- Title: A Comprehensive Dataset for Human vs. AI Generated Image Detection
- ArXiv ID: 2601.00553
- Date: 2026-01-02
- Authors: Rajarshi Roy, Nasrin Imanpour, Ashhar Aziz, Shashwat Bajpai, Gurpreet Singh, Shwetangshu Biswas, Kapil Wanaskar, Parth Patwa, Subhankar Ghosh, Shreyas Dixit, Nilesh Ranjan Pal, Vipula Rawte, Ritvik Garimella, Gaytri Jena, Vasu Sharma, Vinija Jain, Aman Chadha, Aishwarya Naresh Reganti, Amitava Das
📝 Abstract
Multimodal generative AI systems like Stable Diffusion, DALL-E, and MidJourney have fundamentally changed how synthetic images are created. These tools drive innovation but also enable the spread of misleading content, false information, and manipulated media. As generated images become harder to distinguish from photographs, detecting them has become an urgent priority. To combat this challenge, We release MS COCOAI, a novel dataset for AI generated image detection consisting of 96000 real and synthetic datapoints, built using the MS COCO dataset. To generate synthetic images, we use five generators: Stable Diffusion 3, Stable Diffusion 2.1, SDXL, DALL-E 3, and MidJourney v6. Based on the dataset, we propose two tasks: (1) classifying images as real or generated, and (2) identifying which model produced a given synthetic image. The dataset is available at https://huggingface.co/datasets/Rajarshi-Roy-research/Defactify_Image_Dataset.
💡 Summary & Analysis
1. **Dataset Development**: "This paper focuses on developing a dataset for AI-generated image detection, collecting large-scale real images with captions and their synthetic counterparts generated from the same captions. This is akin to ensuring all participants in a fair test receive identical questions."
2. **Theoretical Contribution**: "The dataset proposes two tasks: distinguishing between real and synthetic images and identifying which model created the synthetic ones. It’s like not only detecting fake products but also figuring out which manufacturer produced them."
3. **Technical Contribution**: "A basic classification approach using ResNet-50 is employed to detect synthetic images, working much like a microscope that distinguishes objects based on their light wavelengths."
📄 Full Paper Content (ArXiv Source)
\[email=royrajarshi0123@gmail.com\]
AI-Generated Images ,Detection Techniques ,Synthetic Media ,Generative
AI ,Multimodal AI
style=“width:85.0%” />
Introduction
Generative AI technologies such as Stable Diffusion , DALL-E , and
MidJourney have transformed the production of synthetic visual content.
These tools, powered by advanced neural architectures, enable diverse
applications in fields ranging from advertising and entertainment to
design, with prompt quality playing a crucial role in generation
outcomes . However, the same innovations that facilitate creative
expression also present significant risks when misused. For example, the
propagation of misleading or harmful content can disrupt public
discourse and undermine trust .
Recent high-profile incidents have demonstrated the societal impact of
AI-generated images, from fabricated depictions that trigger public
panic to politically charged visuals intended to sway opinion . The
rapid advancement of image generation models has further blurred the
line between synthetic and authentic imagery, challenging traditional
detection methods and complicating efforts to combat misinformation.
In light of these challenges, there is an urgent need for robust
datasets that support the development and evaluation of effective
detection techniques. In this paper, we introduce a dataset specifically
curated for the detection and analysis of AI-generated images. Our
dataset aggregates a diverse collection of images produced by multiple
generative models alongside authentic real-world images, and it is
enriched with detailed annotations—including the source model, creation
timestamp, and relevant contextual metadata. Figure
[fig:teaser] provides a sample of our
dataset.
By providing a large-scale, representative benchmark, our dataset aims
to advance research in synthetic media detection and foster the
development of scalable countermeasures against AI-enabled
disinformation. Building upon the foundations laid by initiatives such
as the Defactify workshop series , this work bridges the gap between
academic inquiry and practical implementation, offering a valuable
resource for researchers, policymakers, and industry stakeholders
committed to safeguarding the integrity of digital information
ecosystems. This work complements parallel efforts addressing
AI-generated text detection .
Related Work
The rapid growth of generative models has led to highly realistic
AI-generated images, making it harder to tell them apart from real
images. This section reviews existing datasets and detection methods.
AI-Generated Image Datasets
Several datasets have been introduced for AI-generated image detection:
WildFake: collected fake images from various open-source
platforms, covering diverse categories from GANs and diffusion models.
However, the uncontrolled collection leads to mixed image quality and
no alignment between real and synthetic samples, making it hard to
separate generator artifacts from content differences.
GenImage: built a million-scale benchmark with AI-generated and
real image pairs. While large in scale, the dataset mainly features
older generators and lacks fine-grained model labels, limiting its use
for studying modern diffusion models.
TWIGMA: gathered over 800,000 AI-generated images from Twitter
with metadata like tweet text and engagement metrics. While useful for
studying real-world sharing patterns, images from social media have
compression artifacts and lack controlled generation settings.
Fake2M: assembled over two million images and found that humans
misclassify 38.7% of AI-generated images. However, the dataset lacks
caption-aligned real-synthetic pairs, preventing controlled studies of
how different generators interpret the same text prompt.
A shared limitation is the lack of semantic alignment, where real and
synthetic images share the same text description. This alignment is
needed to separate content bias from generation artifacts. Additionally,
few datasets cover both open-source (Stable Diffusion) and closed-source
(DALL-E, MidJourney) generators, or include perturbations for robustness
testing.
Detection Methods
Several approaches have been proposed for detecting AI-generated images:
CLIP-Based Detection : Fine-tuning CLIP on mixed real/synthetic
data can detect AI-generated images effectively. However, these
methods often overfit to specific generators and perform poorly on
images from unseen models.
Hybrid Feature Methods: Combining high-level semantic features
with low-level noise patterns improves cross-generator performance.
Yet, show that many detectors rely on shortcuts—like scene type or
object frequency—rather than true generation artifacts.
Frequency-Domain Analysis : show that synthetic images have
distinct frequency patterns. While effective for GAN-generated
content, diffusion models produce weaker frequency artifacts,
requiring new detection approaches.
Watermark-Based Detection: found that watermark-based methods
outperform passive detectors under perturbations. However,
watermarking needs generator cooperation and fails for models without
embedded watermarks.
Recent work has also focused on systematic benchmarking of text-to-image
generators. present a unified evaluation framework using metrics such as
CLIP similarity, LPIPS, and FID, demonstrating how structured prompts
affect generation quality across different architectures.
Our dataset provides caption-aligned real and synthetic images from five
modern generators (Stable Diffusion 3 , Stable Diffusion 2.1 , SDXL ,
DALL-E 3 , MidJourney v6 ), with model attribution labels and systematic
perturbations for robustness evaluation.
Dataset
In this section, we describe the dataset creation process and analysis.
Image generation and Annotation
Our dataset is built upon the MS COCO dataset , which provides
high–quality real images paired with human-written captions. We randomly
sample 16k image-caption pairs from the MS COCO dataset. Each caption is
used as a textual seed for generating synthetic images using five
image-generation models - Stable Diffusion 3 (SD3 ) , Stable Diffusion
2.1 (SD 2.1) , SDXL , DALL-E 3 , MidJourney v6 . For every caption, each
model produced one synthetic image, resulting in a multi-source
collection of AI-generated visual samples.
All real images originate directly from MS COCO, and all captions were
written by human annotators as provided by the original dataset. No
automated captioning or additional annotation steps are used. All
generated images are purely AI-created, whereas the real subset contains
only human-captured photographs.
Perturbations
To enable robustness and invariance studies, we create perturbed
variants of each generated image using four independent transformations:
Horizontal Flip – Standard horizontal mirroring of the image.
Brightness Reduction – Image brightness scaled by a factor of
$`0.5`$.
Gaussian Noise – Additive Gaussian noise with standard deviation
$`\sigma = 0.05`$.
JPEG Compression – Image re-encoded using JPEG compression with
a quality factor of $`50`$.
Each perturbation is applied separately, generating distinct augmented
versions of each base image. No combined or sequential perturbations are
applied.
Data Structure
After collection, the dataset is organized into a standardized schema
consisting of the following fields:
id — Unique identifier for each sample.
image — The real or model-generated image.
caption — The original MS COCO caption.
label_1 — Binary label indicating whether the image is real (0) or
AI-generated (1).
label_2 — Categorical label indicating the specific generative model
(SD 3, SDXL, SD 2.1, DALL-E 3, or MidJourney 6).
All images are produced or collected at the same native resolution, and
no resizing or normalization is performed prior to dataset storage. Some
examples from the dataset are provided in Figure
[fig:teaser].
Data Analysis
The dataset contains 96,000 image-caption pairs, split into training
(42,000), validation (9,000), and test (45,000) subsets.
Table 1 summarizes the distribution
across sources.
Source
Count
Real (MS COCO)
16,000
SD 2.1
16,000
SDXL
16,000
SD 3
16,000
DALL-E 3
16,000
MidJourney v6
16,000
Total
96,000
Distribution of images by source in the MS COCOAI dataset.
Since all captions originate from MS COCO, they follow its
characteristic style: concise, descriptive sentences. Table
2 provides caption length
statistics.
Statistic
Value
Min words
7
Max words
34
Mean words
10.37
Median words
10
Caption length statistics (word count).
Figure 1 presents a word cloud of all
the captions in our dataset. The visualization reveals the rich semantic
diversity, with prominent terms spanning multiple conceptual categories:
urban environments (street, building, city, traffic), indoor
spaces (kitchen, bathroom, toilet, sink), wildlife (giraffe,
cat, dog, bird, sheep), transportation (train, bus,
motorcycle, airplane, car), human subjects (man, woman,
people, group), and descriptive attributes including colors
(white, black, red, blue, green) and spatial relations
(front, top, side, large, small). This broad semantic coverage
ensures that generative models are evaluated across diverse visual
concepts, reducing the risk of domain-specific biases in detection
performance.
style="width:90.0%" />
Word cloud visualization of all captions in the dataset.
Word size corresponds to term frequency, revealing the semantic
distribution across the corpus. Dominant terms reflect a comprehensive
coverage of everyday scenes, common objects, animals, human activities,
and color descriptors.
Based on the dataset, we propose the following 2 tasks:
Task A (Binary Classification): Discern whether a given image is
AI-generated or captured in the real world.
Task B (Model Identification): Identify the specific generative
model (SD 3, SDXL, SD 2.1, DALL-E 3, or MidJourney 6) responsible for
producing a given synthetic image.
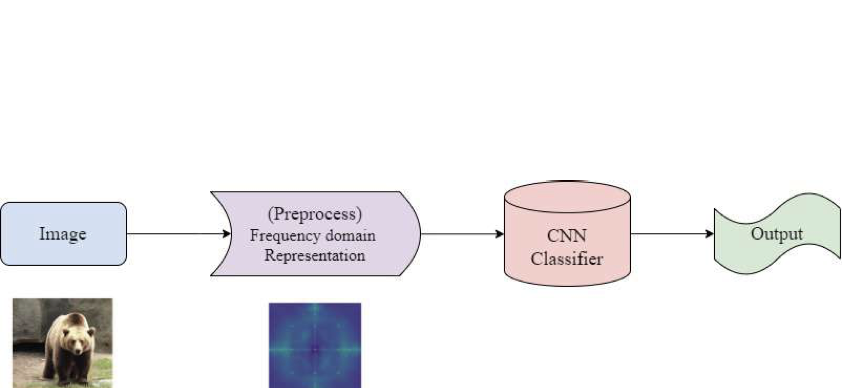
Baseline
To establish a baseline, we train a ResNet-50 classifier using image
representations in the frequency domain. These frequency domain
representations are generated by applying a pre-processing strategy
inspired by the methodology presented in . This transformation captures
global frequency characteristics that help reveal subtle artifacts often
present in synthetic images.
The overall pipeline is illustrated in Figure
[fig:baseline_pipeline].
Starting with an input image, we convert it into its frequency domain
using a 2D Fourier Transform. The resulting representation is then fed
into a ResNet-50 CNN model trained to classify the image into one of the
six classes ( real and one class per image generation model).
This baseline allows us to assess the effectiveness of frequency-based
features, serving as a point of comparison for more sophisticated
techniques.
style=“width:90.0%” />
Results
Baseline performance metrics, given in Table
3 establish benchmarks for
both authenticity detection and model attribution tasks, serving as
reference points for subsequent research developments.
Task
Description
Baseline Score
Task A
Classify each image as either AI-generated or created by a human
0.80144
Task B
Given an AI-generated image, determine which specific model produced it
0.44913
Baseline results for both tasks in the shared task.
For Task A (binary classification distinguishing AI-generated images
from human-created content), the baseline approach achieves a score of
0.80144. For Task B (identifying the specific generative model
responsible for producing AI-generated image), the baseline methodology
yields a score of 0.44913.
These baseline scores, highlight the substantial difficulty differential
between the two tasks, with model attribution proving significantly more
challenging than binary authenticity detection. The performance gap
demonstrates the increased complexity inherent in multi-class
classification scenarios and establishes the dataset as a rigorous
benchmark for advancing sophisticated detection and attribution
methodologies.
Conclusion
In this paper, we release a large-scale dataset for AI-generated image
detection comprising 96,000 real and synthetic image-caption pairs. A
key feature of our dataset is semantic alignment- all synthetic images
are generated from the same captions as their real counterparts,
enabling controlled studies that separate content bias from generation
artifacts.
We propose two tasks based on this dataset: Task A (binary
classification of real vs. AI-generated images) and Task B (identifying
the specific generative model). Our baseline using ResNet-50 achieves a
score of 0.80 on Task A, demonstrating that binary detection is feasible
with relatively simple approaches. However, the baseline score of 0.45
on Task B reveals that model attribution remains significantly more
challenging.
Future research directions include developing more sophisticated
fingerprinting techniques for model attribution, exploring cross-modal
learning approaches that leverage caption-image relationships, and
improving detector robustness against common image transformations.
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.