Exploring the Performance of Large Language Models on Subjective Span Identification Tasks
📝 Original Paper Info
- Title: Exploring the Performance of Large Language Models on Subjective Span Identification Tasks- ArXiv ID: 2601.00736
- Date: 2026-01-02
- Authors: Alphaeus Dmonte, Roland Oruche, Tharindu Ranasinghe, Marcos Zampieri, Prasad Calyam
📝 Abstract
Identifying relevant text spans is important for several downstream tasks in NLP, as it contributes to model explainability. While most span identification approaches rely on relatively smaller pre-trained language models like BERT, a few recent approaches have leveraged the latest generation of Large Language Models (LLMs) for the task. Current work has focused on explicit span identification like Named Entity Recognition (NER), while more subjective span identification with LLMs in tasks like Aspect-based Sentiment Analysis (ABSA) has been underexplored. In this paper, we fill this important gap by presenting an evaluation of the performance of various LLMs on text span identification in three popular tasks, namely sentiment analysis, offensive language identification, and claim verification. We explore several LLM strategies like instruction tuning, in-context learning, and chain of thought. Our results indicate underlying relationships within text aid LLMs in identifying precise text spans.💡 Summary & Analysis
1. **Key Contribution 1:** The paper demonstrates that LLMs are more effective at identifying various types of spans in complex texts, much like how a gardener can identify and manage different kinds of flowers. 2. **Key Contribution 2:** The study analyzes the impact of model size and learning methods on LLM performance, akin to how car speed varies with engine size. 3. **Key Contribution 3:** It evaluates LLM efficiency in low-resource settings and shows that smaller models can be more effective than larger ones, much like a small boat moving quickly.📄 Full Paper Content (ArXiv Source)
Offensive language identification, sentiment analysis, and claim verification are some of the most widely studied tasks at the intersection of social media analysis and NLP . Most of the research on these tasks focuses on predicting post-level categorical labels. In the case of sentiment analysis, for example, these are often expressed in terms of positive, neutral, and negative labels or a Likert-scale representing the positive to negative continuum .
Various studies have addressed model explainability by developing frameworks, datasets, and models to identify attributes in texts through token span prediction. For example, in the toxic spans detection task, models predict the spans of toxic posts that are indicative of toxic label prediction . Going beyond independent token spans, researchers have also proposed more structured formulations to capture relationship between textual elements. One of the most well-established of these formulations is Aspect-Based Sentiment Analysis (ABSA) , which aims to detect aspects and their associated sentiments within a text. This approach is particularly effective for cases with mixed sentiments, such as “The food was delicious, but the service was extremely slow” in a restaurant review. In this example different parts of the text express opposing opinions. In the same vein, in this paper we consider both complex and simple texts and define them as follows:
Complex Text - A text containing more than one type of interrelated
spans, and these related spans belong to different categories, such as
Target and
Aspect in ABSA.
Simple Text - A text with only one span category such as a toxic
span or claim span containing a toxic expression and a claim
respectively.
LLMs have achieved state-of-the-art performance across various NLP tasks, including generation and prediction . Recent studies on evaluating LLMs for sequence labeling tasks such as Named Entity Recognition (NER) suggest that BERT models still outperform LLMs in the in-context learning setting. and proposed approaches that transform the objective of LLMs to improve their performance on classification tasks. While LLMs have been explored for NER and sentiment analysis tasks, they have been unexplored for other token classification tasks like offensive spans and claim spans identification, and our work aims to address this gap.
This paper addresses the following research questions:
-
RQ1: How does the complexity of the text affect the LLM’s ability to identify the different types of spans? Do the models identify specific span types more efficiently than others?
-
RQ2: How do the model size and modeling strategies influence the span identification capabilities of LLMs?
-
RQ3: Are LLMs efficient in a low-resource setting?
Related Work
Offensive language identification, sentiment analysis, and claim verification are some of the widely studied text classification tasks. Several datasets with post-level annotations have been released for offensive language , sentiment analysis , as well as claim verification . Most of the approaches to these tasks rely on pre-trained transformer-based language models like BERT while, more recently, LLMs have also been explored .
While most of the work on the aforementioned three tasks addresses post-level analysis, several datasets and approaches for token-level analysis have also been proposed. For offensive language, the TSD and HateXplain datasets were introduced to identify the token spans containing offensive or toxic content, or specific rationales contributing to the predicted labels while TBO was created, to identify the offensive spans and their associated targets. Similarly, ABSA aims to identify the aspects, which are token spans from the text describing the targets or entities, as well as the sentiment labels associated with these aspects. further annotated this dataset to identify the opinion terms. Approaches like Relation-aware Collaborative Learning (RACL) , which considers the relationship between the different types of spans, have showed promising results.
While LLMs have not been used extensively for token span identification tasks, there are some works that have leveraged these models on a few similar tasks. leveraged GPT for four tasks, namely NER, Relation Extraction, Entity Extraction, and ABSA. The authors observe that LLMs achieve lower performance compared to smaller BERT-based models. To improve the LLM performance on token spans tasks like NER, ABSA, etc, approaches that remove the causal mask from the LLM layers have been proposed . While these approaches improve the performance on the token spans identification tasks, removing the causal mask changes the training objective of the models, essentially transforming the model from autoregressive to a masked language model. In this work, we leverage the autoregressive capabilities of the LLMs to evaluate their performance using different approaches.
Datasets
We acquire four English datasets for our experiments, two with complex text spans and two with simple text spans. The example instances from each dataset are presented in Table [tab:dataset-examples], while the data statistics are presented in Table [tab:data-stats].
Complex Text Datasets
We acquire Target Based Offensive Language (TBO) and the Aspect Based Sentiment Analysis (ABSA) dataset by . The instances in the TBO dataset were annotated with Arguments, which are offensive phrases in the text, and Target representing the subject of the arguments. The ABSA dataset is annotated with Aspects and their corresponding Opinion spans.
Simple Text Datasets
We use the Claim Spans Identification (CSI) and Toxic Span Detection (TSD) datasets. CSI is annotated with claim spans from social media posts, while the TSD dataset is annotated for toxic and harmful spans.
Experiments
We describe the models used in our experiments. BERT models are fine-tuned with task-specific datasets, while instruction-tuning, in-context learning, and chain-of-thought are used for LLMs.
Baselines
We use the BERT-large model as a baseline for our experiments. We fine-tune the model with the task-specific training datasets. For the progress test, the models are fine-tuned with a randomly sampled subset of the training set.
LLMs
We utilize the Qwen2.5 and Llama-3.1 model families due to the availability of multiple model sizes, enabling evaluation across different model scales. Specifically, we employ the 7B, 14B, 32B, and 72B parameter variants for Qwen, and 8B and 70B for Llama.
Approaches
We utilize three LLM approaches in our experiments. All LLMs are instruction-tuned (IT) on all the tasks. The task-specific example prompts are shown in Appendix 8.1. In-context Learning (ICL) is used to evaluate off-the-shelf models. More specifically, 0-, 3-, and 5-shot approaches are used. For few-shot learning, an embedding for each test instance is generated using a sentence-transformer model, and top-k similar instances from the training set are used as few-shot exemplars. Finally, we employ the zero-shot chain-of-thought (CoT) prompting strategy for token spans identification.
Evaluation Metrics
We evaluate the performance of the models, using the following two metrics: Token F1 (TF1) calculates the F1 score, considering the individual tokens. The final F1-score is the average across all the instances. Span F1 (SF1) considers the exact match with the gold standard annotation. The F1 score is calculated considering the total correct predictions across all instances.
Results
Table [tab:combined-results] show the token-level and span-level F1 scores of the best-performing Llama and Qwen models for all the tasks (the performance of all other models is shown in Table [tab:all-results]). For TBO and ABSA tasks, few-shot learning achieves the best performance, followed by instruction-tuned models. CoT is the least performing on both these tasks, however, the performance is comparable to zero-shot, in identifying the target and argument spans. However, for ABSA, identifying the aspect spans is more efficient in zero-shot setting compared to CoT.
On simple texts, the instruction-tuned models outperform other approaches for the TSD task. However, instruction-tuned Llama models underperform most other models and approaches for CSI. The 5-shot performance of LLMs for this text type is slightly better than the 3-shot evaluation. In the zero-shot setting, the models achieve a comparable performance to the few-shot evaluation for the CSI, whereas there is a significant performance difference for the TSD. CoT achieves a better performance than the zero-shot for the TSD task, while it underperforms for the CSI task.
Discussion
In this section, we revisit the four research questions mentioned in Section 1.
RQ1:
How does the complexity of the text affect the LLM’s ability to
identify the different types of spans? Do the models identify specific
span types more efficiently than others?
As seen in Section 5, LLMs generally have a better
performance on complex spans compared to simple spans. These models are
more efficient at identifying the span types that are explicitly
mentioned in the text, like targets in TBO or aspects in ABSA. However,
LLMs may struggle to identify subjective spans like offensive arguments
or opinion terms, that are context-dependent or indirect expressions.
For example, the sentence “You are dead to me” may be perceived as
offensive, although it does not contain any profane words. Several
factors like ambiguity, interpretability, implicit nature, etc, of the
spans can influence the model performance, for example in CSI task.
While these factors influence the LLM performance in identifying the
token spans, several other factors, like identifying irrelevant tokens,
splitting the token spans into multiple distinct spans, etc, can also
contribute to a lower performance for the LLMs. For example, in TSD
task, LLMs tend to identify not only the toxic spans but also the
context words, as seen in
Figure 6. Such factors especially contribute
to the lower Span F1 scores for certain tasks.
We also aim to identify how text complexity affects the LLMs performance in identifying different types of spans. For the two complex tasks, TBO and ABSA, we assess how well the models identify different span types - individually and combined, using a sample of one hundred instances in a zero-shot setting. As seen in Figure 1, the models, when prompted to identify the two span types together, outperform the models when they are prompted to identify them individually. This indicates that the complexity in the text and the underlying relationships between different span types help the LLMs accurately identify different span types.
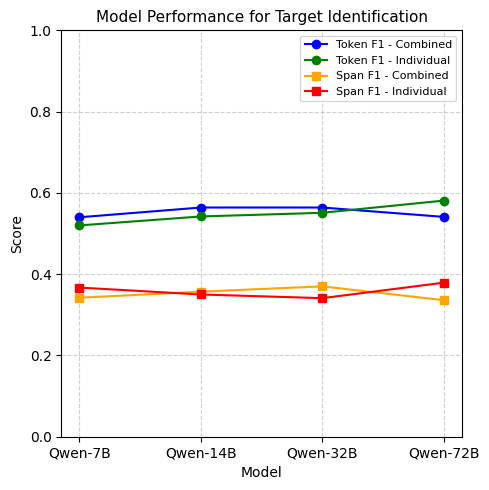
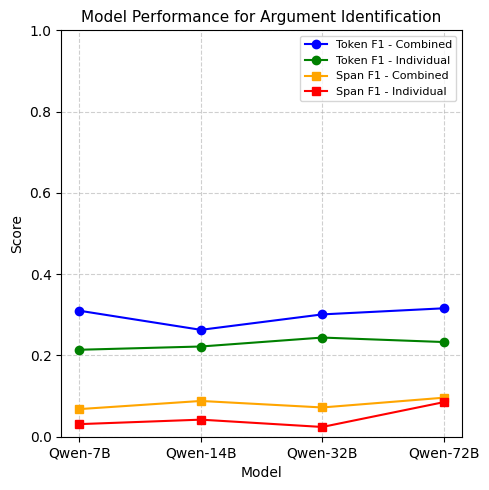
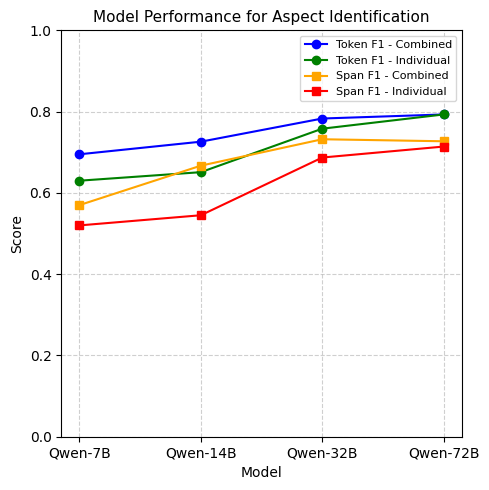
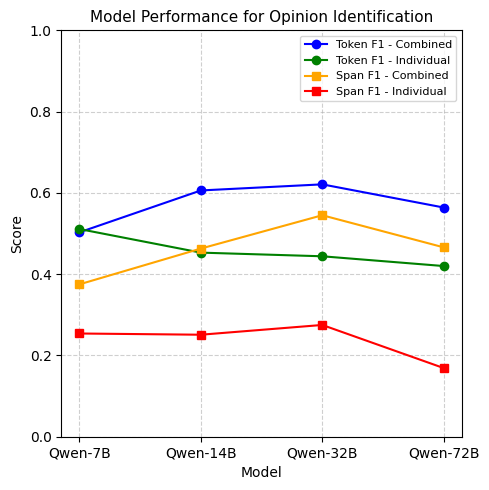
RQ2:
How do the model size and modeling strategies influence the span
identification capabilities of LLMs?
The results indicate that for complex text, LLMs in a few-shot setting
outperform all other approaches. In-context examples in the prompts aid
the models in identifying the different types of spans. CoT
underperforms both zero-shot learning, while IT improves the model
performance, especially on subjective spans. Instruction-tuning
outperforms all other approaches for both CSI and TSD. The models
struggle in zero-shot and CoT for TSD. An analysis of the outputs
indicates that some approaches produce irrelevant or extraneous text
spans. Furthermore, few-shot learning outperform fine-tuned BERT models
on TBO and CSI, while IT has comparable performance to BERT on TSD.
show that with increasing model size, the performance improves. To test this hypothesis, we experiment with different model sizes ranging from 7B to 72B parameters. Our experimental results suggest that while the model size increases, there is only a marginal performance improvement. Overall results show that among the Qwen models, the 7B parameter model is the least performing model, whereas among 14B, 32B, and 72B, either model outperforms the others. While for Llama models, the 70B model consistently outperforms the 8B model. However, the performance difference across models with varying parameter sizes is only marginal. With extensive computational resources required for larger models and only marginal performance improvement, smaller models may represent a more efficient choice for these tasks.
RQ3:
Are LLMs efficient in a low-resource setting?
Training language models requires extensive training data. However, some
of the token classification tasks may have data scarcity. Hence, to
assess how the data scarcity affects the performance of language models,
fine-tune both small language models (SLM) and large language models
(LLM) with varying training data sizes, ranging from 200 to 1000
samples. For this specific experiment, we compare the performance of
BERT-large and Qwen-7B models.
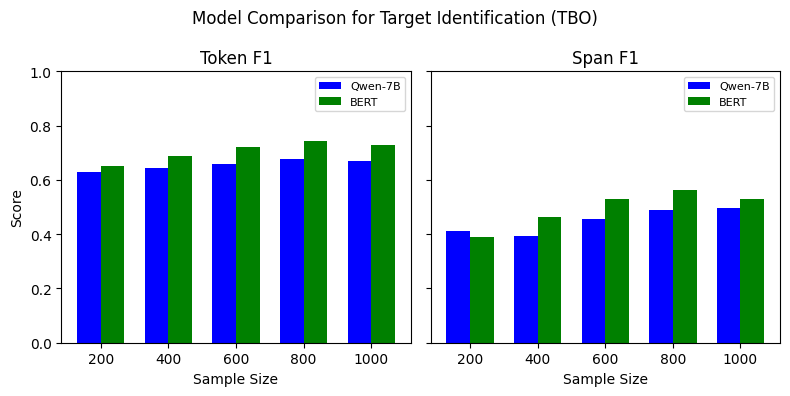
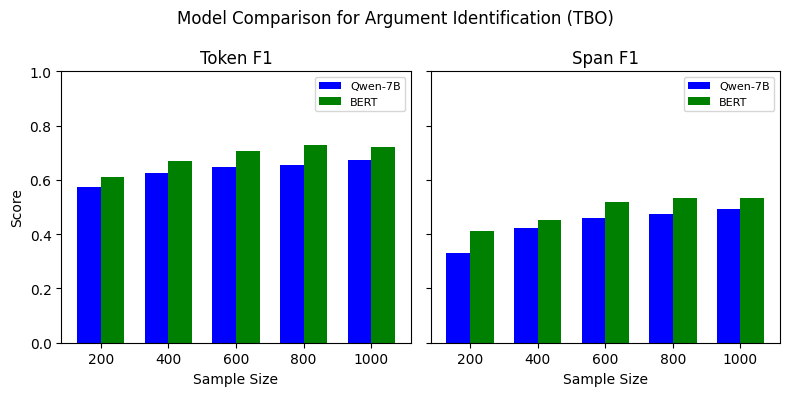
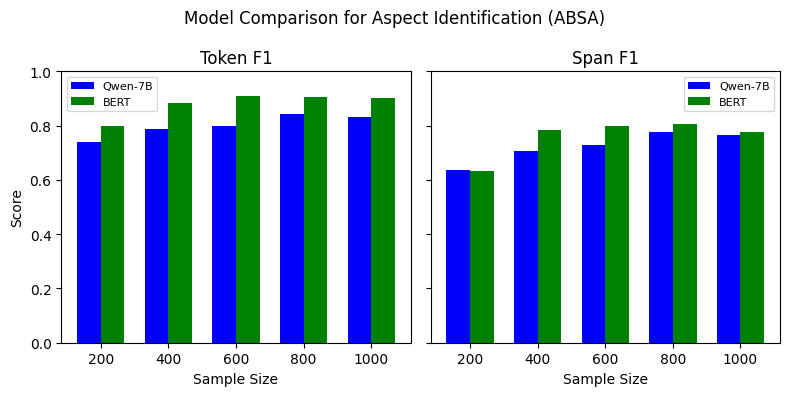
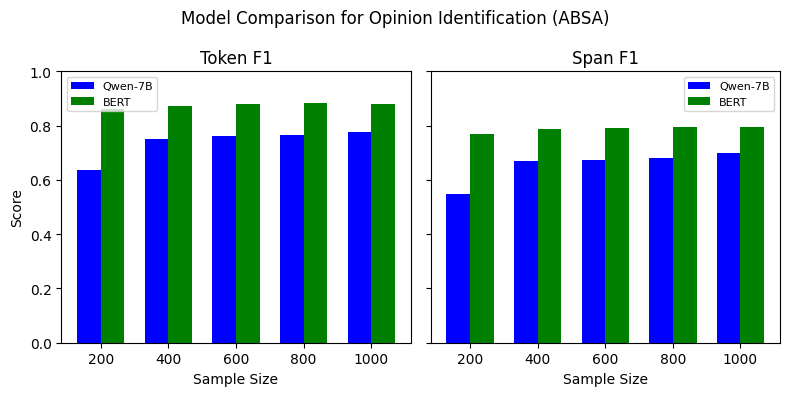
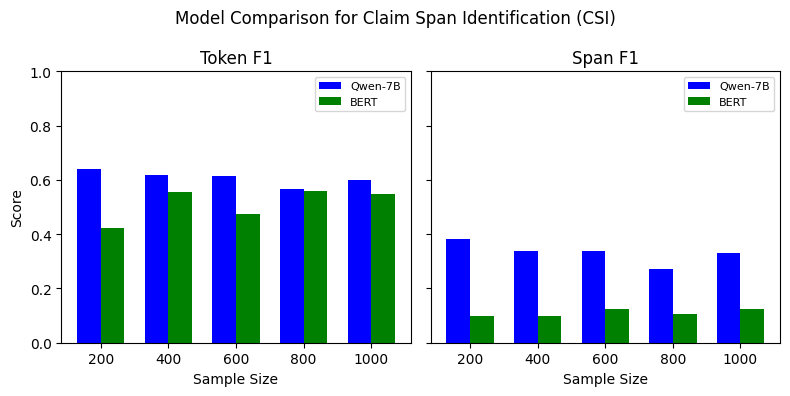
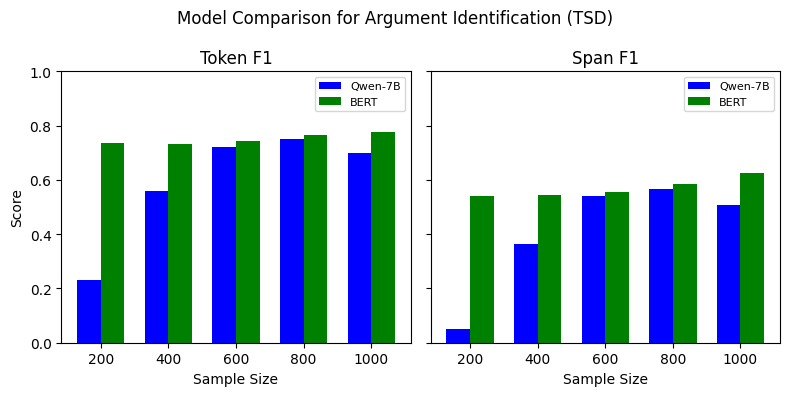
Our experiments indicate that, for the TBO, ABSA, and TSD tasks, BERT outperforms Qwen-7B model for all data sizes (See Figure 7). The performance varies depending on the span type and number of training examples used, where it is comparable for some span types while substantial for the others. However, the SLM outperforms the LLM on CSI, especially on the span F1 score. This indicates that LLM identifies the exact claim spans more precisely than the smaller models. The findings suggest that SLMs generally outperform LLMs when fine-tuned with limited labeled training data. However, few-shot learning with LLMs can be leveraged in such scenarios due to its higher performance, as indicated in Tables [tab:combined-results].
Conclusion
In this work, we evaluate several LLMs with different approaches on subjective span identification. We answer important research questions pertaining to text complexity and model size, and further explore the capabilities of LLMs in a low-resource setting. Our findings suggest that the complexity and underlying relationships within text aid LLMs in identifying precise text spans. Furthermore, for the specific task of span identification, the model size does not have a significant impact on the performance. Although SLMs like BERT still outperform LLMs, approaches like few-shot learning can be leveraged in a low-resource setting. While LLMs have shown exceptional ability in explicit and context-independent span identification, they still underperform smaller models in identifying subjective spans.
In future work, we would like to explore approaches to improve the LLMs understanding of the input for accurate span identification, especially considering the context from both left and right. We further plan to explore other challenging datasets on related subjective tasks including multimodal data where text and images are paired . Finally, we plan to expand this work to non-English datasets with the goal of evaluating the multilingual capabilities of the current generation of LLMs.
Acknowledgments
The authors would like to thank the anonymous reviewers for their insightful feedback.
Marcos Zampieri is partially supported by the Virginia Commonwealth Cyber Initiative (CCI) award number N-4Q24-009.
Limitations
The main limitation of this paper is that we only evaluate two open-source model families. However, other open-source or proprietary models may achieve comparable performance. Additionally, the prompts used in the experiments follow a specific template style. Experimenting with different prompt templates may generate different results. The task-specific instructions within the prompts can be adjusted to generate more efficient outputs. In the few-shot experiments, we use three and five examples in the prompts. However, including additional examples can enhance the model’s performance. Moreover, our evaluations are focused on English datasets. Expanding this work to encompass additional languages and task datasets may offer further insights into the token span identification capabilities of LLMs.
Appendix
LLM Prompt
Figure 2 shows the prompt template used in our experiments. Table [tab:inst-tune-prompts] shows the task-specific prompts. Each prompt consists of instructions describing the tasks and each type of span to extract. Additionally, the prompts include the input instances.
Hyper-parameters
To fine-tune the models, we experiment with several learning rate values, with 1e-4 giving an optimal performance and minimum average loss. A per-device batch size of 2 with a gradient accumulation size of 8 was used to instruction-tune the LLMs. We chose a lower batch size to accommodate the limited computational resources available. We further leveraged the Adam optimizer and fine-tuned the models for ten epochs. For LoRA, we use the alpha value of 16 and the r value of 64, as these values provided the best performance. A dropout of 0.1 was used. To evaluate the LLMs with CoT and ICL, we use a temperature value of 0.0001 (as models like Llama do not allow a temperature value of 0) to allow deterministic outputs.
Additional Results
In this section, we present additional results for our experiments. While Table [tab:combined-results] shows the F1-scores of the best performing Qwen and Llama models, we present the results for all other models in Table [tab:all-results].
Task-Specific Outputs
We show outputs for all the tasks in Figures 3- 6. For each task, the outputs generated by the Llama model with different approaches are shown. For the few-shot setting, we show the outputs of 5-shot experiments.
Progress Test
Figure 7 shows the performance of Qwen-7B compared to BERT when trained with varying training data sizes. We perform this experiment to understand how LLMs perform in a low-resource setting. For the TBO and ABSA tasks, BERT outperform the Qwen-7B model. Similarly, for TSD, BERT outperforms Qwen-7B when fine-tuned with 200 instances, but as we increase the number of training instances, the F1 score difference decreases. Unlike the other three tasks, Qwen-7B outperforms BERT, with a substantial Span F1 difference between the two models. However, as we increase the training dataset, the difference in Token F1 for this task gradually decreases. The experiment indicates that the performance of SLMs and LLMs differs, considering the type of task.
📊 논문 시각자료 (Figures)