Improving Scientific Document Retrieval with Academic Concept Index
📝 Original Paper Info
- Title: Improving Scientific Document Retrieval with Academic Concept Index- ArXiv ID: 2601.00567
- Date: 2026-01-02
- Authors: Jeyun Lee, Junhyoung Lee, Wonbin Kweon, Bowen Jin, Yu Zhang, Susik Yoon, Dongha Lee, Hwanjo Yu, Jiawei Han, Seongku Kang
📝 Abstract
Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.💡 Summary & Analysis
1. **Introduction of Academic Concept Index**: A structured representation extracted from each document to serve as a foundation for concept-based retrieval enhancement. 2. **CCQGen: Concept-Aware Query Generation**: This method enhances the generation process by conditioning LLMs on uncovered concepts, leading to diverse training queries that better reflect the academic content. 3. **CCExpand: Concept-Focused Context Augmentation**: Generates concept-specific snippets from documents for fine-grained relevance matching without requiring additional model training.Simple Explanation and Metaphors (Sci-Tube Style Script)
- Beginner: This paper explores ways to improve scientific document search using AI. It uses LLMs to create better queries and provide extra context that helps understand the core content of documents.
- Intermediate: The academic concept index is like a map highlighting key ideas and terms in each document, making it easier for AI to generate relevant queries and extract useful snippets.
- Advanced: This paper introduces methods to enhance scientific document retrieval by integrating an academic concept index into query generation and context augmentation processes, leading to more effective and fine-grained search results.
📄 Full Paper Content (ArXiv Source)
<ccs2012> <concept> <concept_id>10002951.10003317</concept_id> <concept_desc>Information systems Information retrieval</concept_desc> <concept_significance>500</concept_significance> </concept> <concept> <concept_id>10002951.10003317.10003318.10003321</concept_id> <concept_desc>Information systems Content analysis and feature selection</concept_desc> <concept_significance>500</concept_significance> </concept> <concept> <concept_id>10002951.10003317.10003325</concept_id> <concept_desc>Information systems Information retrieval query processing</concept_desc> <concept_significance>300</concept_significance> </concept> </ccs2012>
Introduction
Scientific document retrieval is a fundamental task that supports scientific progress by enabling efficient access to technical knowledge . Recently, pre-trained language model (PLM)-based retrievers have shown strong performance in general-domain search tasks, benefiting from pre-training followed by fine-tuning on annotated query–document pairs. However, adapting these general-domain retrievers to scientific domains faces two major challenges. First, acquiring large-scale domain-specific relevance annotations is highly costly and requires substantial expert effort . Second, scientific corpora differ markedly from general-domain data in both vocabulary and information needs, which often leads to degraded retrieval performance .
With the rapid advancement of large language models (LLMs) , recent studies have explored two major directions to improve scientific document retrieval. The first direction is synthetic query generation . LLMs are prompted to generate training queries for each document with an instruction such as “generate five relevant queries to the document” . These generated queries act as proxies for real user queries. Advances in prompting schemes, including example-augmented prompting and pairwise generation , have further improved the quality and diversity of synthetic queries. Retrievers fine-tuned on these improved queries often achieve higher performance on specialized corpora.
The second direction focuses on generating auxiliary contexts to bridge the vocabulary and semantic gap between queries and documents . For example, expands the original query by prompting LLMs to produce additional semantic cues such as relevant keywords, entities, and summaries. generates hypothetical documents that serve as pseudo-answers to the query, providing richer interpretations to the user’s information need while aligning the expression styles with actual documents. These generated contexts provide valuable signals that help the retriever capture relevance beyond surface-level text similarity. A notable advantage of this line of work is that it is training-free, requiring no retriever fine-tuning and thus allowing flexible deployment across different corpora. This property is particularly appealing for scientific retrieval, where research labs and institutions often maintain their own local scientific corpora with unique distributions and terminologies. In such environments, retraining a dedicated retriever for every individual corpus is impractical, making training-free augmentation methods especially valuable.
Despite their effectiveness, both lines of research share a fundamental limitation: they do not explicitly incorporate the academic concepts embedded within scientific documents. Academic concepts refer to fundamental ideas, theories, and methodologies that constitute the core content of scientific texts . A scientific document typically discusses multiple such concepts, spanning fundamental ideas, theories, and methodologies, and domain-specific challenges. However, existing LLM-based approaches do not model these conceptual structures. In the synthetic query generation line, LLMs often focus on only a narrow subset of the document’s concepts, resulting in redundant queries with limited concept coverage . Likewise, in the context-augmentation line, without direct guidance, the generated contexts often fail to reflect the diverse concepts in the document, yielding only a narrow contextual signal and consequently limited improvements.
To address this limitation, we introduce an academic concept index that provides a structured representation of the key concepts discussed within each document (Figure 1a). The index is constructed by extracting high-level topics, domain-specific phrases, and their related terminology using LLMs and a concept extractor. This structured organization offers a principled view of the document’s conceptual space. We aim to improve both query generation and context-augmentation directions based on this academic concept index. To this end, we propose two methods that leverage the academic concept index: CCQGen for concept-aware query generation, and CCExpand for concept-focused, training-free context augmentation.
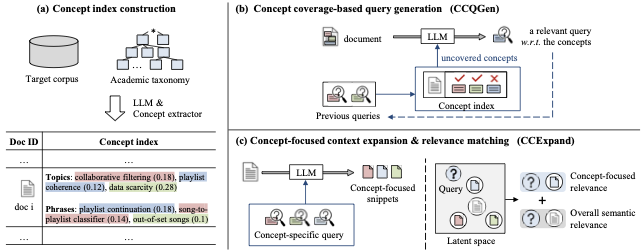
The first method is CCQGen, which enhances the synthetic query generation line by incorporating the academic concept index into the generation process (Figure 1b). For each document, we identify the set of core concepts captured in the index and monitor which concepts are already represented in previously generated queries. We then condition the LLM to generate additional queries targeting the remaining, uncovered concepts. This adaptive procedure reduces redundancy, encourages broader concept coverage, and results in training queries that better reflect the diverse academic aspects of scientific documents. By generating concept-aware and complementary queries, CCQGen improves the effectiveness of fine-tuning retrievers on specialized scientific corpora.
 />
/>
The second method is CCExpand, which strengthens context augmentation through concept-focused snippets extracted from the documents (Figure 1c). Based on the concept index, CCExpand generates a set of targeted snippets that serve as concise responses to the concept-aware queries produced by CCQGen. These snippets provide concept-specific views of the document, complementing the overall semantic similarity captured from surface text. During retrieval, the query is matched not only against the global document representation but also against these concept-focused snippets, allowing the retriever to capture fine-grained conceptual signals without any additional model training. Because CCExpand is fully training-free, it is easily deployable across diverse scientific corpora while providing structured, concept-grounded augmentation that enhances existing retrieval pipelines.
Our contributions are summarized as follows:
-
We introduce the academic concept index, a structured representation of key topics and domain-specific terminology extracted from each document. This index provides a foundation for concept-based retrieval enhancement.
-
We propose CCQGen, a concept-aware query generation method that adaptively conditions LLMs on uncovered concepts to produce complementary and diverse training queries.
-
We propose CCExpand, a training-free, concept-focused context augmentation method that generates concept-specific document snippets for fine-grained relevance matching.
-
Through extensive experiments, we show that CCQGen and CCExpand effectively improve retrieval performance, validating the importance of modeling the concept index in scientific document retrieval.
Related Work
PLM-based retrievers have become the standard foundation for modern retrieval, and many studies have sought to enhance them through two major directions: synthetic query generation and auxiliary context augmentation. In this section, we review PLM-based retrieval and these two lines of work.
PLM-based retrieval models
The advancement of PLMs has led to significant progress in retrieval. Recent studies have introduced retrieval-targeted pre-training , distillation from cross-encoders , and advanced negative mining methods . There is also an increasing emphasis on pre-training methods specifically designed for the scientific domain. In addition to pre-training on academic corpora , researchers have exploited metadata associated with scientific papers. uses journal class, use citations, uses co-citation contexts, and utilizes venues, affiliations, and authors. devise multi-task learning of related tasks such as citation prediction and paper classification. Very recently, leverage corpus-structured knowledge (e.g., core topics and phrases) for academic concept matching.
To perform retrieval on a new corpus, a PLM-based retriever is typically fine-tuned using a training set of annotated query-document pairs. For effective fine-tuning, a substantial amount of training data is required. However, in specialized domains such as scientific document search, constructing vast human-annotated datasets is challenging due to the need for domain expertise, which remains an obstacle for applications .
Synthetic query generation
Earlier studies have employed dedicated query generation models, trained using massive document-query pairs from general domains. Recently, there has been a shift towards replacing these generation models with LLMs . Recent advancements have centered on improving prompting schemes to enhance the quality of these queries. We summarize recent methods in terms of their prompting schemes.
Few-shot examples. Several methods incorporate a few examples of relevant query-document pairs in the prompt. The prompt comprises the following components: $`P = \{inst, (d_i, q_i)^k_{i=1}, d_t\}`$, where $`inst`$ is the textual instruction1, $`(d_i, q_i)^k_{i=1}`$ denotes $`k`$ examples of the document and its relevant query, and $`d_t`$ is the new document we want to generate queries for. By providing actual examples of the desired outputs, this technique effectively generates queries with distributions similar to actual queries (e.g., expression styles and lengths) . It is worth noting that this technique is also utilized in subsequent prompting schemes.
Label-conditioning. Relevance label $`l`$ (e.g., relevant and irrelevant) has been utilized to enhance query generation . The prompt comprises $`P = \{inst, (l_i, d_i, q_i)^k_{i=1}, (l_t, d_t)\}`$, where $`k`$ label-document-query triplets are provided as examples. $`l_i`$ represents the relevance label for the document $`d_i`$ and its associated query $`q_i`$. To generate queries, the prompt takes the desired relevance label $`l_t`$ along with the document $`d_t`$. This technique incorporates knowledge of different relevance, which aids in improving query quality and allows for generating both relevant and irrelevant queries .
Pair-wise generation. To further enhance the query quality, the state-of-the-art method introduces a pair-wise generation of relevant and irrelevant queries. It instructs LLMs to first generate relevant queries and then generate relatively less relevant ones. The prompt comprises $`P = \{inst, (d_i, q_i, q^-_i)^k_{i=1}, d_t\}`$, where $`q_i`$ and $`q^-_i`$ denote relevant and irrelevant query for $`d_i`$, respectively. The generation of irrelevant queries is conditioned on the previously generated relevant ones, allowing for generating thematically similar rather than completely unrelated queries. These queries can serve as natural ‘hard negative’ samples for training .
While these prompting schemes enhance the realism and diversity of synthetic queries, they do not explicitly ensure coverage of the document’s academic concepts. This limitation motivates our concept-aware query generation approach, CCQGen, which leverages the academic concept index to generate more comprehensive query sets.
Auxiliary context generation
Another line of research enriches the retrieval process by generating auxiliary contexts for relevance matching. A notable advantage of this line of work is that it is training-free, requiring no retriever fine-tuning and allowing flexible deployment across different corpora. Early studies explored methods such as pseudo-relevance feedback and topic-based query enrichment . More recently, generative models, including LLMs, have been leveraged to create richer contextual signals. GAR expands queries by generating in-domain contexts, such as answers, answer-containing sentences, or passage titles, and appends them to form generation-augmented queries. GRF proposes prompting LLMs to generate a diverse set of semantic signals, such as keywords, entities, pseudo-queries, and summaries, which are aggregated to refine the query representation. This multi-signal augmentation allows the retriever to capture various semantic facets of the user intent. Query2doc generates short document-like expansions conditioned on the query to enrich its semantic representation. HyDE also adopts a related strategy by generating hypothetical documents conditioned on the query. These pseudo-documents resemble the style of scientific documents while introducing terms and expressions not explicitly present in the original query, thereby providing richer semantic evidence. Beyond query-side augmentation, document-side expansion approaches have been widely explored. Doc2query generates synthetic queries for each document and appends them to expand its lexical footprint. Doc2query$`--`$ improves this strategy by filtering low-quality generated queries to reduce noise in document expansion. These approaches collectively demonstrate the utility of generated content for enhancing both query and document representations.
Such training-free approaches can be particularly appealing for scientific retrieval, where research institutions often maintain their own local scientific corpora with different distributions. In these settings, retraining a dedicated retriever for every individual corpus is costly and impractical, making training-free augmentation methods especially valuable. However, existing methods are not grounded in the conceptual structure of documents and therefore do not account for its diverse academic concepts, motivating concept-aware augmentation approaches such as our CCExpand.
Academic Concept Index Construction
We construct an academic concept index that captures the key concepts associated with each document (Figure 2). The index serves as the foundation for both directions explored in this work: concept-aware synthetic query generation (CCQGen) and concept-focused context augmentation (CCExpand). To build this index, we first identify the core academic concepts of each document at two levels of granularity (i.e., topics and phrases) and then enrich these concepts by estimating their importance and incorporating strongly related concepts that may not appear explicitly in the text.
 style="width:100.0%" />
style="width:100.0%" />
Concept Identification
Scientific documents typically cover multiple academic concepts, ranging from broad research areas to fine-grained technical details. To obtain a structured representation of these concepts, we identify core topics and core phrases for each document. Topic-level concepts reflect high-level research themes such as “collaborative filtering” or “machine learning”, while phrase-level concepts capture document-specific terminology such as “playlist continuation” or “song-to-playlist classifier”. These two levels provide complementary perspectives for characterizing the document’s content.
A straightforward approach is to instruct LLMs to list topics or phrases contained in the document. However, such direct generation often exhibits two limitations: the results may contain concepts not covered by the document, and there is always a potential risk of hallucination. As a solution, we propose a new approach that first constructs a candidate set, and then uses LLMs to pinpoint the most relevant ones from the given candidates, instead of directly generating them. By doing so, the output space is restricted to the predefined candidate space, greatly reducing the risk of hallucinations while effectively leveraging the language-understanding capability of LLMs.
Core topics identification
To identify the core topics of documents, we propose using an academic topic taxonomy . In the scientific domain, academic taxonomies are widely used for categorizing studies in various institutions and can be easily obtained from the web.2 A taxonomy refers to a hierarchical tree structure outlining academic topics (Figure 2). Each node represents a topic, with child nodes corresponding to its sub-topics. Leveraging taxonomy allows for exploiting domain knowledge of topic hierarchy and reflecting researchers’ tendency to classify studies.
Candidate set construction. One challenge in finding candidate topics is that the taxonomy obtained from the web is often very large and contains many irrelevant topics. To effectively narrow down the candidates, we employ a top-down traversal technique that recursively visits the child nodes with the highest similarities at each level. For each document, we start from the root node and compute its similarity to each child node. We then visit child nodes with the highest similarities.3 This process recurs until every path reaches leaf nodes, and all visited nodes are regarded as candidates.
The document-topic similarity $`{s}(d, c)`$ can be defined in various ways. As a topic encompasses its subtopics, we collectively consider the subtopic information for each topic node. Let $`\mathcal{N}_c`$ denote the set of nodes in the sub-tree having $`c`$ as a root node. We compute the similarity as: $`{s}(d, c) = \frac{1}{|\mathcal{N}_c|}\sum_{j \in \mathcal{N}_c} \operatorname{cos}(\mathbf{e}_{d}, \mathbf{e}_{j})`$, where $`\mathbf{e}_d`$ and $`\mathbf{e}_j`$ denote representations from PLM for a document $`d`$ and the topic name of node $`j`$, respectively.4
Core topic selection. We instruct LLMs to select topics most aligned with the document’s central theme from the candidate set. An example of an input prompt is:
We set $`k^t=10`$. For each document $`d`$, we obtain core topics as $`\mathbf{y}^t_d \in \{0,1\}^{|\mathcal{T}|}`$, where $`y^t_{di}=1`$ indicates $`i`$ is a core topic of $`d`$, otherwise $`0`$. $`\mathcal{T}`$ denotes the topic set obtained from the taxonomy.
Core phrases identification
From each document, we identify core phrases used to describe its concepts. These phrases offer fine-grained details not captured at the topic level. We note that not all phrases in the document are equally important. Core phrases should describe concepts strongly relevant to the document but not frequently covered by other documents with similar topics. For example, among documents about ‘recommender system’ topic, the phrase ‘user-item interaction’ is very commonly used, and less likely to represent the most important concepts of the document.
Candidate set construction. Given the phrase set $`\mathcal{P}`$ of the corpus5, we measure the distinctiveness of phrase $`p`$ in document $`d`$. Inspired by recent phrase mining methods , we compute the distinctiveness as: $`\exp(\operatorname{BM25}(p, d))/\,(1 + \sum_{d'\in\mathcal{D}_{d}}\exp(\operatorname{BM25}(p, d')))`$. This quantifies the relative relevance of $`p`$ to the document $`d`$ compared to other topically similar documents $`\mathcal{D}_{d}`$. $`\mathcal{D}_{d}`$ is simply retrieved using Jaccard similarity of core topics $`\mathbf{y}^t_d`$. We set $`|\mathcal{D}_{d}|=100`$. We select phrases with top-20% distinctiveness score as candidates.
Core phrase selection. We instruct LLMs to select the most relevant phrases (up to $`k^p`$ phrases) from the candidates, using the same instruction format used for the topic selection. We set $`k^p=15`$. The core phrases are denoted by $`\mathbf{y}^p_d \in \{0,1\}^{|\mathcal{P}|}`$, where $`y^p_{dj}=1`$ indicates $`j`$ is a core phrase of $`d`$, otherwise $`0`$.
Concept Enrichment
We have identified core topics and phrases representing each document’s concepts. We further enrich this information by (1) measuring their relative importance, and (2) incorporating strongly related concepts (i.e., topics and phrases) not explicitly revealed in the document. This enriched information serves as the basis for generating queries.
Concept extractor. We employ a small model called a concept extractor. For a document $`d`$, the model is trained to predict its core topics $`\mathbf{y}^{t}_{d}`$ and phrases $`\mathbf{y}^{p}_{d}`$ from the PLM representation $`\mathbf{e}_d`$. We formulate this as a two-level classification task: topic and phrase levels.
Topics and phrases represent concepts at different levels of granularity, and learning one task can aid the other by providing a complementary perspective. To exploit their complementarity, we employ a multi-task learning model with two heads . Each head has a Softmax output layer, producing probabilities for topics $`\hat{\mathbf{y}}^{t}_{d}`$ and phrases $`\hat{\mathbf{y}}^{p}_{d}`$, respectively. The cross-entropy loss is then applied for classification learning: $`-\sum_{i=1}^{|\mathcal{T}|} y^t_{di} \log \hat{y}^{t}_{di} - \sum_{j=1}^{|\mathcal{P}|} y^p_{dj} \log \hat{y}^{p}_{dj}`$.
Concept enrichment. Using the trained concept extractor, we compute $`\hat{\mathbf{y}}^{t}_{d}`$ and $`\hat{\mathbf{y}}^{p}_{d}`$, which reveal their importance in describing the document’s concepts. Also, we identify strongly related topics and phrases that are expressed differently or not explicitly mentioned, by incorporating those with the highest prediction probabilities. For example, in Figure 2, we identify phrases ‘cold-start problem’, ‘filter bubble’, and ‘mel-spectrogram’, which are strongly relevant to the document’s concepts but not explicitly mentioned, along with their detailed importance. These phrases are used to aid in articulating the document’s concepts in various related terms.
In sum, we obtain $`k^{t'}`$ enriched topics and $`k^{p'}`$ enriched phrases for each document with their importance from $`\hat{\mathbf{y}}^{t}_{d}`$ and $`\hat{\mathbf{y}}^{p}_{d}`$. We set the probabilities for the remaining topics and phrases as $`0`$, and normalize the probabilities for selected topics and phrases, denoted by $`\bar{\textbf{y}}^t_d`$ and $`\bar{\textbf{y}}^p_d`$. These enriched concept representations collectively form the academic concept index, which serves as the foundation for the two different directions explored in this work: CCQGen and CCExpand.
CCQGen: Concept Coverage-based Query set Generation
We introduce CCQGen, which enhances synthetic query generation by explicitly grounding the process in the academic concept index. CCQGen is designed to meet two desiderata for high-quality training queries: (1) the generated queries should collectively provide complementary coverage of the document’s concepts, and (2) each query should articulate the concepts using diverse and conceptually related terminology, rather than repeating surface-level phrases from the document.
Given previously generated queries $`Q^{m-1}_d = \{q^1_d, ..., q^{m-1}_d\}`$, we compare their concept coverage with the document’s concept index to identify concepts that remain insufficiently covered. These uncovered concepts are then encoded as explicit conditions in the prompt to guide the LLM toward producing the next query $`q^{m}_d`$. A final filtering stage ensures the quality and conceptual correctness of the generated queries. This process is repeated until a predefined number ($`M`$) of queries per document is achieved. $`M`$ is empirically determined, considering available training resources such as GPU memory and training time. For the first query of each document, we impose no conditions, thus it is identical to the results obtained from existing methods. Figure 3 illustrates the workflow.
Identifying Uncovered Concepts
The enriched concept index provides distributions $`\bar{\mathbf{y}}^t_d`$ and $`\bar{\mathbf{y}}^p_d`$ indicating the relative importance of topics and phrases for document $`d`$. Our key idea is to generate queries that align with this distribution to ensure comprehensive coverage of the document’s concepts. To estimate the concepts already expressed in earlier queries, we apply the concept extractor to the concatenated text $`Q^{m-1}_d`$, yielding $`\bar{\mathbf{y}}^t_Q`$ and $`\bar{\mathbf{y}}^p_Q`$.
Based on the concept coverage information, we identify concepts that need to be more emphasized in the subsequently generated query. A concept is “under-covered’’ if its value is high in $`\bar{\mathbf{y}}^p_d`$ but low in $`\bar{\mathbf{y}}^p_Q`$. We formalize the under-coverage concept distribution as:
\begin{equation}
\boldsymbol{\pi} = \operatorname{normalize}(\,\max(\bar{\textbf{y}}^p_d - \bar{\textbf{y}}^p_Q, \,\epsilon)\,)
\end{equation}We set $`\epsilon = 10^{-3}`$ as a minimal value to the core phrases for numerical stability. Here, we use phrase-level concepts for explicit conditioning because they are more naturally incorporated into prompts than broad topic labels. Note that topics are implicitly reflected in identifying and enriching core phrases. We sample $`\lfloor \frac{k^{p'}}{M} \rfloor`$ phrases according to the multinomial distribution:
\begin{equation}
\mathcal{S} = \operatorname{Multinomial} \left(\left\lfloor \frac{k^{p'}}{M} \right\rfloor, \boldsymbol{\pi}\right),
\end{equation}where $`\mathcal{S}`$ denotes the set of sampled phrases and $`M`$ is the total number of queries to be generated for the document. As queries accumulate, $`\bar{\mathbf{y}}^p_Q`$ updates dynamically, enabling progressive concept coverage.
To illustrate this process, consider the example in Figure 3. Given the previously generated queries, the concept extractor identifies which concepts have already been expressed and which remain insufficiently covered. For instance, phrases such as ‘playlist continuation’, ‘song-to-playlist classifier,’ and ‘out-of-set songs’ exhibit relatively low under-coverage values (indicated by $`\downarrow`$), as they already appear in earlier queries. In contrast, concepts such as ‘cold-start problem’, ‘audio features’, ‘mel-spectrogram’, and ‘data scarcity’ receive higher under-coverage values (indicated by $`\uparrow`$), reflecting their absence from prior queries despite their importance in the document. Based on the distribution $`\boldsymbol{\pi}`$, CCQGen increases the sampling probability of these uncovered concepts, making them more likely to be selected as conditioning phrases.
 style="width:100.0%" />
style="width:100.0%" />
Concept-Conditioned Query Generation
The sampled phrases are leveraged as conditions for generating the next query $`q^m_d`$. Controlling LLM outputs through prompt-based conditioning has been widely studied in tasks such as sentiment control, keyword guidance, and outline-based text generation . Following these studies, we impose a condition by adding a simple textual instruction $`C`$: “Generate a relevant query based on the following keywords: [Sampled phrases]”. While more sophisticated instruction could be employed, we obtained satisfactory results with our choice.
Let $`P`$ denote any existing prompting scheme (e.g., few-shot examples) discussed in Section 2.2. The final prompt is constructed as $`[P; C]`$, and the LLM generates the next query according to:
\begin{equation}
q^m_d = \operatorname{LLM}([P; C]).
\label{eq:ccqgen_generation}
\end{equation}This integration allows us to inherit the strengths of existing techniques, while explicitly steering the LLM toward under-covered concepts. For example, in Figure 3, the concept condition includes phrases like ‘cold-start problem’ and ‘audio features’, which are not well covered by the previous queries. Based on this concept condition, we guide LLMs to generate a query that covers complementary aspects to the previous ones. It is important to note that $`C`$ adds an additional condition for $`P`$; the query is still about playlist recommendation, the main task of the document.
By contrast, when no concept condition is applied—as illustrated in the bottom-right of the figure—the LLM tends to produce queries that are fluent yet semantically redundant, often revisiting concepts already well covered by earlier queries. This highlights the necessity of concept-conditioned prompting for systematically broadening conceptual coverage instead of relying solely on unconstrained LLM generation.
Concept coverage-based consistency filtering. After generating a query, we apply a filtering step to ensure its quality. A key criterion is round-trip consistency : the document that produced a query should also be retrieved by that query. Prior work implements this by retaining a query $`q_d`$ only if its source document $`d`$ appears within the top-$`N`$ results of a retriever. However, this approach is often dominated by surface-level lexical matching. In scientific domains, conceptually aligned queries frequently use terminology that differs from the exact phrasing in the document, causing retrievers to overlook semantically valid queries.
To address this issue, we incorporate concept-level similarity into the filtering stage. For a query–document pair $`(q_d,d)`$, we compute textual similarity $`s_{\text{text}}(q_d,d)`$ from the retriever and concept similarity $`s_{concept}(q_d,d) = sim(\bar{\mathbf{y}}^p_{q_d}, \,\bar{\mathbf{y}}^p_d)`$, where $`sim(\cdot)`$ is inner-product similarity over the top 10% phrases. We then define a combined score for filtering:
\begin{equation}
\label{eq:dual_score}
s_{\text{filtering}}(q_d,d) = f(s_{\text{text}}(q_d,d),\ s_{\text{concept}}(q_d,d)),
\end{equation}where $`f`$ denotes the function to consolidate two scores. Here, we use simple addition after z-score normalization. Round-trip consistency is assessed using this combined score. By jointly considering surface-level and concept-level signals, this filtering more reliably preserves semantically meaningful queries that would otherwise be discarded due to lexical mismatch. The resulting query–document pairs are used to fine-tune the retriever using a standard contrastive learning .
Remarks on the efficiency of CCQGen. CCQGen iteratively assesses the generated queries and imposes conditions for subsequent generations, which introduces additional computation during the generation phase. However, it incurs no extra cost during fine-tuning or inference. Further, CCQGen consistently yields large improvements, even when the number of queries is highly limited, whereas existing methods often fail to improve the retriever (Section 6.2.2).
CCExpand: Concept-focused Context Expansion for Retrieval
We now propose CCExpand, a training-free context augmentation method grounded in the academic concept index. While CCQGen utilizes the concept index to generate training signals, CCExpand uses it to construct a set of document snippets, each focusing on complementary academic concepts covered in the document. During retrieval, the query is matched not only against the document representation but also against these concept-focused snippets, enabling the retriever to capture fine-grained conceptual signals without any additional model training.
 style="width:100.0%" />
style="width:100.0%" />
Concept-focused Snippet Generation
A fundamental limitation of a dense retriever is that it compresses an entire document into a single vector representation, often resulting in the loss of fine-grained information . This issue is particularly critical in scientific retrieval, where a single paper typically encompasses various academic concepts. When these diverse concepts are blended into a single vector, the retriever struggles to distinguish among the document’s conceptually distinct aspects.
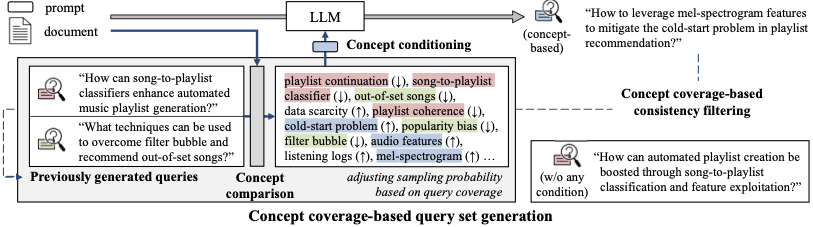
To address this limitation, we leverage the academic concept index to construct a set of snippets that each reflect a different conceptual aspect of the document. We note that, through CCQGen, we can already generate a concept-aware query set that comprehensively covers the document’s key concepts. Naturally, each query in $`Q_d`$ serves as a natural language instantiation of a specific subset of the concepts encoded in the document $`d`$. Conditioned on each concept-aware query, we employ an LLM to generate a concept-focused snippet that tailors the document to answer that query.
Formally, the snippet $`s_d`$ corresponding to a query $`q_d`$ is generated as:
\begin{equation}
s_d = \text{LLM}(inst, d, q_d),
\end{equation}where $`inst`$ denotes the instruction. An example of an input prompt is:
By repeating this process, we obtain a set of concept-focused snippets $`S_d = \{s^1_d, \dots, s^M_d\}`$, where $`M`$ is the number of generated queries per document. Figure 4 illustrates this process. Unlike generic augmentation methods , which produce auxiliary content without explicit conceptual grounding, our approach leverages the concept index to ensure that the generated snippets collectively and systematically cover the diverse concepts present in the document.
Concept-focused Relevance Matching
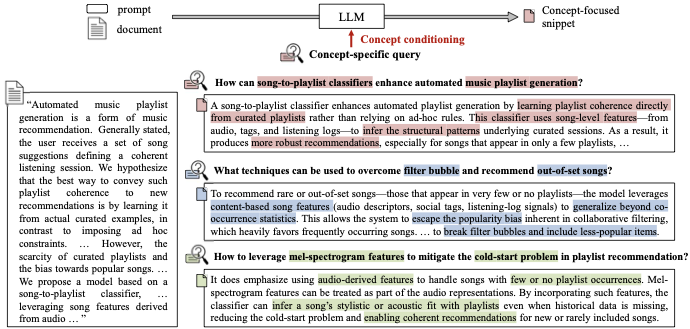
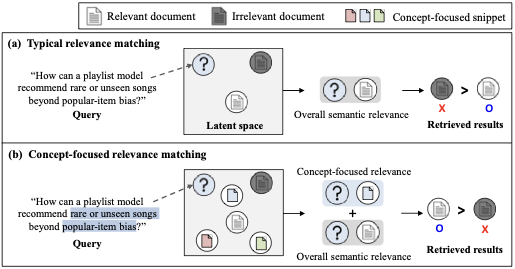
As discussed earlier, compressing an entire scientific document into a single vector often fails to preserve its concept-specific information, making it difficult for the retriever to answer queries targeting particular academic concepts. We introduce a concept-focused relevance matching strategy that leverages the most aligned concept snippet as auxiliary context during retrieval.
Given a query–document pair $`(q_{test}, d)`$, we first identify the snippet that best reflects the concepts emphasized in the query:
\begin{equation}
s^*_{d} = \arg\max_{s \in S_d} (sim(q_{test}, s)),
\end{equation}where $`sim(\cdot,\cdot)`$ denotes the retriever’s similarity score. We then compute the refined relevance score by combining the overall textual similarity with the concept-focused similarity:
\begin{equation}
\text{rel}(q_{test}, d)
= f\Big( sim(q_{test}, d),\; sim(q_{test}, s_d^{*}) \Big)
\end{equation}In practice, we use a simple linear combination, i.e., $`f(a, b) = (1-\alpha)\, a + \alpha\, b`$, where $`\alpha \in [0, 1]`$ is a hyperparameter that balances two views. This process is illustrated in Figure 5.
The proposed concept-focused matching offers several benefits. First, it strengthens the relevance matching by injecting concept-specific information that is otherwise diluted in a single document vector. By matching the query against the snippet most aligned with its conceptual focus, the retriever can better distinguish documents that share similar global semantics but address different academic concepts. Second, this approach is entirely training-free: it requires no modification or fine-tuning of the retriever, making it easily applicable across different scientific corpora and compatible with any dense retriever.
 style="width:80.0%" />
style="width:80.0%" />
Discussion on inference latency. A key advantage of CCExpand is that all snippet generation is performed entirely offline. During inference, the snippets are already vectorized and indexed for ANN search, requiring no LLM calls. This contrasts sharply with recent online LLM-based augmentation methods , whose latency is dominated by real-time prompting and decoding. Moreover, concept-focused matching is applied only to a small subset of candidate documents rather than the full corpus. Given a query, the retriever first computes standard similarity scores using the global document representations and selects the top-$`K`$ candidates (we use $`K=1000`$). Concept-focused similarities are then computed only between the query and the snippets of these candidates. Detailed efficiency analyses are provided in Section 6.3.3.
Experiments
Experimental Setup
Datasets
We conduct a thorough review of the literature to find retrieval datasets in the scientific domain, specifically those where relevance has been assessed by skilled experts or annotators. We select two recently published datasets: CSFCube and DORIS-MAE . They offer test query collections annotated by human experts and LLMs, respectively, and embody two real-world search scenarios: query-by-example and human-written queries. For both datasets, we conduct retrieval from the entire corpus, including all candidate documents. CSFCube dataset consists of 50 test queries, with about 120 candidates per query drawn from approximately 800,000 papers in the S2ORC corpus . DORIS-MAE dataset consists of 165,144 test queries, with candidates drawn similarly to CSFCube. We consider annotation scores above ‘2’, which indicate documents are ‘nearly identical or similar’ (CSFCube) and ‘directly answer all key components’ (DORIS-MAE), as relevant. Note that training queries are not provided in both datasets.
Academic topic taxonomy
We utilize the field of study taxonomy from Microsoft Academic , which contains $`431,416`$ nodes with a maximum depth of $`4`$. After the concept identification step (Section 3.1), we obtain $`1,164`$ topics and $`18,440`$ phrases for CSFCube, and $`1,498`$ topics and $`34,311`$ phrases for DORIS-MAE.
Metrics
Following , we employ Recall@$`K`$ (R@$`K`$) for a large retrieval size ($`K`$), and NDCG@$`K`$ (N@$`K`$) and MAP@$`K`$ (M@$`K`$) for a smaller $`K`$ ($`\leq 20`$). Recall@$`K`$ measures the proportion of relevant documents in the top $`K`$ results, while NDCG@$`K`$ and MAP@$`K`$ assign higher weights to relevant documents at higher ranks.
Backbone retrievers
We employ two representative models: (1) Contriever-MS is a widely
used retriever fine-tuned using vast labeled data from general domains
(i.e., MS MARCO). (2) SPECTER-v2 is a PLM specifically developed for
the scientific domain. It is trained using metadata (e.g., citation
relations) of scientific papers. For both models, we use public
checkpoints: facebook/contriever-msmarco and allenai/specter2_base.
Implementation details
All experiments are conducted using PyTorch with CUDA. For the concept extractor, we employ a multi-gate mixture of expert architecture , designed for multi-task learning. We use three experts, each being a two-layer MLP. We set the number of enriched topics and phrases to $`k^{t'}=15`$ and $`k^{p'}=20`$, respectively.
CCQGen. We conduct all experiments using 4 NVIDIA RTX A5000 GPUs,
512 GB memory, and a single Intel Xeon Gold 6226R processor. For
fine-tuning, we use top-50 BM25 hard negatives for each query . We use
10% of training data as a validation set. The learning rate is set to
$`10^{-6}`$ for Contriever-MS and $`10^{-7}`$ for SPECTER-v2, after
searching among $`\{10^{-7}, 10^{-6}, ..., 10^{-3}\}`$. We set the batch
size as $`64`$ and the weight decay as $`10^{-4}`$. We report the
average performance over five independent runs. For all query generation
methods, we use gpt-3.5-turbo-0125. For all methods, we generate five
queries for each document ($`M=5`$). For the few-shot examples in the
prompt, we randomly select five annotated examples, which are then
excluded in the evaluation process . We follow the textual instruction
used in . For other baseline-specific setups, we adhere to the
configurations described in the original papers. For the consistency
filtering, we set $`N=5`$.
CCExpand. For all LLM-based baselines and CCExpand, we use
gpt-4o-mini.6 In our experiments, we set $`\alpha = 0.6`$ for
CSFCube and $`\alpha = 0.4`$ for DORIS-MAE to balance the contributions
of overall and concept-focused similarities. We generate five snippets
per document, matching the number of concept-aware queries produced by
CCQGen. For fair comparison across all context generation baselines, we
keep both the number and type of auxiliary contexts consistent.
Specifically, all document-expansion methods use five pseudo-queries,
GRF generates topics, keywords, and summaries, and HyDE produces five
hypothetical documents.
Experiment results for CCQGen
In this section, we present comprehensive experiments evaluating the effectiveness of CCQGen.
Compared methods
We compare various synthetic query generation methods. For each document, we generate five relevant queries .
- GenQ employs a specialized query generation model, trained with
massive document-query pairs from the general domains. We use T5-base,
trained using approximately $`500,000`$ pairs from MS MARCO dataset :
BeIR/query-gen-msmarco-t5-base-v1.
CCQGen can be integrated with existing LLM-based methods to enhance the concept coverage of the generated queries. We apply CCQGen to two recent approaches, discussed in Section 2.2.
-
Promptgator is a recent LLM-based query generation method that leverages few-shot examples within the prompt.
-
Pair-wise generation is the state-of-the-art method that generates relevant and irrelevant queries in a pair-wise manner.
Additionally, we devise a new competitor that adds more instruction in the prompt to enhance the quality of queries: Promptgator_diverse is a variant of Promptgator, where we add the instruction “use various terms and reduce redundancy among the queries”.
Effectiveness of CCQGen
Table [tab:main] presents retrieval performance after fine-tuning with various query generation methods. CCQGen consistently outperforms all baselines, achieving significant improvements across various metrics with both backbone models. We observe that GenQ underperforms compared to LLM-based methods, showing the advantages of leveraging the text generation capability of LLMs. Also, existing methods often fail to improve the backbone model (i.e., no Fine-Tune), particularly Contriever-MS. As it is trained on labeled data from general domains, it already captures overall textual similarities well, making further improvements challenging. The consistent improvements by CCQGen support its efficacy in generating queries that effectively represent the scientific documents. Notably, Promptgator_diverse struggles to produce consistent improvements. It often generates redundant queries covering similar aspects, despite increased diversity in their expressions (further analysis provided in Section 6.2.6). This underscores the importance of proper control over generated content and supports the validity of our approach.
Impact of amount of training data. In Figure 6, we further explore the retrieval performance by limiting the amount of training data, using Contriever-MS as the backbone model. The existing LLM-based generation method (i.e., Pair-wise gen.) shows limited performance under restricted data conditions and fails to fully benefit from an increasing volume of training data. This supports our claim that the generated queries are often redundant and do not effectively introduce new training signals. Conversely, CCQGen consistently delivers considerable improvements, even with a limited number of queries. CCQGen guides each new query to complement the previous ones, allowing for reducing redundancy and fully leveraging the limited number of queries.
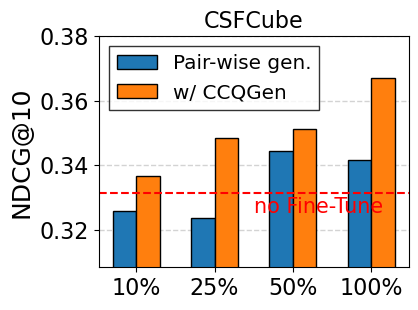
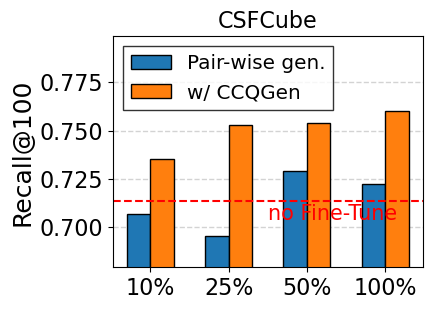
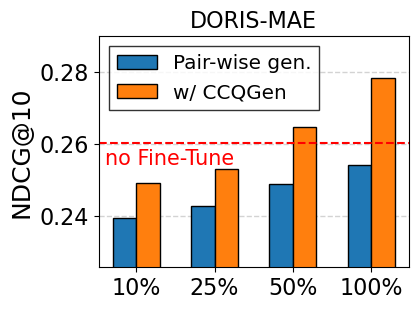
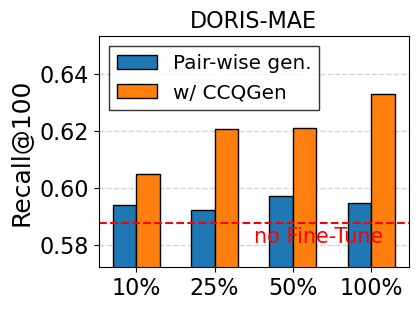
Compatibility with retrieval enhancement methods
Many recent methods enhance retrieval by incorporating additional signals such as LLM-generated semantic cues and topic-level relevance modeling . To examine the compatibility of CCQGen with these approaches, we integrate it with two representative enhancement techniques: (1) GRF , which augments queries using LLM-generated contexts; (2) ToTER , which measures relevance using taxonomy-grounded topic distributions. In addition, the concept-aware relevance modeling in Eq. [eq:dual_score], originally used in CCQGen for query filtering, can also be applied at inference time to provide complementary concept-matching signals. We denote this extended variant as CCQGen++.
Across all comparisons, we use the same retriever architecture (Contriever-MS) fine-tuned with CCQGen(prompting scheme: pair-wise generation). Table [tab:compatibility] reports the performance gains. The results show that our concept-based framework integrates well with existing enhancement strategies and consistently yields additional improvements. Also, CCQGen++ achieves the strongest overall performance across datasets, showing that concept-level signals offer complementary information beyond what conventional enhancement methods capture. These findings indicate that the academic concept index can function as a flexible and broadly applicable component within diverse retrieval pipelines. Exploring integration with other techniques is a promising direction for future work.
Effectiveness of concept-based filtering
Figure 7 presents the improvements achieved through the filtering step, which aims to remove low-quality queries that the document does not answer. The proposed filtering technique can enhance retrieval accuracy by incorporating concept information. This enhanced accuracy helps to accurately measure round-trip consistency, effectively improving the effects of fine-tuning.
Results with a smaller LLM
In Table [tab:Llama], we explore the effectiveness of the proposed approach using a smaller LLM, Llama-3-8B, with Contriever-MS as the backbone model. Consistent with the previous results, the proposed techniques (CCQGen and CCQGen++) consistently improve the existing method. We expect CCQGen to be effective with existing LLMs that possess a certain degree of capability. Since comparing different LLMs is not the focus of this work, we leave further investigation on more various LLMs and their comparison for future study.
Analysis of generated queries
We analyze whether CCQGen indeed reduces redundancy among the queries and includes a variety of related terms. We introduce two criteria: (1) redundancy, measured as the average cosine similarity of term frequency vectors of queries.7 A high redundancy indicates that queries tend to cover similar aspects of the document. (2) lexical overlap, measured as the average BM25 score between the queries and the document. A higher lexical overlap indicates that queries tend to reuse terms from the document.
In Table [tab:query_analysis], the generated queries show higher lexical overlap with the document compared to the actual user queries. This shows that the generated queries tend to use a limited range of terms already present in the document, whereas actual user queries include a broader variety of terms. With the ‘diverse condition’ (i.e., Promptgator_diverse), the generated queries exhibit reduced lexical overlap and redundancy. However, this does not consistently lead to performance improvements. The improved term usage often appears in common expressions, not necessarily enhancing concept coverage. Conversely, CCQGen directly guides each new query to complement the previous ones. Also, CCQGen incorporate concept-related terms not explicitly mentioned in the document via enrichment step (Section 3.2). This provides more systematic controls over the generation, leading to consistent improvements. Furthermore, in Table [tab:case_study], we provide an additional case study that compares two approaches. CCQGen shows enhanced term usage and concept coverage, which supports its superiority in the previous experiments.
Experiment results for CCExpand
In this section, we present comprehensive experimental evaluations of CCExpand.
Compared methods
We compare CCExpand with a range of LLM-based auxiliary context generation approaches. First, we consider recent methods that expand either the document or the query using LLM-generated contexts:
-
Doc expansion: A widely used strategy is to augment each document with synthetic queries to mitigate term mismatch with real user queries. Following prior work, we evaluate two variants of document expansion: (i) the strongest competing query generation method (i.e., pair-wise generation), denoted BestQGen, and (ii) document expansion using our concept-aware queries generated by CCQGen, denoted Ours.
-
GRF : It performs query expansion by prompting LLMs to generate diverse auxiliary contexts such as keywords, entities, and summaries. The expanded queries are directly used during relevance matching.
-
CCExpand$`--`$: A variant of CCExpand that averages all LLM-generated snippets into a single vector representation. This baseline isolates the benefit of selecting the most concept-aligned snippet, allowing us to measure the importance of focused concept matching.
Detailed comparative analysis with these methods is provided in Section 6.3.2. Second, we focus on comparing with HyDE , a recent context generation method closely related to CCExpand.
- HyDE: It generates multiple hypothetical documents conditioned on the query. These documents introduce terms and expression styles not explicitly present in the original query, enriching the semantics for retrieval. The final relevance is computed based on the weighted sum of similarities with both the original query and the generated hypothetical documents.
Though effective, it does not consider document-level concept structure and performs online expansion, which increases latency at inference time. Furthermore, because HyDE improves query-side context, it can be combined with our document-side augmentation (CCExpand) for additional benefits. The detailed results are presented in Section 6.3.3.
Comparison with document and query expansion methods
Table [tab:cc_expand_results] presents retrieval performances with various context generation methods. CCExpand outperforms all compared methods across most metrics. Notably, simply expanding documents (i.e., Doc exp. (BestQGen)) or queries (i.e., GRF) often degrades the retrieval performance, indicating that naively leveraging LLM-generated contexts does not necessarily guarantee improvements. Interestingly, ‘Doc exp. (Ours)’, a concatenation of our concept-aware queries to documents, yields consistent gains compared to ‘Doc exp. (BestQGen)’. This underscores the importance of concept-grounded signals in context augmentation. However, this approach remains limited: once the expanded document is compressed into a single embedding, much of its concept-specific information becomes diluted. In contrast, CCExpand achieves consistent and substantial improvements by explicitly identifying and utilizing the snippet most aligned with the query. Interestingly, averaging similarity scores over all snippets yields limited effectiveness, as the averaging dilutes the most discriminative concept signals. This result supports our design choice of selecting the most relevant snippet for relevance matching.
Comparison with HyDE
We provide a comparative analysis with HyDE in terms of both retrieval effectiveness and efficiency, highlighting the advantages of our concept-focused expansion.
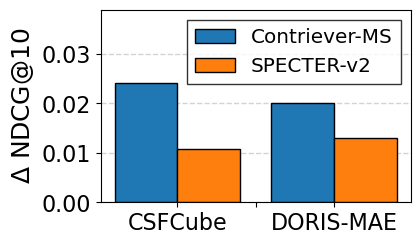
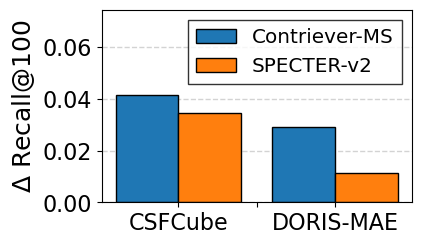
Retrieval effectiveness. Table [tab:hyde_cc_expand_results] summarizes the retrieval performance. For a fair comparison, both HyDE and CCExpand generate the same number of hypothetical documents and snippets (five in our experiments). The results reveal two key findings regarding stability and synergy. First, HyDE shows notable performance instability across different backbones; with Contriever-MS, it often underperforms the backbone itself (marked in red), likely due to hallucinations or domain mismatches introducing noise. In contrast, CCExpand consistently outperforms the backbone in all settings, showing strong robustness. Second, the hybrid approach, HyDE + CCExpand, achieves the best overall performance. This suggests a complementary relationship: while HyDE enriches the query context, CCExpand anchors the relevance matching with precise, concept-grounded snippets from the document, effectively mitigating noise introduced by HyDE.
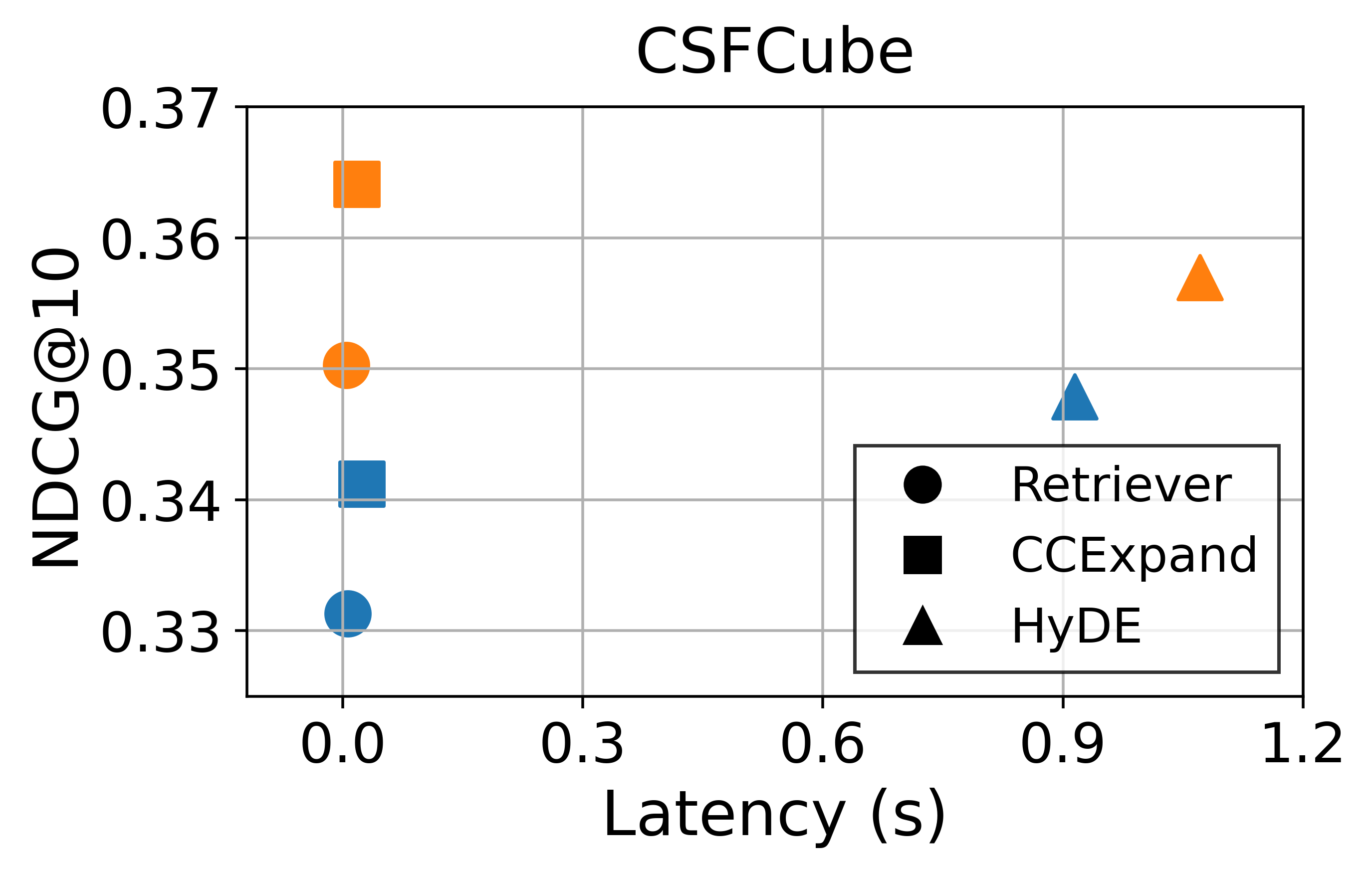
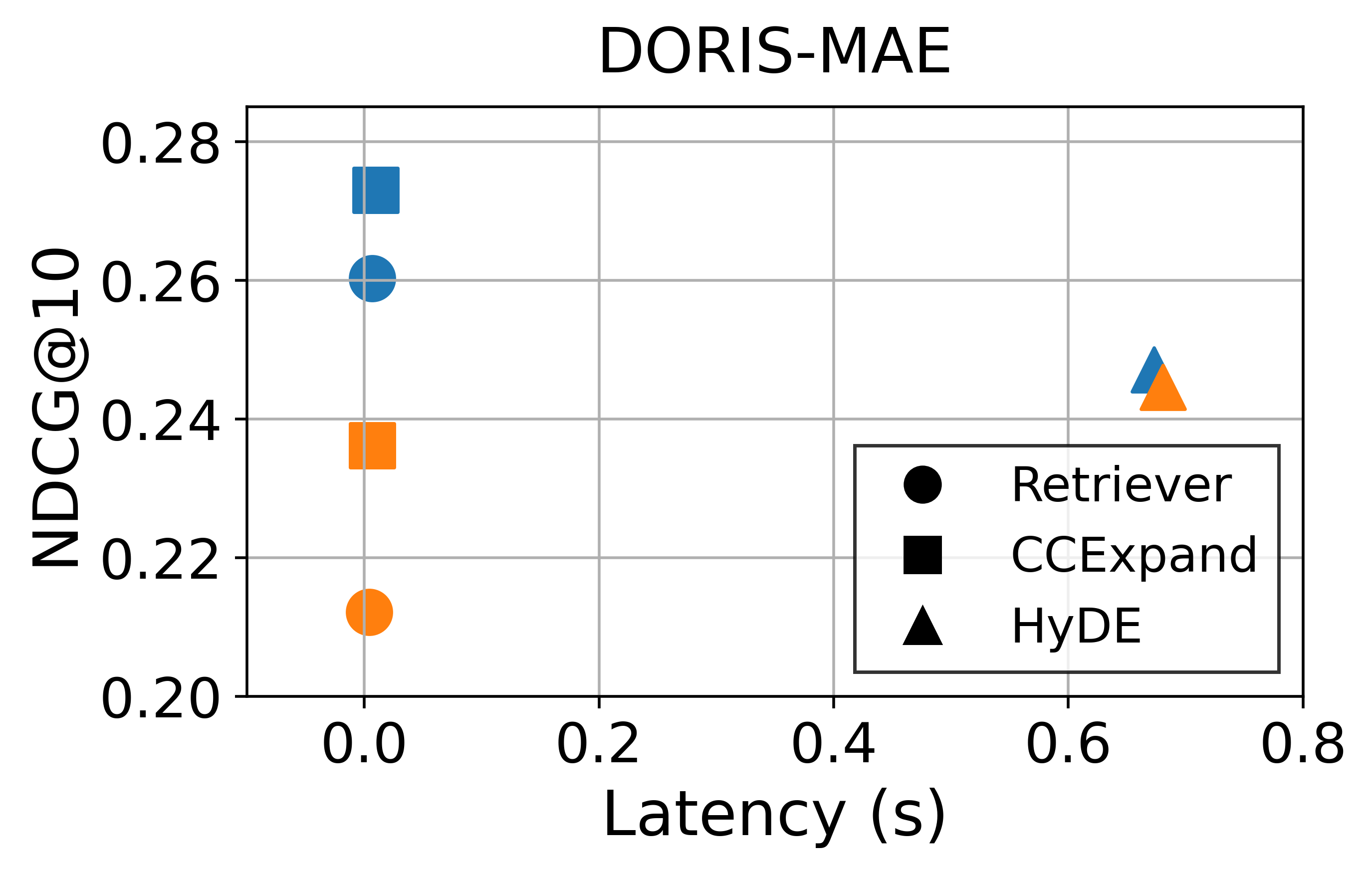
Effectiveness-efficiency trade-off. In addition to retrieval performance, inference latency is a critical factor for real-world deployment. Figure 10 illustrates the trade-off between effectiveness and inference latency. Latency is measured on an Intel Xeon Gold 6530 CPU with a single NVIDIA RTX PRO 6000 Blackwell Max-Q GPU. While HyDE yields improvements to some extent, these gains come at the costs of substantially higher latency. This reflects its core limitation: the reliance on LLM inference at serving time, making it difficult to deploy in latency-sensitive retrieval systems. In contrast, CCExpand also introduces additional computations due to the use of concept-focused snippets, but all snippet generation and indexing are performed offline. As a result, the runtime overhead during retrieval is negligible across all settings.
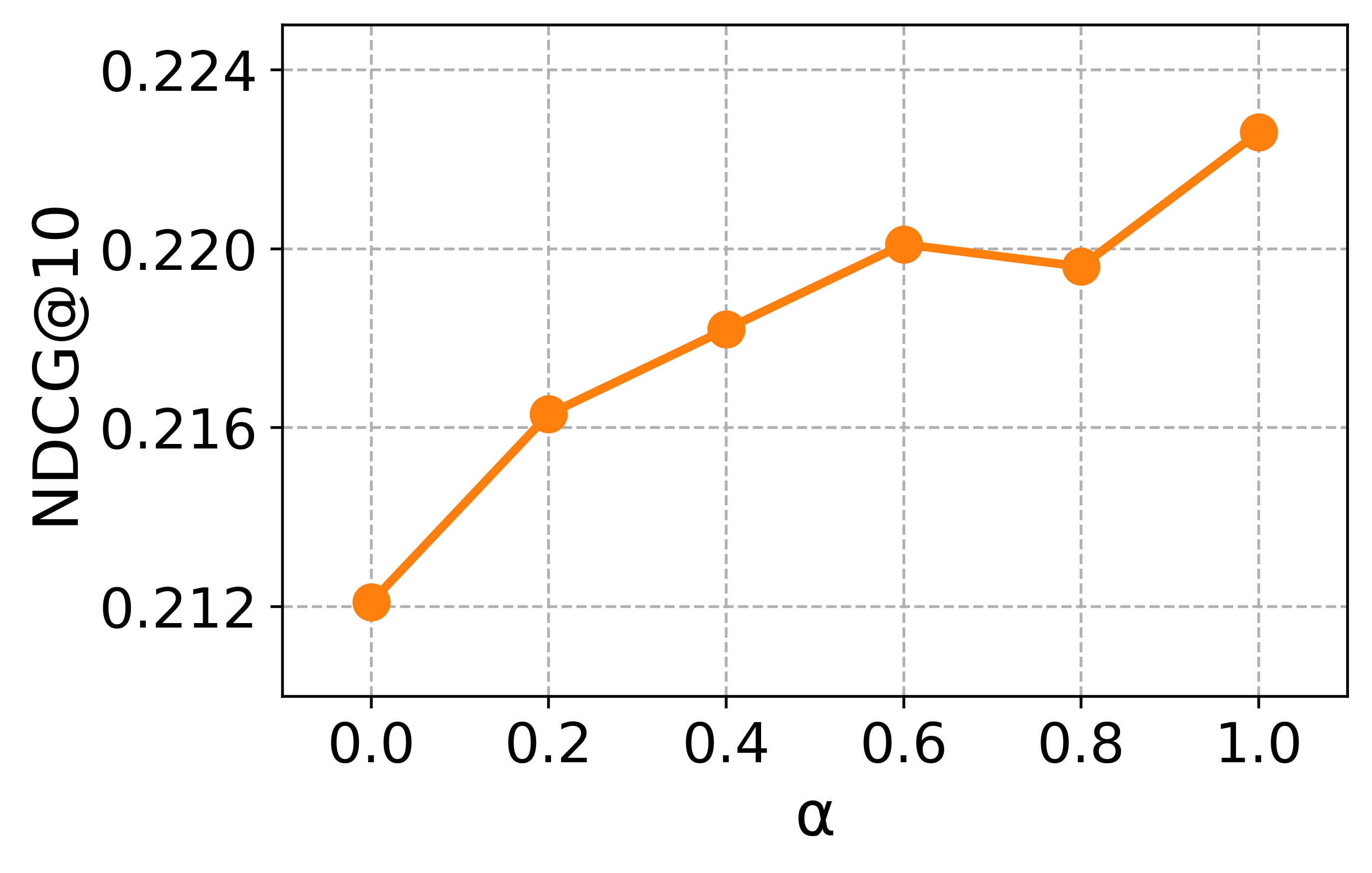
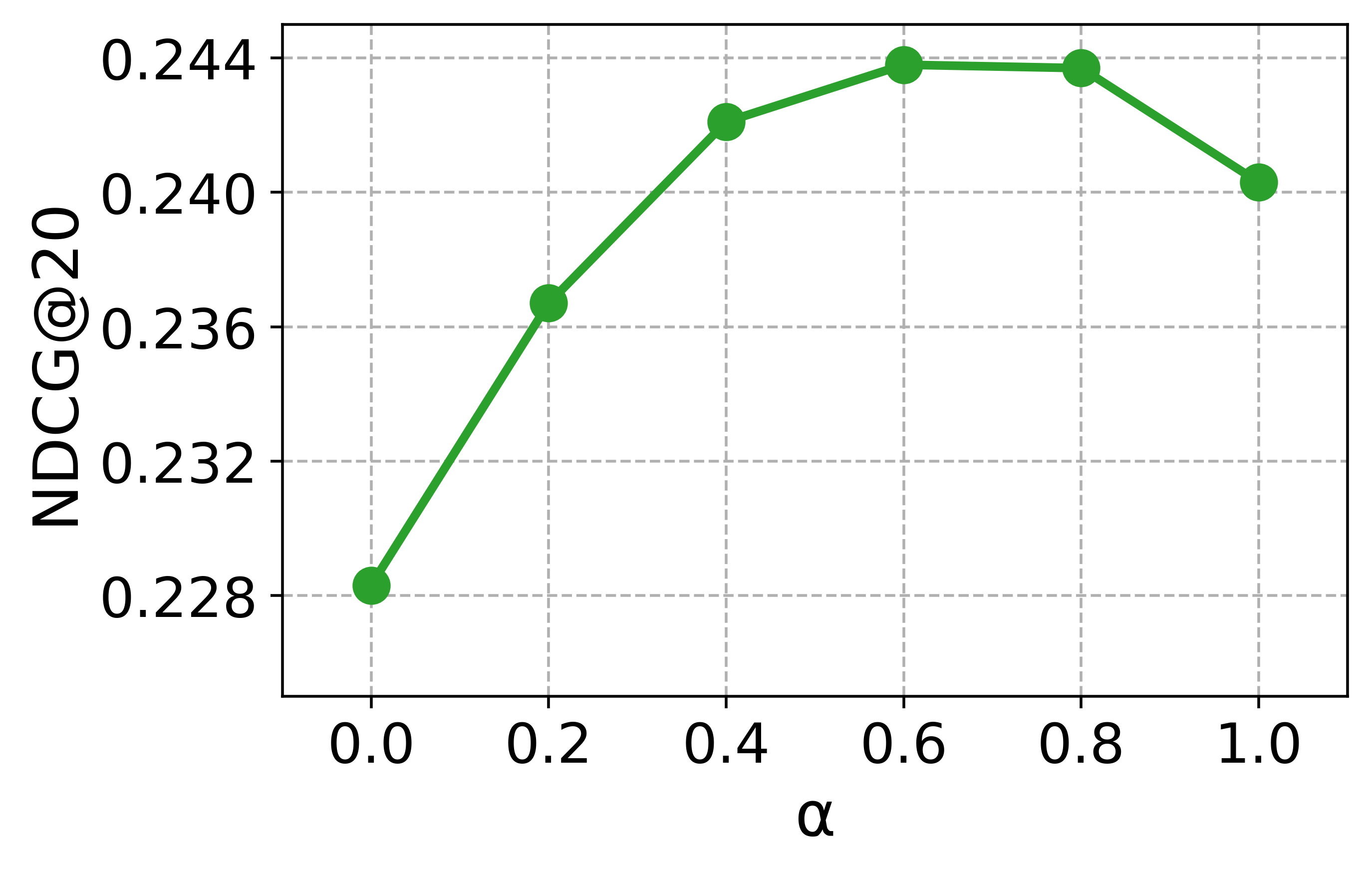
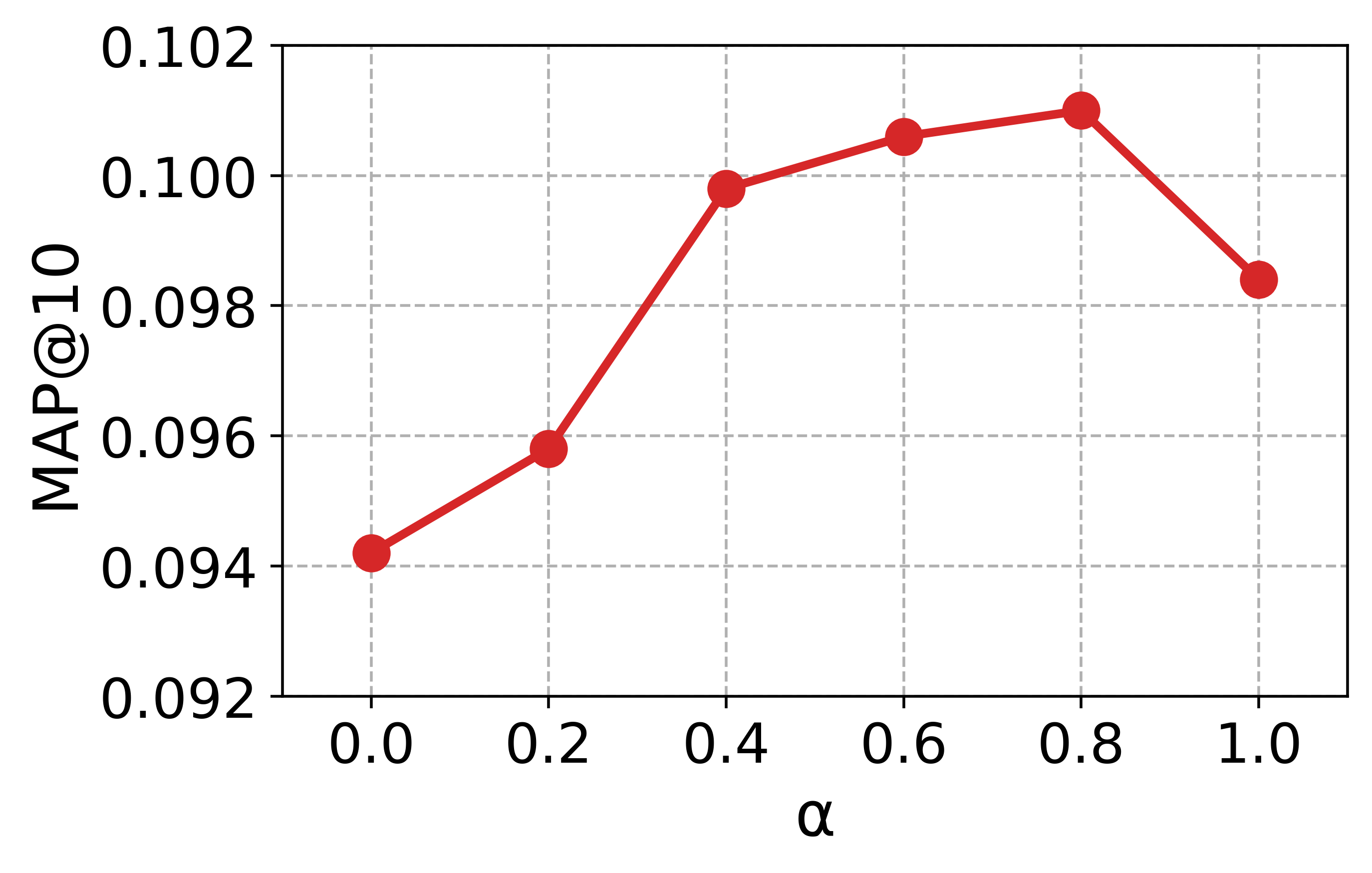
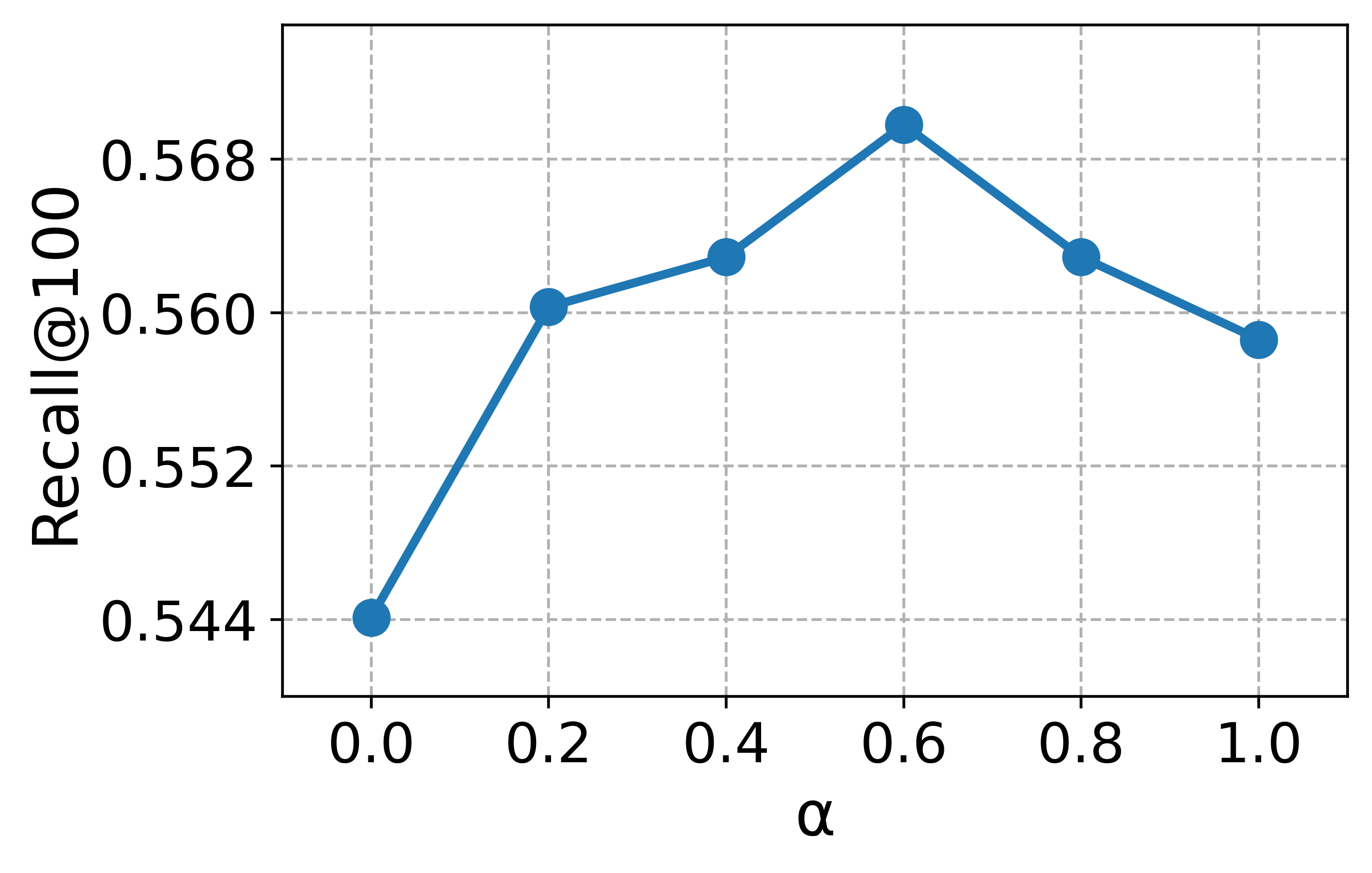
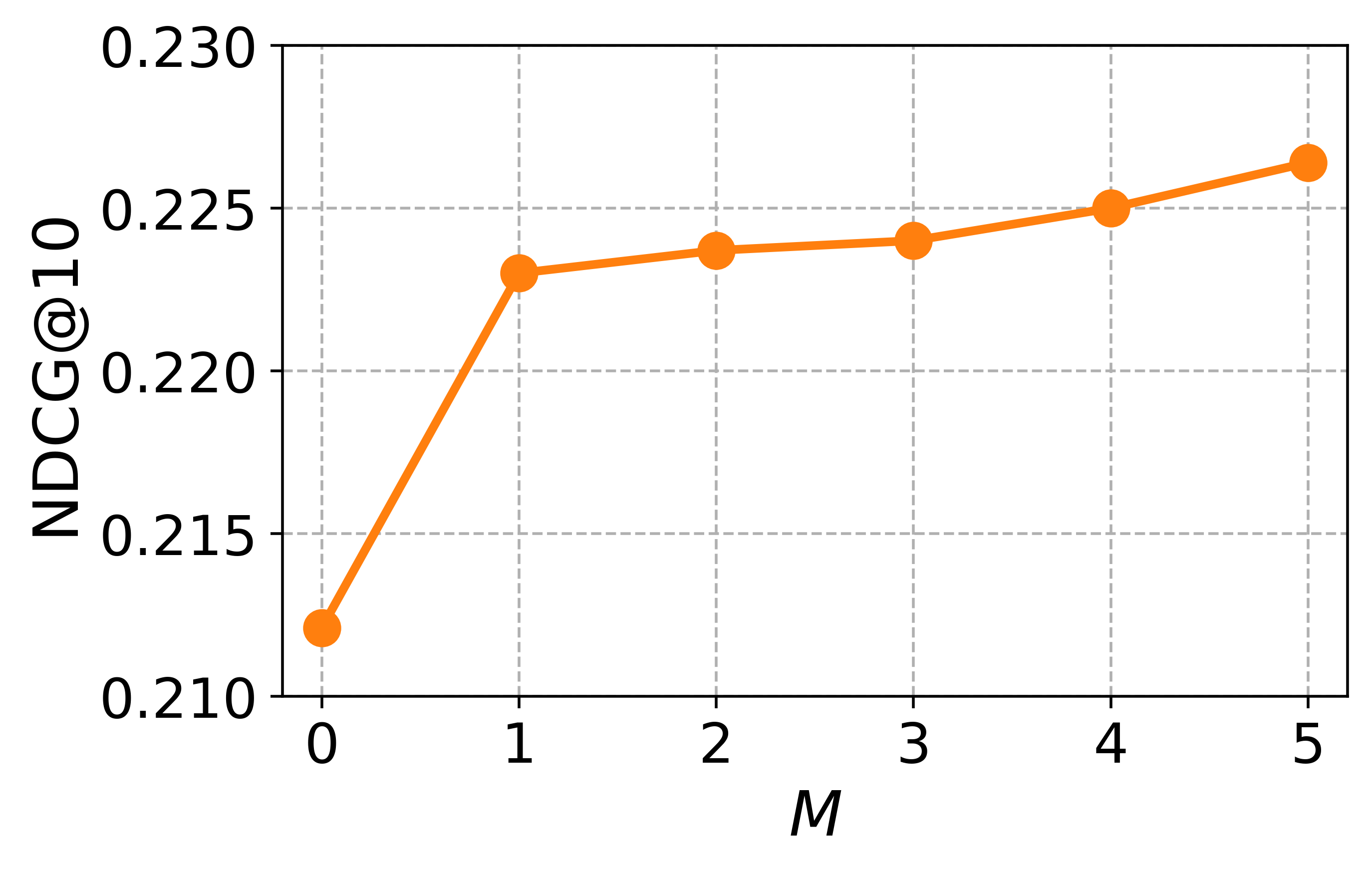
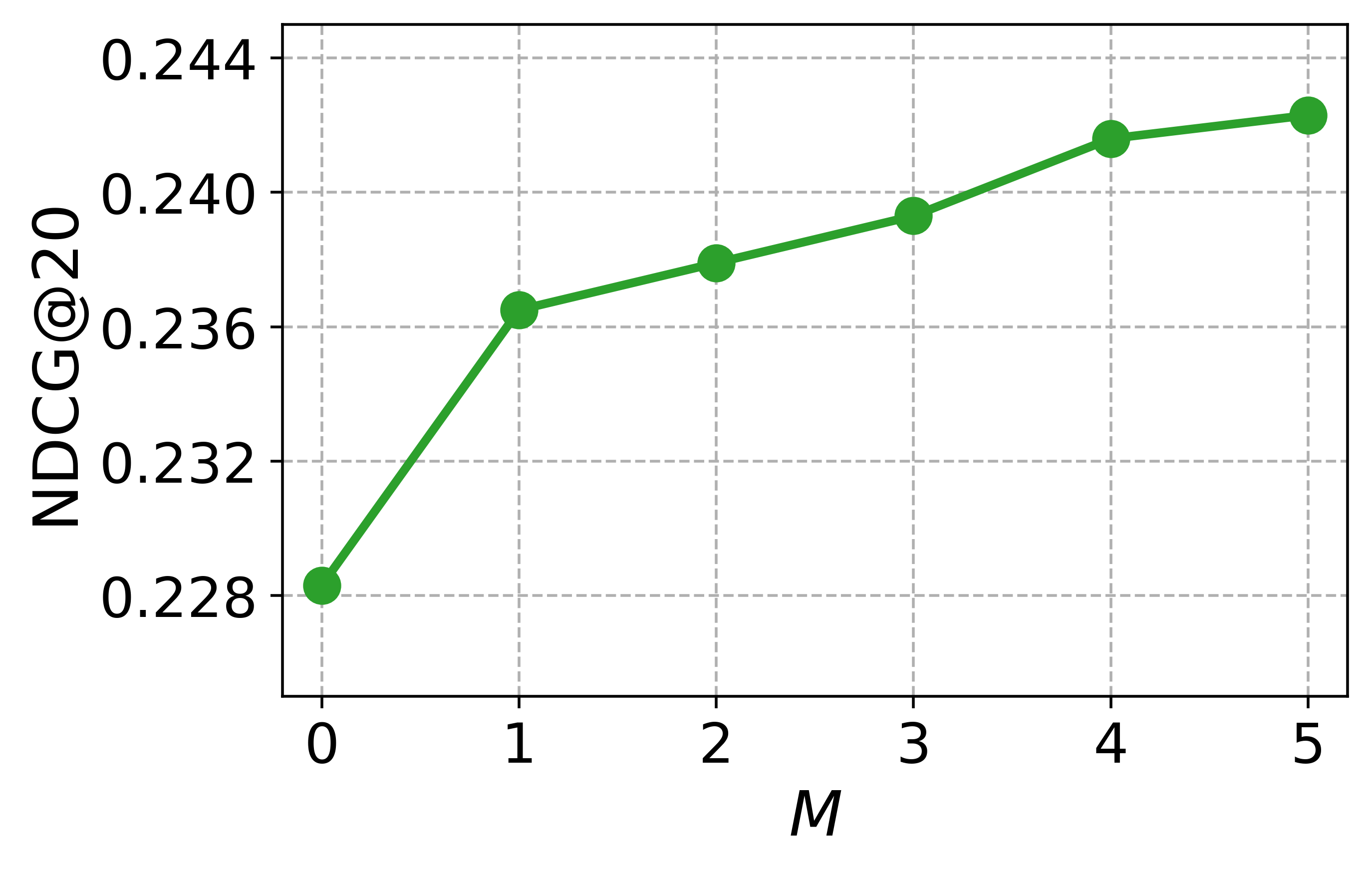
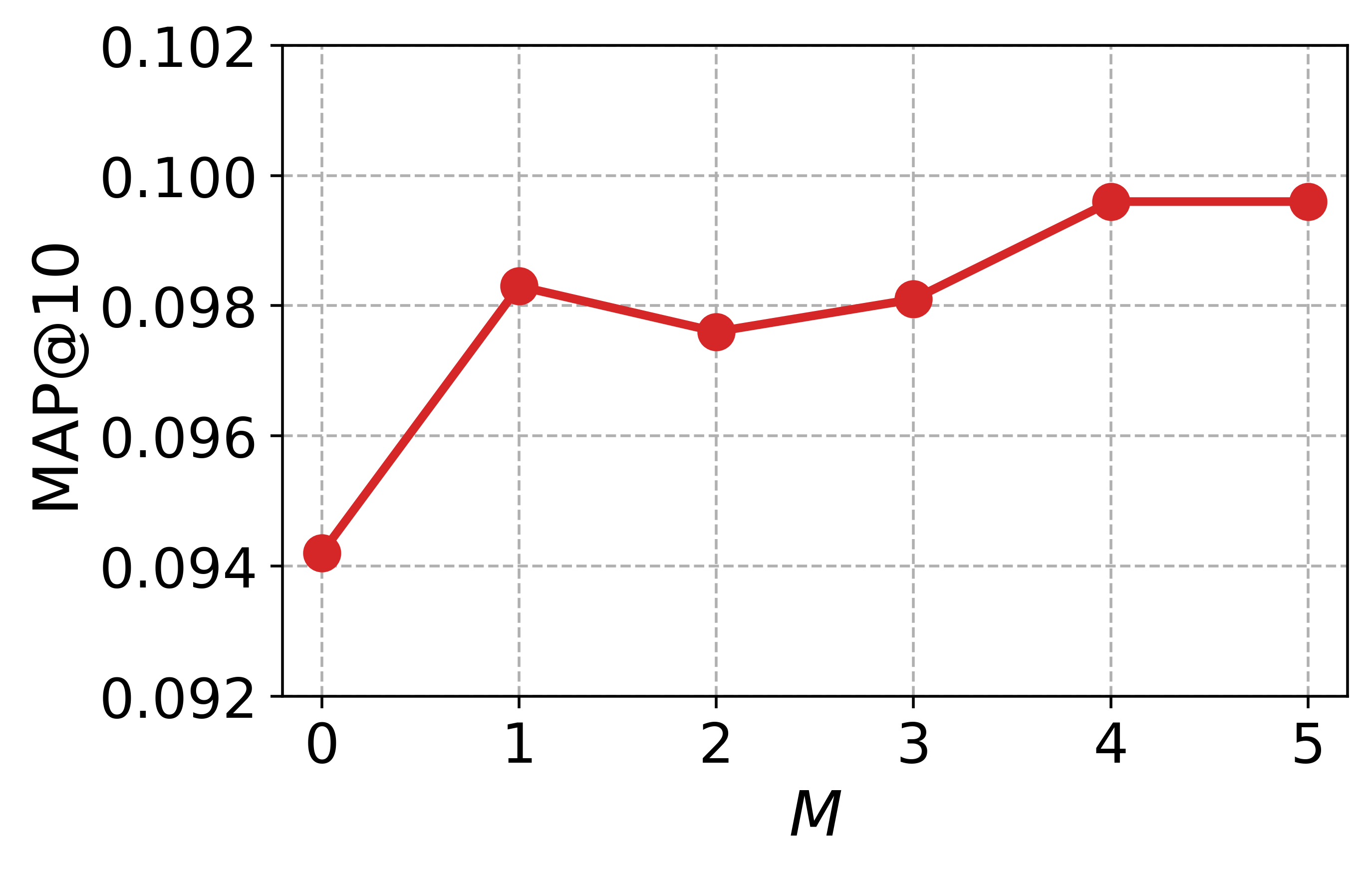
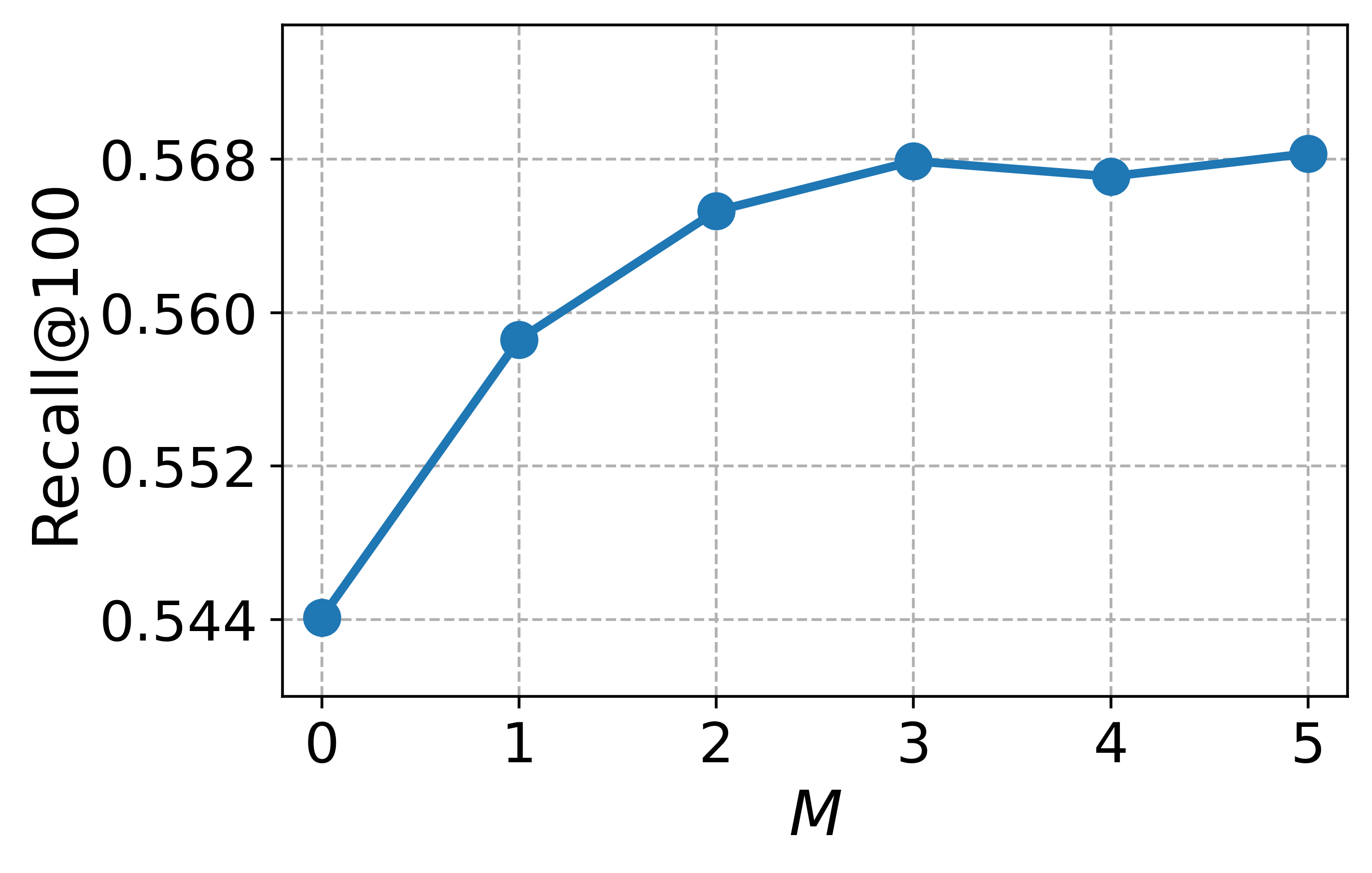
Hyperparameter study
To guide the hyperparameter selection of CCExpand, we conduct a detailed analysis on DORIS-MAE using SPECTER-v2 as the backbone model. In Figure 13, we examine two hyperparameters: the balancing coefficient $`\alpha`$, which controls the contribution of concept-focused similarity, and the number of snippets $`M`$.
Impact of the balancing coefficient. Most metrics peak at values between 0 and 1, and the best results are obtained around $`\alpha \in \{0.6, 0.8, 1.0\}`$, indicating that the original document and the concept-focused snippets provide complementary semantic signals. This observation further supports our methodology, showing that representing both texts as separate vectors enables more effective relevance matching between user queries and scientific documents.
Impact of the number of snippets. We observe a substantial performance leap when increasing $`M`$ from 0 to 5, where $`M=0`$ corresponds to using only the original document. The performance gains become less pronounced after $`M=3`$, and the best results are obtained around $`M \in \{4,5\}`$, confirming the benefit of incorporating multiple concept-specific views of the document. Thus, while larger $`M`$ yields the highest effectiveness, using $`M=3`$ offers a practical trade-off by reducing generation cost while retaining most of the performance gains.
Case study of CCExpand
Table [tab:rank_improvement_case] presents case studies of CCExpand on DORIS-MAE. Leveraging the concept index and the concept-aware queries, CCExpand generates concise snippets that articulate the specific concepts discussed in each document. Notably, by tailoring each snippet as a direct response to the concept-aware query, the generated text elaborates the underlying concepts using broader and related terminology, resulting in a higher semantic overlap with the user query. By matching the user query against the most concept-aligned snippet, CCExpand can effectively compare fine-grained conceptual signals, improving retrieval quality.
Conclusion
We introduce the academic concept index, a structured representation of document-level concept information, and investigate how it can systematically guide two major lines of retrieval enhancement. First, we propose CCQGen, a concept-aware synthetic query generation method that adaptively conditions LLMs on uncovered concepts to produce complementary queries with broader conceptual coverage. Second, we introduce CCExpand, a training-free context-augmentation method that generates concept-focused snippets and strengthens relevance matching through concept-centric signals. These two components provide complementary benefits: CCQGen improves the quality and diversity of training data for fine-tuning, whereas CCExpand enhances inference-time relevance estimation without requiring any retriever updates. Extensive experiments validate that the proposed methods substantially improve conceptual alignment, reduce redundancy, and boost retrieval performance. We believe that integrating concept-aware signals into broader retrieval pipelines such as reranking, continual updating offers promising directions for future research.
Acknowledgements. This work was supported by KT(Korea Telecom)-Korea University AICT R&D Cener, ICT Creative Consilience Program through the IITP grant funded by the MSIT (IITP-2025-RS-2020-II201819), IITP grants funded by the MSIT (RS-2024-00457882), and Basic Science Research Program through the NRF funded by the Ministry of Education (NRF-2021R1A6A1A03045425).
📊 논문 시각자료 (Figures)

A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
For example, “Given a document, generate five search queries for which the document can be a perfect answer”. The instructions vary slightly across methods, typically in terms of word choice. In this work, we follow the instructions used in . ↩︎
-
E.g., IEEE Taxonomy ( link ), ACM Computing Classification System ( link ). ↩︎
-
We visit multiple child nodes and create multiple paths, as a document usually covers various topics. For a node at level $`l`$, we visit $`l+2`$ nodes to reflect the increasing number of nodes at deeper levels of the taxonomy. The root node is level $`0`$. ↩︎
-
We use BERT with mean pooling as the simplest choice. ↩︎
-
The phrase set is obtained using an off-the-shelf phrase mining tool . ↩︎
-
gpt-3.5-turbo-0125was categorized as a legacy model by OpenAI at the time of this study. ↩︎ -
We use CountVectorizer from the SciKit-Learn library. ↩︎