Recent reinforcement learning has enhanced the flow matching models on human preference alignment. While stochastic sampling enables the exploration of denoising directions, existing methods which optimize over multiple denoising steps suffer from sparse and ambiguous reward signals. We observe that the high entropy steps enable more efficient and effective exploration while the low entropy steps result in undistinguished roll-outs. To this end, we propose E-GRPO, an entropy aware Group Relative Policy Optimization to increase the entropy of SDE sampling steps. Since the integration of stochastic differential equations suffer from ambiguous reward signals due to stochasticity from multiple steps, we specifically merge consecutive low entropy steps to formulate one high entropy step for SDE sampling, while applying ODE sampling on other steps. Building upon this, we introduce multi-step group normalized advantage, which computes group-relative advantages within samples sharing the same consolidated SDE denoising step. Experimental results on different reward settings have demonstrated the effectiveness of our methods. Our code is available at https: //github.com/shengjun-zhang/VisualGRPO.
Recent advances in generative models have significantly propelled the field of visual content creation, enabling a wide array of applications ranging from artistic design and entertainment to medical imaging and virtual reality. Stateof-the-art diffusion models [13,29,33] and flow-based approaches [19,21] have achieved remarkable fidelity in generating high-quality images and videos [5,8,26].
In large language models, reinforcement learning has demonstrated its effectiveness on the alignment with human preferences, including Proximal Policy Optimization (PPO) [30], Direct Policy Optimization (DPO) [28], and Group Relative Policy Optimization (GRPO) [32]. Thus, reinforcement learning from human feedback (RLHF) [4,9] has been employed in post-training stages for visual generation. Since GRPO simplifies the architecture by eliminating the value network, using intra-group relative rewards to compute advantages directly, recent works [20,38] integrate this into flow models with stochastic differential equations (SDE). To enhance the efficiency of sampling, some methods [12,17,22,40] introduce a mixture of SDE sampling and ODE sampling, while others [10,18] propose a tree-based structure for less sampling steps.
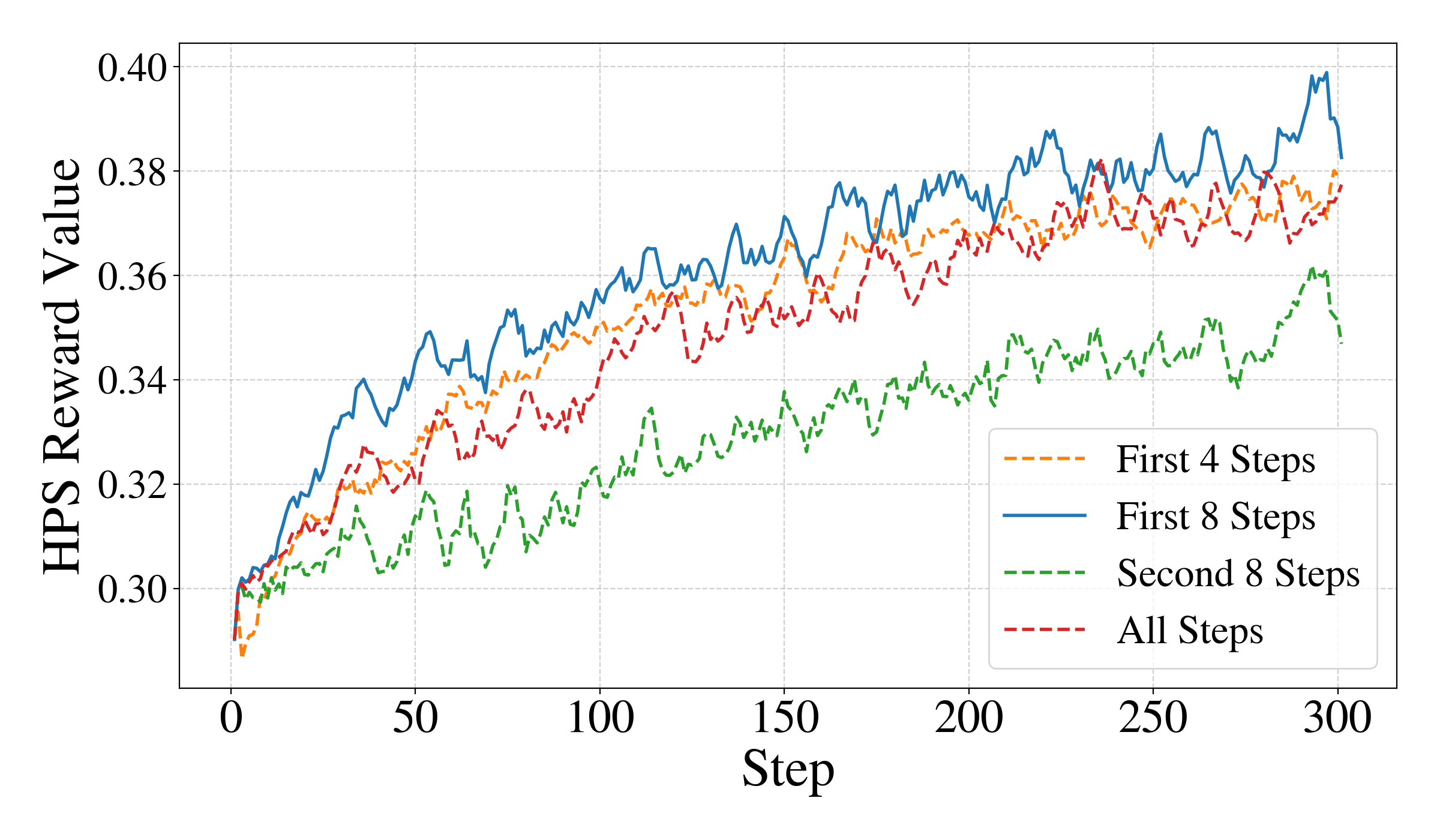
Despite these advancements, existing GRPO-based methods apply policy optimization across multiple denoising timesteps, resulting in sparse and ambiguous reward signals that hinder effective alignment. We observe that only high-entropy timesteps contribute meaningfully to training dynamics. As shown in Figure 1 (b), stochastic exploration via SDE at timesteps with higher noise level possess larger entropy. We visualize the generated images under different circumstances, where high-entropy timesteps yield diverse images with distinguishable reward variations, while lowentropy timesteps produce less reward differences, which are similar to those induced by adding 10% random noise to the final image. This phenomenon implies that reward models struggle to discern subtle trajectory deviations in lowentropy regimes. Furthermore, we implement GRPO with SDE sampling on four settings: (i) the first 4 timesteps, (ii) the first 8 timesteps, (iii) the second 8 timesteps, and (iv) all 16 steps. Notably, optimization on the first half timesteps performs even better than on all timesteps, which indicates that the second half timesteps are largely uninformative.
To address this limitation, we propose E-GRPO, an entropy-aware SDE sampling strategy for more effective exploration during GRPO training. An intuitive approach would be to employ multi-step continuous SDE sampling to broaden exploration. However, this introduces cumulative stochasticity results in ambiguous reward attribution across steps, so that a beneficial exploration in one step may be penalized due to suboptimal downstream trajectory deviations, leading to optimization in the opposing direction. Instead, we consolidate multiple low-entropy SDE steps into a single effective SDE step while keeping the remaining steps deterministic as ODE sampling, thereby preserving highentropy exploration only where informative and ensuring reliable reward attribution. Building upon this, we introduce multi-step group normalized advantage, which computes group-relative advantages within samples sharing the same consolidated SDE step. This mechanism provides dense and trustworthy reward signals, enhancing the alignment of generative trajectories with human preferences.
We conduct experiments on both single-reward settings and multi-reward settings and evaluation on in-domain and out-of-domain matrices. Experimental results demonstrate the effectiveness and efficiency of our method. Our main contribution can be summarized as follows: 1. We provide a comprehensive entropy-based analysis of denoising timesteps in GRPO training process, revealing that effective alignment can be achieved by optimizing exclusively at high-entropy steps. 2. We propose E-GRPO, an entropy-aware SDE sampling strategy for GRPO training of flow models, which consolidates multiple low-entropy steps into a single highentropy SDE step, thereby expanding meaningful exploration while eliminating reward attribution ambiguity. 3. We conduct extensive experiments under both singlereward and multi-reward settings, clearly demonstrating that E-GRPO consistently outperforms prior meth-ods, validating the efficacy and robustness of targeted, entropy-guided stochastic optimization.
RL Alignment for Image Generation. Reinforcement Learning from Human Feedback (RLHF) [3,24] and Reinforcement Learning with Verifiable Rewards (RLVR) [16] have emerged as powerful paradigms for aligning large language models (LLMs) with human preferences [1,3,31].
Early frameworks based on Proximal Policy Optimization (PPO) [30] rely on a value model to guide policy updates, whereas recent approaches such as Group Relative Policy Optimization (GRPO) [7,23,32] achieve greater stability and efficiency by leveraging relative group-wise comparisons instead of absolute rewards. These advancements in language alignment have inspired increasing interest in transferring RL techniques to align visual generative models with human preferences. In the visual generation domain, diffusion [13,33] and flow matching models [19,21,25] have demonstrated strong generative capabilities through iterative denoising processes [26,29].
To enhance alignment with human feedback, recent studies have adapted RLHF to these models. Diffusion-DPO [34], and D3PO [39] extend Direct Preference Op-timization (DPO) [28] to diffusion models. However, these methods suffer from distribution shifting because no new samples are generated during the training process. While DanceGRPO [38] and Flow-GRPO [20] reformulate deterministic ODE-based sampling into stochastic SDE trajectories, enabling GRPO-style policy updates in visual domains. Building upon this foundation, Granular-GRPO [40] refines timestep granularity for more precise and dense credit assignment across denoising steps, and TempFlow-GRPO [12] introduces temporally-aware weighting to alleviate the limitations of uniform optimization across timesteps. MixGRPO [17] further improves training efficiency through a hybrid ODE-SDE sampling mechanism, while BranchGRPO [18] enhances exploration efficiency via branching rollouts and structured pruning. Despite these advancements, existing GRPO frameworks for flow models typically optimize uniformly across all timesteps, overlooking the heterogeneity of exploration potential during the denoising process and suffering from sparse or noisy reward signals. Our work addresses these challenges by leveraging step-wise entropy as a measure of exploration capacity, enabling optimization on high entropy steps to improve both stability and efficiency. Entropy-Guided Exploration and Alignment. Early work in reinforcement learning (RL) has recognized the importance of entropy as a mechanism for promoting effective exploration. In particular, strategies such as policy entropy regularization have been widely used to stabilize learning and encourage diverse behavior [2]. For example, Soft Actor-Critic (SAC) [11] explicitly maximizes the expected reward while also maximizing policy entropy, resulting in more robust and sample-efficient exploration.
More recently, entropy-based insights have been applied to large language models (LLMs) in the context of reinforcement learning for reasoning. Study shows that a small fraction of high-entropy tokens disproportionately drives policy improvement, highlighting the significance of tokenlevel uncertainty in guiding exploration [35]. Complementary work further formalizes entropy as a lens for understanding exploration dynamics, demonstrating that highentropy regions correspond to critical decision points that are most informative for learning [6]. Inspired by these findings, we investigate whether similar entropy-driven patterns arise in flow matching models, and propose an entropyaware GRPO framework that prioritizes informative denoising steps, leading to more efficient and stable alignment with human preferences.
To enable exploration in reinforcement learning, flow-based Group Relative Policy Optimization (GRPO) converts de-terministic ODE sampling:
into an equivalent SDE:
with ϵ ∼ N (0, I) and σ t = a t 1-t . With SDE sampling, flow-based GRPO integrates online reinforcement learning into flow matching models by framing the reverse sampling as a Markov Decision Process (MDP) with states s t = (x t , t), actions a t = x t-1 ∼ π θ (•|s t ), and terminal rewards R(x 0 , c) for prompt c. The policy optimizes
The clipped surrogate objective f (r, A, θ, ϵ) is defined as:
where r
, and p θ (x
) is the policy function for output x (i) at timestep t -1. The group-normalized advantages A (i) is formulated as:
Following the practices of previous methods [17,38], the KL-regularization item is omitted in the objective function.
In flow-based Group Relative Policy Optimization, the reverse sampling process from an SDE is framed as a Markov Decision Process (MDP). To derive the entropy of the reverse SDE step, we start from the given forward SDE and apply Bayes’ theorem. The forward SDE is given by:
where ϵ ∼ N (0, I) injects stochasticity, and the drift term is:
The transition probability of the forward SDE is a Gaussian distribution: Reverse SDE via Bayes’ Theorem. The reverse transition probability p r (x t | x t+∆t ), which corresponds to the policy π θ in GRPO, can be derived using Bayes’ theorem:
For a Gaussian process, the reverse transition is also a Gaussian distribution:
where μθ is the reverse drift and σt is the reverse diffusion coefficient. For linear Gaussian SDEs, the diffusion coefficient is the same in both directions when the process is time-reversible, where σt = σ t . For the reverse drift μθ , the log of the forward transition probability is:
Taking the derivative with respect to x t , we find the reverse drift is formulated as:
Entropy of the Reverse SDE Step. The entropy of a multivariate Gaussian distribution N (µ, Σ) is given by:
where d is the dimension of the random variable y. For the reverse SDE step, the covariance matrix is given by: The determinant of this diagonal matrix is (σ 2 t ∆t) d . Substituting this into the entropy formula:
Substituting σ t = a t 1-t , we get:
To address the sparse and ambiguous reward attribution of uniform optimization across timesteps, we propose an entropy-aware GRPO (E-GRPO) framework, which integrates an entropy-driven step merging strategy and multistep group normalized advantage estimation. The core design prioritizes meaningful exploration by consolidating low-entropy SDE steps into informative sampling events.
Given a sequence of denoising timesteps {t T , …, t 1 , t 0 }, the relation of timesteps and the entropy is formulated as:
Practically, flow models adjust time shift to balance quality and efficiency:
where tk = k T . Substituting this into (11), we get:
.
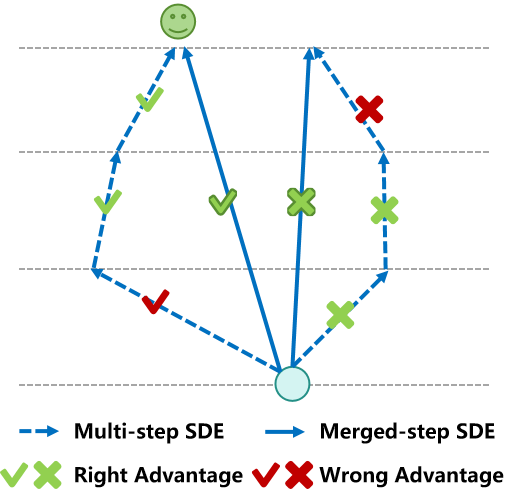
We define an adaptive entropy threshold τ to classify timesteps into high-entropy ones {t T , • • • , t M +1 } with e h(t k ) ≥ τ and low-entropy ones {t M , • • • , t 0 } with e h(t k ) < τ . For a low-entropy timestep t m , we can introduce multi-step SDE sampling on consecutive timesteps {t m , …, t m-l }. As shown in Figure 3, this introduces cumulative stochasticity results in ambiguous reward attribution across steps, so that a beneficial exploration in one step may be penalized due to suboptimal downstream trajectory deviations, leading to optimization in the opposing direction. Thus, we consolidate consecutive timesteps into a single equivalent SDE step to eliminate ambiguous reward signals. Merging l consecutive low-entropy SDE steps requires preserving the total diffusion effect while reducing step count. For the consolidated timesteps, the time interval is ∆t = t m -t m-l . Substituting ∆t to (4), we have:
According to (6), the reverse SDE step is formulated as:
Thus, the entropy for the merged timestep is given by:
,
where e h(t k ) is an increasing function of l.
Instead of using a uniform l for all low-entropy timesteps, we propose an adaptive strategy to select an optimal l for each low-entropy timestep, where l is determined such that the entropy of the merged step just exceeds the threshold τ . This design avoids excessively large entropy of a single merged step, which would make it difficult to find a proper optimization direction under limited exploration attempts. The adaptive selection of l ensures that each merged step maintains a moderate entropy level-sufficient to retain meaningful exploration signals while preventing the entropy from becoming too high to guide effective optimization. By aligning the merged entropy with the predefined threshold, we balance the efficiency gain from step merging and the reliability of reward-guided exploration.
Input: Initial policy θ old , prompt set C, total timesteps T , active SDE sampling timesteps {t T ,
for c ∼ C (sample prompt) do 3:
for N ≤ n ≤ T do 4:
Generate G (n) trajectories with T n 6:
Compute rewards {R(x
end for 10:
Construct clipped surrogate: f (r, A, θ, ϵ) end for 14: end forreturn Optimized policy θ
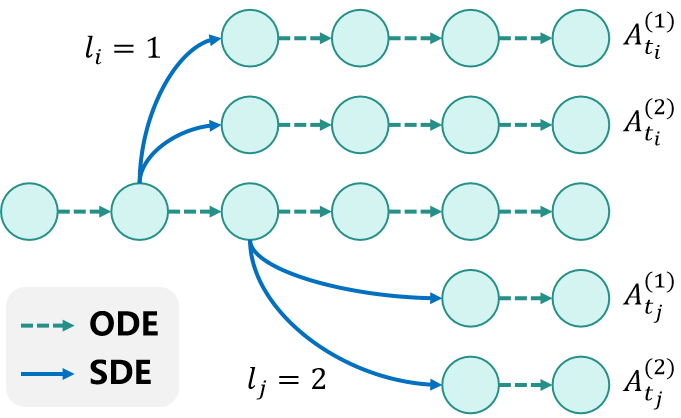
To resolve reward attribution ambiguity, we extend GRPO’s group normalization to merged steps by defining mergegrouped samples. We designate a set of active SDE timesteps {t T , • • • , t N }, where each timestep t n (with N ≤ n ≤ T ) is associated with a merging step count l n determined by the entropy-driven strategy in Section 3.3.1. For a given prompt c, we generate G n trajectories for each active timestep t n , where all G n trajectories share the same consolidated merged timesteps
Within each merge group T n , we first compute the advantage estimates using the G n trajectories, ensuring reward signals are attributed consistently to the merged timesteps. The advantage of the i-th trajectory at state x tn estimated over the merge group T n is given by:
where x (j) 0,tn denotes the j-th generated results with active SDE timestep t n . The final clipped surrogate objective f (r, A, θ, ϵ), adapted to merge-grouped samples, is then formulated as: where T = T -N and the ratio r
tn is given by:
Building on the clipped surrogate objective of GRPO, E-GRPO restricts optimization to consolidated high-entropy steps. The objective function is modified to:
i=1 ∼π θ old (•|c),N ≤n≤T f (r, A, θ, ϵ). Our strategy is illustrated in Algorithm 1. We first Compute h(t k ) for all timesteps using (10) and determine τ . Then, we cluster consecutive low-entropy steps T i for timestep t i . We generate trajectories using ODE for other steps and consolidated SDE for merged steps. Finally, we estimate advantages A (i) tn and ratio via ( 12) and ( 13) so that reward signals are attributed consistently to the merged timesteps, and update p θ by minimizing J E-GRPO (θ).
Dataset and Model. We conduct our experiments on the HPD dataset [36], a large-scale dataset for human preference evaluation, containing approximately 103,000 text prompts for training and 400 prompts for testing. For our experiments, we adopt FLUX. 1-dev [15] as the backbone flow matching model, consistent with prior works such as DanceGRPO [38] and MixGRPO [17]. Evaluation Settings. To assess alignment with human preferences, we employ several representative reward models, each capturing different aspects of generated images. HPS-v2.1 [36] and PickScore [14] are both trained on large-scale human preference data, thus reflecting human judgments of overall image quality and text-image consistency. CLIP Score [27] primarily measures the semantic alignment between the generated image and the input prompt. ImageReward [37] focuses on the perceptual quality and aesthetic
As shown in Tab. 1, we evaluate our method against several recent methods, including the baseline FLUX. 1-dev [15], DanceGRPO [38], MixGRPO [17], BranchGRPO [18], TempFlowGRPO [12] and GranularGRPO [40]. When trained with the single HPS-v2.1 reward, our method achieves a new state-of-the-art performance, surpassing DanceGRPO by 10.8% on the HPS metric. This demonstrates that our entropy-guided exploration effectively identifies high-value denoising steps, leading to more precise and stable policy optimization.
However, as discussed in DanceGRPO [38], training solely with HPS-v2.1 can lead to reward hacking, resulting in overly saturated visual results that do not align with genuine human preferences. To address this, we follow prior works [17,38,40] and adopt a joint reward scheme using both HPS-v2.1 and CLIP score as reward during training. Under this more robust multi-reward setting, our approach not only maintains its SOTA performance on the in-domain HPS metric but also achieves substantial improvements on out-of-domain metrics. In particular, compared with Dance-GRPO, our method improves ImageReward by 32.4% and PickScore by 4.4%, highlighting that entropy-guided optimization promotes broader generalization across reward models and effectively mitigates reward hacking.
Figure 5 presents qualitative comparisons among FLUX.1-dev, DanceGRPO, BranchGRPO, MixGRPO, G2RPO, and our proposed E-GRPO. As shown in the first row (prompt: “A papaya fruit dressed as a sailor”), E-GRPO generates a composition that naturally integrates the papaya’s structure with human-like attire, yielding images of higher aesthetic quality and greater realism. In contrast, baseline methods either misinterpret the prompt (e.g., DanceGRPO generates a person holding a papaya) or produce visually incoherent results (e.g., MixGRPO and G2RPO). In the third row (prompt: “A spoon dressed up with eyes and a smile”), E-GRPO produces expressive and visually consistent humanized faces while preserving the metallic texture of the spoon, whereas other methods generate unrealistic facial blending or lose material fidelity. These results highlight that E-GRPO achieves superior semantic grounding and visual coherence, leading to images that more faithfully reflect textual intent and human aesthetic preference.
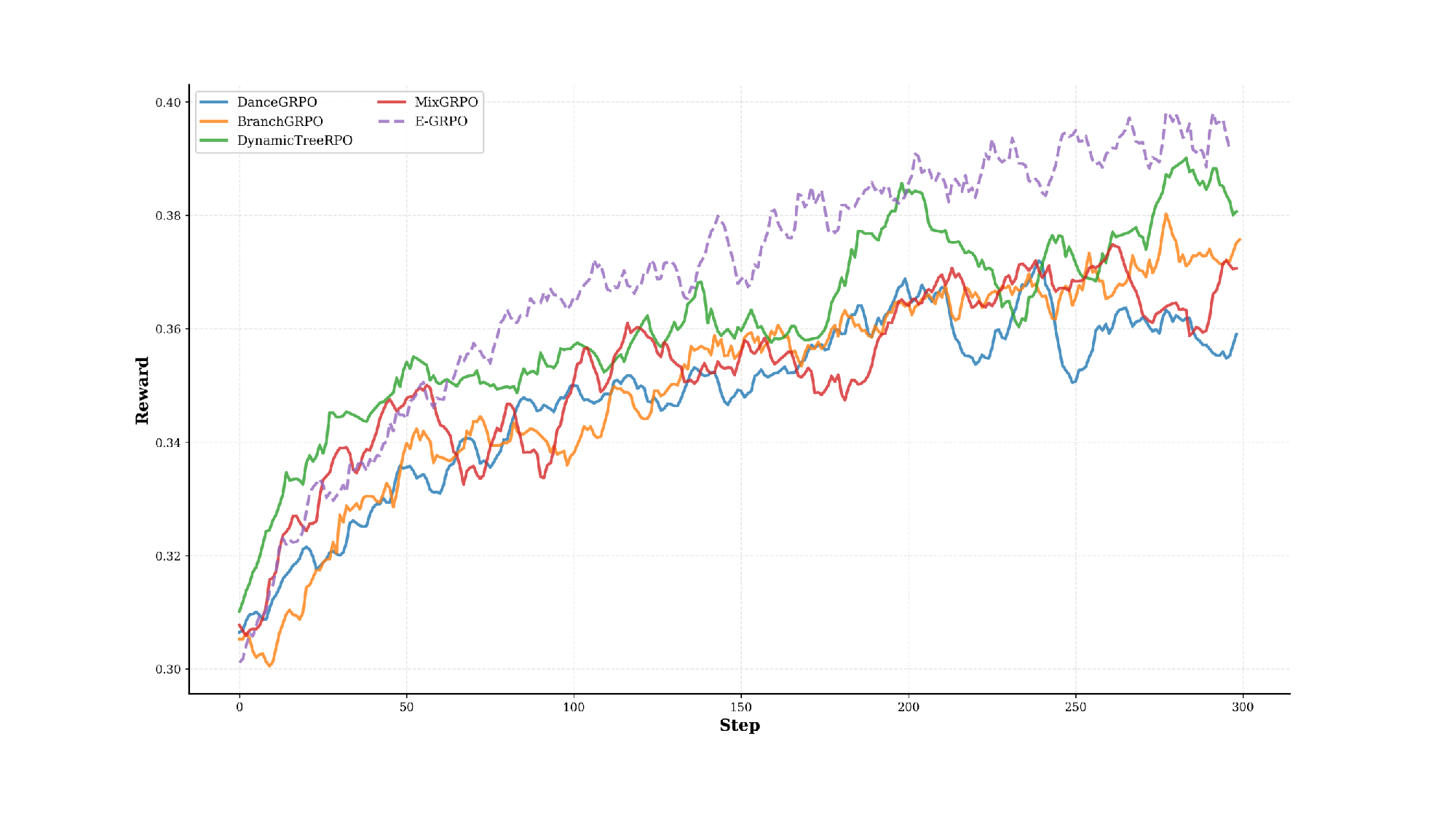
Figure 4 illustrates the reward trajectories during training. Compared with prior work, our method exhibits faster early-stage reward growth and smoother convergence, achieving a higher final reward. This indicates that the entropy-guided step selection stabilizes optimization by focusing updates on the most informative denoising steps, improving both efficiency and reliability.
In order to evaluate the effectiveness of the proposed method, we conduct a series of ablation experiments to understand the design of E-GRPO.
Step Merging Strategies. We evaluate several step merging strategies to verify the effectiveness of our entropybased adaptive merging scheme during training. As shown in Tab. 2, our method consistently outperforms the naive 2-step, 4-step, and 6-step merging baselines across almost all evaluation metrics, demonstrating both efficiency and robustness. Compared with fixed merging strategies that combine multiple steps regardless of their exploration level, our entropy-aware adaptive merging dynamically adjusts the merging behavior to maintain comparable exploration across steps, leading to more accurate and efficient optimization.
Step Entropy Analysis. To validate the rationality of the entropy-based analysis and effectiveness of the proposed entropy-aware GRPO method, we conduct experiments by training models on different subsets of denoising steps. Specifically, we train separate models using (1) the first 4 steps, (2) the first 8 steps, (3) the last 8 steps, and (4) all steps. As shown in Fig. 1(c), training on the first 8 highentropy steps achieves the best performance, followed by using the first 4 steps. In contrast, training on all steps yields similar results to the first 4-step case but with substantially higher computational cost. When the model is trained on the last 8 (low-entropy) steps, the performance drops dramatically. These results indicate that focusing training on early high-entropy steps is sufficient to achieve strong performance, while involving too many later low-entropy steps introduces unnecessary noise and inefficiency. Therefore, we adopt the first 8 denoising steps as our default training configuration. Tab. 3 further provides quantitative results for different subsets of training steps. In our main paper, we introduce an adaptive entropy threshold τ to separate timesteps into high-entropy and lowentropy groups. During sampling, consecutive low-entropy steps are merged until their entropy reaches the threshold. This threshold serves as a critical hyperparameter in our entropy-driven step-merging strategy. To claim the effectiveness of the proposed method and assess its sensitivity to τ , we conducted a series of experiments with different threshold values. Specifically, we trained E-GRPO with τ set to 0 (meaning all steps are treated equally and no merging ooccurs), 1.8, 2.0, 2.2 (our default setting), and 2.6 under the HPS reward configuration. The results are summarized in Table 4.
As shown in Table 4, the model behaves noticeably differently under varying threshold values. As τ increases, the achievable HPS score also improves, indicating the effectiveness of entropy as a guidance signal during training. However, when τ becomes excessively large, a long sequence of steps may be merged, occasionally combining steps that still contain useful entropy or gradient information. This leads to overly coarse updates and, consequently, a slight degradation in performance. Notably, our default choice of τ = 2.2 strikes an effective balance between leveraging entropy for guidance and avoiding excessive merging, yielding the best overall performance in our experiments.
To further demonstrate the superiority of our proposed E-GRPO, we provide additional qualitative comparisons with 6 and Figure 7. As illustrated in these figures, E-GRPO consistently produces results that are more faithful to the text prompts. For example, under the prompt " An award-winning portrait of a lemon in a muted, space age style reminiscent of the 1930s." E-GRPO successfully generates a portrait that combines a space-age aesthetic with the intended compositional structure. Likewise, for the prompt “A lot of buildings on each side of the road, with a very curvy road in the middle.” our method captures the “curvy” characteristic more accurately and achieves higher aesthetic quality compared with baseline methods. These results further validate that by focusing on high-entropy steps, E-GRPO enables more effective exploration and better alignment with complex human preferences.
Despite the robustness of E-GRPO, we observe several recurring failure patterns when handling challenging prompts. Reward Hacking. As discussed in the main paper, using only the HPS reward tends to produce overly saturated images, making the CLIP reward necessary as a counterbalance. Nevertheless, reward hacking still occurs in some cases. For instance, in the prompts shown in Figure 8, such as “A jellyfish sleeping in a space station pod. " and “The image depicts alien flowers and plants surrounded by visceral exoskeletal formations in front of mythical mountains with dramatic contrast lighting, created with surreal hyper detailing in a 3D render. “, the model occasionally introduces human faces or humanoid shapes that should not be present. These artifacts reflect the model’s tendency to exploit biases in the reward models, a limitation that is common across many RL-based training frameworks. Improving reward model reliability will be crucial for advancing RL in visual generation.
Overall, these observations highlight several key challenges faced by RL-based visual generation systems. Future research may explore solutions guided by these identified limitations.
Figure 6. Additional visualization comparisons between E-GRPO and other baseline methods.
Figure 7. Additional visualization comparisons between E-GRPO and other baseline methods.
Figure 8. Failure cases of E-GRPO
This content is AI-processed based on open access ArXiv data.