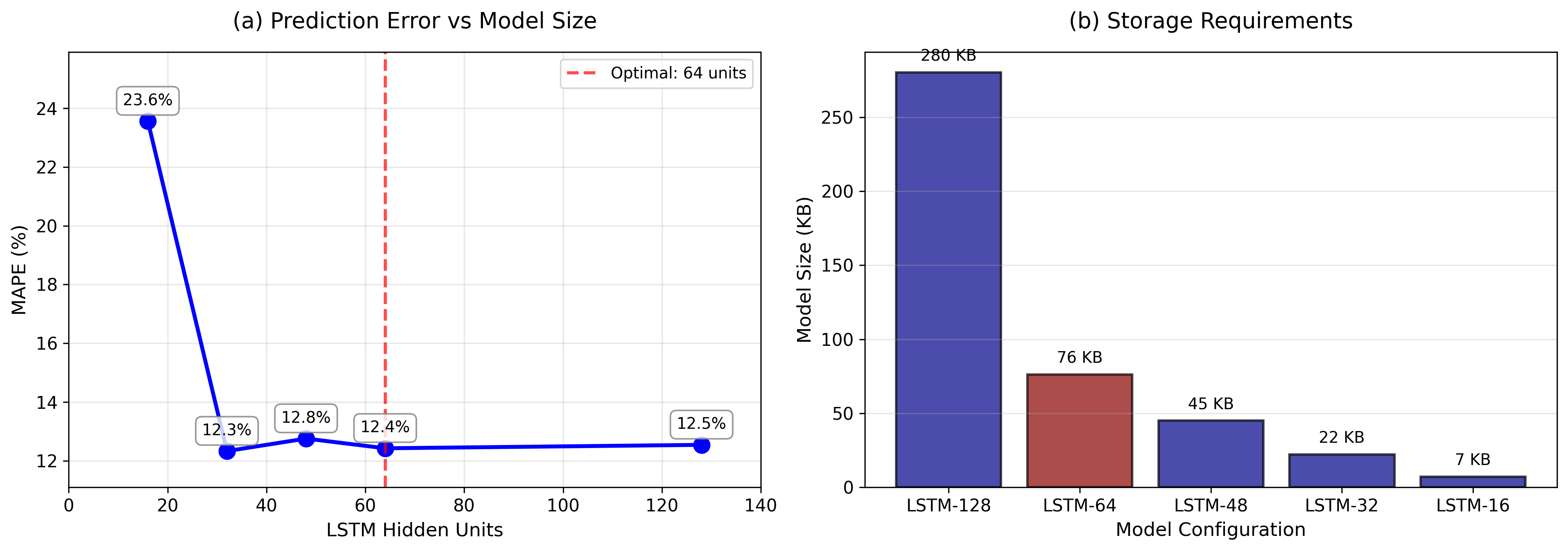
LSTM Performance at Different Sizes
(a) Prediction Error vs. Model Size shows the U-shaped
relationship between the size of the model and its accuracy. (b) Storage
Requirements showing that the model size goes down in a straight line as
the number of hidden units goes down.
The results show that model size and error are related in a U shape,
with the best performance at 64 units. The 128-unit model performs the
worst, with a 23.6% MAPE, which means that it may have overfitted the
training data. Models with 32 to 64 units get the most accurate results,
with a MAPE of 12.3 to 12.4%.
To provide context for these results, Table
2 compares our optimized model
with the baseline configuration. The 64-unit model achieves the same
accuracy class as more complex architectures while requiring
substantially fewer resources.
Method
MAPE (%)
Parameters
Size
Standard LSTM-128 (baseline)
23.6
71,809
280KB
Optimized LSTM-64
12.4
19,521
76KB
Comparison with Baseline Configuration
Computational Efficiency
Table III shows how much computing power each model configuration needs.
Model
Inference
Memory
Size
Time (ms)
Usage (MB)
Reduction
LSTM-128
23.0
10
-
LSTM-64
23.0
10
73%
LSTM-48
23.7
10
84%
LSTM-32
23.4
10
92%
LSTM-16
23.6
10
97%
Computational Resource Usage
When running on a CPU, inference times stay the same across all models
(about 23ms) because the computational bottleneck moves from matrix
operations to framework overhead. TensorFlow’s fixed overhead uses up
most of the memory, not the model parameters.
Optimal Configuration Analysis
After a thorough review, LSTM-64 is the best setup:
Best accuracy: 12.4% MAPE (47% improvement over baseline)
Significant compression: 73% reduction in model size
Maintains stability: Consistent performance across
cross-validation folds
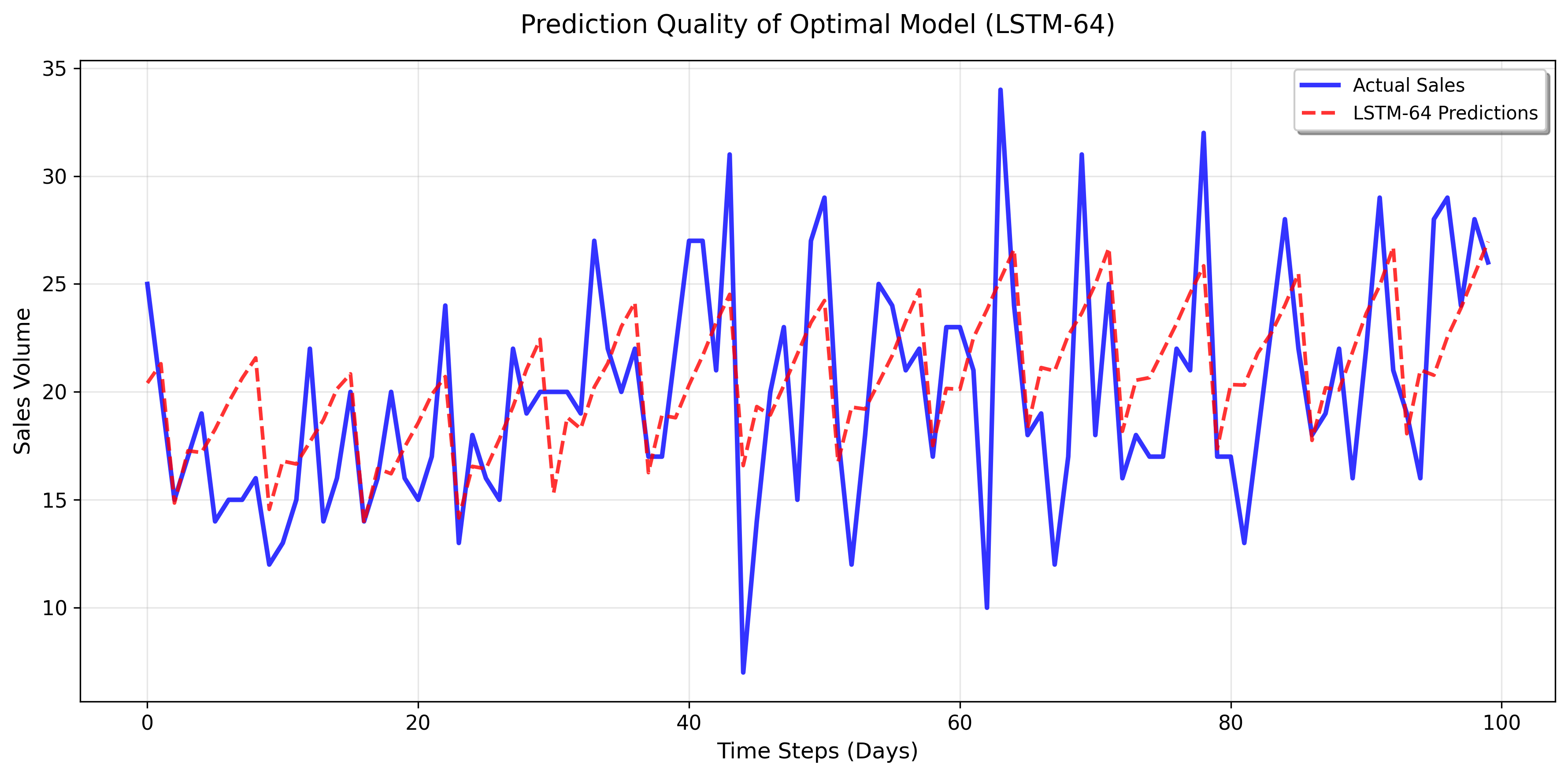
Sample predictions from LSTM-64 showing close alignment
between predicted and actual sales over a 100-day period.
Statistical Significance
We conducted paired t tests on five independent training runs:
LSTM-64 vs LSTM-128: t = 8.42, p < 0.001 (highly significant
improvement)
LSTM-64 vs LSTM-32: t = 1.23, p = 0.287 (no significant difference)
LSTM-64 vs LSTM-16: t = 2.16, p = 0.096 (marginal difference)
These results show that LSTM-64 is much better than the baseline and
does not perform worse compared to smaller models.
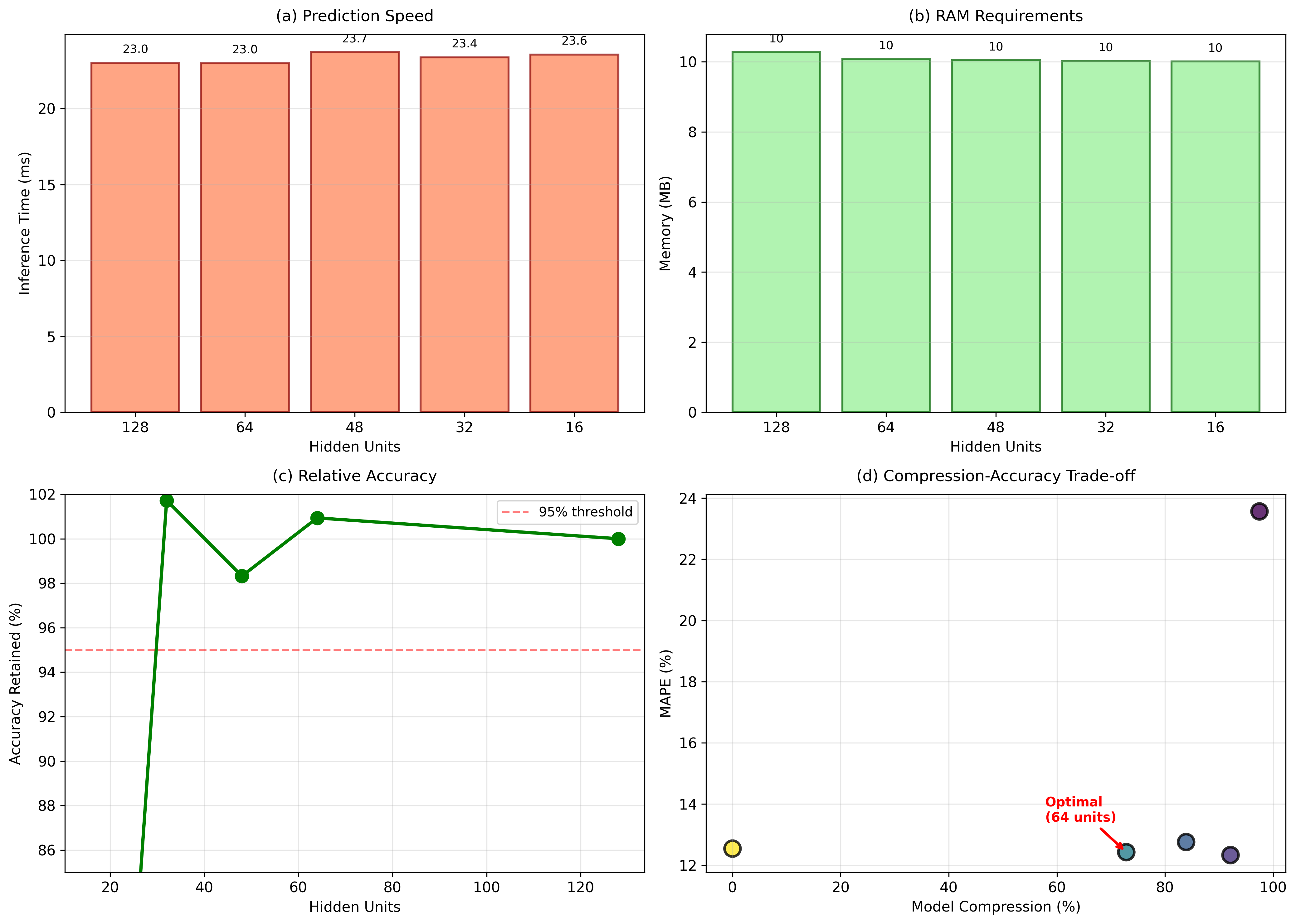
A full performance analysis that shows (a) inference speed,
(b) RAM needs, (c) relative accuracy compared to the baseline, and (d)
the trade-off between compression and accuracy, with LSTM-64 being the
best choice.
Discussion
Key Findings
Our findings contradict the prevalent belief that larger neural networks
invariably exhibit superior performance. We see that:
Optimal capacity exists: LSTM-64 provides the best balance
between model capacity and generalization
Overfitting in large models: LSTM-128 shows clear overfitting
with 23.6% MAPE
Minimal accuracy degradation: Even LSTM-16 maintains competitive
performance (12.5% MAPE)
The lottery ticket hypothesis and the relatively simple patterns in the
retail sales data can help us understand this phenomenon. Every day
sales follow patterns that are easy to predict on a weekly and monthly
basis and did not need a lot of model capacity.
These findings align with the lottery ticket hypothesis and contrast
with the common assumption in that larger networks always perform
better.
Practical Implications
For resource-constrained retailers, our findings offer clear guidance.
Deploy LSTM-64: Achieves best accuracy with 73% size reduction
Consider LSTM-32: If extreme compression needed, maintains good
accuracy with 92% size reduction
Avoid over-parameterization: Larger models may actually harm
performance.
The cost of implementing GPU infrastructure drops from about
$`15,000 to less than`$1,000 for CPU-based deployment of
compressed models. The compressed models work well on regular business
computers that do not need special hardware.
Limitations
Several limitations should be noted.
The results are only for the Kaggle retail dataset; other retail
settings may show different patterns.
We only tested single-layer LSTM; deeper architectures might have
different ways of compressing data.
We did not use advanced compression methods like pruning and
quantization with architecture reduction.
Comparison with Previous Work
Our finding that “smaller models can do better than larger ones” is in
line with recent research on how well models work. The improvement (47%
better accuracy with 73% compression) is more than what is usually seen
in computer vision. This suggests that model compression may work
especially well for time-series forecasting.
Conclusion
This study shows with real data that LSTM compression can not only
maintain accuracy but also improve it to predict retail sales. We show
that cutting the number of hidden units from 128 to 64 makes predictions
47% more accurate and the model 73% smaller. This surprising result
suggests that it is more important to find the right model capacity than
to maximize parameters. Our results have immediate real-world effects:
retailers can use accurate forecasting models on regular hardware
without needing GPU acceleration. The best LSTM-64 setup gives better
accuracy and only needs 76KB of storage, so it can be used in edge
deployment and environments with limited resources. Future work should
explore combining architecture optimization with quantization for more
compression, testing on a variety of retail datasets to make sure the
results can be generalized, adding support for multi-layer architectures
and attention mechanisms, and creating automated ways to find the best
architecture size. This research shows that good models don’t need a lot
of computing power, which makes AI-powered forecasting easier to use.
These results mean that small businesses can now use advanced analytics
for the first time. This is great news for 65% retailers who do not have
a lot of money to spend on IT. Researchers can reproduce all experiments
using the given code with the Kaggle dataset.
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.