HFedMoE Resource-aware Heterogeneous Federated Learning with Mixture-of-Experts
📝 Original Paper Info
- Title: HFedMoE Resource-aware Heterogeneous Federated Learning with Mixture-of-Experts- ArXiv ID: 2601.00583
- Date: 2026-01-02
- Authors: Zihan Fang, Zheng Lin, Senkang Hu, Yanan Ma, Yihang Tao, Yiqin Deng, Xianhao Chen, Yuguang Fang
📝 Abstract
While federated learning (FL) enables fine-tuning of large language models (LLMs) without compromising data privacy, the substantial size of an LLM renders on-device training impractical for resource-constrained clients, such as mobile devices. Thus, Mixture-of-Experts (MoE) models have emerged as a computation-efficient solution, which activates only a sparse subset of experts during model training to reduce computing burden without sacrificing performance. Though integrating MoE into FL fine-tuning holds significant potential, it still encounters three key challenges: i) selecting appropriate experts for clients remains challenging due to the lack of a reliable metric to measure each expert's impact on local fine-tuning performance, ii) the heterogeneous computing resources across clients severely hinder MoE-based LLM fine-tuning, as dynamic expert activations across diverse input samples can overwhelm resource-constrained devices, and iii) client-specific expert subsets and routing preference undermine global aggregation, where misaligned expert updates and inconsistent gating networks in troduce destructive interference. To address these challenges, we propose HFedMoE, a heterogeneous MoE-based FL fine-tuning framework that customizes a subset of experts to each client for computation-efficient LLM fine-tuning. Specifically, HFedMoE identifies the expert importance based on its contributions to fine-tuning performance, and then adaptively selects a subset of experts from an information bottleneck perspective to align with each client' s computing budget. A sparsity-aware model aggregation strategy is also designed to aggregate the actively fine-tuned experts and gating parameters with importance weighted contributions. Extensive experiments demonstrate that HFedMoE outperforms state-of-the-art benchmarks in training accuracy and convergence speed.💡 Summary & Analysis
1. **HFedMoE Framework Introduction:** HFedMoE introduces a framework that customizes subsets of experts for each client to enable efficient fine-tuning of models. This is akin to creating personalized dishes using various ingredients.-
Expert Importance Identification: HFedMoE measures the contribution of each expert and prioritizes critical ones, similar to how a chef selects key ingredients for cooking.
-
Resource-aware Expert Selection: It dynamically chooses a subset of crucial experts aligned with each device’s computational budget without compromising model performance, much like a skilled cook making the best dish within limited time and resources.
📄 Full Paper Content (ArXiv Source)
Federated learning, mixture of experts, large-scale language model, fine-tuning.
Introduction
Recently, large language models (LLMs) such as GPT , LLaMA , and DeepSeek have attracted significant attention from both academia and industry due to their superior ability in handling high-complexity and large-scale datasets . LLMs generally follow a two-stage training procedure. First, LLMs are pre-trained on massive text corpora (e.g., Wikipedia) to learn universal linguistic and semantic representations. Second, the pre-trained LLMs are adapted to a downstream task with task-specific data. However, the excessive data required for fine-tuning LLMs raises serious privacy concerns, posing a substantial barrier to the implementation of LLM fine-tuning. For instance, clients are often reluctant to share their privacy-sensitive data, such as personal healthcare records or financial information , to train a shared LLM.
To address the above issue, federated learning (FL) has emerged as a viable alternative, which enables collaborative training across clients without exposing raw data. The standard FL procedure for LLM fine-tuning comprises three phases: i) Each client independently fine-tunes its LLM using local private dataset; ii) All clients upload their locally updated LLM to a central server for model aggregation (e.g., via weighted averaging); and iii) the aggregated LLM is distributed back to clients before the next training round. Despite its privacy-preserving nature, fine-tuning LLMs via FL is computationally prohibitive on resource-constrained devices . Commercial-grade on-device GPUs (e.g., NVIDIA Jetson Orin) lack sufficient processing capacities to fine-tune LLMs like LLaMA-2 7B, which demands nearly 60 GB of GPU memory1 and 187.9 TFLOPs per 4K tokens , far exceeding the capabilities of mobile client devices. To reduce the LLM fine-tuning overhead, parameter-efficient fine-tuning (PEFT) techniques such as LoRA and Adapters have been proposed. While PEFT significantly reduces the number of trainable parameters, it entails full forward and backward propagation through the entire LLM. Due to the large model size of LLMs, client devices still do not sufficiently meet the computing demands for PEFT LLM via FL. Even with LoRA, fine-tuning LLaMA-2 7B requires over 20 GB of GPU memory, which easily overwhelms most mobile client devices .
 style="width:8.5cm" />
style="width:8.5cm" />
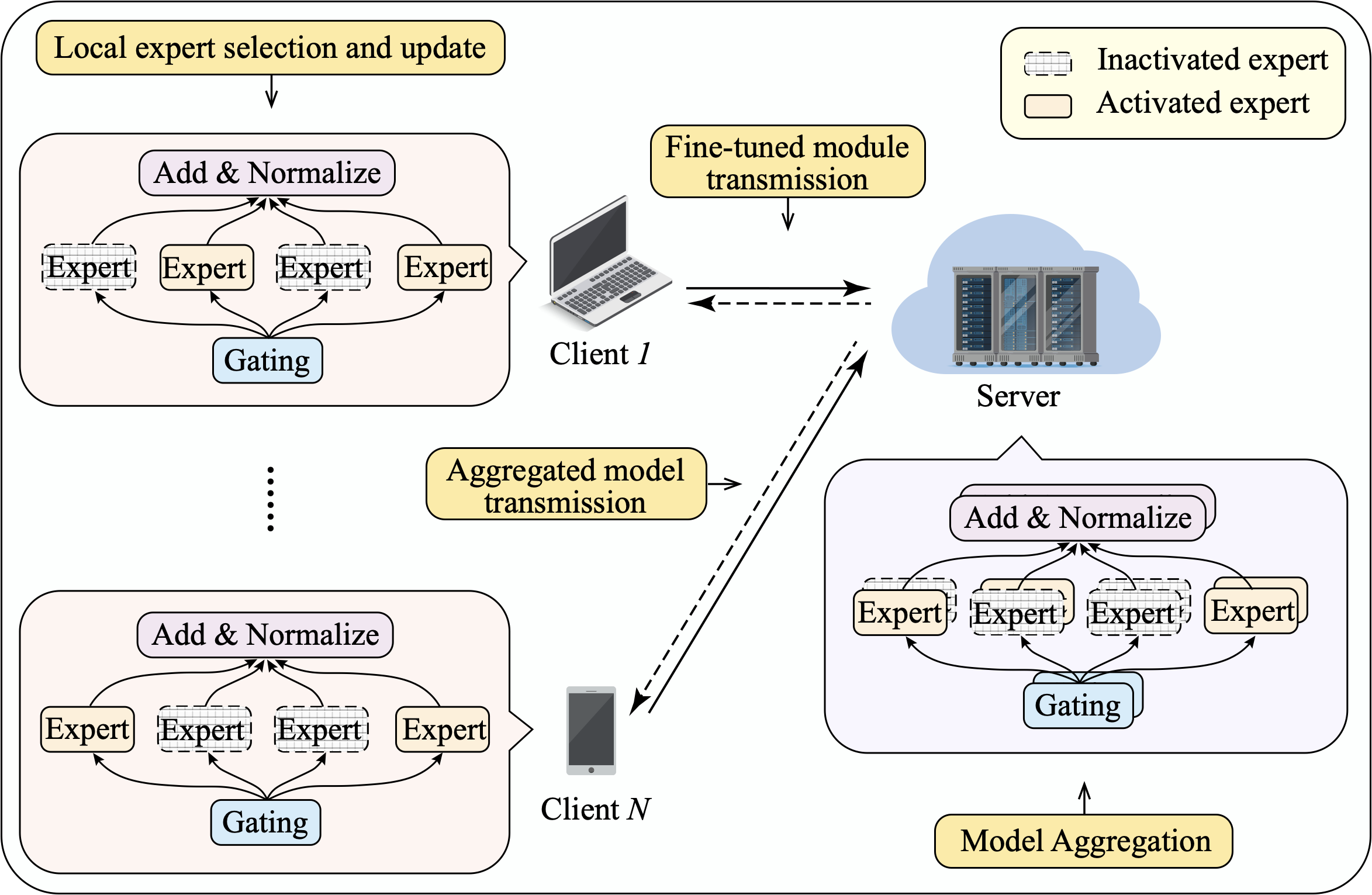
Mixture-of-experts (MoE) offers a structurally efficient solution to fine-tune LLMs on resource-limited mobile client devices via FL. Different from PEFT methods that require full-model forward and backward propagation, MoE activates only a small number of experts (e.g., top-1 or top-2) for each input, while keeping the rest inactive. This sparse activation preserves the full representational capacity of the model while substantially reducing the computational cost , particularly during gradient computation and weight updates, which dominate training cost in LLM fine-tuning . Beyond computational benefits, MoE is naturally well-suited for FL, as input-dependent expert routing enables client-specific specialization, facilitating personalized model adaptation. Fig. 1 illustrates how MoE integrates with FL for LLM fine-tuning. Each client device fine-tunes a personalized subset of experts selected by a gating network. Then, all client devices upload the gating network and experts to the server for model aggregation to update the LLM. This design can achieve comparable performance of large dense models (e.g., LLaMA-2 7B) while consuming less than 40% of the computation .
While integrating MoE into FL holds significant promise, it encounters several critical challenges. First, selecting appropriate experts for each client is non-trivial, due to client heterogeneity in local datasets. The performance of individual experts varies significantly across clients , i.e., certain experts may generalize well to specific client datasets, they may offer negligible benefit to others. As a result, a shared gating network for expert selection fail to capture these client-specific differences, leading to suboptimal expert utilization. This misalignment not only wastes computing resources but also compromises the overall performance of the model. Second, heterogeneous computing resources across clients severely limit the deployment of MoE-based fine-tuning via FL. The divergent expert activation across input tokens leads to an increased number of experts concurrently activated within one training batch , varying from a few for simple samples to many for complicated ones. This can easily exceed the computing capabilities of resource-constrained client devices, thus resulting in fine-tuning failures and severely lowering the overall training efficiency. Third, varying computing resources and data distributions results in client-specific expert selections and routing preferences, making model aggregation in MoE-based FL particularly challenging. Each client fine-tunes only a subset of experts aligned with its local data, leaving other experts undertrained and making clients’ gating networks to favor distinct expert subsets. Such misalignment causes severe interference during aggregation, thus degrading the generalization of the global model. We will empirically conduct measurement studies in Sec. 2 to investigate these challenges.
To tackle the above challenges, we propose a heterogeneous federated learning framework for MoE-based LLM fine-tuning, named HFedMoE, to selectively fine-tune the subset of experts for each client under heterogeneous edge computing systems. First, to select appropriate experts for each client device, we introduce an expert importance identification scheme that quantifies each expert’s contribution to the fine-tuning performance of diverse clients. Second, to accommodate the heterogeneous computing budgets of client devices, we propose a resource-aware expert selection method that dynamically selects the subset of critical experts to align with each device’s computing budget from the information bottleneck perspective, enhancing training efficiency without compromising model performance. Finally, to mitigate aggregation discrepancies caused by partial expert updates and diverse routing preferences, we design a sparsity-aware model aggregation strategy that updates only the experts actively trained on clients, while aggregating gating parameters with importance-weighted contributions, enhancing the generalization of the global MoE model with structural heterogeneity. The key contributions of this paper are summarized as follows.
-
We propose HFedMoE, a MoE-based FL fine-tuning framework to customize the subset of experts to each client for model training, enabling efficient LLM fine-tuning under heterogeneous edge computing capabilities.
-
We design an expert importance identification scheme to quantify experts’ contributions to local training performance, so as to prioritize critical experts for fine-tuning.
-
We devise resource-aware expert selection to dynamically select a subset of critical experts to align with each device’s computing budget during fine-tuning.
-
We develop a sparsity-aware model aggregation strategy to explicitly handle partial expert updates and routing inconsistency, mitigating performance degradation caused by structural heterogeneity across clients.
-
We empirically validate the fine-tuning performance of HFedMoE with extensive experiments, demonstrating the superiority of HFedMoE over state-of-the-art frameworks in both model accuracy and convergence speed.
This paper is organized as follows. Sec. 2 motivates the design of HFedMoE by revealing the challenges of incorporating MoE in FL network. Sec. 3 elaborates on the framework design, followed by performance evaluation in Sec. 5. Related works and technical limitations are discussed in Sec. 6. Finally, conclusions are presented in Sec. 7.
Challenges and Motivation
In this section, we conduct extensive pilot measurement studies to elaborate the key challenges of fine-tuning MoE-based LLM in federated learning, which motivates the design of HFedMoE.
Suboptimal Expert Utilization
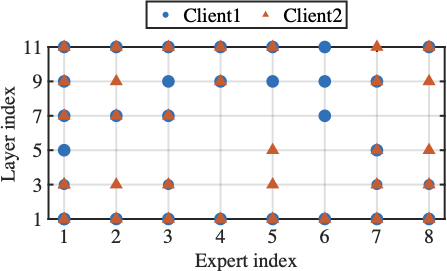
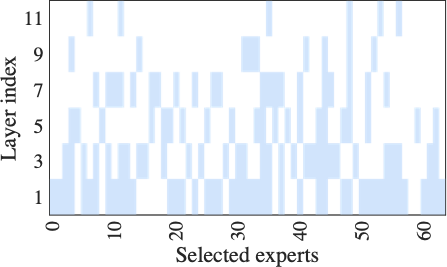
For MoE-based FL fine-tuning, expert routing is typically controlled by a shared global gating network . Although this enables centralized coordination, it fails to capture the heterogeneity of client-specific data distributions. Since each expert focuses on distinct semantic features , its contribution (i.e., the task-relevant information it provides) vary significantly among clients . However, the global gating network is optimized by average routing performance across all clients, ignoring client-specific preferences. This mismatch causes critical experts for some clients to be underutilized, while frequently activated experts may contribute little locally, ultimately leading to suboptimal expert utilization and degrading training performance.
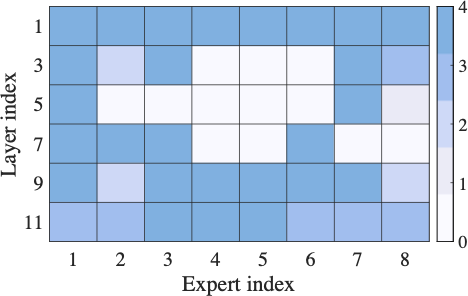
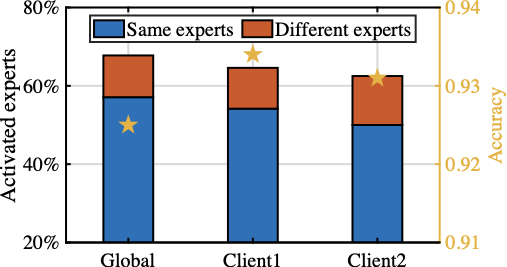
To investigate the impact of suboptimal expert utilization, we conduct a motivating study using Switch Transformer with 8 experts per layer on AGNew dataset . We compare global routing (i.e., all clients share a single gating network) with client-specific routing (i.e., each client independently trains its gating network). Fig. [fig:mtv_expert_selection] shows that local expert selections diverge significantly across clients, indicating the sensitivity of experts to local dataset. Furthermore, Fig.[fig:mtv_expert_performance] reveals that gating network aggregation changes local expert selections and fails to accurately prioritize vital experts to specific clients, thereby degrading local fine-tuning accuracy (yellow star in the figure) These observations underscore the necessity of identifying expert importance and selectively activating experts specific to each client for enhancing both efficiency and personalization.
Heterogeneous Computing Resources
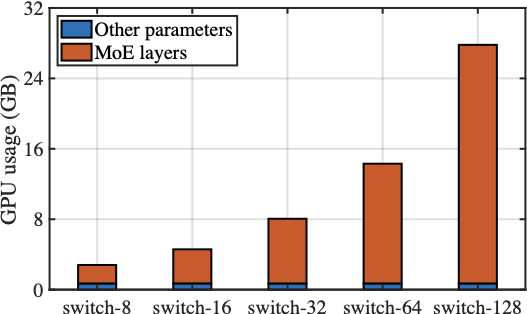
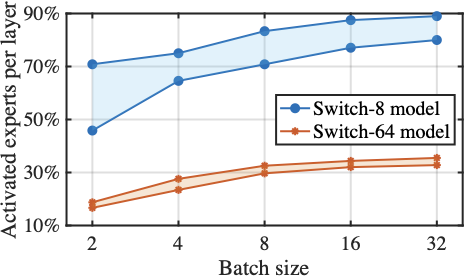
While MoE models enable sparse expert activation for efficient LLM fine-tuning, the heterogeneity in computing capabilities across client devices, stemming from differences in hardware configurations and deployment environments , poses significant challenges. Despite the selective activation of top-1 expert per token, variations in expert selection from one token to another across samples within a training batch often lead to varying number of experts being activated concurrently . This undermines the intended sparsity design of MoE and imposes a heavy computing burden on resource-constrained clients (e.g., those equipped with commercial-grade GPUs). Consequently, this mismatch in resource demand and availability makes on-device fine-tuning of FL infeasible. For instance, fine-tuning the DeepSeekMoE-16B model requires 74.4T FLOPs per 4K tokens , still exceeding the processing capabilities of most client GPUs and thus degrading the overall training efficiency.
To better understand the impact of heterogeneous client computing capabilities on FL training performance, we conduct motivating experiments using Switch Transformer with 8 or 64 experts per layer on the AGNews dataset. By analyzing expert activations at a fixed sequence length of 128 under varying batch sizes, Fig. [fig:mtv_computing_activation] reveals that even with top-1 routing and a small batch size of 2, over 15% of the 64 experts are activated—substantially exceeding the intended selection of one expert per layer. Additionally, Fig. [fig:mtv_computing_hetero] shows that the clients with limited resources frequently fail to complete local LLM fine-tuning, and severe disparities in computational capacity among clients significantly degrade the overall convergence and stability of collaborative training. These results underscore the negative impact of inefficient token-wise expert selection for resource-constrained MoE fine-tuning, motivating the design of a resource-aware expert selection mechanism.
Model Aggregation Discrepancy
In conventional federated learning, model aggregation methods assume uniform model structures and meaningful updates for all parameters. However, in MoE-based FL, each client fine-tunes only a sparse expert subsets tailored to its local data distribution through its gating network, resulting in structural discrepancies where many experts remain untouched or never used. Moreover, clients develop divergent routing preferences as their gating networks tend to favor distinct expert subsets, which leads to inconsistent updates of gating parameters for expert selection in each client. Directly aggregating such heterogeneous model structures introduces destructive interference, thus degrading the generalization of the global model.
 style="width:16cm" />
style="width:16cm" />
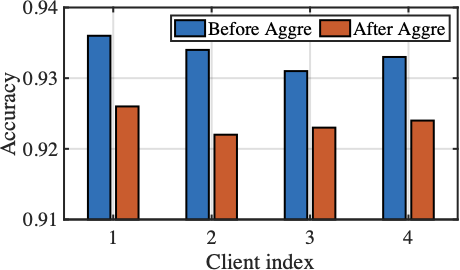
To empirically demonstrate how model discrepancies impact aggregation performance, we conduct an experiment on AGNews dataset using Switch Transformer with 8 experts, where each client independently selects and fine-tunes a subset of experts aligned with its local data. It is shown in Fig. [fig:mtv_aggregation_overlap] that nearly 25% of the experts are never activated across clients during local fine-tuning, indicating expert discrepancies in parameter updates. In contrast, over 20% of experts are selected by different clients, highlighting divergent routing preferences across clients. Moreover, Fig. [fig:mtv_aggregation_performance] reveals a notable performance gap in client-specific models before and after standard FedAvg aggregation, highlighting the degraded performance caused by both expert discrepancies and inconsistent gating network updates. These observations underscore the necessity of sparsity-aware aggregation strategies that explicitly handle the model discrepancies from client-specific routing preferences and expert selections, thereby fully realizing the potential of MoE-based LLM in federated environments.
Framework Design
In this section, we introduce HFedMoE, an MoE-based FL fine-tuning framework designed for heterogeneous edge computing systems to dynamically select the subset of critical experts. We will first outline the system overview and then present a detailed description of the HFedMoE framework.
Overview
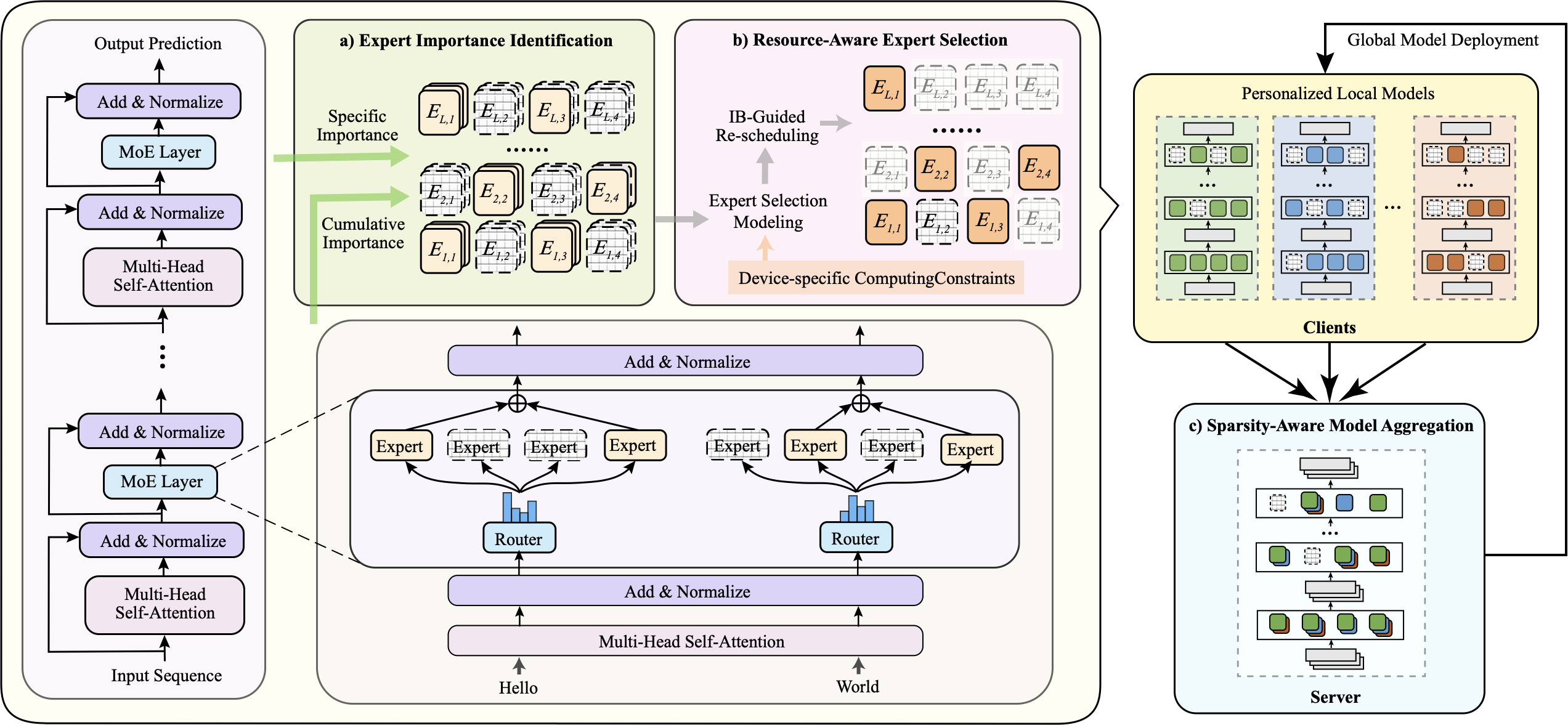
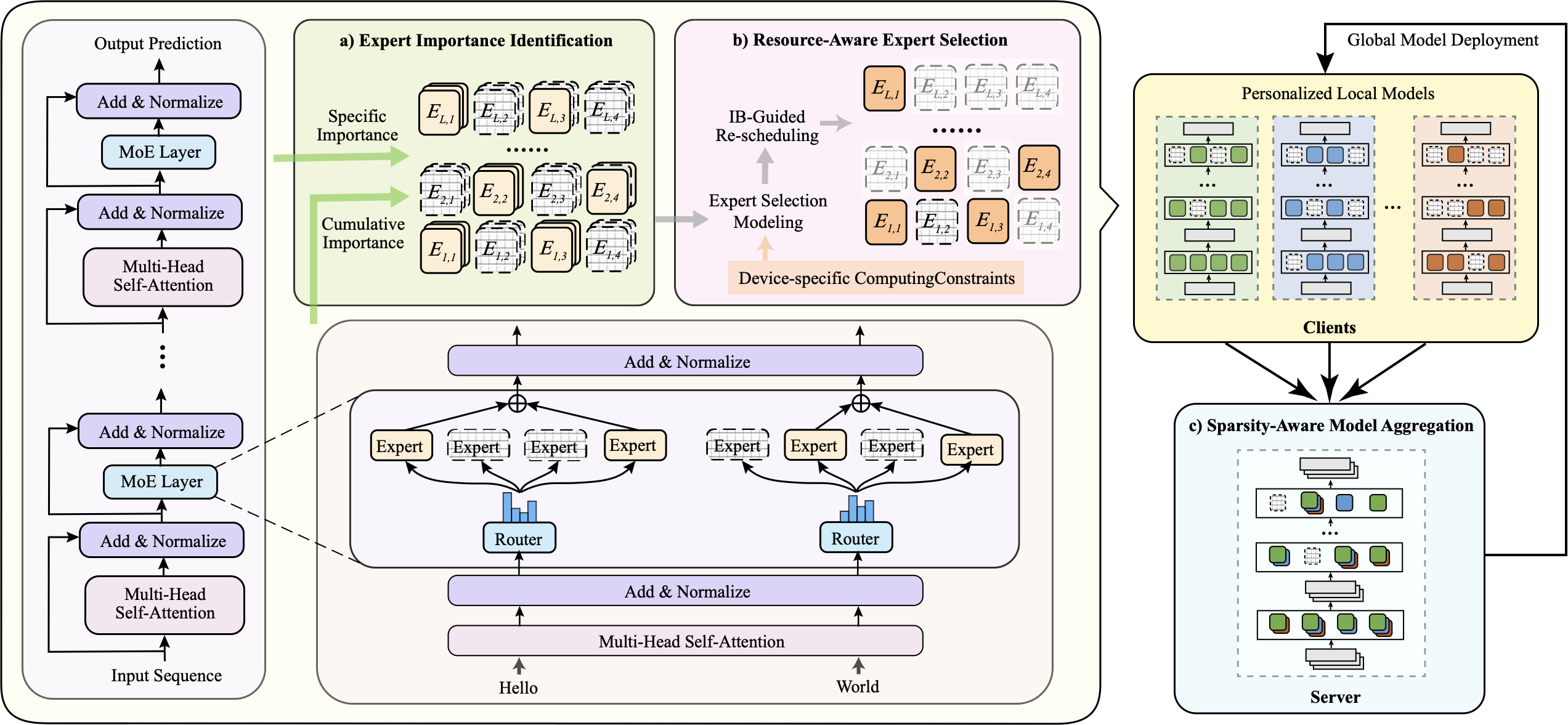
To tackle the above challenges, we propose HFedMoE, a resource-efficient FL framework for fine-tuning MoE-based LLMs under computing heterogeneity. Our design comprises three core components: expert importance identification, resource-aware expert selection, and selective model aggregation. First, to select appropriate experts for each client, we introduce an expert importance identification scheme that quantifies each expert’s contribution to local fine-tuning performance (Sec. 3.3). Second, to accommodate heterogeneous computing resources across clients during fine-tuning, the resource-aware expert selection module models the expert selection from the information bottleneck perspective (Sec. 3.4.1) and re-schedules the most critical experts for activation within client-specific computing budgets (Sec. 3.4.2). Finally, we design a sparsity-aware model aggregation strategy to selectively upload only active experts across varying model structures (Sec. 3.5.1) and adaptively aggregate the parameters of gating network with importance-weighted contributions (Sec. 3.5.2), enhancing global generalization while preserving critical local updates.
As shown in Fig. 5, the workflow of HFedMoE follows three steps: i) During local fine-tuning, each client identifies the importance of experts based on its local data. ii) Leveraging the estimated expert importance, clients selectively activate a subset of high-impact experts within their local computing budgets. iii) After local updates, only the actively trained experts and gating networks are uploaded. The server then performs sparsity-aware model aggregation and distributes the aggregated model to all clients for the next training round.
System Model
We consider a federated setting with $`C`$ clients collaboratively fine-tuning a shared MoE-based LLM under heterogeneous computing resource constraints. Each client $`c \in \{1, \dots, C\}`$ holds a private dataset $`\mathcal{D}_c`$, sampled from a distinct data distribution. The global model consists of a shared gating network $`\mathcal{R}`$ and an expert set $`\mathcal{E} = \{ \mathbf{E}_{1,1}, \dots, \mathbf{E}_{L,S}\}`$, where each of the $`L`$ MoE layers contains $`S`$ parallel experts. For each input token, the gating network computes a routing score and activates a top-$`k`$ subset of experts per layer ($`k \ll S`$). This sparse activation allows experts to specialize in local datasets across clients, facilitating personalized model adaptation with reduced computational cost.
During local training round $`t`$, each client $`c`$ updates only a selected expert subset $`\mathcal{E}_c \subseteq \mathcal{E}`$ and gating network $`\mathcal{R}_c`$ using its local data, constrained by its computing budget $`B_c`$. Let $`\theta_c^t`$ denote the local model parameters updated by client $`c`$ and $`\theta^t`$ denote the global model. Each client minimizes a local objective $`\mathcal{L}_c(\theta_c^t) = \mathbb{E}_{(x,y) \sim \mathcal{D}_c} \left[ \ell(f(x; \theta_c^t), y) \right],`$ where $`\ell(\cdot)`$ is the task-specific loss function and $`f(\cdot; \theta_c^t)`$ denotes the MoE model’s output with parameters $`\theta_c^t`$. After local training, clients upload the heterogeneous model parameters $`\{\mathcal{E}_c, \mathcal{R}_c\}`$ to the server, which then aggregates the received sparse updates to update global model $`\theta^{t+1}_{\text{global}}`$. Our objective is to enable each client to select critical experts tailored to its local data within computing constraints, while collaboratively contributing to a globally shared model that balances accuracy and efficiency.
Expert Importance Identification
Recalling Sec. 2.1, the gating network in MoE is typically optimized for average routing performance across all clients, often failing to accurately prioritize experts most beneficial to each client. This leads to suboptimal expert utilization and degraded fine-tuning performance, highlighting the need to estimate expert importance for more effective selection. Therefore, we propose an expert importance identification scheme that quantifies the contribution of each expert to local fine-tuning performance, enabling clients to select a subset of experts that are most relevant to their local data.
In standard MoE models, the gating network in each layer computes routing score $`G_e(x)`$ for each expert $`e`$ based on input token $`x`$. After softmax normalization, these scores reflect the relative contribution of each expert to the current input. Thus, the top-$`k`$ experts with the highest scores are selected for fine-tuning as
\begin{equation}
\mathcal{E}_c = \text{Top-}k\left(\{Softmax(\mathbf{G}(x))\}_{e \in \mathcal{E}}\right),
\end{equation}Finally, the output $`y`$ of this MoE layer is computed as a weighted sum of the selected experts:
\begin{equation}
y = \sum_{e \in \mathcal{E}_c} G_e(x) \cdot \mathbf{E}_e(x),
\end{equation}where $`\mathbf{E}_e(x)`$ represents the output of expert $`e`$’s network for input token $`x`$. This routing score $`G_e(x)`$ serves as an estimate of expert importance.
While this per-token routing mechanism supports dynamic expert selection, it operates on isolated tokens without considering consistent expert activations across samples. However, certain experts are frequently activated in local data and contribute more to specific clients , failing to capture these cross-sample activations limits model’s ability to learn client-specific expert preferences. To address this, we quantify expert importance by analyzing expert activations across all tokens within a batch. As mini-batch processing is standard in LLM training, this incurs negligible overhead while supporting more stable and personalized expert selection for resource-efficient fine-tuning. To the end, we identify experts that are either consistently useful across diverse inputs or particularly important for specific samples as follows.
-
Cumulative Importance: Experts with high cumulative contributions typically capture generalizable features , providing effective representation across diverse samples. Prioritizing consistently informative experts minimizes redundant activations, thereby promoting shared computation without sacrificing model performance. As a result, we define cumulative importance of expert $`e`$ as its averaged activation across all samples $`x_i`$ in the batch of size $`B`$, which is given by
MATH\begin{equation} s_b^{cumul}(e) = \frac{1}{B}\sum_{i=1}^{B} G_e(x_i). \end{equation}Click to expand and view moreThis metric reflects the activation frequency and response strength of expert $`e`$, serving as a surrogate for its ability to capture label-relevant features across the batch.
-
Specific Importance: Relying solely on the cumulative contribution across samples fails to capture experts that are infrequently activated but provide critical responses for specific, often hard-to-classify, samples. For instance, an expert may contribute substantially to only a few challenging instances, indicating strong class-specific representational capacity. Ignoring such experts risks degrading model performance on minority or difficult classes. To account for this, we introduce the specific importance, which evaluates contribution of experts in individual samples, ensuring that critical responses to challenging inputs are preserved. Specifically, we use the maximum routing score of each expert across all samples in a mini-batch to capture its maximum relevance and peak influence on any single sample, formulated as
MATH\begin{equation} s_b^{specific}(e) = \max_{1 \leq i \leq B} G_e(x_i). \end{equation}Click to expand and view moreThis metric captures the expert’s peak influence on single sample, ensuring that low-frequency but high-impact experts are preserved during fine-tuning.
Finally, the overall expert importance $`s_b(e)`$ for expert $`e`$ in the batch $`b`$ can be expressed as a weighted combination of its cumulative and specific importance:
\begin{equation}
\label{eq:expert_importance}
s_b(e) = \lambda \cdot s_b^{cumul}(e) + (1 - \lambda) \cdot s_b^{specific}(e),
\end{equation}where $`\lambda`$ is a hyperparameter that controls the trade-off between activation diversity and specificity. This allows us to strike a balance between generalization and personalization in expert selection, improving both efficiency and effectiveness.
Resource-aware Expert Selection
As explained in Sec. 2.2, fine-tuning MoE models on resource-constrained clients is hindered by excessive expert activations across samples. Existing studies primarily select top-$`k`$ experts per token based on routing scores, overlooking the cumulative computing burden across all tokens within a batch, often exceeding client capabilities. To address this bottleneck, we design a resource-aware expert selection strategy that adaptively limits the number of experts activated per batch according to each client’s computing budget.
Expert Selection Modeling
Achieving efficient fine-tuning on resource-constrained clients necessitates the selective activation of experts within each client’s computing budget. A straightforward approach is to randomly drop a number of experts selected by the gating network. However, it is observed in Fig. [fig:dsn_expert_number] that while reducing the number of experts lowers computational costs, it leads to notable performance degradation. Fortunately, Fig. [fig:dsn_expert_subset] reveals that expert selections are highly imbalanced, where a small subset of experts contributes most performance gains, while others offer marginal benefit. These observations motivate us to narrow the candidate expert set through a contribution-guidance selection strategy, thereby better aligning resource constraints without compromising model performance.
Inspired by the information bottleneck (IB) principle , the compact subset of experts can be viewed as a compressed representation that retains maximal task-relevant information under limited computational budgets, where the contribution of each expert is quantified by its task-relevant information, and the minimization of input redundancy encourages sparse expert activation. Therefore, we introduce an IB-based interpretation for expert selection modeling, enabling improved explainability and adaptability to heterogeneous client constraints.
Specifically, we reinterpret expert activation patterns over a batch as a stochastic latent representation $`\mathbf{z} = \{z_e, \forall e \in \mathcal{E}\}`$, where $`z_e \in \{0, 1\}`$ indicates whether expert $`e`$ is activated for a given input $`x`$. From the IB perspective, the expert activation pattern $`\mathbf{z}`$ serves as a compressed intermediate representation of the input $`x`$ for predicting the target label $`y`$. Based on the classical IB formulation , we aim to select a sparse subset of experts by maximizing the following objective:
\begin{equation}
\label{eq:ib_objective}
\max_{p(\mathbf{z}|x)} ~ I(\mathbf{z};y) - \beta \cdot I(\mathbf{z};x)
\end{equation}where $`I(\mathbf{z};y)`$ measures the task-relevant information preserved in expert activation pattern $`\mathbf{z}`$, reflecting its contribution to model performance. In contrast, $`I(\mathbf{z};x)`$ represents the redundancy of input information, serving as a proxy for computational cost. The hyperparameter $`\beta`$ strikes a balance between task-relevant informativeness and resource compression.
Since $`I(\mathbf{z};y)`$ and $`I(\mathbf{z};x)`$ are intractable in MoE models, we employ the variational approximation :
\begin{align}
&I(\mathbf{z};x) \le \mathbb{E}_{x} \left[ KL(p(\mathbf{z}|x)||p(\mathbf{z})) \right] \\
I(\mathbf{z};y) &\ge \mathbb{E}_{(x,y)} \left[ \mathbb{E}_{\mathbf{z} \sim p(\mathbf{z}|x)} (\log q(y|\mathbf{z})) \right] + H(y)
\end{align}Here, $`p(\mathbf{z}|x)`$ is the conditional distribution over expert activation given input $`x`$, $`p(\mathbf{z}) \sim \mathcal{N}(0,I)`$ is the prior, and $`q(y|\mathbf{z})`$ is a variational decoder that approximates the label likelihood. As $`H(y)`$ is independent of expert behavior, it can be omitted for importance comparison (i.e., in the formulated optimization). Under the principle of optimal information compression, we approximate the intractable joint optimization in the original IB objective (Eqn. [eq:ib_objective]) by independently evaluating the IB contribution of each expert within a batch $`b`$. For each expert $`e`$, its IB contribution is defined as
\begin{equation}
\begin{split}
I_b(e) &= I(z_e;y) - \beta I(z_e;x) \ge \mathbb{E}_{z_e \sim p(z_e|x)} \left[ \log q(y|z_e) \right] \\
&+ H(y) - \beta \cdot KL(p(z_e|x)||p(z_e))
\end{split}
\end{equation}where $`I_b(e)`$ denotes the informativeness of expert $`e`$. Expert $`e`$ is considered more critical when $`I_b(e)`$ is higher, as it suggests greater task relevance and a more compact representation.
In MoE frameworks, expert activations $`z_e`$ are not explicitly modeled but are implicitly determined by the gating network. Since the routing score $`G_e(x)`$ reflect how input $`x`$ are assigned to expert $`e`$, the activation distribution $`p(z_e|x)`$ can be naturally approximated by $`G_e(x)`$. Consequently, the marginal distribution $`p(z_e)`$ can be estimated as its averaged routing probability over a batch of size $`B`$:
\begin{equation}
p(z_e|x) = G_e(x),~p(z_e) = \frac{1}{B} \sum_{j=1}^{B} G_e(x_j),
\end{equation}Therefore, the approximation of $`I(z_e;x)`$ and $`I(z_e;y)`$ can be represented directly from routing behavior as
\begin{align}
% \hat I(z_e;x) = \frac{1}{B} \sum_{i=1}^B \left[ G_e(x_i) \cdot \log G_e(x_i) \right].
K&L(p(z_e|x)||p(z_e)) = \frac{1}{B} \sum_{i=1}^B G_e(x_i) \log \frac{G_e(x_i)}{p(z_e)}, \\
&\mathbb{E}_{z_e \sim p(z_e|x)} \left[ \log q(y|z_e) \right] = p(z_e|x) \cdot \log q(y|z_e).
% &\hat I(z_e;y) = \sum_{j=1}^C p(z_e,y) \log \frac{p(z_e,y)}{p(z_e)p(y)}.
\end{align}However, the label likelihood conditioned on the expert activation $`q(y|z_e)`$ is not explicitly available. To address this, we estimate $`I(z_e;y)`$ by analyzing the routing behavior of expert $`e`$. The key insight is that if $`G_e(x)`$ is consistently high for a group of inputs $`x`$ sharing the same label $`y_i`$, then expert $`e`$ likely captures representative and discriminative patterns relevant to $`y_i`$. Under this observation, routing behavior itself indirectly reflects mutual information:
\begin{equation}
% \mathbb{E}_{z_e \sim p(z_e|x)} \left[ \log q(y|z_e) \right] = \hat p(z_e|x) \cdot \log q(y|z_e).
I(z_e;y) \approx f(\left \{G_e(x)\right \}_{i=1}^B)
\end{equation}To facilitate efficient and interpretable estimation, we instead derive a tractable approximation that decomposes $`I(z_e;y)`$ into two interpretable components: cumulative importance $`s_b^{cumul}(e)`$ and specific importance $`s_b^{specific}(e)`$, as defined in Eqn. [eq:expert_importance]. To this end, the IB contribution $`I_b(e)`$ for expert $`e`$ over the entire batch $`b`$ can be expressed as
\begin{equation}
\label{eq:expert_information}
\begin{split}
% I_b(e) &= \lambda \cdot s_b^{cumul}(e) + (1 - \lambda) \cdot s_b^{specific}(e) \\
I_b(e) = s_b(e) - \beta \cdot \frac{1}{B} \sum_{i=1}^B G_e(x_i) \log \frac{G_e(x_i)}{p(z_e)}
\end{split}
\end{equation}A higher $`I_b(e)`$ indicates that expert $`e`$ is both informative and compact, making it a strong candidate for selective fine-tuning under computing resource constraints.
 style="width:7.2cm" />
style="width:7.2cm" />
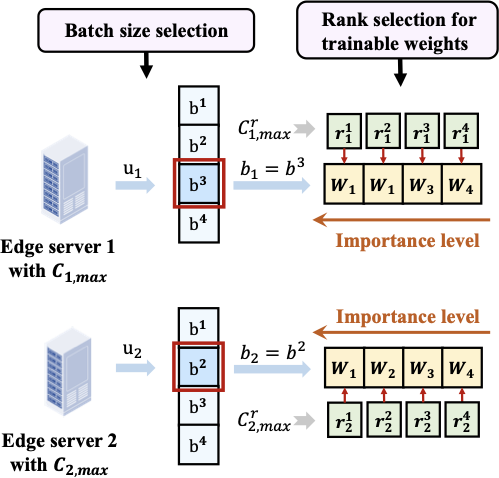
IB-Guided Expert Re-scheduling
Given the expert contribution $`I_b(e)`$ for all experts $`e \in \{\mathbf{E}_1, \dots, \mathbf{E}_S\}`$ in client $`c`$’s model, we aim to select a subset $`\mathcal{E}_{\text{active}}(c)`$ for each client $`c`$ of at most $`C_{\text{budget}}(c)`$ experts to be activated across the batch, where the most informative experts are prioritized for activation. Let $`\mathcal{E}_{\text{union}}(c) = \bigcup_{i=1}^{B} \mathcal{E}_i^{\text{route}}(c)`$ denote the union of selected experts for all samples in batch $`b`$, where gating network selects top-$`k`$ experts $`\mathcal{E}_i^{\text{route}}`$ for each sample. Under the computing budget $`C_{\text{budget}}(c)`$ for client $`c`$ (i.e., the maximum number of experts can be activated per batch), we solve the following selection problem, guided by the optimization objective in Eqn. [eq:ib_objective], as
\begin{equation}
\label{eq:expert_selection}
\mathcal{E}_{\text{active}}(c) =
\arg \max_{\substack{
\mathcal{E}_{\text{active}}(c) \subseteq \mathcal{E}_{\text{union}}(c) \\
|\mathcal{E}_{\text{active}}(c)| \leq C_{\text{budget}}(c)
}}
\sum_{e \in \mathcal{E}_{\text{active}}(c)} I_b(e)
\end{equation}To achieve this, we re-schedule forward-selected experts to activate only critical ones during backward propagation, as shown in Fig. 7. In the forward pass, for each sample $`x_i`$ in the batch, the gating network selects its top-$`k`$ experts $`\mathcal{E}_i^{\text{route}}(c)`$ based on the routing scores, preserving the original sample-level routing decisions. In the backward pass, we re-schedule expert activation across the batch to satisfy the computing constraint using the following resource-aware procedure:
-
Importance-based sorting: We sort all $`e \in \mathcal{E}_{\text{union}}(c)`$ in descending order based on their importance scores $`s_b(e)`$.
-
Layer-wise coverage: To ensure all MoE layers remain functional, we first select the most important expert in each layer.
-
Budget-constrained selection: With the remaining budget, we continue selecting the highest-scoring experts regardless of their layer, until the total number of activated experts reaches the budget limit $`C_{\text{budget}}(c)`$.
During backward propagation, only the selected experts in $`\mathcal{E}_{\text{active}}`$ participate in gradient computation and parameter updates. Gradients for all other inactive experts are masked, thus reducing computational cost without degrading model performance. The expert selection process is refreshed in each training round, ensuring dynamic adaptation to local data. The model is optimized using standard task loss functions (e.g., cross-entropy) without introducing any additional regularization during the expert selection phase.
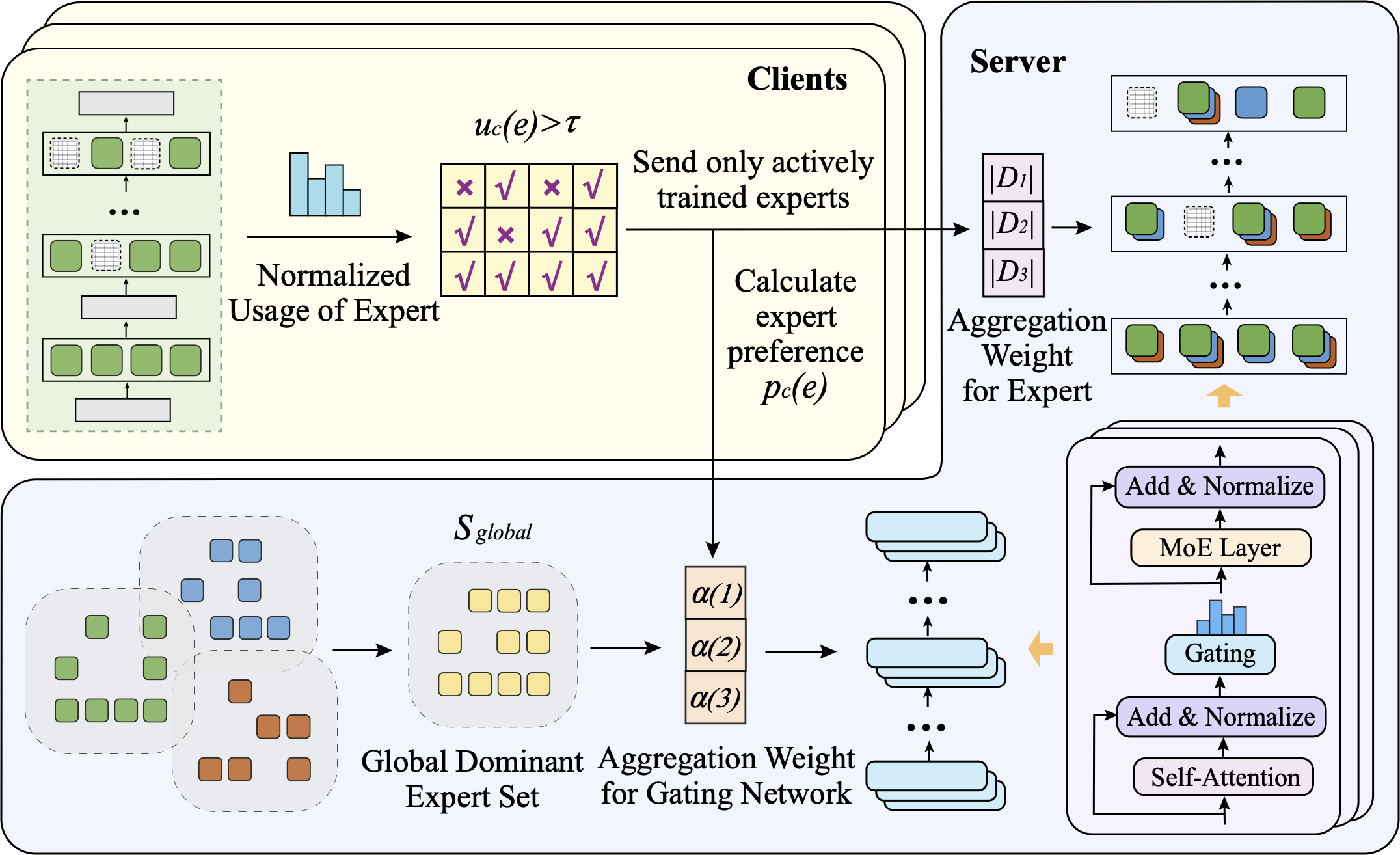
Sparsity-aware Model Aggregation
As discussed in Sec. 2.3, client-specific constraints lead to distinct routing preferences and personalized expert selections, which introduces destructive interference and severely undermines the performance of the global model. These discrepancies are further exacerbated by heterogeneous computing resources, as the resource-aware expert selection activates only important experts on each client. To address this issue, as shown in Fig. 8, we develop a sparsity-aware model aggregation strategy that updates only the experts actively trained on clients, while aggregating gating parameters with importance-weighted contributions to ensure the global router properly captures client-specific routing behaviors. We summarize the proposed MoE-based LLM fine-tuning via FL in Algorithm [alg:name].
Selective Expert Aggregation
In MoE-based federated learning, each client updates only a subset of experts based on its local gating network, leaving many experts partially trained or entirely untouched with random initialization. However, standard aggregation such as FedAvg assumes a consistent model structure with meaningful updates for all parameters among clients. This mismatch causes destructive interference when aggregating irrelevant or stale expert weights, and thus degrading the generalization of the global model.
To address discrepancies in partial expert updates, we propose a selective expert aggregation strategy. Instead of applying direct aggregation across all experts indiscriminately, we only update experts that have been actively trained on a client. Denote $`u_{c}(e)`$ as the normalized usage of expert $`e`$ on client $`c`$ over local samples $`D_{c}`$, which is estimated as
\begin{equation}
\label{eq:active_expert}
u_{c}(e) = \frac{1}{\left | D_{c} \right |} \sum_{x_i \in D_{c}} G_e(x_i).
\end{equation}To filter out unreliable or inactive expert updates, we introduce a usage threshold $`\tau`$, such that each client uploads only the experts with usage $`u_{c}(e) \ge \tau`$. The server then keeps the inactive experts unchanged and only aggregates these active experts as follows
\begin{equation}
\label{eq:expert_aggregation}
E_e^{t+1} = \sum_{c=1}^C \frac{\vert D_{c} \vert {\bf 1}(u_j(e)\ge\tau)}{\sum_{j=1}^C \vert D_j\vert {\bf 1}(u_j(e)\ge\tau)} E_e^t(c) \cdot \mathbf{1}(u_c(e) \ge \tau),
\end{equation}where $`E_e^t(c)`$ represent the parameters of expert $`e`$ on the client $`c`$ after local fine-tuning in round $`t`$. The indicator function $`\mathbf{1}(\cdot)`$ ensures that expert $`e`$ from a client contributes to aggregation only when it has been actively trained; otherwise, it is excluded if it remains unused or undertrained. This strategy prevents updates from clients with insufficient interactions with experts, thereby improving parameter consistency and preserving expert specialization.
Importance-Weighted Gating Aggregation
Apart from partial expert updates, clients also develop divergent routing preferences as their gating networks tend to prioritize distinct expert subsets. This divergence yields inconsistent values of gating parameters across clients, reflecting distinct expert activation patterns. Directly aggregating gating parameters without accounting for client-specific routing preferences dilutes the locally learned expert selection patterns, leading to ambiguous routing decisions. As a result, the aggregated gating network struggles to adapt expert selection to local data, undermining training stability and thus hindering model convergence.
 style="width:8cm" />
style="width:8cm" />
To mitigate this inconsistency, we propose an importance-weighted gating aggregation strategy that explicitly incorporates expert preference and routing consistency. The key idea is to adjust each client’s contribution to the global gating network according to its expert preferences and their consistency with the global distribution. Clients with higher contributions are assigned larger aggregation weights, ensuring that the global gating network is not distorted by divergent routing behaviors.
To quantify the consistency of routing behaviors across clients, we focus on the dominant experts that capture the routing preferences of each client. For each client $`c`$, the dominant expert subset is determined by the actively trained experts under local data, which contribute most to routing decisions. Given the normalized usage $`u_c(e)`$ of expert $`e`$ in Eqn. [eq:active_expert], the dominant expert subsets of client $`c`$ can be expressed as $`\mathcal{S}_c = \{e|u_c(e) \ge \tau \}`$, and the global dominant expert set is $`\mathcal{S}_{\text{global}} = \cup \mathcal{S}_c`$. The routing consistency $`r(c)`$ of client $`c`$ is then quantified as the proportion of overlap between its dominant experts and the global dominant expert set:
\begin{equation}
\label{eq:routing_consistency}
r(c) = \frac{|\mathcal{S}_c \cap \mathcal{S}_{\text{global}}|}{|\mathcal{S}_{\text{global}}|},
\end{equation}where a higher value indicates more aligned and reliable routing behavior for aggregation.
While dominant expert overlap captures whether clients focus on similar subsets of experts, it fails to account for the relative significance of those experts, which may differ substantially across local data distributions. To further account for the contribution of individual experts, we incorporate expert importance into the aggregation weights. As the expert importance score $`s_b(e)`$ in Eqn. [eq:expert_importance] provides an estimate of expert importance under local data distribution, it is adopted as the expert preference to ensure that experts with greater influence on local performance play a more decisive role in the aggregation of the global gating network. By calculating the expert importance in dominant expert subsets, the preference of expert $`e`$ for client $`c`$ is given by
\begin{equation}
\label{eq:expert_preference}
p_c(e) = u_c(e) \cdot s_b^c(e), \forall e \in S_c.
\end{equation}Finally, the aggregation weight of client $`c`$ is defined as the joint consideration of its routing consistency $`r(c)`$ and expert preference $`p_c(e)`$:
\begin{equation}
% \alpha(c) = \frac{\text{Consistency}(c) \cdot \text{Preference}(c)}{\sum_{c=1}^C \text{Preference}(c)}.
\alpha(c) = \frac{\sum_{e \in \mathcal{S}_c} p_c(e)}{|\mathcal{S}_{\text{global}}|},
\end{equation}which emphasizes experts that are both commonly selected and locally important. The global gating network parameters are then updated through importance-weighted averaging:
\begin{equation}
\label{eq:gating_aggregation}
G_{\text{gating}}^{t+1} = \sum_{c=1}^C \alpha(c) \cdot G_c^t,
\end{equation}where $`G_c^t`$ denotes the parameters of gating network in client $`c`$ at the $`t`$-th training round. This gating aggregation strategy ensures that clients with experts that are both frequently activated and consistently utilized have greater impact on the aggregation, thereby improving stability and convergence of MoE-based FL training.
Input: Total training rounds $`T`$, local epochs $`E`$, Computing
budget $`C_{\text{budget}}`$
Initialize global model $`\theta^{0}`$ for all experts $`e`$ Output:
Final global model $`\theta_{\text{global}}^{T}`$
Simulation Setup
In this section, we demonstrate the detailed simulation setup to evaluate our HFedMoE for heterogeneous MoE-based LLM fine-tuning using Switch Transformer with 64 experts per layer and DeepSeek-MoE-16 models. The performance of HFedMoE is evaluated against several baselines using carefully selected hyper-parameters to ensure a fair comparison.
Model and dataset
For our experiments, we employ two representative MoE-based LLMs, Switch Transformer and DeepSeek-MoE-16B . Switch Transformer adopts a top-1 gating mechanism for 64 experts per layer, enabling efficient scaling to over 395B model parameters while activating only 11B parameters. DeepSeek-MoE-16B leverages a more expressive backbone with a top-2-of-64 gating, achieving comparative performance of LLaMA2-7B model. To evaluate model performance, we report test accuracy for converged global model on excessive widely used datasets covering tasks from basic semantic classification to advanced knowledge reasoning: (1) AGNews : Four-class topic classification of news titles and descriptions across World, Sports, Business, and Sci/Tech domains. (2) PIQA : A binary-choice dataset for physical commonsense reasoning. Given a short scenario, the model selects the more plausible of two solutions. (3) HellaSwag : A four-way multiple-choice benchmark for commonsense reasoning. Each instance requires selecting the most plausible continuation of a given context. The data is adversarially filtered to discourage superficial pattern matching. (4) MMLU : A 57-task benchmark covering diverse academic and professional domains. Each task contains four-choice questions designed to test multi-domain reasoning.
Baselines
To investigate the advantages of our HFedMoE framework, we compare it with the following baselines:
-
**FedAvg ** aggregates model weights via weighted averaging, serving as a standard baseline for FL optimization.
-
**PFL-MoE ** integrates MoE with personalized federated learning by allowing each client to train a subset of shared experts based on local data, enabling client-specific expert selection from globally shared knowledge.
-
**FedMoE ** reduces the per-client computing burden by identifying a suboptimal submodel during preliminary fine-tuning, limiting expert activation to a smaller subset.
-
**SEER-MoE ** enhances the efficiency of sparse expert activation in MoE models by pruning the total number of experts with gating regularization, optimizing computation through better utilization of expert resources.
 style="width:8.2cm" />
style="width:8.2cm" />
Hyper-parameters
In the experiments, we implement HFedMoE prototype for MoE-based LLM instruction fine-tuning using Switch-base-64 and DeepSeek-MoE-16B as pre-trained backbone models, with 8-rank QLoRA applied for loading DeepSeek-MoE-16B model. As illustrated in Fig. 9, our distributed system consists of a central server equipped with NVIDIA GeForce RTX 4090 GPUs and $`C=4`$ clients running in synchronized mode, each implemented on NVIDIA Jetson AGX Xavier kits. Each client uses a learning rate of 0.0001 and the batch size for local fine-tuning is set to $`B=8`$. We set the hyperparameters as $`\lambda=0.9`$, $`\beta=0.1`$, and $`\tau=0.05`$. To simulate computing heterogeneity, we constrain each client’s maximum computing resource available for fine-tuning by sampling uniformly from 12 GB to 32 GB. Since the fine-tuning of Switch-base-64 and DeepSeek-MoE-16B requires at least 22 GB, approximately 50% of clients have to select experts in order to participate in fine-tuning.
Performance Evaluation
In this section, we evaluate the overall performance and the computing efficiency of HFedMoE against various benchmarks. We further investigate the impact of different hyper-parameter settings within our HFedMoE framework. The contributions of each meticulously designed component in HFedMoE are also analyzed to illustrate their individual roles in the proposed framework.
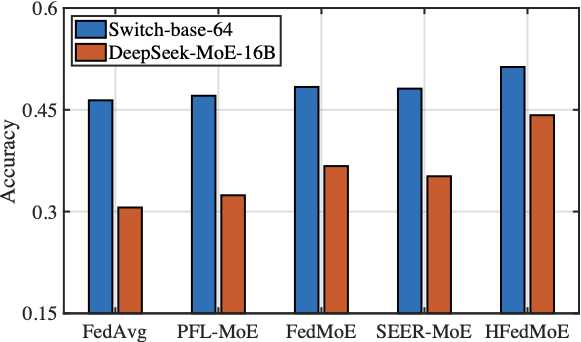
The Overall Performance
The test accuracy
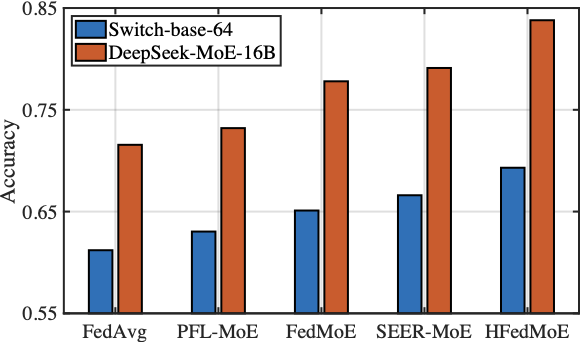
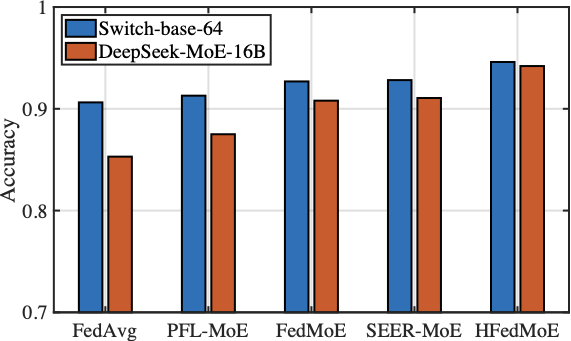
Fig. 10 presents the test accuracy of HFedMoE and other benchmarks on four datasets under computing heterogeneity. HFedMoE demonstrates superior performance across diverse benchmarks, achieving test accuracy over 94%, 81%, 72%, and 45% on AGNews, PIQA, HellaSwag, and MMLU, respectively. Compared to federated MoE fine-tuning, such as FedMoE and PFL-MoE, HFedMoE greatly improves model performance due to the proposed sparsity-aware model aggregation strategy, which aligns client-specific routing preference and aggregates heterogeneous MoE submodels with selective expert activation. While FedMoE and SEER-MoE also reduce the number of activated experts, their performance degrades significantly due to the lack of accurate expert importance identification and the inability to handle concurrent expert activations during expert selection, leading to suboptimal model updates and degraded generalization. In contrast, by identifying expert importance across samples and dynamically selecting critical experts to align with each client’s computing budgets, HFedMoE enforces resource-aware expert selection to enable efficient local fine-tuning without sacrificing performance.
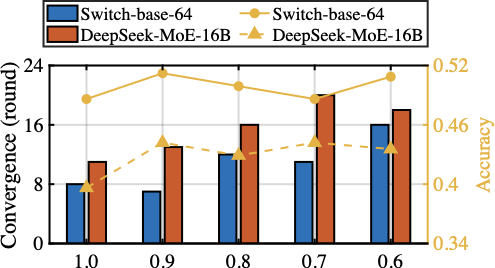
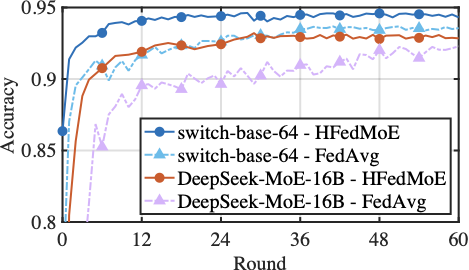
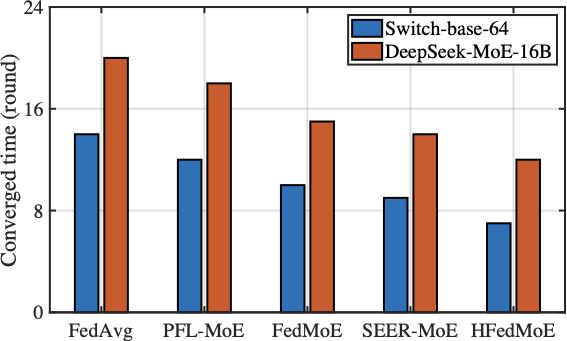
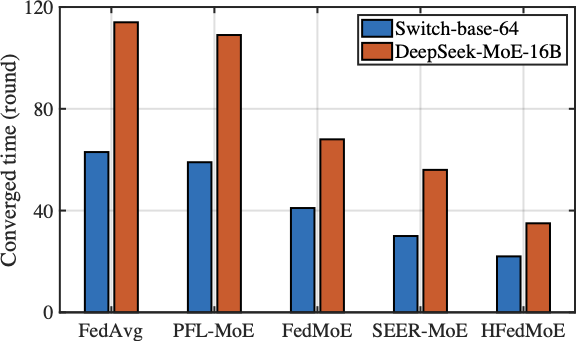
The Convergence Performance
Fig. 11 compares the convergence time of HFedMoE and other four benchmarks on AGNews (classification) and MMLU (reasoning) tasks using Switch-base-64 and DeepSeek-MoE-16B models under heterogeneous computing constraints. Across both datasets and models, HFedMoE consistently achieves fastest convergence, yielding over x1.4 and x1.6 speedups on Switch-base-64 and DeepSeek-MoE-16B models, respectively. This improvement arises from HFedMoE’s resource-aware expert selection, which mitigates local fine-tuning failures caused by computational overload while preserving the most informative expert activations for fine-tuning. Although SEER-MoE also selectively activates critical experts to alleviate computational burden, its absence of aggregation designs leads to severe interference in expert selection, substantially degrading convergence speed. PFL-MoE and FedMoE, on the other hand, enable client-specific expert selection and aggregates shared experts, but still overlooks the routing divergence among clients, which leads to inconsistent updates of gating parameters for expert selection in each client, resulting in unstable convergence. In contrast, sparsity-aware aggregation in HFedMoE explicitly accounts for discrepancies in client-specific routing preferences and expert selection, thereby achieving faster convergence across heterogeneous settings.
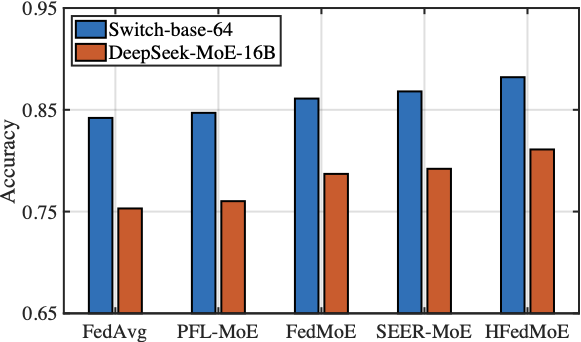
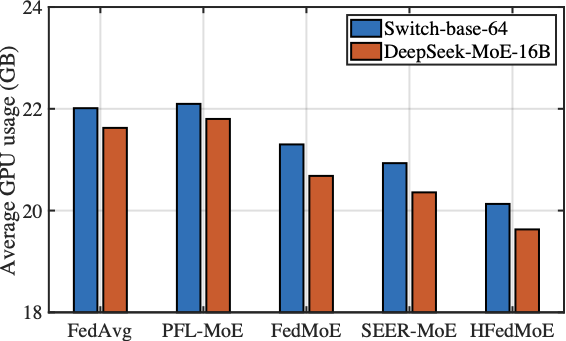
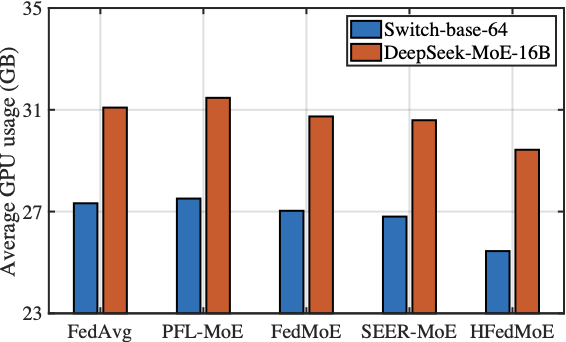
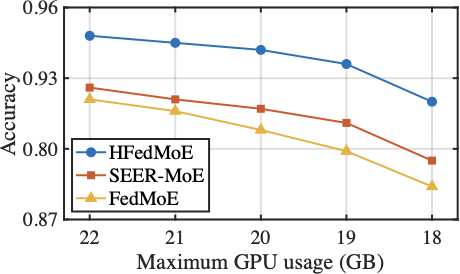
The Computing Efficiency
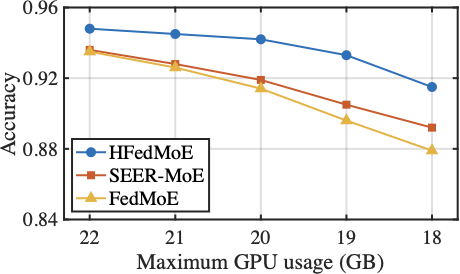
Fig. 12 compares the the average GPU usage of HFedMoE and other four benchmarks on AGNews and MMLU datasets when fine-tuning Switch-base-64 and DeepSeek-MoE-16B models under heterogeneous computing constraints. As shown in the figure, HFedMoE demonstrates superior computational efficiency: beyond the inherent efficiency of sparse expert activation, it further reduces average GPU usage by 10% compared to the FedAvg and PFL-MoE baselines without computing constraints. This advantage stems from HFedMoE’s expert importance identification that quantifies experts’ contribution to local performance, ensuring the limited computational resources are allocated to the most critical experts, especially under limited computing budgets. By pruning redundant computations from low-impact experts, HFedMoE’s resource-aware expert selection strategy dynamically adjusts active expert subsets under local computing constraints, allowing clients with heterogeneous resources to participate effectively participate while preserving representative expert diversity. In contrast, while FedMoE and SEER-MoE significantly reduce client’s computing burden after the selection of a compact expert subset, acquiring stable expert subsets remains computationally challenged, leading to noticeably higher average GPU usage.
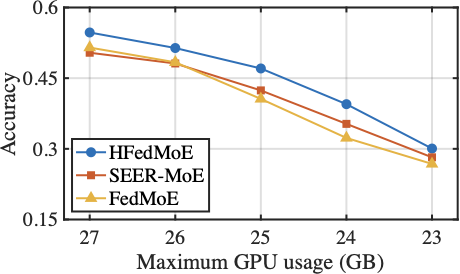
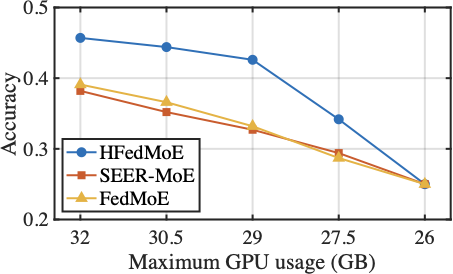
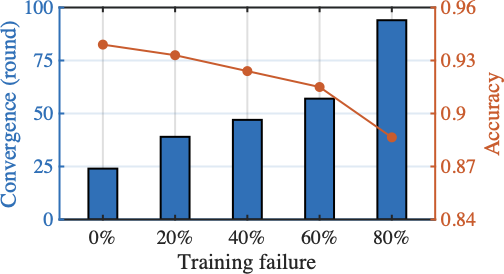
The Impact of Computational Limitation
Fig. 13 reports the impact of computing limitation for HFedMoE on converged test accuracy using AGNews and MMLU tasks. While all baseline methods exhibit inevitable accuracy degradation under reduced computing capacity, HFedMoE demonstrates remarkable robustness by maintaining over 95% of its full-performance accuracy, even when half of clients face substantial resource constraints. This is primarily attributed to HFedMoE’s resource-aware expert selection strategy, which effectively allocates limited resources to the most informative local updates, and its sparsity-aware aggregation for experts and gating networks, which explicitly handles partial expert updates and divergent routing preferences. Although FedMoE and SEER-MoE also incorporate expert importance estimation to reduce memory, its coarse-grained importance estimation fails to account for input-specific contributions across samples while concurrent expert activations across samples during preliminary training severely increases the client burden, leading to severe accuracy degradation under tight computing budgets.
The Optimal Hyper-parameters
Varying Weighted Combination of Expert Importance
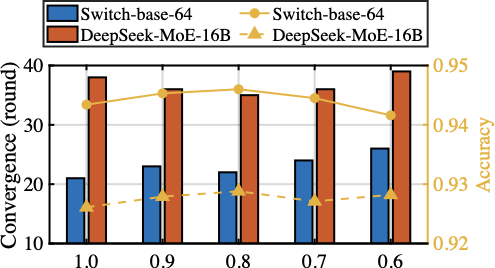
Table [fig:hyperparameter_lambda] demonstrates the impact of varying weighting coefficient $`\lambda`$ in HFedMoE, which controls the balance between cumulative and specific importance in expert importance identification. Experiments on the AGNews and MMLU datasets using Switch-base-64 and DeepSeek-MoE-16B models demonstrate that convergence time and test accuracy exhibit a clear dependency on the choice of $`\lambda`$. When $`\lambda`$ is small, expert selection relies more on specific importance, emphasizing adaptation to specific and often hard-to-classify samples. This leads to faster initial convergence as critical responses are preserve during fine-tuning, but also increases the risk of overfitting to suboptimal routing patterns, resulting in lower accuracy. In contrast, a larger $`\lambda`$ increases the weight of cumulative importance, encouraging effective representation across samples and improving generalization, though at the cost of slower convergence due to reduced expert diversity. Moreover, we observe that the optimal value of $`\lambda`$ varies across datasets: a smaller value ($`\lambda=0.8`$) performs better on AGNews, while a larger setting ($`\lambda=0.9`$) achieves the best trade-off between convergence and accuracy on MMLU, suggesting that datasets with higher heterogeneity benefit from higher cumulative importance to stabilize expert selection.
Varying Usage Threshold for Actively Trained Experts
Table [fig:hyperparameter_tau] presents the impact of varying the usage threshold $`\tau`$ on convergence time and test accuracy when aggregating Switch-base-64 and DeepSeek-MoE-16B models on the AGNews and MMLU datasets. The results highlight the advantage of excluding undertrained experts from the global aggregation. Without selective expert aggregation ($`\tau=0`$), partially trained or entirely untouched experts are still aggregated indiscriminately, introducing interference among inconsistently optimized experts and degrading the generalization of the global model. Such aggregation hinders the alignment of expert specialization across clients, leading to slower convergence and reduced generalization capability of the global model. In contrast, setting $`\tau`$ too high restricts aggregation to only a small subset of experts, limiting global knowledge sharing and diminishing the diversity of learned representations, thus resulting in suboptimal accuracy. A moderate threshold ($`\tau=0.05`$) provides the best balance by filtering out inactively trained experts while retaining diverse and actively trained experts for aggregation, leading to more stable convergence and highest accuracy on AGNews and MMLU.
Ablation Experiments
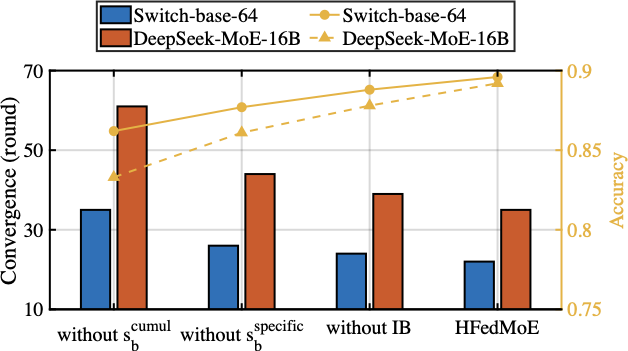
Expert Importance Identification
Fig. 14 illustrates the impact of expert importance estimation on convergence time and test accuracy for fine-tuning Switch-base-64 and DeepSeek-MoE-16B models. The results demonstrate that both cumulative and specific importance of experts contribute notably to performance improvements, while the absence of the IB optimization objective yields less discriminative expert selection and reduced accuracy. Specifically, cumulative importance captures the overlap of expert usage across input samples, enables substantial computation sharing and redundant computation reduction, thereby accelerating convergence x1.35 under constrained computing resources. Incorporating specific importance further captures each expert’s distinct contribution to local data, allowing enhanced adaptation to better aligns with client-specific data distributions. This yields an additional x1.2 speedup and improves test accuracy by approximately 2%, showcasing the superior performance of the proposed expert importance metrics.
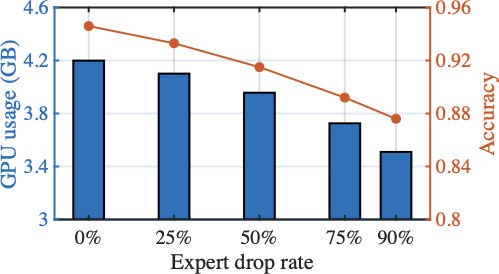
Resource-aware Expert Selection
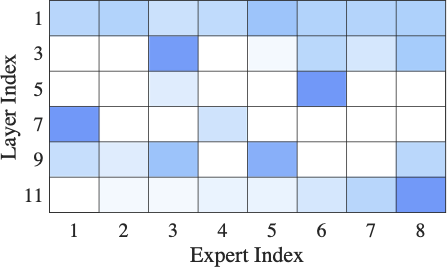
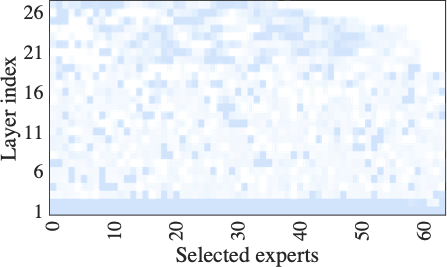
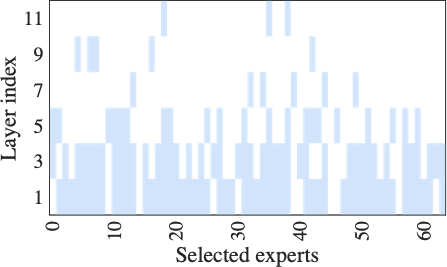
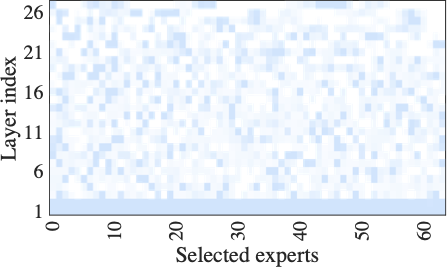
Fig. 15 shows the number and distribution of experts activated during fine-tuning under limited computing resources. HFedMoE activates about 25% and 78% of the experts during fine-tuning on the Switch-base-64 and DeepSeek-MoE-16B models, respectively, while maintaining over 95% of their original test accuracy. These results underscore the capability of HFedMoE to achieve efficient resource utilization with marginal performance degradation, highlighting its potential for deployment on resource-constrained devices. This efficiency is driven by the proposed resource-aware expert selection, which prioritizes high-impact experts while reducing redundancy on experts with minimal impact on performance. Moreover, it is observed that expert selection is not uniformly applied across layers: deeper layers tend to retain fewer experts, whereas more functionally critical layers maintain a higher degree of activation. This adaptive allocation maximizes computational efficiency and aligns with prior observations suggesting that deeper layers in large-scale models are often more redundant.
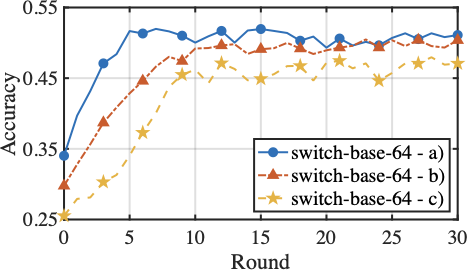
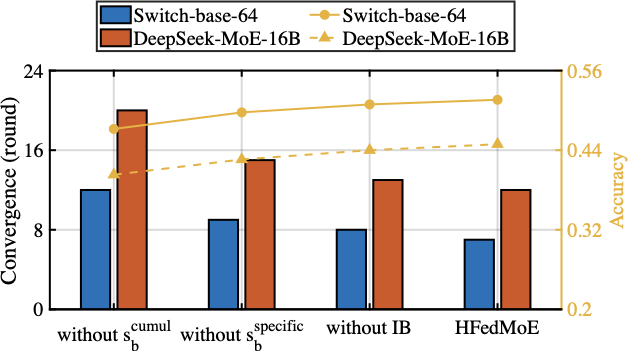
Sparsity-aware Model Aggregation
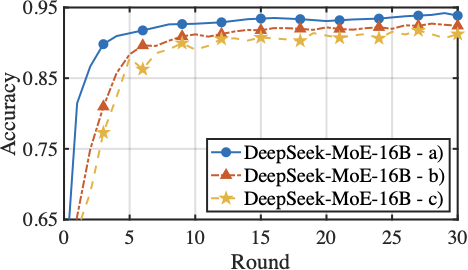
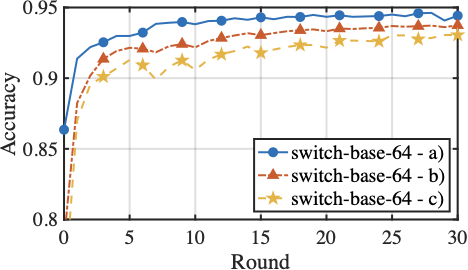
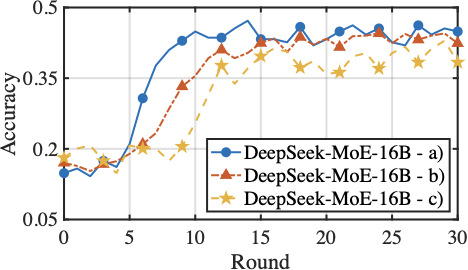
Fig. 16 presents the fine-tuning performance of model aggregation on the Switch-base-64 and DeepSeek-MoE-16B models under heterogeneous computing resources. Three aggregation conditions are compared: a). selectively aggregate experts while aggregating gating parameters with importance-weighted contributions, b). selective expert aggregation without accounting for divergent routing preferences across clients, and c). standard FedAvg aggregation, which aggregates all expert and gating parameters uniformly across clients. Compared to the standard aggregation that assumes uniform model structures and meaningful updates for all parameter, HFedMoE achieves consistently better accuracy and faster convergence on both Switch-base-64 and DeepSeek-MoE-16B. This improvement stems from the proposed sparsity-aware model aggregation, which filters out unreliable expert updates and aggregates only active experts, effectively mitigating the interference caused by partial expert updates across clients. Moreover, importance-weighted gating aggregation alleviates the inconsistent routing behaviors by adjust each client’s contribution to the global gating network according to its expert preferences and routing consistency, yielding additional benefits on test accuracy and convergence.
Related Work
MoE-based LLM in Federated Learning: By selectively activating a subset of experts, MoE provides a promising solution to reduce computational overhead while preserving model’s representational capacity. Leveraging this efficiency, MoE has been adopted as a foundational framework in the development of LLMs , achieving superior performance at low computational costs. Further investigations have extended MoE to personalized FL , where client-specific expert activation allows each client to fine-tune only the experts most relevant to its local data. While improving local adaptation, these approaches often rely on shared gating networks for expert selection, overlooking each expert’s contribution to critical local features and resulting in suboptimal performance. Moreover, most existing works fail to account for the limited computing resources in client devices, significantly limiting the deployment of MoE-based LLMs in heterogeneous federated environments.
MoE-based LLM Fine-tuning for Computational Reduction: To further reduce computing overhead of MoE-based LLMs, recent work has investigated dedicated expert selection strategies. Current resource-constrained FL methods, such as FedMoE , use preliminary training to identify client-specific expert subsets, thereby alleviating the client’s memory pressure during subsequent fine-tuning. However, the preliminary training phase to acquire stable expert subsets remains computationally demanding due to the elevated computation imposed by concurrent expert activations across diverse samples, thus limiting its ability to mitigate computing resource constraints. Moreover, failing to handle routing divergence among clients and accurately estimate expert importance restrict the attainment of reliable and optimal structures necessary for effective resource mitigation. Alternatively, pruning-based approaches reduce resource consumption during fine-tuning by eliminating experts with low average activation frequency. However, they similarly fail to account for the concurrent activation in expert selection across diverse inputs and fail to accommodate the heterogeneous computing capacities across client devices, hindering their ability to achieve an optimal trade-off between performance and efficiency in federated settings, especially under client-specific resource constraints during fine-tuning.
Model Aggregation for Federated MoE Fine-tuning: Despite growing interest in integrating MoE models into FL, effectively aggregating structurally heterogeneous local models while preserving global performance poses significant challenges. Current FL approaches usually assume that all clients share identical model structures, whereas distinct expert subsets and divergent routing preferences render naive parameter aggregation ineffective. Several recent studies attempt to alleviate structural heterogeneity among experts but still overlook diverse expert activation patterns during aggregation, thus failing to handle partial expert updates and inconsistent gating networks and leading to degraded performance in MoE-based federated learning. Although some approaches preserve local adaptability by maintaining private gating networks and aggregating only expert parameters, the resulting partial expert updates across clients lead to misaligned optimization, thus weakening expert specialization and impairing model generalization.
Conclusion
In this paper, we have proposed a heterogeneous federated learning framework, named HFedMoE, to enhance the effectiveness of MoE-based LLM fine-tuning across heterogeneous clients with diverse computing capabilities. First, the expert importance identification scheme quantifies each expert’s contribution to the fine-tuning performance across diverse clients. Second, based on each expert’s importance, the resource-aware expert selection method ensures that the critical experts are dynamically chosen under each client’s computing budget. Finally, the selective expert aggregation strategy further enhances model generalization, mitigating the impact of expert structural heterogeneity. Extensive experimental results have demonstrated that HFedMoE outperforms the state-of-the-art benchmarks, achieving significantly improved convergence with minimal accuracy degradation.
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
In this paper, we use GPU memory footprint as a proxy to quantify the computing resource consumption . Since memory-intensive operations, such as intermediate state memory storage and large matrix multiplication, dominate LLM fine-tuning, the GPU memory footprint can reflect the computing demands of LLM fine-tuning. This makes it an effective measure for fine-tuning feasibility on resource-constrained client devices. ↩︎